Embed Size (px)
Citation preview

Esperimentazioni di Fisica
Scopo:• Carattere sperimentale della Fisica (Metodo Galileiano)• Effettuare misure di laboratorio
• Imparare a valutare correttamente gli errori di misura
Testi consigliati:• J.R. Taylor, Introduzione all’analisi degli errori,
ed. Zanichelli• (L. Bussetti, Esercitazioni pratiche di Fisica,
ed. Levrotto e Bella)

La Fisica come scienza sperimentale: il metodo Galileiano
• Ogni teoria deve fornire predizioni quantitative per una determinata grandezza fisica: Xteo
• L’esperimento ci permette di misurare (con un certo errore ΔX) questa grandezza fisica e di determinare che essa si trova in un
certo intervallo di valori: Xexp - ΔX < Xvero < Xexp + ΔX• Confronto teoria-esperimento:
Xexp - ΔX < Xteo < Xexp + ΔX La teoria viene accettata
X
Xteo <Xexp - ΔX o Xteo > Xexp + ΔX La teoria viene rigettata
X

Esempio: la relativitá generale
• Teoria della relativitá generale (Einstein, 1916) : la luce proveniente da una stella viene deviata di α=1.8’’quando transita vicino al sole.
• Teoria classica: prevede una deviazione α=0.9’’• Esperimento (Dyson, Eddington e Davidson):
valore misurato: α=2’’, errore stimato Δα=0.3’’cioè l’intervallo di α individuato dall’esperimento è1.7’’ < α < 2.3’’ α teor. cl. α teor. Einstein
α
Dunque la teoria classica è da rigettare, quella di Einstein da accettare
Morale: è cruciale saper valutare correttamente gli errori di misura !
Terra
Sole
Stella
α

Errori sistematici - I
Errori sistematici•Dovuti ad un intrinseco difetto dello strumento di misura o del metodo di misura utilizzato. •Non si evidenziano con misure ripetute piu’ volte.
Esempio strumento difettoso : righello con tacche spaziate di 0.95 mm anziche’ di 1 mm: la misura vi dice che l’oggetto che state misurando e’ lungo 20 tacche, voi dite dunque che e’ lungo 20 mm, ma in realta’ e’ lungo 19 mm.
Esempio problemi del metodo di misura: determino l’accelerazione di gravita’ misurando il tempo impiegato da un grave a cadere da un altezza di 50 m. Commetto un errore sietematico se non correggo il tempo misurato per l’attrito (viscoso) del grave con l’aria che ne riduca la velocita’.

Non esiste una ricetta “universale” per trattare gli errori sistematici, che devono essere valutati caso per caso (correggendo di conseguenza il risultato ottenuto). Non e’ facile accorgersi se una misura e’ affetta da errore sistematico! Gli Errori Sistematici non sono qui approfonditi ulteriormente
Errori sistematici - II

Errori casuali- I
Errori casualiMentre gli errori sistematici sono in linea di principio eliminabili
(con le dovute attenzioni), gli errori casuali non lo sono. Possono solo essere resi (in linea di principio e con molta fatica) piccoli apiacere, disponendo di strumenti di misura sempre piu’ sofisticati.
Il calcolo degli errori casuali di misura e’ oggetto di questo corso.
Tre casi notevoli:
• Singola misura
• Poche misure (meno di dieci)
• Molte misure (piu’ di dieci)

Singola Misura - I
Esempio: misura dellalunghezza di una scrivaniamediante metro con scalagraduata a passi di cm.
0 1 2 3 118 119 120 121 122 123
In generale il secondo bordo dellascrivania non coincide con una taccadel metro ma andrà a cadere tra due tacche.
Potremmo interpolare ad occhio e dire che la scrivania ha lunghezza L=122.6 cm.
D’altro canto un collega potrebbeeffettuare la stessa interpolazione e dire che L=122.8 cm.
Poichè non vi è ragione per preferireuna interpolazione all’altra dobbiamolimitarci a dire che122 < L < 123 cm.

Singola Misura - II
L’errore che si commette in una singola misura èdeterminato dalla sensibilità S dello strumentoutilizzato, che è definita come la minima variazione della quantità che si vuol misurarepercepibile dal nostro strumento. Infatti nel nostroesempio (lo strumento ha una scala graduata a passidi 1 cm) è difficile apprezzare variazioni di lunghezzadella scrivania inferiori a circa 0.5 cm o, piùprudentemente, di circa 1 cm. Nel nostro esempio èdunque S= 1 cm.(Ovviamente se avessimo usato per la misura un metro con scala graduata a passi di 1 mm sarebbestato S=1 mm).

Singola Misura - III
Nel caso di una singola misura l’errore è datodalla sensibilità dello strumento e possoasserire che il valore “vero” XV dellagrandezza da misurare è dato da:XV = X ± S ; ovvero X-S < XV < X+Sdove X è il valore letto sulla scala di misura.Nel ns. esempio sarà: LV = 123 ± 1 cm ovvero122 cm < LV < 124 cm

Poche misure - I
Nel caso in cui si effettuino piu’ di una, ma meno di 10 misure, occorreseguire il seguente procedimento.
Ripetendo le misure ottengo sempre il medesimo risultato. Cio’significa che sono in grado di controllare la riproducibilita’ delle mie misure con una accuratezza migliore della sensibilita’ del mio strumento (vedi sotto) . In questo caso l’errore e’ dato dalla sensibilita’ dello strumento, come nel caso della singola misura.Ripetendo le misure ottengo risultati diversi. Il fatto di ottenere risultati diversi ripetendo la stessa misura e’ del tutto normale. Infatti, quando si compie una misura, si commettono errori quali ades. (supponendo di misurare sempre la lunghezza di una scrivania):- non perfetto posizionamento dello zero del metro in corrispondenza di un bordo della scrivania.- non perfetta ortogonalita’ del metro rispetto ai bordi della scrivania.- errore di parallasse nella lettura della tacca del metro corrispondente al secondo bordo della scrivania.

Poche misure - IITali errori sono ovviamente diversi ogni volta che viene ripetuta la misura; se l’entita’ di tali errori e’ maggiore della sensibilita’ dello strumento, si avranno risultati diversi in misure ripetute (accuratezza peggiore della sensibilita’). Si procede allora come segue:• Risultato - poiche’ nessuno dei risultati ottenuti e’ in linea di principio
da preferire agli altri, il risultato complessivo sara’ la media aritmeticadei risultati delle singole misure (valor medio empirico)
con
• Errore - poiche’ non e’ possibile effettuare una analisi statistica dell’errore, come nel caso delle molte misure, si preferisce calcolarel’errore massimo Δx:
∑=
=N
1iix
N1x
misuraesimairisultatoxeffettuatemisurenumeroN
empiricomediovalorx
i ____
__
−=
==
( )minmax xx21x −=Δ

Poche misure - IIIDove xmax ed xmin sono il piu’ grande ed il piu’ piccolo fra i risultati ottenuti.Si noti che questo modo di valutare l’errore tende a sovrastimare l’ incertezzadelle misure ed infatti prende il nome di errore massimo. La sovrastima cresce con il numero delle misure effettuate e tale errore non ha alcun significato non ha alcun significato statistico.statistico.
Esempio: misura lunghezza scrivania mediante metro con scala graduataa passi di 1 mm. La misura e’ ripetuta 5 volteRisultati ottenuti: x1= 1203 mm, x2=1205 mm, x3=1204 mm, x4=1202 mm, x5=1206 mm
Valor medio empirico:
Errore massimo:
Risultato della misura: (ovvero )
( ) mm1204mm1206120212041205120351x =++++=
( ) mm2mm1202120621x =−=Δ
mm2mm1204x ±= mm1206xmm1202 ≤≤

Molte misure - ISe si effettuano molte misure (N>10) si puo’ effettuare una analisi statistica dell’errore. Cio’ ovviamente solo se ripetendo la misura ottengo risultati fra loro diversi (se continuo ad ottenere sempre lo stesso risultato non vi è ragione di continuare a ripetere la misura). Nel caso delle molte misure, la giustificazione della procedura per l’elaborazione dei dati è piuttosto complessa. Ci serviamo allora del solito esempio della misura della lunghezza della scrivania, ripetutaquesta volta 20 volte.
Risultati ottenuti (espressi in mm):
x1= 1200, x2=1198, x3=1201, x4=1200, x5=1199
x6= 1200, x7=1199, x8=1201, x9=1199, x10=1199
x11= 1199, x12=1199, x13=1200, x14=1198, x15=1201
x16= 1200, x17=1199, x18=1199, x19=1200, x20=1200

Molte misure - II
I risultati ottenuti possono essere suddivisi in M classi.Ad es. la scelta più semplice è quella di far coincidere la larghezza di ciascuna classe con la sensibilità dello strumento (nel ns. esempio 1 mm).
In questo caso a ciascuna classe apparterrà uno solo fra i diversi valori ottenuti ripetendo le misure ed il valore centrale della classe xk coincide con tale valore.
In alternativa si puo’ anche scegliere di raggruppare i dati in classi di maggior larghezza, in modo tale che in ciascuna di queste stiano diversi valori ottenuti ripetendo le misure. In questo caso, di cui si vedrà un esempio in seguito, il valore centrale di ciascuna classe coincide con la media aritmetica fra l’estremo superiore e quello inferiore della classe.

Molte misure - III
Per ciascuna classe, a partire dalla tabella della pagina seguente, calcoliamo la frequenza empirica assoluta nk, che è pari al numero di volte in cui si èottenuto un risultato che cade nella k-esima classe. La somma delle nk è pari al numero N di misure effettuate (nel ns. es. 20).
Infine, possiamo definire le frequenze empiriche relative νk, che sono definite come νk= nk/N. La somma delle nk è pari ad 1.
Quanto detto, è riassunto dalla tabella e dall’istogramma delle frequenze riportati nella slide successiva, sempre in relazione al ns. esempio.
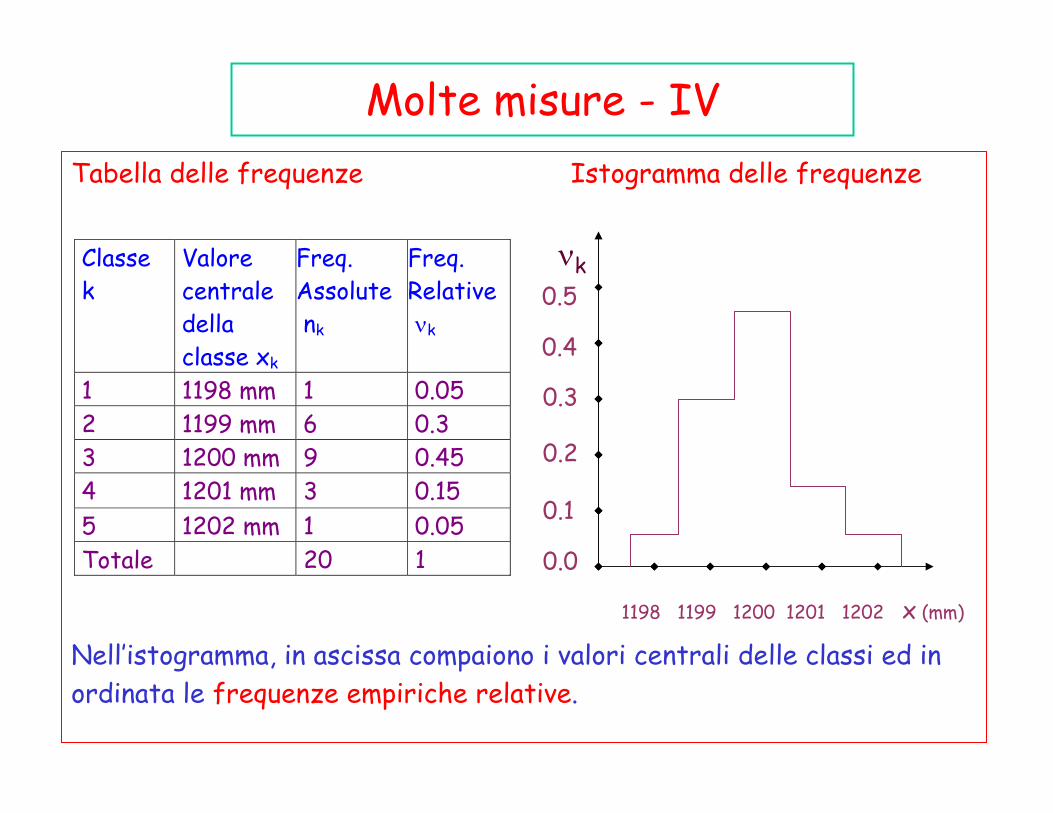
Molte misure - IVTabella delle frequenze Istogramma delle frequenze
νk0.5
0.4
0.3
0.2
0.1
0.0
1198 1199 1200 1201 1202 x (mm)
Nell’istogramma, in ascissa compaiono i valori centrali delle classi ed in ordinata le frequenze empiriche relative.
Classe k
Valore centrale della classe xk
Freq. Assolute nk
Freq. Relative νk
1 1198 mm 1 0.05 2 1199 mm 6 0.3 3 1200 mm 9 0.45 4 1201 mm 3 0.15 5 1202 mm 1 0.05 Totale 20 1

Molte misure - V
Come valutare il risultato dell’insieme di misure e l’errore?In analogia con quanto discusso nel caso delle poche misure, siamo anche qui portati a dire che la miglior stima del valore vero della grandezza che stiamo misurando è rappresentata dal valor medio empirico. Essendo i dati espressi in termini di classi e di frequenze, possiamo calcolare il valor medio empirico come media pesata dei valori centrali delle classi, dove il peso di ciascuna classe è dato dalle νk.
Dove M è il numero di classi, k è l’indice che enumera le classi, xk e νk sono il valore centrale e la frequenza empirica relativa della k-esima classe.
Si dimostra che questo modo di calcolare il valor medio empirico è equivalente a quello visto precedentemente (basato sui risultati di poche misure) e perciò le due formule possono essere usate indifferentemente.
Dove N è il n. delle misure effettuate ei è l’indice che enumera le misure
∑=
ν=M
1kkkxx
∑∑∑∑====
===ν=N
1iik
M
1kk
kM
1kkk
M
1kk x
N1nx
N1
Nn
xxx

Molte misure - VI
Il passo successivo è quello di valutare l’errore. Vogliamo chiarire sin dall’inizio che, poichè il risultato dellenostre misure è il valor medio empirico, l’errore dovràindicarci di quanto il valor medio empirico puo’ discostarsidal valore vero.
Con questo in mente, iniziamo il (lungo) percorso che ciporterà ad identificare l’espressione dell’errore nel casodelle molte misure ed il suo significato.

Molte Misure VII
Si è già discusso nel caso delle poche misure come glierrori casuali, dovuti sia alla maggiore o minoreabilità dello sperimentatore che alle caratteristichedello strumento utilizzato, determinino l’ottenimentodi risultati diversi in misure ripetute di una stessagrandezza. La larghezza dell’istogramma delle frequenzeempiriche è chiaramente legata all’entità degli erroricasuali: uno sperimentatore più abile otterrà un istogramma delle frequenze più “stretto”, uno menoabile un istogramma più “largo”. Possiamo dunque sin d’ora concludere che la larghezza dell’istogramma èsicuramente legata all’entità dell’ errore sulla nostra misura.

Molte misure - VIIIIl passo successivo consiste nell’identificare un singolo parametro da
utilizzare come indicatore della “larghezza” dell’istogramma delle freq. empiriche.A questo scopo, è naturale considerare gli scarti dal valor medio empirico:
(in termini di misure singole)
(in termini di classi e freq. empiriche)
La prima idea che puo’ venire in mente è quella di quantificare la larghezza delloistogramma mediante il valor medio delle di (o dk). In realtà si vede subito chetale valor medio è sempre nullo (proprietà del valor medio empirico). Infatti:
Notando che il valor medio delle di (o dk) è nullo poichè queste quantità possonoavere segno sia positivo che negativo, l’idea successiva è di considerare il valor medio del quadrato degli scarti, che è una grandezza definita positiva e cheprende il nome di varianza empirica σ2.
ii xxd −=
kk xxd −=
0xxNN1x
N1x
N1)xx(
N1d
N1d
N
1ii
N
1i
N
1ii
N
1ii =−⋅⋅=−=−== ∑∑∑∑
====

Molte misure - IX
(in termini di singole misure)
(in termini di classi e frequenze emp.)
Notiamo comunque che la varianza empirica certamente non puo’ essere usataper stimare l’errore sulla grandezza che si sta misurando, in quanto l’ unità di misura della σ2 è non è la stessa della grandezza che si sta misurando, bensì èpari al suo quadrato. Dunque σ2 non è un buon candidato per stimare l’erroresulla misura, poichè quest’ultimo deve avere le stesse dimensioni dellagrandezza misurata. Questo inconveniente puo’ essere superato considerando la deviazione standard empirica σE, definita come la radice quadrata dellavarianza empirica:
Ribadiamo, onde evitare ogni confusione, che la σE è un parametro che, come vedremo serve per calcolare l’errore, ma non è l’errore. Questo perchè l’erroreci deve dire quanto si discosta il valor medio empirico dal valore vero, mentre la σE ci dice (per quanto ne sappiamo fin qui) di quanto le singole misure sidiscostano dal valor medio empirico.
2N
1ii
2N
1ii
2 )xx(N1)d(
N1 ∑∑
==
−==σ
k2
M
1kkk
2M
1kk
2 )xx()d( ν⋅−=ν⋅=σ ∑∑==
2E σ=σ

Molte misure - X
L’istogramma delle frequenze e la distribuzione gaussianaConsideriamo nuovamente il nostro esempio in cui si vuole misurare la lunghezza di una scrivania. Se si effettua una seconda serie di N=20 misure, i risultati ottenuti (cioè le frequenze empiriche νk) saranno in generale diverse da quelle ottenute nella prima serie di 20 misure.In analogia con quento fatto con la prima serie di misure, possiamostilare una nuova tabella e riportare le νk sotto forma di istogramma.
Vi è un commento molto importanti da fare:Confrontando gli istogrammi relativi alle due serie di misurepossiamo notare che, nonostante le differenti frequenzeempiriche ottenute nelle due serie di misure, entrambimostrano una caratteristica forma a campana.
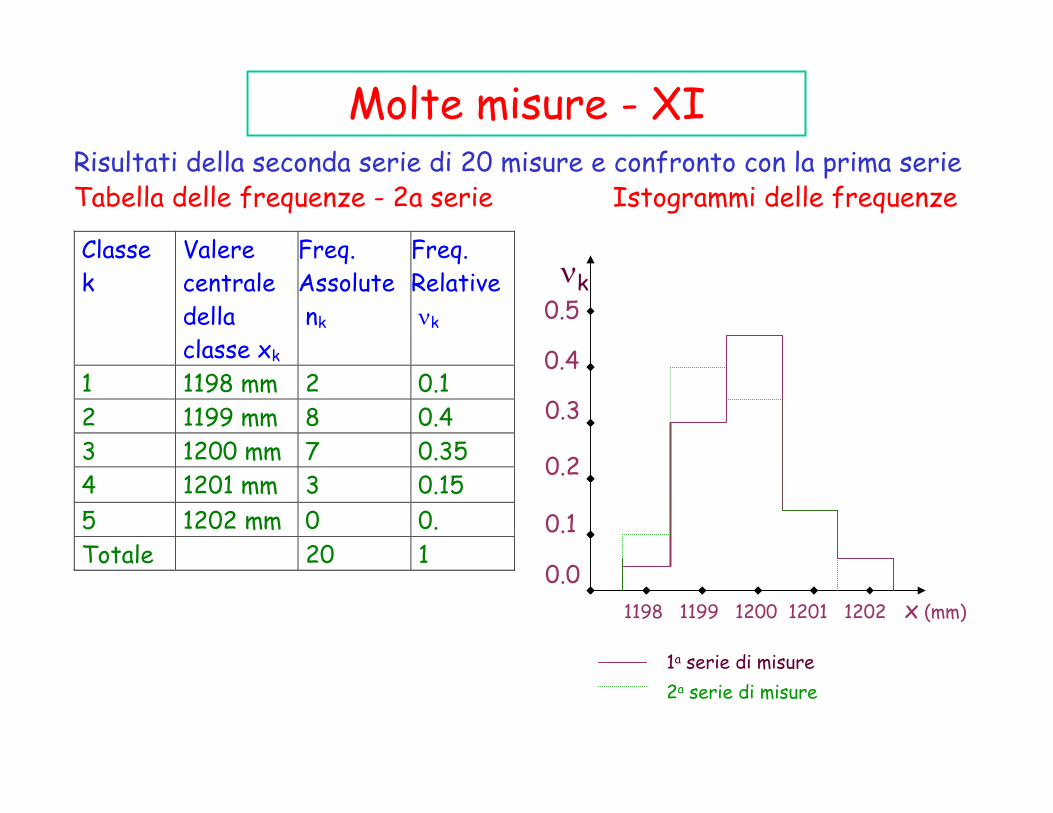
Molte misure - XIRisultati della seconda serie di 20 misure e confronto con la prima serieTabella delle frequenze - 2a serie Istogrammi delle frequenze
νk0.5
0.4
0.3
0.2
0.1
0.01198 1199 1200 1201 1202 x (mm)
1a serie di misure2a serie di misure
Classek
Valerecentraledellaclasse xk
Freq.Assolute nk
Freq.Relative νk
1 1198 mm 2 0.12 1199 mm 8 0.43 1200 mm 7 0.354 1201 mm 3 0.155 1202 mm 0 0.Totale 20 1

Il gioco dei dadiLa ragione per cui ripetendo la serie di misure si giunga a risultati non uguali, ma simili, puo’ essere capito attraverso l’analogia con i familiarigiochi dei dadi a della roulette.
Il gioco dei dadi: se si effettuano N=30 lanci di un dado a sei facce, I risultati possono essereespressi tramite le frequenze empiriche νk con cui si sono presentati i seirisultati possibili (1,2,…6). Una seconda serie di lanci porterà a frequenze emp. non uguali a quelle della prima serie, ma ad esse simili. Più precisamente siosserverà che per entrambi le serie di misure le frequenze empiriche sonogrossomodo uguali fra loro, conducendo ad un istogramma delle frequenzesostanzialmente costante (“piatto”), anzichè a campana, come nel caso dellemisure della lunghezza del tavolo.Cio’ è dovuto a ragioni prettamente statistiche. Infatti, in ciascun lancio del dado, tutti i possibili risultati k (k=1,2,…, 6) hanno la stessa probabilità pk =1/6 di verificarsi. Se si esegue un numero limitato di lanci (N=30 nel ns. esempio), le frequenze emp. relative νk possono differire dalle pk a causa delle fluttuazionistatistiche. Tale differenza si riduce al crescere del n. N di lanci e per N→∞ le νk tendono alle pk (legge dei grandi numeri). Percio’ per N→∞ si avrà νk→pk=1/6.

La misura (ripetuta) di una grandezza fisica
Nel caso delle misure ripetute (della lunghezza della scrivania nel ns. esempio) ci troviamo in una situazione simile: ciascuna delle νk è “figlia”della probabilità pk che si ha, in una singola misura, di ottenere il valorexk (o meglio un valore che si situa nella k-esima classe). Se invece di eseguire un numero limitato di misure ne eseguissimo N→∞ , le frequenzeempiriche tenderebbero alle probabilità pk.Il caso delle misure di grandezze fisiche si differenzia rispetto a quellodel lancio dei dadi in quanto le pk non sono fra loro uguali bensì seguono(come indicato dalla forma dell’istogramma delle frequenze) unadistribuzione di probabilità “a campana”. Quanto detto ci porta a pensare che la distribuzione “ a campana” sia in realtà intimamente connessa con il concetto di misura di una grandezza e che pertanto abbia un carattere “universale”, applicabile, mutatis mutandis (valor medio e larghezza della distribuzione) a qualunquemisura.

La distribuzione gaussianaLa forma a campana della distribuzione riflette il fatto che, quando sieffettuano delle misure, la probabilità di commettere piccoli errori (cioèdi trovare valori prossimi al valor medio della distribuzione) è maggioredi quella di commettere grandi errori (cioè di trovare valori lontani dalvalor medio).L’espressione analitica della distribuzione a campana è data dallafunzione gaussiana, la cui espressione per una generica variabile x è :
Dove i parametri μ e σ coincidono rispettivamente con il valor medioteorico e la deviazione standard della distribuzione
2
2
2)x(
e2
1)x(f σ
μ−−
πσ=
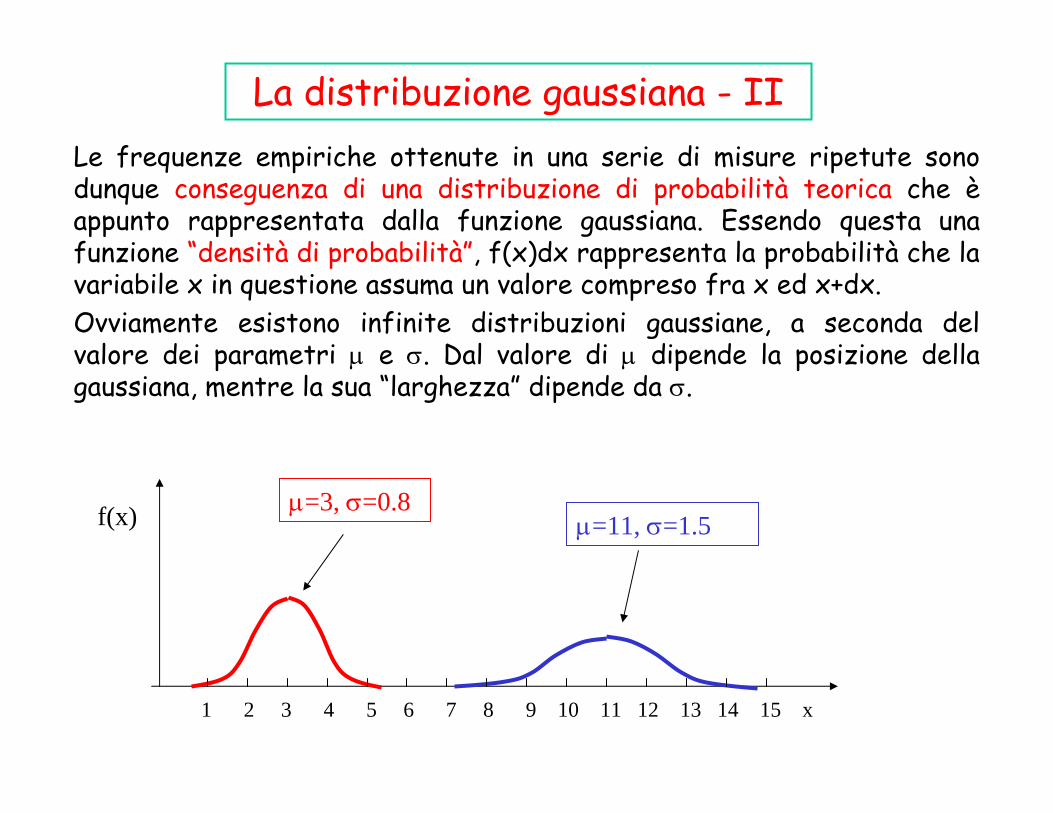
La distribuzione gaussiana - IILe frequenze empiriche ottenute in una serie di misure ripetute sonodunque conseguenza di una distribuzione di probabilità teorica che èappunto rappresentata dalla funzione gaussiana. Essendo questa unafunzione “densità di probabilità”, f(x)dx rappresenta la probabilità che la variabile x in questione assuma un valore compreso fra x ed x+dx.Ovviamente esistono infinite distribuzioni gaussiane, a seconda del valore dei parametri μ e σ. Dal valore di μ dipende la posizione dellagaussiana, mentre la sua “larghezza” dipende da σ.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 x
f(x) μ=3, σ=0.8μ=11, σ=1.5

La distribuzione gaussiana - IIIVi è una fondamentale differenza fra il caso del lancio dei dadi e quellodelle misure. Mentre nel primo caso siamo in grado di calcolare a priori le probabilitá pk, non siamo in grado di fare altrettanto per quanto riguardale misure di grandezze fisiche. Questo perché non siamo in grado di determinare, a priori e su basipuramente teoriche, il valore dei parametri μ e σ della specifica funzionegaussiana che descrive le misure in questione.Il valore del parametro μ (che coincide con il valor medio teorico di tale distribuzione) dipende dalla grandezza che si vuole misurare. Si pensi ad es. a due tavoli di lunghezza diversa: le rispettive misuresaranno descritte da due distribuzioni gaussiane caratterizzate daiparametri μ1 e μ2. In ultima analisi, μ coincide con il valore “vero” dellagrandezza da misurare. Non lo conosciamo ovviamente a priori e tutto quello che possiamo fare è stimare μ con ilvalor medio empirico che otteniamo delle nostre misure.

La distribuzione gaussiana - IV
Per quanto riguarda il parametro σ, che come detto determina la “larghezza” delladistribuzione, dipende esclusivamente dallaabilità dello sperimentatore e dallo strumentoutilizzato. Ad es. se diversi sperimentatorimisurano la lunghezza dello stesso tavolo, lo sperimentatore piú bravo (o dotato del miglior strumento) otterrá una distribuzionedi risultati piú “stretta”.

Errore nel caso di molte misure
L’errore nel caso di molte misureSiamo a questo punto in grado di fornire l’espressione dell’errore nel caso delle molte misure. Riassumendo quanto detto, il valore vero della grandezza che si vuole misurare (cioè il valor medio teorico, coincidente con parametro μ della distribuzione gaussiana) viene stimato mediante il valor medio empirico. Di conseguenza, l’errore nel caso di molte misure coincide proprio con l’errore che si commette stimando il valor medio teorico con il valor medio empirico. Dobbiamo dunque valutare di quanto il valor medio empirico possa discostarsi dal valor medio teorico.A questo scopo, la prima osservazione da farsi è che il valor medio empirico è anch’esso (proprio come il risultato di ciascuna singola misura) una variabile casuale (o stocastica).Per rendersi conto di ciò basta rifarsi all’esempio citato: ripetendo una seconda volta la serie di N=20 misure della lunghezza di un tavolo si ottengono delle νkdiverse da quelle della prima serie di misure. Di conseguenza anche i valori medi empirici saranno diversi per le due serie di misure.

Errore nel caso di molte misure - II
Se si ripete un gran numero di volte la serie di N misure si otterrannomolti valori medi emprici fra loro diversi, che posso raggruppare in classialle quali competono delle frequenze empiriche, rappresentabili tramiteistogramma, proprio come per risultati di ciascuna serie di N misure.Quale distribuzione di probabilità è seguita dallavariabile valor medio empirico?Per rispondere a questa domanda occorre tener presente la definizionedi valor medio empirico. Si nota che il valor medio empirico è dato dallasommatoria di N variabili gaussiane (le xi, che sono i risultati dellesingole misure), moltiplicata per il fattore 1/N. Denominando s tale sommatoria possiamo scrivere il valor medio empirico come:
, avendo postosN1x
N1x
N
1ii ⋅== ∑
=∑
=
=N
1iixs

Errore nel caso di molte misure III
Per il teorema della somma di variabili gaussiane (vedi parte seguente) siha che s è ancora una variabile gaussiana con valor medio teorico
(le variabili xi hanno tutte lo stessovalor medio teorico μ)
e varianza (σs)2 pari a:(le variabili xi hanno tutte la stessavarianza teorica σ2)
Di conseguenza, per il teorema del prodotto di variabile gaussiana per una costante si ha che la variabile valor medio empirico è anche lei unavariabile gaussiana con valor medio teorico μ (lo stesso delladistribuzione delle singole misure!) e deviazione standard teorica .Infatti:
e
μ=μ=μ ∑=
NN
1iis
2N
1i
2i
2s Nσ=σ=σ ∑
=
N/σ
μ=μ⋅=μ=μ NN1
N1
sx NN
N1
N1 2
22
2s2
2x
σ=σ⋅=σ=σ
Nxσ
=σ

Errore nel caso di molte misure IV
Riassumendo:Nel caso di molte misure di una grandezza siamo portati a stimare mediante il valor medio empirico il valore vero della grandezza. Tale valore vero si assume coincida con μ, il valor medio teorico sia della distribuzione gaussiana dei risultati delle singole misure che di quella della variabile valor medio empirico. Siamo pertanto portati a dare come errore della misura (cioè come indice dell’errore che si commette stimando il valor medio teorico μ con quello empirico) la deviazione standard della distribuzione del valor medio empirico:
con e N= n. misureNotiamo che, come il valor medio teorico, anche le deviazioni standard teoriche non sono note a priori e pertanto sono stimate mediante quelle empiriche. Notiamo infine che al crescere del numero N di misure l’errore diminuisce , in quanto diminuisce (fattore ) la deviazione standard del valor medio empirico (non quella delle singole misure).
Exvero xx σ±=μ≡ NEE
x σ=σ
N1

Errore nel caso di molte misure V
Significato statistico dell’erroreNel caso di molte misure l’errore ha un preciso significato statistico.Per le proprietà dell’integrale gaussiano (vedi capitolo successivo) le probabilitàp(1σ), p(2σ) e p(3σ) che una variabile gaussiana x assuma un valore che disti dal suo valor medio teorico μ meno di 1, 2 o 3 deviazioni standard σ, valgono rispettivamente:
p(1σ)=0.68, p(2σ)=0.95 e p(3σ)=0.997Dunque la probabilità che il valor vero della variabile da misurare (coincidente con μ) disti meno di dal valor medio empirico è pari a circa il 68%, quella che disti meno di è pari a circa il 95% e quella che disti meno di èmaggiore del 99% :
Non vi è dunque la certezza che il valore vero giaccia in un intervallo di ampiezza 1σ,2σ, 3σ dal valor medio empirico, ma solo una certa probabilità (che peraltro nel caso delle 3s è molto vicina ad 1)
Exσ
Ex2σ E
x3σ
[ ] %68xxxp Exvero
Ex ≅σ+≤≤σ−
[ ] %952xx2xp Exvero
Ex ≅σ+≤≤σ− [ ] %993xx3xp E
xveroEx ≅σ+≤≤σ−

Cifre significative - I
Supponiamo di porci nel caso in cui si sia misurate la lunghezza di un tavolo ripetendo 20 volte la misura (solo per fissare le idee, quanto qui detto vale anche nel caso di poche misure). In generale, il valor medio empirico e la deviazione standard che si ottengono dai dati contengono un elevato numero di cifre. Ad es., nel caso considerato uno potrebbe ottenere:
eCi poniamo il seguente quesito: specificare tutte queste cifre nel risultato della misura ha un senso? La risposta è no, solo alcune di queste cifre sono significative. Vediamo perché.Cominciamo dall’errore. Ripetendo una seconda volta la serie di 20 misure otterremo, come già detto, delle frequenze empiriche leggermente diverse e, di conseguenza, anche un valore di diverso.Si adotta allora la seguente regola pratica. Se la prima cifra (da sinistra) non nulla dell’errore è pari a 1, si assumono significative le prime due cifre. Pertanto, nel ns. esempio si approssima con
mm5572.1199x = mm193326149.0Ex =σ
Exσ
mm19.0Ex =σ
mm193326149.0Ex =σ

Cifre significative - II
Se invece la la prima cifra non nulla dell’errore è maggiore di 1 si assume
significativa la prima cifra. Ad es. se l’errore ottenuto èlo si approssima con:La ragione di questa differenza è che, se la prima cifra non nulla è 1, approssimare con una sola cifra puo’ implicare una approssimazione piuttosto drastica (ad es. se approssimo 0.01472 con 0.01 compio un arrotondamento del 40% circa). Se invece la prima cifra non nulla èmaggiore di 1, l’approssimazione ad una sola cifra implica un arrotondamento di entità percentualmente inferiore. Ad es. approssimando 3.3476 con 3 compio un arrotondamento del 10% solamente.E’ bene precisare che comunque questa regola è semplicemente dettata dal buon senso e (ragionevoli) deroghe sono ammesse.Una volta eliminate le cifre non significative sull’errore, passiamo a vedere quali sono le cifre significative sul risultato (cioè sul valor medio empirico). Tornando al ns. esempio iniziale si ha:
e
mm32332.0Ex =σ
mm3.0Ex =σ
mm5572.1199x = mm19.0Ex =σ

Cifre significative - III
Nel ns. esempio si vede che, essendo l’errore pari a 0.19 mm, già la prima cifra dopo il punto del risultato è affetta da errore. In altri termini, l’incertezza è sui decimi di millimetro. Notando che non ha alcun significato specificare nel risultato finale cifre che sono più piccole dell’errore, siamo condotti a troncare il risultato alla cifra corrispondente all’errore. Nel ns. esempio si ha allora:
dove le cifre a destra della barra verticale rossa sono non-significative (e pertanto sono omesse nel risultato finale) mentre quelle a sinistra sono quelle significative e sono specificate nel risultato finale. Altro esempio:approssimo l’errore con: ed ometto dal risultato le cifre non significative:
mm19.056.1199x ±=mm19.0Ex =σ
mm5572.1199x =
mm1365.1199x = mm452.2Ex =σ
mm2Ex =σ
mm1365.1199x =
mm2Ex =σ mm21199x ±=

Un esempio -I
Uno sperimentatore ha misurato 100 volte il tempo di deflusso di un fluido attraverso il capillare di un viscosimtero di Ostwald utilizzando un cronometro con sensibilitá par ad un centesimo di secondo (0.01s). I tempi ottenuti sono riassunti nella seguente tabella (sono espressi in secondi).
25.94 26.06 25.78 25.88 25.98 25.92 25.88 25.84 25.84 25.9525.86 25.84 25.92 25.88 26.00 25.94 25.93 25.87 25.83 25.8425.89 25.88 25.87 25.90 25.93 26.02 25.87 25.86 25.96 25.9525.86 25.84 25.81 25.89 25.83 25.94 25.83 25.77 25.92 25.8725.99 25.91 25.97 25.88 25.80 25.94 25.99 25.84 25.93 25.9125.81 25.85 25.95 25.87 25.94 25.83 25.82 25.91 25.87 25.8325.87 25.62 25.93 25.82 25.77 25.90 25.91 25.91 25.96 25.9025.96 25.83 25.82 25.88 25.81 25.90 25.64 26.02 25.81 25.7825.85 25.86 25.74 25.84 25.96 25.83 25.90 25.79 25.90 25.8525.91 25.71 25.89 25.78 25.81 25.81 25.91 25.85 25.91 25.87
2 5.8 1
Al fine di suddividere i dati in classi, notiamo che i dati sono compresi tra tmin=25.62 s e tmax=26.06 s. Poiché tmax- tmin =0.44 s , i 100 dati sono pochi per scegliere 0.01 s (pari alla sensibilità del cronometro) come ampiezza di ciascuna classe. Così facendo, infatti, si avrebbero 100 dati da accomodare in 44 classi: alcune di queste sarebbero vuote. Conviene definire un numero minore di classi, con ampiezza maggiore di 0.01 s.

Un esempio -II
Ad es. posso scegliere di dividere i dati in 9 classi di ampiezza pari a 0.05 s (*). Per ogni classe calcolo il valore centrale tk (media tra estremo sup. tsupk ed inf. tinfkdella classe), quindi le frequenze empiriche assolute (nk) e relative (νk). Si compila dunque la seguente tabella e la si rappresenta con l’istogramma della frequenze.
k tinfk - tsupk(sec.)
tk
(sec.)nk νk
1 25.63 – 25.67 25.65 2 0.022 25.68 – 25.72 25.70 1 0.013 25.73 – 25.77 25.75 3 0.034 25.78 – 25.82 25.80 14 0.145 25.83 – 25.87 25.85 30 0.306 25.88 – 25.92 25.90 26 0.267 25.93 – 25.97 25.95 17 0.178 25.98 – 26.02 26.00 6 0.069 26.03 – 26.06 26.05 1 0.01
totale 100 1
νk
0.1
0.2
25.70 25.80 25.90 26.00 t(s)(*) anche se tsupk - tinfk = 0.04 s, l’ampiezza delle classi è di 0.05 s. Infatti in ciascuna classe posso accomodare 5 diversi risultati e la distanza tra i tk è 0,05 s (cfr. tabella)

Un esempio -IIIPosso a questo punto valutare “a occhio” il valor medio empirico e la deviazione standard empirica basandomi sull’istogramma. Posso stimare il valor medio stimando la posizione del massimo (poiché in una distr. gaussiana le due grandezze coincidono). Il max. dell’istog. si ha per t= 25.87 s circa. La deviazione standard è stimata mediante la FWHM (vedi il capitolo sulle proprietà della funzione gaussiana) : quest’ultima è circa pari a 0.15 s e dunque σ≈ 0.15/2.35 = 0.064 s. A questo punto posso eseguire i calcoli mediante le formule già viste:
, e
Sostituendo i valori numerici della tabella si ottiene:
Dopo aver notato che i risultati ottenuti sono simili a quelli stimati “ad occhio” (il che indica che non ci sono grossi errori di calcolo), diamo il risultato finale considerando le sole cifre significative:
Notiamo infine esplicitamente che le formule per il calcolo del valor medio e della deviazione standard empirici basate sulle frequenze sono in realtà approssimate quando, come in questo esempio, l’ampiezza di ciascuna classe è maggiore della sensibilità dello strumento. Infatti nei calcoli si usa il valore centrale delle classi, e non il valor medio delle misure che cadono in ciascuna classe. Se avessimo usato le formule basate sulle singole misure (vedi pag. 14 e 17) i risultati ottenuti sarebbero stati leggermente diversi (provare per credere).
∑=
ν=M
1kkktt k
2M
1kk )tt( ν⋅−=σ ∑
= Ntσ
=σ
s8755.25t = s071587359.0=σ s0071587359.0t =σ
s007.0876.25t ±=

Proprietà della distribuzione gaussiana -I
In questo capitolo sono riassunte alcune proprietà della funzione gaussiana di interesse generale. Non sono qui date la dimostrazioni di tali proprietà, che possono comunque nella maggior parte dei casi essere dedotte dal lettore mediante l’analisi matematica. Più complesso risulta invece il calcolo dell’integrale gaussiano, che è in ogni caso trattato su testi specialistici.
Studio della funzione gaussiana.
1) Massimo della funzione per x=μIl parametro μ corrisponde al massimo della funzione, con
2) Limiti per x →∞Sia per x→+∞ che per x → -∞ la funzione tende a zero.
41
2
2
2)x(
e2
1)x(f σ
μ−−
πσ=
πσ=μ 21)(f

Proprietà della distribuzione gaussiana -II
3) Flessi per x=μ+σ e per x=μ-σDunque i flessi distano σ da μ (cioè dal massimo). Il valore della funzione
in corrispondenza dei flessi è:(cioè leggermente maggiore della metà del valore della funzione per x=μ)
4) Full Width Half Maximum (FWHM)Definiamo la larghezza totale a metà altezza (FWHM) come la larghezza della “campana” a metà del valore massimo della funzione (vedi figura).
21
e)21()(f−
⋅πσ=σ±μ
μ
σ σ
flessoflesso
FWHM
f(μ)
0.606f(μ)
f(μ)/2
Dalla figura si evince che la FWHM è leggermente maggiore di due volte σ. In particolare si puo’ dimostrare che vale la relazione: FWHM=2.35·σ

Proprietà della distribuzione gaussiana -III
5) Variabile centrata e ridottaEsistono infinite distribuzioni gaussiane, in quanto l’espressione della funzione gaussiana contiene due parametri arbitrari (μ e σ) che determinano la posizione del massimo e la larghezza della distribuzione.E’ peraltro possibile ricondurre una qualsiasi distribuzione gaussiana a quella caratterizzata dai parametri μ=0 (centrata) e σ=1 (ridotta). A questo scopo, basta effettuare la sostituzione di variabile
dove la variabile y così definita prende il nome di variabile centrata e ridotta. Èfacile dimostrare che con tale cambio di variabile la (generica) distribuzione gaussiana seguita dalla variabile x si trasforma nella distribuzione gaussiana centrata e ridotta seguita dalla nuova variabile y:
Con la sostituzione sopra citata è possibile dunque ricondurre qualsiasi distribuzione gaussiana ad un’unica distribuzione, quella centrata e ridotta, che (formalmente) non contiene parametri liberi. Le proprietà che valgono per quest’ultima valgono per ogni distribuzione gaussiana.
σμ−= /)x(y
2
2
2)x(
e2
1)x(f σ
μ−−
πσ= 2
y2
e21)y(f −
π=

Proprietà della distribuzione gaussiana -IV
6) L’integrale gaussianoSi vuole valutare l’integrale
con a e b estremi di integrazione generici. Si passa allora alla variabile centrata e ridotta, definita precedentemente e si ottiene:
dove e
L’integrale ottenuto non dipende più dal valore dei parametri μ e σ: ci siamo cioè ricondotti, attraverso l’uso della variabile centrata e ridotta, ad un unico integrale che ci consente di risolvere il nostro problema giungendo, mediante la soluzione di un solo integrale, a risultati validi per tutte le funzione gaussiane.Esaminiamo ora alcuni casi notevoli per gli estremi di integrazione.
dxe2
1dx)x(fIb
a2
)x(b
ab,a2
2
∫∫ σμ−
−
πσ==
dye21I 2
y
b,a
2
∫β
α
−
π= σ
μ−=α
aσ
μ−=β
b

Proprietà della distribuzione gaussiana -V
a=-∞ , b =+ ∞ α=-∞ , β =+ ∞Tenendo presente che l’integrale definito è uno degli integrali fondamentali della fisica-matematica e vale si ha:
Verifichiamo dunque che l’integrale da - ∞ a + ∞ della funzione gaussiana vale 1, come deve essere per una funzione di probabilità.
a=μ-γσ , b =μ+γσ (con γ reale positivo) α=- γ , β =+ γVogliamo cioè calcolare l’integrale gaussiano in una regione compresa fra il massimo meno γ volte σ ed il massimo più γ volte σ (vedi figura).
1221dye
21I 2
y
,
2
=π⋅π
=π
= ∫∞+
∞−
−
+∞∞−
dye 2y2
∫∞+
∞−
−
π2
μμ−γσ μ+γσ

Proprietà della distribuzione gaussiana -VI
I risultati ottenuti sono qui tabulati i valori dell’integrale I (da μ−γσ a μ+γσ) per diversi valori di γ
γ I γ I γ I 0.1 0.0797 1.1 0.7287 2.1 0.96460.2 0.1585 1.2 0.7699 2.2 0.97220.3 0.2358 1.3 0.8064 2.3 0.97860.4 0.3108 1.4 0.8385 2.4 0.98360.5 0.3829 1.5 0.8664 2.5 0.98760.6 0.4515 1.6 0.8904 2.6 0.99070.7 0.5161 1.7 0.9109 2.7 0.99310.8 0.5763 1.8 0.9281 2.8 0.99490.9 0.6319 1.9 0.9426 2.9 0.99631.0 0.6827 2.0 0.9545 3.0 0.9973
Valori notevoli: γ = 1,2 e 3
Le probabilità che una variabile gaussiana x assuma un valore compreso negli intervalli centrati attorno a μ e di ampiezza σ, 2σ e3σ sono rispettivamente pari al68%, 95% e 99.7%
∫σ+μ
σ−μσ+μσ−μ ≅= 68.0dx)x(fI ,
∫σ+μ
σ−μσ+μσ−μ ≅=2
22,2 95.0dx)x(fI
∫σ+μ
σ−μσ+μσ−μ ≅=3
33,3 997.0dx)x(fI

Proprietà della distribuzione gaussiana -VII
7) Valor medio teorico di una distribuzione gaussianaRicordiamo che, data una distribuzione di probabilità continua f(x), il valor medio teorico (o momento del primo ordine) Mx è definito come:
(si tratta di una media pesata dove il peso che compete a ciascun valore della variabile x è rappresentato dalla probabilità f(x)dx che la variabile x assuma tale valore). Nel caso in cui f(x) sia una distribuzione gaussiana, posso calcolare il valor medio teorico passando alla variabile centrata e ridotta:
di qui si ha:
dove l’ultima eguaglianza è dovuta al fatto che il primo è un integrale di una funzione disparie dunque è nullo, mentre il secondo è l’integrale già incontrato (vedi par. 6) ed è pari a . In conclusione abbiamo dimostrato che il valor medio teorico Mx di una distribuzione gaussiana coincide con il parametro μ.
∫+∞
∞−⋅=Μ dx)x(fxx
dye)y(21M 2
y
x
2
∫∞+
∞−
−⋅μ+σ
π=
μ=⋅π
μ+⋅
πσ
= ∫∫∞+
∞−
−∞+
∞−
−dye
2dyye
2M 2
y2
y
x
22
dxex2
1M 2
2
2)x(
x ∫∞+
∞−σμ−
−⋅
πσ=
π2

Proprietà della distribuzione gaussiana -VIII
8) Deviazione standard teorica di una distribuzione gaussianaRicordiamo che, data una distribuzione di probabilità continua f(x), la varianza teorica rappresenta il valor medio (teorico) del quadrato degli scarti dal valor medio (teorico):
mentre la deviazione standard teorica è data daNel caso della distribuzione gaussiana puo’ essere calcolata effettuando il consueto passaggio alla variabile centrata e ridotta:
Riscrivendo come segue l’integrale ed integrando per parti si ha:
Ricordando la relazione sopra menzionata tra varianza e deviazione standard teoriche, concludiamo che la deviazione standard teorica di una distribuzione gaussiana coincide con il parametro σ ella distribuzione stessa :
2xσ
∫+∞
∞−⋅−=σ dx)x(f)Mx( 2
x2x
2xx σ=σ
2xσ
dxe)x(2
1 2
2
2)x(
22x ∫
∞+
∞−σμ−
−⋅μ−
πσ=σ dyey
22
y2
22x
2
∫∞+
∞−
−⋅
πσ
=σ
[ ] 22
2y
2y2
2y2
2x 20
2dyeey
2dy)ey(y
2
222
σ=π−π
σ−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡−⋅
πσ
−=⋅−⋅π
σ−=σ ∫∫
∞+
∞−
−∞+∞−
−∞+
∞−
−
σ=σx

Proprietà della distribuzione gaussiana -IX
9) Teorema sulla somma di variabili gaussiane“Siano date N variabili gaussiane (x1,x2,…xN ), ciascuna con valor medio teorico μi e deviazione standard teorica σi. Sia inoltre y la somma delle N variabili gaussiane. Si dimostra che y è ancora una variabile gaussiana con valor medio e varianza (teorici) pari rispettivamente alla somma dei valori medi e varianze (teorici) delle variabili xi, cioè:
Ci limiteremo qui per semplicità a dimostrare l’asserto nel caso N=2. Inoltre, senza perdere di generalità, considereremo variabili centrate e ridotte, a cui, come visto in precedenza, è sempre possibile ricondursi.
y= x1+x2 (con x1, x2 centrate e ridotte) x2=y-x1Pertanto per ottenere la probabilità g(y) che la variabile somma assuma un valore y è occorre sommare (ossia integrare) su tutti i modi possibili in cui, sommando x1ed x2 , posso ottenere il valore y (similitudine il caso in cui lancio di 2 dadi e faccio la somma dei risultati).
∑=
=N
1iixy ∑
=
μ=μN
1iiy ∑
=
σ=σN
1i
2i
2y ∑
=
σ=σN
1i
2iy

Proprietà della distribuzione gaussiana -XPoiché nel nostro caso le distribuzioni sono gaussiane centrate e ridotte si ha:
riscrivendo il prodotto degli esponenziali come un unico esponenziale si ha:
Il termine in parentesi tonda ad esponente puo’ essere scritto come somma di un quadrato (contenente x1) ed un termine in y che puo’ essere portato fuori integrale:
Sostituendo nell’integrale da calcolarsi si ha:
tenendo presente che quest’ultimo integrale è gaussiano (con μ=y/2 e σ2=1/2) puo’ essere calcolato (passando alla variabile centrata e ridotta) e vale .
Si ha allora: , che è una distribuzione gaussiana con μ=0 e σ2=2.Poiché le due distribuzioni di partenza avevano μ1=μ2=0 e σ1= σ2 =1, abbiamo verificato che la distribuzione della variabile y ha parametri μ = μ1+μ2 eσ2 =(σ1 )2+ (σ2 )2 c.v.d.
12)(
2111
21
21
221)()()( dxeedxxyfxfyg
xyx
x
−−∞+
∞−−∞+
∞− ⋅=⋅−⋅= ∫∫ π43421
1
)yx2x2y(21
dxe21)y(g 1
21
2
∫∞+
∞−
−+−
π=
2
1
2
1
2
1
2)y2
1x(2y2
1yx2x2y −+=−+
1
)2yx(
4y
dxee21)y(g
21
2
∫∞+
∞−
−−−
π=
π
22y2
e22
1)y(g ⋅−
π=

Proprietà della distribuzione gaussiana -X
10) Teorema sul prodotto di una variabile gaussiana per unacostante reale.
Sia x una variabile gaussiana con valor medio μ e deviazione standard σ. Si dimostra che la variabile y=αx, con α costante reale, è anch’essa gaussiana con parametri μy=αμ e σy=ασx.Infatti, la probabilità che la variabile y assuma un valore compreso fra y ed y+dy è pari a quella che la variabile x ne assuma uno compreso fra x e x +dx. Cioè si ha g(y)dy=f(x)dx (dove g(y) è la distribuzione seguita dalla var. y). Esplicitando la
distr. Gaussiana seguita dalla var. x e tenedo presente che x=y/α e che dx=dy/α
si ha:
Notiamo che l’ultimo termine dell’equazione è una funzione gaussiana con valor medio μy=αμ e deviazione standard σy=ασ, che è quanto dovevasi dimostrare.
22
2
2
2
2)x(
2)x(
e2
1dxe2
1dy)y(g σααμ−
−σμ−
−
πασ=
πσ=

Formulario - I
• Valor medio empirico
• Varianza empirica
• Deviazione standard empirica
• Deviazione standard del valor medio empirico
• Larghezza a meta’ altezza FWHM=σ · 2.35
∑=
=N
1iix
N1x ∑
=
ν=M
1kkkxx
2N
1ii
2N
1ii
2 )xx(N1)d(
N1 ∑∑
==
−==σ k2
M
1kkk
2M
1kk
2 )xx()d( ν⋅−=ν⋅=σ ∑∑==
NEEx σ=σ
2E σ=σ





























