Embed Size (px)
Citation preview

Statistikk er begripelig…

…men man må begynne
med ABC

ANOVA
ANOVA er brukt til å sammenligne
gjennomsnittsverdier
Slik er det, selv om det er Analysis
of Variance man sier

BIVARIAT
Bivariat analyse er godt nok for å
gi litt lyse
Men for å finne strukturer må vi
bruk multivariat analyse

Univariat analyse Beskrivelse eller test av en
variabel
Bivariat analyse Beskrivelse eller test av en
variabel mot en uavhengig
variabel; lønn mot kjønn f eks
Multivariat
analyse
Flere enn to variabler i
analysen. Hvordan flere
uavhengige variabler påvirker
en avhengig variabel eller
sammenheng på annen måte.

COX-REGRESJON
Cox-regresjon er brukt for
overlevelsedaten
Den avhengige variabelen er
hasardraten.

Data
Data er opplysninger som
foreligger som tall
Er det annen type av opplysninger
kan de uttrykkes som tall i alle fall

Alder 15, 22, 38 og så videre
Kjønn Mann=0
Kvinne=1
Helse Godt helse=10
….
Dårlig helse=1

Ensidig test
Ensidige tester må brukes med
stor forsiktighet
Brukes bare når man har en svært
god grunn til å gjøre det

Frekvensfordeling
Frekvensfordelingen er hvor
dataanalysen starter, det gjelder all
Hvor mange ganger de forskjellige verdiene på en variabel forekommer presenteres i prosenter eller absolutte tall
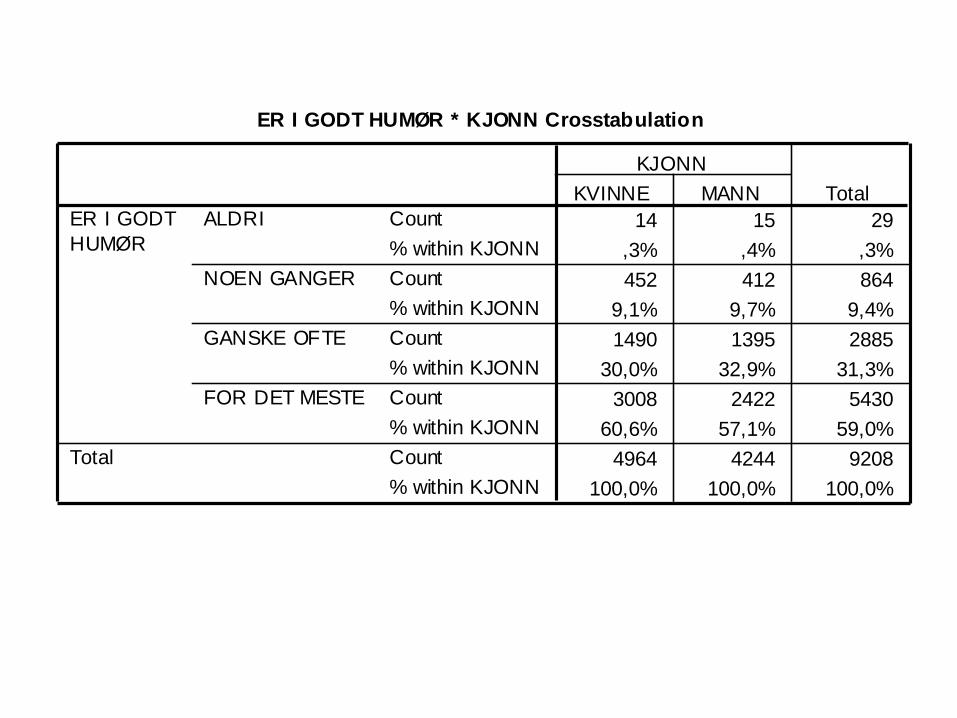
ER I GODT HUMØR * KJONN Crosstabulation
14 15 29
,3% ,4% ,3%
452 412 864
9,1% 9,7% 9,4%
1490 1395 2885
30,0% 32,9% 31,3%
3008 2422 5430
60,6% 57,1% 59,0%
4964 4244 9208
100,0% 100,0% 100,0%
Count
% within KJONN
Count
% within KJONN
Count
% within KJONN
Count
% within KJONN
Count
% within KJONN
ALDRI
NOEN GANGER
GANSKE OFTE
FOR DET MESTE
ER I GODT
HUMØR
Total
KVINNE MANN
KJONN
Total

Gjennomsnitt
Gjennomsnittlig behagelig temperatur
har den som ligger med hode i
stekeovnen og bena i isvann
Bruk gjennomsnitt med godt forstand,
når det finns ekstreme observasjoner
er det bedre med median.

Gjennomsnittlige liggetider for
pasienter
Liggetidene for syv pasienter ved en
medisinsk avdeling var 22 dager.
Kan dette brukes for planlegging på
avdelingen?

Observert antall
De observerte liggetidene (i dager):
5, 5, 5, 7, 10, 16 og 106
Gjennomsnittsverdien ER 22 dager
Gjennomsnittet hvis vi fjerner den ekstreme
observasjonen er 8 dager
Medianen er 7 dager.

Histogram
Histogram viser det antall
forekomster som er i hvert intervall

Alder, HUNT2
20 40 60 80
ALDER VED FREMMØTE
0
500
1000
1500
Co
un
t

Bars show counts
ALDRI NOEN GANGER GANSKE OFTEFOR DET MEST E
ER I GODT HUMØR
1000
2000
3000
4000
5000
Co
un
t
29 864 2885 5430
ER I GODT HUMØR
543210
Fre
qu
en
cy
6 000
5 000
4 000
3 000
2 000
1 000
0
Mean =3,49Std. Dev. =0,676
N =9 208

Ikke-parametriske tester
Ikke-parametriske tester skal
brukes når dine data ikke er
normalfordelt
i små sampel, for kvalitative
variabler og i en fordeling som er
skjevfordelt

Kji-kvadrat-test
Kji-kvadrat-test er brukt for
uavhengighetstest
Når data er delt i kategorier kan
dette være best

ER I GODT HUMØR * KJONN Crosstabulation
14 15 29
,3% ,4% ,3%
452 412 864
9,1% 9,7% 9,4%
1490 1395 2885
30,0% 32,9% 31,3%
3008 2422 5430
60,6% 57,1% 59,0%
4964 4244 9208
100,0% 100,0% 100,0%
Count
% within KJONN
Count
% within KJONN
Count
% within KJONN
Count
% within KJONN
Count
% within KJONN
ALDRI
NOEN GANGER
GANSKE OFTE
FOR DET MESTE
ER I GODT
HUMØR
Total
KVINNE MANN
KJONN
Total
Kji-2=12,0; P=0,007

Konfidensintervall
Konfidensintervallet indikerer hvor
presist
det populasjonsverdi du søker kan
bli vist

38% av en tilfeldig utvalgt gruppe kvinner
sov dårlig fordi deres ektefeller snorket så
kraftig. 95% konfidensintervall for andelen
med forstyrret nattsøvn var 20 til 56%.
Hvor stor andel i populasjonen?
Omtrent 38%
Men: 5% risiko att andelen er lavere en 20%
eller høyre en 56%

Logistisk regresjon
Logistisk regresjon er brukt for å
forklare binære responser
log-odds for å forklare eller
predikere er resultatene av
logistiske regresjonsanalyser

log-odds -> OR=Odds Ratio
mann kvinne
Høyt
kolesterol-
verdi
60 75
Normalt
kolesterol-
verdi
40 25
Risiko for mann: 60/100=0,60
Odds for mann: 60/40=1,5
Risiko for kvinne: 75/100=0,75
Odds for kvinne: 75/25=3
OR=(Odds for kvinne)/(Odds for mann)=3/1,5=2

Målenivå
Målenivå beskriver type av skala
hvis dine variabler er nominala,
kvantitative eller ordinala

Nominalt nivå
Nominale variabler deler inn i
kategorier
kjønn eller diagnoser er noen
eksempler

Ordinalt nivå
Ordinale variablers kategorier har
innebygd gradient
Når helse måles ordinalt blir
rekkefølgen kjent

Alle målenivåer
Nominalt nivå – gruppering etter kategori
Ordinalt nivå – gruppering etter kategorier
som har gitt ordning
Intervallnivå – ekvidistant skala; like lang
avstand fra en verdi til neste på skalaen
langs hele skalaen
Ratio skala – ekvidistant skala med absolutt
nullpunkt
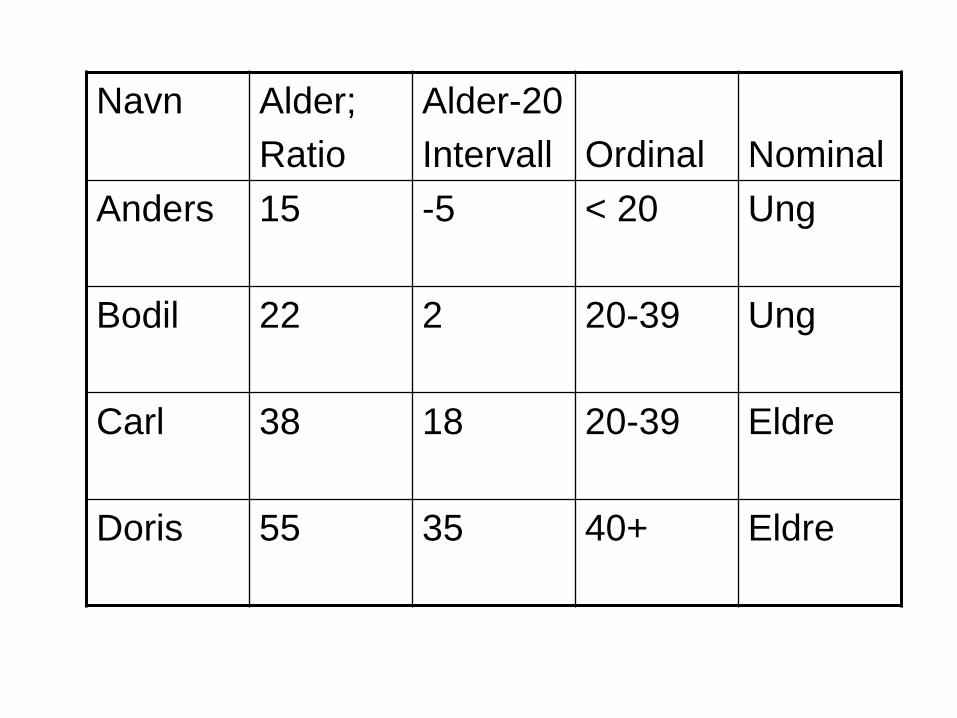
Navn Alder;
Ratio
Alder-20
Intervall
Ordinal
Nominal
Anders 15 -5 < 20 Ung
Bodil 22 2 20-39 Ung
Carl 38 18 20-39 Eldre
Doris 55 35 40+ Eldre

P-verdi
P-verdi er ett måle på fare
at vårt resultat ble til av tilfeldig
variasjon bare

qvartiler
Qvartiler deler data i fjerdedeler
Men på norsk skriver man disse
som kvartiler

Regresjon
Regresjonsanalyse er brukt for å
estimere modeller
for en avhengig variabels
sammenheng med uavhengige
variabler

Standardavvik
Standardavvik sier hvor langt det
er
fra enkeltdataene til gjennomsnittet
som er i senter

ALDER VED FREMMØTE
100806040200
Fre
qu
en
cy
250
200
150
100
50
0
Histogram
Mean =49,42Std. Dev. =16,454
N =9 258

t-test
t-test er test for gjennomsnitt, en
mye brukt test
for små utvalg og intervalldata kan
dette være best

Utvalg
Utvalget er den gruppe vi valgt å
studere
Med tilfeldige utvalg kan vi også
generalisere

Variasjonskoeffisient
Variasjonskoeffisient er
standardavvik delt på gjennomsnittet, det angis som prosent
Med slik måle kan du sammenligne uavhengig enhet, kroner med kg eller gradient

x
x er en variabel, en egenskap som
varierer
Variabelverdier for hver
observasjonsenhet er hva vi
registrerer.

y
Avhengig variabel er ofte kallet y Vi spørrer oss hvilke x påvirker y
og hvor my’

z
z-transformasjon gjør en variabel
standardisert, z-variabelen
har gjennomsnittsverdien null,
standardavvik er en

Omregning til z-skårer
En 80-åring går 400 meter på 5,1 minutter
og skårer 70 av 100 mulige poeng på en
hukommelsetest.
Er han bedre til å gå eller til å huske?
Vi beregner z-skårer etter
gjennomsnittsresultat og standardavvik for
referansegruppen:

80-
åringen
Gjennom
snitt
Standard
avvik
z
Gå 400
meter
5,1
minutter
8,9
minutter
5,5
minutter
(5,1-8,9)/5,5
= -4,8/5,5 =
-0,7
Huske 70
poeng
68
poeng
25 poeng (70-68)/25
= 2/25 =
0,1

Å
Å sammenlike forskjellige grupper
gjør man best
Med ett utvalg av statistiske
teknikker; analyser og test






























