Embed Size (px)
Citation preview

STK643 PEMODELAN NON-PARAMETRIK
Pendugaan Fungsi Kepekatan

MATERI
1. Pendahuluan • Mengapa pemodelan nonparametrik • Penerapan pemodelan nonparametrik (Eksplorasi data dan Inferensia)
2. Pendugaan fungsi kepekatan peubah tunggal • Metode Histogram (Naive Histogram) • Metode Kernel
3. Pendugaan fungsi kepekatan peubah ganda
4. Penerapan pendugaan fungsi kepekatan 5. Pemodelan nonparametrik
• Pemulusan plot tebaran • Metode pemulus Kernel
6. Pemodelan nonparametrik peubah ganda 7. Regresi Spline 8. Model aditif

METODE HISTOGRAM
• Deskripsi tentang penyebaran, kemiringan atau kemenjuluran, dan
kemungkinan adanya modus ganda
Histogram
• Gambaran perilaku data sebagai komponen penting dalam analisis data
• Pola data ideal yang simetrik tidak selalu tergambarkan secara baik Metode Pendugaan Nonparametrik
Pemulusan

METODE HISTOGRAM
• Data contoh acak x1 , x2 , ... , xn • Fungsi teoritik bersifat kontinu dan memiliki turunan sedangkan fungsi
empirik bersifat diskrit (terputus-putus)

HISTOGRAM
• Fungsi kepekatan menjelaskan sebaran suatu peubah X dan peluang P(a<X<b) dapat dituliskan sebagai berikut:
𝑃 𝑎 < 𝑋 < 𝑏 = 𝑓 𝑢 𝑑𝑢
𝑏
𝑎
• Penduga nonparametrik fungsi kepekatan berdasarkan definisi berikut:
𝑓(𝑥) ≡𝑑
𝑑𝑥𝐹(𝑥) ≡ lim
ℎ→0
𝐹 𝑥 + ℎ − 𝐹(𝑥)
ℎ
𝐹 𝑥 =#(𝑥𝑖 ≤ 𝑥)
𝑛
HISTOGRAM
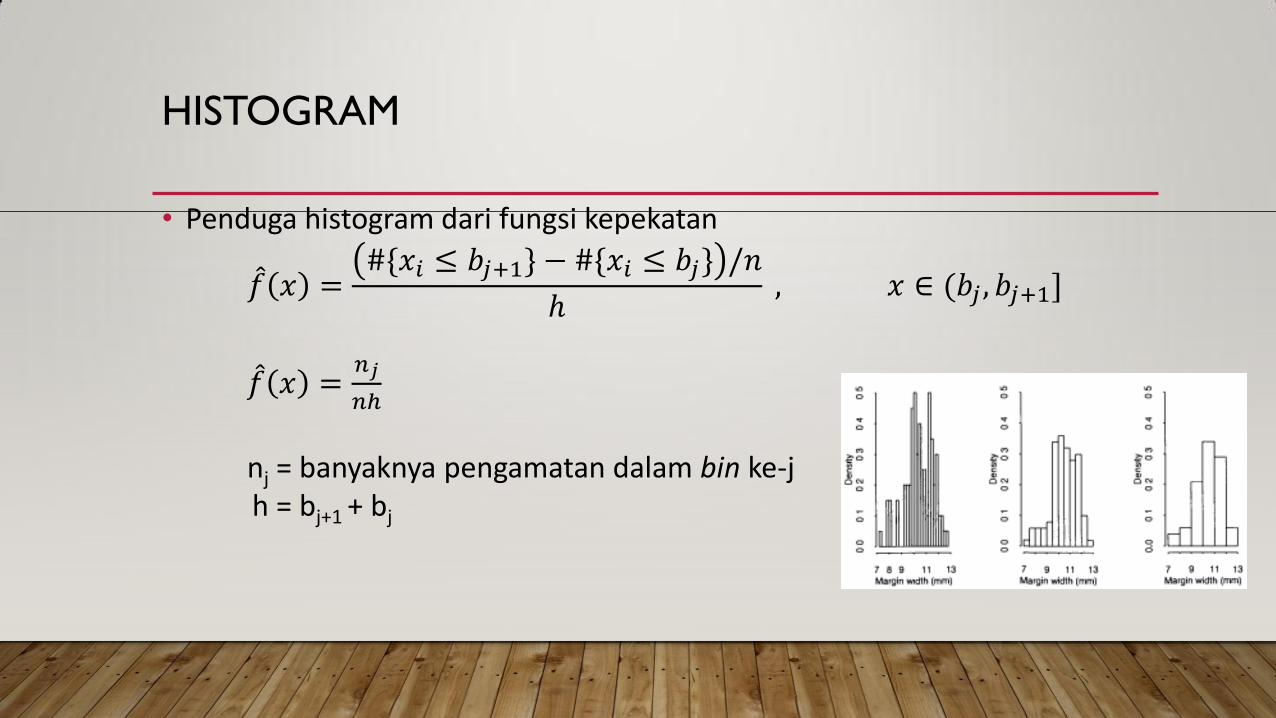
• Penduga histogram dari fungsi kepekatan
𝑓 𝑥 =#{𝑥𝑖 ≤ 𝑏𝑗+1} − #{𝑥𝑖 ≤ 𝑏𝑗} /𝑛
ℎ , 𝑥 ∈ (𝑏𝑗 , 𝑏𝑗+1]
𝑓 𝑥 =𝑛𝑗
𝑛ℎ
nj = banyaknya pengamatan dalam bin ke-j
h = bj+1 + bj

HISTOGRAM
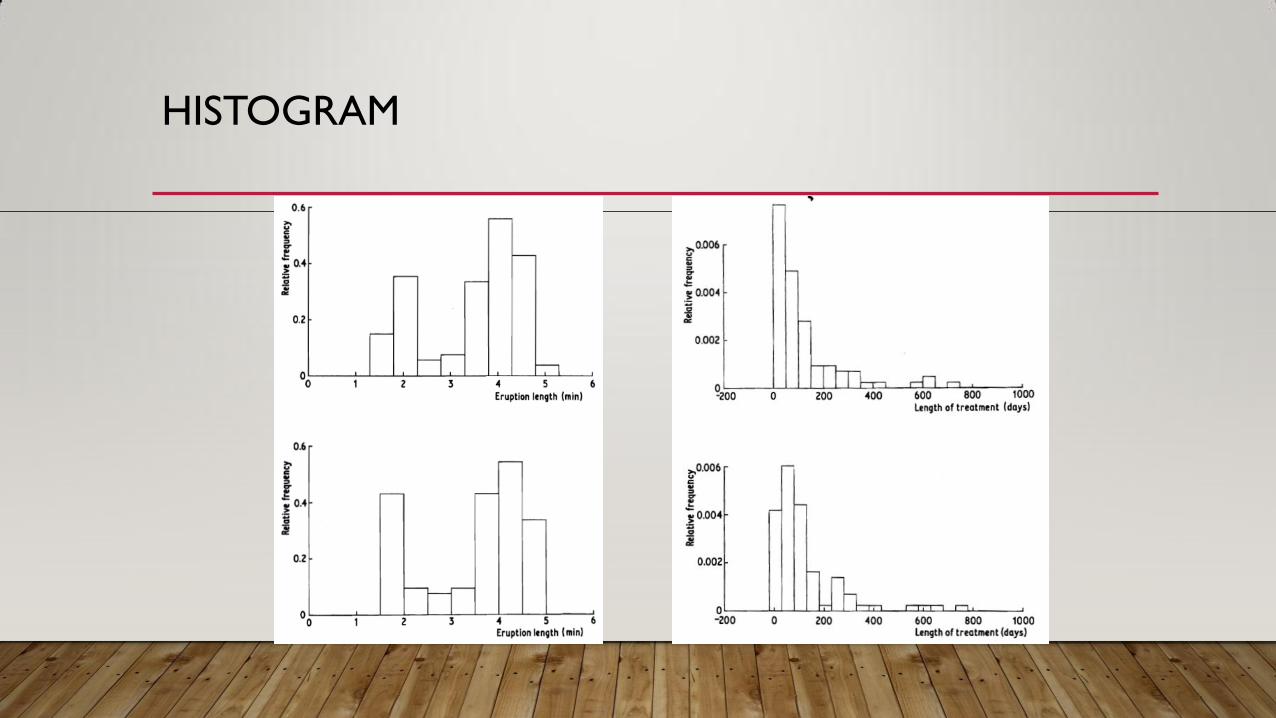
• Histogram merupakan penduga fungsi kepekatan nonparametrik
• Proses penyusunan histogram: • Penentuan jumlah kelas (segmen) nilai
• Penentuan lebar kelas
• Penentuan lokasi nilai tengah masing-masing kelas
• Pengalokasian pengamatan ke dalam salah satu kelas
• Pembuatan kotak (persegipanjang) pada setiap kelas dengan tinggi kotak
masing-masing merupakan frekuensi

HISTOGRAM
• Sturges (1926) : banyaknya kelas atau segmen (L)
n = 2L-1 atau L = [1 + log2n]
h = R/L
• Scott (1979) : lebar kelas (h)
h = 3.49 s n-(1/3)
HISTOGRAM

HISTOGRAM
• Data pengamatan data x1 , x2 , ... , xn • Selang nilai data [a,b] dibagi menjadi m segmen dengan lebar h • Titik batas a+ih untuk 0 ≤ i ≤ m
aj = a + jh nj = banyaknya data amatan xi dalam kelas atau selang [aj-1 , aj]

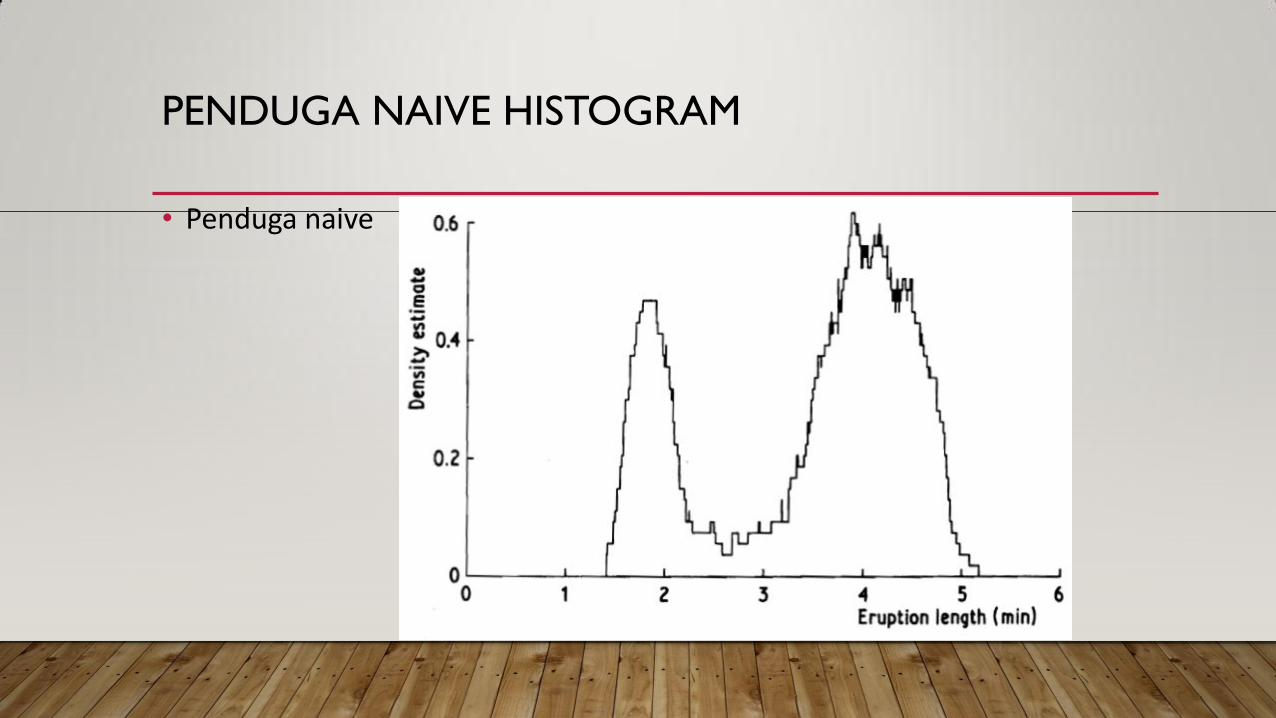
PENDUGA NAIVE HISTOGRAM
• Berdasarkan definisi kepekatan peluang, jika peubah acak X mempunyai
kepekatan f, maka
𝑓 𝑥 = limℎ→0
1
2ℎ𝑃 𝑥 − ℎ < 𝑋 < 𝑥 + ℎ
• Untuk h tertentu, penduga P(x-h<X<x+h) adalah proporsi contoh dalam
selang (x-h<X<x+h) • Penduga naive adalah
𝑓 𝑥 =1
2ℎ𝑛[𝑏𝑎𝑛𝑦𝑎𝑘𝑛𝑦𝑎 𝑥𝑖 𝑑𝑖 𝑑𝑎𝑙𝑎𝑚 (x−h,x+h)

PENDUGA NAIVE HISTOGRAM
• Penduga naive dapat dituliskan
𝑓 𝑥 =1
𝑛
1
ℎ
𝑛
𝑖=1
𝑤𝑥 − 𝑥𝑖ℎ
fungsi pembobot w
𝑤 𝑥 =
1
2𝑗𝑖𝑘𝑎 𝑥 < 1
0 𝑠𝑒𝑙𝑎𝑖𝑛𝑛𝑦𝑎
PENDUGA NAIVE HISTOGRAM
• Penduga naive
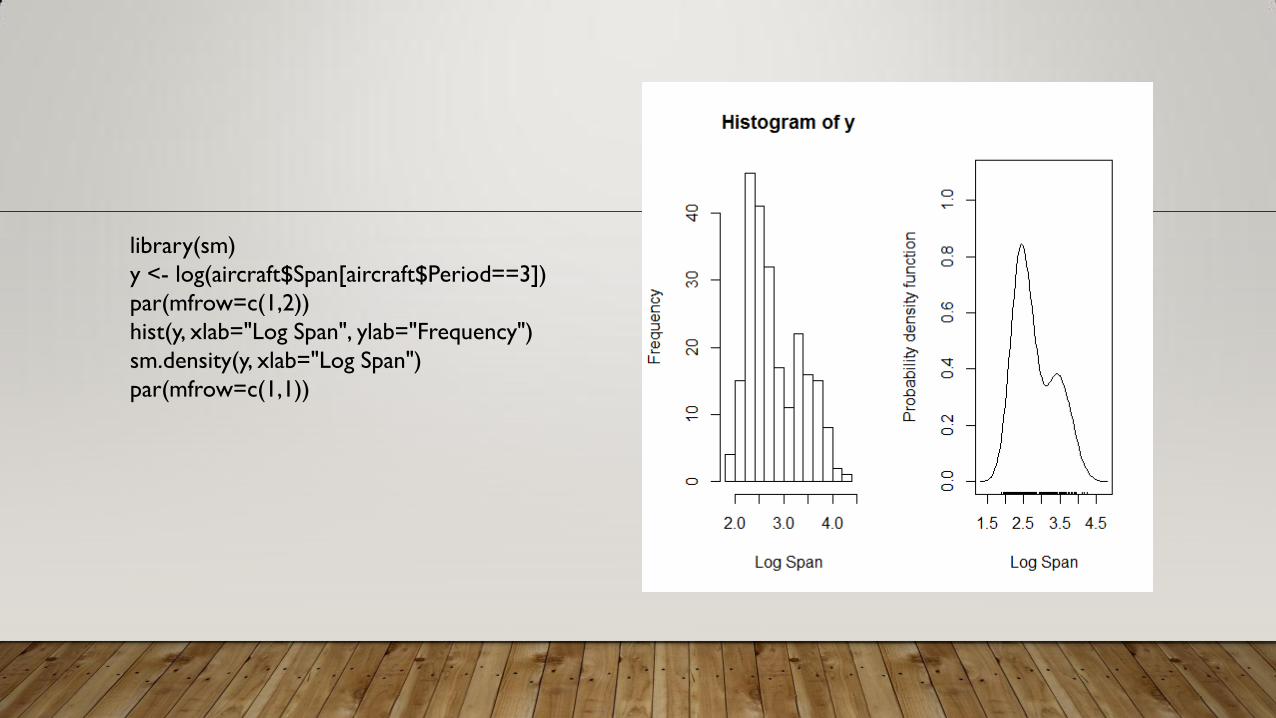
library(sm)
y <- log(aircraft$Span[aircraft$Period==3])
par(mfrow=c(1,2))
hist(y, xlab="Log Span", ylab="Frequency")
sm.density(y, xlab="Log Span")
par(mfrow=c(1,1))
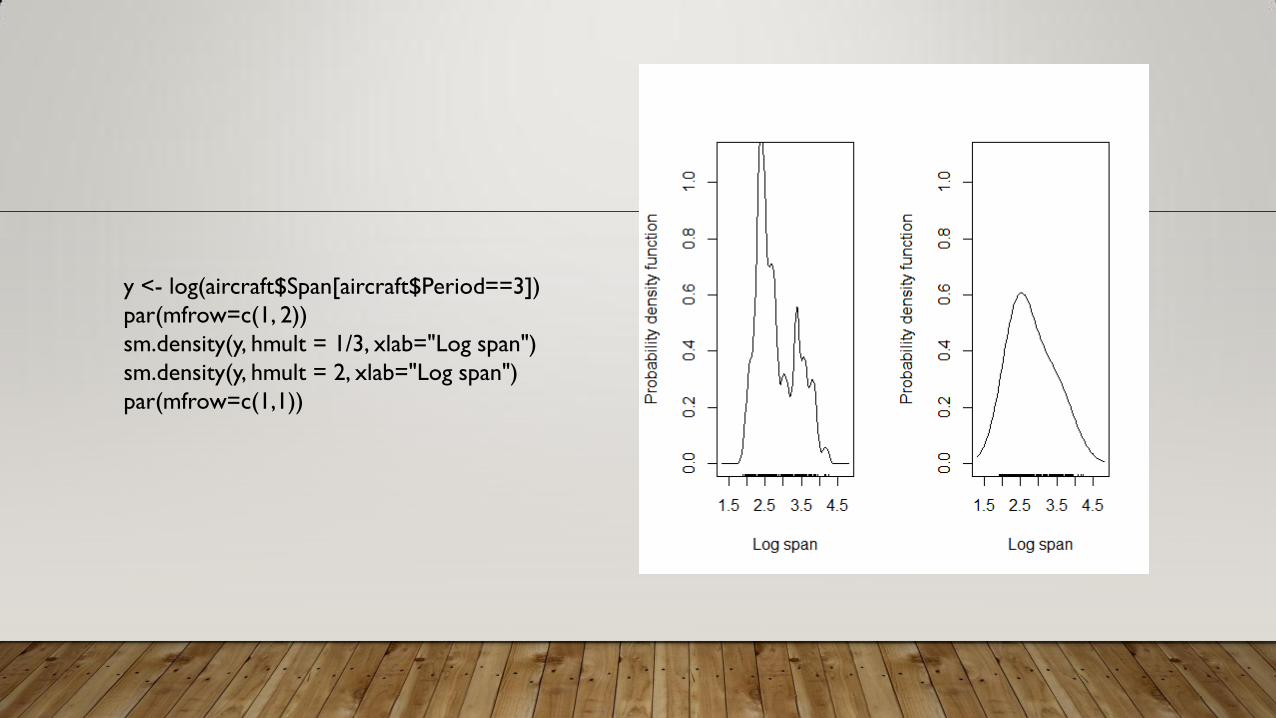
y <- log(aircraft$Span[aircraft$Period==3])
par(mfrow=c(1, 2))
sm.density(y, hmult = 1/3, xlab="Log span")
sm.density(y, hmult = 2, xlab="Log span")
par(mfrow=c(1,1))
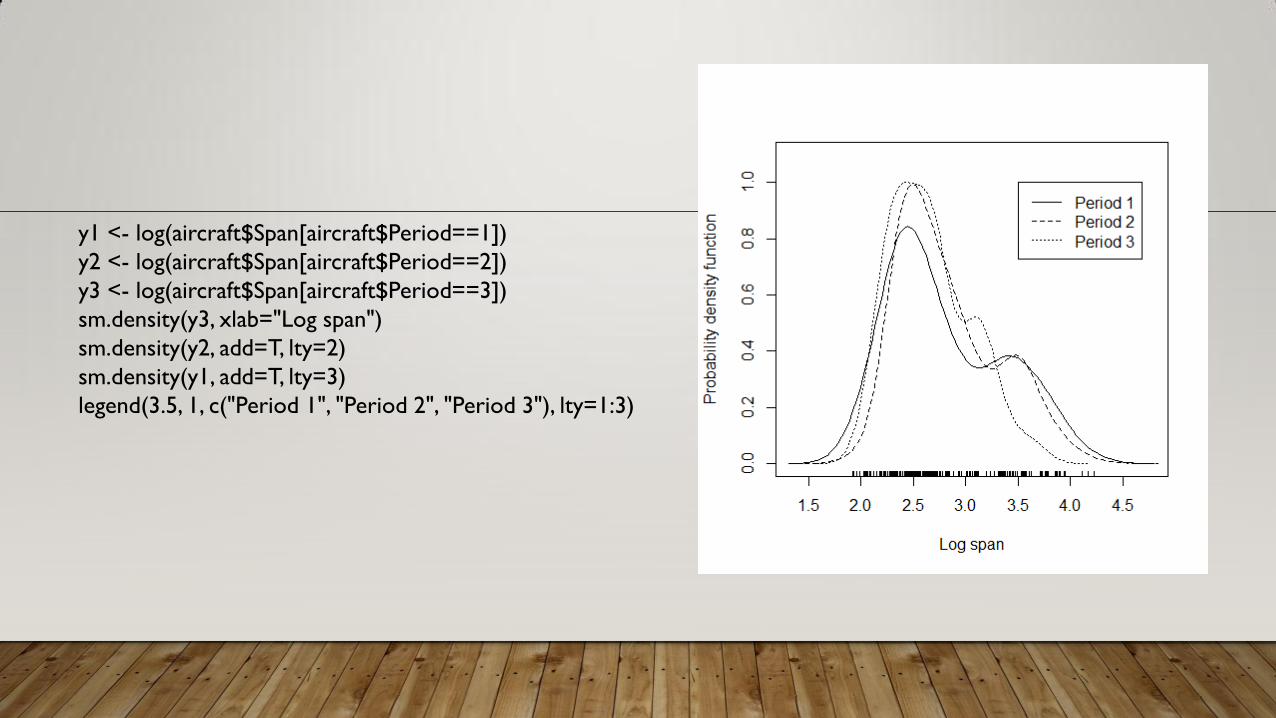
y1 <- log(aircraft$Span[aircraft$Period==1])
y2 <- log(aircraft$Span[aircraft$Period==2])
y3 <- log(aircraft$Span[aircraft$Period==3])
sm.density(y3, xlab="Log span")
sm.density(y2, add=T, lty=2)
sm.density(y1, add=T, lty=3)
legend(3.5, 1, c("Period 1", "Period 2", "Period 3"), lty=1:3)
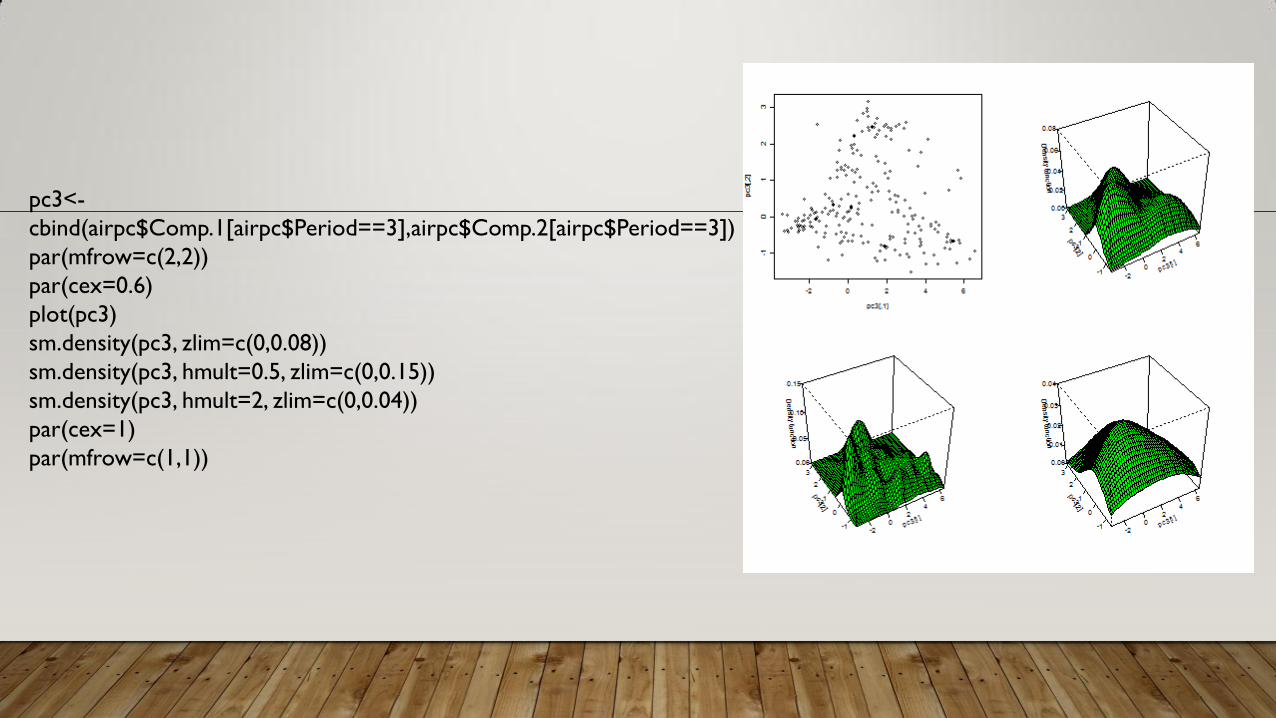
pc3<-
cbind(airpc$Comp.1[airpc$Period==3],airpc$Comp.2[airpc$Period==3])
par(mfrow=c(2,2))
par(cex=0.6)
plot(pc3)
sm.density(pc3, zlim=c(0,0.08))
sm.density(pc3, hmult=0.5, zlim=c(0,0.15))
sm.density(pc3, hmult=2, zlim=c(0,0.04))
par(cex=1)
par(mfrow=c(1,1))
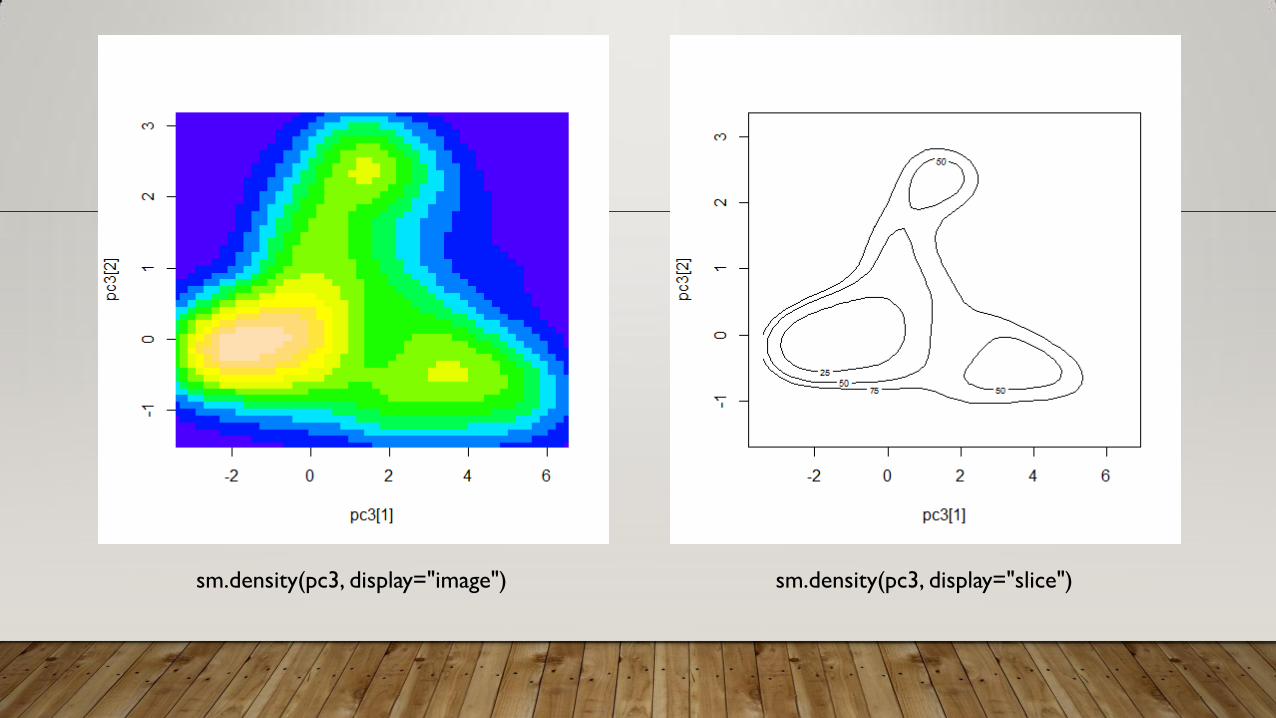
sm.density(pc3, display="image") sm.density(pc3, display="slice")
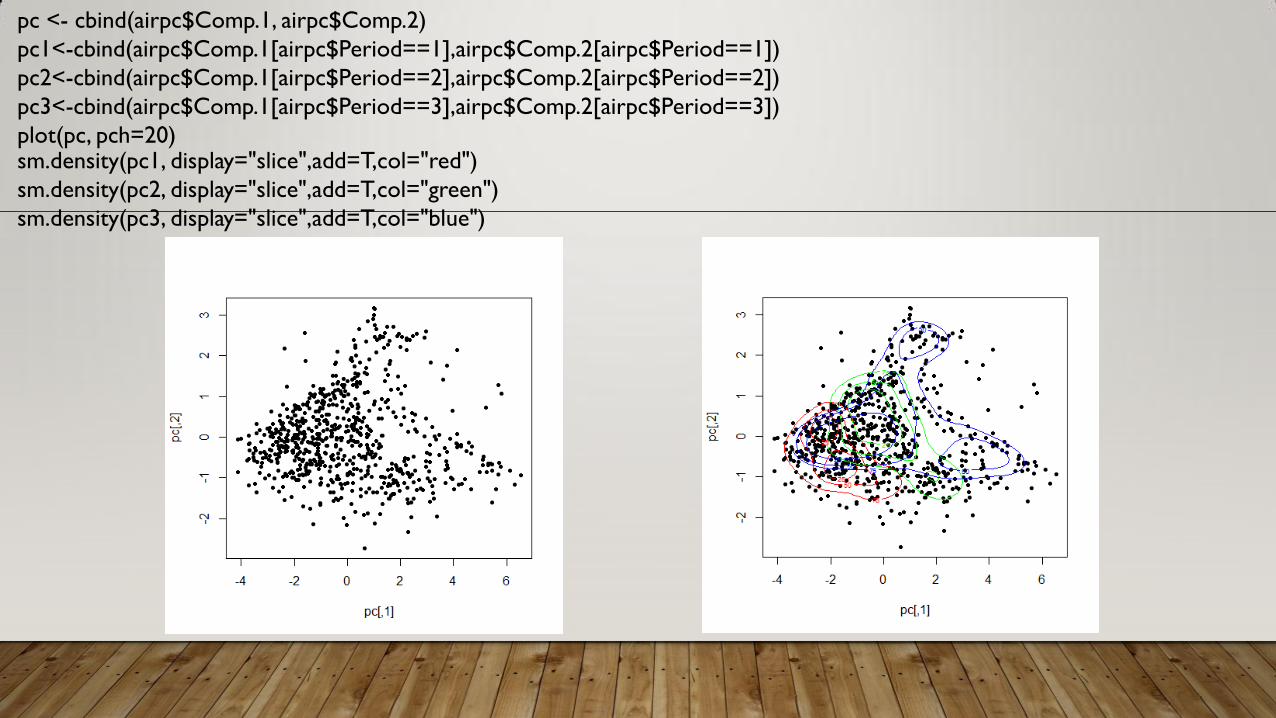
pc <- cbind(airpc$Comp.1, airpc$Comp.2)
pc1<-cbind(airpc$Comp.1[airpc$Period==1],airpc$Comp.2[airpc$Period==1])
pc2<-cbind(airpc$Comp.1[airpc$Period==2],airpc$Comp.2[airpc$Period==2])
pc3<-cbind(airpc$Comp.1[airpc$Period==3],airpc$Comp.2[airpc$Period==3])
plot(pc, pch=20) sm.density(pc1, display="slice",add=T,col="red")
sm.density(pc2, display="slice",add=T,col="green")
sm.density(pc3, display="slice",add=T,col="blue")

METODE KERNEL
• Pembobot w disubstitusi dengan fungsi kernel K sehingga diperoleh penduga kernel
𝑓 𝑥 =1
𝑛
1
ℎ
𝑛
𝑖=1
𝑤𝑥 − 𝑥𝑖ℎ
• Penduga kernel
𝑓 𝑥 =1
𝑛
1
ℎ
𝑛
𝑖=1
𝐾𝑥 − 𝑥𝑖ℎ
• Fungsi kernel K memenuhi
𝐾 𝑢 𝑑𝑢 = 1
+~
−~
• Fungsi K biasanya berupa fungsi kepekatan peluang simetri seperti kepekatan normal h disebut window width atau parameter pemulus (smoothing) atau band width.
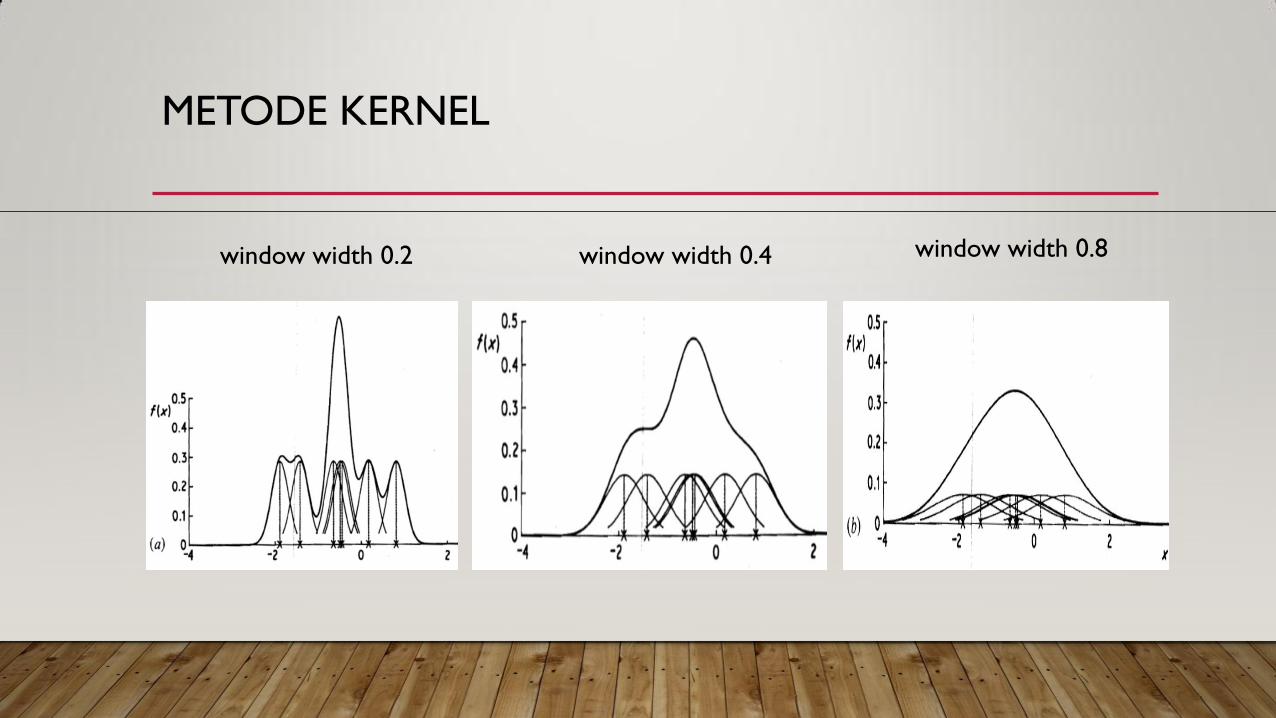
METODE KERNEL
window width 0.4 window width 0.2 window width 0.8
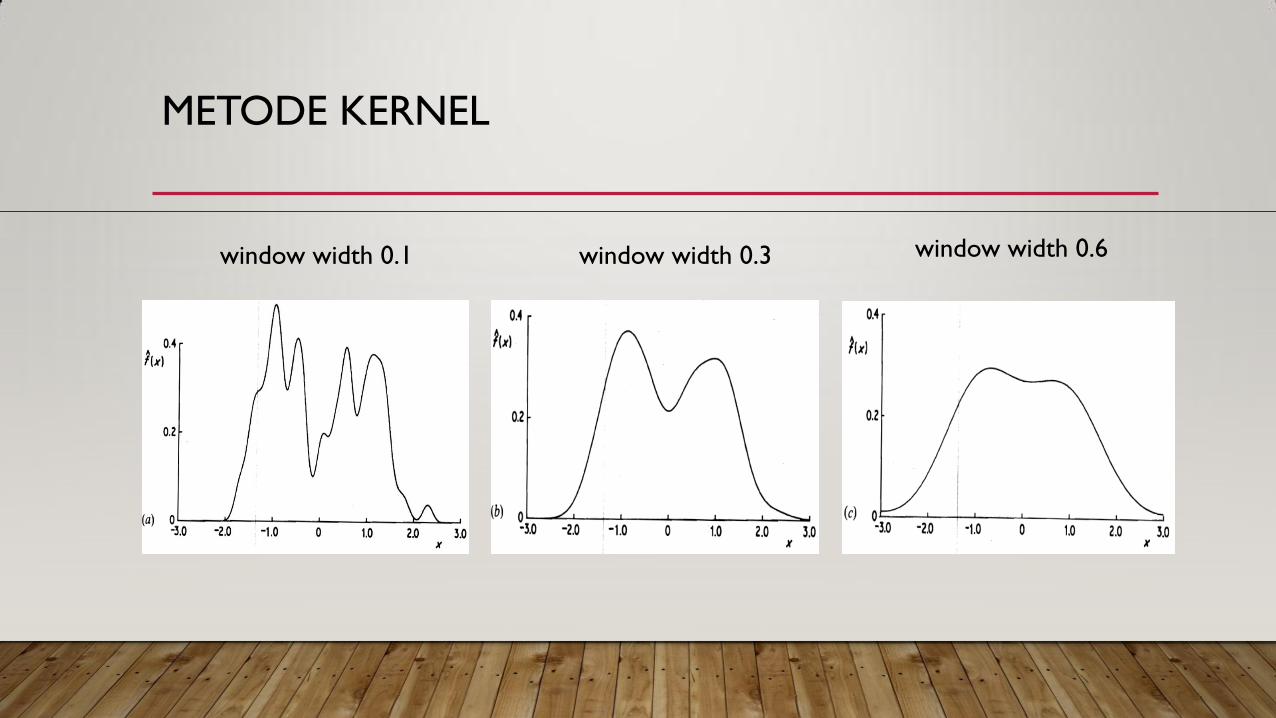
METODE KERNEL
window width 0.3 window width 0.1 window width 0.6
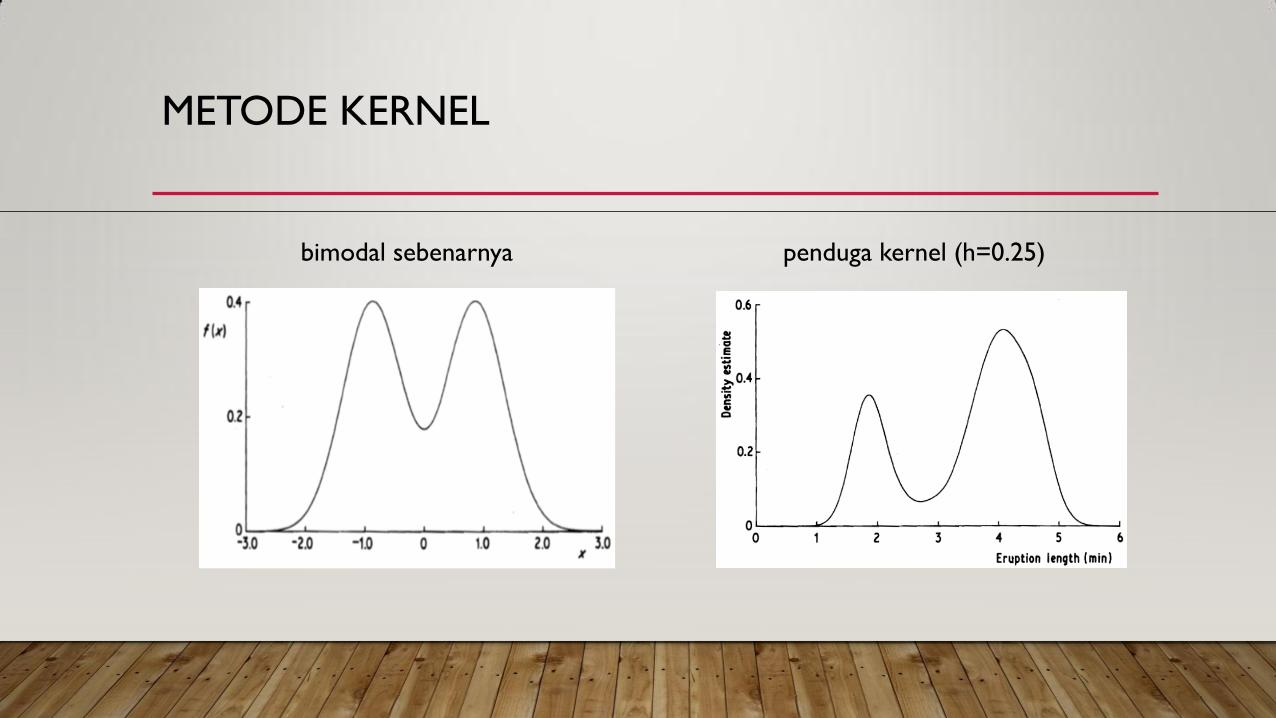
METODE KERNEL
penduga kernel (h=0.25) bimodal sebenarnya

METODE KERNEL PENENTUAN LEBAR JENDELA
• 𝑓 𝑥 merupakan penduga bagi f berdasarkan nilai h tertentu
• Nilai h yang kecil menunjukkan ketergantungan pada data yang berdekatan dengan x,
sebaliknya nilai h yang besar menunjukkan data yang agak berjauhan akan mempunyai
sumbangan yang hampir sama dengan data yang berdekatan dengan x
• Beberapa kriteria penduga kepekatan yang baik:
• MSE (mean square error)
• ISE (integrated squared error)
• MISE (mean integrated squared error)
• AMISE (asymptotic mean integrated squared error)

METODE KERNEL PENENTUAN LEBAR JENDELA
• MSE (mean square error)
𝑀𝑆𝐸 𝑓 (𝑥) = 𝐸 𝑓 𝑥 − 𝑓(𝑥) 2 =var 𝑓 (𝑥) +(bias{𝑓 (𝑥)})2
bias{𝑓 (𝑥) = E{𝑓 (𝑥)} – f(x)
• MSE tergantung pada parameter

METODE KERNEL PENENTUAN LEBAR JENDELA
• ISE (integrated squared error)
ISE(h) = 𝑓 𝑥 − 𝑓(𝑥) 2
• ISE(h) adalah fungsi dari nilai pengamatan x melalui f(x)
• ISE(h) tergantung pada nilai f(x), penduga fungsi, dan ukuran contoh
• MISE (mean integrated squared error)
MISE(h) = E{ISE(h)}
• MISE(h) dan ISE(h) sebagai ukuran kualitas penduga fungsi, 𝑓 𝑥
• AMISE (asymptotic mean integrated squared error)

METODE KERNEL PENENTUAN LEBAR JENDELA
• AMISE (asymptotic mean integrated squared error)
AMISE(h) = (𝑅(𝑘)
𝑛ℎ+
ℎ4𝜎𝑘4𝑅(𝑓")
4
Nilai h meminimum AMISE(h):
h = 𝑅(𝐾)/𝑛𝜎𝑘4𝑅(𝑓") 1/5
R(g) = ukuran kekasaran fungsi g
= 𝑔2(z)dz
Jika g ~N(µ,σ2) maka R(g’) = 1
4 𝜋𝜎3 dan R(g”) =
3
8 𝜋𝜎5

METODE KERNEL PENENTUAN LEBAR JENDELA
• Validasi Silang
• Penduga fungsi 𝑓 𝑥 di suatu titik ke-i diduga berdasarkan seluruh pengamatan tanpa
pengamatan ke-i
𝑓 𝑥 =1
ℎ(𝑛 − 1) 𝐾
(𝑥𝑖 − 𝑥𝑗
ℎ𝑗≠𝑖
• Besarnya h diperoleh dengan memaksimumkan pseudo-likelihood berikut:
𝑃𝐿 ℎ = 𝑓−𝑖
𝑛
𝑖
(𝑥𝑖)

METODE KERNEL PENENTUAN LEBAR JENDELA
• Validasi Silang
• Penentuan h dengan ISE(h)
𝐼𝑆𝐸 ℎ = 𝑅 𝑓 − 2𝐸 𝑓 𝑥 + 𝑅(𝑓)
R(f) adalah suatu konstanta
2E{f(x)} diduga dengan 2
𝑛 𝑓−𝑖(𝑥𝑖)𝑖
Nilai h diperoleh dengan meminimumkan fungsi
𝑈𝐶𝑉 ℎ = 𝑅 𝑓 −2
𝑛 𝑓−𝑖(𝑥𝑖)
𝑖
• Metode ini disebut validasi silang tak bias di mana E{UCV(h)} = MISE(h)

METODE KERNEL PENENTUAN LEBAR JENDELA
• Validasi Silang
• Penentuan h berdasarkan validasi silang berbias, BCV(h), dengan meminimumkan
AMISE(h)
• Metode validasi silang memerlukan komputasi intensif
• Beberapa rumus h (secara plug-in):
1. ℎ = 1.06𝜎𝑛−1
5 (Silverman 1986)
2. ℎ = 1.59𝜎𝑛−1
3 (Sheather dan Jones 1991)
3. ℎ = 1.44𝜎𝑛−1
5 (Terrell 1990)

METODE KERNEL PEMILIHAN FUNGSI KERNEL
• Beberapa fungsi kernel
• Normal
1
2𝜋𝑒−
1
2𝑡2
, −∞ < 𝑡 < +∞
• Uniform (kotak)
1
2𝑢𝑛𝑡𝑢𝑘 𝑡 < 1
0 𝑠𝑒𝑙𝑎𝑖𝑛𝑛𝑦𝑎

METODE KERNEL PEMILIHAN FUNGSI KERNEL
• Beberapa fungsi kernel
• Epanechnikov
34
1 −15𝑡2
5𝑢𝑛𝑡𝑢𝑘 𝑡 < 5
0 𝑠𝑒𝑙𝑎𝑖𝑛𝑛𝑦𝑎
• Triangle (segitiga)
1 − |𝑡| 𝑢𝑛𝑡𝑢𝑘 𝑡 < 10 𝑠𝑒𝑙𝑎𝑖𝑛𝑛𝑦𝑎

METODE KERNEL PEMILIHAN FUNGSI KERNEL
• Beberapa fungsi kernel
• Biweight (penimbang ganda)
• 15
161 −
1
5𝑡2
2𝑢𝑛𝑡𝑢𝑘 𝑡 < 1
0 𝑠𝑒𝑙𝑎𝑖𝑛𝑛𝑦𝑎
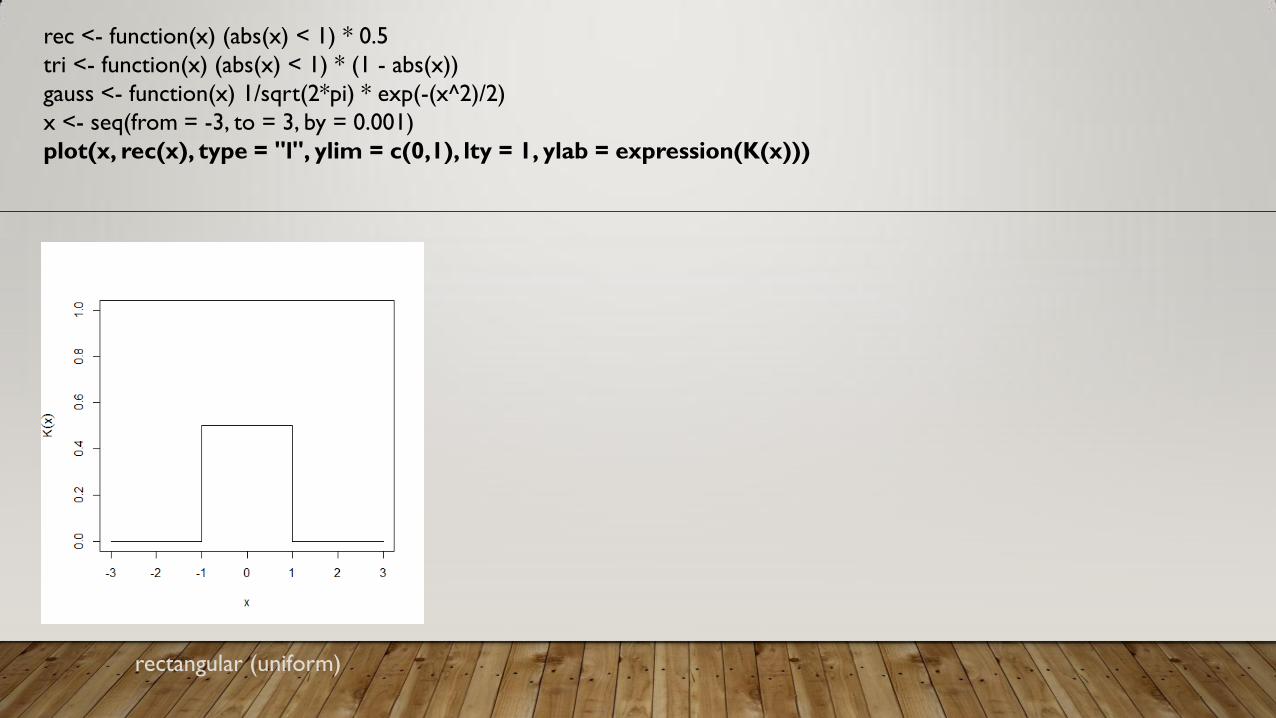
rec <- function(x) (abs(x) < 1) * 0.5
tri <- function(x) (abs(x) < 1) * (1 - abs(x))
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
x <- seq(from = -3, to = 3, by = 0.001)
plot(x, rec(x), type = "l", ylim = c(0,1), lty = 1, ylab = expression(K(x)))
rectangular (uniform)
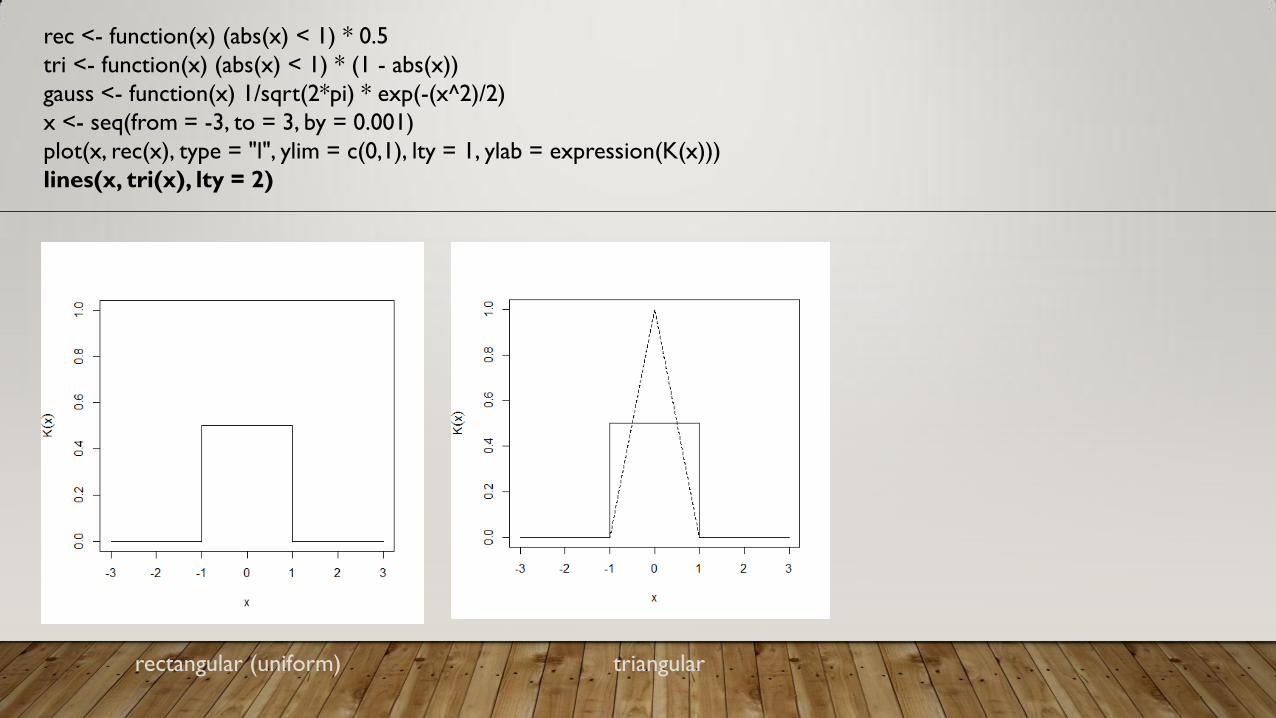
rec <- function(x) (abs(x) < 1) * 0.5
tri <- function(x) (abs(x) < 1) * (1 - abs(x))
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
x <- seq(from = -3, to = 3, by = 0.001)
plot(x, rec(x), type = "l", ylim = c(0,1), lty = 1, ylab = expression(K(x)))
lines(x, tri(x), lty = 2)
rectangular (uniform) triangular
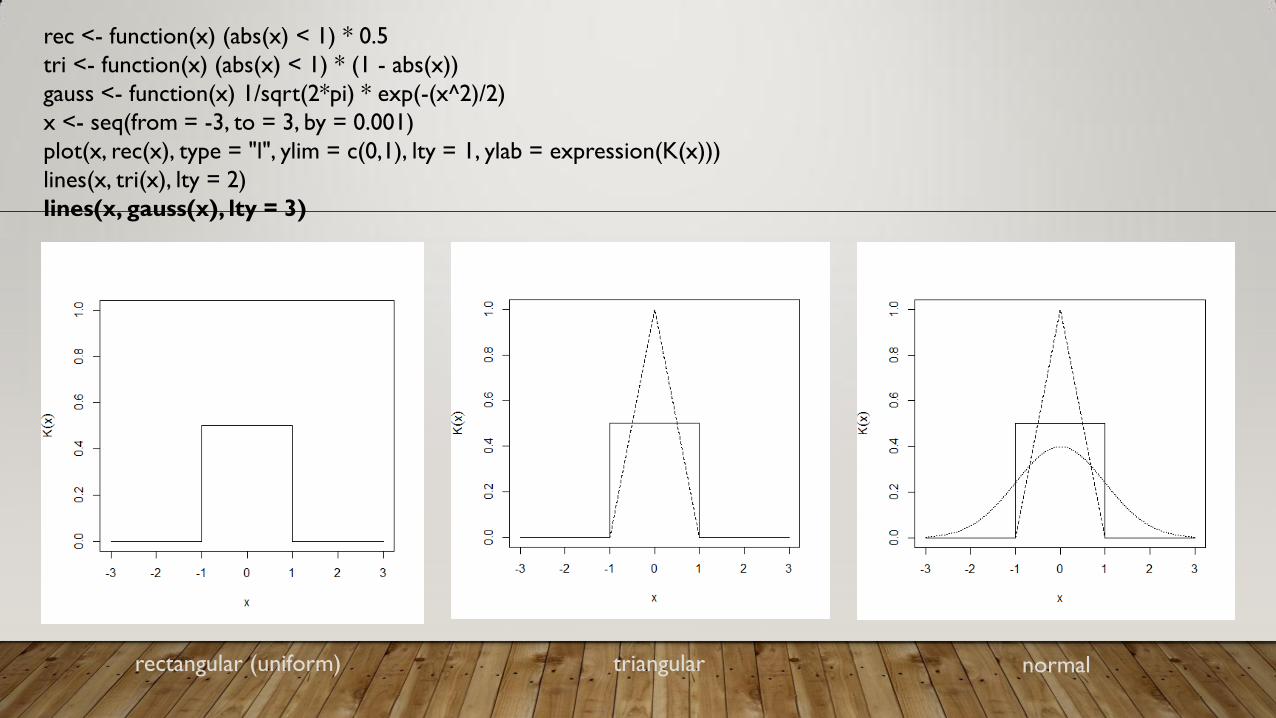
rec <- function(x) (abs(x) < 1) * 0.5
tri <- function(x) (abs(x) < 1) * (1 - abs(x))
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
x <- seq(from = -3, to = 3, by = 0.001)
plot(x, rec(x), type = "l", ylim = c(0,1), lty = 1, ylab = expression(K(x)))
lines(x, tri(x), lty = 2)
lines(x, gauss(x), lty = 3)
rectangular (uniform) triangular normal

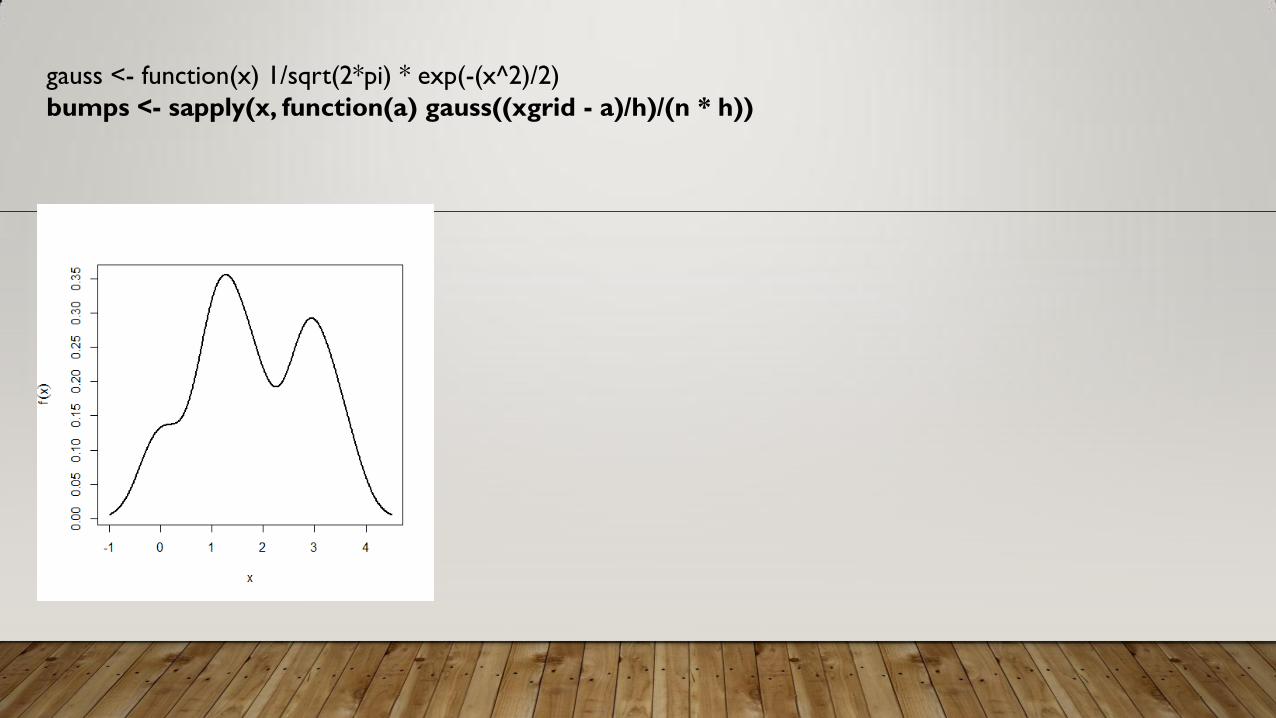
CONTOH
x <- c(0, 1, 1.1, 1.5, 1.9, 2.8, 2.9, 3.5)
n <- length(x)
xgrid <- seq(from = min(x) - 1, to = max(x) + 1, by = 0.01)
h <- 0.4
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
bumps <- sapply(x, function(a) gauss((xgrid - a)/h)/(n * h))
plot(xgrid, rowSums(bumps), ylab = expression(hat(f)(x)),type = "l", xlab = "x", lwd = 2)
rug(x, lwd = 2)
out <- apply(bumps, 2, function(b) lines(xgrid, b))
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
bumps <- sapply(x, function(a) gauss((xgrid - a)/h)/(n * h))
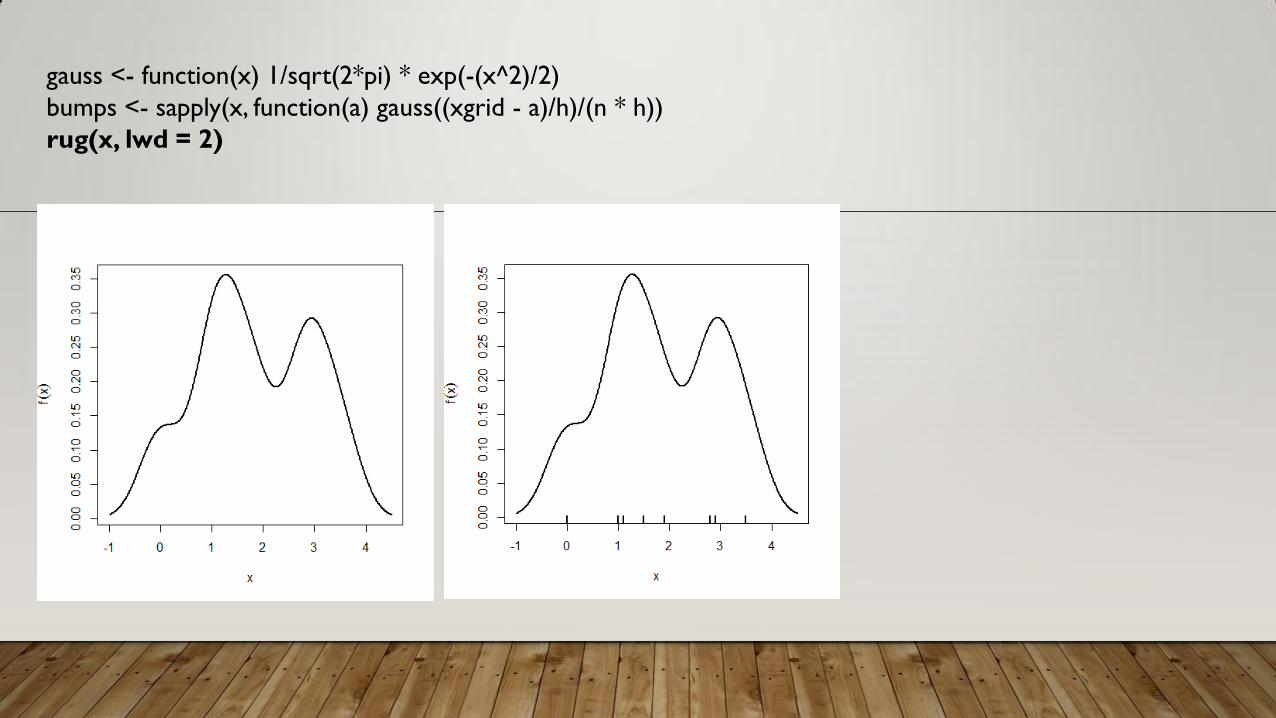
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
bumps <- sapply(x, function(a) gauss((xgrid - a)/h)/(n * h))
rug(x, lwd = 2)
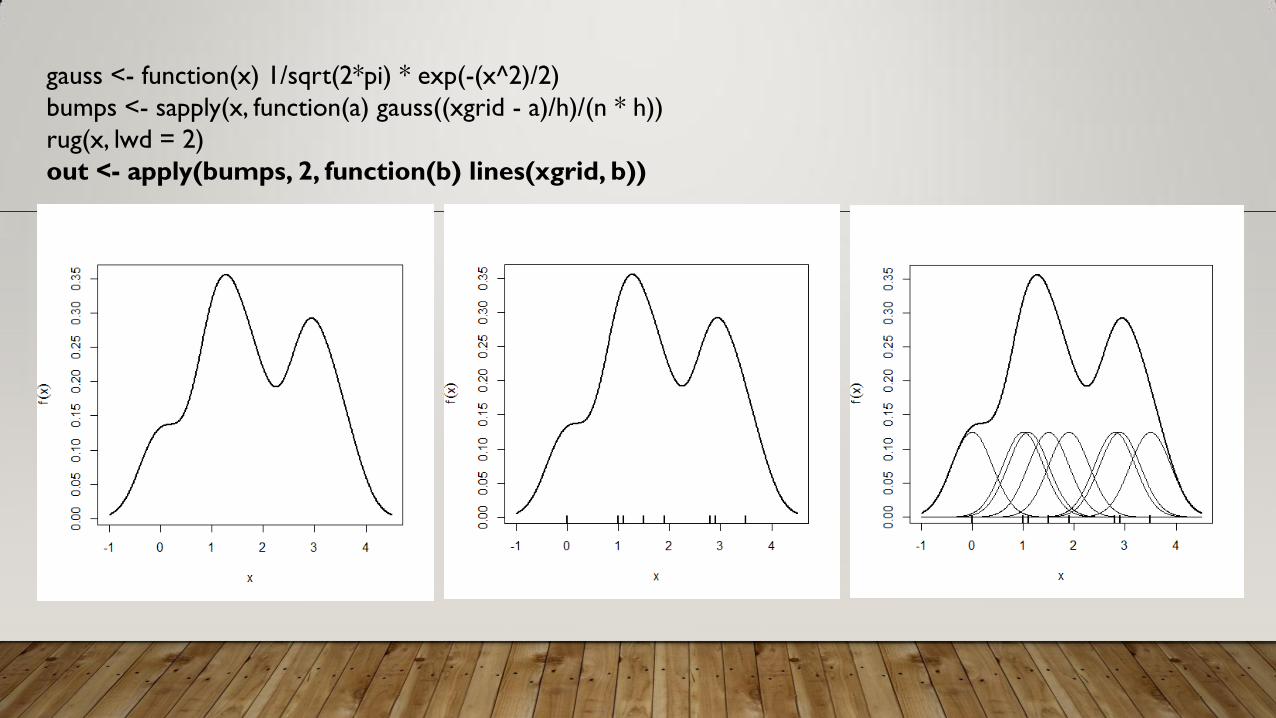
gauss <- function(x) 1/sqrt(2*pi) * exp(-(x^2)/2)
bumps <- sapply(x, function(a) gauss((xgrid - a)/h)/(n * h))
rug(x, lwd = 2)
out <- apply(bumps, 2, function(b) lines(xgrid, b))
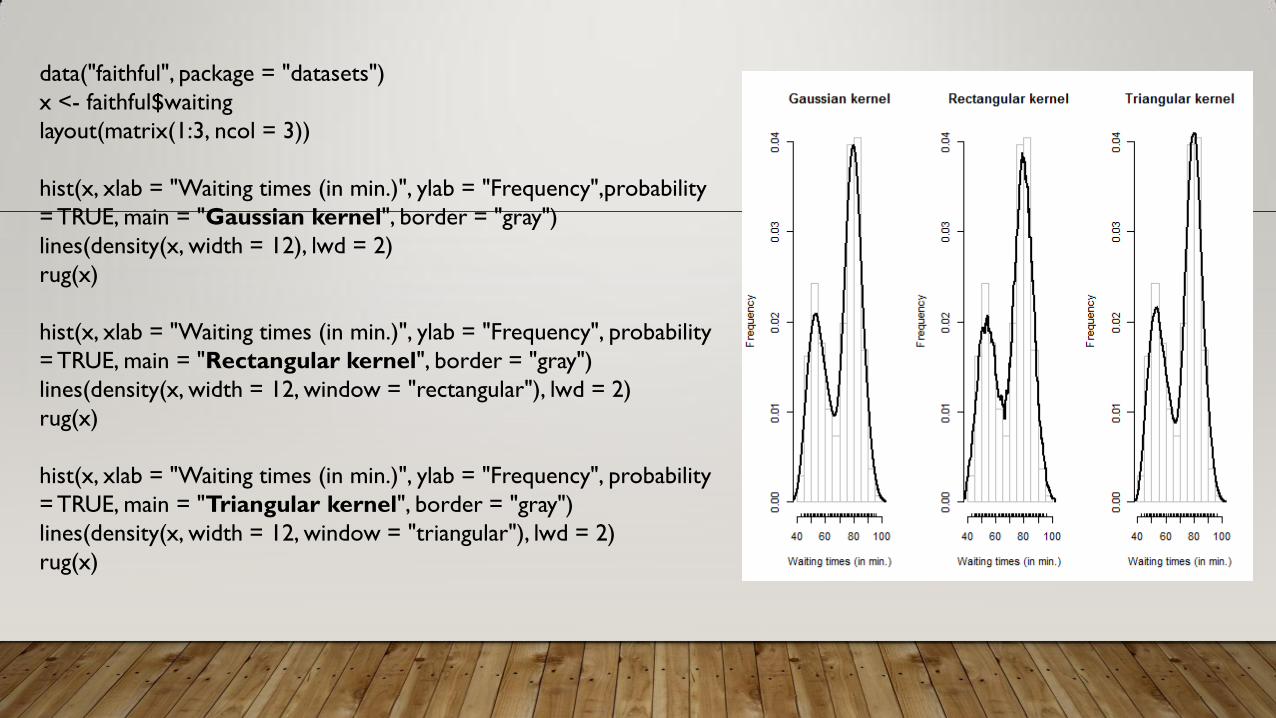
data("faithful", package = "datasets")
x <- faithful$waiting
layout(matrix(1:3, ncol = 3))
hist(x, xlab = "Waiting times (in min.)", ylab = "Frequency",probability
= TRUE, main = "Gaussian kernel", border = "gray")
lines(density(x, width = 12), lwd = 2)
rug(x)
hist(x, xlab = "Waiting times (in min.)", ylab = "Frequency", probability
= TRUE, main = "Rectangular kernel", border = "gray")
lines(density(x, width = 12, window = "rectangular"), lwd = 2)
rug(x)
hist(x, xlab = "Waiting times (in min.)", ylab = "Frequency", probability
= TRUE, main = "Triangular kernel", border = "gray")
lines(density(x, width = 12, window = "triangular"), lwd = 2)
rug(x)

KEPUSTAKAAN
1) Bowman AW, Azzalini A. 1997. Applied Smoothing Techniques for Data Analysis: the Kernel
Approach With S-Plus Illustrations. Oxford University Press. London.
2) Silverman BW. 1986. Density Estimation for Statistics and Data Analysis. Vol. 26 of
Monographs on Statistics and Applied Probability. Chapman & Hall/CRC. London.
3) Simonoff JS. 1996. Smoothing Methods in Statistics. Springer. New York.





























