Embed Size (px)
Citation preview

Sveuciliste J. J. Strossmayera u Osijeku
Odjel za matematiku
Ivan Kovacevic
Genetski algoritam za optimizaciju funkcije
Diplomski rad
Osijek, 2012.

Sveuciliste J. J. Strossmayera u Osijeku
Odjel za matematiku
Ivan Kovacevic
Genetski algoritam za optimizaciju funkcije
Diplomski rad
Mentor: prof. dr. sc. Ninoslav Truhar
Osijek, 2012.

Sadrzaj
Uvod 1
1 Problemi optimizacije 4
1.1 Funkcija cilja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Strukture optimizacijskih algoritama . . . . . . . . . . . . . . . . . . . 9
1.3 Fitnes kao mjera korisnosti . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.4 Preuranjena konvergencija . . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Genetski algoritmi 16
2.1 Prikaz rjesenja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.1.1 Binarni prikaz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.1.2 Prikaz kromosoma kao broja s pomicnom tockom . . . . . . . . 19
2.2 Postupak selekcije . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.1 Jednostavna selekcija . . . . . . . . . . . . . . . . . . . . . . . . 22
2.2.2 Turnirska selekcija . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.3 Rangirajuca selekcija . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3 Genetski operatori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3.1 Funkcije jedne varijable . . . . . . . . . . . . . . . . . . . . . . 27
2.3.2 Funkcije vise kriterija . . . . . . . . . . . . . . . . . . . . . . . . 29
2.4 Generiranje pocetne populacije i kriterij zaustavljanja . . . . . . . . . . 32
3 Teorem sheme 33
4 Usporedba rada genetskog algoritma i metode simpleksa 38
4.1 Rezultati usporedbe metoda . . . . . . . . . . . . . . . . . . . . . . . . 42
Literatura 46
Sazetak 47
Summary 48
Zivotopis 49
3

Uvod
Prema [5] genetski algoritam je metoda optimizacije inspirirana evolucijom. Evolu-
cija dolazi od latinske rijeci evolutio i znaci razvoj ili razvitak, a u bioloskom smislu
promatra razvoj organizama iz jednostavnijeg u slozeniji oblik.
U svom djelu “O podrijetlu vrsta” C. Darwin identificira prirodnu selekciju kao
glavni pokretacki mehanizam evolucije. Kako se u prirodi uvijek rada vise jedinki nego
sto to resursi odredenog stanista na kojem te jedinke borave mogu podnijeti, odredeni
broj njih ce umrijeti prije nego sto uspiju stvoriti potomke. Princip prirodne selekcije
kaze da ce jedinke koje su bolje prilagodene svojoj okolini (bolje pronalaze hranu, izvore
vode, skloniste, brze su od predatora, uspjesnije pronalaze partnera za reprodukciju,
. . . ) u prosjeku iza sebe ostaviti vise potomaka nego slabije jedinke koje ne krase ova
navedena svojstva. Na taj nacin se u svakoj sljedecoj generaciji pojavljuje sve vise
jedinki bolje prilagodenih uvjetima okoline (vidi [2]).
Prema [3], da bi se prirodna selekcija mogla nazvati evolucijom potrebno je jos
ukljuciti dvije stvari: nasljedivanje dobrih svojstava i raznolikost populacije. Naime,
bez raznolikosti populacije, ne bi postojale bolje i losije prilagodene jedinke, pa bi
prirodna selekcija bila slucajan proces. Nasljedivanje dobrih svojstava od roditelja
osigurava selekcijskom procesu da u svakoj sljedecoj generaciji dobije jedinke bolje
prilagodene od svojih roditelja. Sve informacije o rastu i razvoju jedinke su zapisane
u kromosomima koji se nalaze u jezgri svake stanice. Skup informacija koje odreduju
jedno svojstvo (visina, boja koze, boja ociju i sl.) zapisan je u dijelu kromosoma
koji se naziva gen. Prilikom razmnozavanja dvaju jedinki, svaki roditelj prenosi dio
svog genetskog materijala na potomke koji tada imaju kombinaciju gena oba rodite-
lja. Zbog toga odredeni potomci nasljeduju i razvijaju dobra svojstva oba roditelja
(bolje jedinke) a drugi pak nasljeduju i razvijaju manje dobrih svojstava (losije je-
dinke). Takvo nasljedivanje svojstava u kombinaciji s mutacijom gena dovodi do bitnih
razlicitosti jedinki nove populacije. Mutacija naime omogucava slucajne promjene gena
kod potomaka i time omogucava pojavu novih svojstava, kako dobrih tako i losih, koja
nijedan roditelj nije imao (vidi [3]).
Prema [7], analogija evolucije i genetskih algoritama ocituje se u procesu prirodne se-
lekcije, krizanja (reprodukcije) i spomenute mutacije koje algoritmi imitiraju s ciljem
dobivanja boljih jedinki u svakoj sljedecoj generaciji. Svako rjesenje optimizacijskog
problema promatra se kao jedinka sa svojim svojstvima. Skup mogucih rjesenja koje na-
1

Genetski algoritam za optimizaciju funkcije 2
zivamo populacijom kodira se u strukturu nalik kromosomu gdje su zapisana najvaznija
svojstva svakog rjesenja. Genetski algoritam tada vrsi selekciju nad populacijom na
nacin da odreduje koja rjesenja bolje optimiraju dani problem i dodjeljuje im mjeru
kvalitete ili prikladnosti. Ta mjera se jos naziva fitnes ili dobrota (vidi [7]). Rjesenja
koja imaju vecu vrijednost dobrote (bolje optimiraju zadani problem) imaju i vecu vje-
rojatnost prezivljavanja dok losija rjesenja bivaju odbacena. Dobra rjesenja (jedinke)
tada reprodukcijom (rekombinacijom) prenose svoja svojstva na potomke pa novonas-
tala populacija zadrzava dobra svojstva prethodne populacije. Za vrijeme tog procesa,
zahvaljujuci mutaciji, neka rjesenja u novoj populaciji dobiju nova izmijenjena svojstva
koja nisu postojala u prethodnoj generaciji. Tada genetski algoritam ponovo primje-
njuje selekciju na novonastaloj populaciji kako bi odredio jos bolja rjesenja i postupak
se ponavlja. Takav ciklus selekcije i genetskih operatora krizanja i mutacije se nastavlja
sve dok nije zadovoljen kriterij zaustavljanja algoritma. Takvo sto u prirodi naravno
nije moguce.
Prema [7] genetski algoritam je klasa evolucijskih algoritama; heuristickih metoda op-
timizacije koje imitiraju evolucijski proces i evolucijske mehanizme s ciljem pronala-
ska optimalnog rjesenja. Klasicni deterministicki algoritmi za optimizaciju funkcija
su ograniceni na konveksne, regularne funkcije koje posjeduju “lijepa” svojstva, koja
tada koristimo za odredivanje tocaka optimuma. Jedan od klasicnih algoritama bila bi
Newtonova metoda za jednodimenzionalnu minimizaciju zadana rekurzivnom formu-
lom:
xn+1 = xn −f ′(xn)
f ′′(xn). (1)
Prema [4], pretpostavljamo da je funkcija dva puta neprekidno derivabilna na intervalu
[a, b] i da je x∗ ∈ (a, b) tocka lokalnog minimuma funkcije f . To znaci da je f ′(x∗) = 0 i
f ′′(x∗) > 0. I obrnuto, ako je f ′(x∗) = 0 i f ′′(x∗) > 0, onda funkcija f u tocki x∗ postize
lokalni minimum. Iz navedenog slijedi da se lokalni minimum x∗ funkcije f moze traziti
tako da najprije lokaliziramo interval u kojem funkcija postize lokalni minimum. Nakon
toga na intervalu rijesimo jednadzbu f ′(x) = 0 primjenom neke od metoda za rjesavanje
nelinearne jednadzbe. Tocka x∗ za koju vrijedi f(x∗) = 0 naziva se stacionarna tocka
funkcije f . Ako za rjesavanje jednadzbe f ′(x) = 0 primjenimo Newtonovu metodu
uz odgovarajuci izbor pocetne aproksimacije x0, dobivamo iterativnu metodu zadanu
rekurzivnom formulom 1.
Minimiziramo li tom metodom funkciju zadanu formulom f(x) = 0.25x4 − 2x3 +
4x2− 2x+ 10 uz pocetnu aproksimaciju x0 = 4, dolazimo do rjesenja koje nam kaze da
funkcija ima minimum u x∗ = 4.21432. Medutim, koristimo li za istu funkciju i isti al-
goritam pocetnu aproksimaciju x0 = −4 dolazimo do rjesenja da funkcija ima minimum
u tocki x∗ = 0.324869. Razlog tomu mozemo iscitati sa slike 1 grafa funkcije iz koje
vidimo da postoje dva minimuma. Kako se metoda sluzi pocetnom aproksimacijom za
odredivanje minimuma, moguce je da pogresnom aproksimacijom umjesto globalnog

Genetski algoritam za optimizaciju funkcije 3
Slika 1: Graf funkcije s dva minimuma
minimuma nademo lokalni minimum. Nedostatak ove metode je sto ne mozemo biti
sigurni je li minimum koji smo pronasli zaista globalni ili je pak nasa metoda “zapela”
u lokalnom minimumu.
Newtonova metoda je pogodna za optimizaciju funkcija koje su unimodalne i dva
puta neprekidno derivabilne, uz uvjet f ′′(x) 6= 0. Genetski algoritmi nemaju takve
zahtjeve i ovisno o nacinu konstruiranja, rade na vise razlicitih klasa funkcija.
Neka od podrucja primjene genetskih algoritama su (vidi [6]):
• Umjetna inteligencija: grana racunalne znanosti s ciljem stvaranja inteligentnog
agenta (programa) koji percipira okolinu i poduzima takve radnje koje povecavaju
njegovu vjerojatnost uspjeha. Pri tome se problemi rasudivanja, znanja, plani-
ranja, komunikacije i manipuliranja objektima mogu rijesiti principom trazenja
svih mogucih rjesenja i odabirom najboljeg. Zbog velikog broja mogucih odluka,
klasicni algoritmi su spori ili neupotrebljivi.
• Cobwebov model ponude i potraznje: proizvodac nekog dobra formira cijenu
ponude na temelju proslog razdoblja, a cijena potraznje se formira na temelju
tekuceg razdoblja. Genetski algoritmi se koriste kao metode ucenja i odlucivanja
o kolicini proizvedenog dobra u tekucem razdoblju, iako se proizvodnja odvija u
sljedecem razdoblju. Optimalna odluka smanjuje troskove proizvodnje a povecava
cijenu dobra, a time i zaradu proizvodaca.
• Kontrola kvalitete: primjena procedura koje kontroliraju neki proces s ciljem da
rezultati tog procesa zadovoljavaju prethodno zadane norme i da je pri tome cijeli
proces pod kontrolom. Kako je potrebno odrediti optimum za vise od jednog
parametra, genetski algoritmi su puno brze metode optimizacije od klasicnih
metoda.

Poglavlje 1
Problemi optimizacije
1.1 Funkcija cilja
Iako su termini i nacini rada operatora genetskih algoritama slicni evolucijskim proce-
sima, sama evolucija nije optimizacijski proces s ciljem pronalaska globalnog optimuma.
Evolucija jednostavno stvara bolje prilagodene jedinke unutar populacije kroz odredeni
broj generacija. Takoder je ogranicena fizickim mogucnostima pojedine vrste, pa stoga
ne moze razmotriti bas svako rjesenje problema (vidi [3]).
Primjer 1.1.1 Uzmimo za primjer jednu vrstu ribe koja zivi u jezeru. Svedemo li
njezine parametre optimizacije na prehranu i prezivljavanje, mozemo doci do pogresnog
zakljucka da ce jedinka koja je veca biti bolje prilagodena svom okolisu. Medutim, neo-
granicen rast takve jedinke, tj. njezinih potomaka kroz populacije, doveo bi do nestanka
vrste zbog nedostatka hrane. Takoder, veca riba je uocljivija predatoru, pa bi takve je-
dinke nestale prije no sto dobiju priliku za reprodukciju. S druge strane, jedinka koja je
manja, bila bi sporija od predatora i teze bi dolazila do izvora hrane kraj ostalih jedinki
svoje vrste, koje bi bile vece od nje. Zato minimizacija ili maksimizacija samo jedne
varijable ne daje uvijek optimalno rjesenje.
Kao sto u prirodi nije jednostavno reci sto je optimalno rjesenje problema pojedine
jedinke, tako i u genetskim algoritmima moramo definirati sto se smatra optimalnim,
koje kriterije genetski algoritam mora postivati i koja rjesenja uzimati u obzir. Glo-
balnom optimizacijom smatramo onu optimizaciju kojoj je za cilj pronaci element x∗
koji zadovoljava skup kriterija F = {f1, f2, . . . , fn} (vidi [2]).
Definicija 1.1.1 (Funkcija cilja) Funkciju koja je objekt optimizacije zadanu sa f :
X→ Y gdje je Y ⊆ R, zovemo funkcija cilja.
Prema [2], domena X ove funkcije naziva se prostor problema i moze predstavljati
razne strukture podataka: brojevi, nizovi, simboli, matrice i slicno. Odabir nacina
predstavljanja tih podataka ovisi o tipu problema i vrsti algoritma koji se koristi. Za
globalni optimum funkcije f(x) definirane na skupu R uzimati cemo njezin globalni
4

Genetski algoritam za optimizaciju funkcije 5
minimum. Ako je pak potrebno maksimizirati funkciju, jednostavno se minimizira
funkcija −f(x). Za takvu funkciju mozemo lako definirati lokalni minimum xl i globalni
minimum x.
Definicija 1.1.2 (Lokalni minimum) Neka je X ⊆ R. Kazemo da je xl ∈ X lokalni
minimum funkcije f : X → Y ako postoji okolina O tocke xl tako da je f(xl) ≤ f(x)
za svaki x ∈ O ∩ X.
Definicija 1.1.3 (Globalni minimum) Kazemo da je x ∈ X globalni minimum funk-
cije f : X→ Y ako je f(x) ≤ f(x) ∀x ∈ X.
Slicno se definiraju lokalni i globalni minimumi za funkcije s domenom X ⊆ Rn i takva
definicija optimuma ne predstavlja znacajan problem.
Medutim, ako je potrebno odrediti optimum funkcije F s vise kriterija, tada se nasa
funkcija cilja sastoji od n funkcija fi, pri cemu svaka predstavlja jedno svojstvo koje
je potrebno optimirati. Prema [2] promatramo ju kao skup gdje je svaki kriterij za
optimizaciju predstavljen jednom funkcijom fi(x):
F = {fi : X→ Yi : 0 < i ≤ n, Yi ⊆ R} (1.1)
Problematika definiranja globalnog optimuma takve funkcije je opisana u primjeru
1.1.2.
Primjer 1.1.2 Potrebno je optimirati rad tvornice jahti na nacin da se zadovolje
sljedeci kriteriji:
1. Smanjiti vrijeme potrebno za izradu jahte.
2. Povecati zaradu od svake prodane jahte.
3. Smanjiti troskove reklamiranja, menadzmenta i sirovina.
4. Povecati kvalitetu jahti.
5. Smanjiti negativan utjecaj na okolis.
Vidimo da ovdje nije jednostavno optimirati sve kriterije, posto se neki moraju sma-
njiti (vrijeme proizvodnje, troskovi rada, utjecaj na okolis) a neki moraju povecati
(profit, kvaliteta). Takoder, izmedu odredenih kriterija postoji kontradiktornost jer
smanjenje troskova sirovina potrebnih za proizvodnju jahte (kvalitetno drvo, kvalite-
tan celik) sigurno utjece na kvalitetu proizvoda, a samim time i na zaradu. Medutim,
medudjelovanje kriterija kvalitete i profita nije potpuno ocito jer je moguce da tvornica
ostvari veci profit smanjenjem troskova sirovina, kao i da izgubi profit jer je konacan
proizvod na odredenom trzistu neatraktivan. Stoga nema smisla govoriti o globalnom
minimumu ili maksimumu, pa se definira skup optimalnih elemenata X∗ (vidi [2]).

Genetski algoritam za optimizaciju funkcije 6
Definicija 1.1.4 Skup X∗ koji sadrzi sve optimalne elemente x∗i , i = 1 . . . n funkcija
fi(x) : X→ Y zovemo skup optimalnih elemenata.
Prema [2], jedan od nacina kako definirati optimum problema u primjeru 1.1.2 je do-
djeljivanje tezina funkcijama koje predstavljaju kriterije optimizacije. Svaka funkcija
fi se mnozi sa tezinom wi koja predstavlja njenu vaznost. Ako je potrebno neki kriterij
fa minimizirati, dodijelimo mu tezinu wa = 1, dok za kriterij fb koji se maksimizira do-
dijelimo tezinu wb = −1. Na taj nacin istovremeno mozemo minimizirati prvu funkciju
a maksimizirati drugu na nacin da odredimo minimum funkcije g(x) definirane sa:
g(x) =n∑i=1
wifi(x) =∑∀fi∈F
wifi(x) (1.2)
x∗ ∈ X∗ ⇔ g(x∗) ≥ g(x) ∀x ∈ X (1.3)
Problem ove tehnike je u tome sto je primjenjiva samo na funkcije koje rastu ili padaju
istom brzinom. Pogledamo li grafove funkcija f1(x) = −x2 i f2(x) = ex−2 na slici 1.1
(vidi [2]), ocito da optimirajuci njihovu sumu g(x) = f1(x) + f2(x) uvijek dolazi do
odbacivanja jedne od zadanih funkcija. Za malen x utjecaj funkcije f2(x) na g(x) je
zanemariv, posto joj je vrijednost vrlo malena. Za velike vrijednosti x utjecaj funkcije
f1(x) na g(x) je zanemariv jer funkcija f2(x) raste brze nego sto f1(x) pada.
Rjesenje problema koristenja tezina zove se pareto dominacija. Prema [2], pareto
Slika 1.1: Problem koristenja tezina
optimum nam govori gdje je granica rjesenja koja se moze postici uz dozvoljeno zane-
marivanje konfliktnih kriterija na optimalan nacin.

Genetski algoritam za optimizaciju funkcije 7
Definicija 1.1.5 Element x1 dominira nad elementom x2 (x1 ` x2) ako je bolji od
njega po barem jednom kriteriju i nije losiji u odnosu na ostale kriterije.
Primjenom na funkciju cilja F sa n kriterija predstavljenima funkcijama fi pisemo:
x1 ` x2 ⇔ ∀i : 0 < i ≤ n⇒ wifi(x1) ≤ wifi(x2) ∧∃j : 0 < j ≤ n : wjfj(x1) < wjfj(x2)
(1.4)
wi =
{1 ako je potrebno minimizirati fi−1 ako je potrebno maksimizirati fi
(1.5)
Za razliku od tezina wi kod prethodne metode, ovdje koristeni faktor wi sluzi samo
kao informacija koji kriterij treba maksimizirati a koji minimizirati (vidi [2]).
Definicija 1.1.6 Za element x∗ ∈ X kazemo da je Pareto optimalan (samim time
element skupa X∗) ako nije dominiran od nijednog drugog elementa u prostoru problema
X. Tada skup X∗ nazivamo Pareto skup ili Pareto granica.
x∗ ∈ X∗ ⇔ @x ∈ X : x ` x∗ (1.6)
Metoda koristenja tezina i metoda pareto dominacije sluze kako bi definirali sto je
optimalno u smislu funkcija s vise kriterija. Obe metode usporeduju elemente prostora
problema u odnosu na njihovu kvalitetu kao rjesenja i nad tim prostorom postavljaju
uredaj. Ako usporedimo x1 i x2 moguca su tri slucaja: x1 je bolji od x2, x1 je losiji od
x2 ili su oba rjesenja jednake kvalitete (vidi [2]).
Slika 1.2: Pareto optimizacija
Primjer 1.1.3 Prema [2] pretpostavimo da imamo problem s vise funkcija cilja od
kojih se za funkcije f1(x) i f2(x) trazi maksimum. Na slici 1.2 je Pareto optimalno
podrucje tih funkcija predstavljeno tamno osjencano. Vrijedi X∗ = [x2, x3] ∪ [x5, x6].

Genetski algoritam za optimizaciju funkcije 8
Rjesenja u podrucju izmedu x1 i x2 su dominirana od strane svih ostalih rjesenja u tom
podrucju ili od strane rjesenja iz [x2, x3]. Razlog tomu je sto, pocevsi od x1, mozemo
uzeti mali pomak ∆x > 0 takav da vrijedi f1(x1 + ∆x) > f1(x1) i f2(x1 + ∆x) >
f2(x1). To vrijedi sve dok ne dodemo do rjesenja x2 koje predstavlja globalni maksi-
mum za f2(x). Daljnjim pomicanjem u desno, za f2(x) uvijek dobijemo losija rjesenja.
Medutim, f1(x) nastavlja rasti i dolazi do sve boljih rjesenja. Iako za neka rjesenja
x ∈ [x1, x2) funkcija f2(x) poprima vecu vrijednost nego za x ∈ [x2, x3], sto ta rjesenja
cini boljima za maksimizaciju, funkcija f1(x) nastavlja rasti. Zato sve x ∈ [x2, x3]
gledamo kao Pareto dominantne nad x ∈ [x1, x2). To vrijedi sve do rjesenja x3 u ko-
jem f2(x) naglo pada, na vrijednosti nize nego za f2(x5). Kako su sada vrijednosti
f1(x) vece za x ∈ [x5, x6], kazemo da su sva ta rjesenja dominantna nad rjesenjima
x ∈ (x3, x4].

Genetski algoritam za optimizaciju funkcije 9
1.2 Strukture optimizacijskih algoritama
Da bi genetski algoritam mogao raditi, potrebno mu je strogo definirati tip podatka
nad kojima vrsi optimizaciju. Trazimo li optimum neke funkcije, kandidate za rjesenje
mozemo uzeti iz skupa R ili iz skupa C. Mozemo se cak ograniciti i na skup N.
Ovakav odabir domene funkcije cilja bitno utjece na vrstu operatora koje koristimo
u optimizaciji, njihov rad i opcenito rad samog algoritma, te tocnost rezultata koje
dobivamo. Prema [2] definiraju se kandidati za rjesenje, prostor rjesenja i prostor
pretrage.
Definicija 1.2.1 Skup svih elemenata x koji mogu biti rjesenje optimizacijskog pro-
blema zovemo prostor problema i oznacavamo sa X. Elemente x zovemo kandidati za
rjesenje.
Za x ∈ X koristimo i naziv fenotip, koji je naslijeden iz evolucijskih procesa. Genetika
definira fenotip kao skup svih obiljezja po kojima se jedinke razlikuju unutar svoje vrste.
Ta obiljezja su promijenjiva i rezultat su djelovanja okoline i genetskog potencijala
jedinke. Analogija termina je u tome sto su svi x ∈ X podaci istog tipa (realni brojevi),
medutim razlicitih vrijednosti i kao takvi daju drugacija rjesenja problema optimizacije.
Definicija 1.2.2 Unija svih rjesenja optimizacijskog problema naziva se prostor rjesenja
S. Vrijedi X∗ ⊆ S ⊆ X.
Ocito je da neka rjesenja x mogu biti dobra za optimizacijske probleme, ali ne moraju
pripadati skupu X∗ (to bi bili lokalni optimumi).
Definicija 1.2.3 Prostor pretrage G je skup svih elemenata g nad kojima se vrse op-
timizacijske operacije pretrage. Za prostor pretrage G koristi se i naziv genom.
Za elemente g ∈ G koristimo jos i naziv genotip, takoder naslijeden iz evolucije. Ge-
netika definira genotip kao skup svih gena koje jedinka posjeduje. Sve karakteristike
jedinke su zapisane u jedinicama informacija koje nazivamo geni koje se u biologiji
nalaze poredane u molekuli DNK. Vrijednost pojedinog gena naziva se alel a smjestaj
tog gena, njegov redoslijed u DNK nazivamo lokus. Same veze ovih pojmova jasnije su
prikazane na slici 1.3 (vidi [2]).
Primjer 1.2.1 Prema [2] pretpostavimo da imamo problem odredivanja cjelobrojne ko-
ordinate neke tocke u Kartazijevom sustavu. Slika 1.4 opisuje problem pretrage prostora
genoma gdje su genotipi predstavljeni sa binarnim brojevima od (0, 0, 0, 0) do (1, 1, 1, 1).
Pri tome svaki od njih kodiramo tako da na prva dva mjesta nosi informaciju o apscisi,
a na zadnja dva mjesta nosi informaciju o ordinati tocke koju trazimo. Tada za oda-
brani element (0, 1, 1, 1) kazemo da na mjestu (lokus) 1 ima gen sa vrijednosti (0, 1) a
da na mjestu 2 ima gen sa vrijednosti (1, 1). Odgovarajucim dekodiranjem taj genotip
si predstavljamo kao tocku T (1, 3) i ona je tada kandidat za rjesenje. Ona sama postoji

Genetski algoritam za optimizaciju funkcije 10
(a) Prostor pretrage G (b) Prostor problema X (c) Prostor vrijednosti Y
Slika 1.3: Veza prostora pretrage, problema i vrijednosti
u prostoru problema zajedno sa svim ostalim tockama sa cjelobrojnim koordinatama.
Dakle, da bi nas zamisljeni algoritam mogao doci do tocke T (1, 3) mi moramo sve
tocke iz prostor pretrage G kodirati u prostora problema X kako bi odgovarajuci opera-
tori pretrage mogli raditi i kako bi bilo moguce ocijeniti optimalnost nadenog rjesenja.
Slika 1.4: Primjer 1.2.1
Prema [2] definiraju se genotip-fenotip mapiranje, jedinka i populacija jedinki.
Definicija 1.2.4 Genotip-fenotip mapiranje gfm : G → X je binarna relacija koja
stavlja u odnos elemente prostora pretrage g ∈ G sa elementima prostora problema
x ∈ X.
∀g ∈ G ∃x ∈ X : gfm(g) = x (1.7)
Definicija 1.2.5 Jedinkom p smatramo uredeni par (pg, px) sastavljen od elementa
pg ∈ G i njegovog odgovarajuceg elementa px ∈ X tako da vrijedi gfm(pg) = px.
Definicija 1.2.5 koristi oznaku pg koja predstavlja genotip jedinke, dok oznaka px pred-
stavlja fenotip te iste jedinke.
Definicija 1.2.6 Populacija Pop je skup jedinki koje sudjeluju u optimizacijskom pro-
cesu.
Pop ⊆ G× X : ∀p = (pg, px) ∈ Pop⇒ px = gfm(pg) (1.8)

Genetski algoritam za optimizaciju funkcije 11
Prema formuli 1.7, genotip-fenotip mapiranje mora biti takvo da poveze svaki element
iz G s barem jednim elementom iz X. Takoder treba biti surjektivno pridruzivanje kako
bi svi kandidati za rjesenje iz X bili dostupni genetskom algoritmu za evaluaciju. U
suprotnome, postojali bi kandidati koji nikada ne bi bili pretrazeni operatorima pre-
trage pa nema garancije da je moguce naci rjesenja danog problema. Ako je mapiranje
injektivno kazemo da je slobodno od suvisnosti, barem one koja ne koristi algoritmu.
Optimizacijski algoritam je dobro definiran ako su mu poznati prostor problema X,
fukcija cilja F , prostor pretrage G, genotip-fenotip mapiranje gfm i operatori pretrage
(vidi [2]).

Genetski algoritam za optimizaciju funkcije 12
1.3 Fitnes kao mjera korisnosti
Nakon sto smo definirali sve potrebne elemente za rad optimizacijskog algoritma, po-
trebno je jos vidjeti koliko je on dobar u svom radu. Prema [2] sva rjesenja koja
algoritam pronade ocjenjuju funkcije cilja fi ∈ F , i = 1, . . . , n tako da svakom od njih
dodjele numericku vrijednost koja opisuje karakteristike tog rjesenja.
Definicija 1.3.1 Prostor vrijednosti ili cilja Y je prostor razapet kodomenama funkcija
cilja.
F = {fi : X→ Yi : 0 < i ≤ n, Yi ⊆ R} ⇒ Y = Y1 × Y2 × . . .× Yn (1.9)
Prilikom optimizacije funkcije s vise kriterija, elementi skupa Y su realni vektori. Takvi
vektori se ne mogu uvijek usporediti izravno na konzistentan nacin, pa je potrebna
neka komparativna mjera koja nam kaze koji od njih je dobar u smislu optimizacije.
Pridruzivanje pozitivnih realnih vrijednosti tim vektorima nam omogucava postavljanje
djelomicne relacije uredaja na podskupu prostora cilja V ⊆ R+. Tako pridruzena realna
vrijednost svakom kandidatu za rjesenje x predstavlja njegov fitnes ili njegovu kvalitetu
u smislu rjesenja optimizacijskog problema (vidi [2]).
Definicija 1.3.2 Vrijednost fitnesa v(x) ∈ V za element x ∈ X predstavlja korisnost
kandidata za rjesenje x u smislu optimizacije problema.
Ime i primjena fitnesa u optimizacijskim algoritmima dolaze iz prvih evolucijskih al-
goritama gdje je funkcija cilja imala jednu varijablu pa se za fitnes rjesenja koristila
izravno vrijednost funkcije za to rjesenje v(x) = f(x), ∀x ∈ X. U slozenijim proble-
mima vrijednost funkcije cilja odredenog kandidata F (x) ostaje nepromijenjena, dok
se njegov fitnes v(x) moze mijenjati u svakoj generaciji genetskog algoritma. Razlog
tomu je cinjenica da fitnes kandidata ima smisla samo u odnosu na ostale kandidate
trenutne populacije. U funkcijama s vise kriterija optimizacije, fitnes moze biti redni
broj rjesenja koja su Pareto optimalna, dakle relativan u odnosu na ostale kandidate
za rjesenje. U kontekstu ovog rada, funkcije cilja se minimiziraju, pa ce elementi koji
imaju manji fitnes biti bolji od onih s vecim fitnesom (vidi [2]).
Veze izmedu fenotipa i genotipa neke jedinke, te njezine vjerojatnosti za reprodukci-
jom, najbolje se proucavaju vizualizacijom kroz sliku fitnesa. Prema [2], slika fitnesa
se promatra kao ravnina u kojoj svaki vrh predstavlja vrijednost rjesenja za funkciju
cilja. U primjerima 1.3.1 i 1.3.2 navedenima u [2] vidljiva je veza fitnesa i slozenosti
rada algoritma.

Genetski algoritam za optimizaciju funkcije 13
Slika 1.5: Primjer slike fitnesa
Primjer 1.3.1 Na slici 1.5 vidimo funkciju cilja definiranu na dvodimenzionalnom
skupu X koja se optimira. Oznaceni su lokalni minimum xl i globalni minimum x∗, te
prostor izmedu njih sa losim fitnesom. Svaki optimizacijski algoritam ce prije ili kasnije
pronaci xl ili x∗, s tim da xl ima vecu vjerojatnost odabira jer lezi blize sredini X prema
kojoj postoji blagi gradijentni pad. Klasicni optimizacijski algoritmi zato imaju manju
vjerojatnost uspjeha jer ce prije pronaci lokalni optimum i iz njega nece moci izaci,
dok genetski algoritmi to mogu.

Genetski algoritam za optimizaciju funkcije 14
(a) Najbolji slucaj (b) Multimodalan slucaj (c) Slucaj bez korisnih infor-macija
(d) Obmanjujuci slucaj (e) Neutralan slucaj (f) Najgori slucaj
Slika 1.6: Razlicita svojstva slike fitnesa
Primjer 1.3.2 Na slici 1.6 vidimo neke primjere slike fitnesa. Vrijednosti funkcije
cilja f(x) se minimiziraju a krugovi na slici predstavljaju kandidate za rjesenje koji se
procjenjuju. Strelica od jednog do drugog kandidata pokazuju da se do drugog kandi-
data doslo primjenom operatora pretrage na prvom. Slika 1.6a pokazuje najbolji slucaj
minimizacije funkcije, gdje svaki korak vodi ka globalnom minimumu. Slika 1.6b prika-
zuje kako algoritam pretrage ne uspijeva izaci iz prostora lokalnog minimuma, te nije
u stanju otkriti globalni minimum. Na slici 1.6c prikazana je funkcija cija slika fitnesa
ne daje nikakve korisne informacije operatoru pretrage, te on ne uspijeva odrediti niti
lokalni minimum. Slika 1.6d daje privid pronalaska globalnog optimuma, medutim to
je samo lokalni minimum. Neutralan slucaj na slici 1.6e prikazuje podrucje u kojem
operator pretrage ne moze otkriti u kojem smjeru krenuti. Najgori slucaj prikazan je
na slici 1.6f.

Genetski algoritam za optimizaciju funkcije 15
1.4 Preuranjena konvergencija
Genetski algoritam je konvergirao ako ne moze naci novi kandidat za rjesenje ili ako
nove kandidate pronalazi samo u malom podskupu prostora problema (vidi [2]). Pos-
tavlja se pitanje: je li to rjesenje koje imamo lokalni ili globalni optimum? To pitanje
postaje narocito tesko kada optimiziramo F (x) multimodalnu funkciju cilja cije funkcije
fi(x) imaju visestruke optimume (minimume ili maksimume), nisu neprekinute niti su
derivabilne. Problem preuranjene konvergencije nastaje kada algoritam vise nije spo-
soban istraziti druga podrucja prostora problema u kojima se nalaze bolja rjesenja, kao
na slici 1.6b. Do ovog problema dolazi jer genetski algoritam pronalazi nova rjesenja
rekombinirajuci postojeca sa dobrim svojstvima, bez obzira na ostale kandidate koji,
iako u tom trenutku s losijim fitnesom, vode algoritam prema globalnom optimumu.
Na taj se nacin utjecaj trenutno losijih kandidata svodi na minimum, te u dovoljno
frekventnoj mutaciji, oni bivaju potpuno odbaceni. Svaki dobar genetski algoritam
mora obratiti paznju na odnos izmedu pretrazivanja prostora rjesenja i iskoristavanja
postojeceg kandidata. Pretrazivanje prostora rjesenja odnosi se na pronalazak novih
kandidata za rjesenje u onom dijelu prostora u kojem algoritam jos nije bio. Previse
pretrazivanja moze dovesti do toga da operatori pretrage ne nadu dobra rjesenja jer
zure kroz prostor i zbog ogranicene velicine populacije odbacuju prethodno ocijenjene
jedinke. S druge strane, takvi algoritmi su brzi ali imaju rizik ne pronalaska globalnog
optimuma. Iskoristavanje postojeceg kandidata znaci da algoritam koristi jedinke za
koje zna da imaju dobra svojstva, te kombinacijom njihovih dijelova pokusava napra-
viti slicne jedinke s boljim svojstvima. Medutim, previse rafiniranja jednog kandidata
za rjesenje moze dovesti do preuranjene konvergencije jer nastaju slicna rjesenja koja
ne vode algoritam dalje u nove dijelove prostora problema i cine algoritam sporijim. S
druge strane, pronade li takav algoritam globalni optimum, on ce biti tocniji.
Jedan od nacina rjesavanja ovog problema je ponovno pokretanje optimizacijskog pro-
cesa u odredenom trenutku tijekom optimizacije. Samim ponovnim pokretanjem, al-
goritam bi napravio istu pogresku, ali usporedivanjem rjesenja u trenutku prekida sa
pocetnom aproksimacijom, moguce je izvuci zakljucke krece li se algoritam u dobrom
smjeru ili dolazi do preuranjene konvergencije.
Drugi nacin rjesavanja ovog problema je omoguciti algoritmu svojstvo samoprilagodbe.
To znaci da algoritam, kada dovoljno brzo i siroko pretrazi prostor problem, uzme vise
vremena da rafinira one kandidate koji se cine boljima. Na taj se nacin i ubrzava
algoritam i izbjegava mogucnost preuranjene konvergencije.

Poglavlje 2
Genetski algoritmi
Genetski algoritmi su podvrste evolucijskih algoritama koji kandidate za rjesenje ko-
diraju u obliku binarnih nizova ili nizova slicnih struktura. Genetski algoritmi nastaju
50-ih godina proslog stoljeca iz potrebe da se racunalno potpomognutom simulacijom
sazna vise o genetskim procesima prilikom prirodne selekcije. Razvojem i radom Johna
Hollanda postaju formalizirani i popularni kao novi pristup rjesavanja problema (vidi
[2]). Pojmovi koji se koriste u genetskim algoritmima zasnivaju se na pojmovima iz
biologije jer operacije koje se izvrsavaju predstavljaju apstrakciju bioloskih procesa.
Svaki genetski algoritam odrzava i manipulira populacijom Pop od n jedinki kroz ge-
neracije, gdje se jedinkom p smatra jedan kandidat za rjesenje problema x (vidi [2]).
Prema [7] prva populacija se generira slucajnim odabirom rjesenja iz domene iako
je moguce generirati uniformnu populaciju ili u pocetnu populaciju usaditi inicijalno
rjesenje dobiveno nekom drugom metodom optimiranja. Pri tome se svaka jedinka koja
predstavlja jedno rjesenje kodira u obliku kromosoma. Kromosomi se sastoje od vise
gena prikazanih jednakom podatkovnom strukturom (broj, niz, matica) gdje svaki gen
predstavlja jedno svojstvo jedinke, tj. jednu varijablu rjesenja. Na primjer, ako imamo
problem sa tri varijable x1, x2 i x3 jedan nacin kodiranja kromosoma prikazuje slika
2.1.
10110011︸ ︷︷ ︸x1
11101010︸ ︷︷ ︸x2
01001100︸ ︷︷ ︸x3
Slika 2.1: Prikaz kromosoma s tri varijable
Svakom rjesenju se pridjeljuje mjera kvalitete (fitnes ili dobrota) koja govori koliko
to rjesenje dobro optimizira pocetni problem a funkcija koja tu kvalitetu odreduje na-
ziva se funkcija fitnesa ili funkcija dobrote. Tada se iz postojece populacije selektiraju
kromosomi sa dobrim svojstvima i prelaze u novu populaciju, zvanu medupopulacija.
Kako jedinke s losijim svojstvima nisu odabrane, medupopulacija Pop′ nema n jedinki
16

Genetski algoritam za optimizaciju funkcije 17
pa se nad nekima od dobrih jedinki vrse genetski operatori krizanja i mutacije. Pri tome
krizanje stvara nove jedinke koje zamjenjuju one koje nisu odabrane kako bi populacija
brojala n clanova. Mutacija pak uzima neke jedinke i slucajnom promjenom njihovog
genetskom materijala izaziva pojavu novih svojstava. Na taj nacin nastaje nova popu-
lacija nad kojom se ponovo vrsi selekcija , krizanje i mutacija. Nakon odredenog broja
ponavljanja ovih operacija (generacija), citav postupak se zaustavlja, a najbolji clan
trenutne populacije predstavlja rjesenje problema.
Prema [1] tipicni genetski algoritam, zapisan u pseudokodu, imao bi strukturu kao sto
je prikazano u algoritmu 2.1.
Algoritam 2.1 Struktura jednostavnog genetskog algoritma
t = 0generiraj populaciju Pop(0) od n jedinki i svakoj pridruzi njezinu dobrotusve dok nije zadovoljen uvjet zavrsetkat = t+ 1;selektiraj jedinke Pop′(t) iz Pop(t− 1);krizaj jedinke iz Pop′(t) i djecu spremi u Pop(t);mutiraj jedinke iz Pop(t);ispisi rjesenje;
Prema [7], kod upotrebe genetskog algoritma za optimizaciju funkcije moguce je
koristiti dva pristupa rjesavanja problema: prilagodba genetskog algoritma problemu
ili prilagodba problema genetskom algoritmu. Ukoliko prilagodavamo algoritam pro-
blemu, potrebno je definirati drugacije strukture podataka i operatora genetskog al-
goritma u skladu sa specificnostima problema. Usko specijalizirani genetski algoritmi,
koji se nazivaju evolucijski programi, daju bolja rjesenja i imaju veliku korisnost u
podrucju svoga djelovanja. S druge strane, prilagodavamo li problem genetskom algo-
ritmu, potrebno je podatke definirati u odredenoj strukturi koju operatori algoritma
razumiju i nad kojima mogu djelovati. U nekim slucajevima to nije moguce, tako da pri
optimiranju genetskim algoritmom treba paziti na odabir pravilnog pristupa koji nije
na stetu brzine izvodenja ili tocnosti rjesenja. Zato je prije svake upotrebe genetskog
algoritma potrebno precizno definirati 6 osnovnih elemenata algoritma (vidi [1]):
• Prikaz rjesenja
• Funkcija evaluacije
• Postupak selekcije
• Genetski operatori
• Generiranje pocetne populacije
• Kriterij zaustavljanja

Genetski algoritam za optimizaciju funkcije 18
2.1 Prikaz rjesenja
Kao sto je ranije receno, prikaz rjesenja izravno utjece na to kako je problem strukturi-
ran u genetskom algoritmu i koji operatori se koriste pri rjesavanju problema. U prirodi,
DNK je ta koja kodira informaciju o fenotipskim znacajkama svake jedinke. Zbog slicne
linearne strukture (slika 2.1), elementi prostora pretrage genetskih algoritama nazivaju
se kromosomi. Najcesca vrsta kodiranja kromosoma genetskih algoritama je u obliku
n-torki fiksne duljine gdje je svaki gen predstavljen binarnim prikazom svoje realne
vrijednosti (vidi [2]). Iako je moguce konstruirati genom koji sadrzi genotipe razlicitih
struktura, cesce su svi istog tipa podataka (binarni brojevi).
Jednostavni genetski algoritam predstavljen od strane Johna Hollanda koristio je
binarni prikaz kromosoma. Kasnijim eksperimentiranjem doslo se do zakljucka da u
nekim slucajevima prirodniji prikaz kromosoma kao broja s pomicnom tockom rezultira
brzim radom algoritama te preciznijim i konzistentnijim rjesenjima.
2.1.1 Binarni prikaz
Prema [7] kromosom promatramo kao binarni vektor duljine n kojim mozemo prikazati
svaki realan broj x ∈ [a, b], a, b ∈ R pomocu prirodnog binarnog koda. Za zadani realan
broj x kodiranje se obavlja prema formuli:
g =x− ab− a
(2n − 1) . (2.1)
Tada se broj g zapisuje kao binaran vektor [g0g1 . . . gn−1] gdje je gi ∈ {0, 1}. Pri
tome binarni vektor [000 . . . 0] predstavlja rjesenje kada je x = a, dok vektor [111 . . . 1]
predstavlja rjesenje kada je x = b. Na taj je nacin kromosom predstavljen nizom bitova
duljine n. Dekodiranje kromosoma g u rjesenje x vrsi formulama:
g =n−1∑i=0
gi2i (2.2)
x = a+g
2n − 1(b− a) . (2.3)
Dekodiranje je vazan proces jer se fitnes svake jedinke p ne ocjenjuje na njenom ge-
notipu pg vec u fenotipu px. Duljina kromosoma n oznacava broj bitova u jednom
kromosomu i kao takva utjece na preciznost.
Zbog svoje jednostavnosti, binarno kodiranje je pogodno za implementaciju u genet-
skim algoritmima.
Primjer 2.1.1 Pretpostavimo da je algoritam odabrao broj 33.57 ∈ [33.5, 33.6] kao
kandidat za rjesenje i da mu je duljina kromosoma 8 bitova. Po formuli za binarno
kodiranje 2.1 taj broj se pretvara u g = 178.5. Zapisan kao binarni vektor taj broj ima

Genetski algoritam za optimizaciju funkcije 19
oblik [10110010]. Ako algoritam zadrzi taj broj, bez primjene genetskih operatora, on
ga dekodira i salje na evaluaciju njegovog fitnesa. Dekodiran, broj glasi:
g = [10110010] = 178
x = 33.5 +178
28 − 1(33.6− 33.5) = 33.56980392
Vidimo da se sam broj promijenio s odredenom tocnoscu sto je moguce ispraviti koristenjem
duljeg kromosoma. Za n = 16, isti broj kodiran i dekodiran prima vrijednost x =
33.56999924, sto predstavlja vecu preciznost.
Prema [7] jedini nedostatak koji ima binarni prikaz je potencijalno velika Hammingova
udaljenost medu susjednim brojevima. Hammingova udaljenost izmedu dva binarna
broja jednake duljine je broj bitova u kojem se ta dva broja razlikuju. Hammingova
udaljenost izmedu 12710 = 011111112 i 12810 = 10000000 iznosi 8. Na primjer, ako
je genetski algoritam pronasao dobro rjesenje za kromosom zapisan kao binarni vektor
[01111111], a optimum postize u kromosomu zapisanom kao [10000000], treba promije-
niti svih 8 bitova kako bi se postigao optimum, sto usporava algoritam. Za ispravljanje
takvog nedostatka koristi se Grayev kod. Njegova prednost je u tomu sto se susjedni
brojevi kodirani u Grayevom kodu razlikuju u samo jednom bitu. Nacin transforma-
cije nekog binarnog broja g = g0g1 . . . gn−1 u Grayev kod g′ = g′0g′1 . . . g
′n−1 dan je
algoritmom 2.2 (vidi [7]).
Algoritam 2.2 Algoritam transformacije binarnog broja u Grayev kod
g′n−1 = gn−1g′k = gk ⊕ gk+1, k = 0, 1, . . . , n− 1gk =
∑n−1k=j g
′k(mod2), j = 0, 1, . . . , n− 1
Takva transformacija nam daje Grayev kod koji je ciklicki, sto znaci da mu se
susjedni brojevi razlikuju samo u jednom bitu. U teoriji, prednost ovakvog kodiranja
kromosoma lezi u cinjenici da genetski algoritam brze prolazi kroz prostor rjesenja i
time brze provjerava kromosome koji se nalaze u blizini nekog potencijalno dobrog
rjesenja u potrazi za jos boljim rjesenjem.
2.1.2 Prikaz kromosoma kao broja s pomicnom tockom
Realan broj mozemo zapisati i u eksponencijalnom prikazu. Tako zapisan broj ima
oblik
M ·BE
gdje je M mantisa (decimalan broj s predznakom), B baza (u dekadskom sustavu 10,
u binarnom 2) i E eksponent (cijeli broj). Ideja takvog prikaza uzeta je kao temelj
kodiranja realnog broja u obliku broja s pomicnom tockom. Takav broj se zapisuje,

Genetski algoritam za optimizaciju funkcije 20
ovisno o preciznosti, u slijedecem formatu: prvi bit je predznak broja (S). Slijedi
eksponent od 8, odnosno 11 bitova (ovisno o preciznosti) i frakcija od 23 ili 52 bita.
Zorniji prikaz vidimo na slici 2.2 (vidi [7]).
Slika 2.2: Broj s pomicnom tockom jednostruke (dvostruke) preciznosti
Prednost ovakvog prikaza je u tome sto nije potreban poseban mehanizam dekodi-
ranja kao kod binarnog prikaza. Genotip-fenotip mapiranje nije potrebno jer je fenotip
jedinke px zapisan u obliku broja s pomicnom tockom. Genetski algoritam koristi taj
zapis kao genotip pg nad kojim vrsi operacije bez da mu mijenja oblik ili odbacuje bitove
koje ne moze prikazati. Sama tocnost algoritma tada proizlazi iz njegovih mogucnosti
rada a ne iz mogucnosti kodiranja i predstavljanja podataka. Takoder, zbog izostanka
genotip-fenotip mapiranja, brzina rada algoritma se povecava.
Primjer 2.1.2 Pretpostavimo da je algoritam odabrao 33.57 ∈ [33.5, 33.6] kao kandi-
dat za rjesenje i da ga prikazuje kao broj s pomicnom tockom jednostruke preciznosti,
dakle koristeci 32 bita. Kodiran u binarnom zapisu broj glasi
b = [01000010000001100100011110101110].
Prevedemo li ga nazad u dekadski zapis, bez primjene genetskih operatora, on glasi
x = 33.5699997.
U odnosu na primjer 2.1.1 vidimo da je postignuta veca tocnost, sto je jedna od pred-
nosti ovakvog zapisa. Takoder je izbjegnuto kodiranje i dekodiranje po formulama 2.1,
2.2 i 2.3 sto znatno utjece na brzinu rada genetskog algoritma.

Genetski algoritam za optimizaciju funkcije 21
2.2 Postupak selekcije
Genetski algoritmi koriste mehanizam selekcije za odabir jedinki koje sudjeluju u re-
produkciji i stvaraju sljedecu generaciju. Selekcija jedinki se vrsi tako da bolje jedinke
imaju vecu vjerojatnost prezivljavanja od losijih. Pri tome, vazno je da svaka jedinka
ima vjerojatnost da bude izabrana jer neke lose jedinke mogu posjedovati dobra svoj-
stva. Takoder, svaka jedinka moze biti izabrana nekoliko puta, ovisno o njenoj dobroti i
nacinu selekcije. Kljuc selekcije je funkcija cilja koja nam govori koliko je neko rjesenje
dobro i zelimo li ga dalje koristiti (poboljsati) ili u potpunosti odbaciti. Imamo li funk-
ciju s vise kriterija, kljuc selekcije je vrijednost fitnesa ili dobrote rjesenja, kao sto je
navedeno u definiciji 1.3.2. Na taj nacin je omoguceno genetskom algoritmu da svakoj
jedinki populacije Pop pridruzi vjerojatnost selekcije obzirom na njezinu kvalitetu u
smislu rjesenja problema.
Prema [2] postupci selekcije se dijele na selekciju sa zamjenama i selekciju bez
zamjena. Selekcija bez zamjene uzima u obzir dobrotu svake jedinke iz populacije Pop
pa tako svaka jedinka ima vjerojatnost (manju ili vecu) da sudjeluje u reprodukciji, ali
najvise jednom. Selekcija sa zamjenama moze uzeti vise puta istu jedinku, ako je njen
fitnes bolji od ostalih jedinki i cesce se koristi u genetskim algoritmima.
Ovisno o metodi odabira jedinki, postupci selekcije se dijele na proporcionalne i
rangirajuce. Proporcionalna selekcija odabire jedinke s vjerojatnoscu koja je propor-
cionalna dobroti jedinke a rangirajuca selekcija odabire jedinke s vjerojatnoscu koja
ovisi o polozaju jedinke u poretku svih jedinki sortiranih po dobroti. Detaljnija podjela
selekcija vidljiva je na slici 2.3 (vidi [7]).
Kod selekcije vazno je spomenuti i pojam elitizma (vidi [2]). Zbog nacina na koji
algoritmi odabiru jedinke za mutaciju, postoji mogucnost da jedinka s dobrim svoj-
stvima bude mutirana u cilju poboljsanja njenih svojstava. Medutim, takva mutacija
moze rezultirati losijim svojstvima, pa dobra jedinka biva potpuno izgubljena. Stoga se
u genetske algoritme ugraduje svojstvo elitizma koje u svakoj generaciji odabire najbo-
lju jedinku i sprema je u zasebnu arhivu Arc. Na kraju genetski algoritam usporeduje
najbolje rjesenje zadnje populacije Pop s rjesenjima pohranjenima kroz generacije Arc,
i kao optimum vraca najbolje rjesenje. Elitizam mozemo smatrati mehanizmom zastite
najbolje jedinke od eliminacije i utjecaja genetskih operatora, jer ostaje pohranjeno u
arhivi Arc premda ga algoritam izmjeni i izgubi u populaciji Pop. Genetski algoritam
sa takvim mehanizmom osigurava konvergenciju prema globalnom optimumu, ako taj
optimum bude pronaden u bilo kojoj generaciji. S druge strane, koristenje arhive Arc
koju mozemo smatrati populacijom najboljih jedinki kroz generacije, zahtjeva vise rada
algoritma, koje ga nekad uspori.

Genetski algoritam za optimizaciju funkcije 22
Slika 2.3: Vrste selekcija
2.2.1 Jednostavna selekcija
Prva metoda selekcije predlozena od strane Johna Hollanda je jednostavna proporci-
onalna selekcija1 gdje je vjerojatnost odabira jedinke proporcionalna njezinoj dobroti.
Postoji puno principa selekcije koji koriste ovakvu selekciju od kojih je bitno spomenuti
Monte Carlo selekciju s kotacem ruleta na kojem svi brojevi nemaju jednake kruzne
isjecke, vec je zamisljena velicina kruznog isjecka jedinke proporcionalna njenoj dobroti,
tj. vjerojatnosti selekcije kao na slici 2.4.
Slika 2.4: Monte Carlo selekcija
U populaciji Pop od n jedinki, dobrota jedne jedinke pi predstavljena je njezinom
1Fitness proportionate selection

Genetski algoritam za optimizaciju funkcije 23
vrijednoscu fitnesa v(pi). Prema [1],[2] vjerojatnost odabira jedinke P (pi) proporci-
onalna je njezinoj dobroti a obrnuto proporcionalna sumi dobrota svih jedinki u popu-
laciji te je dana formulom:
P (pi) =v(pi)n∑j=1
v(pj)(2.4)
Ova metoda selekcije ogranicava algoritam na maksimizaciju jer veci fitnes predstavlja
vecu vjerojatnosti odabira. Kod minimizacije, bolje jedinke imaju manju vrijednost
funkcije cilja, dakle i manji fitnes. Takoder se dodatno ogranicava genetski algoritam
jer formula 2.4 ne vrijedi ako funkcija cilja prima prevelike vrijednosti. U takvom
slucaju moze doci do toga da sve jedinke imaju veliku vjerojatnost selekcije pa jednos-
tavna selekcija postaje slucajan odabir i nema smisla. Stoga je potrebno normalizirati
vrijednosti dobrote kako bi se omogucila minimizacija genetskim algoritmom, te kako
bi fitnes jedinke zaista predstavljao mjeru koja pokazuje vjerojatnost nastanka boljih
jedinki. U tu svrhu se koristimo formulama od 2.5 do 2.8 (vidi [2]).
vmin = min{v(p), ∀p ∈ Pop} (2.5)
vmax = max{v(p), ∀p ∈ Pop} (2.6)
vnorm(p) =vmax − v(p)
vmax − vmin(2.7)
P (pi) =vnorm(pi)n∑j=1
vnorm(pj)(2.8)
Primjer 2.2.1 Uzmimo populaciju Pop = {x1, x2, x3, x4} sa zadanim vrijednostima
funkcije cilja f(x1) = 10, f(x2) = 20, f(x3) = 30 i f(x4) = 40. Jednostavna selekcija
kotacem za rulet izgledala bi kao na slici 2.5a. Vidimo kako je povrsina kotaca propor-
cionalna vrijednosti rjesenja u funkciji cilja. Medutim, kako je potrebno minimizirati
funkciju, vidljivo je da x4 ima najvecu vjerojatnost odabira, sto nije povoljno za algo-
ritam. Zato, normalizirana selekcija ima prikaz kao na slici 2.5b. Na njoj je vidljivo
kako je povrsina, a samim time i vjerojatnost odabira za rjesenja x4 smanjena na nulu.
Na taj nacin je omoguceno da algoritam odabire samo najbolja rjesenja za reprodukciju
u smislu minimizacije (vidi [2]).

Genetski algoritam za optimizaciju funkcije 24
(a) Monte Carlo selekcija (b) Normalizirana Monte Carlo selekcija
Slika 2.5: Graficki prikaz selekcije kotacem za rulet
2.2.2 Turnirska selekcija
Prema [2] najpopularnija i najucinkovitija selekcijska metoda je turnirska selekcija.
Ona na jednostavan nacin eliminira nedostatke jednostavne selekcije tako da iz po-
pulacije Pop sa n elemenata nasumicno odabire k ≤ n elemenata koje tada u obliku
turnira usporeduje medusobno jedan s drugim. Kako turnirsku selekciju ne zanima
ukupna dobrota populacije, cinjenica da su neki fitnesi jako veliki u odnosu na druge
ne predstavlja problem. Ona jednostavno odabire najbolju jedinku i dopusta joj re-
produkciju.
Turnirska selekcija sa zamjenama dopusta istoj jedinki da vise puta sudjeluje u
reprodukciji jer zbog svog fitnesa pobjeduju u najvise turnira. Selekcija bez zamjene
moze ograniciti usporedivanje jedinke same sa sobom ili ograniciti njezinu reprodukciju
na samo jednom (vidi [2]).
Primjer 2.2.2 Uzmimo populaciju Pop(t) = {x1, x2, x3, x4} sa zadanim vrijednostima
funkcije cilja f(x1) = 10, f(x2) = 20, f(x3) = 30 i f(x4) = 40 nad kojom se vrsi tur-
nirska selekcija sa zamjenama za k = 2. To znaci da selekcija odabire dva elementa i
usporeduje ih obzirom na vrijednosti njihovih fitnesa. Jedna moguca selekcija bi rezul-
tirala medupopulacijom:
Pop′(t+ 1) = {usporedi(p1, p3), usporedi(p2, p4),usporedi(p3, p1), usporedi(p4, p2)}
Pop′(t+ 1) = {p1, p2, p1, p2}
Ako je potrebno da nova populacija ima jednako mnogo elementa kao i prethodna, u
prosjeku ce svaka jedinka sudjelovati u dva turnira. Pri tome ce najbolja jedinka p1 po-
bijediti u svakom turniru i najvise puta sudjelovati u reprodukciji. Jedinka losijeg fitnesa
p2 koja je bolja od polovice populacije ce u prosijeku pobijediti u pola turnira. Jedinke
najlosijeg fitnesa nece sudjelovati u reprodukciji jer ce izgubiti u svakom usporedivanju.

Genetski algoritam za optimizaciju funkcije 25
Turnirska selekcija sa zamjenama za k = 3 bi mogla imati oblik:
Pop′(t+ 1) = {usporedi(p1, p2, p3), usporedi(p2, p3, p4),usporedi(p3, p4, p1), usporedi(p4, p1, p2)}
Pop′(t+ 1) = {p1, p2, p1, p1}
Prema [2], povecanjem k povecava se i selekcijski pritisak: algoritam odabire sve vise i
vise jedinki s dobrim svojstvima, dok jedinke s losim svojstvima imaju sve manju vje-
rojatnost odabira. Na taj nacin u reprodukciji sudjeluje veliki broj kopija dominantnih
jedinki i skoro nijedna losa. Za probleme gdje je potrebna brza konvergencija algoritma
ovakvo svojstvo ne predstavlja problem. Medutim, isto tako se moze dogoditi da lose
jedinke koje nisu odabrane a sadrze dobra svojstva na ovaj nacin nestanu iz populacije.
2.2.3 Rangirajuca selekcija
Vjerojatnost odabira jedinki kod rangirajuce selekcije je proporcionalna njihovom po-
retku (rangu) u sortiranoj listi svih jedinki populacije (vidi [1], [2]). Ona ublazava
problem velike razlike vrijednosti funkcije cilja za jedinke i naglasava male razlike.
Geometrijska sortirajuca selekcija2 sortira jedinke od najbolje prema najlosijoj, s tim
da najbolja ima indeks 1, a najgora indeks n. Prema [1] svakoj se jedinki dodjeljuje
vjerojatnost selekcije P (pi) po principu normalne geometrijske distribucije
P (pi) = q′ (1− q)r−1 (2.9)
gdje je:
q - vjerojatnost odabira najbolje jedinke,
r - indeks (redni broj) jedinke,
n - velicina populacije,
q′ - izraz dan sa q1−(1−q)n .
Primjer 2.2.3 Uzmimo populaciju Pop(t) = {x1, x2, x3, x4} sa zadanim vrijednostima
funkcije cilja f(x1) = 10, f(x2) = 20, f(x3) = 30 i f(x4) = 40 nad kojom vrsimo
geometrijsku sortirajucu selekciju. Kako su jedinke vec rangirane od najbolje x1 do
najlosije x4, lagano se izracuna vjerojatnost odabira za svaku od njih. Vrijedi da je q =
0.25, n = 4 i q′ = 415
. Uvrstavanjem u formulu 2.9 dobijemo: P (p1) = 0.2667, P (p2) =
0.2, P (p3) = 0.15 i P (p4) = 0.1125.
Za razliku od turnirske selekcije koja stvara veliku medupopulaciju dobrih jedniki, ge-
ometrijska selekcija dodjeljuje veliku vjerojatnost selekcije nekolicini najboljih jedniki.
Medutim, kako i najlosije jedinke dobivaju vjerojatnost selekcije, manja je sansa da
neka dobra svojstva, pohranjena u losijim jedinkama, nestanu iz populacije.
2Normalized geometric selection

Genetski algoritam za optimizaciju funkcije 26
2.3 Genetski operatori
Kao sto u prirodi dobre jedinke prezive i imaju priliku reprodukcije, tako je i u ge-
netskom algoritmu potrebno osigurati mehanizam reprodukcije, tj. stvaranja novih
rjesenja iz postojecih dobrih. Taj mehanizam cine genetski operatori krizanja i mu-
tacije. Krizanje imitira biolosku razmjenu gena koja nastaje tijekom reprodukcije
na nacin da uzima dvije jedinke koje predstavljaju roditelje3 i mijesanjem njihovih
gena stvori dvije nove jedinke koje predstavljaju potomstvo4. Na taj nacin potomci
zadrzavaju dobra svojstva roditelja koja u narednim generacijama mogu postati jos i
bolja (vidi [7]). Mutacija mijenja svojstva jedinke na nacin da slucajnom promjenom
jednog ili vise gena u kromosomu stvara novu jedinku koja moze imati nova svojstva
koja nisu postojala u populaciji. Genetski operator mutacije je zasluzan za “bijeg”
genetskih algoritama iz lokalnih minimuma. Prema [7], ako cijela populacija rjesenja
zavrsi u lokalnom minimumu, samo slucajna promjena osobina jedinki moze popula-
ciju dovesti u prostor gdje se nalazi bolje rjesenje. Oba genetska operatora su ovisna o
nacinu prikaza rjesenja pa cemo njih i njihove inacice opisati kroz binarni (za funkcije
jedne varijable) i realni prikaz (funkcije cilja s vise varijabli) kromosoma (vidi [1]).
Bitnu razliku u odabiru i nacinu rada operatora cini i duljina kromosoma. Najpopular-
nija metoda je koristenje kromosoma jednake i fiksne duljine. Na taj nacin operatori
nemaju problema sa krizanjem, jer za svaki gen koji zele zamijeniti postoji gen s kojim
ga mogu zamijeniti. Isto tako, mutacija kromosoma duljine 16 bitova nece kreirati
kromosom duljine 32 bita koji tada ne bi bilo moguce ni dekodirati, ni evaluirati jer
bi takav mutirani kromosom mogao biti van prostora pretrage. Medutim, moguce je
da kromosomi koji sudjeluju u krizanju i mutaciji nemaju istu duljinu. Za takve kro-
mosome je vrlo bitno dobro definirati genetske operatore i prostor pretrage, kako ne bi
izazvali prekid rada algoritma ili pretjeranu slozenost (vidi [2]).
3eng. parents4eng. offspring

Genetski algoritam za optimizaciju funkcije 27
2.3.1 Funkcije jedne varijable
Prema [1], neka su X i Y dva vektora duljine m koji kodiraju dvije razlicite jedinke u
populaciji. Za binarni prikaz tih vektora definirani su genetski operatori jednostavne
mutacije5 i jednostavnog krizanja6.
Jednostavna mutacija mijenja svaki bit kromosoma u populaciji s jednakom vjero-
jatnoscu Pm po sljedecoj formuli:
x′i =
{1− xi , ako je U(0, 1) < Pmxi , inace
(2.10)
gdje U(0, 1) predstavlja slucajan broj iz intervala (0, 1). Na slici 2.6a (vidi [2]) je
oznacen bit koji je mutirao pa jedinka s lijeve strane nakon mutacije poprima drugi
oblik i samim time druga svojstva (bolja ili losija).
(a) Mutacija jednog gena (b) Mutacija vise gena jednogsvojstva
(c) Mutacija vise gena
Slika 2.6: Jednostavna mutacija binarno prikazanih gena
Jednostavno krizanje generira slucajan broj r izmedu 1 i m i kreira dvije nove
jedinke X′
i Y′
po formulama 2.11 i 2.12:
x′i =
{xi , ako je i < ryi , inace
(2.11)
y′i =
{yi , ako je i < rxi , inace
(2.12)
Zorniji prikaz vidimo na slici 2.7(vidi [2]) gdje su s lijeve strane svake slike prikazani
roditelji a s desne potomci tih roditelja. Na slici 2.7a se oba roditelja dijele u jednoj
tocki (genu) na dva dijela te potomci nastaju kombinacijom prvog dijela prvog roditelja
s drugim dijelom drugog roditelja, i obratno. Svo genetsko nasljede je sacuvano, ali
rekombinirano s ciljem dobivanja novih rjesenja.
Primjer 2.3.1 Neka su x1 = 17 i x2 = 14 dva rjesenja kodirana binarnim prikazom u
obliku kromosoma g1 = [00010001] i g2 = [00001110] fiksne duljine m = 8.
5eng. Binary mutation6eng. Simple crossover

Genetski algoritam za optimizaciju funkcije 28
(a) Krizanje u jednoj tocki (b) Krizanje u dvije tocke (c) Krizanje u vise tocaka
Slika 2.7: Jednostavna mutacija binarno prikazanih gena
Mutacija s vjerojatnoscu Pm = 0.5 mutira ove kromosome na nacin da nastaju nove
jedinke. One bi mogle imati oblik:
g′1 = [00110110]
g′2 = [00101001].
Dekodiranjem, vidimo da su to sada x′1 = 54 i x′2 = 41. Na taj nacin algoritam moze
pretrazivati nove dijelove prostora rjesenja jer ga je slucajna promjena jednog gena
odvela daleko od pocetnog prostora rjesenja. Sto je vjerojatnost mutacije veca, to su
nova rjesenja dalje od pocetnih. Iako na taj nacin algoritam brzo pretrazuje, cesta
promjena gena moze dovesti i do gubitka dobrih svojstava jedinke.
Krizanjem u jednoj tocki za r = 3 nastaju potomci oblika:
g′1 = [00010110]
g′2 = [00001001].
Njihovim dekodiranjem vidimo da su to kandidati za rjesenja x′1 = 22 i x′2 = 9.
Ovakav operator ne daje nova rjesenja daleko od pocetnog dijela prostora, no to mu i
nije smisao. Rekombinirajuci dobra svojstva dva roditelja mogu nastati bolji potomci,
a njih ionako nema smisla traziti u prostoru daleko od roditelja.

Genetski algoritam za optimizaciju funkcije 29
2.3.2 Funkcije vise kriterija
Prema [1], za prikaz vektora X i Y kao brojeva s pomicnom tockom definirani su
genetski operatori uniformne mutacije7, neuniformne mutacije8, multi neuniformne
mutacije9, granicne mutacije10, jednostavnog krizanja11, aritmetickog krizanja12 i he-
uristickog krizanja13. Ovakav prikaz se koristi kod funkcija s vise kriterija gdje svaki
dio kromosoma (alel) predstavlja jednu varijablu koji zelimo optimirati. Neka su za
svaku varijablu xi dane donja granica ai i gornja granica bi.
Uniformna mutacija odabire jednu varijablu j i mijenja joj vrijednost po formuli:
x′i =
{U(ai, bi) , ako je i = j
xi , inace(2.13)
Granicna mutacija odabire jednu varijablu j i mijenja joj vrijednost na njenu gornju
ili donju granicu ovisno o koeficijentu r = U(0, 1) po formuli:
x′i =
ai , ako je i = j, r < 0.5bi , ako je i = j, r ≥ 0.5xi , inace
(2.14)
Neuniformna mutacija odabire jednu varijablu j i mijenja joj vrijednost po formuli:
x′i =
xi + (bi − xi)f(t) , ako je r1 < 0.5xi − (xi + ai)f(t) , ako je r1 ≥ 0.5
xi , inace(2.15)
pri cemu su:
f(t) = (r2(1− ttmax
))b,
r1, r2 = uniforman slucajan broj U(0, 1),
t = trenutna generacija populacije,
tmax = maksimalan broj generacija,
b = parametar oblika.
Multi neuniformna mutacija vrsi neuniformnu mutaciju na svim varijablama jednog
kromosoma, pa ju nije potrebno definirati posebnom formulom.
7eng. Uniform mutation8eng. Non-uniform mutation9eng. Multi-non-uniform mutation
10eng. Boundary mutation11eng. Simple crossover12eng. Arithmetic crossover13eng. Heuristic crossover

Genetski algoritam za optimizaciju funkcije 30
Primjer 2.3.2 Neka je jedan kandidat za rjesenje X = (2.25, 2.75, 2.5) i neka je xi ∈[2, 3] za i = 1, 2, 3. Promotrimo sto se dogada s varijablom na drugom mjestu ovog
vektora kada na njega djeluju razlicite vrste mutacija.
Uniformna mutacija odabire varijablu x2 = 2.75, pa bi novonastali vektor imao oblik
X′= (2.25, 2.58884, 2.5).
Granicna mutacija odabire varijablu x2 = 2.75 i za r = 0.3 kreira vektor
X′= (2.25, 2, 2.5).
Za r = 0.6 novi vektor bi imao oblik
X′= (2.25, 3, 2.5).
Neuniformna mutacija u 15-oj generaciji od ukupno 100 generacija za parametre
r1 = 0.3, r2 = 0.5 i b = 1 uzima drugu varijablu i novonastali vektor ima oblik
X′= (2.25, 2.85625, 2.5).
Multi neuniformna mutacija bi, sa istim parametrima kao u neuniformnoj mutaciji,
promijenila sve varijable i dala vektor
X′= (2.56875, 2.85625, 2.7125).
Jednostavno krizanje realnih vektora funkcije s vise ciljeva obavlja se po formulama
2.11 i 2.12 pa ga nije potrebno dodatno definirati.
Aritmeticko krizanje uzima jedinke roditelje i od njih stvara dva komplementarno
linearna potomka koristeci r = U(0, 1) po formulama:
X′= rX + (1− r)Y (2.16)
Y′= (1− r)X + rY (2.17)
Heuristicko krizanje daje potomke linearnom ekstrapolacijom. Ovaj operator koristi
i informaciju korisnosti (dominacije) jedne jedinke nad drugom. Nova jedinka, X′,
kreira se po formulama 2.18 i 2.19, gdje je r = U(0, 1) i X je dominantan nad Y .
Ako tako dobiven potomak X′ne zadovoljava uvjet formule 2.20, generira se novi broj
r i kreira nova jedinka po vec spomenutim formulama 2.18 i 2.19. Ako potomak X′
zadovoljava uvjet po formuli 2.20, tada se za nove jedinke uzimaju X′
i Y′. Kako bi
ova metoda osigurala zaustavljanje ako kroz odredeni broj pokusaja t ne uspije naci
bolje potomke od roditelja, za potomke se uzimaju roditelji i prelazi se na novi par
jedinki za krizanje.

Genetski algoritam za optimizaciju funkcije 31
X′= X + r(X − Y ) (2.18)
Y′= X (2.19)
dopustivost =
{1 , ako je x′i ≥ ai , x′i ≤ bi ∀i0 , inace
(2.20)
Primjer 2.3.3 Neka su dani vektori roditelja X = (2.25, 2.75, 2.5) i Y = (2.45, 2.15, 2.9)
i neka je xi ∈ [2, 3], yi ∈ [2, 3] za i = 1, 2, 3. Promotrimo kako nastaju vektori potomaka
kada primijenimo razlicite vrste krizanja.
Jednostavno krizanje sa r = 2 zamijeni x1 sa y1 i daje vektore potomaka
X′= (2.45, 2.75, 2.5)
Y′= (2.25, 2.15, 2.9).
Aritmeticko krizanje sa r = 0.3 zamijeni bi dalo vektore potomaka
X′= (2.39, 2.33, 2.78)
Y′= (2.31, 2.57, 2.62).
Posebno zanimljivo je heuristicko krizanje uz pretpostavku da X dominira nad Y ,
tj. da ima bolji fitnes. Tada za r = 0.7 dobivamo potomke
X′=(2.11 3.17 2.22
)Y′=(2.25 2.75 2.5
).
Kako potomak X′
ne zadovoljava uvjet 2.20 jer ocito x′2 nije iz intervala [2, 3],
generira se novi r = 0.3. Sada dobivamo potomke
X′=(2.19 2.93 2.38
)Y′=(2.25 2.75 2.5
).
Kako ovi potomci zadovoljavaju uvjet dopustivosti 2.20 operator zavrsava.

Genetski algoritam za optimizaciju funkcije 32
2.4 Generiranje pocetne populacije i kriterij zaus-
tavljanja
Prema [2] pocetna populacija Pop(0) nastaje slucajnim kreiranjem n jedinki u prostoru
pretrage G. Te jedinke nemaju roditelje niti naslijedena svojstva, pa se nad njima prvo
vrsi postupak selekcije kako bi odabrali najbolje od njih. Nakon odabira najboljih,
kreira se medupopulacija koja se popunjava do velicine n radom genetskih operatora.
Po zavrsetku njihovog rada, dobije se populacija Pop(1) koja ima bolji prosjecni fitnes
od populacije Pop(0). U pocetnu populaciju je moguce ugraditi i jedinke koje su
nastale kao rezultat nekog drugog optimizacijskog procesa istog problema, a za njih
je utvrdeno da su blizu optimuma kojeg trazimo (vidi [7]). Na taj nacin je moguce
skratiti vrijeme rada genetskog algoritma, jer medu slucajno odabranim jedinkama ima
onih koje ga vode ka optimumu. Medutim, ako su te jedinke lokalni optimumi, moguce
je da algoritam “zastane” u lokalnom minimumu ili maksimumu jer je u ranoj fazi
odbacio neko od ostalih slucajnih rjesenja. Isto tako je moguce za pocetnu populaciju
uzeti populaciju koja je rezultat nekog drugog optimizacijskog procesa, ali opet sa istim
rizikom od lokalnih optimuma.
Genetski algoritam je iterativna metoda optimiranja kojem svaka iteracija rezultira
novom generacijom rjesenja, po uzoru na biolosku analogiju evolucije. Najcesca me-
toda zaustavljanja algoritma je odredivanje maksimalnog broja generacija tmax. Proces
optimiranja se moze zaustaviti ako genetski algoritam kroz odredeni broj iteracija ne
pronalazi rjesenja s boljim fitnesom od onih rjesenja koja u tom trenutku ima u popu-
laciji. Tada se za rjesenje uzima najbolja jedinka koja u toj populaciji postoji i ona,
vrlo vjerojatno, predstavlja globalni optimum. Kako genetski algoritmi poboljsavaju
dobra rjesenja a odbacuju losija, vecina populacije ce konvergirati oko nekog rjesenja.
Kada suma razlika izmedu fitnesa takvih jedinki postane manja od nekog definiranog
broja, genetski algoritam se zaustavlja po kriteriju konvergencije populacije. Prema
[2] sve ove kriterije zaustavljanja mozemo koristiti istovremeno na jednom genetskom
algoritmu, kako bismo osigurali njegovo zaustavljanje.

Poglavlje 3
Teorem sheme
Prema [2], vecina optimizacijskih algoritama pociva na pretpostavci da su rjesenja pro-
blema elementi kontinuiranog prostora kojeg je moguce aproksimirati postupno ili da
su elementi manjih modula koji imaju dobra svojstva cak i kada se javljaju zasebno.
Dizajn prostora pretrage G i definiranje genotip-fenotip mapiranja su vitalni za uspjeh
optimizacije jer odreduju do kojeg stupnja se ocekivana dobra svojstva mogu iskoris-
titi. Jedinke p su okarakterizirane svojim svojstvima φ (razlicitim vrijednostima gena
na odredenim mjestima u kromosomu) koja, iako nebinta za samo genotip-fenotip ma-
piranje i odredivanje fitnesa, utjecu na performanse optimizacije. Opcenito, mozemo
zamisliti neko svojstvo φi kao neku vrstu funkcije koja pridruzuje razlicite jedinke iz
populacije vrijednostima tog svojstva. Na osnovi svojstva φi mozemo definirati relaciju
ekvivalencije ∼φi formulom:
p1 ∼φi p2 ⇒ φi(p1) = φi(p2) ∀p1, p2 ∈ G× X (3.1)
Ocito je da za svaka dva kandidata za rjesenje x1 i x2 vrijedi, ili x1 ∼φi x2 ili x1 �φi x2.
Ove relacije dijele prostor pretrage u klase ekvivalencije Aφi=v.
Definicija 3.0.1 Klasa ekvivalencije Aφi=v koja sadrzi sve jedinke koje dijele iste ka-
rakteristike v u smislu svojstva φi naziva se forma ili predikat.
Aφi=v = {∀p ∈ G× X : φi(p) = v} (3.2)
∀p1, p2 ∈ Aφi=v ⇒ p1 ∼φi p2 (3.3)
Primjer 3.0.1 Neka je dana populacija funkcija kao na slici 3.1 (vidi [2]). To su
redom f1(x) = x+1, f2(x) = x2+1.1, f3(x) = x+2, f4(x) = 2(x+1),f5(x) = (x+1) sinx
i f6(x) = (x+ 1) cosx. Definirajmo sljedece svojstva:
φ1 =
{1 , ako je funkcija sadrzi izraz x+ 10 , ako je ne sadrzi izraz x+ 1
33

Genetski algoritam za optimizaciju funkcije 34
φ2 =
{1 , ako je |f(0)− 1| ≤ 0.10 , inace
Vidimo da vrijedi forma Aφ1=1 = {f1, f4, f5, f6} posto sve funkcije sadrze izraz x + 1.
Isto tako vrijedi forma Aφ1=0 = {f2, f3} posto niti jedna od njih ne sadrzi izraz x + 1.
Jos vrijede forme Aφ2=1 = {f1, f2, f6} i Aφ2=0 = {f3, f4, f5}.
Dvije forme Aφi=v i Aφj=w su kompatibilne (pisemo Aφi=v ./ Aφj=w) ako postoji
barem jedna jedinka koja pripada i jednoj i drugoj formi. Iz primjera forme 3.0.1 ocito
je da su forme Aφ1=1 i Aφ2=1 kompatibilne, dok za dvije razlicite forme istog svojstva,
Aφ1=1 i Aφ1=0 uvijek vrijedi da su nekompatibilne.
Slika 3.1: Primjer populacije
Teorem shema14 je poseban slucaj forme za genetske algoritme postavljen od strane
J. Hollanda. Prema [2], pretpostavimo da je genotip g ∈ G kodiran u obliku niza
znakova (binarni prikaz) fiksne duljine l. Za takve genome, kao svojstva genotipa
promatramo vrijednosti gena na odredenim mjestima (lokusima).
Definicija 3.0.2 Za genom fiksne duljine kodiran u binarnom prikazu definiramo skup
svih genotipskih maski Ml kao partitivni skup odgovarajucih lokusa Ml = P({1, . . . , l}).
Svaka maska mi ∈Ml definira svojstvo φi i relaciju ekvivalencije:
g ∼φi h⇔ g[j] = h[j] ∀j ∈ mi. (3.4)
Pri tome je red maske |mi| jednak broju lokusa definiranih s njom a duljina maske
δ(mi) je maksimalna udaljenost dva indeksa u maski.
Primjer 3.0.2 Prema [2], neka su genotipi nizovi duljine l = 3 sastavljeni u genomu
G = B3. Tada je skup maski M3 = {{1}, {2}, {3}, {1, 2}, {1, 3}, {2, 3}, {1, 2, 3}}. Neka
maska m1 = {1, 2} odreduje da vrijednosti na lokusima 1 i 2 na genotipu oznacavaju
14The Schema Theorem

Genetski algoritam za optimizaciju funkcije 35
vrijednost svojstva φ1 i da je vrijednost bita na lokusu 3 nebitna. Na taj nacin mozemo
definirati cetiri forme:
Aφ1=(0,0) = {(0, 0, 0), (0, 0, 1)}Aφ1=(0,1) = {(0, 1, 0), (0, 1, 1)}Aφ1=(1,0) = {(1, 0, 0), (1, 0, 1)}Aφ1=(1,1) = {(1, 1, 0), (1, 1, 1)}.
Definicija 3.0.3 Forma definirana na binarno prikazanim genomima koja se tice vri-
jednosti bitova na odredenim lokusima se naziva shema.
Drugi nacin definiranja sheme je upotreba simbola “nebitan lokus” koji smjestamo na
onaj lokus koji se ne tice sheme, tj. koji nije bitan za svojstvo koje shema opisuje. Na
taj nacin kreiramo nacrte H po formuli (vidi [2]):
∀j ∈ 1 . . . l⇒ H[j] =
{g[j] , ako je j ∈ mi
∗ , inace(3.5)
Primjer 3.0.3 Sada se shema iz primjera 3.0.2 redefinira kao:
Aφ1=(0,0) ≡ H1 = (0, 0, ∗)Aφ1=(0,1) ≡ H2 = (0, 1, ∗)Aφ1=(1,0) ≡ H3 = (1, 0, ∗)Aφ1=(1,1) ≡ H4 = (1, 1, ∗).
Sheme u primjeru 3.0.3 prikazujemo pomocu hiperravnina u prostoru pretrage G, kao
na slici 3.2.
Brid koji spaja genotip (0, 1, 0) sa (0, 1, 1) na slici 3.2 smatramo nacrtom H2 =
(0, 1, ∗), brid koji spaja genotip (0, 0, 0) sa (0, 0, 1) nacrtom H1 = (0, 0, ∗), brid koji
spaja genotip (1, 1, 0) sa (1, 1, 1) nacrtom H4 = (1, 1, ∗) i brid koji spaja genotip (1, 0, 0)
sa (1, 0, 1) nacrtom H3 = (1, 0, ∗). Mozemo definirati i nacrt H5 = (1, ∗, ∗) koji za
bitna svojstva uzima samo gen na prvom lokusu kada je on vrijednosti 1. Tada je on
predstavljen desnom bocnom ravninom na crtezu 3.2 jer spaja sve genotipe sa zadanim
svojstvom (vidi [2]).
Hollandov teorem sheme je definiran za genetske algoritme sa jednostavnom pro-
porcionalnom selekcijom gdje je fitnes subjekt maksimizacije.

Genetski algoritam za optimizaciju funkcije 36
Slika 3.2: Primjer shemate za genom duljine 3 bita
Teorem 3.0.1 (Hollandov teorem sheme) Broj pojavljivanja genoma iz sheme H
u generaciji t+ 1 je
E(H, Pop)t+1 ≥E(H, Pop)t · v(H)t
vt(1− p) (3.6)
Pri cemu je:
• E(H, Pop)t broj pojavljivanja elemenata dane sheme definirane nacrtom H u po-
pulaciji Pop u trenutku (generaciji) t
• v(H)t prosjecan fitnes elemenata dane sheme
• vt prosjecan fitnes populacije u trenutku t
• p vjerojatnost da ce element dane sheme nestati prilikom reprodukcije
Iz ovako zadanog teorem moze se zakljuciti da genetski algoritmi, za sheme iznadpro-
sijecnog fitnesa, generiraju eksponencijalno rastuci broj uzoraka sheme, dakle genoma
sa iznadprosjecnim fitnesom. Medutim, takav zakljucak da dobre sheme rastu ekspo-
nencijalno nije uvijek istinit. Prema [5] ovaj teorem mozemo promatrati kao donju
granicu pojavljivanja dobrih genoma koja sigurno vrijedi za jednu generaciju t. Ako
jako dobra shema ima puno potomaka s jako dobrim fitnesom, tada se i fitnes ukupne
populacije mijenja, i s time se vjerojatnosti u formuli 3.6 mijenjaju. Takoder, genetski

Genetski algoritam za optimizaciju funkcije 37
algoritmi dijeluju na uzorku ogranicene velicine prostora pretrage G, pa ne mozemo sa
sigurnoscu tvrditi da prosjecan fitnes elemenata dane sheme v(H)t zaista predstavlja
prosjecan fitnes svih elemenata sheme v(H), osim u tom odredenom trenutku (genera-
ciji) t. Kao sto je vec spomenuto, za genetske algoritme ne mora uvijek biti dobro da se
rafiniraju samo elementi jedne odredene sheme, iako imaju iznadprosjecan fitnes, jer to
moze dovesti do preuranjene konvergencije u lokalnom optimumu. Upotreba teorema
kako bi se doslo do predvidanja rada genetskog algoritma za vise od jedne ili dvije
generacije unaprijed moze dovesti do pogresnih zakljucaka (vidi [2]).

Poglavlje 4
Usporedba rada genetskogalgoritma i metode simpleksa
U ovom poglavlju je dana usporedba rada genetskog algoritma i Nelder-Mead sim-
pleks algoritma. U usporedbama smo koristili programe iz programskog paketa Ma-
tlab. Nelder-Mead metoda optimizacije simpleksom je robusna metoda koja posjeduje
pseudo-globalne optimizacijske karakteristike. Simpleks je geometrijska figura od n+ 1
vrhova i spojnica tih vrhova u n dimenzija (u dvije dimenzije to je trokut, u tri di-
menzije je tetraedar)(vidi [4]). Vrhovi simpleksa {xj}n+1j=1 su aproksimacije rjesenja oko
optimalne tocke, sortirani u odnosu na vrijednosti funkcije:
f(x1) ≤ f(x2) ≤ . . . ≤ f(xn+1). (4.1)
Vrh x1 predstavlja najbolju, a xn+1 najlosiju aproksimaciju rjesenja. Nelder-Mead
algoritam zamjenjuje najlosiji vrh xn+1 sa novim vrhom po formuli
x(µ) = (1 + µ)x− µxn+1, (4.2)
pri cemu je x centroid konveksne ljuske podataka {xj}n+1j=1 izracunat po formuli
x =1
n
n∑i=1
xi. (4.3)
Vrijednost µ se nalazi u intervalima
−1 < µuk < 0 < µvk < µr < µe.
Algoritam ima tri osnovne radnje za pretrazivanje: refleksija, ekspanzija i kontrakcija,
pa mu vrijednost µ odreduje kakav ce se korak izvrsavati u algoritmu. Algoritam
zavrsava kada je razlika f(xn+1)− f(x1) manja od unaprijed zadane tolerancije tol ili
kada se izvrsi odredeni broj pozivanja funkcije f u cilju evaluacije vrhova kmax. Nelder-
Mead simpleks metoda ne moze garantirati konvergenciju ka globalnom optimumu, ali
u praksi pokazuje dobre performanse rada algoritma. Zato se u svrhu poboljsanja
38

Genetski algoritam za optimizaciju funkcije 39
konvergencije koristi iterirani simpleks. Ova metoda ponovo pokrece algoritam na
novom skupu tocaka, pri cemu se za jedan vrh takvog novog simpleksa uzme najbolje
rjesenje, prethodno dobiveno istim algoritmom (vidi [3]). Optimizacija Nelder-Mead
simpleksom je sastavni dio Matlab-ovih funkcija optimizacije i poziva se naredbom:
[x,fval,exitflag,output]=fminsearch(fun,x0,options)
pri cemu su izlazne varijable:
• x je konacno rjesenje,
• fval je vrijednost funkcije za dobiveno rjesenje,
• exitflag je oznaka nacina zavrsetka algoritma (zavrsetak zbog konvergencije
rjesenju x, dosegnutog maksimalnog broja iteracija ili maksimalnog broja eva-
luacija kmax),
• output je poruka zavrsetka koja sadrzi informacije o metodi optimizacije, broju
iteracija i broju evaluacija kmax.
Ulazne varijable su:
• fun je poziv funkcije koju minimiziramo,
• x0 je pocetna aproksimacija rjesenja,
• options su parametri kontrole optimizacijskog procesa kao sto su prikaz koraka
algoritma, maksimalno dozvoljeni broj iteracija, maksimalno dozvoljeni broj eva-
luacija funkcija kmax, tolerancija zavrsetka tol.
Genetski algoritam 2.1 je implementiran u Matlab-u u obliku skupa funkcija, od kojih
svaka implementira jedan dio algoritma. Funkcija koja simulira rad genetskog algoritma
oznacena je sa ga i poziva se naredbom (vidi [1]):
[x,endPop,bPop,traceInfo]=ga(bounds,evalFN,evalParams,params,startPop,
termFN,termParams,selectFN,selectParams,
xOverFNs,xOverParams,mutFNs,mutParams)
pri cemu su izlazne varijable:
• x je najbolje rjesenje (konacno rjesenje),
• endPop je zadnja populacija koja sadrzi najbolje rjesenje,
• bPop je matrica najboljih jedinki i odgovarajucih generacija u kojima su nadene,
• traceInfo je matrica optimalnih i srednjih funkcijskih vrijednosti populacije za
svaku generaciju.

Genetski algoritam za optimizaciju funkcije 40
Ulazne varijable su:
• bounds matrica donjih i gornjih granica kandidata za rjesenja,
• evalFN funkcija evaluacije
• evalParams matrica parametara za funkciju evaluacije
• params vektor opcija oblika [epsilon prob param disp param] sa zadanom vri-
jednoscu [1e−6 1 0] gdje epsilon odreduje minimalnu razliku izmedu dva kandi-
data za rjesenja da bi ih se smatralo razlicitim rjesenjima
• startPop matrica pocetne populacije i njihovih vrijednosti
• termFN funkcija zavrsetka rada algoritma
• termParams vektor parametara za termFN
• selectFN selekcijska funkcija postavljena na normalnu geometrijsku selekciju
• selectParams vektor parametara za selekcijsku funkciju
• xOverFN niz metoda krizanja populacije, ovisan o prikazu rjesenja
• xOverParams matrica parametara za krizanje
• mutFN niz metoda mutiranja, ovisan o prikazu rjesenja
• mutParams matrica parametara za krizanje.
Usporedba rada metode simpleksa i genetskog algoritma provedena je na funkciji
Corana definiranoj sa:
f(x) =
{0.15di(0.05S(zi) + zi)
2 , ako je |xi − zi| < 0.05dix
2i , inace
}.
Pri tome su:
zi = 0.2⌊∣∣∣ xi
0.2+ 0.49999
∣∣∣⌋S(xi),
S(zi) =
1 ako je zi > 00 ako je zi = 0−1 ako je zi < 0
,
di mod 4 = {1, 1000, 10, 100} .
Prema [1], ovako definiranu Corana funkciju mozemo zamisliti kao n-dimenzionalne
parabole sa pravokutnim “dzepovima” u kojima su lokalni minimumi, dok se globalni
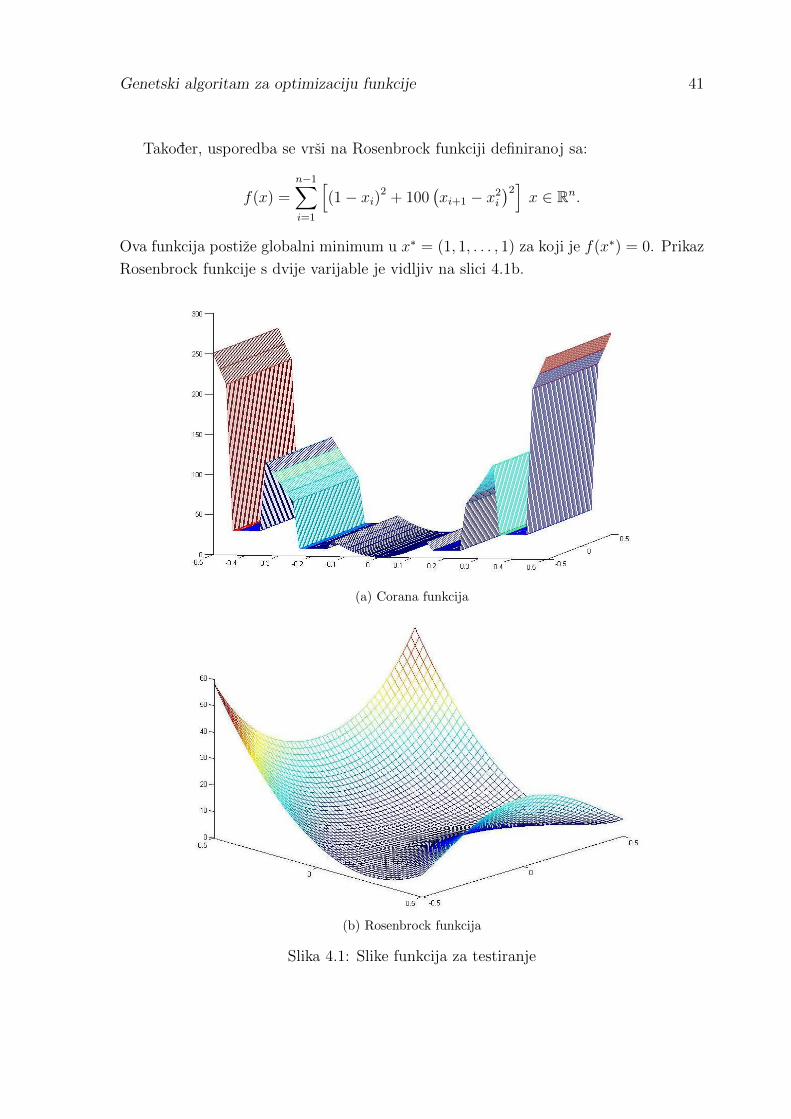
minimum postize u tocki x∗ = (0, 0, . . . , 0) za koju je f(x∗) = 0. Prikaz Corana funkcije
s dvije varijable je vidljiv na slici 4.1a.
Genetski algoritam za optimizaciju funkcije 41
Takoder, usporedba se vrsi na Rosenbrock funkciji definiranoj sa:
f(x) =n−1∑i=1
[(1− xi)2 + 100
(xi+1 − x2i
)2]x ∈ Rn.
Ova funkcija postize globalni minimum u x∗ = (1, 1, . . . , 1) za koji je f(x∗) = 0. Prikaz
Rosenbrock funkcije s dvije varijable je vidljiv na slici 4.1b.
(a) Corana funkcija
(b) Rosenbrock funkcija
Slika 4.1: Slike funkcija za testiranje

Genetski algoritam za optimizaciju funkcije 42
4.1 Rezultati usporedbe metoda
Primjenom Nelder-Mead simpleks algoritma na minimalizaciju Rosenbrock funkcije
u deset nezavisnih pokusa dobivaju se rezultati prikazani u tablici 4.1. Podaci nam
pokazuju da ugradena Matlab funkcija primjenjuje Nelder-Mead algoritam na brz i
efikasan nacin. U prosjeku, globalni minimum biva pronaden unutar 319 koraka, tj.
refleksija, ekspanzija i kontrakcija s tocnoscu 10−9. Medutim, to mu polazi za rukom
u samo 7 od 10 neovisnih pokusa koji su izvedeni. Razlog tomu je taj sto Nelder-
Mead simpleks algoritam ovisi o odabiru pocetne aproksimacije, tj. pocetnog vrha
simpleksa x0, pa iako posjeduje pseudo-globalna svojstva, ne moze uvijek dohvatiti
globalni minimum.
x0 Pogreske |(1, 1, 1, 1)− x∗| f(x∗)Brojiteracija
(7.220, 0.275, 6.704, -3.72) 10−5 · (0.53, 0.83, 1.62, 2.89) 2.14 · 10−9 292(8.586, 7.462, 0.846, -1.06) 10−5 · (0.22, 0.36, 1.01, 1.90) 1.14 · 10−9 299(-3.09, 3.779, -1.37, 7.015) 10−5 · (0.17, 0.05, 0.32, 0.93) 2.18 · 10−9 348(8.701, 3.246, 1.059, -4.56) (1.776, 0.387, 0.618, 0.854) 3.70142 248(4.485, 8.758, -3.55, 8.933) 10−5 · (0.55, 0.93, 1.83, 3.88) 1.28 · 10−9 291(-3.54, -0.71, -3.02, 5.955) (1.747, 0.430, 0.668, 0.890) 3.70251 132(-0.82, 6.358, 9.131, 2.329) (1.776, 0.387, 0.618, 0.854) 3.70143 442(3.203, 6.306, 9.342, 3.678) 10−5 · (0.19, 0.13, 0.26, 0.19) 1.87 · 10−9 346(9.363, 0.707, 3.628, -1.44) 10−5 · (0.85, 1.89, 3.86, 7.25) 4.44 · 10−9 296(9.473, 3.517, -4.10, 1.883) 10−5 · (0.10, 0.18, 0.85, 1.85) 2.65 · 10−9 359
Tablica 4.1: 10 pokusa Nelder-Mead algoritma
S druge strane, genetski algoritam nam moze garantirati vecu vjerojatnost prona-
laska globalnog minimuma ali uz znatno vise iteracija. Pocetna populacija startPop
sastoji se od 80 jedinki slucajno generiranih unutar intervala [−5, 10], te se u 100000
generacija primjenjuje geometrijska sortirajuca selekcija s vjerojatnoscu 0.08 za odabir
najbolje jedinke. Koristimo heuristicko krizanje koje primjenjujemo 2 puta u sva-
koj generaciji s ogranicenjem da ga na jednom paru jedinki roditelja primjenjujemo
najvise t = 3 puta i multi neuniformnu mutaciju koju primjenjujemo 6 puta u svakoj
generaciji s parametrom oblika b = 3. Ovakav pokus nam daje globalni minimum
x∗ = (1.0003, 1.0006, 1.0012, 1.0023) s vrijednoscu f(x∗) = −1.7985 · 10−6. Medutim,
potrebno je previse vremena za izvrsavanje ovakvog algoritma. U smislu poboljsanja,
genetski algoritam izvrsavamo 10 puta, neovisno jedan o drugom, sa maksimalnim bro-
jem generacija 100 ali uz primjenu mutacije koja se izvrsava 26 puta u svakoj generaciji.
Na taj nacin dopustamo algoritmu da brzo pretrazuje prostor rjesenja, te dobivamo
podatke prikazane u tablici 4.2.
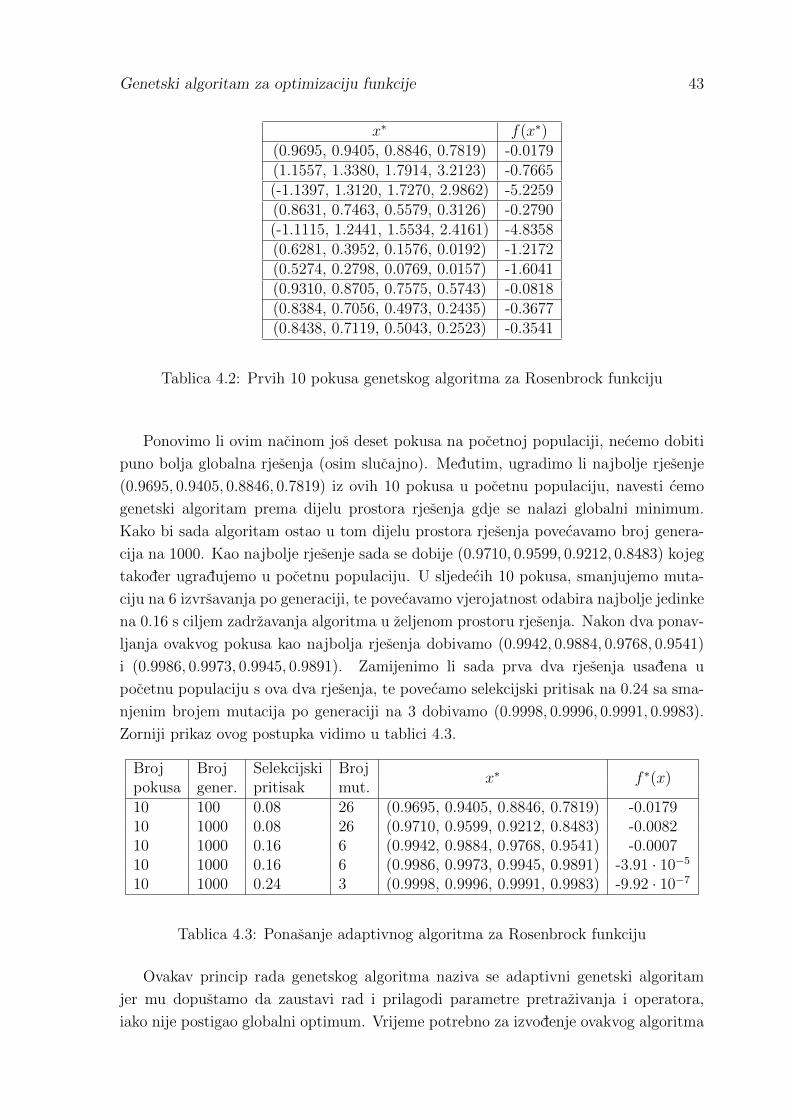
Genetski algoritam za optimizaciju funkcije 43
x∗ f(x∗)(0.9695, 0.9405, 0.8846, 0.7819) -0.0179(1.1557, 1.3380, 1.7914, 3.2123) -0.7665(-1.1397, 1.3120, 1.7270, 2.9862) -5.2259(0.8631, 0.7463, 0.5579, 0.3126) -0.2790(-1.1115, 1.2441, 1.5534, 2.4161) -4.8358(0.6281, 0.3952, 0.1576, 0.0192) -1.2172(0.5274, 0.2798, 0.0769, 0.0157) -1.6041(0.9310, 0.8705, 0.7575, 0.5743) -0.0818(0.8384, 0.7056, 0.4973, 0.2435) -0.3677(0.8438, 0.7119, 0.5043, 0.2523) -0.3541
Tablica 4.2: Prvih 10 pokusa genetskog algoritma za Rosenbrock funkciju
Ponovimo li ovim nacinom jos deset pokusa na pocetnoj populaciji, necemo dobiti
puno bolja globalna rjesenja (osim slucajno). Medutim, ugradimo li najbolje rjesenje
(0.9695, 0.9405, 0.8846, 0.7819) iz ovih 10 pokusa u pocetnu populaciju, navesti cemo
genetski algoritam prema dijelu prostora rjesenja gdje se nalazi globalni minimum.
Kako bi sada algoritam ostao u tom dijelu prostora rjesenja povecavamo broj genera-
cija na 1000. Kao najbolje rjesenje sada se dobije (0.9710, 0.9599, 0.9212, 0.8483) kojeg
takoder ugradujemo u pocetnu populaciju. U sljedecih 10 pokusa, smanjujemo muta-
ciju na 6 izvrsavanja po generaciji, te povecavamo vjerojatnost odabira najbolje jedinke
na 0.16 s ciljem zadrzavanja algoritma u zeljenom prostoru rjesenja. Nakon dva ponav-
ljanja ovakvog pokusa kao najbolja rjesenja dobivamo (0.9942, 0.9884, 0.9768, 0.9541)
i (0.9986, 0.9973, 0.9945, 0.9891). Zamijenimo li sada prva dva rjesenja usadena u
pocetnu populaciju s ova dva rjesenja, te povecamo selekcijski pritisak na 0.24 sa sma-
njenim brojem mutacija po generaciji na 3 dobivamo (0.9998, 0.9996, 0.9991, 0.9983).
Zorniji prikaz ovog postupka vidimo u tablici 4.3.
Broj Broj Selekcijski Brojx∗ f ∗(x)
pokusa gener. pritisak mut.10 100 0.08 26 (0.9695, 0.9405, 0.8846, 0.7819) -0.017910 1000 0.08 26 (0.9710, 0.9599, 0.9212, 0.8483) -0.008210 1000 0.16 6 (0.9942, 0.9884, 0.9768, 0.9541) -0.000710 1000 0.16 6 (0.9986, 0.9973, 0.9945, 0.9891) -3.91 · 10−5
10 1000 0.24 3 (0.9998, 0.9996, 0.9991, 0.9983) -9.92 · 10−7
Tablica 4.3: Ponasanje adaptivnog algoritma za Rosenbrock funkciju
Ovakav princip rada genetskog algoritma naziva se adaptivni genetski algoritam
jer mu dopustamo da zaustavi rad i prilagodi parametre pretrazivanja i operatora,
iako nije postigao globalni optimum. Vrijeme potrebno za izvodenje ovakvog algoritma
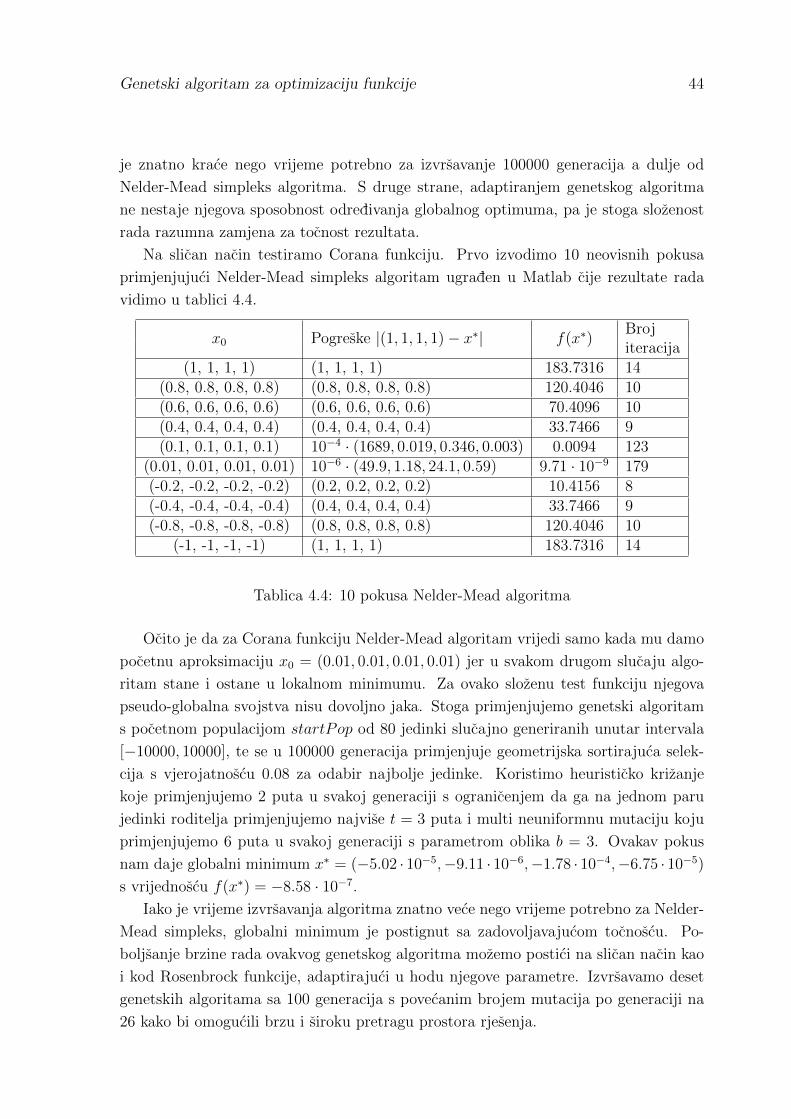
Genetski algoritam za optimizaciju funkcije 44
je znatno krace nego vrijeme potrebno za izvrsavanje 100000 generacija a dulje od
Nelder-Mead simpleks algoritma. S druge strane, adaptiranjem genetskog algoritma
ne nestaje njegova sposobnost odredivanja globalnog optimuma, pa je stoga slozenost
rada razumna zamjena za tocnost rezultata.
Na slican nacin testiramo Corana funkciju. Prvo izvodimo 10 neovisnih pokusa
primjenjujuci Nelder-Mead simpleks algoritam ugraden u Matlab cije rezultate rada
vidimo u tablici 4.4.
x0 Pogreske |(1, 1, 1, 1)− x∗| f(x∗)Brojiteracija
(1, 1, 1, 1) (1, 1, 1, 1) 183.7316 14(0.8, 0.8, 0.8, 0.8) (0.8, 0.8, 0.8, 0.8) 120.4046 10(0.6, 0.6, 0.6, 0.6) (0.6, 0.6, 0.6, 0.6) 70.4096 10(0.4, 0.4, 0.4, 0.4) (0.4, 0.4, 0.4, 0.4) 33.7466 9(0.1, 0.1, 0.1, 0.1) 10−4 · (1689, 0.019, 0.346, 0.003) 0.0094 123
(0.01, 0.01, 0.01, 0.01) 10−6 · (49.9, 1.18, 24.1, 0.59) 9.71 · 10−9 179(-0.2, -0.2, -0.2, -0.2) (0.2, 0.2, 0.2, 0.2) 10.4156 8(-0.4, -0.4, -0.4, -0.4) (0.4, 0.4, 0.4, 0.4) 33.7466 9(-0.8, -0.8, -0.8, -0.8) (0.8, 0.8, 0.8, 0.8) 120.4046 10
(-1, -1, -1, -1) (1, 1, 1, 1) 183.7316 14
Tablica 4.4: 10 pokusa Nelder-Mead algoritma
Ocito je da za Corana funkciju Nelder-Mead algoritam vrijedi samo kada mu damo
pocetnu aproksimaciju x0 = (0.01, 0.01, 0.01, 0.01) jer u svakom drugom slucaju algo-
ritam stane i ostane u lokalnom minimumu. Za ovako slozenu test funkciju njegova
pseudo-globalna svojstva nisu dovoljno jaka. Stoga primjenjujemo genetski algoritam
s pocetnom populacijom startPop od 80 jedinki slucajno generiranih unutar intervala
[−10000, 10000], te se u 100000 generacija primjenjuje geometrijska sortirajuca selek-
cija s vjerojatnoscu 0.08 za odabir najbolje jedinke. Koristimo heuristicko krizanje
koje primjenjujemo 2 puta u svakoj generaciji s ogranicenjem da ga na jednom paru
jedinki roditelja primjenjujemo najvise t = 3 puta i multi neuniformnu mutaciju koju
primjenjujemo 6 puta u svakoj generaciji s parametrom oblika b = 3. Ovakav pokus
nam daje globalni minimum x∗ = (−5.02 · 10−5,−9.11 · 10−6,−1.78 · 10−4,−6.75 · 10−5)
s vrijednoscu f(x∗) = −8.58 · 10−7.
Iako je vrijeme izvrsavanja algoritma znatno vece nego vrijeme potrebno za Nelder-
Mead simpleks, globalni minimum je postignut sa zadovoljavajucom tocnoscu. Po-
boljsanje brzine rada ovakvog genetskog algoritma mozemo postici na slican nacin kao
i kod Rosenbrock funkcije, adaptirajuci u hodu njegove parametre. Izvrsavamo deset
genetskih algoritama sa 100 generacija s povecanim brojem mutacija po generaciji na
26 kako bi omogucili brzu i siroku pretragu prostora rjesenja.
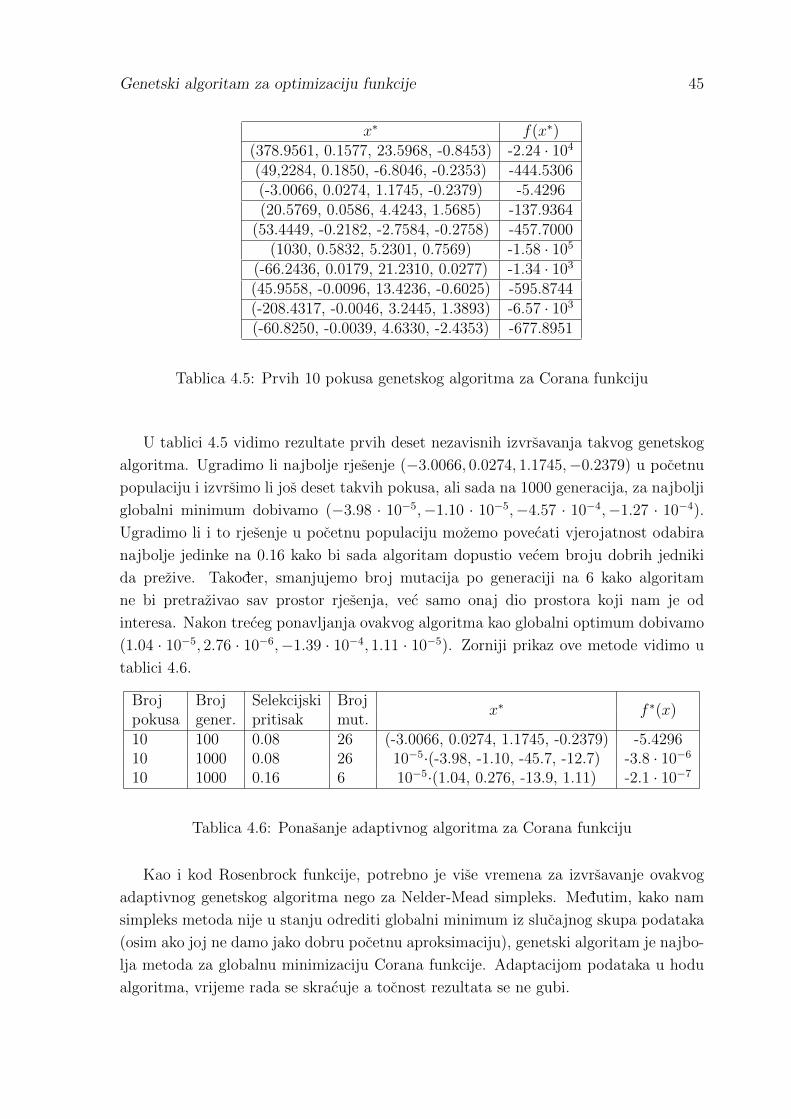
Genetski algoritam za optimizaciju funkcije 45
x∗ f(x∗)(378.9561, 0.1577, 23.5968, -0.8453) -2.24 · 104
(49,2284, 0.1850, -6.8046, -0.2353) -444.5306(-3.0066, 0.0274, 1.1745, -0.2379) -5.4296(20.5769, 0.0586, 4.4243, 1.5685) -137.9364
(53.4449, -0.2182, -2.7584, -0.2758) -457.7000(1030, 0.5832, 5.2301, 0.7569) -1.58 · 105
(-66.2436, 0.0179, 21.2310, 0.0277) -1.34 · 103
(45.9558, -0.0096, 13.4236, -0.6025) -595.8744(-208.4317, -0.0046, 3.2445, 1.3893) -6.57 · 103
(-60.8250, -0.0039, 4.6330, -2.4353) -677.8951
Tablica 4.5: Prvih 10 pokusa genetskog algoritma za Corana funkciju
U tablici 4.5 vidimo rezultate prvih deset nezavisnih izvrsavanja takvog genetskog
algoritma. Ugradimo li najbolje rjesenje (−3.0066, 0.0274, 1.1745,−0.2379) u pocetnu
populaciju i izvrsimo li jos deset takvih pokusa, ali sada na 1000 generacija, za najbolji
globalni minimum dobivamo (−3.98 · 10−5,−1.10 · 10−5,−4.57 · 10−4,−1.27 · 10−4).
Ugradimo li i to rjesenje u pocetnu populaciju mozemo povecati vjerojatnost odabira
najbolje jedinke na 0.16 kako bi sada algoritam dopustio vecem broju dobrih jedniki
da prezive. Takoder, smanjujemo broj mutacija po generaciji na 6 kako algoritam
ne bi pretrazivao sav prostor rjesenja, vec samo onaj dio prostora koji nam je od
interesa. Nakon treceg ponavljanja ovakvog algoritma kao globalni optimum dobivamo
(1.04 · 10−5, 2.76 · 10−6,−1.39 · 10−4, 1.11 · 10−5). Zorniji prikaz ove metode vidimo u
tablici 4.6.
Broj Broj Selekcijski Brojx∗ f ∗(x)
pokusa gener. pritisak mut.10 100 0.08 26 (-3.0066, 0.0274, 1.1745, -0.2379) -5.429610 1000 0.08 26 10−5·(-3.98, -1.10, -45.7, -12.7) -3.8 · 10−6
10 1000 0.16 6 10−5·(1.04, 0.276, -13.9, 1.11) -2.1 · 10−7
Tablica 4.6: Ponasanje adaptivnog algoritma za Corana funkciju
Kao i kod Rosenbrock funkcije, potrebno je vise vremena za izvrsavanje ovakvog
adaptivnog genetskog algoritma nego za Nelder-Mead simpleks. Medutim, kako nam
simpleks metoda nije u stanju odrediti globalni minimum iz slucajnog skupa podataka
(osim ako joj ne damo jako dobru pocetnu aproksimaciju), genetski algoritam je najbo-
lja metoda za globalnu minimizaciju Corana funkcije. Adaptacijom podataka u hodu
algoritma, vrijeme rada se skracuje a tocnost rezultata se ne gubi.

Literatura
[1] C. R. Houck, J. A. Joines, M. G. Kay: A Genetic Algorithm for Function
Optimization: A Matlab Implementation, Transactions on Mathematical Software,
22(1996), 1-14.
[2] T. Weise: Global Optimization Algorithms – Theory and Application, samostalno
objavljena na http://www.it-weise.de/projects/book.pdf, (26. 6. 2009.)
[3] P. Charbonneau: An introduction to genetic algorithms for numerical optimi-
zation, Atmospheric Research, 1(2002), 27-40
[4] R. Scitovski: Metode optimizacije - predavanja, Osijek, 2009.
[5] D. Whitley: A genetic algorithm tutorial, Statistic and Computing 4(1994),
65-85,
[6] Popis genetskih algoritama s primjenama
http://en.wikipedia.org/wiki/List of genetic algorithm applications (1.5.2012.)
[7] M. Golub: Genetski algoritam - skripta, Zagreb, 2010.
46

Sazetak
U ovom radu opisan je genetski algoritam za optimizaciju funkcije sa primjenom u
programskom paketu MATLAB.
U prvom poglavlju opisana je problematika optimizacije funkcije s naglaskom na
najcesce probleme i njihova rjesenja. Takoder su definirani osnovni pojmovi globalnih
optimizacijskih algoritama i njihove medusobne veze. Kroz primjere su opisane klase
funkcija za ciju optimizaciju nisu dovoljni klasicni algoritmi.
U drugom poglavlju se definira genetski algoritam kao metoda globalne optimizacije,
njegov nastanak i analogija s evolucijskim procesima. Navedeni su problemi koristenja
genetskih algoritama i rjesenja tih problema, te definirani su genetski operatori. Ovisno
o nacinu primjene, navedeni su primjeri za binarno i realno kodiranje rjesenja genetskih
algoritama, te jednodimenzionalnu i visedimenzionalnu optimizaciju.
U trecem poglavlju opisana je teorija na kojoj leze pretpostavke rada genetskih
algoritama, te je iskazan Holland-ov teorem sheme.
U cetvrtom poglavlju demonstrira se rad genetskog algoritma na testnim funkcijama
Corana i Rosenbrock, te se rezultati usporeduju s Nelder-Mead simpleks algoritmom za
optimizaciju funkcije. Dani su primjeri poboljsanja rada genetskih algoritama u smislu
procesorskog vremena, te tocnosti globalnog minimuma.
47

Summary
Genetic algorithm for function optimization
This paper describes the application of genetic algorithms using software package MA-
TLAB in global optimization.
The first chapter describes the most common problems of global optimization and
defines basic terms. We also explained on the examples different classes of function
problems for global optimization.
The second chapter defines genetic algorithm, his origin and evolution analogies. We
list problems for use of GA and solutions to these problems and define genetic operators.
Depending of the way we use GA, it describes binary vs. float number representation
and also gives examples for uni-modal and multi-modal function optimization.
The third chapter describes theory that gives meaning to use of GA.
The fourth chapter contains examples of GA use on Corana and Rosenbrock test
problems. It also compares performance of these GA examples with Nelder-Mead sim-
plex algorithm witch is part of MATLAB optimization functions. We give suggestions
how to improve GA performance in terms of processing time and calculating global
minimum.
48

Zivotopis
Ivan Kovacevic roden je 12.veljace.1985. godine u Nasicama, Republika Hrvatska. Os-
novnu skolu”Ivane Brlic - Mazuranic” u Koski zavrsava 1999. godine. Iste godine upi-
suje Prirodoslovno-matematicku gimnaziju u Nasicama. 2003. godine zavrsava srednju
skolu i upisuje se na prvu godinu studija na Sveucilistu J.J.Strossmayera, Odjel za
matematiku, smjer matematika i informatika, te 2005. godine prelazi na sveucilisni
nastvanicki studij matematike i informatike. Studij zavrsava 2012. godine.
49





























