Embed Size (px)
Citation preview

1
TERM Identification Tagging and Extraction TERMite is a semantic indexing engine that manages the ambiguity in naming of terms in scientific text. Analysing raw data at speeds of up to 1 Million words a second, free-text documents are converted into structured data enabling new discovery. With TERMite, your internal databases, reports and document management systems become part of a wider big data ecosystem facilitating business intelligence, hypothesis generation and identification of hidden trends and relationships. High-Quality Vocabularies High performance biomedical text analytics requires extensive ontologies covering all of
TERMite
2
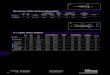
the synonyms and different forms of names for the same entity. Many existing solutions are supplied with poor quality ontologies, taken directly from public resources with minimal additional development. SciBite is different; we believe semantic text-analytics requires an exceptional foundation. Supporting the TERMite engine is a collection of more than 80 Vocabularies spanning the Life Sciences sector. These Vocabularies are enriched through a unique combination of automated analysis and expert manual curation and contain over 20 million synonyms. Many of our vocabularies are unique to SciBite. Others originate from public domain sources but are many times enriched. For example, our human phenotype vocabulary contains over 1.5 million phenotype terms, compared to about 40,000 available in the public domain.
Enhancing Semantic Search and Discovery DATA
SHEE
T

www.scibite.com @SciBite [email protected]
3
Scientifically Aware System While the speed and coverage of TERMite bring value to any organisation, it has additional capabilities to provide a more scientifically aware entity extraction solution. Ambiguity Detection; Knowing when “GSK” means “Glaxosmithkline” and not “Glycogen Synthase Kinase”, when “Pacific” means the biotechnology company and not the ocean and when “hedgehog” means the protein, not the spiky animal Relevance Detection; Distinguishing between terms that are “throwaway mentions” and those that really matter to the context of the document Pattern Detection; Able to identify patterns such as genes causing disease, toxicities of drugs, association of phenotypes with pathways and many more where they are grouped by type e.g. Protein or Indication. LIVE and Simple to Deploy Developed in Java, TERMite is a simple API which can be run either in the end-user interface or embedded into other applications opening up semantic text analytics to a much
4
wider audience. Setup is simple and can take just a few minutes. Use-Cases Existing customers are using TERMite to: • Datamine the entire Medline database
for gene-phenotype-disease correlations
• Analyse grants to discover new trends
• Scan internal documents to find
hidden target-drug-indication relationships
• Investigate disease genetics, biomarker
discovery, drug repurposing, drug toxicity,
competitor intelligence and much more About SciBite SciBite provides a flexible environment for semantic text analytics and data intelligence for Biopharma, Biotech & beyond through a collection of applications, platforms and web services. Built on an entity identification and extract engine, SciBite’s capabilities can unlock the value often missed in raw text. From instant annotation of simple documents through to the indexing of enterprise search systems, contact us now to find out how we can help you get more from your data.
Enriched Vocabularies Powering TERMite


























![Rayap...ssst..terminix aja [design visual termite control]](https://img.pdfslide.tips/doc/110x75/5582a548d8b42a94688b54dc/rayapssstterminix-aja-design-visual-termite-control.jpg)
