Embed Size (px)
Citation preview

Trasowanie ( Routing)
�Protokoły wyznaczania tras (routingu) są kluczowe dla działania intersieci ( internet)
�W sieciach IP ( Internet) routery przekazują datagramy IP między routerami na ścieżce od źródła do przeznaczenia
�Router powinien mieć wiedzę o topologii intersieci
�Protokoły routingu muszą dostarczać i przekazywać te informacje

Zasady routingu w Internecie
�Routery otrzymują i przekazują datagramy IP (zazwyczaj w ramkach warstwy liniowej)
�Podejmują decyzje o trasach w oparciu o swoją wiedzę o topologii i warunkach w Sieci
�Decyzje powinny opierać się na kryteriach minimalizacji kosztów�Co może być kosztem ?
�Stały Routing�Pojedyncza stała trasa skonfigurowana dla każdej
pary źródło - przeznaczenie�Stałe trasy

Przykład konfiguracji

Tablice routingu
�W przykładzie (poprzedni slajd)�5 sieci, 8 routerów�Koszt łącza dla wyjścia dla każdego routera�Każdy router ma tablicę trasowania (routing table )
� Routing Table�Wymagana dla każdego routera�Wpis dla każdej sieci
⌧Ale nie dla każdego przeznaczenia⌧Routing wymaga tylko części sieci
�Datagram docierający do routera w sieci przeznaczenia może przekazać go do hosta
�Adres IP address typowo zawiera część sieci i hosta (lub w kombinacji z maska sieci)
�Każdy wpis pokazuje następny węzeł na drodze do przeznaczenia⌧Ale nie całą trasę

Tablice routingu w hostach
�Mogą też występować w hostach i występują�/sbin/route lub inne komendy pokazujące tablice
routingu jądra
�Przy przyłączeniu hosta do pojedynczej sieci z jednym routerem tablica jest prosta i zawiera tylko część sieci lokalnej ( ale niekoniecznie) i wskazanie na router jako bramę ( gateway) ⌧Cały ruch musi przejść przez ten router ( gateway)
�Jeśli routerów jest kilka host wymaga tablicy wskazującej który z routerów powinien być użyty dla danego datagramu ( adres IP przeznaczenia)

Przykłady tablic routingu

Czyli routing to :
�Trasowanie – kierowanie pakietów od źródła do przeznaczenia�Często wymaga przejścia przez wiele wezłów -
przeskoki ( hops)
�W węzlach ( routerach) kierowanie pakietu w takie miejsce, które jest bliżej miejsca przeznaczenia (lub tak uważa dany router na podstawie swojej tablicy tras)�Sieci datagramowe
�Wirtualne obwody – virtual circuits - VCs

Porównanie sieci
datagramowych i obwodów
Łatwa, ale potrzebne wcześniejsza alokacja buforów dla każdego VC
TrudnaKontrola zatorów
Zakończenie wszystkich VC przechodzących przez router
Praktycznie żaden, utrata pakietów w trakcie awarii
Efekt awarii routera
Trasa ustalana podczas zestawiania VC
Każdy pakiet kierowany niezależnie
Trasowanie
WymaganaNiekoniecznaZnajomość sieci
Każdy pakiet zawiera krótki numer VC
Każdy pakiet zawiera pełny adres źródła i przeznaczenia
Adresowanie
WymaganeNie potrzebnePołączenie
Virtual circuitDatagram Zagadnienie

Efekt zatoru
Brak kontroli
�Routing powinien radzić
z przeciążeniem sieci

Mechanizmy kontroli zatorów

Zasady zapobiegania przeciążeniom
� Transportowa� Zasady retransmisji� Buforowania niezgodnie z kolejnością� Zasady potwierdzeń� Sterowania przesyłem�Ustalania limitów czasowych
� Warstwa sieciowa�Wybór obwodów wirtualnych lub sieci datagramowych � Zasady usług i kolejkowania� Zasady odrzucania pakietów ( zrzut obciążenia)
⌧Np. RED – Random Early Detection -
� Algorytmy routingu� Zarządzanie czasem życia pakietów
� Warstwa liniowa� Zasady retransmisji� Zasady buforowania niezgodne z kolejnością� Zasady potwierdzeń� Zasady sterowania przepływem

Cechy algorytmu rutującego
�Optymalność�Też efektywność vs „sprawiedliwość”
�Prostota i małe obciążenie zasobów
�Odporność i stabilność�Reakcja na zmiany topologii i ruchu – bez
angażowania wszystkich hostów sieci
�Szybka zbieżność – ustalenie właściwych dróg trasowania

Podstawowy podział rutowania
� Rutowanie statyczne ( nieadaptacyjne)� Rutowanie dynamiczne (adaptacyjne)
� Rutowanie wg reguł (policy routing)�W IP według adresu źródłowego + warunki dodatkowe
�Wewnątrzdomenowe i międzydomenowe� Ponadto:
�Routing hierarchiczny – np. AS�Routing dla mobilnych hostów
⌧home & foreign agents⌧Gratuitous ARP – przełączanie tablic arp na HA / host
�Routing broadcastowy i multicastowy – ruchu do wielu hostów jednocześnie

Rutowanie Statyczne
�Trasy ustalane w momencie załadowania pamięci routerów
�Najszybsze�Ze względu na wydajność rutera
�Ze względu na obciążenie sieci
�Wymaga „ręcznej” konfiguracji�Lub wczytania tablicy tras
�Nie jest odporne na awarie

Rutowanie dynamiczne
� Zmienne – zależne od stanu sieci (topologia, ruch)� Tablice rutowania budowane są w oparciu o informacje
płynące od sąsiadów �Tylko od sąsiadów ? Zawsze ?�Kto jest sąsiadem ?
�W przypadku awarii dokonuje się automatyczna rekonfiguracja tablic rutowania�Co rozumiemy pod pojęciem awaria ?
�W przypadku zmian stopnia obciążenia sieci możliwa jest�Rekonfiguracja sieci�Równoważenie obciążenia

Wady rutowania dynamicznego� Złożone algorytmy wymagające znacznej mocy obliczeniowej� Zwiększenie ruchu w sieci – wymiana informacji
�Np. wymiana BGP – tablice ok. 60-80 MB to wymaga pasma ok. 128 kbs� Jeżeli odpowiedź na zmianę metryki (topologii) następuje zbyt wolno –
występują długie okresy niedziałania sieci, zbyt szybko oscylacje� Tworzą się patologie takie jak:
�Fluttering - oscylacje⌧Szybkie oscylacje w rutowaniu⌧Np. przy próbach równoważenia obciążenia⌧Jeżeli pojawia się tylko w jednym kierunku, to charakterystyka ruchu w obie strony
się różni, co generuje problemy w niektórych aplikacjach (np. NTP)⌧Problemy z wykorzystaniem czasów RTT ( duża zmienność) do obliczeń RTO
(czasów retransmisji segmentów)⌧Dostarczanie datagramów TCP w innym porządku, co z kolei generuje retransmisje
i niepotrzebne „zapychanie” łącz
�Zapętlenia⌧Jeżeli pewien pakiet w podróży do celu powtórnie odwiedzi ten sam ruter,
tzn., że wystąpiła pętla⌧Pakiet albo nigdy nie dotrze do celu albo dotrze z dużym opóźnieniem

Zasada optymalności
(a) Sieć routerów (b) Odwrócone drzewo dla routera B.

Systemy autonomiczne� System pod wspólnym zarządem, w którym występują takie same zasady
rutowania� Protokoły „wymarłe”
� GGP ( Gateway to Gateway Protocol) – wymiana informacji między routerami podstawoywmi
� EGP ( Exterior Gateway Protocol ) – jak w. Routery zewnętrzne� IGP ( Interior Gateway Protocol ) – protokoły dla routerów wewnętrznych� Hello – protokół typu IGP (jak i RIP ) – bazujący na opóźnieniach w sieci
� IRP ( Interior Routing Protocol )– algorytmy rutowania wewnątrz systemu autonomicznego� Algorytmy odległości wektorowej (Distance-Vector)
⌧ RIP ( Routing Information Protocol)� Algorytmy stanu łącza
⌧ OSPF ( Open Short Path First)� Algorytmy hybrydowe
⌧ IGRP, EIGRP , ( Enhanced Interior Gateway Protocol) - Cisco
� ERP ( Exterior Routing Protocol )– algorytmy rutowania pomiędzy systemami autonomicznymi� BGP ( Border Gateway Protocol )� IDRP ( Interdomain Routing Protocol)

Algorytmy routingu
�SPF – shortest path routing
�Flooding - zalewanie
�Flow based routing –
�DV – distance vector�Bellman-Ford, Ford-Fulkerson
�Algorytm w ARPANET – RIP
�Link State Routing – LS�W Arpanet od 1979
�OSPF , IS-IS
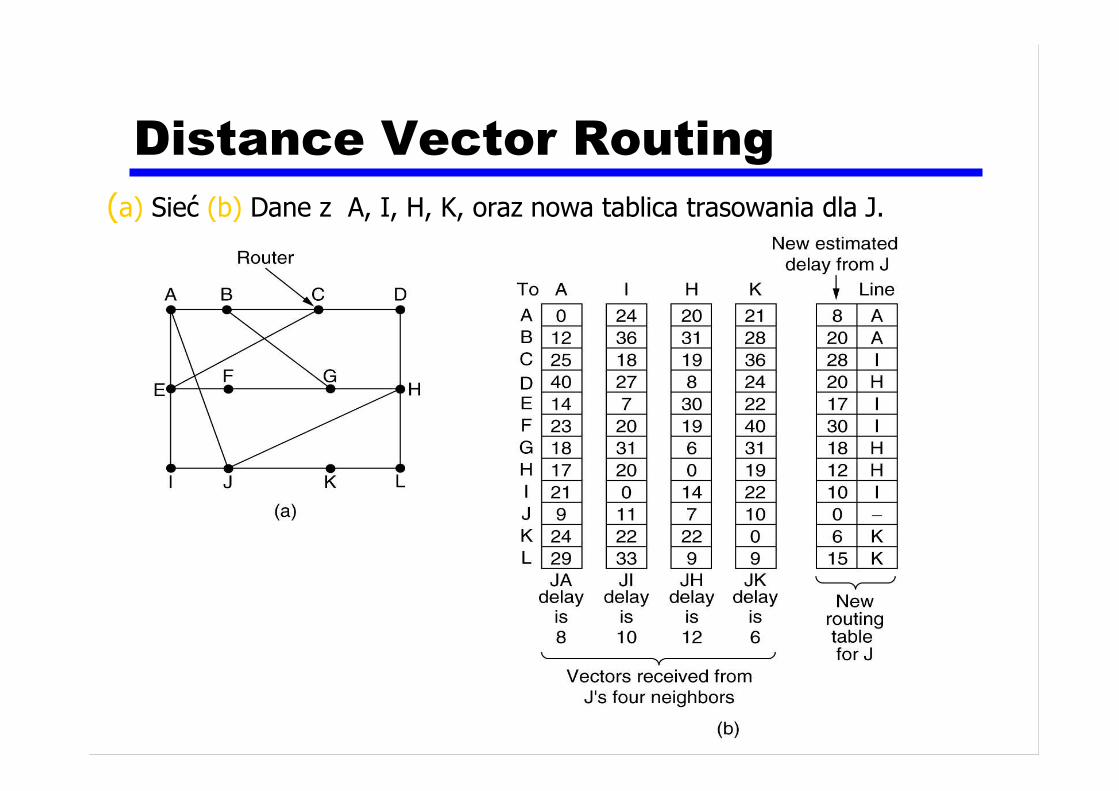
Distance Vector Routing
(a) Sieć (b) Dane z A, I, H, K, oraz nowa tablica trasowania dla J.

RIP
�Algorytm opiera się na adresach klasowych�RIP ver. 2 wspiera maski
�Podstawową metryką jest ilość ruterów pośredniczących w wymianie datagramów�Ale można danemu połączeniu zmienić metrykę
�Posługują się rozproszonym algorytmem BF
�W zasadzie zakłada równe obciążenie wszystkich łączy

RIP – zasada działania� Co ok. 30s każdy ruter wysyła do swoich sąsiadów informację o
znanych sobie kosztach połączeń do poszczególnych sieci� Ver 1 � UDP� Ver 2 � Multicast
� Po odebraniu tej informacji, � Jeśli dotychczas dany ruter nie znał trasy do tej sieci to wpisuje ją do
swojej tablicy rutingu z metryką większą o 1� Jeśli taka trasa już była, to jeśli odebrana metryka (+1) jest lepsza od
poprzedniej to zastępuje ją.� Jeśli metryka jest taka sama, to ruter używa wszystkich tras o tej
samej metryce

Ramka RIP
Format ramki protokołu RIP
komenda (1 oktet) wersja (1 oktet) musi być zero (2 oktety)
identyfikator rodziny adresów (2 oktety) musi być zero (2 oktety)
adres IP (4 oktety)
musi być zero (4 oktety)
musi być zero (4 oktety)
metryka (4 oktety)
. . . . .

Format ramki RIP

Reakcja na zmiany topologii
�Jak rozległy może być AS stosujący algorytm RIP?�W przypadku powstania pętli mogłyby powstawać
metryki rzędu milionów
�Dlatego przyjęto arbitralnie, że „∞=16”
�Jeżeli metryka do danej sieci osiągnie 16, to oznacza to, że trasa jest niedostępna

Distance Vector Routing (2)
The count-to-infinity problem.

Reakcja na zmiany topologii
� Zasada podzielonego horyzontu „Split-Horizon”�Nie wysyłać aktualizacji w tę stronę, z której ją otrzymano
�Split Horizon a bardziej złożone topologie ( zamknięte)
� Zasada wstecznego zatruwania „Poisoned Reverse”�Wysyłać takie aktualizacje z metryką 16
�Szybsza zbieżność, szczególnie w przypadku większych pętli
� Holddown timer�Przez 3 * czas aktualizacji nie przyjmowane są „gorsze” trasy
� Też split horizon z zatruwaniem :�Zawsze wysyłanie informacji o metryce 16 w kierunku danej
sieci

Flooding
� Każdy ruter wysyła informację na każdy swój interfejs� Każdy sąsiad retransmituje tę informację na wszystkie swoje
interfejsy (z wyjątkiem tego, z którego dotarł)�Liczba pakietów rośnie wykładniczo w nieskończoność�Aby tego uniknąć rutery rozpoznają czy dany pakiet jest powtórzony i
jeśli tak to go kasują
� Selektywny flooding – tylko w „kierunku” przeznaczenia� Flooding – Cechy
�Wszystkie trasy pomiędzy danym ruterem a każdym innym są wypróbowane⌧SPF jest bardzo odporny
�Ponieważ wszystkie trasy są wypróbowane, przynajmniej jedna jestnajlepsza
�Informacja szybko osiągnie wszystkie rutery�Wszystkie węzły były odwiedzone�Wada – bardzo duży ruch w sieci w czasie inicjalizacji

Open Shortest Path First (OSPF)
� Ograniczenia RIP w dużych sieciach� OSPF jest preferowanym protokołem w sieciach TCP/IP do
wewnętrznego routingu IRP� Stosuje algorytm stanu łącza LS (Link state)� Link State Routing
�W czasie startu, router określa koszt łącza na każdym interfejsie�Router ogłasza te koszty do wszystkich routerów�Router monitoruje te koszty
⌧Jeśli się zmieniają, są ponownie rozgłaszane
�Każdy router konstruuje topologię i oblicza najkrótszą ścieżkę do każdej sieci przeznaczenia
�Brak dystrybucji algorytmów�Można używać dowolnego
⌧Algorytm Dijkstry najpopularniejszy

Flooding – jako metoda w LS� Pakiety są wysyłane przez router do każdego sąsiada
� Przychodzący pakiet jest przesyłany na każde wyjście z wyjątkiemźródłowego
� Duplikaty są usuwane w celu uniknięcia zbędnego ruchu
� Wszystkie możliwe trasy zostaną wypróbowane, pakiet przejdzie jeśli tylko droga istnieje� Pewne
� Co najmniej jeden pakiet przejdzie trasę o minimalnym opóźnieniu�Wszystkie routery zostaną szybko osiągnięte
� Wszystkie węzły połączone ze źródłem zostaną odwiedzone�Wszystkie routery dostaną informacje do zbudowania tablic routingu
� Duże obciążenie ruchem

Przykład zalewanie (Flooding)

OSPF � Routery zarządzają opisem stanu lokalnych łączy� Przekazują zaktualizowane informacje do wszytkich znanych
sobie routerów� Router otrzymujący aktualizację musi ją potwierdzić
�Generuje to dużo ruchu�Każdy router zarządza swoją bazą danych ( tablicą)
� OSPF �Protokół bezpośrednio nad IP - nr 89�Może używać też adresów grupowych – TTL w IP =1
⌧Grupa multicast All_SPF_Routers (224.0.0.5)⌧Grupa multicast All_D_Routers (224.0.0.6)
�Bez numerów portów – ale typy pakietów OSPF• Hello• Opis Bazy• Żądanie informacji o łączy• Odpowiedź – uaktualnienia• Potwierdzenia odbioru uaktualnień

Przykładowy
System
Autonomiczny ( AS)

Wynikowy
Graf
� Z kosztami łączy
� Czasem niesymetryczne

Koszty łączy
�Koszt każdego skoku w każdym kierunku jest zwany metryką routingu
�OSPF stosuje elastyczny system metryk oparty na typie usług IP ( pole TOS)�Normal (TOS) 0 - normalny�Minimize monetary cost (TOS 2) – koszty pieniężne�Maximize reliability (TOS 4) - pewność�Maximize throughput (TOS 8) -przepustowość�Minimize delay (TOS 16) - opoźnienie
�Każdy router generuje 5 spinających drzew ( spanning trees) i 5 tablic routingu

Drzewo SPF
dla
Routera 6

Format pakietu OSPF

Pola pakietu OSPF
� Numer wersji – obecnie 2� Typ: od 1 do 5 p. niżej� Długość pakietu: w oktetach łącznie z nagłówkiem� ID Routera: 32 bit – źródło pakietu � Area id: Obszar do którego należy źródłowy router� Authentication type: bez (0) , proste hasło lub szyfrowanie� Authentication data: używana przez procedure autentykacji � Typy pakietów OSPF
�Hello: used in neighbor discovery�Database description: Defines set of link state information present in
each router’s database�Link state request�Link state update�Link state acknowledgement

OSPF - obszary
� Pojedynczy obszar OSPF dostosowany jest do mniej więcej 50 ruterów
� Jeśli ruterów jest więcej trzeba podzielić dany AS � Operacje obszarów
�Każdy uruchamia osobną kopie algorytmu LS⌧Baza danych topologii tylko danego obszaru⌧Informacje o stanach łącza rozgłaszane do innych routerów
obszaru⌧Zmniejszenie ruchu ⌧Routing między obszarowy polega na lokalnych informacjach o
stanie łączy
� Rutery które należą do kilku obszarów AS nazywane są ruterami szkieletowymi (wewnątrz AS)�Czasami mówi się, że nie należą do żadnego obszaru (area 0)
�Wiele ruterów w sieci LAN –� Rutery desygnowane

Porównanie algorytmów
�W stabilnych warunkach wynik działania algorytmu jest zawsze taki sam
�W algorytmie BF trzeba znać tylko koszt połączenia do sąsiada i koszty dostępu od sąsiada
�W algorytmie Dijkstry (LS) potrzebna jest znajomość całej topologii sieci�Uaktualnienia gdy zmiana topologii, zawierają koszt scieżki
�W przypadku gdy zmienia się koszt połączenia, który zależy m.in. od obciążenia, ze względu na sprzężenie zwrotne algorytm może okazać się niestabilny�Na tego typu niestabilność bardziej narażony jest algorytm BF
� Algorytm BF wymaga znacząco mniejszych mocy obliczeniowych, pamięci.�W dużych sieciach związany jest ze zwiększonym ruchem�Informacja wysyłana regularnie

BGP�Najpowszechniej stosowany ruting EGP�BGP Border Gateway Protocol�Tranzyt przez systemy autonomiczne AS
� Dlaczego algorytmy DV, LS nie nadają się do EGP�Zarówno algorytmy DV, jak i LS żądają, żeby była używana ta sama
metryka w całej sieci⌧Jeśli metryka jest różna, to zbudowanie poprawnej sieci jest wyzwaniem
�Nie ma możliwości zablokowania ruchu pewnego rodzaju�Rozpiętość sieci jest zbyt duża
⌧Dla LS zbyt wielkie drzewa⌧Dla DV zbyt duże metryki odległości
�Modyfikacja Distance-Vector � Path-Vector�Z każdego rutera istnieje pełna ścieżka do każdego AS, który może
osiągnąć�Tablice rutowania są dziś rzędu 70-80MB�Ponieważ znana jest ścieżka, to można wprowadzić reguły rutowania

Format
Wiadomości BGP
�Marker:�Zarezerwowany dla
autentykacji
�Length:�W oktetach
�Typ:�Open
�Update
�Keepalive
�Notification

Reguły rutowania
� Policy routing�Nie przepuszczaj pakietów przez niektóre AS
�Nie używaj tras w USA jeżeli źródło i cel pakietu znajduje się wKanadzie
�Przepuszczaj przez Albanię tylko jeśli inaczej nie można
�Komunikacja pomiędzy oddziałami Sun nigdy nie przechodzi przez sieć Microsoft ☺
�TPSA blokuje polskie AS-y jeśli wchodzą z zagranicy !!
� Oparte najczęściej na adresach źródłowych�Ale też czasem na protokołach czy wręcz usługach (portach)
⌧Nie mylić routingu (wybór trasy – interfejsu), z klasą usług (kolejkowanie ), czy kształtowaniem ruchu (traffic control, shaping)

Trasowanie – podsumowanie
�Współpraca pomiędzy algorytmami i protokołami�Demony gated (RIP, BGP, OSPF) , routed (RIP)
� Routing bezklasowy�VLSM – Variable-length subnet masking �Protokoły wspierające VLSM – RIPv2, OSPF, BGP, EIGRP
� Obsługa masek sieci (podsieci i nadsieci)�Co robić przy tych samych sieciach a różnych maskach ?
⌧Przeglądać tablice tras zaczynając od najdłuższych masek (najmniejsze sieci )
�Wymiana informacji pomiędzy fragmentami sieci używającymi różnych protokołów rutowania
� Policy routing�Rutowanie po adresach źródłowych

Protokoły OSI
� End System-to-Intermediate System (ES-IS)�Raczej odkrywanie jakie rutery sąsiadują z hostem
�Pierwowzór protokołów takich jak HSRP czy RDP, ICMP Redirect
� Intermediate System-to-Intermediate Systems (IS-IS)
� Interdomain Routing Protocol (IDRP)�Następca BGP (Wraz z IPv6)
�Zhierarchizowane BGP
�AS łączy się w konfederacje
�Te konfederacje w konfederacje wyższego rzędu
�W danej konfederacji stosowany jest ruting typu Path-Vector
�Doskonale dostosowany do MPLS

Mobile IP
�Jak zrobić, żeby komputer z tym samym oprogramowaniem działał w różnych sieciach?
�DHCP nie jest tu rozwiązaniem ze względu na zmianę adresu IP
�Zmiana miejsca pobytu ma być przezroczysta dla oprogramowania hosta
�Zmiany tablic rutingu w ruterze są wykuczone
�Jeśli host jest „u siebie” nie wiąże się to z żadnym nadmiarowym ruchem

Mobile IP
�Tunelowanie –�Home i Foreign Agent
�IP w IP
�Bezpieczeństwo – weryfikacja i szyfrowanie połączenia
�Na bazie proxy ARP :�Ruter (Home Agent) „w domu” odpowiada na
zapytania ARP swoim adresem � gratuitous ARP (dobrowolne?).
�Przekazuje pakiet w szyfrowanym tunelu do rutera (foreign agent), który aktualnie „opiekuje się” hostem

![PROJEKT Załącznik nr 1– Pismo wysyłane w … · Web view[prosimy o wypełnianie białych pól pod pytaniami w każdej kategorii]](https://img.pdfslide.tips/doc/110x75/5c651e9909d3f2876e8c323b/projekt-zalacznik-nr-1-pismo-wysylane-w-web-viewprosimy-o-wypelnianie.jpg)