Embed Size (px)
Citation preview

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
1 / 23
Uvod v SPSS
SPSS je kratica za Statistical package for Social Sciences. Zadnja verzija je 16.0.
Delovno okolje v SPSS-u je sestavljeno iz več oken: okna s podatki (data editor), okna z
rezultati (output) in sintakse. Hkrati imate lahko odprtih po več oken vsakega tipa, privzeta je
vedno zadnja odprta.1
Okno s podatki ima dva pogleda – pogled na podatke (data view) in pogled na spremenljivke
(variable view). Pogled na spremenljivke podaja opis spremenljivk: ime, tip (numerična,
opisna,…), oznako (label) spremenljivke, oznako vrednosti, manjkajoče vrednosti in format
zapisa.
Do vključno verzije 12 je veljalo, da imajo imena spremenljivk lahko največ osem znakov, od
verzije 13 pa so lahko imena tudi daljša. Še vedno pa velja, da se imena spremenljivk ne
morejo začeti s številko (čeprav lahko vsebujejo številke), omejeni pa smo tudi pri uporabi
posebnih znakov (dovoljeni so le »_«, »$« in od verzije 13 dalje tudi »@«). Šumnike lahko
uporabljate, jih pa ne priporočam.
Vaja: Ustvari dve novi spremenljivki, številsko in opisno. Dolo�i, naj 999 pomeni manjkajo�o vrednost.
Branje in izvoz podatkov
SPSS bere podatke v različnih formatih. Najpogostejša formata, s katerima se boste verjetno
srečali sta delimited text in Excelov format. S tabulatorji ali podpičji ločen tekst je verjetno
najpogostejši format za prenos podatkov med različnimi programi in sistemi. Tekst uvozite z
izbiro File | Open | Data in kot tip podatkov izberete tekst. Niz menijev vas vodi skozi proces
uvoza podatkov.
Uvoz iz Excelove datoteke (*.xls) poteka podobno. Novejše verzije SPSS-a berejo podatke iz
vseh verzij Excela, starejše so brale le do verzije 4.0 ali starejše.
Izvoz podatkov poteka na podoben način kot uvoz, izberete File | Save as in izberete želen tip
zapisa.
Izmenjave podatkov med SPSS-om in drugimi programi, npr. Excelom, lahko potekajo tudi
prek sistema kopiraj-prilepi.
Vaja: Uvozi podatke iz datoteke formata delimited text (data.txt) in iz excelove datoteke (data.xls).
1 Verzije SPSS-a do vklju�no verzije 13 imajo lahko odprtih ve� oken z rezultati in sintakso, a le eno s
podatki.
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
2 / 23
Koristne nastavitve v SPSS-u in okno Syntax Do sistemskih nastavitev SPSS-a pridemo z izbiro Edit | Options. Tu najdemo kar nekaj
listov, najpomembnejša sta General in Viewer. Na listu General nastavimo npr. dnevnik
(journal), ki sledi vsem našim ukazom. V listu Viewer nastavljamo prikaz rezultatov.
Sintakso uporabljamo za vpisovanje ukazov v programskem jeziku SPSS. V ve�ini primerov je to
hitrejši in u�inkovitejši na�in dela od dela prek menijev. Sintakse se najla�e nau�imo tako, da
jo najprej »prilepimo« iz menijev in jo nato popravljamo. Prilepimo jo lahko tudi iz dnevnika ali iz
izpisa, �e se nam tam izpisuje. Vodnik po sintaksi nam je v pomo� pri pisanju ukazov.
Vaja: Prilepi ukaz iz dnevnika v okno s sintakso.
Opisne mere
Opisne mere za spremenljivke lahko dobimo s pomo�jo dveh procedur, vgrajenih v SPSS. Prvo
dobimo z izbiro Analyze | Descriptive statistics | Desriptives. Vendar te procedure ne bomo
podrobno obravnavali, saj so v drugih zajete skoraj vse funkcije te procedure.2
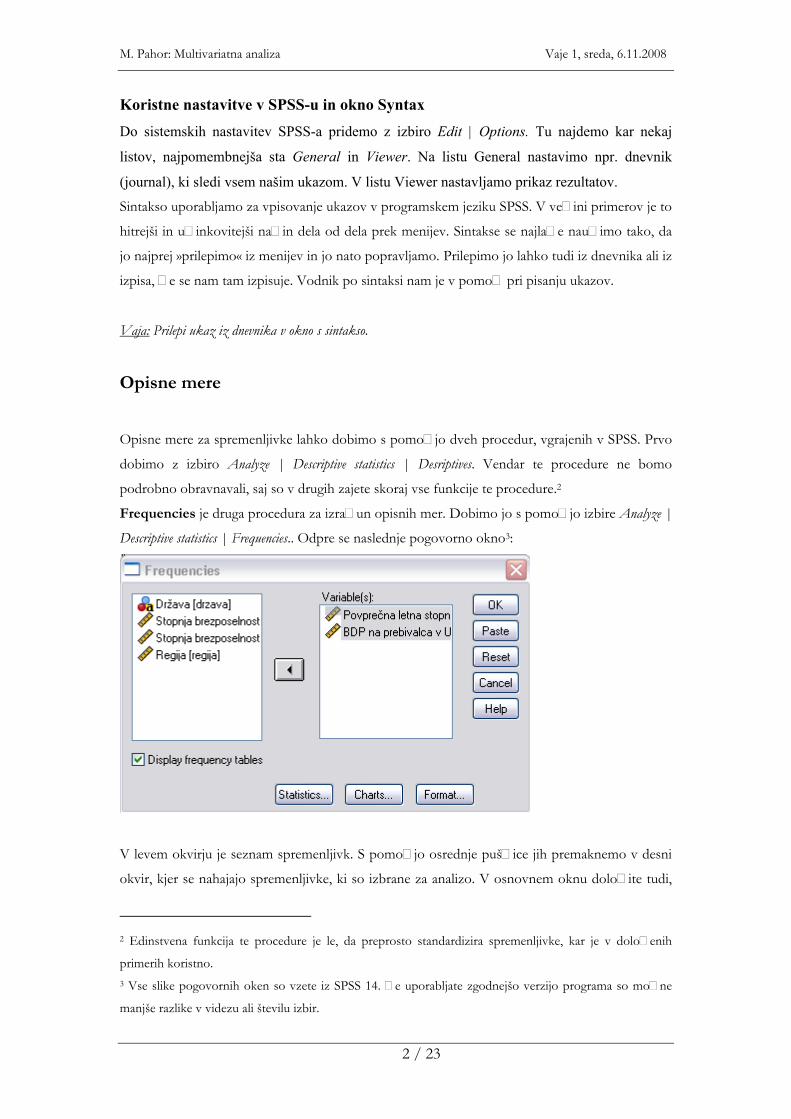
Frequencies je druga procedura za izra�un opisnih mer. Dobimo jo s pomo�jo izbire Analyze |
Descriptive statistics | Frequencies.. Odpre se naslednje pogovorno okno3:
V levem okvirju je seznam spremenljivk. S pomo�jo osrednje puš�ice jih premaknemo v desni
okvir, kjer se nahajajo spremenljivke, ki so izbrane za analizo. V osnovnem oknu dolo�ite tudi,
2 Edinstvena funkcija te procedure je le, da preprosto standardizira spremenljivke, kar je v dolo�enih
primerih koristno. 3 Vse slike pogovornih oken so vzete iz SPSS 14. �e uporabljate zgodnejšo verzijo programa so mo�ne
manjše razlike v videzu ali številu izbir.
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
3 / 23
ali naj se izpiše tabela frekven�ne porazdelitve (vse vrednosti spremenljivke in ustrezne
frekvence). To je smiselno le za spremenljivke z relativno malo vrednostmi (npr. do 20 razli�nih
vrednosti).
Izbira Format... vam prika�e okno, v katerem dolo�ite format izpisa.
Gumb Charts... vam da mo�nost izrisa grafikonov. Izbirate lahko med �rtnimi grafikoni in
torticami (oboje za absolutne in relativne frekvence) ter histogram, v katerega lahko (za vizuelno
primerjavo) vrišemo �rto normalne porazdelitve (z isto aritmeti�no sredino in standardnim
odklonom; to je smiselno le za intervalne ali razmernostne spremenljivke!!!!). V statisti�ne
namene se najpogosteje uporabljajo histogrami.
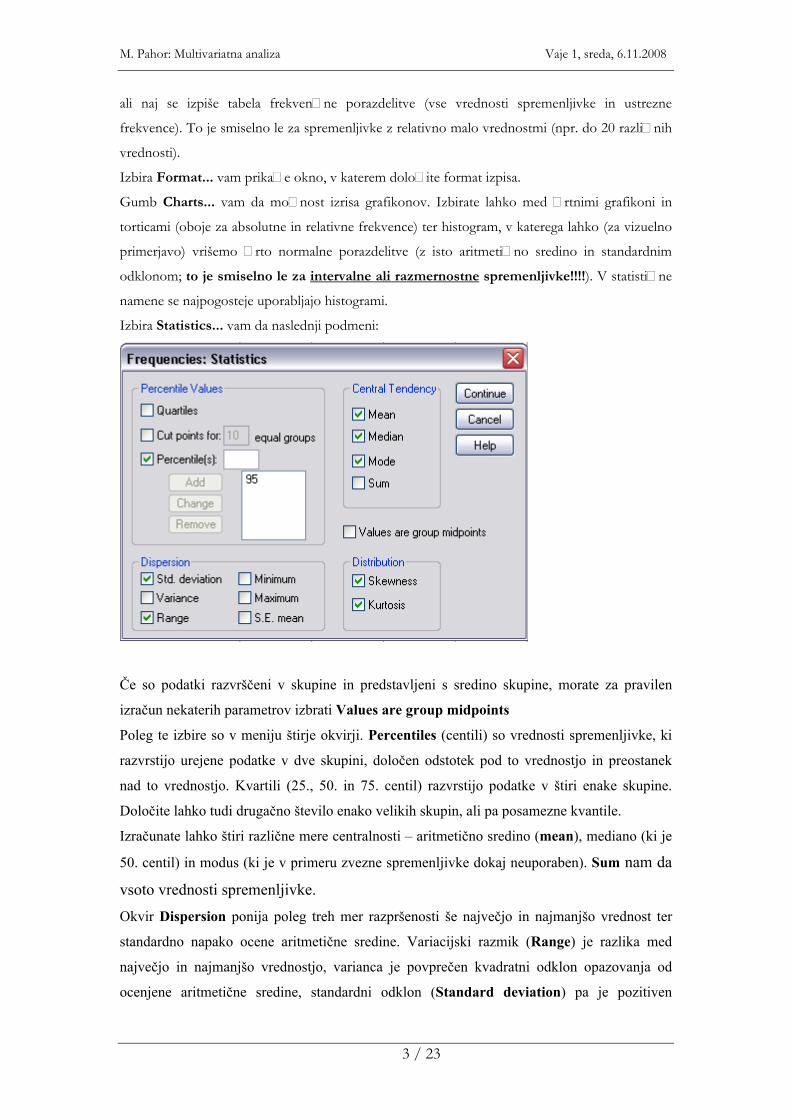
Izbira Statistics... vam da naslednji podmeni:
Če so podatki razvrščeni v skupine in predstavljeni s sredino skupine, morate za pravilen
izračun nekaterih parametrov izbrati Values are group midpoints
Poleg te izbire so v meniju štirje okvirji. Percentiles (centili) so vrednosti spremenljivke, ki
razvrstijo urejene podatke v dve skupini, določen odstotek pod to vrednostjo in preostanek
nad to vrednostjo. Kvartili (25., 50. in 75. centil) razvrstijo podatke v štiri enake skupine.
Določite lahko tudi drugačno število enako velikih skupin, ali pa posamezne kvantile.
Izračunate lahko štiri različne mere centralnosti – aritmetično sredino (mean), mediano (ki je
50. centil) in modus (ki je v primeru zvezne spremenljivke dokaj neuporaben). Sum nam da
vsoto vrednosti spremenljivke.
Okvir Dispersion ponija poleg treh mer razpršenosti še največjo in najmanjšo vrednost ter
standardno napako ocene aritmetične sredine. Variacijski razmik (Range) je razlika med
največjo in najmanjšo vrednostjo, varianca je povprečen kvadratni odklon opazovanja od
ocenjene aritmetične sredine, standardni odklon (Standard deviation) pa je pozitiven
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
4 / 23
kvadratni koren variance. Standardna napaka ocene aritmetične sredine (Standard error of
the mean) je izračunana kot
V okvirju Distribution najdemo dve meri, ki opisujejo porazdelitev. Obe primerjata dano
porazdelitev z normalno. Skewness je mera asimetrije. Simetrična distribucija ima vrednost 0,
pozitivna vrednost kaže asimetrijo v desno in negativna asimetrijo v levo. Kaj je kritična
vrednost je stvar okusa, večje od 1 je ponavadi precej asimetrično. Kurtosis je mera
sploščenosti. Normalna porazdelitev ima vrednost 0, pozitivno je bolj sploščeno, negativno pa
manj. Kritična vrednost je nekje okrog 3.
Vaja: Izračunaj kvartile, mere centralnosti, mere variabilnosti in mere porazdelitve za dve
spremenljivki iz baze.
Nekaj opisnih mer je mogo�e dobiti v okviru ve�ine SPSS-ovih procedur. Obi�ajno jih
pregledamo zato, da preverimo, ali podatki v grobem ustrezajo pri�akovanjem.
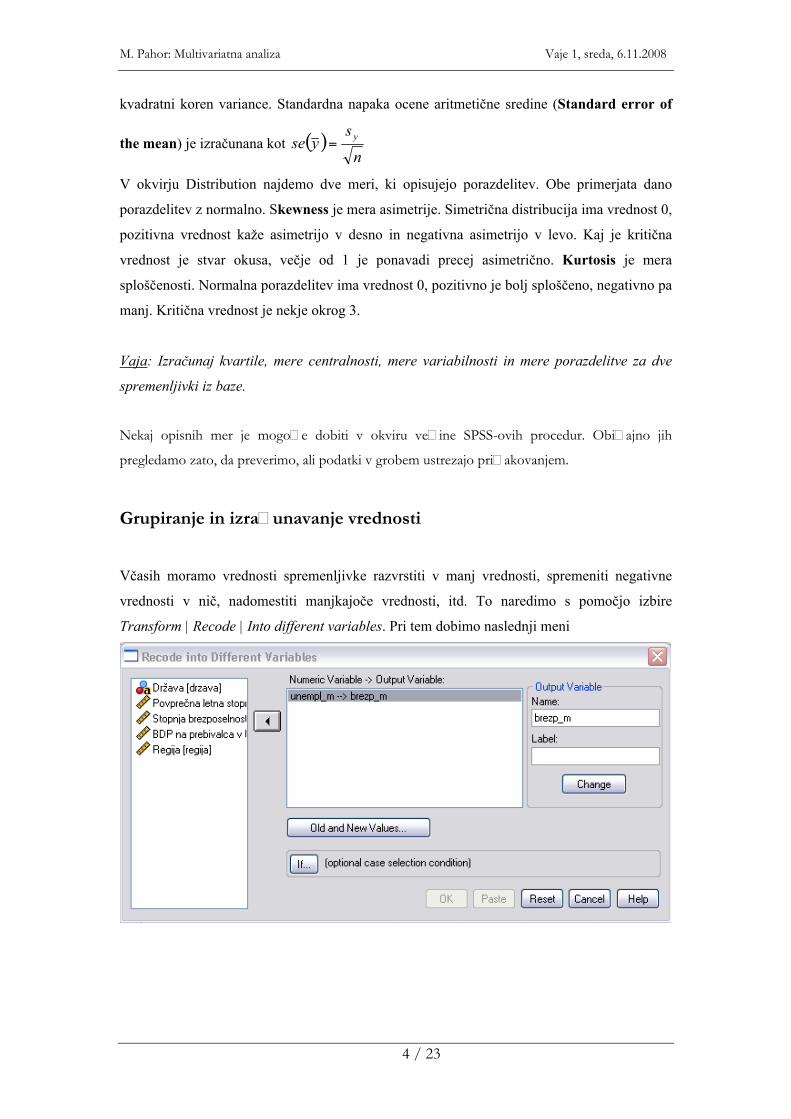
Grupiranje in izra�unavanje vrednosti
Včasih moramo vrednosti spremenljivke razvrstiti v manj vrednosti, spremeniti negativne
vrednosti v nič, nadomestiti manjkajoče vrednosti, itd. To naredimo s pomočjo izbire
Transform | Recode | Into different variables. Pri tem dobimo naslednji meni
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
5 / 23
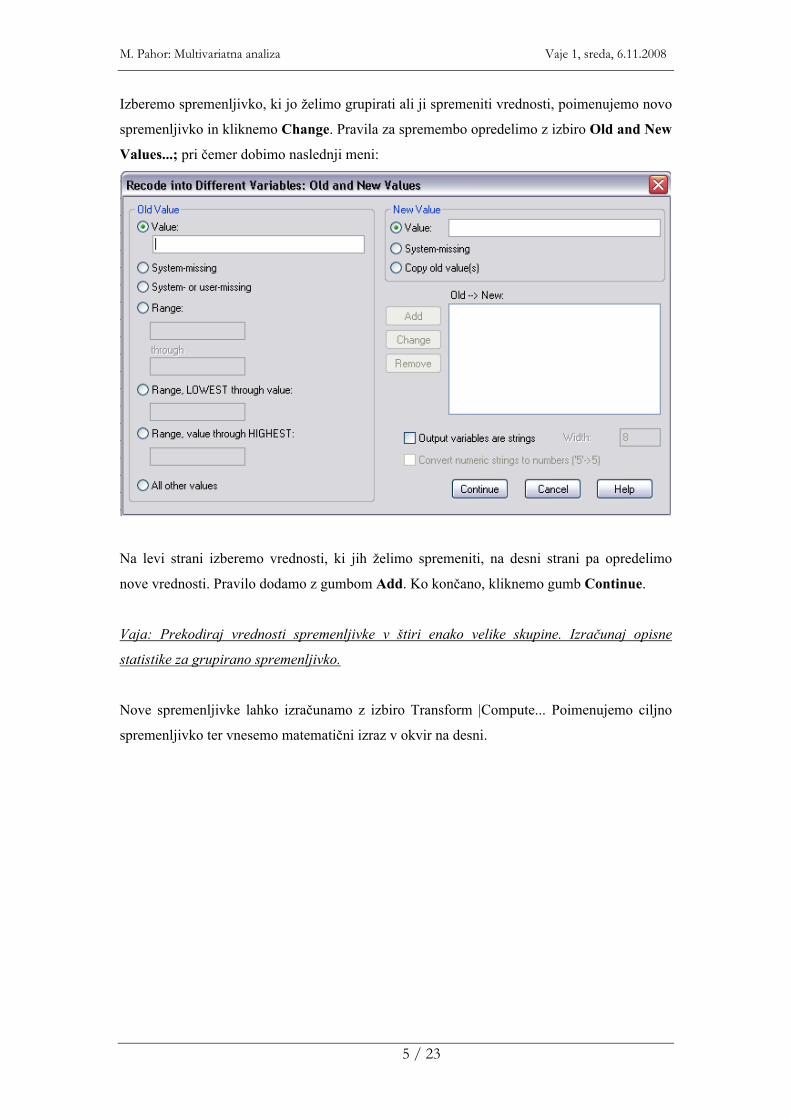
Izberemo spremenljivko, ki jo želimo grupirati ali ji spremeniti vrednosti, poimenujemo novo
spremenljivko in kliknemo Change. Pravila za spremembo opredelimo z izbiro Old and New
Values...; pri čemer dobimo naslednji meni:
Na levi strani izberemo vrednosti, ki jih želimo spremeniti, na desni strani pa opredelimo
nove vrednosti. Pravilo dodamo z gumbom Add. Ko končano, kliknemo gumb Continue.
Vaja: Prekodiraj vrednosti spremenljivke v štiri enako velike skupine. Izračunaj opisne
statistike za grupirano spremenljivko.
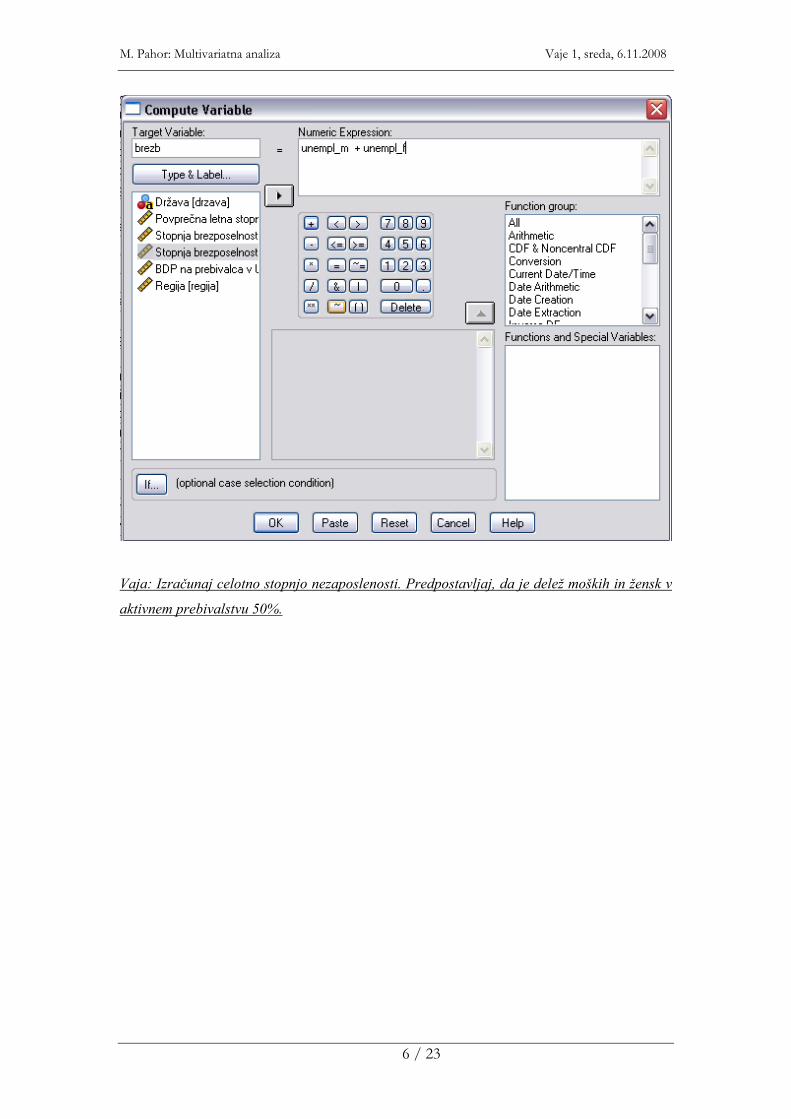
Nove spremenljivke lahko izračunamo z izbiro Transform |Compute... Poimenujemo ciljno
spremenljivko ter vnesemo matematični izraz v okvir na desni.
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
6 / 23
Vaja: Izračunaj celotno stopnjo nezaposlenosti. Predpostavljaj, da je delež moških in žensk v
aktivnem prebivalstvu 50%.

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
7 / 23
Preizkušanje domnev Pri preizkušanju domnev imamo opravka z dvema izključujočima domnevama: ničelno
domnevo H0 in alternativno domnevo H1. Običajno damo v alternativno domnevo to, kar nas
zanima oz. kar želimo dokazati, v ničelno domnevo pa ostalo (trenutno stanje).
Po uporabi ustreznega preizkusnega izraza dobimo neko stopnjo značilnosti, ki je v grobem
verjetnost za napako prve vrste. Če je ta manjša od neke izbrane mejne vrednosti (običajno
5%, lahko tudi več ali manj, odvisno od okoliščin) zavrnemo ničelno domnevo in sprejmemo
alternativno. Če je pa ta verjetnost večja od določene mejne vrednosti, preprosto ne zavrnemo
ničelne domneve, ne sprejemamo pa ničesar (v tem primeru v bistvu ne vemo ničesar, ker ne
poznamo verjetnosti za napako druge vrste).
Domneve so lahko enostranske ali dvostranske. Če v SPSS-u ni eksplicitno podano, da gre za
enostransko domnevo, potem je stopnja značilnosti večinoma izračunana tako, kot bi šlo za
dvostransko domnevo, obstajajo pa tudi izjeme. Stopnjo značilnost pri enostranski domnevi
dobimo preprosto tako, da stopnjo značilnosti dvostranskega preizkusa delimo z dva. Če
imamo teorijo o tem, na kateri strani porazdelitve bi morala biti značilnost, podamo
enostransko domnevo, če pa smo v dvomih, podamo dvostransko domnevo.
Preizkus domneve o eni aritmetični sredini - Pri vseh teh preizkusih je vprašljivo, ali so smiselni za take podatke (razmislite o tem)
- Pri preizkusu o eni aritmetični sredini gre za to, da imaš neko domnevo o tem, koliko
bi morala biti aritmetična sredina in preizkušaš, ali je res toliko
- Domneve H0: µ=µ0 ; H1: µ≠µ0
- Primer: Domnevamo, da šteje povprečno gospodinjstvo 4 člane. Preizkusimo to na
našem vzorcu. Stopnja značilnosti je nad 0,5, razlike niso značilne. To pomeni, da ni
razloga za trditev, da je število članov gospodinjstva v populaciji različno od 4.
- Izberemo Analyze | Compare means | One sample t-test

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
8 / 23
- Primer: Ali je povprečen GDPpc manjši od 7500$
- H0: µGDPpc=6500 ; H1: µGDPpc< 7500
- Preizkus je pokazal značilne razlike pri α=0,05 (enostranski preizkus)
T-TEST /TESTVAL = 7500 /MISSING = ANALYSIS /VARIABLES = gdppc /CRITERIA = CI(.95) .
T-Test
Preizkus domneve o razliki med aritmetičnima sredinama za odvisne vzorce
(preizkus dvojic) - Potrebno je najprej definirati, kaj pomeni odvisni vzorec. To pomeni, da gre za iste
enote, pri katerih merimo isto stvar v dveh različnih situacijah. Tipičen primer
odvisnega vzorca je kaka panelna raziskava.
- Domneve H0: µd=0 ; H1: µd≠0
- Preizkus dvojic je lahko zanimiv in koristen, njegova uporaba je velikokrat vprašljiv
- Izberemo Analyze | Compare means | Paired samples t-test
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
9 / 23
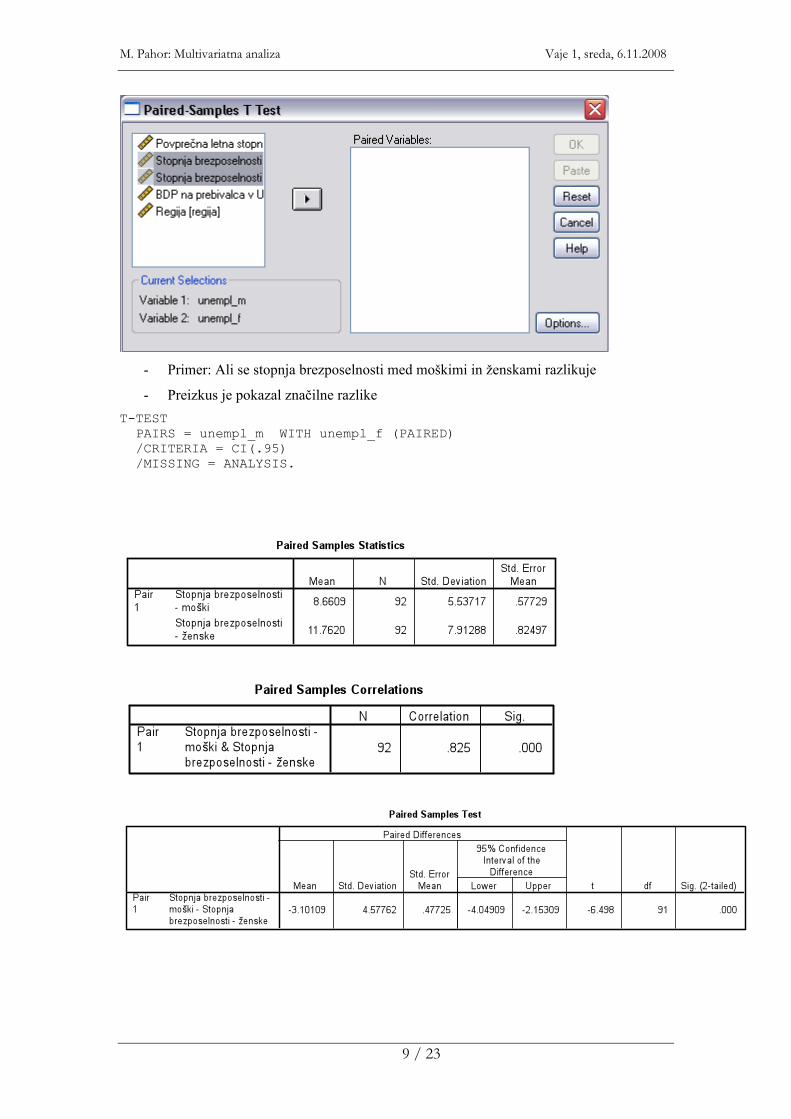
- Primer: Ali se stopnja brezposelnosti med moškimi in ženskami razlikuje
- Preizkus je pokazal značilne razlike T-TEST PAIRS = unempl_m WITH unempl_f (PAIRED) /CRITERIA = CI(.95) /MISSING = ANALYSIS.
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
10 / 23
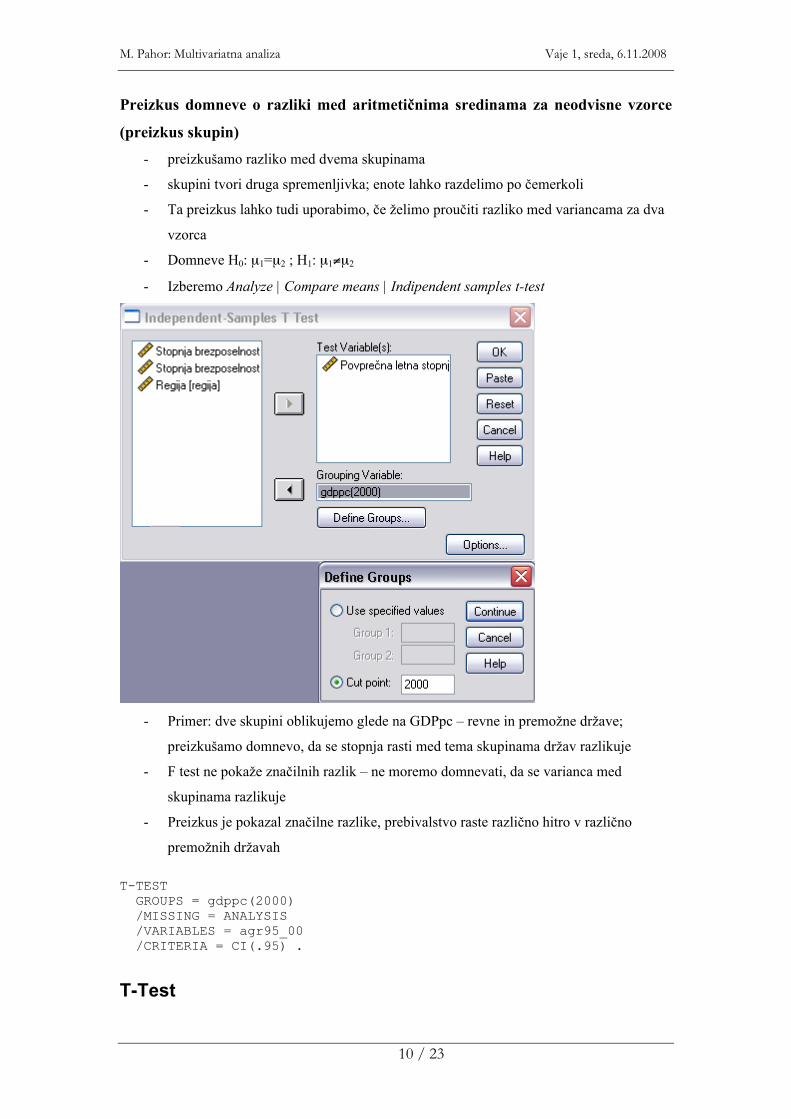
Preizkus domneve o razliki med aritmetičnima sredinama za neodvisne vzorce
(preizkus skupin) - preizkušamo razliko med dvema skupinama
- skupini tvori druga spremenljivka; enote lahko razdelimo po čemerkoli
- Ta preizkus lahko tudi uporabimo, če želimo proučiti razliko med variancama za dva
vzorca
- Domneve H0: µ1=µ2 ; H1: µ1≠µ2
- Izberemo Analyze | Compare means | Indipendent samples t-test
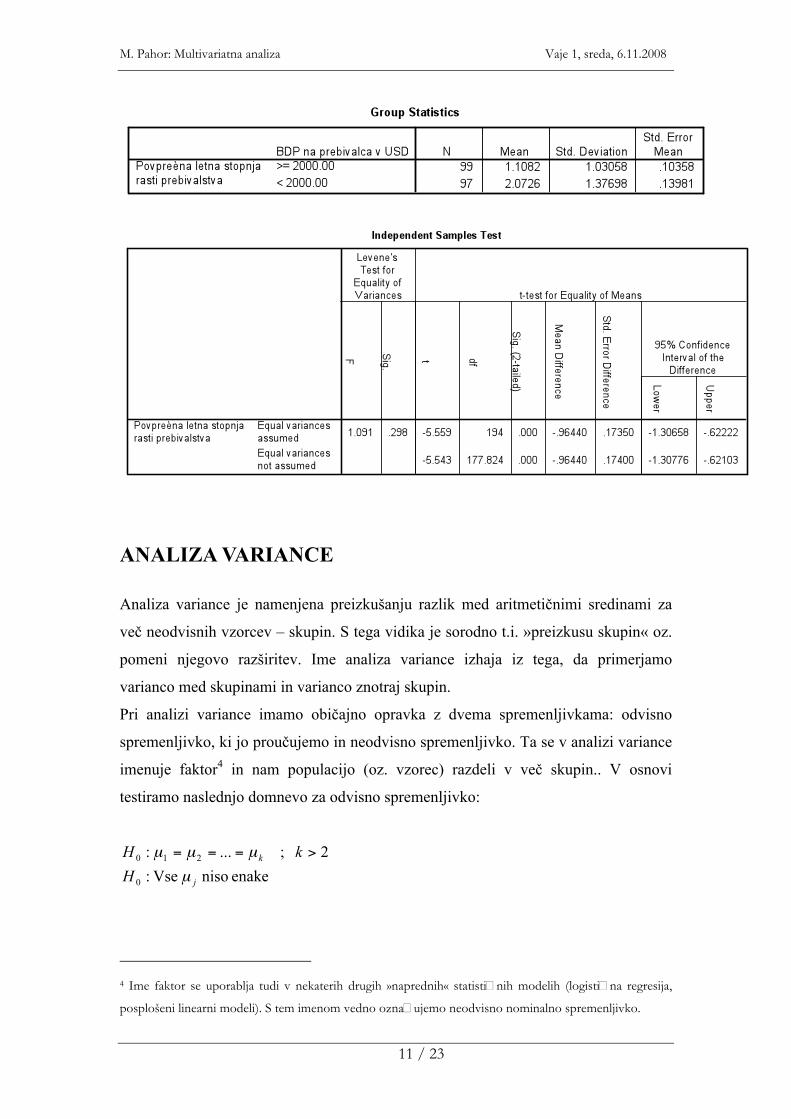
- Primer: dve skupini oblikujemo glede na GDPpc – revne in premožne države;
preizkušamo domnevo, da se stopnja rasti med tema skupinama držav razlikuje
- F test ne pokaže značilnih razlik – ne moremo domnevati, da se varianca med
skupinama razlikuje
- Preizkus je pokazal značilne razlike, prebivalstvo raste različno hitro v različno
premožnih državah T-TEST GROUPS = gdppc(2000) /MISSING = ANALYSIS /VARIABLES = agr95_00 /CRITERIA = CI(.95) .
T-Test
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
11 / 23
ANALIZA VARIANCE
Analiza variance je namenjena preizkušanju razlik med aritmetičnimi sredinami za
več neodvisnih vzorcev – skupin. S tega vidika je sorodno t.i. »preizkusu skupin« oz.
pomeni njegovo razširitev. Ime analiza variance izhaja iz tega, da primerjamo
varianco med skupinami in varianco znotraj skupin.
Pri analizi variance imamo običajno opravka z dvema spremenljivkama: odvisno
spremenljivko, ki jo proučujemo in neodvisno spremenljivko. Ta se v analizi variance
imenuje faktor4 in nam populacijo (oz. vzorec) razdeli v več skupin.. V osnovi
testiramo naslednjo domnevo za odvisno spremenljivko:
4 Ime faktor se uporablja tudi v nekaterih drugih »naprednih« statisti�nih modelih (logisti�na regresija,
posplošeni linearni modeli). S tem imenom vedno ozna�ujemo neodvisno nominalno spremenljivko.

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
12 / 23
K je število skupin, ki jih določa faktor. Ta spremenljivka mora torej biti diskretna in
imeti končno število vrednosti.
Za uspešno izvedbo analizo variance morajo biti izpolnjene predpostavke, na katerih
metoda temelji. Te predpostavke so:
1. Predpostavka o normalnosti
- predpostavljamo, da se mora spremenljivka porazdeljevati normalno v celoti
in znotraj vsake posamezne skupine.
- Če je število enot dovolj veliko, veljajo sklepi, bazirani na podlagi
predpostavke o normalnosti, tudi če se spremenljivke ne porazdeljujejo
normalno. Kljub temu je tudi pri velikih vzorcih normalna porazdelitev
zaželena.
- Če porazdelitev znotraj skupin ni normalna, je pa med skupinami približno
enaka, so sklepi na podlagi predpostavke o normalnosti še vedno pravilni
2. Predpostavka o enakosti varianc
- Predpostavka pravi, da je varianca v vseh skupinah enaka
- enakost varianc preizkušamo z Levenovim preizkusom o enakosti varianc
- predpostavka je lahko kršena, če imamo enako velike skupine, posebej še, če
imamo opravka z velikimi vzorci
3. Predpostavka o neodvisnosti
- domnevamo, da znotraj skupin ni odvisnosti
- predpostavka se uporablja le pri (kronološko) zaporednih podatkih
- predpostavko proučujemo s koeficientom avtokorelacije
OSNOVNI PREIZKUS PRI ANALIZI VARIANCE
V osnovi preizkušamo že zapisano domnevo
To naredimo F preizkusom in sicer s pomočjo naslednje tabele

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
13 / 23
Vir
variiranja
Vsota kvadratov
odklonov
Stopinje
prostosti
Ocena variance Preizkus
Med
skupinami
K - 1
Znotraj
skupin N – k
Skupaj
N - 1
Izberemo Analyze | Compare means | One-way ANOVA.
APRIORNA ANALIZA – ANALIZA S KONTRASTI
Pri kontrastih primerjamo razmerje med dvema ali več aritmetičnimi sredinami
posameznih skupin. Pri tem izhajamo iz vsebine problema in vnaprej
predpostavljenimi razmerji med temi aritmetičnimi sredinami.
Kontrast običajno označimo z D, oblikujemo pa ga tako, da aritmetični sredini vsake
skupine pripišemo nek ponder cj.
Da lahko govorimo o kontrastih, mora veljati . V nasprotnem primeru
govorimo o linearnih kombinacijah, za katere pa veljajo posebna pravila.
Splošno lahko domnevo, ki jo preizkušamo pri analizi s kontrasti zapišemo kot

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
14 / 23
, pri čemer gre pri j' in j'' za različne skupine.
Kontrasti so med sabo lahko odvisni ali neodvisni. Za vsako kombinacijo skupin
imamo največ k-1 neodvisnih kontrastov. Kontrasta sta neodvisna ko je vsota
produktov istoležnih ponderjev enaka 0, torej ko velja , kjer je c1j
ponder v prvem in c2j ponder v drugem kontrastu.
Podobno kot pri preizkusu skupin (ki ga lahko izvedemo tudi kot kontrast) se tudi pri
analizi s kontrasti obrazci za izračun kontrastov se razlikujejo glede na to, ali imamo
opravka z enakimi ali različnimi variancami med skupinami.
Če predpostavka o enakosti varianc velja, kontraste preizkušamo z naslednjim
obrazcem:
, pri čemer je prvi D ocenjen, drugi pa predpostavljen; slednji je običajno
0, v tem primeru vrednost t izračunamo tako
Preizkus se porazdeljuje v t porazdelitvi z n-k stopinjami prostosti.
Če predpostavka o enakosti varianc ne velja, t izračunamo po drugačnem obrazcu in
sicer
Preizkus pa se porazdeljuje z naslednjimi stopinjami prostosti
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
15 / 23
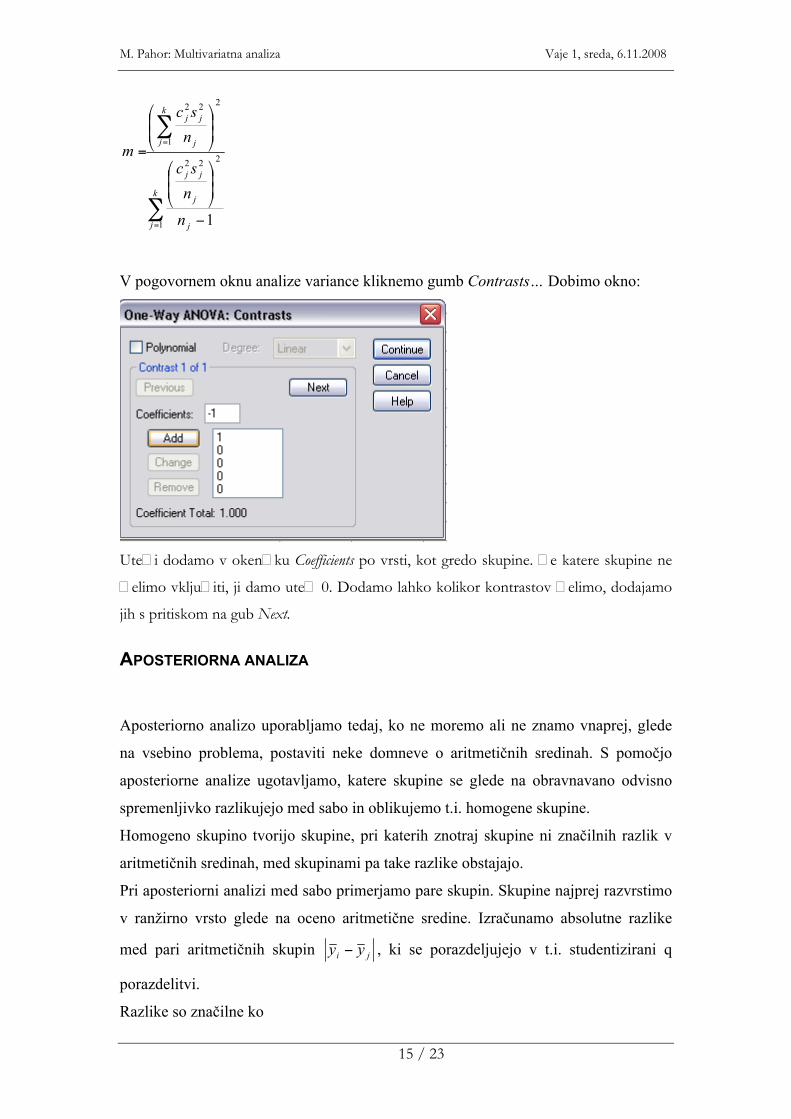
V pogovornem oknu analize variance kliknemo gumb Contrasts… Dobimo okno:
Ute�i dodamo v oken�ku Coefficients po vrsti, kot gredo skupine. �e katere skupine ne
�elimo vklju�iti, ji damo ute� 0. Dodamo lahko kolikor kontrastov �elimo, dodajamo
jih s pritiskom na gub Next.
APOSTERIORNA ANALIZA
Aposteriorno analizo uporabljamo tedaj, ko ne moremo ali ne znamo vnaprej, glede
na vsebino problema, postaviti neke domneve o aritmetičnih sredinah. S pomočjo
aposteriorne analize ugotavljamo, katere skupine se glede na obravnavano odvisno
spremenljivko razlikujejo med sabo in oblikujemo t.i. homogene skupine.
Homogeno skupino tvorijo skupine, pri katerih znotraj skupine ni značilnih razlik v
aritmetičnih sredinah, med skupinami pa take razlike obstajajo.
Pri aposteriorni analizi med sabo primerjamo pare skupin. Skupine najprej razvrstimo
v ranžirno vrsto glede na oceno aritmetične sredine. Izračunamo absolutne razlike
med pari aritmetičnih skupin , ki se porazdeljujejo v t.i. studentizirani q
porazdelitvi.
Razlike so značilne ko

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
16 / 23
q se porazdeljuje v posebni, q porazdelitvi z dvojimi stopinjami prostosti
- prve stopinje prostosti so m = n – k
- druge označimo z r in pomenijo razdaljo v rangih med skupinami. Dve
sosednji (zaporedni) enoti imajo r=2, kar je tudi najmanjši r sploh.
Ko primerjamo aritmetične sredine skupin med sabo, različne procedure uporabljajo
različne vrednosti q-ja in različne vrednosti za r. Glede na to se različne procedure
med sabo ločijo po strogosti in po tem, kako strog je test. Strožji ko je test, manj
značilnih razlik odkrije in obratno.
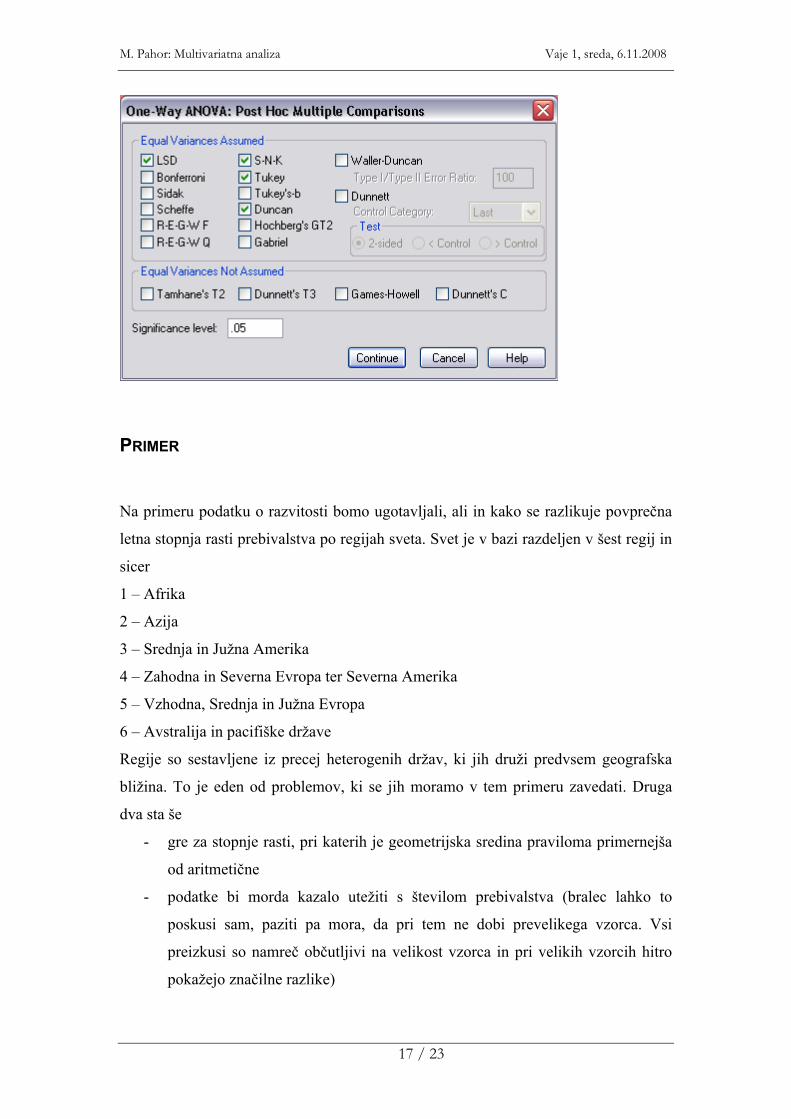
Tukey, Student-Newman-Keuls in LSD (least significant difference) uporabljajo iste
vrednosti q porazdelitve in te vrednosti navadno tudi najdemo tabelirane v knjigah. Ti
testi se med seboj razlikujejo po tem, kaj vzamejo za vrednost r; glede na to se
razlikujejo v strogosti in številu značilnih razlik, ki jih odkrijejo.
r strogost znač. razlike Posebnost
LSD rmin=2 ° °
Duncan r ° ° nižje vrednosti q
S-N-K r ° °
Tukey rmax ° °
Shaffe rmax ° ° višje vrednosti q
Dejanska odločitev o tem, kateri test sprejmemo je stvar primera in naše odločitve.
Običajno se odločimo za tisti test, ki nam najbolje odkrije homegene skupine oz. tisti,
pri katerem homogene skupine najlaže pojasnimo.
V pogovornem oknu analize variance kliknemo gumb Post Hoc… Dobimo okno:
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
17 / 23
PRIMER
Na primeru podatku o razvitosti bomo ugotavljali, ali in kako se razlikuje povprečna
letna stopnja rasti prebivalstva po regijah sveta. Svet je v bazi razdeljen v šest regij in
sicer
1 – Afrika
2 – Azija
3 – Srednja in Južna Amerika
4 – Zahodna in Severna Evropa ter Severna Amerika
5 – Vzhodna, Srednja in Južna Evropa
6 – Avstralija in pacifiške države
Regije so sestavljene iz precej heterogenih držav, ki jih druži predvsem geografska
bližina. To je eden od problemov, ki se jih moramo v tem primeru zavedati. Druga
dva sta še
- gre za stopnje rasti, pri katerih je geometrijska sredina praviloma primernejša
od aritmetične
- podatke bi morda kazalo utežiti s številom prebivalstva (bralec lahko to
poskusi sam, paziti pa mora, da pri tem ne dobi prevelikega vzorca. Vsi
preizkusi so namreč občutljivi na velikost vzorca in pri velikih vzorcih hitro
pokažejo značilne razlike)
M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
18 / 23
Analiza predpostavk
Zavedajoč se problemov pristopimo k analizi. Najprej preizkusimo predpostavke
modela s pomočjo kazalcev sploščenosti in asimetrije. Report Povprečna letna stopnja rasti prebivalstva
Regija N Mean Median Skewness Kurtosis Afrika 54 2.5281 2.4400 2.941 11.656 Azija 38 2.0395 2.0050 .010 -.306 Srednja in Juzna Amerika 38 1.4366 1.4050 .360 .831 Zahodna Evropa in Severna Amerika 19 .6032 .5200 .355 -1.144
Vzhodna, Srednja in Juzna Evropa 35 .2860 .0200 1.479 2.909
Avstralija in pacifiska drzave 14 1.7336 1.5950 .195 -.725
Total 198 1.5876 1.6500 1.008 4.617
Iz kazalnikov lahko ugotovimo, da je porazdelitev spremenljivke v celoti rahlo
asimetrična v desno in precej sploščena. Po posameznih skupinah se porazdelitev
dokaj dobro približuje normalni porazdelitvi, razen v Afriki, kjer je porazdelitev
precej asimetrična v desno in hudo sploščena. Predpostavka o normalni porazdelitvi je
do neke mere kršena, imamo pa opravka z relativno velikim vzorcem.
Predpostavko o enakosti varianc preizkušamo z Levenovim preizkusom.
Levenov preizkus izvedemo takole5:
– v vseh skupinah izračunamo vrednosti nove spremenljivke V , ki so enake absolutnim vrednostim odklonov vrednosti spremenljivke Y od ocene pripadajoče aritmetične sredine skupine:
; ;
– izvedemo postopek analize variance: na podlagi vrednosti nove spremenljivke V izračunamo vrednost Levenovega preizkusa kot razmerja med oceno variance med skupinami in oceno variance znotraj skupin.
Najprej ocenimo aritmetične sredine nove spremenljivke V za vse skupine
;
nato skupno aritmetično sredino 5 Vir: Rovan, 2000, neobjavljeno

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
19 / 23
pri čemer je
in končno vrednost Levenovega preizkusa
Zaradi poenostavitve računanja in zmanjšanja zaokrožitvenih napak je najprimerneje, da vsote kvadratov v zgornjem izrazu izračunamo takole:
in
kjer je:
; ; ; ;
Ničelno domnevo zavrnemo, če je vrednost
Levenovega preizkusa v kritičnem območju, pri čemer upoštevamo naslednjo
alternativno domnevo
kjer je
Ker smo za izračun vrednosti Levenovega preizkusa uporabili postopek analize variance, izvedemo enostranski F-preizkus. Pri tem je vrednost F-porazdelitve pri stopinjah prostosti in ter stopnji značilnosti α .
Levenov preizkus je za računanje na roke zelo zamuden, zato se ustavimo le pri
tolmačenju računalniškega izpisa. Test of Homogeneity of Variances Povprečna letna stopnja rasti prebivalstva
Levene Statistic df1 df2 Sig.
1.250 5 192 .287

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
20 / 23
Test ne pokaže značilnih razlik. To pomeni, da ne moremo zavrniti ničelne domneve,
da so vse variance enake. Nadaljnje teste torej delamo pod to predpostavko.
Osnovni preizkus
Preverimo najprej osnovno domnevo analize variance, torej domnevo
Domnevo preverimo z izračunom Fisherjeve tabele ANOVA Povprečna letna stopnja rasti prebivalstva
Sum of
Squares df Mean Square F Sig. Between Groups 134.403 5 26.881 26.145 .000 Within Groups 197.403 192 1.028 Total 331.807 197
F preizkus pokaže značilne razlike pri zanemarljivi stopnji tveganja. Torej lahko
zavrnemo ničelno domnevo in sprejmemo sklep, da je povprečna stopnja rasti vsaj v
eni regiji drugačna kot v ostalih.
Analiza s kontrasti
Pri analizi s kontrasti si vsebinsko zastavimo nekaj primerjav, ki jih želimo izvesti
znotraj analize variance. Ker imamo 6 skupin imamo lahko 5 neodvisnih kontrastov.
Oblikovali bomo tri in sicer bomo primerjali
1. stopnjo rasti v manj razvitih regijah (Azija, Afrika, Srednja in Južna Amerika) s
tisto v bolj razvitih regijah (S. Amerika, Evropa, Avstralija)
2. Primerjali bomo stopnje rasti v Afriki in Aziji
3. Ali se stopnja rasti v S. Ameriki in Z. Evropi razlikuje od tiste v J. in V. Evropi.
Ker domneve o enakosti varianc nismo zavrnili, uporabljamo obrazce, ki veljajo pri
tej predpostavki.
Prvi kontrast

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
21 / 23
Vrednost preizkusnega izraza
, m = n – k = 205 – 6 = 199
Razlike so značilne pri zanemarljivi stopnji tveganja. Zavrnemo ničelno domnevo in
sprejmemo sklep, da imajo manj razvite regije različno (višjo) povprečno stopnjo rasti
prebivalstva kot bolj razvite regije.
Podobno kot pri prvem lahko zavrnemo ničelno domnevo tudi pri drugem kontrastu,
le da tu pri nekoliko višji, 4,8% stopnji značilnosti.
Pri tretjem kontrastu ne moremo zavrniti ničelne domneve. Ne moremo torej trditi, da
se stopnja rasti v S. Ameriki in Z. Evropi razlikuje od tiste v J. in V. Evropi.
Aposteriorna analiza
Aposteriorno analizo uporabljamo za določanje homogenih skupin. Na voljo imamo
več različnih procedur, ki se med sabo ločijo po strogosti.
Največ značilnih razlik ugotovi LSD procedura.
Procedura primerja absolutno vrednost razlike med dvema skupinama s
studentiziranim razmikom.
Za prvi par (Afrika in Azija) znaša absolutna razlika 0,4472. Kritično vrednost, s
katero primerjamo to porazdelitev izračunamo

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
22 / 23
→ vrednost odčitamo v tabelah
, razlike niso značilne
Nadaljnje razlike, ki jih odkrije LSD procedura, lahko zapišemo tudi v taki tabeli, kjer
zvezdice predstavljajo značilne razlike
V. in J.
Evropa Z. Evropa in
S. Amerika Lat. Amerika Azija Australija Afrika
V. in J.
Evropa
Z. Evropa in
S. Amerika
Lat. Amerika * * Azija * * * Australija * * Afrika * * * *
LSD in tudi večina ostalih procedur loči Evropske in S. Ameriške države od ostalih,
pri tem pa še loči Afriko od Lat. Amerike. Praktično to pomeni, da imamo opravka z
dvema homogenima skupinama.

M. Pahor: Multivariatna analiza Vaje 1, sreda, 6.11.2008
23 / 23





























