Embed Size (px)
Citation preview

Változók eloszlása,középértékek,
szóródás

Populáció jellemzése
• Empirikus kutatás (statisztikai elemzés) célja: a mintából a populációra következtetni.
• Minta: egy adott változó a megfigyelési egységeken mért értékei.
• Minta elemzése/jellemzése: leíró statisztika.
A leíró statisztikában megállapított jellemzők:
• Gyakoriság,
• Eloszlás,
• Középérték,
• Szóródás.

Változók populációbeli eloszlása
• Statisztikai elemzés célja: a mintából a populációra következtetni
• Egy megfigyelési egység: nő vagy férfi a populáció: nem nő v. ffi hanem x%-a nő a populációt nem a kategóriák, hanem az összetétel jellemzi
• Változó eloszlása: Egy populáció egy adott változó szerinti jellegét az adja meg, hogy annak egyes értékei milyen gyakran fordulnak elő az adott populációban.

Eloszlás
• A változó eloszlása elvben elégséges ahhoz, hogy a változó populációbeli viselkedését megismerjük:
• ebből meghatározható a leggyakoribb/legtipikusabb érték, a populáció átlaga, a populáció heterogenitásának foka, stb.
• Ez a valószínűségi alapú statisztikai elemzés alapja!
• Az eloszlás másként értelmezhető/számítható diszkrét és folytonos esetben.

Diszkrét változók eloszlása
• Diszkrét változó: értékei megszámolhatók, felsorolhatók.
• Diszkrét esetben az érték gyakorisága
arány =
• kategória elemszáma/összes;
százalékos arány =
• arány*100
• Az egyes értékeket táblázatba foglaljuk.

Diszkrét változók eloszlásaMo. lakosságának iskolai végzettsége:
alsófokú középfokú felsőfokú
Gyakoriság:
3 150 000 4 500 000 1 800 000
Relatív gyakoriság:35% 45% 20% (össz. 100%)
Kumulatív gyakoriság (mediánhoz jön jól):
35% 80% 100%
Az előfordulás valószínűsége:
p = 0,35 p = 0,45 p = 0,20 (össz. 1)

Diszkrét változók eloszlásaMo. lakosságának iskolai végzettsége:
alsófokú középfokú felsőfokú
Gyakoriság:
3 150 000 4 500 000 1 800 000
Relatív gyakoriság:35% 45% 20% (össz. 100%)
Kumulatív gyakoriság (mediánhoz jön jól):
35% 80% 100%
Az előfordulás valószínűsége:
p = 0,35 p = 0,45 p = 0,20 (össz. 1)
A populációból véletlenszerűen választott személy 35% eséllyel lesz alsófokú végzettségű.

Diszkrét változók eloszlása
• Ábrázolás: oszlopdiagramon
Növény- (bal) és állatnevek (jobb) betűhosszának gyakorisága százalékos arányban kifejezve.
Rel
atív
gya
kori
ság
(%)
betűhossz
növénynév állatnév

Folytonos változók eloszlása
• Folytonos változók: értékei a számegyenes egy adott
intervallumán végtelen számosságúak lehetnek.
• Nem tudom megszámolni („túl sok lenne az oszlop, ami
csak 1 magasságú”).
• Megszámlálás helyett azt kellene megtudni, hogy az
értékskála egyes övezeteibe a populáció hányad része
esik. sűrűségfüggvény.
• Sűrűségfüggvény: Ez a fv. a változó minden x értékéhez
egy nem negatív egész f(x) számot rendel: f(x) nagyobb
azokra az x-ekre, melyek környezetében a
populációbeli egyedek jobban sűrűsödnek.
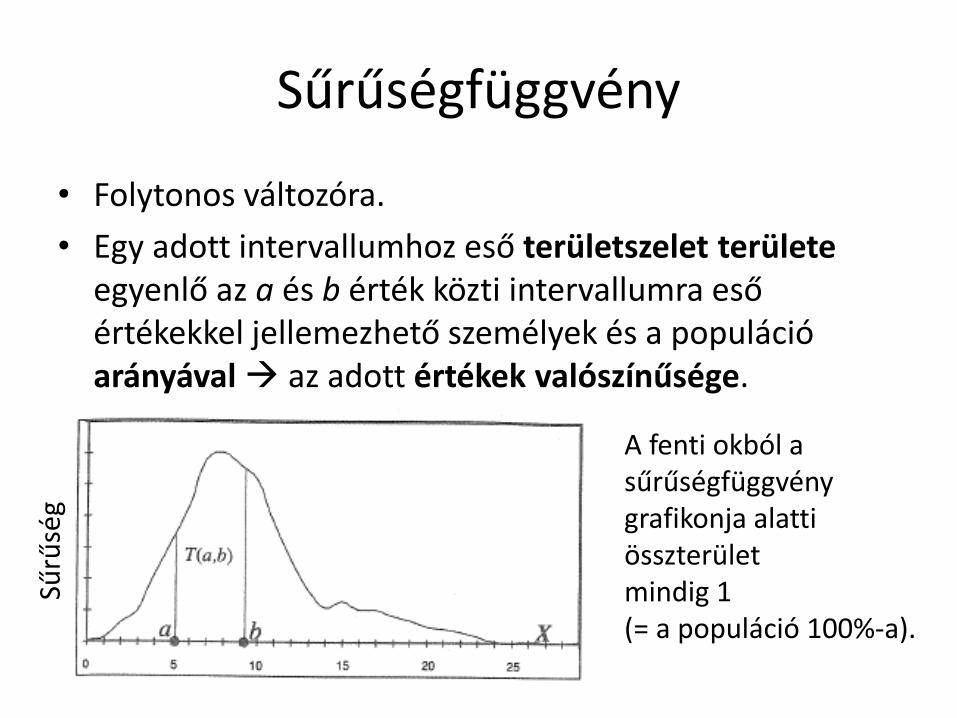
Sűrűségfüggvény
• Folytonos változóra.
• Egy adott intervallumhoz eső területszelet területe egyenlő az a és b érték közti intervallumra eső értékekkel jellemezhető személyek és a populáció arányával az adott értékek valószínűsége.
Sűrű
ség
A fenti okból a sűrűségfüggvény grafikonja alatti összterület mindig 1 (= a populáció 100%-a).

Sűrűségfüggvény értelmezése
5 9életkor
Sűrű
ség
T (a,b) = a populációban az 5 és 9 év köztiek arányaPl.: T = 0,63, akkor a populáció 63 %-a esik ebbe az életkori sávba T = 0,63 a valószínűsége (azaz 63%), hogy ennyi idős embert választok, ha véletlenszerűen választok.

Eloszlás jelentése és jelentősége
• Sorrendbe állított elemek milyen gyakran fordulnak elő.
• Legalább ordinális adatok kellenek hozzá!
• Előállítás: folytonos vagy diszkrét értékek közti interpolációval.
• Interpoláció: a függvénytan (matematika) eszköze, nem ismert értékekre ismert értékek alapján ad becslést.
• Eloszlás jelentősége: ez a valószínűségi statisztikai elemzés alapja!

Tapasztalati vagy empirikus eloszlás
• A változó populációbeli eloszlását valójában sosem ismerjük (a populáció elméleti, végtelen halmaz).
• A változó populációbeli eloszlására az adott mintánk eloszlásából következtetünk, azaz a változó tapasztalati vagy empirikus eloszlásából.

Valószínűségek és statisztika kapcsolata
• Valószínűségszámítás: ismerem a világot (populációt).
Egy betegség előfordulási gyakorisága 20%. Mekkora a
valószínűsége, hogy egy 50 elemű véletlenszerűen
kiválasztott mintában négy beteget találunk?
• Statisztika: nem ismerem a világot (populációt),
hanem a mintából próbálok következtetni rá.
Ha 50 véletlenül kiválasztott egyed között 4 beteget
találunk, mit állíthatunk a betegség előfordulási
gyakoriságáról a populációban?

Eloszlások összehasonlítása
• Empirikus vizsgálatokban, statisztika elemzésben központi kérdés:
• Egyenlő-e két populáció a vizsgált változó szempontjából (vagy az egyikben nagyobbak a vizsgált változó értékei, mint a másikban), vagy másként
• A vizsgált változó szempontjából két populációról vagy egy populációról van-e szó?

Eloszlások összehasonlítása
Egyenlő-e két populáció a vizsgált változó szempontjából?
• Ennek megítélésére vagy a konkrét értékeket, vagy a számok nagyságszintjét, nagyságrendjét hasonlíthatjuk össze, ez utóbbit méri a statisztika a középértékekkel.
• Középérték: „hova esik az adatok sűrűje”.
• A leggyakoribb statisztikai tesztek egy jó részében a középértékeket hasonlítjuk össze.

Statisztikai modellek
• A mintaadatainkból a populációra akarunk következtetni, és a populációra vonatkozó állításainkat (hipotéziseinket) tesztelni.
• Ez úgy lehetséges, ha megfigyeljük a minta tulajdonságait, és ez alapján építünk egy statisztikai modellt, azaz becsüljük a populáció tulajdonságait. – Ahogyan pl. építhetünk hidat is már létező hidak megfigyelésével, a lényegesnek látszó részletekkel.
• Kérdés: a modell mennyire reprezentálja a valóságot (populációt) –ez a fit of the model azaz a belőle nyerhető predikciók mennyire megbízhatók.
• A modell egy pont is lehet – pl. a mintaátlaggal modellezzük a mintát és becsüljük aztán a populációt. (bár sem a populációátlag ((sem a mintaátlag!)) nem mindig ténylegesen része a mintának!),
• Majd azt, hogy milyen jól illeszkedik a modell, megmérhetjük pl. az adatok eltérésével az átlagtól. (l. mindjárt a szóródási mutatókat)

1. Középértékek

Mintabeli középértékek
• A különböző skáláknak megfelelően többféle középérték számolható.
• Átlag: értékek számtani közepe.
• Medián: a növekvő sorba rendezett adatok közül a középső. Ha az elemszám páros, a két középső érték átlaga.
• Módusz: a legnagyobb gyakorisággal előforduló érték.

Mintabeli középértékek
• A különböző skáláknak megfelelően többféle középérték számolható.
• Átlag: értékek számtani közepe (jel.: x ̅ = 63).
• Medián: a növekvő sorba rendezett adatok közül a középső. Ha az elemszám páros, a két középső érték átlaga.
• Módusz: a legnagyobb gyakorisággal előforduló érték.

Mintabeli középértékek
• A különböző skáláknak megfelelően többféle középérték számolható.
• Átlag: értékek számtani közepe (jel.: x ̅ = 63).
• Medián: a növekvő sorba rendezett adatok közül a középső. Ha az elemszám páros, a két középső érték átlaga (jelölése: M = 4)
• Módusz: a legnagyobb gyakorisággal előforduló érték.

Mintabeli középértékek
• A különböző skáláknak megfelelően többféle középérték számolható.
• Átlag: értékek számtani közepe (jel.: x ̅ = 63).
• Medián: a növekvő sorba rendezett adatok közül a középső. Ha az elemszám páros, a két középső érték átlaga (jelölése: M = 4).
• Módusz: a legnagyobb gyakorisággal előforduló érték (Mo = „tollaslabda”).

Átlag vagy medián?I. FELADAT 1-5.: Hány ismerőse van a Facebook-os ismerőseimnek?
11 véletlenszerűen kiválasztott ismerősöm ismerőseinek száma:
546 388 724 269 113 467 682 178 149 382 196 EXCEL: átlag(), medián()
MEGOLDÁS:
Átlag = (546+388+724+269+113+467+682+178+149+382+196)/11 = 372,18. Mit jelent a „…,18”?
Sorba rendezett értékek:
113 149 178 196 269 382 388 467 546 682 724
Középső értek: 6. elem Medián = 382.
12 ismerős esetén a 6. es 7. elem átlaga a medián.

Medián vagy átlag? Módusz?
FELADAT 2: Egy ismerősünk csak tegnap iratkozott fel a Facebook-ra, ezért még csak 11 ismerőse van. Egy másik híres színésznő, neki 5439 ismerőse van.
11 + 149 + 178 + 196 + 269 + 382 + 388 + 467 + 546 + 682 + 5429 átlag? medián?
Átlag = 790,6364
Ha 11 helyett 111 ember adatait vizsgáljuk, kiderül, hogy keveseknek van 791 ismerőse, ez szélső vagy extrém érték.
Érdemes ábrázolni az eloszlást, és átlag helyett mediánt számolni, mert az kevésbé érzékeny az extrém értékekre.
A fenti adatok mediánja továbbra is 382.

Középértékek
• Ezek valójában a minta középértékei, azaz a tapasztalati középértékek.
• Elméleti átlag (medián, módusz): a populációt jellemzi.
• Elméleti átlag: az értékhez tartozó valószínűségekkel súlyozzuk az értékeket a számításhoz, majd összeadjuk, pl:
Példa: ötfokú skálaváltozó diszkrét értékei és a hozzájuk tartozó valószínűségek: P(1) = 0,4096, P(2) = 0,4096, P(3) = 0,1536, P(4) = 0,0256, P(5) = 0,0016.
Populáció elméleti átlaga (azaz a valószínűséggel súlyozott átlag): E(X) = Σ érték × valószínűség = 1×0,4096 + 2×0,4096 + 3×0,1536 + 4×0,0256 + 5×0,0016 = 1,8.

Skálák és középértékek
• Metrikus skálák: átlag, medián (és az alacsonyabb rendűek)
• Ordinális skála: medián, módusz
• Nominális skála: módusz
Alacsonyabb skálákra érvényes statisztikai módszerek mindig használhatók magasabb rendű skálákra, de info. vesztéssel járhatnak.

Eloszlás típusai• Egyenletes. Pl. kockadobáskor a dobott
számok (relatív) gyakorisága
• Ez 100 000 kockadobás eredménye.
Ábrázolás:
• Diszkrét eset a) oszlopdiagram
b) lehet sűrűségfv is, de ált. nem szokás, mert az értékek közt nem értelmezhető
• Folytonos eset a) hisztogram (oszlopdiagram egy alfaja):
osztálygyakoriságokat („bin”) ábrázol, nem az egyes értékek gyakoriságát, hanem az értékeken képzett csoportok gyakoriságait
b) sűrűségfüggvény

Eloszlás típusai
• Unimodális
• Egy módusza(leggyakoribb értéke) van
• Hasonlóság? Különbség?
• Szimmetrikus elolszlás
• Eltérő csúcsosság
• Ezeket lásd később.

Eloszlás típusai
• Bimodális: két módusza van.
• Vajon mikor látunk ilyet?
• Bi- és multimodáliseloszlásra standard statisztikai tesztek nem végezhetők el!

Valószínűségeloszlás típusai (példák)
• Poisson
• Binommiális
• Kevert normális
• Khi-négyzet (2)
• t
• F

2. Szóródás

Értékek szóródása
• Lehet, hogy egy változó
középértéke két populációban
ugyanakkora, de az eloszlás
alakja más.
• Eltérés: a populáció hányad
része esik közel a középérték
által meghatározott
centrumhoz.
• szóródás.
Ugyanakkora átlag és a medián, eltérő szóródás.

Szóródási mutatók
Legalább ordinális skála!
• Terjedelem: értékmax – értékmin
nagyon ki van téve az extrém értékeknek!
• Átlagos abszolút eltérés: a minta értékeinek a minta számtani közepétől (átlag) való távolsága (abszolút értékben), átlagolva (különben elemszámfüggő!).
• Variancia (s2, V): értékek és átlag négyzetes eltéréseinek átlaga (jobb, mert ez mindig pozitív, nem kell az absz. értékekkel varázsolni).
• Szórás (s, SD): variancia gyöke (az eltérések átlagának gyöke!).Excel: szórása() Feladat! xls

II. Feladat 1-2
• Számojuk ki a két facebook-felhasználó mintánk átlagát, szórását!
• Ábrázoljuk a két csoport átlagát és szórását oszlopdiagramon, bajuszokkal (whiskers)!
-1000
-500
0
500
1000
1500
2000
2500
facebook_csop_1 facebook_csop_2
Fő (
db
)
0
500
1000
1500
2000
2500
facebook_csop_1 facebook_csop_2
Fő (
db
)

Szóródási mutatók
A variancia (és a szórás) valójában arra is utalnak, hogy az
átlag mennyire jó modellje a mintának, hiszen az átlag és
az értékek közti átlagos különbséget mutatják.

Kvartilisek, interkvartilis tartomány
• Jelentőség:
– ordinális skálánál, ahol nem értelmezhető az átlag,
– ha az eloszlás ferde (nem ugyanannyi érték van tőle balra és jobbra), ekkor ugyanis más a (négyzetes/abszolút) eltérés az átlag alatt és fölött, ezért a szórás alul- ill. felülbecsüli az eloszlást.
• Interkvartilis tartomány: az X változó értékskálájának az a középen elterülő övezete, ahol a populáció 50%-a található (kumulatív gyakoriság!).
• 1. és 3. kvartilis közé esik.

Interkvartilis tartomány folytonos esetben
1. kvartilis:Osztópont a populáció 25% és 75%-a között
3. KvartilisOsztópont a populáció 75% és 25%-a között
2. kvartilis = medián (folytonos és szimmetrikus esetben)

Interkvartilis tartomány (K3-K1)
Jelentősége:
• A leggyakoribb érték körüli 50%

Interkvartilis tartomány diszkrét esetben
• Diszkrét esetben nem a 25% és 75%-ról van szó, hanem a pl. 100 sorba rendezett adat közül a 25., 50. és 75. adatról ez nem biztos hogy éppen a középső 50%-ot adja ki

Kvartilisek, interkvartilis tartomány
• Kumulatív gyakoriság szerint számolható (ahol az a Kum% átlépi a 25%-ot, majd a 75%-ot)
• Interkvartilis félterjedelem: IF = (K3-K1)/2
• Ha a változó folytonos és az eloszlása szimmetrikus, az interkvartlis tartomány meghatározható az IF-ből így: (K1, K3) = Med(X) ± IF

Kvartilisek, interkvartilis tartomány
• Jelentőség (további): a mediánnál látott módon
ez is kevésbé érzékeny a szélső értékekre.
• II. FELADAT 3: Számoljuk ki a kétféle facebook
felhasználói csoport kvartiliseit!
Excel: kvartilis.kizár()
1.: 113 149 178 196 269 382 388 467 546 682 724
2.: 11 149 178 196 269 382 388 467 546 682 5439

Kvartilisek, interkvartilis tartomány
• Jelentőség (további): a mediánnál látott módon
ez is kevésbé érzékeny a szélső értékekre.
• II. FELADAT 3: Számoljuk ki a kétféle facebook
felhasználói csoport kvartiliseit!
Excel: kvartilis.kizár()
1.: 113 149 178 196 269 382 388 467 546 682 724
2.: 11 149 178 196 269 382 388 467 546 682 5439

Kvartilisek, interkvartilis tartomány
• Jelentőség (további): a mediánnál látott módon
ez is kevésbé érzékeny a szélső értékekre.
• II. FELADAT 3: Számoljuk ki a kétféle facebook
felhasználói csoport kvartiliseit!
Excel: kvartilis.kizár()
1.: 113 149 178 196 269 382 388 467 546 682 724
2.: 11 149 178 196 269 382 388 467 546 682 5439

Interkvartilis tartomány
• Hol használjuk?

Dobozdiagram (boxplot)• Mit figyelhetünk meg?
• Hová esik/milyen széles a megfigyelések középső 50%-ának tartománya?
• Eloszlás szimmetriája?
• Pontok: kilógó érték, azaz outlier: (IT × 1,5-nél messzebb van az ITalsó vagy felső határától, azaz K1-től vagy K3-tól)
K3
K1
K2

Feladatok az SPSS-ben
• Készítsünk dobozdiagramokat (boxplot) a két csoport adataiból az SPSS-ben!
• Készítsünk pontdiagramot (Scatter/Dot) ugyanezen adatokból!
1.: 113 149 178 196 269 382 388 467 546 682 724
2.: 11 149 178 196 269 382 388 467 546 682 5439

Dobozdiagram és pontdiagram

Házi feladat I: barátkozás az SPSS adatkezelési sajátosságaival
Formázzuk meg tisztességesen az adatainkat!
1. Állítsunk be egyértelmű változóneveket (Name)!Vigyázat, ékezetes betűk, szóköz, írásjelek nem használhatók, csak ASCII karakterek!!!
2. Adjuk meg a változó típusát (Type)Lehetőségek: Numeric, String
3. Adjunk címkéket a változókhoz (Label)!Ábrázoláskor ezt fogja megjeleníteni a grafikonon!
4. Állítsuk be, hogy az értékeket hány tizedesjeggyel mutassa az SPSS (Decimal)!
5. Nominális változók esetén állítsuk be a kódok jelentését (Values)!Pl. Value: „f1”, Label „1. csoport”
6. Állítsuk be a skála típusát (Measure)!Lehetőségek: nominal, ordinal, scale.

Házi feladat II: barátkozás az SPSS grafikonszerkesztőjével
Formázzuk meg szépre a dobozdiagramot!
1. Készítsük el újra a dobozdiagramot!Figyelem, ha átállítottunk valamit az adatokban, pl. tizedesjegyekszámát minden ábrát mindig újra el kell készíteni!
2. Tüntessük el az adatfeliratokat!
3. Növeljük meg az összes betű méretét (pl. 16-osra), és állítsuk az összes betűtípust Times New Romanra.
4. Állítsuk be a skálákat úgy, hogy a lehető legkevesebb üres terület maradjon az alsó és felső „bajszok” alatt! (az outlierünk lemarad!)
5. Állítsuk átlátszóra a grafikonterület háttérszínét!
6. Színezzük át a dobozokat (tetszés szerint;)), megváltoztathatjuk a vonalak színét is!






![Konfiguráció menedzsment ansible-velipszilon.niif.hu › 201710_ansible › ansible.pdf · Ansible config és shell változók ansible.cfg [defaults] remote_user = debian become_method](https://img.pdfslide.tips/doc/110x75/5f0fb7337e708231d44587ca/konfigurci-menedzsment-ansible-a-201710ansible-a-ansiblepdf-ansible.jpg)






















