Embed Size (px)
Citation preview

White Paper Lösungsansätze für Big Data
Seite 1 von 16 www.fujitsu.com/de
White Paper Lösungsansätze für Big Data
Das Thema „Big Data“ gewinnt für immer mehr Unternehmen an Bedeutung. Es werden neue Anwendungsfelder erschlossen, bei denen riesige Datenmengen automatisch und kontinuierlich aus unterschiedlichen Datenquellen generiert werden. Bei der Auswertung dieser Daten stößt die traditionelle IT jedoch an ihre Grenzen. Wie lassen sich der hohe Komplexitätsgrad und die Beschränkungen bei der Verarbeitungsgeschwindigkeit überwinden? Verschiedene Lösungsansätze wurden erfolgreich erprobt und bereits produktiv eingesetzt. In diesem White Paper möchte Fujitsu Ihnen Einblicke darin vermitteln, wie in welcher Situation vorzugehen ist.
Inhalt
Unternehmerisches Wunschdenken 2 Daten – Der größte Aktivposten eines jeden Unternehmens 2 Klassische Business Intelligence 2 Die Situation hat sich geändert 2 Veränderte Anforderungen an die Business Intelligence 3 Big Data – Worum geht es dabei eigentlich? 3 Warum traditionelle Lösungen ungeeignet sind 4 Verteilte Parallelverarbeitung 5 Apache Hadoop 5 Hadoop Distributed File System (HDFS) 5 Hadoop MapReduce 6 YARN (Yet Another Resource Negotiator) 6 Apache Hadoop-Unterprojekte 7 Die destillierte Essenz von Big Data 7 In-Memory Plattform 8 In-Memory Datenbanken (IMDB) 8 In-Memory Data Grid (IMDG) 9 Infrastrukturoptimierung für relationale Datenbanken 9 Datenbanken für Big Data 10 Complex Event Processing 12 Referenzarchitektur für Big Data 13 Bei Big Data geht es aber nicht nur um die Infrastruktur 14 Ihr Weg zu Big Data 14 Betrieb von Big-Data-Infrastrukturen 15 IaaS, PaaS, SaaS oder sogar Data Science als Service? 15 Welchen Beitrag kann Fujitsu leisten? 16 Zusammenfassung 16

White Paper Lösungsansätze für Big Data
Seite 2 von 16 www.fujitsu.com/de
Unternehmerisches Wunschdenken Die Steigerung von Rentabilität und Erlösen hat in Unternehmen normalerweise oberste Priorität. Hierzu ist eine beständige Steigerung von Leistungsfähigkeit und Produktivität der Mitarbeiter sowie der Effizienz und Wettbewerbsfähigkeit des Unternehmens als Ganzes bei gleichzeitiger Risikominimierung erforderlich. Die spannende Frage lautet nun, wie sich dies schneller, effektiver und in größerem Umfang erreichen lässt als bei den Mitbewerbern.
Wie wäre es, wenn Sie voraussagen könnten, wie sich Trends, das Verhalten der Kunden oder geschäftliche Chancen entwickeln werden?
Wenn Sie stets die optimale Entscheidung treffen würden? Wenn Sie die Entscheidungsfindung beschleunigen könnten? Wenn entscheidende Maßnahmen automatisch ergriffen würden? Wenn Sie Probleme und Kosten
bis zu ihrem Ursprung zurückverfolgen könnten? Wenn sich sinnlose Aktivitäten eliminieren ließen? Wenn sich Risiken exakt quantifizieren
und auf ein Minimum reduzieren ließen? Bei der Betrachtung solcher Fragen denken viele Manager sofort an die Chancen, die sich daraus für ihr Unternehmen ergeben. Sind dies jedoch lediglich Wunschträume, oder besteht die Chance, dass sie eines Tages verwirklicht werden können? Daten – Der größte Aktivposten eines jeden Unternehmens Neben den Mitarbeitern sind Daten die wertvollste Ressource eines jeden Unternehmens. Bereits vor Jahrzehnten wurde dies erkannt, und man versuchte, Daten profitbringend einzusetzen. Es lag auf der Hand, dass durch die intelligente Nutzung von Daten eine Entscheidungsfindung möglich wurde, die auf fundierten Fakten und nicht auf Intuition beruhte. Hierdurch konnten geschäftliche Abläufe verbessert, das Risiko minimiert, Kosten reduziert und das Geschäft im Allgemeinen gefördert werden. Eine weitere wichtige Erkenntnis bestand darin, dass Daten in ihrer ursprünglichen Form normalerweise nur von geringem Wert waren. Aus diesem Grund wurden Daten aus abrufbereiten Datenquellen – hauptsächlich aus transaktionalen Datenbanken – erfasst, konsolidiert und in eine für die Analyse geeignete Form gebracht, um Beziehungen, Muster und Grundsätze und damit letztendlich ihren echten Wert zu ermitteln. Genau dies war anfänglich der Grundgedanke der Business Intelligence (BI). Klassische Business Intelligence Im Rahmen der Business Intelligence werden die aufbereiteten Daten geladen und in einer speziellen Datenbank gespeichert, dem so genannten Data Warehouse. Dieses ist von den Transaktionssystemen getrennt, um diese nicht mit der Analyse von Unternehmensdaten, der Berichterstellung oder der Visualisierung von Abfrageergebnissen zu belasten. Data Warehouses sind für die Generierung von Reports optimiert. Aus Leistungs- oder Berechtigungsgründen werden multidimensionale Intervalle oder andere spezielle Datenbankansichten als Auszüge des Data Warehouse erstellt. Diese so genannten „Cubes“ oder „Data Marts“ können dann für eine tiefgreifende Analyse oder zur Generierung rollenspezifischer Berichte genutzt werden.
Die traditionelle BI nutzt hauptsächlich interne und historische Datenbank-Views, die sich aus einigen wenigen Datenquellen speisen. Die Daten werden strukturiert und typischerweise in einem relationalen Datenbankmanagementsystem (RDBMS) gespeichert. Business Analytics-Vorgänge werden auf Grundlage eines statischen Modells entworfen und in regelmäßigen Abständen – täglich, wöchentlich oder monatlich – als Batchverarbeitung ausgeführt. Da der durchschnittliche Benutzer meist nicht entsprechend geschult ist, um komplexe Analysen in Eigenregie zu erstellen, ist die Zahl derjenigen, die Abfragen ausführen oder sich mit der Auswertung von Unternehmensdaten beschäftigen, auf einige wenige Fachanwender beschränkt.
Die Situation hat sich geändert Seit den Anfangszeiten der BI haben sich die Dinge erheblich geändert. Es sind eine Reihe vielseitig nutzbarer Datenquellen hinzugekommen, die es zu berücksichtigen gilt. Neben transaktionalen Datenbanken sind es insbesondere die Daten aus dem Internet in Form von Blog-Inhalten oder Click-Streams, die wertvolle Informationen enthalten, ganz zu schweigen von den Inhalten der sozialen Medien, die sich zu den am häufigsten genutzten Kommunikationsplattformen entwickelt haben. Auch aus Multimedia-Daten, z. B. Video, Foto oder Audio, lassen sich Rückschlüsse für unternehmerische Entscheidungen ziehen. Es existiert ein riesiger Fundus an Textdateien, darunter schier endlose Protokolldateien aus IT-Systemen, Notizen und E-Mails, die ebenfalls Indikatoren enthalten, die für Unternehmen interessant sein könnten. Und nicht zuletzt gibt es noch eine Myriade von Sensoren, die in Smartphones, Fahrzeugen, Gebäuden, Robotersystemen, Geräten und Apparaten, intelligenten Netzwerken – schlichtweg in jedem Gerät, das Daten erfasst – in einem Umfang verbaut wurden, der noch vor Kurzem unvorstellbar war. Diese Sensoren bilden die Grundlage für das sich im Aufbau befindliche, vielfach zitierte „Internet der Dinge“. Aus branchenspezifischer Sicht wären außerdem medizinische Untersuchungen im Gesundheitswesen, RFID-Etiketten zur Verfolgung beweglicher Güter sowie geophysische oder dreidimensionale Raumdaten (z. B. GPS-gestützte Ortsdaten) oder Daten von Beobachtungssatelliten zu nennen. Diese Aufzählung ist bei weitem nicht vollständig.

White Paper Lösungsansätze für Big Data
Seite 3 von 16 www.fujitsu.com/de
Natürlich nimmt das Volumen bei allen Arten von Daten beständig zu, aber es sind insbesondere die Sensoren mit ihren automatisch und kontinuierlich generierten Ereignisdaten, die in Zukunft einen enormen Einfluss haben werden. Es überrascht daher kaum, dass wir uns einem exponentiellen Datenwachstum gegenüber sehen. Schauen wir uns einmal ein wenig genauer an, was diese exponentielle Datenentwicklung eigentlich bedeutet. Die Experten sprechen von einem Datenvolumen von 2,5 x 1018 Byte, das täglich hinzukommt. Dabei stammen 90 % aller vorhandenen Daten aus den letzten zwei Jahren. Das Datenvolumen steigt jährlich um 65 % an. Dies entspricht einer Verdopplung der Datenmenge alle 18 Monate bzw. einem Wachstum um den Faktor 12 alle fünf Jahre im Vergleich zum heutigen Stand. Mithin geht es hier nicht nur um Terabyte, sondern um Petabyte, Exabyte, Zettabyte und sogar Yottabyte, und ein Ende ist nicht abzusehen. Viele IT-Manager haben daher das Gefühl, in einer Flut aus Daten buchstäblich unterzugehen. Dabei geht es nicht nur um die Vielzahl von Datenquellen und das anwachsende Datenvolumen, sondern auch um neue Datentypen, die laufend hinzukommen. In der klassischen BI wurden lediglich strukturierte Daten in den festen Tabellenfeldern relationaler Datenbanken berücksichtigt. Heute ist der Großteil der Daten unstrukturiert – Experten sprechen dabei von mehr als 80 %. Unstrukturierte Daten sind etwa Textdaten wie Artikel, E-Mails und andere Dokumente, oder Daten, die nicht in Textform vorliegen, z. B. Audio, Video oder Bilddaten. Zusätzlich zu strukturierten und unstrukturierten Daten gibt es außerdem semistrukturierte Daten, die nicht in festen Datenfeldern vorliegen, sondern durch so genannte Tags in aufeinander folgende Datenelemente unterteilt werden. Beispiele für semistrukturierte Daten sind XML-, HTML- und PDF/A-Daten sowie RSS-Feeds. Abschließend sind noch die polystrukturierten Daten zu nennen, die aus einer Vielzahl unterschiedlicher Datenstrukturen bestehen, die sich zusätzlich noch verändern können. Beispiele für polystrukturierte Daten sind elektronische Datensätze in Form von XML-Dokumenten mit PDF/A-Elementen oder unterschiedliche Versionen eines Dokuments, die sich in der Anzahl der Elemente oder sogar in der Version des zugrunde liegenden XML-Schemas unterscheiden. Veränderte Anforderungen an die Business Intelligence Interessant ist, welche Auswirkungen all diese Überlegungen auf die Business Intelligence von heute haben. Aus unternehmerischer Sicht wurde nämlich schnell klar, dass sich aus dieser Vielzahl unterschiedlicher Datenquellen mit ihren riesigen, aber bislang ungenutzten Datenbeständen – egal ob diese strukturiert, unstrukturiert, semistrukturiert oder polystrukturiert vorliegen – immenser Nutzen schlagen lässt. Aber im Gegensatz zur klassischen BI, als es noch Stunden dauerte, um Berichte im Batchverfahren zu generieren, werden heutzutage Ad-hoc-Abfragen mit Analyseergebnissen in Echtzeit erwartet, die die Grundlage für umgehende, proaktive Entscheidungen bilden oder sogar ein automatisiertes Eingreifen ermöglichen. Hinzu kommt, dass sich die Datenanalyse nicht mehr mit der Beschreibung vergangener Ereignisse allein beschäftigt, sondern vorherzusagen versucht, was in Zukunft passieren wird.
Aufgrund der Vielzahl von Anwendungsmöglichkeiten und Chancen, die sich aus dieser Datenvielfalt ergibt, gibt es aber auch weitaus mehr Benutzer, die sich einen direkten Zugriff auf Analysedaten wünschen, und dies nicht nur vom Büro aus, sondern ortsungebunden von jedem Gerät aus, sei es ein Laptop-Computer, ein Smartphone oder etwas anderes. Natürlich muss eine Lösung, die all dies ermöglicht, zuallererst auch effizient und kostengünstig sein. Hiermit wurden die Grundlagen für ein neues Modewort und eines der am meisten diskutierten Themen in der heutigen IT geschaffen: Big Data. Big Data – Worum geht es dabei eigentlich? Big Data vereint alle oben erörterten Eigenschaften von Daten. Big Data kann für Unternehmen zum Problem werden, bietet aber auch die Chance, sich einen Wettbewerbsvorteil zu erarbeiten. Big Data beginnt bei Datenvolumen im Bereich mehrerer Terabyte und darüber hinaus – mehrere Petabyte sind keine Seltenheit, oft in Form unterschiedlicher Datentypen (strukturiert, unstrukturiert, semistrukturiert und polystrukturiert) aus verschiedenen, geografisch verteilten Datenquellen. Die Daten werden häufig mit hoher Geschwindigkeit generiert und müssen in Echtzeit verarbeitet und analysiert werden. Manchmal verlieren Daten genauso schnell ihre Gültigkeit, wie sie generiert wurden. Inhaltlich gesehen können Daten durchaus ambivalent sein, was ihre Interpretation zu einer echten Herausforderung macht.
Bei Big Data geht es jedoch nicht nur um die Daten selbst, sondern auch um erschwingliche Systeme, die Speicherung, Erschließung und Analyse riesiger Datenmengen in Echtzeit ermöglichen. Dank Verarbeitung in höchster Geschwindigkeit können Abfragen immer weiter verfeinert und die Abfrageergebnisse so Schritt für Schritt verbessert werden. Auf diese Weise ist ein großer Benutzerkreis auch ohne tiefgreifende Vorkenntnisse in der Lage, produktiv mit Analysedaten umzugehen – etwas das noch vor kurzem absolut unvorstellbar gewesen wäre. Big Data verschafft also einen unkomplizierten Zugang zu Analysedaten, und damit zu Wissen, und zwar allen, die diesen Zugang benötigen,.

White Paper Lösungsansätze für Big Data
Seite 4 von 16 www.fujitsu.com/de
Auf die Frage, ob Sie sich mit dem Thema „Big Data“ überhaupt beschäftigen sollten, gibt es eine relativ einfache Antwort. Führen Sie sich einfach vor Augen, dass Sie derzeitig durchschnittlich 5 % Ihrer verfügbaren Daten für Analysezwecke nutzen, was umgekehrt bedeutet, dass 95 % Ihrer Daten brach liegen. Wenn Sie die Möglichkeiten von Big Data ignorieren und sich mit 5 % begnügen, Ihre Mitbewerber – deren Wirkungsgrad bei der Datennutzung ähnlich aussehen dürfte – aber dank Big Data-Technologien 15 % ihrer Daten erschließen, ist es ziemlich offensichtlich, wer am Ende erfolgreicher sein wird. Der Nutzen von Big Data Unternehmen können vielfältigen Nutzen aus Big Data ziehen. Sie gewinnen Erkenntnisse über Kunden, Zulieferer und andere Geschäftspartner, über Märkte und Betriebsabläufe, über die Ursachen von Problemen und Kosten und über die potenziellen Risiken, mit denen Ihr Unternehmen umgehen muss. Alle diese Fakten und Erkenntnisse wären ohne Big Data verborgen geblieben. Aus neu entdeckten Mustern und Verhaltensweisen lassen sich Voraussagen über zukünftige Trends und geschäftliche Chancen ableiten, und dies wird die Geschwindigkeit, Qualität und Zweckdienlichkeit betrieblicher, taktischer und strategischer Entscheidungen eindeutig verbessern. Allein das Vermeiden einer Reihe von sinnlosen Aktivitäten birgt ein enormes Einsparpotenzial. Big Data versetzt Sie in die Lage, Ihre Daten effektiv zur Erlangung eines Wettbewerbsvorteils und zur Steigerung der Wertschöpfung einzusetzen. Die Möglichkeit, Maßnahmen zu automatisieren, trägt dazu bei, diese Ziele noch schneller zu erreichen. Schauen wir uns die Vorteile von Big Data anhand einiger Beispiele genauer an. Neue Erkenntnisse können Ihrem Geschäft, Ihren Produkten und Ihren Services neue Impulse geben. Kunden, die wahrscheinlich abgewandert wären, können gehalten werden, und diejenigen, die bereits das Lager gewechselt haben, werden zurückgewonnen, indem die Kundenstimmung verlässlich analysiert und bewertet wird, z. B. durch Vergleich von Lieferstatus und Kundenanrufen beim Helpdesk. Neukunden werden durch Ermitteln der aktuellen Nachfrage gewonnen, z. B. durch Analyse von sozialen Medien. Gleichzeitig lässt sich durch ein mehr zielgerichtetes Vorgehen die Rentabilität von Marketingkampagnen steigern. Andere Beispiele hängen eng mit der Optimierung von Geschäftsprozessen zusammen. Hier wären die Verkürzung der Forschungs- und Entwicklungsdauer, die Verbesserung von Planung und Prognose durch eine detaillierte Analyse historischer Daten, eine optimierte Bereitstellung und Verteilung von materiellen Ressourcen und Personal oder Leistungs- und Produktivitätssteigerungen durch automatisierte Entscheidungsprozesse in Echtzeit zu nennen. Letztendlich wird durch größere Effizienz und Effektivität die Rentabilität erhöht und das Wachstum gefördert. Die Möglichkeit, Risiken exakt zu quantifizieren und auf ein Minimum zu reduzieren, bedeutet enorme unternehmerische Vorteile. Durch effektive Nutzung von Informationen verbessern Sie Ihre Wettbewerbsfähigkeit.
Warum traditionelle Lösungen ungeeignet sind Wie bereits erwähnt, fungieren Data Warehouses in klassischen BI-Lösungen als Datenspeicher. Normalerweise basieren sie auf relationalen Datenbanken. Für relationale Datenbanken ist immer eine Art von Struktur erforderlich, d. h. unstrukturierte oder semistrukturierte Daten müssen im Vorfeld aufbereitet werden. Die sich dabei ergebenden Tabellen sind oft riesig, enthalten aber vergleichsweise nur wenige Daten. Dies wiederum bedeutet ein große Menge von Metadaten, hohe Speicherkapazitäten und eine geringe Abfragegeschwindigkeit. Eine Strukturierung von Daten in Zeilen eignet sich gut für OLTP-Anwendungen (Online Transaction Processing), bei analytischen Aufgabenstellungen müssen aber zwangsläufig eine Menge irrelevanter Daten aus den vielen Zeilen gelesen werden, da eben nur die Informationen aus manchen Spalten von Bedeutung ist. Lässt sich diese Situation durch eine vertikale Serverskalierung (Scale up) verbessern? Egal wie leistungsstark Ihr Server auch sein mag, für jede seiner physischen Ressourcen gibt es eine Obergrenze, die nicht überschritten werden kann. Heutzutage liegen diese Obergrenzen bei ca. 128 Prozessorkernen, 4 TB Hauptspeicher, 10 - 50 TB an lokalem Festplattenspeicher und 40 GB/s Netzwerkbandbreite. Angesichts des wachsenden Datenvolumens werden diese Obergrenzen früher oder später zum Problem. Zweifellos werden diese Grenzen in Zukunft weiter nach oben verschoben, aber das Gesamtvolumen der Daten, die Sie für Ihre Analysen nutzen, wird um einiges schneller ansteigen. Außerdem werden die Kosten für CPUs, Hauptspeicher und Netzwerkanbindung bei vertikal skalierten Hochleistungsservern immer vergleichsweise hoch sein. Scheidet eine vertikale Skalierung also aus, bleibt die Frage nach relationalen Datenbanken und einer horizontalen Serverskalierung (Scale out) Da mehrere Server auf die Datenbank zugreifen, könnten die Speicherverbindungen zur entscheidenden Schwachstelle werden. Gleichzeitig steigt der Koordinationsaufwand für den Zugriff auf gemeinsam genutzte Daten mit der Anzahl der verwendeten Datenbankserver. Dies führt laut Amdahl‘schem Gesetz zu einer Abnahme der Servereffizienz und einer Einschränkung der Parallelisierung. Nach dem Amdahl‘schen Gesetz begrenzt bei jedem Parallelisierungsansatz der Kehrwert des nicht parallelisierbaren, sequentiellen Anteils die theoretisch erreichbare Leistungssteigerung. Demzufolge ist bei 1000 Rechnerknoten – um auch eine 1000-fache Leistungssteigerung zu erzielen - ein serieller Anteil von unter 0,1% anzustreben. Folglich wären alle Verbesserungsbemühungen in Verbindung mit relationalen Datenbanken, egal ob Sie horizontal oder vertikal skalieren, äußerst zeit- und kostenintensiv und würden Sie dem Ziel einer Datenanalyse in Echtzeit nur unwesentlich näher bringen. Die Analyseergebnisse würden zu spät vorliegen, und die gewonnenen Einsichten könnten zum Zeitpunkt, zu dem sie präsentiert werden, bereits hinfällig sein. Angesichts des hohen Datenvolumens werden relationale Datenbanken die Grenzen der wirtschaftlichen Machbarkeit überschreiten und trotzdem nicht die geforderte Performance erreichen.

White Paper Lösungsansätze für Big Data
Seite 5 von 16 www.fujitsu.com/de
Natürlich wäre es denkbar, getrennte Datenbanken und Data Warehouses aufzubauen und die Analyseaufgaben auf sie zu verteilen. Hierdurch würden jedoch voneinander getrennte Datensilos mit separaten Analyseverfahren entstehen, die Ihnen nicht die erwarteten umfassenden Erkenntnisse liefern. Da Sie bei klassischen Lösungen in allen Bereichen auf Einschränkungen stoßen, sind neue Ansätze erforderlich, die es ermöglichen, die Verarbeitungszeit bei steigendem Datenvolumen konstant zu halten. Verteilte Parallelverarbeitung Der Schlüssel zum Erfolg liegt in der Parallelisierung auf Grundlage einer „Shared Nothing“-Architektur sowie nicht blockierenden Netzwerken, die eine reibungslose Kommunikation zwischen den Servern gewährleisten. Sie verteilen die Ein-/Ausgabe (I/O) auf mehrere Serverknoten, indem Datenuntermengen in den lokalen Speicher der Server ausgelagert werden. Ähnlich wird die Verarbeitung der Daten verteilt, indem Rechenprozesse auf die Serverknoten verlagert werden, auf denen die Daten liegen. Verteilte Parallelverarbeitung bietet eine Reihe von Vorteilen. Das Ausführen einer Abfrage auf einer Vielzahl von Knoten erhöht die Leistung und sorgt so für schnellere Ergebnisse. Sie können mit nur wenigen Servern klein anfangen und bei Bedarf weitere hinzufügen. Im Grunde lässt sich Ihre Infrastruktur linear und ohne Obergrenze horizontal skalieren. Selbst wenn Tausende von Servern nicht ausreichen sollten, bleibt der Vorgang des Hinzufügens immer derselbe. Die Daten werden automatisch auf mehrere Knoten repliziert, um die Konfiguration fehlertolerant zu machen. Fällt ein Server aus, kann die entsprechende Aufgabe auf einem Server mit einer Datenreplik fortgeführt werden, vollkommen transparent für die Softwareentwicklung und den Betrieb.
Da sich solche Serverfarmen aus handelsüblichen Servern, in der Regel mit Dual-Socket-Konfiguration und einigen Terabyte an lokalem Speicherplatz, aufbauen lassen, aber ansonsten keine speziellen Anforderungen an die Hardware gestellt werden, ist die resultierende Lösung normalerweise extrem kostengünstig, was vor einigen Jahren so noch nicht möglich war. Dies wird als eine der wichtigsten technischen Voraussetzungen für Big Data-Analyseverfahren angesehen. Apache Hadoop Als Standard für Big Data und verteilte Parallelverarbeitung hat sich im Markt Hadoop etabliert. Hadoop ist ein Projekt der Apache Software Foundation und ein in der Sprache Java programmiertes Open-Source-Framework für Batchbetrieb. Es lässt sich horizontal von wenigen auf mehrere tausend Serverknoten skalieren, toleriert Serverausfälle, die in großen Server-Farmen als „Normalzustand“ anzusehen sind, und sorgt so für stabile Speicher- und Analyseprozesse. Die Hauptbestandteile von Hadoop sind das Hadoop MapReduce-Framework und das Hadoop Distributed File System (HDFS), die nachfolgend etwas näher beleuchtet werden. Hadoop Distributed File System (HDFS) HDFS ist ein verteiltes Dateisystem, welches insbesondere für die Verarbeitung hoher Volumina und hohe Verfügbarkeit konzipiert und optimiert ist. Es erstreckt sich über die lokalen Speicher eines Clusters bestehend aus mehreren Rechnerknoten. Die zentrale Komponente von HDFS ist der Master Server (NameNode), der die ursprünglichen Daten partitioniert und sie regelbasiert anderen Rechnerknoten zuteilt. Jeder Slave speichert also nur einen Teil der kompletten Datenmenge. Der auf jedem Slave installierte DataNode ist für die lokale Datenverwaltung verantwortlich. Zwecks erhöhter Verfügbarkeit wird jeder Datenblock auf mehrere Server repliziert; standardmäßig gibt es jeden Block dreimal. By default, every data lock exists three times. Neben dem Primärblock existieren eine Kopie typischerweise auf einem zweiten Server innerhalb desselben Server-Racks und eine zusätzliche Kopie in einem anderen Rack. Um die Verfügbarkeit zu erhöhen, lassen sich die Daten auch auf unterschiedliche Lokationen verteilen. Gegen logische Fehler beim Kopieren oder Löschen von Daten hilft das natürlich nicht; hier sind zusätzliche Datensicherungsverfahren anzuwenden. Der HDFS NameNode verwaltet die Metadaten, weiß also jederzeit Bescheid, welche Datenblöcke zu welchen Dateien gehören, wo die Datenblöcke liegen und wo welche Speicherkapazitäten belegt sind. Über periodisch übermittelte Signale kann der NameNode feststellen, ob die DataNodes noch funktionsfähig sind. Anhand ausbleibender Signale erkennt der NameNode den Ausfall von DataNodes, entfernt ausgefallene DataNodes aus dem Hadoop-Cluster und versucht jederzeit, die Datenlast gleichmäßig über die zur Verfügung stehenden DataNodes zu verteilen. Und er sorgt dafür, dass stets die festgelegte Anzahl von Datenblockkopien zur Verfügung steht.

White Paper Lösungsansätze für Big Data
Seite 6 von 16 www.fujitsu.com/de
Um sich gegen einen Ausfall des NameNodes abzusichern, werden zwei NameNodes auf unterschiedlichen Maschinen im Cluster aufgesetzt. Dabei ist zu jeder Zeit einer aktiv und der andere passiv (Hot Stand-by). Änderungen der Daten, sowie ggf. der Metadaten, werden auf den NameNodes protokolliert. Die Synchronisation der Journaldaten kann über einen Shared-Storage (NAS) oder Quorum-basiert über mehrere Rechnerknoten erfolgen. Da immer beide NameNodes von den DataNodes direkt mit aktuellen Blockinformationen und Heartbeat-Signalen versorgt werden, kann bei Ausfall des aktiven NameNodes sehr schnell automatisch umgeschaltet werden. Hadoop MapReduce Wie HDFS, so arbeitet auch das MapReduce-Framework nach dem Master-Slave-Prinzip.. Der Master (JobTracker) zerlegt ein Problem in eine Vielzahl sinnvoller Teilaufgaben (Map-Tasks) und verteilt diese über das Netz auf eine Reihe von Rechnerknoten (TaskTracker) zur parallelen Bearbeitung. Typischerweise laufen die Map-Tasks auf denselben Clusterknoten, auf denen die zu bearbeitenden Daten liegen. Sollte dieser Rechnerknoten schon überlastet sein, so wird ein anderer Knoten ausgewählt, der möglichst nahe bei den Daten liegt, bevorzugt also im selben Rack. Zwischenergebnisse werden zwischen den Knoten ausgetauscht (Shuffling) und danach durch die Reduce-Tasks zu einem Endergebnis zusammengefasst. Da die Bearbeitungsprozesse zu den zu verarbeitenden Daten bewegt werden und nicht umgekehrt, ist es möglich, in der Map-Phase die I/O-Aktivität zu parallelisieren und die Netzbelastung fast vollständig zu vermeiden. Um auch in der Shuffling-Phase Skalierungsengpässe zu vermeiden, ist ein sich nicht blockierendes, leistungsfähiges Switched Network zwischen den Rechnerknoten erforderlich. Optional können Zwischenergebnisse aus der Map-Phase und der Shuffle-Phase aggregiert werden(Combine), um die Datenmenge, die von den Map-Tasks an die Reduce-Tasks übergeben werden müssen, gering zu halten.
Während sich die Eingangsdaten für MapReduce wie auch die Endergebnisse im HDFS befinden, werden Zwischenergebnisse in den lokalen Dateisystemen der DataNodes hinterlegt. Der JobTracker steht ständig mit den Slaves in Kontakt, überwacht die Slaves und sorgt dafür, dass unterbrochene bzw. abgebrochene Tasks erneut ausgeführt werden. Meldet eine Task lange Zeit keinen Fortschritt oder fällt ein Knoten ganz aus, so werden die noch nicht beendeten Tasks auf einem anderen Server neu gestartet, in der Regel auf einem Rechnerknoten, auf dem eine Kopie der betreffenden Daten vorhanden ist. Wenn eine Task sehr langsam läuft, kann der JobTracker den Auftrag auf einem anderen Server noch einmal starten (spekulative Ausführung), um den Gesamtauftrag sicher zu erfüllen. Die einzige Schwachstelle ist der JobTracker selbst, der einen Single Point of Failure darstellt. Dieser Rechner sollte deshalb in sich möglichst viele redundante Komponenten enthalten, um die Ausfallwahrscheinlichkeit so gering wie möglich zu halten. MapReduce wird durchaus zur Ausführung von Business Analytics-Abfragen genutzt werden; ein häufiger Anwendungsfall ist allerdings, große Datenmengen erst in eine für Analyseverfahren optimierte Form zu bringen. YARN (Yet Another Resource Negotiator) YARN ist eine Weiterentwicklung des MapReduce-Frameworks. Die Ressourcenverwaltung und die Applikationssteuerung, die in MapReduce v1 beide vom JobTracker erledigt wurden, sind in zwei von einander getrennte Instanzen aufgeteilt. Nur der schlanke Ressourcen-Manager bleibt als zentrale Instanz vorhanden, während die gesamte Job-Planung an die ApplicationMaster delegiert wird, die auf jedem Slave-Knoten ablaufen können. Pro Job wird ein ApplicationMaster dynamisch auf einem der Slave-Knoten erzeugt und steht exklusiv für diesen Jobauftrag zur Verfügung. MapReduce v2 ist dann nur noch eine von mehreren denkbaren Ausprägungen der parallelen Ablaufsteuerung. Die verteilte Applikationssteuerung erhöht den Grad der Parallelisierung, beseitigt Engpässe und ermöglicht Cluster mit zehntausenden von Rechnerknoten.

White Paper Lösungsansätze für Big Data
Seite 7 von 16 www.fujitsu.com/de
Apache Hadoop-Unterprojekte Neben den beiden Basisfunktionen, dem Hadoop Distributed File System (HDFS) und MapReduce gibt es eine Reihe zusätzlicher Hadoop-Unterprojekte, die in Kombination mit den beiden Kernkomponenten, Hadoop zu einem umfassenden Ökosystem und einer universell einsetzbaren Plattform für Analyseanwendungen machen. Nachfolgend werden die wichtigsten Unterprojekte zusammengefasst. Pig mit der Skriptsprache „Pig Latin“ ermöglicht die Erstellung von Scripts, die in MapReduce-Jobs kompiliert werden. Hive und die deklarative Abfragesprache HiveQL werden für Ad-hoc-Abfragen und die einfache Erstellung von Reports verwendet. Die Kompilierung in die entsprechenden MapReduce-Jobs findet automatisch statt. Hive wird auch verwendet, um Daten aus HDFS in ein bestehendes Data Warehouse zu laden. Sqoop wird für den Import und Export von Massendaten zwischen HDFS und relationalen Datenbanken herangezogen. Flume eignet sich insbesondere für den Import von Datenströmen, wie bspw. Web-Logs oder andere Protokolldaten, in das HDFS. Avro dient der Serialisierung strukturierter Daten. Die strukturierten Daten werden in Bitketten konvertiert und in einem kompakten Format effizient im HDFS abgelegt. Die serialisierten Daten enthalten auch Informationen über das ursprüngliche Datenschema. Die beiden NoSQL Datenbanken HBase und Cassandra erlauben eine sehr effiziente Speicherung großer Tabellen und einen effizienten Zugriff darauf. Mahout ist eine Bibliothek von Moduln für maschinelles Lernen und Data Mining. ZooKeeper ist eine Bibliothek von Modulen zur Implementierung von Koordinations- und Synchronisierungsdiensten in einem Hadoop-Cluster. Abläufe lassen sich mit Oozie beschreiben und automatisieren. Dies geschieht unter Berücksichtigung von Abhängigkeiten zwischen einzelnen Jobs. Chukwa überwacht große Hadoop-Umgebungen. Protokolldaten werden von den Clusterknoten gesammelt und verarbeitet und die Ergebnisse visualisiert. Ambari erlaubt eine einfache Verwaltung von Hadoop-Umgebungen. DataNodes werden hinsichtlich ihres Ressourcenverbrauchs und ihres Gesundheitszustandes überwacht. Cluster-Installation und Upgrades können automatisiert ohne jegliche Serviceunterbrechung durchgeführt werden. Dies erhöht die Verfügbarkeit und beschleunigt die Wiederherstellung im Notfall.
Mit Spark können Daten aus HDFS oder HBase direkt in den Hauptspeicher der Cluster-Knoten geladen werden. So kann für bestimmte Applikationen eine erhebliche Beschleunigung im Vergleich zu Hadoop MapReduce erreicht werden. Dies ist insbesondere dann von Vorteil, wenn mehrfache Abfragen auf dieselben Datenbestände erfolgen, wie dies beispielsweise bei Machine Learning der Fall ist. Die destillierte Essenz von Big Data Wie bereits erwähnt, kann verteilte Parallelverarbeitung auf Basis verteilter Dateisysteme sehr wohl für umfangreiche Analyseaufgaben herangezogen werden. Häufig steht jedoch die Vorverarbeitung großer Datenmengen im Vordergrund. Dabei werden die Daten bereinigt; Redundanzen und Widersprüche werden entfernt; und letztlich werden die Daten in eine Form gebracht, die sich besser für spontane (ad-hoc) Abfragen eignet. Das Ergebnis dieser Transformation ist in der Regel sehr viel kleiner als die Eingangsdatenmenge, enthält aber alle für den Anwendungsfall wichtigen Informationen und lässt sich somit als destillierte Essenz der Gesamtdaten auffassen. Es steht außer Frage, dass der Zugriff zu Daten auf Plattenspeichersystemen oder auch AFA (All-Flash-Arrays), welche sich durch hohe I/O-Leistung und niedrige Latenzzeiten auszeichnen nie so schnell sein kann wie auf Daten, die sich resident im Hauptspeicher eines Servers und somit näher bei den Applikationen befinden. Daher stellt man bei Echtzeitaufgaben die destillierte Essenz in einer In-Memory Plattform bereit, um sie für die Analyseanwendungen schnell zugänglich zu machen.

White Paper Lösungsansätze für Big Data
Seite 8 von 16 www.fujitsu.com/de
In-Memory Plattform Bei einer In-Memory Plattform handelt es sich um einen einzelnen Server oder ein Server-Cluster, dessen Hauptspeicher als Datenspeicher für schnellen Datenzugriff verwendet wird. In der Praxis werden mit der Einführung derartiger In-Memory-Plattformen die Datenzugriffe um das 1.000- bis 10.000-fache beschleunigt. Die Analyse von Geschäftsdaten kann so in Echtzeit erfolgen und nimmt nicht mehr Stunden, Tage oder sogar Wochen in Anspruch. Wichtige Entscheidungen lassen sich somit viel schneller treffen. Um die Datenverfügbarkeit zu erhöhen, können Hauptspeicherinhalte zwischen verschiedenen Rechnerknoten gespiegelt und damit synchron gehalten werden. Natürlich reduziert sich dadurch die insgesamt verfügbare Netto-Hauptspeicherkapazität entsprechend. Für Analysezwecke kann auf Plattenspeicher komplett verzichtet werden. Zu beachten ist allerdings, dass Daten, die sich nur im flüchtigen Hauptspeicher eines Rechners befinden, bei Systemabsturz verloren gehen können, insbesondere natürlich nach einem Stromausfall. Der Einsatz von Notfallbatterien für den Hauptspeicher hilft hier sicher nur temporär. Um Datenverlustes zu verhindern, müssen die Dateninhalte, die sich im Hauptspeicher befinden, zusätzlich auf ein nichtflüchtiges, persistentes Speichermedium gebracht werden. Hierfür sind mehrere Lösungsansätze denkbar. Eine gängige Methode ist die kontinuierliche Replikation der Hauptspeicherdaten auf Platte. Ein identischer Status von Hauptspeicher und Platte ist damit jederzeit garantiert. Zur Reduzierung der I/O-Last können alternativ in regelmäßigen Abständen oder beim kontrollierten Abschalten des Gesamtsystems Snapshot-Dateien erzeugt werden, die den jeweils aktuellen Zustand des Hauptspeicherinhalts festhalten. Bei einem Absturz können hierbei allerdings Datenänderungen, die sich seit dem letzten Snapshot ergeben haben, verloren gehen. Durch Mitprotokollieren sämtlicher Datenänderungen ist auch diese Lücke zu schließen. Aus dem letzten Snapshot und dem Protokoll der inzwischen getätigten Änderungen kann der zuletzt gültige Hauptspeicherinhalt automatisch wiederhergestellt werden.
Als Speicher für die Datenreplikate, die Snapshots bzw. die Änderungsprotokolle kommen sowohl lokale Platten der beteiligten Rechnerknoten, wie auch Speichersysteme im Netz in Betracht. Die Verwendung von Solid State Disks (SSD) beschleunigt natürlich die Wiederherstellung der Daten nach einem Absturz. Infolge der ständig sinkenden Preise für Hauptspeicher und der steigenden Leistung von Netzkomponenten, welche dazu beitragen, die Hauptspeicherinhalte mehrerer Rechner zu einer logischen Einheit zu formen, werden In-Memory-Plattformen mit immer größer werdenden Datenkapazitäten zu einem wichtigen Infrastrukturbaustein für Big Data. Nachfolgend werden verschiedene Implementierungsmöglichkeiten von In-Memory-Plattformen näher unter die Lupe genommen. In-Memory Datenbanken (IMDB) Bei einer In-Memory Datenbank (IMDB) befindet sich der komplette Datenbestand inklusive Verwaltungsdaten komplett im Hauptspeicher. Auch die Datenoperationen werden nur noch im Hauptspeicher durchgeführt, um schnelle Analysen zu ermöglichen. Für die Analysen können Lesevorgänge und Schreivorgänge von und zur Platte entfallen, komplett und ohne Ausnahme. Der Einsatz von IMDB liegt nahe, wenn voneinander unabhängige Applikationen aus vollkommen unterschiedlichen Blickwinkeln auf Datenbestände zugreifen, darauf dynamisch im Vorfeld noch nicht bekannte ad-hoc Abfragen absetzen, und die Ergebnisse in Echtzeit zu bereitzustellen sind. Die ersten im Markt verfügbaren IMDB waren für vertikale Skalierung ausgelegt. Mittlerweile gibt es aber auch IMDB, die horizontal skalieren. Die Skalierbarkeit ist hier jedoch bei weitem nicht so ausgeprägt wie bei Hadoop-Konfigurationen. Der Trend geht derzeit in die Richtung, horizontale und vertikale Skalierung gleichermaßen zu unterstützen. Ob eine In-Memory-Datenbank für die destillierte Essenz in Frage kommt, hängt von verschiedenen Faktoren ab. Zum einen ist dies die Datengröße, welche durch die im gesamten Servercluster verfügbare Hauptspeicherkapazität begrenzt wird. Bei spaltenorientierten Architekturen ist hier auch der Komprimierungsfaktor ausschlaggebend, der je nach IMDB und verwendetem Komprimierungsverfahren bei 10 bis 50 liegt und demzufolge die Kapazitätsgrenze um das 10 - 50-fache nach oben verschieben lässt. Wie viele Rechnerknoten insgesamt verwendet werden dürfen, ist in der Regel auch von IMDB zu IMDB verschieden. Außerdem spielt natürlich das verfügbare Budget eine Rolle; obwohl Arbeitsspeicher ständig preiswerter wird, sind die Kosten im Vergleich zu anderen Speichermedien immer noch vergleichsweise hoch.

White Paper Lösungsansätze für Big Data
Seite 9 von 16 www.fujitsu.com/de
Einige IMDBs beziehen OLTP-Produktionsdaten und störungsfreie OLAP-Abfragen in dieselbe Datenbankinstanz ein und ermöglichen so eine Analyse von Produktionsdaten in Echtzeit. In solchen Implementierungen verwendet man häufig hybride Tabellen, bestehend aus einem für OLAP optimierten Spaltenspeicher und einem Zeilenspeicher. Dabei werden aktuelle Datenänderungen während der Transaktionsverarbeitung im Zeilenspeicher hinterlegt, damit sie nicht ständig in den Spaltenspeicher einsortiert werden müssen. Nach gewissen Kriterien, wie bspw. Systemauslastung, Größe des Update-Zeilenspeichers oder nach einem bestimmten, vorgegebenen Zeitintervall, wird der Inhalt des Zeilenspeichers in den Spaltenspeicher einsortiert. Natürlich laufen Abfragen immer über beide Teile einer Tabelle, sofern es einen nicht-leeren Zeilenspeicher gibt. Kleine Tabellen werden üblicherweise nicht in Spalten konvertiert, ebenso wenig wie Systemtabellen, die in der Regel ja auch klein sind. In-Memory Data Grid (IMDG) Kommt eine IMDB nicht in Frage, verdient ein In-Memory Data Grid (IMDG) zwischen dem Plattenspeicher und den Applikationen Beachtung. Ein IMDG ist ein in der Regel über mehrere Server verteilter residenter Hauptspeicherbereich, in den große Datenbestände von externen Speichersystemen eingelagert werden. Jede Art von Datenobjekt kann in einem IMDG verwaltet werden, also auch vollkommen unstrukturierte Daten, wie man sie bei Big Data mehrheitlich vorfindet. Im Gegensatz zu einer IMDB muss hier nicht zwingend der gesamte Datenbestand in den Hauptspeicher passen. Dennoch wird die I/O-Last drastisch reduziert, Applikationen werden beschleunigt, und Analysen können in Echtzeit durchgeführt werden. Über vertikale und horizontale Skalierung kann mit eventuellem Datenwachstum Schritt gehalten werden. Während sich IMDB für oftmals im Vorfeld noch nicht bekannte ad-hoc Abfragen von unterschiedlichen Anwendungen eignen, welche nach Belieben dynamisch auf den Datenbestand zugreifen, liegt der Haupteinsatz von IMDG eher bei exklusiven Nutzern und vordefinierten, somit also im Vorfeld schon bekannten Abfragen. Die Applikation bestimmt und steuert die Verarbeitung innerhalb der einzelnen Datenobjekte, das IMDG kümmert sich um den Zugriff auf die Daten, ohne dass die Anwendungen wissen müssen, wo sich die Daten befinden. Zusätzliche Funktionen zu Suche und Indexierung der im IMDG gespeicherten Daten lassen die Grenzen zwischen einer IMDG-Lösung und einer NoSQL-Datenbank fließend erscheinen. Ein IMDG kann eine kosteneffiziente Alternative zu einer IMDB sein, vor allem wenn die Dateninhalte nicht häufig aktualisiert werden. Die Anwendungen, die auf die Daten zugreifen, können in der Regel unverändert genutzt werden; bei entsprechend vorhandener Expertise kann aber durch eine Anpassung der Anwendungen der Nutzen eines IMDG optimiert werden. Wo letztlich die Daten in einem IMDG herkommen, spielt für das IMDG keine Rolle. Die Daten können von Speichersystemen im Netz kommen, oder es kann sich um Daten aus dem HDFS handeln. Weniger denkbar sind NoSQL-Datenbanken, da diese oftmals eine integrierte Caching-Funktion besitzen, die bereits manche der Vorteile eines IMDG bietet.
Infrastrukturoptimierung für relationale Datenbanken Zu einer häufig geführten Diskussion führt die Frage, wie vorhandene Infrastrukturen für relationale Datenbanken in die Big Data-Welt integriert werden können. Für relationale Datenbanken gelten die bereits erörterten Einschränkungen. Deshalb kommen sie im Big Data-Umfeld nicht generell zum Einsatz. Relationale Datenbanken können jedoch Datenquellen für Hadoop sein, oder auch der Bestimmungsort für die destillierte Essenz. In beiden Fällen sind die Verarbeitungs- und Zugriffsgeschwindigkeit ausschlaggebend, insbesondere angesichts der steigenden Datenbankgrößen. Wie lässt sich der Datenbankzugriff also beschleunigen? Wie lässt sich die I/O-Aktivität reduzieren, wie holen Sie mehr IOPS aus der Speicherinfrastruktur heraus, und wie erreichen Sie eine kürzere Latenz? Welche Möglichkeiten zur Optimierung der Datenbankinfrastrukturen gibt es? Die bereits vorgestellte In-Memory-Datenbank, sowie das In-Memory Data Grid sind mögliche Lösungsansätze. In diesem Abschnitt werden weitere Alternativen behandelt. Eine Möglichkeit ist das Caching, bei dem häufig abgefragte Datensätze im Hauptspeicher des Datenbankservers verbleiben. Hierdurch werden die Lesevorgänge in der Datenbank beschleunigt, während die Schreibvorgänge direkt auf Festplatte erfolgen. Je größer der Cache, umso mehr Treffer sind zu erwarten und umso geringer die erzeugte I/O-Aktivität. Andererseits werden hierdurch zusätzlicher Speicher für den Cache und ein wenig mehr Arbeitsspeicher sowie zusätzliche CPU-Zyklen für den Cache-Algorithmus benötigt. Werden bestimmte Datensätze aufgrund ihrer besonderen Bedeutung im Hauptspeicher vorgehalten, dann sollten dafür In-Memory-Tabellen verwendet werden. Auch hierfür sind zusätzlicher Arbeitsspeicher und auch zusätzliche CPU-Zyklen zur Tabellenverwaltung erforderlich. Eine weitere Möglichkeit besteht in der Nutzung von RAM-Disks, eine Softwarelösung, bei der ein Teil des Hauptspeichers (RAM) reserviert und wie eine Festplatte genutzt wird. Die bisher vorgestellten Varianten nutzen allesamt die Tatsache, dass eine reine In-Memory-Verarbeitung zu einer Reduzierung der I/O-Aktivität führt. Die Nutzung schnellerer Festplattentechnologien für Ihre Speichersysteme, bspw. SSD (Halbleiterlaufwerke auf Basis von NAND-Flash), könnte aber auch in Betracht gezogen werden. SSDs sind einerseits leistungsfähiger als Festplattenlaufwerke und bieten außerdem mehr Kapazität als der Hauptspeicher. Eine weitere denkbare Alternative besteht darin, die Datenbankserver selbst mit einem lokalen Flash-Speicher (z.B. PCIe SSD) zu versehen, der ein Großteil der zur Bearbeitung benötigten Daten bei extrem verkürzten Zugriffszeiten vorhalten kann.

White Paper Lösungsansätze für Big Data
Seite 10 von 16 www.fujitsu.com/de
Interessant könnte außerdem ein All-Flash-Array (AFA) sein, das dem Speicher-Array vorgeschaltet ist und in dem idealerweise die gesamte Datenbank Platz findet. Eine solche Architektur bedeutet jedoch immer einen Kompromiss zwischen Größe, erforderlicher Systemleistung und Kosten. Unabhängig davon, für welche der Optionen Sie sich entscheiden, ob der Zugriff auf das Speicher-Array direkt erfolgt oder ein Flash-Array zwischen Server und Speicher-Array geschaltet wird – eine Hochgeschwindigkeitsanbindung zwischen Servern und Speicher-Array ist im Grunde unerlässlich. Die latenzarme und leistungsstarke Infiniband-Technologie ist für diesen Zweck bestens geeignet. Um Infiniband in die bereits vorhandenen Speicher- topologien und -protokolle zu integrieren, sind eventuell Hard- oder Software-Gateways erforderlich. Datenbanken für Big Data Verteilte Dateisysteme, wie das HDFS, können problemlos für große Datenmengen und Daten unterschiedlichen Typs verwendet werden. Im Vergleich zu einem Dateisystem erlaubt eine Datenbank auf Grund der bereitgestellten Abfragesprache eine weitaus effizientere Bereitstellung und einfachere Bearbeitung der Daten. Die heute am weitesten verbreitete Form der Datenbank ist die relationale Datenbank. Relationale Datenbanken eignen sich hervorragend für die Transaktionsverarbeitung strukturierter Daten von begrenztem Umfang. Sie sind optimiert für den satzweisen parallelen Zugriff vieler Benutzer, sowie für Operationen zum Einfügen, Aktualisieren und Löschen von Datensätzen. Abfragen dagegen verursachen einen höheren zeitlichen Aufwand. Big Data überschreitet diese Volumenbeschränkung, enthält mehrheitlich unstrukturierte Date und erfordert häufige Abfragen. Dies alles zeigt, dass relationale Datenbanken nicht die beste Wahl für Big Data sind. NoSQL (Not only SQL) Datenbanken sind speziell für Big Data-Anwendungen ausgelegt und können daher die Einschränkungen des relationalen Modells geschickt umgehen. Da sie auf keinem festen Schema aufsetzen, können sie recht einfach beliebige neue Datentypen aufnehmen; ebenso sind Datenformate einfach veränderbar, ohne dabei die Applikationen in irgendeiner Form zu beeinträchtigen. Im Gegensatz zu relationalen Datenbanken, die praktisch für unterschiedlichste Zwecke eingesetzt werden können, sind NoSQL-Datenbanken nur für spezielle Anwendungsfälle gedacht. Auf Grund ihrer Einfachheit kann ein höherer Durchsatz auch bei großen Datenmengen erzielt werden, wie sie bei Big Data typisch sind. Die Abfragen ähneln denen von SQL. Daten und Abfragen lassen sich auf die Rechnerknoten eines Clusters verteilen und ermöglichen fast lineare und unbegrenzte Skalierbarkeit, sowie hohe Fehlertoleranz durch Datenreplikation und automatische Wiederherstellung im Fehlerfall.
Da hohe Geschwindigkeit bei Datenzugriffen und Datenverarbeitung im Vordergrund steht, ist in vielen NoSQL-Implementierungen eine Caching-Funktion integriert, bei der häufig benutzte Daten resident im Hauptspeicher der Rechnerknoten gehalten werden, um die I/O-Last zu reduzieren. Es gibt eine Reihe unterschiedlicher Datenmodelle für NoSQL-Datenbanken, die für die Lösung unterschiedlicher Problemstellungen optimiert wurden. Key-Value Stores Die erste Variante, die wir uns anschauen, sind die Key-Value-Stores, in denen Paare aus Schlüssel und Wert-in großen Mengen gespeichert werden. Der Zugriff auf den Wert erfolgt über den Schlüssel, über den der Wert eindeutig referenziert werden kann. Die Struktur der Values wird nicht von der Datenbank interpretiert; das ist allein Sache der Applikation. Key-Value Stores eignen sich insbesondere für die schnelle Verarbeitung von Daten aus dem Internet, wie bspw. Clickstreams bei Online Shopping-Anwendungen. Suchfunktionen, z.B. in Mail-Systemen, ist ebenfalls ein interessanter Einsatzfall. Dokument-orientierte Datenbanken (Document Stores) Bei Dokument-orientierten Datenbanken werden die Daten in Form von Dokumenten gespeichert. Ähnlich wie bei den Key-Value-Stores werden die Dokumente (Values) durch eindeutige Namen (Keys) referenziert. Jedes Dokument ist vollkommen frei bezüglich seiner Struktur oder seines Schemas; das heißt, es kann das Schema verwendet werden, das für die Applikation benötigt wird. Sollten neue Anforderungen auftreten, so ist leicht eine Anpassung möglich. Neue Felder können hinzugefügt und bereits verwendete Felder können weggelassen werden. Da dokumenten-orientierte Datenbanken über keine Mittel zur Verarbeitung der Dateiinhalte verfügen, ist der Datenzugriff vollständig durch die Applikation zu leisten und die Programmierung etwas aufwändiger. Dokument-orientierte Datenbanken eignen sich besonders zum Speichern zusammenhängender Daten in einem Dokument (bspw. HTML-Seiten), oder serialisierter Objektstrukturen (bspw. im JSON-Format). Beispielsweise setzt Twitter eine Dokument-orientierte Datenbank zur Verwaltung der Nutzerprofile unter Einbeziehung der Follower und Kurznachrichten (Tweets) ein.
White Paper Lösungsansätze für Big Data
Seite 11 von 16 www.fujitsu.com/de
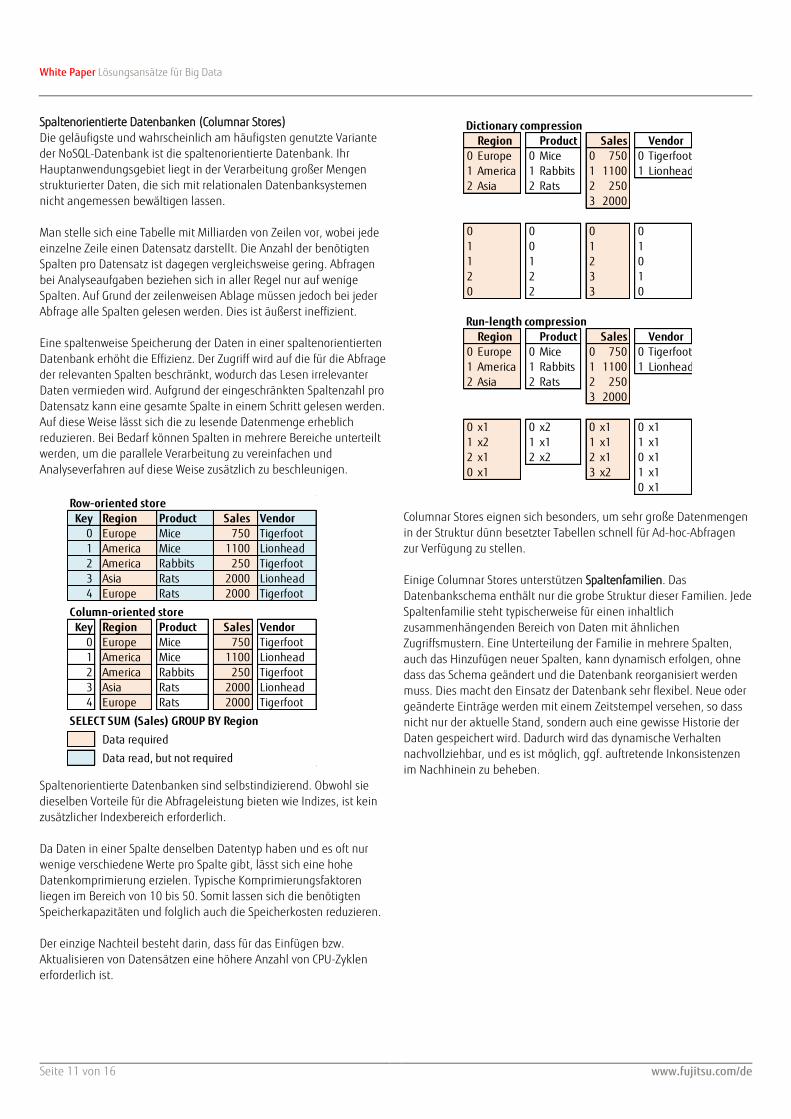
Spaltenorientierte Datenbanken (Columnar Stores) Die geläufigste und wahrscheinlich am häufigsten genutzte Variante der NoSQL-Datenbank ist die spaltenorientierte Datenbank. Ihr Hauptanwendungsgebiet liegt in der Verarbeitung großer Mengen strukturierter Daten, die sich mit relationalen Datenbanksystemen nicht angemessen bewältigen lassen. Man stelle sich eine Tabelle mit Milliarden von Zeilen vor, wobei jede einzelne Zeile einen Datensatz darstellt. Die Anzahl der benötigten Spalten pro Datensatz ist dagegen vergleichsweise gering. Abfragen bei Analyseaufgaben beziehen sich in aller Regel nur auf wenige Spalten. Auf Grund der zeilenweisen Ablage müssen jedoch bei jeder Abfrage alle Spalten gelesen werden. Dies ist äußerst ineffizient. Eine spaltenweise Speicherung der Daten in einer spaltenorientierten Datenbank erhöht die Effizienz. Der Zugriff wird auf die für die Abfrage der relevanten Spalten beschränkt, wodurch das Lesen irrelevanter Daten vermieden wird. Aufgrund der eingeschränkten Spaltenzahl pro Datensatz kann eine gesamte Spalte in einem Schritt gelesen werden. Auf diese Weise lässt sich die zu lesende Datenmenge erheblich reduzieren. Bei Bedarf können Spalten in mehrere Bereiche unterteilt werden, um die parallele Verarbeitung zu vereinfachen und Analyseverfahren auf diese Weise zusätzlich zu beschleunigen. Spaltenorientierte Datenbanken sind selbstindizierend. Obwohl sie dieselben Vorteile für die Abfrageleistung bieten wie Indizes, ist kein zusätzlicher Indexbereich erforderlich. Da Daten in einer Spalte denselben Datentyp haben und es oft nur wenige verschiedene Werte pro Spalte gibt, lässt sich eine hohe Datenkomprimierung erzielen. Typische Komprimierungsfaktoren liegen im Bereich von 10 bis 50. Somit lassen sich die benötigten Speicherkapazitäten und folglich auch die Speicherkosten reduzieren. Der einzige Nachteil besteht darin, dass für das Einfügen bzw. Aktualisieren von Datensätzen eine höhere Anzahl von CPU-Zyklen erforderlich ist.
Columnar Stores eignen sich besonders, um sehr große Datenmengen in der Struktur dünn besetzter Tabellen schnell für Ad-hoc-Abfragen zur Verfügung zu stellen. Einige Columnar Stores unterstützen Spaltenfamilien. Das Datenbankschema enthält nur die grobe Struktur dieser Familien. Jede Spaltenfamilie steht typischerweise für einen inhaltlich zusammenhängenden Bereich von Daten mit ähnlichen Zugriffsmustern. Eine Unterteilung der Familie in mehrere Spalten, auch das Hinzufügen neuer Spalten, kann dynamisch erfolgen, ohne dass das Schema geändert und die Datenbank reorganisiert werden muss. Dies macht den Einsatz der Datenbank sehr flexibel. Neue oder geänderte Einträge werden mit einem Zeitstempel versehen, so dass nicht nur der aktuelle Stand, sondern auch eine gewisse Historie der Daten gespeichert wird. Dadurch wird das dynamische Verhalten nachvollziehbar, und es ist möglich, ggf. auftretende Inkonsistenzen im Nachhinein zu beheben.
Row-oriented storeKey Region Product Sales Vendor
0 Europe Mice 750 Tigerfoot1 America Mice 1100 Lionhead2 America Rabbits 250 Tigerfoot3 Asia Rats 2000 Lionhead4 Europe Rats 2000 Tigerfoot
Column-oriented storeKey Region Product Sales Vendor
0 Europe Mice 750 Tigerfoot1 America Mice 1100 Lionhead2 America Rabbits 250 Tigerfoot3 Asia Rats 2000 Lionhead4 Europe Rats 2000 Tigerfoot
SELECT SUM (Sales) GROUP BY Region
Data required
Data read, but not required
Dictionary compressionRegion Product Sales Vendor
0 Europe 0 Mice 0 750 0 Tigerfoot1 America 1 Rabbits 1 1100 1 Lionhead2 Asia 2 Rats 2 250
3 2000
0 0 0 01 0 1 11 1 2 02 2 3 10 2 3 0
Run-length compressionRegion Product Sales Vendor
0 Europe 0 Mice 0 750 0 Tigerfoot1 America 1 Rabbits 1 1100 1 Lionhead2 Asia 2 Rats 2 250
3 2000
0 x1 0 x2 0 x1 0 x11 x2 1 x1 1 x1 1 x12 x1 2 x2 2 x1 0 x10 x1 3 x2 1 x1
0 x1

White Paper Lösungsansätze für Big Data
Seite 12 von 16 www.fujitsu.com/de
Graph-Datenbanken Bei Graph-Datenbanken werden Informationen in Graphen mit Knoten und Kanten, sowie deren Eigenschaften dargestellt. Eine der häufigsten Berechnungen in einer Graphen-Datenbank ist die Suche nach dem einfachsten und effizientesten Pfad durch den gesamten Graphen. Anwendungsgebiete sind die Fahrplanoptimierung, geografische Informationssysteme (GIS), Hyperlinkstrukturen sowie die Darstellung von Nutzerbeziehungen innerhalb sozialer Netzwerke. Wenn die Anzahl der Knoten und Kanten für einen Server zu groß wird, muss der Graph partitioniert werden, was im Prinzip einer horizontalen Skalierung entspricht. Dabei wird der Gesamtgraph in Teilgraphen zerlegt, was sich als durchaus schwierige, manchmal sogar unlösbare Aufgabe erweisen kann. In letzterem Falle müssten manche Knoten mehreren Teilgraphen zugeordnet werden; man spricht dann auch von einer überlappenden Partitionierung. Bei großen Datenbanken mit hoher Lese-Intensität und relativ geringer Schreiblast, kann eine Replikation der Daten auf mehrere Server zu einer beschleunigten Bearbeitung beitragen.
Complex Event Processing In den bisherigen Abschnitten wurde stets davon ausgegangen, dass Daten auf lokalen oder zentralen Plattenspeichern oder resident im Hauptspeicher von Rechnersystemen ruhen (Data at Rest) und auf Verarbeitung warten. Nun schauen wir uns Daten in Bewegung (Data in Motion) etwas näher an. Ereignisströme (Event Streams) werden kontinuierlich und in hoher Frequenz bspw. von Sensoren erzeugt. Diese Event Streams müssen sofort erfasst und in Echtzeit analysiert werden. Je nach Relevanz werden die Ereignisse gefiltert und korreliert. Die Analyse erfolgt mit Hilfe von vordefinierten Regeln, die jeweils eine Bedingung und eine Aktion enthalten. Wenn die Bedingung erfüllt ist (das kann eine Korrelation sowohl in logischer wie auch in zeitlicher Hinsicht sein), wird die Aktion in Echtzeit angestoßen. Das genau ist das Arbeitsprinzip einer CEP (Complex Event Processing) Engine. Je nach Anwendungsfall sind Hunderttausende oder gar Millionen von Ereignissen pro Sekunde bewältigen. Ein weiterer kritischer Parameter ist die Latenz, d. h. in diesem Fall die Zeit, die zwischen Ereigniseingabe- und Ereignisausgabe verstreichen darf. Typische Anforderungen bezüglich der Latenzwerte liegen im Mikro- bzw. Millisekunden-Bereich.
Eine CEP-Lösung muss demzufolge vor allem schnell und skalierbar sein. Um zeitraubende Plattenzugriffe zu vermeiden, werden die Ereignisströme hauptspeicherresident organisiert. Lediglich Betriebsprotokolldaten werden in eine Datei auf Platte geschrieben, sofern von dieser Option überhaupt Gebrauch gemacht wird. In diesem Protokoll werden unter anderem Engpässe bei Betriebsmitteln festgehalten, oder auch Anomalitäten, um im Nachgang die Ursache dafür zu ermitteln. Ist die auftretende Last nicht von einem Server zu bewältigen, ist eine Verteilung auf mehrere Server erforderlich. Große Datenströme werden auf mehrere Server mit entsprechenden CEP Engines verteilt. Eingehende Ereignisse werden verarbeitet oder an andere Server weiter geroutet. Sind sehr viele Regeln und Abfragen abzuarbeiten, findet eine Verteilung auf mehrere Server mit voneinander unabhängigen CEP Engines statt. Dabei wird versucht, Abfragen die in einer Beziehung miteinander stehen, soweit möglich, auf denselben Rechnerknoten zu dirigieren. Bei Regeln mit hohem Hauptspeicherbedarf, bspw. auf Grund größerer zu betrachtender Zeitfenster, kann ein IMDG helfen, welches sich über mehrere Server erstreckt. Datenverluste können über die in IMDG-Lösungen realisierten Hochverfügbarkeitsfunktionen vermieden werden (bspw. automatische Datenreplikation auf unterschiedlichen Rechnerknoten, bzw. eine temporäre Zwischenlagerung auf persistenten Speichermedien). Komplexe Abfragen, die ein einzelner Server nicht alleine bearbeiten kann, können in Teilaufgaben zerlegt und auf mehrere Server verteilt werden. Je nach Anwendungsfall können von einer CEP-Engine erarbeitete Ergebnisse auch in HDFS (bspw. die Betriebsprotokolldaten), NoSQL-Datenbanken, In-Memory-Datenbanken oder IMDG hinterlegt und für weitere Analysezwecke oder zur Visualisierung, bzw. für das Berichtswesen (Reporting) genutzt werden. Theoretisch ist es auch denkbar, von Sensoren erzeugte Daten in anderen Datenspeichern zu konservieren; bspw. wenn alle Vorgänge nachvollziehbar sein müssen und deshalb sämtliche eintreffenden Daten protokolliert werden.

White Paper Lösungsansätze für Big Data
Seite 13 von 16 www.fujitsu.com/de
Referenzarchitektur für Big Data Nachdem nun die wesentlichen Infrastrukturkonzepte für Big Data behandelt wurden, soll im nächsten Schritt eine Referenzarchitektur betrachtet werden, in der diese Konzepte berücksichtigt sind. Je nach Anwendungsfall kommen manche Technologien nur alternativ zum Einsatz, oder sie sind möglicherweise gar nicht erforderlich. Die Referenzarchitektur stellt letztlich einen Technologiebaukasten dar, aus dem für jede kundenspezifische Situation eine optimale Lösung als Kombination verschiedener Technologien konzipiert werden kann. Beginnen wir mit einer kurzen Zusammenfassung der in der Abbildung unten gezeigten Abläufe. Daten werden aus verschiedenen Datenquellen extrahiert. Bei diesen Datenquellen kann es sich handeln um Transaktionssysteme und Data Warehouses, aber auch um Protokolldateien, Click Streams, Internetseiten, die auch miteinander verlinkt sein können, E-Mails, Textdateien und Multimedia-Dateien. Und falls bereits eine IMDB im Einsatz ist, kann diese auch als Datenquelle herangezogen werden. Zur Beschleunigung der Extraktion von Daten auf Plattenspeichern kann optional ein IMDG eingesetzt werden. Dies ist nicht nur für die Big Data-Anwendung von Vorteil, sondern auch für jede andere Applikation, die diese Daten benötigt. Die Daten aus den genannten Quellen werden in ein verteiltes Datenhaltungssystem importiert, bspw. das HDFS, welches als Sammelbecken für große Datenmengen dient und sich über die lokalen Plattenspeicher von Rechnerknoten erstreckt. Über verteilte Parallelverarbeitung werden die Daten bereinigt und vorbearbeitet. Die Analyse und die Visualisierung der Analyseergebnisse kann unmittelbar auf das verteilte Datenhaltungssystem angewandt werden. Alternativ können durch verteilte Parallelverarbeitung transformierte Daten als destillierte Essenz in ein anderes Datenhaltungssystem exportiert werden. Dies ist in aller Regel entweder eine SQL- oder eine NoSQL-Datenbank. Auf diese Datenbank finden dann entsprechend auch die Analysen statt.
Bei weniger zeitkritischen Anwendungsfällen, kann sich die SQL-Datenbank durchaus auf einem zentralen Plattenspeichersystem befinden, das zweckmäßigerweise über eine Hochgeschwindigkeitsverbindung mit dem entsprechenden Datenbank-Server verfügt. Die Verwendung schneller Speichersysteme, wie bspw. All-Flash-Arrays (AFA), die von Hause aus für Solid State Disks (SSD) konzipiert sind, und sich durch extrem hohe I/O-Leistung und geringe Latenzzeiten auszeichnen, kann hier weitere Vorteile bringen. Sind jedoch Analyseergebnisse in Echtzeit gefragt, bietet sich eine IMDB an. Alternativ kann ein IMDG etabliert werden, um die destillierte Essenz entweder komplett oder zumindest zu großen Teilen hauptspeicherresident zu halten, und die Analyse-Applikationen drastisch zu beschleunigen. Während Daten aus den oben erwähnten Quellen typischerweise mit Hilfe von Hadoop und MapReduce im Batchbetrieb verarbeitet werden, müssen z.B. Sensordaten, Eindringversuche, Kreditkartentransaktionen, oder andere mit hoher Frequenz generierte Ereignisströme mittels einer CEP-Plattform in Echtzeit erfasst und analysiert werden, damit auch die entsprechenden Maßnahmen in Echtzeit eingeleitet werden können. Als Datenspeicher für Complex Event Processing wird der Hauptspeicher genutzt, je nach Komplexität auch ein IMDG. Ergebnisse aus den der CEP-Engines können auch nach Hadoop, bzw. an die destillierte Essenz außerhalb Hadoop zwecks Weiterverarbeitung oder Visualisierung weitergeleitet werden. Gleichermaßen werden Hadoop-Daten manchmal auch für CEP genutzt. Die Pfeilstärke in der Abbildung steht stellvertretend für das Datenvolumen, welches zwischen den einzelnen Instanzen der Big Data-Referenzarchitektur bewegt wird.

White Paper Lösungsansätze für Big Data
Seite 14 von 16 www.fujitsu.com/de
Wie jeder hybride Lösungsansatz erweckt dies auf den ersten Blick den Anschein einer hohen Komplexität. Umso wichtiger ist es, den Endanwender nicht mit dieser hohen Komplexität zu konfrontieren. Dies ist über den Einsatz entsprechender Konnektoren zwischen den Teilsystemen, bzw. durch Datenadapter zu erreichen, die einen reibungslosen Übergang ermöglichen. Letztlich entscheidend für den Endanwender ist jedoch, dass die für ihn bereitgestellten Analysefunktionen sich – für ihn vollkommen transparent - der richtigen Daten aus den richtigen Datenspeichern bedienen. Für den Anwender ist nicht die zu Grunde liegende Technologie entscheidend, sondern die Einsicht in die verfügbaren Daten, und das Gewinnen von Erkenntnissen, die ihn und seinen Geschäftsauftrag nach vorne bringen. Bei Big Data geht es aber nicht nur um die Infrastruktur Bisher wurde erörtert, was unter Big Data zu verstehen ist, welche Vorteile Sie davon erwarten dürfen, welche Lösungsansätze und sogar welche Kombinationen von Lösungsansätzen sinnvoll sein könnten, und wie die Gesamtarchitektur von Lösungen aussieht. Es würde dem Thema jedoch nicht gerecht werden, wenn wir unsere Betrachtung hier beenden würden, da es bei Big Data nicht nur um die Infrastruktur geht. Wer sich für Big Data-Verarbeitung entscheidet, stellt hohe Ansprüche an die Qualität der zu erwartenden Ergebnisse. Hierfür ist die Aufbereitung von Rohdaten zu qualitativ hochwertigen Informationen eine entscheidende Voraussetzung. Daten von geringer Qualität führen zu minderwertiger Ergebnisqualität und einer unbefriedigenden Benutzererfahrung, und Ihr Big Data-Projekt stellt sich im Endeffekt als Zeit- und Geldverschwendung heraus. Eines der am weitesten verbreiteten Probleme, auf das wir in Unternehmen immer wieder stoßen, besteht darin, dass zu viele Daten und zu wenige Ressourcen vorhanden sind und es darüber hinaus auch an analytischem und technischem Know-how mangelt. Dies führt dazu, dass manche Fragen nicht immer hinreichend beantwortet werden können. Hier einige Beispiele:
Welche Daten von welchen Datenquellen? Nach was sollen gesucht werden? Wie sieht die Fragestellung bei den Abfragen aus? Welche Aktionen sind anzustoßen? Welche Analysemethoden? Welche Art der Visualisierung? Welche Tools? Wie sind die Tools zu benutzen? Wie kann man die Bedeutung der Daten entdecken? Wie kann eine interaktive Erforschung der Daten aussehen? Welche Daten sind wie lange aufzubewahren? Welche Daten können gelöscht werden? Wie sehen die ersten Schritte aus?
Besonders der Analysebereich bedarf besonderer Aufmerksamkeit. Immer mehr Unternehmen interessieren sich für den so genannten „Data Scientist“, eine Fachkraft, die Kompetenz in den Bereichen Datenanalyse, Mathematik und Informatik mitbringt, über ein umfangreiches Branchenwissen verfügt und beauftragt wird, sich eingehend mit der Datenthematik zu befassen.
Ihr Weg zu Big Data Schauen Sie sich nun die Schritte an, die zur erfolgreichen Einführung von Big Data-Analyseverfahren in einem Unternehmen erforderlich sind. Zunächst gilt es, die Big Data-Strategie mit Ihrer Unternehmensstrategie in Einklang zu bringen. Ein erster Schritt besteht daher darin, die Bereiche zu identifizieren, in denen durch neue Erkenntnisse die größten Auswirkungen erzielt werden können. Teilen Sie Ihre Big Data-Strategie dann in überschaubare Zwischenziele ein, fragen Sie sich, welche Analyseergebnisse Sie benötigen oder welche Entscheidungen getroffen werden müssen, und was Sie dazu wissen müssen. Hierbei geht es nicht zwangsläufig um Maximalziele. Konzentrieren Sie sich jeweils nur auf ein Teilziel. Dies trägt dazu bei, die Projektzeit zu verkürzen und die Wertschöpfung zu beschleunigen. Stellen Sie eine funktionsübergreifende Arbeitsgruppe aus Dateneigentümern, System- und Tool-Eigentümern sowie Vertretern der Endanwender zusammen. Dateneigentümer kennen sich mit ihren Daten aus. Sie wissen, welche Daten erforderlich sind und aus welchen Quellen sie stammen. System- und Tool-Besitzer kennen sich mit den Systemarchitekturen und den Tools aus. Sie sind mit den in Frage kommenden Tools vertraut und in der Lage, die verteilten Datenquellen zu integrieren. Die Endanwendervertreter sollten eine klare Vorstellung davon haben, welche Anforderungen an die gewünschten Ergebnisse gestellt werden. Sobald Ihr funktionsübergreifendes Team einsatzbereit ist, können Sie damit beginnen, Testfälle zu erstellen. Bereiten Sie die geeigneten Daten für die Analyse vor, stellen Sie die benötigte Hardware und geeignete Tools zusammen, und beginnen Sie nach Möglichkeit mit einer kleinen Infrastruktur. Versuchen Sie nicht, das Rad neu zu erfinden. Besser ist es, nach dem Bibliotheks-Ansatz vorzugehen. Wählen Sie aus den bereits vorhandenen die brauchbaren Algorithmen aus, und passen Sie sie an Ihre Anforderungen an. Hierdurch sparen Sie Zeit und Geld. Analysieren Sie dann die Daten, und visualisieren Sie die Ergebnisse. Probieren Sie unterschiedliche Datenkombinationen aus, um neue Erkenntnisse zutage zu fördern, und stellen Sie Fragen, die bisher noch nicht gestellt wurden. Eines ist hierbei besonders wichtig: Machen Sie die Ergebnisse allen im Unternehmen zugänglich, die Nutzen daraus ziehen könnten. Nur so können Sie von eventuellen Rückmeldungen und Anregungen profitieren. Darüber hinaus müssen Sie sich mit Problemen auseinandersetzen, die in den Bereichen Sicherheit, Datenschutz, Compliance oder Haftung entstehen könnten. Wenn Sie diese Schritte erfolgreich absolviert haben, können Sie den Projektumfang und die Infrastruktur erweitern.

White Paper Lösungsansätze für Big Data
Seite 15 von 16 www.fujitsu.com/de
Bei all dem sollten die erforderlichen Veränderungen innerhalb der Unternehmenskultur nicht unerwähnt bleiben. Insbesondere Daten- und Prozesseigentümer müssen bereit sein, die Kontrolle über Dinge abzugeben, die zuvor allein in ihren Händen lag. Entscheidungsträger müssen lernen, Analyseergebnisse zu akzeptieren und zu respektieren. Häufig ist dies nur möglich, wenn die Geschäftsleitung einen entsprechenden Beitrag leistet und Unterstützung anbietet. Betrieb von Big-Data-Infrastrukturen Nachdem wir nun recht ausführlich über zusammengesetzte Konzepte und Referenzarchitekturen für Big Data mit ihren verschiedenen Technologiebausteinen gesprochen haben, bleibt die Frage, wie die IT-Infrastruktur für Big Data zweckmäßigerweise betrieben werden sollte. Eine Option ist sicherlich der Eigenbetrieb im eigenen Rechenzentrum. Hier können vordefinierte, vorgetestete und vorintegrierte Konfigurationen, Appliances und optimal aufeinander abgestimmte Hardware- und Softwarekomponenten dazu beitragen, die Einführung und auch die Verwaltung entscheidend zu vereinfachen. Der Aufbau, die Integration und der Betrieb einer Big Data-Infrastruktur ist jedoch aufwändig, erfordert Personal und entsprechendes Spezialwissen. Insbesondere bei Personalknappheit oder nicht vorhandenem Spezialwissen, kann es sinnvoll sein, sich auf seine Kernkompetenzen zu konzentrieren und den Betrieb der Infrastruktur einem Dienstleister zu überlassen, der diesen Service schneller, besser und auf Grund der erzielbaren Skaleneffekte auch kostengünstiger bereitstellen kann. Immer mehr Unternehmen sind nicht mehr daran interessiert, komplexe Infrastrukturen im eigenen Rechenzentrum zu halten. In diesem Falle ist Big Data aus der Cloud eine interessante Alternative, die den Anwender schließlich von Vorabinvestitionen und allen Betriebsaufgaben befreit. Der Aufwand für Installation, Konfiguration und Wartung entfällt vollständig. Auch eine Kapazitätsplanung ist nicht mehr erforderlich. Die benötigten Kapazitäten lassen sich flexibel an den sich verändernden Bedarf anpassen, insbesondere im Fall von gelegentlich oder periodisch auftretenden Belastungsspitzen. Insbesondere erübrigt sich dann auch die häufig diskutierte Frage, ob die riesigen Mengen externer Daten tatsächlich durch die Unternehmens-Firewall geschleust werden müssen. Abgerechnet wird Big Data aus der Cloud nach Nutzung der angebotenen Services (Pay-per-Use). Welche Parameter bei der Kostenfindung eine Rolle spielen, hängt vom Cloud-Dienst und vom Cloud-Dienstleister ab. Jedenfalls bietet Big Data aus der Cloud eines Cloud-Anbieters ein beachtliches Potenzial für Kostenreduzierung end ebnet damit den Weg zu Big Data trotz begrenzter Budgets. Falls Big Data aus der Cloud bereitgestellt wird, sollten auch die wesentlichen Datenquellen vom selben Cloud-Anbieter gehostet werden (Storage as a Service). Andernfalls müssten riesige Datenmengen zwischen Netzwerken übertragen werden, was die Ansprüche an eine schnelle Datenanalyse oder gar Echtzeitabfragen ad absurdum führen würde.
Es gibt aber auch gute Gründe, die Daten im eigenen Rechenzentrum zu belassen. So zum Beispiel, wenn es um interne Daten geht, bspw. Sensordaten von Fertigungsstraßen oder Videodaten von Sicherheitssystemen, die einen erheblichen Datenverkehr im Netz verursachen würden. Ebenso bei sensiblen Daten, bei denen der Verlust ein enorm hohes Risiko für das Unternehmen mit sich bringt, bzw. die auf Grund von Compliance-Anforderungen gar nicht in ein Public Cloud verlagert werden dürfen. Oder aber riesige Mengen flüchtiger Daten, die in einer derart hohen Frequenz anfallen, dass sie nicht schnell genug in die Cloud weitergeleitet werden können. IaaS, PaaS, SaaS oder sogar Data Science als Service? Wenn man erst mit Big Data aus der Cloud liebäugelt, stellt sich die Frage, was nun genau aus der Cloud geliefert werden soll. Am einfachsten ist es sicherlich, wenn man sich weder um die Analyse-Applikationen und die Middleware, noch die Infrastruktur inklusive Serversystemen, Speichersystemen und Netzen kümmern muss. Unternehmen können die Infrastruktur eines Cloud-Anbieters inklusive Serversystemen, Speichersystemen und Netzkomponenten nutzen, kümmern sich aber selbst um Middleware und Analysetools. In diesem Fall spricht man von Infrastructure as a Service (IaaS,). Wird zusätzlich zur Infrastruktur auch die Big Data Middleware, bspw. das Hadoop-Ökosystem vom Cloud-Anbieter bezogen, spricht man von Platform as a Service (PaaS). Bei Software as a Service (SaaS) nutzen Unternehmen auch die Analysetools des Cloud-Anbieters. Somit bleibt für das Unternehmen „nur“ noch die Aufgabe, die so oft zitierte Nadel im Heuhaufen zu finden, also die Data Science-Fragen zu klären, für die man angeblich die händeringend gesuchten Data Scientists benötigt. Da diese sehr rar sind, gehen manche Cloud-Anbieter noch einen Schritt weiter und bieten Data Science as a Service an, ein Service, der dem Kunden quasi die Nadel im Heuhaufen sucht und findet.

White Paper Lösungsansätze für Big Data
Seite 16 von 16 www.fujitsu.com/de
Welchen Beitrag kann Fujitsu leisten? Big Data eröffnet Unternehmen nicht nur ungeahnte Möglichkeiten, sondern stellt sie auch vor Herausforderungen hinsichtlich ihrer Geschäftsprozesse und der erforderlichen Infrastruktur, die nicht zu unterschätzen sind. Mit seinem umfassenden und durchgängigen Dienstleistungsangebot deckt Fujitsu sämtliche Aspekte von Big Data ab; seien es die Daten, die Prozesse oder die IT-Infrastruktur. Wir beraten unsere Kunden, was mit Big Data erreicht werden kann und legen gemeinsam die Roadmap für die Erreichung der Ziele fest. Wir planen und priorisieren die Anwendungsfälle, entwerfen und implementieren die Lösung, integrieren sie in die bestehende Systemlandschaft und übernehmen die Wartung für die Gesamtlösung, bei Bedarf auch vollkommen konsistent über Ländergrenzen hinweg oder sogar global. Unsere Services basieren auf bewährten Methoden und unserer Projekterfahrung über verschiedene Branchen hinweg. Fujitsu unterstützt sämtliche relevanten Big Data-Infrastrukturkonzepte und ist daher stets in der Lage, die optimale Kombination von Technologien für eine kundenspezifische Situation und individuelle Anforderungen zu erarbeiten. Ob Sie nun einen Server-Cluster mit Hadoop Open Source-Software benötigen, und egal wie groß dieser auch sein muss, ob Sie In-Memory-Technologien für Echtzeitanforderungen benötigen oder Plattenspeicher-basierte Lösungen ausreichen, oder selbst wenn eine Kombination aus unterschiedlichen Ansätzen speziell für Sie erstellt werden muss, Fujitsu findet stets die richtige Antwort, um die geeignete Lösung vor Ort für Sie bereitzustellen. In Big Data Lösungen von Fujitsu sind enthalten unsere PRIMERGY Industrie-Standard-Server und unsere PRIMEQUEST Server, die selbst Unternehmenskritische Anforderungen höchsten Grades erfüllen. Darüber hinaus die ETERNUS DX Speichersysteme von Fujitsu, bzw. All-Flash-Array von unserem Partner Violin Memory. Die verwendete Software ist entweder von Fujitsu selbst, Open Source, oder von führenden ISV (Independent Software Vendor), mit denen wir eine enge Partnerschaft pflegen. Zur Datensicherung und Archivierung ist Fujitsu ETERNUS CS die Lösung der Wahl. Da die Produkte von Fujitsu auf Standards basieren, vermeiden Sie die Abhängigkeit von einem einzelnen Anbieter. Integrierte Systeme erleichtern den Einstieg und bringen Sie schnell an Ihr Ziel. Besonders erwähnenswert sind in diesem Zusammenhang FUJITSU Integrated System PRIMEFLEX for Hadoop (ein Hadoop-Cluster, das selbst Anwendern aus den Fachbereichen einfache Analysen ermöglicht), FUJITSU Integrated System PRIMEFLEX for SAP HANA (die IMDB-Lösung von SAP) und die IMDG-Lösung FUJITSU Integrated System PRIMEFLEX for Terracotta BigMemory.
Attraktive Finanzierungsoptionen ermöglichen sogar die Einführung von Big Data ohne jede Vorabinvestition.
Wenn Sie noch einen Schritt weiter gehen und den Betrieb Ihrer Big Data-Infrastruktur in unsere Hände legen möchten, damit Sie sich besser um Ihre Kernkompetenzen und strategischen Projekte kümmern können, bietet Fujitsu Ihnen entsprechende „Managed Data Center Services“. Die monatliche Abrechnung lässt dabei Ihre Investitionsausgaben zu Betriebsausgaben werden. Wenn Sie sich überhaupt nicht mit Infrastrukturaspekten befassen möchten, können Sie Big Data-Analysen auch als Service über die Fujitsu Cloud beziehen. Mit anderen Worten: Fujitsu ist Ihre zentrale Anlaufstelle für Big Data-Infrastrukturen, die Ihnen Komplettlösungen inklusive sämtlicher Sourcing-Optionen aus einer Hand bietet. Auf diese Weise reduzieren Sie Komplexität, Zeit und Risiko. Zusammenfassung Bei Big Data geht es nicht allein um große Datenmengen. Ebenfalls charakteristisch ist die Vielzahl unterschiedlicher Datentypen, Datenquellen und Interpretationsmöglichkeiten, die erforderliche Geschwindigkeit angesichts kontinuierlich entstehender neuer Daten und die Herausforderung, Analyseergebnisse möglichst schnell bereitzustellen. Und natürlich geht es auch um die Technologien, die all dies auf erschwingliche Weise ermöglichen sollen. Big Data bietet enormes Wertschöpfungspotenzial. Wenn Sie sich anstelle oftmals falscher Intuitionen auf Echtzeitdaten verlassen, werden Sie in Zukunft intelligentere Entscheidungen treffen. Wenn man wettbewerbsfähig sein möchte, führt kein Weg an Big Data vorbei. Halten Sie sich immer vor Augen: Sie mögen Big Data ignorieren, Ihre Mitbewerber aber bestimmt nicht! Daher empfiehlt es sich, so früh wie möglich im Ozean von Big Data schwimmen zu lernen. Abhängig von den Geschäftsanforderungen, der bereits vorhandenen Infrastruktur und weiteren Aspekten sind eine Vielzahl unterschiedlicher Lösungsansätze und sogar eine Kombination derselben vorstellbar. Fujitsu bietet komplette Big Data-Lösungen inklusive Hardware, Software und Services – alles aus einer Hand. Das macht Fujitsu zum idealen Partner für Big Data-Lösungen und garantiertem Erfolg.
Kontakt FUJITSU Technology Solutions GmbH Mies-van-der-Rohe-Straße 8, 80807 München, Deutschland Tel.: +49-7203-922078 Fax: +49 -821-804-88429 E-Mail: [email protected] Website: www.fujitsu.com/de
ƒ Copyright 2015. Fujitsu und das Fujitsu-Logo sind Marken oder eingetragene Marken von Fujitsu Limited in Japan und anderen Ländern. Andere Firmen-, Produkt- und Servicebezeichnungen können Marken oder eingetragene Marken der jeweiligen Eigentümer sein. Änderungen bei den technischen Daten vorbehalten. Lieferung unter dem Vorbehalt der Verfügbarkeit. Haftung oder Garantie für Vollständigkeit, Aktualität und Richtigkeit der angegebenen Daten und Abbildungen ausgeschlossen. Wiedergegebene Bezeichnungen können Marken und/oder Urheberrechte sein, deren Benutzung durch Dritte für eigene Zwecke die Rechte der Inhaber verletzen kann.





























