Embed Size (px)
DESCRIPTION
Word co-occurrence features for text classification. 報告人: 陳重光. 作者 : Fabio Figueiredo , Leonardo Rocha ,Thierson Couto, Thiago Salles , Marcos Andre Goncalves ,Wagner Meira Jr. 出處 : Information Systems. Outline. 研究相關工作 特徵提取 實驗評估設定、步驟和結果 結論. 研究相關工作. 中文句法上的字詞定義 - PowerPoint PPT Presentation
Citation preview

1
作者: Fabio Figueiredo , Leonardo Rocha ,Thierson Couto,Thiago Salles , Marcos Andre Goncalves ,Wagner Meira Jr. 出處: Information Systems
Word co-occurrence features for text classification
報告人:陳重光

Outline
1. 研究相關工作
2. 特徵提取
3. 實驗評估設定、步驟和結果
4. 結論
2

研究相關工作
• 中文句法上的字詞定義 針對文件分類為什麼沒有人可以做到 100%的斷詞準度 ?– 文章字詞之間缺乏可辨識的無意義字元( ex: 英文中的 SPACE )– 有意義的字詞分佈與無意義字詞非常相近– 缺乏導出索引方面模糊字詞的技術– 關鍵字的雜訊
假設在一句法包含 T 個詞組中有 S 個同義詞,就有 個具有相同含意的字詞
Lewis(1990s)針對所提出幾點下了字詞特徵定義的總結 :
多份文件中在語意上具有低頻率特徵字詞
同義詞的高維度空間可以降低其單詞模糊性
3
TS

研究相關工作
• Word n-grams– n-gram 這種斷詞做法對分類的效益好壞,是來自於原樣本集合的
來源與類別
– 設定一個有效門檻值策略控制 n-gram 建立出來的字詞庫,可有效提升分類效益
– 設定有效的 stop word 也就是文章中無意義的字詞,可有效過濾文件中的雜訊字詞
4
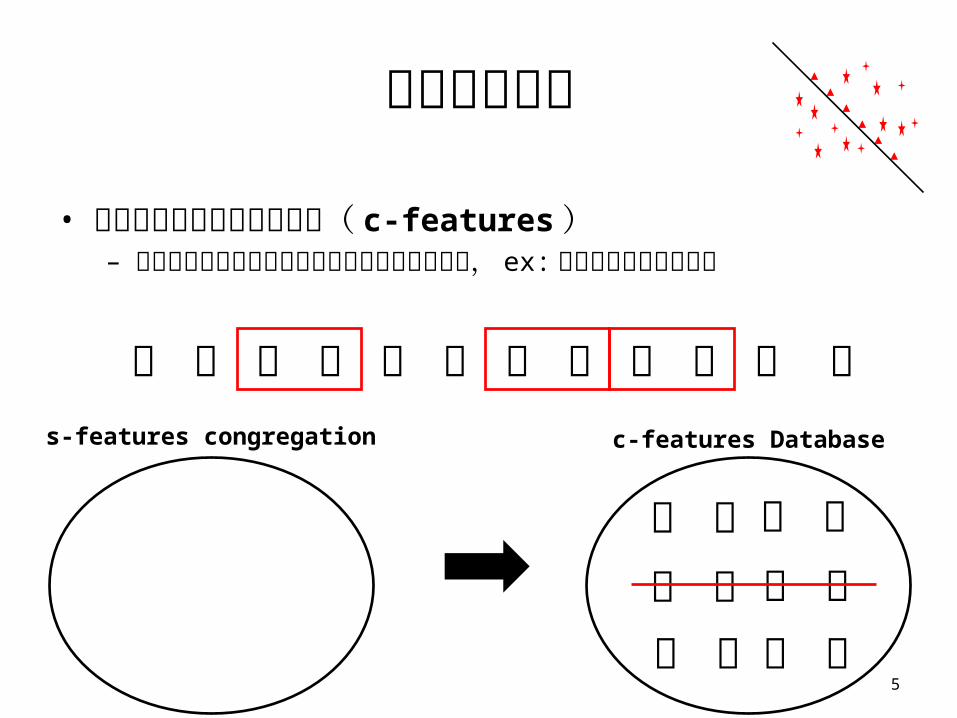
研究相關工作
• 在文章中非相鄰的共同特徵( c-features)– 文件主要的特徵定義在於同類別但不同的詞彙上, ex: 找有關資
訊類別的文章
5
南 台 大 學 程工 學 系s-features congregation
科 技 資 訊c-features Database
科 技資 訊資 訊 程工科 技 程工

特徵提取
• 方法– 用上述所使用的特徵提取方法和一些重要決策去擴充詞庫和改善分類效益
– 利用階層樹降低 Step1 的計算成本Step1:選擇 s-features 與合併 c-features 的策略
選擇 s-features 最佳組合的策略 經由斷詞之後計算其 s-features 權重值
合併成 c-features 的策略 合併高權重 & 非相鄰的 s-feature 成為 c-features 計算 c-features 在文件出現的機率做為字詞的最低門檻值
6
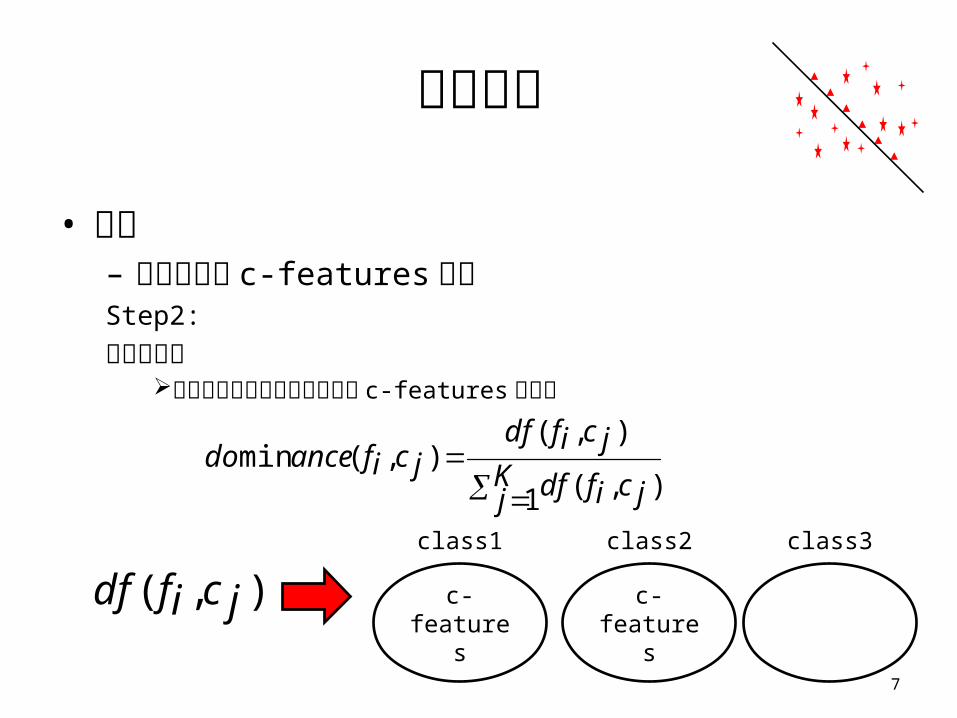
特徵提取
• 方法– 將合併出的 c-features 排名Step2:
排名的策略藉由優化函數判斷所合併出的 c-features 辨識率
7
Kj jcifdf
jcifdfjcifancedo
1 ),(
),(),(min
),( jcifdfc-features c-features
class1 class2 class3

特徵提取
• 方法– c-features 詞庫的擴充Step3:
擴充的策略給定一個門檻值
當 dominance()>= 就將 c-features 插入到訓練集合中
最後以 s-features 和 c-features 混合訓練,當 s-features 屬於 c-features就擴充到詞庫中
8

實驗評估設定、步驟和結果
• 實驗的文件集合1. 20 Newsgroups 18822 : 20 種科學、宗教和政治的新聞文
件共 18828 篇
2. OHSUMED : 23 種新血管疾病的文件共 18302 篇
3. Reuters-21578 : 10 種新聞文件,文章是由標題、作者、發稿日期和文件本體組成共 8184 篇
4. ACM11 : 11 種類別,由 ACM 期刊網站中的文件摘要和標題組成共 29570 篇
9

實驗評估設定、步驟和結果
• 實驗的文件集合– a : 20 Newsgroups 18822
– b : ACM11
– c : OHSUMED
– d : Reuters-21578
10
實驗評估設定、步驟和結果
• 分類效益實驗的評估方法– 評估所提的策略與參數的設置
– 使用 30~70% 之間分成訓練與測試集合
– 評估 kNN 、 Svm 和 Naıve Bayes 分類演算法得到的分類效益
11

實驗評估設定、步驟和結果
• 精確度 (precision)、召回率 (recall) 和 F-Measure(檢測分類系統的品質 )設定
TP(True positives) :所測試的文章屬於某個類別,且被分類到此類別TN(True negatives) :所測試的文章屬於某個類別,但沒有被分類到此類別FP(False positives) :所測試的文章不屬於某個類別,但被分類到此類別FN(False negatives) :所測試的文章不屬於某個類別,且沒有被分類到此類別
12

實驗評估設定、步驟和結果
• 精確度 (precision)、召回率 (recall) 和 F-Measure(檢測分類系統的品質 )評估公式
召回率公式:
精確度公式:
多類別召回率公式:
多類別精確度公式:13
iFNiTPiTP
icr )(
iFPiTPiTP
icp )(
Ki iFNiTP
Ki iTP
icr
1
1)(
Ki iFPiTP
Ki iTP
icp
1
1)(

實驗評估設定、步驟和結果
• 精確度 (precision)、召回率 (recall) 和 F-Measure(檢測分類系統的品質 )評估公式
F-Measure 公式 (micro-average) :
多類別 F-Measure 公式 (macro-average) :
14
)()(
)()(2
CrCP
CrCpiF
K
Ki iCriCp
iCriCp
iF
1 )()(
)()(2

實驗評估設定、步驟和結果
• 針對生成 c-features詞庫大小設定
15

實驗評估設定、步驟和結果
• 評估 c-features的辨識率測試 6 個最低門檻值: 50% 60% 70% 80% 90% 100% 與 dominance 出來的值比較 > dominance 才產出 c-features
設定 4 個類別數量參數 (min_supp) : 2 4 6 8 將產生的 c-features 依不同類別數分類
• Note:實驗都是以 bigrams的做法為基底
• 上述所提到的 N 、 dominance 和 min_supp 參數值定值都來自於 The Art of Computer Systems Performance Analysis : Techniques for Experimental Design 這篇研究 16

實驗評估設定、步驟和結果
• 實驗步驟隨機配置 5 次不同的訓練與測試集合
反覆做 20 次有 c-features 和沒有 c-features 做比較
藉由不同的斷詞方法比較每個分類演算法所得的分類效益
17

實驗評估設定、步驟和結果
• 實驗結果
18
Min_spp : 2詞庫大小:V
SVM:20 Newsgroups:100%Reuters- 21578:100%OHSUMED:90%ACM11:70%
kNN:20 Newsgroups:80%Reuters- 21578:90%OHSUMED:100%ACM11:60%
Naive-Bayes:20 Newsgroups:90%Reuters- 21578:80%OHSUMED:60%ACM11:70%

實驗評估設定、步驟和結果
• 實驗結果
19
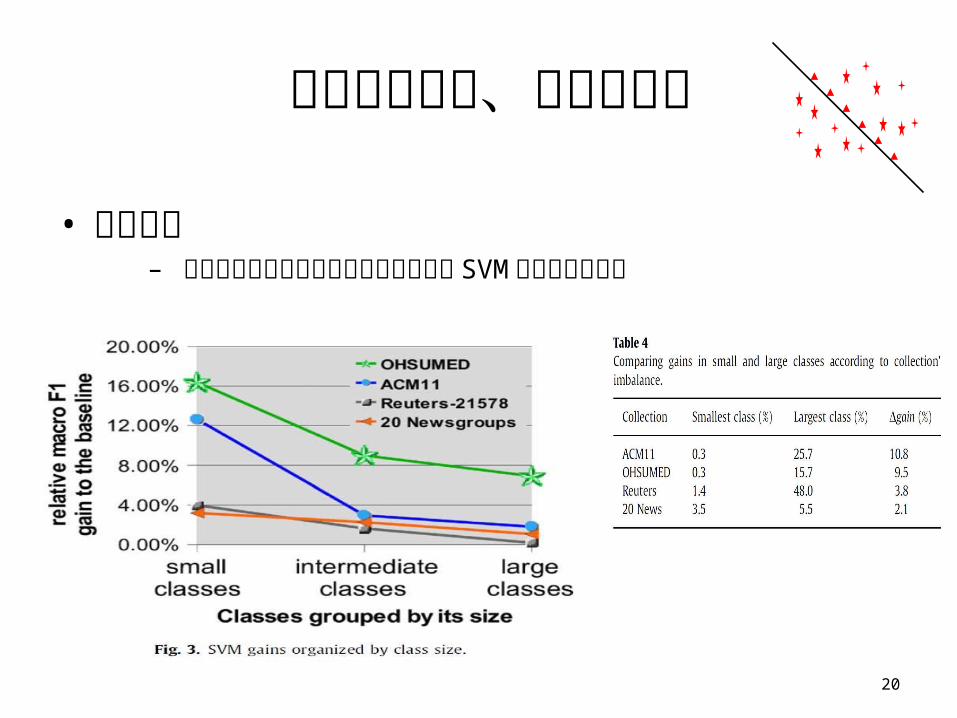
實驗評估設定、步驟和結果
• 實驗結果– 每種樣本利用這篇研究的特徵提取策略 SVM 所得的分類效益
20

實驗評估設定、步驟和結果
• 實驗結果– Min_Supp 參數利用 OHSUMED 樣本對 SVM 分類的影響
21
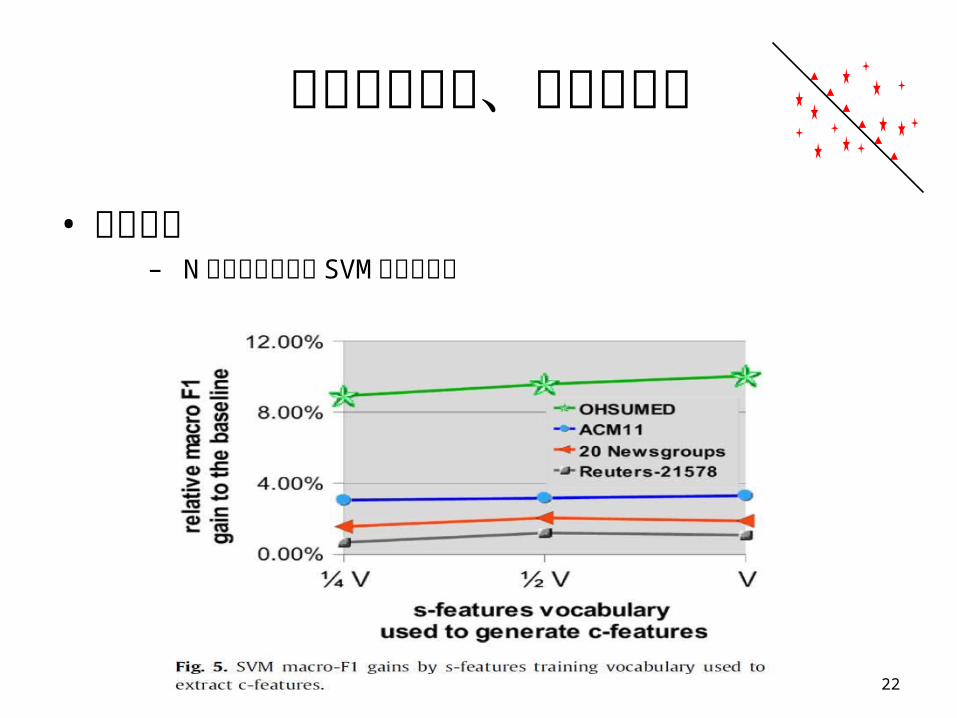
實驗評估設定、步驟和結果
• 實驗結果– N 參數詞庫大小對 SVM 分類的影響
22
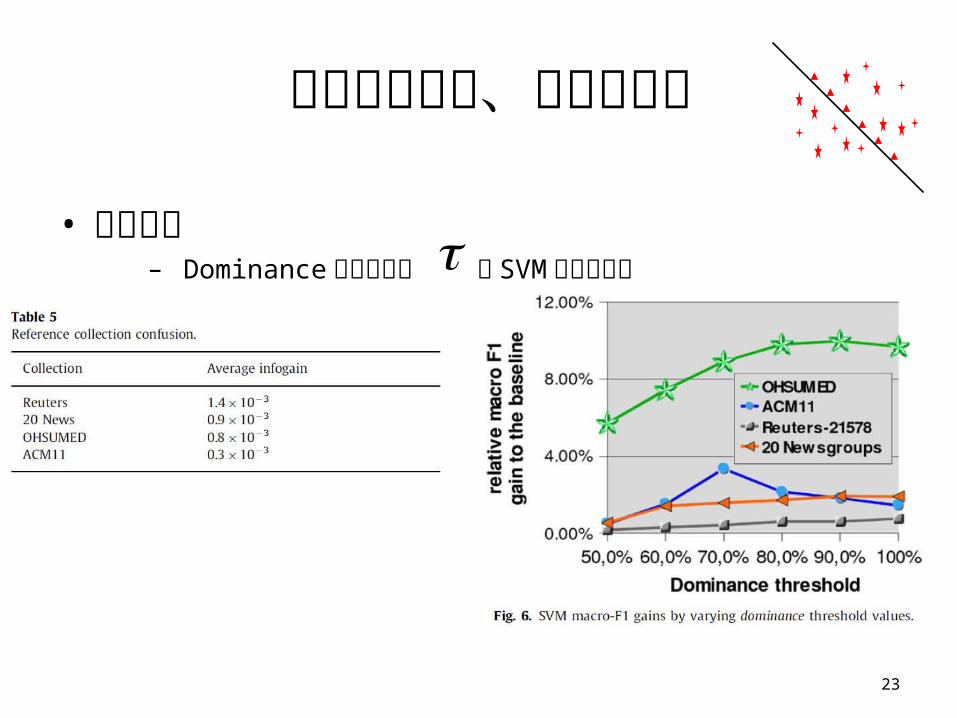
實驗評估設定、步驟和結果
• 實驗結果– Dominance 門檻值參數 對 SVM 分類的影響
23

實驗評估設定、步驟和結果
• 實驗結果– 分析計算成本
24
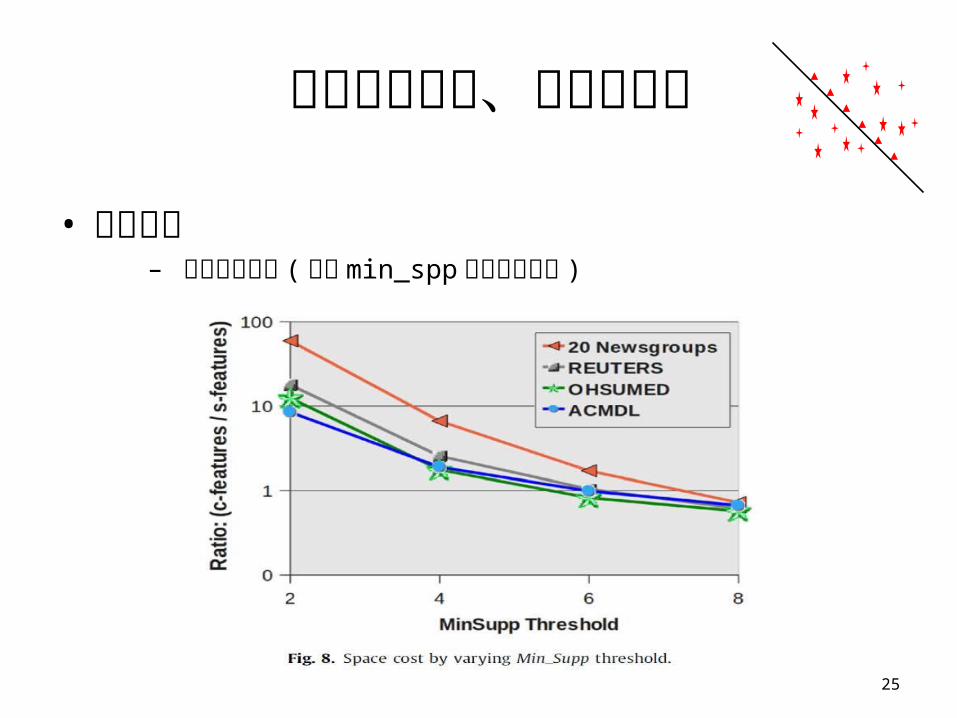
實驗評估設定、步驟和結果
• 實驗結果– 分析計算成本 ( 加入 min_spp 控制詞庫大小 )
25

實驗評估設定、步驟和結果
• 實驗結果– 利用 min_spp 控制詞庫大小所得到的分類效益
26
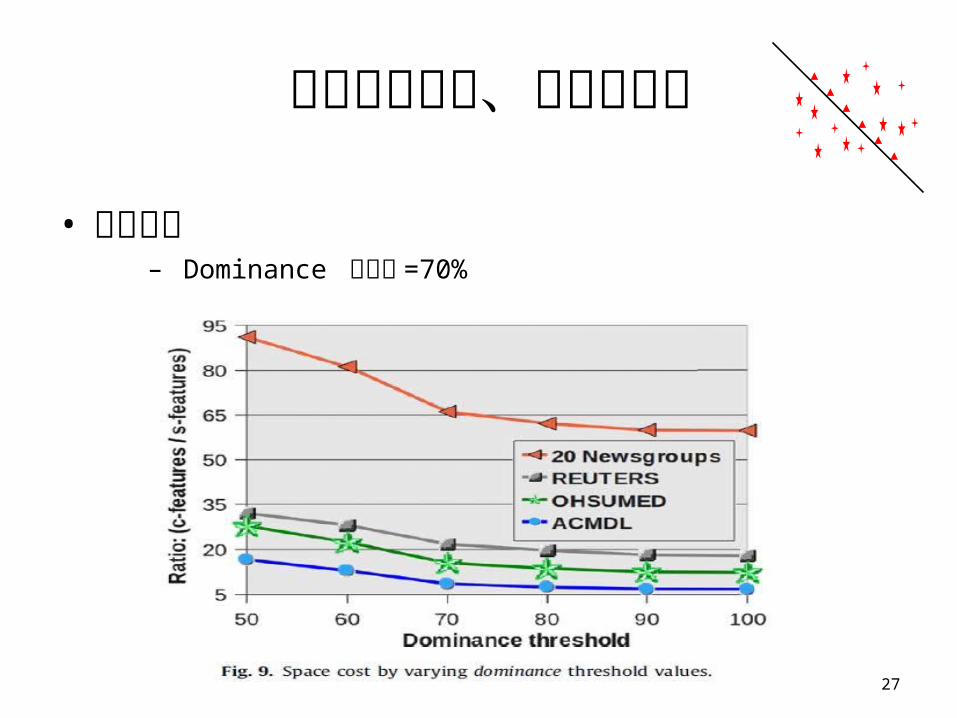
實驗評估設定、步驟和結果
• 實驗結果– Dominance 門檻值 =70%
27
結論
•定義好的文件特徵提取決策創造出有效益的分類器
•這篇研究也將所提出的特徵提取策略套用在傳統的分類演算法中,討論出此策略是適用的
28

感謝大家的聆聽 !
29





























