
FAKULTETA ZA INFORMACIJSKE ŠTUDIJE
V NOVEM MESTU
D I P L O M S K A N A L O G A
UNIVERZITETNEGA ŠTUDIJSKEGA PROGRAMA
PRVE STOPNJE
NEŽA PLUT


FAKULTETA ZA INFORMACIJSKE ŠTUDIJE
V NOVEM MESTU
DIPLOMSKA NALOGA
RAZVOJ PROGRAMSKE OPREME ZA
EKSPERIMENTALNO MERJENJE
KOLEKTIVNEGA ZNANJA
Mentor: doc. dr. Zoran Levnajić
Novo mesto, september 2015 Neža Plut

IZJAVA O AVTORSTVU
Podpisana Neža Plut, študentka FIŠ Novo mesto, izjavljam:
da sem diplomsko nalogo pripravljala samostojno na podlagi virov, ki so navedeni v
diplomski nalogi,
da dovoljujem objavo diplomske naloge v polnem besedilu, v prostem dostopu, na
spletni strani FIŠ oz. v digitalni knjižnici,
da je diplomska naloga, ki sem jo oddala v elektronski obliki, identična tiskani
različici,
da je diplomska naloga lektorirana.
V Novem mestu, dne _________________ Podpis avtorice: ______________________

ZAHVALA
Zahvaljujem se vsem, ki ste na kakršenkoli način crowdsourcali z mano v času študija in
izdelave diplomske naloge; crowdvotali, ko sem potrebovala drugo mnenje, mi skozi crowd
creation pomagali dodelati zamisli in s svojim znanjem v obliki crowd wisdoma razširili moja
obzorja.
Iskreno se zahvaljujem mentorju dr. Zoranu Levnajiću, da je bil del crowd creationa in crowd
wisdoma te diplomske naloge. Hvala za strokovno vodenje in podporo pri pisanju diplomske
naloge.
Posebna zahvala družini za crowdfunding, spodbudne besede in dejanja. Brez vas mi ne bi
uspelo.


POVZETEK
Pojem »crowdsourcing« označuje vrsto aktivnosti, v katerih sodeluje množica ljudi z
namenom reševanja širšega problema. Gre za netradicionalno metodo iskanja najboljše rešitve
zastavljene naloge v skupini ljudi. Problem je javno dostopen na spletu v obliki odprtega klica
in tako se njegovega reševanja lahko loti vsakdo. Posebnost tovrstnega reševanja nalog je, da
se najboljša rešitev oblikuje v procesu komunikacije množice. Ena izmed oblik
crowdsourcinga je kolektivno znanje oz. modrost množice, s katero smo se ukvarjali v
diplomski nalogi. V teoretičnem delu smo raziskali, kaj je kolektivno znanje, kakšne vrste
informacijskih sistemov, ki so namenjeni crowdsourcingu, poznamo, ter kateri so pogoji in
dejavniki kolektivne inteligence. Glavni namen izdelka pa je bil v praktičnem delu izdelati
programsko opremo, s katero bi kasneje eksperimentalno poskušali izmeriti, kako se
spreminja kolektivno znanje s spreminjanjem števila sodelujočih pri reševanju.
KLJUČNE BESEDE: množičenje, kolektivno znanje, kolektivna inteligenca, množica,
sodelovanje, učenje, spletna aplikacija.
ABSTRACT
The concept of crowdsourcing represents a certain type of activities in which a number of
people participates with the aim to solve a wider-set problem. It is a non-traditional method
for searching for the best solution to a given problem in a group of people. The given problem
is publicly available on the web in the form of an open call and thus anyone can try and tackle
it. The specificity of this kind of problem solving is that the best solution is formulated during
the process of communication among the participating people. One of the many forms of
crowdsourcing is collective knowledge or wisdom of the crowd which is the central issue of
this thesis. In the theoretical part of this thesis I made a research about what collective
knowledge actually is, what types of information systems made for crowdsourcing we know
and what the conditions and factors of collective intelligence are. The main purpose in the
practical part was to make a web application for the experimental measurment of collective
knowledge with which we could later determine what happens to the collective knowledge if
the number of participants changes.
KEY WORDS: Crowdsourcing, collective knowledge, collective intelligence, groups,
collaboration, learning, web application.


KAZALO
1. UVOD .................................................................................................................................... 1
1.1 Opredelitev problema ...................................................................................................... 2
1.2 Cilji diplomske naloge ..................................................................................................... 3
1.3 Raziskovalno vprašanje ................................................................................................... 4
1.4 Metodološki pristop ......................................................................................................... 4
1.5 Omejitve raziskave .......................................................................................................... 6
1.6 Struktura diplomske naloge ............................................................................................. 6
2. CROWDSOURCING ............................................................................................................. 7
2.1 Oblike crowdsourcinga .................................................................................................... 8
2.1.1 Modrost množice ................................................................................................... 9
2.1.2 Množično ustvarjanje .......................................................................................... 10
2.1.3 Množično glasovanje .......................................................................................... 11
2.1.4 Množično financiranje ........................................................................................ 12
2.2 Crowdsourcing v informacijskih sistemih ..................................................................... 13
2.2.1 Informacijski sistemi za množično obdelavo ...................................................... 15
2.2.2 Informacijski sistemi za množično ocenjevanje .................................................. 16
2.2.3 Informacijski sistemi za množično reševanje problemov .................................... 16
2.2.4 Informacijski sistemi za množično ustvarjanje ................................................... 17
2.3 Kolektivna inteligenca ................................................................................................... 18
2.3.1 Pogoji za kolektivno inteligenco ......................................................................... 18
2.3.2 Dejavniki kolektivne inteligence ......................................................................... 19
2.4 Vedenje množice pri pojavu crowdsourcinga ................................................................ 20
3. PRAKTIČNA IMPLIKACIJA ............................................................................................. 22
3.1 Spletna aplikacija za eksperimentalno merjenje kolektivnega znanja ........................... 22
3.2 Podatkovna baza Igre črk............................................................................................... 30
3.3 Izboljšave funkcionalnosti ............................................................................................. 33
3.3.1 Posodobitve spletne aplikacije ............................................................................ 34
4. ZAKLJUČEK ....................................................................................................................... 35
5. LITERATURA IN VIRI ...................................................................................................... 28
PRILOGA


KAZALO SLIK
Slika 2.1: Oblike crowdsourcinga ............................................................................................ 15
Slika 3.1: Vstopna stran spletne aplikacije za eksperimentalno merjenje kolektivnega
znanja ....................................................................................................................... 23
Slika 3.2: Neuspešna prijava .................................................................................................... 23
Slika 3.3: Čakanje na pričetek igre ........................................................................................... 24
Slika 3.4: Urejanje profila uporabnika ..................................................................................... 24
Slika 3.5: Administrator določi potek igre ............................................................................... 25
Slika 3.6: Administracija – seznam vseh uporabnikov in iger ................................................. 26
Slika 3.7: Začetek igre .............................................................................................................. 26
Slika 3.8: Beseda je že bila vnesena ......................................................................................... 27
Slika 3.9: Skorajšnji konec igre ................................................................................................ 28
Slika 3.10: Obvestilo o koncu igre ........................................................................................... 28
Slika 3.11: Administratorjeva stran – seznam vseh uporabnikov ............................................ 29
Slika 3.12: Administratorjeva stran – seznam vseh iger .......................................................... 30


1
1. UVOD
V informatiki smo privzeli izrek ameriškega biologa Oduma, da je »celota več kot vsota
njenih delov«, in ga prikrojili v »sistem je več kot le vsota njegovih delov; 1 + 1 > 2«. Tudi
Surowiecki, ki se ukvarja z raziskovanjem modrosti množice, pravi, da imajo skupine
potencial biti več kot zgolj vsota svojih delcev (Surowiecki, 2006). To načelo zelo dobro
opiše tudi pojav crowdsourcinga (slov. množično zunanje izvajanje ali množičenje), s katerim
se bomo v širšem konceptu ukvarjali v pričujoči diplomski nalogi.
Pojem crowdsourcing, ki sta ga leta 2006 skovala Jeff Howe in Mark Robinson, opisuje nov
poslovni model, ki se je razvil na spletu in prav tam tudi funkcionira. Govorimo o pojavu, ko
se (poslovne) naloge ne rešujejo več znotraj podjetja ali institucije, temveč s pomočjo
zunanjih izvajalcev. Pomembno je razumeti, da v tem primeru ne govorimo o že prej znanem
outsourcingu – zunanjem izvajanju; klasični obliki sodelovanja z zunanjimi strokovnjaki za
potrebe nekega projekta. Gre za prav posebno obliko outsourcinga, reševanja nalog – podjetja
te objavijo na spletu in jih tako v obliki odprtega razpisa predstavijo široki, nedefinirani
množici ljudi. Rešitev je tako lahko plod skupnega dela (angl. peer production), včasih pa
pobudo prevzamejo posamezniki te množice (Prpić in Shukla, 2012). Šaljivo bi lahko ta
koncept v slovenščini imenovali množicanje – »žicanje« množic, saj množice prosimo za
sodelovanje pri iskanju najboljše rešitve zadanega problema. Temeljna pogoja za
crowdsourcing sta torej odprt razpis in velika mreža potencialnih delavcev, ki pa je danes na
spletu ni težko doseči (Buecheler in drugi, 2010; Brabham, 2008).
Crowdsourcing je posebna oblika kolektivnega znanja oz. kolektivne inteligence – modrosti
množic. Analogno, kot lahko govorimo o inteligenci posameznika, lahko definiramo tudi
kolektivno inteligenco neke skupine. Kolektivna inteligenca so tako, splošno gledano,
zmožnosti skupine, da reši zastavljene naloge z najrazličnejših področij (Woolley in drugi,
2010). Množica dokazano prekosi industrijo hitreje in ceneje, kot bi to uspelo celo največjim
umom na področju. Gre za velik premik paradigme pogleda na strokovnost, korporacije in
vrednost intelektualnega dela v transnacionalnem svetu (Brabham, 2008). Ta dognanja že
spreminjajo načine, kako množica ljudi generira novo znanje in s tem izpodbija že obstoječa
(Buecheler in drugi, 2010). Interakcije med posamezniki in množico lahko razumemo kot

2
primer kolektivne inteligence, vključujoč soglasno odločanje, množično komunikacijo in
ostale fenomene (Buecheler in drugi, 2010). Ta oblika sodelovalnega reševanja nalog sili
vsakega izmed sodelujočih, da dela, razmišlja in dosega boljše zaključke, kot bi jih kdorkoli
izmed njih sam (Surowiecki, 2006).
Crowdsourcing ni nekakšna modna muha spleta 2.0, za katerega je značilna interakcija
uporabnikov, s strani katerih je kreiranih največ spletnih vsebin (O'Reilly, 2009). Prav tako to
ni zgolj drugačno poimenovanje filozofije odprtih virov (angl. open source) za namene
kapitalizma. Gre za strateški model, ki je zmožen privabljati zainteresirano, motivirano
množico posameznikov, zmožnih poiskati rešitev, boljše kakovosti oz. obsega, kot so tiste v
tradicionalnih oblikah posla. Množica rešuje probleme, ki spravljajo v zadrego strokovnjake v
podjetjih. Množica celo prekaša najboljše znanstvenike na svojem področju v iskanju
inovativne rešitve znanstvenega problema (primer: www.innocentive.com), vsak teden
oblikuje peščico originalnih potiskov za majice (primer: www.threadless.com), ki so
razprodane še pred koncem tedna, proizvaja nepozabne oglase in sveže fotografije (primer:
www.istockphoto.com), ki se lahko kosajo s profesionalnimi izdelki. To je samo nekaj
primerov crowdsourcinga. Med najbolj znanimi projekti, ki so nastali na ta način, je zagotovo
odprtokodni operacijski sistem Linux. Poleg tega je treba omeniti še prosto dostopno spletno
enciklopedijo, Wikipedijo, k rasti in izboljšanju katere lahko s svojim znanjem pripomore
vsak izmed nas (Howe, 2006).
1.1 Opredelitev problema
V zadnjih letih je vse več delovnih nalog opravljenih s strani skupine (so)delavcev, tako v
virtualni; prek računalnika, z uporabo spleta, kot v fizični obliki. To pomeni, da je za
učinkovito vodenje projektne skupine in dobre menedžerske odločitve pomembno
razumevanje zmogljivosti in posledično uspešnosti delovanja skupin ljudi (Woolley in drugi,
2010). Prav zato je v času sodobnih spletnih komunikacij crowdsourcing zelo obetaven
pristop k iskanju najrazličnejših inovacij, vključno z inovacijami v podjetništvu in industriji.
Pojav veliko govori tudi o naravi interakcij in odnosih med ljudmi ter je kot takšen sociološko
zanimiv (Buecheler in drugi, 2010).
Pojem crowdsourcing je novejši, saj ga poznamo šele od leta 2006 (Howe, 2006). Marsikateri
njegov vidik je že raziskan, prav področje kolektivnega znanja pa je najmanj raziskano.

3
S pojmom inteligenca poimenujemo širok spekter lastnosti, ki jih poseduje vsak človek.
Pravimo, da je inteligenca vsota kapacitet posameznika, ki jo ima za različna področja, kot so
logika, spomin, zmožnost reševanja problemov, abstraktno mišljenje, razumevanje,
samozavedanje, načrtovanje ter čustvena inteligenca. S temi veščinami se spoprijemamo z
novimi okoliščinami, v katerih se znajdemo, kjer nam nagon ne pomaga. Inteligenco
posameznega osebka lahko v okviru psihologije s posebno vedo, imenovano psihometrija, na
podlagi psihometričnih testov to tudi izmerimo. Za razliko od te pa testov, ki bi izmerili, kako
uspešno oz. učinkovito se skupina (naključno izbranih) ljudi v množici loti reševanja nalog z
najrazličnejših področij, še ne poznamo (Neisser in drugi, 1996).
Vemo torej, kaj kolektivna inteligenca je, vemo, katere lastnosti človeka vplivajo na
kolektivno znanje, vemo tudi, kateri so dejavniki, ki vplivajo na faktor kolektivnega znanja
množice. Ne vemo pa, kako se faktor kolektivnega znanja spreminja s povečevanjem števila
članov množice, ki stremi k iskanju rešitve zastavljenega problema. Prav to želimo ugotoviti z
izvedbo eksperimenta na podlagi izdelka te diplomske naloge – spletne programske opreme
oz. aplikacije.
1.2 Cilji diplomske naloge
Glavni cilj diplomske naloge je ustvariti spletno programsko opremo za eksperimentalno
merjenje kolektivnega znanja. Aplikacija bo narejena za uporabo prek spleta. Do aplikacije bo
moč dostopati prek spletnega brskalnika z ustreznim URL-naslovom.
Na podlagi raziskovalnega vprašanja smo definirali cilje raziskave:
teoretični pregled crowdsourcinga in kolektivnega znanja,
ustvarjanje koncepta igre, skozi katero bi poskusili eksperimentalno izmeriti
spremembe v kolektivnem znanju,
izdelava spletne programske opreme za eksperimentalno merjenje faktorja
kolektivnega znanja in
popravki oz. modifikacije programske opreme za eksperimentalno merjenje, ki bi jo
lahko neposredno uporabili.

4
1.3 Raziskovalno vprašanje
Raziskovalno vprašanje pričujoče diplomske naloge se glasi: »Kako se faktor kolektivnega
znanja spreminja s povečevanjem števila ljudi, ki so del sodelujoče množice?«. To je hkrati
tudi temeljno vprašanje projekta »Poslovna inovativnost kot evolucijski pojav«, s katerim smo
v preteklem študijskem letu, študijskem letu 2014/15, na Fakulteti za informacijske študije
pričeli to raziskavo. Zanima nas, kako hitro se akumulira znanje, kakšen je prispevek oz.
razlika kolektivnega znanja skupine, ki ima 𝑛 članov (pri čemer je 𝑛 naravno število), v
primerjavi s skupino, ki ima 2𝑛 članov, in ali se kolektivno znanje poveča ali morda po neki
točki celo zmanjša.
S pomočjo podatkov oz. izsledkov, pridobljenih na podlagi te aplikacije, izdelane v okviru
diplomske naloge, bomo poskušali najti formulo, matematično razlago, ki bi pojasnila, kaj se
dogaja s kolektivnim znanjem skupine ob povečevanju števila ljudi, ki sodelujejo pri
reševanju zastavljene naloge.
V nalogi odgovor ne bo podan, saj izvedba eksperimenta ni del diplomske naloge.
1.4 Metodološki pristop
Teoretični del diplomske naloge temelji na pregledu literature ter znanstvenih in strokovnih
člankov z raziskovanega področja. Predstavili bomo teoretična izhodišča in na podlagi teh
opisali ključne koncepte ter podali definicije strokovnih izrazov, ki so specifični za to
področje ter so za bralca tega dela ključnega pomena za razumevanje raziskovanega področja.
Ključni del raziskave obsega izdelavo aplikacije za merjenje kolektivnega znanja, ki se
analogno merjenju individualne inteligence izvede z nekakšnim testom oz. eksperimentom,
saj lahko le na ta način pridobimo relevantne podatke. Namen uporabe raziskovalne metode
eksperimenta je namerno spreminjanje pogojev, pod katerimi se odvija nek pojav. Ugotoviti
namreč želimo, kako ti spremenjeni pogoji vplivajo na opazovan pojav kolektivne inteligence.
Pričakovani rezultat eksperimenta so odgovori na vprašanja o vzroku in posledicah (Kompare
in drugi, 2006). Kot že omenjeno v predhodnem podpoglavju, ta diplomska naloga ne obsega
eksperimentalnega dela in odgovora na raziskovalno vprašanje.

5
Aplikativni del diplomske naloge je sestavljen iz obširne analize potreb eksperimenta in
praktičnega dela – programske kode. Glede na to, da smo aplikacijo pričeli razvijati v času
interdisciplinarnega projekta »Po kreativni poti do praktičnega znanja«, je bilo pomembno, da
smo s sodelujočimi strokovnjaki psihologi; Andreo Guazzinijem, Danielom Vilonejem,
Camilom Donatijem, Annaliso Nardi in mentorjem, prof. Zoranom Levnajićem, natančno
določili, kakšne so funkcionalne potrebe in ne nazadnje tudi videz te aplikacije. Eksperiment
bo moral biti dobro nadzorovan, kar pomeni, da moramo poskrbeti, da med izvajanjem ne
bodo prisotni dejavniki, ki bi motili izvedbo. Tako lahko pridobljene rezultate pripišemo
izključno dejavniku, ki smo ga namerno spreminjali – velikosti skupine množice – in tako
raziskovali, kaj se dogaja s faktorjem kolektivne inteligence.
V nadzorovano okolje spada tudi ustrezna prilagoditev aplikacije potrebam izvedbe
eksperimenta, s katerim bomo skušali izmeriti kolektivno inteligenco. V tem delu je bilo treba
nekajkrat opraviti testiranja; nekatera testiranja smo lahko v času izdelovanja programske
opreme izvedli kar sami, za druga pa smo potrebovali večjo testno skupino oseb. Tako smo
pridobili testne podatke, na podlagi katerih smo dobili dobro predstavo o tem, kako dodelati
oz. spremeniti določene segmente aplikacije, in tako mnogo lažje naredili popravke, s
katerimi smo prišli do skorajda optimalne končne različice programske opreme.
Pri programiranju te programske opreme smo uporabljali različne programske jezike glede na
namen dela opreme. Za programiranje »logike« spletne aplikacije sta najpomembnejša
programska jezika PHP in JavaScript, za asinhrono izmenjavo podatkov med strežnikom in
našo spletno aplikacijo pa smo uporabili programski jezik AJAX. Za povezovanje in delo s
podatkovno bazo, v kateri se nahaja Slovar slovenskega knjižnega jezika, ter bazo, ki bo
hranila podatke o igrah, smo se zaradi zagotavljanja vmesnika med programskim jezikom
PHP in jezikom za podatkovne baze odločili za programski jezik MySQLi. Pri programiranju
grafičnega uporabniškega vmesnika sta bila uporabljena jezika HTML in CSS.
Metodologija te diplomske naloge tako obsega študijo primera, načrtovanje spletne
programske opreme in njenega grafičnega vmesnika, programiranje aplikacije, načrtovanje in
ustvarjanje njenih izboljšav in testiranje uporabne vrednosti vmesnih in končnega izdelka.

6
1.5 Omejitve raziskave
Največja omejitev pri našem raziskovanju je naše znanje s področja spletnega programiranja.
Značilno za to dejavnost (programiranje) je nenehen in zelo hiter razvoj, prav tako se tudi
trendi spreminjajo, zato je treba vseskozi nadgrajevati svoje znanje.
Druga omejitev raziskave je, da je zaradi specifike raziskave, ki jo želimo izvesti v različnih
državah, treba prilagoditi del aplikacije, v katerem se nahaja baza s slovarjem besed. Do težav
lahko pride pri jezikih, ki uporabljajo posebne znake, opuščaje v besedah in podobno.
Naslednja omejitev je, da je treba za raziskavo, kljub temu da bi lahko bila izvedena prek
spleta in bi do nje lahko udeleženci raziskave dostopali od kjerkoli in kadarkoli, vzpostaviti
identično okolje za vse sodelujoče, začenši z ustrezno strojno opremo in dostopom do spleta.
Gre za nadzorovan eksperiment, kar posledično pomeni manjši vzorec sodelujočih.
Omejitev izvedbe eksperimentalnega merjenja kolektivne inteligence je tudi ta, da zgolj na
podlagi te spletne programske aplikacije oz. igre tudi na velikem, statistično gledano,
reprezentativnem vzorcu ne moremo z gotovostjo govoriti o točnosti podatkov. Res je, da bo
aplikacija merila kolektivno inteligenco na podlagi maternega jezika, za katerega lahko
trdimo, da ne preverja nekih specifičnih znanj o jeziku, temveč zelo splošne, osnovne. Še
vedno pa to ne bo dovolj. Prav zato se je v naši raziskovalni skupini porodila ideja o tem, da
poskušamo ustvariti še igro, s katero bi lahko preverjali npr. zelo osnovno matematično
znanje v smislu kolektivne inteligence. Naša diplomska naloga pa ne obsega tega dela
aplikacije.
1.6 Struktura diplomske naloge
Diplomska naloga je sestavljena iz teoretičnega in aplikativnega dela, ki sta razdeljena na dve
poglavji.
V uvodu opredelimo raziskovalni problem, namen in cilj raziskave v širšem kontekstu in v
kontekstu pričujoče diplomske naloge. Ker gre za projekt, ki se ne bo končal z diplomsko
nalogo, temveč želimo z izdelkom (programsko opremo) izvesti znanstveno raziskavo,
govorimo tudi o tem.

7
V drugem poglavju je na podlagi pregleda literature opredeljen ključni pojem, kolektivno
znanje, ki je umeščeno tudi v širšo tematiko t. i. pojava množičenja (»crowdsourcinga«).
Predstavljeni so njen izvor, ključne lastnosti in uporabna vrednost.
V tretjem poglavju se teoretične razlage prenesejo na aplikativno raven, kjer opišemo potek
izdelave programske opreme. Prvi korak pri tem je bila izbira metodologije dela, natančneje
izbira programskega okolja in jezika, v katerem smo programirali. Opisali smo tudi, kako naj
bi bila aplikacija videti in kaj naj bi vsebovala, da bi zadostila potrebam raziskovanja –
tehnične specifikacije. Kot pri vsaki aplikaciji je bilo treba ustvarjeno programsko opremo
nekajkrat testirati in implementirati oz. posodobiti nekatere funkcionalnosti. V zaključku tega
poglavja smo razmislili in predstavili tudi nadaljnje predloge za izboljšavo aplikacije.
Zaključek naloge je namenjen podajanju sklepnih ugotovitev, odgovarjanju na raziskovalno
vprašanje ter izpostavitvi pridobitev in omejitev naloge. Na podlagi odgovora na zastavljeno
raziskovalno vprašanje je v zaključku utemeljena smiselnost uporabe naše programske rešitve
za eksperimentalno merjenje kolektivne inteligence, izpostavili pa smo tudi ključne uporabne
lastnosti te rešitve.
2. CROWDSOURCING
Prvi bolj odmeven primer crowdsourcinga se je odvil v začetku leta 2009 na pobudo
britanskega matematika Tima Gowersa. Gowers je raziskovalni profesor na Oddelku
abstraktne matematike in matematične statistike na Univerzi v Cambridgeu. Med drugim je
tudi prejemnik Fieldsove medalje, ki velja za različico Nobelove nagrade na področju
matematike.
Kot bloger (ustvarjalec spletnega dnevnika) je na svojem blogu (spletnem dnevniku) redno
objavljal najrazličnejše zanimivosti iz sveta matematike. Zanimalo ga je, ali je masivno
sodelovanje na področju matematike sploh možno. S tem namenom je predlagal reševanje
zelo težkega matematičnega problema, trajanje reševanja katerega je ocenil na nekaj mesecev.
The Polymath Project, kot je problem poimenoval, je objavil v obliki odprtega klica (angl.

8
open call), kar pomeni, da je bil ta javno dostopen prek spleta (na Gowersovem blogu). Tako
ga je lahko videl prav vsak posameznik in se tudi lotil reševanja ne glede na matematično
znanje, izobrazbo, kulturno okolje, iz katerega izhaja, politično prepričanje, versko
opredelitev in ostale lastnosti, po katerih se ljudje med seboj razlikujemo.
Začetki so bili počasni, saj v prvih 7 urah po Gowersovi objavi naloge ni bilo nobenega
odziva. Po le nekaj urah pa se je usul plaz komentarjev z različnimi predlogi za njegovo
reševanje. V 37 dneh je tako 27 posameznikov v skupaj okoli 800 komentarjih s
sodelovanjem rešilo ne zgolj prvotno zastavljeni problem, temveč njegovo še mnogo težjo
generalizacijo. Rezultat tega dela so tudi številni znanstveni članki (Nielsen, 2011).
Na podlagi tega in mnogih drugih uspešnih projektov, ki so bili kolektivno reševani na osnovi
crowdsourcinga, trdimo, da lahko s pomočjo interneta zgradimo zelo močna orodja, s katerimi
lahko razširimo svoje zmožnosti in tako uspešno rešujemo še večje intelektualne izzive.
Govorimo torej o orodjih, s katerimi okrepimo kolektivno inteligenco in spremenimo način
konstruiranja znanja.
2.1 Oblike crowdsourcinga
Ob branju najrazličnejše literature in znanstvenih člankov s področja crowdsourcinga smo
ugotovili, da obstaja mnogo različnih pristopov h crowdsourcingu. Nekateri pristopi se
navezujejo na aktivno sodelovanje znotraj skupine posameznikov, medtem ko se drugi
okoriščajo z nasprotnim. Nekateri sistemi namreč ne maksimirajo svoje vrednosti s
sodelovanjem, ampak zgolj z minimalno interakcijo med udeleženci.
Jeff Howe, eden izmed »kovačev« besede crowdsourcing, v svoji knjigi »Crowdsourcing«
opisuje štiri primarne tipe crowdsourcinga (Howe, 2009):
modrost množice (angl. crowd wisdom),
množično ustvarjanje (angl. crowd creation),
glasovanje (angl. crowd voting) in
množično financiranje (angl. crowd funding).

9
2.1.1 Modrost množice
Načelo modrosti množic skuša izkoristiti znanje mnogih ljudi tako, da bi rešili probleme oz.
napovedali prihodnje izide ali neposredno pomagali razviti strategije korporacij. Howe
navaja, da množica ob pravih pogojih skoraj vedno prekaša poljubno število zaposlenih v
podjetju. To dejstvo skušajo danes številna podjetja uporabiti sebi v prid (Howe, 2009),
Če množico ljudi poprosimo, naj oceni, koliko kroglic se nahaja v velikem steklenem
kozarcu, je povprečje vseh odgovorov najverjetneje zelo blizu pravilni številki. Res je, da
lahko kdo izmed posameznikov množice odgovori še bolj natančno, kot kaže povprečje.
Vendar s ponavljanjem vprašanja eni osebi, ta v vsakem naslednjem poskusu ugibanja
odgovora ne bo izboljšala oz. se bolj približala pravilni številki kroglic. Nasprotno pa je
množica bolj »pametna« kot katerikoli posameznik. Ta ugotovitev je nekoliko nasprotna
intuiciji (Surowiecki, 2006).
Pojavi se vprašanje, »zakaj strokovnjaki niso tako zelo pametni«. Običajno strokovnjaki
mislijo enako ali zelo podobno in zato ne odražajo maksimalne raznolikosti mnenj; so
nekonsistentni in slabo sprejmejo svojo pozicijo. V grobem rečeno, so pretirano zaverovani
vase. Kadar sodelujejo v skupini, se nagibajo k strinjanju z odločitvijo najmočnejšega člena –
največjega strokovnjaka, zaradi česar do nestrinjanja znotraj skupine skorajda ne pride.
Namesto da bi reševanje problema predstavljalo izziv, postane rešitev v takih primerih zgolj
dogovor o skladnosti in pristranskosti (Surowiecki, 2009; Howe, 2009).
Neodvisnost pri odločanju je ključnega pomena, vendar pa jo je zelo težko doseči. Ljudje
imamo namreč nagon, da se nagibamo k »čredi«. Veliko varneje je slediti množici, ki ima
racionalno idejo, kot pa posamezniku z enako idejo. Gre za poseben primer »informacijske
kaskade«: pogosto slepo sledimo tistim, ki so prvi, ne da bi preverili, na kakšnih temeljih
slonijo njihove odločitve. Vendar pa vse »informacijske kaskade« niso slabe; inteligentna
imitacija je nekakšen racionalen odziv na naše kognitivne omejitve, posebno, kadar imamo na
razpolago malo časa. Otroci na primer nagonsko posnemajo svoje starše oz. starejše ljudi,
katerih preživetje je dokaz, da delajo pravo stvar. Bolj pomembna, kot je odločitev, in več
časa, kot je na razpolago za razmišljanje, manj verjetno je, da se bo ta kaskada obdržala.

10
Depolarizacija omogoča, da pride do sklepov na objektivni podlagi in ne na podlagi avtoritete.
Takšni sklepi se izkažejo boljše, kot če bi jih prepustili najboljšemu oz. najpametnejšemu
članu skupine. Z drugimi besedami, ključ za uspeh je dobra struktura množice, ki omogoča
dobro združevanje oziroma prepletanje mnenj; dobro agregacijo informacij. V simulacijah so
se dobro urejene skupine izkazale za boljše – do zaključkov so prišle hitreje kot njihov
najpametnejši član (Surowiecki, 2009).
Howe omenja študijo Kalifornijskega inštituta za tehnologijo Caltech pod vodstvom prof.
Scotta E. Pagea, kjer so dokazali, da množica naključno zbranih ljudi, ki sodelujejo pri
reševanju problema, tega reši bolje kot množica visoko inteligentnih ljudi (Howe, 2009).
Da bi množica zares izkoristila svoj potencial in reševala kognitivne probleme na najboljši
možen način, morajo biti izpolnjeni 4 pogoji (Surowiecki, 2006):
zadostna raznovrstnost mnenj,
neodvisnost mnenj posameznikov tako, da med množico ni nikakršnih povezav,
decentralizacija izkušenj,
ustrezni mehanizmi združevanja.
2.1.2 Množično ustvarjanje
Gre za bolj kreativno naravnane projekte, kot so grafično oblikovanje, kreativno pisanje,
oblikovanje oblačil itd.; v zadnjem času ena izmed najbolj priljubljenih oblik združevanja
znanja množice. Ta vrsta projektov se zanaša na javnost, ki naj bi ustvarila vsesplošno
navdušenje in vlagala v imenu tistih, ki rešitev predlagajo (Article One Partners, 2011a).
Ne glede na to, ali podjetje prosi za ustvarjalne odgovore, kot so umetniška dela in videi, ali
prosi za pomoč pri prevajanju, sodelovanje pri humanitarnih dejanjih, je množično ustvarjanje
sprožilo pojav novega interaktivnega obdobja trženja in dosega ciljne publike. Potrošniki
postajajo s svojimi kreativnimi vložki vse bolj vključeni v proces nastajanja blagovnih znamk,
saj so sposobni in željni prispevati (Article One Partners, 2011a).
Bistvo crowdsourcinga je razločevanje med briljantnim in banalnim. To pravilo drži tudi, ko
govorimo o ustvarjalnem delu. Množično zunanje izvajanje ustvarjalnega dela vključuje

11
gojenje robustne skupnosti, sestavljene iz ljudi z globoko zavezanostjo k svoji umetnosti in
povezavi med ljudmi. Najboljše ideje posledično izboljšajo status njihovih avtorjev. Drugi
udeleženci si prizadevajo, da izpolnjujejo ali presežejo standard, ki ga postavljajo najbolj
nadarjeni med vrstniki. Ta težnja učinkovito povečuje splošno kakovost dela, ki ga ustvarja
skupnost. Velik del interakcij med člani skupnosti se vrti okoli izboljšanja njihovih veščin.
Ljudje se radi naučijo novih stvari, prav tako pa radi druge naučijo nekaj, kar sami že
obvladajo. Skupnost ima nezmotljivo sposobnost, da prepozna svoje najbolj nadarjene člane
in izpostavi njihovo delo (Article One Partners, 2011b).
Crowdsourcing stvari, ki jih ljudje kreirajo, za razliko od stvari, ki jih že poznamo, grozi, da
bo zmanjšal dobičke že uveljavljenih podjetij in jih navsezadnje lahko celo izpodrinil. Ljudje
se negativno odzovejo na izjave, da crowdsourcing pomeni prihranek denarja oz. zmanjšanje
stroškov. Nihče noče, da bi se kdo počutil izkoriščenega. Ne gre toliko za dajanje lažjih nalog
množici kot za grajenje strategije, ki sloni na dejstvu, da smo ljudje dobri na različnih
področjih, imamo različno količino časa na voljo za sodelovanje in da imamo preprosto
različne interese (Article One Partners, 2011b).
2.1.3 Množično glasovanje
Množično glasovanje je pojav zbiranja mnenj in presoj o določeni temi, zbranih s strani velike
množice ljudi. Množično glasovanje dopolnjuje sodbo skupnosti o organiziranosti, filtraciji in
urejanju vsebin po ravneh (na primer člankov v časopisih, glasbe in filmov). Je ena izmed
oblik crowdsourcinga, ki generira najvišjo raven udeležbe.
Množično glasovanje je osnovano na modelu 1:10:89, ki pravi, da izmed 100 oseb (Howe,
2009):
1 % oseb ustvari nekaj, kar nosi vrednost,
10 % bo glasovalo in ocenilo predloge,
89 % ljudi bo zgolj uporabljalo, kar se pri tem procesu ustvari (se zgolj okoristilo z
rezultati crowdvotinga).
Za 10 % ljudi, ki glasujejo in ocenjujejo vsebino, je dejanje uporabe pridobljenih ocen prav
tako dejanje ustvarjanja. Splet ponuja različne mehanizme za izvajanje glasovanja: ocene

12
izdelkov, ki jih prebirajo končni uporabniki ali računalniški algoritmi, ki ocenjujejo
priljubljenost prek povezav in ogledov strani.
Veliko spremembo na področju množičnega glasovanja je v Združenih državah Ameriki
povzročil glasbeni šov Ameriški idol (angl. American Idol). Glasovanje tako ni bilo več nekaj,
kar so ljudje počeli vsakih nekaj let enkrat; postalo je nekaj, kar so ljudje počeli vsakih nekaj
dni kar prek svojih mobilnih telefonov. Glasovanje je postalo del kulture. Danes imamo ljudje
možnost glasovati o praktično skorajda vsem (Howe, 2009).
Prispevki množice so tako številni, da jih lahko filtrira zgolj množica sama. Le kolektivna
pozornost množice in njeno navdušenje nad sistemi glasovanja s petimi zvezdicami imata
moč ustvariti učinkovit filter. Kolektivne odločitve na milijonov uporabnikov spleta so
uporabljene za kreiranje celovitega klasifikacijskega sistema, kjer uporabniki glasujejo, katere
dnevne novice si zaslužijo pozornost. Ta pojav lahko opazimo na prav vseh spletnih
novičarskih medijih.
2.1.4 Množično financiranje
Množično financiranje zaobide tradicionalne načine, pri katerih korporacije ponudijo
financiranje posameznikom ali skupinam, v katerih vidijo potencial, vendar ne pridejo do
ustreznega kredita s strani banke. Množično financiranje pomeni, da vsak posameznik znotraj
množice v projekt, v katerega verjame, da lahko uspe, vloži manjši denarni vložek. Navadno
se zbiranje denarja odvija prek spleta. Velika prednost množičnega financiranja prek spleta je
v tem, da projekte in njihove ustvarjalce lahko vidi ves svet in tako je krog potencialnih
vlagateljev znatno večji (Dresner, 2014). Gre za alternativno obliko financiranja, ki se je
pojavila in razvila zunaj tradicionalnega finančnega sistema.
Množica svojo podporo izrazi številnim različnim namenom: od pomoči ob naravnih
katastrofah, finančne pomoči pri objavi knjig še neuveljavljenih avtorjev, financiranja
najrazličnejših umetnikov, ki iščejo podporo, do političnih kampanj in financiranja majhnih
podjetij v zagonu (angl. start-up) (Dresner, 2014; Ordanini in drugi, 2009).
Model množičnega financiranja, morda bi mu lahko rekli celo množično sponzoriranje, žene
gorivo, ki ga sestavljajo tri vrste udeležencev: pobudnik projekta, ki idejo ali projekt predlaga,

13
posamezniki ali skupini, ki idejo podpirajo, in organizacija, ki vse to moderira – nekakšna
spletna platforma, ki združuje eno in drugo stran, da bi skupaj uresničili idejo (Ordanini in
drugi, 2009).
Vložek posameznikov sproži proces crowdfundinga in vpliva na končno vrednost ponudbe ali
izide procesa. Vsak posameznik se obnaša kot prodajni agent; izbira in promovira projekte, v
katere verjame. V nekaterih primerih postanejo delničarji in prispevajo k razvoju in rasti
ponudbe. Posamezniki širijo informacije o projektih, ki jih podpirajo, v svojih spletnih
skupnostih in tako skozi promocijo ustvarjajo dodatno podporo (Ordanini in drugi, 2009).
Motivacija za udeležbo potrošnikov izhaja iz občutka, da so vsaj delno odgovorni za uspeh
pobud drugih (želja po pokroviteljstvu), prizadevajo si tudi, da bi bili del socialne pobude
skupnosti, in iščejo nekakšno obliko povračila svojih denarnih vložkov.
Posameznik, ki se udeležuje v pobudah za množično financiranje, ima navadno več izrazitih
lastnosti: inovativna usmerjenost, ki spodbuja željo po preizkušanju novih načinov interakcij s
podjetji in z ostalimi potrošniki, in družbena identifikacija z vsebino projekta, ki ga podpira
(Ordanini in drugi, 2009; Dresner, 2009).
V zadnjem času je dober tovrsten primer platforma Kickstarter, kjer je do današnjega dne
skušalo uspeti 251.000 projektov, ki so skupno zbrali 1,9 milijona ameriških dolarjev.
(Kickstarter Stats)
2.2 Crowdsourcing v informacijskih sistemih
Obliko informacijskega sistema za izvedbo crowdsourcinga se izbere glede na cilje
specifičnega projekta, ki so sicer na pogled lahko videti podobno, čeprav so osnovani na
podlagi različnih namenov. Posledično se lahko razlikujejo glede na vrsto prispevkov, ki jih
iščejo, in glede na način, kako iz teh pridobijo vrednost (Geiger in drugi, 2012).
Primer za to je prevajanje besedila, ki ga podamo za množično zunanje izvajanje
(crowdsourcing). Če je cilj tovrstnega napora preprosto dobiti hiter prevod, npr.: za uporabo
na zahtevo (angl. on-demand) z mobilnih naprav, se bo uporabljal sistem za obdelavo
množice, ki je neke vrste osnovni sistem zagotavljanja kakovosti prevoda. Če pa je namen

14
dobiti kakovosten prevod za namene produkcije (npr.: prevodi vmesnika socialnega omrežja
Facebook), je najbolje uspešna kombinacija reševanja s strani množice in množičnega
ocenjevanja. Sodelujoči najprej prevedejo izraze, množica pa nato njihove predloge za prevod
ocenjuje in tako izglasuje najboljšega izmed vseh razpoložljivih alternativ, s čimer se poveča
(subjektivna) kakovost prevoda (Geiger in drugi, 2012).
Znanstvena paradigma pravi, da je iskanje najboljše ali optimalne oblike informacijskega
sistema pri reševanju problemov iz realnega življenja pogosto nepremostljiva ovira. Prav
zaradi tega bi morali ciljati na odkrivanje učinkovitih rešitev. Na podlagi tega Nickerson in
drugi (2012) trdijo, da je odločanje za izbiro vrste informacijskega sistema, ki bo namenjen
izvajanju crowdsourcinga, treba izvesti z ozirom na njihovo uporabnost.
V kontekstu informacijskih sistemov poznamo klasifikacijo crowdsourcinga, ki izhaja iz tega,
kako informacijski sistem, namenjen crowdsourcingu, omogoča uporabo prispevkov množice,
da se doseže njegova organizacijska struktura (Geiger in drugi, 2012):
ali sistem skuša doseči homogene ali heterogene prispevke množice in
ali sistem skuša doseči pričakovane ali nepričakovane vrednosti oz. prispevke
množice.
Sistem, ki stremi k homogenim prispevkom množice, ceni vse (utemeljene) prispevke
enakovredno. Homogeni prispevki, ki so v skladu z vnaprej določenimi specifikacijami, so v
kvalitativnem smislu enaki. Sistem je tako usmerjen h kvalitativni obdelavi zbranih rešitev.
Nasprotno pa sistem, ki deluje z namenom zbiranja heterogenih prispevkov, vrednoti te
prispevke glede na njihove individualne lastnosti. Heterogeni prispevki so videti kot
alternative ali dopolnila in so temu ustrezno obdelani. Ta dimenzija se zgleduje po pojmu
heterogenih komponent ali komponente kot take, ki se jo proučuje v različnih sistemih.
Poseben poudarek na heterogenosti lahko najdemo na primeru porazdeljenih računalniških
sistemov (Geiger in drugi, 2012).
Sistem, ki išče pričakovane vrednosti od množice, te vrednosti izpeljuje neposredno iz vseh
ali zgolj nekaterih posameznih, izoliranih prispevkov. V takih sistemih posamezni prispevek
prinaša določeno vrednost, ki je neodvisna od drugih prispevkov. Sistem, ki si prizadeva
iskati nepričakovane vrednosti, pa lahko od svojih sodelavcev znotraj množice uporabno
vrednost izpelje iz celote prispevkov in odnosov med njimi. Posamezni prispevek torej

15
prinaša vrednost kot del celote, ne pa posamezno. Pojav je filozofski koncept, ki je med
drugim osrednji del teorije sistemov za označevanje lastnosti sistema, ki ni omejena z
njegovimi izoliranimi komponentami, temveč se zanaša na razmerja med njimi (Geiger in
drugi, 2012, Heinrich in drugi, 2011).
Z različnimi kombinacijami teh dveh dimenzij dobimo štiri temeljne oblike informacijskih
sistemov crowdsourcinga (Slika 2.1). Vsak tip predstavlja arhetipski sistem z izrazito
organizacijsko funkcijo, ki je poimenovan tako, da opisuje svojo funkcijo in posledično
izdelek ali storitev, ki je njegov končni izdelek (izhod). Podrobno jih bomo opisali v
naslednjih podpoglavjih.
Slika 2.1: Oblike crowdsourcinga
Vir: Geiger in drugi (2012)
2.2.1 Informacijski sistemi za množično obdelavo
Informacijski sistemi za množično obdelavo (angl. crowd processing information systems) se
zanašajo na velike količine homogenih prispevkov, ki iščejo vrednosti oz. rezultate, ki so
izpeljivi neposredno iz posameznih prispevkov. Vsi veljavni prispevki, ki so skladni z

16
določenimi specifikacijami, veljajo za kvalitativno enake in enakovredno prispevajo h
končnemu rezultatu. Ti sistemi uporabljajo dodatne pasovne širine in skalabilnost1, ki jo
prinaša crowdsourcing rešitev za hitro in učinkovito predelavo serije.
Sodelujoči skupaj obdelujejo naloge v velikih količinah z namenom zmanjšanja uporabe
tradicionalnih organizacijskih virov. Mnogi tovrstni sistemi uporabljajo načelo »deli in
vladaj«, ki je doseženo z delitvijo velikih nalog na manjše, enakovredne mikronaloge, ki se jih
razdeli med posameznike. Na koncu se te manjše delce poveže nazaj v celoto, ki je posledica
posameznih prispevkov, združenih v kolektivni rezultat (Geiger in drugi, 2012).
2.2.2 Informacijski sistemi za množično ocenjevanje
Prav tako kot informacijski sistemi za obdelavo množic se tudi sistemi za množično
ocenjevanje (angl. crowd rating information systems) zanašajo na velike količine homogenih,
kvalitativno enakovrednih prispevkov, vendar skušajo v njih najti kolektivno vrednost, ki
nastane, ko na te homogene prispevke gledamo kot na celoto. Pričakovana vrednost izhaja
prav iz lastnosti količinskega zbiranja podatkov. Za posamezen prispevek tako šteje oddani
»glas« na podano temo. Samo pridobitev zadostnega števila teh glasov dovoljuje obteževanje
kolektivnega odziva, kot so npr.: spekter mnenj ali skupnih ocen in predvidevanj, ki odsevajo
»modrost množic« (angl. wisdom of crowds) ali (drugače rečeno) kolektivno inteligenco
(Surowiecki, 2006).
Velike množice sodelujočih z raznolikimi znanjem in drugačnim družbenim ter kulturnim
ozadjem tako ustvarjajo, da sistemi ocenjevanja pridobijo zelo natančne rezultate. Takšni
sistemi se uporabljajo za zbiranje revizijskih ocen (eBay – ocenjevanje prodajalcev) (Geiger
in drugi, 2012).
2.2.3 Informacijski sistemi za množično reševanje problemov
Informacijski sistemi, namenjeni množici za reševanje zastavljenih problemov (angl. crowd
solving information systems), se zanašajo na velike količine nepričakovanih, inovativnih
1 Skalabilnost ali razširljivost je sposobnost sistema prilagajati se povečanjem in zmanjšanjem
obremenitev. Pomeni, da so procesi zastavljeni tako, da je vseeno, ali je uporabnikov sistema 100
ali pa 100.000, saj zaradi povečanega števila uporabnikov ne pride do težav, kot je npr. padec
sistema ali internetne povezave (Scalability, 2015).

17
rešitev, ki izhajajo neposredno iz izoliranih vrednosti njihovih homogenih prispevkov.
Vrednost kvalitativnih lastnosti posameznega prispevka se določi glede na določena merila
vrednotenja in se lahko močno razlikuje; nekatere predlagane rešitve so nepomembne, druge
bolj ustvarjalne in s tem nosijo visok potencial. Prispevki v tovrstnih sistemih predstavljajo
komplementarne ali alternativne rešitve zadane naloge oz. problema.
Podobno kot sistemi, opisani v prejšnjem podpoglavju, imajo informacijski sistemi za
reševanje nalog večje koristi in boljše rezultate na podlagi bolj raznolike množice. Vsak
prispevek potencialno, vendar ne nujno, poveča kakovost končne rešitve, čemur rečemo
kolektivna inteligenca (Brabham in drugi, 2008). Ti sistemi so grajeni na predpostavki
»odprtega klica« množici, ki je dovolj velika, da zajema ljudi z najrazličnejšimi znanji,
izkušnjami in spretnostmi, ki priskrbijo dober končni rezultat. Taki sistemi lažje rešujejo
naloge, ki nimajo optimalnih rešitev.
Končna izvedba je odločena po merilih ocenjevanja, ki so lahko zelo subjektivna, saj se
razvijajo med množičnim reševanjem. Prav tako pa lahko rešujejo tudi zelo zahtevne
matematične naloge ali probleme algoritmične narave, ki temeljijo na objektivnih, dobro
definiranih kriterijih ocenjevanja (Geiger in drugi, 2012). Odličen primer te oblike
pridobivanja kolektivne inteligence je portal InnoCentive, ki je na eni strani namenjen
podjetjem, ki potrebujejo rešitve svojih problemov, in na drugi strani ljudem, ki so
zainteresirani te probleme reševati, ne da bi morali biti prisotni na lokaciji, kjer je ta rešitev
potrebna.
Zanimivo pri vsem tem je, da ljudje, ki te probleme rešujejo, niso to, kar bi pričakovali, saj ne
gre za strokovnjake na iskanem področju. Nemalokrat se izkaže, da je »zmagovalec« nekdo,
ki se s tem področjem ukvarja zgolj v prostem času (hobi). Tako so dokazali močno pozitivno
povezavo med verjetnostjo reševalčevega uspeha in področjem reševanja, s katerega ni imel
formalnih znanj (Howe, 2006).
2.2.4 Informacijski sistemi za množično ustvarjanje
Zadnji primer so informacijski sistemi, namenjeni množičnemu ustvarjanju (angl. crowd
creating information systems). Temeljijo na raznolikosti heterogenih prispevkov, vendar
poskušajo iskati kolektivno vrednost, ki nastaja iz kopičenja prispevkov in medsebojnih

18
odnosov. V nasprotju s sistemi za množično ocenjevanje se pričakovane vrednosti ne nanašajo
zgolj na kvantitativne lastnosti prispevkov, temveč izhajajo predvsem iz kvalitativnih lastnosti
posameznih prispevkov in njihovih odnosov. Posamezni prispevek torej predstavlja
komplementarni del v kreiranju kolektivnega rezultata.
Tovrstne množice temeljijo na velikih, raznovrstnih množicah, ki jim omogočajo združevanje
mnogih prispevkov v celovit artefakt. Primeri vključujejo vse vrste uporabniško ustvarjenih
sistemov vsebin (YouTube), predvsem tistih, ustvarjenih na zalogo (angl. make-to-stock).
Najbolj znan primer je portal iStockphoto, kjer lahko posameznik ne glede na raven znanja
fotografiranja oz. kakovost fotografij svoje izdelke proda množici. Pogosto za npr. ustvarjanje
spletne strani izdelka potrebujemo fotografije, s katerimi ustvarimo zgodbo izdelka. Če te
iščemo na portalu iStockphoto, prav gotovo najdemo fotografijo, ki ustreza našim potrebam in
je predvsem ustrezne kakovosti oz. ločljivosti (česar običajno iskanje za fotografijami v
spletnem brskalniku ne prinese vedno), in jo za ugodno ceno kupimo. Drugi primer takšnih
sistemov vsebin so tudi sistemi, ki vzdržujejo znanje, med katerimi je najbolj znana
Wikipedija.
2.3 Kolektivna inteligenca
2.3.1 Pogoji za kolektivno inteligenco
Pogoji, pod katerimi lahko govorimo o modrosti množice oz. kolektivni inteligenci, so
naslednji:
vključevanje raznovrstnosti,
neodvisnost in
decentralizacija.
Ti so ključnega pomena za dobre odločitve, ki so posledica nesoglasja in tekmovanja med
posamezniki, bolj kot soglasja oz. kompromisa.
Raznovrstnost v smislu modrosti množice pomeni, da imajo posamezniki določene
informacije, ki jih ostali nimajo, oziroma da si drugače interpretirajo splošno znana dejstva
(Brabham in drugi, 2008; Surowiecki, 2006). Večja raznovrstnost povečuje možnost, da

19
posameznik pride do bolj radikalne zamisli. Skupina, ki vključuje posameznike z različnimi
stopnjami inteligence, pokaže boljše rezultate kot tista, v kateri imamo zgolj posameznike z
visoko inteligenco. »Ljudje, ki vedo manj«, izboljšujejo učinek skupine. Homogene skupine
so običajno res uspešne pri tem, kar počnejo, vendar postajajo progresivno manj zmožne
odkrivanja alternativni rešitev (Buecheler in drugi, 2010; Prpić in Shukla, 2012).
Ohranjanje neodvisnosti je odvisno od raznovrstnosti oseb, ki sestavljajo množico.
Neodvisnost označuje sposobnost kreiranja lastnega mnenja, ko naše mnenje ni odvisno ali
pogojeno z mnenjem ljudi okoli nas, temveč je grajeno na lastnih znanjih, izkustvih in
prepričanjih. Različna okolja, iz katerih člani izhajajo, prinaša raznovrstne informacije,
predvsem pa se s tem zmanjšuje možnost, da bi vsi udeleženci na podlagi enakih verjetij
storili enake napake (Buecheler in drugi, 2010).
Decentralizacija spodbuja posameznike, da pomembne odločitve sprejemajo na različnih
lokacijah, na podlagi specifičnih raznovrstnih znanj, pogojenih z okoljem, iz katerega
izhajajo. Tako širijo lokalno znanje in prispevajo k raznovrstnosti mnenj (Surowiecki, 2006).
Združevanje različnih mnenj v končno rešitev zagotavlja rešitev, za katero je zelo verjetno, da
je boljša od najpametnejše rešitve osebe znotraj množice (Buecheler in drugi, 2010).
Ob izpolnjevanju naštetih pogojev se znanje oz. modrost množice poveča – opravijo boljše
razsodbe in odločitve. Zanimivo pri tem je, da se v praksi dosti bolje obnesejo naključno
izbrane oz. formirane množice kot tiste, ki so namensko sestavljene zaradi reševanja
specifičnega problema (Surowiecki, 2006).
2.3.2 Dejavniki kolektivne inteligence
Psihologi so že večkrat pokazali, da enotni statistični faktor, pogosto imenovan »splošna
inteligenca«, nastane kot korelacija med sposobnostjo opravljanja najrazličnejših kognitivnih
nalog. Ni pa raziskano, ali obstaja podobna oblika »kolektivne inteligence«, ki jo najdemo v
množicah. Izvedeni sta bili dve študiji, v katerih je sodelovalo 699 ljudi, ki so bili razdeljeni v
skupine od 2 do 5 ljudi. Izsledki so zelo podobni, saj se je v obeh izkazalo, da obstaja faktor
kolektivne inteligence c, ki pojasnjuje, kako se skupina odreže pri reševanju nalog z
najrazličnejših področij. Kolektivna inteligenca je lastnina vseh oseb znotraj množice, ki so
prispevale k njenemu nastanku, in ne zgolj posameznih sodelujočih (Woolley in drugi, 2010).

20
Čeprav psihologi in drugi strokovnjaki že desetletja proučujejo, kako dobro množice rešujejo
specifične naloge, kolektivna inteligenca nikoli ni bila izmerjena na enak način, kot se meri
individualno inteligenco. Ne tako, da bi lahko na podlagi te raziskave ocenjevali, kako dobro
bo ista skupina ljudi opravila novo zastavljene naloge z najrazličnejših področij (Woolley in
drugi, 2010).
V raziskavi so 63 posameznikom za reševanje zastavili nalogo, ki so jo morali rešiti sami. Pod
temi pogoji eksperimenta je bila individualna inteligenca pomemben prediktor kakovosti
podane rešitve. Ko pa so isto nalogo zastavili skupinam, se stopnja povprečne inteligence ni
odražala v napovedi kakovosti rešitve, ki jo je našla množica. Preiskovali so številne
individualne in skupinske faktorje, ki bi lahko bili dober napovedovalec faktorja c. Izkazalo se
je, da številni faktorji, za katere bi predvidevali, da imajo pomemben vpliv na napovedovanje
uspešnosti skupine, kot so npr.: kohezivnost množice, motivacija in zadovoljstvo, niso tako
pomembni (Woolley in drugi, 2010).
Raziskavi, v katerih je množica opravljala različne naloge – reševala uganke, viharila
možgane (angl. brainstorming), skupaj odločala o moralnosti podanih študij primera in se
pogajala o omejenih resursih, sta pokazali, da faktor c ni močno povezan s povprečno
vrednostjo individualne inteligence v množici, prav tako ni močne povezave med največjim
inteligenčnim kvocientom posameznikov.
Kolektivna inteligenca, faktor c, pa je v močno pozitivni korelaciji s povprečno družbeno
občutljivostjo oz. dovzetnostjo za okolico (angl. social sensitivity) članov skupine, z enakim
deležem vodenja diskusije med člani in deležem žensk v skupini (Woolley in drugi, 2010).
2.4 Vedenje množice pri pojavu crowdsourcinga
Ljudje imamo prirojen nagon oz. težnjo za delovanje v skupinah. Prav zato ima vsakdo vsaj
minimalno sposobnost usklajevanja dejavnosti z drugimi osebami in usmerjanja procesa
reševanja problemov (Guillaume, 2011 in Jiang in drugi, 2015). Vendar pa ta sposobnost
nikakor ni nekaj preprostega. Zahteva kompleksno sodelovanje med sinhronizacijo,
dojemanjem, komunikacijo in kognitivno reprezentacijo naloge v podani situaciji (Baumol,
1986; Sauermann in drugi, 2015).

21
Velika skupina oz. množica je pogoj za stabilno podporo skupnosti. Istočasno kot poteka
iskanje najboljše rešitve podanega problema, se ustvarja socioekološko okolje. V tem se
vzpostavi tudi nekakšna niša, v kateri se znajdejo t. i. samotni jezdeci (angl. free riders). Gre
za osebe, ki se obnašajo individualistično, problem rešujejo same in se navadno okoristijo z
razpoložljivo socialno podporo, k projektu pa ne prispevajo prav veliko (Baumol, 1986;
Sauermann in drugi, 2015).
Poseben fenomen, povezan z individualizmom v crowdsourcingu, predvsem v informacijskih
sistemih za iskanje rešitev in informacijskih sistemih za množično ustvarjanje, je, da
posameznik običajno ne najde najboljše rešitve. Vendar pa se v primeru, da vseeno pride do
tega, da posameznik najde najboljšo rešitev, nauči veliko več, kot bi se med skupinskim
reševanjem. V vsaki množici sodelujočih oseb pride do tega, da se nekatere osebe odločijo za
sodelovanje s preostalimi, medtem ko skušajo druge do rešitve priti same. Pride do
zanimivega kontrasta, ki nastane kot posledica velikosti prvotne skupine (Baumol, 1986;
Sauermann in drugi, 2015).
V majhnih skupinah, ki jim je zadana zelo enostavna naloga, se igralci običajno nagibajo k
sodelovanju. V nasprotju pa se ljudje v večjih skupinah pri lažjih nalogah bolj nagibajo k
individualnem reševanju, saj je določena stopnja novo usvojenega znanja že zagotovljena.
Prav v tovrstnih skupinah bolj do izraza pridejo individualistično usmerjeni samotni jezdeci,
ki k skupini ne prispevajo prav veliko, se pa okoristijo z novostmi, do katerih pride skupina
(Guazzini in drugi, 2015).
Zanimivo je tudi, da se v manjših skupinah želja po sodelovanju z olajševanjem težavnosti
naloge povečuje. Za igralce je manj koristi, če se obnašajo individualistično, saj se tako
velikost sodelujoče podmnožice hitro zmanjša na tako majhno število, da ni koristi za nikogar
– nihče ne pridobi.
Pri zelo težkih nalogah ni opaziti očitnejših razlik v obnašanju oz. odločanju posameznikov o
tem, ali bodo sodelovali z ostalimi udeleženci ali se bodo reševanja naloge lotili sami. Ker je
zelo težke naloge težko rešiti v vsakem primeru, se izrazitejše preference ne kažejo. S
sodelovanje s preostalo množico igralec bolj verjetno pridobi vsaj nekaj novega znanja.

22
Numerični model, ki so ga pripravili raziskovalci pod vodstvom Andree Guazzinija, je
pokazal, da je optimalna množica sestavljena iz polovice oseb prvotne množice. Je namreč
dovolj velika oz. majhna, da sta kolektivizem in individualizem enakomerno zastopana – ne
prihaja do razlik ne glede na težavnost naloge. V množicah ustrezne velikosti je novo
pridobljeno znanje največje, tudi kapacitete znanja so najboljše. To pomeni, da je optimalna
raba crowdsourcinga možna le na podlagi upravljanja števila sodelujočih subjektov. To pa
pomeni, da ne moremo več reči, da gre za »naraven« proces, temveč nadzorovanega
(Guazzini in drugi, 2015).
Zanimivo je, da je akumulacija znanja v prevelikih množicah počasnejša kot v skupinah
zmerne velikosti, kjer sta, kot že rečeno, kolektivizem in individualizem uravnotežena. V
velikih skupinah se običajno pojavi preveč posameznikov, ki zavirajo generiranje znanja. Po
drugi strani pa bi lahko prav posameznik prišel do nekih novih dognanj, do katerih v principu
kolektivizma ne bi prišlo. To znanje se še vedno lahko deli s preostalo skupnostjo in je tako
na razpolago vsem (Guazzini in drugi, 2015). Prav tako pa manjše skupine, ki ne dosegajo
kritične mase, nimajo zadostnega znanja oz. je to pomanjkljivo. Prav tako je pomanjkljivo
tudi kulturno ozadje, ki igra pomembno vlogo pri reševanje naloge (Derex in drugi, 2013).
Kljub temu gre v zgornjem primeru zgolj za numerični model, ki sloni na predpostavkah o
tem, kako se človek obnaša in kako se odzove v določeni situaciji. Prav za namene
podrobnejšega raziskovanja smo pod vodstvom dr. Guazzinija pripravili koncept spletne
aplikacije »Igre črk«, ki smo jo izdelali v okviru te diplomske naloge.
3. PRAKTIČNA IMPLIKACIJA
3.1 Spletna aplikacija za eksperimentalno merjenje kolektivnega znanja
Spletno aplikacijo je možno najti na URL-naslovu igracrk.fis.unm.si.

23
Vstopna stran spletne aplikacije za eksperimentalno merjenje kolektivnega znanja (Slika 3.1)
vsebuje prijavni obrazec, v katerega je treba vpisati uporabniško ime in geslo, ki ga vnaprej
pripravi administrator.
Slika 3.1: Vstopna stran spletne aplikacije za eksperimentalno merjenje kolektivnega znanja
Vir: Plut, lastni prikaz (2015)
V primeru neuspešne prijave v sistem zaradi vpisanega napačnega uporabniškega imena ali
gesla je uporabnik o tem obveščen (Slika 3.2). Zaradi varovanja podatkov se pri spletnem
programiranju držimo pravila, da opozorilo ne izpiše, kje je prišlo do napake; v uporabniškem
imenu ali geslu. Tako je sistem še nekoliko bolj varen pred zlorabami.
Slika 3.2: Neuspešna prijava
Vir: Plut, lastni prikaz (2015)

24
Ob uspešnem vpisu v spletno aplikacijo se uporabniku odpre zaslon, prikazan na Sliki 3.3.
Igra se prične šele, ko administrator izbere velikost skupine. Do tedaj pa uporabnik čaka.
Slika 3.3: Čakanje na pričetek igre
Vir: Plut, lastni prikaz (2015)
Čas čakanja lahko izkoristi tako, da uredi uporabniški profil, kjer izpolni obrazec o
demografskih podatkih: spol in starost. Spremembe lahko shrani ali prekliče, kar je razvidno s
Slike 3.4.
Slika 3.4: Urejanje profila uporabnika
Vir: Plut, lastni prikaz (2015)
Administrator ima pregled nad prijavljenimi uporabniki; vidi, kdo je prijavljen in kakšno je
skupno število trenutno aktivnih oseb, glej Sliko 3.5. Seznam na desni strani
administratorjevega zaslona se osvežuje vsake 3 sekunde.
Administrator določi, kako velike bodo skupine igralcev, ki bodo sodelovale pri iskanju
besed. Iz spustnega menija lahko izbira med velikostjo skupin 1, 2, 4, 8, 16 in 32. V primeru,
da se število igralcev ne more razdeliti v skupine določene velikosti tako, da bi bilo deljenje
brez ostanka, se razdelijo v manjše skupine ustrezne velikosti (32, 16, 8, 4, 2, 1). Primer: v
igro je prijavljenih 31 igralcev. Administrator izbere velikost skupine 16, kar pomeni, da

25
imamo samo eno skupino velikosti 16 igralcev. Preostalih 15 igralcev je razdeljenih v
največje možne skupine, manjše od 16 igralcev – dobimo še 4 skupine: skupino z 8 igralci,
skupino s 4 igralci, skupino z 2 in »skupino«, ki vsebuje samo enega igralca.
Administrator prav tako določa, koliko črk, iz katerih bodo igralci sestavljali besede, jim bo
na voljo. Iz drugega spustnega menija izbere dolžino izvirne besede, ki je iz baze izbrana
naključno in katere črke so pred začetkom igre premešane.
Administrator lahko s tretjim spustnim menijem določa dolžino igre, ki je lahko med 1 in 10
minutami. Ne glede na dolžino igre pa ostaja čas priprave na igro, to je čas, ko se igralec
spoznava s črkami, vendar še ne more sestavljati besed, enak – 1 minuta.
Svojo izbiro vseh treh nastavitev potrdi s klikom na gumb »Prični«.
Slika 3.5: Administrator določi potek igre
Vir: Plut, lastni prikaz (2015)
Administratorju se na administratorski strani v seznamu interaktivno izpisuje, kateri
uporabniki so trenutno aktivni – prijavljeni v aplikacijo. Vidi tudi, koliko časa je preostalo do
konca igre in katero je izvorno geslo, iz katerega udeleženci gradijo besede. V naslednjem
primeru je bilo geslo izbrano iz baze Slovarja slovenskega knjižnega jezika »findesiclovski«,
do konca igre pa sta preostali še 2 minut in 1 sekunda (Slika 3.6).
Statistika, ki jo administrator lahko pregleduje, vsebuje tudi podrobnosti o vseh igrah ter
igralcih.
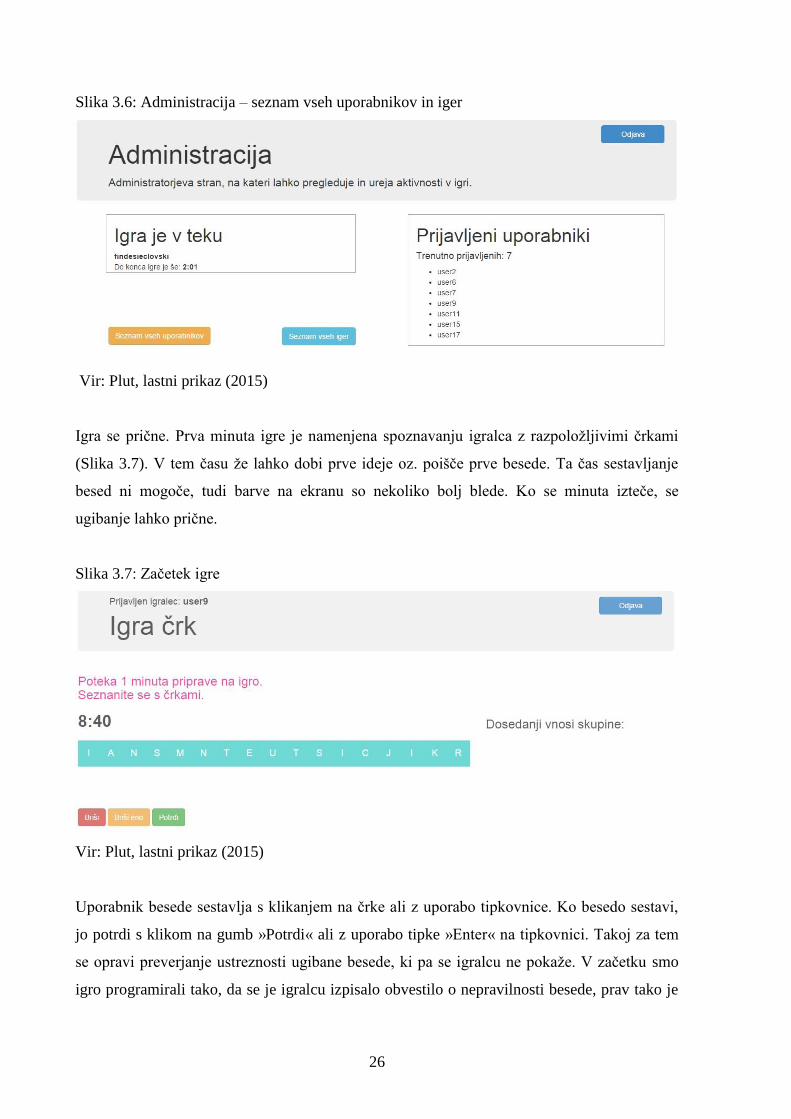
26
Slika 3.6: Administracija – seznam vseh uporabnikov in iger
Vir: Plut, lastni prikaz (2015)
Igra se prične. Prva minuta igre je namenjena spoznavanju igralca z razpoložljivimi črkami
(Slika 3.7). V tem času že lahko dobi prve ideje oz. poišče prve besede. Ta čas sestavljanje
besed ni mogoče, tudi barve na ekranu so nekoliko bolj blede. Ko se minuta izteče, se
ugibanje lahko prične.
Slika 3.7: Začetek igre
Vir: Plut, lastni prikaz (2015)
Uporabnik besede sestavlja s klikanjem na črke ali z uporabo tipkovnice. Ko besedo sestavi,
jo potrdi s klikom na gumb »Potrdi« ali z uporabo tipke »Enter« na tipkovnici. Takoj za tem
se opravi preverjanje ustreznosti ugibane besede, ki pa se igralcu ne pokaže. V začetku smo
igro programirali tako, da se je igralcu izpisalo obvestilo o nepravilnosti besede, prav tako je
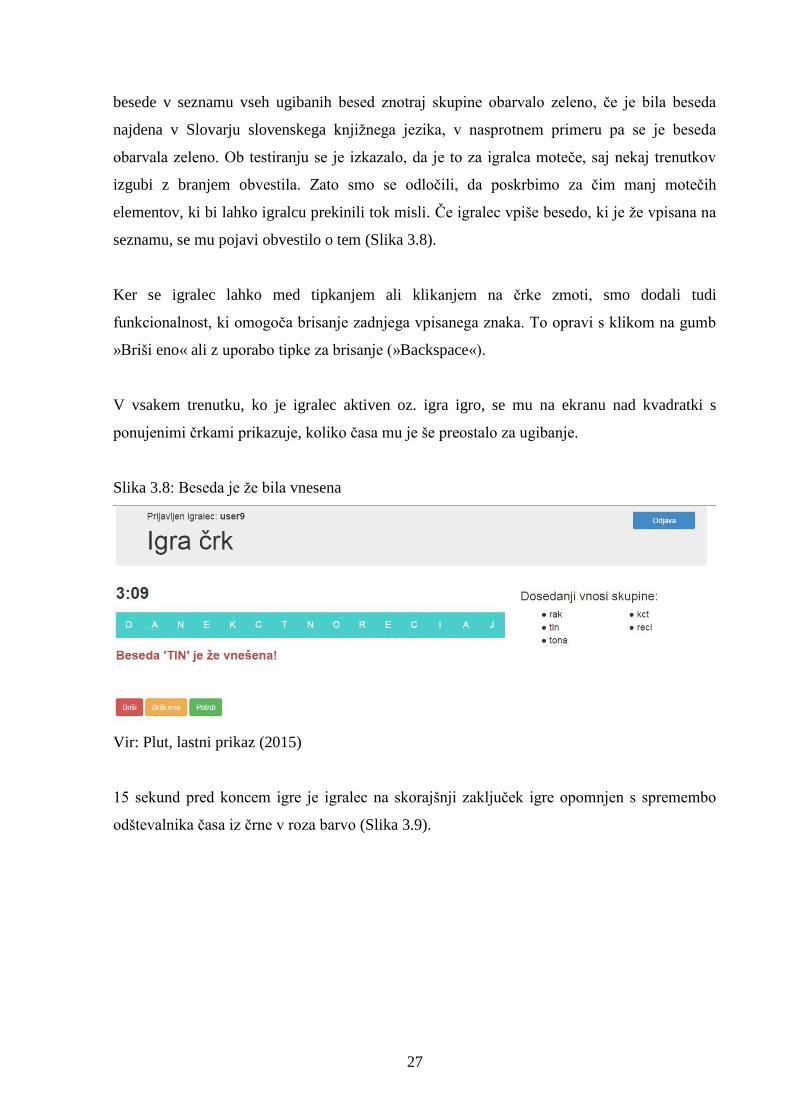
27
besede v seznamu vseh ugibanih besed znotraj skupine obarvalo zeleno, če je bila beseda
najdena v Slovarju slovenskega knjižnega jezika, v nasprotnem primeru pa se je beseda
obarvala zeleno. Ob testiranju se je izkazalo, da je to za igralca moteče, saj nekaj trenutkov
izgubi z branjem obvestila. Zato smo se odločili, da poskrbimo za čim manj motečih
elementov, ki bi lahko igralcu prekinili tok misli. Če igralec vpiše besedo, ki je že vpisana na
seznamu, se mu pojavi obvestilo o tem (Slika 3.8).
Ker se igralec lahko med tipkanjem ali klikanjem na črke zmoti, smo dodali tudi
funkcionalnost, ki omogoča brisanje zadnjega vpisanega znaka. To opravi s klikom na gumb
»Briši eno« ali z uporabo tipke za brisanje (»Backspace«).
V vsakem trenutku, ko je igralec aktiven oz. igra igro, se mu na ekranu nad kvadratki s
ponujenimi črkami prikazuje, koliko časa mu je še preostalo za ugibanje.
Slika 3.8: Beseda je že bila vnesena
Vir: Plut, lastni prikaz (2015)
15 sekund pred koncem igre je igralec na skorajšnji zaključek igre opomnjen s spremembo
odštevalnika časa iz črne v roza barvo (Slika 3.9).

28
Slika 3.9: Skorajšnji konec igre
Vir: Plut, lastni prikaz (2015)
Ko se čas reševanja izteče, se na zaslonu prikaže napis, da je igra končana. Odštevalnik časa
se ustavi, črke se obarvajo rožnato in sistem se ne odziva več na vnose, gumba »Briši« in
»Potrdi« sta zatemnjena in ju ni mogoče več klikniti. Te spremembe so vidne na Sliki 3.10.
Čez nekaj trenutkov podatki o zadnji igri izginejo in igralcu je vrnjen začetni, čakajoči zaslon.
Slika 3.10: Obvestilo o koncu igre
Vir: Plut, lastni prikaz (2015)
Administrator lahko pregleduje seznam uporabnikov po abecednem redu – vidi lahko
uporabniška imena, spol ter starost in kdaj je bil igralec nazadnje aktiven (prijavljen v spletni
aplikaciji). S klikom na gumb »Uredi« lahko igralcem spremeni uporabniško ime in geslo ter
določi spol in starost. Na enak način lahko z vnosom podatkov v zastavljeno polje doda
novega uporabnika (Slika 3.11).
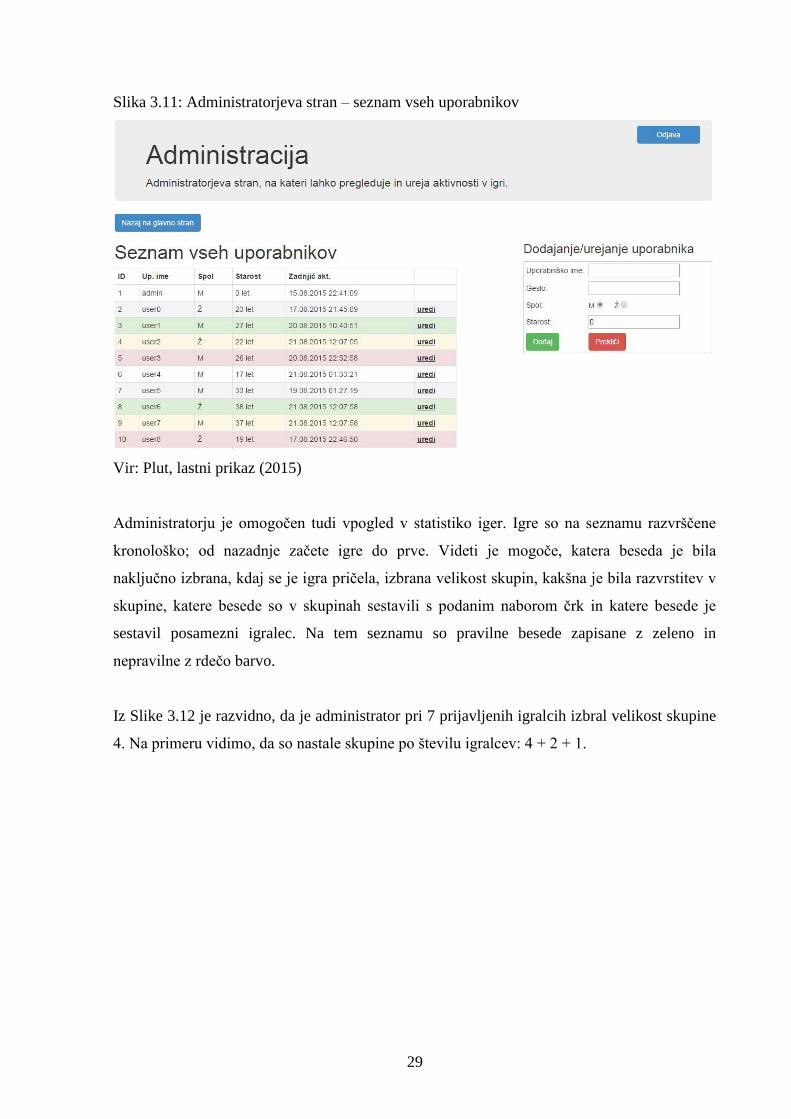
29
Slika 3.11: Administratorjeva stran – seznam vseh uporabnikov
Vir: Plut, lastni prikaz (2015)
Administratorju je omogočen tudi vpogled v statistiko iger. Igre so na seznamu razvrščene
kronološko; od nazadnje začete igre do prve. Videti je mogoče, katera beseda je bila
naključno izbrana, kdaj se je igra pričela, izbrana velikost skupin, kakšna je bila razvrstitev v
skupine, katere besede so v skupinah sestavili s podanim naborom črk in katere besede je
sestavil posamezni igralec. Na tem seznamu so pravilne besede zapisane z zeleno in
nepravilne z rdečo barvo.
Iz Slike 3.12 je razvidno, da je administrator pri 7 prijavljenih igralcih izbral velikost skupine
4. Na primeru vidimo, da so nastale skupine po številu igralcev: 4 + 2 + 1.

30
Slika 3.12: Administratorjeva stran – seznam vseh iger
Vir: Plut, lastni prikaz (2015)
3.2 Podatkovna baza Igre črk
Kot že omenjeno, je za delovanje spletne aplikacije potrebna podatkovna baza. Podatkovna
baza je model okolja, v katerem so v nekakšni zbirki med seboj povezani podatki, ki so
osnova za sprejemanje najrazličnejših odločitev in posledično dogodkov oz. akcij. Poleg tega
je namenjena beleženju številnih parametrov igre (Beal, 2013). S podatki, zabeleženimi v
podatkovni bazi, je mogoče delati analizo iger in pripraviti različne statistike. Na podlagi tega
pa je možno izpeljati formule, ki bi pojasnjevale, kako se kolektivno znanje spreminja s
spreminjanjem velikosti množice in ostalih dejavnikov.
Podatkovna baza spletne aplikacije Igra črk je sestavljena iz petih tabel: slovar, igra, skupina,
vnos in uporabnik. Shema podatkovne baze se nahaja v prilogi.
Prva tabela, imenovana slovar, vsebuje dva atributa: »idSlovar« in »Beseda«. Gre za tabelo, v
kateri se nahaja Slovar slovenskega knjižnega jezika. Spremenljivka »idSlovar« je tipa »int«
(integer) oz. celo število. Namenjena je enoličnemu določanju besed, razvrščenih po
abecednem redu. Vsaka beseda znotraj slovarja je tako določena tudi z identifikatorjem (id).
Spremenljivka »Beseda« pa vsebuje po eno slovensko besedo in je podatkovnega tipa

31
»varchar«, kar pomeni, da so znaki, iz katerih je lahko sestavljena, poleg črk tudi vezaj,
presledek in podobno.
Druga tabela je namenjena beleženju podatkov o igri. Tabela igra vsebuje šest atributov. Ko
se igra prične, dobi svoj unikaten celoštevilski (integer) identifikator »idIgra«, spletna
aplikacija iz tabele slovar naključno izbere besedo – »idSlovar« iz tabele slovar. Besedi nato
premeša črke in jih ponudi igralcem, da iz teh sestavljajo oz. ugibajo besede. Atribut
»dolzinaBesede« je potreben zato, da lahko administrator določi, koliko črk bodo imeli igralci
na voljo. Če na primer izbere besedo dolžine 12, to pomeni, da bo iz baze naključno izbrana
beseda, ki je dolga 12 črk. Te črke bodo naključno premešane in prikazane igralcu, ki bo iz
teh poskušal sestaviti čim več besed. Spremenljivki »Start« in »End« sta tipa »timestamp« in
beležita datum in točen čas, ko se je igra pričela in končala. Atribut »velikostSkupine« je celo
število, ki hrani podatek o tem, v kako velike skupine je administrator razdelil množico
igralcev.
Naslednja tabela je namenjena beleženju statistike o skupinah. Tabelo skupina predstavljajo
trije atributi. »idSkupina« je enolično določen celoštevilski identifikator. Vsako igro so igralci
naključno razporejeni v skupine take velikosti, kot jo določi administrator. To pomeni, da se
skupine vseskozi spreminjajo. Vsaki skupini je vsako igro določen »idIgra«, ki se ne more
ponoviti. Zadnji atribut shranjuje imena igralcev znotraj posamezne skupine. Odločili smo se
za podatkovni tip »text« – vanj lahko poleg črk zapišemo tudi vse ostale znake. Zaradi lažje
kasnejše obdelave podatkov so igralci v tem polju med seboj ločeni z vejicami.
Tabela vnos hrani podatke o posameznih vnosih – ugibanih besedah igralcev. Vsako besedo,
ki jo igralec sestavi iz podanih črk in jo potrdi s klikom na gumb »Potrdi«, se oštevilči z
enolično oznako »idVnos«. Niz teh črk pa se shrani v atribut »pojem«. Tabela shranjuje tudi
podatke o tem, kateri igralec je besedo vnesel (idUporabnik), kdaj natančno se je to zgodilo
(Cas), kateri skupini igralec pripada (idSkupina) in med katero igro se je vse našteto zgodilo
(idIgra). Zadnji atribut, ustrezen, pa v binarnem zapisu označuje, ali beseda obstaja v slovarju.
Z 1 so označene besede, ki obstajajo v slovarju in se posledično smatrajo za pravilne, z 0 pa
so označene tiste, ki niso pravilne.
Tabela uporabnik hrani podatke o vseh igralcih, ki so kadarkoli igrali Igro črk. Vsakemu
izmed njih so bili določeni enoličen »idUporabnika«, ime in geslo. V razdelku »Profil

32
uporabnika« lahko vsak igralec zabeleži svoje podatke o spolu in starosti. Vpogled v
spremenljivko »lastActive« nam poda natančno informacijo o zadnji aktivnosti vsakega
uporabnika – vidimo namreč datum in točen čas (na sekundo natančno). Zadnja aktivnost
pomeni zadnjo odjavo iz Igre črk.
Tabele so med seboj povezane z različnimi povezavami, ki jih razlikujemo glede na števnost.
Povezava med tabelama »igra« in »slovar« je 1:0 ali mnogo. To pomeni, da se vsaka beseda
iz slovarja v premetani obliki lahko sploh ne pojavi, lahko pa se pojavi večkrat. Besede so
namreč izbrane naključno iz baze Slovarja slovenskega knjižnega jezika, kar pomeni, da se
posamezna beseda v igri pojavi z verjetnostjo približno 0,001 %.2
Števnost povezave med tabelo »uporabnik« in tabelo »vnos« je 1:0 ali mnogo. To pomeni, da
lahko en uporabnik med igro sploh ne poskuša sestavljati besed, lahko pa teh sestavi poljubno
mnogo.
Povezava med tabelama »skupina« in »vnos« je 1:0 ali mnogo. Skupina igralcev vnaša
besede. Teoretično se lahko zgodi tudi, da noben izmed igralcev ne sestavi nobene besede iz
podanih črk in tako igra ne beleži nobenega vnosa.
Števnost povezave med tabelama »skupina« in »igra« je 1:1. Ena skupina igralcev, teoretično
gledano, odigra samo eno igro. Ker so tudi skupine naključno generirane po tem, ko
administrator izbere njihovo velikost, je verjetnost, da bi se enaka skupina igralcev ponovila,
zelo majhna oz. skorajda zanemarljiva.
Povezava med tabelama »igra« in »vnos« je prav tako 1:0 ali mnogo. Enako kot pri povezavi
»skupina« in »vnos« se lahko zgodi primer, ko ni sestavljena nobena beseda oz. ni opravljen
noben poskus, vendar pa se običajno vnese mnogo vnosov, saj vsak igralec poizkuša več kot
zgolj enkrat.
2 V Slovarju slovenskega knjižnega jezika se nahaja 93.152 pojmov. Statistični izračun 1:93.152
nam poda številko 0,00001073514, kar ob pretvorbi v odstotke in zaokroževanju pomeni, da se
posamezna beseda v igri pojavi z verjetnostjo 0,001 %.

33
3.3 Izboljšave funkcionalnosti
Ko je bil zadani osnovni del spletne programske opreme končan, je sledilo testiranje. To je
sicer sestavni del programiranja, predvsem pri tistih, ki smo v spletnem programiranju
novinci. Pogosto je namreč, da se zdi nekaj povsem logično, potem pa to funkcionalnost
skušaš sprogramirat in ne deluje, kot si si zamislil, ker si pozabil na neko ključno stvar. S
testiranjem tako hitro ugotoviš, da se bo stvari treba lotiti na drugačen način. Pri testiranju
programske opreme med programiranjem je šlo bolj za preverjanje funkcionalnosti in
skladnosti delovanja aplikacije z načrtom.
V drugem delu pa so nam na pomoč priskočili ostali sodelujoči na projektu. Igra se bo, kot že
omenjeno v začetnem poglavju, uporabila za poskusno testiranje oz. merjenje kolektivnega
znanja. Prav zato je treba pri tem upoštevati številne smernice družboslovnega raziskovanja in
spremenljivke, ki delujejo na (nezavedni) psihološki ravni. Vse navedeno bo ustvarjalo
pogoje, potrebne za izvedbo eksperimenta.
Predlogi za izboljšave so zastavljeni predvsem z izvedbenega vidika oz. priprave primernega
okolja za izvedbo testiranja. Prav tako pa je pomembna tudi uporabniška izkušnja. Zato je pri
tej fazi testiranja sodelovalo kar nekaj naključnih oseb, ki so aplikacijo preizkusile in opisale
svojo uporabniško izkušnjo; kaj jih moti in kaj bi lahko po njihovem mnenju bilo videti
drugače. Pomemben del testiranja je bilo tudi preizkušanje delovanja aplikacije v različnih
spletnih brskalnikih – vključena brskalnika sta široko razširjena Chrome in Mozilla Firefox.
Pomembno je namreč, da se aplikacija prikazuje in obnaša identično, ne glede na okolje, v
katerem se izvaja. Tako omogočamo, da je uporabniška izkušnja nespremenjena.
Predloge smo z mentorjem in psihologi prediskutirali ter določili, katere so relevantne oz.
pomembne za eksperiment, in smo jih nato v nadaljevanju izdelave diplomske naloge tudi
implementirali.

34
3.3.1 Posodobitve spletne aplikacije
Predlogi izboljšav spletne aplikacije za eksperimentalno merjenje kolektivnega znanja, za
katere smo se odločili, so naslednji:
omogočanje brisanja zadnje črke v besedi, ki jo posameznik sestavlja iz podanega
nabora črk. Prej je bilo mogoče v primeru, da si je igralec med sestavljanjem besede
premislil oz. pritisnil napačno črko, zbrisati zgolj celo sestavljano besedo. To je bilo
zelo nepraktično, sploh pri daljših besedah. Sedaj je dodana funkcionalnost, ki
omogoča brisanje posamičnega znaka iz sestavljane besede – briše zadnjo dodano črko
v nizu. Brisanje je možno vršiti s klikom na gumb ali z uporabo tipke za brisanje;
ko so osebe, sodelujoče v eksperimentu, pripravljene na igro in s strani administratorja
razdeljene v skupine, se igra prične. Novost je, da se pred pričetkom igre igralci
najprej seznanijo s ponujenim naborom črk, iz katerega kasneje sestavljajo besede.
Izbor črk si na ekranu lahko ogledujejo eno minuto. Med tem časom je sestavljanje
besed onemogočeno. Igralcem omogočimo, da vnaprej vedo, katere črke so jim na
voljo, in na ta način še pred začetkom igre poiščejo nekaj besed oz. dobijo prve
asociacije besed, ki jih lahko sestavijo s ponujenim naborom črk;
novost v igri je tudi, da lahko igralci črke za ugibane besede izbirajo s pomočjo
tipkovnice. Omogočena je le izbira črk, ki so v ponujenem naboru. Če igralec pritisne
tipko s črko, ki ni v podanem naboru, je ta ignorirana in se ne zapiše. S tem
omogočimo hitrejše odzive oz. igranje, saj je igralcem vnos črk s tipkovnico navadno
bolj domač oz. »nativen« (angl. native use). Omogočeno je tudi potrjevanje besed in
brisanje črk s pomočjo tipkovnice;
dodatek igri je tudi kreiranje profila uporabnika. Vsak igralec lahko na posebni strani
ureja demografske podatke o sebi – spol, starost, izobrazba itd. Ta segment je
pomemben zgolj za raziskovalce – psihologe, ki bodo po zaključenem testiranju igre
lahko analizirali in na podlagi tega morda prišli do pomembnih zaključkov na
področju kolektivnega znanja;
izboljšava, ki je pomembna za nadaljnjo obdelavo podatkov, pridobljenih na osnovi
igre, je, da v primeru, da je število igralcev takšno, da jih ni vseh možno razdeliti v
skupine izbrane velikosti, se preostanek deli na manjše skupine, ki po velikosti
ustrezajo raziskavi (1, 2, 4, 8, 16, 32);

35
še ena pomembna izboljšava za namene raziskave je, da lahko administrator določi, iz
koliko črk bodo uporabniki sestavljali besede in koliko časa jim bo dal na voljo za to
nalogo. Izbira lahko med besedami v dolžini 8 – 22 črk, časovni interval pa ima
razpon med 1 in 10 minutami. To pomeni, da lahko igralcem v primeru širšega nabora
črk ponudi daljši čas reševanja in obratno. Nesmiselno bi bilo namreč, da bi igralci pri
majhnem številu ponujenih črk imeli na voljo veliko časa.
4. ZAKLJUČEK
Raziskovalno vprašanje, ki se je še pred začetkom pisanja diplomske naloge zastavilo v
okviru projekta, v katerem smo sodelovali (»Po kreativni poti do praktičnega znanja«) na
Fakulteti za informacijske študije v Novem mestu, je bilo: »Kako se faktor kolektivnega
znanja spreminja s povečevanjem števila ljudi, ki so del sodelujoče množice?«. Odgovora na
to vprašanje v diplomski nalogi nismo podali, ker to ni bil njen namen.
Vsi cilji diplomske naloge so bili doseženi. Pripravili smo teoretični pregled širšega pojma –
množičnega zunanjega izvajanja oz. crowdsourcinga in raziskali, kaj je kolektivno znanje.
Spoznali smo tudi, da obstajajo najrazličnejše oblike crowdsourcinga, najbolj razširjene so
naslednje štiri: modrost množice, množično ustvarjanje, množično glasovanje in množično
financiranje.
Ker je množično zunanje izvajanje koncept, ki živi na spletu, obstajajo za njegovo izvajanje
štiri večje različice informacijskih sistemov: informacijski sistemi za množično obdelavo,
informacijski sistemi za množično ocenjevanje, informacijski sistemi za množično reševanje
problemov in informacijski sistemi za množično ustvarjanje.
Izdelali smo koncept spletne aplikacije, ki bo lahko skozi igro eksperimentalno na podlagi
statističnih spremenljivk merila, kaj se dogaja s faktorjem kolektivnega znanja, če
spreminjamo obseg sodelujoče množice. Igra črk je primerna za merjenje kolektivnega
znanja, ker temelji na preverjanju znanja osnovnih gradnikov maternega jezika – besed.
Igralci v omejenem času iz podanih črk skušajo sestaviti čim več besed. Igralci so razdeljeni v

36
skupine določene velikosti, ki jo izbere administrator. Kolektivno znanje se v igrici kaže na
naslednji način: vsaka ugibana beseda se v seznamu pokaže tudi ostalim igralcem v skupini.
Na ta način igralci dobijo navdih za grajenje novih besed, ki pa se nekako smiselno
navezujejo na že sestavljene besede soigralcev.
V aplikativnem delu diplomske naloge je bil glavni poudarek izdelava spletne aplikacije –
igrice, s katero bi kasneje poskušali eksperimentalno izmeriti, kako se kolektivno znanje
spreminja s spreminjanjem velikosti množice igralcev. Izdelava spletne aplikacije je potekala
v naslednjem vrstnem redu:
proučevanje teoretičnega ozadja crowdsourcinga,
snovanje koncepta Igre črk,
izdelava – programiranje Igre črk,
testiranje Igre črk,
odkrivanje možnosti izboljšav in popravkov,
implementacija in testiranje izboljšav.
V spletni aplikaciji Igra črk so bile izvedene naslednje izboljšave:
brisanje enega znaka iz sestavljane besede,
1-minutno seznanjanje s črkami pred začetkom igre,
sestavljanje besed s pomočjo tipkovnice,
uporabniški profil,
v primeru razdelitev igralcev v skupine, pri kateri pride do ostanka, se izvede delitev
preostalih uporabnikov v manjše skupine od izbrane, ki po številu sodelujočih
ustrezajo velikosti 2𝑛, pri čemer velja 𝑛 ≥ 0,
omogočanje izbire števila črk administratorju v razponu od 8 do 22, med katerimi
igralci iščejo besede,
omogočanje izbire časovnega intervala administratorju v intervalu od 1 do 10 minut.
Z zaključkom pričujoče diplomske naloge se najpomembnejši del raziskave šele pričenja.
Teoretična podlaga, potrebna za izvedbo eksperimenta, je pripravljena. Kolegi znanstveniki so
pripravili tudi numerični model, na podlagi katerega so predvideli rezultate testiranja. Ključni
del raziskave, izvedba eksperimenta, še sledi. Nato bo mogoče potegniti vzporednice med
numeričnim modelom in realnostjo. Na podlagi statističnih podatkov, ki jih bo prinesel

37
laboratorijski eksperiment v nadzorovanem okolju, je pričakovati pomembne novosti na
področju kolektivnega znanja, ki imajo potencial spreminjanja pogleda na množično zunanje
izvajanje in odkrivanja neslutenih potencialov tega.
Zbrati bo treba dovolj veliko množico med seboj čim bolj različnih oseb – tako, da bo
laboratorijski eksperiment čim bolj podoben »naravnemu« poteku crowdsourcinga. Najbolje
bi bilo, da bi bili sodelujoči različnih narodnosti, izobrazb, znanj in zanimanj ter verskih
prepričanj. Pod temi pogoji bi res lahko govorili o raznolikosti, kot se pojavlja v resničnosti.
V tovrstnih projektih namreč sodelujejo ljudje s praktično vsega sveta, saj svetovni splet to
omogoča brez kakršnihkoli omejitev. Za najboljše rešitve je namreč pomembno, da so se
sodelujoči med seboj razlikujejo v kulturno-socialnem ozadju, saj se s tem zagotavlja, da so
mnenja in prepričanja ljudi zelo raznovrstna, s čimer je tudi možnost ponavljanja istih napak
manjša.
Ne glede na to, katero obliko crowdsourcinga opazujemo; modrost množice (angl. crowd
wisdom), množično ustvarjanje (angl. crowd creation), množično glasovanje (angl. crowd
voting) ali množično financiranje (angl. crowd funding), je vsem skupno, da je osnova za
delovanje množica, ki nam pomaga rešiti problem, in da se najboljše rešitve ustvarijo, če je
množica kar se da raznolika. Vedno pa se izkaže, da množica ljudi, ki med seboj sodelujejo z
namenom reševanja nekega zastavljenega problema, pride do boljših rešitev kot vsak
posameznik, tudi najboljši strokovnjak s področja, prav tako je problem rešen v veliko
krajšem času.


38
5. LITERATURA IN VIRI
1. ARTICLE ONE PARTNERS (2011a) Crowdsourcing Series: Crowd Creation and
Wisdom. Dostopno prek: http://info.articleonepartners.com/crowdsourcing-series-crowd-
creation-and-wisdom/ (17. 7. 2015).
2. ARTICLE ONE PARTNERS (2011b) Crowdsourcing Series: The Increasing Blur
Between Expert And Amateur. Dostopno prek: http://info.articleonepartners.
com/blog/bid/55429/Crowdsourcing-Series-The-Increasing-Blur-Between-Expert-and-
Amateur (29. 6. 2015).
3. BAUMOL, WILLIAM J. (1986) Productivity Growth, Convergence and Welfare: What
the Long-Run Data Show. The American Economic Review, 76 (5), str. 1072–1085.
4. BEAL, VANGIE (2013) Database. Dostopno prek: http://www.webopedia.com/TERM/
D/database.html (16. 7. 2015).
5. BRABHAM, DAREN C. (2008) Crowdsourcing as a Model for Problem Solving: An
Introduction and Cases. Convergence: The International Journal Of Research into New
Media Technologies, 14 (1), str. 75–90.
6. BRABHAM, DAREN C. (2013) Crowdsourcing. MIT Press essential knowledge series.
Cambridge, Massachusetts; London, England: The MIT Press.
7. BUECHELER, THIERRY, SIEG, JAN HENRIK, FÜCHSLIN, RUDOLF M. in
PFEIFER, ROLF (2010) Crowdsourcing, Open Innovation and Collective Intelligence in
the Scientific Method: A Research Agenda and Operational Framework. V: Proc. Of the
Alife XII Conference, str. 679-686.
8. DE LIDDO, ANNA, SÁNDOR, ÁGNES in BUCKINGHAM SHUM, SIMON (2012)
Contested Collective Intelligence: Rationale, Technologies, and a Human-Machine
Annotation Study. Computer Supported Cooperative Work, 21, str.417-448.
9. DEREX, MAXIME, BEUGIN, MARIE-PAULINE, GODELLE, BERNARD in
RAYMOND, MICHEL (2013) Group size and cultural complexity. Nature, 503 (7476),
str. 389–391.
10. DRESNER, STEVEN (2014) Crowdfunding: A Guide to Raising Capital on the Internet.
Hoboken, New Yersey: John Wiley & Sons.


39
11. DUMAS, GUILLAUME (2001) Towards a two-body neuroscience, Communicative &
Integratove Biology. Biology, 4 (3), str. 349–252.
12. GEIGER, DAVID, ROSEMAN, MICHAEL, FIELT, ERVIN in SCHADER, MARTIN
(2012) Crowdsourcing Information Systems – Definition, Typology, and Design. V:
Thirty Third International Conference of Information Systems.
13. GUAZZINI, ANDREA, VILONE, DANIELLE, DONATI, CAMILLO, NARDI.
ANNALISA in LEVNAJIĆ, ZORAN (2015) Modeling crowdsourcing as collective
problem solving. Dostopno prek: http://arxiv.org/pdf/1506.09155v1.pdf (17. 7. 2015).
14. HOWE, JEFF (2006) The Rise of Crowdsourcing. Wired Magazine, 14 (6), str. 1-4.
15. HOWE, JEFF (2009) Why the Power of the Crowd is Driving the Future of Business.
New York: Crown Publishing Group.
16. JĘDRZEJOWICZ, PIOTR, THANH NGUYEN, NGOC in HOANG, KIEM (2011)
Computational Collective Intelligence: Technologies and Applications, Proceedings, Part
II. V: Third International Conference, ICCCI 2011.
17. JIANG, JING, CHEN, CHUANSHENG, DAI, BOHAN, SHI, GUAN, DING,
GUOSHENG, LIU, LI in LU, CHUNMING (2015) Leader emergence through
interpersonal neural synchronization. PNAS, 112 (14), str. 4274–4279.
18. KICKSTARTER STATS (2015). Dostopno prek: https://www.kickstarter.com/help/stats
(19.8.2015).
19. KOMPARE, ALENKA, STRAŽIŠAR, MIHAELA, DOGŠA, IRENA, VEC, TOMAŽ in
CURK, JANINA (2006) Uvod v psihologijo: učbenik za psihologijo v 2. letniku
gimnazijskega in srednješolskega strokovnega izobraževanja. Ljubljana: DZS.
20. LEBRATY, JEAN-FABRICE, LEBRATY LOBRE, KATIA (2013) Crowdsourcing: One
Step Beyond. Hoboken: John Wiley & Sons, Inc.; London: ISTE Ltd.
21. LEIMEISTER, JAN MARCO (2010) Collective Intelligence. Business & Information
Systems Engineering, 2 (4), str. 245–248.
22. MALONE, W. THOMAS, LAUBACHER, ROBERT in DELLAROCAS,
CHRYSANTHOS (2009) Harnessing Crowds: Mapping the Genome of Collective
Intelligence. Cambridge: Massachusetts Institute of Technology.
23. NEISSER, ULRIC, BOODOO GWYNETH, BOUCHARD Jr., THOMAS, BOYKIN, A.
WADE, BRODY, NATHAN, HALPERN J., STEPHEN, LOEHLIN F., DIANE,
PERLOFF, ROBERT, STERNBERG, ROBERT J. in URBINA, SUSANA (1996)
Intelligence: Knowns and unknowns. American Psychologist, 51 (2), str. 77–101.


40
24. NICKERSON, ROBERT C., VARSHNEY, UPKAR in MUNTERMANN, JAN (2013) A
method for taxonomy development and its application in information systems. European
Journal of Information Systems, 22, str. 336–359.
25. NIELSEN, MICHAEL (2011) TEDx talk: Open science now! Dostopno prek:
http://www.ted.com/talks/michael_nielsen_open_science_now (17. 7. 2015).
26. ORDANINI, ANDREA, MICELO, LUCIA, PIZZETI, MARTA in PAEASURAMAN,
A. (2009) Crowdfunding: Transformin Customers into Investors through Innovative
Service Platforms. V: Frontiers in Service Conference.
27. O'REILLY, TIM (2009) What is Web 2.0? Sebastopol, CA; O'Reilly Media.
28. POETZ, MARION K. in SCHREIER, MARTIN (2012) The value of Crowdsourcing:
Can Users Really Compete with Professionals in Generating New Product Ideas? J Prod
Innov Manag, 29 (2), str. 245–256.
29. PRPIĆ, JOHN in SHUKLA, PRASHANT (2012) The Theory Of Crowd Capital. V:
Proceedings of the Hawaii International Conference on Systems Sciences #46. January
2013, Maui, Hawaii, USA. Maui: IEEE Computer Society Press, str. 3505–3514.
30. PRPIĆ, JOHN, JACKSON, PIPER in NGUYEN, THAI (2014) A Computational Model
Of Crowds for Collective Intelligence. Collective Intelligence 2014. Center for Collective
Intelligence.
31. SAFIRE, WILLIAM (2009) On Language: Crowdsourcing. New York Time Magazine.
Dostopno prek: http://www.nytimes.com/2009/02/08/magazine/08wwln-safire-t.html (15.
7. 2015).
32. SAUERMANN, HENRY in FRANZONI, CHIARA (2015) Crowd sceince user
contribution patterns and their implications. PNAS, 112 (3), str. 679–684.
33. SEGARAN, TOBY (2007) Programming Collective Intelligence. Sebastopol: O'Reilly
Media, Inc.
34. SCALABILITY (2015). Dostopno prek: https://en.wikipedia.org/wiki/Scalability (9. 8.
2015).
35. SCHENK, ERIC in GUITTARD, CLAUDE (2009) Crowdsourcing: What can be
Outsourced to the Crowd, and Why? Dostopno prek: https://halshs.archives-
ouvertes.fr/file/index/docid/439256/filename/Crowdsourcing_eng.pdf (8. 8. 2015).
36. SUROWIECKI, JAMES (2006) The Wisdom Of Crowds: Why The Many Are Smarter
Than The Few. London: Abacus.
37. ULE, ANDREJ (2004) Znanost v družbi znanja. Teorija in praksa, 41 (1–2). str. 256–
271.


40
38. WOLPERT, DAVID H. in TUMER, KAGAN (2008) An Introduction to Collective
Intelligence: Applied Intelligent Systems. Berlin: Springer Berlin Heidelberg, str. 133–
178.
39. WOOLLEY WILLIAMS, ANITA, CHABRIS F., CHRISTOPHER, PENTLAND,
ALEX, HASHMI, NADA in MALONE, THOMAS W. (2010) Evidence for a Collective
Intelligence Factor in the Performance of Human Groups. Science, 330 (6004), str. 686–
688.


PRILOGA
Priloga 1: Shema podatkovne baze Igre črk


Priloga 1: Shema podatkovne baze Igre črk
Vir: Plut, lastni prikaz (2015)
Recommended

















