
L’analisi della varianza
Introduzione e concetti generali
Giovanni Battista Flebus AA 2013-14

L’analisi della varianza (ANOVA, ANalysi Of VAriance) è una tecnica statistica che permette di valutare se le medie di due o più gruppi sono uguali fra loro.
La variabile Dipendente è misurata su una scala a intervalli e ha una distribuzione normale
La variabile indipendente (classificazione in più gruppi) è una misurazione a livello di scala nominale
La classificazione è fatta in modo indipendente

L’analisi della varianza
• Si basa su due principi:• (1) si può stimare la varianza della
popolazione in due modi diversi, che tengano conto della suddivisione in gruppi
• (2) Si possono confrontare due varianze e verificare se sono estratte dalla stessa popolazione

Le ipotesi di ricerca
• Le due ipotesi di ricerca sono le seguenti
• H0 : le medie dei k gruppi sono uguali
• H1 : almeno una delle medie dei k gruppi è diversa dalle altre

Ulteriori esplorazioni
• Se il test statistico permette di concludere che c’è almeno un gruppo diverso dagli altri, si possono applicare altre tecniche per individuare i gruppi diversi

Esempio preliminare
• In un campione di studenti, si rileva il senso di benessere (un test, scala a intervalli) per vedere se le bocciature a scuola hanno influenza su tale tratto.
• Il benessere si rileva con un test (BeSco, Test di Benessere Scolastico)
• Le bocciature a scuola (nessuna, una o due), anche se sono una scala a rapporti, sono considerate qui come una classificazione e quindi come scala nominale.
• La frequenza dei tre gruppi è la seguente
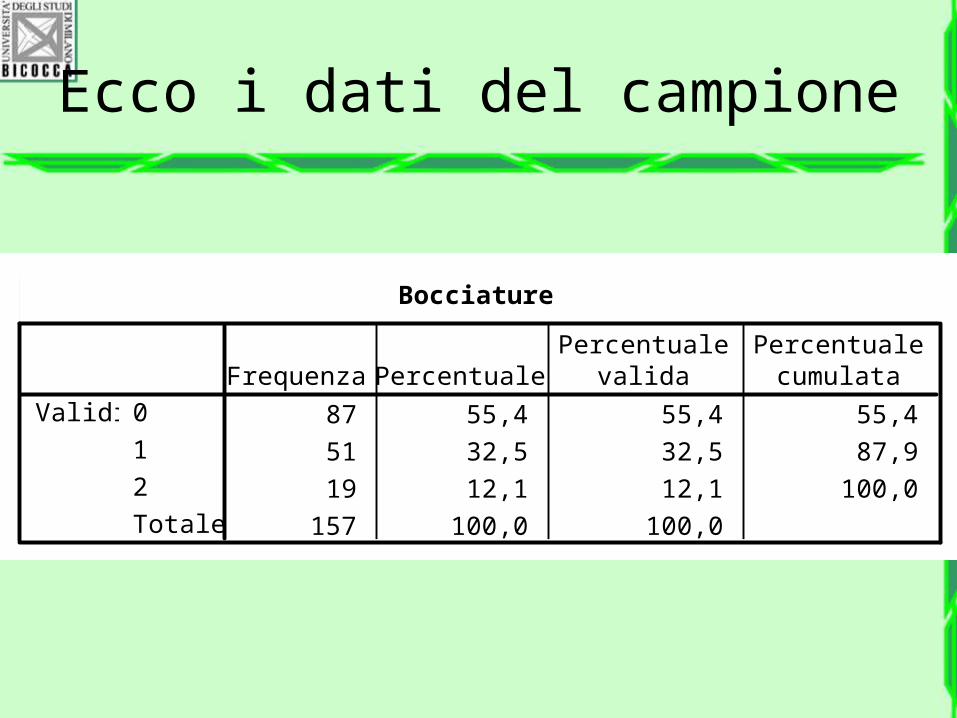
Bocciature
87 55,4 55,4 55,4
51 32,5 32,5 87,9
19 12,1 12,1 100,0
157 100,0 100,0
0
1
2
Totale
ValidiFrequenza Percentuale
Percentualevalida
Percentualecumulata
Ecco i dati del campione
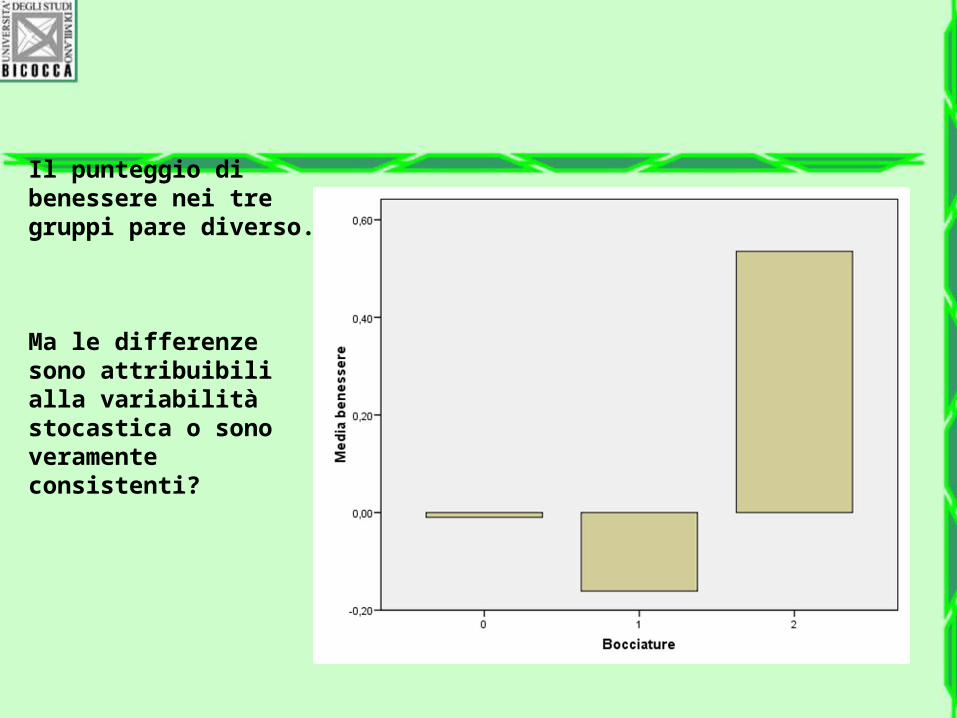
Il punteggio di benessere nei tre gruppi pare diverso.
Ma le differenze sono attribuibili alla variabilità stocastica o sono veramente consistenti?

• Ma queste differenze sono reali o non sono piuttosto dovuti a fluttuazioni casuali?
• Ricorriamo al grafico con basette
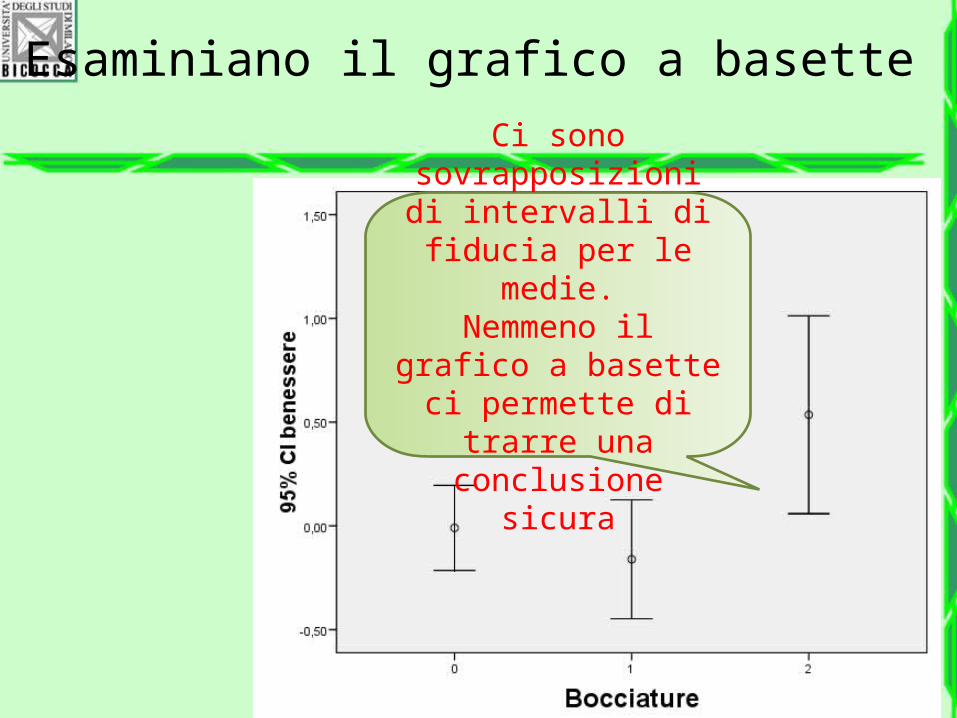
Esaminiano il grafico a basette
Ci sono sovrapposizioni di intervalli di fiducia
per le medie.Nemmeno il grafico
a basette ci permette di trarre una conclusione
sicura

Esaminiamo i risultati dell’ANOVA
ANOVA univariata
benessere
6,767 2 3,384 3,495 ,033149,111 154 ,968155,878 156
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.
La significatività ci dice che le tre
medie non possono essere considerate
uguali
Questa tabella è prodotta
dall’applicazione dell’ANOVA ai dati, che ci permette di
passare alla conclusione…

Principio dell’ANOVA
• Si può stimare la varianza della popolazione in due modi diversi e confrontare le due stime
• Primo metodo: calcolare la varianza delle k medie come se fossero k osservazioni
• Secondo metodo: calcolare la varianza media, usando tutte le osservazioni, eliminando però da ciascuna osservazione l’influenza del proprio gruppo.
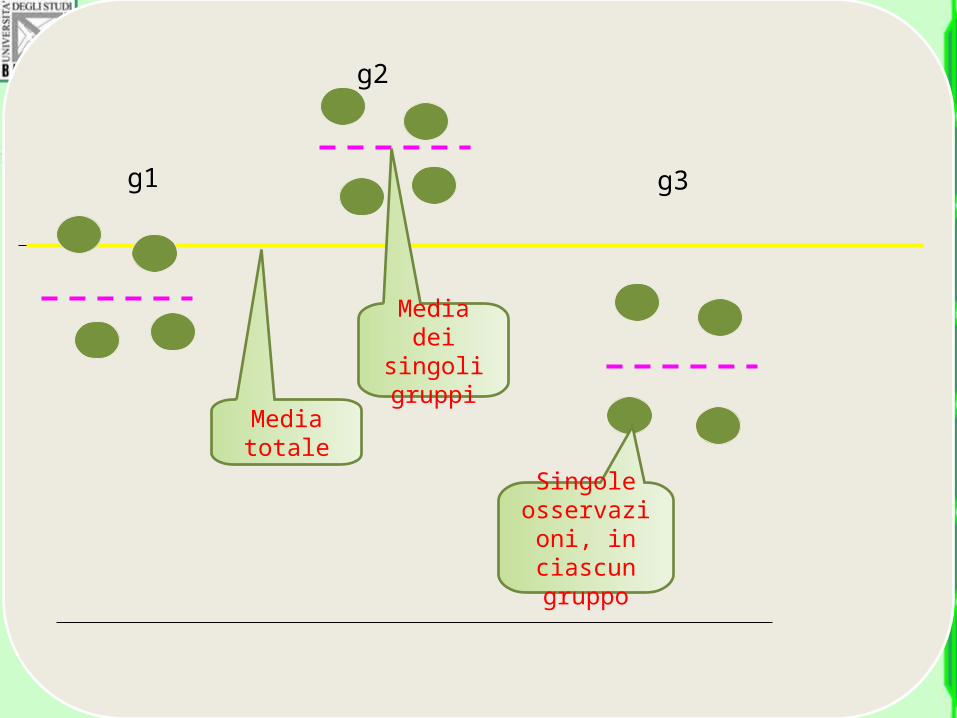
g1
g2
g3
Media totale
Media dei
singoli gruppi
Singole osservazion
i, in ciascun gruppo
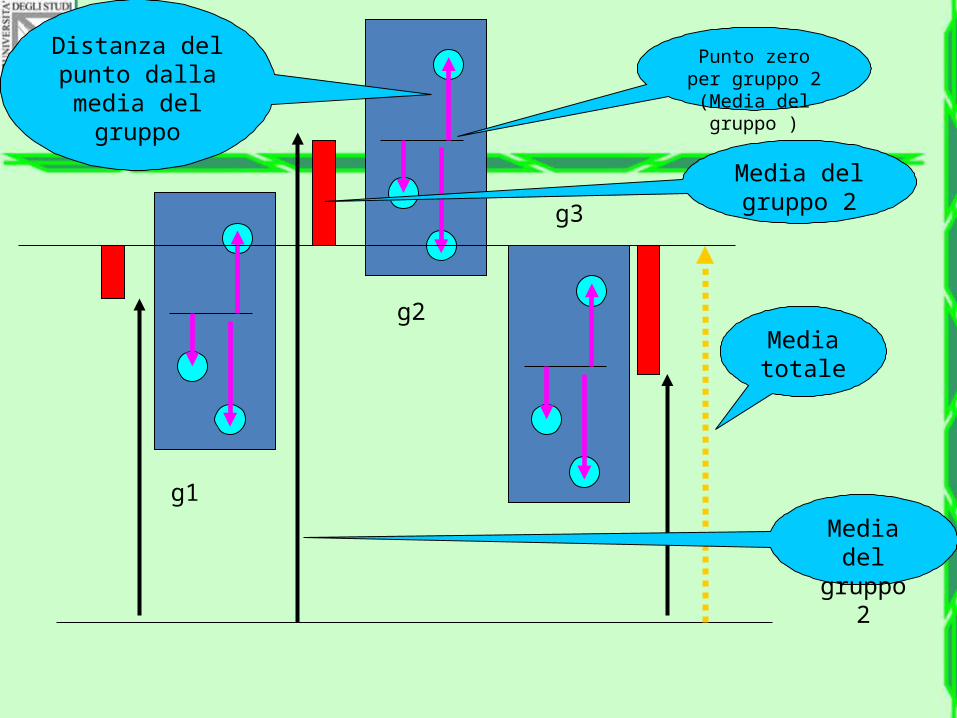
Media totale
g1
g2
g3
Punto zero per gruppo 2
(Media del gruppo )
Media del
gruppo 2
Distanza del punto dalla media del
gruppo
Media del gruppo 2

Piccolo esempio numerico
• Un ricercatore pensa che il tempo passato a muoversi in città sia di detrimento per il rendimento accademico degli studenti universitari. Ha osservato il numero di esami di 12 studenti, suddivisi in tre gruppi secondo l’uso di trasporto per andare in facoltà:
• A) prendono i mezzi • B) Hanno un loro mezzo (moto – auto)• C) vivono in zona e quindi vanno a piedi
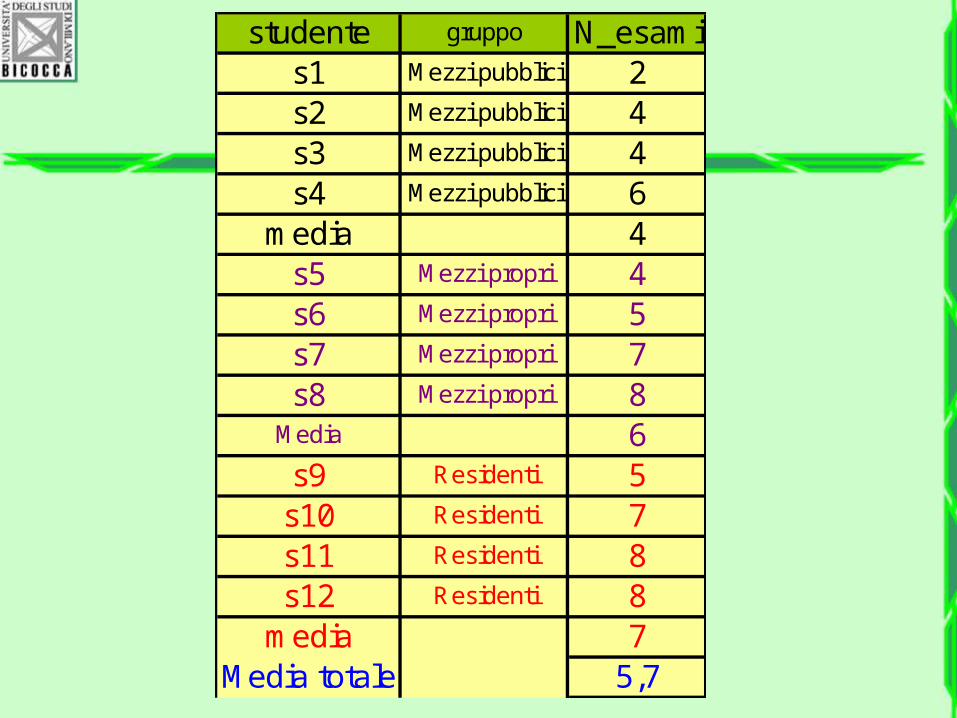
studente gruppo N_esamis1 Mezzi pubblici 2s2 Mezzi pubblici 4s3 Mezzi pubblici 4s4 Mezzi pubblici 6
media 4s5 Mezzi propri 4s6 Mezzi propri 5s7 Mezzi propri 7s8 Mezzi propri 8
Media 6s9 Residenti 5
s10 Residenti 7s11 Residenti 8s12 Residenti 8
media 7Media totale 5,7
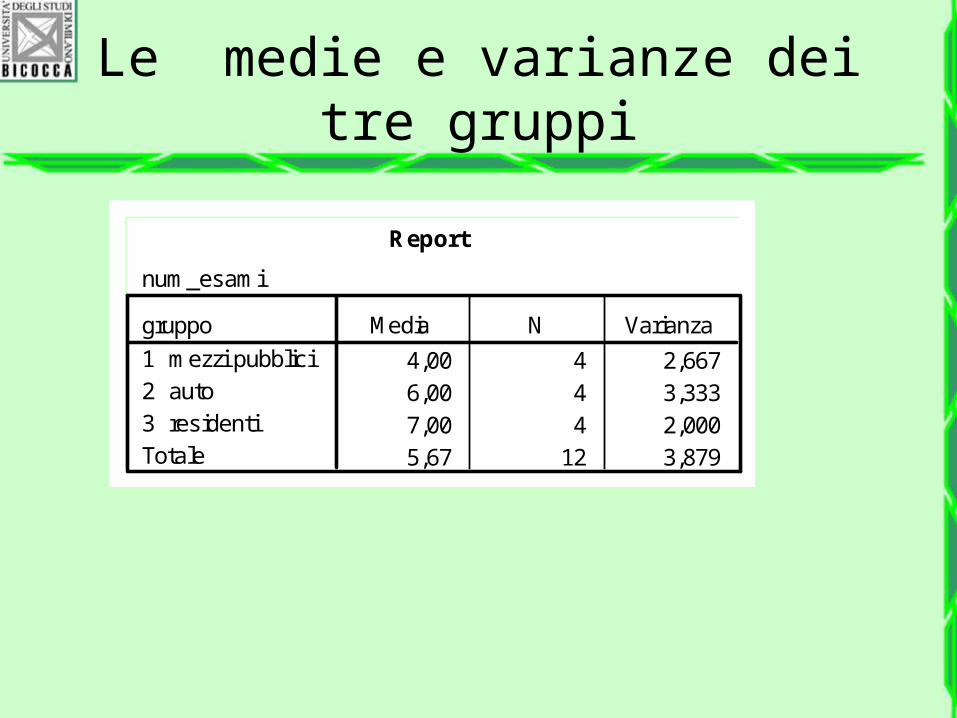
Le medie e varianze dei tre gruppi
Report
num_esami
4,00 4 2,6676,00 4 3,3337,00 4 2,0005,67 12 3,879
gruppo1 mezzi pubblici2 auto3 residentiTotale
Media N Varianza
Report
num_esami
4,00 4 2,6676,00 4 3,3337,00 4 2,0005,67 12 3,879
gruppo1 mezzi pubblici2 auto3 residentiTotale
Media N Varianza
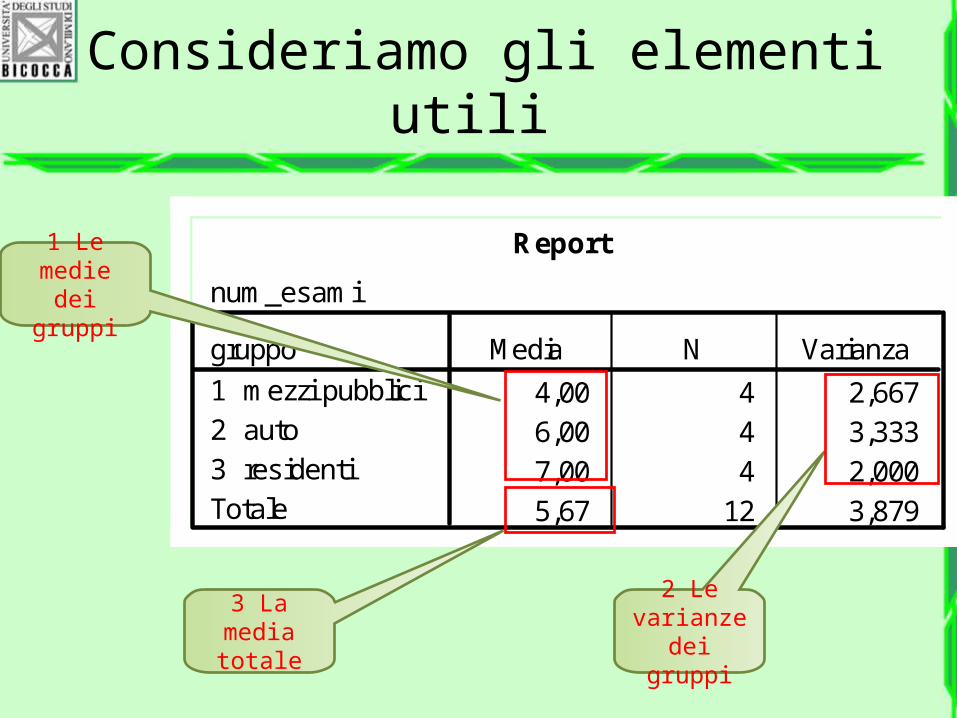
Consideriamo gli elementi utili
1 Le medie dei
gruppi
2 Le varianze
dei gruppi
3 La media totale

Report
num_esami
4,00 4 2,6676,00 4 3,3337,00 4 2,0005,67 12 3,879
gruppo1 mezzi pubblici2 auto3 residentiTotale
Media N Varianza
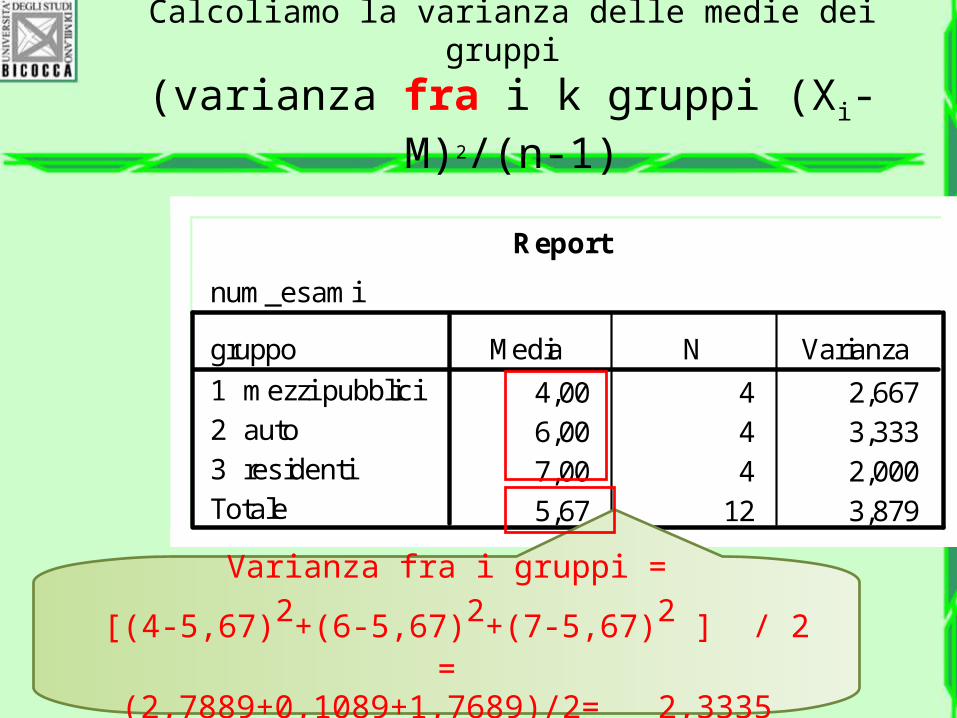
Calcoliamo la varianza fra i gruppi
1 Le medie dei
gruppi
3 La media totale
2 La numerosità dei gruppi è 3
Report
num_esami
4,00 4 2,6676,00 4 3,3337,00 4 2,0005,67 12 3,879
gruppo1 mezzi pubblici2 auto3 residentiTotale
Media N Varianza
Calcoliamo la varianza delle medie dei gruppi
(varianza fra i k gruppi (Xi-M)2/(n-1)
Varianza fra i gruppi =
[(4-5,67)2+(6-5,67)2+(7-5,67)2 ] / 2 =(2,7889+0,1089+1,7689)/2= 2,3335

La varianza delle k medie (s2) è però la varianza della distribuzione campionaria
delle medie: s2 /nA noi serve la varianza della popolazione:
s2
Perciò dobbiamo moltiplicare il valore per n (numerosità nei gruppi):
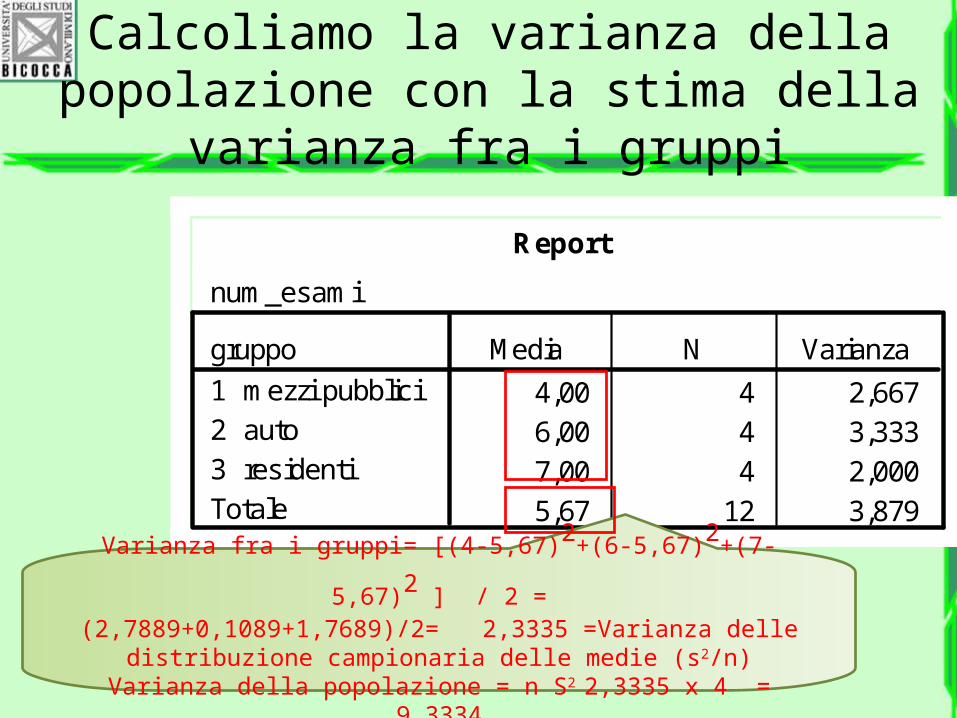
Varianza della popolazione o varianza della distribuzione campionaria delle medie?
Report
num_esami
4,00 4 2,6676,00 4 3,3337,00 4 2,0005,67 12 3,879
gruppo1 mezzi pubblici2 auto3 residentiTotale
Media N Varianza
Calcoliamo la varianza della popolazione con la stima della
varianza fra i gruppi
Varianza fra i gruppi= [(4-5,67)2+(6-5,67)2+(7-5,67)2 ] / 2 =
(2,7889+0,1089+1,7689)/2= 2,3335 =Varianza delle distribuzione campionaria delle medie (s2/n)
Varianza della popolazione = n S2 2,3335 x 4 = 9,3334

Report
num_esami
4,00 4 2,6676,00 4 3,3337,00 4 2,0005,67 12 3,879
gruppo1 mezzi pubblici2 auto3 residentiTotale
Media N Varianza
Calcoliamo la media delle varianze nei gruppi:
2,667+3,333+2,000=8,00Media della varianza nei gruppi
8,00/3= 2,667
Calcoliamo la varianza della popolazione con la stima della
varianza dentro i gruppi

I gradi di libertà
• I gradi di libertà sono dati da • (1) Numero di gruppi -1 per la
varianza fra i gruppi• (2) Numero di osservazioni meno i
gruppi, per la varianza nei gruppi.• Nel nostro caso, 3-1= 2 gl per la
varianza fra i gruppi• 12-3 = 9 gl per la varianza nei gruppi

Otteniamo il valore di F
• Il rapporto fra le due stime della varianza della popolazione (una nei gruppi e l’altra fra i gruppi) ha una distribuzione descritta dalla variabile casuale F di Fisher Snedecor con gl1 e gl2 gradi di libertà.

Nel nostro caso otteniamoF= 9,334/ 2,666 = 3,500 con 2 e 9 gradi di libertà.
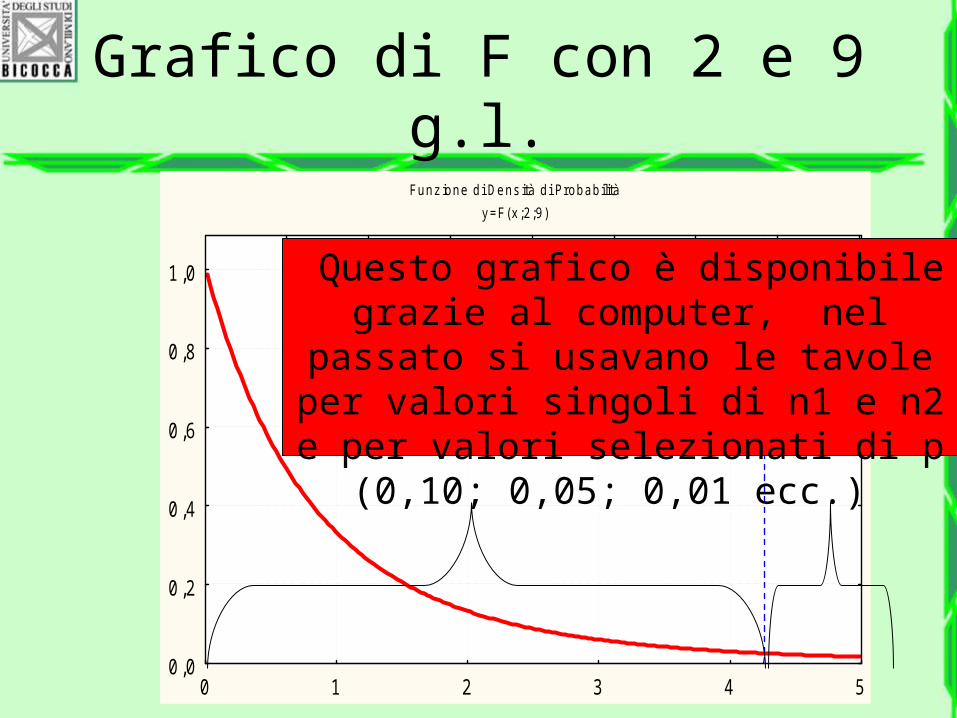
Grafico di F con 2 e 9 g.l.Funz ione di Dens ità di Probabilità
y =F(x ;2;9)
0 1 2 3 4 50,0
0 ,2
0 ,4
0 ,6
0 ,8
1 ,0 Questo grafico è disponibile grazie al computer, nel passato si
usavano le tavole per valori singoli di n1 e n2 e per valori
selezionati di p (0,10; 0,05; 0,01 ecc.)
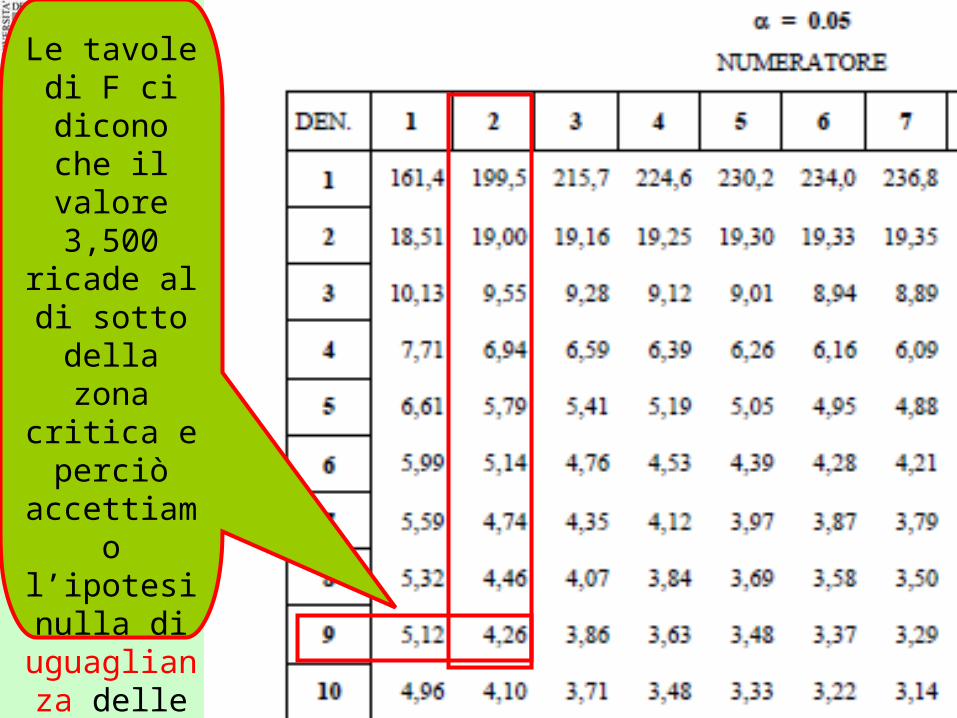
Le tavole di F ci
dicono che il valore 3,500
ricade al di sotto della
zona critica e perciò
accettiamo l’ipotesi nulla di
uguaglianza delle
medie dei tre gruppi
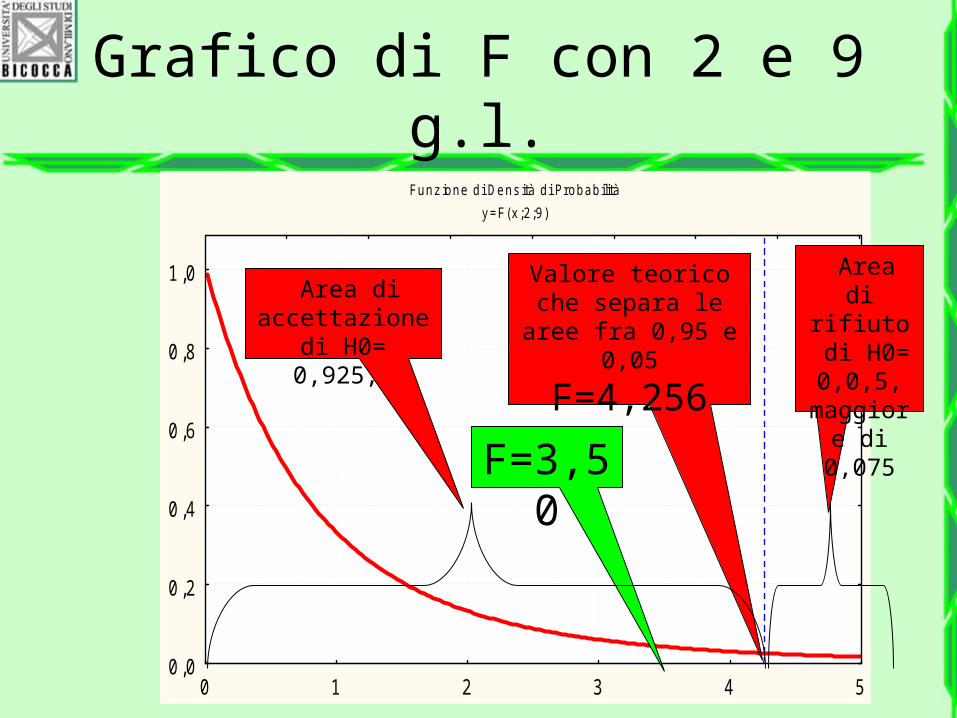
Grafico di F con 2 e 9 g.l.Funz ione di Dens ità di Probabilità
y =F(x ;2;9)
0 1 2 3 4 50,0
0 ,2
0 ,4
0 ,6
0 ,8
1 ,0 Area di rifiuto di H0= 0,0,5,
maggiore di
0,075
Area di accettazione
di H0= 0,925,
Valore teorico che separa le
aree fra 0,95 e 0,05
F=4,256
F=3,50

Per il calcolo con spss
Le due varianze sono però calcolate in modo diverso da quello che è stato
presentato: si parte dalla somma dei quadrati (distanza dell’osservazione dalla
media) (devianza in italiano, Sum of squares in inglese) dentro e fra i gruppi,
divisi per i rispettivi gradi di libertà.
Il rapporto F è sempre stampato usando la devianza nei e fra i gruppi. La loro somma è uguale alla devianza totale
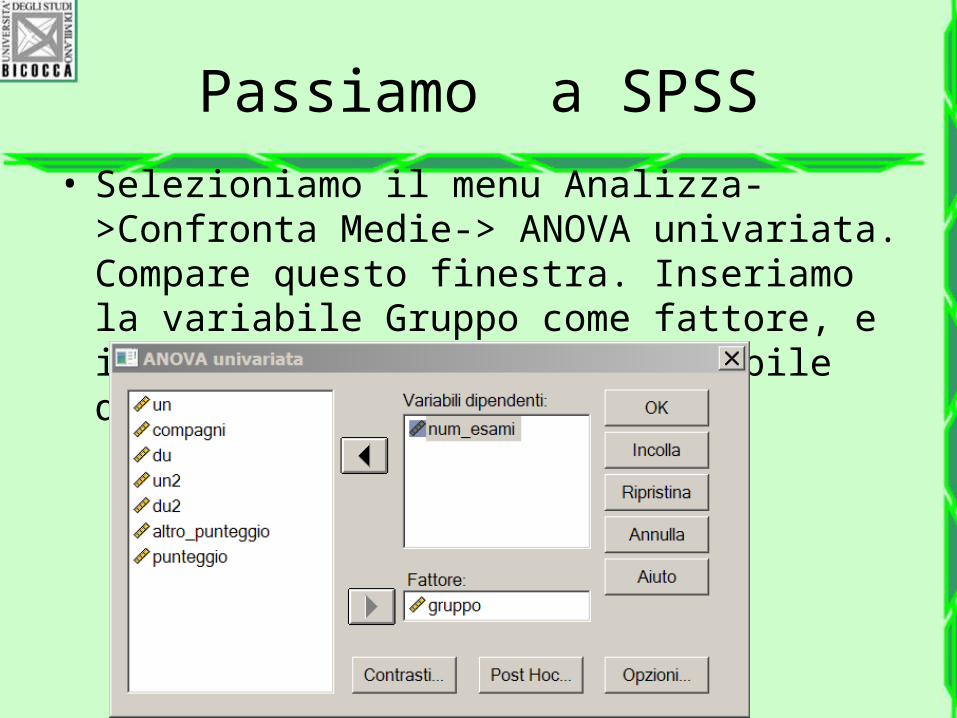
Passiamo a SPSS• Selezioniamo il menu Analizza-
>Confronta Medie-> ANOVA univariata. Compare questo finestra. Inseriamo la variabile Gruppo come fattore, e il numero di esami come variabile dipendente
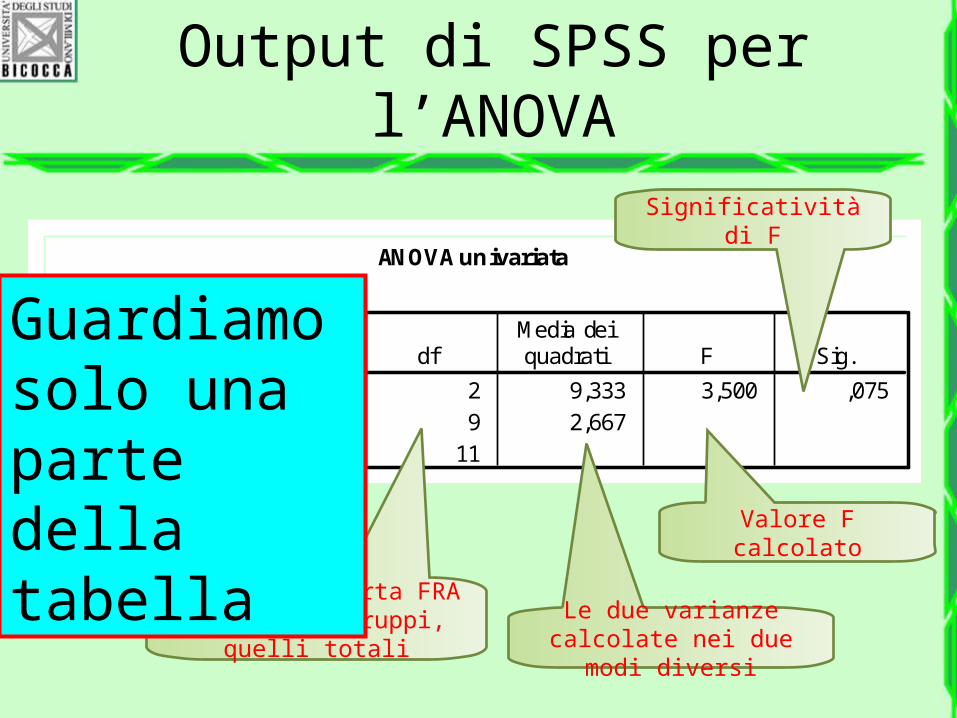
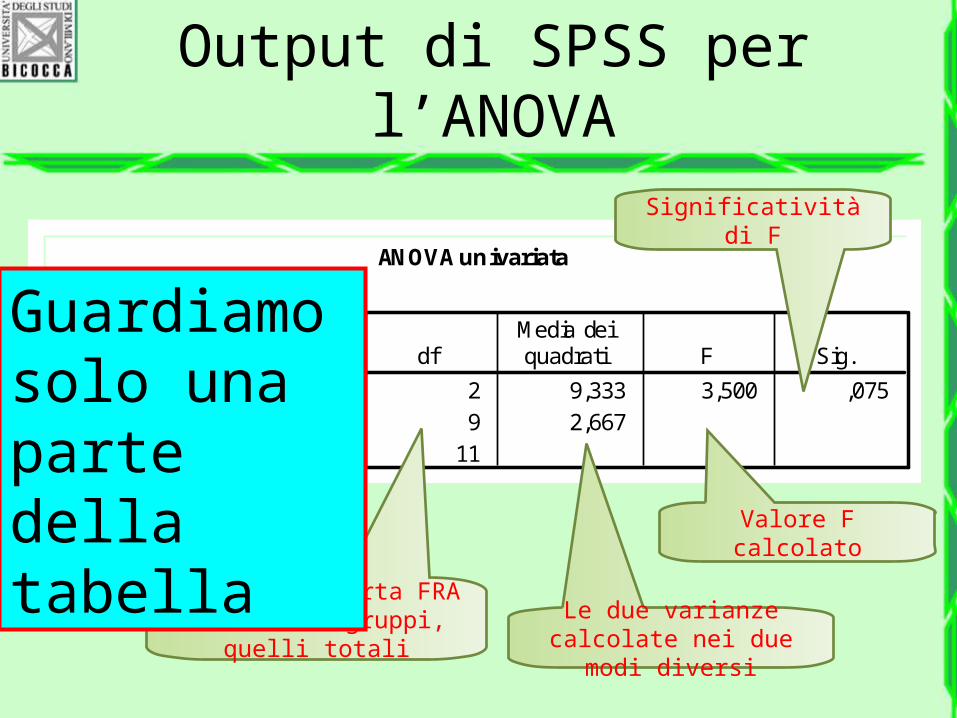
Output di SPSS per l’ANOVA
ANOVA univariata
num_esami
18,667 2 9,333 3,500 ,07524,000 9 2,66742,667 11
Fra gruppiEntro gruppiTotale
Somma deiquadrati df
Media deiquadrati F Sig.
Valore F calcolato
Gradi di liberta FRA e DENTRO i gruppi,
quelli totali
Le due varianze calcolate nei due modi
diversi
Significatività di F
Guardiamo solo una parte della tabella

Il metodo di calcolo seguito è diverso
• Le due varianze appena confrontate sono di solito concepite come un rapporto di scarti quadrati, divisi per i rispettivi gradi di libertà, per produrre delle stime delle varianze
• Per rendere questo metodo di calcolo utilizzabile con gruppi di diversa numerosità, si procede ricordando il concetto di devianza totale, suddivisa in devianza fra i gruppi e devianza nei gruppi

La variabilità totale è descritta da SQT, ovvero Devianza totale:
Scomposizione della variabilità totale
p
i
n
jij
i
yySQT1 1
2

La variabilità fra i gruppi è descritta con la formula seguente
Devianza fra i gruppi:
Scomposizione della variabilità totale
k
iii yynSQF
1
2

La variabilità nei (o dentro i) gruppi è descritta dalla SSE detta anche variabilità dell’errore:
Devianza dentro i gruppi:
Scomposizione della variabilità totale
k
i
n
jiij
i
yySQE1 1
2

Rappresentazione grafica della devianza

Dalle devianze alle due varianze
• Le due varianze (dentro e fra i gruppi) sono quindi calcolate come rapporti fra due somme di quadrati, divise dai rispettivi gradi di libertà.

I risultati del test F per la ANOVA sono generalmente presentati in una tabella come questa:
Test F per ANOVA
Fonti di Variabilità
Devianze g.l. Varianze F
Fra i gruppi SS(A) k-1 MS(A) MS(A)/ MS(E) Entro i gruppi SS(E)
nt-k MS(E)
Totale SSTOT nt-1 MSTOT
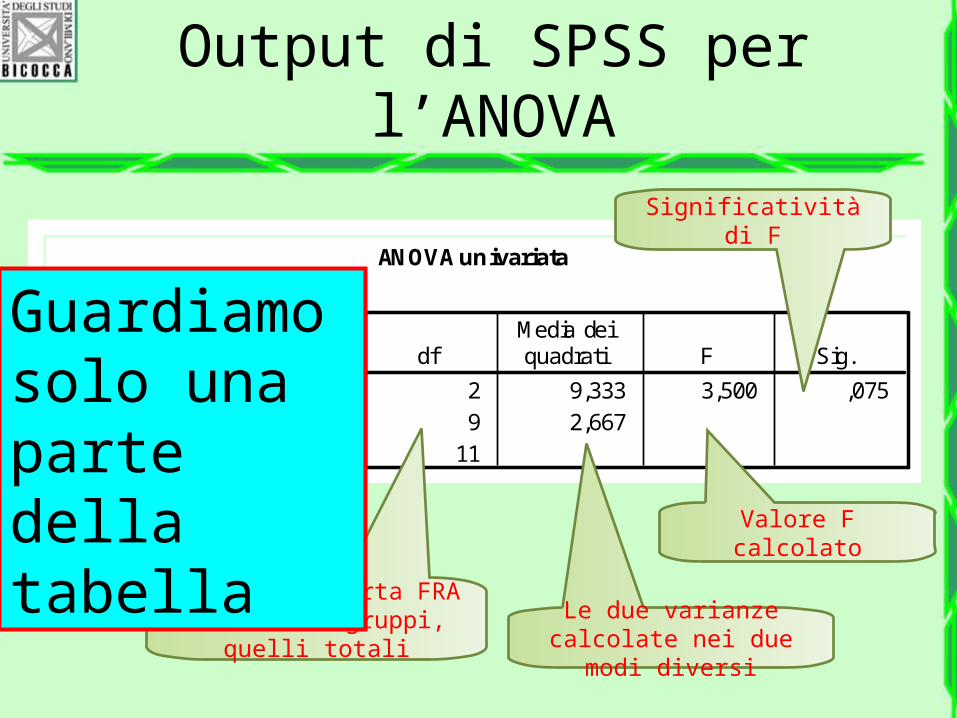
Output di SPSS per l’ANOVA
ANOVA univariata
num_esami
18,667 2 9,333 3,500 ,07524,000 9 2,66742,667 11
Fra gruppiEntro gruppiTotale
Somma deiquadrati df
Media deiquadrati F Sig.
Valore F calcolato
Gradi di liberta FRA e DENTRO i gruppi,
quelli totali
Le due varianze calcolate nei due modi
diversi
Significatività di F
Guardiamo solo una parte della tabella
Output di SPSS per l’ANOVA
ANOVA univariata
num_esami
18,667 2 9,333 3,500 ,07524,000 9 2,66742,667 11
Fra gruppiEntro gruppiTotale
Somma deiquadrati df
Media deiquadrati F Sig.
Valore F calcolato
Gradi di liberta FRA e DENTRO i gruppi,
quelli totali
Le due varianze calcolate nei due modi
diversi
Significatività di F
Guardiamo solo una parte della tabella

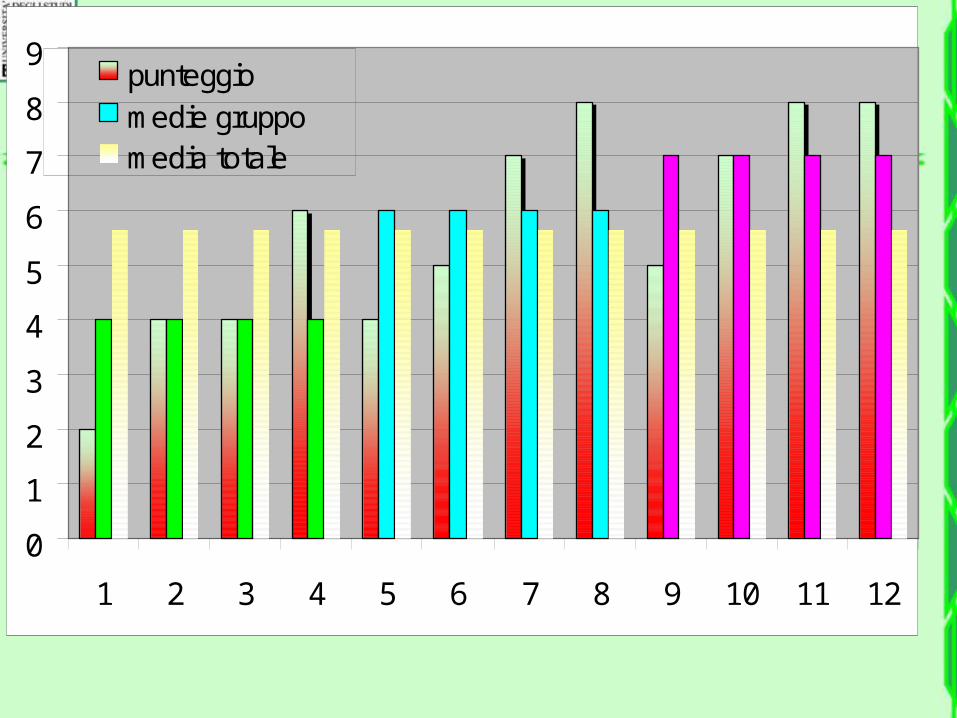
Nel grafico seguente, per ogni n osservazione, sono riportati solo
gli scarti dalle medie: dalla media generale, dalla media del gruppo e scarto del gruppo dalla
media generale.

Rappresentazione grafice di punteggi, scarti dalla media
e devianza
0
1
2
3
4
5
6
7
8
9
1 2 3 4 5 6 7 8 9 10 11 12
punteggiomedie gruppomedia totale

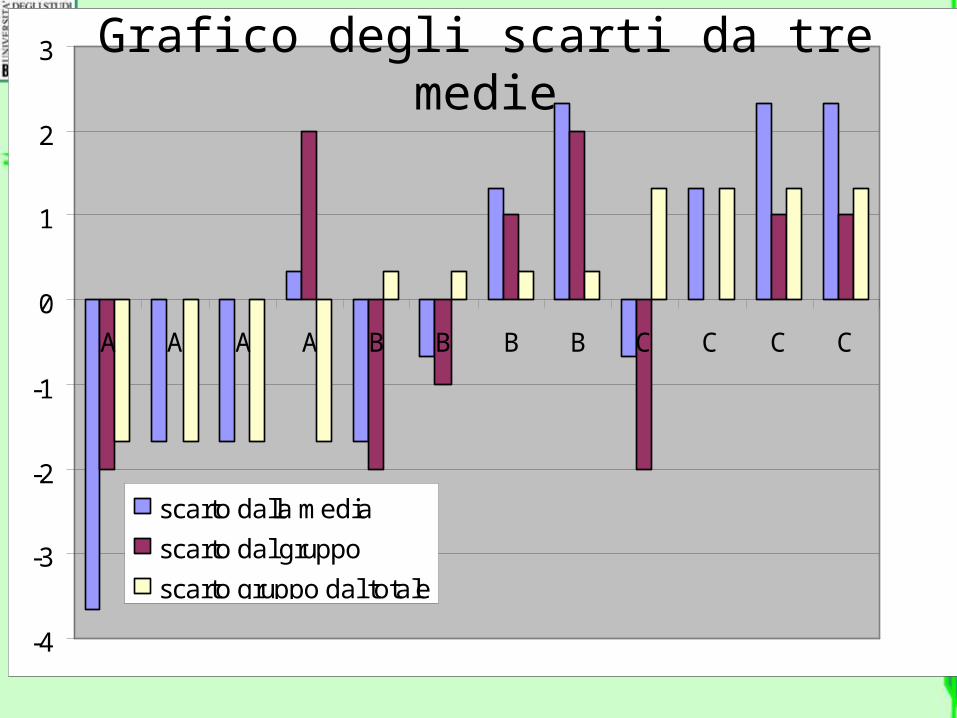
Rappresentazione degli scarti dalle medie
-4
-3
-2
-1
0
1
2
3
A A A A B B B B C C C C
scarto dalla media
scarto dal gruppo
scarto gruppo dal totale
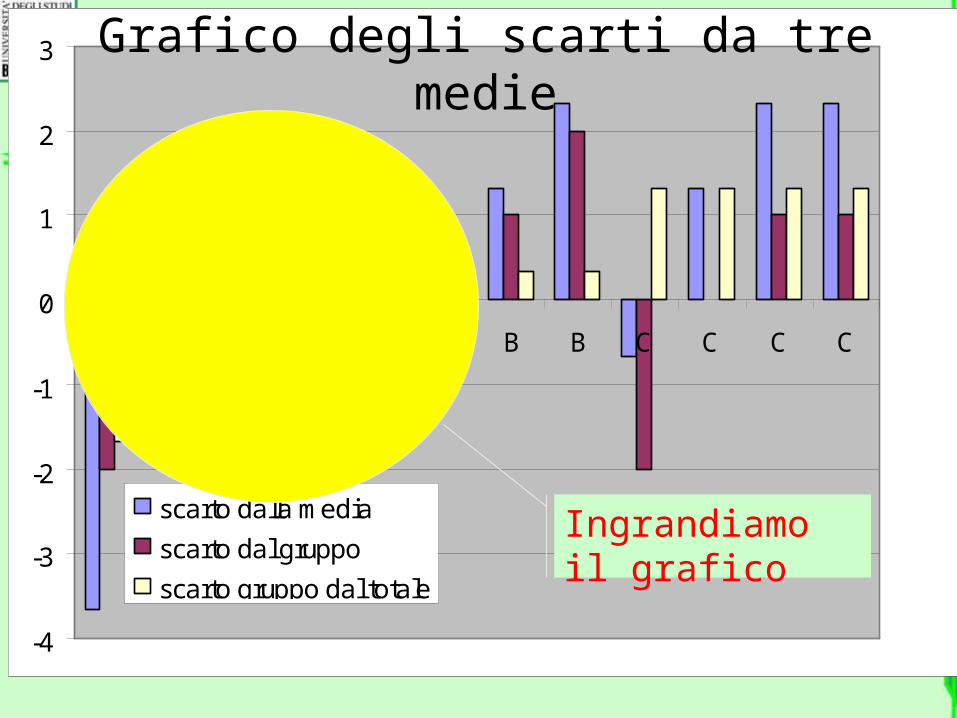
Grafico degli scarti da tre medie
-4
-3
-2
-1
0
1
2
3
A A A A B B B B C C C C
scarto dalla media
scarto dal gruppo
scarto gruppo dal totale
Grafico degli scarti da tre medie
Ingrandiamo il grafico
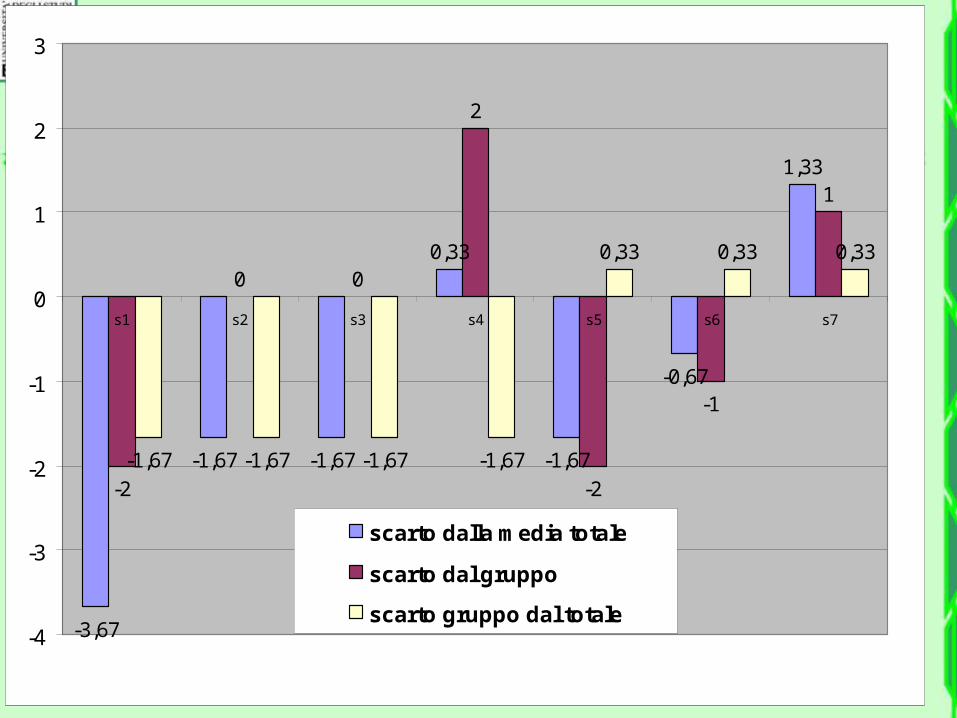
-3,67
-1,67 -1,67
0,33
-1,67
-0,67
1,33
-2
0 0
2
-2
-1
1
-1,67 -1,67 -1,67 -1,67
0,33 0,33 0,33
-4
-3
-2
-1
0
1
2
3
s1 s2 s3 s4 s5 s6 s7
scarto dalla media totale
scarto dal gruppo
scarto gruppo dal totale
-3,67
-1,67 -1,67
0,33
-1,67
-0,67
1,33
-2
0 0
2
-2
-1
1
-1,67 -1,67 -1,67 -1,67
0,33 0,33 0,33
-4
-3
-2
-1
0
1
2
3
s1 s2 s3 s4 s5 s6 s7
scarto dalla media totalescarto dal grupposcarto gruppo dal totale
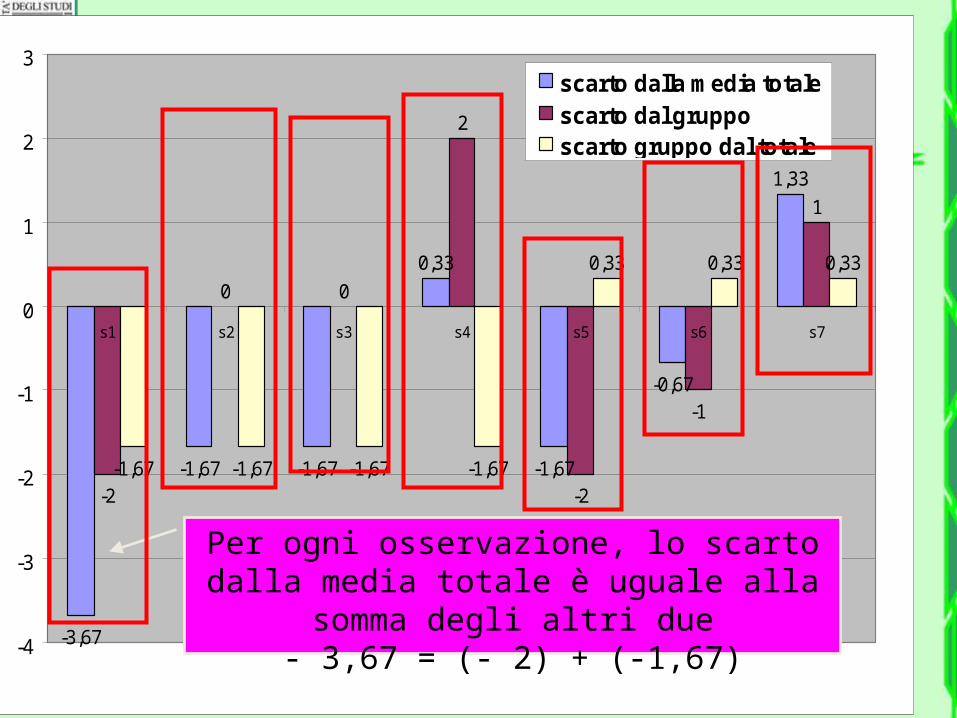
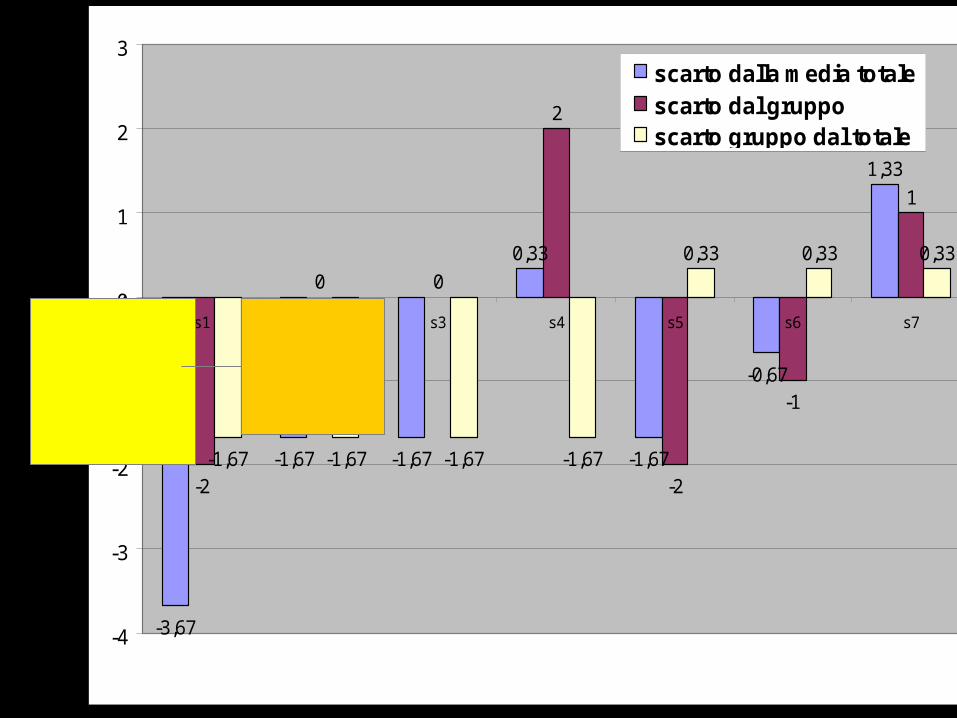
Per ogni osservazione, lo scarto dalla media totale è uguale alla somma degli
altri due- 3,67 = (- 2) + (-1,67)

La devianza
Si usa il termine devianza per indicare
la somma dei quadrati delle distanze dalla media.
In inglese Sum of Squares
• La varianza stimata della popolazione si ottiene dividendo la devianza per il numero dei gradi di libertà– Si usano i termini inglesi within (W) per
indicare la devianza nei gruppi e between (B) per indicare la devianza fra i gruppi

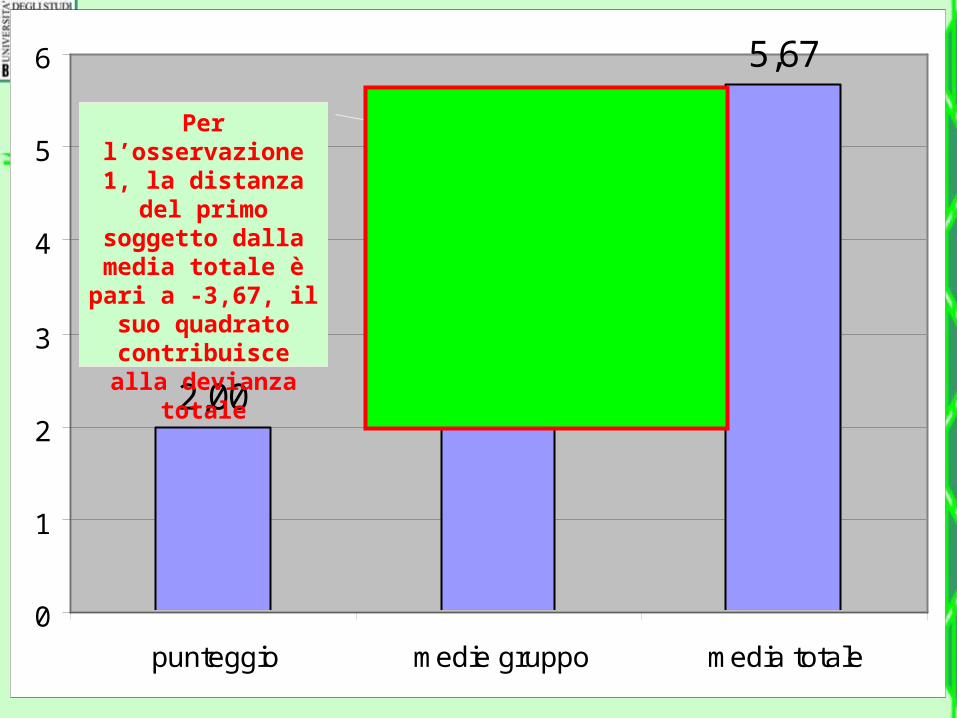
• Esaminiamo il primo studente, che ha un
• Numero di esami pari a 2• La media del suo gruppo è 4• La media dell’intero campione è pari
a 5,67
5,67
4,00
2,00
0
1
2
3
4
5
6
punteggio medie gruppo media totale
Per l’osservazione 1, la distanza del primo soggetto
dalla media totale è pari a -
3,67, il suo quadrato
contribuisce alla devianza totale
5,67
4,00
2,00
0
1
2
3
4
5
6
punteggio medie gruppo media totale
5,67
4,00
2,00
0
1
2
3
4
5
6
punteggio medie gruppo media totale
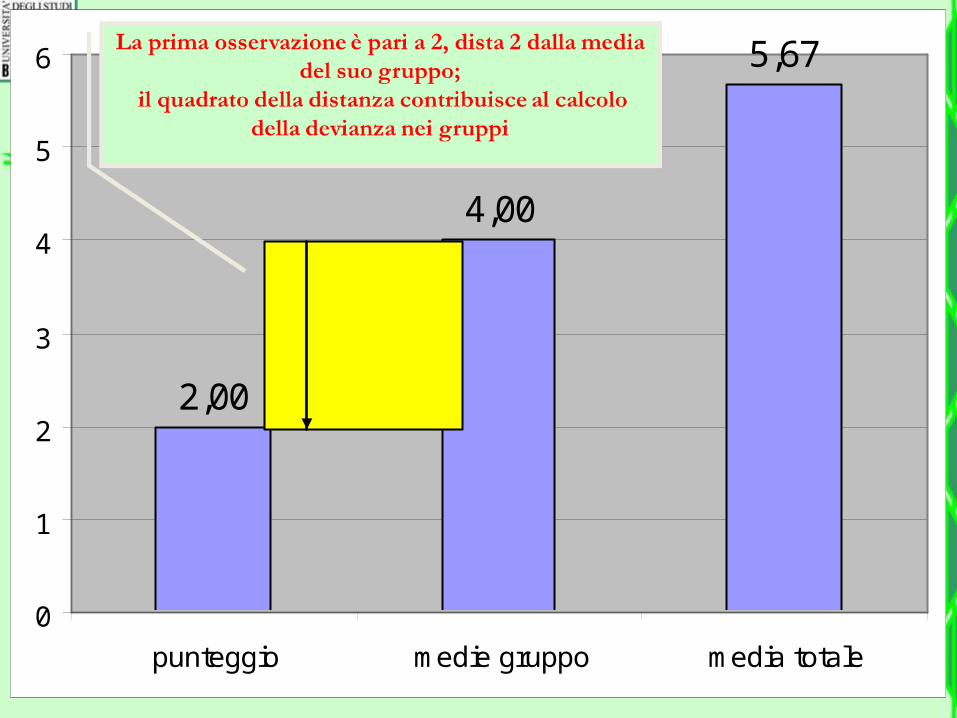
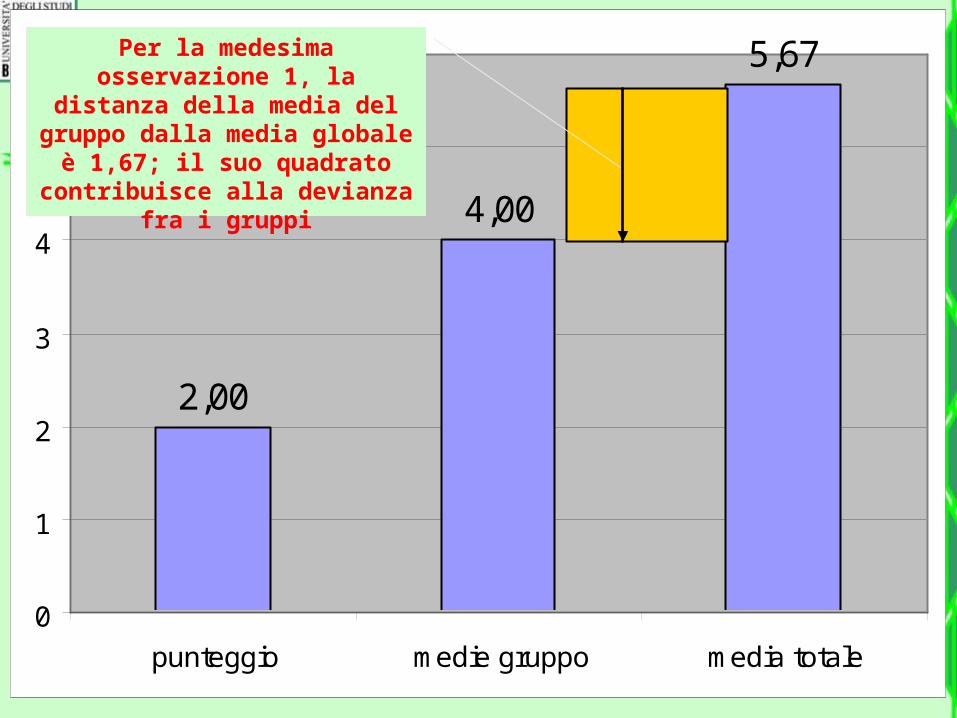
Per la medesima osservazione 1, la distanza
della media del gruppo dalla media globale è 1,67;
il suo quadrato contribuisce alla devianza fra i gruppi

• Usando gli scarti dalla media, rappresentiamo i due quadrati per il primo caso (osservazione) che ha un punteggio di 2. La media del suo gruppo è 4 e quella del campione intero è pari a 5,67
-3,67
-1,67 -1,67
0,33
-1,67
-0,67
1,33
-2
0 0
2
-2
-1
1
-1,67 -1,67 -1,67 -1,67
0,33 0,33 0,33
-4
-3
-2
-1
0
1
2
3
s1 s2 s3 s4 s5 s6 s7
scarto dalla media totalescarto dal grupposcarto gruppo dal totale
-3,67
-1,67 -1,67
0,33
-1,67
-0,67
1,33
-2
0 0
2
-2
-1
1
-1,67 -1,67 -1,67 -1,67
0,33 0,33 0,33
-4
-3
-2
-1
0
1
2
3
s1 s2 s3 s4 s5 s6 s7
scarto dalla media totalescarto dal grupposcarto gruppo dal totale
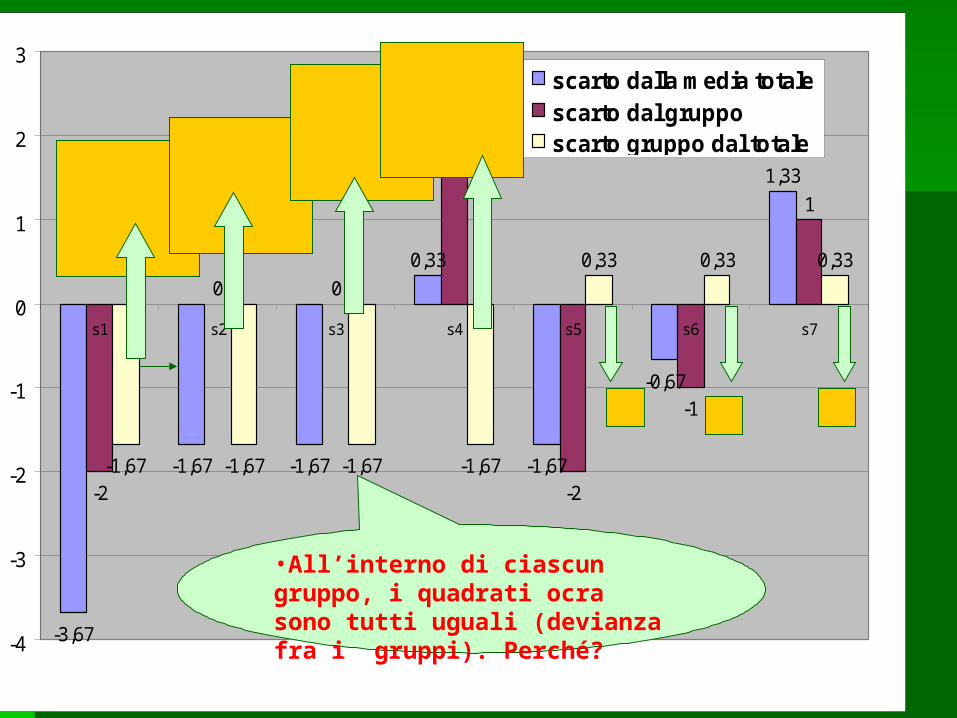
•All’interno di ciascun gruppo, i quadrati ocra sono tutti uguali (devianza fra i gruppi). Perché?
Dati sul foglio excel
stud gruppoN_esa
mimedie gruppo
media totale
scarto dalla media totale quadrato
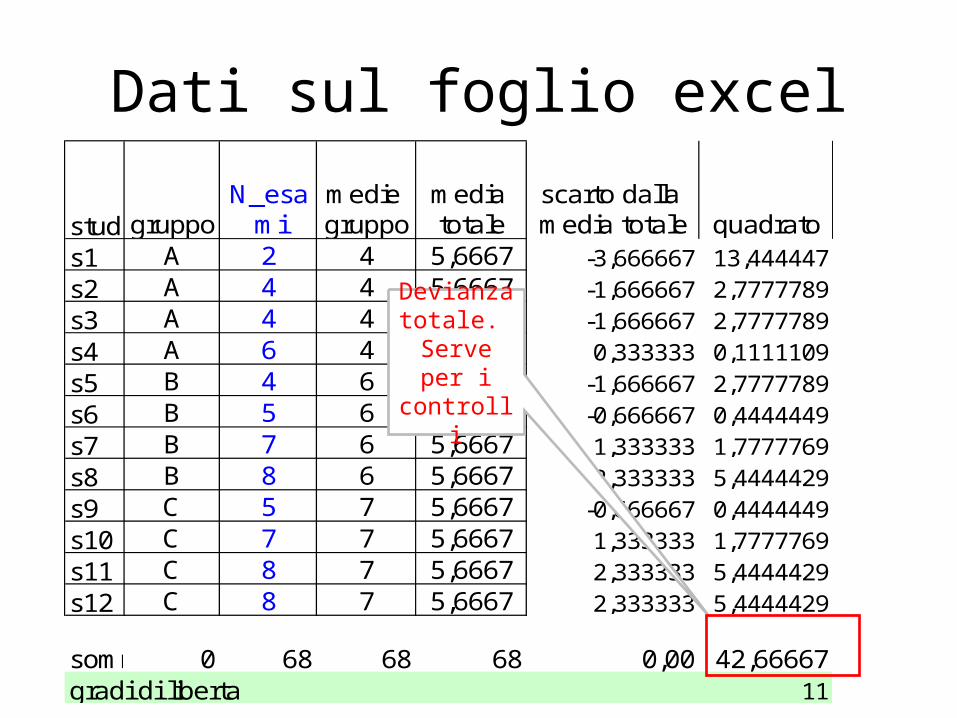
s1 A 2 4 5,6667 -3,666667 13,444447s2 A 4 4 5,6667 -1,666667 2,7777789s3 A 4 4 5,6667 -1,666667 2,7777789s4 A 6 4 5,6667 0,333333 0,1111109s5 B 4 6 5,6667 -1,666667 2,7777789s6 B 5 6 5,6667 -0,666667 0,4444449s7 B 7 6 5,6667 1,333333 1,7777769s8 B 8 6 5,6667 2,333333 5,4444429s9 C 5 7 5,6667 -0,666667 0,4444449s10 C 7 7 5,6667 1,333333 1,7777769s11 C 8 7 5,6667 2,333333 5,4444429s12 C 8 7 5,6667 2,333333 5,4444429
somma 0 68 68 68 0,00 42,66667gradi di liberta 11
Devianza totale.
Serve per i controlli
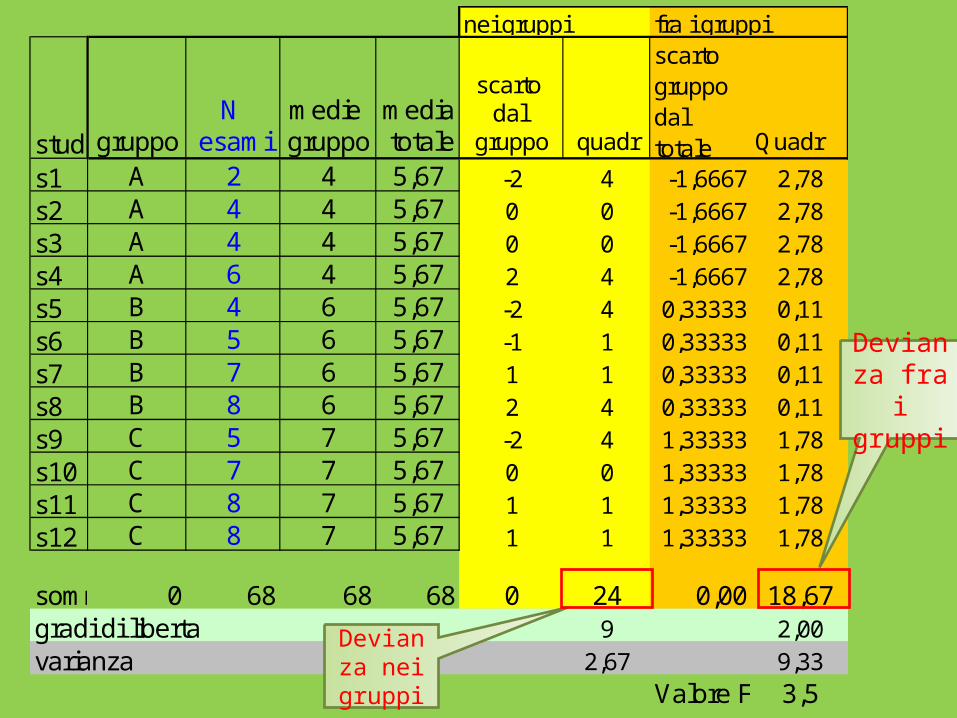
stud gruppoN
esamimedie gruppo
media totale
scarto dal
gruppo quadr
scarto gruppo dal totale Quadr
s1 A 2 4 5,67 -2 4 -1,6667 2,78s2 A 4 4 5,67 0 0 -1,6667 2,78s3 A 4 4 5,67 0 0 -1,6667 2,78s4 A 6 4 5,67 2 4 -1,6667 2,78s5 B 4 6 5,67 -2 4 0,33333 0,11s6 B 5 6 5,67 -1 1 0,33333 0,11s7 B 7 6 5,67 1 1 0,33333 0,11s8 B 8 6 5,67 2 4 0,33333 0,11s9 C 5 7 5,67 -2 4 1,33333 1,78s10 C 7 7 5,67 0 0 1,33333 1,78s11 C 8 7 5,67 1 1 1,33333 1,78s12 C 8 7 5,67 1 1 1,33333 1,78
somma 0 68 68 68 0 24 0,00 18,67gradi di liberta 9 2,00varianza 2,67 9,33
Valore F 3,5
nei gruppi fra i gruppi
Devianza nei gruppi
Devianza fra i gruppi

I gradi di libertà
Ad ognuna delle devianze sono associati i gradi di libertà:• la devianza totale ha n − 1 gradi di libertà• la devianza tra gruppi ha k − 1 gradi di libertà• la devianza entro i gruppi ha n - p gradi di libertà
Dividendo ciascuna devianza per i rispettivi gradi di libertà si ottengono le media dei quadrati, cioè le VARIANZE:
1var
p
SQFfra
pn
SQEerr
t var
Varianza tra i gruppi Varianza entro i gruppi

Il rapporto F
• La statistica F è quindi un rapporto fra due varianze, calcolate dividendo la devianza fra i gruppi per la devianza nei gruppi, ognuno divisa per i rispettivi gradi di libertà
)(
)1/(
knSQdentro
kSQfra

Output completo di SPSS
ANOVA univariata
num_esami
18,667 2 9,333 3,500 ,07524,000 9 2,66742,667 11
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.
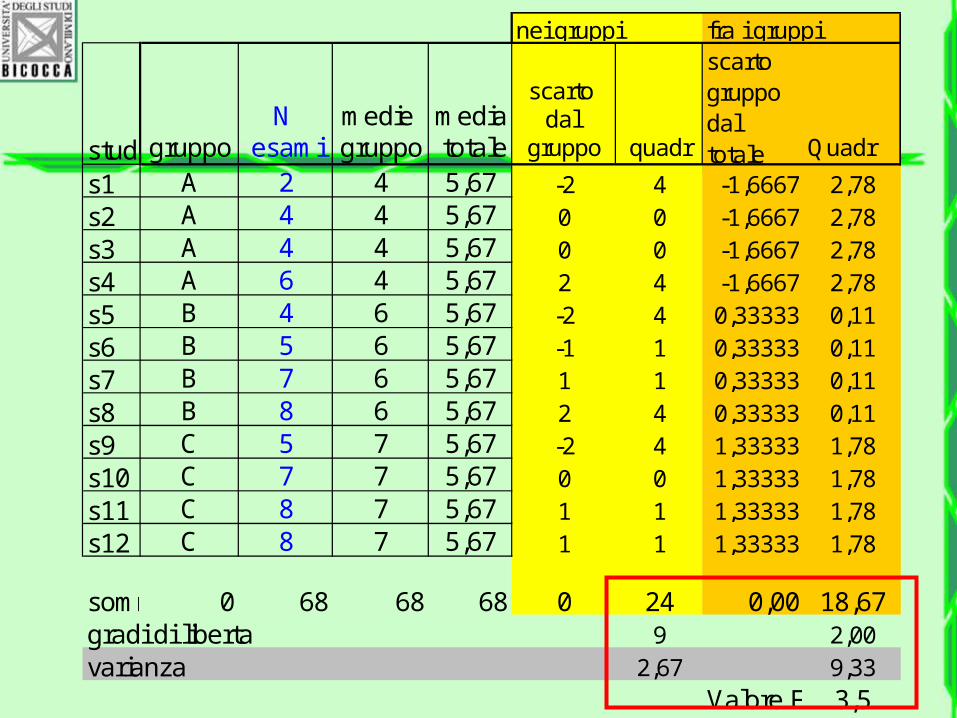
stud gruppoN
esamimedie gruppo
media totale
scarto dal
gruppo quadr
scarto gruppo dal totale Quadr
s1 A 2 4 5,67 -2 4 -1,6667 2,78s2 A 4 4 5,67 0 0 -1,6667 2,78s3 A 4 4 5,67 0 0 -1,6667 2,78s4 A 6 4 5,67 2 4 -1,6667 2,78s5 B 4 6 5,67 -2 4 0,33333 0,11s6 B 5 6 5,67 -1 1 0,33333 0,11s7 B 7 6 5,67 1 1 0,33333 0,11s8 B 8 6 5,67 2 4 0,33333 0,11s9 C 5 7 5,67 -2 4 1,33333 1,78s10 C 7 7 5,67 0 0 1,33333 1,78s11 C 8 7 5,67 1 1 1,33333 1,78s12 C 8 7 5,67 1 1 1,33333 1,78
somma 0 68 68 68 0 24 0,00 18,67gradi di liberta 9 2,00varianza 2,67 9,33
Valore F 3,5
nei gruppi fra i gruppi
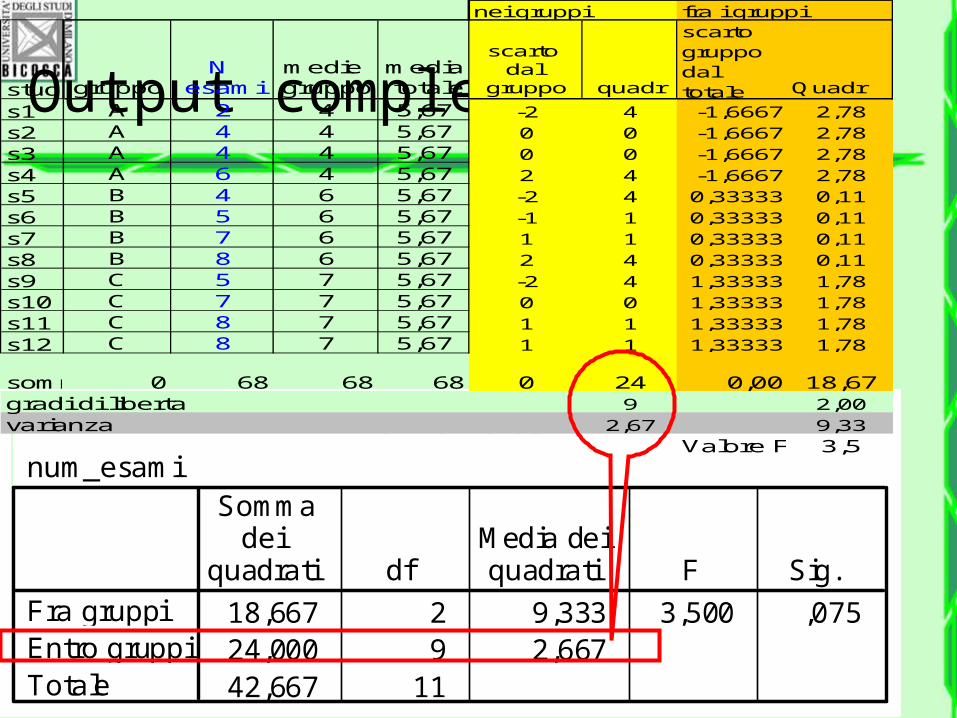
Output completo di SPSS
ANOVA univariata
num_esami
18,667 2 9,333 3,500 ,07524,000 9 2,66742,667 11
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.
stud gruppoN
esamimedie gruppo
media totale
scarto dal
gruppo quadr
scarto gruppo dal totale Quadr
s1 A 2 4 5,67 -2 4 -1,6667 2,78s2 A 4 4 5,67 0 0 -1,6667 2,78s3 A 4 4 5,67 0 0 -1,6667 2,78s4 A 6 4 5,67 2 4 -1,6667 2,78s5 B 4 6 5,67 -2 4 0,33333 0,11s6 B 5 6 5,67 -1 1 0,33333 0,11s7 B 7 6 5,67 1 1 0,33333 0,11s8 B 8 6 5,67 2 4 0,33333 0,11s9 C 5 7 5,67 -2 4 1,33333 1,78s10 C 7 7 5,67 0 0 1,33333 1,78s11 C 8 7 5,67 1 1 1,33333 1,78s12 C 8 7 5,67 1 1 1,33333 1,78
somma 0 68 68 68 0 24 0,00 18,67gradi di liberta 9 2,00varianza 2,67 9,33
Valore F 3,5
nei gruppi fra i gruppi
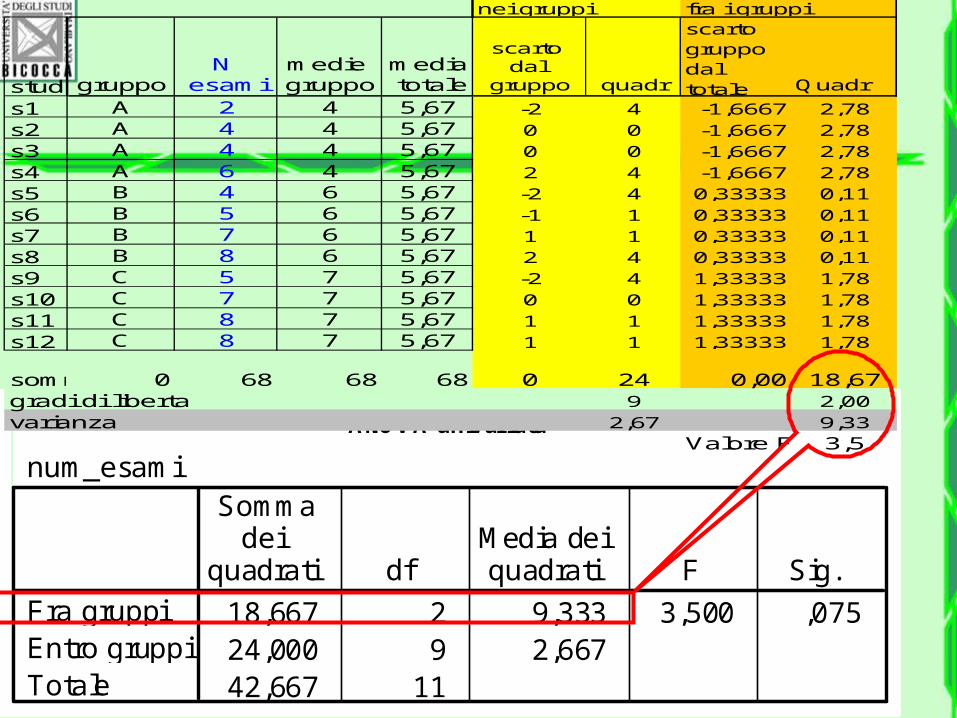
ANOVA univariata
num_esami
18,667 2 9,333 3,500 ,07524,000 9 2,66742,667 11
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.
stud gruppoN
esamimedie gruppo
media totale
scarto dal
gruppo quadr
scarto gruppo dal totale Quadr
s1 A 2 4 5,67 -2 4 -1,6667 2,78s2 A 4 4 5,67 0 0 -1,6667 2,78s3 A 4 4 5,67 0 0 -1,6667 2,78s4 A 6 4 5,67 2 4 -1,6667 2,78s5 B 4 6 5,67 -2 4 0,33333 0,11s6 B 5 6 5,67 -1 1 0,33333 0,11s7 B 7 6 5,67 1 1 0,33333 0,11s8 B 8 6 5,67 2 4 0,33333 0,11s9 C 5 7 5,67 -2 4 1,33333 1,78s10 C 7 7 5,67 0 0 1,33333 1,78s11 C 8 7 5,67 1 1 1,33333 1,78s12 C 8 7 5,67 1 1 1,33333 1,78
somma 0 68 68 68 0 24 0,00 18,67gradi di liberta 9 2,00varianza 2,67 9,33
Valore F 3,5
nei gruppi fra i gruppi

Concludendo…• Se le k medie sono simili, la variabilità fra i k gruppi è
bassa, la varianza della popolazione è stimata in modo corretto, (tenuto conto della variabilità stocastica), il rapporto F è vicino all’unità e si conclude con l’accettazione di H0.
• Se c’è molta variabilità fra i k gruppi, la variabilità fra i gruppi è elevata, la varianza della popolazione è sovrastimata, il rapporto F è molto più grande dell’unità, il test statistico di F dà valori di probabilità molto bassi
• Se la probabilità di ottenere il valore F calcolato è molto bassa, si conclude con il rifiuto dell’ipotesi di nullità di differenze, per accettare l’ipotesi alternativa: almeno un gruppo proviene da una popolazione diversa, ossia con medie diverse

ANOVA per due gruppi?
• Il test dell’ANOVA dà gli stessi risultati della t di Student: infatti il rapporto F è il quadrato della t.

Confronti post-hoc
• Sono confronti che si fanno a posteriori, se l’Anova è significativa e se ci sono più di 2 gruppi in una variabile indipendente
• La logica è quella di tenere sotto controllo i problemi di significatività legati ai confronti multipli.
• Vi sono diverse procedure di confronti• alcuni presumono che le varianze siano uguali: LSD (Least
Significant Difference), Bonferroni,Sidak, Scheffé, SNK (Student-Neumann-Kouls), Tukey HSD (Honestly Significant Difference), Duncan, Hochberg, Gabriel, Waller-Duncan, Dunnett
• altre no: Tamhane, Dunnett, Games-Howell, C di Dunnett• In Spss, premete il bottone Post Hoc... e selezionate tutti i test che
volete• gli output sono di due tipi: confronti multipli completi oppure
gruppi omogenei
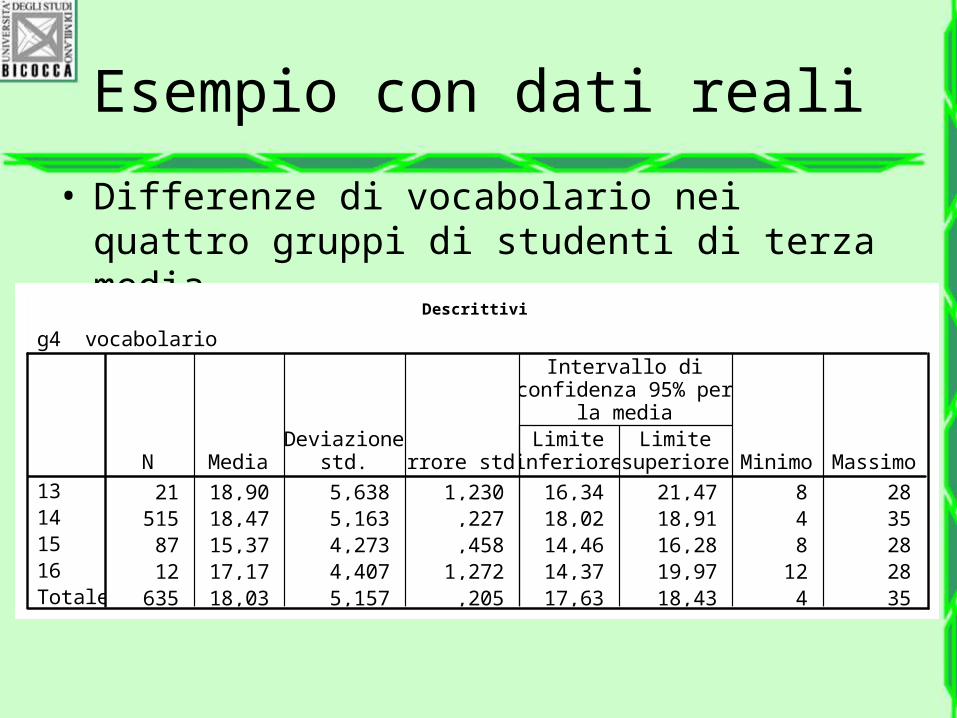
Esempio con dati reali
• Differenze di vocabolario nei quattro gruppi di studenti di terza media
Descrittivi
g4 vocabolario
21 18,90 5,638 1,230 16,34 21,47 8 28515 18,47 5,163 ,227 18,02 18,91 4 3587 15,37 4,273 ,458 14,46 16,28 8 2812 17,17 4,407 1,272 14,37 19,97 12 28
635 18,03 5,157 ,205 17,63 18,43 4 35
13141516Totale
N MediaDeviazione
std. Errore std.Limite
inferioreLimite
superiore
Intervallo diconfidenza 95% per
la media
Minimo Massimo
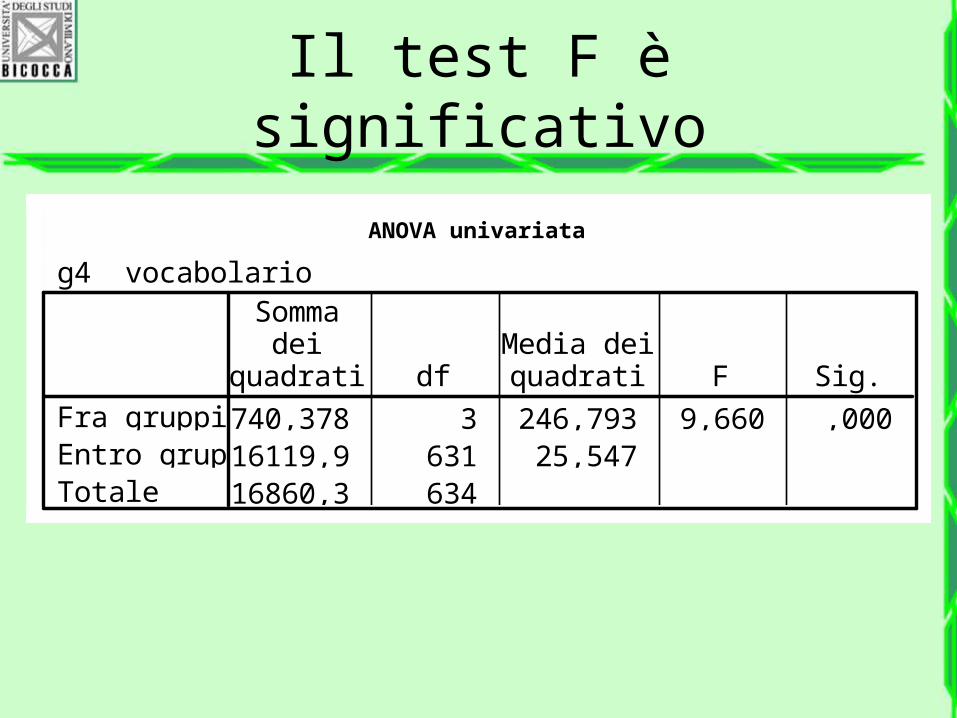
ANOVA univariata
g4 vocabolario
740,378 3 246,793 9,660 ,00016119,9 631 25,54716860,3 634
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.
Il test F è significativo

Si conclude che…
Almeno un gruppo ha la media diversa dagli altri.
In altre parole, il gruppo con la media più alta è statistica mente diverso dal gruppo con la media più bassa.
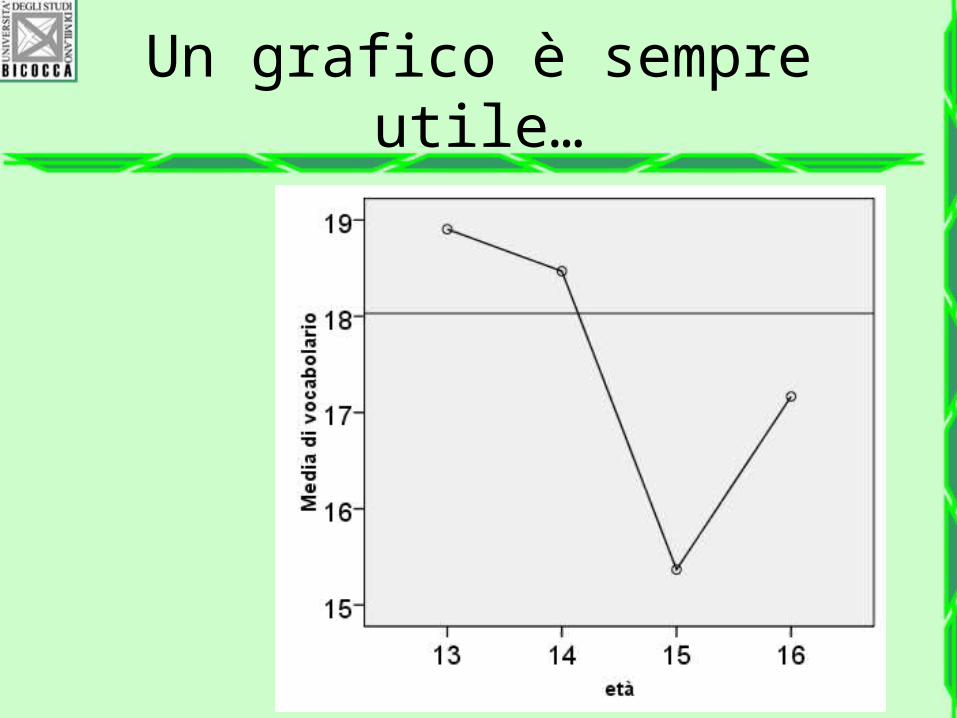
Un grafico è sempre utile…

E degli altri gruppi, che si può dire?
Come si differenziano fra di loro? Esiste un solo gruppo diverso dagli altri? Esistono più gruppi diversi dagli altri? Si possono individuare i gruppi simili e quelli diversi?

Differenze a priori e a posteriori
Si può dare risposta a questi interrogativi con i post hoc (termine latino per indicare che si cercano differenze fra i gruppi a posteriori, ossia dopo che si è stabilità la differenza statistica fra i gruppi.
I confronti pianificati invece si cercano a priori, perché la teoria prevede già una differenza nei gruppi
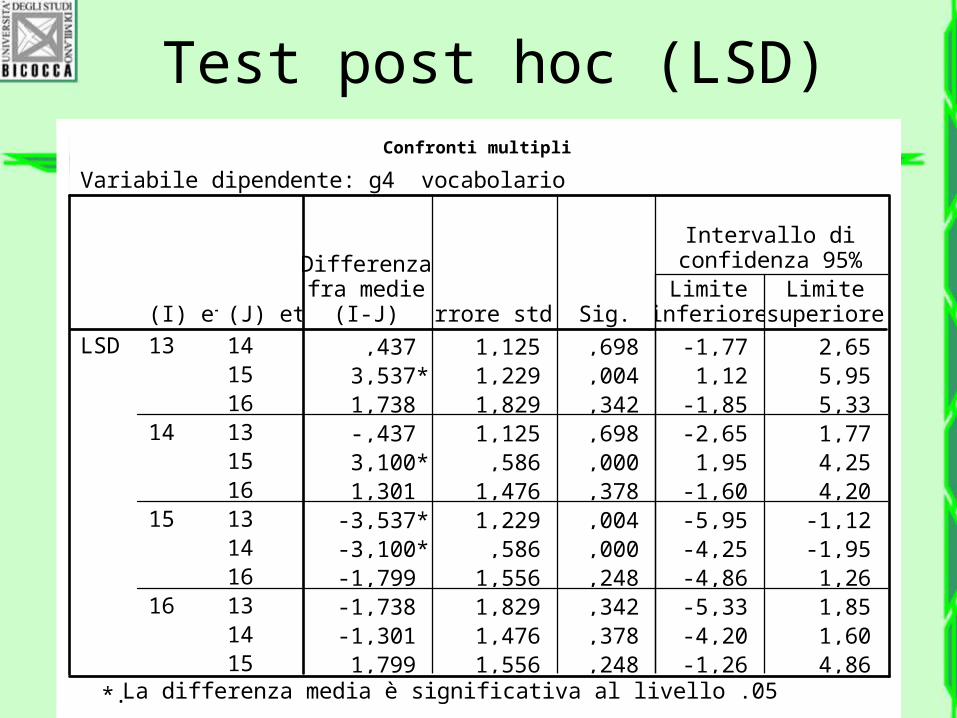
Test post hoc (LSD)Confronti multipli
Variabile dipendente: g4 vocabolario
,437 1,125 ,698 -1,77 2,653,537* 1,229 ,004 1,12 5,951,738 1,829 ,342 -1,85 5,33-,437 1,125 ,698 -2,65 1,773,100* ,586 ,000 1,95 4,251,301 1,476 ,378 -1,60 4,20
-3,537* 1,229 ,004 -5,95 -1,12-3,100* ,586 ,000 -4,25 -1,95-1,799 1,556 ,248 -4,86 1,26-1,738 1,829 ,342 -5,33 1,85-1,301 1,476 ,378 -4,20 1,601,799 1,556 ,248 -1,26 4,86
(J) età141516131516131416131415
(I) età13
14
15
16
LSD
Differenzafra medie
(I-J) Errore std. Sig.Limite
inferioreLimite
superiore
Intervallo diconfidenza 95%
La differenza media è significativa al livello .05*.

Test dei sottoinsieme omogenei (SNK)
g4 vocabolario
87 15,3712 17,17 17,17
515 18,47 18,4721 18,90
,059 ,407
età15161413Sig.
Student-Newman-Keuls
a,b
N 1 2
Sottoinsieme peralfa = .05
Sono visualizzate le medie per i gruppi di sottoinsiemi omogenei.
Utilizza dimensione campionaria media armonica =27,703.
a.
Le dimensioni dei gruppi non sono uguali. Verràutilizzata la media armonica delle dimensioni deigruppi. Non vengono garantiti i livelli di errore Tipo I.
b.
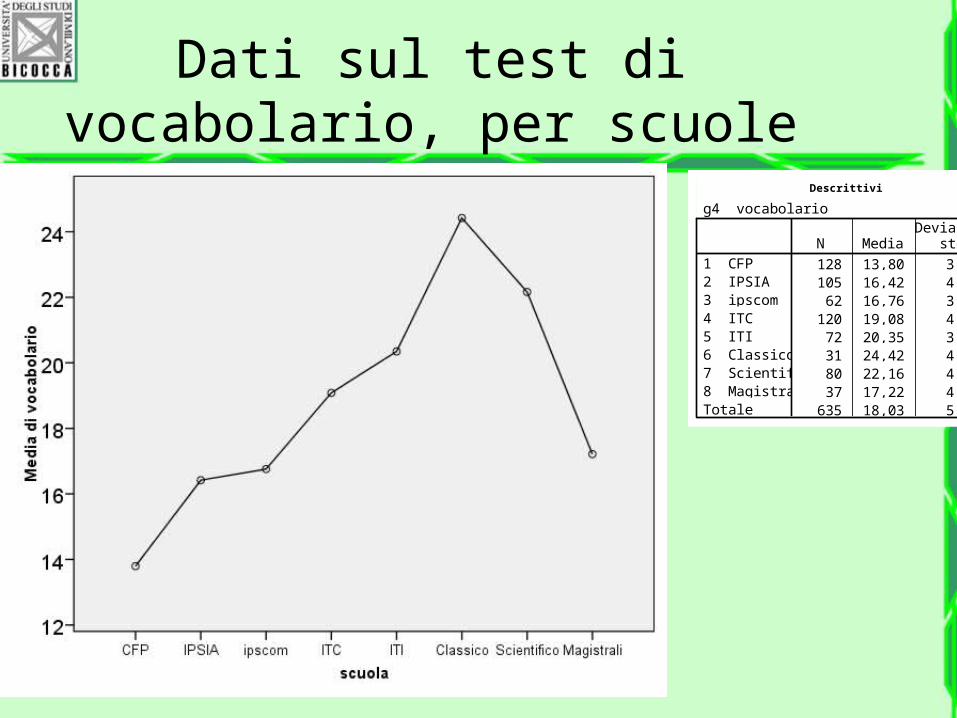
Dati sul test di vocabolario, per scuole
Descrittivi
g4 vocabolario
128 13,80 3,528105 16,42 4,25862 16,76 3,570
120 19,08 4,57272 20,35 3,95831 24,42 4,91180 22,16 4,81137 17,22 4,158
635 18,03 5,157
1 CFP2 IPSIA3 ipscom4 ITC5 ITI6 Classico7 Scientifico8 MagistraliTotale
N MediaDeviazione
std.
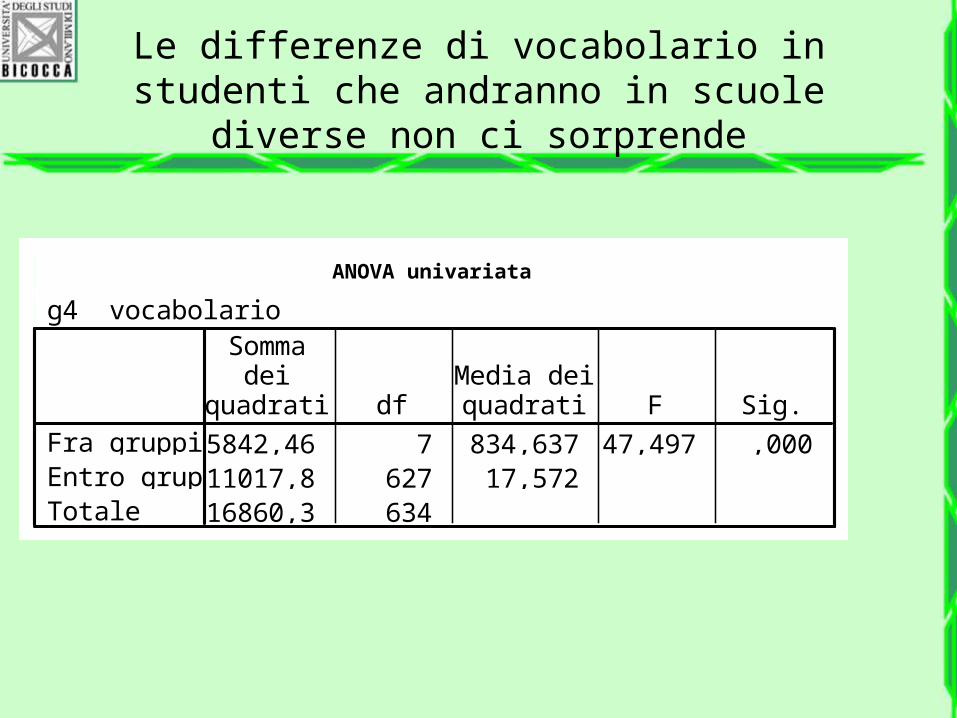
Le differenze di vocabolario in studenti che andranno in scuole diverse non ci sorprende
ANOVA univariata
g4 vocabolario
5842,46 7 834,637 47,497 ,00011017,8 627 17,57216860,3 634
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.
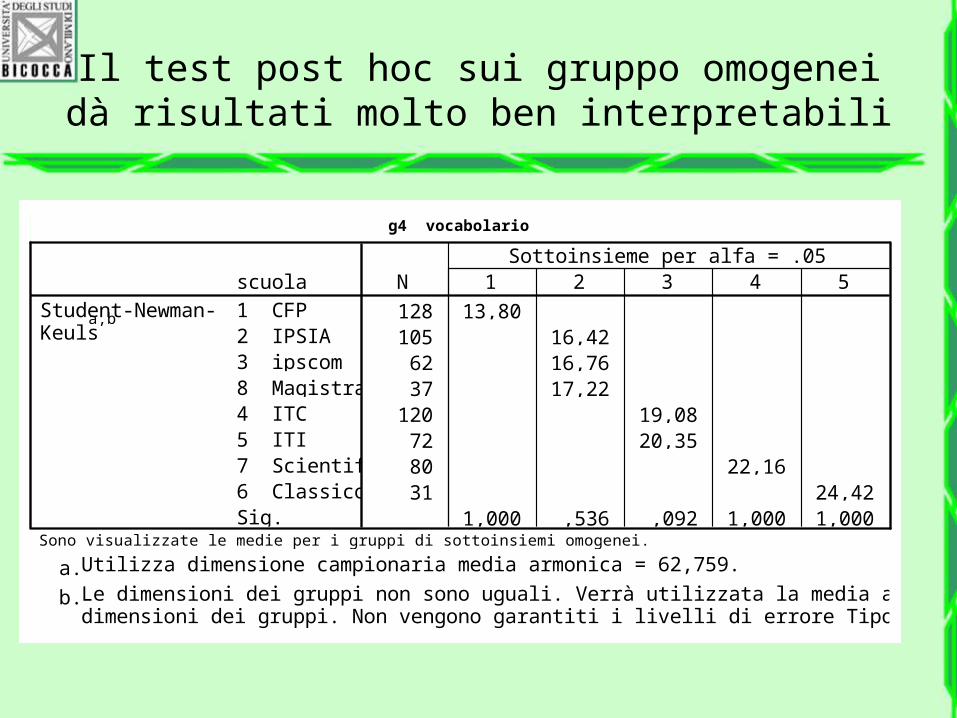
Il test post hoc sui gruppo omogenei dà risultati molto ben interpretabili
g4 vocabolario
128 13,80105 16,4262 16,7637 17,22
120 19,0872 20,3580 22,1631 24,42
1,000 ,536 ,092 1,000 1,000
scuola1 CFP2 IPSIA3 ipscom8 Magistrali4 ITC5 ITI7 Scientifico6 ClassicoSig.
Student-Newman-Keuls
a,b
N 1 2 3 4 5Sottoinsieme per alfa = .05
Sono visualizzate le medie per i gruppi di sottoinsiemi omogenei.
Utilizza dimensione campionaria media armonica = 62,759.a.
Le dimensioni dei gruppi non sono uguali. Verrà utilizzata la media armonica delledimensioni dei gruppi. Non vengono garantiti i livelli di errore Tipo I.
b.
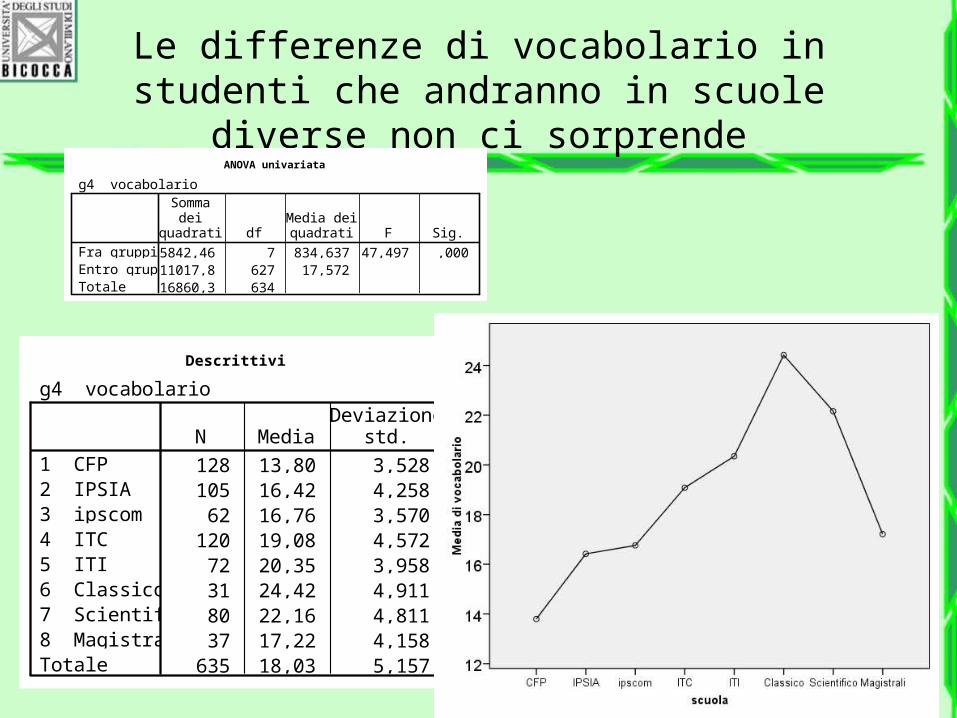
Le differenze di vocabolario in studenti che andranno in scuole diverse non ci sorprende
Descrittivi
g4 vocabolario
128 13,80 3,528105 16,42 4,25862 16,76 3,570
120 19,08 4,57272 20,35 3,95831 24,42 4,91180 22,16 4,81137 17,22 4,158
635 18,03 5,157
1 CFP2 IPSIA3 ipscom4 ITC5 ITI6 Classico7 Scientifico8 MagistraliTotale
N MediaDeviazione
std.
ANOVA univariata
g4 vocabolario
5842,46 7 834,637 47,497 ,00011017,8 627 17,57216860,3 634
Fra gruppiEntro gruppiTotale
Sommadei
quadrati dfMedia deiquadrati F Sig.

Confronti a priori• Oltre ai post hoc si possono effettuare dei confronti a priori ovvero
decisi prima ancora di effettuare l’anova, sulla base di una teoria• Questi confronti si chiamano anche contrasti perché contrastano la
media di uno o più gruppi con quella di altriAnche in questo caso ci sono due possibilità:• contrasti predefiniti: lineare, quadratico, Helmert...contrasti decisi da
noi In Spss, premete il bottone Contrasti...• se selezionare Polinomiale, poi potete scegliere fra Lineare,• Quadratico, Cubico... (ipotizzo che le medie aumentano o• diminuiscono nella varie categorie in modo lineare, quadratico...)• altrimenti dovrete inserire dei coefficienti (uno alla volta e poi
premere Aggiungi).• dopo aver inserito un contrasto è possibile inserirne un secondo• tramite il pulsante Successivo
Recommended

















