
Learning Continuous Control Policies by
Stochastic Value GradientsNIPS2015読み会
藤田康博
Preferred Networks Inc.
January 20, 2016

話す人▶ 藤田康博
▶ Preferred Networks Inc.▶ Twitter: @mooopan▶ GitHub: muupan▶ 強化学習・ゲーム AIに興味があります▶ 最近のお仕事(この発表とは関係ない)
(https://twitter.com/hillbig/status/684813252484698112)

読む論文
▶ Learning Continuous Control Policies by Stochastic ValueGradients
▶ Nicolas Heess, Greg Wayne, David Silver, TimothyLillicrap, Yuval Tassa, Tom Erez (Google DeepMind)
▶ 強化学習で状態・行動がともに連続値を取る確率的な制御問題を扱うためのアルゴリズムの提案
▶ モデル・価値関数・policyそれぞれ NNで表す▶ reparameterization trickを使う

問題設定▶ Markov Decision Process
▶ 状態 st ∈ RNS
▶ 行動 at ∈ RNA
▶ 初期状態分布 s0 ∼ p0(·)▶ 遷移分布 st+1 ∼ p(·|st , at)
▶ st と at から確率的に st+1 が決まる▶ 報酬関数 r t = r(st , at , t)(時間依存)
▶ 求めたいもの▶ (確率的な)policy at ∼ p(·|st ; θ)
▶ st から確率的に at が決まる
▶ 最大化したいもの▶ 報酬の和の期待値 J(θ) = E[
∑Tt=0 γ
tr t |θ]▶ γ ∈ [0, 1]は割引率

価値関数
▶ 状態行動価値関数Qt(s, a) = E[
∑τ=t γ
τ−tr τ |s t = s, at = a, θ]
▶ 状態価値関数 V t(s) = E[∑
τ=t γτ−tr τ |s t = s, θ]
▶ (確率的)Bellman方程式
V (s) = Ea∼p(·|s)[r(s, a) + γEs′∼p(·|s,a)[V′(s ′)]]
= Ea∼p(·|s)[Q(s, a)]
▶ ′は次の時間ステップを表すのに使われる

表記に関する注意
▶ 下付き文字は偏微分を表す▶ πθ =
∂π∂θ
▶ 「パラメータ θで表された π」ではない▶ (でも 1箇所 πθを後者の意味で使ってる場所が…)
▶ 上付き文字は時間ステップだったり指数だったりする▶ 報酬の和の期待値(再掲) J(θ) = E[
∑Tt=0 γ
tr t |θ]▶ r t は時間ステップ t における報酬▶ γt は γ の t 乗
▶ 時間依存のものかどうかで判断するしか…

行動が連続値であるということ
▶ 「DQNじゃ駄目なの?」▶ DQN [Mnih et al. 2013; Mnih et al. 2015]は状態行動価値 Q(s, a; θ)を学習し,行動 argmaxa Q(s, a; θ)を選択する
▶ aが連続値だと argmaxを求められない!
▶ そこで policyを直接パラメータで(NNで)表す▶ at ∼ p(·|st ; θ)▶ 行動を選ぶ際はサンプリングするだけ▶ θを更新する方法として,この論文では policy
gradient methodsという種類の方法を扱う

Policy Gradient Methods
▶ 目標:J(θ) = E[∑T
t=0 γtr t |θ]を最大化するような policy
のパラメータ θを求めたい▶ そのために∇θJ(θ)(policy gradient)を求めたい
▶ これが求まれば勾配法で policyを最適化できる(policygradient methods)
▶ ではどうやって求めればいいか?▶ likelihood ratio methods▶ value gradient methods

Likelihood Ratio Methods (1)
▶ 分布 p(y |x)の上での,ある関数 g(y)の期待値の勾配∇xEp(y |x)g(y)を求めたい
▶ スコア関数∇x log p(y |x)を使うと
∇xEp(y |x)g(y) = Ep(y |x)[g(y)∇x log p(y |x)]
≈ 1
M
M∑i=0
g(y i)∇x log p(y i |x), y i ∼ p(y i |x)
▶ ∇θEp(y ;θ)g(y)も同様に求まる▶ likelihood ratio methods, score function estimators,
REINFORCEと様々に呼ばれる

Likelihood Ratio Methods (2)
▶ これを使うと∇θJ(θ)をサンプルから推定できる[Williams 1992; Sutton et al. 1999]
∇θJ(θ) = Es∼ρπ ,a∼p(·|s;θ)[Q(s, a)∇θ log p(a|s; θ)]
▶ policy gradientを求める方法として広く使われている
▶ 欠点▶ Q(s, a)の勾配情報を使えない▶ varianceが大きい

Deterministic Value Gradients (1)
▶ Backpropagationにより価値関数の勾配(value gradient)を求める(value gradient methods)
▶ J(θ) = Es0∼p0V0(s0)なので V 0
θ が計算できれば良い▶ MDPと policyが決定的(s ′ = f (s, a), a = π(s))なら,決定的な Bellman方程式
V (s) = r(s, π(s)) + γV ′(f (s, π(s)))
を微分して value gradientが計算できる
Vs = rs + raπs + γV ′s′(fs + faπs) (3)
Vθ = raπθ + γV ′s′faπθ + γV ′
θ (4)
= Qaπθ + γV ′θ
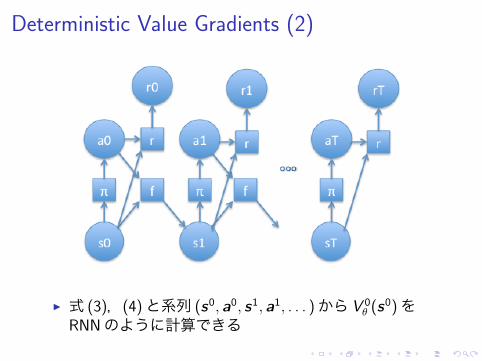
Deterministic Value Gradients (2)
▶ 式 (3),(4)と系列 (s0, a0, s1, a1, . . . )から V 0θ (s
0)をRNNのように計算できる

Deterministic Value Gradients (3)
▶ 欠点▶ 確率的なMDPや policyを扱えない
▶ 異なるが区別できない状態がある(state aliasing)と確率的な policyが必要になる
▶ 例:灰色の状態をエージェントが区別できない場合,決定的な policyでは開始地点によっては一生お金に辿りつけない
▶ reparameterization trickでこれを解決

Reparameterization Trick
▶ ∇xEp(y |x)g(y)を求める別の方法
▶ p(y |x)からのサンプリングを決定的な関数 f とノイズ変数 ξを使って書く:y = f (x , ξ), ξ ∼ ρ(·)
▶ 例:p(y |x) = N (µ(x), σ2(x))ならy = µ(x) + σ(x)ξ, ξ ∼ N (0, 1)
▶ そうするとそのまま微分できる
∇xEp(y |x)g(y) = Eρ(ξ)gy fx
≈ 1
M
M∑i=0
gy fx |ξ=ξi (5)
▶ likelihood ratio methodsと異なり g の勾配の情報を使っており,varianceが低い

Stochastic Value Gradients
▶ 遷移分布を s ′ = f (s, a, ξ),policyを a = π(s, η; θ)とそれぞれ reparameterizeすれば
Vs = Eρ(η)[rs + raπs + γEρ(ξ)V′s′(fs + faπs)] (7)
Vθ = Eρ(η)[raπθ + γEρ(ξ)[V′s′faπθ + γV ′
θ]] (8)
= Eρ(η)[Qaπθ + γV ′θ]
▶ MDPが確率的でも,policyが確率的でも,valuegradientが求まる!(stochastic value gradient)

ノイズの復元
▶ 遷移関数 f は実際には未知なので学習することになるが,s ′ = f (s, a, ξ)ではなく実際に観測された s ′を使って勾配を計算したい
▶ f の予測誤差の影響を抑えるため
▶ 昔のパラメータ θk を使って選んだ ak = π(sk , η; θk)を使って,今のパラメータ θt での勾配を計算したい
▶ experience replay(経験の再利用)を可能にするため
▶ サンプリング結果からノイズを復元する必要があるξ ∼ p(ξ|s, a, s ′), η ∼ p(η|s, a)
▶ Gaussianの場合は η = (ak − µ(sk))/σ(sk)で求める(著者に確認した)

3種類のアルゴリズム
▶ value gradientの求め方の異なる 3種類のアルゴリズムを提案
▶ SVG(∞)▶ SVG(1)▶ SVG(0)

SVG(∞)
▶ 遷移関数 f (s, a, ξ)と policy π(s, η)を一緒に学習

SVG(1)
▶ 遷移関数 f (s, a, ξ)と policy π(s, η)と V (s)を一緒に学習▶ f を 1ステップ使って残りは V を使う▶ experience replayを使う場合を特に SVG(1)-ERと表記

SVG(0)
▶ policy π(s, η)と Q(s, a)を一緒に学習▶ 遷移関数は使わない
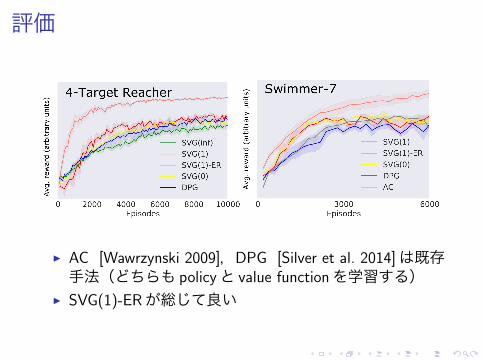
評価
▶ AC [Wawrzynski 2009],DPG [Silver et al. 2014]は既存手法(どちらも policyと value functionを学習する)
▶ SVG(1)-ERが総じて良い
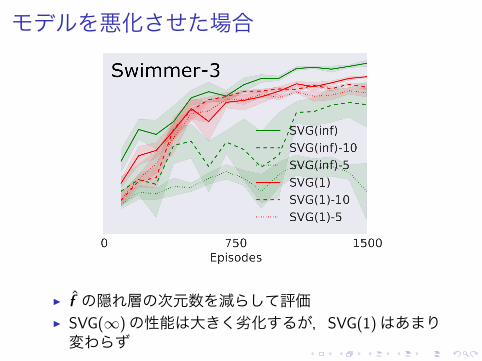
モデルを悪化させた場合
▶ f の隠れ層の次元数を減らして評価▶ SVG(∞)の性能は大きく劣化するが,SVG(1)はあまり変わらず
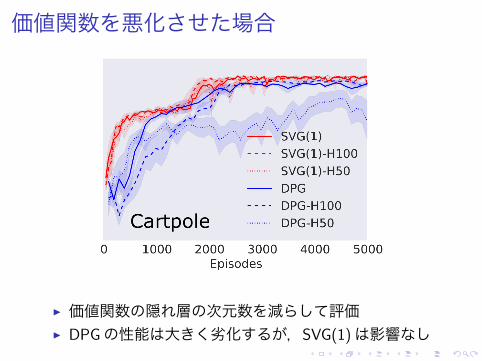
価値関数を悪化させた場合
▶ 価値関数の隠れ層の次元数を減らして評価▶ DPGの性能は大きく劣化するが,SVG(1)は影響なし

まとめ
▶ likelihood ratio methodsの代わりに reparameterizationtrickが使える
▶ 確率的なMDP,確率的な policyに対しても valuegradientを計算できる(stochastic value gradients)
▶ 提案アルゴリズムのうち実験では SVG(1)-ERが良い性能

感想
▶ reparameterization trickは便利▶ likelihood ratio methodsの代わりに使えそうなら使おう▶ 行動が離散的だと reparameterization trickが使えないので likelihood ratio methodsに頼るしか無い?
▶ SVG(0)-ERを評価していないのが気になる
▶ experience replayは重要

参考文献 I
[1] Volodymyr Mnih et al. “Human-level control through deep reinforcementlearning”. In: Nature 518.7540 (2015), pp. 529–533.
[2] Volodymyr Mnih et al. “Playing Atari with Deep Reinforcement Learning”. In:NIPS 2014 Deep Learning Workshop. 2013, pp. 1–9. arXiv:arXiv:1312.5602v1.
[3] David Silver et al. “Deterministic Policy Gradient Algorithms”. In: ICML 2014.2014, pp. 387–395.
[4] Richard S. Sutton et al. “Policy Gradient Methods for Reinforcement Learningwith Function Approximation”. In: In Advances in Neural InformationProcessing Systems 12. 1999, pp. 1057–1063.
[5] Pawel Wawrzynski. “Real-time reinforcement learning by sequentialActor-Critics and experience replay”. In: Neural Networks 22.10 (2009),pp. 1484–1497.
[6] RJ Williams. “Simple statistical gradient-following algorithms for connectionistreinforcement learning”. In: Reinforcement Learning 8.3-4 (1992), pp. 229–256.
Recommended


















