
Modelagem de Risco de Crédito
Douglas Beserra Pinheiro
23/02/2017

Agenda
Papel da Área de Risco de Crédito
Exemplo de desenvolvimento de um modelo de previsão de inadimplência
Perfil dos profissionais da área
Referências

Papel da Área de Risco de Crédito
Modelagem de Risco de Crédito◦ Estimar os parâmetros de risco que compõem a perda esperada
(PD, EAD, LGD)
◦ Acompanhar a performance dos modelos
◦ Sugerir ações que mantenham o risco dentro dos limites
definidos pela instituição
Políticas de Crédito◦ Determina os limites de exposição nos diferentes produtos e
acompanha tanto a inadimplência como a rentabilidade dos
mesmos.

Modelo de PD
O objetivo do modelo de PD (Probability of Default) é o de estimar a probabilidade de um cliente não pagar a dívida, ou seja, inadimplir.
O modelo pode ser apresentado na forma de classificação de risco (rating) ou pontuação (score).
As metodologias são classificadas em:
Massificado
Julgamental
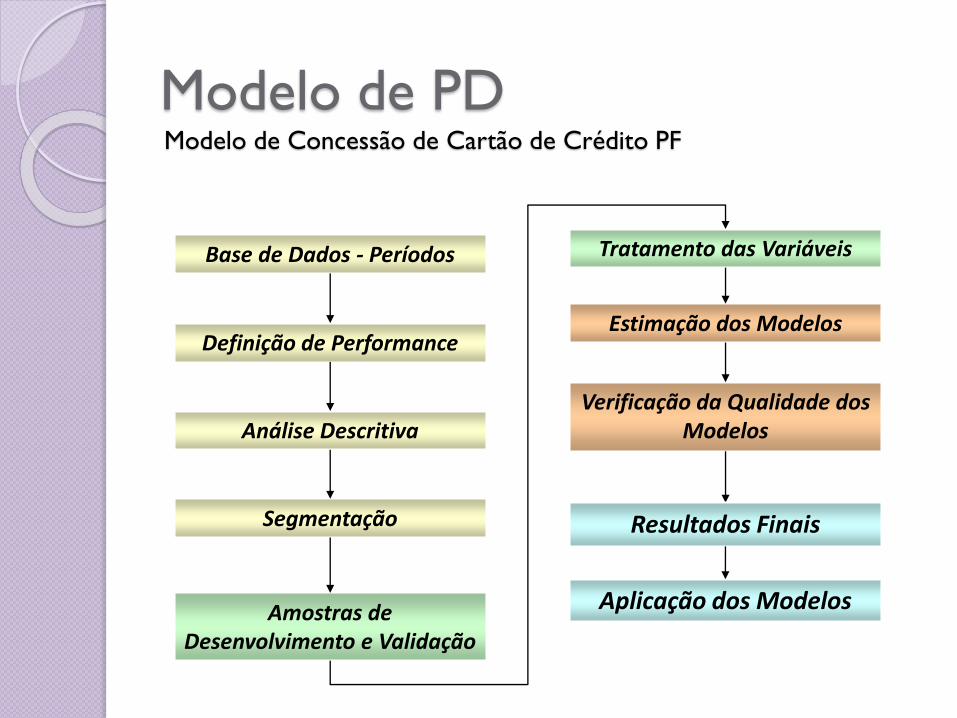
Base de Dados - Períodos
Definição de Performance
Análise Descritiva
Segmentação
Amostras de Desenvolvimento e Validação
Tratamento das Variáveis
Estimação dos Modelos
Verificação da Qualidade dos Modelos
Resultados Finais
Aplicação dos Modelos
Modelo de PDModelo de Concessão de Cartão de Crédito PF
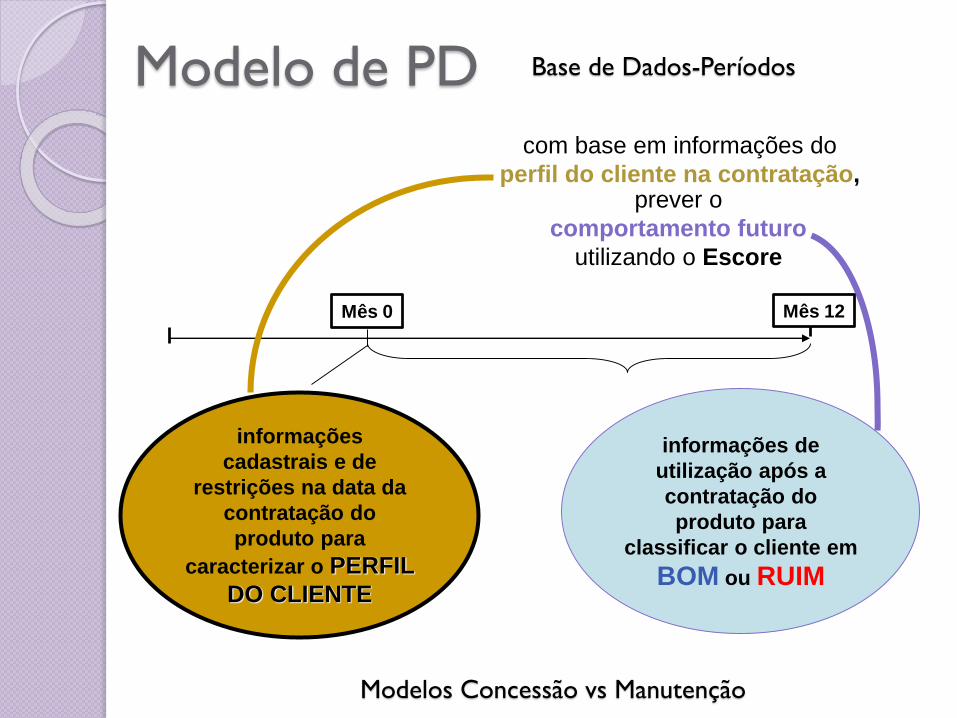
Modelo de PD
Mês 0
com base em informações do
perfil do cliente na contratação,
informações de
utilização após a
contratação do
produto para
classificar o cliente em
BOM ou RUIM
informações
cadastrais e de
restrições na data da
contratação do
produto para
caracterizar o PERFIL
DO CLIENTE
Mês 12
prever o
comportamento futuro
utilizando o Escore
Base de Dados-Períodos
Modelos Concessão vs Manutenção

Modelo de PD Definição de Performance
Exclusões◦ Cartão Fraudado, Roubado/Perdido, Não ativado, Desistente.
Ruins◦ Cartão com mais de 90 dias de atraso.
Indeterminados◦ Cartão com atraso entre 31 e 90 dias.
Experiência Insuficiente◦ Menos de 6 meses de ativação na janela, inativo posteriormente.
Bons◦ Cartão sem atraso acima de 31 dias.

Modelo de PD Análise Descritiva
Número de Dependen tes Ru ins Bons %B ons /% Ru ins
0 3818 3576 0 ,94
1 272 184 0 ,68
2 300 212 0 ,71
3 106 72 0 ,68
4 17 11 0 ,65
5 4 0 0 ,00
miss ing 483 945 1 ,96
Total 5000 5000
Núm e ro de De pende ntes Ruins Bons %Bons /% Ruins
0 3818 3576 0,94
ma ior 1 699 479 0,69
m iss ing 483 945 1,96
Tot al 5000 5000
Nú mero de D epend en te s Ruin s Bon s % Bon s/% Ruin s
0 413 9 378 7 0 ,9 1
1 27 9 20 4 0 ,7 3
2 7 0 4 6 0 ,6 6
3 2 5 1 6 0 ,6 4
4 2 2 1 ,0 0
5 2 0 0 ,0 0
Miss in g 48 3 94 5 1 ,9 6
Total 500 0 500 0
Nú m ero de D epend en te s Ruin s Bon s % Bon s/% Ruin s
0 413 9 378 7 0 ,9 1
m aior 1 37 8 26 8 0 ,7 1
M iss in g 48 3 94 5 1 ,9 6
Total 500 0 500 0
Balanceamento da amostra
Análise de observações sem informação (missing)
Quantidade de Dependentes Menores
Quantidade de Dependentes Maiores

Modelo de PD Segmentação
SEGMENTAÇÃO
Técnicas: CHAID, Árvore de decisão
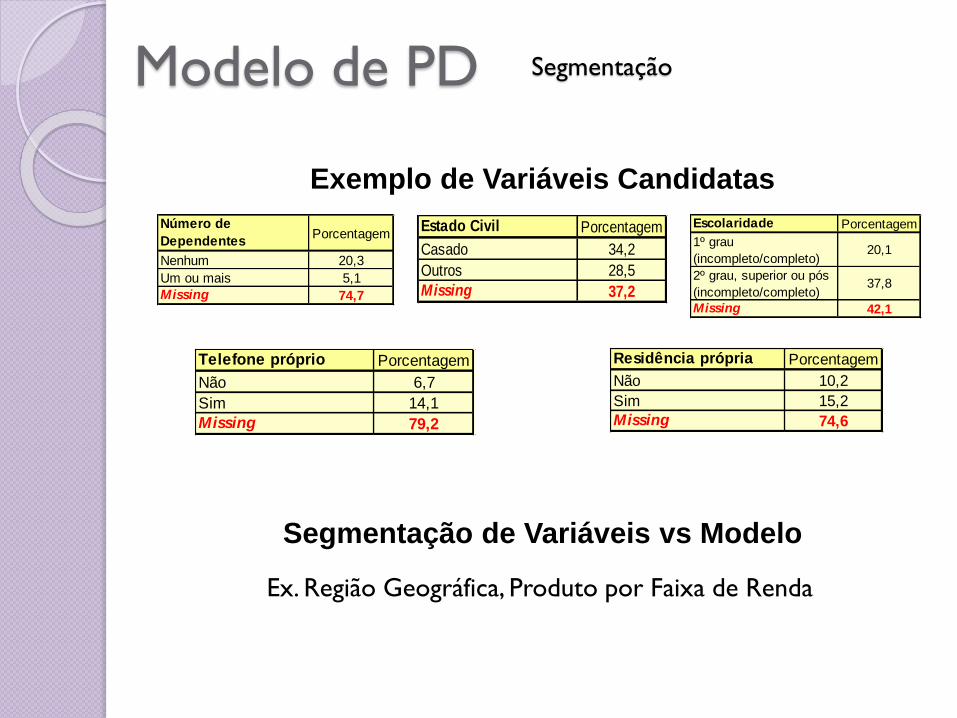
Modelo de PD Segmentação
Exemplo de Variáveis Candidatas
Número de
DependentesPorcentagem
Nenhum 20,3
Um ou mais 5,1
Missing 74,7
Estado Civil Porcentagem
Casado 34,2
Outros 28,5
Missing 37,2
Escolaridade Porcentagem
1º grau
(incompleto/completo)20,1
2º grau, superior ou pós
(incompleto/completo)37,8
Missing 42,1
Telefone próprio Porcentagem
Não 6,7
Sim 14,1
Missing 79,2
Residência própria Porcentagem
Não 10,2
Sim 15,2
Missing 74,6
Segmentação de Variáveis vs Modelo
Ex. Região Geográfica, Produto por Faixa de Renda
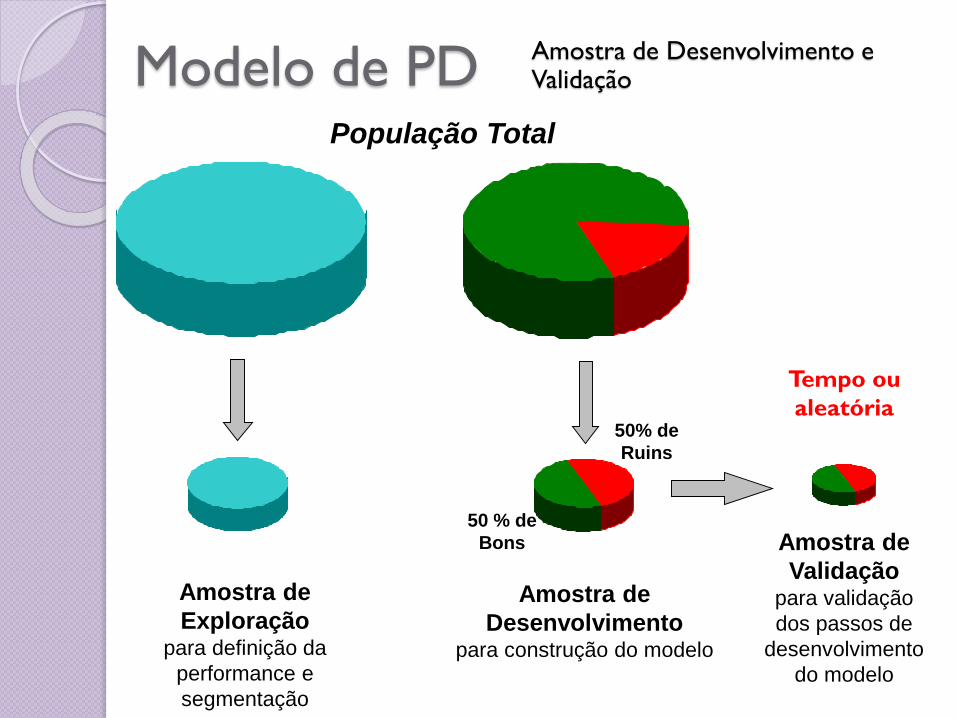
Modelo de PD População Total
Amostra de
Exploraçãopara definição da
performance e
segmentação
Amostra de
Desenvolvimentopara construção do modelo
50% de
Ruins
50 % de
Bons Amostra de
Validaçãopara validação
dos passos de
desenvolvimento
do modelo
Tempo ou
aleatória
Amostra de Desenvolvimento e Validação
Modelo de PD Tratamento das variáveis
Tratamento das Variáveis
Categorização Estabilidade
Conceitos Dummy
Dummy: Variáveis binárias (categóricas), eficientes nos casos de falta de preenchimento, outliers, não linearidade com a resposta
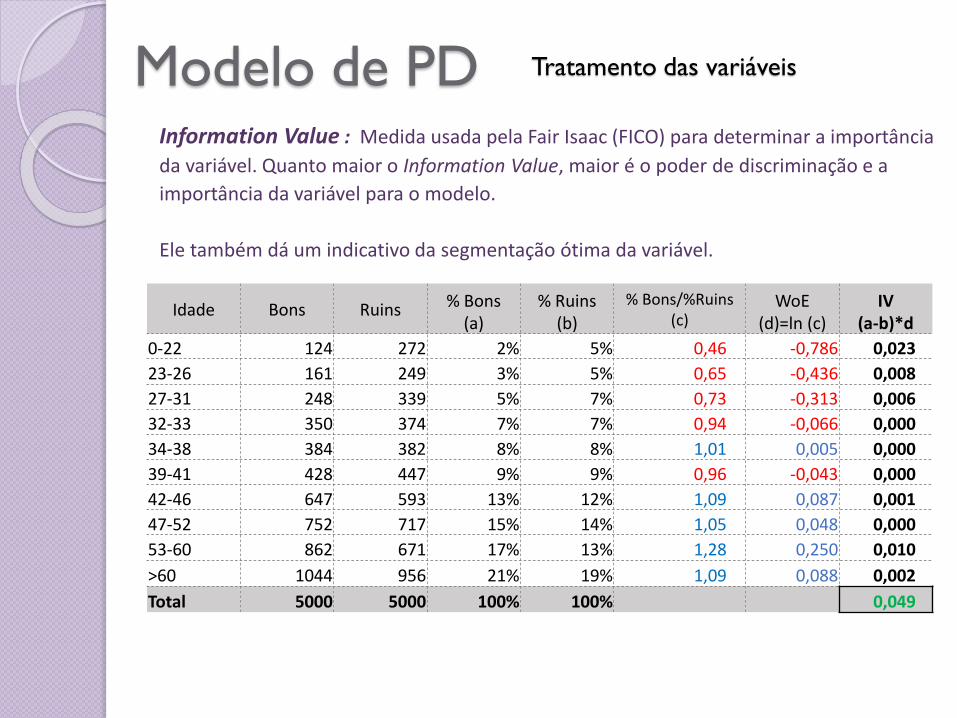
Modelo de PD Tratamento das variáveis
Idade Bons Ruins % Bons(a)
% Ruins(b)
% Bons/%Ruins (c)
WoE(d)=ln (c)
IV(a-b)*d
0-22 124 272 2% 5% 0,46 -0,786 0,023
23-26 161 249 3% 5% 0,65 -0,436 0,008
27-31 248 339 5% 7% 0,73 -0,313 0,006
32-33 350 374 7% 7% 0,94 -0,066 0,000
34-38 384 382 8% 8% 1,01 0,005 0,000
39-41 428 447 9% 9% 0,96 -0,043 0,000
42-46 647 593 13% 12% 1,09 0,087 0,001
47-52 752 717 15% 14% 1,05 0,048 0,000
53-60 862 671 17% 13% 1,28 0,250 0,010
>60 1044 956 21% 19% 1,09 0,088 0,002
Total 5000 5000 100% 100% 0,049
Information Value : Medida usada pela Fair Isaac (FICO) para determinar a importância
da variável. Quanto maior o Information Value, maior é o poder de discriminação e a
importância da variável para o modelo.
Ele também dá um indicativo da segmentação ótima da variável.

Modelo de PD Tratamento das variáveis
IDADE BONS %B RUINS %R%B - %R
(a)
%B / %R
(b)
log(b)
(c)(a) * (c)
Até 35 anos 2.000 40% 2.000 40% 0,00 1,00 0,00 0,00
35 anos ou mais 3.000 60% 3.000 60% 0,00 1,00 0,00 0,00
Total 5.000 100% 5.000 100%
Information Value:
0,00 + 0,00 = 0,00
IDADE BONS %B RUINS %R%B - %R
(a)
%B / %R
(b)
log(b)
(c)(a) * (c)
Até 35 anos 2.000 40% 3.000 60% -0,20 0,67 -0,41 0,08
35 anos ou mais 3.000 60% 2.000 40% 0,20 1,50 0,41 0,08
Total 5.000 100% 5.000 100%
Information Value:
0,08 + 0,08 = 0,16
IDADE BONS %B RUINS %R%B - %R
(a)
%B / %R
(b)
log(b)
(c)(a) * (c)
Até 35 anos 2.000 40% 4.000 80% -0,40 0,50 -0,69 0,28
35 anos ou mais 3.000 60% 1.000 20% 0,40 3,00 1,10 0,44
Total 5.000 100% 5.000 100%
Information Value:
0,28 + 0,44 = 0,72
Po
der d
e D
iscrim
inação
-
+

Modelo de PD Tratamento das variáveis
Idade
21
22
23
.
.
.
84
85
86
.
.
.
Idade (Categorizada)
Categ1 - 21 a 25
Categ2 - 26 a 30
Categ3 - 31 a 35
.
.
.
Categ n - 61 a 65
Categ n+1 - 66 a 70
Categ n+2 - 70 a 75
.
.
.
Idade (Dummy)
Dummy1 = 1 se idade está em (21 a 25)
Dummy1 = 0 Caso Contrário
Dummy2 = 1 se idade está em (26 a 30)
Dummy2 = 0 Caso Contrário
.
.
.
Dummy n = 1 se idade está em (61 a 65)
Dummy n = 0 Caso Contrário
.
.
.
Exemplo de construção de variáveis binárias.
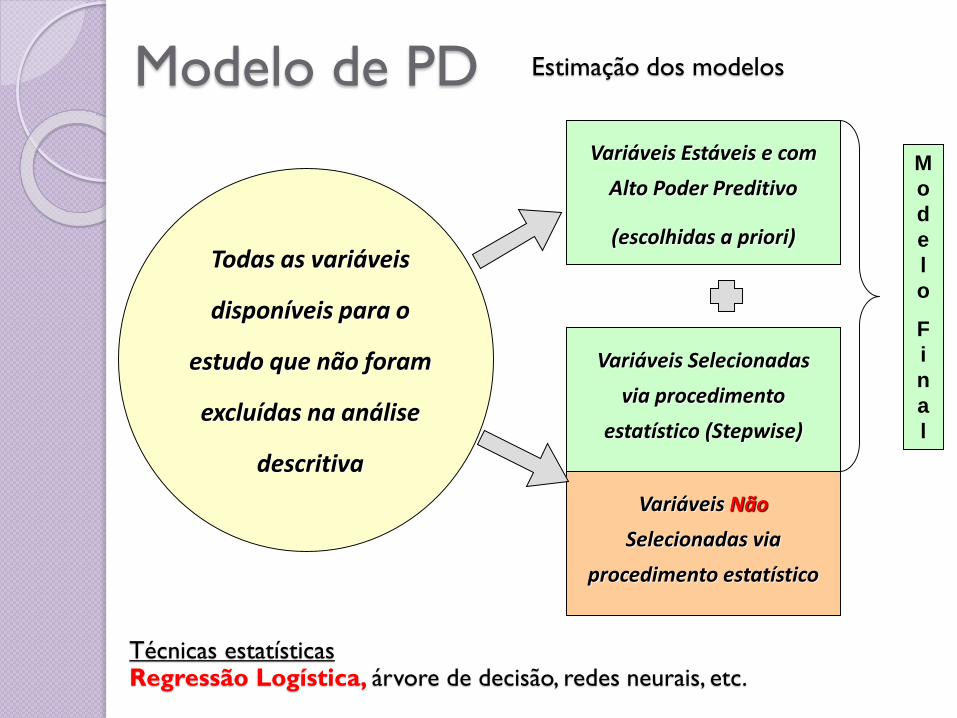
Modelo de PD Estimação dos modelos
Todas as variáveis
disponíveis para o
estudo que não foram
excluídas na análise
descritiva
Variáveis Estáveis e com
Alto Poder Preditivo
(escolhidas a priori)
Variáveis Selecionadas
via procedimento
estatístico (Stepwise)
Variáveis Não
Selecionadas via
procedimento estatístico
M
o
d
e
l
o
F
i
n
a
l
Técnicas estatísticasRegressão Logística, árvore de decisão, redes neurais, etc.

Modelo de PD
No exemplo:
Média Bons = 635
Variância Bons =
2885
e
Média Ruins = 530
Variância Ruins =
3530
Portanto,
IV = 3,44
Verificação da qualidade dos modelos
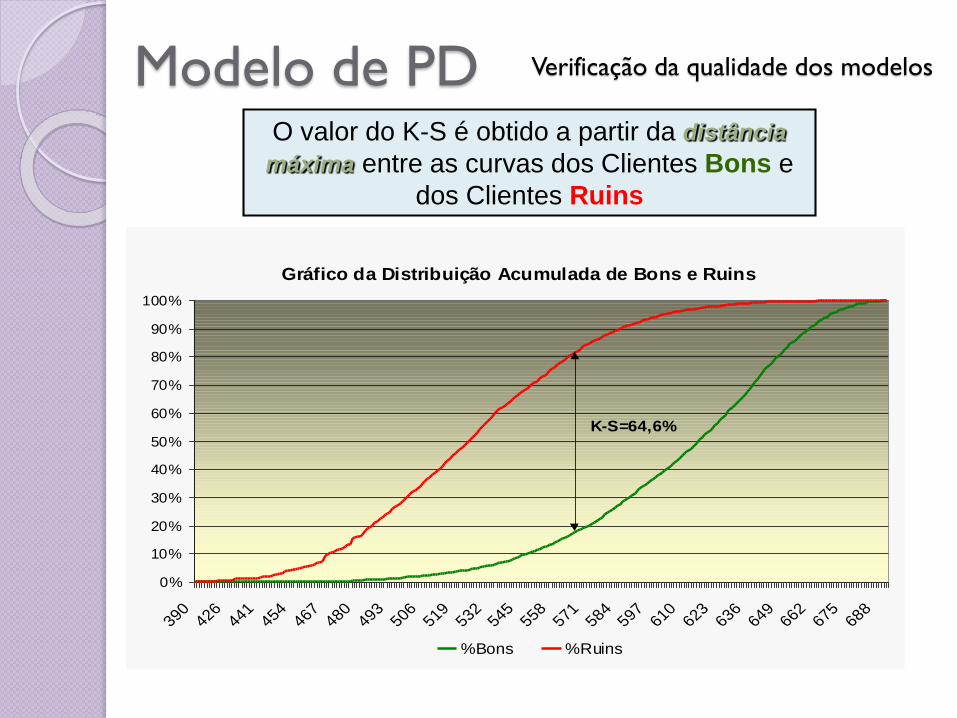
Modelo de PD Verificação da qualidade dos modelos
O valor do K-S é obtido a partir da distância
máxima entre as curvas dos Clientes Bons e
dos Clientes Ruins
Gráfico da Distribuição Acumulada de Bons e Ruins
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
390426
441454
467480
493506
519532
545558
571584
597610
623636
649662
675688
%Bons %Ruins
K-S=64,6%
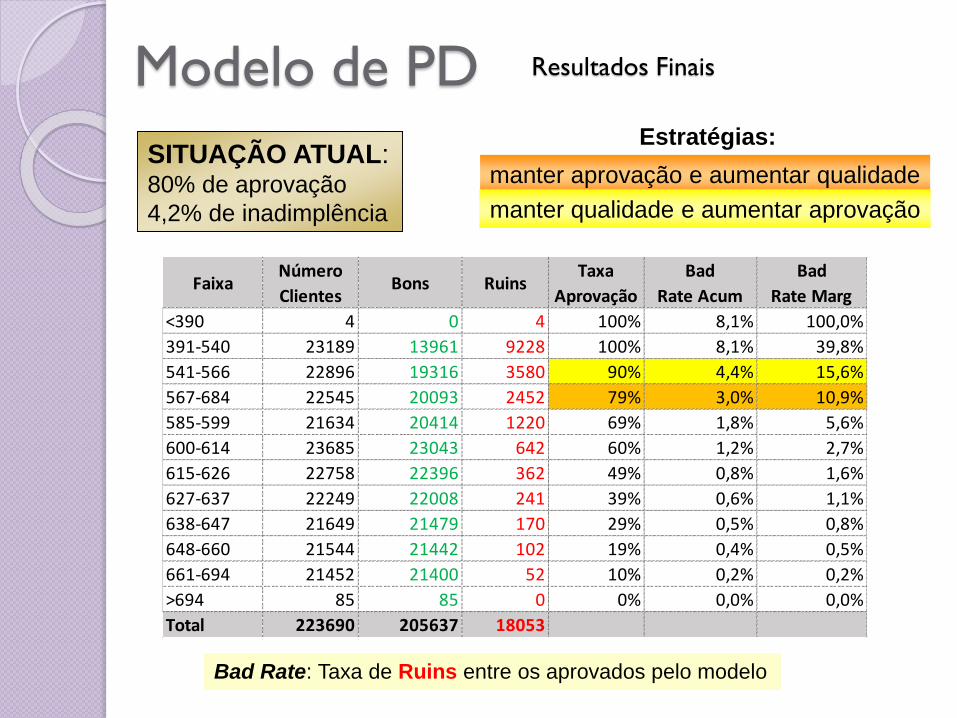
Modelo de PD Resultados Finais
Bad Rate: Taxa de Ruins entre os aprovados pelo modelo
Estratégias:
manter aprovação e aumentar qualidade
manter qualidade e aumentar aprovação
SITUAÇÃO ATUAL:80% de aprovação
4,2% de inadimplência
FaixaNúmero
ClientesBons Ruins
Taxa
Aprovação
Bad
Rate Acum
Bad
Rate Marg
<390 4 0 4 100% 8,1% 100,0%
391-540 23189 13961 9228 100% 8,1% 39,8%
541-566 22896 19316 3580 90% 4,4% 15,6%
567-684 22545 20093 2452 79% 3,0% 10,9%
585-599 21634 20414 1220 69% 1,8% 5,6%
600-614 23685 23043 642 60% 1,2% 2,7%
615-626 22758 22396 362 49% 0,8% 1,6%
627-637 22249 22008 241 39% 0,6% 1,1%
638-647 21649 21479 170 29% 0,5% 0,8%
648-660 21544 21442 102 19% 0,4% 0,5%
661-694 21452 21400 52 10% 0,2% 0,2%
>694 85 85 0 0% 0,0% 0,0%
Total 223690 205637 18053

Modelo de PD Aplicação dos Modelos
Concessão de Crédito
Cobrança
Fraude
Renovação de limites
Segmentação de produtos e canais de
atendimento
Sinistralidade de seguros

Perfil dos profissionais da área
Críticos e curiosos
Habilidade com ferramentas de programação e estatística
Mão na massa
Provenientes de diversas áreas, do conhecimento, entre elas, Matemática, Estatística, Administração, Economia, Física, Contabilidade, Engenharia...
Perfil dos profissionais da área
Big Data
Localização
Mobile
Informações
Públicas
Softwares
SAS, SPSS, R, Stata,
Orange, Matlab,
etc.

Referências
Lima, Jorge Claudio C.O. “Importância de Conhecer a Perda Esperada”
Revista do BNDES, Rio de Janeiro, V. 15, N. 30, P. 271-302, dez. 2008
Apesar de focar em modelagem corporate, apresenta de forma simples os conceitos
relacionados à perda esperada.
The Credit Scoring Toolkit: Theory and Practice for Retail Credit Risk
Management and Decision Automation. Raymond Anderson.
https://www.datacamp.com/courses/introduction-to-credit-risk-modeling-
in-r
Ótimo curso online, apesar do conteúdo resumido, detalha bem a parte de tratamento de dados
e validação de modelos.
Recommended


![HEGATS - Uberanuberan.eus/wordpress/wp-content/uploads/2018/07/hegats-55.pdf · lqgdu hwd jrjr edwhn lgd]whud exow]dw]hq glwxhodnr lgd]whq gxwh +xqnljduuld gd lgd]whnr duud]rl remhnwleruln](https://img.pdfslide.tips/doc/110x75/5f4d3a82247d006dc23bad60/hegats-lqgdu-hwd-jrjr-edwhn-lgdwhud-exowdwhq-glwxhodnr-lgdwhq-gxwh-xqnljduuld.jpg)















