Univerzita Pavla Jozefa Šafárika v Košiciach,Príirodovedecká fakulta
Strojové učenieLineárna regresia
Gabriela Andrejková, Ľubomír Antoni

Úvod
Dôležitým problémom v strojovom učení, je odvodenie (učenie sa)funkcionálnych vzťahov medzi atribútovými premennými a s nimiasociovanou odozvou alebo cieľovými premennými.
Tak bude možné predpovedať odozvu pre ľubovoľnú množinuhodnôt atribútových premenných.
Napríklad chceme vytvoriť „modelÿ, ktorý bude predpovedaťpríchod geomagnetickej búrky o niekoľko hodín na základeniekoľkých meraných parametrov.

Úvod
Modelom v strojovom učení bude vlastne výsledok programu,ktorý rieši daný problém na základe dát.Tento program nájde funkcionálne vzťahy z dát. Očakávanímurčitých vzťahov taký typ modelu vieme navrhnúť. V prípadegeomagnetických búrok modelom je funkcia, ktorá búrkypredpovedá.
Na to je potrebnéI mať k dispozícii namerané údaje ďalších veličín, od ktorých je
cieľová premenná závislá a poznať ich vlastnosti.I predpokladať nejaký vzťah medzi nimi.

Lineárne modelovanie
Najjednoduchším príkladom učiacich sa problémov je lineárnemodelovanie, t. j. učenie sa lineárnych vzťahov medzi atribútmi aodozvami.
V tabuľke na ďalšej stránke sú rekordné výsledky v skoku do diaľkyu mužov wikipedia: https : //sk .wikipedia.org/wiki/Skok do dialky .
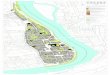
Na obrázku sú tieto výsledky znázornené graficky v paneli A.
Rekordy tvoria rastúcu funkciu. Náš cieľ je použiť tieto údaje naučenie pre model funkcionálnej závislosti (ak existuje) medzi rokmirekordov a dosiahnutými výsledkami.

Rekordy v skoku do diaľky
Tabuľka: Muži, skok do diaľky
Výkon (m) Atlét Miesto Dátum7,61 Sp. kráľovstvo Peter O’Connor Dublin 5. 8. 19017,69 USA Edwin Gourdin Cambridge 23. 7. 19237,76 USA Robert LeGendre Paríž 7. 7. 19247,89 USA William DeHart Hubbard Chicago 13. 6. 19257,90 USA Edward Hamm Cambridge 7. 7. 19287,93 Haiti Sylvio Cator Paríž 9. 9. 19287,98 Japonsko Chuhei Nambu Tokio 27. 10. 19318,13 USA Jesse Owens Ann Arbor 25. 5. 19358,21 USA Ralph Boston Walnut 12. 8. 19608,24 USA Ralph Boston Modesto 27. 5. 19618,28 USA Ralph Boston Moskva 16. 7. 19618,31 ZSSR Igor Ter-Ovanesyan Jerevan 10. 6. 19628,31 USA Ralph Boston Kingston 15. 8. 19648,34 USA Ralph Boston Los Angeles 12. 9. 19648,35 USA Ralph Boston Modesto 29. 5. 19658,35 ZSSR Igor Ter-Ovanesyan Mexiko 19. 10. 19678,90 USA Bob Beamon Mexiko 18. 10. 19688,95 USA Mike Powell Tokio 30. 8. 1991

Rekordy v skoku do diaľky

Rekordy v skoku do diaľky
Náš cieľ je použiť tieto údaje na učenie pre model funkcionálnejzávislosti (ak existuje) medzi rokmi rekordov a dosiahnutýmivýsledkami.
Je nám jasné, že rok nie je jediným faktorom, ktorý ovplyvňujerekord. Keby sme chceli predpovedať seriózne, budeme musieť braťdo úvahy aj iné faktory, napríklad formu súťažiacich. Avšak na prvýkontakt s lineárnym modelom nám tieto údaje postačia.
Nakoniec by sme chceli vedieť, v ktorom roku by sme mohliočakávať ďalší rekord.

Definícia modeluZačneme definíciou nášho modelu ako funkcie, ktorá mapuje naše
vstupné atribúty, v tomto prípade roky rekordov v skoku dodiaľky na
výstupné alebo cieľové hodnoty - dĺžky skokov.
Je mnoho funkcií, ktoré by sme mohli použiť na toto modelovanie.
Ak označíme x vstupný atribút (rok) a t výstupný atribút (dĺžkuskoku), matematicky to budeme zapisovať
t = f(x)
.

Definícia modelu
Okrem vstupných atribútov funkcia spravidla obsahuje ďalšieparametre, z ktorých niektoré sú modifikovateľné (napríklad učenímsa).Parametre učiaceho sa modelu sú ústrednou témou strojovéhoučenia. Budeme používať zápis
t = f (x ; a)
pre vyjadrenie toho, že funkcia pracuje na atribútoch x a máparametre a. Je zrejmé, že aj premenných aj parametrov môže byťviac.

Lineárna regresia
Prvý model
Náš prvý model bude lineárny a bude mať jednu premennú a dvaparametre,
y = f (x ; k , q) = kx + q,
kde k , q sú konštanty a x je premenná a z geometrického hľadiskatáto funkcia predstavuje priamku.Aby sme vedeli vybrať model, potrebujeme určiť predpokladycharakterizujúce vzťah medzi x a t.

Lineárna regresia
Prvý model
Pre prvý model sme stanovili, že vzťah bude lineárny. Dáta naobrázku v paneli A by mohli byť modelované pomocou priamky.Teda
y = f (x ; k , q) = kx + q, (1)
K tomu, aby sme pre k a q vybrali najlepšie hodnoty, potrebujemedefinovať, čo to znamená najlepšie.
Naším cieľom bude, aby model pre všetky vstupné údaje dávalvýstupy, ktoré sa budú od skutočných výstupných hodnôt líšiť čonajmenej (chyba modelu bude čo najmenšia).

Lineárna regresia
Predpokladajme, že sú dané dvojice vstupných a výstupnýchhodnôt (tréningová vzorka) {(x1, t1), (x2, t2), . . . , (xN , tN)}.Chyba modelu pre jednu dvojicu je
En(tn; f (xn; k , q) = (tn − f (xn; k , q))2 (2)
Pre všetky dvojice budeme používať kvadratickú chybovú funkciu
E =1N
N∑n=1
En(tn; f (xn; k , q)) (3)
Najlepší modelom bude taký, pre ktorý bude chyba (3) najmenšia.

Lineárna regresia
Matematicky to zapíšeme
argmink,q1N
N∑n=1
En(tn; f (xn; k , q)), (4)
čo znamená nájsť argumenty, ktoré minimalizujú . . ..

Lineárna regresia
Odvodenie vzťahov pre výpočet k a q
Chyba pre danú tréningovú vzorku {(x1, t1), (x2, t2), . . . , (xN , tN)}
E =1N
N∑n=1
En(tn; f (xn; k , q)) =1N
N∑n=1
(tn − (kxn + q))2
=1N
N∑n=1
(t2n − 2tn(kxn + q) + k2x2n + 2kqxn + q2)
=1N
N∑n=1
(k2x2n + 2kxn(q − tn) + q2 − 2tnq + t2n) (5)

Lineárna regresia
K výpočtu minima vypočítame najprv parciálne derivácie podľa k a q Parciálnaderivácia podľa k je
∂E
∂k=2kN
N∑n=1
x2n +2N
N∑n=1
(xn(q − tn)) (6)
Parciálna derivácia podľa q je
∂E
∂q=2kN
N∑n=1
xn + 2q − 2N
N∑n=1
tn (7)
Označme x priemer hodnôt x1, . . . , xn a t priemer hodnôt t1, . . . , tn , t. j.
x =1N
N∑n=1
xn, t =1N
N∑n=1
tn

Lineárna regresia
Položíme (7) rovné 0
2kN
N∑n=1
xn + 2q − 2N
N∑n=1
tn = 2kx + 2q − 2t = 0
teda q = t − kx .Označme x2 priemer hodnôt x21 , . . . , x
2n a xt priemer hodnôt x1t1, . . . , xntn, t. j.
x2 =1N
N∑n=1
x2n , xt =1N
N∑n=1
xntn
Položíme (6) rovné 0
2kN
N∑n=1
x2n +2N
N∑n=1
(xn(q − tn)) = 2kx2 + 2qx − 2xt = 0

Lineárna regresia
Dosadením q = t − kx dostaneme
2kx2 + 2(t − kx)x − 2xt = 0 (8)
Úpravou dostaneme výrazy pre k a q
k =xt − xt
x2 − x2, q = t − kx (9)
Výpočtom druhej derivácie sa presvedčíme, že ide o minimum.
Pre náš príklad dostávame výsledky uvedené v nasledujúcej tabuľke

Lineárna regresia
Muži, skok do diaľky a vypočítané hodnotyPor. č Rok Skok Rok*Skok Rok*Rok1 1901 7,61 14466,61 36138012 1923 7,69 14787,87 36979293 1924 7,76 14930,24 37017764 1925 7,89 15188,25 37056255 1928 7,90 15231,20 37171846 1928 7,93 15289,04 37171847 1931 7,98 15409,38 37287618 1935 8,13 15731,55 37442259 1960 8,21 16091,60 384160010 1961 8,24 16158,64 384552111 1961 8,28 16237,08 384552112 1962 8,31 16304,22 384944413 1964 8,31 16320,84 385729614 1964 8,34 16379,76 385729615 1965 8,35 16407,75 386122516 1967 8,35 16424,45 386908917 1968 8,90 17515,20 387302418 1991 8,95 17819,45 3964081
(1/N)∑N
n=1 1947,7 8,1739 15927,40 3793921

Lineárna regresia
Hodnoty pre k , q a E sú
k = 0.0143; q = −19.7139; E = 0.0193
V paneli B na predchádzajúcom obrázku sa nachádza vypočítanápriamka aj nakreslená a vidíme, aký trend mali rekordy v skoku dodiaľky.

Lineárna regresia
Predikcia rekordu
Trendovú priamku môžeme použiť na predikciu, aký rekord by smemohli očakávať v niektorom z nasledujúcich rokov.Očakávaný rekordv roku 2018 je y = 0.0143 ∗ 2018− 19.7139 = 9, 14m.a v roku 2019 je y = 0.0143 ∗ 2019− 19.7139 = 9, 16m.
Treba tu poznamenať, že tieto predikcie sú len orientačné. Toto saprejavuje aj v predchádzajúci rokoch.

Lineárna regresia
Zovšeobecnenie lineárnych modelov
y = f (x ;w) = w0 + w1x + w2x2 = f (x ;w), (10)
Model je stále lineárny v parametroch, ale kvadratický v dátach.
Všeobecnejší model je lineárny v parametroch, polynomiálny vdátach
f (x ;w) =K∑
k=0
wkxk , x0 = 1; (11)

Lineárna regresia
Zovšeobecnenie lineárnych modelovAk by sme vytvorili vektory a maticu
w = (w0,w1 . . .wK ), x = (x0, x1 . . . xK ), t = (t1, t2 . . . tN)T
X =
x01 x11 x21 . . . xK1x02 x12 x22 . . . xK2...
......
......
x0N x1N x2N . . . xKN
XwT = t, XTXwT = XT t, wT = (XTX)−1XT t

Lineárna regresia
Obr.: Rekordy v behu mužov, 100m, na OH

Lineárna regresia
Zovšeobecnenie lineárnych modelov
Matica dát má tvar
X =
x01 x11 x21 . . . xK1x02 x12 x22 . . . xK2...
......
......
x0N x1N x2N . . . xKN

Lineárna regresia
Zovšeobecnenie lineárnych modelovNie je nutné používať len polynomiálne funkcie, je možné použiť Kiných funkcií, hk(x). Matica dát má potom tvar
X =
h1(x1) h2(x1) h3(x1) . . . hK (x1)h1(x2) h2(x2) h3(x2) . . . hK (x2)
......
......
...h1(xN) h2(xN) h3(xN) . . . hK (xN)
f (x ;w) =K∑
k=0
wk ∗ hk(x); (12)

Lineárna regresia
Generalizácia a prefitovanie
Naším originálnym cieľom je hľadanie modelu, ktorý bude robiťnajlepšie (presnejšie) predikcie. Takým modelom bude ten, ktorýbude generalizovať (zovšeobecňovať) a dávať dobré výsledky ajokrem trénovacích dát. To znamená model by mal minimalizovaťchybu aj na dátach, na ktorých nebol trénovaný.
Ak navrhneme modely, ktoré sú zložitejšie, tieto modely sa môžudostať bližšie k tréningovým dátam. Budú fitovať s menšou chybou,ale ich predikcia sa rapídne zhorší. Sú prefitované (over-fittinfg).

Lineárna regresia
Bias – variance tradeoff
Hľadanie zložitosti optimálneho modelu, ktorý je schopnýgeneralizovať bez prefitovania, je veľmi ťažká úloha. Tento vzťah sanazýva bias-variance tradeoff.
I Predpokladajme, že poznáme pravdepodobnostné rozdeleniedát, p(x, t), z ktorých trénovacia vzorka bola vybraná.
I Použitím tohto rozdelenia by sme teoreticky mohli vypočítaťočakávanú hodnotu kvadratickej chyby medzi odhadnutýmihodnotami parametrov a správnymi hodnotami.
I Chceme, aby táto hodnota, označená M, bola čo najmenšia.

Lineárna regresia
Bias- - variance tradeoff
I Hodnota M môže byť dekomponovaná do dvoch termovnazvaných bias, B, a variancia, V,
M = B + V.
I Bias popisuje systematickú nezhodu medzi naším modelom aprocesom, ktorý generoval dáta. Variancia popisuje možnúchybu.
I Model, ktorý je príliš jednoduchý, bude mať veľký bias(podtrénovanie – under-fitting).

Lineárna regresia
Bias-variancia tradeoff
I Je možné znížiť bias tým, že použijeme zložitejší model.I Zložitejší model bude mať ale vyššiu varianciuI Teda hľadanie správneho vyváženia medzi generalizáciou a
prefitovaním/podfitovaním (over/under-fitting) znamená ajhľadanie správneho vyváženia medzi biasom a varianciou.

Lineárna regresia
Validácia modelu
Jeden spôsob, ako sa vyhnúť tomuto problému, je použitie druhéhodatasetu, ktorý sa nazýva tiež validačný (potvrdzujúci). Je taknazvaný preto, lebo sa používa na potvrdenie prediktívnejschopnosti modelu.
Validačné dáta možno pripraviť separovane alebo výberom ztréningovej vzorky.

Lineárna regresia
Obr.: Rekordy v behu mužov, 100m, na OH

Lineárna regresia
Krížová validáciaJe to technika, ktorá nám umožňuje efektívnejšie využitie danýchdát.K-zložková validácia rozdelí dáta do K rovnakých podmnožín.Každá podmnožina sa stane raz validačnou množinou.Spriemernenie K chybových hodnôt dáva výslednú chybovúhodnotu.Špeciálny prípad, K=N: Leave One Out Cross Validation - LOOCV
LCV =1N
N∑n=1
(tn − wT−nxn)2
kde w−n je odhad parametrov bez n-tého príkladu.

Lineárna regresia
RegularizáciaUvažujme triviálny model
f (x ;w) = wTX
kde w = [0, 0, . . . 0]T . Model predikuje vždy 0, ale je tonajjednoduchší model. Ak sa zmení niektorá hodnota vo w, modelbude zložitejší. Uvažujme
f (x ;w) = w0 + w1x + w2x2 + w3x
3 + w4x4 + w5x
5
Ak w0 6= 0 a ostatné parametre budú 0, tak model budepredpovedať konštantu w0.

Lineárna regresia
Regularizácia
Pridaním ďalších parametrov bude model zložitejší. Mohli by smeuvažovať súčet absolutných hodnôt parametrov.
Čım je vyšší, tým je model zložitejší. . .
Vo všeobecnosti budeme predpokladať, že vyššia hodnota súčtovabsolutných hodnôt váh znamená zložitejší model (nechcemekladné hodnoty kompenzovať zápornými).

Lineárna regresia
Regularizácia
Od absolutných hodnôt prejdeme ku kvadratickým hodnotám∑i
w2i = wwT
Ak nechceme mať model príliš zložitý, má zmysel mať tútohodnotu malú.

Lineárna regresia
Regularizácia
Budeme minimalizovať regularizovanú chybu, ktorá je súčtompredchádzajúcej chyby a výrazu penalizujúceho zložitosť modelu
L′ = L+ λwwT
Parameter λ riadi vzťah (trade-off) medzi penalizáciou zlefitujúcich dát (L) a penalizáciou zložitosti modelov.Platí
L =1N(t− Xw)(t− Xw)T

Lineárna regresia
Regularizácia
Parciálne derivácie L′ podľa w nám dajú
∂L′
∂w=
2N
XTXw − 2N
XT t + 2λw
Ak položíme výraz rovný 0, dostaneme
2N
XTXw − 2N
XT t + 2λw = 0
(XTX + NλI)w = XT t

Lineárna regresia
Dostávame regularizovanú hodnotu chyby najmenších štvorcov
w = (XXT + NλI)−1XT t (13)
Ak λ sa rovná 0, dostaneme originálne nastavenie parametrov.Inak sú parametre upravené.

Lineárna regresia
Obr.: Dôsledky meniaceho sa parametra λ.

Lineárna regresia
Úlohy:
1. Na predchádzajúcich dátach (100 m muži) vyskúšajmepoužitie parametricky lineárneho modelu s funkciami:
h1(x) = 1; h2(x) = x ; h3(x) = sin(x − a
b)
Zvoľte rôzne a a b.
2. Analyzujte skoky do diaľky u žien.
Recommended