Embed Size (px)
Citation preview

Лекция 3. Виртуальные топологии в MPI. Параллельные алгоритмы в стандарте MPI умножения матрицы на вектор, метода Монте-Карло, решение линейных алгебраических уравнений (СЛАУ) методами Гаусса и сопряжённых градиентов.
Пазников Алексей Александрович
Параллельные вычислительные технологии СибГУТИ (Новосибирск) Осенний семестр 2015
www: cpct.sibsutis.ru/~apaznikov/teaching q/a: piazza.com/sibsutis.ru/fall2015/pct2015fall

Виртуальные декартовые топологии

3
Виртуальные топологии
Для чего нужны виртуальные топологии:
▪ Удобное наименование процессов.
▪ Схема именования процесса подходит к модели межпроцессных взаимодействий.
▪ Облегчает написание кода.
▪ Может позволить MPI оптимизировать коммуникации.

4
Виртуальные топологии
Для чего нужны виртуальные топологии:
▪ Удобное наименование процессов.
▪ Схема именования процесса подходит к модели межпроцессных взаимодействий.
▪ Облегчает написание кода.
▪ Может позволить MPI оптимизировать коммуникации.
Как создать виртуальную топологию:
▪ Создание топологии создаёт новый коммуникатор.
▪ MPI реализует функции отображения:
▫ для определения ранга процесса по его имени в схеме топологии
▫ и наоборот

5
Декартовые топологии
0(0, 0)
3(1, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
7(2, 1)
10(3, 1)
2(0, 2)
5(1, 2)
8(2, 2)
11(3, 2)
Ранг процессаДекартовые координаты
процесса
Декартовые топологии:
▪ Каждый процесс связан с соседями в виртуальную решётку.
▪ Границы могут быть циклическими или нет.
▪ Процессы идентифицируются по декартовым координатам.

6
Создание декартовых топологий
int MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims, int *periods, int reorder, MPI_Comm *comm_cart);
0(0, 0)
3(1, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
7(2, 1)
10(3, 1)
2(0, 2)
5(1, 2)
8(2, 2)
11(3, 2)
comm_old = MPI_COMM_WORLDndims = 2dims = (4, 3)periods = (1, 0)reorder = 1
comm_old – старый коммуникаторndims – количество размерностейdims – размер каждой размерностиperiods – наличие циклов в каждой из размерностейreorder – разрешение переупорядочиванияcomm_cart – новый коммуникатор

7
Ранги в декартовых топологиях
0(0, 0)
3(1, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
7(2, 1)
10(3, 1)
2(0, 2)
5(1, 2)
8(2, 2)
11(3, 2)
Ранг процессав новом коммуникаторе
comm_cart
Декартовые координаты процесса
▪ Ранги процессов в новом коммуникаторе могут отличаться от рангов в старом, если reorder = 1.
▪ Переупорядочивание может позволить MPI оптимизировать информационные обмены.
7
11
3
6
10
2
5
9
1
4
8
0
Ранг процесса в старом коммуникаторе
comm_old

8
Получение координат и рангов в декартовых топологиях
5(1, 2)
ранг процессакоординаты процесса в решётке
int MPI_Cart_coords(MPI_Comm comm_cart, int rank, int maxdims, int *coords);
Отображение ранга rank процесса в его декартовые координаты coords
5(1, 2)
ранг процессакоординаты процесса в решётке
int MPI_Cart_rank(MPI_Comm comm_cart, int *coords, int *rank);
Отображение декартовых координат процесса coords в ранг процесса rank

5(1, 2)
3(1, 0)
7(2, 1)
9
Получение соседних процессов в декартовых топологиях
int MPI_Cart_shift(MPI_Comm comm_cart, int direction, int disp, int *rank_source, int *rank_dest);
0(0, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
10(3, 1)
2(0, 2)
8(2, 2)
11(3, 2)
Определение рангов соседних процессов
MPI_Cart_shift(comm_cart, direction, disp, rank_source, rank_dest);
0 1 1 7 1 1 3 5
Пример для процесса 4:

10
Разделение декартовых топологий
int MPI_Cart_sub(MPI_Comm comm_cart, int *remain_dims, MPI_Comm *comm_slice);
0(0, 0)
3(1, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
7(2, 1)
10(3, 1)
2(0, 2)
5(1, 2)
8(2, 2)
11(3, 2)
▪ Разрезать сетку процессов на полосы (slices).
▪ Для каждой части создатся отдельный коммуникатор.
▪ Каждая часть может выполнять собственные коллективные операции.
0(0)
1(1)
3(3)
2(2)
0(0)
1(1)
3(3)
2(2)
0(0)
1(1)
3(3)
2(2)

11
Разделение декартовых топологий
int MPI_Cart_sub(MPI_Comm comm_cart, int *remain_dims, MPI_Comm *comm_slice);
0(0, 0)
3(1, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
7(2, 1)
10(3, 1)
2(0, 2)
5(1, 2)
8(2, 2)
11(3, 2)
0(0)
1(1)
3(3)
2(2)
0(0)
1(1)
3(3)
2(2)
0(0)
1(1)
3(3)
2(2)
Ранг процессав comm_slice
Декартовые координаты процесса в comm_slice

12
Пример: передача сообщений по кольцу
0 1 2 3 6
Необходимо вычислить сумму всех рангов процессов:

13
Пример: передача сообщений по кольцу
int main() { int i, commrank, size, left, right; int sum, send_buf, rec_buf; MPI_Comm ring_comm; int dims[1], periods[1], reorder;
MPI_Status send_status, rec_status; MPI_Request request;
MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &commrank); MPI_Comm_size(MPI_COMM_WORLD, &size);
// Задать декартовую топологию dims[0] = size; periods[0] = 1; reorder = 1; MPI_Cart_create(MPI_COMM_WORLD, 1, dims, periods, reorder, &ring_comm); MPI_Cart_shift(ring_comm, 0, 1, &left, &right);
0 1 2 3 6
Необходимо вычислить сумму всех рангов процессов:

14
Пример: передача сообщений по кольцу
// Передача сообщений по кольцу и вычисление суммы рангов sum = 0; send_buf = commrank; for (i = 0; i < size; i++) { MPI_Issend(&send_buf, 1, MPI_INT, right, tag, ring_comm, &request); MPI_Recv(&rec_buf, 1, MPI_INT, left, tag, ring_comm, &rec_status);
sum += rec_buf;
MPI_Wait(&request, &send_status);
send_buf = rec_buf; }
printf("Proc %d, sum %d, should be %d\n", commrank, sum);
MPI_Finalize(); return 0;}

15
Пример: передача сообщений по кольцу
// Передача сообщений по кольцу и вычисление суммы рангов sum = 0; send_buf = commrank; for (i = 0; i < size; i++) { MPI_Issend(&send_buf, 1, MPI_INT, right, tag, ring_comm, &request); MPI_Recv(&rec_buf, 1, MPI_INT, left, tag, ring_comm, &rec_status);
sum += rec_buf;
MPI_Wait(&request, &send_status);
send_buf = rec_buf; }
printf("Proc %d, sum %d, should be %d\n", commrank, sum);
MPI_Finalize(); return 0;}
Proc 0, sum 6, should be 6Proc 1, sum 6, should be 6Proc 2, sum 6, should be 6Proc 3, sum 6, should be 6

16
Пример: передача сообщений по тору
18
Необходимо вычислить сумму всех рангов процессов по каждой плоскости двумерной решётки:
0(0, 0)
3(1, 0)
6(2, 0)
9(3, 0)
1(0, 1)
4(1, 1)
7(2, 1)
10(3, 1)
2(0, 2)
5(1, 2)
8(2, 2)
11(3, 2)
22
26

17
Пример: передача сообщений по тору – 1 вариант
int main(int argc, char *argv[]) { int i, commrank, size, left, right; int sum, send_buf, rec_buf; MPI_Comm torus_comm; int dims[2], periods[2], reorder, dir;
MPI_Status send_status, rec_status; MPI_Request request;
MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &commrank); MPI_Comm_size(MPI_COMM_WORLD, &size);
// Задать декартовую топологию periods[0] = periods[1] = 1; reorder = 1; dims[0] = dims[1] = 0; dir = 0; MPI_Dims_create(size, 2, dims);
MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, reorder, &torus_comm); MPI_Cart_shift(torus_comm, dir, 1, &left, &right);

18
// Расчитать глобальную сумму sum = 0; send_buf = commrank; for (i = 0; i < dims[dir]; i++) { MPI_Issend(&send_buf, 1, MPI_INT, right, tag, torus_comm, &request); MPI_Recv(&rec_buf, 1, MPI_INT, left, tag, torus_comm, &rec_status); sum += rec_buf; MPI_Wait(&request, &send_status); send_buf = rec_buf; }
printf("Proc %d, sum %d\n", commrank, sum);
MPI_Finalize();}
Пример: передача сообщений по тору – 1 вариант

19
// Расчитать глобальную сумму sum = 0; send_buf = commrank; for (i = 0; i < dims[dir]; i++) { MPI_Issend(&send_buf, 1, MPI_INT, right, tag, torus_comm, &request); MPI_Recv(&rec_buf, 1, MPI_INT, left, tag, torus_comm, &rec_status); sum += rec_buf; MPI_Wait(&request, &send_status); send_buf = rec_buf; }
printf("Proc %d, sum %d\n", commrank, sum);
MPI_Finalize();}
Proc 0, sum 18Proc 9, sum 18Proc 3, sum 18Proc 2, sum 26Proc 11, sum 26Proc 1, sum 22Proc 10, sum 22Proc 4, sum 22Proc 5, sum 26Proc 6, sum 18Proc 7, sum 22Proc 8, sum 26
Пример: передача сообщений по тору – 1 вариант

20
periods[0] = periods[1] = 1; reorder = 1; dims[0] = dims[1] = 0; remain_dims[0] = 1; remain_dims[1] = 0;
MPI_Dims_create(size, 2, dims);
MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, reorder, &torus_comm);
MPI_Cart_sub(torus_comm, remain_dims, &torus_slice);
MPI_Allreduce(&commrank, &sum, 1, MPI_INT, MPI_SUM, torus_slice);
printf("Proc %d, sum %d\n", commrank, sum);
Proc 0, sum 18Proc 9, sum 18Proc 3, sum 18Proc 2, sum 26Proc 11, sum 26Proc 1, sum 22Proc 10, sum 22Proc 4, sum 22Proc 5, sum 26Proc 6, sum 18Proc 7, sum 22Proc 8, sum 26
Пример: передача сообщений по тору – 2 вариант

Распределение элементов матрицы в MPI-программе

22
Распределение матрицы по строкам
Матрица n × m
n
1
1 m
P0
a_full

23
Матрица n × m
n
1
1 m
P0
P1
P2
P3
P0
a_full
a_chunk
a_chunk
a_chunk
a_chunk
Распределение матрицы по строкам

24
Матрица n × m
n
1
1 m
P0
P1
P2
P3
P0
sendcounts[0]
sendcounts[1]
sendcounts[2]
sendcounts[3]
recvcounts[0]
recvcounts[1]
recvcounts[2]
recvcounts[3]
displs[0]
displs[1]
displs[2]
displs[3]
a_full
a_chunk
a_chunk
a_chunk
a_chunk
MPI_Scatterv(a_full, sendcounts, displs, mpi_type, a_chunk, recvcounts[myrank], mpi_type, 0, comm);
Распределение матрицы по строкам

25
void distr_matrix_by_rows(atype *a_full, atype *a_chunk, int ncols, int mrows, MPI_Comm comm){ int commsize; MPI_Comm_size(comm, &commsize);
int *displs = (int *)malloc(sizeof(int) * commsize); int *sendcounts = (int *)malloc(sizeof(int) * commsize); int *recvcounts = (int *)malloc(sizeof(int) * commsize);
int rank, myrank; MPI_Comm_rank(comm, &myrank);
for (rank = 0; rank < commsize; rank++) { displs[rank] = chunk_low(rank, commsize, mrows) * ncols; sendcounts[rank] = recvcounts[rank] = chunk_size(rank, commsize, mrows) * ncols; }
MPI_Scatterv(a_full, sendcounts, displs, mpi_type, a_chunk, recvcounts[myrank], mpi_type, 0, comm);
free(displs); free(sendcounts); free(recvcounts);}
Распределение матрицы по строкам

26
int main() { int worldrank, worldsize;
MPI_Init(NULL, NULL); MPI_Comm_rank(MPI_COMM_WORLD, &worldrank); MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
srand48(time(NULL) * worldrank);
atype *a_full = NULL;
if (worldrank == 0) { a_full = (atype*) malloc(sizeof(atype) * (ncols * mrows)); fill_matrix_randomly(a_full, ncols, mrows); }
atype *a_chunk = (atype*) malloc(sizeof(atype) * chunk_size(worldrank, worldsize, mrows) * ncols);
distr_matrix_by_rows(a_full, a_chunk, ncols, mrows, MPI_COMM_WORLD);
if (a_full != NULL) free(a_full);
MPI_Finalize();}
Распределение матрицы по строкам

27
Матрица n × m
n
1 m
P0
a_full
Распределение матрицы по столбцам
P0 P1 P2 P3

28
Матрица n × m
n
row
1 m
P0
P0
a_full
Распределение матрицы по столбцам
displs[1]displs[0]
displs[3]displs[2]
P1 P2 P3
for (row = 0; row < mrows; row++) { MPI_Scatterv(&a_full[row * ncols], sendcounts, displs, mpi_type, &a_chunk[recvcounts[myrank] * row], recvcounts[myrank], mpi_type, 0, comm);}
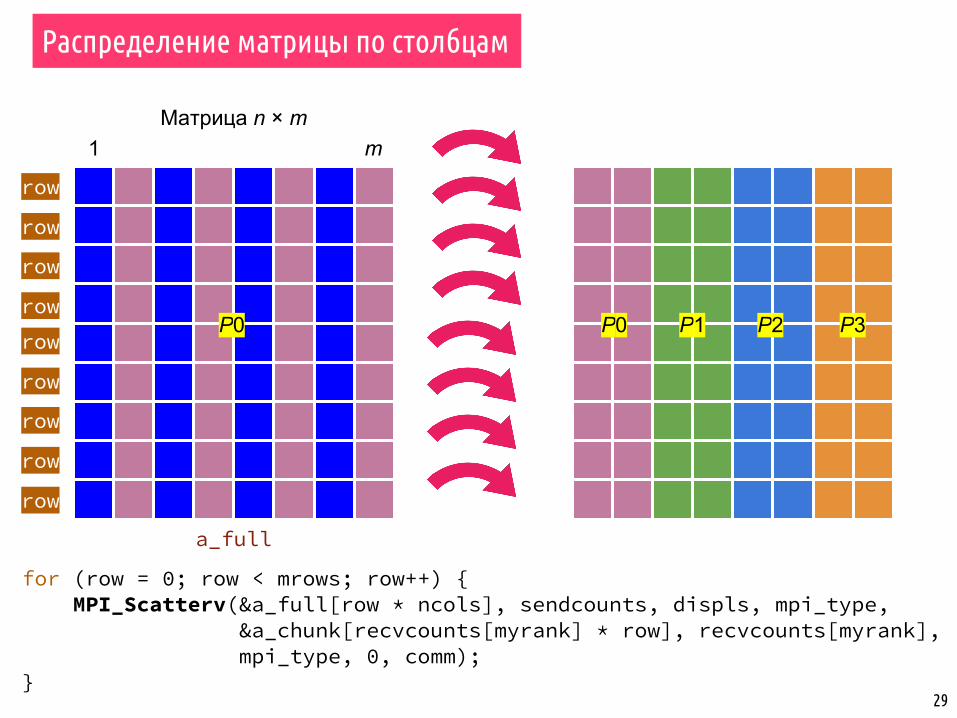
29
Матрица n × m
row
1 m
P0P0
a_full
for (row = 0; row < mrows; row++) { MPI_Scatterv(&a_full[row * ncols], sendcounts, displs, mpi_type, &a_chunk[recvcounts[myrank] * row], recvcounts[myrank], mpi_type, 0, comm);}
Распределение матрицы по столбцам
P1 P2 P3
row
row
row
row
row
row
row
row

30
void distr_matrix_by_cols(atype *a_full, atype *a_chunk, int ncols, int mrows, MPI_Comm comm) { int commsize; MPI_Comm_size(comm, &commsize);
int *displs = (int *)malloc(sizeof(int) * commsize); int *sendcounts = (int *)malloc(sizeof(int) * commsize); int *recvcounts = (int *)malloc(sizeof(int) * commsize);
int rank, myrank; MPI_Comm_rank(comm, &myrank);
for (rank = 0; rank < commsize; rank++) { displs[rank] = chunk_low(rank, commsize, ncols); sendcounts[rank] = recvcounts[rank] = chunk_size(rank, commsize, ncols); }
int row; for (row = 0; row < mrows; row++) { MPI_Scatterv(&a_full[row * ncols], sendcounts, displs, mpi_type, &a_chunk[recvcounts[myrank] * row], recvcounts[myrank], mpi_type, 0, comm); }
free(displs); free(sendcounts); free(recvcounts);}
Распределение матрицы по столбцам

31
int main() { int worldrank, worldsize;
MPI_Init(NULL, NULL); MPI_Comm_rank(MPI_COMM_WORLD, &worldrank); MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
srand48(time(NULL) * worldrank);
atype *a_full = NULL;
if (worldrank == 0) { a_full = (atype*) malloc(sizeof(atype) * (ncols * mrows)); fill_matrix_randomly(a_full, ncols, mrows); }
atype *a_chunk = (atype*) malloc(sizeof(atype) * chunk_size(worldrank, worldsize, ncols) * mrows);
distr_matrix_by_cols(a_full, a_chunk, ncols, mrows, MPI_COMM_WORLD);
if (a_full != NULL) free(a_full);
MPI_Finalize();}
Распределение матрицы по столбцам

32
Матрица n × m
n
1 m
P0
a_full
Распределение матрицы блоками
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10

33
Матрица n × m
n
1 m
P0
a_full
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
const int ndims = 2;size[0] = size[1] = 0;MPI_Dims_create(worldsize, ndims, size);periodic[0] = periodic[1] = 0;MPI_Cart_create(MPI_COMM_WORLD, ndims, size, periodic, reorder, cart_comm);
Распределение матрицы блоками

34
Матрица n × m
n
1 m
P0
a_full
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
const int chunk_mrows = chunk_size(mycoords[0], dims[0], mrows);
if (mycoords[1] == 0) { a_row = (atype*) malloc(sizeof(atype) * chunk_mrows * ncols);
distr_matrix_by_rows(a_full, a_row, ncols, mrows, comm_col);}
MPI_
Scat
terv
Распределение матрицы блоками

35
Матрица n × m
n
1 m
P0
a_full
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
const int chunk_mrows = chunk_size(mycoords[0], dims[0], mrows);
if (mycoords[1] == 0) { a_row = (atype*) malloc(sizeof(atype) * chunk_mrows * ncols);
distr_matrix_by_rows(a_full, a_row, ncols, mrows, comm_col);}
MPI_
Scat
terv
Распределение матрицы блоками

36
Матрица n × m
n
1 m
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Распределение матрицы блоками

37
Матрица n × m
n
1 m
MPI_Comm comm_row;MPI_Cart_sub(comm, remain_dims, &comm_row);const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols);*a_chunk = (atype*) malloc(sizeof(atype) * chunk_mrows * chunk_ncols);
distr_matrix_by_cols(a_row, *a_chunk, ncols, chunk_mrows, comm_row);
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
MPI_Scatterv
MPI_Scatterv
MPI_Scatterv
Распределение матрицы блоками

38
Матрица n × m
n
1 m
MPI_Comm comm_row;MPI_Cart_sub(comm, remain_dims, &comm_row);const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols);*a_chunk = (atype*) malloc(sizeof(atype) * chunk_mrows * chunk_ncols);
distr_matrix_by_cols(a_row, *a_chunk, ncols, chunk_mrows, comm_row);
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
MPI_Scatterv
MPI_Scatterv
MPI_Scatterv
Распределение матрицы блоками

39
void distr_matrix_by_blocks(atype *a_full, atype **a_chunk, int ncols, int mrows, MPI_Comm comm) { int ndims = 0; MPI_Cartdim_get(comm, &ndims);
int dims[ndims], periods[ndims], mycoords[ndims], remain_dims[ndims]; MPI_Cart_get(comm, ndims, dims, periods, mycoords);
MPI_Comm comm_col, comm_row;
remain_dims[0] = 1; remain_dims[1] = 0; MPI_Cart_sub(comm, remain_dims, &comm_col);
int *a_row = NULL; const int chunk_mrows = chunk_size(mycoords[0], dims[0], mrows);
if (mycoords[1] == 0) { a_row = (atype*) malloc(sizeof(atype) * chunk_mrows * ncols); distr_matrix_by_rows(a_full, a_row, ncols, mrows, comm_col); }
remain_dims[0] = 0; remain_dims[1] = 1; MPI_Cart_sub(comm, remain_dims, &comm_row);
const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols); *a_chunk = (atype*) malloc(sizeof(atype) * chunk_mrows * chunk_ncols);
distr_matrix_by_cols(a_row, *a_chunk, ncols, chunk_mrows, comm_row);
if (mycoords[1] == 0) free(a_row);}
Распределение матрицы блоками

40
Распределение матрицы блоками
int main() { int worldrank, worldsize;
MPI_Init(NULL, NULL); MPI_Comm_rank(MPI_COMM_WORLD, &worldrank); MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
srand48(time(NULL) * worldrank);
atype *a_full = NULL;
MPI_Comm cart_comm; const int ndims = 2; create_cart_comm(ndims, &cart_comm);
int mycoords[ndims], cart_rank; MPI_Comm_rank(cart_comm, &cart_rank); MPI_Cart_coords(cart_comm, cart_rank, ndims, mycoords);
if ((mycoords[0] == 0) && (mycoords[1] == 0)) { a_full = (atype*) malloc(sizeof(atype) * (ncols * mrows)); fill_matrix_randomly(a_full, ncols, mrows); } atype *a_chunk = NULL; distr_matrix_by_blocks(a_full, &a_chunk, ncols, mrows, cart_comm);
if (a_full != NULL) free(a_full);
MPI_Finalize();}

41
Распределение матрицы блоками
int main() { int worldrank, worldsize;
MPI_Init(NULL, NULL); MPI_Comm_rank(MPI_COMM_WORLD, &worldrank); MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
srand48(time(NULL) * worldrank);
atype *a_full = NULL;
MPI_Comm cart_comm; const int ndims = 2; create_cart_comm(ndims, &cart_comm);
int mycoords[ndims], cart_rank; MPI_Comm_rank(cart_comm, &cart_rank); MPI_Cart_coords(cart_comm, cart_rank, ndims, mycoords);
if ((mycoords[0] == 0) && (mycoords[1] == 0)) { a_full = (atype*) malloc(sizeof(atype) * (ncols * mrows)); fill_matrix_randomly(a_full, ncols, mrows); } atype *a_chunk = NULL; distr_matrix_by_blocks(a_full, &a_chunk, ncols, mrows, cart_comm);
if (a_full != NULL) free(a_full);
MPI_Finalize();}
void create_cart_comm(int ndims, MPI_Comm *cart_comm) { int worldsize; MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
int size[2]; size[0] = size[1] = 0;
MPI_Dims_create(worldsize, ndims, size); int periodic[2]; periodic[0] = periodic[1] = 0; const int reorder = 1;
MPI_Cart_create(MPI_COMM_WORLD, ndims, size, periodic, reorder, cart_comm);}

42
Распределение матрицы блоками
Matrix: 14 40 54 41 40 58 25 34 14 40 96 31 31 92 34 18 39 45 32 61 10 85 65 21 98 17 70 4 15 93 47 34 99 56 66 48 35 53 8 32 59 96 22 5 58 2 65 34 31 91 42 33 92 50 54 18 80 52 37 79 0 99 6 34 54 90 19 29 90 46 55 99 94 31 87 25 82Process 0: 14 40 54 41 40 31 31 92 34 18Process 1: 58 25 34 14 40 96 39 45 32 61 10 85Process 2: 65 21 98 17 70 56 66 48 35 53Process 3: 4 15 93 47 34 99 8 32 59 96 22 5Process 4: 58 2 65 34 31 18 80 52 37 79 19 29 90 46 55Process 5: 91 42 33 92 50 54 0 99 6 34 54 90 99 94 31 87 25 82

Умножение матрицы, распределённой блоками, на вектор

44
Матрица a, n × m
n
1 m
Умножение матрицы на вектор
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
× =
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Вектор x, m Вектор y, n
45
Матрица a, n × m
n
1 m
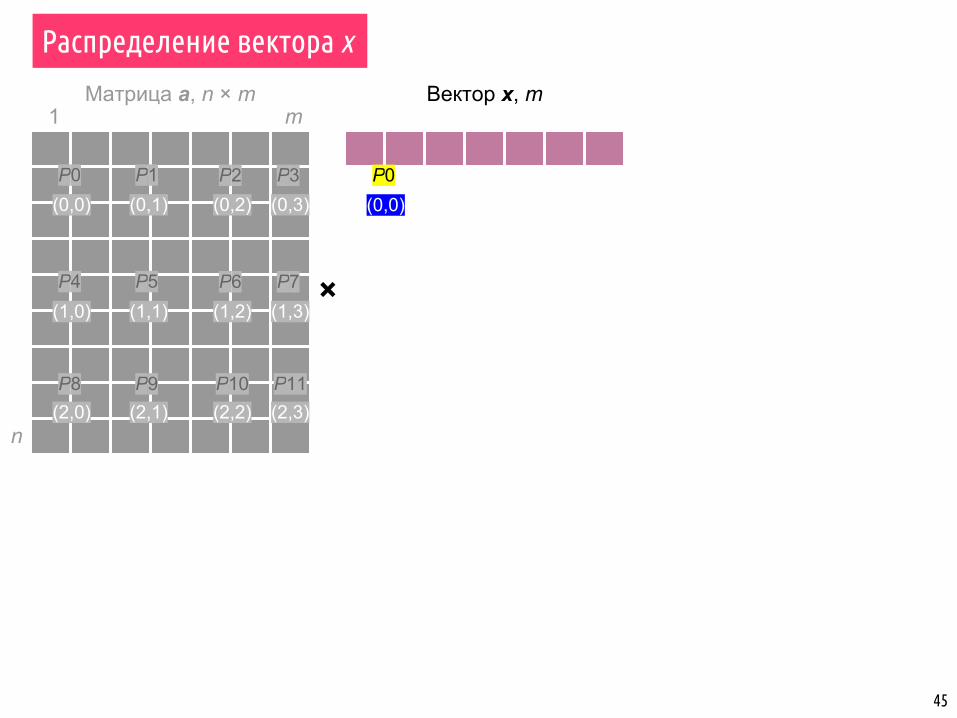
Распределение вектора x
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
×
P0(0,0)
Вектор x, m

46
Матрица a, n × m
n
1 m
Распределение вектора x
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
×
MPI_
Bcas
t
P0
P4
P8
(0,0)
(1,0)
(2,0)
int remain_dims[ndims] = {1, 0};MPI_Comm comm_col;MPI_Cart_sub(cart_comm, remain_dims, &comm_col);
if (mycoords[1] == 0) { if (mycoords[0] != 0) *x_full = (atype*) malloc(sizeof(atype) * ncols);
MPI_Bcast(*x_full, ncols, mpi_type, 0, comm_col);}
Вектор x, m

47
Матрица a, n × m
n
1 m
Распределение вектора x
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
×
P0
P4
P8
(0,0)
(1,0)
(2,0)
remain_dims[0] = 0;remain_dims[1] = 1;MPI_Comm comm_row;MPI_Cart_sub(cart_comm, remain_dims, &comm_row);
const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols);*x_chunk = (atype*) malloc(sizeof(atype) * chunk_ncols);
distr_matrix_by_cols(*x_full, *x_chunk, ncols, 1, comm_row);
distr_matrix_by_cols
distr_matrix_by_cols
distr_matrix_by_cols
P1
P5
P9
P2 P3
P6 P7
P11P10
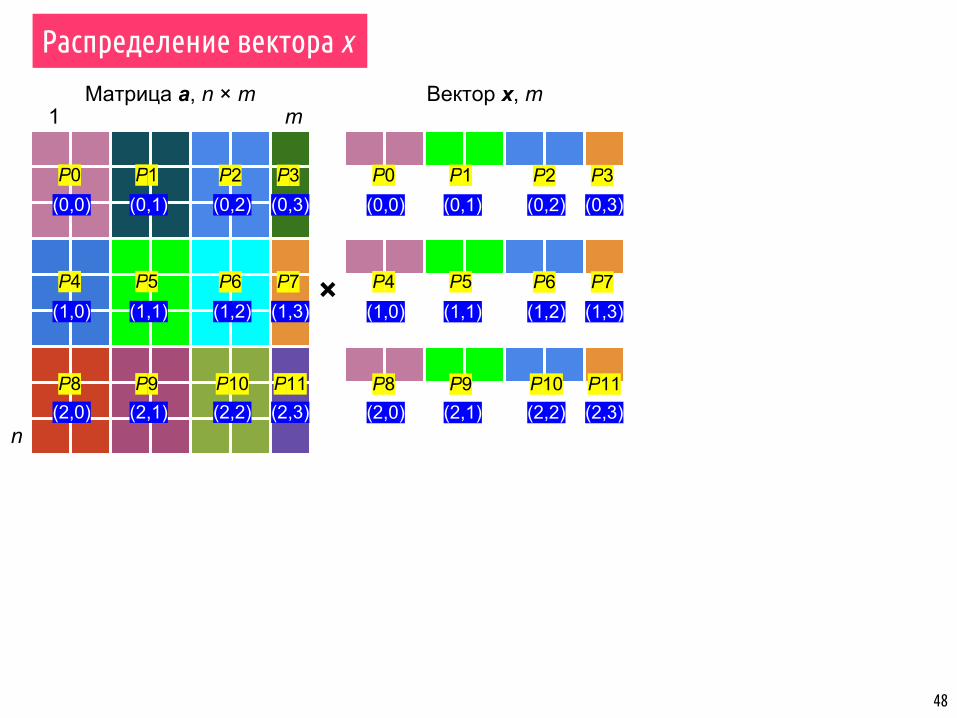
48
Распределение вектора x
×
P0
P4
P8
(0,0)
(1,0)
(2,0)
P1
P5
P9
P2 P3
P6 P7
P11P10
Матрица a, n × m
n
1 m
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Вектор x, m
(0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)
(2,1) (2,3)(2,2)

49
Получение частичных сумм
×
P0
P4
P8
(0,0)
(1,0)
(2,0)
P1
P5
P9
P2 P3
P6 P7
P11P10
Матрица a, n × m
n
1 m
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Вектор x, m
=
P0 P1
P4 P5
P2 P3
P6 P7
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
Вектор y', n
P9P8 P11P10(2,1) (2,3)(2,2)(2,0)
(0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)
(2,1) (2,3)(2,2)
atype *y_tmp = (atype*) malloc(sizeof(atype) * chunk_mrows);int i, j;
for (i = 0; i < chunk_mrows; i++) { y_tmp[i] = 0;
for (j = 0; j < chunk_ncols; j++) y_tmp[i] += a_chunk[i * chunk_ncols + j] * x_chunk[j];}

50
Вычисление результирующего вектора
×
P0
P4
P8
(0,0)
(1,0)
(2,0)
P1
P5
P9
P2 P3
P6 P7
P11P10
Матрица a, n × m
n
1 m
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Вектор x, m
=
P0 P1
P4 P5
P2 P3
P6 P7
Вектор y', n
P9P8 P11P10
(0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)
(2,1) (2,3)(2,2)
int remain_dims[ndims];remain_dims[0] = 0;remain_dims[1] = 1;
MPI_Comm comm_row;MPI_Cart_sub(cart_comm, remain_dims, &comm_row);
*y_chunk = (atype*) malloc(sizeof(atype) * chunk_mrows);MPI_Allreduce(y_tmp, *y_chunk, chunk_mrows, mpi_type, MPI_SUM, comm_row);
+
+
+
+
+
+
+
+
+

51
×
P0
P4
P8
(0,0)
(1,0)
(2,0)
P1
P5
P9
P2 P3
P6 P7
P11P10
Матрица a, n × m
n
1 m
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Вектор x, m
=
Вектор y', n
(0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)
(2,1) (2,3)(2,2)
int remain_dims[ndims];remain_dims[0] = 0;remain_dims[1] = 1;
MPI_Comm comm_row;MPI_Cart_sub(cart_comm, remain_dims, &comm_row);
*y_chunk = (atype*) malloc(sizeof(atype) * chunk_mrows);MPI_Allreduce(y_tmp, *y_chunk, chunk_mrows, mpi_type, MPI_SUM, comm_row);
P0 P1
P4 P5
P9P8
P2 P3
P6 P7
P11P10
(0,0) (0,1) (0,3)(0,2)
(1,1) (1,3)(1,2)(1,0)
(2,1) (2,3)(2,2)(2,0)
Вычисление результирующего вектора

52
Умножение матрицы на вектор
int main() { MPI_Comm cart_comm; const int ndims = 2;
create_cart_comm(ndims, &cart_comm);
int mycoords[ndims], cart_rank; MPI_Comm_rank(cart_comm, &cart_rank); MPI_Cart_coords(cart_comm, cart_rank, ndims, mycoords);
if ((mycoords[0] == 0) && (mycoords[1] == 0)) { a_full = (atype*) malloc(sizeof(atype) * (ncols * mrows)); fill_matrix_randomly(a_full, ncols, mrows);
x_full = (atype*) malloc(sizeof(atype) * ncols); fill_matrix_randomly(x_full, ncols, 1); }
atype *a_chunk = NULL; distr_matrix_by_blocks(a_full, &a_chunk, ncols, mrows, cart_comm);
atype *x_chunk = NULL; distr_vector(&x_full, &x_chunk, ncols, cart_comm);
atype *y_chunk = NULL; matrix_vec_mult(a_chunk, x_chunk, &y_chunk, ncols, mrows, cart_comm);
...}

53
void distr_vector(atype **x_full, atype **x_chunk, int ncols, MPI_Comm cart_comm) { int ndims = 0; MPI_Cartdim_get(cart_comm, &ndims);
int dims[ndims], periods[ndims], mycoords[ndims]; MPI_Cart_get(cart_comm, ndims, dims, periods, mycoords);
MPI_Comm comm_col; cart_slice_col(cart_comm, &comm_col);
if (mycoords[1] == 0) { if (mycoords[0] != 0) *x_full = (atype*) malloc(sizeof(atype) * ncols);
MPI_Bcast(*x_full, ncols, mpi_type, 0, comm_col); }
MPI_Comm comm_row; cart_slice_row(cart_comm, &comm_row);
const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols); *x_chunk = (atype*) malloc(sizeof(atype) * chunk_ncols);
distr_matrix_by_cols(*x_full, *x_chunk, ncols, 1, comm_row);
if ((mycoords[1] == 0) && (mycoords[0] != 0)) free(*x_full);}
Умножение матрицы на вектор

void distr_vector(atype **x_full, atype **x_chunk, int ncols, MPI_Comm cart_comm) { int ndims = 0; MPI_Cartdim_get(cart_comm, &ndims);
int dims[ndims], periods[ndims], mycoords[ndims]; MPI_Cart_get(cart_comm, ndims, dims, periods, mycoords);
MPI_Comm comm_col; cart_slice_col(cart_comm, &comm_col);
if (mycoords[1] == 0) { if (mycoords[0] != 0) *x_full = (atype*) malloc(sizeof(atype) * ncols);
MPI_Bcast(*x_full, ncols, mpi_type, 0, comm_col); }
MPI_Comm comm_row; cart_slice_row(cart_comm, &comm_row);
const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols); *x_chunk = (atype*) malloc(sizeof(atype) * chunk_ncols);
distr_matrix_by_cols(*x_full, *x_chunk, ncols, 1, comm_row);
if ((mycoords[1] == 0) && (mycoords[0] != 0)) free(*x_full);}
54
Умножение матрицы на вектор
void cart_slice_row(MPI_Comm cart_comm, MPI_Comm *comm_row) { int ndims = 0; MPI_Cartdim_get(cart_comm, &ndims); int remain_dims[ndims]; remain_dims[0] = 0; remain_dims[1] = 1; MPI_Cart_sub(cart_comm, remain_dims, comm_row);}
void cart_slice_col(MPI_Comm cart_comm, MPI_Comm *comm_col) { int ndims = 0; MPI_Cartdim_get(cart_comm, &ndims); int remain_dims[ndims]; remain_dims[0] = 1; remain_dims[1] = 0; MPI_Cart_sub(cart_comm, remain_dims, comm_col);}

55
void matrix_vec_mult(atype *a_chunk, atype *x_chunk, atype **y_chunk, int ncols, int mrows, MPI_Comm cart_comm) { int ndims = 0; MPI_Cartdim_get(cart_comm, &ndims); int dims[ndims], periods[ndims], mycoords[ndims]; MPI_Cart_get(cart_comm, ndims, dims, periods, mycoords);
const int chunk_mrows = chunk_size(mycoords[0], dims[0], mrows); const int chunk_ncols = chunk_size(mycoords[1], dims[1], ncols);
atype *y_tmp = (atype*) malloc(sizeof(atype) * chunk_mrows);
int i, j; for (i = 0; i < chunk_mrows; i++) { y_tmp[i] = 0;
for (j = 0; j < chunk_ncols; j++) y_tmp[i] += a_chunk[i * chunk_ncols + j] * x_chunk[j]; }
MPI_Comm comm_row; cart_slice_row(cart_comm, &comm_row);
*y_chunk = (atype*) malloc(sizeof(atype) * chunk_mrows); MPI_Allreduce(y_tmp, *y_chunk, chunk_mrows, mpi_type, MPI_SUM, comm_row);
free(y_tmp);}
Умножение матрицы на вектор

56
Умножение матрицы на вектор
Matrix a: 14 40 54 41 40 58 25 34 14 40 96 31 31 92 34 18 39 45 32 61 10 85 65 21 98 17 70 4 15 93 47 34 99 56 66 48 35 53 8 32 59 96 22 5 58 2 65 34 31 91 42 33 92 50 54 18 80 52 37 79 0 99 6 34 54 90 19 29 90 46 55 99 94 31 87 25 82
Vector x: 13 41 66 85 74 80 36 12 44 8 57
Process 0: 24187 24701 24758
Process 1: 24187 24701 24758
Process 2: 20684 27024 26631 35734
Process 3: 20684 27024 26631 35734

Задача классификации документов

58
Задача классификации документов
Прочитать словарь
Найти документы
Прочитать файлы
Получить статистику
Вывести статистику

59
Задача классификации документов
Прочитать словарь
Найти документы
Прочитать файл
1
Получить статистику
1
Вывести статистику
Прочитать файл
0
Прочитать файлn – 1
Получить статистику
n – 1
Получить статистику
0

60
Задача классификации документов
▪ Количество заданий неизвестно на этапе компиляции.
▪ Задания независимы друг от друга.
▪ Время, необходимое на обработку каждого задания может существенно различаться.
Архитектура manager/worker:
▪ Менеджер ответственен за назначение заданий.
▪ Рабочие процессы выполняют задания и возвращают результаты.
▪ Рабочим процессам назначается по одному заданию, что позволяет сбалансировать их загрузку.
▪ Возможный недостаток – увеличение накладных расходов на коммуникации.

61
Задача классификации документов
Менеджер
Рабочий процесс 1
Рабочий процесс 2
Назначить задание
Назначить задание
Получить результат
Получить результат

62
Задача классификации документов
Менеджер
Рабочий процесс 1
Рабочий процесс 2
Рабочий процесс 3
Рабочий процесс 0Файл
Файл Файл
Файл
Словарь Выходной файл

63
Прочитать словарь.Разослать словарь всем процессам.Определить список файлов для подсчета статистики.
assigned_cntr = 0terminated_cntr = 0do { Получить имя файла или запрос для задание. if получили запрос Получить статистику встречаемости слов
if assigned_cntr < ntasks (назначены не все файлы) Назначить задание: отправить имя очередного файла assign_cntr++ else Отправить процессу сообщение о завершении работы terminated++} while terminated < commsize (остались незавершённые процессы)
Вывести массив stat
Менеджер – псевдокод

64
Получить от менеджера словарь.Отправить менеджеру запрос на получение задания.
for (;;) { Получить имя файла filename от менеджера
if вместо имени файла получили сигнал о завершении Выйти из цикла else (получили задание) Прочитать файл filename и сформировать вектор статистики profile_vec Отправить менеджеру имя файла Отправить массив со статистикой profile_vec менеджеру}
Рабочий процесс – псевдокод

65
const auto FILENAME_TAG = 1, PROFILE_TAG = 2, EMPTY_TAG = 3;const auto ARG_DIR = 1, ARG_DICT = 2, ARG_RES = 3;
int main() { MPI_Init(&argc, &argv); auto worldrank = 0, worldsize = 0; MPI_Comm_rank(MPI_COMM_WORLD, &worldrank); MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
if (worldrank == 0) { const auto nargs = 4; if (argc != nargs) { std::cerr << "Usage: " << argv[0] << " <dir> <dict> <results>" << std::endl; MPI_Abort(MPI_COMM_WORLD, 1); } if (worldsize < 2) { std::cerr << "Number of processes must be at least 2" << std::endl; MPI_Abort(MPI_COMM_WORLD, 1); } }
if (worldrank == 0) { manager(argc, argv); } else { worker(argc, argv); }
MPI_Finalize();
Классификация документов

66
void manager(char **argv) { // Прочитать словарь из файла в строку std::string dictionary_str; read_dictionary(std::string{argv[ARG_DICT]}, dictionary_str);
// Отправить длину словаря и сам словарь auto dictfile_len = dictionary_str.length(); MPI_Bcast(&dictfile_len, 1, MPI_INT, 0, MPI_COMM_WORLD); MPI_Bcast(const_cast<char*>(dictionary_str.c_str()), dictfile_len, MPI_CHAR, 0, MPI_COMM_WORLD);
// Прочитать список имён файлов std::vector<std::string> filenames; get_filenames(std::string{argv[ARG_DIR]}, filenames);
auto commsize = 0; MPI_Comm_size(MPI_COMM_WORLD, &commsize); auto const nworkers = commsize - 1;
// Разбить словарь на слова std::vector<std::string> dict_words; parse_dict(dictionary_str, dict_words);
// Проинициализировать ассоц. массив для отображения статистики на имя файла std::map<std::string, std::vector<int>> allstat; init_allstat(filenames, dict_words.size(), allstat);
Классификация документов – реализация менеджера

67
do { // Получить имя файла или запрос std::string filename; MPI_Status status; recv_str(filename, MPI_ANY_SOURCE, FILENAME_TAG, MPI_COMM_WORLD, &status); auto src = status.MPI_SOURCE;
if (!filename.empty()) { // Получить профиль файла: вектор со статистикой MPI_Recv(allstat[filename].data(), dict_words.size(), MPI_INT, src, PROFILE_TAG, MPI_COMM_WORLD, &status); }
if (assign_cntr < filenames.size()) { // Отправить задание (имя файла) MPI_Send(filenames[assign_cntr].c_str(), filenames[assign_cntr].length(), MPI_CHAR, src, FILENAME_TAG, MPI_COMM_WORLD); assign_cntr++; } else { // Отправить сообщение о завершении работы рабочего процесса MPI_Send(NULL, 0, MPI_CHAR, src, FILENAME_TAG, MPI_COMM_WORLD); terminated++; } } while (terminated < nworkers);
// Вывести статистику в файл write_profiles(std::string{argv[ARG_RES]}, allstat);
Классификация документов – реализация менеджера

68
// Получить строку заранее неизвестного размераvoid recv_str(std::string &received_str, int src, int tag, MPI_Comm comm, MPI_Status *status){ auto len = 0;
MPI_Probe(src, tag, comm, status); MPI_Get_count(status, MPI_CHAR, &len);
if (len > 0) { std::shared_ptr<char> raw_str{new char[len]}; MPI_Recv(raw_str.get(), len, MPI_CHAR, src, FILENAME_TAG, comm, status); received_str.assign(raw_str.get(), len); } else { MPI_Recv(NULL, 0, MPI_CHAR, src, FILENAME_TAG, comm, status); received_str.clear(); }}
Классификация документов – реализация менеджера

69
void worker() { // Получить длину словаря (длину строки) и словарь auto dictfile_len = 0; MPI_Bcast(&dictfile_len, 1, MPI_INT, 0, MPI_COMM_WORLD); std::shared_ptr<char> dictionary{new char[dictfile_len]}; MPI_Bcast(dictionary.get(), dictfile_len, MPI_CHAR, 0, MPI_COMM_WORLD);
// Проинициализировать профиль (ассоциативный массив) std::map<std::string, int> profile; init_profile(dictionary.get(), profile);
// Создать вектор для передачи профиля менеджеру std::vector<int> profile_vec(profile.size());
Классификация документов – реализация рабочего потока

70
for (;;) { // Получить имя очередного файла (или сигнал о завершении работы) std::string filename; MPI_Status status; recv_str(filename, 0, FILENAME_TAG, MPI_COMM_WORLD, &status);
if (filename.empty()) // Строка пустая, значит получили сигнал завершения работы break;
// Сформировать профиль файла (в ассоциативном массиве) make_profile(filename, profile);
// Скопировать профиль в вектор make_vector_from_profile(profile, profile_vec);
// Отправить менеджеру имя файла, профиль которого сейчас построили MPI_Send(filename.c_str(), filename.length(), MPI_CHAR, 0, FILENAME_TAG, MPI_COMM_WORLD);
// Отправить сам профиль, записанный в векторе MPI_Send(profile_vec.data(), profile_vec.size(), MPI_INT, 0, PROFILE_TAG, MPI_COMM_WORLD); }}
Классификация документов – реализация рабочего потока

for (;;) { // Получить имя очередного файла (или сигнал о завершении работы) std::string filename; MPI_Status status; recv_str(filename, 0, FILENAME_TAG, MPI_COMM_WORLD, &status);
if (filename.empty()) // Строка пустая, значит получили сигнал завершения работы break;
// Сформировать профиль файла (в ассоциативном массиве) make_profile(filename, profile);
// Скопировать профиль в вектор make_vector_from_profile(profile, profile_vec);
// Отправить менеджеру имя файла, профиль которого сейчас построили MPI_Send(filename.c_str(), filename.length(), MPI_CHAR, 0, FILENAME_TAG, MPI_COMM_WORLD);
// Отправить сам профиль, записанный в векторе MPI_Send(profile_vec.data(), profile_vec.size(), MPI_INT, 0, PROFILE_TAG, MPI_COMM_WORLD); }}
71
Классификация документов – реализация рабочего потока
void make_vector_from_profile(const std::map<std::string, int> &profile, std::vector<int> &profile_vec) { typedef std::pair<std::string, int> pair_t; std::vector<pair_t> vec_pairs{profile.begin(), profile.end()};
std::sort(vec_pairs.begin(), vec_pairs.end(), [](pair_t lhs, pair_t rhs){ return lhs.second < rhs.second; });
for (auto i = 0u; i < profile_vec.size(); i++) profile_vec[i] = vec_pairs[i].second;}

Моделирование с помощью метода Монте-Карло

73
Метод Монте-Карло – вычисление числа пи
(0, 1)
(0, 1)
(1, 1)
(1, 0)
1. Сгенерировать пару случайных координат (x, y).
2. Определить, принадлежит ли точка с координатами (x, y) окружности (x2 + y2 ≤ 1).
3. Количество f точек, принадлежающих окружности, примерно равно / 4, поэтому ≈ 4 f.

74
Метод Монте-Карло – вычисление числа пи
(0, 1)
(0, 1)
(1, 1)
(1, 0)
1. На каждом процессе выполнять считать количество точек, попавших внутрь окружности.
2. Определить общее число точек (MPI_Reduce).
(0, 1)
(0, 1)
(1, 1)
(1, 0)
(0, 1)
(0, 1)
(1, 1)
(1, 0)
P0 P1 PN
. . .
f0 f1 fN
f
MPI_Reduce

75
Метод Монте-Карло – генерация случайных чисел
Требования к генератору равномерно распределённых случайных чисел:
▪ Он должен обеспечивать равномерное распределение, т.е. вероятности появления всех чисел равны.
▪ Числа не коррелируют.
▪ Не образуются циклы, т.е. числа никогда не повторяют друг друга.
▪ Можно повторно воспроизвести.
▪ Не зависит от архитектуры ВС; генератор работает одинаковым образом на любом компьютере.
▪ Генерируемые числа можно изменить с помощью начального значения (“seed”).
▪ Можно легко разбить на несколько независимых последовательностей.
▪ Генерация происходит быстро
▪ и не требует много памяти.

76
Метод Монте-Карло – генерация случайных чисел
Требования к генератору равномерно распределённых случайных чисел:
▪ Он должен обеспечивать равномерное распределение, т.е. вероятности появления всех чисел равны.
▪ Числа не коррелируют.
▪ Не образуются циклы, т.е. числа никогда не повторяют друг друга.
▪ Можно повторно воспроизвести.
▪ Не зависит от архитектуры ВС; генератор работает одинаковым образом на любом компьютере.
▪ Генерируемые числа можно изменить с помощью начального значения (“seed”).
▪ Можно легко разбить на несколько независимых последовательностей.
▪ Генерация происходит быстро
▪ и не требует много памяти.
Ни один генератор не удовлетворяет всем требованиям!

77
Метод Монте-Карло – параллельная генерация случайных чисел
Требования к генерации случайных чисел в MPI:
▪ Отсутствует корреляция среди чисел в последовательностях разных процессов.
▪ Масштабируемость. Метод можно использовать для большого числа процессов, у каждого из которых своя последовательность.
▪ Локальность. Процесс может начать новую последовательность случайных чисел без информационных обменов.

78
Методы параллельной генерации случайных чисел
Метод на основе менеджера (manager-worker method)Процесс-менеджер генерирует случайные числа и рассылает их рабочим процессамНедостатки
▪ корреляция в последовательностях▪ скорость вычислений превышает скорость передачи случайных чисел▪ большая нагрузка на сеть.
Циклический метод (round-robin, leapfrog)Процессы используют одну и ту же последовательность; процесс использует каждый p-й элемент в последовательности.Недостатки
▪ корреляция в изначальной последовательности▪ нет возможности динамического создания случайной последовательности
Разбиение последовательности или блочный метод (sequence splitting, blocked)Пусть генератор имеет период n. Тогда первые n чисел разбиваются на p частей, каждая из которых используется своим процессом.Недостатки
▪ процесс должен сначала перейти на начало своего блока▪ корреляция в изначальной последовательности
Параметризация (parameterization)В каждом процессе используется генератор инициализируется различными значениями параметров.Недостатки
▪ не всегда легко подобрать тип генератора и параметры

79
Задача переноса нейтронов (neutron transport)
▪ Нейтроны бомбардируют гомогенную двумерную пластину толщиной h и бесконечной высотой.
▪ Нейтрон может отражаться (reflect) от пластины, поглощаться (absorb) пластиной и проходить (pass through) сквозь пластину.
▪ Необходимо расчитать частоту каждого из этих событий.
▪ Взаимодействие характеризует две константы: поперечное сечение захвата cc и поперечное сечение рассеивания cs. Суммарное значение c = cc + cs.
a
b
c
h

80
Задача переноса нейтронов (neutron transport)
1. Вычислить дистанцию, которую прошёл нейтрон s = – 1 / c * ln u.
2. Нейтрон либо отскакивает с вероятностью cs / c, либо, в противном случае, поглощается с вероятностью cc / c = 1 – cs / c.
3. Если нейтрон отскакивает, то он движется в любом направлении d (равновероятно от 0 до ). Новое положение x = s cos d.
4. Если новая координата x меньше 0, значит нейтрон отразился, если больше h, значит, нейтрон прошёл сквозь пластину.
a
b
c
h

81
Задача переноса нейтронов (neutron transport)
auto const NSAMPLES = 1'000'000;auto const CS_CAPTURE = 0.3;auto const CS_SCATTER = 0.5;auto const THICKNESS = 4.0;
int main(int argc, char** argv) { MPI_Init(&argc, &argv);
auto worldrank = 0, worldsize = 0;
MPI_Comm_rank(MPI_COMM_WORLD, &worldrank); MPI_Comm_size(MPI_COMM_WORLD, &worldsize);
auto nreflected = 0, nabsorbed = 0, ntransmitted = 0;
neutron_transport(NSAMPLES, CS_CAPTURE, CS_SCATTER, THICKNESS, nreflected, nabsorbed, ntransmitted);
if (worldrank == 0) std::cout << std::setprecision(3) << double(nreflected) / (NSAMPLES * worldsize) << " reflected\n" << double(nabsorbed) / (NSAMPLES * worldsize) << " absorbed\n" << double(ntransmitted) / (NSAMPLES * worldsize) << " transmitted" << std::endl;
MPI_Finalize(); return 0;}

82
Задача переноса нейтронов (neutron transport)
void neutron_transport(int nsamples, double cs_capture, double cs_scatter, double thickness, int &nrefl, int &nabs, int &ntrans) { auto const cs = cs_capture + cs_scatter; auto nrefl_part = 0, nabs_part = 0, ntransm_part = 0; for (auto i = 0; i < nsamples; i++) { auto direction = 0, pos = 0; auto is_still_bouncing = true; while (is_still_bouncing) { // пока нейтрон продолжает движение auto uniform_val = get_uniform_val(); auto dist_before_col = -(1 / cs) * log(uniform_val); pos += dist_before_col * cos(direction); if (pos < 0) { // отразился nrefl_part++; is_still_bouncing = false; } else if (pos >= thickness) { // прошёл насквозь ntrans_part++; is_still_bouncing = false; } else if (uniform_val < cs_capture / cs) { // поглощён nabs_part++; is_still_bouncing = false; } else // продолжает движение direction = uniform_val * M_PI; } }
MPI_Reduce(&nrefl_part, &nrefl, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD); MPI_Reduce(&nabs_part, &nabs, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD); MPI_Reduce(&ntrans_part, &ntrans, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);

83
Задача переноса нейтронов (neutron transport)
void neutron_transport(int nsamples, double cs_capture, double cs_scatter, double thickness, int &nrefl, int &nabs, int &ntrans) { auto const cs = cs_capture + cs_scatter; auto nrefl_part = 0, nabs_part = 0, ntransm_part = 0; for (auto i = 0; i < nsamples; i++) { auto direction = 0, pos = 0; auto is_still_bouncing = true; while (is_still_bouncing) { // пока нейтрон продолжает движение auto uniform_val = get_uniform_val(); auto dist_before_col = -(1 / cs) * log(uniform_val); pos += dist_before_col * cos(direction); if (pos < 0) { // отразился nrefl_part++; is_still_bouncing = false; } else if (pos >= thickness) { // прошёл насквозь ntrans_part++; is_still_bouncing = false; } else if (uniform_val < cs_capture / cs) { // поглощён nabs_part++; is_still_bouncing = false; } else // продолжает движение direction = uniform_val * M_PI; } }
MPI_Reduce(&nrefl_part, &nrefl, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD); MPI_Reduce(&nabs_part, &nabs, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD); MPI_Reduce(&ntrans_part, &ntrans, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
double get_uniform_val(){ static auto myrank = -1; static std::once_flag flag; std::call_once(flag, []() { MPI_Comm_rank(MPI_COMM_WORLD, &myrank); });
static std::random_device rd; static std::mt19937 gen(rd() * myrank);
return std::generate_canonical<double, std::numeric_limits<double>::digits>(gen);}

Решение систем линейных алгебраических уравнений (СЛАУ)

85
Классификация СЛАУ
Линейное алгебраическое уравнение
a0x0 + a1x1 + … + xn-1xn-1 = b
Система линейных алгебраических уравнений (СЛАУ)
a00x0 + a01x1 + … + a0,n-1xn-1 = b0
a11x0 + a11x1 + … + a1,n-1xn-1 = b1
…
an-1,0x0 + an-1,1x1 + … + an-1,n-1xn-1 = bn-1
Обычно записывается как Ax = b, где A – это матрица n × n, содержащая значения aij,
а x и b – n-элементные векторы, содержащие значения xi и bi.

86
Классификация матриц
▪ Матрица n × n называется симметричной (symmetrically banded) с параметром w, если
i – j > w ⇒ aij = 0 и j – i > w ⇒ aij = 0
Другими словами, все ненулевые элементы матрицы расположены на главной диагонали или на одной из ближайших w диагоналей, которые выше или ниже главной диагонали.
▪ Матрица называется верхней треугольной (upper triangular), если
i > j ⇒ aij = 0
▪ Матрица называется нижней треугольной (lower triangular), если
i < j ⇒ aij = 0
▪ Матрица называется с преобладающей диагональю (strictly diagonally dominant), если
|aii| > |ai0| + |ai1| + |ai,i-1| + |ai,i+1| + |ai,n-1| = 0, 0 ≤ i < n
▪ Матрица называется симметричной (symmetric), если
aij = aji

87
Решение верхней треугольной матрицы – разбиение по строкам
Матрица a, n × n
n
1 n
b x
P3
P2
P1

88
Решение верхней треугольной матрицы – разбиение по строкам
Матрица a, n × n
n
1 n
b x
P3
P2
P1
MPI_Bcast

89
Решение верхней треугольной матрицы – разбиение по строкам
Матрица a, n × n
n
1 n
b x
P3
P2
P1

90
Решение верхней треугольной матрицы – разбиение по строкам
Матрица a, n × n
n
1 n
b x
P3
P2
P1
MPI_Bcast

91
Решение верхней треугольной матрицы – разбиение по строкам
Матрица a, n × n
n
1 n
b x
P3
P2
P1

92
Решение верхней треугольной матрицы – разбиение по строкам
Матрица a, n × n
n
1 n
b x
P3
P2
P1
Вычислительная сложность О(n2 / p)Количество сообщений O(n log p)
Коммуникационная сложность O(n log p)

93
int main(i) { int commrank, commsize;
MPI_Init(NULL, NULL); MPI_Comm_rank(MPI_COMM_WORLD, &commrank); MPI_Comm_size(MPI_COMM_WORLD, &commsize);
srand48(time(NULL) * commrank); atype *a_full = NULL, *b_full = NULL;
if (commrank == 0) { a_full = (atype*) malloc(sizeof(atype) * (n * n)); fill_matrix_randomly(a_full, n, n); make_upper_triang(a_full, n);
b_full = (atype*) malloc(sizeof(atype) * n); fill_matrix_randomly(b_full, n, 1); }
atype *a_chunk = NULL; distr_matrix_by_rows(a_full, &a_chunk, n, n, MPI_COMM_WORLD);
atype *b_chunk = NULL; distr_matrix_by_cols(b_full, &b_chunk, n, 1, MPI_COMM_WORLD);
atype *x_full = malloc(sizeof(atype) * n); back_subst_by_rows(a_chunk, b_chunk, x_full, n);
// ...
MPI_Finalize();
Решение верхней треугольной матрицы – разбиение по строкам

94
void back_subst_by_rows(atype *a_chunk, atype *b_chunk, atype *x_full, int n) { int commsize, myrank; MPI_Comm_size(MPI_COMM_WORLD, &commsize); MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
const int a_chunk_low = chunk_low(myrank, commsize, n); const int a_chunk_high = chunk_high(myrank, commsize, n); const int a_chunk_size = chunk_size(myrank, commsize, n);
int i, j;
for (i = n - 1; i >= 0; i--) { int owner = chunk_owner(i, commsize, n); int i_chunk = i - a_chunk_low;
if (myrank == owner) x_full[i] = b_chunk[i_chunk] / a_chunk[i_chunk * n + i];
MPI_Bcast(&x_full[i], 1, mpi_type, owner, MPI_COMM_WORLD);
for (j = a_chunk_size - 1 - non_negative(a_chunk_high - (i - 1)); j >= 0; j--) { b_chunk[j] -= x_full[i] * a_chunk[j * n + i]; } }}
Решение верхней треугольной матрицы – разбиение по строкам

95
Matrix a:14.00 40.00 54.00 41.00 40.00 58.00 25.00 34.00 0.00 40.00 96.00 31.00 31.00 92.00 34.00 18.00 0.00 0.00 32.00 61.00 10.00 85.00 65.00 21.00 0.00 0.00 0.00 4.00 15.00 93.00 47.00 34.00 0.00 0.00 0.00 0.00 35.00 53.00 8.00 32.00 0.00 0.00 0.00 0.00 0.00 2.00 65.00 34.00 0.00 0.00 0.00 0.00 0.00 0.00 54.00 18.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 34.00
Vector b:54.00 90.00 19.00 29.00 90.00 46.00 55.00 99.00
Vector x:-2979.48 1695.16 -846.23 475.33 42.39 -28.06 0.05 2.91
Решение верхней треугольной матрицы – разбиение по строкам

96
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
P1 P2 P3

97
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
P1 P2 P3

98
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
P1 P2 P3

99
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
MPI_Send
P1 P2 P3

100
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
P1 P2 P3

101
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
MPI_Send
P1 P2 P3

102
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
P1 P2 P3

103
Решение верхней треугольной матрицы – разбиение по столбцам
Матрица a, n × n
n
1 nb x
P3P2P1
b b
P1 P2 P3
Вычислительная сложность О(n2)Количество сообщений O(n)
Коммуникационная сложность O(n2)

104
Прямой ход метода Гаусса: получение верхней треугольной матрицы
Матрица a, n × n
n
1 n
Элементы, которые не будут изменены
Опорная строка
Элементы, которые будут изменены
Элементы, обращённые в 0
Получение верхней треугольной матрицы в методе Гаусса

105
Прямой ход метода Гаусса: получение верхней треугольной матрицы
Матрица a, n × n
n
1 n
Треугольная матрица с изменённым порядком строк
loc
0
1
2
3
45
6
7
8
3
8
1
2
5
4
0
7
6

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
MPI_Allreduce
struct { double value; int index;} local, global;
local.value = fabs(a[i * n + j]);local.index = i;
MPI_Allreduce(&local, &global, 1, MPI_DOUBLE_INT, MPI_MAX_LOC, MPI_COMM_WORLD);
n
1 n
106

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
n
1 n
107
Максимальный элемент в столбце
MPI_Bcast

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
n
1 n
108
Максимальный элемент в столбце
MPI_Bcast
Элементы, обращённые в 0

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
n
1 n
109
MPI_Allreduce

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
n
1 n
110
MPI_Bcast

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
n
1 n
111
MPI_Bcast

Прямой ход метода Гаусса: получение верхней треугольной матрицыМатрица a, n × n
n
1 n
112
MPI_Bcast
Недостаток алгоритма – невозможность выполнять вычисления во время рассылки MPI_Bcast

Прямой ход метода Гаусса с конвейеризацией
Матрица a, n × n1 n
113
P3
P2
P1
P4
0
1
2
3
45
6
7
8

Прямой ход метода Гаусса с конвейеризацией
Матрица a, n × n1 n
114
P3
P2
P1
P4
строка 0
0
1
2
3
45
6
7
8

Прямой ход метода Гаусса с конвейеризацией
Матрица a, n × n1 n
115
P3
P2
P1
P4
строка 1
0
1
2
3
45
6
7
8
строка 0
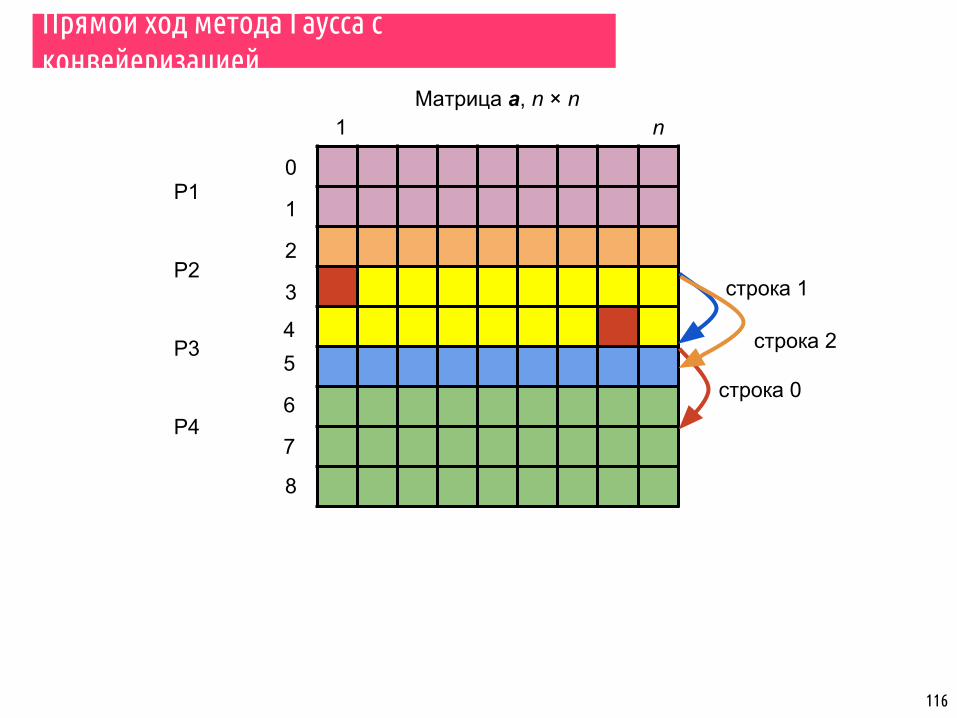
Прямой ход метода Гаусса с конвейеризацией
Матрица a, n × n1 n
116
P3
P2
P1
P4
0
1
2
3
45
6
7
8
строка 0
строка 1
строка 2

Прямой ход метода Гаусса с конвейеризацией
Матрица a, n × n1 n
117
P3
P2
P1
P4
0
1
2
3
45
6
7
8
строка 1
строка 2
строка 3
строка 4

Метод Якоби решения разреженных СЛАУ
118
Матрица a, n × n
n
1 n
b xk
P3
P2
P1
xk+1
Матрица разреженная, главная диагональ ненулевая

Метод сопряжённых градиентов решения СЛАУ
119
▪ Матрица A называется симметричной (symmetric), если
aij = aji
▪ Матрица A называется положительно определённой (positive definite), если для каждого ненулевого вектора x и его транспонированного вектора xT, произведение xTAx > 0.
▪ Матрица называется ленточной (band matrix) с параметром b, если все её элементы находятся на главной диагонали и на b ближайших к ней диагоналях.
Если матрица симметрична и положительна определена, то функция
q(x) = ½ * xTAx - xTb + c
имеет единственное значение вектора x, при котором значение функции минимально. Этот вектор x является решением уравнения Ax = b.

Метод сопряжённых градиентов решения СЛАУ
120
Итерации метода сопряжённого градиента:
x(t) = x(t – 1) + s(t) d(t)
Т.е. новое значение x – это функция от старого значения x, скалярного шага s и вектора направления d.
В начале итераций x(0), d(0) – нулевые векторы, g(0) проинициализирован –b.
Алгоритм:
1. Расчитать градиентg(t) = Ax(t – 1) – b
2. Вычислить вектор направления
d(t) = – g(t) + (g(t)T g(t)) * d(t – 1) / (g(t – 1)T g(t – 1))
где g(t)T g(t) – скалярное произведение транспонированного вектора g(t) и вектора g(t).
3. Вычислить размер шага
s(t) = – (d(t)T g(t)) / (d(t)T Ad(t))
4. Расчитать новое приближенное значение x
x(t) = x(t – 1) + s(t) d(t)

Метод сопряжённых градиентов решения СЛАУ
121
for i = 0 to n – 1 do d[i] = x[i] = 0 g[i] = -b[i]
for j = 1 to n do d1 = inner_product(g, g) g = matrix_vector_product(A, x)
for i = 0 to n - 1 do g[i] = g[i] - b[i] n1 = inner_product(g, g)
if n1 < eps break
for i = 0 to n - 1 d[i] = -g[i] + (n1 / d1) * d[i]
n2 = inner_product(d, g) t = matrix_vector_product(A, d) d2 = inner_product(d, t) s = -n2 / d2
for i = 0 to n - 1 x[i] = x[i] + s * d[i]

122
Ленточная матрица a, 7 × 7, b = 2
1 n
P3
P2
P1
Хранение ленточной матрицы
a11 a12 a13
a21 a22 a23 a24
a31 a32 a33 a34 a35
a42 a43 a44 a45 a46
a53 a54 a55 a56 a57
a64 a65 a66 a67
a75 a76 a77
1 b * 2+ 1
a11 a12 a13
a21 a22 a23 a24
a31 a32 a33 a34 a35
a42 a43 a44 a45 a46
a53 a54 a55 a56 a57
a64 a65 a66 a67
a75 a76 a77n n
Хранение ленточной матрицы





























