Embed Size (px)
Citation preview

Demand-Based Coordinated Scheduling for SMP VMs
Hwanju Kim1, Sangwook Kim2, Jinkyu Jeong1, Joonwon Lee2, and Seungryoul Maeng1
Korea Advanced Institute of Science and Technology (KAIST)1
Sungkyunkwan University2
The 18th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
Houston, Texas, March 16-20 2013
1

Software Trends in Multi-core Era
• Making the best use of HW parallelism
• Increasing “thread-level parallelism”
HW
SW
“Convergence of Recognition, Mining, and Synthesis Workloads and Its Implications”, Proceedings of IEEE, 2008
Processor
OS
App App App
Apps increasingly being multithreadedRMS apps are “emerging killer apps”
Processors increasingly adding more cores
2/28

Software Trends in Multi-core Era
• Synchronization (communication)
• The greatest obstacle to the performance of multithreaded workloads
HW
SW
Processor
OS
App App App
Barrier
Barrier
Thread
Lock wait
SpinlockSpinwait
CPU
3/28
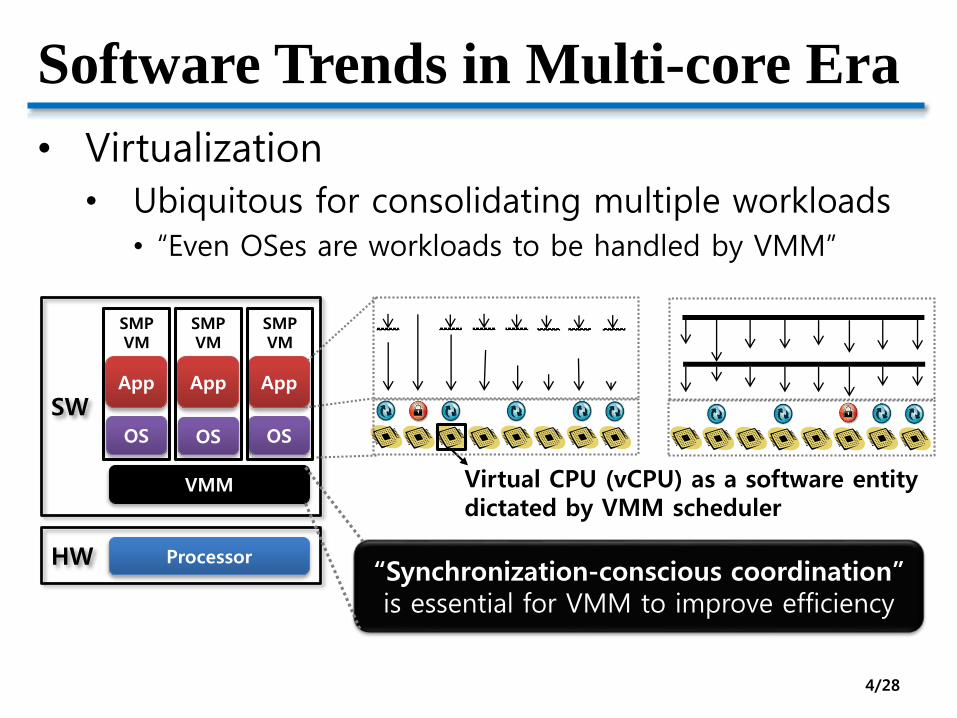
Software Trends in Multi-core Era
• Virtualization
• Ubiquitous for consolidating multiple workloads• “Even OSes are workloads to be handled by VMM”
HW
SW
Processor
OS
App App App
OS OS
VMM
SMPVM
SMPVM
SMPVM
“Synchronization-conscious coordination” is essential for VMM to improve efficiency
Virtual CPU (vCPU) as a software entity dictated by VMM scheduler
4/28
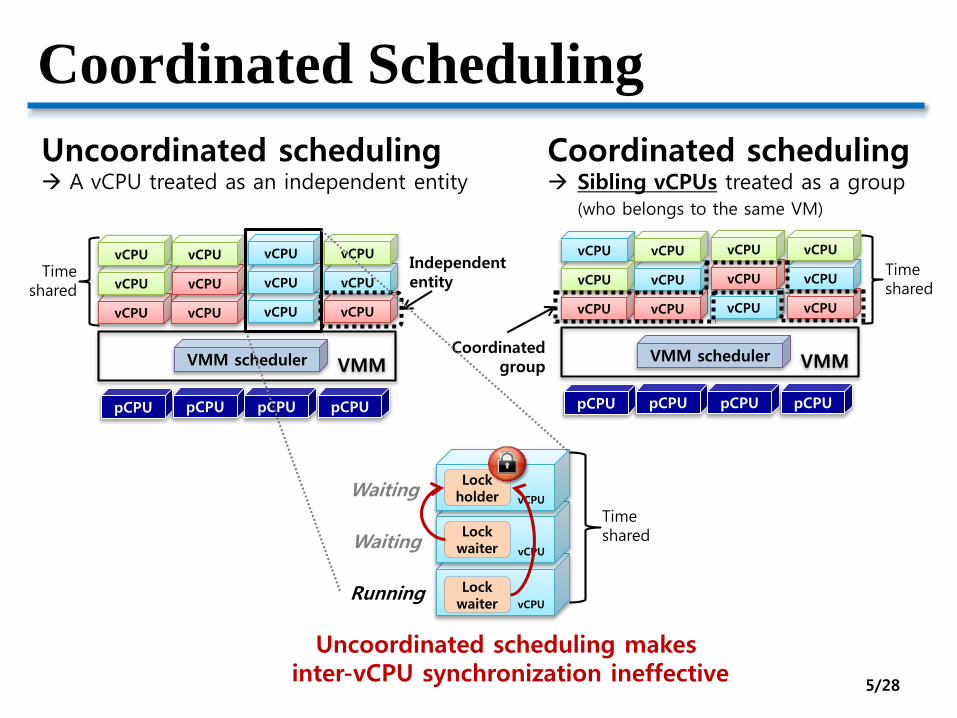
Coordinated Scheduling
vCPU
VMM scheduler VMM
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
Timeshared
Uncoordinated scheduling A vCPU treated as an independent entity
Independententity
vCPU
VMM scheduler VMM
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
Coordinated scheduling Sibling vCPUs treated as a group
(who belongs to the same VM)
Coordinatedgroup
vCPU
vCPU
vCPU
Timeshared
Lock holder
Lock waiter
Lock waiter
Running
Waiting
Waiting
Uncoordinated scheduling makes inter-vCPU synchronization ineffective
Timeshared
5/28

Prior Efforts for CoordinationCoscheduling [Ousterhout82]
: Synchronizing execution
Time
pCPU
pCPU
pCPU
pCPU
vCPU execution
Illusion of dedicated multi-core,but CPU fragmentation
Relaxed coscheduling [VMware10]
: Balancing execution time
Time
pCPU
pCPU
pCPU
pCPU
Stop execution for siblings to catch up
Good CPU utilization & coordination,but not based on synchronization demands
Time
pCPU
pCPU
pCPU
pCPU
Balance scheduling [Sukwong11]
: Balancing pCPU allocation
Good CPU utilization & coordination,but not based on synchronization demands
Selective coscheduling [Weng09,11]…
: Coscheduling selected vCPUs
Time
pCPU
pCPU
pCPU
pCPU
Better coordination through explicit information,but relying on user or OS support
Selected vCPUs
Need for VMM scheduling based on synchronization (coordination) demands
6/28

Overview
• Demand-based coordinated scheduling
• Identifying synchronization demands
• With non-intrusive design
• Not compromising inter-VM fairness
Time
pCPU
pCPU
pCPU
pCPU
Demand of coscheduling for synchronization
Demand of delayed preemption for synchronization
Preemptionattempt
7/28

Coordination Space
• Time and space domains
• Independent scheduling decision for each domain
SpaceWhere to schedule?
TimeWhen to schedule?
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
CoordinatedgroupPreemptive scheduling policy
Coscheduling Delayed preemption
pCPU assignment policy
8/28

Outline
• Motivation
• Coordination in time domain
• Kernel-level coordination demands
• User-level coordination demands
• Coordination in space domain
• Load-conscious balance scheduling
• Evaluation
vCPU
pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
Space
Time
9/28

Synchronization to be Coordinated
• Synchronization based on “busy-waiting”
• Unnecessary CPU consumption by busy-waiting for a descheduled vCPU• Significant performance degradation
• Semantic gap• “OSes make liberal use of busy-waiting (e.g., spinlock)
since they believe their vCPUs are dedicated”
Serious problem in kernel
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
• When and where to demand synchronization?
• How to identify coordination demands?
10/28

Kernel-Level Coordination Demands
• Does kernel really need coordination?
• Experimental analysis• Multithreaded applications in the PARSEC suite
• Measuring “kernel time” when uncoordinated
Solorun (no consolidation) Corun (w/ 1 VM running streamcluster)A 8-vCPU VM on 8 pCPUs
0%
20%
40%
60%
80%
100%
bla
cksc
hole
s
bodyt
rack
canneal
dedup
face
sim
ferr
et
fluid
anim
ate
freqm
ine
rayt
race
stre
am
clust
er
swaptions
vips
x264
CPU
tim
e (
%)
Kernel time User time
0%
20%
40%
60%
80%
100%
bla
cksc
hole
s
bodyt
rack
canneal
dedup
face
sim
ferr
et
fluid
anim
ate
freqm
ine
rayt
race
stre
am
clust
er
swaptions
vips
x264
CPU
tim
e (
%)
Kernel time User timeKernel time ratio is largely amplified by x1.3-x30 “Newly introduced kernel-level contention”
11/28
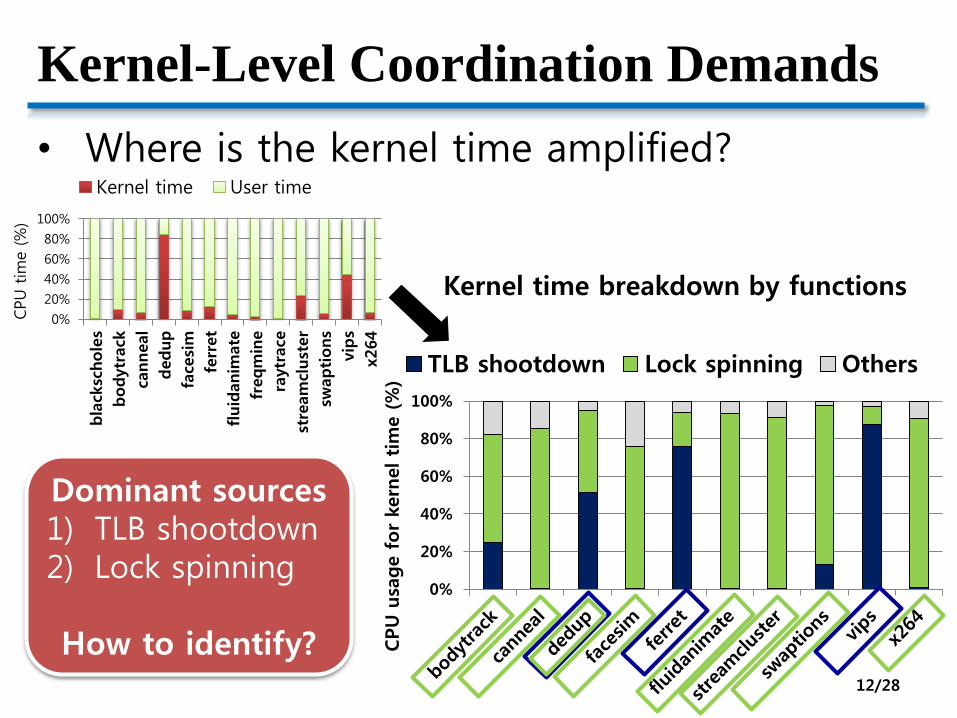
Kernel-Level Coordination Demands
• Where is the kernel time amplified?
0%
20%
40%
60%
80%
100%
bla
cksc
hole
s
bodytr
ack
canneal
dedup
face
sim
ferr
et
fluid
anim
ate
freqm
ine
raytr
ace
stre
am
clust
er
swaptions
vip
s
x264
CPU tim
e (%
)
Kernel time User time
0%
20%
40%
60%
80%
100%CPU
usa
ge f
or
kern
el tim
e (
%)
TLB shootdown Lock spinning Others
Kernel time breakdown by functions
Dominant sources1) TLB shootdown2) Lock spinning
How to identify?12/28
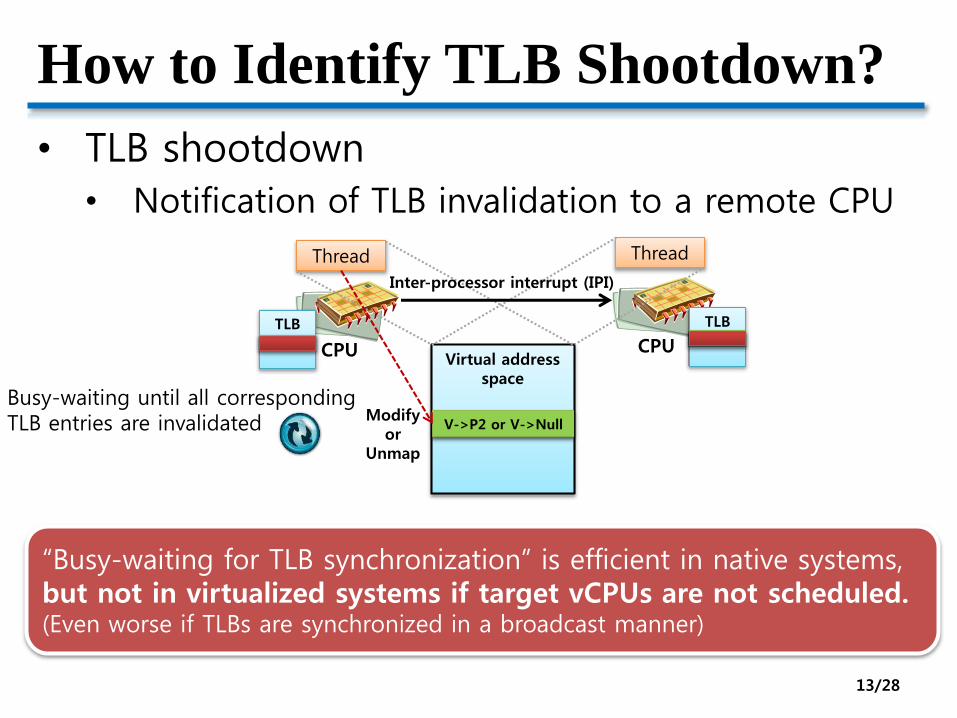
How to Identify TLB Shootdown?
• TLB shootdown
• Notification of TLB invalidation to a remote CPU
CPU
Thread
CPU
Thread
Virtual address space
TLB TLB
V->P1
V->P1
V->P1
V->P2 or V->NullModify
orUnmap
Inter-processor interrupt (IPI)
Busy-waiting until all correspondingTLB entries are invalidated
“Busy-waiting for TLB synchronization” is efficient in native systems,but not in virtualized systems if target vCPUs are not scheduled.(Even worse if TLBs are synchronized in a broadcast manner)
13/28

How to Identify TLB Shootdown?
• TLB shootdown IPI
• Virtualized by VMM
• Used in x86-based Windows and Linux
0%
20%
40%
60%
80%
100%
bodytr
ack
canneal
dedup
face
sim
ferr
et
fluid
ani…
stre
am
cl…
swaptions
vip
s
x264
CPU
usa
ge for
kern
el tim
e (
%)
TLB shootdown Lock spinning Others
0
500
1000
1500
2000
bodytr
ack
canneal
dedup
face
sim
ferr
et
fluid
anim
…
stre
am
clu…
swaptions
vip
s
x264
# o
f IP
Is /
vCPU
/
sec
“A TLB shootdown IPI is a signal for coordination demand!” Co-schedule IPI-recipient vCPUs with its sender vCPU
TLB shootdown IPI traffic
14/28

How to Identify Lock Spinning?
• Why excessive lock spinning?
• “Lock-holder preemption (LHP)”• Short critical section can be unpredictably prolonged by
vCPU preemption
• Which spinlock is problematic?vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
0%
20%
40%
60%
80%
100%
Lock
wait t
ime (%
) Other locks
Runqueue lock
Pagetable lock
Semaphore wait-queue lock
Futex wait-queue lock
Spinlockwait time
breakdown82%
93%
15/28
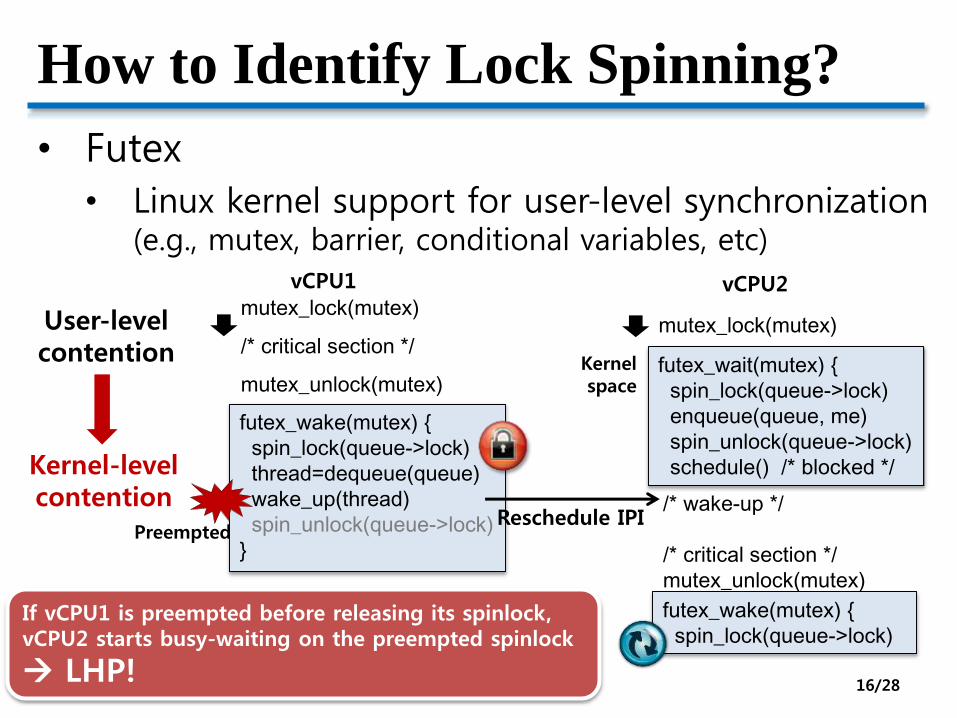
How to Identify Lock Spinning?
• Futex
• Linux kernel support for user-level synchronization (e.g., mutex, barrier, conditional variables, etc)
mutex_lock(mutex)
/* critical section */
mutex_unlock(mutex)
futex_wake(mutex) {
spin_lock(queue->lock)
thread=dequeue(queue)
wake_up(thread)
spin_unlock(queue->lock)
}
mutex_lock(mutex)
futex_wait(mutex) {
spin_lock(queue->lock)
enqueue(queue, me)
spin_unlock(queue->lock)
schedule() /* blocked */
vCPU1 vCPU2
/* wake-up */
/* critical section */
mutex_unlock(mutex)
futex_wake(mutex) {
spin_lock(queue->lock)
Reschedule IPI
User-levelcontention
Kernel-levelcontention
If vCPU1 is preempted before releasing its spinlock,vCPU2 starts busy-waiting on the preempted spinlock
LHP!
Kernelspace
16/28
Preempted
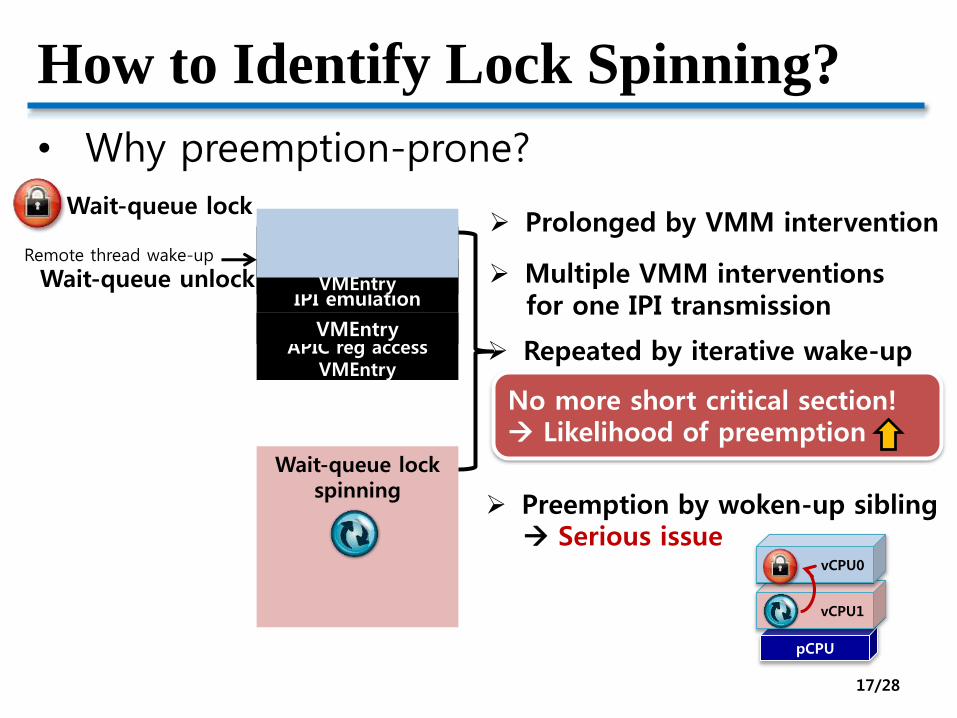
How to Identify Lock Spinning?
• Why preemption-prone?
pCPU
vCPU1
vCPU0
VMExit
IPI emulation
Wait-queue lock
VMExitAPIC reg access
VMEntry
VMExitAPIC reg access
VMEntry
Wait-queue unlock
VMEntry
Wait-queue lockspinning
Prolonged by VMM intervention
Multiple VMM interventionsfor one IPI transmission
Repeated by iterative wake-up
No more short critical section! Likelihood of preemption
Preemption by woken-up sibling Serious issue
Remote thread wake-up
17/28

How to Identify Lock Spinning?
• Generalization: “Wait-queue locks”
• Not limited to futex wake-up
• Many wake-up functions in the Linux kernel• General wake-up
• __wake_up*()
• Semaphore or mutex unlock
• rwsem_wake(), __mutex_unlock_common_slowpath(), …
• “Multithreaded workloads usually communicate and synchronize on wait-queues”
“A Reschedule IPI is a signal for coordination demand!”Delay preemption of an IPI-sender vCPU
until a likely-held spinlock is released
18/28

Outline
• Motivation
• Coordination in time domain
• Kernel-level coordination demands
• User-level coordination demands
• Coordination in space domain
• Load-conscious balance scheduling
• Evaluation
vCPU
pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
Space
Time
19/28
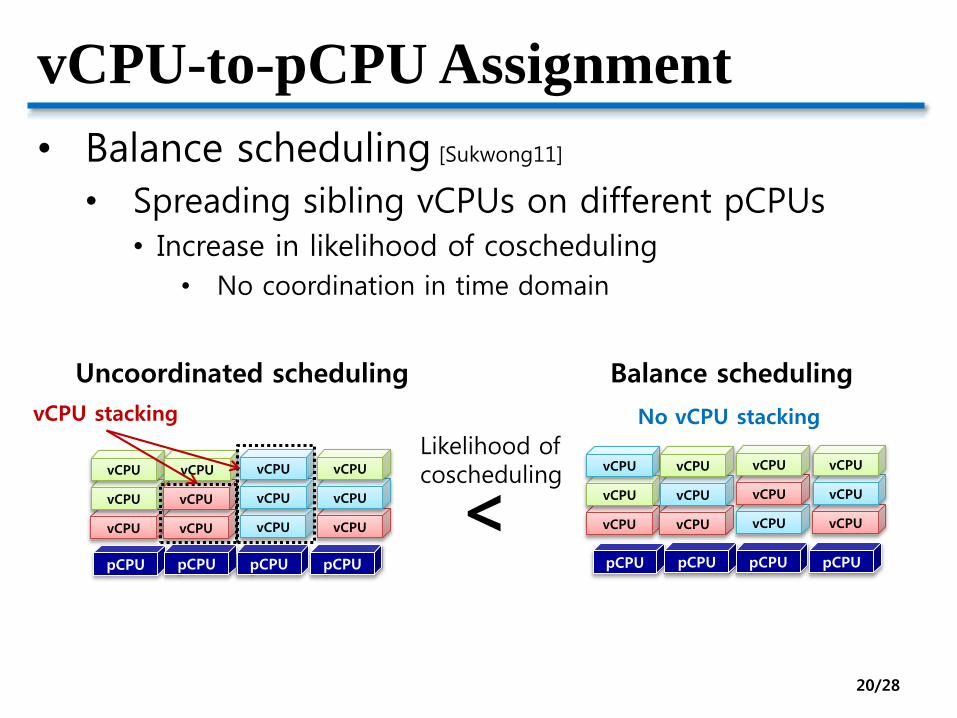
vCPU-to-pCPU Assignment
• Balance scheduling [Sukwong11]
• Spreading sibling vCPUs on different pCPUs• Increase in likelihood of coscheduling
• No coordination in time domain
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
pCPU pCPU pCPU pCPU
Uncoordinated scheduling Balance scheduling
vCPU stacking
Likelihood of coscheduling
<
No vCPU stacking
20/28

vCPU-to-pCPU Assignment
• Balance scheduling [Sukwong11]
• Limitation• Based on “global CPU loads are well balanced”
• In practice, VMs with fair CPU shares can have
vCPU vCPU
vCPU
vCPU vCPU
x4 shares
SMP VM
UP VM
vCPU vCPU
vCPU
vCPU vCPUSMP VM
SMP VM
Inactive vCPUs
Single-threaded workload
Multithreaded workload
Different # of vCPUs Different TLP
0
200
400
600
800
5 15 25 35 45 55 65 75 85 95CPU
usa
ge (
%)
Time (sec)
canneal
0
200
400
600
800
1 4 7 10 13 16 19 22CPU
usa
ge (
%)
Time (sec)
dedupTLP can be changed
in a multithreaded app
TLP: Thread-level parallelism
pCPU pCPU
vCPUvCPU
pCPU pCPU
vCPU vCPU
vCPU vCPU
High scheduling latency
Balance scheduling on imbalanced loads
21/28

Proposed Scheme
• Load-conscious balance scheduling
• Adaptive scheme based on pCPU loads
• When assigning a vCPU, check pCPU loads
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
If load is balanced Balance scheduling
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPUvCPU vCPU
vCPU
If load is imbalanced Favoring underloaded pCPUs
CPU load > Avg. CPU load
overloaded
Handled by coordinationin time domain
22/28

Outline
• Motivation
• Coordination in time domain
• Kernel-level coordination demands
• User-level coordination demands
• Coordination in space domain
• Load-conscious balance scheduling
• Evaluation
23/28

Evaluation
• Implementation
• Based on Linux KVM and CFS
• Evaluation
• Effective time slice• For coscheduling & delayed preemption
• 500us decided by sensitive analysis
• Performance improvement
• Alternative• OS re-engineering
24/28
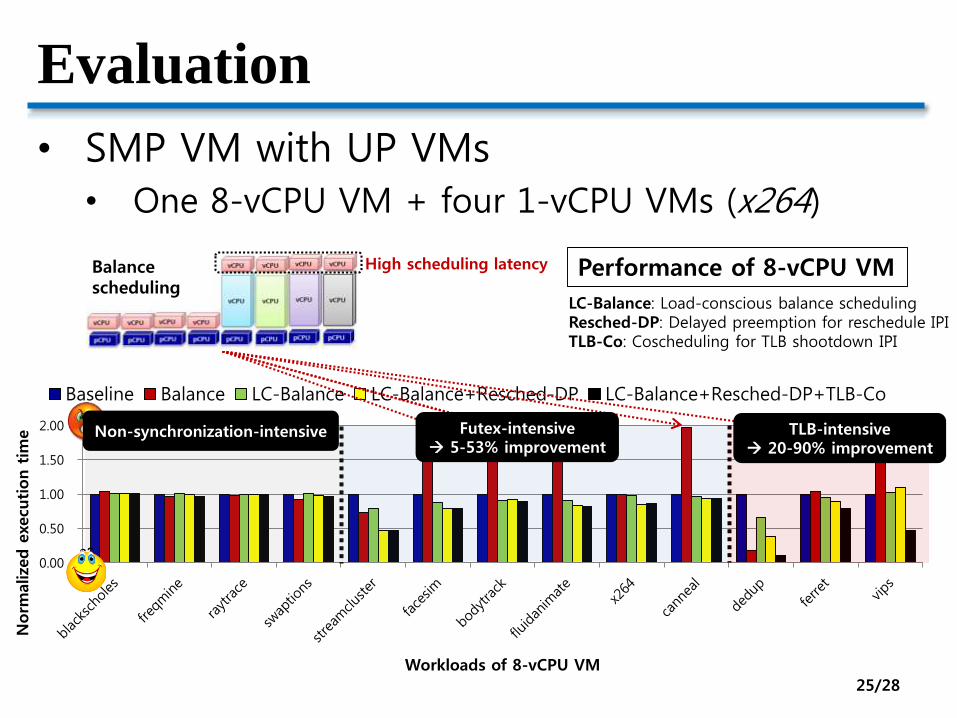
Evaluation
• SMP VM with UP VMs
• One 8-vCPU VM + four 1-vCPU VMs (x264)
0.00
0.50
1.00
1.50
2.00
Norm
alize
d e
xecu
tion t
ime
Workloads of 8-vCPU VM
Baseline Balance LC-Balance LC-Balance+Resched-DP LC-Balance+Resched-DP+TLB-Co
Futex-intensive 5-53% improvement
TLB-intensive 20-90% improvement
Performance of 8-vCPU VM
LC-Balance: Load-conscious balance schedulingResched-DP: Delayed preemption for reschedule IPITLB-Co: Coscheduling for TLB shootdown IPI
Non-synchronization-intensive
25/28
High scheduling latencyBalancescheduling

Alternative: OS Re-engineering
• Virtualization-friendly re-engineering
• Decoupling reschedule IPI transmission from thread wake-up
wake_up (queue) {
spin_lock(queue->lock)
thread=dequeue(queue)
wake_up(thread)
spin_unlock(queue->lock)
}
Reschedule IPI
Delayed reschedule IPI transmission
• Modified wake_up func• Using per-cpu bitmap• Applied to futex_wakeup
& futex_requeue
One 8-vCPU VM + four 1-vCPU VMs (x264)
Delayed reschedule IPI is virtualization-friendly to resolve LHP problems
26/28
0.00
0.20
0.40
0.60
0.80
1.00
1.20
facesim streamcluster
Norm
alize
d e
xecu
tion t
ime
Baseline
Baseline w/ DelayedResched
LC_Balance
LC_Balance w/ DelayedResched
LC_Balance w/ Resched-DP
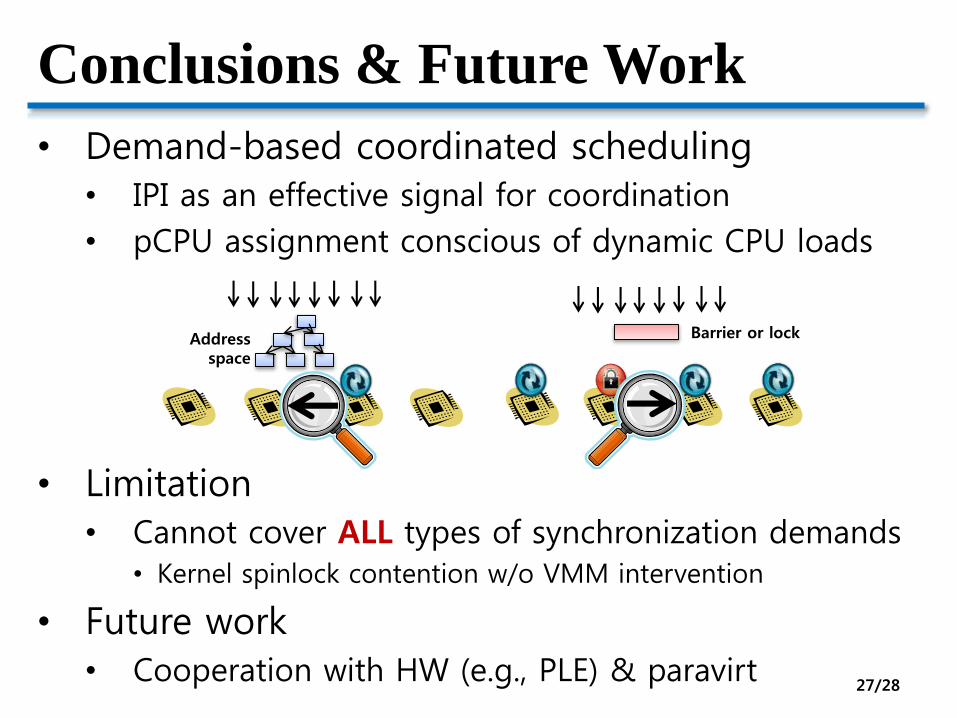
Conclusions & Future Work
• Demand-based coordinated scheduling
• IPI as an effective signal for coordination
• pCPU assignment conscious of dynamic CPU loads
• Limitation
• Cannot cover ALL types of synchronization demands• Kernel spinlock contention w/o VMM intervention
• Future work
• Cooperation with HW (e.g., PLE) & paravirt
Barrier or lock
27/28
Addressspace
Thank You!
• Questions and comments
• Contacts
• http://calab.kaist.ac.kr/~hjukim
28/28

EXTRA SLIDES
29
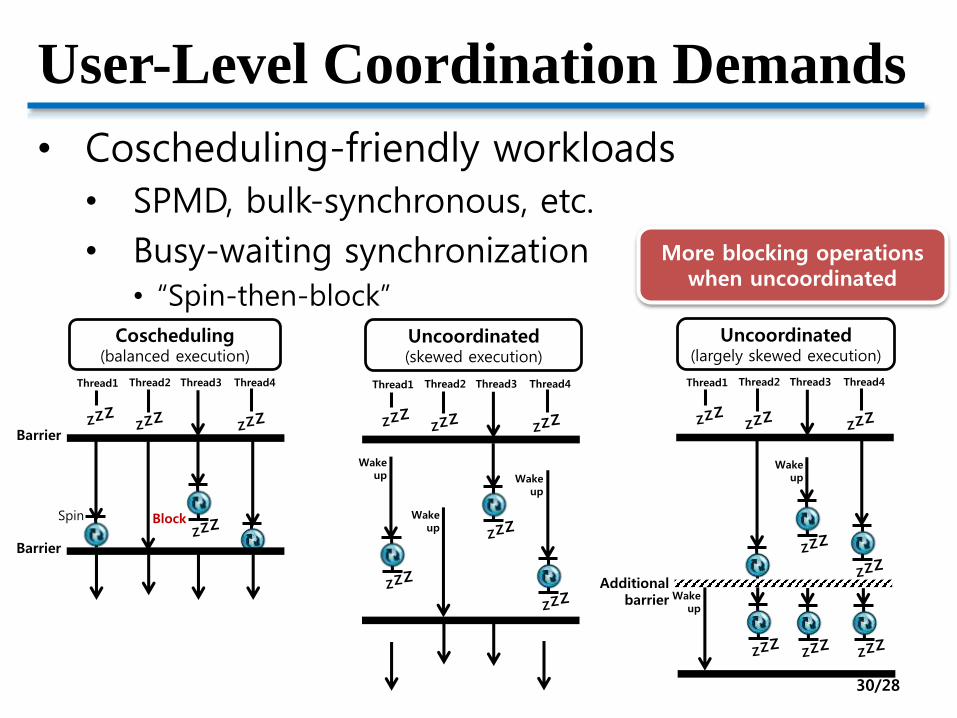
User-Level Coordination Demands
• Coscheduling-friendly workloads
• SPMD, bulk-synchronous, etc.
• Busy-waiting synchronization• “Spin-then-block”
Barrier
Barrier
Thread1 Thread2 Thread3 Thread4
Wakeup
Wakeup
Wakeup
Wakeup
Additionalbarrier
Thread1 Thread2 Thread3 Thread4 Thread1 Thread2 Thread3 Thread4
Wakeup
Coscheduling(balanced execution)
Uncoordinated(largely skewed execution)
Uncoordinated(skewed execution)
More blocking operations when uncoordinated
Spin Block
30/28

User-Level Coordination Demands
• Coscheduling
• Avoiding more expensive blocking in a VM• VMExits for CPU yielding and wake-up
• Halt (HLT) and Reschedule IPI
• When to coschedule?• User-level synchronization involves reschedule IPIs
Providing a knob to selectively enable this coscheduling for coscheduling-friendly VMs
Reschedule IPI traffic of streamcluster
Barriers Barriers Barriers Barriers Barriers Barriers“A Reschedule IPI is a signal for coordination demand!”Co-schedule IPI-recipient vCPUs with a sender vCPU
31/28

Urgent vCPU First (UVF) Scheduling
• Urgent vCPU
• 1. Preemptively scheduled if fairness is kept
• 2. Protected from preemption once scheduled• During “Urgent time slice (utslice)”
pCPU
vCPU vCPU vCPU
Urgent queue Runqueue
vCPU
pCPU
vCPU vCPU vCPUvCPU
FIFO order Proportional shares order
vCPU : urgent vCPU
vCPU vCPU
Wait queue
If inter-VM fairness is kept
Coscheduled
Protected frompreemption
32/28
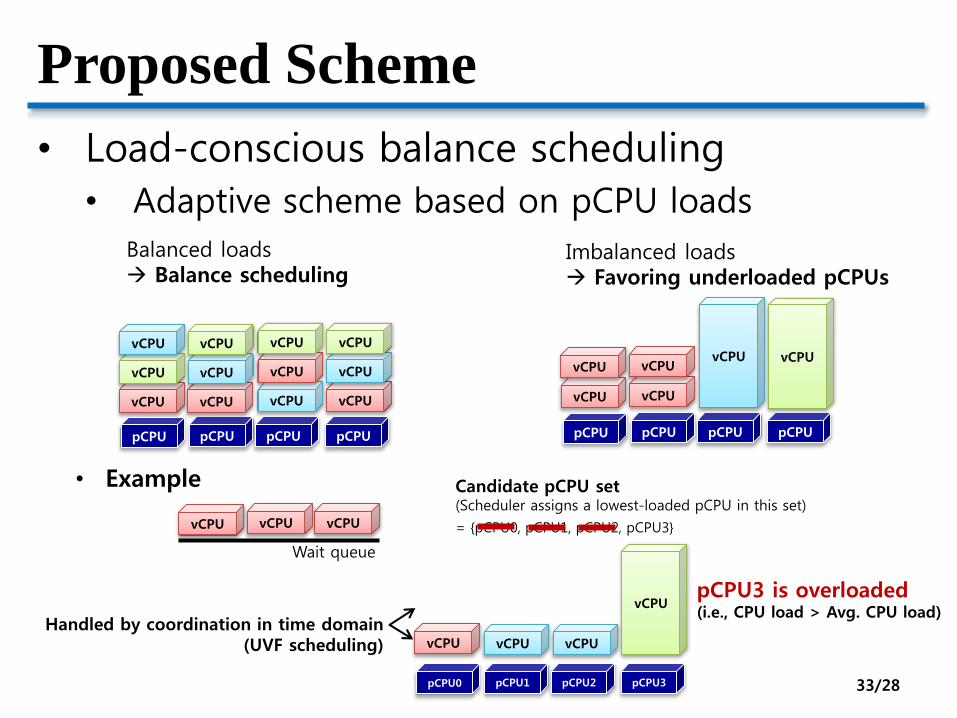
Proposed Scheme
• Load-conscious balance scheduling
• Adaptive scheme based on pCPU loads
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
vCPU
Balanced loads Balance scheduling
vCPU
pCPU pCPU pCPU pCPU
vCPU
vCPUvCPU vCPU
vCPU
Imbalanced loads Favoring underloaded pCPUs
vCPU
pCPU0 pCPU1 pCPU2 pCPU3
vCPU
vCPU vCPU
Wait queue
• Example
vCPUvCPU vCPU
Candidate pCPU set(Scheduler assigns a lowest-loaded pCPU in this set)
= {pCPU0, pCPU1, pCPU2, pCPU3}
pCPU3 is overloaded(i.e., CPU load > Avg. CPU load)
Handled by coordination in time domain(UVF scheduling)
33/28

Evaluation
• Urgent time slice (utslice)
• 1. Utslice for reducing LHP
• 2. Utslice for quickly serving multiple urgent vCPUs
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 300 500 700 1000
# o
f fu
tex q
ueue L
HP
Utslice (usec)
bodytrack
facesim
streamcluster
Workloads:A futex-intensive workload in one VM+ dedup in another VM as a preempting VM
>300us utslice2x-3.8x LHP reduction
Remaining LHPs occur during local wake-up orbefore reschedule IPI transmission Unlikely lead to lock contention
34/28

Evaluation
• Urgent time slice (utslice)
• 1. utslice for reducing LHP
• 2. utslice for quickly serving multiple urgent vCPUs
30
35
40
45
50
55
60
0
2
4
6
8
10
12
14
16
100 500 1000 3000 5000
Avera
ge e
xecu
tion t
ime (se
c)
CPU
cycl
es
(%)
Utslice (usec)
Spinlock cycles (%)
TLB cycles (%)
Execution time (sec)
Workloads:3 VMs, each of which runs vips(vips - TLB-IPI-intensive application)
As utslice increases, TLB shootdown cycles increase
500usec is an appropriate utslice for bothLHP reduction and multiple urgent vCPUs
~11% degradation
35/28
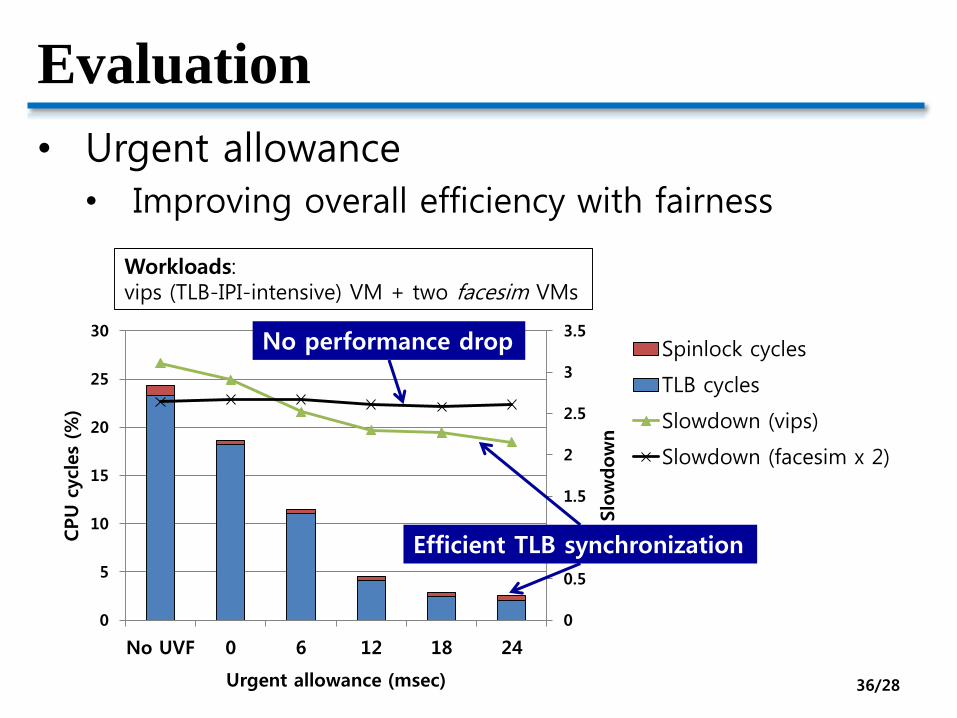
Evaluation
• Urgent allowance
• Improving overall efficiency with fairness
0
0.5
1
1.5
2
2.5
3
3.5
0
5
10
15
20
25
30
No UVF 0 6 12 18 24
Slo
wdow
n
CPU
cycl
es
(%)
Urgent allowance (msec)
Spinlock cycles
TLB cycles
Slowdown (vips)
Slowdown (facesim x 2)
Workloads:vips (TLB-IPI-intensive) VM + two facesim VMs
Efficient TLB synchronization
No performance drop
36/28

Evaluation
• Impact of kernel-level coordination
• One 8-vCPU VM + four 1-vCPU VMs (x264)
0.00
0.50
1.00
1.50
Norm
alize
d e
xecu
tion t
ime
Co-running workloads with 1-vCPU VM (x264)
Baseline Balance LC-Balance LC-Balance+Resched-DP LC-Balance+Resched-DP+TLB-Co
Performance of 1-vCPU VM
LC-Balance: Load-conscious balance schedulingResched-DP: Delayed preemption for reschedule IPITLB-Co: Coscheduling for TLB shootdown IPI
Unfaircontention
Balancescheduling
Balance scheduling Up to 26% degradation
37/28
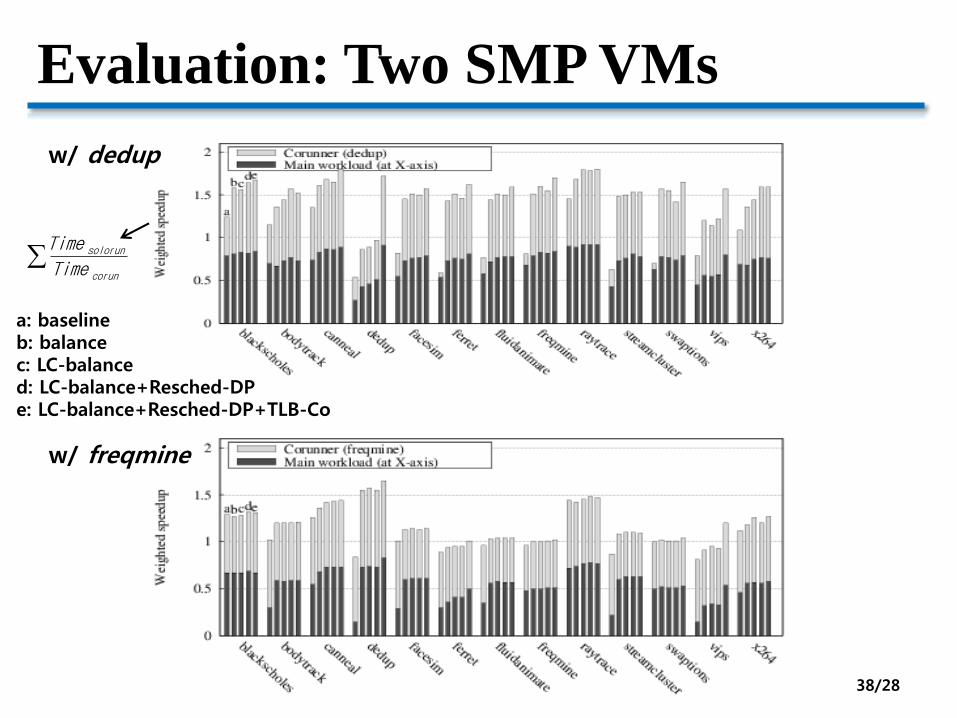
Evaluation: Two SMP VMs
w/ dedup
w/ freqmine
a: baselineb: balancec: LC-balanced: LC-balance+Resched-DPe: LC-balance+Resched-DP+TLB-Co
corun
solorun
Time
Time
38/28
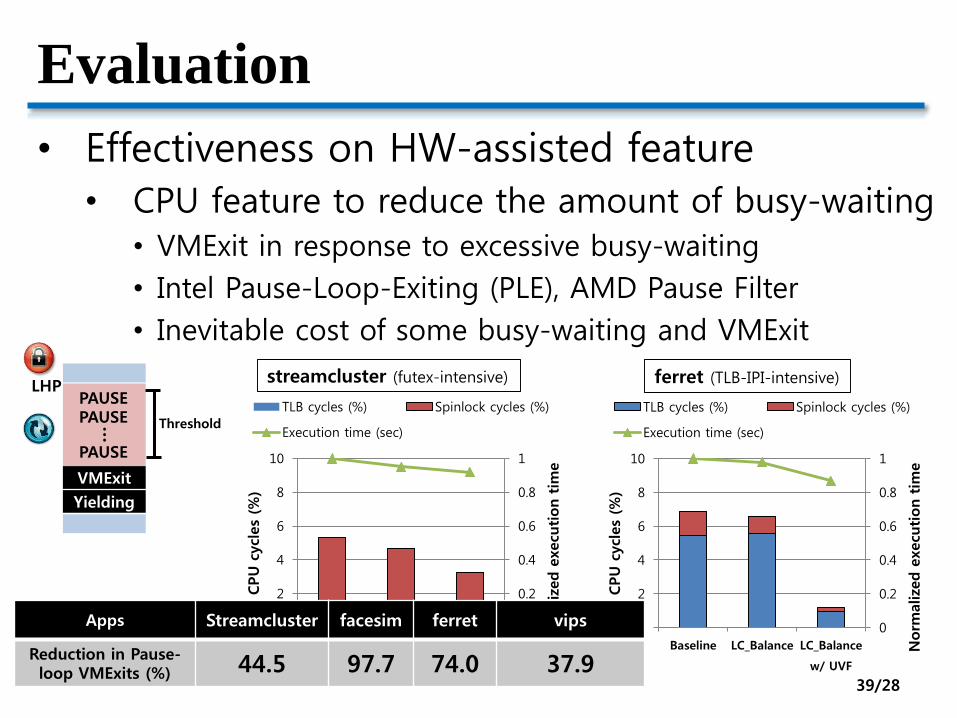
Evaluation
• Effectiveness on HW-assisted feature
• CPU feature to reduce the amount of busy-waiting• VMExit in response to excessive busy-waiting
• Intel Pause-Loop-Exiting (PLE), AMD Pause Filter
• Inevitable cost of some busy-waiting and VMExit
LHPPAUSEPAUSE
PAUSE
… Threshold
VMExit
Yielding
0
0.2
0.4
0.6
0.8
1
0
2
4
6
8
10
Baseline LC_Balance LC_Balance
w/ UVF
Norm
alize
d e
xecu
tion t
ime
CPU
cycl
es
(%)
TLB cycles (%) Spinlock cycles (%)
Execution time (sec)
0
0.2
0.4
0.6
0.8
1
0
2
4
6
8
10
Baseline LC_Balance LC_Balance
w/ UVF
Norm
alize
d e
xecu
tion t
ime
CPU
cycl
es
(%)
TLB cycles (%) Spinlock cycles (%)
Execution time (sec)
streamcluster (futex-intensive) ferret (TLB-IPI-intensive)
Apps Streamcluster facesim ferret vips
Reduction in Pause-loop VMExits (%) 44.5 97.7 74.0 37.9
39/28
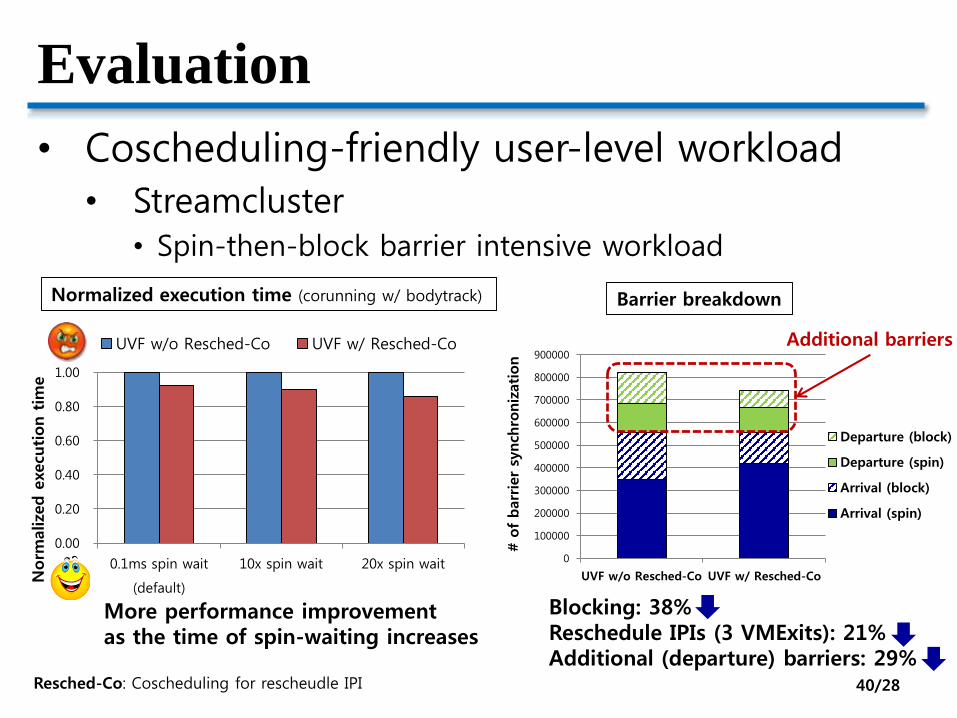
Evaluation
• Coscheduling-friendly user-level workload
• Streamcluster• Spin-then-block barrier intensive workload
0
100000
200000
300000
400000
500000
600000
700000
800000
900000
UVF w/o Resched-Co UVF w/ Resched-Co
# o
f barr
ier
synch
roniz
ation
Departure (block)
Departure (spin)
Arrival (block)
Arrival (spin)
More performance improvementas the time of spin-waiting increases
Blocking: 38%Reschedule IPIs (3 VMExits): 21%Additional (departure) barriers: 29%
Normalized execution time (corunning w/ bodytrack)
Additional barriers
Barrier breakdown
Resched-Co: Coscheduling for rescheudle IPI
0.00
0.20
0.40
0.60
0.80
1.00
0.1ms spin wait
(default)
10x spin wait 20x spin wait
Norm
alize
d e
xecu
tion t
ime
UVF w/o Resched-Co UVF w/ Resched-Co
40/28





























