Embed Size (px)
DESCRIPTION
医学生物学研究で用いる傾向スコアマッチと多重補完法をできるだけやさしく解説しています。
Citation preview

Propensity score matching after multiple imputation
25th July, 2014
Atsushi Shiraishi, MDTrauma and Emergency Medical Center, Tokyo Medical and Dental University

データ欠損があったらどうなるか
• 配布した “ PSM2.R” をエディタで開いて下さい
• 丸ごと R のコンソールに貼り付け、リターンを押して実行して下さい。
• オリジナルデータセットでの PSM と、ランダムに 10% の欠損値を作ったデータセットでの PSM を出力します。

After PSM ( 欠損値なし )
Stratified by treat 0 1 p test n 150 150 age (mean (sd)) 25.41 (6.86) 25.48 (7.29) 0.929 educ (mean (sd)) 10.11 (1.67) 10.29 (1.77) 0.349 black (mean (sd)) 0.87 (0.33) 0.87 (0.34) 0.864 hisp (mean (sd)) 0.05 (0.23) 0.06 (0.24) 0.804 married (mean (sd)) 0.18 (0.39) 0.16 (0.37) 0.646 nodegr (mean (sd)) 0.81 (0.40) 0.77 (0.42) 0.399 re74 (mean (sd)) 1821.88 (4792.12) 1517.04 (4370.13) 0.565 re75 (mean (sd)) 1329.82 (3350.84) 914.13 (1943.45) 0.190 re78 (mean (sd)) 4064.76 (4568.86) 6149.53 (7960.04) 0.006 u74 (mean (sd)) 0.76 (0.43) 0.78 (0.42) 0.682 u75 (mean (sd)) 0.68 (0.47) 0.68 (0.47) 1.000

After PSM ( 欠損値あり )
Stratified by treat 0 1 p test n 36 36 age (mean (sd)) 24.69 (4.60) 24.94 (6.37) 0.849 educ (mean (sd)) 10.44 (1.40) 10.22 (1.91) 0.576 black (mean (sd)) 0.86 (0.35) 0.83 (0.38) 0.747 hisp (mean (sd)) 0.06 (0.23) 0.08 (0.28) 0.649 married (mean (sd)) 0.14 (0.35) 0.11 (0.32) 0.726 nodegr (mean (sd)) 0.78 (0.42) 0.72 (0.45) 0.592 re74 (mean (sd)) 2525.86 (6186.79) 1184.89 (3236.43) 0.253 re75 (mean (sd)) 1160.82 (3337.37) 761.30 (1286.41) 0.505 re78 (mean (sd)) 4705.77 (5523.46) 6854.06 (10779.25) 0.291 u74 (mean (sd)) 0.72 (0.45) 0.78 (0.42) 0.592 u75 (mean (sd)) 0.69 (0.47) 0.64 (0.49) 0.623

Rubin’s causal modelMultiple imputation も私が開発しました。
Donald Rubin (b 1943)

Multiple imputation
欠損値を代入したデータセットを複数作成し、その結果を統合することで欠損値データの統計的推測を行う方法である (Rubin 1987) 。
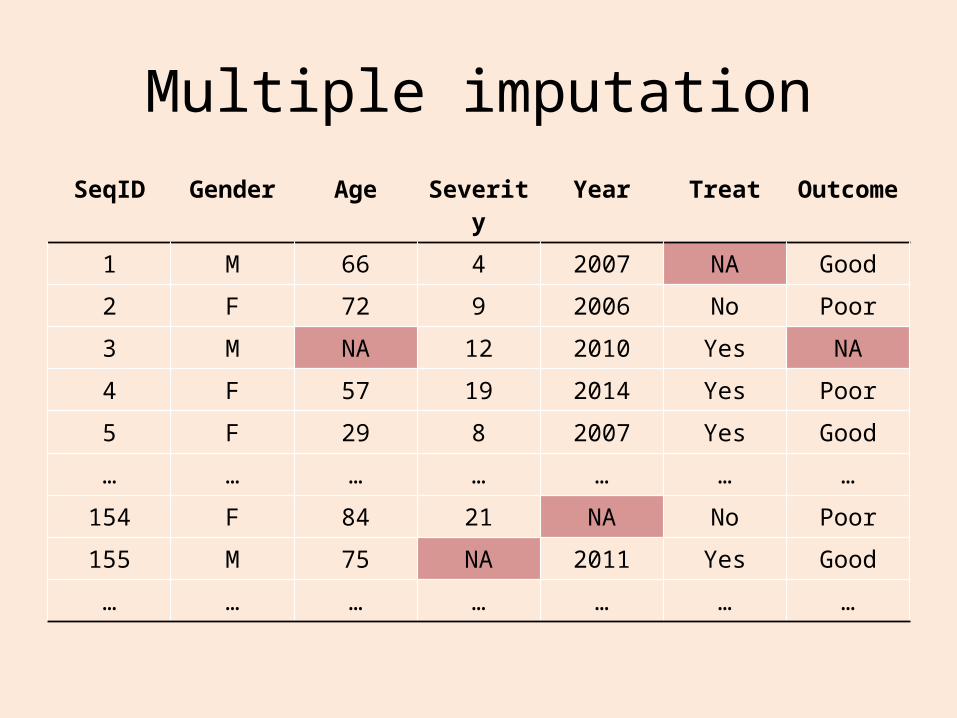
SeqID Gender Age Severity Year Treat Outcome
1 M 66 4 2007 NA Good
2 F 72 9 2006 No Poor
3 M NA 12 2010 Yes NA
4 F 57 19 2014 Yes Poor
5 F 29 8 2007 Yes Good
… … … … … … …
154 F 84 21 NA No Poor
155 M 75 NA 2011 Yes Good
… … … … … … …
Multiple imputation

SeqID Gender Age Severity Year Treat Outcome
1 M 66 4 2007 NA Good
2 F 72 9 2006 No Poor
3 M NA 12 2010 Yes NA
4 F 57 19 2014 Yes Poor
5 F 29 8 2007 Yes Good
… … … … … … …
154 F 84 21 NA No Poor
155 M 75 NA 2011 Yes Good
… … … … … … …
Multiple imputation

SeqID Gender Age Severity Year Treat Outcome
1 M 66 4 2007 NA Good
2 F 72 9 2006 No Poor
3 M NA 12 2010 Yes NA
4 F 57 19 2014 Yes Poor
5 F 29 8 2007 Yes Good
… … … … … … …
154 F 84 21 NA No Poor
155 M 75 NA 2011 Yes Good
… … … … … … …
分布に応じて、データセット数の値を乱数的に発生させる
重回帰分析などを用いて、値を予測する
Multiple imputation

Multiple imputation
欠損値を含むデータセッ
ト
データセット1
データセット2
データセットm
…
データセット1
データセット2
データセットm
…統合された解析結果

Multiple imputation
欠損値を含むデータセッ
ト
データセット1
データセット2
データセットm
…
データセット1
データセット2
データセットm
…統合された解析結果
m 個の補完済みデータセットを生
成

Multiple imputation
欠損値を含むデータセッ
ト
データセット1
データセット2
データセットm
…
データセット1
データセット2
データセットm
…統合された解析結果
m 個の補完済みデータセットを生
成
任意の統計解析

Multiple imputation
欠損値を含むデータセッ
ト
データセット1
データセット2
データセットm
…
データセット1
データセット2
データセットm
…統合された解析結果
m 個の補完済みデータセットを生
成
任意の統計解析
得られた統計量を統合(単純平均)

Multiple imputation
欠損値を含むデータセッ
ト
データセット1
データセット2
データセットm
…
データセット1
データセット2
データセットm
…統合された解析結果
m 個の補完済みデータセットを生
成
得られた統計量を統合(単純平均)
PSM の場合 PS を先に平均し マッチングを行い 統計解析を行う任意の統計解析

MI+PSM もやってみましょう
• 配布した “ PSM3.R” をエディタで開いて下さい• 丸ごと R のコンソールに貼り付け、リターンを
押して実行して下さい。• 以下の PSM を行います。
– オリジナルデータセットでの PSM– ランダムに 10% の欠損値を作ったデータ
セットでの PSM– 欠損値を多重補完したデータセットでの
PSM

After PSM ( 欠損値なし )
Stratified by treat 0 1 p test n 150 150 age (mean (sd)) 25.41 (6.86) 25.48 (7.29) 0.929 educ (mean (sd)) 10.11 (1.67) 10.29 (1.77) 0.349 black (mean (sd)) 0.87 (0.33) 0.87 (0.34) 0.864 hisp (mean (sd)) 0.05 (0.23) 0.06 (0.24) 0.804 married (mean (sd)) 0.18 (0.39) 0.16 (0.37) 0.646 nodegr (mean (sd)) 0.81 (0.40) 0.77 (0.42) 0.399 re74 (mean (sd)) 1821.88 (4792.12) 1517.04 (4370.13) 0.565 re75 (mean (sd)) 1329.82 (3350.84) 914.13 (1943.45) 0.190 re78 (mean (sd)) 4064.76 (4568.86) 6149.53 (7960.04) 0.006 u74 (mean (sd)) 0.76 (0.43) 0.78 (0.42) 0.682 u75 (mean (sd)) 0.68 (0.47) 0.68 (0.47) 1.000

After PSM ( 欠損値有り )
Stratified by treat 0 1 p test n 36 36 age (mean (sd)) 24.69 (4.60) 24.94 (6.37) 0.849 educ (mean (sd)) 10.44 (1.40) 10.22 (1.91) 0.576 black (mean (sd)) 0.86 (0.35) 0.83 (0.38) 0.747 hisp (mean (sd)) 0.06 (0.23) 0.08 (0.28) 0.649 married (mean (sd)) 0.14 (0.35) 0.11 (0.32) 0.726 nodegr (mean (sd)) 0.78 (0.42) 0.72 (0.45) 0.592 re74 (mean (sd)) 2525.86 (6186.79) 1184.89 (3236.43) 0.253 re75 (mean (sd)) 1160.82 (3337.37) 761.30 (1286.41) 0.505 re78 (mean (sd)) 4705.77 (5523.46) 6854.06 (10779.25) 0.291 u74 (mean (sd)) 0.72 (0.45) 0.78 (0.42) 0.592 u75 (mean (sd)) 0.69 (0.47) 0.64 (0.49) 0.623

After MI+PSM
Stratified by treat 0 1 p test n 139 139 age (mean (sd)) 25.58 (6.61) 26.02 (7.11) 0.588 educ (mean (sd)) 10.29 (1.70) 10.22 (1.94) 0.767 black (mean (sd)) 0.87 (0.34) 0.91 (0.29) 0.343 hisp (mean (sd)) 0.05 (0.22) 0.05 (0.22) 1.000 married (mean (sd)) 0.19 (0.39) 0.19 (0.39) 1.000 nodegr (mean (sd)) 0.76 (0.43) 0.76 (0.43) 1.000 re74 (mean (sd)) 1500.88 (4143.39) 1443.69 (3509.35) 0.901 re75 (mean (sd)) 1068.95 (2424.18) 1021.02 (1941.02) 0.856 re78 (mean (sd)) 3886.44 (4330.99) 5724.39 (7367.12) 0.012 u74 (mean (sd)) 0.79 (0.41) 0.77 (0.42) 0.665 u75 (mean (sd)) 0.70 (0.46) 0.66 (0.47) 0.522

Multiple imputation利点
• 一部の欠損値のために多数の非欠損値を捨てるバイアスを回避できる。
• 統計学的検出力を高める。• 従来の補完法と比較して、欠損値による推定の不確定さ
を結果に反映させることができる。

Multiple imputation欠点
• 欠損値を最小化するようデザインするのが本質です。• 現時点で reporting guideline が存在しない。• バイアスを大きくするのか小さくするのか、まだ議論
がある。• 計算時間が長く、大きなデータセットでは計算不能に
なる。

Propensity score matching after multiple imputation
• 後ろ向きデータで因果関係に言及できる方法です。• ビッグデータ推奨。• ランダム化試験より低コストで倫理審査の壁が低くラン
ダム化が不可能な介入の解析もできます。• バイアスは小さくできると信じられています。• PSM の検出力は高くないが、 MI と組み合わせることで
その低下を限ることができます。