Embed Size (px)
Citation preview

学術コンテンツサービスでの活用事例
国立情報学研究所 大向 一輝
@i2k

自己紹介 • 対象 • ソーシャルメディア:ブログ・SNS・Twitter…
• 学術情報サービス・ビブリオメトリクス
• 技術 • セマンティックウェブ・Linked Open Data(LOD)
• ネットワーク分析・データマイニング • クラウドソーシング
• オープンデータ
• 内閣官房 電子行政オープンデータ実務者会議 公開支援WG • 経済産業省 IT融合フォーラム 公共データWG
• オープン&ビッグデータ活用・地方創生推進機構 利活用・普及委員会 • NPOリンクト・オープン・データ・イニシアティブ

自己紹介

国立情報学研究所(NII)

NIIの2つのミッション
学術基盤推進部
「研究と事業を車の両輪として情報学による未来価値を創成」

NIIの略史
年 月 事 項
昭和51(1976)年5月 東京大学情報図書館学研究センター発足
昭和58(1983)年4月 東京大学文献情報センター設置(情報図書館学研究センターを改組)
昭和61(1986)年4月 学術情報センター(NACSIS)設置
平成12(2000)年4月 国立情報学研究所(NII)設置(学術情報センターの廃止・転換)
平成16(2004)年4月 大学共同利用機関法人 情報・システム研究機構 国立情報学研究所設置

図書館文化と検索技術
• 少なくとも2000年以上の歴史 • 大量の情報を「探す」「見つける」不変のミッション
• コンピュータ以前の検索
• 冊子体目録(カタログ)
• カード目録
• 1960s~:電算化とOPAC
• 専門技能としての検索
• 厳密な記述規則と組織化
• 教育システム
出典:ndl.go.jp


図書館文化と検索技術
• 形態素解析?N-Gram? • 分かち書き
• 分かち書きは、検索語となる自立語を対象とする。日本語の場合は、日本語として不自然でない意味のまとまりで分かち書きを行う。
• 例外多数
• 地名に付属する「史」「誌」は地名との複合形をもって一語とする。また、地名に行政単位等を示す語が付属する場合は、行政単位等を示す語と「史」「誌」との複合形をもって一語とし、地名を分割する。
• 例:日本史 仙台史 愛知△県史

図書館文化と検索技術
• かな漢字変換? • 読みの付与
• ウェブらしさを考える本
• →ウェブ△ラシサ△ヲ△カンガエル△ホン
• 三國志
• →サンゴクシ?san guo zhi?
• 多言語対応
• 翻字と包摂
• ß→ss Д→d 谷→穀
• ローマ字入力:ヘボン式?訓令式?

包摂の例

図書館文化と検索技術
• 各言語の取り扱いは国ごと・言語圏ごとに大きく異なる • グローバルに1つの検索エンジンは可能か?
• 初学者の存在
• 文化受容の歴史(和製英語・和製漢語)
• 大学図書館・研究図書館における再現率の重視
• 引用・被引用関係に基づく確からしさの評価
• 見逃しは許されない
• 情報システムとしての要求の変化
• 専門家のための道具から一般向けのサービスへ
• インターネット・ウェブ
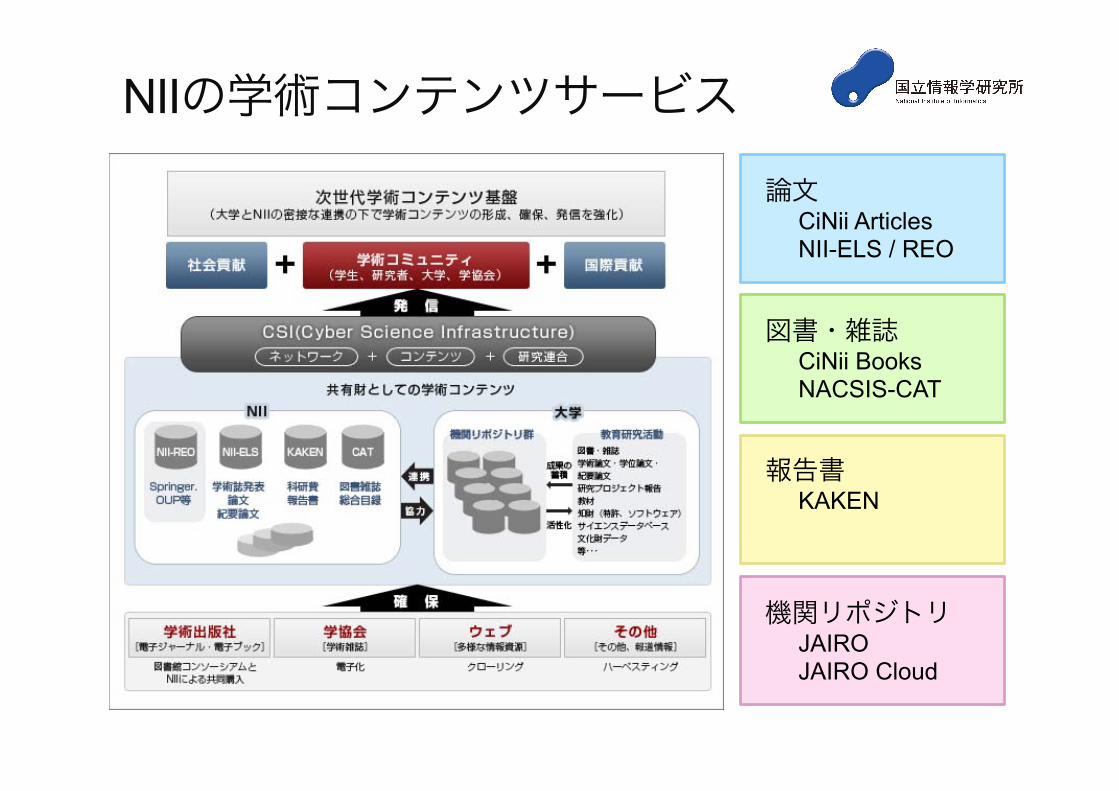
NIIの学術コンテンツサービス
論文 CiNii Articles NII-ELS / REO
図書・雑誌 CiNii Books NACSIS-CAT
報告書 KAKEN
機関リポジトリ JAIRO JAIRO Cloud

2つのCiNii
1800万件の 日本語論文データを検索
800万件はダウンロード可能
大学図書館1200館の 1100万種類・1億2000万冊の
本のデータを検索
Articles Books

Articles
Books

Articles API
Books API
OpenSearch 100,946,269 RDF 182,235,701
OpenSearch 9,902,483 RDF 8,512,362

2つ(3つ)のCiNii
• CiNii Articles(2009~)論文 • 検索エンジン:某社某パッケージ+Solr
• DB:PostgreSQL
• CiNii Books(2011~)図書
• 検索エンジン:Solr
• DB:MySQL
• CiNii Dissertations(2015~)博士論文
• 検索・DB:ElasticSearch
• UI/UXは統一、中身は別物
• データ構造の違い・潜在的ユーザ数の違い(A>>B>>D)
• 適材適所の技術導入・楽しく開発!

CiNii BooksとSolr
• Articlesは2007年仕様策定、当時はOSS採用への抵抗感あり • Booksは2009年開発開始、事例の増加と商用パッケージはエンタープライズ検索に特化傾向
• 図書館文化との親和性
• 多言語が同一フィールドに混在する
• アルファベットはスペース区切り、他の文字はN-Gramとしたい→CJKTokenizerの拡張
• 漢字統合を含む多段的な包摂・正規化処理が必要
• 業務で作られたルールセットをそのまま利用可能に
• https://github.com/atware/lucene-tokenizers-for-multilang
• ルールセットは未公開…

CiNii BooksとSolr
• 搭載データ • 書誌:11,055,402
• 著者:1,656,648
• 週次で全件を再投入(業務プロセス簡略化のため)
• 安定稼働
• リリース以来Solr起因のトラブルは皆無
• 法定停電時はパブリッククラウドでサービス継続
• 継続的課題
• スケーラビリティ:大ヒットしてもコストがかけられない
• 可用性:3.11の教訓・お役所的勤務体系
• ElasticSearchのテスト・KAKEN/SEIKAの挑戦


KAKEN/SEIKA
• KAKEN:科学研究費補助金の成果報告書データベース • 年間2000億円超の研究費の説明責任と成果のショーケース
• 研究費獲得のための先行研究調査
• データ:課題78万件・報告書138万件
• アクセス:検索400万・詳細表示2200万・PDFダウンロード80万
• 要求の変化
• 毎年変更される分類体系への追従
• 他省庁の補助金制度への対応
• 現行システムはHyper Estraier+MySQL
• スケーラビリティ・可用性

科研費の細目



新KAKEN/SEIKA
• Riakベース • 分散KVS
• 分類体系の変更に追従しやすい
• スケーラビリティ・可用性への配慮
• Version 2.0から検索エンジンにSolrを採用
• 疎結合のアーキテクチャにより責任分界とメンテナンスが容易 • Solrコミュニティの成果を生かしやすい
• 10月リリース予定

まとめ
• 図書館文化と検索技術 • ウェブの母体
• 自然言語処理と意味処理の融合体
• 確率モデルとグラフモデルによる次世代の検索へ











![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://img.pdfslide.tips/doc/110x75/554f64f5b4c905c8088b4ccc/hic2011-using-hadoop-lucene-solr-for-large-scale-search-by-systex.jpg)