Embed Size (px)
Citation preview

文章読解支援のための 語彙平易化
首都大学東京 梶原 智之

自己紹介 • 梶原 智之 @moguranosenshi
• 新居浜工業高等専門学校(愛媛県) – 遺伝的アルゴリズムを用いた自動作曲
• 長岡技術科学大学(新潟県)http://www.jnlp.org/ – 言い換え、特に語彙的換言 – テキスト簡単化、特に語彙平易化
• 首都大学東京(東京都)http://cl.sd.tmu.ac.jp/ – 言い換え – テキスト簡単化 – NLP若手の会プログラム委員 2

修士論文
文章読解支援のための語彙平易化
長岡技術科学大学大学院 工学研究科 電気電子情報工学専攻 学籍番号:11313388
梶原 智之
指導教員 山本 和英 准教授 2015年2月12日 3
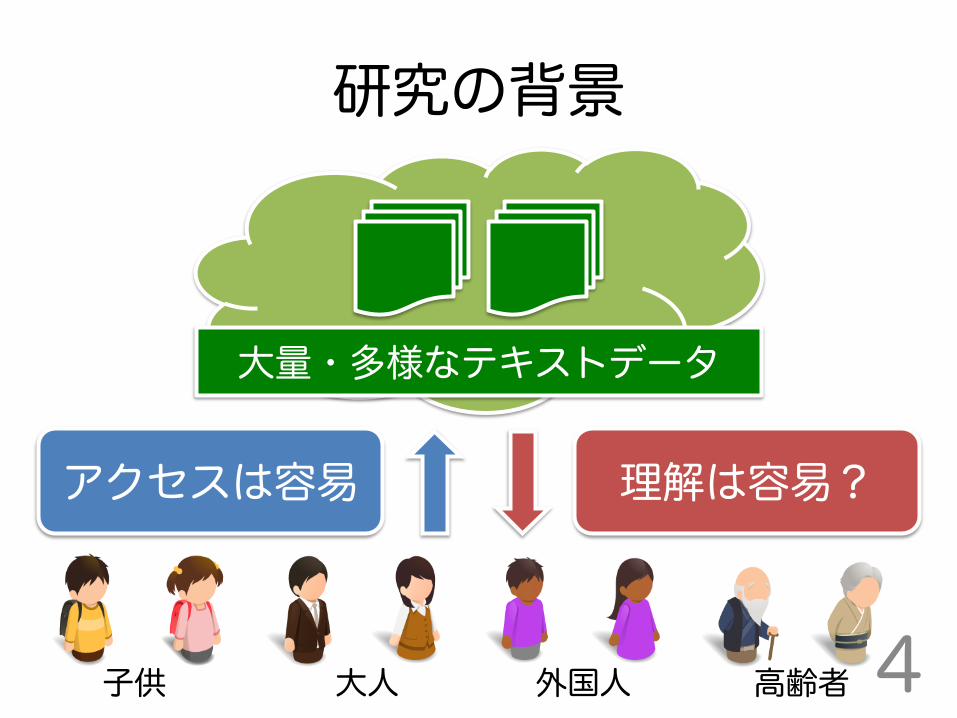
研究の背景
4
大量・多様なテキストデータ
アクセスは容易 理解は容易?
子供 大人 外国人 高齢者
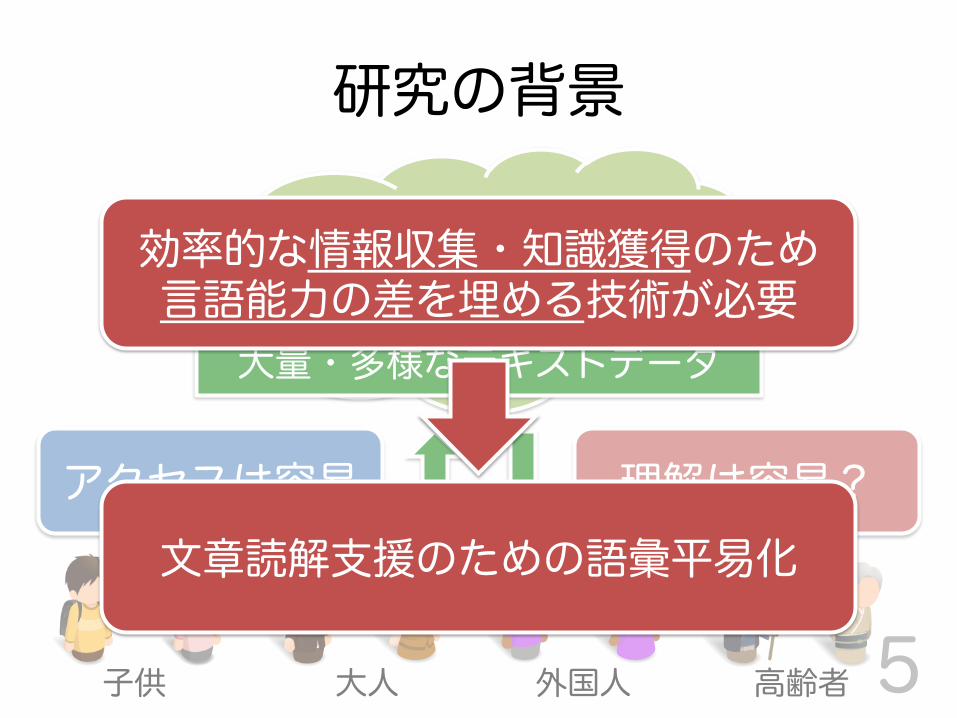
研究の背景
5
大量・多様なテキストデータ
アクセスは容易 理解は容易?
子供 大人 外国人 高齢者
効率的な情報収集・知識獲得のため 言語能力の差を埋める技術が必要
文章読解支援のための語彙平易化

語彙平易化
6
文中の難解な語をより平易な同義語に置換
四国に赴く
四国に行く
対象 評価尺度 赴く 行く 大人 単語親密度DB 難:1 → 易:7 5.0 6.469 子ども 学習基本語彙 難:- → 易:✓ - ✓ 外国人 日本語能力試験 難:1 → 易:4 1 4 外国人 日本語教育語彙表 難:6 → 易:1 5 1
幅広い読者の文章読解を支援する

文章読解支援のための語彙平易化
• 語彙平易化システム – 梶原智之, 山本和英. 日本語の語彙平易化システムの構築. 情報処理学会第77回全国大会講演論文集(第2分冊), pp.167-168, 2015.
• 語彙平易化の評価のためのデータセット – 梶原智之, 山本和英. 日本語の語彙平易化評価セットの構築. 言語処理学会第21回年次大会発表論文集, pp.501-504, 2015.
7

関連研究 • SemEval-2012: English Lexical Simplification Task [1] • 9つのシステムが参加 • 文脈を考慮して高頻度語に置換
• Simple English Wikipedia • 語彙と文法に制限をかけた平易なWikipedia • Wikipediaとのアライメント → 対訳コーパス [2], [3] • 語彙平易化規則を学習 [4] • 統計翻訳の枠組みで平易化 [5], [6]
[1] Lucia Specia et al. (2012) “Semeval-2012 Task 1: English Lexical Simplification” [2] Zhemin Zhu et al. (2010) “A Monolingual Tree-based Translation Model for Sentence Simplification” [3] David Kauchak (2013) “Improving Text Simplification Language Modeling Using Unsimplified Text Data” [4] Colby Horn et al. (2014) “Learning Lexical Simplifier Using Wikipedia” [5] William Coster and David Kauchak (2011) “Learning to Simplify Sentences Using Wikipedia” [6] Sander Wubben et al. (2012) “Sentence Simplification by Monolingual Machine Translation” 8
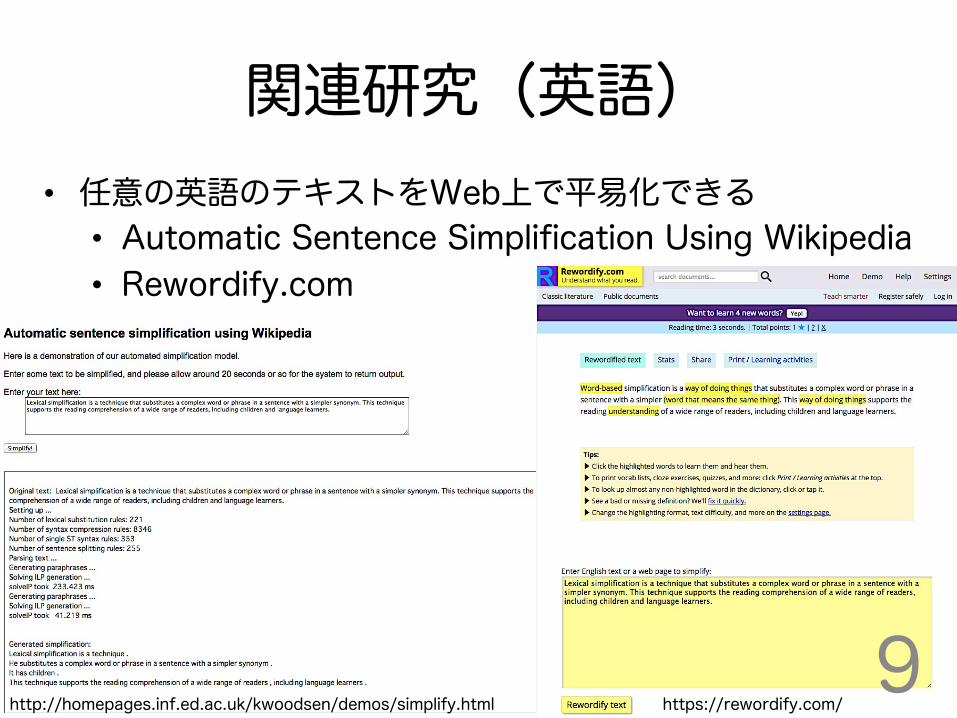
関連研究(英語)
http://homepages.inf.ed.ac.uk/kwoodsen/demos/simplify.html https://rewordify.com/ 9
• 任意の英語のテキストをWeb上で平易化できる • Automatic Sentence Simplification Using Wikipedia • Rewordify.com
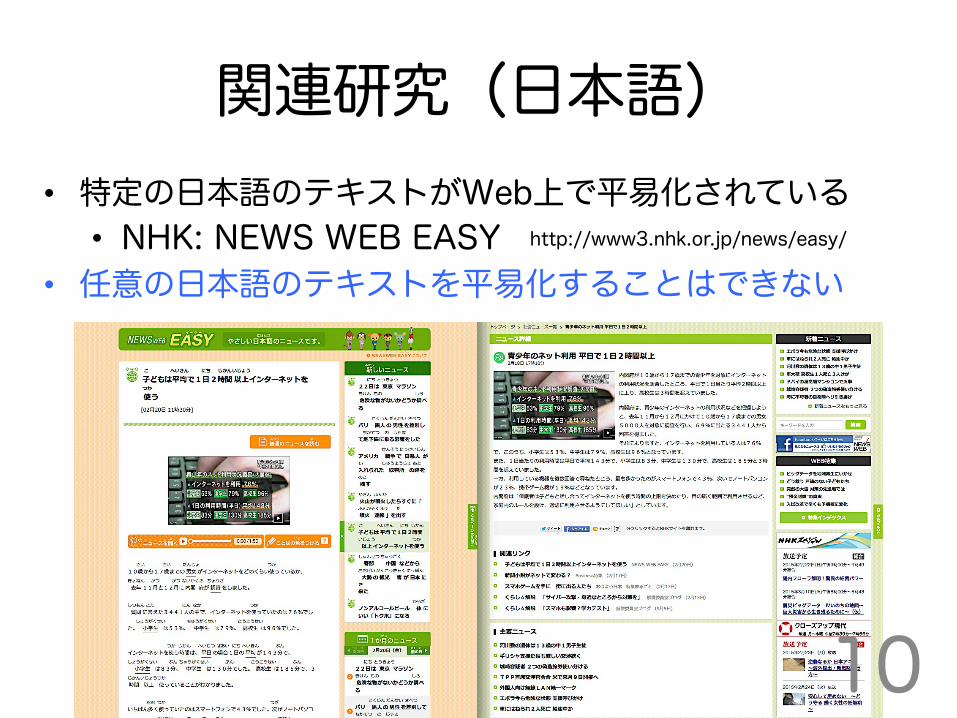
関連研究(日本語)
http://www3.nhk.or.jp/news/easy/
10
• 特定の日本語のテキストがWeb上で平易化されている • NHK: NEWS WEB EASY
• 任意の日本語のテキストを平易化することはできない

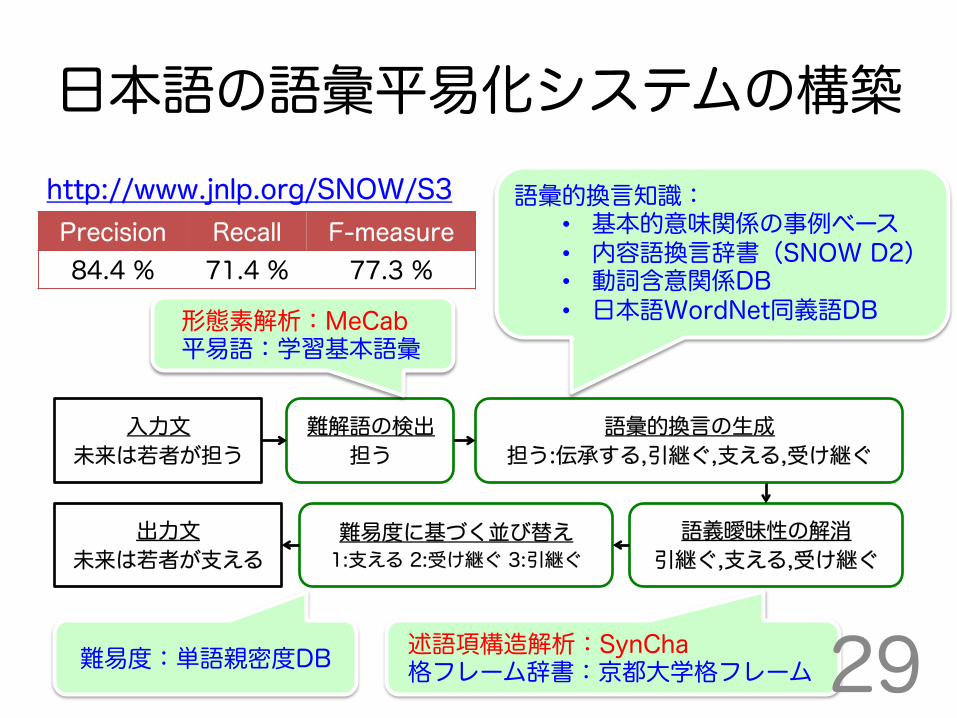
日本語の語彙平易化システムの構築 本研究の目的
読解支援を必要とする読者に 語彙平易化の技術を届ける
本研究の貢献 ・任意の日本語の文を平易化 するシステムを構築した ・日本語の平易化システムを 初めてWebで公開した
http://www.jnlp.org/SNOW/S3
11
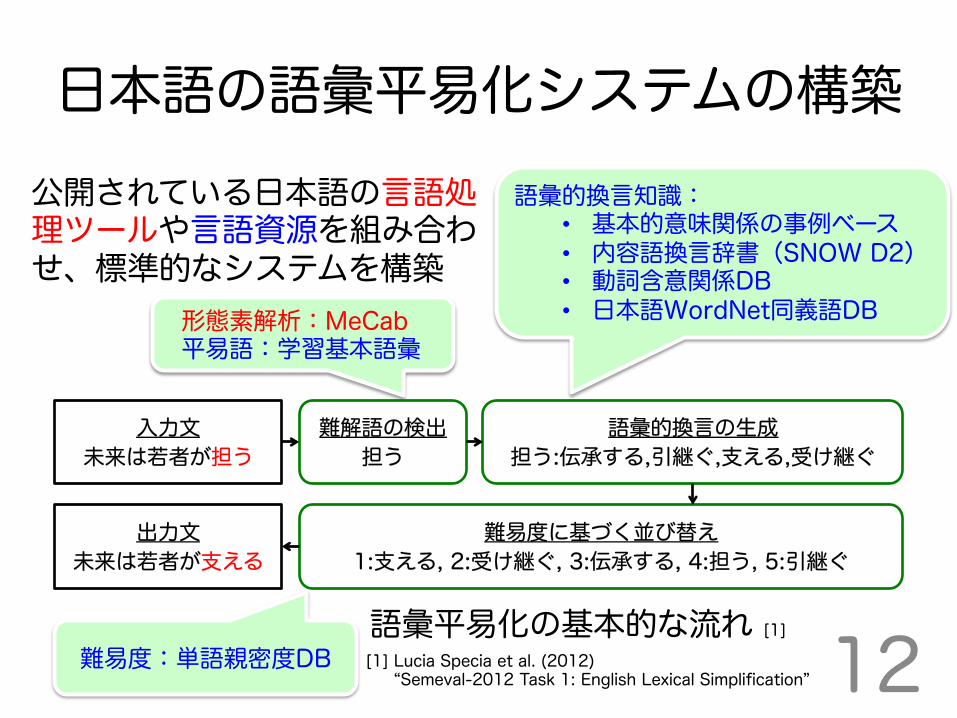
日本語の語彙平易化システムの構築 公開されている日本語の言語処 理ツールや言語資源を組み合わ せ、標準的なシステムを構築
形態素解析:MeCab 平易語:学習基本語彙
語彙的換言知識: • 基本的意味関係の事例ベース • 内容語換言辞書(SNOW D2) • 動詞含意関係DB • 日本語WordNet同義語DB
難易度:単語親密度DB 12
入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 難易度に基づく並び替え
1:支える, 2:受け継ぐ, 3:伝承する, 4:担う, 5:引継ぐ
[1] Lucia Specia et al. (2012) [1] “Semeval-2012 Task 1: English Lexical Simplification” 語彙平易化の基本的な流れ [1]
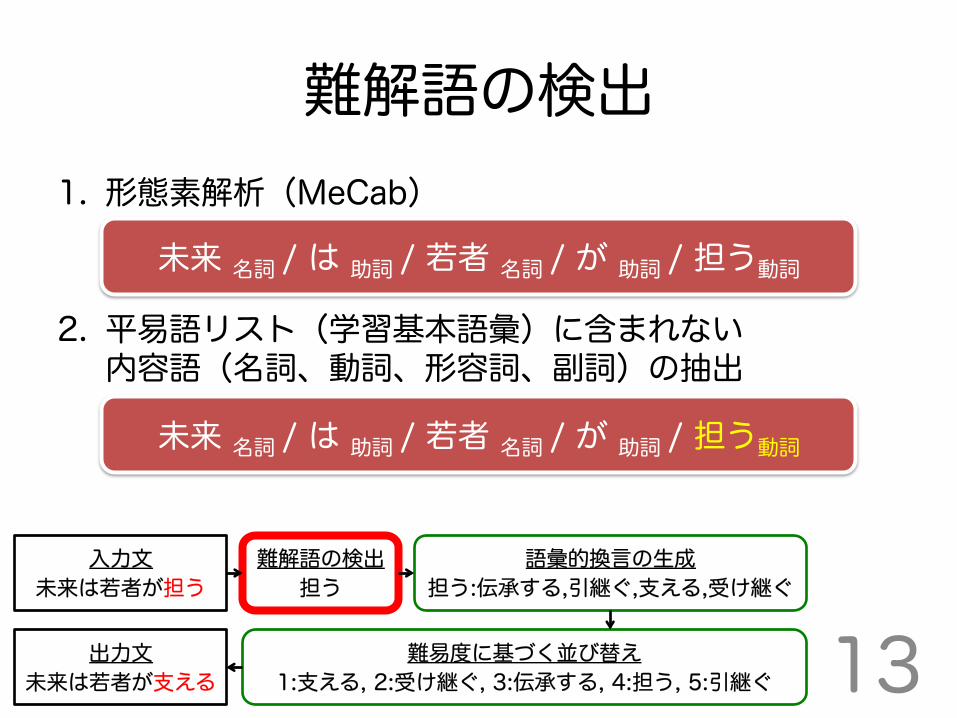
1. 形態素解析(MeCab) 2. 平易語リスト(学習基本語彙)に含まれない 内容語(名詞、動詞、形容詞、副詞)の抽出
13
難解語の検出
未来 名詞 / は 助詞 / 若者 名詞 / が 助詞 / 担う動詞
未来 名詞 / は 助詞 / 若者 名詞 / が 助詞 / 担う動詞
入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 難易度に基づく並び替え
1:支える, 2:受け継ぐ, 3:伝承する, 4:担う, 5:引継ぐ
14
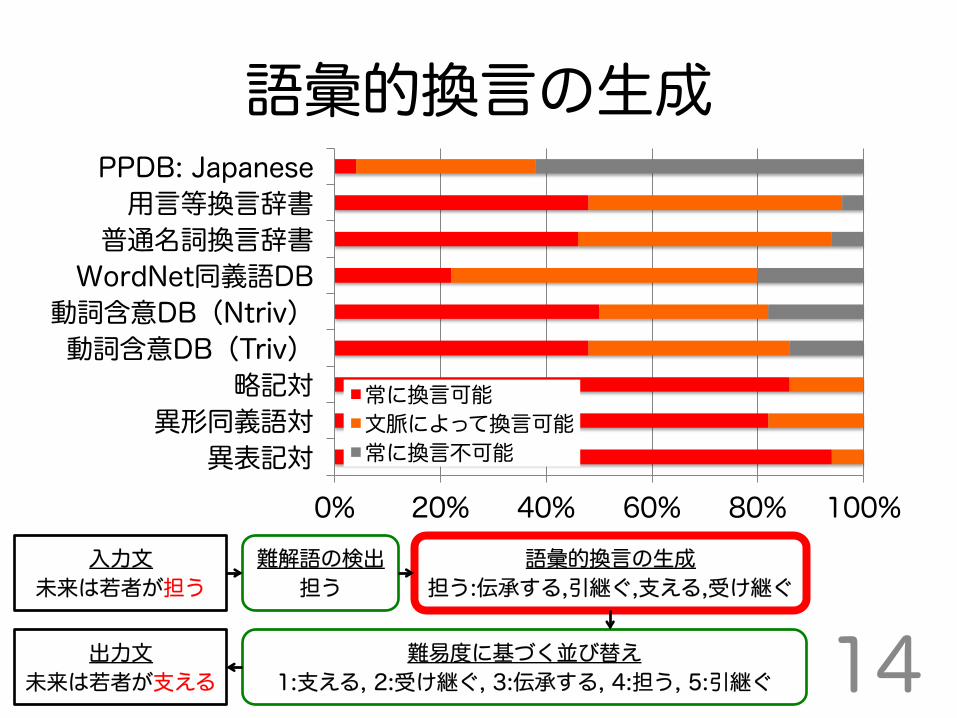
語彙的換言の生成
0% 20% 40% 60% 80% 100%
PPDB: Japanese 用言等換言辞書 普通名詞換言辞書 WordNet同義語DB 動詞含意DB(Ntriv) 動詞含意DB(Triv)
略記対 異形同義語対 異表記対
常に換言可能 文脈によって換言可能 常に換言不可能
入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 難易度に基づく並び替え
1:支える, 2:受け継ぐ, 3:伝承する, 4:担う, 5:引継ぐ

• 先行研究 [7] の調査に基づき、 比較的高精度な言い換えを換言知識から収集 • 内容語換言辞書(SNOW D2) • 日本語WordNet同義語データベース • 動詞含意関係データベース • 基本的意味関係の事例ベース
[7] 梶原智之, 山本和英 (2014) “日本語の語彙的換言知識の質的評価”
15
語彙的換言の生成
入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 難易度に基づく並び替え
1:支える, 2:受け継ぐ, 3:伝承する, 4:担う, 5:引継ぐ
16
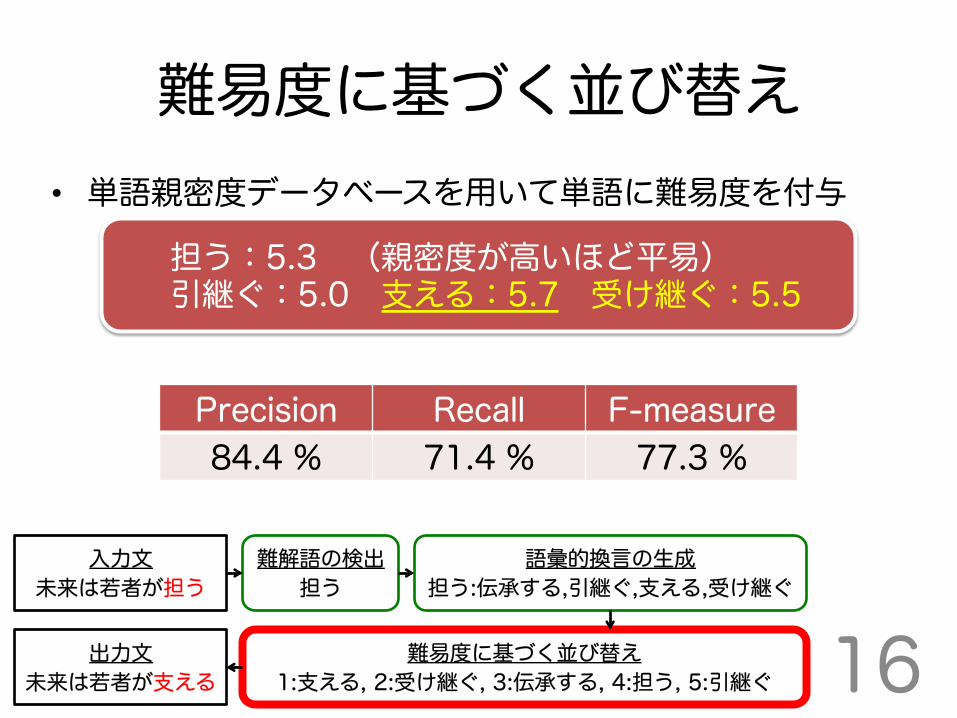
難易度に基づく並び替え • 単語親密度データベースを用いて単語に難易度を付与
担う:5.3 (親密度が高いほど平易) 引継ぐ:5.0 支える:5.7 受け継ぐ:5.5
入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 難易度に基づく並び替え
1:支える, 2:受け継ぐ, 3:伝承する, 4:担う, 5:引継ぐ
Precision Recall F-measure 84.4 % 71.4 % 77.3 %

システム入出力 http://www.jnlp.org/SNOW/S3
17
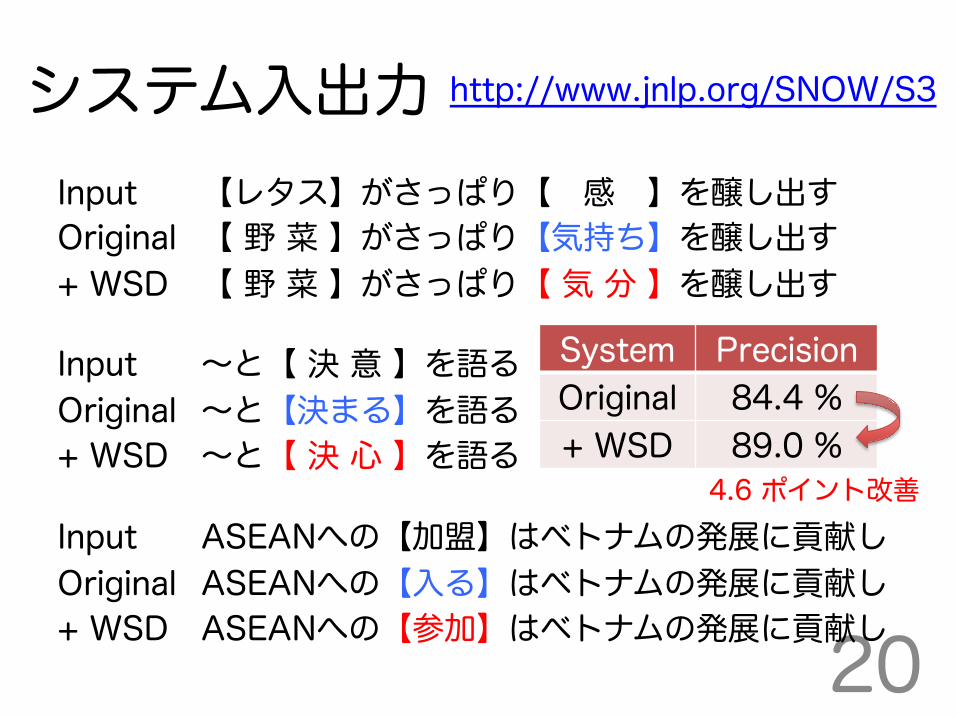
【百貨店】から離れがちな【顧客】を、どう引き戻すか。 【デパート】から離れがちな【お客さん】を、どう引き戻すか。
【よもや】と思う変化が【いとも】簡単に起こる。 【まさか】と思う変化が【とても】簡単に起こる。
自覚の【欠如】が【嘆かわしい】。 自覚の【不足】が【悲しい】。
その笑顔には、子供を【慈しむ】父親の【眼差し】があった。 その笑顔には、子供を【愛する】父親の【視線】があった。
【ただただ】【感嘆する】ばかりである。 【とにかく】【感動する】ばかりである。

Precisionの改善 • Precision:84.4 % ← 誤った16%の変換は理解を妨害
• 誤りの例 • 高騰する:上がる, 値上がりする, ・・・ • 石油の値段が【高騰する】→ 石油の値段が【上がる】 • 石油が【高騰する】→ 石油が【上がる】 石油が【値上がりする】
• 解決策 • 「値段」は上がる • 「石油」は上がらない → 述語と項の関係を評価すれば精度が上がる! → 述語項構造解析を用いた語義曖昧性の解消
19 入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 語義曖昧性の解消
引継ぐ,支える,受け継ぐ 難易度に基づく並び替え
1:支える 2:受け継ぐ 3:引継ぐ
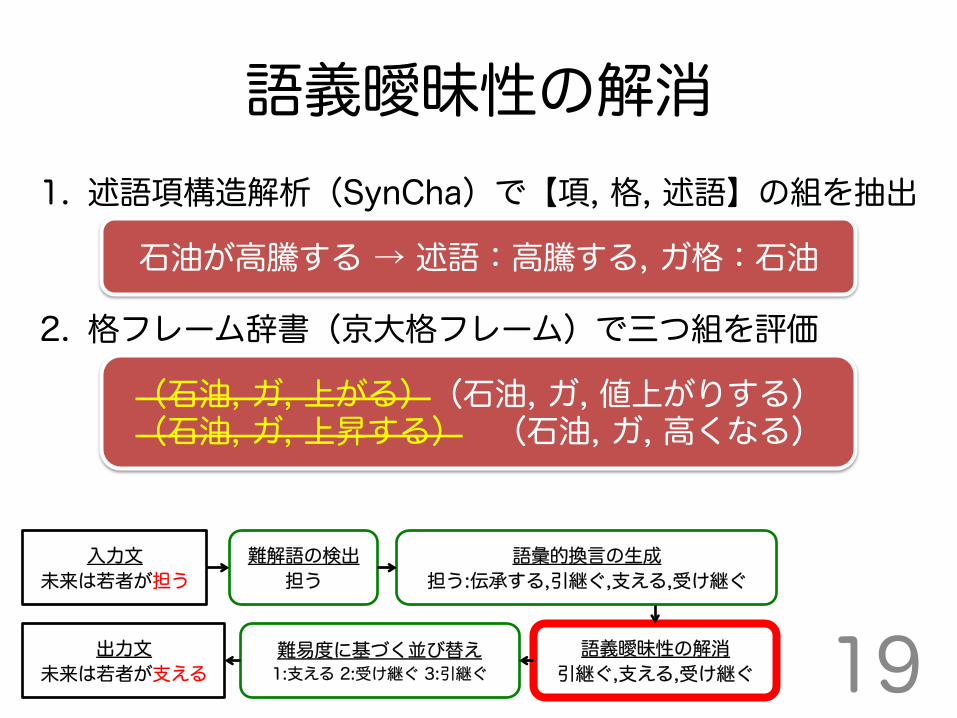
語義曖昧性の解消 1. 述語項構造解析(SynCha)で【項, 格, 述語】の組を抽出 2. 格フレーム辞書(京大格フレーム)で三つ組を評価
石油が高騰する → 述語:高騰する, ガ格:石油
(石油, ガ, 上がる)(石油, ガ, 値上がりする) (石油, ガ, 上昇する) (石油, ガ, 高くなる)
システム入出力 http://www.jnlp.org/SNOW/S3
20
Input 【レタス】がさっぱり【 感 】を醸し出す Original 【 野 菜 】がさっぱり【気持ち】を醸し出す + WSD 【 野 菜 】がさっぱり【 気 分 】を醸し出す Input ~と【 決 意 】を語る Original ~と【決まる】を語る + WSD ~と【 決 心 】を語る Input ASEANへの【加盟】はベトナムの発展に貢献し Original ASEANへの【入る】はベトナムの発展に貢献し + WSD ASEANへの【参加】はベトナムの発展に貢献し
System Precision Original 84.4 % + WSD 89.0 %
4.6 ポイント改善

文章読解支援のための語彙平易化
• 語彙平易化システム – 梶原智之, 山本和英. 日本語の語彙平易化システムの構築. 情報処理学会第77回全国大会講演論文集(第2分冊), pp.167-168, 2015.
• 語彙平易化の評価のためのデータセット – 梶原智之, 山本和英. 日本語の語彙平易化評価セットの構築. 言語処理学会第21回年次大会発表論文集, pp.501-504, 2015.
21

研究資源の公開の重要性 • 語彙平易化システムの公開 [8]
• 読解支援を必要とする読者に語彙平易化の技術を届ける • http://www.jnlp.org/SNOW/S3
• 語彙平易化の評価のためのデータセットの公開
• 従来の人手評価のコストと再現性の課題を解決し、 適合率および再現率の自動評価の枠組みを提供する • 複数の語彙平易化システムの性能を直接比較する • http://www.jnlp.org/SNOW/E4
[8] 梶原智之, 山本和英 (2015) “日本語の語彙平易化システムの構築” 22

日本語の語彙平易化評価セット
• 語彙的換言データセットの構築:対象語の選定 1. IPA辞書 ∩ JUMAN辞書の内容語(名詞、動詞、形容詞、副詞) 2. 平易な語を削除 ※学習基本語彙(小学生のための理解語彙)に含まれる語を削除
3. 換言が存在しない語を削除 ※内容語換言辞書(SNOW D2)に含まれない語を削除
4. 低頻度語を削除 ※新聞記事15年分での出現頻度が10未満の語を削除
対象語:名詞・動詞 75語、形容詞・副詞 50語(無作為抽出) 23
1.語彙的換言 データセットの構築
2.語彙平易化 データセットへの変換

日本語の語彙平易化評価セット
24
• 語彙的換言データセットの構築:換言の付与 • 各対象語に10種類の文脈を新聞記事から無作為に付与 • 5人のアノテータが文脈中で対象語の言い換えを列挙 • アノテータ:クラウドソーシングで募集(http://www.lancers.jp/)
• 平均 5.38 語の語彙的換言が付与された(一致率:17.8%)
• 語彙的換言データセットの構築:付与された換言の評価 • 5人のアノテータのうち3人以上が 「適切な言い換えである」と回答した表現のみ採用
• アノテータ:新たにクラウドソーシングで募集 • 平均 4.50 語の語彙的換言が採用された(一致率:66.4%)

日本語の語彙平易化評価セット • 語彙平易化データセットへの変換:難易度で並び替え
• 5人のアノテータが文脈中で対象語とその換言を 平易な順に並び替え(一致率:33.2%)
• アノテータ:換言の評価の際に募った作業者
• 語彙平易化データセットへの変換:難易度ランクの統合 • 5人の難易度ランクの平均値
• クラウドソーシング:のべ500人が作業 • 換言の付与:のべ250人 • 換言の評価と並び替え:のべ250人
25
• 語彙的換言と語彙平易化の評価のためのデータセット 二つの位置がピッタリ合ったところを【検出する】か、 差を【検出する】かという部分だけが異なる。 • 【検出する】発見する 1;検知する 4;見つける 1; • 平易 ← (見つける) (発見する・【検出する】) (検知する) → 難解
26
日本語の語彙平易化評価セット
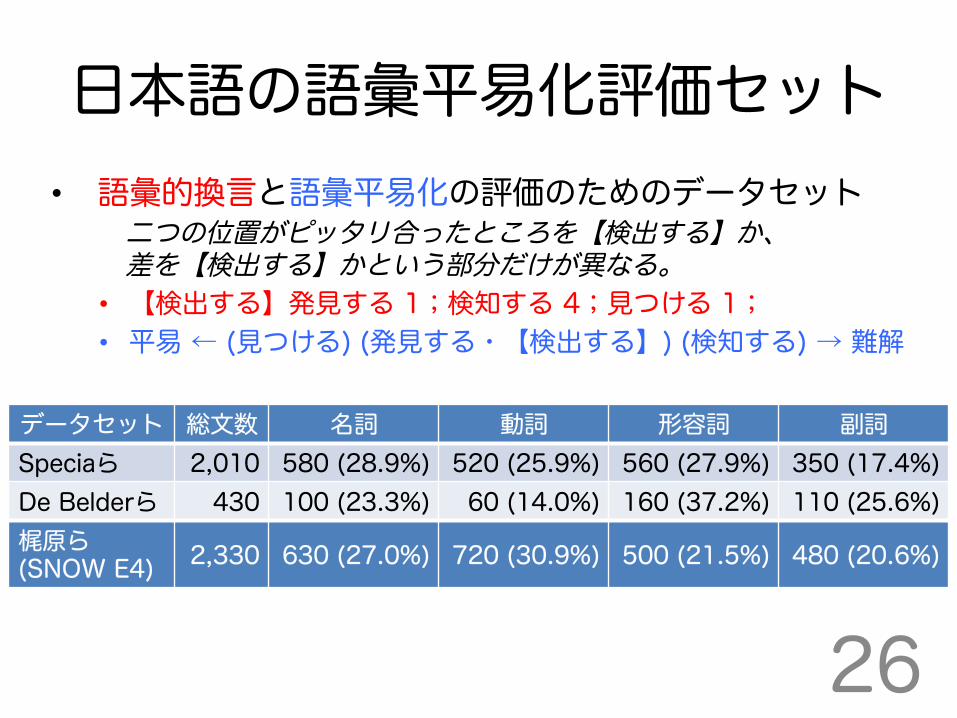
データセット 総文数 名詞 動詞 形容詞 副詞 Speciaら 2,010 580 (28.9%) 520 (25.9%) 560 (27.9%) 350 (17.4%) De Belderら 430 100 (23.3%) 60 (14.0%) 160 (37.2%) 110 (25.6%) 梶原ら (SNOW E4) 2,330 630 (27.0%) 720 (30.9%) 500 (21.5%) 480 (20.6%)

データセットの特性
27
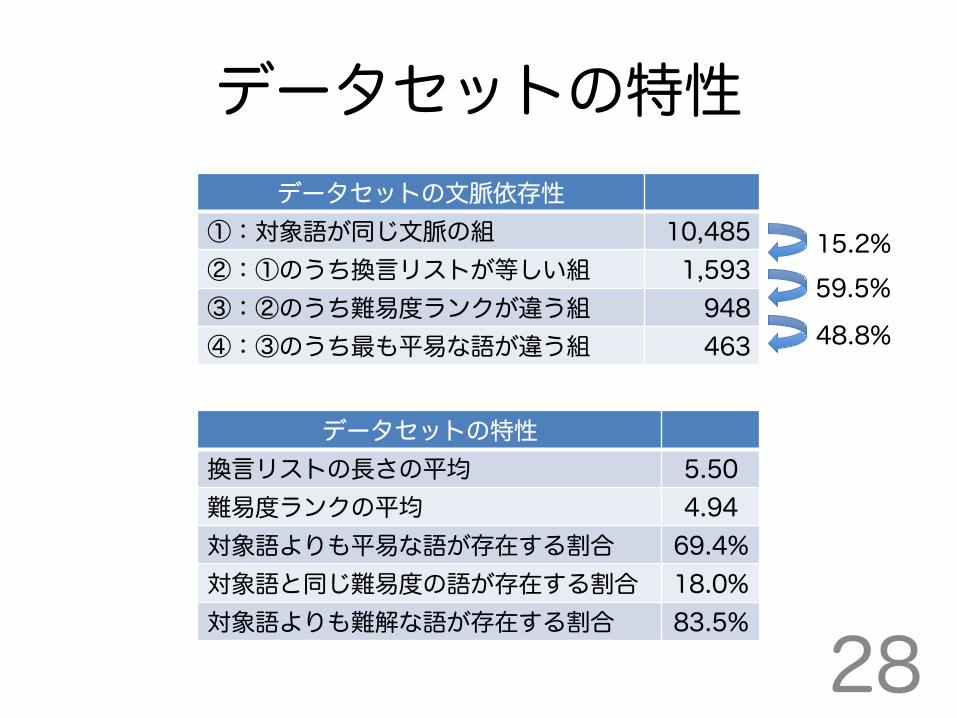
データセットの文脈依存性 ①:対象語が同じ文脈の組 10,485 ②:①のうち換言リストが等しい組 1,593 ③:②のうち難易度ランクが違う組 948 ④:③のうち最も平易な語が違う組 463
15.2% 59.5%
48.8%
対象語と文脈 換言リスト(上段)と難易度ランク(下段) グルメというのが、食のバブルであるとするなら、それは【とっくに】終わった文化である
すでに;既に;とうに;随分前に;前に;もう;
{とっくに}{すでに}{もう}{既に}{とうに}{前に}{随分前に}
どうやら職場での飲酒は【とっくに】ばれていたらしい
とうの昔に;すでに;既に;とうに;随分前に;もう; {とっくに}{すでに}{既に もう}{とうの昔に}{とうに}{随分前に}
【とっくに】気付いているかもしれないが、写真中央にいるのはF1でもおなじみのナイジェル・マンセルだ
とうの昔に;すでに;既に;とうに;随分前に;もう;
{すでに}{もう}{とっくに}{既に}{とうに}{とうの昔に 随分前に}
データセットの特性
28
データセットの文脈依存性 ①:対象語が同じ文脈の組 10,485 ②:①のうち換言リストが等しい組 1,593 ③:②のうち難易度ランクが違う組 948 ④:③のうち最も平易な語が違う組 463
データセットの特性 換言リストの長さの平均 5.50 難易度ランクの平均 4.94 対象語よりも平易な語が存在する割合 69.4% 対象語と同じ難易度の語が存在する割合 18.0% 対象語よりも難解な語が存在する割合 83.5%
15.2% 59.5%
48.8%
日本語の語彙平易化システムの構築
入力文
未来は若者が担う 語彙的換言の生成
担う:伝承する,引継ぐ,支える,受け継ぐ 難解語の検出
担う
出力文
未来は若者が支える 語義曖昧性の解消
引継ぐ,支える,受け継ぐ 難易度に基づく並び替え
1:支える 2:受け継ぐ 3:引継ぐ
形態素解析:MeCab 平易語:学習基本語彙
語彙的換言知識: • 基本的意味関係の事例ベース • 内容語換言辞書(SNOW D2) • 動詞含意関係DB • 日本語WordNet同義語DB
難易度:単語親密度DB 述語項構造解析:SynCha 格フレーム辞書:京都大学格フレーム 29
http://www.jnlp.org/SNOW/S3 Precision Recall F-measure 84.4 % 71.4 % 77.3 %

日本語の語彙平易化評価セットの構築 http://www.jnlp.org/SNOW/E4
1. 語彙的換言データセットの構築 1. 対象語の選定 2. クラウドソーシングを用いた語彙的換言の列挙 3. 複数の作業者による作業結果の統合
(クラウドソーシングを用いた語彙的換言の評価)
2. 語彙平易化データセットへの変換 1. クラウドソーシングを用いた平易化候補の難易度による並び替え 2. 複数の作業者による作業結果の統合
• 語彙的換言と語彙平易化の評価のためのデータセット 二つの位置がピッタリ合ったところを【検出する】か、 差を【検出する】かという部分だけが異なる。 • 【検出する】発見する 1;検知する 4;見つける 1; • 平易 ← (見つける) (発見する・【検出する】) (検知する) → 難解
30





























![[クリアテスト|語彙 DB4500 クリアテスト 語彙...[クリアテスト|語彙DB4500] 1 DB4500 クリアテスト 語彙 [第1 回目] 受講についての注意 1 試験開始の合図があるまで,問題を見てはいけません。](https://img.pdfslide.tips/doc/110x75/5ffb7fae3fe71872762a1d34/fffioee-db4500-fff-e-fffioeedb4500.jpg)