Embed Size (px)
Citation preview

メッセージ伝搬アルゴリズムとその応用
堀井俊佑早稲田大学
May, 29, 2015
1 / 54

1 確率推論とメッセージ伝搬アルゴリズム
2 誤り訂正符号の復号への応用
3 圧縮センシングへの応用
2 / 54

確率推論問題• X1, · · · ,XN ∈ X:確率変数• p(x1, · · · , xN):同時密度関数
確率推論問題X1, · · · ,XN のうち,Xn+1, · · · ,XNの観測値 an+1, · · · , aN が与えられたとき,以下を計算する問題.
p(Xi|Xn+1 = an+1, · · · ,XN = aN), i = 1, · · · , n (1)
• 例えば,X1ならば,以下を計算する.
α∑
x2,··· ,xn
p(X1 = x, x2, · · · , xn, an+1, · · · , aN), x ∈ X (2)
(αは正規化定数)3 / 54

確率推論問題
例X1:風邪かどうか, X2:インフルエンザかどうか, X3:体温,X4:喉の痛みの有無,X5:筋肉痛の有無
p(x1, x2, x3, x4, x5)は既知と仮定.
「体温が 37℃,喉の痛みがある,筋肉痛がある」とき,風邪である確率は?⇒ p(X1 = 1|X3 = 37,X4 = 1,X5 = 1)を求めれば良い.
4 / 54

問題の困難なところ
• 計算したいもの:∑
{∼xi}p(x1, · · · , xn, an+1, · · · , aN) =
∑
{∼xi}f (x1, · · · , xn)
• {∼ xi}は xi以外の変数での和を表す.• f (x1, · · · , xn) ! p(x1, · · · , xn, an+1, · · · , aN)とおいた.
• まともに計算すると nの指数オーダーの計算量(Xが連続のときは積分計算が困難)• 誤り訂正符号の復号問題では nは数千
5 / 54

分配法則を利用した効率化
f (x1, · · · , xn)が構造を持てば,効率的に計算可能な場合がある.
例: f (x1, · · · , x5) = fA(x1)fB(x2)fC(x1, x2, x3)fD(x3, x4)fE(x3, x5)のように因数分解できたとする.このとき,
∑
{∼x1}f (x1, · · · , x5) = fA(x1) ×
∑
x2,x3
(fB(x2)fC(x1, x2, x3)
×(∑
x4
fD(x3, x4))×
(∑
x5
fE(x3, x5)))
⇒ O(|X|4)の計算がO(|X|2)に.他の変数についても同様に効率化可能.
6 / 54
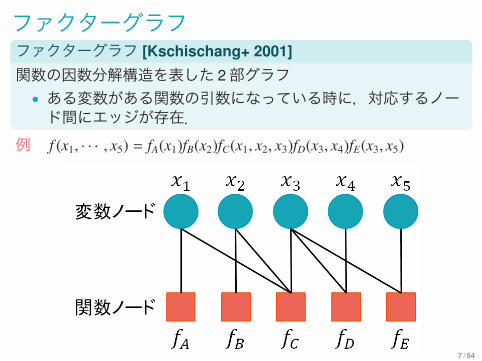
ファクターグラフファクターグラフ [Kschischang+ 2001]関数の因数分解構造を表した 2部グラフ• ある変数がある関数の引数になっている時に,対応するノード間にエッジが存在.
例 f (x1, · · · , x5) = fA(x1)fB(x2)fC(x1, x2, x3)fD(x3, x4)fE(x3, x5)
7 / 54
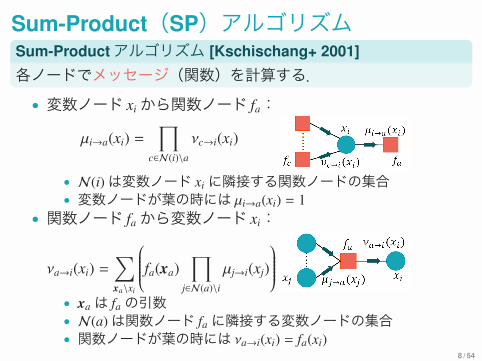
Sum-Product(SP)アルゴリズムSum-Productアルゴリズム [Kschischang+ 2001]各ノードでメッセージ(関数)を計算する.• 変数ノード xiから関数ノード fa:
µi→a(xi) =∏
c∈N(i)\aνc→i(xi)
• N(i)は変数ノード xiに隣接する関数ノードの集合• 変数ノードが葉の時には µi→a(xi) = 1
• 関数ノード faから変数ノード xi:
νa→i(xi) =∑
xa\xi
⎛⎜⎜⎜⎜⎜⎜⎝fa(xa)
∏
j∈N(a)\iµj→i(xj)
⎞⎟⎟⎟⎟⎟⎟⎠
• xaは faの引数• N(a)は関数ノード faに隣接する変数ノードの集合• 関数ノードが葉の時には νa→i(xi) = fa(xi)
8 / 54

Sum-Product(SP)アルゴリズム例
f (x1, · · · , x5) = fA(x1)fB(x2)×fC(x1, x2, x3)fD(x3, x4)fE(x3, x5)
νA→1(x1)νC→1(x1) = fA(x1)∑
x2,x3
(fC(x1, x2, x3)µ2→C(x2)µ3→C(x3))
= fA(x1)∑
x2,x3
(fC(x1, x2, x3)νB→2(x2)νD→3(x3)νE→3(x3)
)
= fA(x1)∑
x2,x3
(fC(x1, x2, x3)fB(x2)
∑
x4
(fD(x3, x4)µ4→D(x4)
)∑
x5
(fE(x3, x5)µ5→E(x5)
))
= fA(x1)∑
x2,x3
(fB(x2)fC(x1, x2, x3)
∑
x4
(fD(x3, x4)
)∑
x5
(fE(x3, x5)
))
9 / 54

SPアルゴリズムの問題点とLoopy BP
• SPアルゴリズムで必ず周辺化計算が行えるか?• No.ファクターグラフに閉路が存在しない場合のみ,正しく計算可能.
• グラフに閉路が存在する場合は?• 正しい周辺化計算が行える保証はないが,アルゴリズムを適用することはできる.
⇒ Loopy Belief Propagation (BP)• Loopy BPの性能は?
• 実験的には上手くいくことも多い.• 誤り訂正符号 (LDPC符号)の復号や圧縮センシングでは,性能の理論解析が盛んに行われている.• Density Evolution,State Evolution
10 / 54
誤り訂正符号とは
データの通信や記録を行う際,物理現象に伴う雑音によりデータに誤りが生じる場合がある.
誤り訂正符号通信(記録)を行う前に,予めデータを符号化しておくことで誤りを訂正することが可能.
11 / 54

応用例:QRコード
テキスト情報をバイナリで記録する 2次元コード
QRコードの容量• 数字のみ:最大 7089文字• 英数:最大 4296文字• バイナリ:2953バイト
約 30%の誤りを訂正可能.
12 / 54
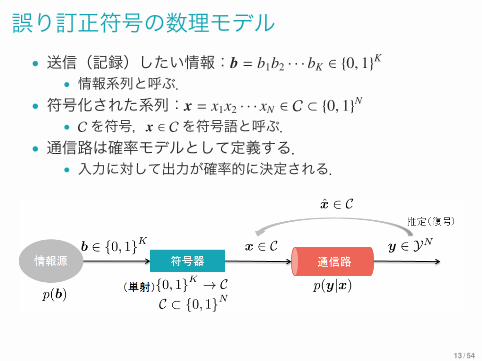
誤り訂正符号の数理モデル• 送信(記録)したい情報:b = b1b2 · · · bK ∈ {0, 1}K
• 情報系列と呼ぶ.• 符号化された系列:x = x1x2 · · · xN ∈ C ⊂ {0, 1}N
• Cを符号,x ∈ Cを符号語と呼ぶ.• 通信路は確率モデルとして定義する.
• 入力に対して出力が確率的に決定される.
13 / 54
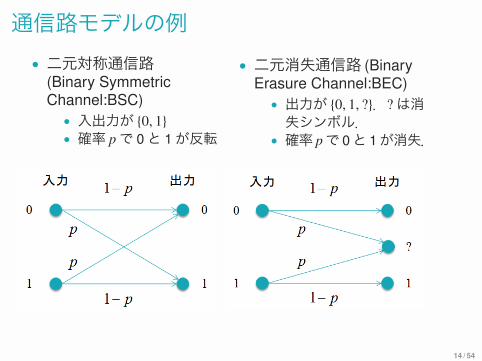
通信路モデルの例• 二元対称通信路
(Binary SymmetricChannel:BSC)• 入出力が {0, 1}• 確率 pで 0と 1が反転
• 二元消失通信路 (BinaryErasure Channel:BEC)• 出力が {0, 1, ?}.?は消失シンボル.
• 確率 pで 0と 1が消失.
14 / 54

簡単な符号化・復号の例 (q回反復符号)符号化法:各情報記号を q回繰り返す(qは奇数).
復号法:各情報記号に対して多数決により復号.
各符号語に対して,誤りの数が q/2より小さければ正しく復号可能.
15 / 54

誤り訂正符号の評価基準• 符号化比率
• 情報系列長 K÷符号長 N• 通信速度の評価(記録容量の効率)• q回反復符号の符号化比率:1/q
• 復号誤り率• 復号後の誤り率
• 系列単位:ブロック誤り率 Pr(x̂ ! x)• 記号単位:シンボル誤り率 Pr(x̂i ! xi), i = 1, · · · ,N
• 信頼性の評価• BSCにおける q回反復符号のブロック誤り率は
q∑
i=⌈q/2⌉qCipi(1 − p)q−i
• 符号化・復号にかかる計算量
16 / 54
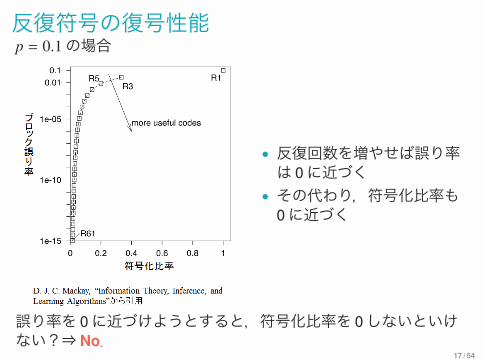
反復符号の復号性能p = 0.1の場合
• 反復回数を増やせば誤り率は 0に近づく
• その代わり,符号化比率も0に近づく
誤り率を 0に近づけようとすると,符号化比率を 0しないといけない?⇒No.
17 / 54

通信路符号化定理
通信路符号化定理 [Shannon 1948]通信路に対して定義される通信路容量 Cに対し,符号化比率が Cよりも小さければ,N → ∞でブロック誤り率を任意に小さくできる符号が存在する.逆に符号化比率が通信路容量 C以上であれば,そのような符号は存在しない.
• 1つの限界を示す定理.• 存在証明であり,具体的な符号化法・復号法を示しているわけではない⇒具体的な方式の探求(誤り訂正符号の理論)
18 / 54
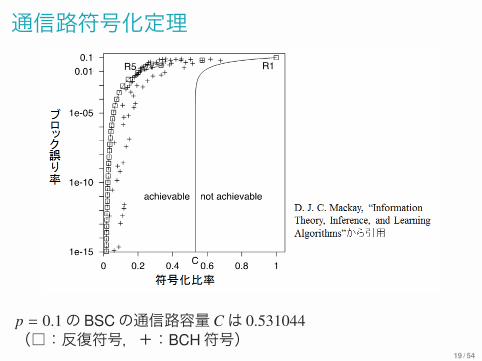
通信路符号化定理
p = 0.1の BSCの通信路容量Cは 0.531044(□:反復符号,+:BCH符号)
19 / 54

通信路容量を達成する符号と復号
最近の研究では,多項式時間で符号化・復号が可能で通信路容量を達成する方法が見つかっている.• Expandar符号+線形計画復号• Polar符号+Successive復号• 空間結合 LDPC符号+Sum-Product復号
※通信路にもよる.
LDPC符号はWiMAXやデジタルテレビの衛星通信などで実用的にも使われている.
20 / 54
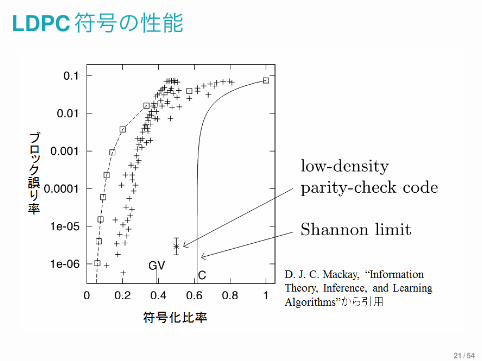
LDPC符号の性能
21 / 54

LDPC符号の概要パリティ検査行列• 符号語の満たすべき条件を行列表記したもの.
例:3回反復符号の場合
パリティ検査行列の決定≒符号の決定(正則)LDPC符号パリティ検査行列の行重み dc(各行の 1の数)や列重み dv(各列の 1つの数)が,dc, dv << N.
22 / 54
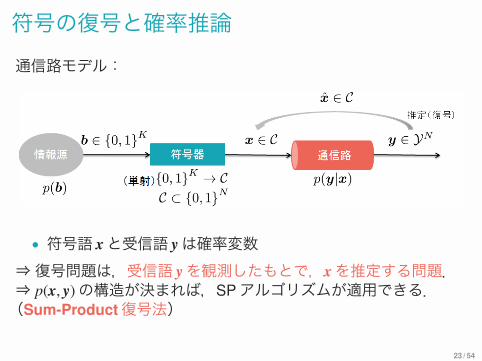
符号の復号と確率推論通信路モデル:
• 符号語 xと受信語 yは確率変数⇒復号問題は,受信語 yを観測したもとで,xを推定する問題.⇒ p(x, y)の構造が決まれば,SPアルゴリズムが適用できる.(Sum-Product復号法)
23 / 54

符号の復号と確率推論• p(x, y) = p(x)p(y|x)と分解.•
p(x) ={ 1|C| if x ∈ C0 otherwise
=1|C|
m∏
j=1
Ij(x)
• Ij(x):パリティ検査行列の j行目の制約条件を満たしていれば1,そうでなければ 0をとる関数.
• m:パリティ検査行列の行数.• p(y|x) =
∏Ni=1 p(yi|xi)
• 例えば誤り率 pの BSCならば p(yi|xi) = pxi⊕yi(1 − p)1−xi⊕yi
24 / 54
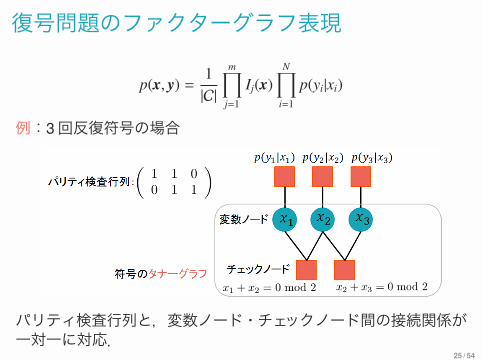
復号問題のファクターグラフ表現
p(x, y) =1|C|
m∏
j=1
Ij(x)N∏
i=1
p(yi|xi)
例:3回反復符号の場合
パリティ検査行列と,変数ノード・チェックノード間の接続関係が一対一に対応.
25 / 54
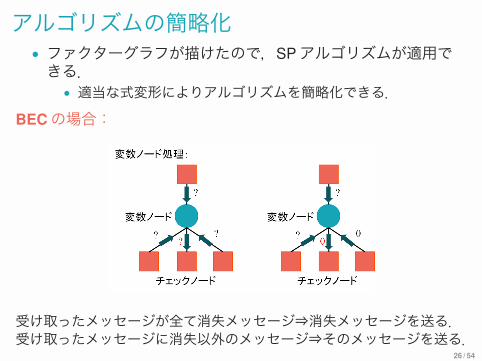
アルゴリズムの簡略化• ファクターグラフが描けたので,SPアルゴリズムが適用できる.• 適当な式変形によりアルゴリズムを簡略化できる.
BECの場合:
受け取ったメッセージが全て消失メッセージ⇒消失メッセージを送る.受け取ったメッセージに消失以外のメッセージ⇒そのメッセージを送る.
26 / 54
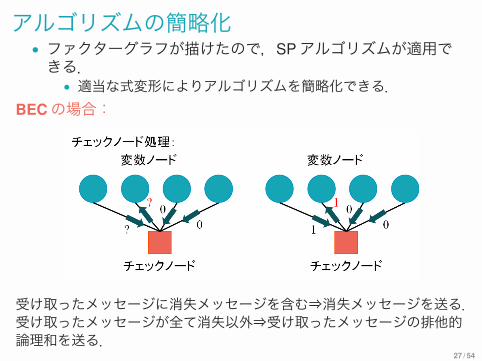
アルゴリズムの簡略化• ファクターグラフが描けたので,SPアルゴリズムが適用できる.• 適当な式変形によりアルゴリズムを簡略化できる.
BECの場合:
受け取ったメッセージに消失メッセージを含む⇒消失メッセージを送る.受け取ったメッセージが全て消失以外⇒受け取ったメッセージの排他的論理和を送る.
27 / 54

SP復号の誤り率解析
• LDPC符号+SP復号の誤り率を理論的に求めたい.⇒反復符号+多数決復号のように簡単には計算出来ない.
誤り率解析のポイント:アンサンブル解析:1つの符号の誤り率を求めるのではなく,符号のクラスを考えて,平均的な振る舞いを解析.Density Evolution (DE):ファクターグラフが部分的に木であると仮定して,エッジを流れるメッセージの確率分布を求める.
28 / 54
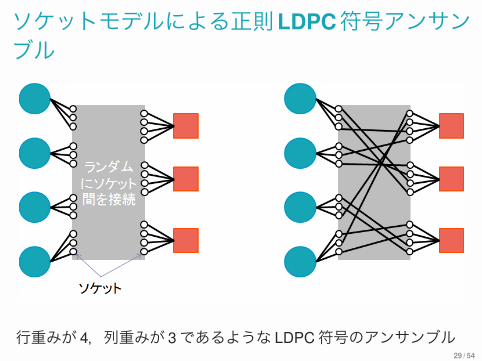
ソケットモデルによる正則LDPC符号アンサンブル
行重みが 4,列重みが 3であるような LDPC符号のアンサンブル29 / 54
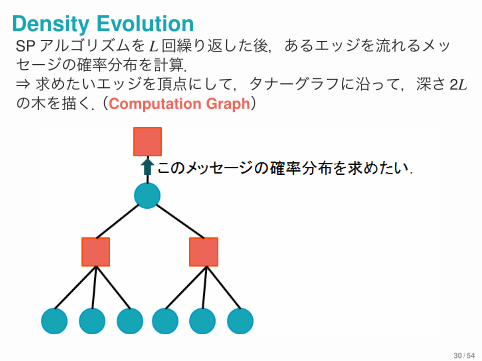
Density EvolutionSPアルゴリズムを L回繰り返した後,あるエッジを流れるメッセージの確率分布を計算.⇒求めたいエッジを頂点にして,タナーグラフに沿って,深さ 2Lの木を描く.(Computation Graph)
30 / 54
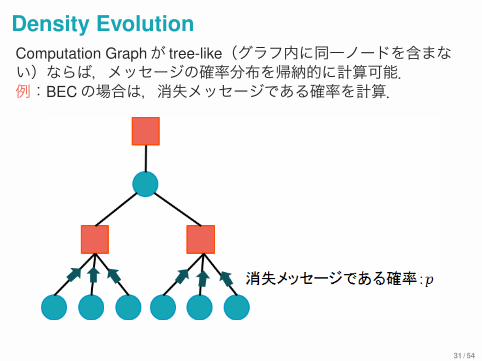
Density EvolutionComputation Graphが tree-like(グラフ内に同一ノードを含まない)ならば,メッセージの確率分布を帰納的に計算可能.例:BECの場合は,消失メッセージである確率を計算.
31 / 54
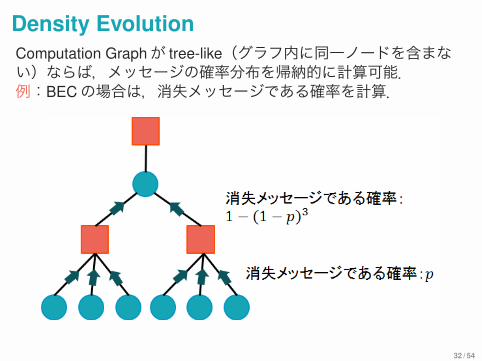
Density EvolutionComputation Graphが tree-like(グラフ内に同一ノードを含まない)ならば,メッセージの確率分布を帰納的に計算可能.例:BECの場合は,消失メッセージである確率を計算.
32 / 54
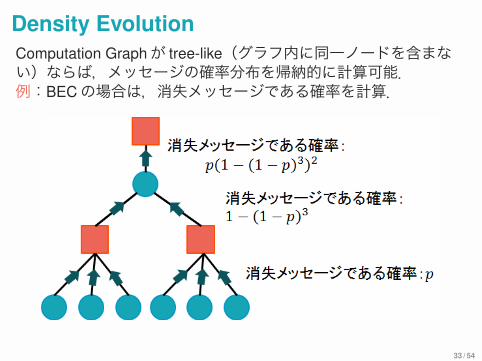
Density EvolutionComputation Graphが tree-like(グラフ内に同一ノードを含まない)ならば,メッセージの確率分布を帰納的に計算可能.例:BECの場合は,消失メッセージである確率を計算.
33 / 54

Density Evolution
BECに対する密度発展方程式 [Richardson+ 2001]
x(−1) = 1x(t) = p(1 − (1 − x(t−1))dc−1)dv−1
(dc:行重み,dv:列重み)• 深さ 2LのComputation Graphが tree-likeであるとき,反復回数 Lにおいて,変数ノードからチェックノードへのメッセージが消失メッセージである確率は x(L)となる.
• ソケットモデルのアンサンブルを考えると,ComputationGraphが tree-likeにならない確率は N → ∞で 0に収束.
34 / 54
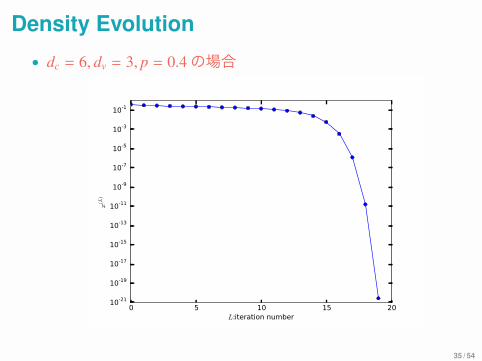
Density Evolution• dc = 6, dv = 3, p = 0.4の場合
35 / 54

Density Evolution• dc = 6, dv = 3, p = 0.42の場合
36 / 54
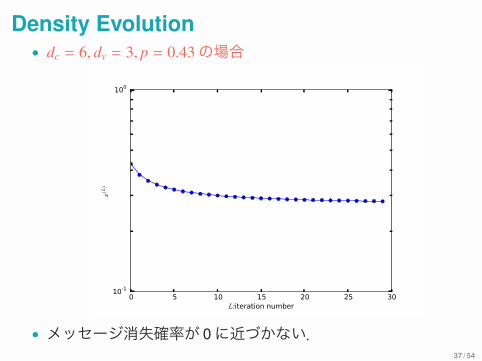
Density Evolution• dc = 6, dv = 3, p = 0.43の場合
• メッセージ消失確率が 0に近づかない.37 / 54

Density Evolution
• DEの不動点を解析することで,通信路の消失確率 pがいくつ以下ならば復号誤り率を 0に近づけられるかが分かる(BP閾値).• dc = 6, dv = 3の正則 LDPC符号の場合,0.429...
• 消失確率 pの消失通信路の通信路容量は 1 − p.• p = 0.43の消失通信路の通信路容量は 0.57.• dc = 6, dv = 3の正則 LDPC符号の符号化比率は基本的には 0.5.
⇒正則 LDPC符号で,通信路容量を達成するとは言えない.• 空間結合MacKay-Neal符号は消失通信路で通信路容量を達成することが証明可能.[Kasai+ 2011]• ポテンシャル関数を用いた解析が有効.[Yedla+ 2012]
38 / 54

符号理論への応用のまとめ
• 符号の復号問題を確率推論の問題と見ることができる.• LDPC符号に対して Sum-Productアルゴリズムを用いた復号を適用すると良い性能が得られる.
• LDPC符号に対する SP復号の性能を解析する方法としてDensity Evolutionがある.
• DEにより通信路容量を達成することが証明可能な符号が存在.
39 / 54

圧縮センシングの問題設定
• 原信号:x ∈ Rn
• 観測行列:Φ ∈ Rm×n(m < n)• 観測信号:y = Φx
問題設定yを観測したもとで,xを復元する問題.(Φは既知.)⇒ m < nなので,何の仮定もなければ xを一意に復元することはできない.
xが疎であることがわかっているときに,その疎性を利用して解を導く.応用:MRI,通信,機械学習 (LASSO), etc.
40 / 54

行列の制約等長性 (RIP)
観測行列の性質が復元可能かどうかの鍵.行列ΦのRIP定数 δs(1 ≤ s ≤ n)∀T ⊂ {1, · · · , n}, |T | ≤ s, c ∈ R|T |
(1 − δ)||c||2 ≤ ||ΦTc||2 ≤ (1 + δ)||c||2
が成り立つ最小の正実数 δ.(ΦT は Tで指定される列から構成されるΦの部分行列.)
• δ = 0⇒ ΦT は正規直交系⇒ δs:部分行列が正規直交系に近いかを示す指標
41 / 54

RIP定数と ℓ0復元
ℓ0復元の成功条件 [Candes & Tao 2005]T = supp(x)とする(xの非 0位置).δ2s < 1,|T | ≤ sならば,
minx̃∈Rn||x̃||0 subject to y = Φx̃
の解は原信号 xに一致する.(||x̃||0 = {i : xi ! 0})
• この最適化問題はNP困難.
42 / 54

RIP定数と ℓ1復元
ℓ1復元の成功条件 [Candes & Tao 2005]
T = supp(x)とする(xの非 0位置).δ2s <√
2 − 1,|T | ≤ sならば,
minx̃∈Rn||x̃||1 subject to y = Φx̃
の解は原信号 xに一致する.(||x̃||1 =∑N
i=1 |xi|)
• この最適化問題は線形計画問題として定式化可能.⇒ Nの多項式オーダで解ける.
43 / 54

ランダム行列のRIP定数
• RIP定数の小さい行列をどのようにして作るか?• RIP定数の評価自体が計算量的に困難.⇒ランダム行列アンサンブル
Gaussianランダム行列のRIP定数 [Candes & Tao 2005]観測行列Φ ∈ Rm×nの各要素を独立に N(0, 1/m)に従って定める.このとき α = m/nを有限とした n→ ∞の極限において,ρ = s/nがある値 ρc(α)より小さければ小さければ,δ2s <
√2 − 1となる確
率は(nに関して指数的に)1に近づく.
• 証明はランダム行列の固有値の漸近分布に関する結果を利用.
44 / 54

復元アルゴリズムに関する研究
• ℓ1復元は nの多項式オーダで実行可能.• 実際の問題では nは数千~数万⇒単体法や内点法は重い.• ℓ1復元を行うためのアルゴリズムに関する研究が盛ん.
• Matching Pursuit• 射影勾配型• メッセージパッシング型
今のところ,問題の中に確率的要素は無いが・・・
45 / 54

ℓ1復元の確率推論としての定式化
xに対する以下の様な確率密度を考える.
p(x) =1Z
n∏
i=1
exp (−β|xi|)m∏
a=1
δ{ya=(Φx)a}
• Z:正規化定数• β > 0:パラメータ• δ{ya=(Φx)a} :ya = (Φx)a上のディラック関数
β→ ∞で,p(x)の密度は ℓ1復元の最適解周辺に集中.⇒ p(x)の周辺確率が計算できれば,ℓ1復元の最適解が得られる.⇒ SPアルゴリズムの出番
46 / 54
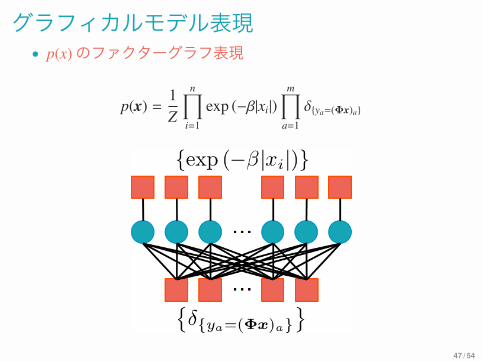
グラフィカルモデル表現• p(x)のファクターグラフ表現
p(x) =1Z
n∏
i=1
exp (−β|xi|)m∏
a=1
δ{ya=(Φx)a}
47 / 54
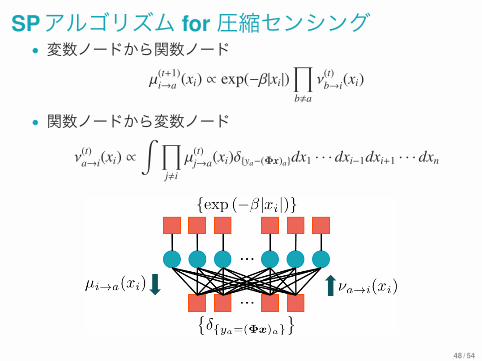
SPアルゴリズム for圧縮センシング• 変数ノードから関数ノード
µ(t+1)i→a (xi) ∝ exp(−β|xi|)
∏
b!a
ν(t)b→i(xi)
• 関数ノードから変数ノード
ν(t)a→i(xi) ∝
∫ ∏
j!i
µ(t)j→a(xi)δ{ya−(Φx)a}dx1 · · · dxi−1dxi+1 · · · dxn
48 / 54

Approximate Message Passingアルゴリズム
• メッセージの計算が解析的にできない.• n→ ∞, β→ ∞の極限を考え,中心極限定理などを使って,
SPアルゴリズムを更に近似する.(AMP:ApproximateMessage Passing [Maleki+ 2009])
• ここでは導出は省略.
49 / 54

Approximate Message PassingアルゴリズムAMPアルゴリズム
x(t+1) = ηt
(Φ∗z(t) + x(t)
)= η
(Φ∗z(t) + x(t); τ(t)
)
z(t) = y −Φx(t) +1α
⟨η′t−1
(Φ∗z(t−1) + x(t−1)
)⟩
τ(t) =τ(t−1)
α
⟨η′t−1
(Φ∗z(t−1) + x(t)
⟩)
•
η(·, b) =
⎧⎪⎪⎪⎨⎪⎪⎪⎩
x − b if b < x0 if − b ≤ x ≤ bx + b if x < −b
• α = m/n• ⟨x⟩ = n−1 ∑n
i=1 xi
50 / 54

State Evolution
• ファクターグラフが密なグラフなので,LDPC符号と同様の解析はできない.
• スピングラス理論で TAP方程式を解析するために考えられたconditioning technique [Bolthausen 2009]を使って解析.⇒ State Evolution (SE) [Bayati+ 2011]• SEで AMPの性能を記述できることは以前から実験的に分かっていたが,[Bayati+ 2011]によって理論的な証明が与えられた.
51 / 54

State Evolution
State Evolution [Bayati+ 2011]
σ2t = E
[||x(t) − x||22
]とおく.Φの各要素がN(0, 1/m)に従うとき,以
下が成り立つ.
σ2t+1 =
1αE
[|ηt(X + σtZ) − X|2
]
ただし,Xは観測信号の経験分布に従う確率変数,Z ∼ N(0, 1)で,期待値は Xと Zに関してとる.
• 実際にはもう少し一般的な形で証明されている.• これにより,平均二乗誤差が 0に収束するかどうかが分かる.
52 / 54

圧縮センシングへの応用のまとめ
• ℓ1復元問題は線形計画問題だが,仮想的に確率推論の問題と見ることができる.
• Sum-Productアルゴリズムは適用できないが,その近似アルゴリズムとして Approximate Message Passing (AMP)アルゴリズムがある.
• AMPの性能を解析する方法として State Evolutionがある.• AMPは低計算量で,復元性能は ℓ1復元とほぼ同等.
53 / 54

まとめ
• メッセージ伝搬アルゴリズムは誤り訂正符号の復号や圧縮センシングにおいて有効.• 特にこれらの分野では,Density Evolutionや State Evolutionなど,性能を理論的に解析する手法が存在.
• それ以外にも様々な場面に応用.• 画像復元,医療システム,etc.
• 圧縮センシングのように,一見確率推論の問題でない問題でも,最適化アルゴリズムとしてメッセージ伝搬アルゴリズムが有効な場合もある.⇒新たな応用の発見
54 / 54





























