Embed Size (px)
DESCRIPTION
Андрей Плахов, ЯндексЗакончил с отличием механико-математический факультет МГУ в 2002 году. Защитил кандидатскую диссертацию по программированию в Институте прикладной математики им. Келдыша РАН. В Яндексе – три года, всё это время занимается повышением качества веб-поиска. Автор поискового релиза «Спектр». До Яндекса в течение семи лет делал компьютерные видеоигры. Внерабочие интересы: P-NP проблема, квантовые вычисления, структурная лингвистика, системная биология, рисование слонов шариковой ручкой.Тема докладаПоисковая технология «Спектр».ТезисыБольшое количество запросов, отправленных в поиск Яндекса, формулируются неоднозначно. Например, по запросу [наполеон] кто-то хочет найти французского императора, а кто-то – рецепт торта. А задавая вопрос [пицца], человек может искать и ресторан с доставкой на дом, и рецепты, и даже фотографии пиццы. В основе работы «Спектра» лежит статистика поисковых запросов. Система исследует запросы всех пользователей Яндекса и выделяет в них различные объекты. Далее объекты распределяются по категориям: имена людей, названия фильмов и книг, города, модели автомобилей и т.д. «Спектр» учитывает, в какую категорию попадает объект, что обычно люди про него спрашивают, что пишут в интернете, и оценивает, какой процент людей ищут этот объект с каждой из возможных целей. Результаты поиска по многозначным запросам ранжируются с помощью вероятностной модели восприятия страницы результатов, при этом максимизируемой характеристикой является вероятность того, что пользователь получит нужный ему ответ.
Citation preview

YaC, Москва, 19 сентября 2011 года
Старший разработчик Андрей Плахов
Поисковая технология «Спектр»


Немного истории

Немного истории

Немного истории

Немного истории

Что такое «хороший поиск»?
Наивный подход

Что такое «хороший поиск»?
Наивный подход
Находить больше правильных ответов

Что такое «хороший поиск»?
Наивный подход
Находить больше правильных ответов
Показывать их выше

Что такое «хороший поиск»?
Discounted cumulative gain (DCG)
pRelj – вероятность того,
что j-й результат релевантен
poswj – вес j-й позиции

Что такое «хороший поиск»?
Discounted cumulative gain (DCG)
Проблема: как правильно
выбрать веса poswj?

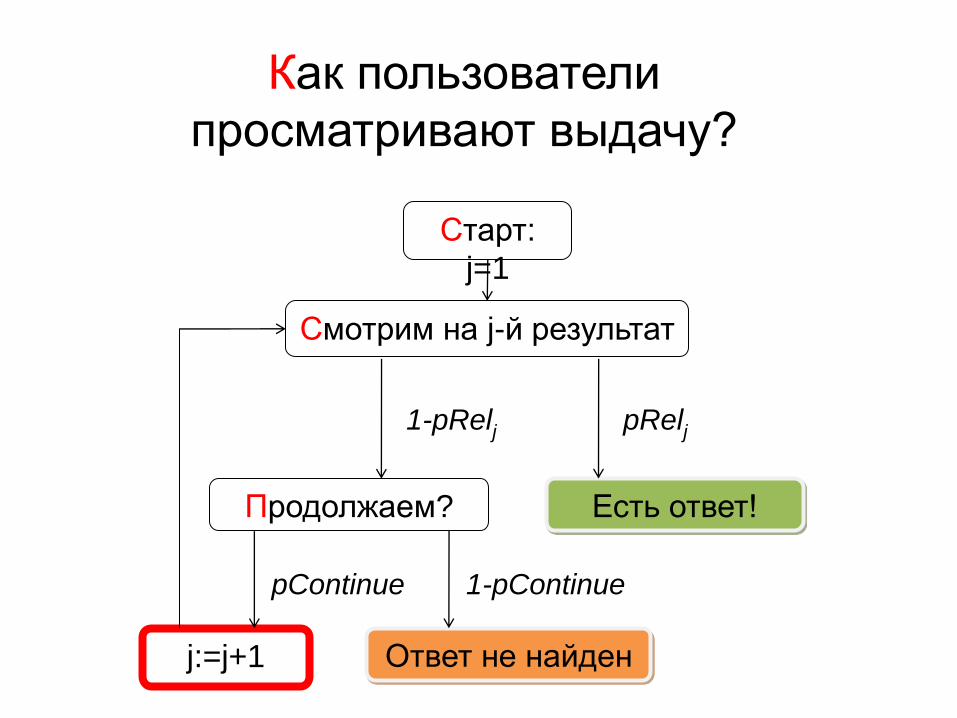
Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue
Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Как пользователи
просматривают выдачу?
Старт:
j=1
Смотрим на j-й результат
Есть ответ!
Продолжаем?
Ответ не найден j:=j+1
pRelj 1-pRelj
pContinue 1-pContinue

Основная метрика Яндекса:
pFound
MatrixNet отлично строит выдачу,
максимизирующую pFound


Основная метрика Яндекса:
pFound
Проблема: максимум достигается,
когда топ однороден

Неоднозначные запросы
[МГУ] Фото главного здания?
Приемная комиссия?
Список факультетов?
История?
Что и в каких пропорциях
показывать?

[Ягуар] – автомобиль? Животное? Напиток?
10 результатов об автомобилях хорошо выглядят на метриках, но устраивают далеко не всех Что бы ещё показать?
Неоднозначные запросы

Что же такое «Спектр» Метод, используемый поиском
Яндекса
на неоднозначных запросах:
[МГУ]
[Иоанн Павел II]
[Черепахи]
[Аспирин]
[Ягуар]
Запущен в конце 2010 года
Работает на 15-20% запросов к Яндексу

Метрика качества: wide
pFound
Wi – процент i-той поисковой потребности
pfoundi – вероятность найти ответ на i-тую потребность
Проблема: максимум, когда топ однороден

Метрика качества: wide
pFound
Wi – процент i-той поисковой потребности
pfoundi – вероятность найти ответ на i-тую потребность
Проблема: максимум, когда топ однороден

Метрика качества: wide
pFound
Wi – процент i-той поисковой потребности
pfoundi – вероятность найти ответ на i-тую потребность
Проблема: откуда мы узнаем потребности?

Поток запросов
Их миллиарды!

Поток запросов
Их миллиарды! И вот лишь некоторые примеры:
[как сделать мотоцикл из двух зажигалок]

Поток запросов
Их миллиарды! И вот лишь некоторые примеры:
[как сделать мотоцикл из двух зажигалок]
[ресторан в темноте]

Поток запросов
Их миллиарды! И вот лишь некоторые примеры:
[как сделать мотоцикл из двух зажигалок]
[ресторан в темноте]
[взрыв в индии сегодня]

Поток запросов
Их миллиарды! И вот лишь некоторые примеры:
[как сделать мотоцикл из двух зажигалок]
[ресторан в темноте]
[взрыв в индии сегодня]
[оральный секс у летучих мышей]

Поток запросов
[как сделать мотоцикл из двух зажигалок]
[ресторан в темноте]
[взрыв в индии сегодня]
[оральный секс у летучих мышей]
[изменения в ст 290 ук рф]
Их миллиарды! И вот лишь некоторые примеры:

Поток запросов: примеры
…
турбаза старый замок алтай
турбаза старый замок астрахань
турбаза старый замок на телецком
турбаза старый замок святогорск
турбаза старый замок телецкое
турбаза старый замок телецкое озеро
турбаза старый замок телецкое адрес
турбаза старый замок телецкое телефон
…

…
audi a8 4.2 quattro расход топлива
audi a8 4.2 quattro расход
audi a8 4.2 quattro киев
audi a8 4.2 quattro цены
audi a8 4.2 quattro комплектация
audi a8 4.2 quattro комплектация 2003
audi a8 4.2 quattro обзор
audi a8 4.2 quattro отзывы владельцев
audi a8 4.2 quattro характеристики
…
Поток запросов: примеры

Используем лог запросов, и узнаем,
какие потребности есть у пользователей!
Увы, не всѐ так просто…
Итак, что будем делать?

Используем лог запросов, и узнаем,
какие потребности есть у пользователей!
Увы, не всѐ так просто…
Не все уточнения – «потребности»
Итак, что будем делать?

Используем лог запросов, и узнаем,
какие потребности есть у пользователей!
Увы, не всѐ так просто…
Не все уточнения – «потребности»
Они отличаются не только весами
Итак, что будем делать?

Используем лог запросов, и узнаем,
какие потребности есть у пользователей!
Увы, не всѐ так просто…
Не все уточнения – «потребности»
Они отличаются не только весами
Разные уточнения – но одна и та же
потребность
Итак, что будем делать?

Зачем нам «семантика»?
Не все расширения полезны
[москва] и [москва тула]
[минута] и [минута славы]
[время] и [время намаза]
[юбки] и [юбки порно]

Зачем нам «семантика»?
Не все расширения полезны
[москва] и [москва тула]
[минута] и [минута славы]
[время] и [время намаза]
[юбки] и [юбки порно]
Нужно отобрать «правильные» расширения

Использование семантики
Сосредоточимся на запросах о том, что нам понятно
Фильмы
Книги
Люди
Гаджеты
Автомобили
Болезни и лекарства
…
Будем распознавать объекты этих категорий.
Для каждой из них - свои поисковые потребности.

Технология «Спектр»

Технология «Спектр»
выясняем, в какие категории попадает запрос

Технология «Спектр»
выясняем, в какие категории попадает запрос
объединяем поисковые потребности, имеющие смысл для этих категорий

Технология «Спектр»
выясняем, в какие категории попадает запрос
объединяем поисковые потребности, имеющие смысл для этих категорий
назначаем им веса

выясняем, в какие категории попадает запрос
объединяем поисковые потребности, имеющие смысл для этих категорий
назначаем им веса
получаем лучшие документы для каждой потребности
Технология «Спектр»

Технология «Спектр»
выясняем, в какие категории попадает запрос
объединяем поисковые потребности, имеющие смысл для этих категорий
назначаем им веса
получаем лучшие документы для каждой потребности
формируем выдачу, максимизирующую wide pFound

Но всѐ сложнее содержательные сложности
Сложности классификации
Неклассифицированные запросы
Непонятные результаты
Геолокальность
Временная зависимость
Опасные ответы
…и многие, многие другие
Н

Обрабатывать миллиарды запросов, классифицировать, устанавливать взаимосвязи
Получать ответы по всем поисковым потребностям
(не задавая 15 запросов вместо одного)
На каждый запрос решать
по NP-полной задаче
• ѐ
…и многие, многие другие
И ещѐ сложнее технологические сложности

Хорошие новости Меньше популярных запросов без кликов
CTR отдельных результатов растѐт
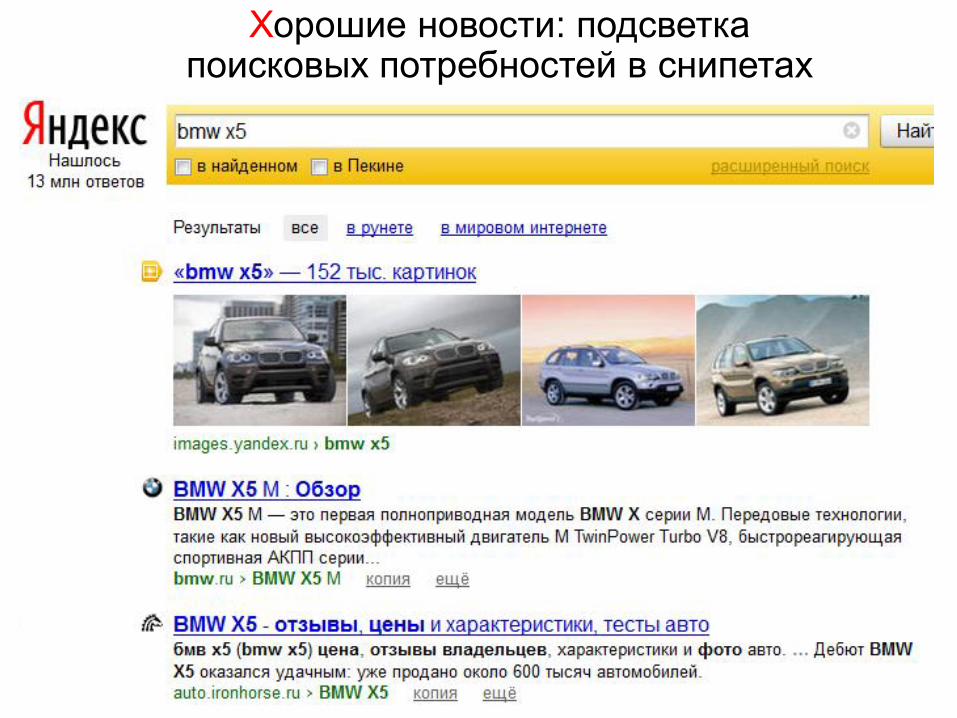
Хорошие новости: подсветка поисковых потребностей в снипетах

И ещѐ сложнее Простыми методами давно уже не обойтись

И ещѐ сложнее Простыми методами давно уже не обойтись
Нам нужно:
больше знать об окружающем мире

И ещѐ сложнее Простыми методами давно уже не обойтись
Нам нужно:
больше знать об окружающем мире
лучше понимать пользовательские сессии

И ещѐ сложнее Простыми методами давно уже не обойтись
Нам нужно:
больше знать об окружающем мире
лучше понимать пользовательские сессии
лучше понимать естественные языки

И мы с этим
справимся!