Embed Size (px)
Citation preview

Cloud storage in azienda:perchè riak ci è piaciuto
Cloud storage in azienda:perchè riak ci è piaciuto
Alberto Eusebi [email protected]
Biodec Srlhttp://www.biodec.com
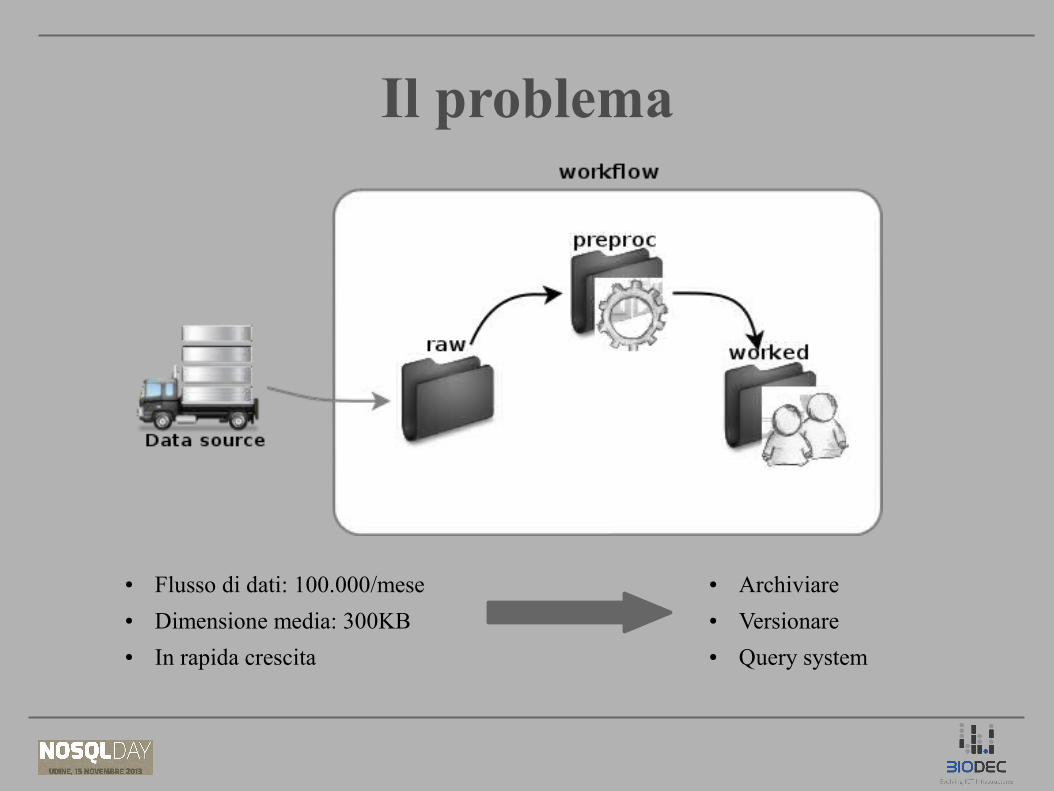
Il problemaIl problema
● Flusso di dati: 100.000/mese● Dimensione media: 300KB● In rapida crescita
● Archiviare● Versionare● Query system

Idee?Idee?
● Storage basato su db SQL
● Storage su filesystem (metadati su SQL)
● Dati su NoSql (metadati su SQL)

La scelta: Riak + PostgresLa scelta: Riak + Postgres
● Usato e consigliato in scenari simili● Ridondanza● High availability e affidabilità (masterless; no single
point of failure)● Scalabilità● Setup -ragionevolmente- semplice● Versatilità (eg. pluggable storage backends)● Buona documentazione e supporto tecnico● Codice open; progetto “vivo”

RiakRiak● Rilasciato nel 2009 da Basho Technology● Basato su Amazon Dynamo
– http://docs.basho.com/riak/latest/theory/dynamo/
● Licenza Apache2● Altri prodotti:
– Riak CS
– Versioni enterprise
● Erlang (C, Java, Javascript)● API native:
– Http
– Protocol Buffer (Google)
● Clients libraries (Basho supported): Java, Erlang, Ruby, Php, Python– http://docs.basho.com/riak/latest/dev/using/libraries/

Anti-outline Anti-outline
● Map-reduce● Strutture dati specifiche:
– Full text search (tagging)
– Key indexing (2i)
– Link walking
● Gestione avanzata di conflitti (vector clocks)

Requisiti e progettazioneRequisiti e progettazione
● System:– Red Hat based: Red Hat Enterprise Linux, CentOS, Fedora
– Debian based: Debian, Ubuntu
– Solaris based: Sun Solaris, OpenSolaris
● Hardware
– Multi-core 64-bit CPU
– Minimum 4 GB RAM
– Multiple Fast Hard Disks (RAID and/or SSD)
– Fast Network (Gigabit +)
● Virtualization?
● Network load balancing (eg. Haproxy)

SetupSetup
● Packages (deb, rpm …)– Un nodo per macchina
– Facile gestione dell'upgrade
– Limitazione di problemi con Erlang
● Source tarball– Massima libertà nel setup (ambiente di test)
– Utilizzo di make e rebar per la creazione e la distribuzione dei nodi
– Gestire la dipendenza con Erlang (kerl)

Partizionamento dei datiPartizionamento dei dati● Indirizzamento basato sugli hash delle chiavi (consistent hashing)● Spazio di indirizzamento: 160-bit (“bucket/key”)● Numero di partizioni fissato (ring_creation_size)
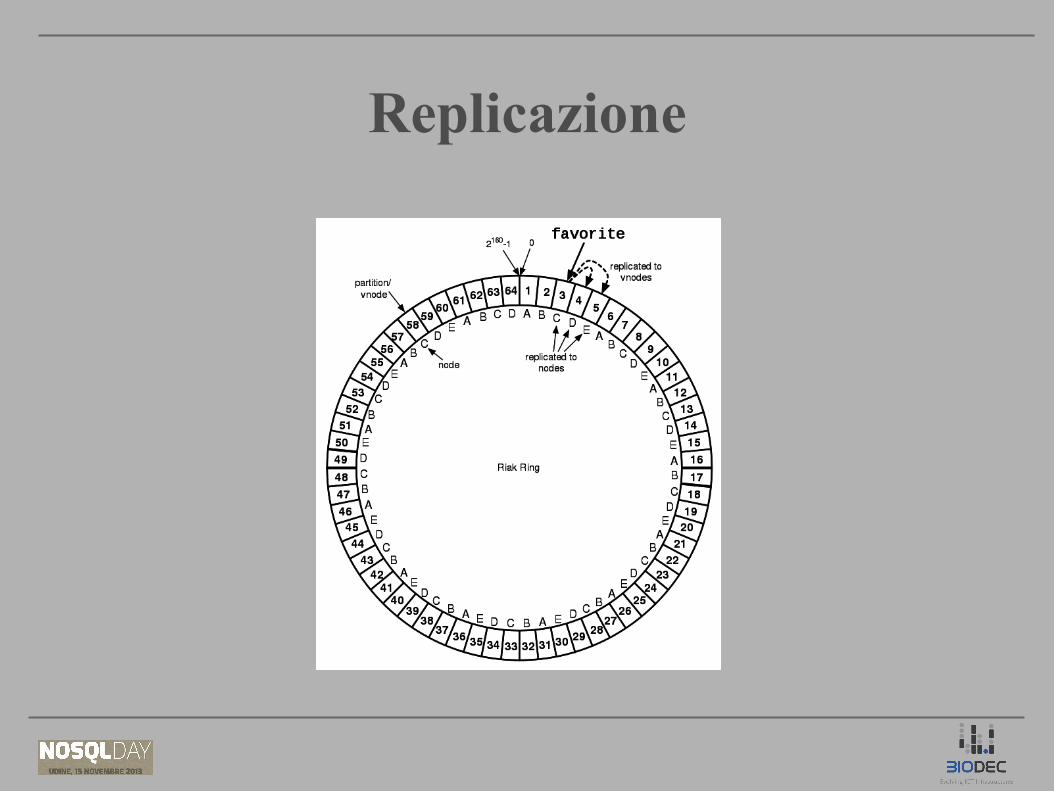
ReplicazioneReplicazione
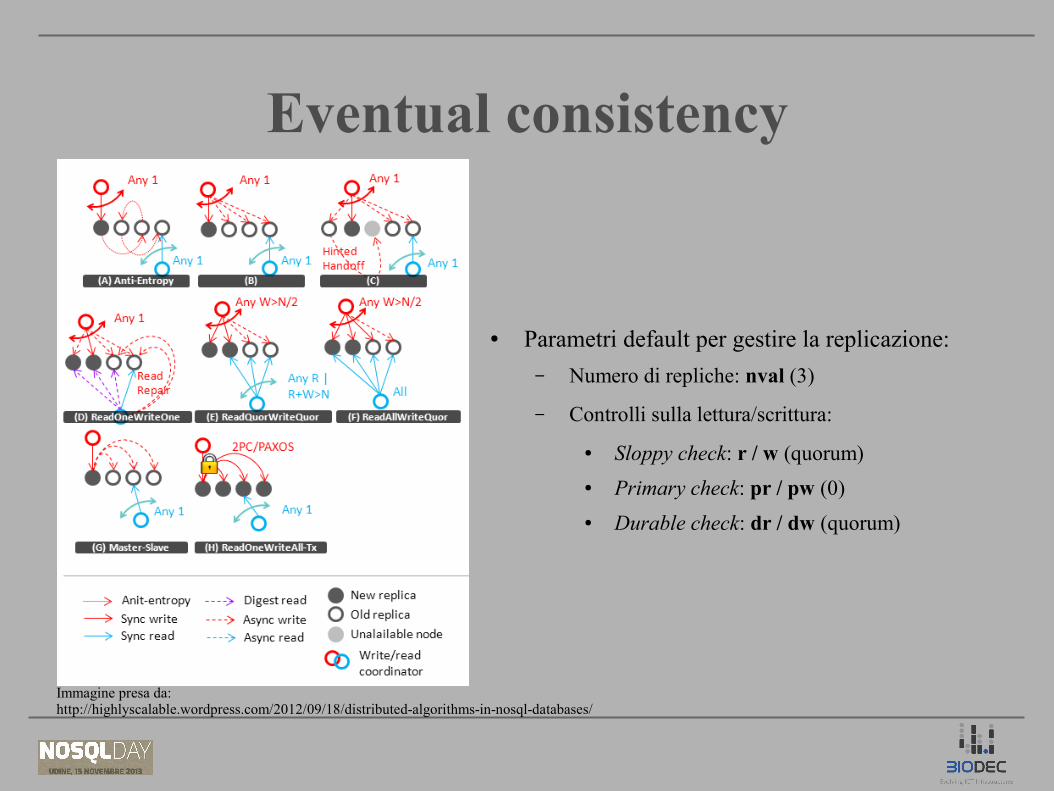
Eventual consistencyEventual consistency
● Parametri default per gestire la replicazione:
– Numero di repliche: nval (3)
– Controlli sulla lettura/scrittura:
● Sloppy check: r / w (quorum)
● Primary check: pr / pw (0)
● Durable check: dr / dw (quorum)
Immagine presa da:http://highlyscalable.wordpress.com/2012/09/18/distributed-algorithms-in-nosql-databases/

EntropyEntropy
● Inconsistenza in scrittura
– last write wins (default)
– allow multi (disabilitato)
● Inconsistenza in lettura
– (Passive/Active) Read repair

Scelta del backendScelta del backend
● Bitcask (default)● LevelDB● Memory● Multi
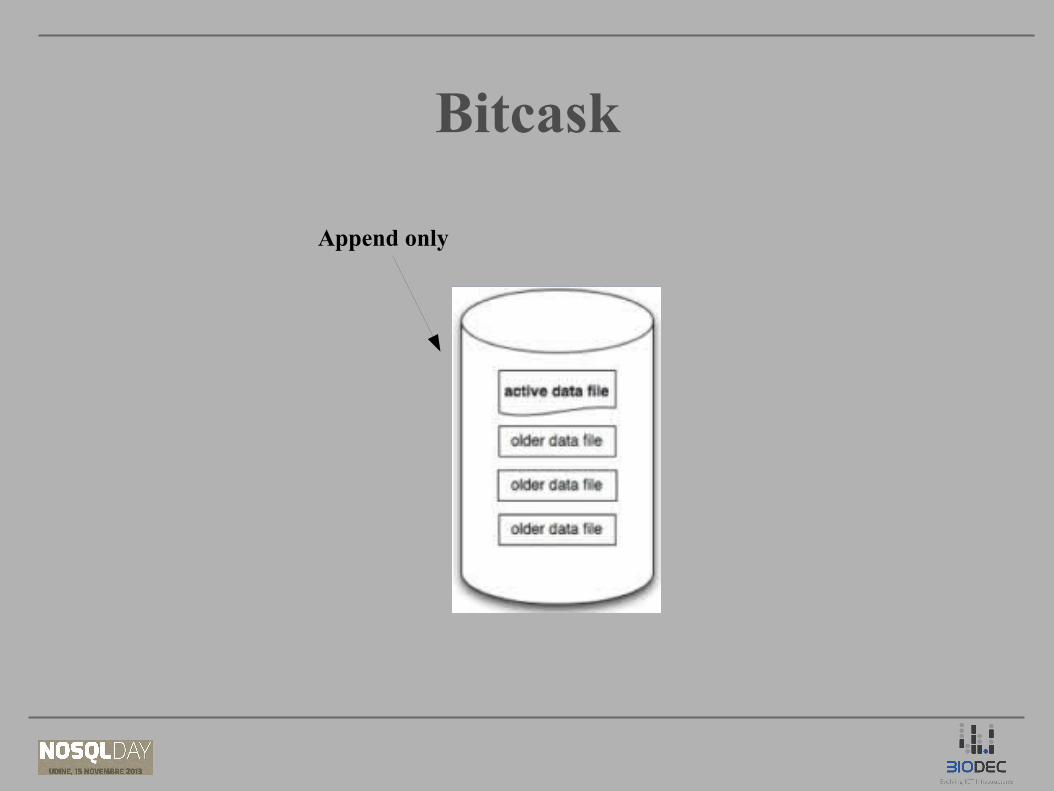
BitcaskBitcask
Append only

BitcaskBitcask
● Bassa latenza (Append only)● High throughhput● Backup agevolato
Attenzione a:● Uso della ram (chiavi in memoria)● Overheads sull'utilizzo del disco● Open files limit
Live demoLive demo
Gestione del clusterGestione del cluster
● Aggiornamento● Scalabilità: verticale vs orizzontale● Backup● Monitoraggio

LimitiLimiti
● Limite nella dimensione degli oggetti● Gestione degli errori rivedibile● Fallimento a cascata● Occhio al tuning

Domande?Domande?
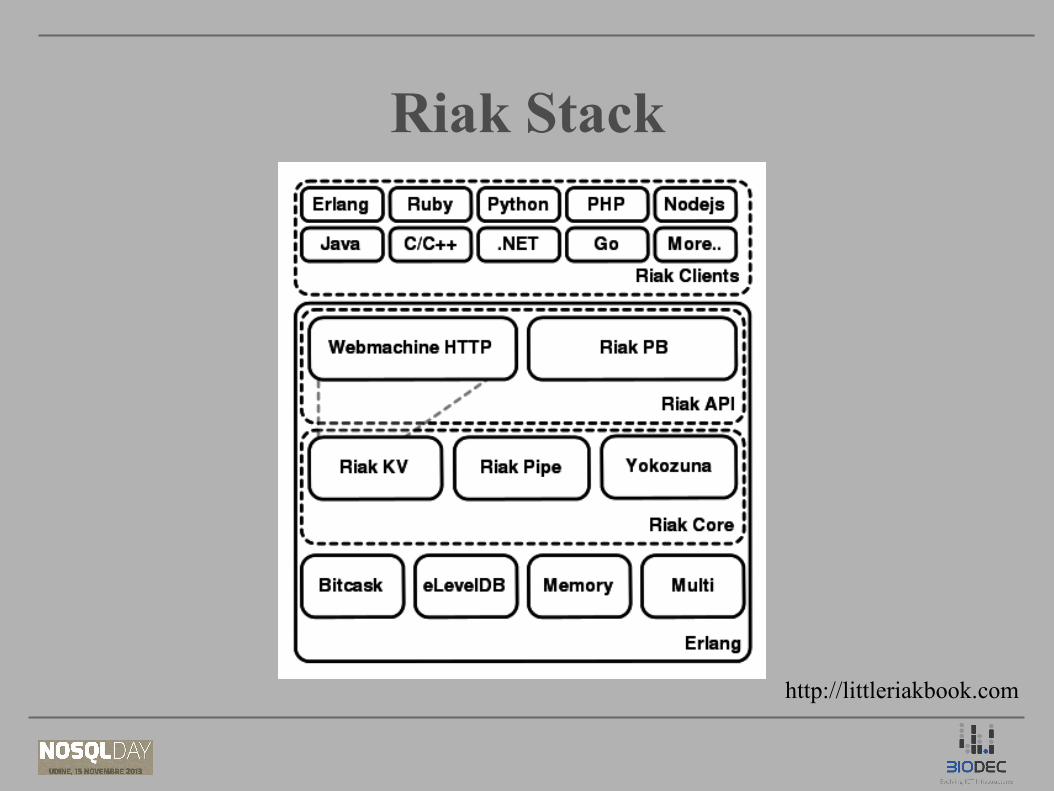
Riak StackRiak Stack
http://littleriakbook.com
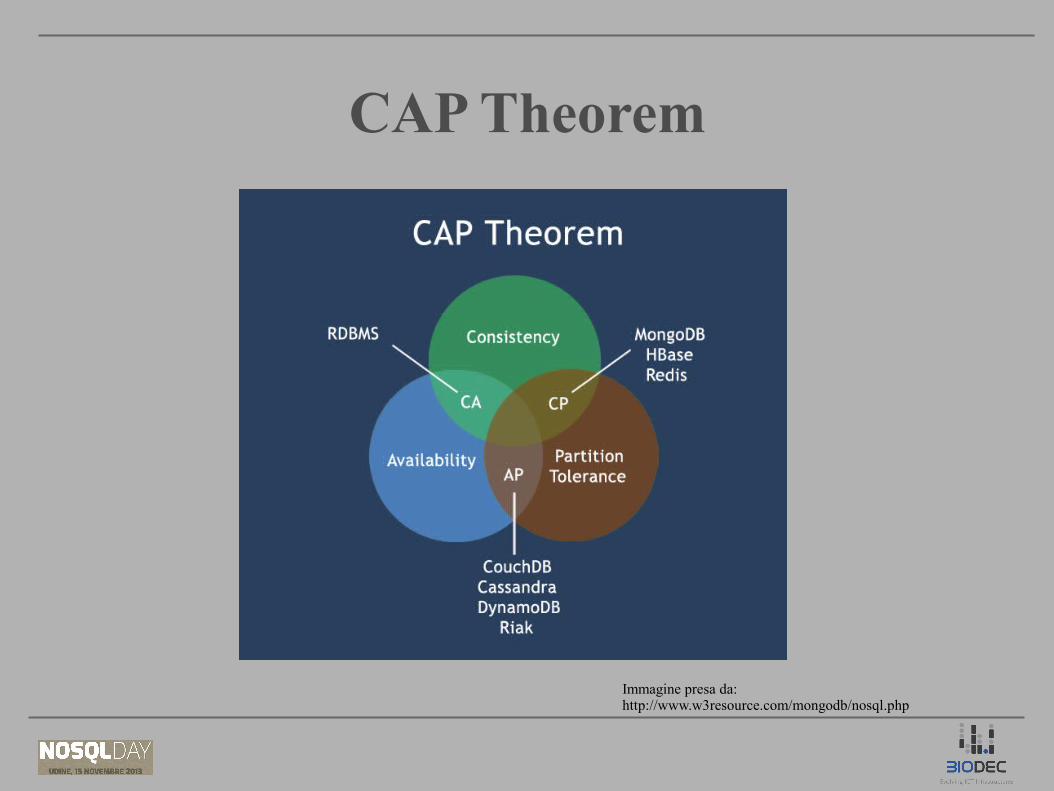
CAP TheoremCAP Theorem
Immagine presa da:http://www.w3resource.com/mongodb/nosql.php

Il “buon” vecchio metodoIl “buon” vecchio metodo
● Directories enormi
● Ridondanza/partizionamento manuale
● Sistema di ricerca improvvisato





























