Embed Size (px)
Citation preview

Usare al meglio strumenti come Dandelion API e
Atokaper estrarre informazioni utili al proprio lavoro
Matteo Brunati - Community Manager SpazioDati - @dagoneye
Corso “Media digitali e Data Journalism” 19 novembre 2015
Ci serve partire da lontano
Contesto tra Web of Data e
Web as Content
Strumenti per giocare con
entrambi, grazie al lavoro di SpazioDati
obiettivo: quale?
consapevolezza
scenari e il mondo del possibile
collegamenti tra mondi diversi

...uno spunto per partire...

WHAT and WHY
“la fonte, il dato” devono tornare ad
essere un tema centrale #fact-checking

http://datadrivenjournalism.net/news_and_analysis/How_to_become_a_data_journalist_Day_3

quindi sembra facile oggi...
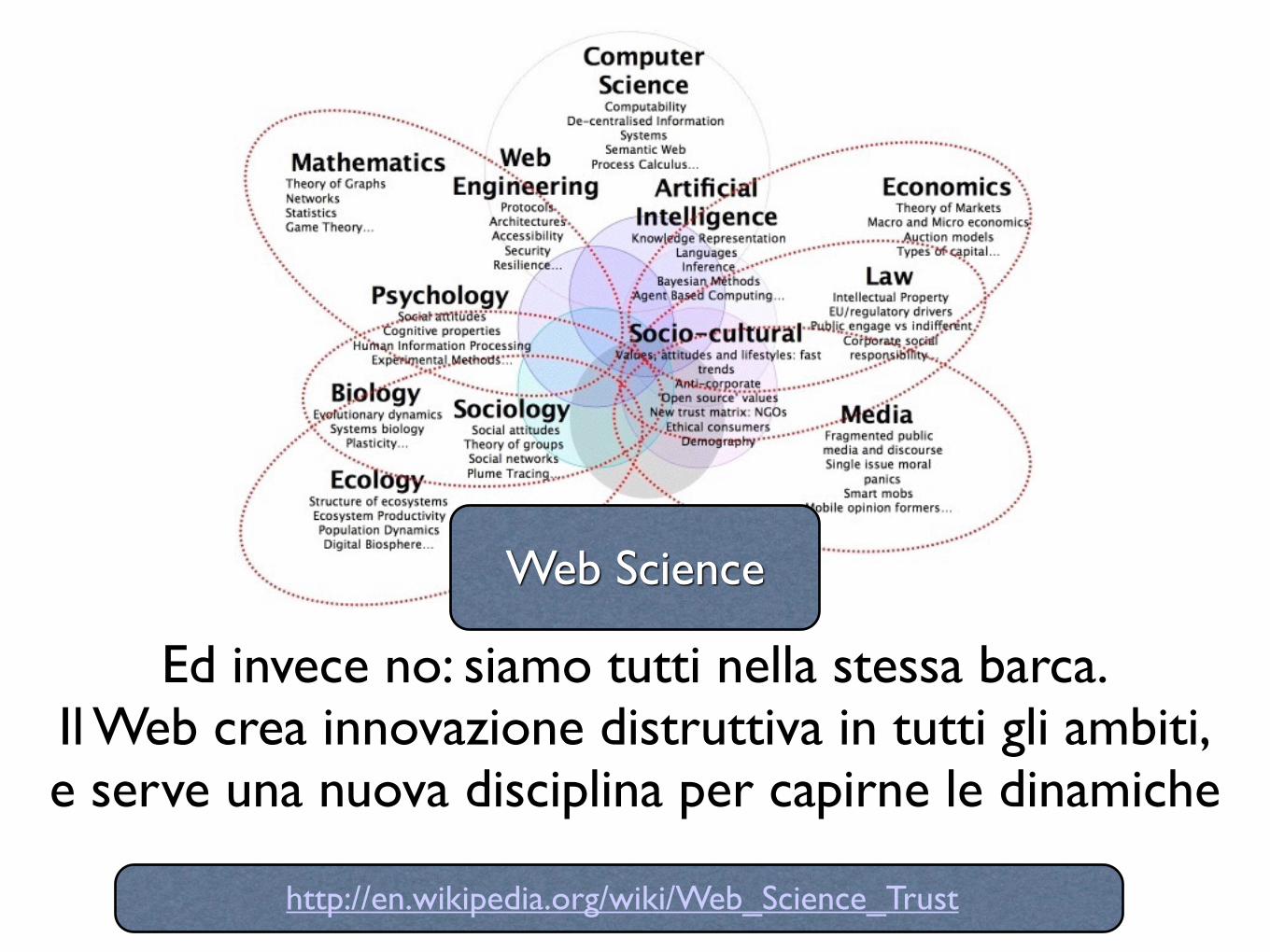
Ed invece no: siamo tutti nella stessa barca.Il Web crea innovazione distruttiva in tutti gli ambiti,e serve una nuova disciplina per capirne le dinamiche
Web Science
http://en.wikipedia.org/wiki/Web_Science_Trust
modellidi business
intermediazione
competenze catena del valore
anche il giornalismo è in costante cambiamento

ma qualche percorso esiste, e si staconsolidando...

:)
http://datajournalismhandbook.org/1.0/en/
ecco il tema dei DATI

approfondiamoquesti dati allora...
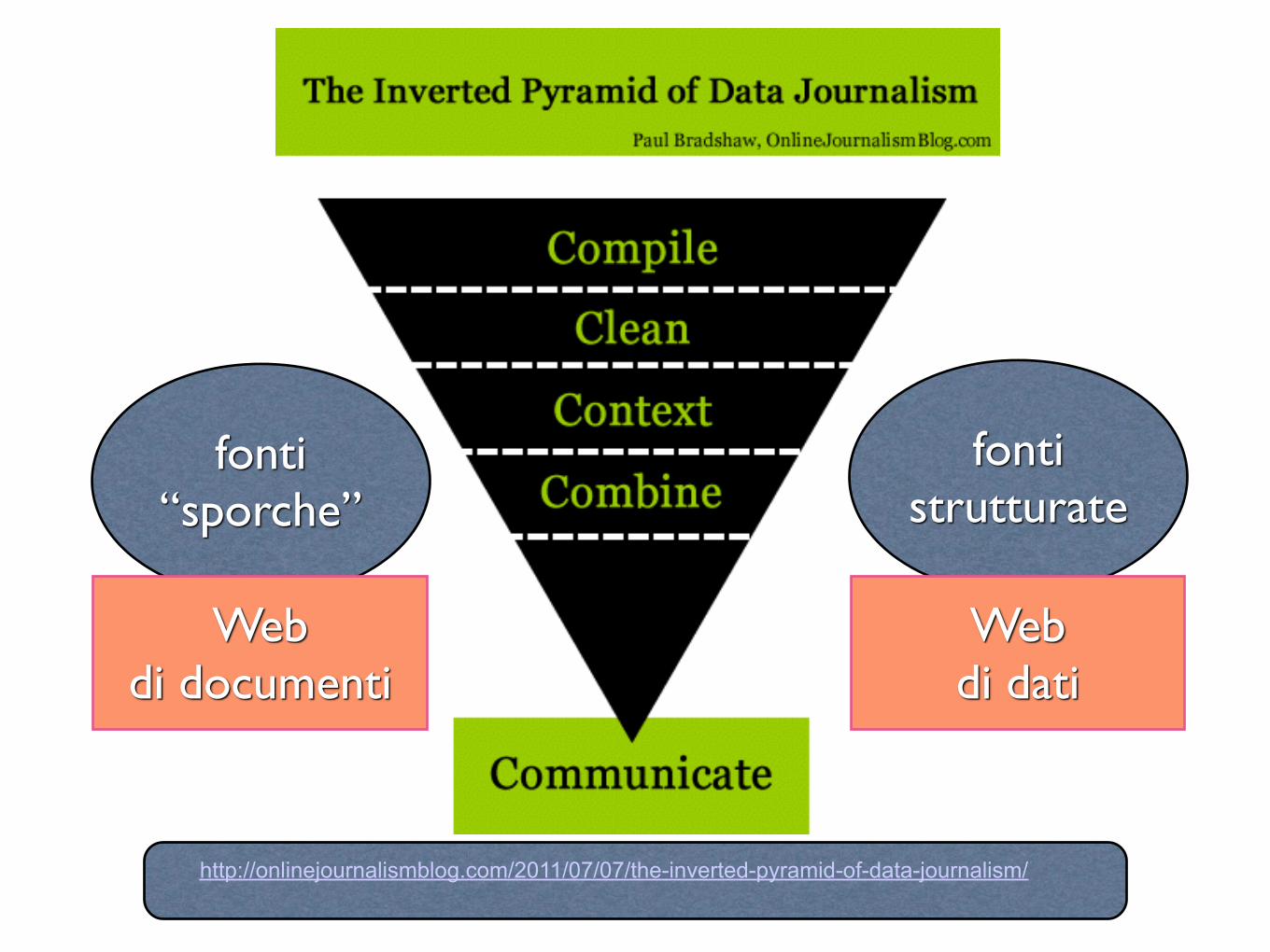
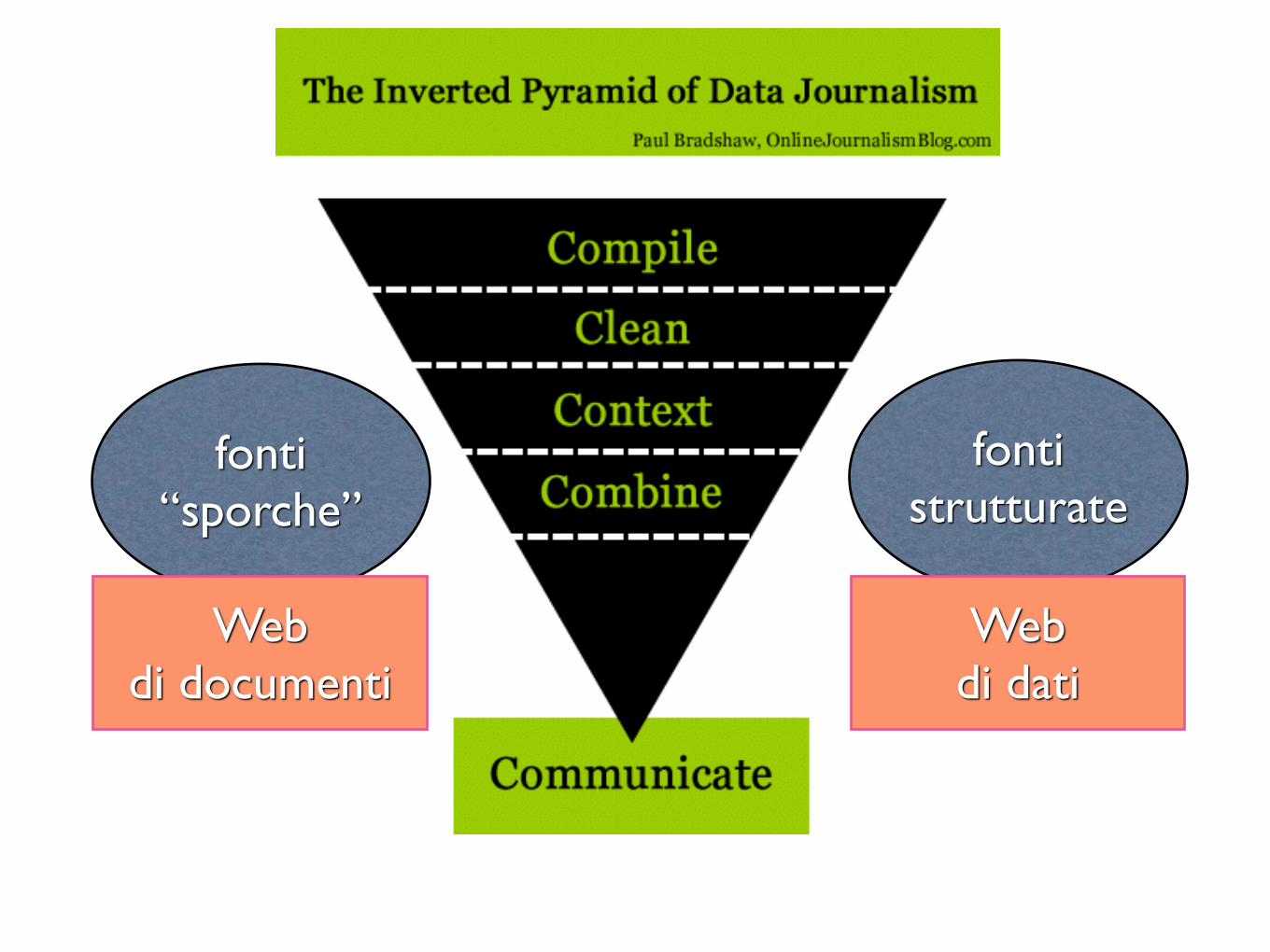
http://onlinejournalismblog.com/2011/07/07/the-inverted-pyramid-of-data-journalism/
fonti “sporche”
fonti strutturate
Web di documenti
Web di dati

diamo uno sguardo a questi dati strutturati...
fonti strutturate
Web di dati

Per capire il WEB dei dati, serve fare un ripassosu cosa sia il WEB

sappiamo cos’è il WEB ed abbiamocapito perchè è nato?
Il Web in un paper nel 1989, ed aveva già molto oltre semplici link
ai documenti
Il web come spazio di condivisione delle
informazioni, che PERMANE, e decentralizzato
a chi devo chiedere di inserire un link?
avevo l’email e gli allegati: cosa mi offre in
più?
http://www.garrygolden.net/2010/01/30/davos-2010-ideas-lab-talks-from-mit-group-on-nature-of-social-and-connected-intelligence-5-videos/

principio del Least Power,ovvero umiltà del design
con il riuso che è insito nella trasparenza della struttura del Web...
http://www.shirky.com/writings/view_source.html

cos’è un testo?
contenuto
contenitoreparagrafi
titolipiè di pagina
immagini
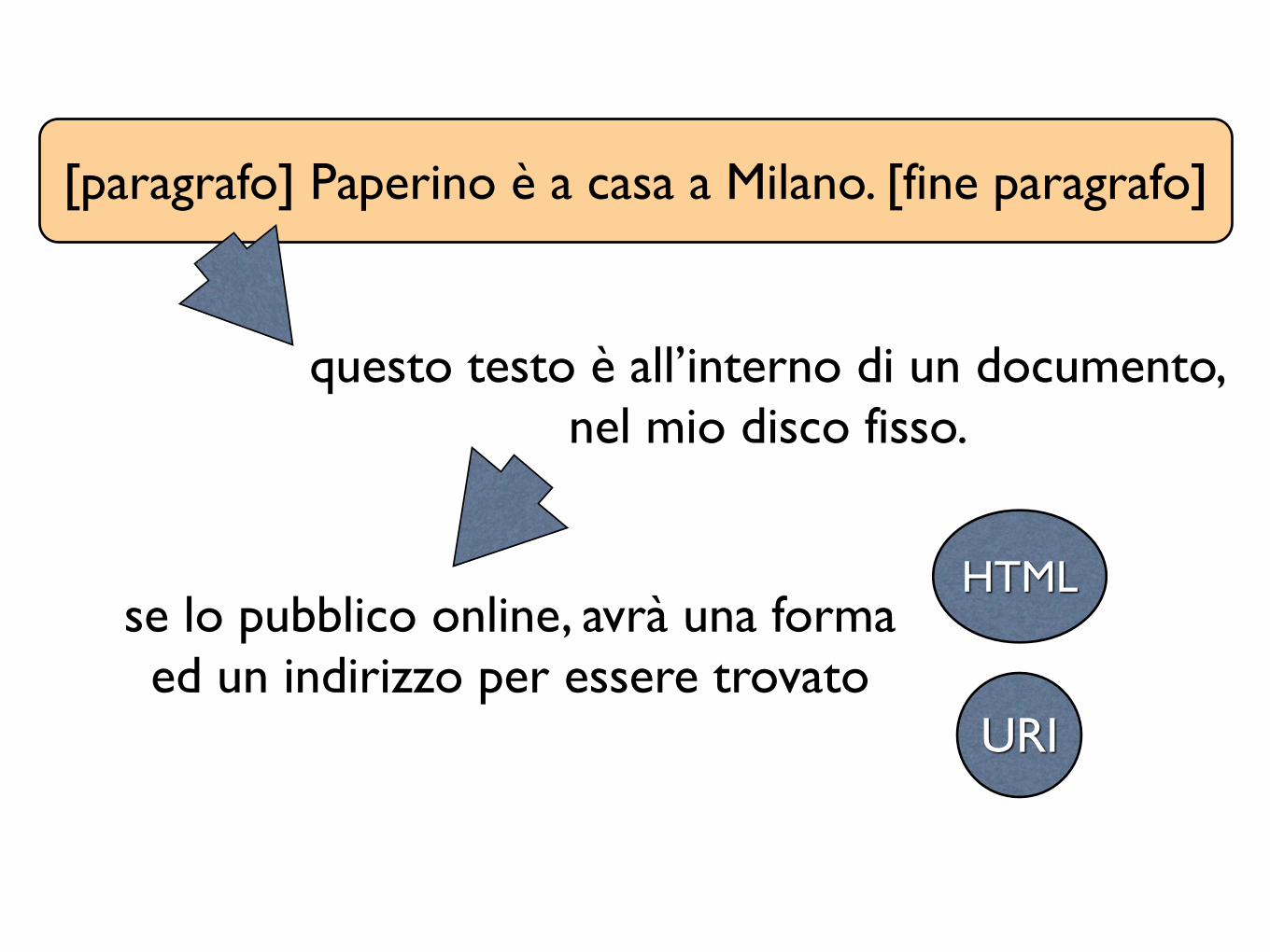
[paragrafo] Paperino è a casa a Milano. [fine paragrafo]
questo testo è all’interno di un documento,nel mio disco fisso.
se lo pubblico online, avrà una formaed un indirizzo per essere trovato
URI
HTML
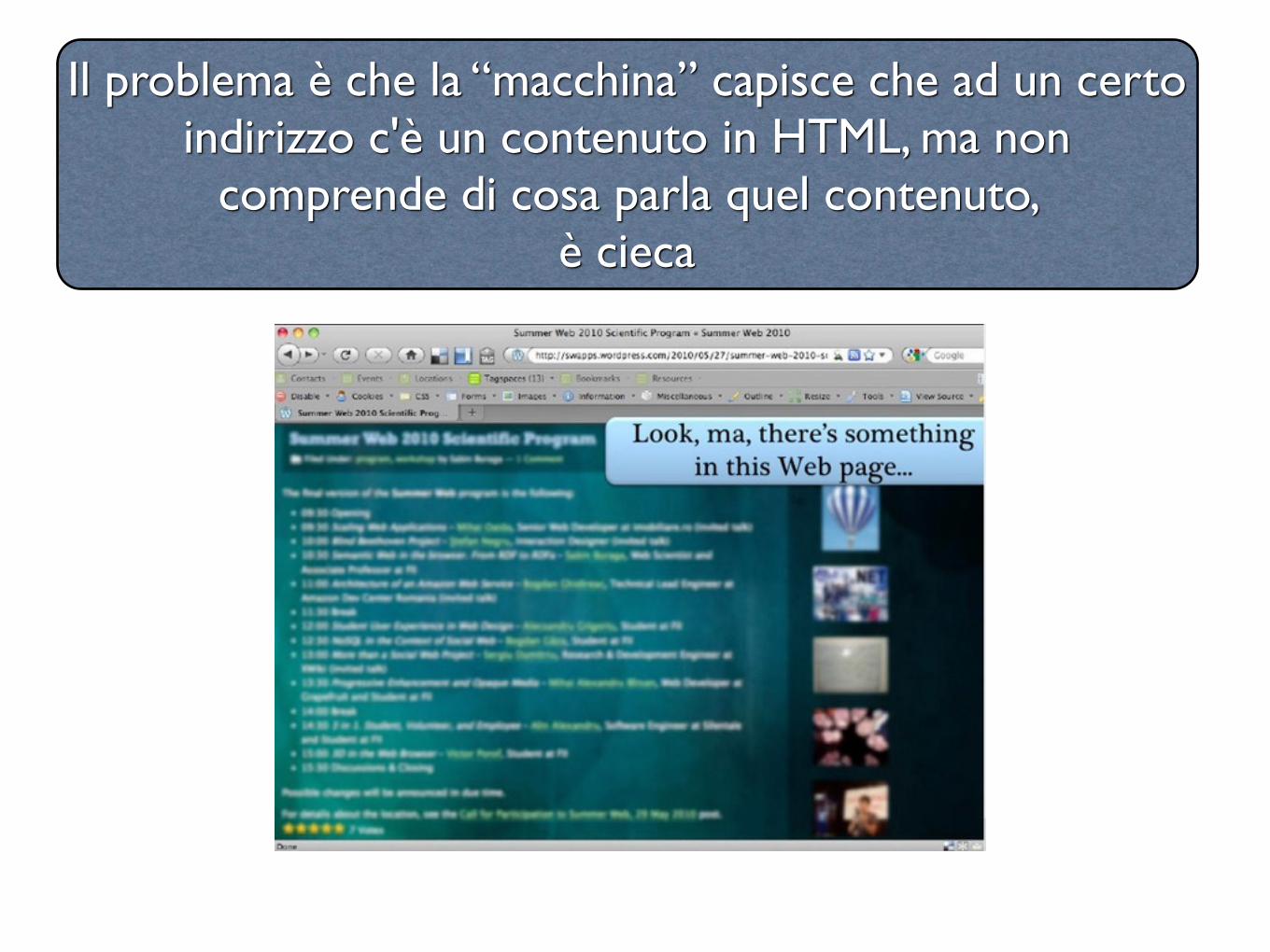
Il problema è che la “macchina” capisce che ad un certo indirizzo c'è un contenuto in HTML, ma non
comprende di cosa parla quel contenuto, è cieca

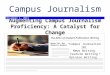
Ed ecco perché si va verso il mondodei Linked Data

Linked Data è pubblicare i dati online,ma non solo sul Web,
ma anche NEL Web

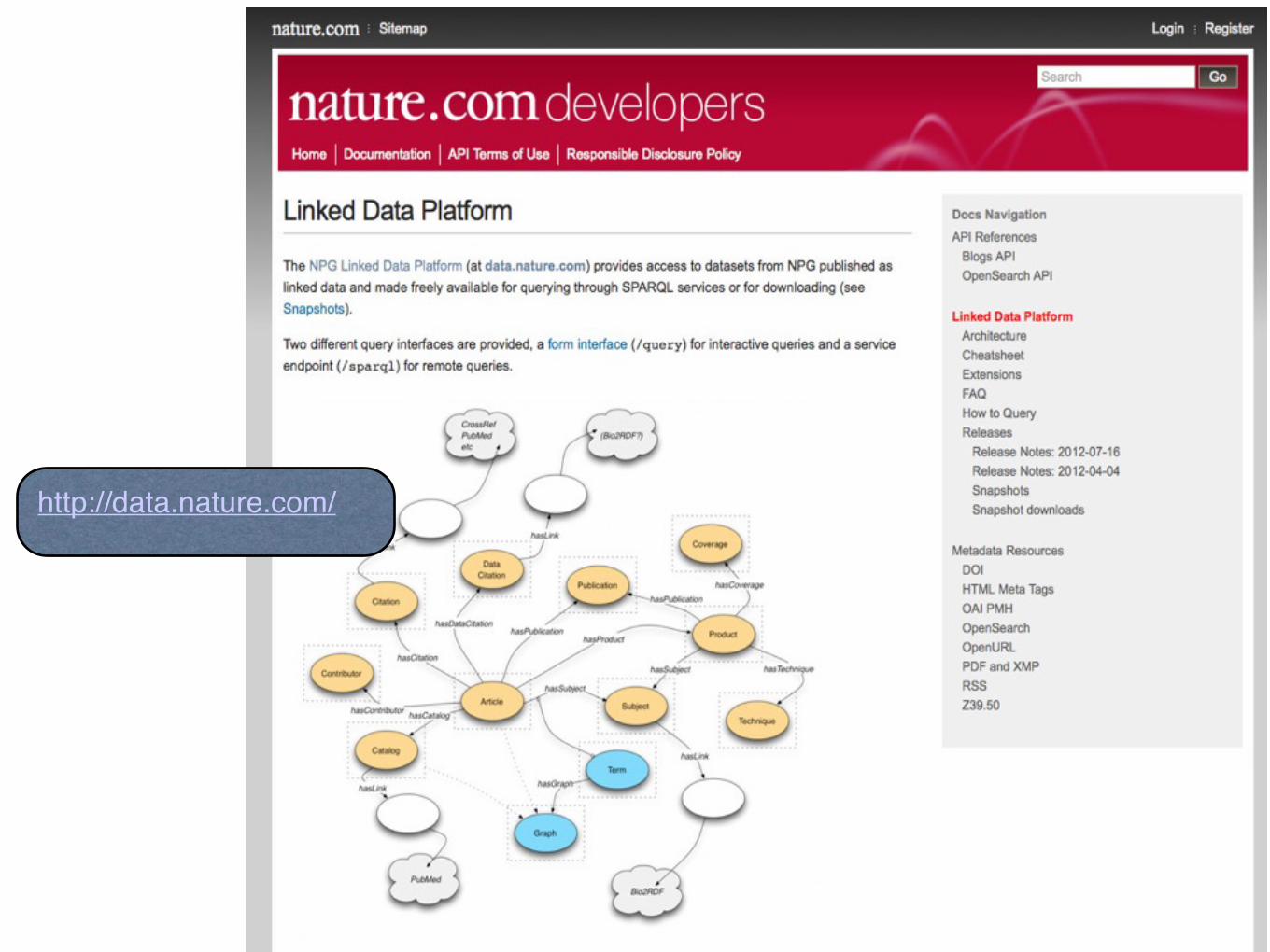
LINKED OPEN DATA CLOUD

Diversi livelli di avvicinamento in questo percorso
I dati Linked sono fatti per essere letti dai
programmi

Linked Data è una delle sintesi migliori del vecchio nome “Semantic Web”
Linked Data è già OGGI una delle fonti, ed è quella più complessa, perché
pensata per le macchine

http://www.guardian.co.uk/help/insideguardian/2010/jan/25/news-linked-data-summit

Ce ne sono molte ormaiin giro... e dovete sapere che
ce ne saranno sempre di più...

it.dbpedia.org

Così un po' abbiamo digeritol'idea del Semantic Web: rendere
la macchina capace di tracciare LINK
e RELAZIONI con il contenuto,andando oltre alla pagina come
elemento atomico del contenuto...

“A thing is defined by its relationships”

…relazioni che creano percorsi pensati per essere visti dalle macchine:ovviamente come non pensare
alla SEO? :)

SEO = Search Engine Optimization,
ovvero come farsi trovare dai motori di ricerca:
che sono di nuovo “macchine”:)
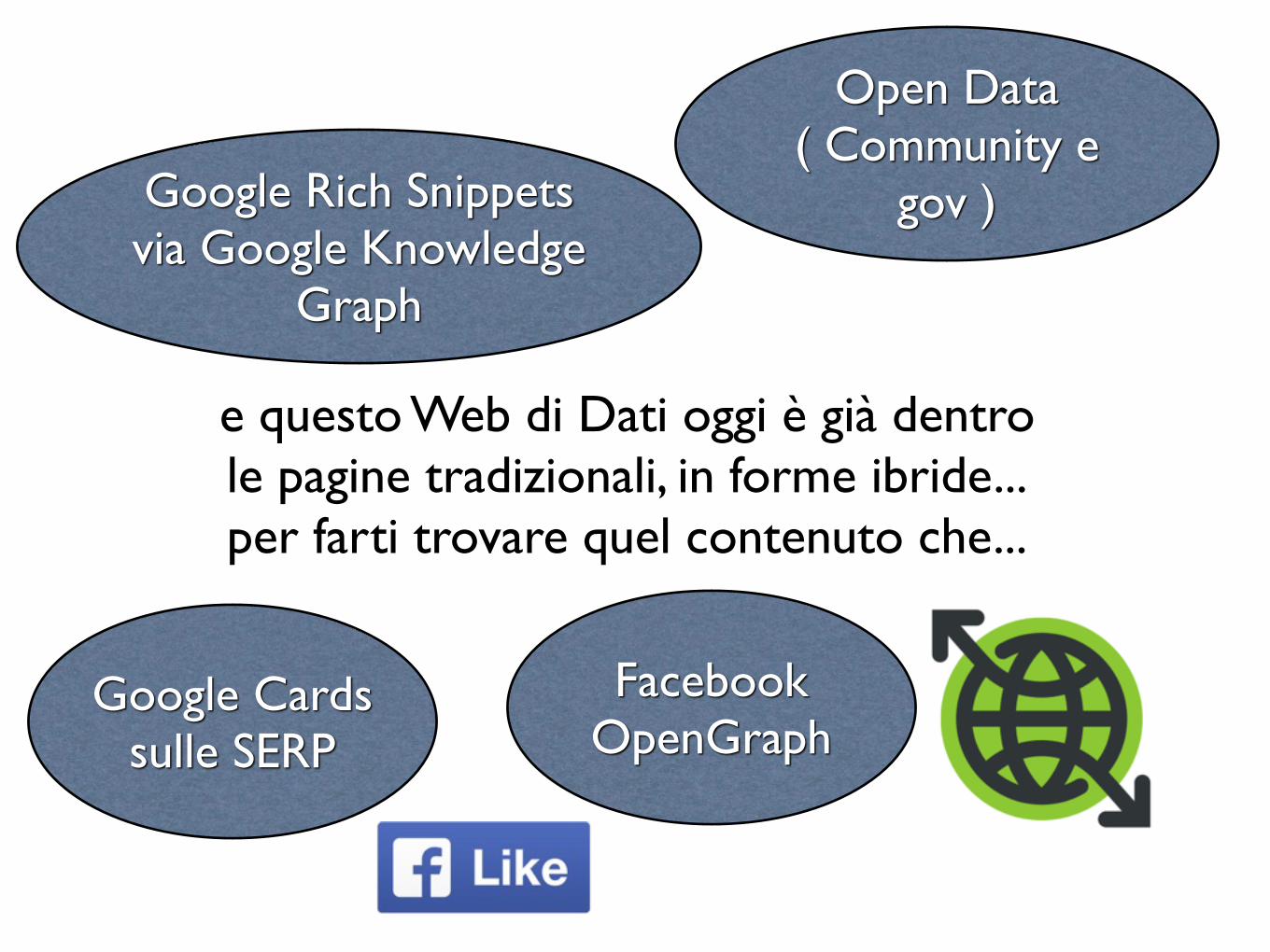
e questo Web di Dati oggi è già dentrole pagine tradizionali, in forme ibride...per farti trovare quel contenuto che...
Facebook OpenGraph
Google Rich Snippets via Google Knowledge
Graph
Open Data( Community e
gov )
Google Cards sulle SERP

Ci sono alcuni determinati formati nelle pagine,tutti col nome “dati strutturati”
http://webdatacommons.org/structureddata/index.html#results-2013-1
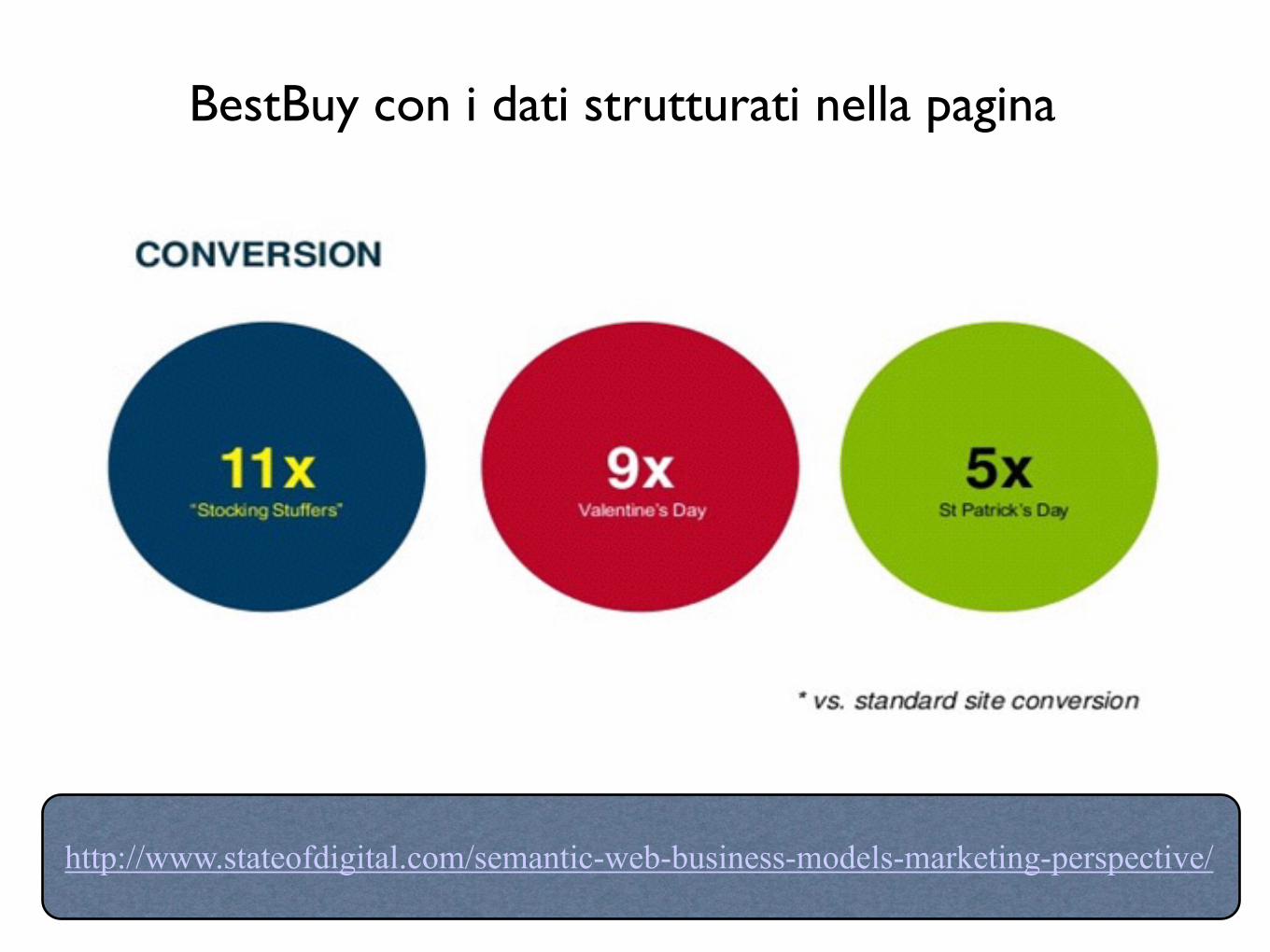
BestBuy con i dati strutturati nella pagina
http://www.stateofdigital.com/semantic-web-business-models-marketing-perspective/
per provare a vedere questi strati di
informazione strutturata
https://developers.google.com/structured-data/testing-tool/
Google structured data testing tool

ma io “giornalista”, con questi Linked Data, perchè devo averci a che fare?
stimolare i programmatori ed i tecnici a darmi una mano, consapevole che
esistono quei dati e quelle fonti
chiedere lumi a chi li ha pubblicati, come con quelli
Open Data + semplici: stimolare
feedback e miglioramento continuo
fonti “sporche”
fonti strutturate
Web di documenti
Web di dati
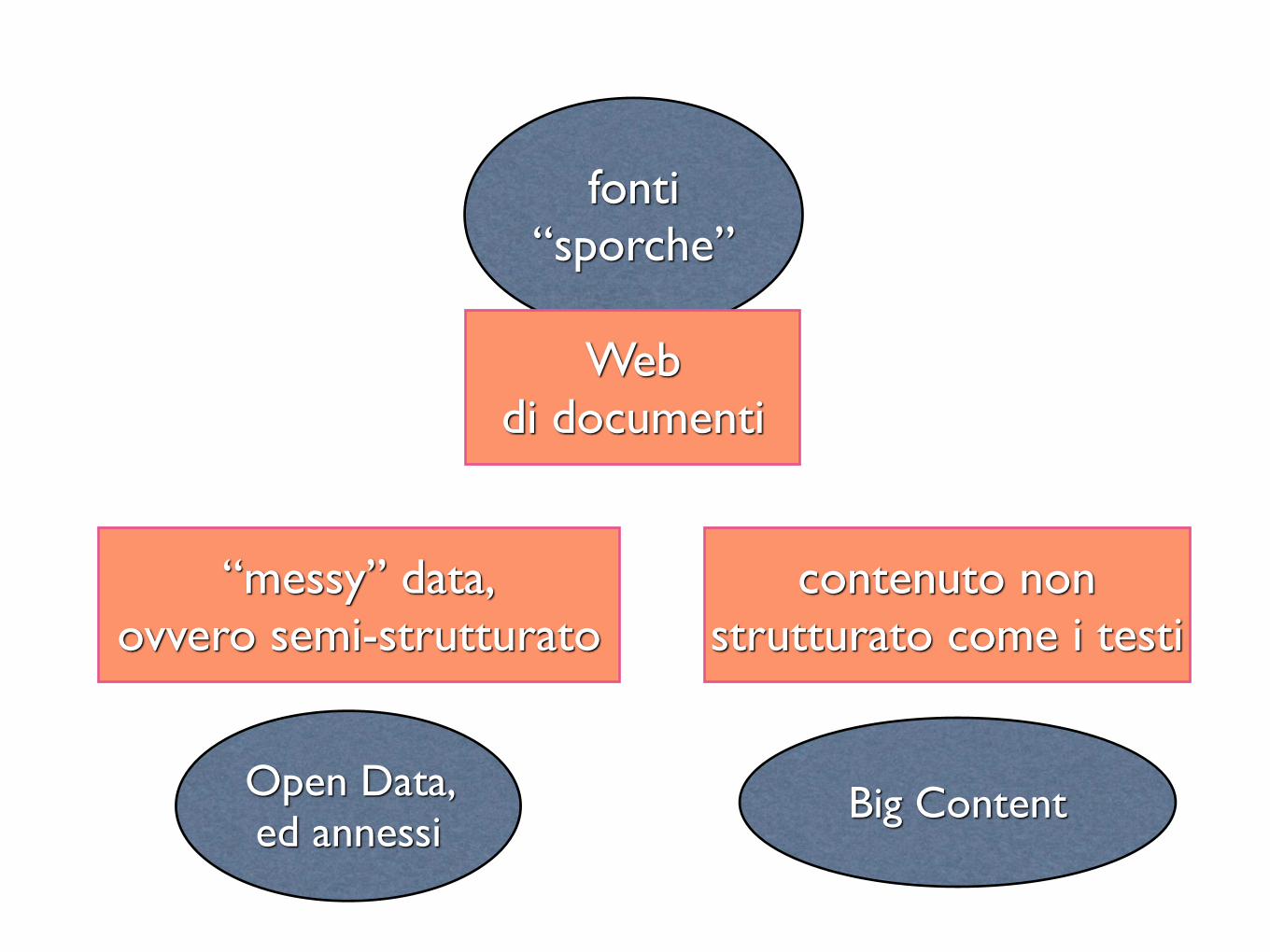
fonti “sporche”
Web di documenti
contenuto non strutturato come i testi
“messy” data,ovvero semi-strutturato
Big ContentOpen Data, ed annessi
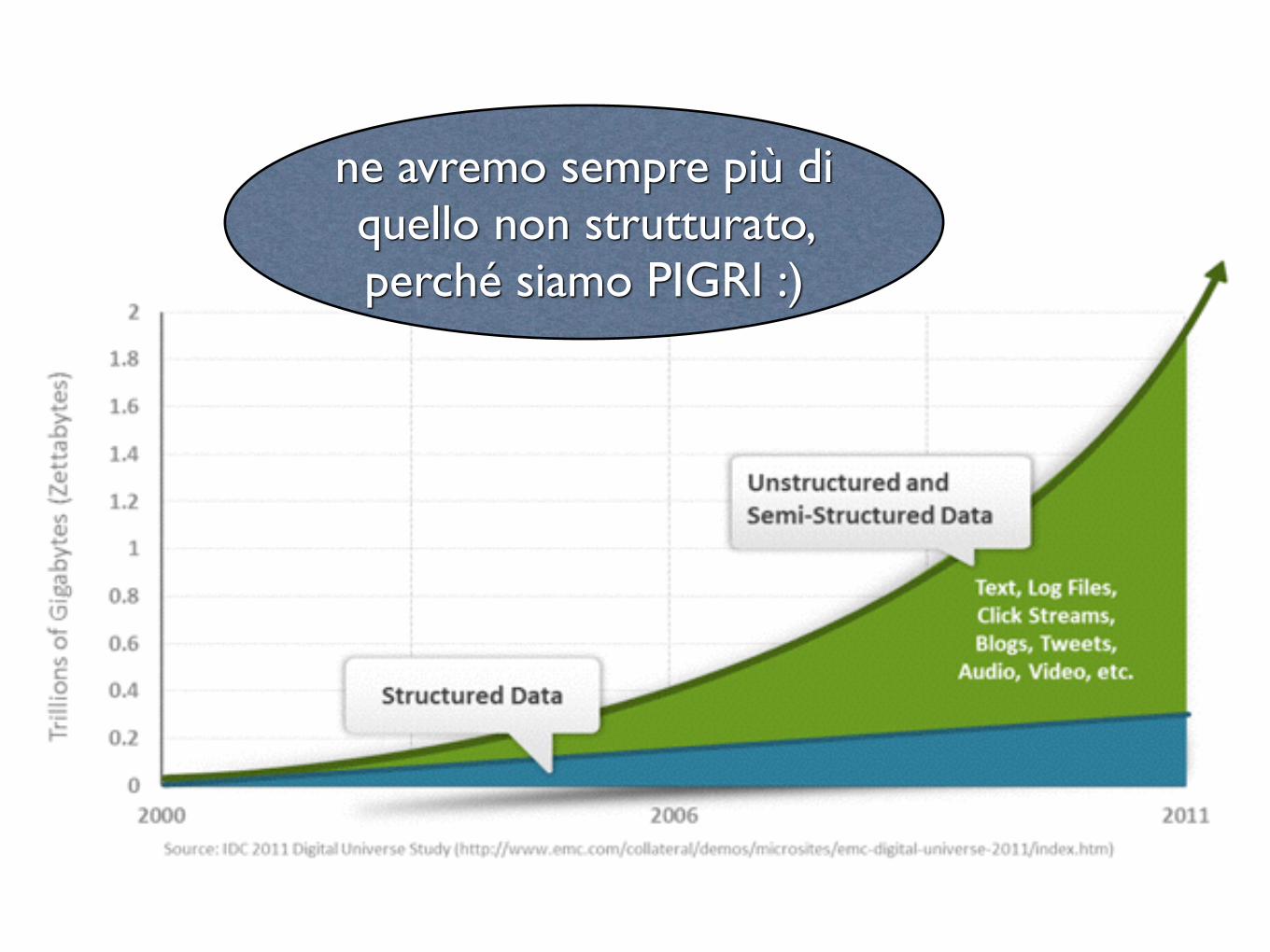
ne avremo sempre più di quello non strutturato, perché siamo PIGRI :)
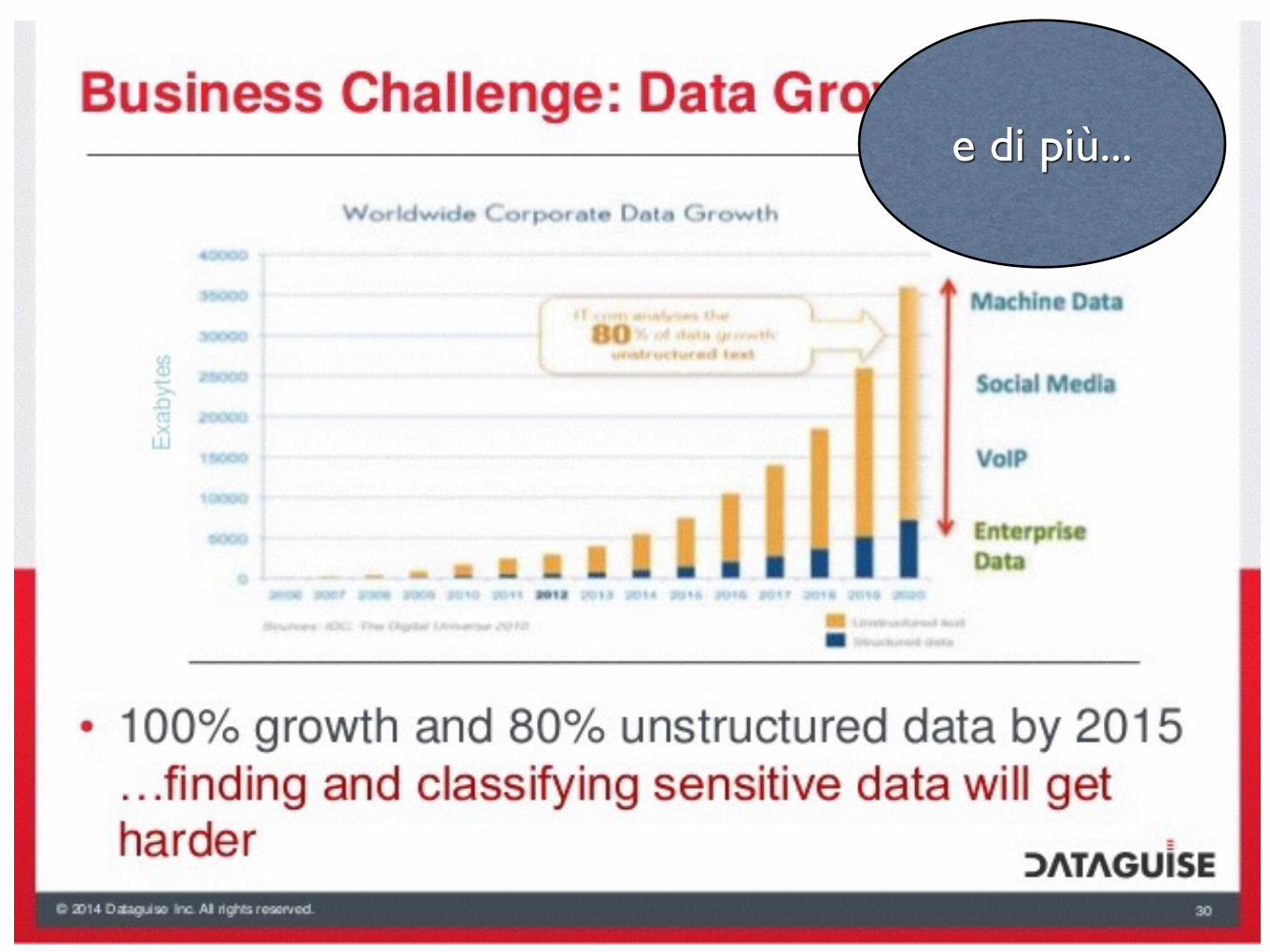
e di più...
Anche se chi li pubblica, sarà sempre
più attento
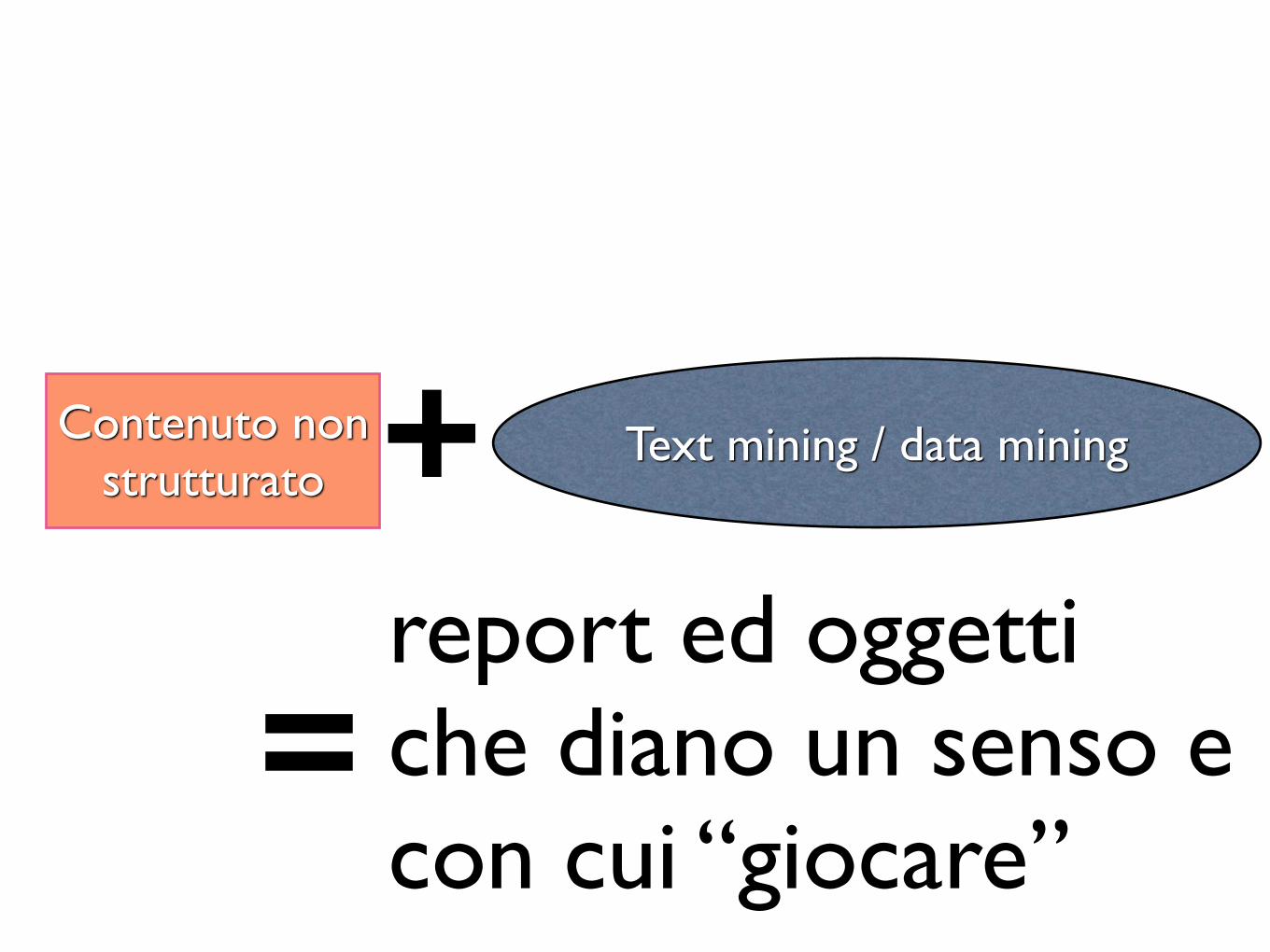
Contenuto non strutturato
Text mining / data mining+
=report ed oggettiche diano un senso econ cui “giocare”

“What I do is text analysis, which covers the aggregation of texts, machine learning, natural language processing, applied to text files to understand the context. There is a specific set of skills for data journalists to learn, as it is more and more becoming common place to find information in text files, ranging from material published by governments to corporations. And if you can learn those skills you can start to
find meaningful patterns in these documents.”
http://blogs.dw.de/innovation/data-science-the-software-that-is-out-there-is-getting-easier-to-use/

ed ora proviamo a capire come funzionail text mining con uno strumento
che ci dirà “qualcosa” su un testo...
https://dandelion.eu
API, ovvero oggetti manipolabili dai
programmatori / macchine
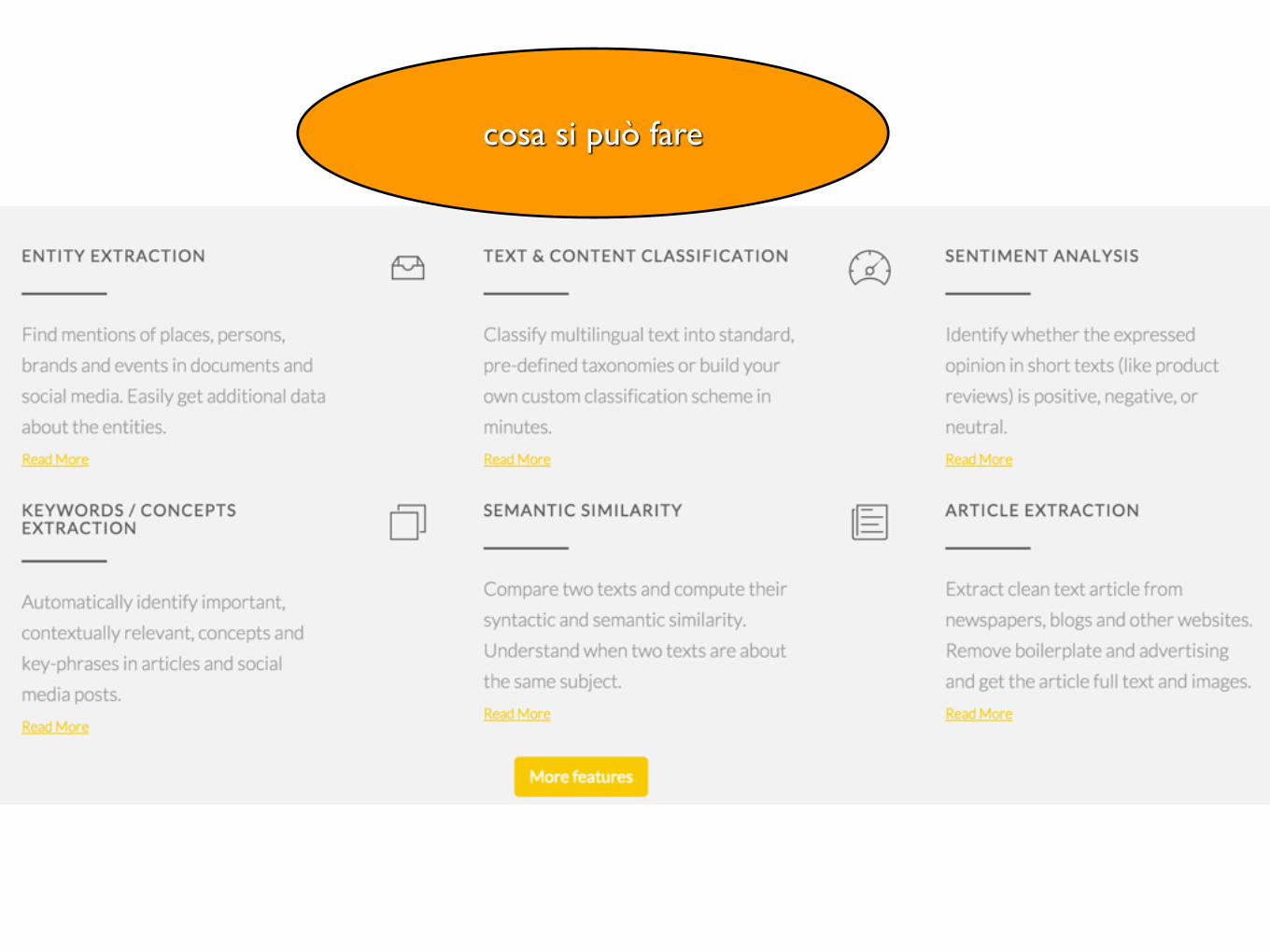
cosa si può fare
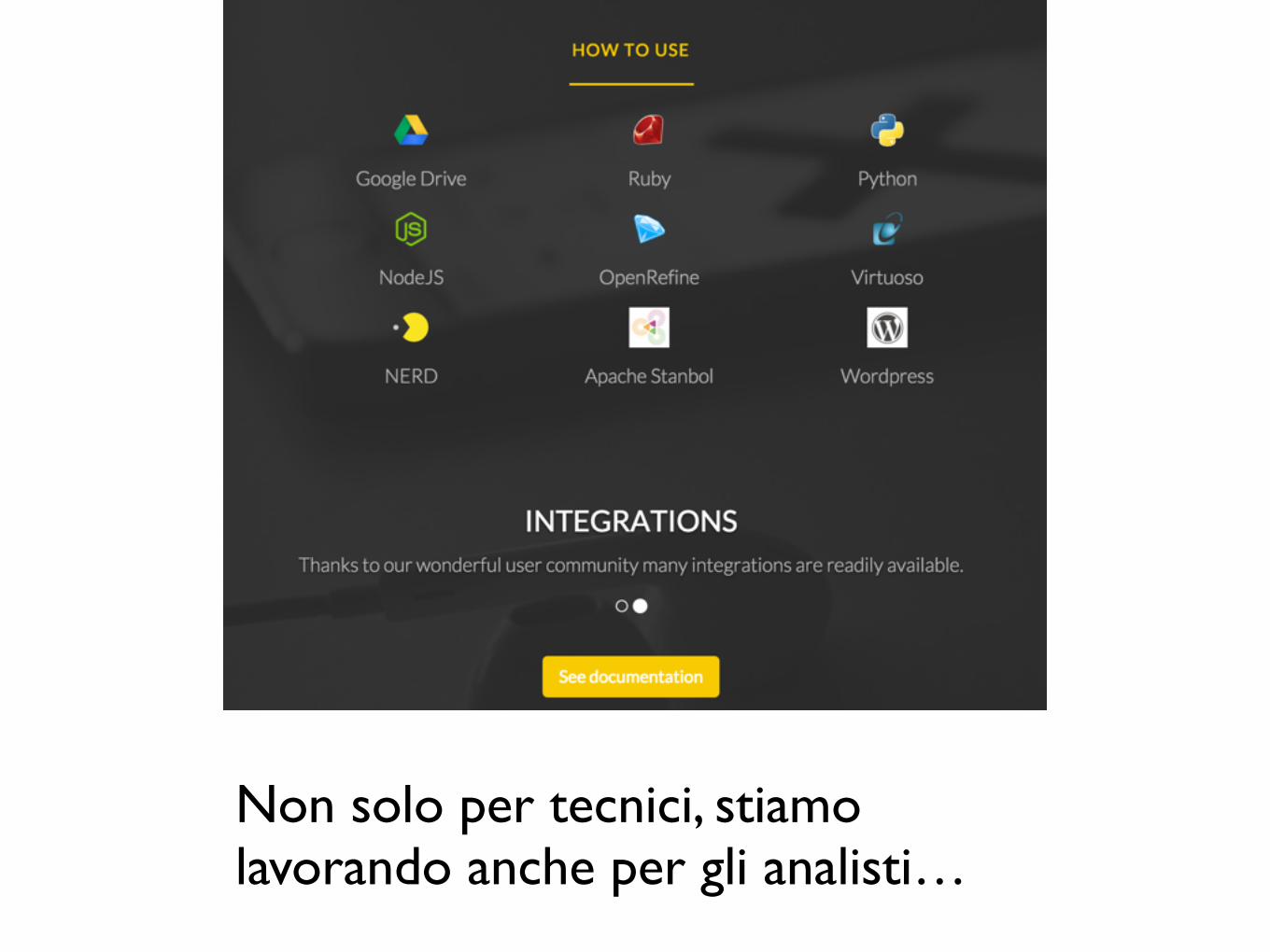
Non solo per tecnici, stiamo lavorando anche per gli analisti…
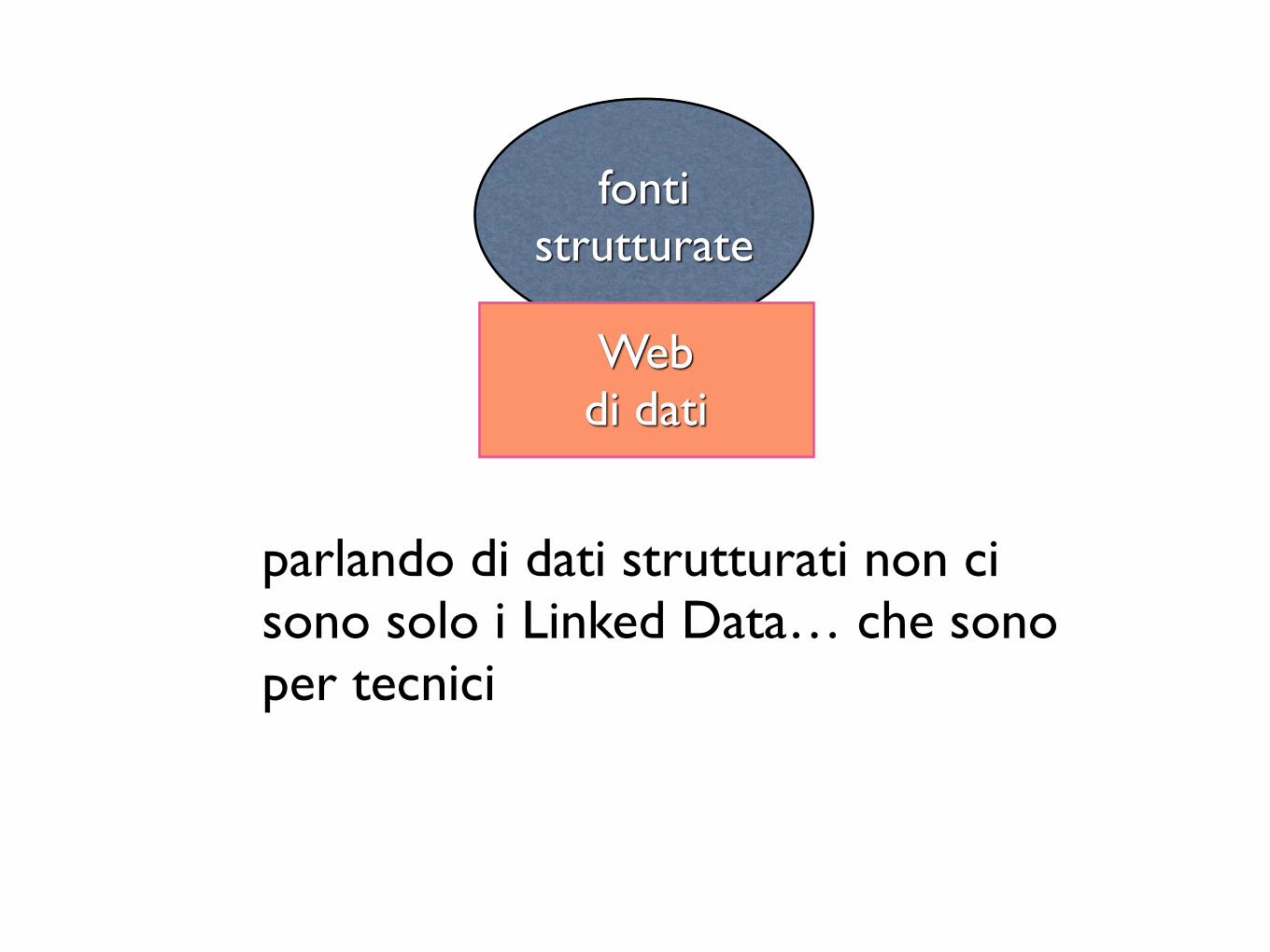
parlando di dati strutturati non ci sono solo i Linked Data… che sono per tecnici
fonti strutturate
Web di dati
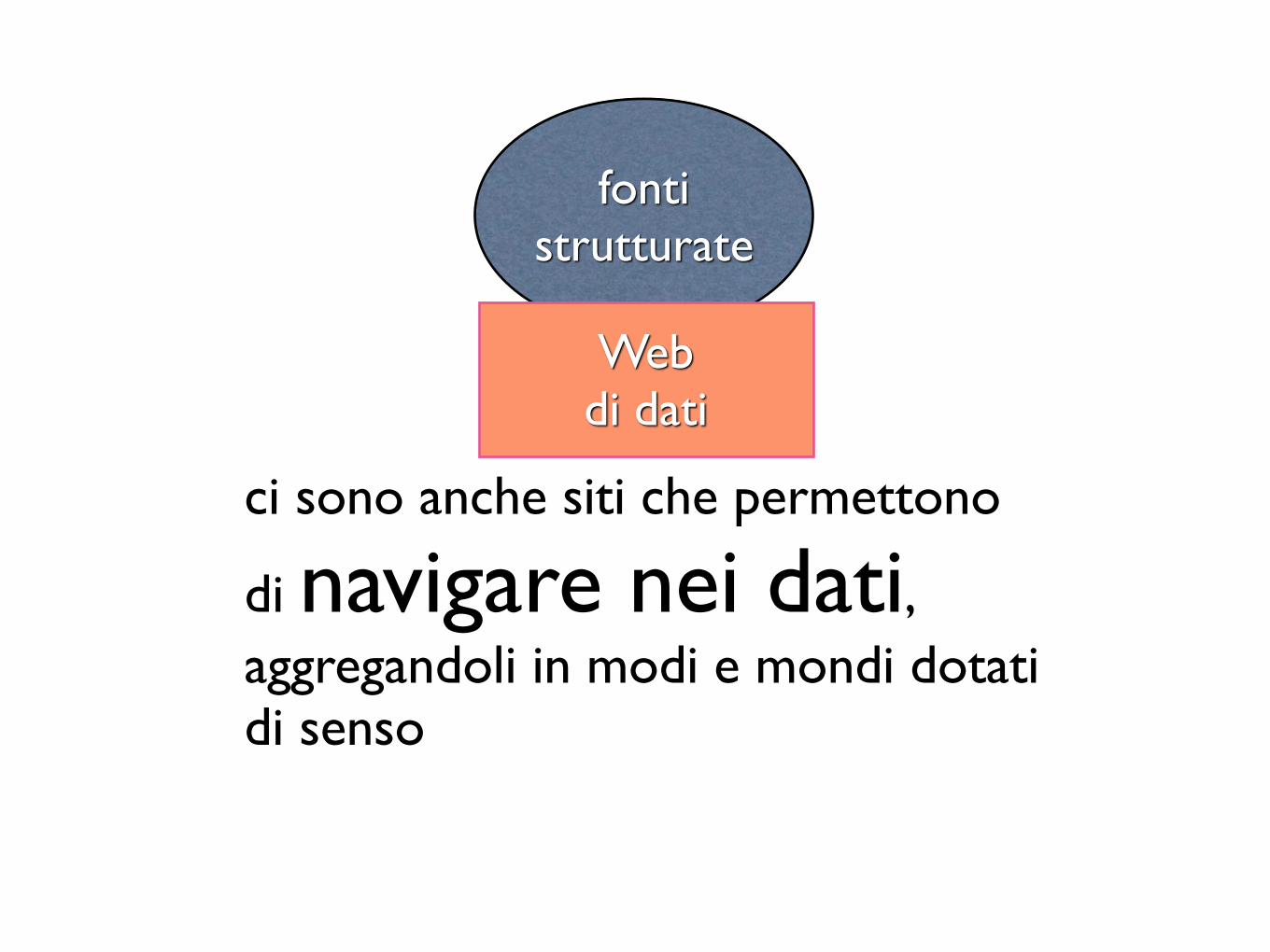
ci sono anche siti che permettono
di navigare nei dati, aggregandoli in modi e mondi dotati di senso
fonti strutturate
Web di dati
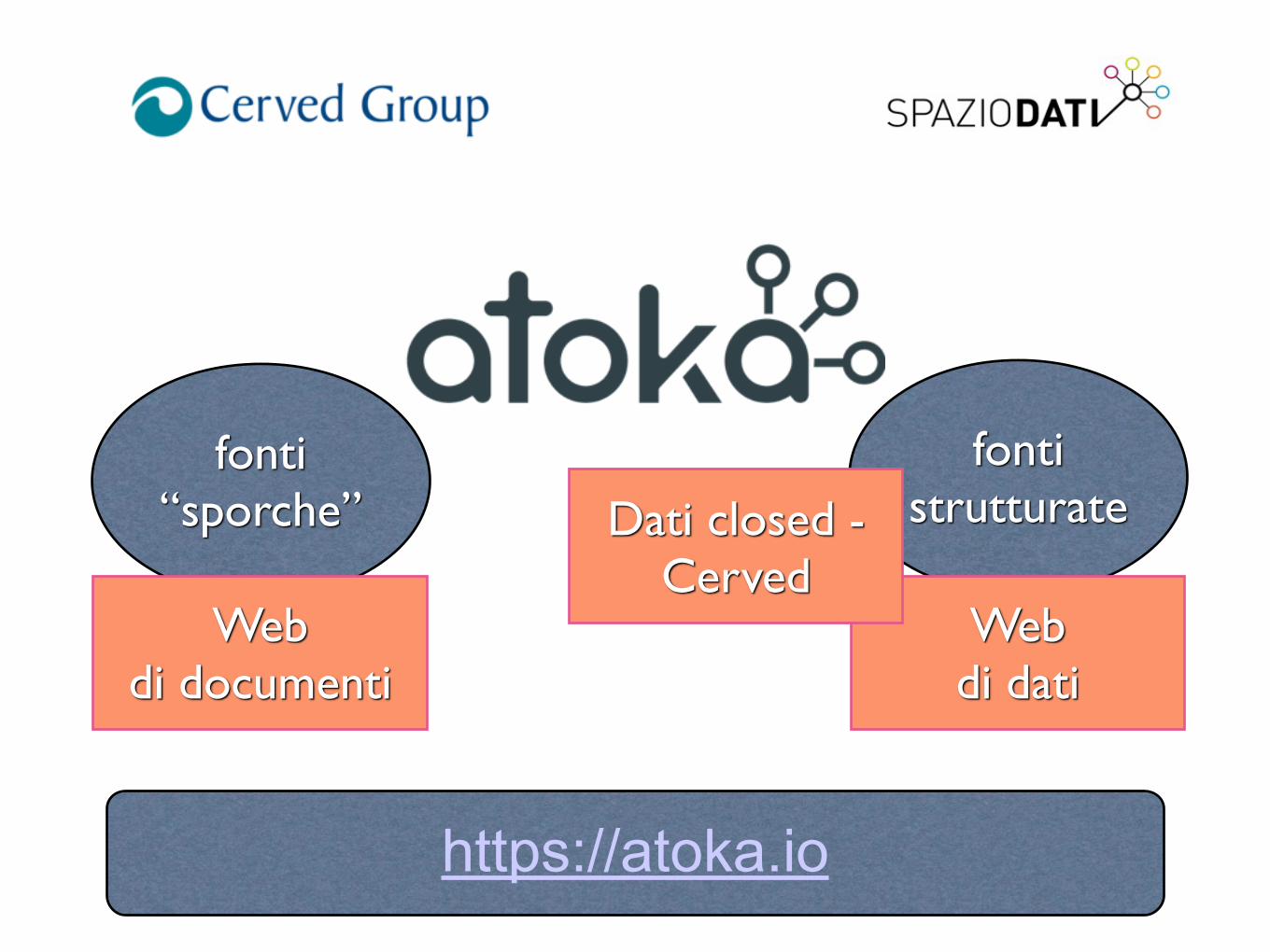
fonti “sporche”
fonti strutturate
Web di documenti
Web di dati
https://atoka.io
Dati closed - Cerved
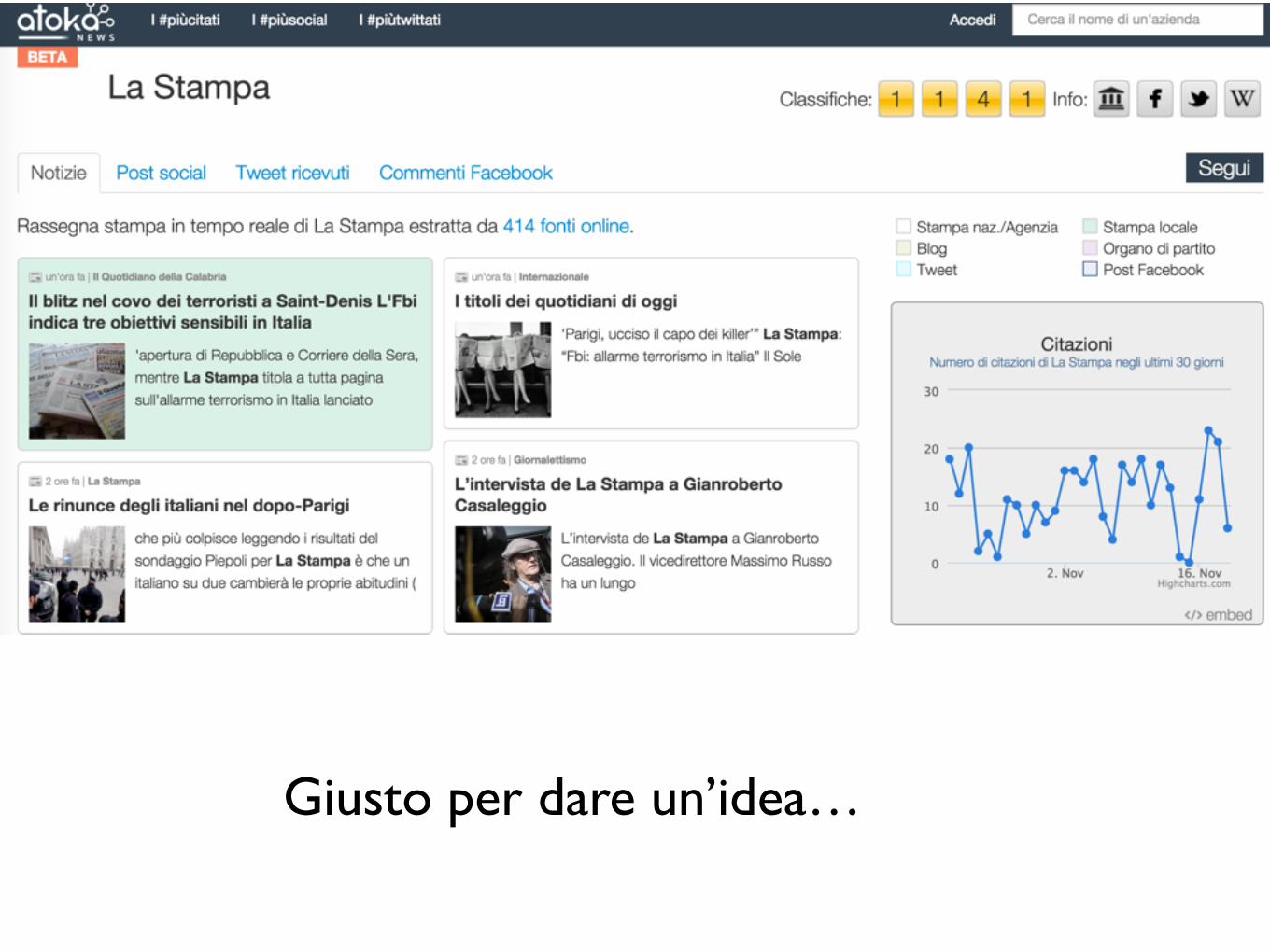
Giusto per dare un’idea…

Ed ora, mettiamo le mani in pasta...

Text analytics su GDrive usando Dandelion API Demo RASFF - http://bit.ly/RASFF_data
Web di dati
Contenutonon strutturato
https://dandelion.eu/semantic-text/entity-extraction-demo/
https://developers.google.com/structured-data/testing-tool/https://developers.facebook.com/tools/debug/og/object/
Ovvero confrontare le testate dei giornali nel modo in cui fanno parte del Web dei dati / non strutturato

Alcuni link veloci condivisi in un pirate pad
http://piratepad.net/K3WHEAqwlJ


http://www.edizionilswr.it/libri/creare-valore-con-big-data/