Embed Size (px)
Citation preview

Spark y la relación entre sus distintos módulos

Quienes somos
Quienes somos
JORGE LOPEZ-MALLA
Tras trabajar con algunasmetodologías tradicionalesempecé a centrarme en el
mundo del Big Data, del cualme enamoré. Ahora soy
arquitecto Big Data en Stratio yhe puesto proyectos en
producción en distintas partesdel mundo.
SKILLS

Jorge López-Malla [email protected]
Introducción
● Introducción al Big Data
● Hadoop
● ¿Por qué Spark?
1 2
5
3 Spark SQL
● Introducción
● Dataframe
● ¿Cómo relacionamos Core y
SQL?
● Ejemplos prácticos
Spark core
● RDD
● Transformaciones/Acciones con
RDD
● Ejemplo de operaciones
Spark Streaming
● Introducción
● DStreams
● Operaciones "Stateful"
● ¿Cómo se relaciona con el Batch?
MlLib
● Introducción
● Modelos
● ¿Cómo relacionamos Batch y
MLib?
● ¿Cómo usamos MlLib en Streaming
ÍndiceÍndice
4

Introducción1

Jorge López-Malla [email protected]
Introducción
● Introducción al Big Data
● Hadoop
● ¿Por qué Spark?
1 2
5
3 Spark SQL
● Introducción
● Dataframe
● ¿Cómo relacionamos Core y
SQL?
● Ejemplos prácticos
Spark Streaming
● Introducción
● DStreams
● Operaciones "Stateful"
● ¿Cómo se relaciona con el Batch?
MlLib
● Introducción
● Modelos
● ¿Cómo relacionamos Batch y
MLib?
● ¿Cómo usamos MlLib en Streaming
ÍndiceÍndice
4
Spark core
● RDD
● Transformaciones/Acciones con
RDD
● Ejemplo de operaciones

Introducción
Introducción al Big Data

Introducción
Map&Reduce es un modelo de programación utilizado por Google para dar soporte a
la computación paralela sobre grandes colecciones de datos en grupos de
computadoras y al commodity computing. El nombre del framework está inspirado
en los nombres de dos importantes métodos, macros o funciones en programación
funcional: Map y Reduce. MapReduce ha sido adoptado mundialmente, ya que
existe una implementación OpenSource denominada Hadoop. Su desarrollo fue
liderado inicialmente por Yahoo y actualmente lo realiza el proyecto Apache. En esta
década de los años 2010 existen diversas iniciativas similares a Hadoop tanto en la
industria como en el ámbito académico, entre ellas está Spark.
Introducción al Big Data

Introducción
Introducción al Big Data
Map(k1,v1) -> list(k2,v2)
Reduce(k2,list(v2)) -> (k3,v3)

Introducción al Big Data
Fases opcionales del modelo
Aunque el modelo Map & Reduce puede realizarse únicamente con las fases de Map y de Reduce existen
una serie de fases opcionales que nos ayudan a mejorar y optimizar nuestros procesos. Estas fases son:
● Combiner (Fase de Combinación)● Partitioner (Fase de Particionado)
Map Combiner Partitioner Reduce
Introducción

Hadoop
Apache Hadoop es un framework de procesamiento, almacenamiento y gestión de
procesos distribuido que facilita la programación de tareas mediante el paradigma map
& reduce y es escalable desde unos pocos hasta miles de nodos. Es bastante robusto y
está diseñado para trabajar en alta disponibilidad, con tolerancia a fallos y en su versión
reciente gestionar recursos de manera muy eficiente.
Introducción

Hadoop
Introducción

¿Por qué Spark?
Apache Spark es una framework de procesamiento distribuido en memoria de
segunda generación que facilita la analítica de grandes conjuntos de datos
integrando diferentes paradigmas como Bases de Datos NoSQL, analítica
en tiempo real, machine learning o análisis de grafos mediante un
único lenguaje común.
SPARK CORE
SQL RSTREAMING MlLib GraphX
Introducción

Introducción al Modelo de Map & Reduce
¿Por qué Spark?
• API única para todo
• Presente y Futuro• Gran adopción• Integración con Hadoop
• Facilidad de uso• Tolerancia a fallos• Production-ready• Multilenguaje

Spark Core2

Jorge López-Malla [email protected]
Introducción
● Introducción al Big Data
● Hadoop
● ¿Por qué Spark?
1 2
5
3 Spark SQL
● Introducción
● Dataframe
● ¿Cómo relacionamos Core y
SQL?
● Ejemplos prácticos
Spark core
● RDD
● Transformaciones/Acciones
con RDD
● Ejemplo de operaciones
Spark Streaming
● Introducción
● DStreams
● Operaciones "Stateful"
● ¿Cómo se relaciona con el Batch?
MlLib
● Introducción
● Algoritmos
● Ejemplos prácticos
ÍndiceÍndice
4

Definición:
Un RDD en Spark es una colección de colecciones de objetos inmutable y distribuida. Cada RDD está
dividido en diferentes particiones, que pueden ser computadas en los distintos nodos del Cluster de Spark.
Es la Unidad mínima de computación en Spark
Ej:
El RDD numbers es un rdd de enteros que está distribuido por en un cluster con 3 Workers{W1, W2, W3}
numbers = RDD[1,2,3,4,5,6,7,8,9,10]
Conceptos de Spark
RDD
W1 W2 W2
[1,5,6,9] [2,7,8] [3,4,10]

Los RDD tienen dos tipos de operaciones:
1. Transformaciones: Son aquellas operaciones que tras ejecutarlas nos devuelven otro RDD. Como un RDD no
deja de ser una colección distribuida estas operaciones son Lazy por lo que no se realizará ningún cálculo a
no ser que al final del árbol de operaciones haya una acción.
2. Acciones: Son operaciones que una vez realizadas sobre un RDD nos devuelven un objeto distinto a un RDD
o vacío. Este tipo de operaciones hace que se lance la ejecución del workflow y por consiguiente que se
ejecute nuestra aplicación de Spark.
Spark Core
Transformaciones

Spark Core
Transformaciones
map
Devuelve el rdd resultante de aplicar una función a cada uno de los elementos del rdd que lo
invoca:
map
scala> val rddUpper = rddCow.map(_.toUpperCase)
rddUpper: org.apache.spark.rdd.RDD[String] = MappedRDD[1] at map
rddCow rddUpper
I've never seen a purple cow
I never hope to see one
But i can tell you, anyhow,
I’d rather see than be one
I'VE NEVER SEEN A PURPLE COW
I NEVER HOPE TO SEE ONE
BUT I CAN TELL YOU, ANYHOW,
I’D RATHER SEE THAN BE ONE
Spark Core
Transformaciones
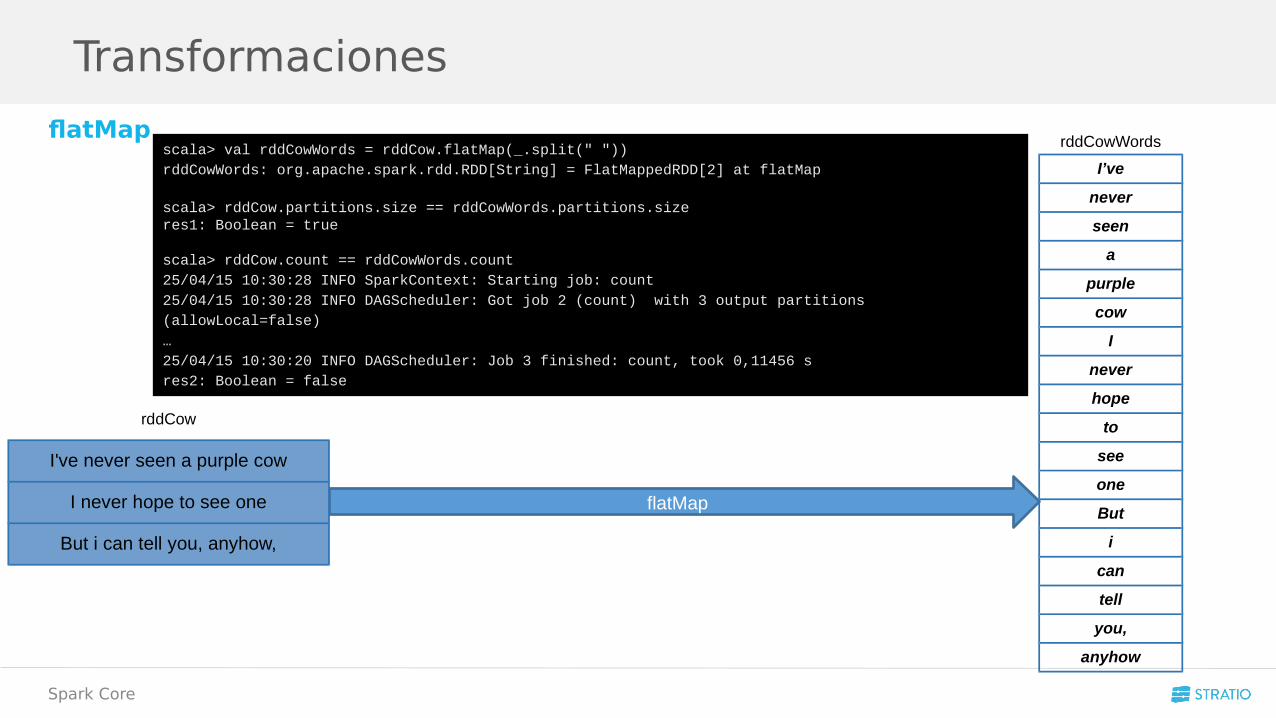
flatMapscala> val rddCowWords = rddCow.flatMap(_.split(" "))rddCowWords: org.apache.spark.rdd.RDD[String] = FlatMappedRDD[2] at flatMap
scala> rddCow.partitions.size == rddCowWords.partitions.size res1: Boolean = true
scala> rddCow.count == rddCowWords.count25/04/15 10:30:28 INFO SparkContext: Starting job: count 25/04/15 10:30:28 INFO DAGScheduler: Got job 2 (count) with 3 output partitions (allowLocal=false)…25/04/15 10:30:20 INFO DAGScheduler: Job 3 finished: count, took 0,11456 sres2: Boolean = false
flatMap
rddCowWords
I've never seen a purple cow
I never hope to see one
But i can tell you, anyhow,
I’ve
never
seen
a
purple
cow
I
never
hope
to
see
one
But
i
can
tell
you,
anyhow
rddCow

rddVisits
combineByKey:
Spark Core
Shuffle
(February, (5, 1))
(January, (21, 5))
(June, (2,2))
(March, (2,2))
rddMeanVisitsByMonth
scala> val rddMeanVistisByMonth = rddVisits.combineByKey( (visit: Int) => (visit, 1), (comb: (Int, Int), visit) => (comb._1 + visit, comb._2 + 1), (combAcc: (Int, Int), comb: (Int, Int)) => (combAcc._1 + comb._1, combAcc._2 + comb._2))
rddMeanVistisByMonth: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[2]
2
1
3
(March, 4)
(March, 4)
(January, 4)
(January, 4)
(January, 3)
(January, 5)
(June, 2)
(March, 3)
(February, 5)
(June, 1)
(January, 5)
1
1
1
1
1
1
1
2
1
1
2
1
1
2
3
3
3
3
Transformaciones

Acciones:
Las acciones son los métodos de Spark que hacen que se ejecute todo el workflow asociado a
una acción. Hasta el momento no se ha ejecutado ninguna operación ni se han movido los datos
de los repositorios distribuidos.
Hay que tener cuidado con algunas de estas operaciones porque pueden dar como resultado el
traer todos los datos de un repositorio Big Data a una sola máquina.
A continuación enumeramos algunas de las usadas.
Spark Core
Acciones

foreach
Recorre todo el RDD ejecutando una acción. Esta acción no debe devolver ningún valor.
Spark Core
Acciones
(January, (3, 5, 7))
(March, (3))
(February, (5))
(June, (1, 2))
(March, (4, 4))
(January, (4, 4))
rddVisitsByMonth
scala> rddVisitsByMonth.foreach(tuple => println(tuple._2.reduce(_ + _)))
1535388

Spark SQL3

Jorge López-Malla [email protected]
Introducción
● Introducción al Big Data
● Hadoop
● ¿Por qué Spark?
1 2
5
3 Spark SQL
● Introducción
● Dataframe
● ¿Cómo relacionamos Core y
SQL?
● Ejemplos prácticos
Spark core
● RDD
● Transformaciones/Acciones con
RDD
● Ejemplo de operaciones
Spark Streaming
● Introducción
● DStreams
● Operaciones "Stateful"
● ¿Cómo se relaciona con el Batch?
MlLib
● Introducción
● Algoritmos
● Ejemplos prácticos
ÍndiceÍndice
4

Spark Sql
Introducción
Spark SQL nace en la versión 1.0 y quiere aunar y mejorar diferentes iniciativas de
"SQL-on-Hadoop" ya existentes.
• Ejecuta consultas SQL / HiveQL sobre RDD’s o datasources.
• Conecta herramientas de BI a Spark mediante JDBC vía "thrift server"
• Manejo con Python, Scala, Java, R

Spark Sql
DataFrame
Un DataFrame es una colección de Rows que contiene un esquema específico
indícando el nombre de las columnas y el tipo de dato que contiene cada una de
ellas.
Conceptualmente es equivalente a una tabla en una base de datos relacional
pero con una capa de optimización que transforma lógica SQL en un plan
"físico" basado en RDD’s para ser ejecutados en Spark.

Spark Sql
DataFrame API
El trabajo con SQL puede hacerse de forma directa haciendo consultas en este
lenguaje o haciendo uso de una completa API que han desarrollado y que permite
trabajar de forma programática con todas la funcionalidad del lenguaje y
añadiendo la propia, integrada totalmente con el core de Spark.
• Proyección y filtrado de columnas• Joins entre datasources
diferentes• Funciones de agregación• Soporte para UDF’s• API extensible

Spark Sql
DataFrame API

Spark Sql
Datasources

Spark Sql
¿Cómo mezclamos el Core con el SQL?
Como hemos explicado antes, un Dataframe no deja de ser un RDD de un tipo
concreto, Row.
La forma más sencilla de mezclarlos es mediante la creación de un Dataframe a
partir de un RDDimport org.apache.spark.sql.functions._import sqlContext.implicits._
val flightsTicketsText = sc.textFile("/home/meetup/datasets/flightsTickets.dat")
val flightsArray = flightsText.map(line => line.split(","))
val ticketsDF = flightsArray.map(ticket => (ticket(0).toInt, ticket(1), ticket(2), ticket(3).toBoolean)) .toDF("idFlight", "dni", "dest", "isPersonal").cache()

Spark Sql
¿Cómo mezclamos el Core con el SQL?
Al ser ambos RDD también podemos hacer cualquier operación de las vistas
anteriormente para los RDD
import org.apache.spark.sql.functions._import sqlContext.implicits._
val personsRDD = sc.textFile("/home/jlmalla/meetup/datasets/persons.dat") .map(line => line.split(",")) .map{case (id, name, gender, revenue) => (id, (name, gender, revenue))}
val joinTicketsPersons = ticketsDF.map(row => (row(1), row)).join(personsRDD)
val fligths = joinTicketsPersons.map{ case (id, (Array((idFlight, dni, dest, isPersonal), (name, gender, revenue))) => (dni, name, gender, revenue, idFligth, isPersonal)} .toDF("dni", "name", "gender", "revenue", "dest", "idFligth", "isPersonal")

Spark Sql
¿Cómo mezclamos el Core con el SQL?
Pero hacer esto carecería de sentido dado que todo RDD con estructura se pude
transformar a un Dataframe y aprovechar las mejoras de Spark SQL
import org.apache.spark.sql.functions._import sqlContext.implicits._
val personsDF = sc.textFile("/home/meetup/datasets/persons.dat").map(line => line.split(",")) .map{case (dni, name, gender, revenue) => (dni, (name, gender, revenue))} .toDF(“id", "name", "gender", "revenue“)
val joinTicketsPersons = ticketsDF.join(personsDF, ticketsDF("dni") === personsDF("id"))
val fligths = joinTicketsPersons.select("dni", "name", "gender", "revenue", "dest", "idFligth", "isPersonal")

Spark Sql
Ejemplos Prácticos
Leemos los datos de los aeropuertos de un CSV los juntamos con datos de vuelos
de un RDD y escribimos las estadísticas en Mongo

Spark Sql
Ejemplos Prácticos
import org.apache.spark.sql.Row
val aiports = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").option("inferSchema", "true").load("/home/jlmalla/meetup/files/airports")
airpots: DataFrame = [id: int, name: string, description: string]
val flightsToAnalyze = fligths.select("dest", "gender").map(row => { val Row(dest, gender) = row val male = if (gender.asInstanceOf[String] == "H") 1 else 0 val female = if (gender.asInstanceOf[String] == "M") 1 else 0 (dest.asInstanceOf[String], (male, female))}).reduceByKey((gender1, gender2) => (gender1._1 + gender2._1, gender1._2 + gender2._2)).map{case (dest, (male, female)) => (dest, male, female)}.toDF("dest", "male", "female") val airportStatictis = flightsToAnalyze.join(aiports, flightsToAnalyze("dest") === aiports("name"))
airportStatictis.select("name", "male", "female").write.format("com.stratio.datasource.mongodb").options(Map("host" -> "localhost:27017", "database" -> "meetup", "collection" -> "staticts")).save()

Spark Streaming4

Jorge López-Malla [email protected]
Introducción
● Introducción al Big Data
● Hadoop
● ¿Por qué Spark?
1 2
5
3 Spark SQL
● Introducción
● Dataframe
● ¿Cómo relacionamos Core y
SQL?
● Ejemplos prácticos
Spark core
● RDD
● Transformaciones/Acciones con
RDD
● Ejemplo de operaciones
Spark Streaming
● Introducción
● DStreams
● Operaciones "Stateful"
● ¿Cómo se relaciona con el Batch?
MlLib
● Introducción
● Algoritmos
● Ejemplos prácticos
ÍndiceÍndice
4

Introduccion
SPARK STREAMING OVERVIEW
Spark Streaming es la solución de Spark para la análitica en tiempo real.
Al igual que Spark Core y SparkSQL tienen como unidad mínima de computación el
RDD y el Dataframe correspondienmente Spark Streaming tiene como unidad
mínima de computación: el DStream

Definición:
Un DStream representa una corriente de datos, un conjunto de datos que llegan de manera continua desde una
fuente. En Spark este concepto se implementa como "micro batchs" de RDDs.
Es la unidad mínima de procesamiento de Spark Streaming
Ej:
Conceptos de Spark
DStream
DStream
RDD
RDD
RDD
RDD
Spark Streaming
InputDStream y Receivers
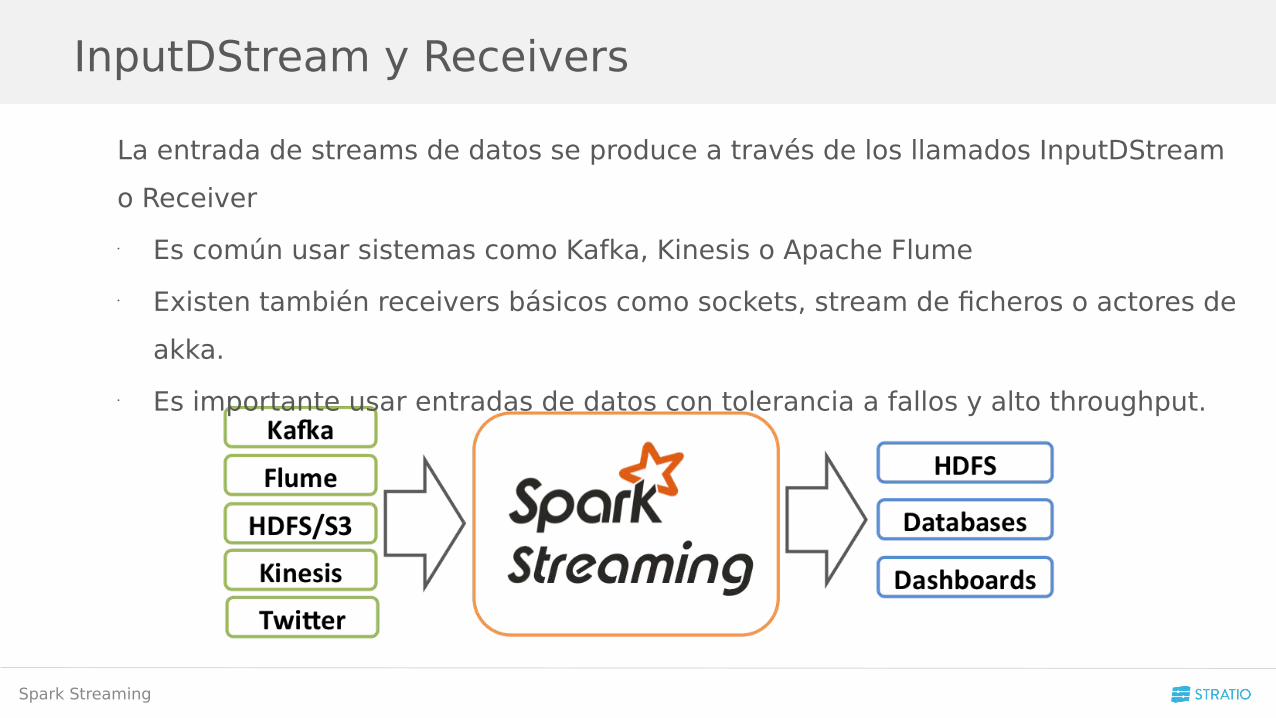
La entrada de streams de datos se produce a través de los llamados InputDStream
o Receiver
• Es común usar sistemas como Kafka, Kinesis o Apache Flume
• Existen también receivers básicos como sockets, stream de ficheros o actores de
akka.
• Es importante usar entradas de datos con tolerancia a fallos y alto throughput.

Spark Streaming
DStream
Un DStream representa una entrada de datos en tiempo real en un intervalo de
tiempo determinado.
• La entrada de datos es dividida en micro batches.
• Cada micro-batch es un RDD
• El Dstream es una secuencia de RDD’s

Spark Streaming
DStream

Spark Streaming
Operaciones stateful (I)
Hay operaciones especiales que mantienen estados y se actualizan en cada batch
interval, son llamadas stateful.
• Estas operaciones son UpdateStateByKey y ReduceByKeyAndWindow
• Estos estados se mantienen en memoria. Se pueden crear, actualizar y eliminar.
• Estas operaciones requieren de checkpointing para recuperación de errores.
El flujo normal de un stream es el siguiente
• Cada Batch interval se genera un Dstream
• A los datos contenidos en ese Dstream se le aplican
transformaciones
• Se realiza una o varias acciones con estos datos.
¿Cómo haríais un simple wordcount que se mantenga a lo largo del
tiempo?

Operaciones Stateful (II)
Spark Streaming
UpdateStateByKey
def updateStateByKey[S](updateFunc: (Seq[V], Option[S]) ⇒ Option[S])
• Para cada clave K mantiene un Option[S]
• Option a None elimina el estado.

Spark Sql
Ejemplo
val sparkConf = new SparkConf().setAppName(“StreamingTest") val ssc = new StreamingContext(sparkConf, Seconds(2)) val stream = TwitterUtils.createStream(ssc, None, filters)
val hashTags = stream.flatMap(status => status.getText.split(" ").filter(_.startsWith("#")))
val topCounts60 = hashTags.map((_, 1)).reduceByKeyAndWindow(_ + _, Seconds(60)) .map{case (topic, count) => (count, topic)} .transform(_.sortByKey(false))
val topCounts10 = hashTags.map((_, 1)).reduceByKeyAndWindow(_ + _, Seconds(10)) .map{case (topic, count) => (count, topic)} .transform(_.sortByKey(false))
// Print popular hashtags topCounts60.foreachRDD(rdd => { val topList = rdd.take(10) println("\nPopular topics in last 60 seconds (%s total):".format(rdd.count())) topList.foreach{case (count, tag) => println("%s (%s tweets)".format(tag, count))} })
ssc.start() ssc.awaitTermination()

¿Cómo relacionamos Batch y Streaming?
Spark Streaming
Como el resto de relaciones entre módulos de Spark todo tiene que ver con sus
unidades mínimas de computación.
Los DStream no son sino conjuntos de mini batches de RDDs
La combinación entre ambos módulos se hace mediante las operaciones
forEachRDD y transform

¿Cómo se relaciona con el Batch?
Spark Streaming
TransformRDD
def transform[U](transformFunc: (RDD[T]) ⇒ RDD[U]) : DStream[U]
Con esta operación transformaremos todos los RDDs pertenecientes a un
micro batch.
Las operaciones que crean los RDDs que representan el “Batch” se realizan en el
driver por lo que no se corre ningún riesgo de serialización.
Con esta operación, aún **, no se puede mezclar Streaming y SQL dado que la
salida que busca es un RDD y no un Dataframe

¿Cómo se relaciona con el Batch?
Spark Streaming
foreachRDD
def foreachRR[U](transformFunc: (RDD[T]) ⇒ Unit : Unit
Esta operación es exactamente igual que el foreach de un RDD sólo que aplicada a
todos los RDD contenidos en un microbatch de Streaming.
Aquí ya se puede relacionar Streaming y SQL

¿Cómo se relaciona con el Batch?
Spark Streaming
val ssc = new StreamingContext(sc, Seconds(2)) ssc.checkpoint("/tmp/chechkpointdir")
val props = Map("metadata.broker.list" -> "localhost:9092", "auto.offset.reset" -> "smallest") val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, props, = Set("meetup-1"))
Val batchStream = kafkaStream.map{case (key, value) => value}.transform(rdd =>{ val context: SparkContext = rdd.sparkContext val persons = context.textFile("/home/jlmalla/meetup/datasets/persons.dat").map(line => line.split(",")) .map{case Array(dni, name, gender, revenue) => (dni, gender)} val fligths = rdd.flatMap(line => { val splitedLine: Array[String] = line.split(",") if (splitedLine.size == 3) { val Array(id, airpot, _) = splitedLine Some((id, airpot)) }else None } ) fligths.join(persons).map{case (id, (airpot, gender)) => { val male = if (gender == "H") 1 else 0 val female = if (gender == "M") 1 else 0 (airpot, (male, female)) }}.reduceByKey((gender1, gender2) => (gender1._1 + gender2._1, gender1._2 + gender2._2)).map{case (dest, (male, female)) => (dest, male.toDouble, female.toDouble)}
})

¿Cómo se relaciona con el Batch?
Spark Streaming
batchStream.foreachRDD(rdd => { val context = rdd.sparkContext val sqlContext = new SQLContext(context) import sqlContext.implicits._ val airportStatictis = rdd.toDF("name", "male", "female") airportStatictis.select("name", "male", "female") .write.format("com.stratio.datasource.mongodb").mode(SaveMode.Append).options(Map("host" -> "localhost:27017", "database" -> "meetup", "collection" -> "staticts")).save() })
ssc.start() ssc.awaitTermination()

MlLib5

Jorge López-Malla [email protected]
Introducción
● Introducción al Big Data
● Hadoop
● ¿Por qué Spark?
1 2
5
3 Spark SQL
● Introducción
● Dataframe
● ¿Cómo relacionamos Core y SQL?
● Ejemplos prácticos
Spark core
● RDD
● Transformaciones/Acciones con
RDD
● Ejemplo de operaciones
Spark Streaming
● Introducción
● DStreams
● Operaciones "Stateful"
● ¿Cómo se relaciona con el Batch?
MlLib
● Introducción
● Algoritmos
● ¿Cómo se relaciona con el Batch?
● ¿Cómo se relaciona con el SQL?
● ¿Cómo se relaciona con el Streaming?
ÍndiceÍndice
4

MlLib
Introducción
MlLib es la librería de Machine Learning de Spark. Su objetivo es dar los
mecanismos necesarios para poder realizar diferentes algoritmias de Machine
Learning aplicadas a grandes cantidades de datos.
Como todas las piezas del ecosistema de Spark, tiene como base los RDDs para la
ejecución de estas algoritmias.
MlLib "únicamente" nos proporciona, de una manera sencilla y eficiente, los
métodos y las API necesarias para poder ejecutarlos, pero estos algoritmos tienen
que ser alimentados por modelos matemáticos generados por el usuario.

MlLib
Algoritmos
MlLib tiene implementados varios algoritmos de distinta índole para distintos
problemas de Machine Learning.
Dada la variedad de algoritmia relacionadas con el Machine Learning y su
complejidad explicar cada uno de estos algoritmos queda fuera de este meetup.
No obstante mostraremos el funcionamiento, mediante ejemplos, de dos
algoritmos bastante usados dentro de la comunidad de Spark KMeans y ALS

MlLib
Algoritmos
Todos los algoritmos de MlLib necesitan alimentarse de un RDD que les proporcione
datos para formular modelos
Algunos de estos modelos podrán ser usados más adelante para predecir el
comportamiento de otros elementos ajenos al dataset de pruebas

MlLib
Ejemplo ALS relación con Batch
import org.apache.spark.mllib.recommendation.ALSimport org.apache.spark.mllib.recommendation.MatrixFactorizationModelimport org.apache.spark.mllib.recommendation.Rating
val data = sc.textFile("data/mllib/als/test.data")val ratings = data.map(_.split(',') match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble) })
val rank = 10val numIterations = 10val model = ALS.train(ratings, rank, numIterations, 0.01)
val usersProducts = ratings.map { case Rating(user, product, rate) => (user, product) }
val predictions = model.predict(usersProducts).map { case Rating(user, product, rate) => ((user, product), rate) }
val ratesAndPreds = ratings.map { case Rating(user, product, rate) => ((user, product), rate)}.join(predictions)

MlLib
Ejemplo Kmeans relación con Batch
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}import org.apache.spark.mllib.linalg.Vectors
// Load and parse the dataval data = sc.textFile("data/mllib/kmeans_data.txt")val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// Cluster the data into two classes using KMeansval numClusters = 2val numIterations = 20val clusters = KMeans.train(parsedData, numClusters, numIterations)
// Evaluate clustering by computing Within Set Sum of Squared Errorsval WSSSE = clusters.computeCost(parsedData)println("Within Set Sum of Squared Errors = " + WSSSE)
// Save and load modelclusters.save(sc, "myModelPath")val sameModel = KMeansModel.load(sc, "myModelPath")

¿Cómo se relaciona con el SQL?
MlLib
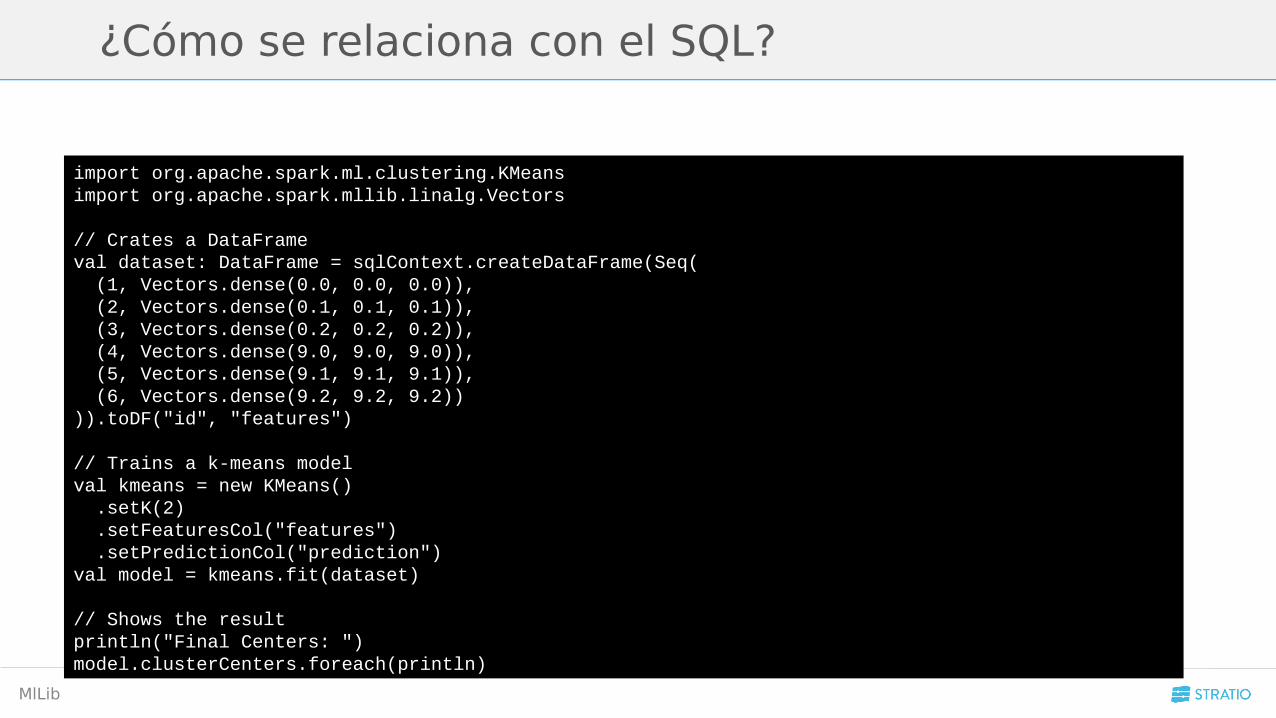
A partir de la versión 1.4.0 de Spark se ha integrado una nueva forma de usar los
RDD para cargar información para los modelos.
En vez de usar un RDD y transformalo a un formato usable por el algoritmo se
pueden usar Dataframes y cargar la información directamente usando una
variable de la tabla.
¿Cómo se relaciona con el SQL?
MlLib
import org.apache.spark.ml.clustering.KMeansimport org.apache.spark.mllib.linalg.Vectors
// Crates a DataFrameval dataset: DataFrame = sqlContext.createDataFrame(Seq( (1, Vectors.dense(0.0, 0.0, 0.0)), (2, Vectors.dense(0.1, 0.1, 0.1)), (3, Vectors.dense(0.2, 0.2, 0.2)), (4, Vectors.dense(9.0, 9.0, 9.0)), (5, Vectors.dense(9.1, 9.1, 9.1)), (6, Vectors.dense(9.2, 9.2, 9.2)))).toDF("id", "features")
// Trains a k-means modelval kmeans = new KMeans() .setK(2) .setFeaturesCol("features") .setPredictionCol("prediction")val model = kmeans.fit(dataset)
// Shows the resultprintln("Final Centers: ")model.clusterCenters.foreach(println)

¿Cómo se relaciona con el Streaming?
MlLib
La mayoría de algoritmia relacionada con el cáculo de algoritmos de Machine
Learning es de ámbito batch, necesitamos todos los datos para calcular los
algoritomos
Desde que Spark permitió el guardado de modelos en repositorios distribuidos
se puede mezclar ambos mundos mediante la lectura del módelo y pasando este
como variable, similar a la relación de Batch y Streaming, para predecir nuevos
registros que lleguen en Streaming.

¿Cómo se relaciona con el Streaming?
MlLib
import org.apache.spark.SparkConfimport org.apache.spark.mllib.clustering.KMeansModelimport org.apache.spark.mllib.linalg.Vectorimport org.apache.spark.streaming.twitter._import org.apache.spark.streaming.{Seconds, StreamingContext}
/** * Pulls live tweets and filters them for tweets in the chosen cluster. */object Predict { def main(args: Array[String]) { if (args.length < 2) { System.err.println("Usage: " + this.getClass.getSimpleName + " <modelDirectory> <clusterNumber>") System.exit(1) }
val Array(modelFile, Utils.IntParam(clusterNumber)) = Utils.parseCommandLineWithTwitterCredentials(args)
println("Initializing Streaming Spark Context...") val conf = new SparkConf().setAppName(this.getClass.getSimpleName) val ssc = new StreamingContext(conf, Seconds(5))
println("Initializing Twitter stream...") val tweets = TwitterUtils.createStream(ssc, Utils.getAuth) val statuses = tweets.map(_.getText)

¿Cómo se relaciona con el Streaming?
MlLib
println("Initalizaing the the KMeans model...") val model = KmeansModel.load(ssc.sparkContext, modelFile)
val filteredTweets = statuses .filter(t => model.predict(Utils.featurize(t)) == clusterNumber) filteredTweets.print()
// Start the streaming computation println("Initialization complete.") ssc.start() ssc.awaitTermination() }}






























