Embed Size (px)
Citation preview

Hadoop Eco System
Presented by : Sreenu Musham
27th March, 2015
Sreenu Musham Data Warehouse
Architect
Hadoop Introduction

AgendaBigData and Its Challenges(Recap)
Hadoop and Its Evolution
Terminology used
HDFS
MapReduce
Hadoop Eco System
Hadoop Distributors
Feel of Hadoop (how it looks?)

Big Data and Challenges
1024 KB = 1MB 1024 MB = 1GB 1024 GB = 1TB 1024 TB = 1Petabyte So on … Exabytes, Zettabytes, Yottabytes,
Brontobytes, Geopbytes
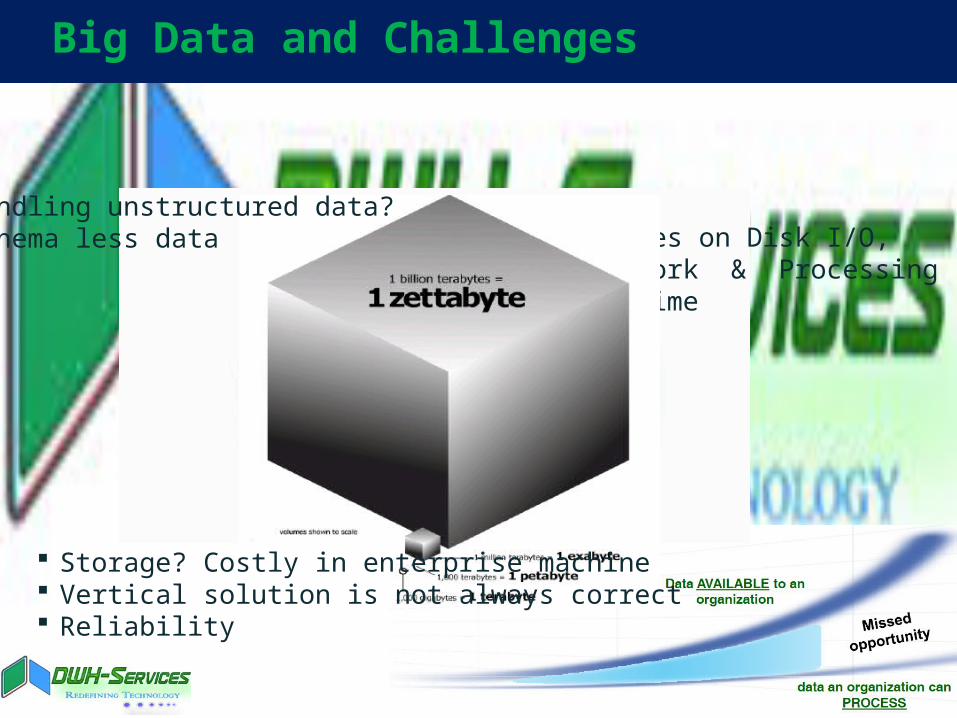
Big Data and Challenges
Issues on Disk I/O, Network & Processing in time
Storage? Costly in enterprise machine Vertical solution is not always correct Reliability
handling unstructured data?Schema less data
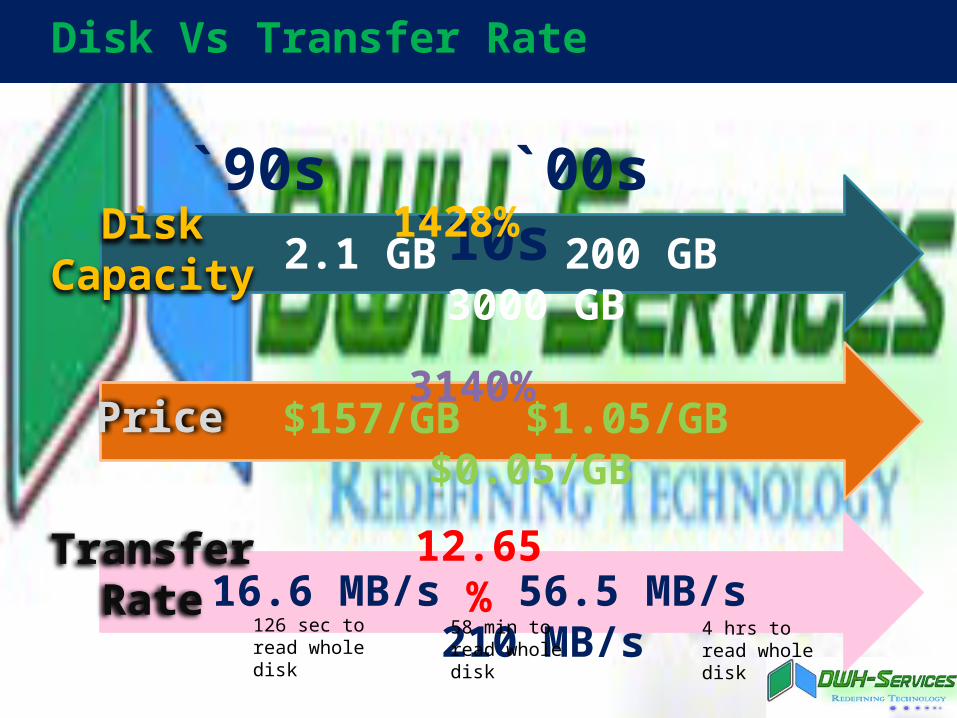
Disk Vs Transfer Rate
DiskCapacity
Price
TransferRate
`90s `00s `10s 2.1 GB 200 GB 3000 GB
$157/GB $1.05/GB $0.05/GB
16.6 MB/s 56.5 MB/s 210 MB/s
1428%
3140%
12.65%
126 sec to read whole disk
58 min to read whole disk
4 hrs to read whole disk

What is Hadoop?
Apache Open source Software Framework for reliable, scalable, distributed computing of massive amount of data
A framework where the job is divided among the nodes and process them in parallel
Hides underlying system details and complexities from user
Developed in JAVA A set of machines running on HDFS and
MapReduce is known as Hadoop cluster Core Components
HDFS MapReduce

Hadoop is not for all type of work
• Process transactions
• Low-Latency data Access
• Lot of Small Files
• Intensive calculations with little data
Hadoop initiated new kinds of analysis • Not jus old thinking on bigger data• Iterate over whole data sets, not only
sample sets• Use multiple data sources (beyond
structured data)• Work with schema-less data
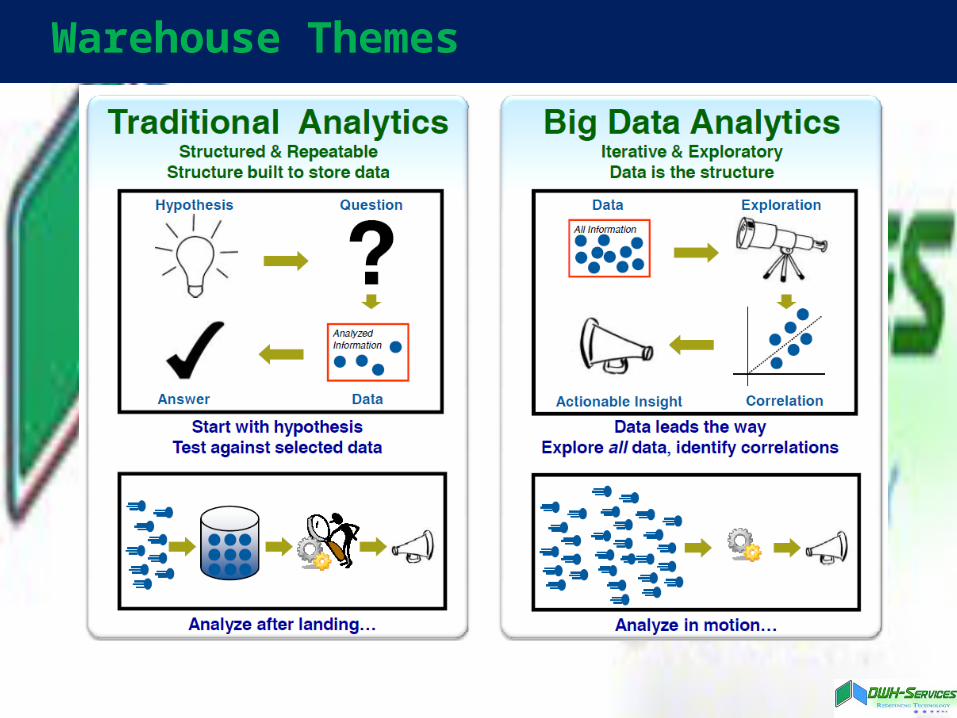
Warehouse Themes
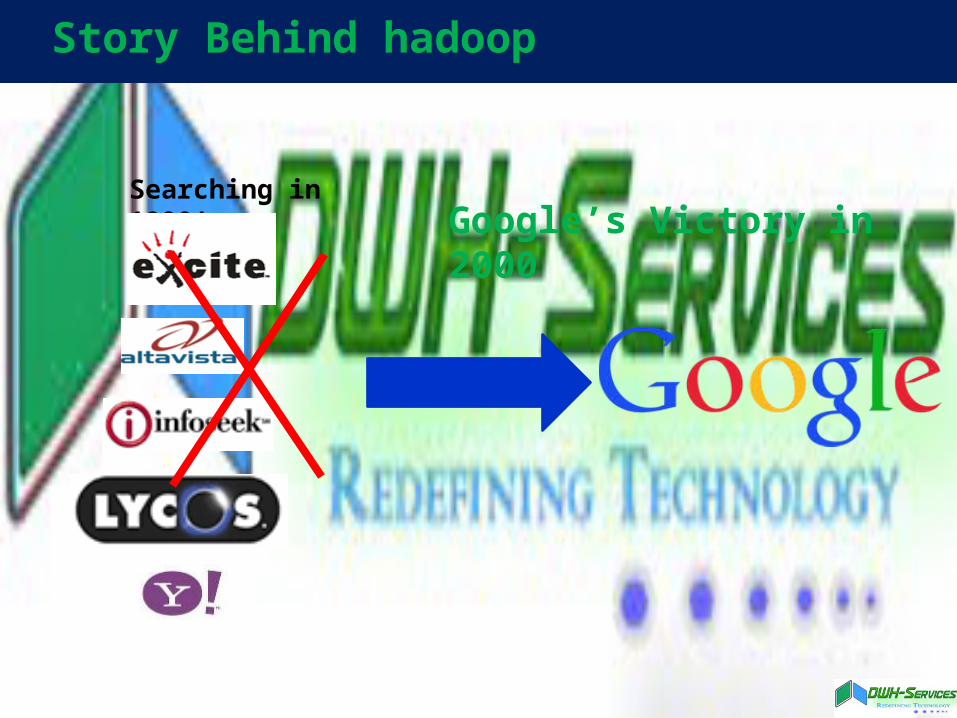
Story Behind hadoop
Google’s Victory in 2000Searching in 1990’s
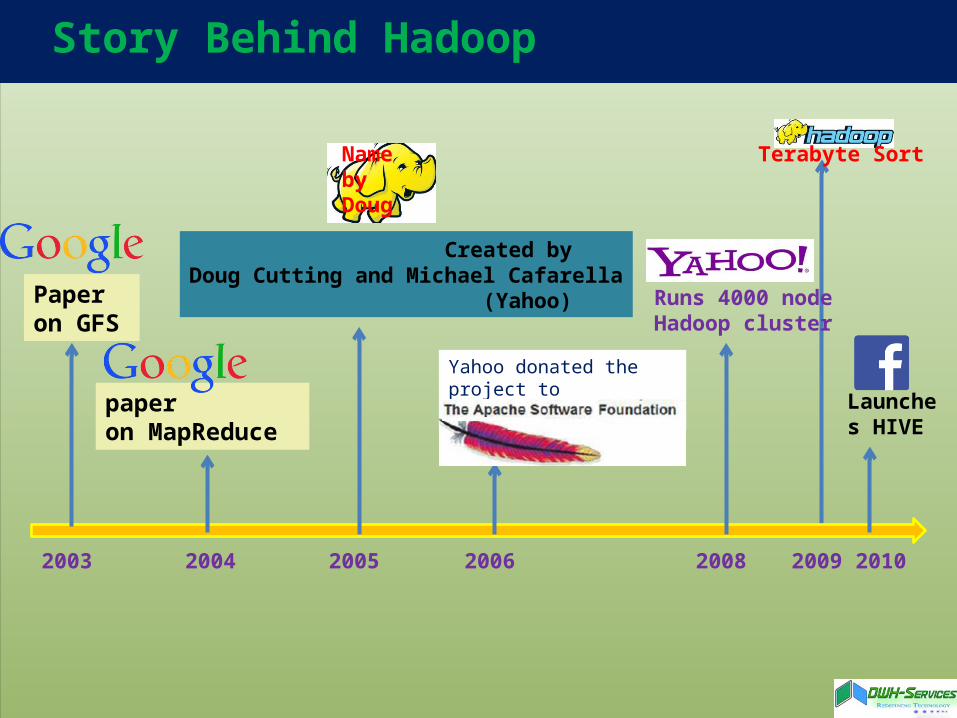
Story Behind Hadoop
2003 2004 2005
Created by Doug Cutting and Michael Cafarella (Yahoo)
2006
Yahoo donated the project to
Paper on GFS
paper on MapReduce
2008 2009
Name by Doug
Terabyte Sort
2010
Launches HIVE
Runs 4000 nodeHadoop cluster
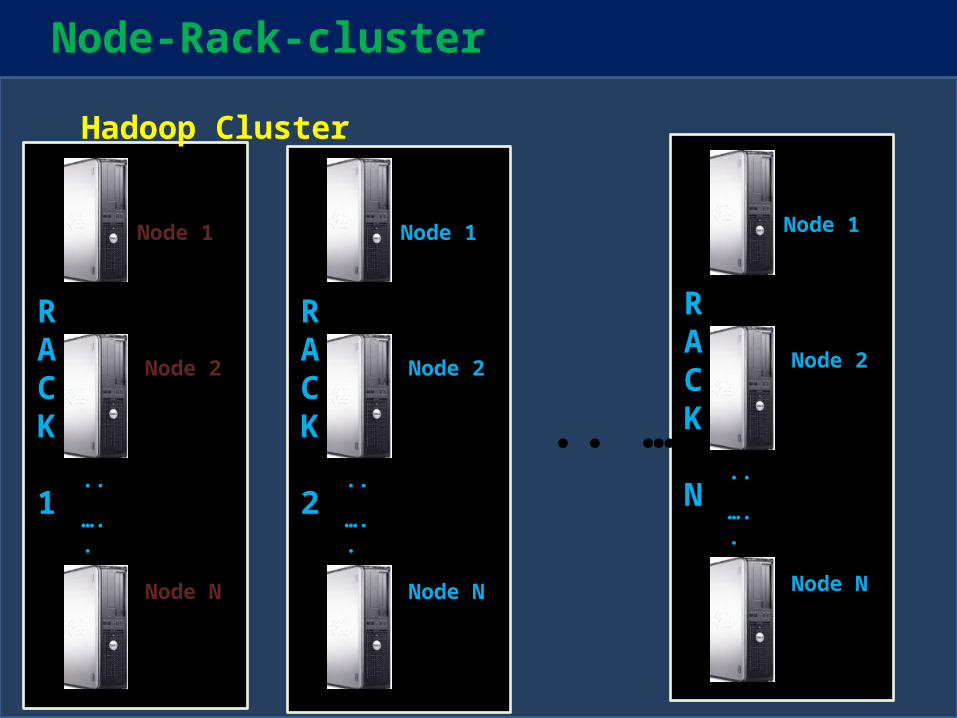
Node-Rack-cluster
HA
Node 1
Node 2
Node N
..
…..
RACK
1
Node 1
Node 2
Node N
..
…..
RACK
2
Node 1
Node 2
Node N
..
…..
RACK
N
.. …
Hadoop Cluster
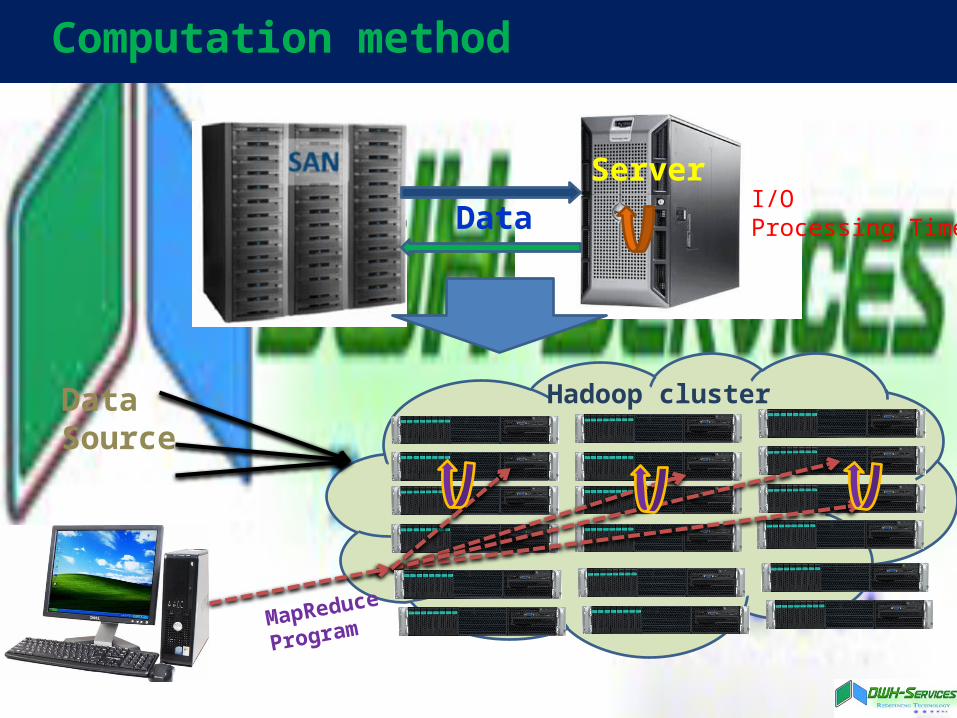
Computation method
DataSource
Server
Data
Hadoop cluster
MapReduce
Program
I/OProcessing Time
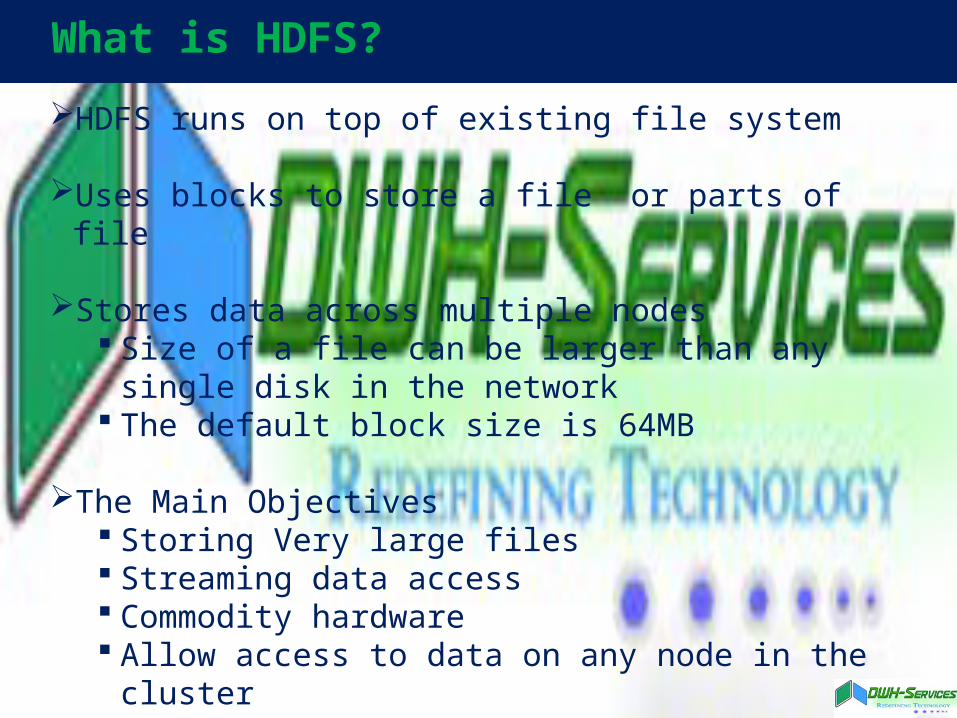
What is HDFS?
HDFS runs on top of existing file system
Uses blocks to store a file or parts of file
Stores data across multiple nodes Size of a file can be larger than any single disk in
the network The default block size is 64MB
The Main Objectives Storing Very large files Streaming data access Commodity hardware Allow access to data on any node in the cluster Able to handle hardware failures

What is HDFS?
If a chunk of the file is smaller than HDFS block size Only the needed space is used
Example: 300MB
HDFS blocks are replicated to several nodes for reliability
Maintains checksums of data for corruption detection and recovery

What is MapReduce?
Is a algorithm/programming model to process the data in the hadoop cluster
Consists of two phases: Map, and then ReduceEach Map task operates on a discrete portion of the
overal dataset• Typically one HDFS block of data
After all Maps are complete, the MapReduce system disstribute the intermediate data to nodes which perform the Reduce phase
Hadoop framework parallelizes the computation, handles failures, efficient communication and performance issues.
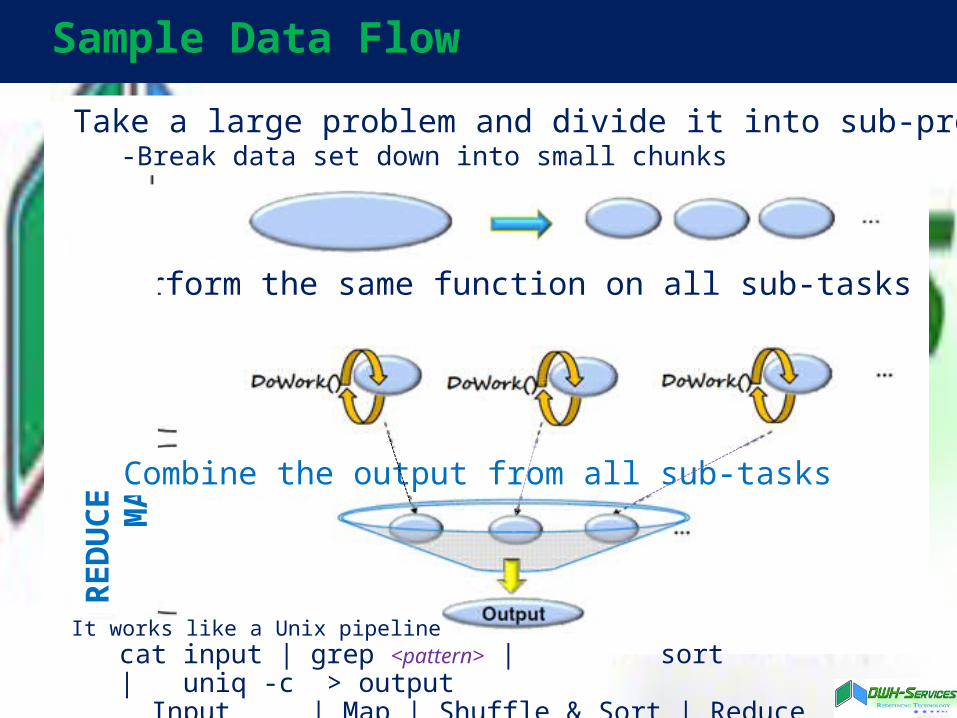
Sample Data Flow
Take a large problem and divide it into sub-problems-Break data set down into small chunks
Perform the same function on all sub-tasks
RE
DU
CE
MA
P
Combine the output from all sub-tasks
It works like a Unix pipelinecat input | grep <pattern> | sort | uniq -c > output Input | Map | Shuffle & Sort | Reduce | Output
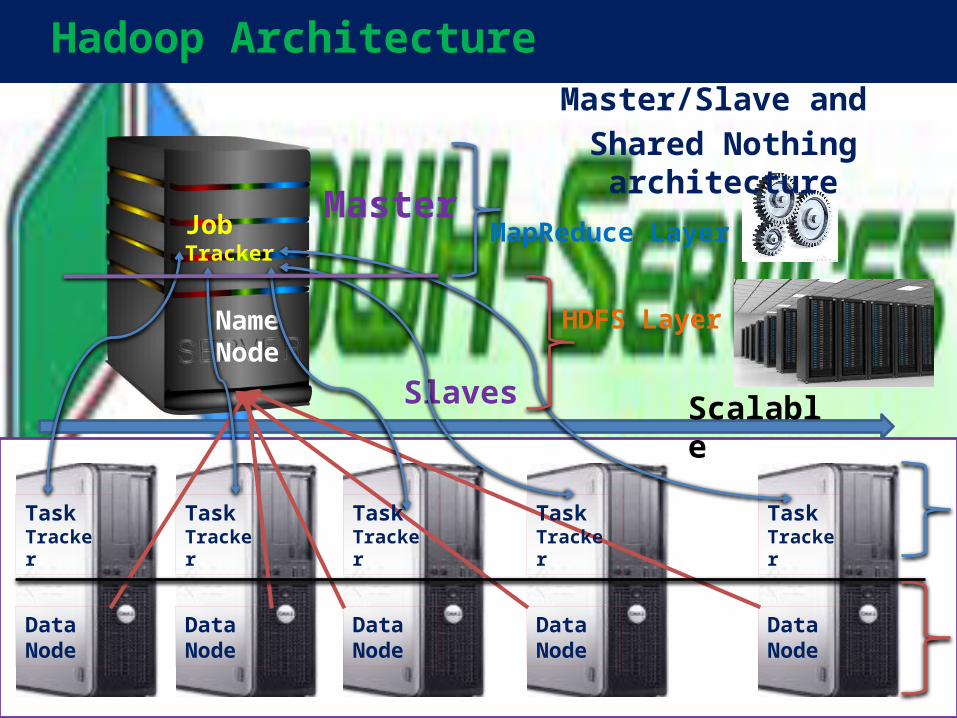
Hadoop Architecture
Data Node
NameNode
Data Node
Data Node
Data Node
Data Node
Scalable
Master
Slaves
Master/Slave and Shared Nothing
architecture
TaskTracker
TaskTracker
TaskTracker
TaskTracker
TaskTracker
Job Tracker
HDFS Layer
MapReduce Layer

Sample Data Flow- Word Count
AirBoxCarBoxDoAir
Air,2Box,2Car,1Do,1
(0, Air)(1, Box)(2, Car)(3, Box)(4, Do)(5, Air)
(Air, [1, 1])(Box, [1, 1])(Car, [1] )(Do, [1] )
(Air, 2)(Box, 2)(Car, 1)(Do, 1)
(Air, 1)(Box, 1)(Car, 1)(Box, 1)(Do, 1)(Air, 1)
Input Outputmap Shuffle &Sort Reduce
<k1, v1> list(<k2, v2>) <k2, list( v2)> list(<k3, v3>)
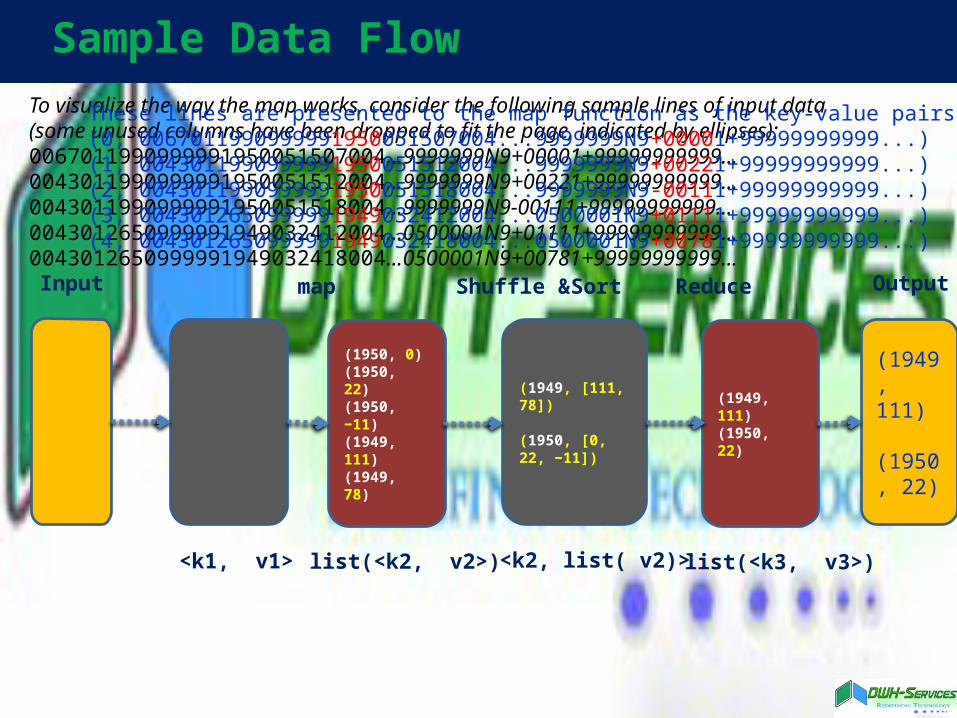
Sample Data Flow
(1949, 111)
(1950, 22)
(1949, [111, 78])
(1950, [0, 22, −11])
(1949, 111)(1950, 22)
(1950, 0)(1950, 22)(1950, −11)(1949, 111)(1949, 78)
Input Outputmap Shuffle &Sort Reduce
<k1, v1> list(<k2, v2>) <k2, list( v2)> list(<k3, v3>)
To visualize the way the map works, consider the following sample lines of input data(some unused columns have been dropped to fit the page, indicated by ellipses):0067011990999991950051507004...9999999N9+00001+99999999999...0043011990999991950051512004...9999999N9+00221+99999999999...0043011990999991950051518004...9999999N9-00111+99999999999...0043012650999991949032412004...0500001N9+01111+99999999999...0043012650999991949032418004...0500001N9+00781+99999999999...
These lines are presented to the map function as the key-value pairs:(0, 0067011990999991950051507004...9999999N9+00001+99999999999...)(1, 0043011990999991950051512004...9999999N9+00221+99999999999...)(2, 0043011990999991950051518004...9999999N9-00111+99999999999...)(3, 0043012650999991949032412004...0500001N9+01111+99999999999...)(4, 0043012650999991949032418004...0500001N9+00781+99999999999...)
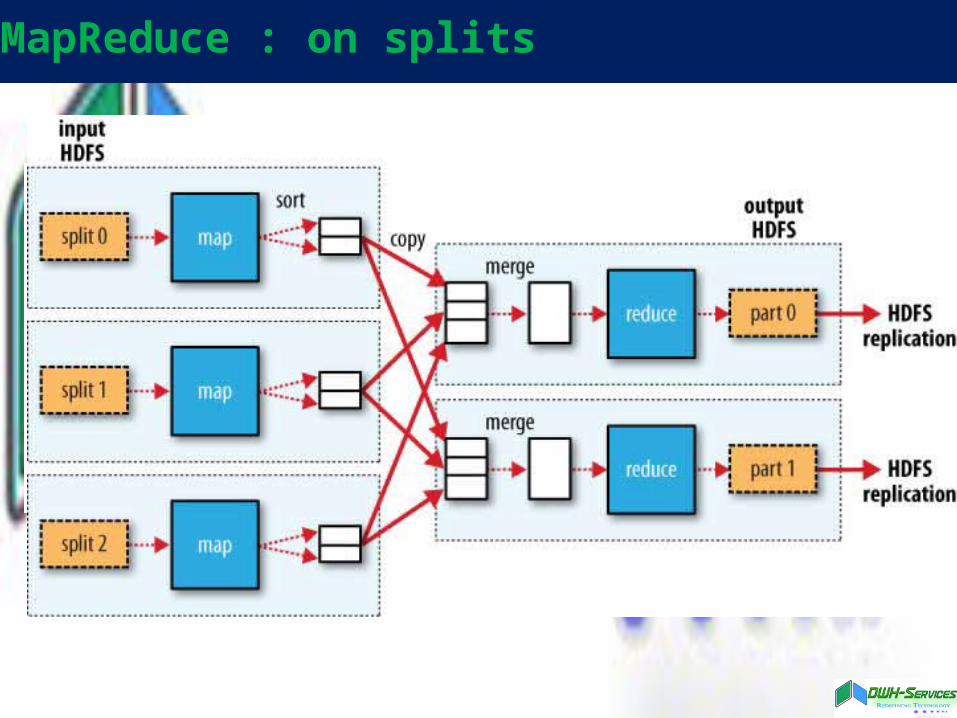
MapReduce : on splits
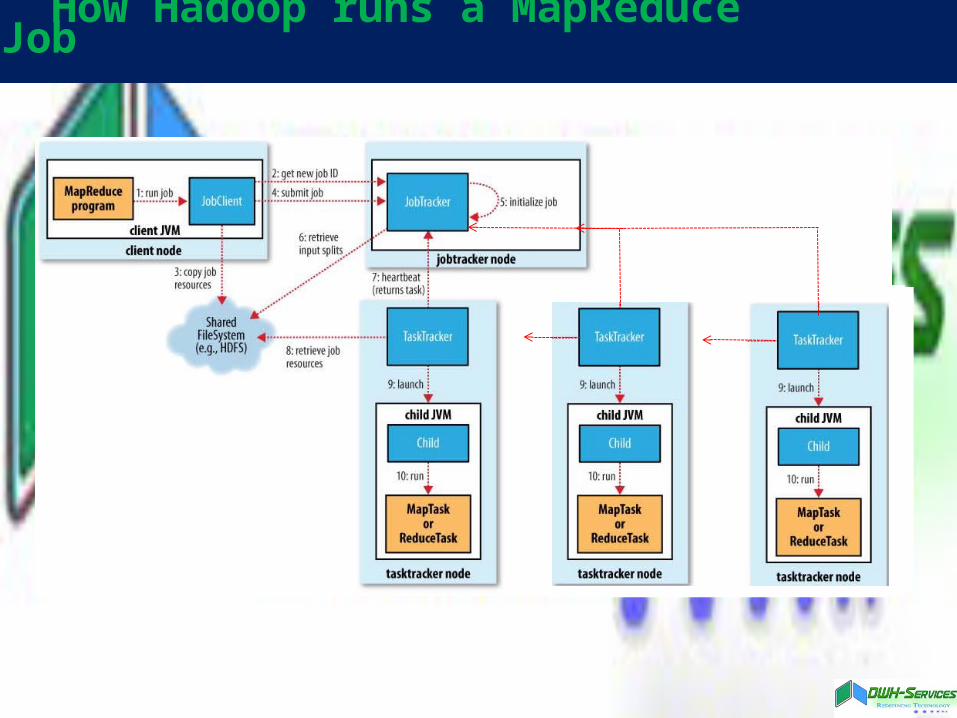
How Hadoop runs a MapReduce Job
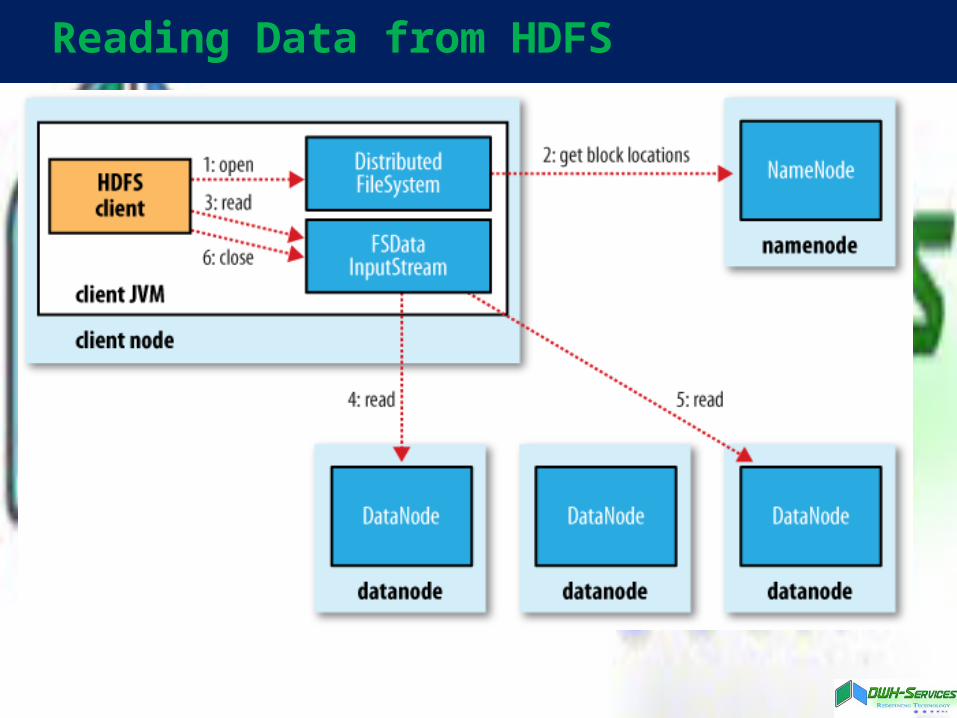
Reading Data from HDFS
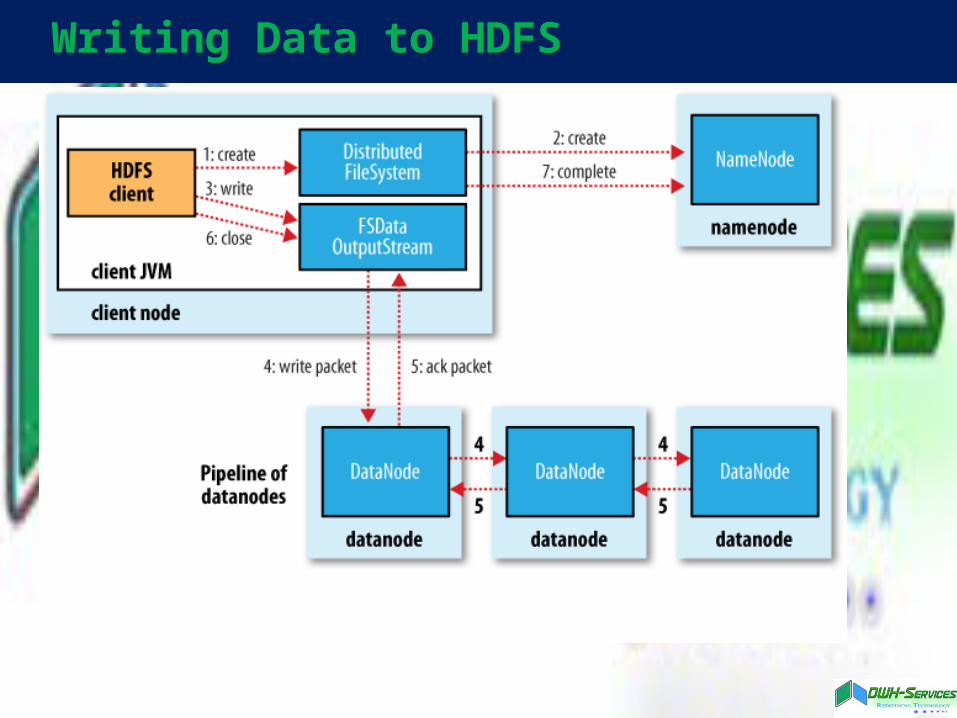
Writing Data to HDFS
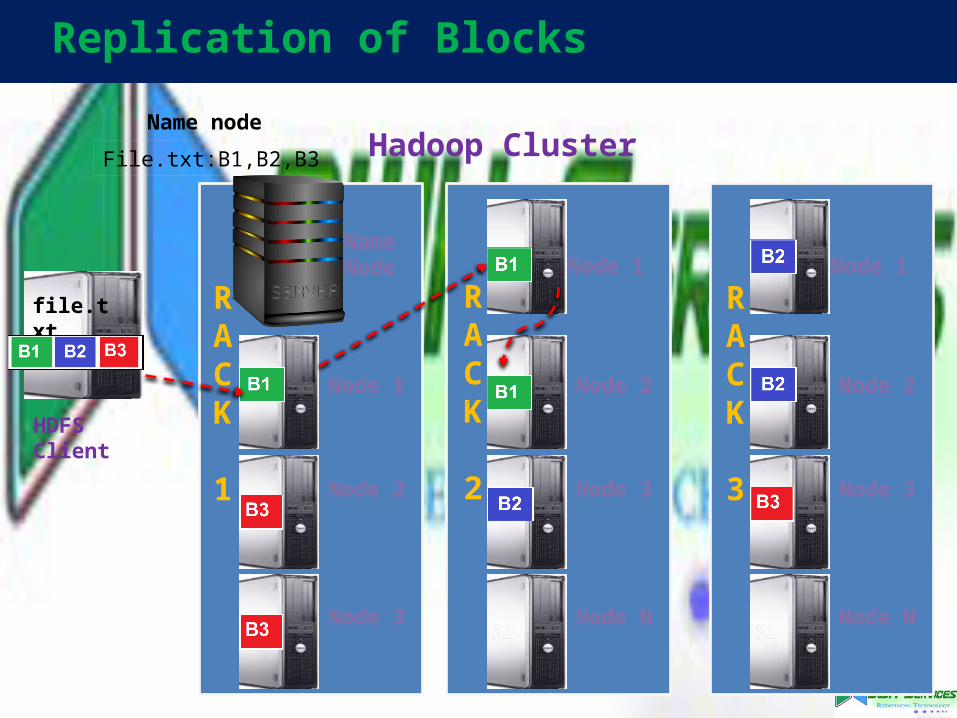
Replication of Blocks
Node 1
Node 2
Node N
RACK
2
Hadoop Cluster
Node 3
Node 1
Node 2
Node N
RACK
3 Node 3
Name Node
Node 1
Node 3
RACK
1 Node 2
HDFS Client
file.txt
File.txt:B1,B2,B3
Name node
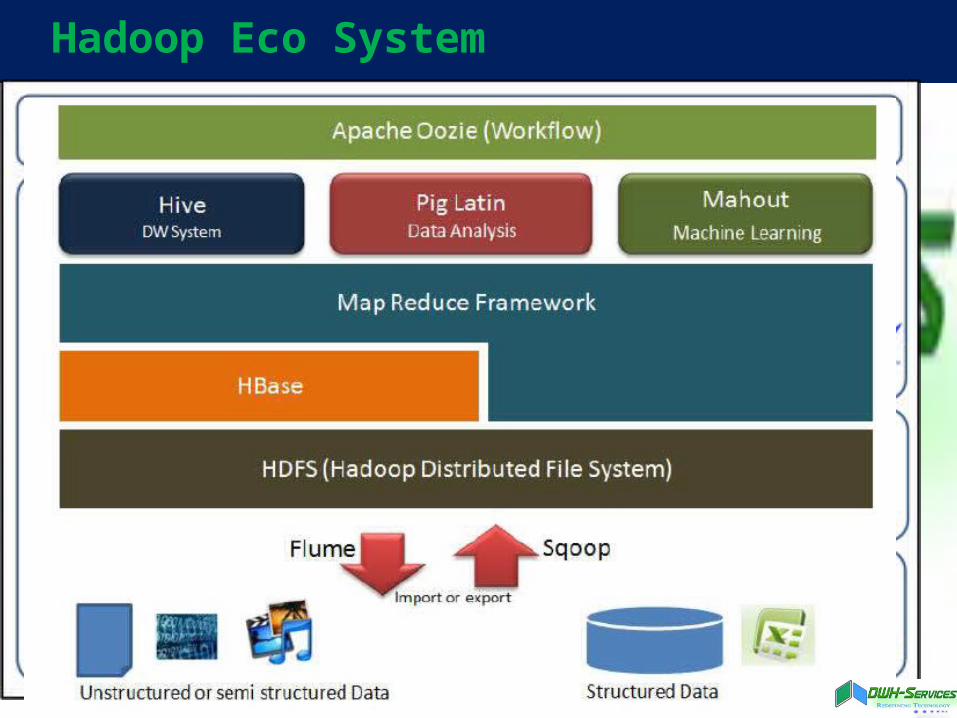
Hadoop Eco System

Hadoop Distributions.
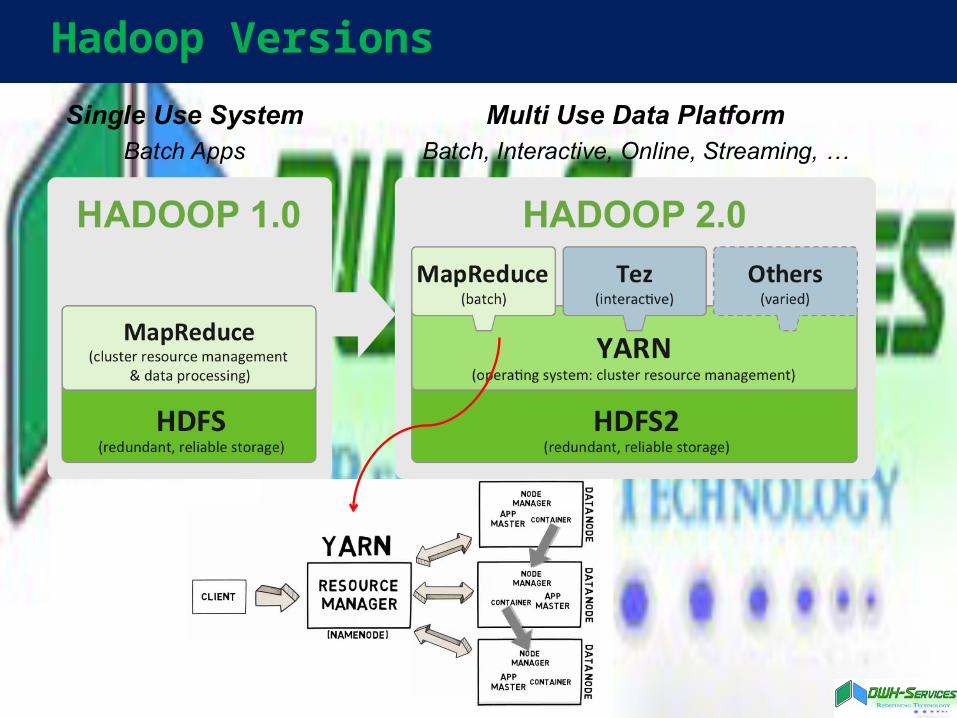
Hadoop Versions
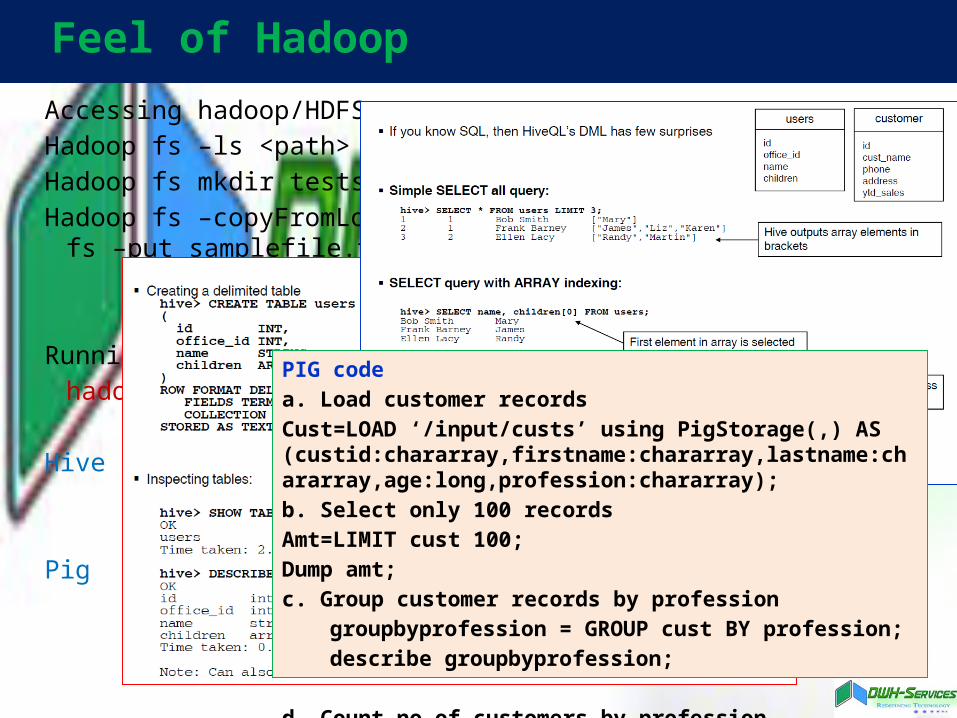
Accessing hadoop/HDFSHadoop fs –ls <path>Hadoop fs mkdir testsreenuHadoop fs –copyFromLocal samplefile.txt : Hadoop fs –put samplefile.txt
Running mapreducehadoop jar newjob.jar samplefile in_dir out_dir
Hive
Pig
PIG codea. Load customer recordsCust=LOAD ‘/input/custs’ using PigStorage(,) AS (custid:chararray,firstname:chararray,lastname:chararray,age:long,profession:chararray);b. Select only 100 recordsAmt=LIMIT cust 100;Dump amt;c. Group customer records by profession
groupbyprofession = GROUP cust BY profession;describe groupbyprofession;
d. Count no of customers by profession countbyprofession = FOREACH groupbyprofession GENERATE group,COUNT(cust)’Dump countbyprofession;
Feel of Hadoop

Hadoop Vs Other Systems
29
Distributed Databases Hadoop
Computing Model - Notion of transactions- Transaction is the unit of work- ACID properties, Concurrency control
- Notion of jobs- Job is the unit of work- No concurrency control
Data Model - Structured data with known schema- Read/Write mode
- Any data will fit in any format - (un)(semi)structured- ReadOnly mode
Cost Model - Expensive servers - Cheap commodity machines
Fault Tolerance - Failures are rare- Recovery mechanisms
- Failures are common over thousands of machines
- Simple yet efficient fault tolerance
Key Characteristics - Efficiency, optimizations, fine-tuning - Scalability, flexibility, fault tolerance
• Cloud Computing• A computing model where any computing
infrastructure can run on the cloud• Hardware & Software are provided as remote
services• Elastic: grows and shrinks based on the user’s
demand• Example: Amazon EC2
Elastic:grows and shrinks based on user’s demand

Q & A
Hadoop Eco System
Presented By
Sreenu Musham





![9. eloadas DWH Teradata alapokon.ppt [Kompatibilis mód]gajdos/2012adatb2/9. eloadas DWH... · DWH @ Adatb haladóknak Adattárház és céljai (5p) zMi az adattárház?(Inmon/Kimball)](https://img.pdfslide.tips/doc/110x75/5e8a65dda09d5920e27a3883/9-eloadas-dwh-teradata-kompatibilis-md-gajdos2012adatb29-eloadas-dwh.jpg)







![[RakutenTechConf2013] [B-3_2] DWH/Hadoop in Rakuten Ichiba](https://img.pdfslide.tips/doc/110x75/545cf0b2b0af9f12318b4c1a/rakutentechconf2013-b-32-dwhhadoop-in-rakuten-ichiba.jpg)











![,16758& ,81, 35235,, '( 660 3HUVRQDOL]DWH](https://img.pdfslide.tips/doc/110x75/618f95a04021d47c6d509b05/16758amp-81-35235-660-3huvrqdoldwh.jpg)


