Embed Size (px)
Citation preview

1
RDBからの脱却:新ERP"HUE"におけるCassandra
株式会社ワークスアプリケーションズ堤 勇人HUE BT Back-end team
Cassandra Summit Tokyo 2015
2015/04/21

2
前置き

3
堤 勇人 @2t3
2010年からエンタープライズ向けメーラーWebmailにてCassandraを使い始める。
現在はHUE BT Back-end teamにて裏側全般を見ています。
自己紹介

4
Webmail
➢ エンタープライズ向けメールサービス➢ 2010年から5年間、開発・運用している➢ Cassandraで動く➢ 毎分2000通のメールを処理する
自己紹介2

5
Cassandraをエンタープライズで使うとはどういうことか?
今日のテーマ

6
➢大企業向けのシステム
➢様々な状況に効率的に対応するため、複雑な業務が行われる。
➢それら複雑な業務のための、多くの機能、細かい機能が求められる。
エンタープライズとは何か?

7
➢ コストパフォーマンスが悪い?➢ 開発が大変な割に、単純なことしかできない
➢ 必須機能が無い?➢ トランザクション、join、index、etc...
➢ 結果整合性なんていらない?➢ 厳密なデータが必須➢ gmailで件数がmanyと出るのは良いが、給料がmanyと書かれていたら怒る
何故エンタープライズ分野ではCassandraが使われて来なかったのか?

8
という認識を覆して登場したのが...

9
➢ High Usability➢ 100msの応答性能➢ 脱RDB
「HUE」

10
➢ どのようなレベルか➢ Googleトップページが100ms➢ 検索結果になると300~400ms
➢ 単に早くレスポンスするというだけではない
➢ トライアンドエラーを可能にすることで、新しい価値を提供できる
100msの応答性能

11
トライアンドエラーの例
可能ならデモ

12
これを実現するためのCassandra

13
何故Cassandraか?

14
➢ 100msの要求性能➢ DBの許容時間は20ms
➢ 20msを普通のRDBで出すには➢ 非正規化する➢ joinしない➢ ソート済みデータを用意する
しかない
✗ もしくは高いサーバにメモリを積む
何故Cassandraか?

15
➢ 設定➢ CPU 1処理 約0.3[ns]➢ CPUキャッシュアクセス速度 0.5~5[ns]➢ メモリアクセス速度 10~数10[ns]➢ 処理1ループを、100[ns]とする
➢ 10万件ソートすると N logN = 1,600,000
試算(実行時ソート)

16
➢ 1,600,000 * 100[ns] = 160[ms]➢遅い
➢ メモリに全部データが載っているとしてもなかなか大変な計算
➢ コア数にも限界がある
試算(実行時ソート)

17
➢ スループットが簡単にスケールすることも重要➢ バッチ処理の時間はスループットに依存する
➢8時間かかっていたバッチが20分になれば➢ より詳細なデータを提供できる➢他の業務をやる時間ができる➢働き方自体が変わる
何故Cassandraか?2

18
試算2

19
試算2

20
➢ 可用性➢ スケールする
➢ 3台から1000台レベルのクラスタまで同様にスケールする
➢ むしろ台数が増えると安定する➢ マスター無し
➢小さなダウンタイムも無い➢ 実はマスタースレイブ切り替えの際にダウンタイムがあるシステムは多い
Cassandraの有用性

21
➢ 可用性➢ スケールする➢ マスター無し
これらが簡単に行えることが重要
Cassandraの有用性2

22
➢ 100msのような高速域ではRDBの良さは失われる。
➢ Cassandraではスループットをコストパフォーマンス良く上げることができる
➢簡単に分散システムの恩恵を受けられる
何故Cassandraか?まとめ

23
Cassandra周りの技術
24
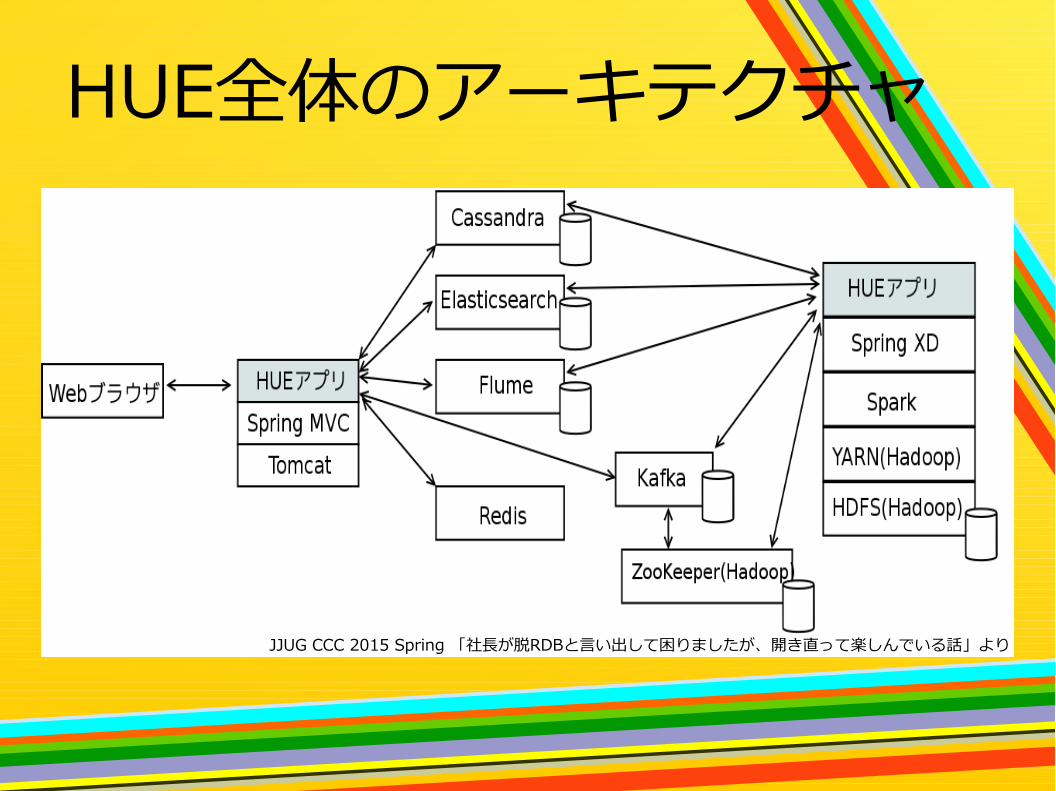
HUE全体のアーキテクチャ
JJUG CCC 2015 Spring 「社長が脱RDBと言い出して困りましたが、開き直って楽しんでいる話」より

25
Cassandra周りのフレームワーク➢Key Value Access Library
➢ いわゆるObject Mapper➢ POJOの形でCassandraとやり取り➢ 様々な属性はannotationで管理
➢ CQLAPIを隠蔽➢格好いい名前を考えろと言われている

26
Cassandra周りのフレームワーク2➢ Index creation framework
➢ Index、非正規化データを自動メンテナンス➢ Elasticsearch等へも同期可能
➢ Key Value Accessへの入力を取得➢ Kafkaでキューイングし、非同期に実行

27
Cassandra周りのフレームワーク3➢ EDP2
➢ Enterprise Distributed Processing Platform➢ 分散処理に関わるリソースを自動的に管理する
➢ バッチの予定終了時刻に合わせて、Sparkのworkerを追加したり、Cassandra自体をスケールさせたりする。
28
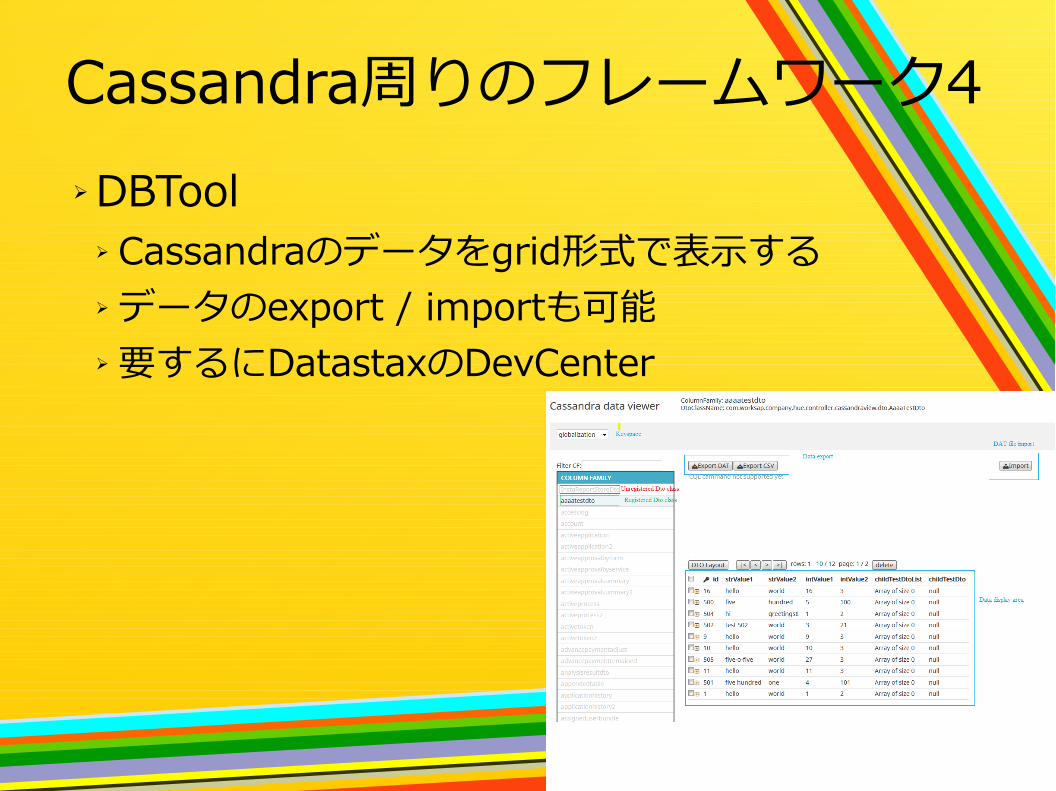
Cassandra周りのフレームワーク4➢ DBTool
➢ Cassandraのデータをgrid形式で表示する➢ データのexport / importも可能➢ 要するにDatastaxのDevCenter

29
開発中に出てきたCassandraの問題点

30
開発中に出てきた問題➢ トランザクション➢N+1問題➢ 多テーブル問題
➢逆に意外と何とかなる問題➢ 複雑なクエリ➢ join➢ index➢ validation

31
➢ 結論から先に言ってしまうと、全てどうにかなる。
➢ しかし、前項の有用性のように、簡単にはいかないものばかり。
開発中に出てきた問題

32
➢ これまでトランザクションを利用していた処理の99.9%は対応不要か、Lightweight Transactionで対応可能。
➢残りの0.1%、特にisolationが必要な場合には特別な仕組みが必要となってくる。
トランザクション

33JJUG CCC 2015 Spring 「社長が脱RDBと言い出して困りましたが、開き直って楽しんでいる話」より

34JJUG CCC 2015 Spring 「社長が脱RDBと言い出して困りましたが、開き直って楽しんでいる話」よりJJUG CCC 2015 Spring 「社長が脱RDBと言い出して困りましたが、開き直って楽しんでいる話」より

35
➢ 例えば別順でソートさせたい時indexテーブルからソート済みIDをロード➔ 実テーブルにそのIDでアクセス
➢ joinもinも使えないため、対象者数回+1のアクセスが発生する。
➔全て並列で取得している。(力技)接続先が分散されるので、パフォーマンス的問題は起こっていない。
N+1問題

36
➢ 多数のテーブルを作るとCassandraが重くなり、やがては起動しなくなる➢ Cassandraは1テーブル辺り約1MBのメモリオーバーヘッドが全ノードにかかる
➢ HBaseでも似たような問題がある➢ Elasticsearchでも似たような問題がある➢ マルチテナンシを考慮するとさらに倍率がかかる
➢ そしてERPは扱うデータの種類が極めて多い➢ 弊社人事給与で3,000テーブル、会計となると単独でそれ以上の数になる
多テーブル問題

37
➢ データの種類毎の汎用テーブルを用意し、複数のテーブルを一つのテーブルに入れてしまう。
多テーブル問題2

38
create table generic_table {table_name text,joined_pk blob,ck1 blob,ck2 blob,ck3 blob,ck4 blob,ck5 blob,column_name text,value blob,primary key ((table_name, joined_pk), ck1,
ck2, ck3, ck4, ck5, column_name)}
多テーブル問題3

39
➢弊害と恩恵➢ かなり独自のテーブルにしてしまった結果、DevCenterのようなツールが使えなくなった。➔ DBToolを作成
➢想定される種類のテーブル構造が予め定義されていることにより、遅い定義が行われる余地が無くなった。
➢ thriftのダイナミックカラムが再び利用可能に
多テーブル問題4

40
まとめ

41
まとめ
➢ Cassandraは今後もっとエンタープライズの領域で使われていき、進化していく
➢逆にエンタープライズ分野もCassandraのような特性を求め、社会に圧倒的なメリットを提供するようになる

42
以上、ありがとうございました
質疑+時間があれば、おまけ

43
Cassandraあれこれ
Appendix

44
ERPにおけるデータパターン究極的にはこの2個しかない
➢ event➢不変の事実➢ これが蓄積されていく➢ e.g. 申請書、取引、発令、etc...
➢ changeset➢ eventが蓄積された結果を示す歴史➢ e.g. 人事異動履歴、組織、会社
データデザインパターン

45
その応用➢ Tree➢ Relation➢ Group➢ Analyze➢ Header-Body➢ etc...
データデザインパターン2

46
100%
ここ1年のCassandraの稼働率
ここ1年、サービスダウンはおろかノードダウンすらしていない。
(Webmail運用実績値、計画的メンテナンス除く)

47
SCassandra
エラーケースのテスト等に大変便利。
Cassandraでのテスト

48
➢ Replica:3, R/W=QUORUM➢王道
➢ メモリ設定はそのまま、newgenを増やす
➢遅くなる兆候、遅いテーブルは、cfhistogramsをJMXで監視する
Cassandraの設定

49
Cassandra自体は動作させたままrolling updateできるが、APサーバの無停止バージョンアップや、データ移行を考えると難しくなってくる。
バージョンアップ戦略

50
Tableの作成やカラム追加だけで済む場合
バージョンアップ戦略1
➢問題なし、そのままバージョンアップ

51
データの移行が必要な場合
バージョンアップ戦略2
➢移行スクリプト実行後、そのままバージョンアップ

52
データの移行が必要かつ、移行中に入力されたデータの移行も必要な場合
バージョンアップ戦略3
➢ まず移行スクリプトを当てる➢ その後、移行後データが無い場合はその場で移行する”lazy migration”バージョンを作る
➢ 新データに移行を行う
➢ ”lazy migration”処理を外しバージョンアップを行う

53
データの移行が必要かつ、移行中に入力されたデータの移行も必要で、処理を遅くできない場合
バージョンアップ戦略4
➢移行先のテーブル or カラムを別途作る➢ 結果を移行元と移行先両方に書き込むバージョンへアップデートする
➢移行スクリプトを当てる➢読み込み先を移行先に変更する➢移行先にのみ読み書きするバージョンにアップデートする

54
以上、ありがとうございました





























