Embed Size (px)
Citation preview

Presented by:
Ehsan Asgarian


NoSQL doesn’t mean no data
• It’s not Anti SQL or absolutely no SQL
• N(ot) O(nly) SQL
• Non-relational Databases
Why not SQL?
• Internet scale
• 100s of millions of concurrent users
• Massive data collections –Terabytes to Petabytes of data
• 24/7 across the globe
What is NoSQL good for? BIG DATA
• High Availability
• High Performance
• Horizontal Scalability
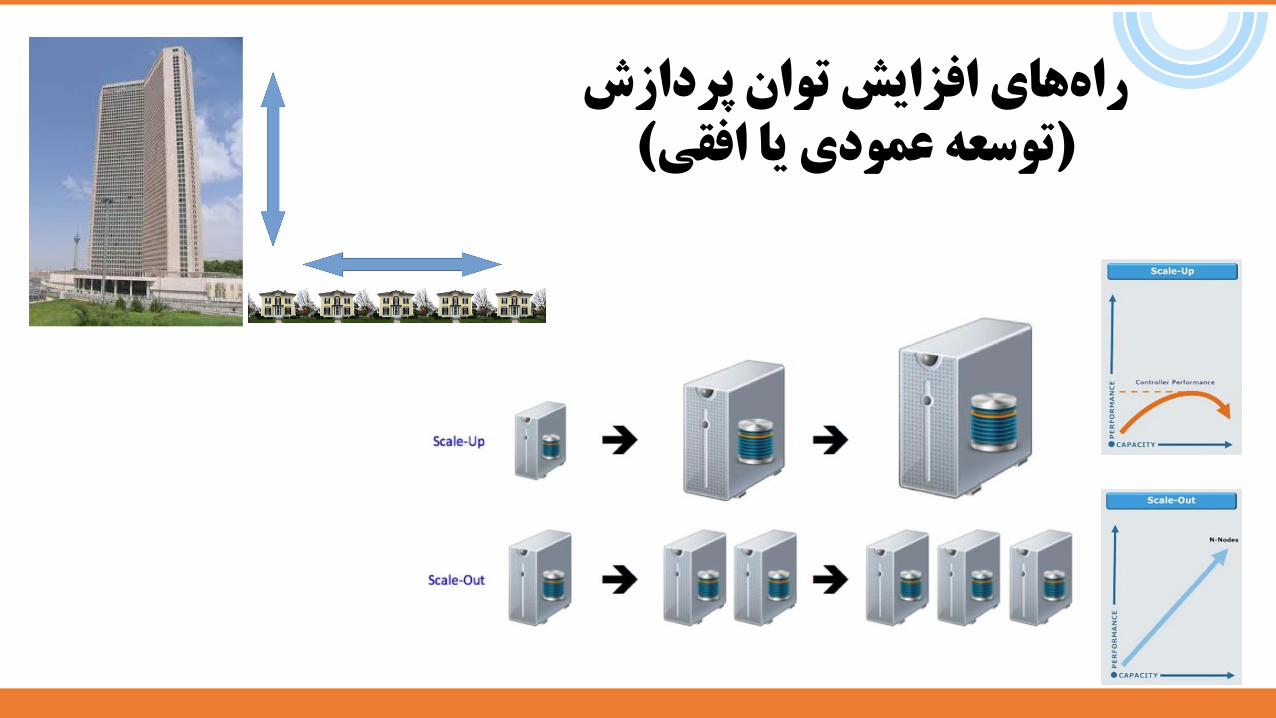
پردازشراههایافزایشتوان(توسعهعمودییاافقی)

• Consistency - This means that all nodes see the same data at the same time.
• Availability - This means that the system is always on, no downtime.
• Partition Tolerance - This means that the system continues to function even if the communication among the servers is unreliable
•SQL - CA
•NoSQL - AP
CAP theorem (Consistency, Availability and Partition-tolerance)

NoSQL ACID Trade-offs
• Dropping Atomicity lets you shorten the time tables (sets of data) are locked.
MongoDB, CouchDB.
• Dropping Consistency lets you scale up writes across cluster nodes.
Riak, Cassandra.
• Dropping Durability lets you respond to write commands without flushing to disk.
Memcache, Redis.

ACID vs. BASE
• ACID:• Atomic: Every transaction should succeed else transaction is rolled back
• Consistent: Every transaction leaves database in a valid (consistent) state
• Isolation: Transactions don’t interfere with each other
• Durable: Completed transactions persist, even when servers restart

ACID vs. BASE
• BASE• Basic Availability: The data store should be up all of the time
• Soft state: The data store can be cached somewhere else if the data store is not available
• Eventual consistency: The data store can have conflicting transactions, but should eventually reach a valid state

Different types of NOSQLKey-Value Store
• A key that refers to a payload• MemcacheDB, Azure Table Storage, Redis
Graph Store
• Nodes are stored independently, and the relationship between nodes (edges) are stored with data
• Neo4j
Column Store• Column data is saved together, as opposed to row data• Super useful for data analytics• Cassandra, Hypertable
Document / XML / Object Store
• Key (and possibly other indexes) point at a serialized object• DB can operate against values in document• MongoDB, CouchDB, RavenDB, ElasticSearch

NoSQL document example{
"_id": ObjectId,"description": String,"total": Number,"notes": [{
"_id": ObjectId,"text": String
}],"exclusions": [{
"_id": ObjectId,"text": String
}],"categories": {
"ref1": {"name": String,"status": String,"price": Number
},"ref2": {
"name": String,"status": String,"price": Number
}}
}
ORM (Object-relational mapping)
● Entity Framework (.NET)● Hibernate (Java)● Django (Python)● Sequelize (JS) is an ORM for Node.js and io.js
j = { name : "mongo" }k = { x : 3 }
db.things.insert( j )db.things.insert( k )
db.things.find()
{"_id" : ObjectId("4c2209f9f3924d31102bd84a"), "name" : "mongo"}{"_id" : ObjectId("4c2209fef3924d31102bd84b"), "x" : 3 }
ODM (Object Data Manager)
● Mongoose (Mongo)

Use SQL if:
● Data integrity is essential
● Standards-based proven technologies with good developer experience and support
● Logical related discrete data requirements which can be identified up-front
● Prefer SQL

Use NoSQL if:
● Data requirements are unrelated, indeterminate or evolving
● Project objectives are simpler of less specific and allow starting to code immediately
● Speed and scalability is imperative
● Prefer NoSQL

SQL Products and customers
December, 2015

NoSQL products and customers

:NoSqlمزایای پایگاه داده های
oسرعت بیشتر درج اطالعات
o ترو امکان گسترش راحت(مدیریت بخش های داده)پذیرمقیاس
o دادهکاربردهای خاص و قالب های مختلف مناسب و بهینه شده برای
o انعطاف پذیری(Flexibility ) باال بدلیلSchemaless بودن که در.داده ها در پایگاه داده ساده است( ویژگی ها)نتیجه تغییر ساختار
o انه نیازی به زبان جداگ)دسترسی به داده ها با استفاده از شیءگرایی(برای دسترسی و تغییر داده ندارندSQLمانند
oOpen sourceبودن اغلب آنها
:NoSqlنقاط ضعف پایگاه داده های
o های ویژگیتمام عدم پشتیبانی آنها از ACID
oکنترل سازگاری داده ها دشوار است
o براینامناسبjoinهاداده
o سرعت بازیابی(select ) بر روی ( داده های سازمانی)حجم متوسط داده هاینسبت به پایگاه داده های( شدهایندکس )و عادی( سرور تک)nodeیک
.رابطه ای بطور قابل مالحظه پایین تر هست
o عدم پشتیبانی ازtrigger
A well-designed SQL database will almost certainly perform better than a badly designed NoSQL equivalent and vice versa.
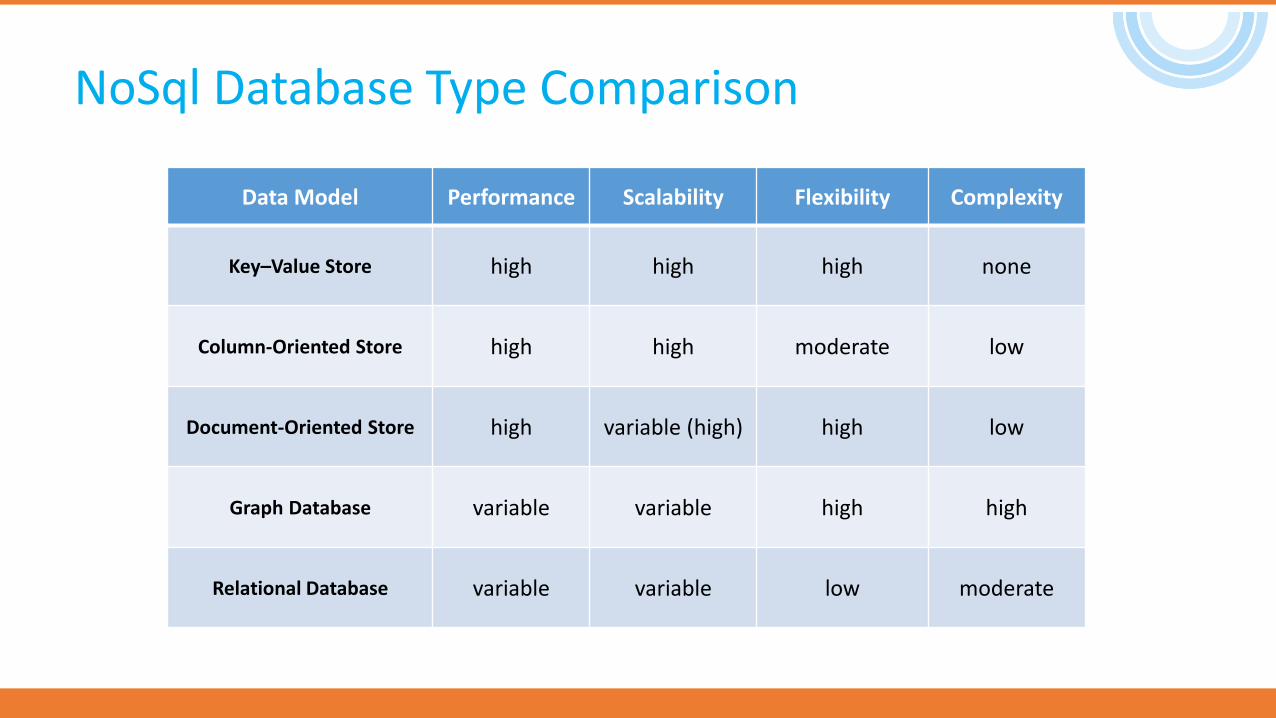
NoSql Database Type Comparison
Data Model Performance Scalability Flexibility Complexity
Key–Value Store high high high none
Column-Oriented Store high high moderate low
Document-Oriented Store high variable (high) high low
Graph Database variable variable high high
Relational Database variable variable low moderate

Summary
SQL - works great, isn’t scalable for large data 😞
NoSQL - works great, isn’t suitable for everyone 😞
SQL + NoSQL 😊


• Efficient indexing of data
• On all fields / combination of fields
• Analyzing data
• Text Search• Tokenizing
• Stemming
• Filtering
• Understanding locations
• Date parsing
• Relevance scoring
What is a search engine?

• Finding word boundaries
• Not just explode(‘ ‘, $text);
• Chinese has no spaces. (Not every single character is a word.)
• Understand patterns:
• URLs
• Emails
• #hashtags
• Twitter @mentions
• Currencies (EUR, €, …)
Tokenizing

• “Stemming is the process for reducing inflected (or sometimes derived) words to their stem, base or root form.”• Conjugations• Plurals
• Example:• Fishing, Fished, Fish, Fisher > Fish• Better > Good
• Several ways to find the stem:• Lookup tables• Suffix-stripping• Lemmatization• …
• Different stemmers for every language.
Stemming

Filtering
• Remove stop words
• Different for every language
• HTML
• If you’re indexing web content, not every character is meaningful.

Understanding locations
• Reverse geocoding of locations to longitude & latitude
• Search on location:
• Bounding box searches
• Distance searches
• Searching nearby
• Geo Polygons
• Searching a country
•(Note: Relational DBs also have geospatial indeces.)

Relevance Scoring
• From the matched documents, which ones do you show first?
• Several strategies:
• How many matches in document?
• How many matches in document as percentage of length?
• Custom scoring algorithms
• At index time
• At search time
• … A combination
Think of Google PageRank.

Apache lucene•“Information retrieval software library”
•Free/open source
•Supported by Apache Foundation
•Created by Doug Cutting
•Written in 1999
•The latest version of Lucene is 6.5.0 which was released on March 27, 2017.
“There’s software a Java library for that.”
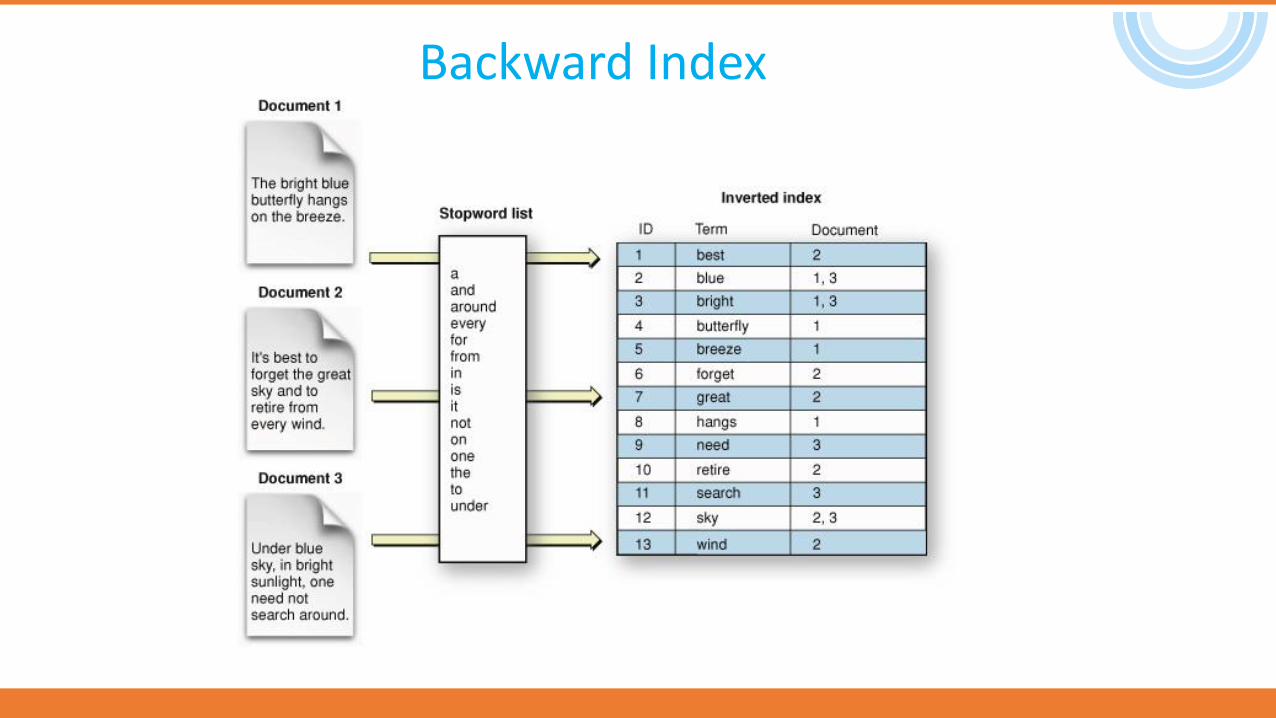
Backward Index
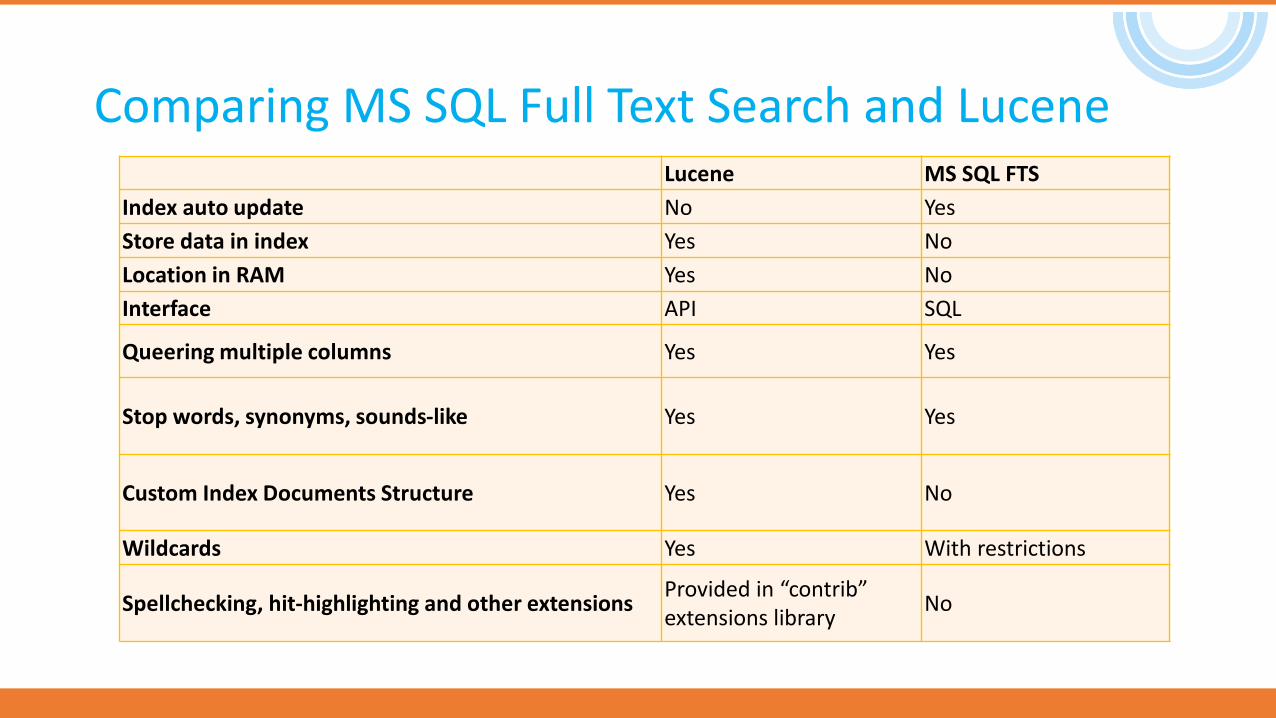
Comparing MS SQL Full Text Search and LuceneLucene MS SQL FTS
Index auto update No Yes
Store data in index Yes No
Location in RAM Yes No
Interface API SQL
Queering multiple columns Yes Yes
Stop words, synonyms, sounds-like Yes Yes
Custom Index Documents Structure Yes No
Wildcards Yes With restrictions
Spellchecking, hit-highlighting and other extensionsProvided in “contrib” extensions library
No
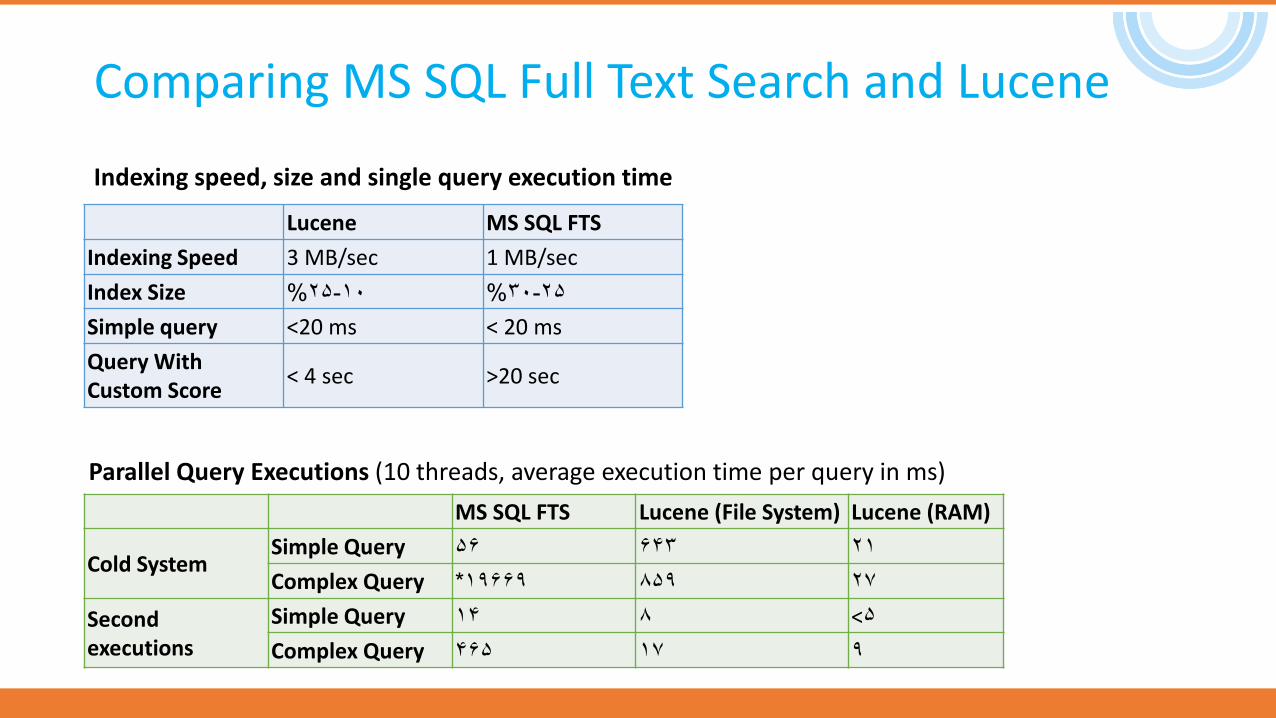
Comparing MS SQL Full Text Search and Lucene
Lucene MS SQL FTS
Indexing Speed 3 MB/sec 1 MB/sec
Index Size 10-25% 25-30%
Simple query <20 ms < 20 ms
Query With Custom Score
< 4 sec >20 sec
MS SQL FTS Lucene (File System) Lucene (RAM)
Cold SystemSimple Query 56 643 21
Complex Query 19669* 859 27
Second executions
Simple Query 14 8 <5
Complex Query 465 17 9
Indexing speed, size and single query execution time
Parallel Query Executions (10 threads, average execution time per query in ms)


Elasticsearch
• ElasticSearch is a free and open source distributed inverted index.
• Built on top of Lucene Lucene is a most popular java-based full text search index implementation.
• Created by Shay Banon @kimchy
• Versions
First public release, v0.4 in February 2010
Now stable version at 5.3.0 (March 28, 2017)
• In Java, so inherently cross-platform
• Repository : github.com/elastic/elasticsearch
• Website : www.elastic.co/products/elasticsearch

Why ElasticSearch?
Easy to scale (Distributed)
Everything is one JSON call away (RESTful API)
Unleashed power of Lucene under the hood
Excellent Query DSL
Multi-tenancy (multi cluster, node, shards)
Support for advanced search features (Full Text)
Configurable and Extensible
Document Oriented
Schema free
Conflict management (Optimistic Concurrency Control using Versioning)
Active community
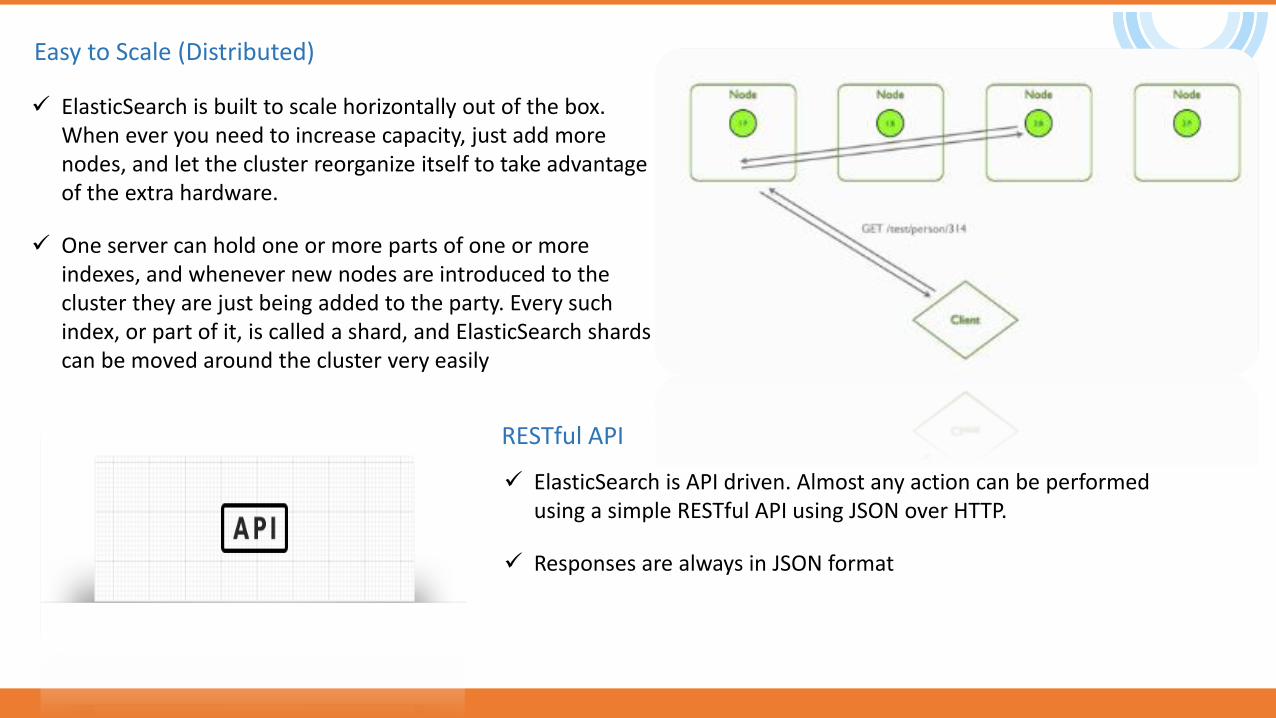
ElasticSearch is built to scale horizontally out of the box. When ever you need to increase capacity, just add more nodes, and let the cluster reorganize itself to take advantage of the extra hardware.
One server can hold one or more parts of one or more indexes, and whenever new nodes are introduced to the cluster they are just being added to the party. Every such index, or part of it, is called a shard, and ElasticSearch shards can be moved around the cluster very easily.
Easy to Scale (Distributed)
RESTful API
ElasticSearch is API driven. Almost any action can be performed using a simple RESTful API using JSON over HTTP. .
Responses are always in JSON format.

Apache Lucene is a high performance, full-featured Information Retrieval library, written in Java. ElasticSearch uses Lucene internally to build its state of the art distributed search and analytics capabilities.
Since Lucene is a stable, proven technology, and continuously being added with more features and best practices, having Lucene as the underlying engine that powers ElasticSearch.
Build on top of Apache Lucene
Excellent Query DSL (Domain Specific Language)
The REST API exposes a very complex and capable query DSL, that is very easy to use. Every query is just a JSON object that can practically contain any type of query, or even several of them combined.
Using filtered queries, with some queries expressed as Lucene filters, helps leverage caching and thus speed up common queries, or complex queries with parts that can be reused.
Faceting, another very common search feature, is just something that upon-request is accompanied to search results, and then is ready for you to use.

Multiple indexes can be stored on one ElasticSearch installation - node or cluster. Each index can have multiple "types", which are essentially completely different indexes.
The nice thing is you can query multiple types and multiple indexes with one simple query.
Multi-tenancy
Support for advanced search features (Full Text)
ElasticSearch uses Lucene under the covers to provide the most powerful full text search capabilities available in any open source product.
Search comes with multi-language support, a powerful query language, support for geolocation, context aware did-you-mean suggestions, autocomplete and search snippets.
Script support in filters and scorers

Many of ElasticSearch configurations can be changed while ElasticSearch is running, but some will require a restart (and in some cases re-indexing). Most configurations can be changed using the REST API too.
ElasticSearch has several extension points - namely site plugins (let you serve static content from ES - like monitoring java script apps), rivers (for feeding data into ElasticSearch), and plugins to add modules or components within ElasticSearch itself. This allows you to switch almost every part of ElasticSearch if so you choose, fairly easily.
Configurable and Extensible
Document Oriented
Store complex real world entities in ElasticSearch as structured JSON documents. All fields are indexed by default, and all the indices can be used in a single query, to return results at breath taking speed.
Per-operation Persistence
ElasticSearch primary moto is data safety. Document changes are recorded in transaction logs on multiple nodes in the cluster to minimize the chance of any data loss.

ElasticSearch allows you to get started easily. Send a JSON document and it will try to detect the data structure, index the data and make it searchable.
Schema free
Conflict management
Optimistic version control can be used where needed to ensure that data is never lost due to conflicting changes from multiple processes.
Active community The community, other than creating nice tools and plugins, is very helpful and supporting.
The overall vibe is really great, and this is an important metric of any OSS project.
There are also some books currently being written by community members, and many blog posts around the net sharing experiences and knowledge

Terminology
SQL Elastic Search
Database Index
Table Type
Row Document
Column Field
Schema Mapping
Index Everything is indexed
SQL Query DSL
SELECT * FROM table … GET http://…
UPDATE table SET … PUT http://…










What Does It Add To Lucene?
• RESTfull Service
• JSON API over HTTP
• Want to use it from .Net, Python, PHP, …?• CURL Requests, as if you’d do requests to the Facebook Graph API.
• High Availability & Performance
• Clustering
• Distributed system on top of Lucene
• Provides other supporting features like thread pool, queues, node/cluster monitoring API ,data monitoring API ,Cluster management etc.

… vs. SOLR
• +
• Also built on Lucene
• So similar feature set
• Also exposes Lucene functionality, like Elastic Search, so easy to extend.
• A part of Apache Lucene project
• Perfect for Single Server search
• -
• ElasticSearch is easier to use and maintain
• Clustering is there. But it’s definitely not as simple as ElasticSearch’
• Fragmented code base. (Lots of branches.)
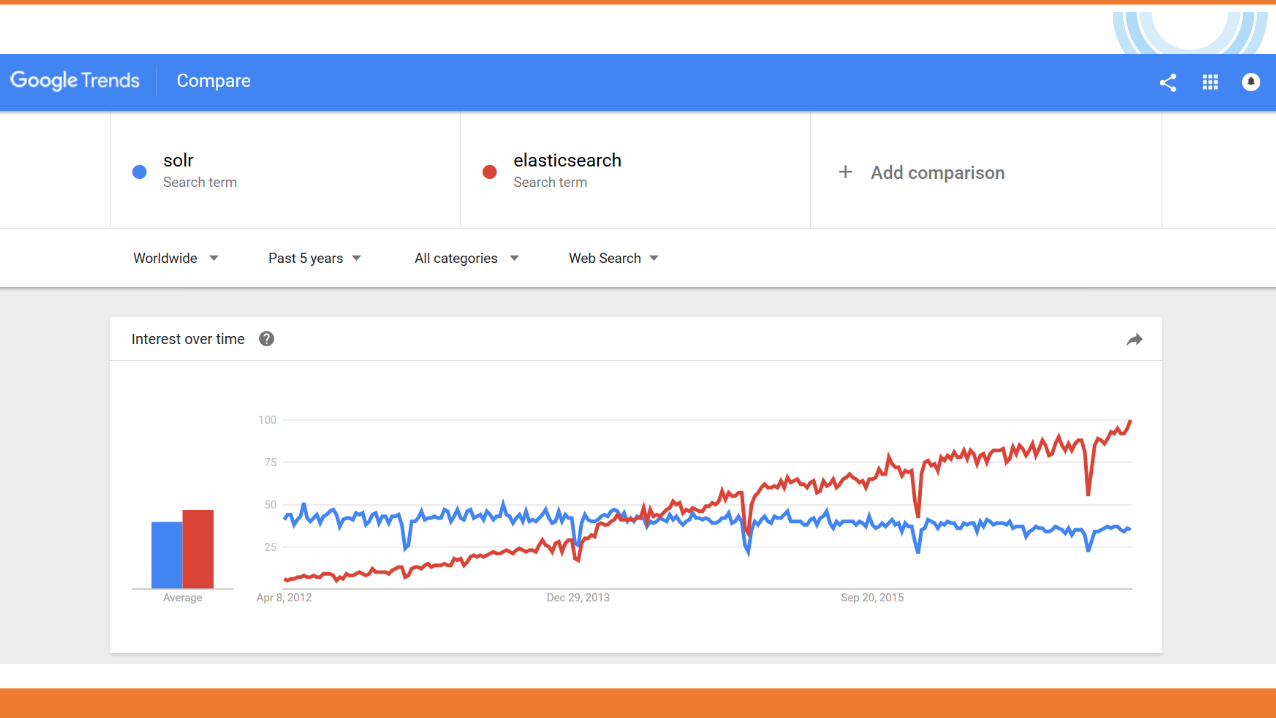
… vs. SOLR

What in a Distribution?

Configuration cluster.name : Cluster name identifies cluster for auto-discovery. If production environment has multiple clusters on the
same network, cluster name must be unique.
node.name : Node names are generated dynamically on startup. But user can specify a name to node manually.
node.master & node.data : Every node can be configured to allow or deny being eligible as the master, and to allow or
deny to store the data. Master allow this node to be eligible as a master node (enabled by default) and Data allow this
node to store data (enabled by default).
Following are the settings to design advanced cluster topologies.
1. If a node to never become a master node, only to hold data. This will be the "workhorse" of the cluster.
node.master: false, node.data: true
2. If a node to only serve as a master and not to store data and to have free resources. This will be the "coordinator"
of the cluster. node.master: true, node.data: false
3. If a node to be neither master nor data node, but to act as a "search load balancer" (fetching data from nodes,
aggregating, etc.)
node.master: false, node.data: false

Configuration Index: A number of options (such as shard/replica options, mapping or analyzer definitions, translogsettings, ...) can be
set for indices globally, in this file. Note, that it makes more sense to configure index settings specifically for a certain
index, either when creating it or by using the index templates API..
example. index.number_of_shards: 5, index.number_of_replicas : 1
Discovery: ElasticSearch supports different types of discovery, which imakes multiple ElasticSearch instances talk to each
other.
The default type of discovery is multicast. Unicast discovery allows to explicitly control which nodes will be used to
discover the cluster. It can be used when multicast is not present, or to restrict the cluster communication-wise.

Cluster logical grouping of multiple nodes Nodes in cluster that store data or nodes that just help in speeding up search queries.
Node An elasticsearch server instance Usually you should have one node per server Master – in charge of managing cluster-wide operations
Only one, responsible for distribution/balancing of shards No bottleneck for queries Master node is chosen automatically by the cluster
Shard A shard in elasticsearch is a Lucene index, and a Lucene index is broken down into segments. low-level worker instance that holds a slice of all data Each document belongs to a single primary shard
Created during index creation Determines the number of data stored in each shard
Replica A copy of a master shard on a different node (increase failover + increase [search] performance) Automatic Master detection + failover Spreading over nodes => done automatically Can be created any time
Scalability - Architecture
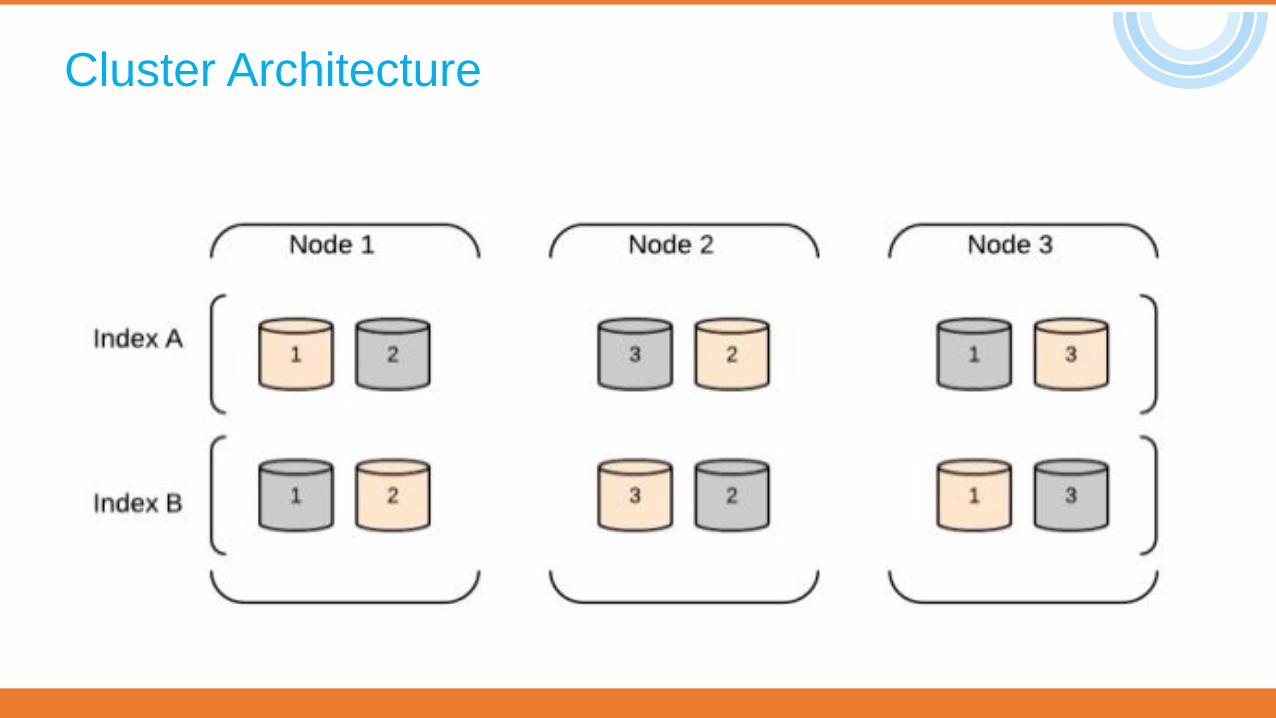
Cluster Architecture

Is it running?
http://localhost:9200/?pretty
Response :
{ "status" : 200, "name" : “elasticsearch", "version" : { "number" : "1.3.4", "build_hash" : "f1585f096d3f3985e73456debdc1a0745f512bbc", "build_timestamp" : "2015-04-21T14:27:12Z", "build_snapshot" : false, "lucene_version" : "4.9"
}, "tagline" : "You Know, for Search"
}
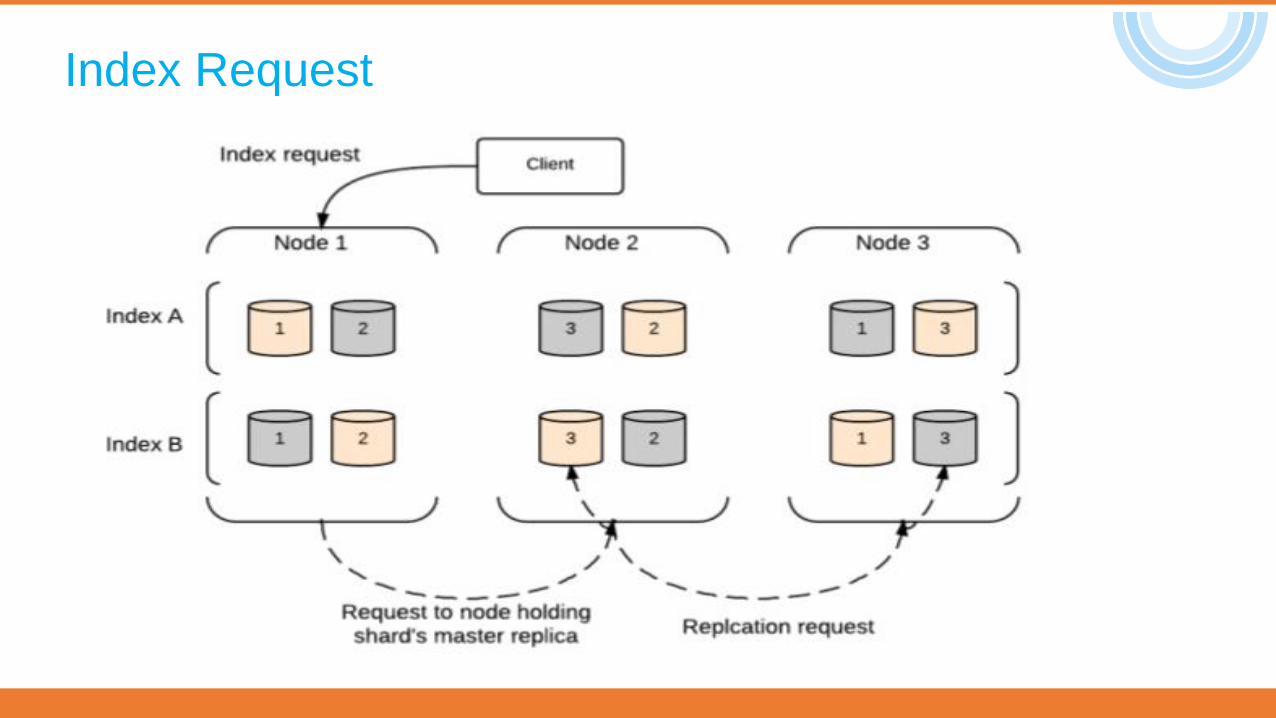
Index Request

Indexing a documentRequest :
PUT test/cities/1{
"rank": 3, "city": "Hyderabad", "state": "Telangana", "population2014": 7750000, "land_area": 625, "location":
{ "lat": 17.37, "lon": 78.48
}, "abbreviation": "Hyd"
}Response : { "_index": "test", "_type": "cities", "_id": "1", "_version": 1, "created": true }
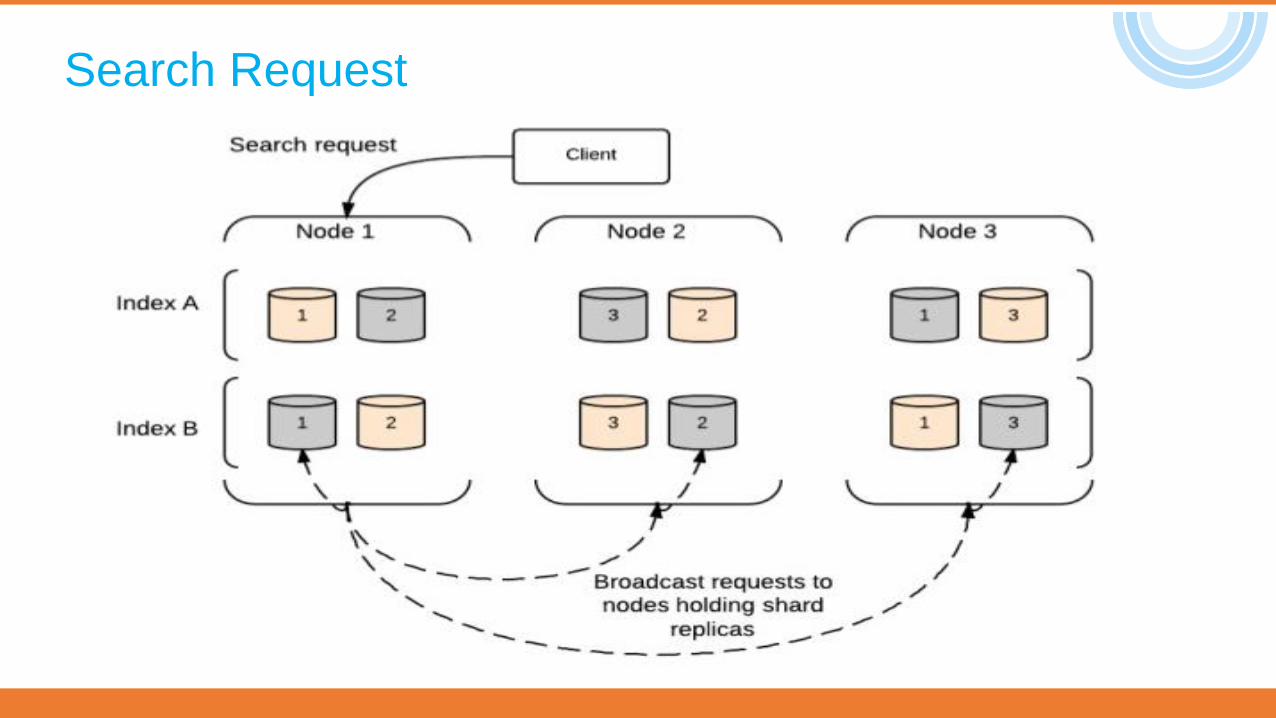
Search Request

Getting a documentRequest :
GET test/cities/1?prettyResponse :
{"_index": "test","_type": "cities","_id": "1","_version": 1,"found": true,"_source": {
"rank": 3,"city": "Hyderabad","state": "Telangana","population2014": 7750000,"land_area": 625,"location": {
"lat": 17.37,"lon": 78.48
},"abbreviation": "Hyd"
}}

Updating a document
Request : PUT test/cities/1{
"rank": 3, "city": "Hyderabad", "state": "Telangana", "population2013": 7023000,"population2014": 7750000, "land_area": 625, "location":{
"lat": 17.37, "lon": 78.48
}, "abbreviation": "Hyd"
}
Response : {"_index": "test", "_type": "cities", "_id": "1", "_version": 2, "created": false}

Data Synchronization
Elastic search is typically not the primary data store.
Implement a queue or use rivers or window service.
A river is a pluggable service running within elasticsearch cluster pulling data (or being pushed with data) that is then indexed into the cluster. (https://github.com/jprante/ElasticSearch-river-jdbc)
Rivers are available for mongodb, couchdb, rabitmq, twitter, wikipedia, mysql, and etc
The relational data is internally transformed into structured JSON objects for the schema-less indexing model of ElasticSearch documents.
The plugin can fetch data from different RDBMS source in parallel, and multithreaded bulk mode ensures high throughput when indexing to ElasticSearch.
Typically ElasticSearch implements worker role as a layer within the application to push data/entities to Elastic search.

Products (Open Source + Commercial)
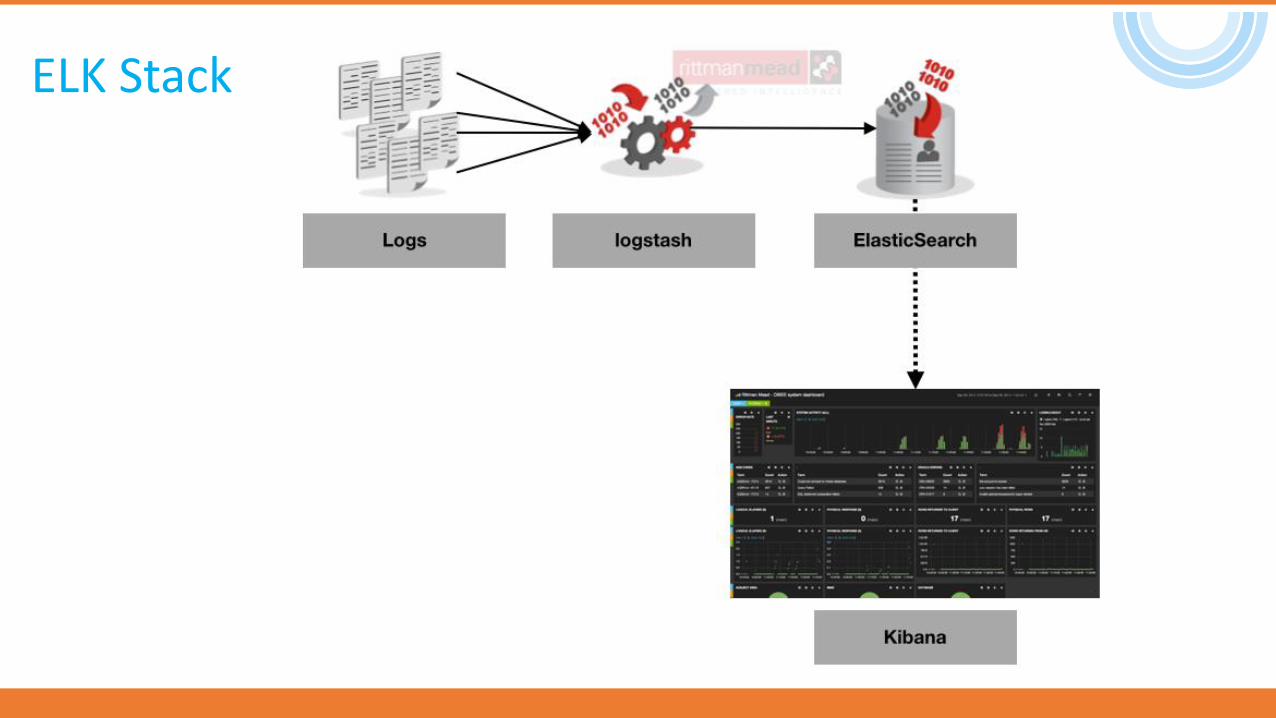
ELK Stack
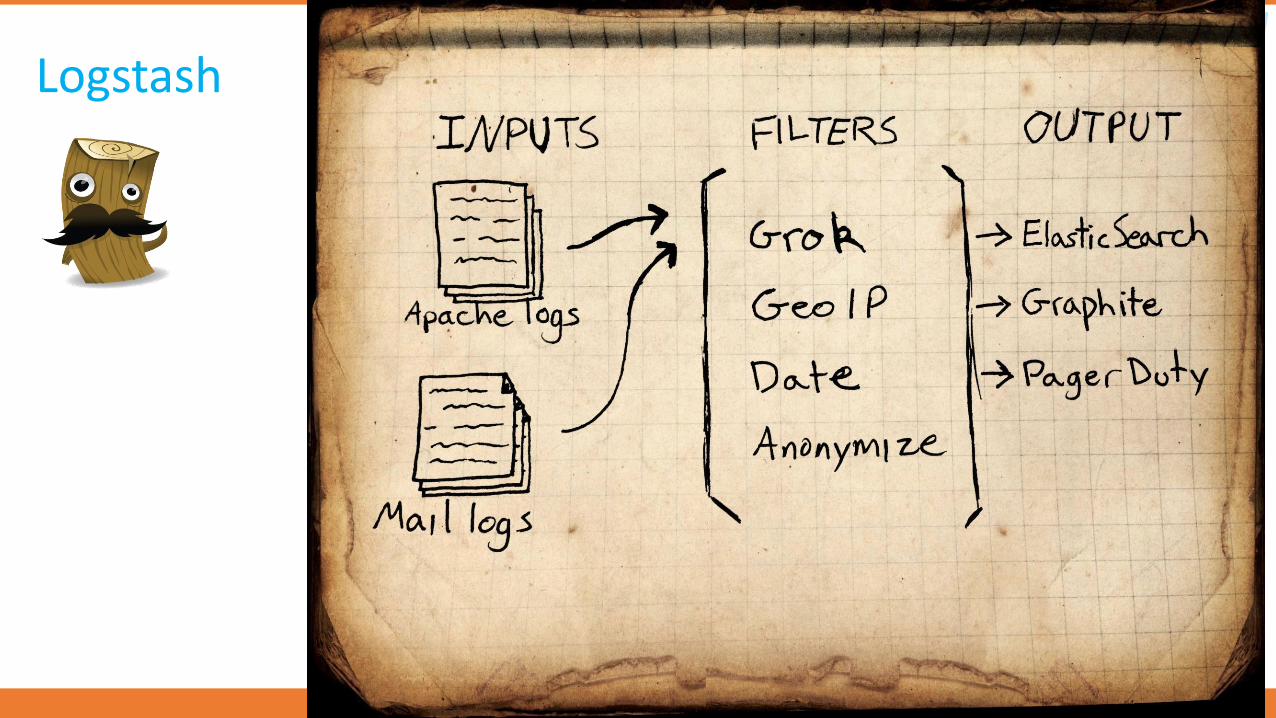
Logstash

Kibana
•Powerful front-end dashboard for visualizing indexed information from elastic cluster.
•Capable to providing historical data in form of graphs, charts, etc.
•Enables real-time search of indexed information.
Data Visualization + Data Discovery
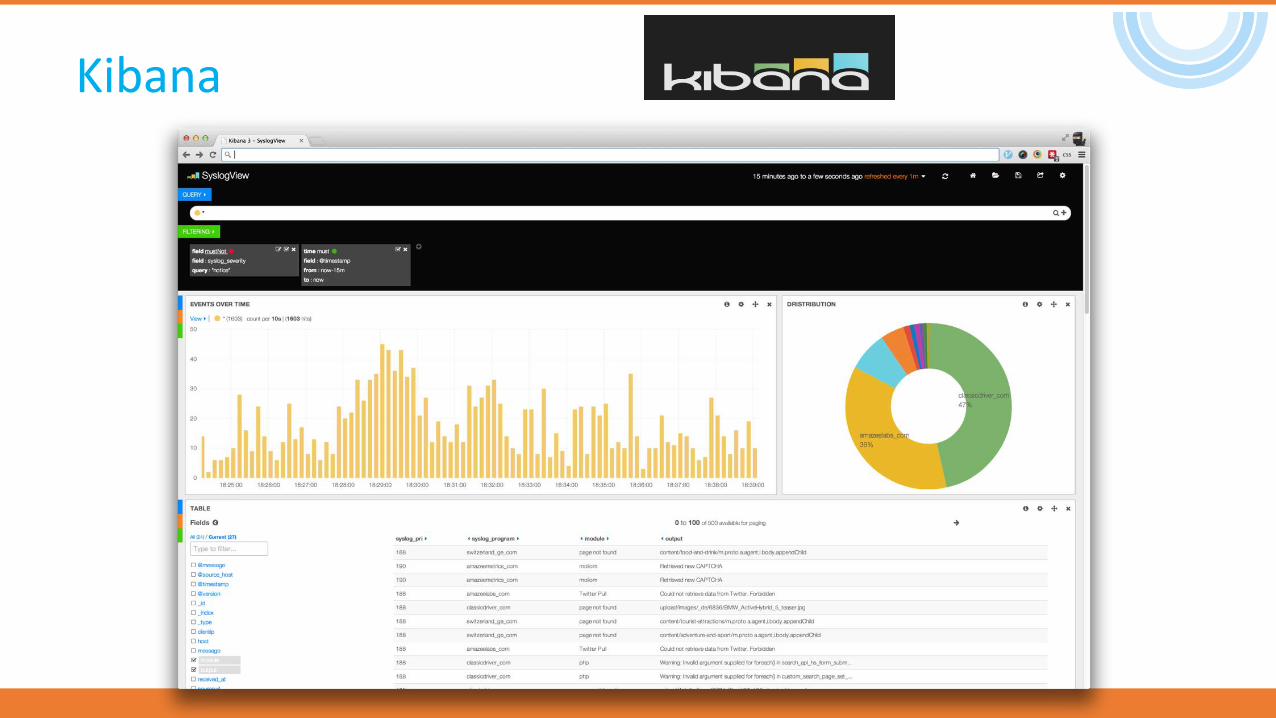
Kibana
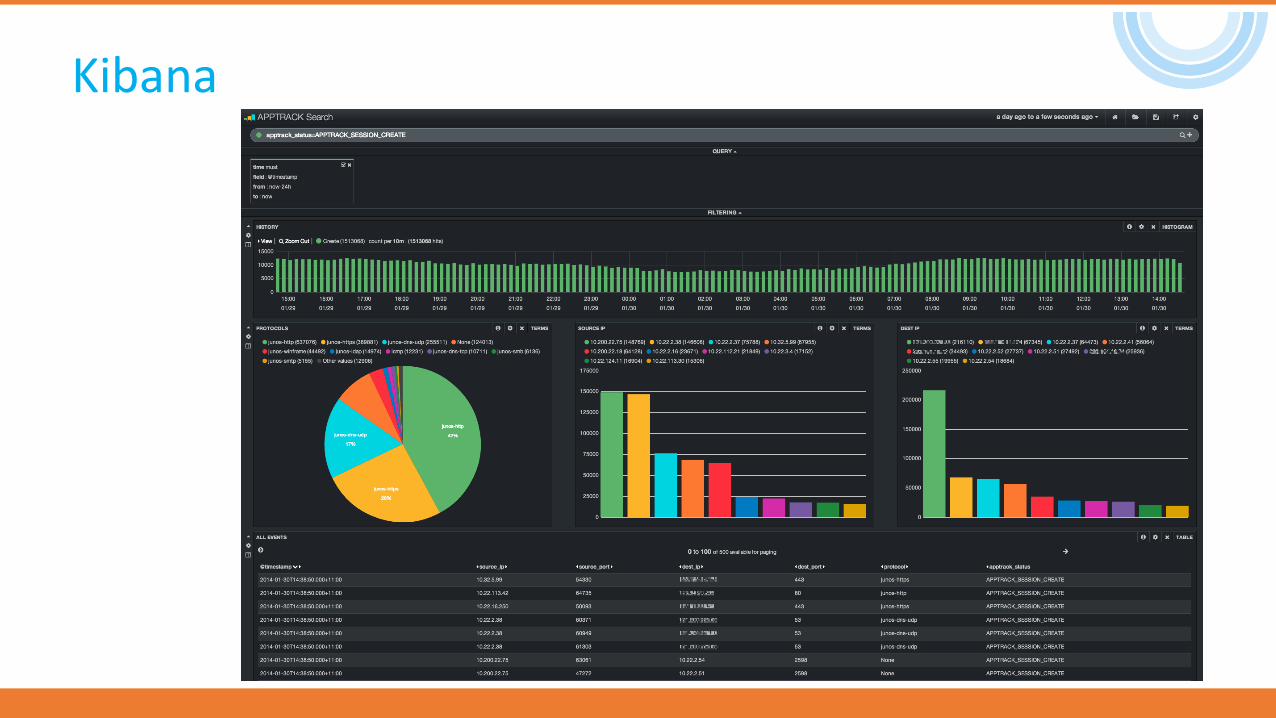
Kibana
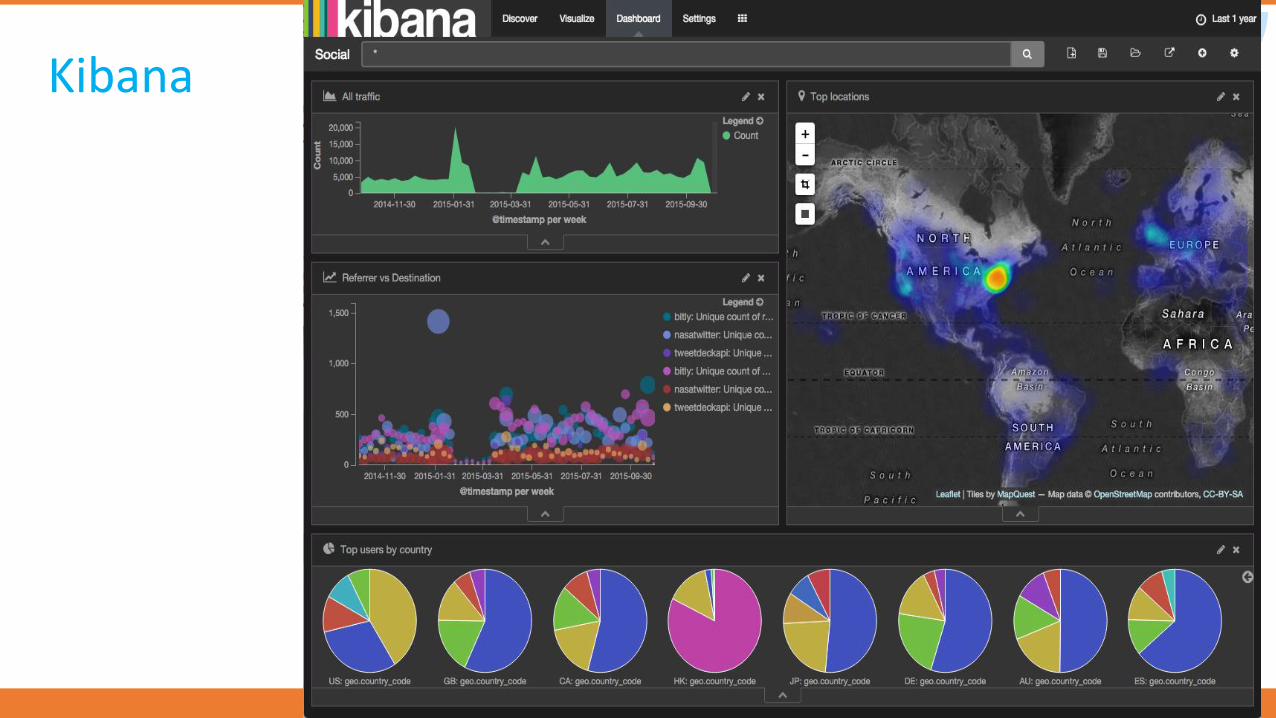
Kibana

Elasticsearch plugins
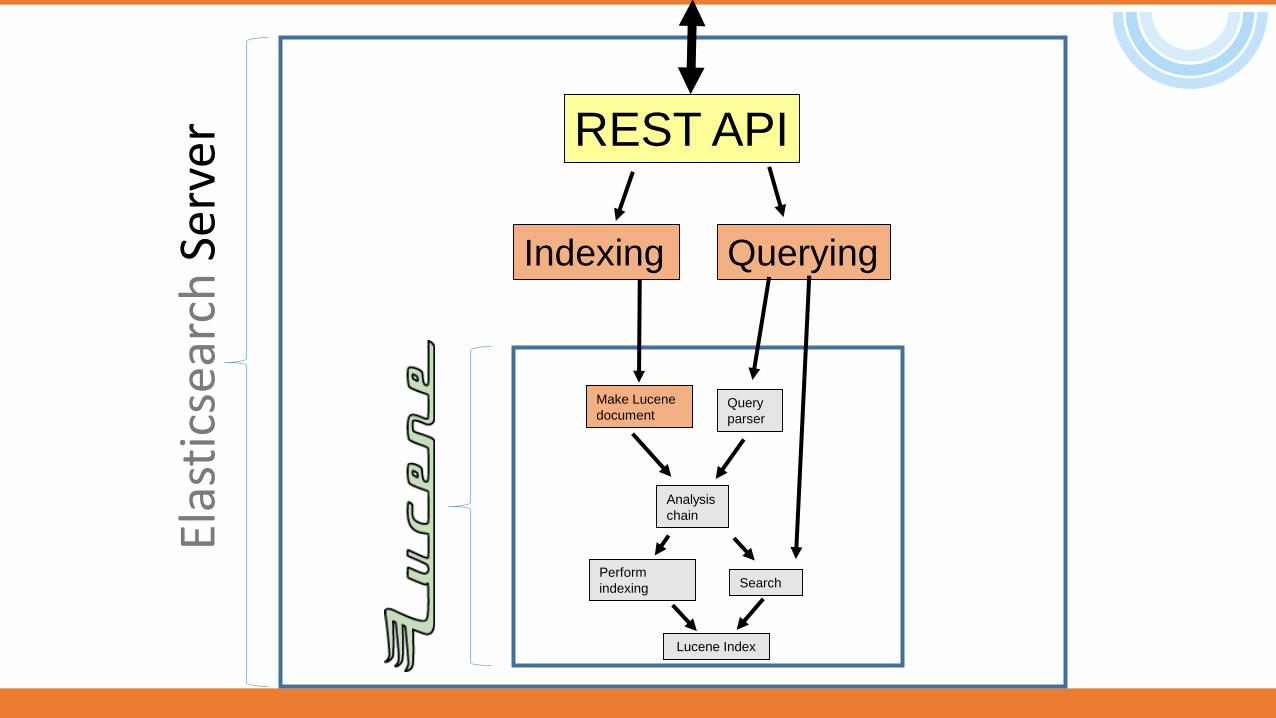
REST API
Analysis
chain
Search
Querying
Query
parser
Lucene Index
Perform
indexing
Indexing
Make Lucene
document
Elas
tics
earc
hSe
rver
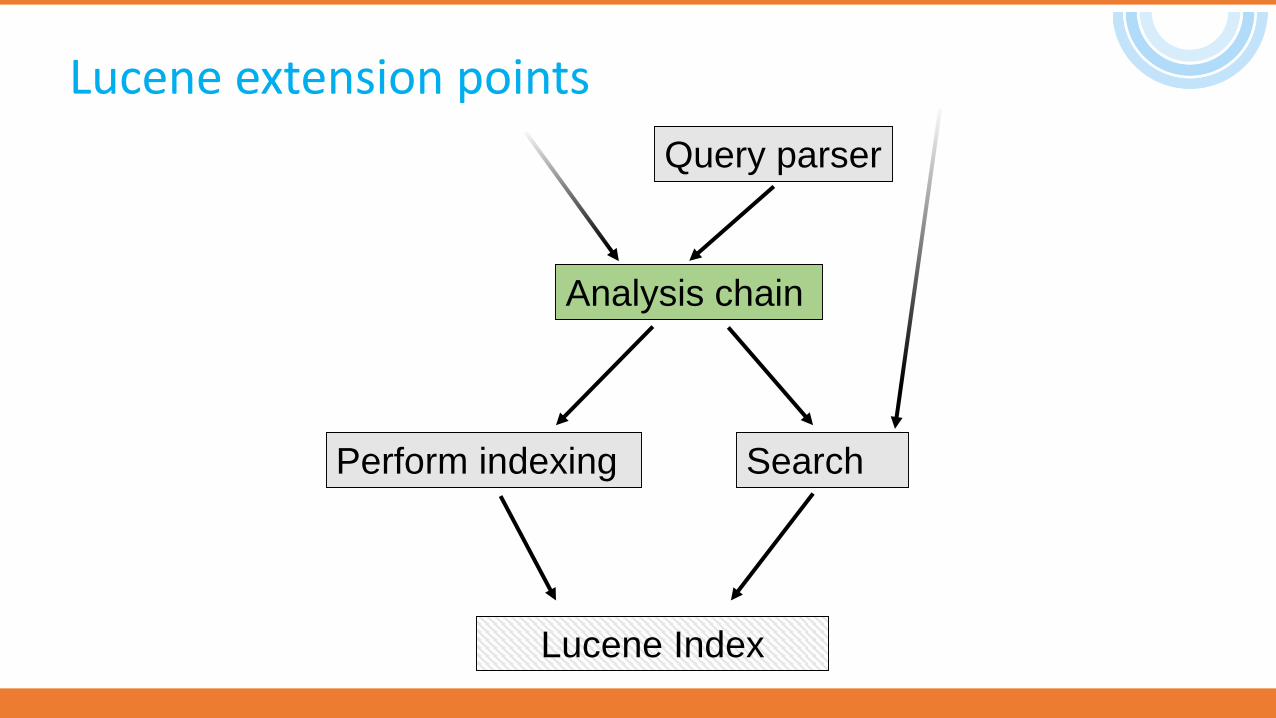
Lucene extension points
Analysis chain
Search
Query parser
Lucene Index
Perform indexing
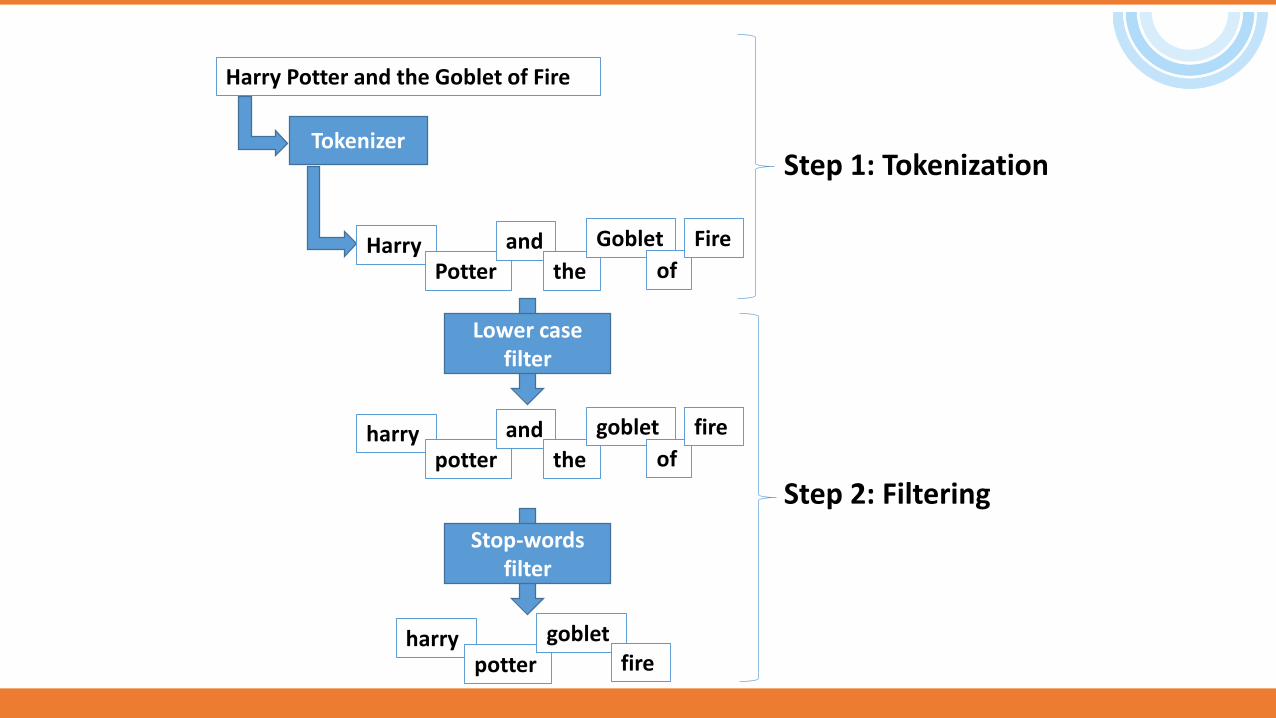
Harry Potter and the Goblet of Fire
Tokenizer
HarryPotter
and
the
Goblet
of
Fire
Lower case filter
harrypotter
and
the
goblet
of
fire
Stop-words filter
harrypotter
gobletfire
Step 1: Tokenization
Step 2: Filtering
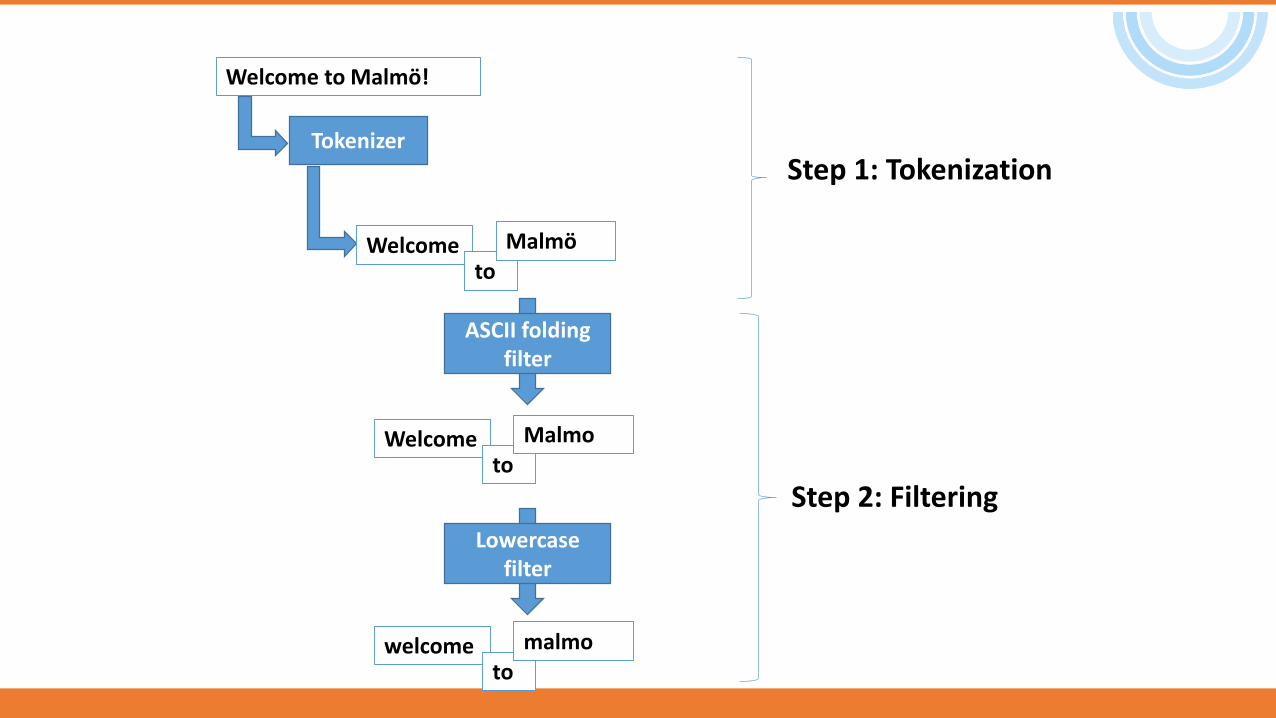
Welcome to Malmö!
Tokenizer
Welcometo
Malmö
ASCII folding filter
Lowercase filter
Step 1: Tokenization
Step 2: Filtering
Welcometo
Malmo
welcometo
malmo

Harry Potter and the Goblet of Fire
Tokenizer
HarryPotter
and
the
Goblet
of
Fire
Lower case filter
harrypotter
and
the
goblet
of
fire
Stop-words filter
harrypotter
gobletfire
Potter
Tokenizer
Potter
Lower case filter
potter
Stop-words filter
potter
QueryIndexing

Analyzers
The quick brown fox jumped over the lazy dog,
[email protected] 123432.
StandardAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dog] [[email protected]] [123432]
StopAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dog] [bob] [hotmail] [com]
SimpleAnalyzer:
[the] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dog] [bob] [hotmail] [com]
WhitespaceAnalyzer:
[The] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dog,] [[email protected]] [123432.]
KeywordAnalyzer:
[The quick brown fox jumped over the lazy dog, [email protected] 123432.]

Custom analyzers from code

Custom scoring & similarity
• Function score query• Previously known as Custom Score Query
• Similarity

Elastic AND .NET
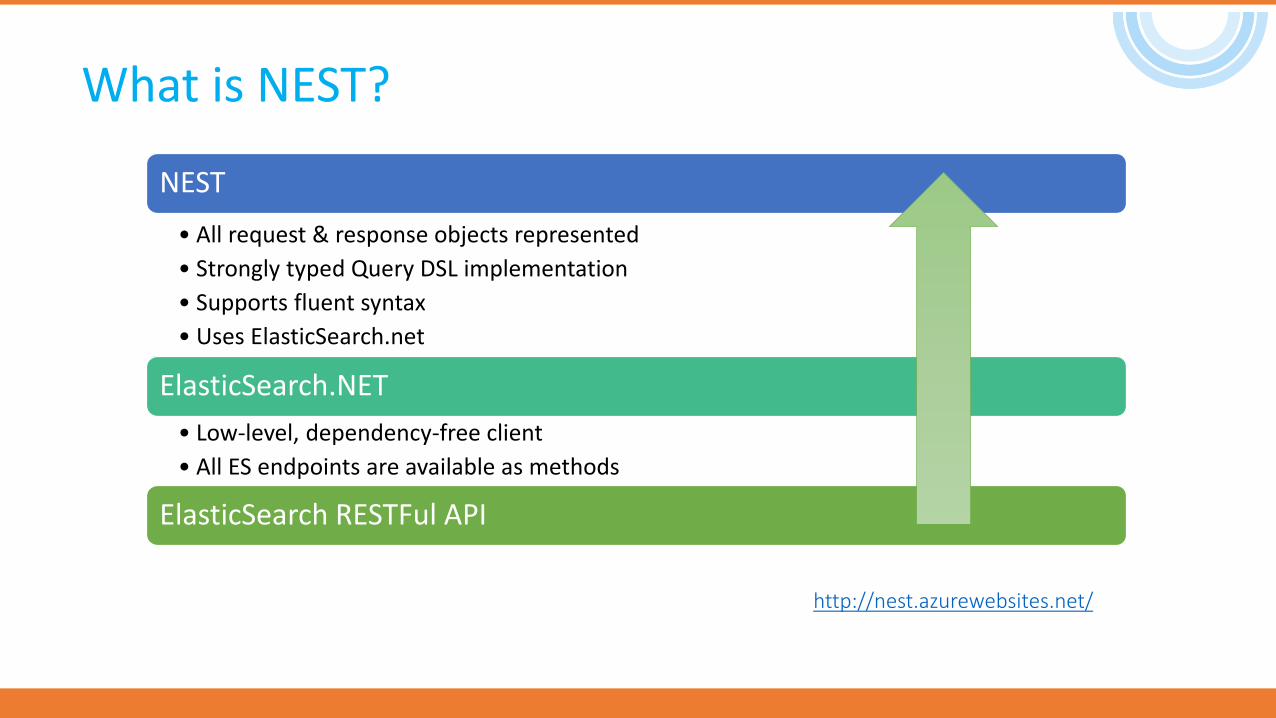
What is NEST?
NEST
• All request & response objects represented
• Strongly typed Query DSL implementation
• Supports fluent syntax
• Uses ElasticSearch.net
ElasticSearch.NET
• Low-level, dependency-free client
• All ES endpoints are available as methods
ElasticSearch RESTFul API
http://nest.azurewebsites.net/

NEST – Connection Initialization
• Initialize an ElasticClient:
All actions on the ElasticSearch cluster are performed using the ElasticClient
For example:• Search
• Index
• DeleteIndex/CreateIndex
• …
Uri node = new Uri("http://192.168.137.73:9200");ConnectionSettings settings = new ConnectionSettings(node, defaultIndex: "products");ElasticClient client = new ElasticClient(settings);

Index your Content - .NET
• Raw JSON string
• Type based indexation
• Modify out-of-the-box behavior using decorators
client.Raw.Index("products", "product", new JavaScriptSerializer().Serialize(prod));
client.Index(product);
[ElasticType(Name = "Product", IdProperty="id")]public class Product{
public int id { get; set; }[ElasticProperty(Name = "name", Index = FieldIndexOption.Analyzed, Type = FieldType.String, Analyzer = "standard")]public string name { get; set; }
…

Query your content – Query DSL .NET
• Retrieve all products from an index using a MatchAll search
• Retrieve all products by using a term query
• Search on all fields using the _all built-in property
• Search on a combination of fields using boolean operators (see fiddler result)
result = client.Search<Product>(s => s.MatchAll());
result = client.Search<Product>(s => s.Query(q => q.Term(t => t.name, "macbook")));
result = client.Search<Product>(s => s.Query(q => q.Term("name", "macbook")));
result = client.Search<Product>(s => s.Query(q => q.Term("_all", "macbook")));
result = client.Search<Product>(s => s.Query(q => q.Term("name", "macbook") || q.Term("descr","macbook")));

Query your content – Query DSL
• Search on a combination of fields using boolean operators and a date range filter
• Some more advanced query examples: • Wildcard Query - use wildcards to search for relevant documents• Span Near - search for word combinations within a certain span in the document• More like this query - finds documents which are ‘like’ a given set of documents using
representative terms
result = client.Search<Product>(s => s.Query(q => (q.Term("name", "macbook") || q.Term("descr", "macbook"))
&& q.Range(r => r.OnField("price").Greater(1000).LowerOrEquals(2000))));

Query your content – Fuzzy searches
• Perform a fuzzy search to overcome query string errors
result = client.Search<Product>(s => s.Query(q => q
.Match(m => m.Query("makboek").OnField("name").Fuzziness(10).PrefixLength(1))));

Query your content - Paging
• Select pages from the full result set using the From & Size filters
result = client.Search<Product>(s => s.Query(q => q.Term("name", "macbook") || q.Term("descr", "macbook")).From(0).Size(1));

http://www.elastic.co/guide/en/elasticsearch/guide/current/index.html
http://www.elasticsearchtutorial.com/
http://lucene.apache.org/
Lucene in Action
SlideShare.net presentations on ElasticSearch
References