Embed Size (px)
Citation preview

KDD 2015 勉強会関東会場
E-commerce in your inbox:Product Recommendations at scale
Akira Saigo
2015/8/29
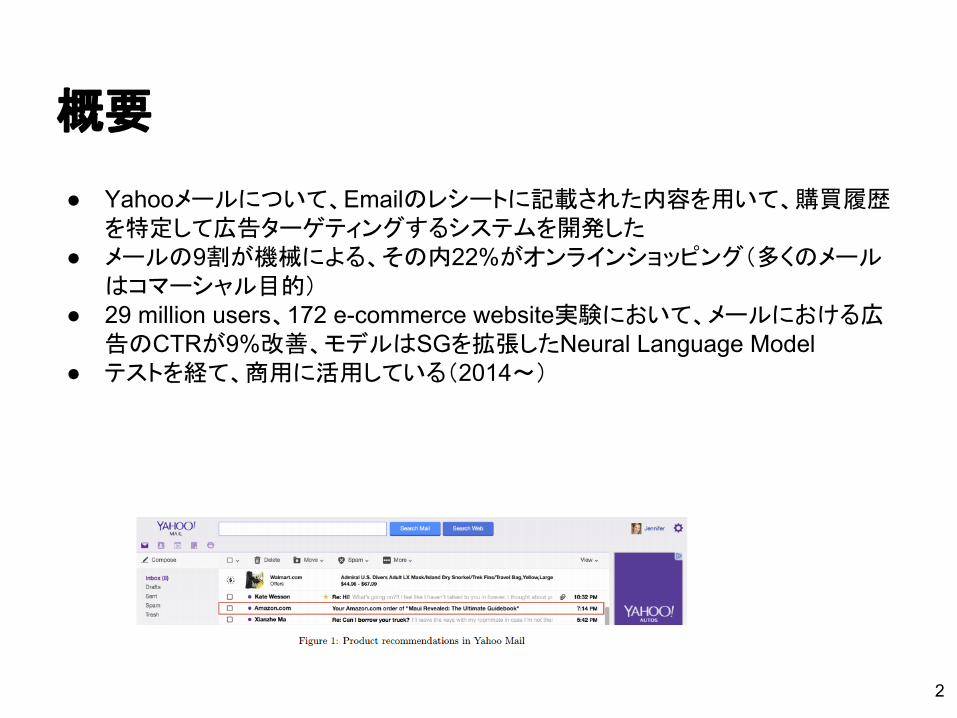
概要
● Yahooメールについて、Emailのレシートに記載された内容を用いて、購買履歴を特定して広告ターゲティングするシステムを開発した
● メールの9割が機械による、その内22%がオンラインショッピング(多くのメールはコマーシャル目的)
● 29 million users、172 e-commerce website実験において、メールにおける広告のCTRが9%改善、モデルはSGを拡張したNeural Language Model
● テストを経て、商用に活用している(2014~)
2

関連研究 & motivation● 広告の関連研究では、広告主、パブリッシャー、ユーザーなど様々な視点で研
究が行われている○ 見ているパブリッシャー側(サイト)の傾向で購買傾向を予測する
■ [9]N. Djuric., In IEEE International Conference on Data Mining, Dec 2014.
● ただしpurchase intent しか分からない->ダイレクトな広告実施をしたい
● メールに限らず、レコメンデーションの研究も積極的○ 行動が類似するユーザーから最も興味があるであろう商材を予測
■ [1]G. Linden, B. Smith, and J. York. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing, 7(1):76–80, Jan. 2003.
● emailのレシートを読み込むことにより、数百の異なったe-commerceのデータからより精度の高い予測が可能
3
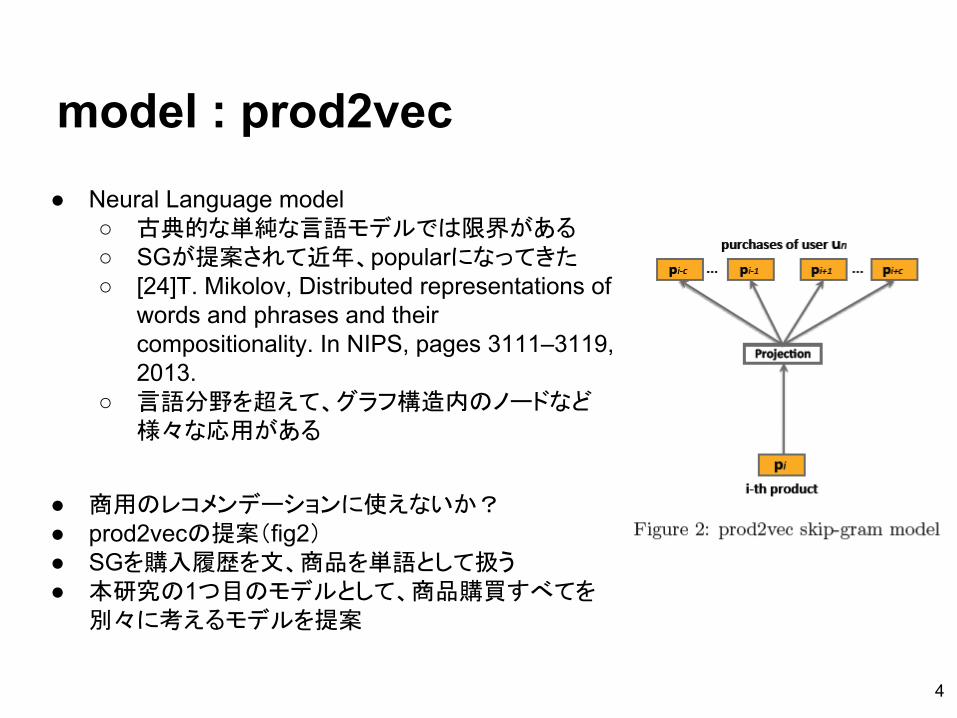
model : prod2vec● Neural Language model
○ 古典的な単純な言語モデルでは限界がある○ SGが提案されて近年、popularになってきた○ [24]T. Mikolov, Distributed representations of
words and phrases and their compositionality. In NIPS, pages 3111–3119, 2013.
○ 言語分野を超えて、グラフ構造内のノードなど様々な応用がある
● 商用のレコメンデーションに使えないか?● prod2vecの提案(fig2)● SGを購入履歴を文、商品を単語として扱う● 本研究の1つ目のモデルとして、商品購買すべてを
別々に考えるモデルを提案
4

model : prod2vec● Objective function
○ 下記の対数尤度を目的関数として最大化したい
● Soft-max function○ 上記のP(周辺商品の条件付き確率)は下記のソフトマックス関
数で定義され、これに従って入出力ベクトルV,V’を最適化する○ 実際はSGDで求めたいところだが、計算を緩和するためネガ
ティブサンプリングで解いている[24]
5
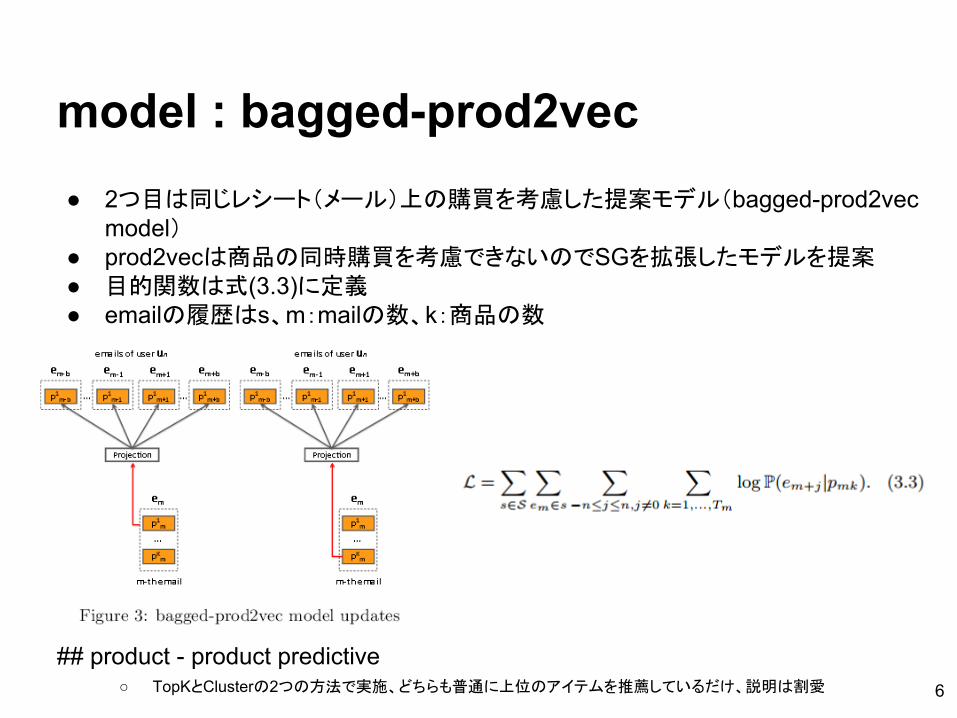
model : bagged-prod2vec● 2つ目は同じレシート(メール)上の購買を考慮した提案モデル(bagged-prod2vec
model)● prod2vecは商品の同時購買を考慮できないのでSGを拡張したモデルを提案● 目的関数は式(3.3)に定義● emailの履歴はs、m:mailの数、k:商品の数
6
## product - product predictive○ TopKとClusterの2つの方法で実施、どちらも普通に上位のアイテムを推薦しているだけ、説明は割愛
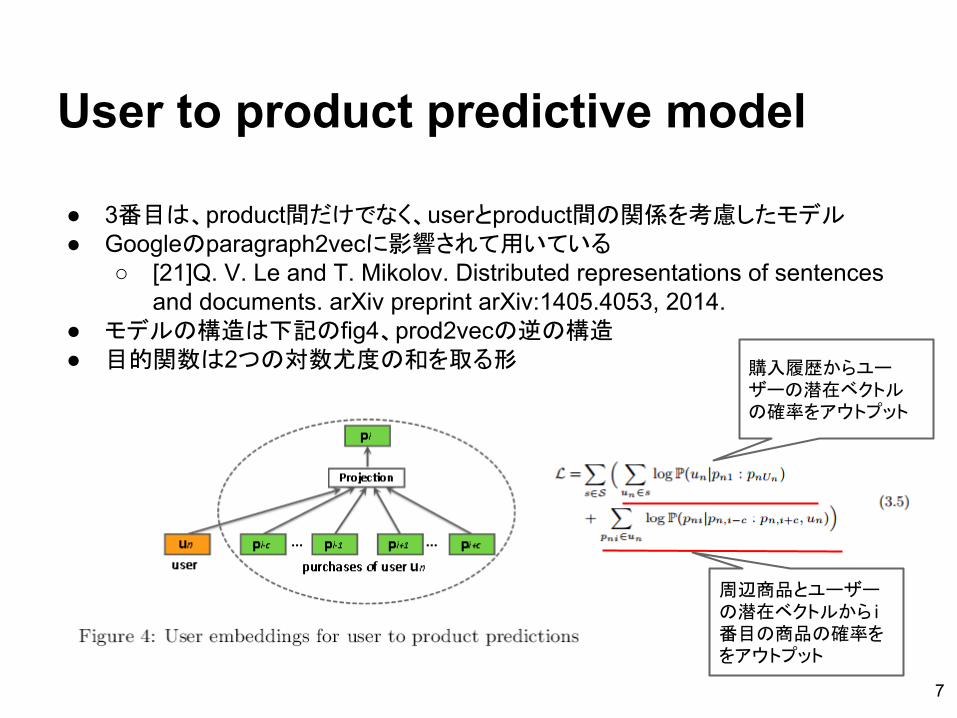
User to product predictive model
● 3番目は、product間だけでなく、userとproduct間の関係を考慮したモデル● Googleのparagraph2vecに影響されて用いている
○ [21]Q. V. Le and T. Mikolov. Distributed representations of sentences and documents. arXiv preprint arXiv:1405.4053, 2014.
● モデルの構造は下記のfig4、prod2vecの逆の構造● 目的関数は2つの対数尤度の和を取る形
7
周辺商品とユーザーの潜在ベクトルから i番目の商品の確率ををアウトプット
購入履歴からユーザーの潜在ベクトルの確率をアウトプット
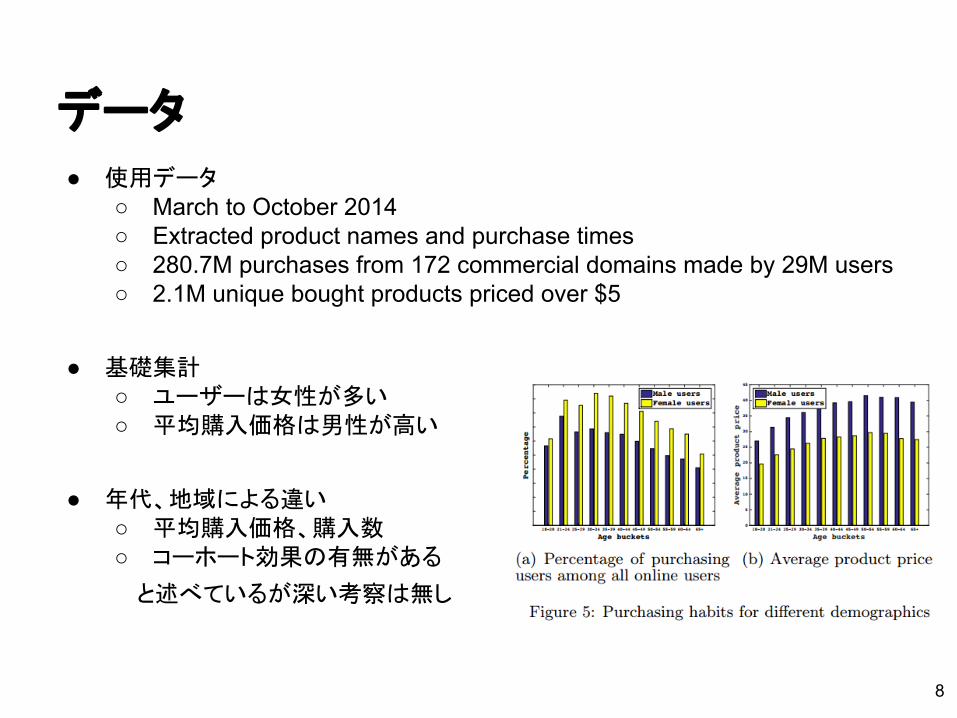
データ● 使用データ
○ March to October 2014 ○ Extracted product names and purchase times ○ 280.7M purchases from 172 commercial domains made by 29M users○ 2.1M unique bought products priced over $5
● 基礎集計○ ユーザーは女性が多い○ 平均購入価格は男性が高い
● 年代、地域による違い○ 平均購入価格、購入数○ コーホート効果の有無がある
と述べているが深い考察は無し
8
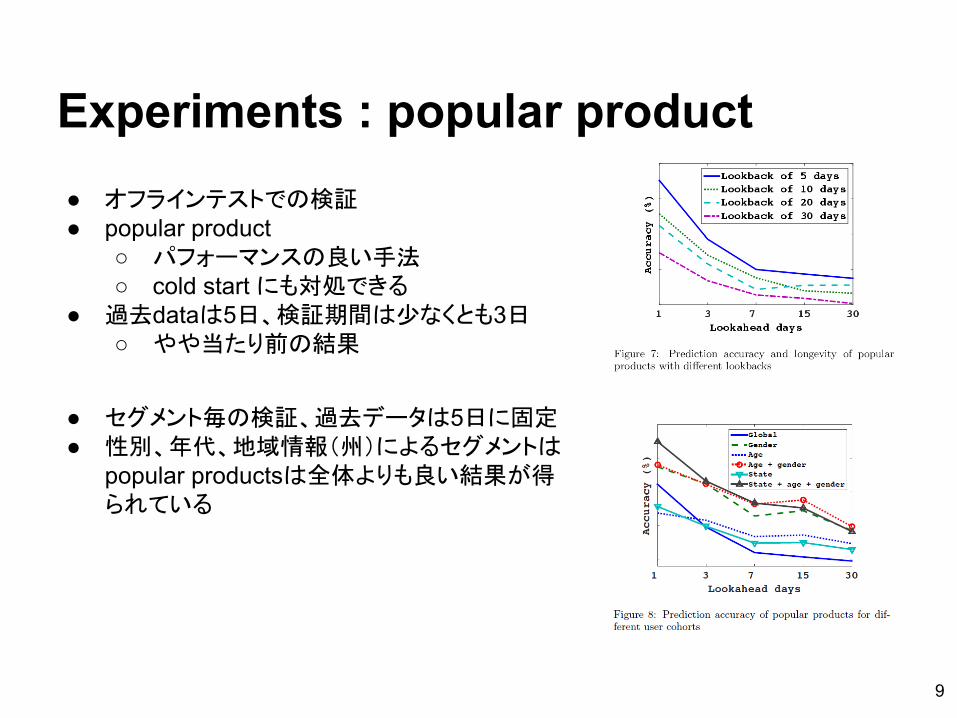
Experiments : popular product● オフラインテストでの検証● popular product
○ パフォーマンスの良い手法○ cold start にも対処できる
● 過去dataは5日、検証期間は少なくとも3日○ やや当たり前の結果
● セグメント毎の検証、過去データは5日に固定● 性別、年代、地域情報(州)によるセグメントは
popular productsは全体よりも良い結果が得られている
9

Experiments : Recommending predicted products
● オフラインテストでの検証○ prod2vec-topK○ bagged-prod2vec-topK
■ topKの商品を単純に並び替え○ bagged-prod2vec-cluster
■ 商品iが所属するクラスターと遷移するクラスター内で商品を並び替え
○ user2vec○ co-purchase
10
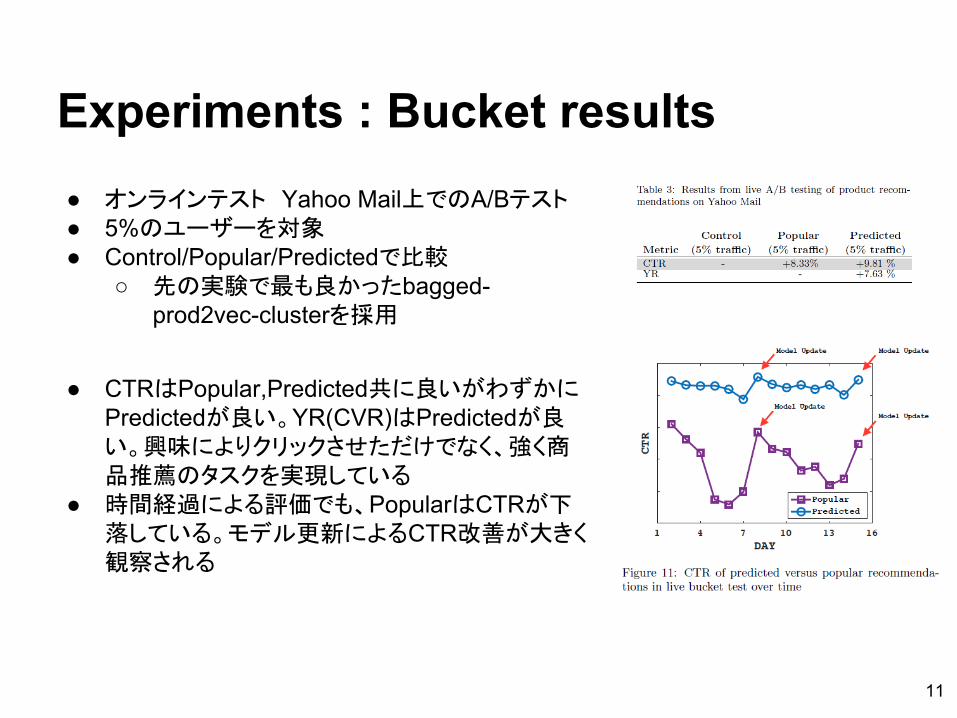
Experiments : Bucket results● オンラインテスト Yahoo Mail上でのA/Bテスト● 5%のユーザーを対象● Control/Popular/Predictedで比較
○ 先の実験で最も良かったbagged-prod2vec-clusterを採用
● CTRはPopular,Predicted共に良いがわずかにPredictedが良い。YR(CVR)はPredictedが良い。興味によりクリックさせただけでなく、強く商品推薦のタスクを実現している
● 時間経過による評価でも、PopularはCTRが下落している。モデル更新によるCTR改善が大きく観察される
11

System deployment● ファイルシステムはHDFS● 独自のストレージシステム 分散KVS(similar to Cassandra)● ユーザープロファイル(商品情報)は時間でUPDATE● ユーザーの購買データは60日間保持● 人気商品は3日ごとに再計算、過去5日のデータを利用
● 商品推薦の広告はjsとHTMLで実装● アフィリエイトパートナーから500msのSLA● etc
12

Conclusion● Yahoo Mailにて商用adにおける大規模商品推薦を実施● Neural language modelを商品推薦に用いた
○ SGを用いたモデル、及びその拡張
● 複数のモデルをオフラインでテスト● 性能がよかったモデル候補をオンラインテストにかけ、最後に商用環境にローン
チを行った● 今後も継続し、view,click,cv等のデータを用い推薦システムを改善していく予定
13

参考
本論文に関して
http://astro.temple.edu/~tuc17157/pdfs/grbovic2015kddB_slides.pdfhttp://astro.temple.edu/~tua95067/grbovic_mail_kdd.pdf
W2V,SGに関して
http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdfhttp://arxiv.org/pdf/1301.3781.pdfhttp://cs.stanford.edu/~quocle/paragraph_vector.pdfhttp://arxiv.org/pdf/1411.2738v1.pdf
その他(メールや広告、Yahoo関係など)http://astro.temple.edu/~tua95067/grbovic_cikm.pdfhttp://astro.temple.edu/~tua95067/grbovic_www.pdf
14





























