Embed Size (px)
Citation preview

ScaleGraphA High-Performance Library for Billion-Scale Graph Analytics
Toyotaro Suzumura1,2 and Koji Ueno21 IBM T.J. Watson Research Center, New York, USA2 Tokyo Institute of Technology, Tokyo, Japan
戦略的創造研究推進事業Core Research for Evolutional Science and Technology
Core Research for Evolutional Science and Technology
戦略的創造研究推進事業
Core Research for Evolutional Science and TechnologyCore Research for Evolutional Science and Technology戦略的創造研究推進事業
戦略的創造研究推進事業Core Research for Evolutional Science and Technology
Core Research for Evolutional Science and Technology
戦略的創造研究推進事業
Core Research for Evolutional Science and TechnologyCore Research for Evolutional Science and Technology戦略的創造研究推進事業

Billion-Scale Data § World Population: 7.15 billion (2013/07)
§ Social Network– Facebook : 1.23 billion users (2013/12)– WhatsApp : 1 billion users (2015/08)
§ Internet of Things / M2M: 26 billiondevices by 2020 (2013/12, Gartner)
§ RDF (Linked Data) Graph: 2.46 billion triples in DBPedia
§ Human Brain : 100 billion neurons with 100 trillion connections

Large-Scale Graph Mining is Everywhere
Internet Map
Symbolic Networks:
Protein Interactions Social Networks
Cyber Security (15 billion log entries / day for large enterprise)
CybersecurityMedical InformaticsData EnrichmentSocial NetworksSymbolic Networks
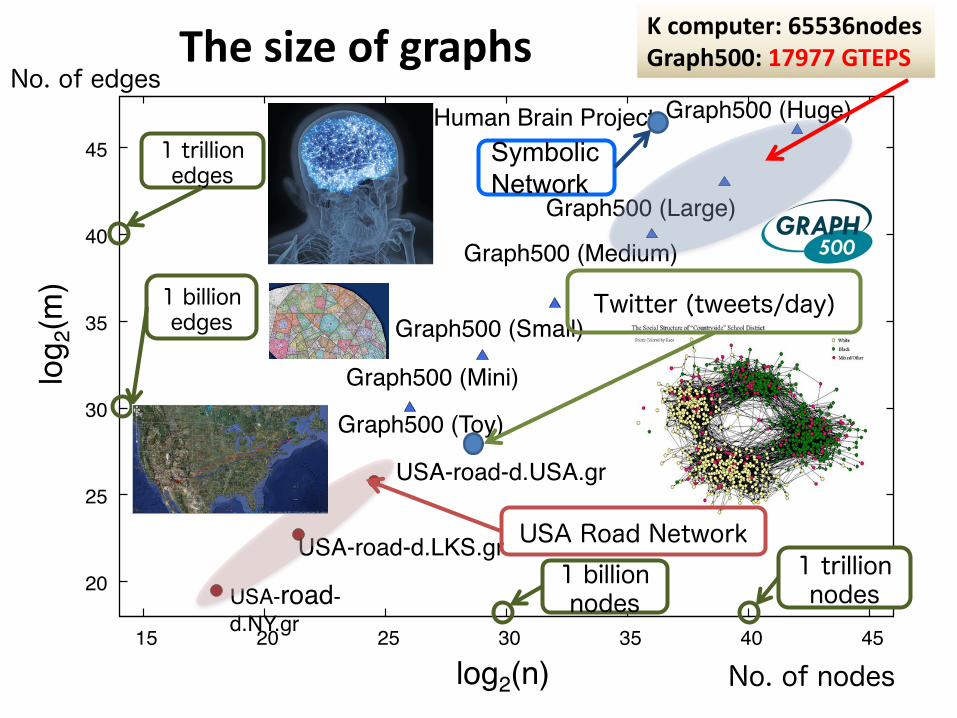
20
25
30
35
40
45
15 20 25 30 35 40 45
log 2
(m)
log2(n)
USA-road-d.NY.gr
USA-road-d.LKS.gr
USA-road-d.USA.gr
Human Brain Project
Graph500 (Toy)
Graph500 (Mini)
Graph500 (Small)
Graph500 (Medium)
Graph500 (Large)
Graph500 (Huge)
1 billion nodes
1 trillion nodes
1 billion edges
1 trillion edges
Symbolic Network
USA Road Network
Twitter (tweets/day)
No. of nodes
No. of edges
Kcomputer:65536nodesGraph500:17977GTEPSThesizeofgraphs
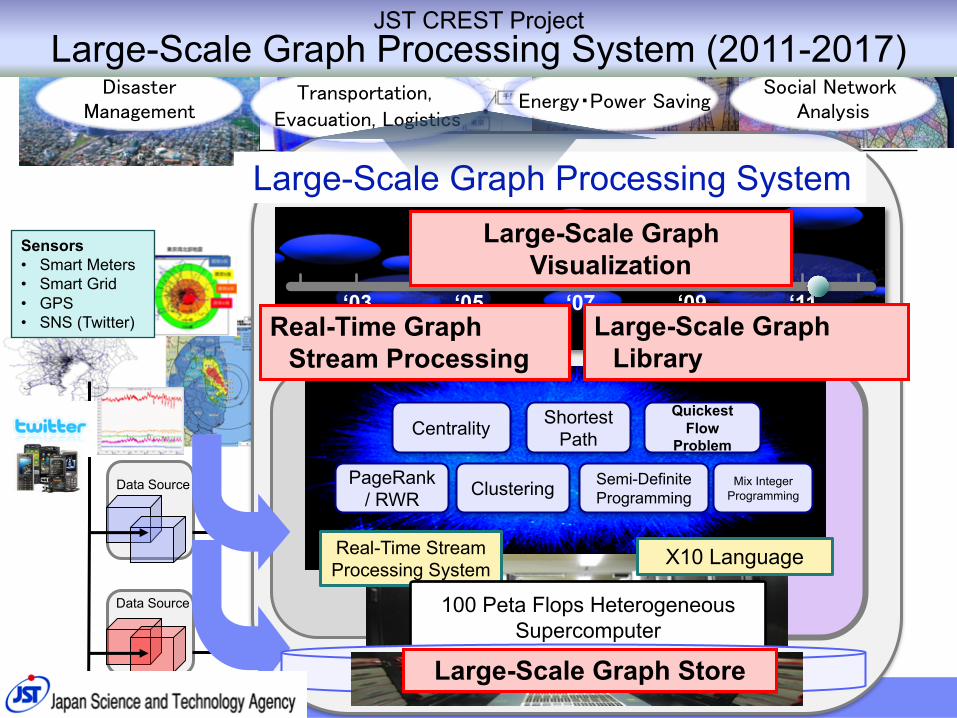
‘03 ‘05 ‘07 ‘09 ‘11
Data Source
Data Source
Sensors• Smart Meters• Smart Grid• GPS• SNS (Twitter)
Large-Scale Graph Visualization
Large-Scale Graph Processing System
DisasterManagement
Transportation,
Evacuation, Logistics
Social Network AnalysisEnergy・Power Saving
PageRank / RWR
Centrality
Clustering
Shortest Path
Quickest Flow
Problem
Semi-Definite Programming
Mix IntegerProgramming
X10 LanguageReal-Time Stream Processing System
Real-Time Graph Stream Processing
Large-Scale Graph Library
100 Peta Flops Heterogeneous Supercomputer
Large-Scale Graph Store
JST CREST Project Large-Scale Graph Processing System (2011-2017)

Project Goal: ScaleGraph Library§Build an open source Highly Scalable Large
Scale Graph Analytics Library beyond the scale of billions of vertices and edges on Distributed Systems
6
Internet Map
Symbolic Networks:
Protein Interactions Social Networks
Cyber Security (15 billion log entries / day for large enterprise)

Research Challenges and Problem Statement
§ Programming Model – Should have sufficient capabilities of representing various graph algorithms– Should be easy-to-use programming model for users, Sync. vs. Async. ?
§ Data Representation and Distribution– Should be as much efficient as possible, and need to handle highly skewed
workload imbalance
§ Programming Language– Java, C/C++, or new HPCS language ? – Should cope with the advance of the underlying hardware infrastructure (e.g.
Accelerator, etc)
§ Communication Abstractions : MPI, PAMI (BG/Q), GASNet (LLNL), Threads,..7
How do you design and implement a high performance graph analytics platform that is capable of dealing with various distributed-memory or many-core environments in a highly productive manner ?

Related Work: Distributed Graph Analytics Platforms
§ MPI-based libraries – PBGL2 (Parallel Boost Graph Library, C++) [Gregor,
Oopsla 2005]: Active Messages– GraphLab/GraphChi (C++/MPI) : Asynchronous
Model
§ Hadoop-based libraries / Apache Projects– Giraph (Pregel Model, Java)– GraphX/ Spark– PEGASUS (Generalized Iterative Sparse Matrix
Vector Multiplication, Java CMU), etc
§ Others– GPS (Graph Processing System - Pregel Model,
Stanford, Java + NIO)8
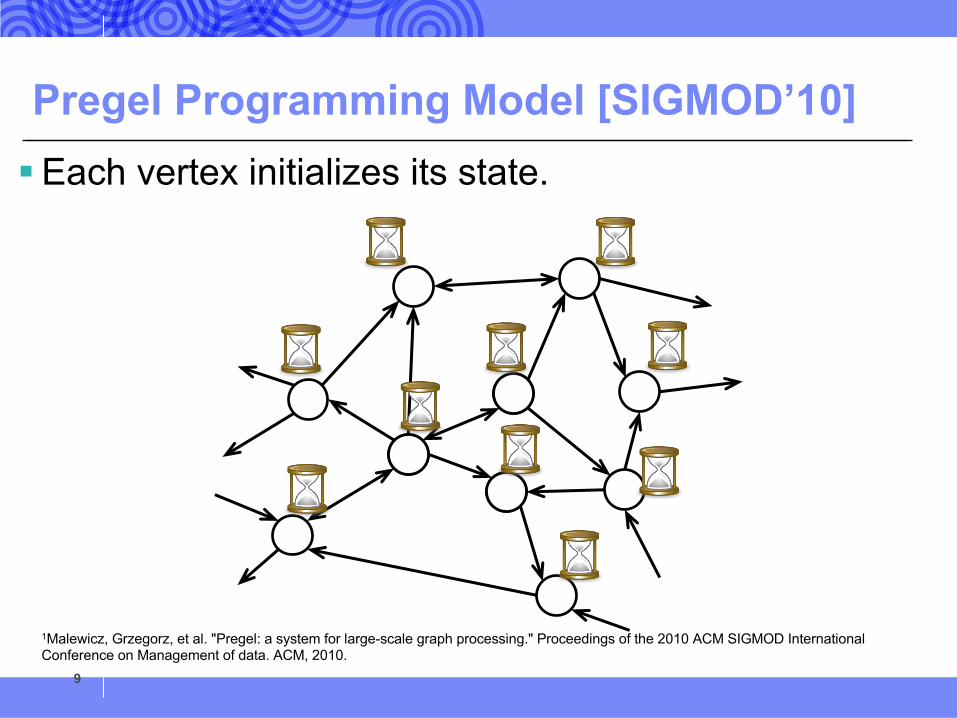
Pregel Programming Model [SIGMOD’10]§Each vertex initializes its state.
9
1Malewicz, Grzegorz, et al. "Pregel: a system for large-scale graph processing." Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. ACM, 2010.
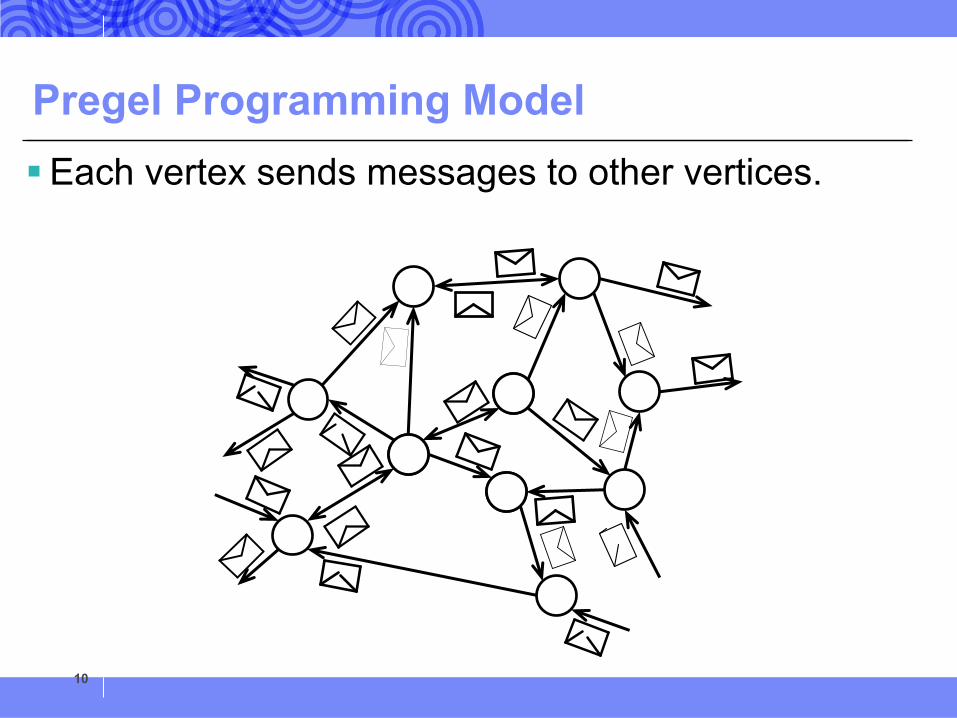
Pregel Programming Model§Each vertex sends messages to other vertices.
10
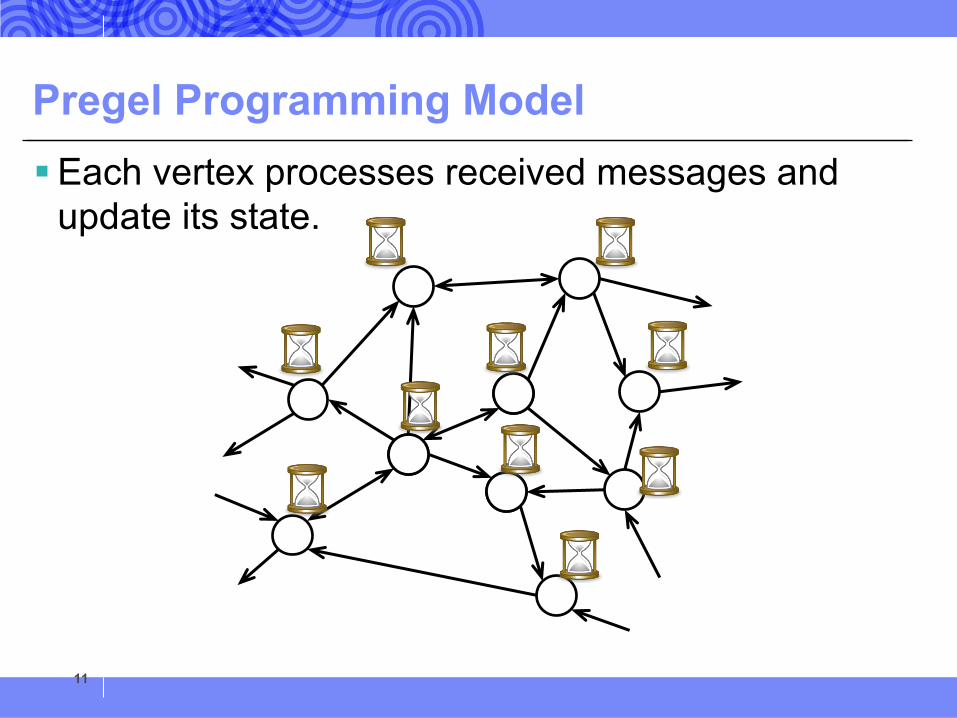
Pregel Programming Model§Each vertex processes received messages and
update its state.
11
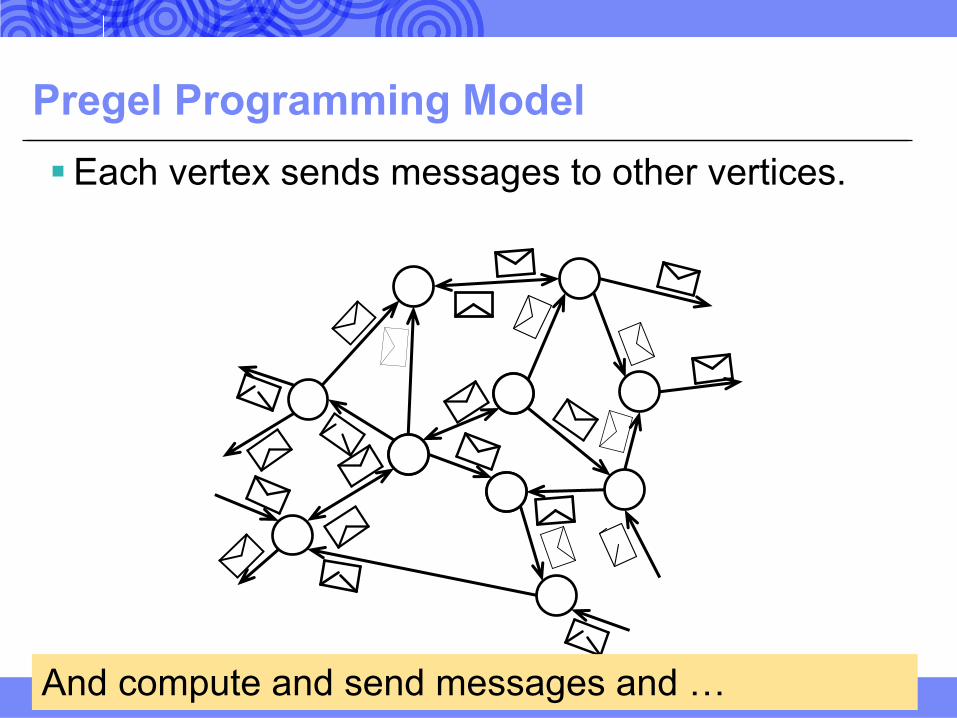
Pregel Programming Model§Each vertex sends messages to other vertices.
12And compute and send messages and …

Design of ScaleGraph
§ Language Choice : X10 (IBM Research)
§ Programming Model: – Pregel computation model or SpMV Model
§ Graph Representation – Distributed Sparse Matrix (1D or 2D)
§ Performance and Memory Management Optimization– Optimized collective routines (e.g., alltoall, allgather, scatter and barrier)– Message Optimization – Highly optimized array data structure (i.e., MemoryChunk) for very large
chunk of memory allocation

14 Credit: X10 Overview by Vijay Saraswat (IBM Research)

Why X10 as the underlying language ? § High Productivity
– X10 allows us to write a platform on distributed systems in a highly productivity manner than C/C++/Fortran with MPI.
– Examples: • Graph Algorithm (Degree distribution) → 60 lines of X10 codes• XPregel (Graph Processing System) → 1600 lines of X10 codes
(Apache Giraph : around 11,000 only for communication package)
§ Interoperability with existing C/C++ codes– X10 program can call functions written in native language (C/C++)
without performance loss.– It is easy to integrate existing native libraries (such as SCALAPACK,
ParMETIS and PARPACK).– We can also write performance critical codes in C/C++ and integrate it
with X10 program.
§ Communication Abstraction
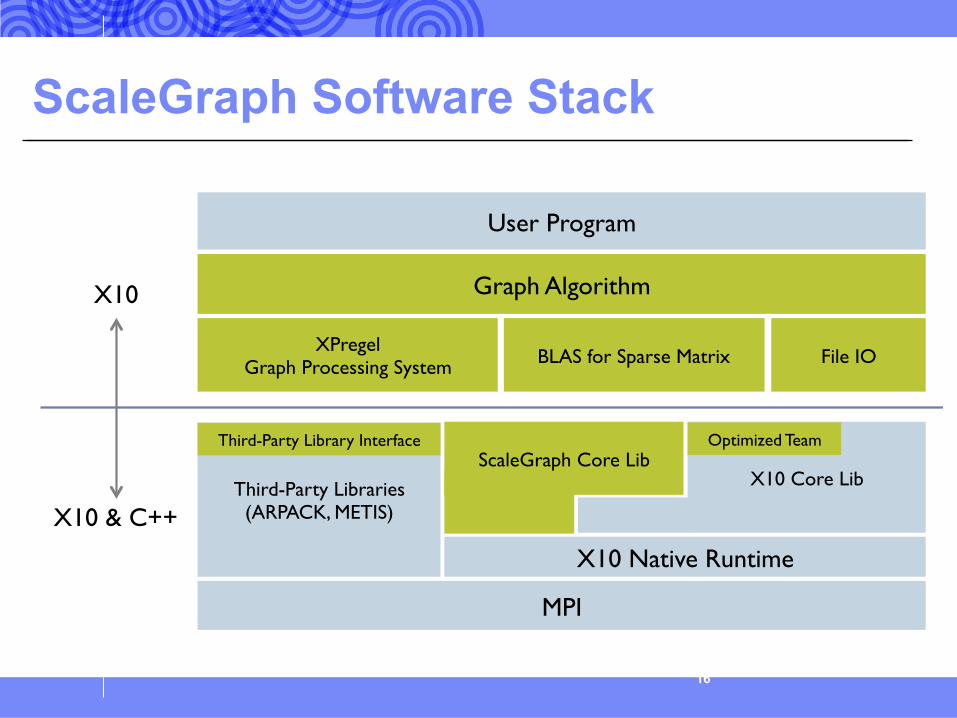
ScaleGraph Software Stack
16
XPregel Graph Processing System
ScaleGraph Core Lib �
MPI
Graph Algorithm �
X10 Core Lib �
X10 �
BLAS for Sparse Matrix� File IO �
User Program�
Third-Party Libraries (ARPACK, METIS) �X10 & C++ �
Optimized Team
X10 Native Runtime
Third-Party Library Interface

Two Models for Computing Graph Algorithms
§Pregel [G. Malewicz, SIGMOD '10]
– Programming model and system for graph processing.– Based on Bulk Synchronous Parallel Model [Valient, 1990]
– We built a Pregel-model platform with X10 named XPregel
§Sparse Matrix Vector Multiplication– PageRank, Random walk with Restart, Spectral Clustering
(which uses eigen vector computation)

XPregel : X10-based Pregel Runtime
§ X10-based Pregel-model runtime platform that aims at running on various computing environments from many-core systems to distributed systems
§ Performance Optimization 1. Utilize native MPI collective communication for message
exchange.2. Avoid serialization, which enables utilizing fast inter-
communication of supercomputers3. The destination of message can be computed by a simple bit
manipulation because of the vertex id renumbering.4. Optimized message communication method that can be
used when a vertex send the same message to all the neighbor vertices.
18

Programming Model§ The core algorithm of a graph kernel can be
implemented by calling iterate method of XPregelGraph as shown in the example.
§ Users are also required to specify the type of messages (M) as well as the type of aggregated value (V).
§ The method accepts three closures: computeclosure, aggregator closure, and end closure.
§ In each superstep (iteration step), a vertex contributes its value, which depends on the number of links, to its neighbors.
§ Each vertex summarizes the score from its neighbors and then set the score as its value.
§ The computation continues until the aggregated value of change in vertex’s value less than a given criteria or the number of iterations less than a given value.
xpgraph.iterate[Double,Double](// Compute closure (ctx :VertexContext[Double, Double, Double, Double],messages :MemoryChunk[Double]) => {
val value :Double;if(ctx.superstep() == 0) {// calculate initial page rank score of each vertexvalue = 1.0 / ctx.numberOfVertices();}
else {// for step onward, value = (1.0-damping) / ctx.numberOfVertices() +
damping * MathAppend.sum(messages);}// sum scorectx.aggregate(Math.abs(value - ctx.value()));// set new rank scorectx.setValue(value);// broadcast its score to its neighborsctx.sendMessageToAllNeighbors(value /
ctx.outEdgesId().size());},
// Aggregate closure: calculate aggregate value(values :MemoryChunk[Double]) => MathAppend.sum(values),// End closure : should continue ? (superstep :Int, aggVal :Double) => {
return (superstep >= maxIter || aggVal < eps);});
PageRank Example
public def iterate[M,A](compute :(ctx:VertexContext [V,E,M,A],
messages:MemoryChunk[M]) => void, aggregator :(MemoryChunk[A])=>A,end :(Int,A)=>Boolean)
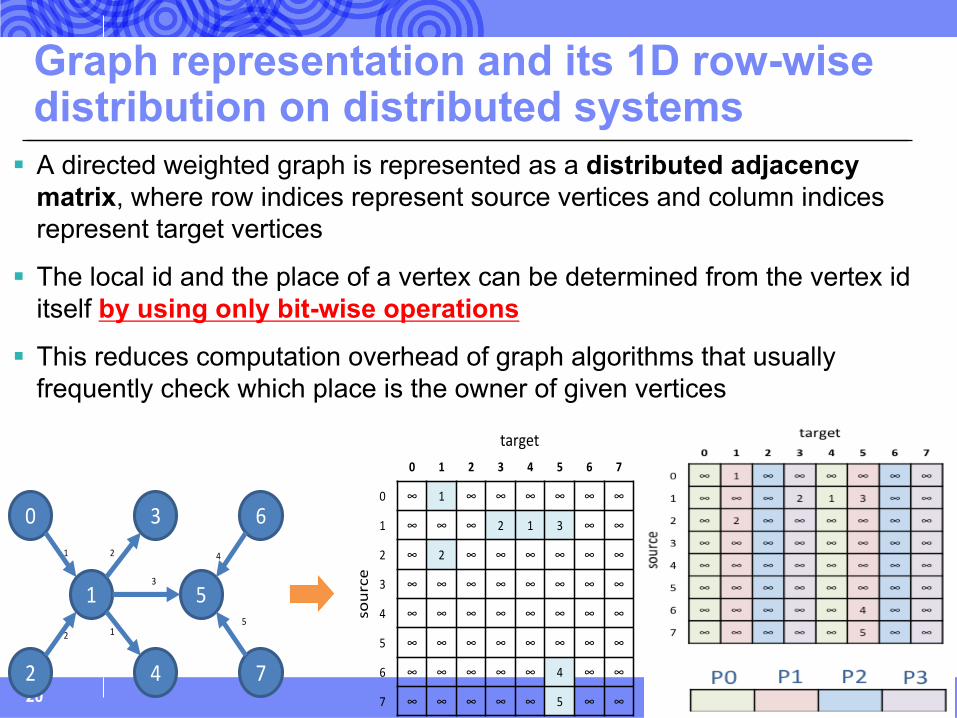
Graph representation and its 1D row-wise distribution on distributed systems
§ A directed weighted graph is represented as a distributed adjacency matrix, where row indices represent source vertices and column indices represent target vertices
§ The local id and the place of a vertex can be determined from the vertex id itself by using only bit-wise operations
§ This reduces computation overhead of graph algorithms that usually frequently check which place is the owner of given vertices
20
0 3
2 4
1 5
6
7
1
2 1
2
3
4
5
0 1 2 3 4 5 6 7
0 ∞ 1 ∞ ∞ ∞ ∞ ∞ ∞
1 ∞ ∞ ∞ 2 1 3 ∞ ∞
2 ∞ 2 ∞ ∞ ∞ ∞ ∞ ∞
3 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
4 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
5 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
6 ∞ ∞ ∞ ∞ ∞ 4 ∞ ∞
7 ∞ ∞ ∞ ∞ ∞ 5 ∞ ∞
target
source

Various distributions of distributed sparse matrix on four Places§ For two-dimensional block distribution, the sparse matrix will be partitioned into blocks. The number
of the blocks is given by R×C and must match the number of the given places, where R is the number of rows and C is the number of columns to partition.
§ 2D block (R=2,C=2), 1D column wise (R=1, C=4), and 1D row wise (R=4,C=1)
21
0 1 2 3 4 5 6 7
0 ∞ 1 ∞ ∞ ∞ ∞ ∞ ∞
1 ∞ ∞ ∞ 2 1 3 ∞ ∞
2 ∞ 2 ∞ ∞ ∞ ∞ ∞ ∞
3 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
4 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
5 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
6 ∞ ∞ ∞ ∞ ∞ 4 ∞ ∞
7 ∞ ∞ ∞ ∞ ∞ 5 ∞ ∞
target
source
P0 P1 P2 P3
0 1 2 3 4 5 6 7
0 ∞ 1 ∞ ∞ ∞ ∞ ∞ ∞
1 ∞ ∞ ∞ 2 1 3 ∞ ∞
2 ∞ 2 ∞ ∞ ∞ ∞ ∞ ∞
3 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
4 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
5 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
6 ∞ ∞ ∞ ∞ ∞ 4 ∞ ∞
7 ∞ ∞ ∞ ∞ ∞ 5 ∞ ∞
targetsource
0 1 2 3 4 5 6 7
0 ∞ 1 ∞ ∞ ∞ ∞ ∞ ∞
1 ∞ ∞ ∞ 2 1 3 ∞ ∞
2 ∞ 2 ∞ ∞ ∞ ∞ ∞ ∞
3 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
4 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
5 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞
6 ∞ ∞ ∞ ∞ ∞ 4 ∞ ∞
7 ∞ ∞ ∞ ∞ ∞ 5 ∞ ∞
target
source
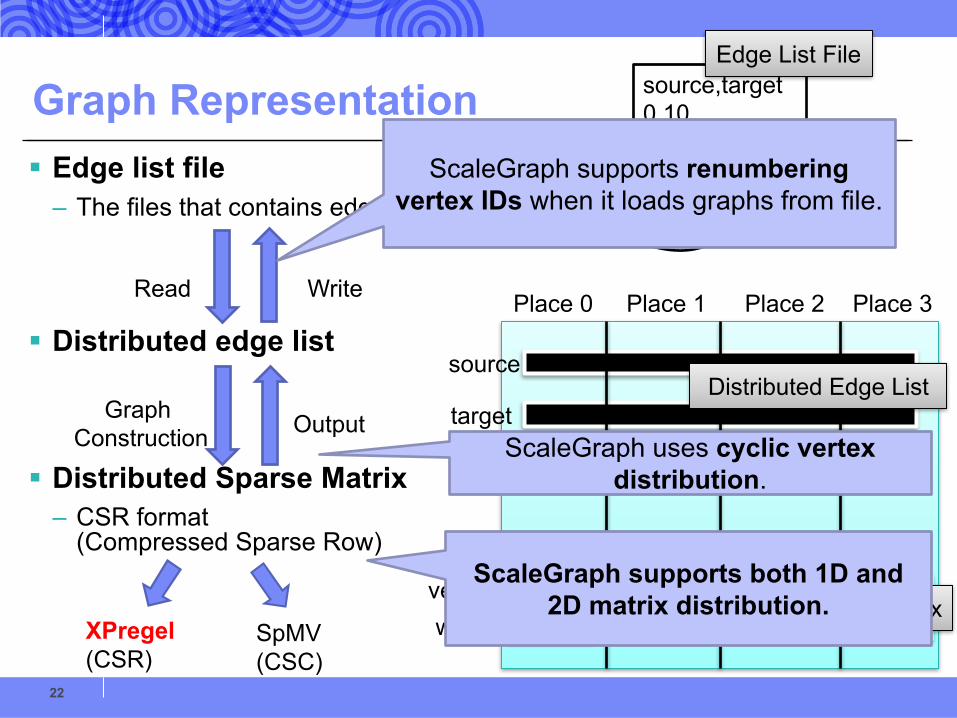
Graph Representation§ Edge list file
– The files that contains edge list.
§ Distributed edge list
§ Distributed Sparse Matrix– CSR format
(Compressed Sparse Row)
source,target0,100,131,23,5…
Place 0 Place 1 Place 2 Place 3
Edge List File
source
target
offsetverticesweight
Read Write
GraphConstruction Output
Distributed Edge List
Distributed Sparse Matrix
ScaleGraph supports renumbering vertex IDs when it loads graphs from file.
ScaleGraph uses cyclic vertex distribution.
ScaleGraph supports both 1D and 2D matrix distribution.
XPregel(CSR)
SpMV(CSC)
22
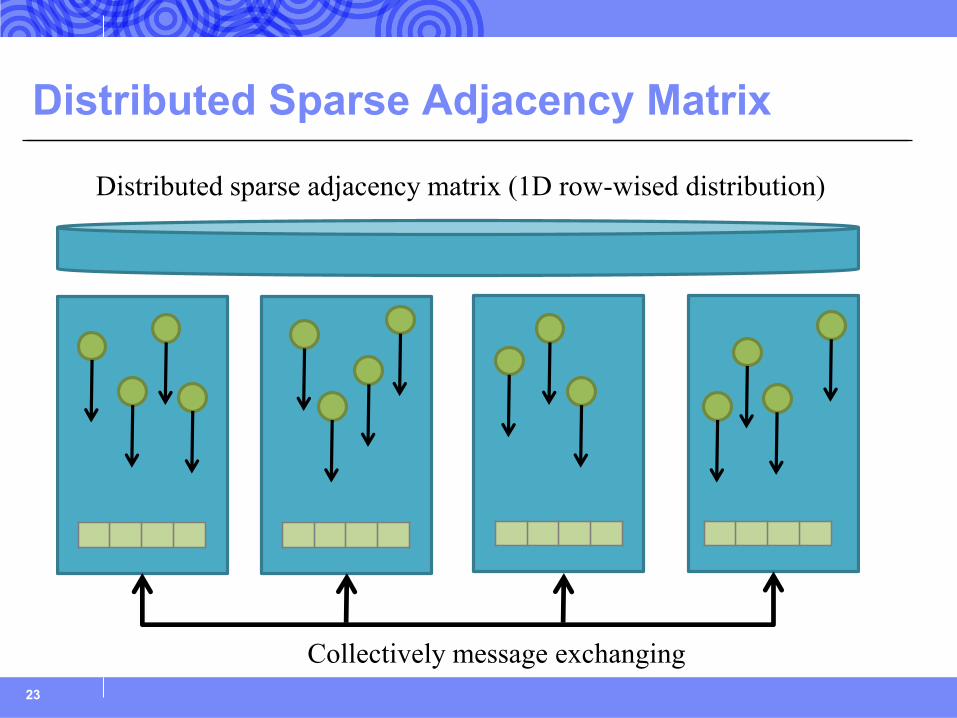
Distributed Sparse Adjacency Matrix
23
Distributed sparse adjacency matrix (1D row-wised distribution)
Collectively message exchanging

Our Proposed Optimization (1): - Efficient Memory Management for Big Graphs § Our proposed Explicit Memory Management (EMM) can be used through an array,
MemoryChunk (used as the same as X10’s native array)
§ It is designed to deal with a large number of items.
§ The memory allocation in MemoryChunk consists of two modes for small memory requests and large memory requests, respectively. – The appropriate mode is determined internally from the size of requested memory and a certain
memory threshold.
§ For small memory requests, MemoryChunk uses Boehm GC (Garbage Collection) allocation scheme, while for large memory requests,MemoryChunk explicitly uses malloc and free system calls
24 PageRank on RMAT scale 24 graph
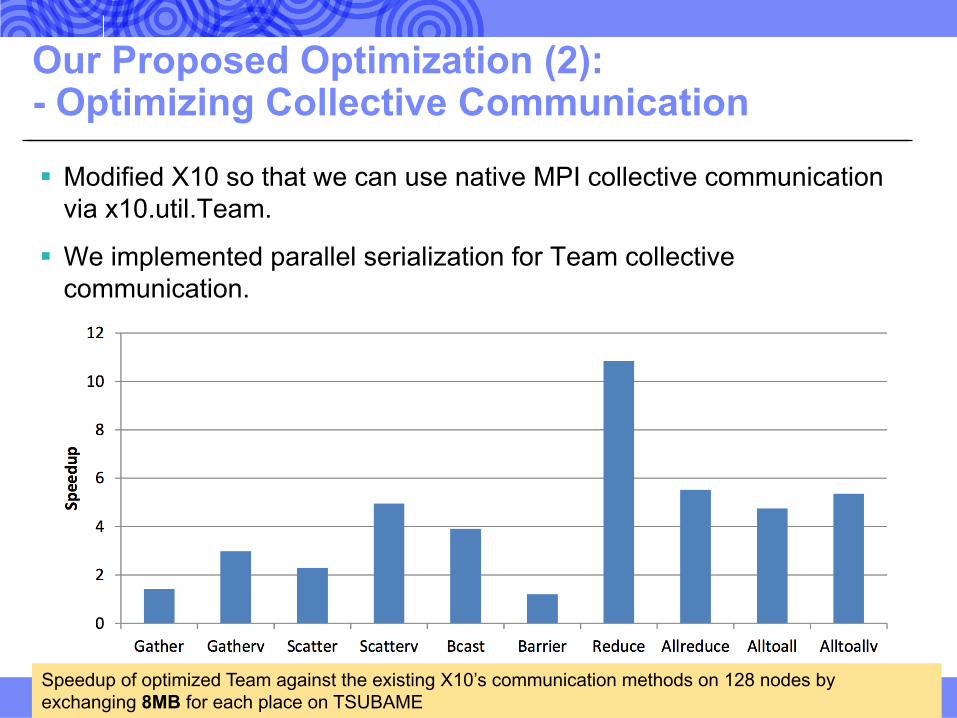
Our Proposed Optimization (2): - Optimizing Collective Communication
§ Modified X10 so that we can use native MPI collective communication via x10.util.Team.
§ We implemented parallel serialization for Team collective communication.
25Speedup of optimized Team against the existing X10’s communication methods on 128 nodes by exchanging 8MB for each place on TSUBAME
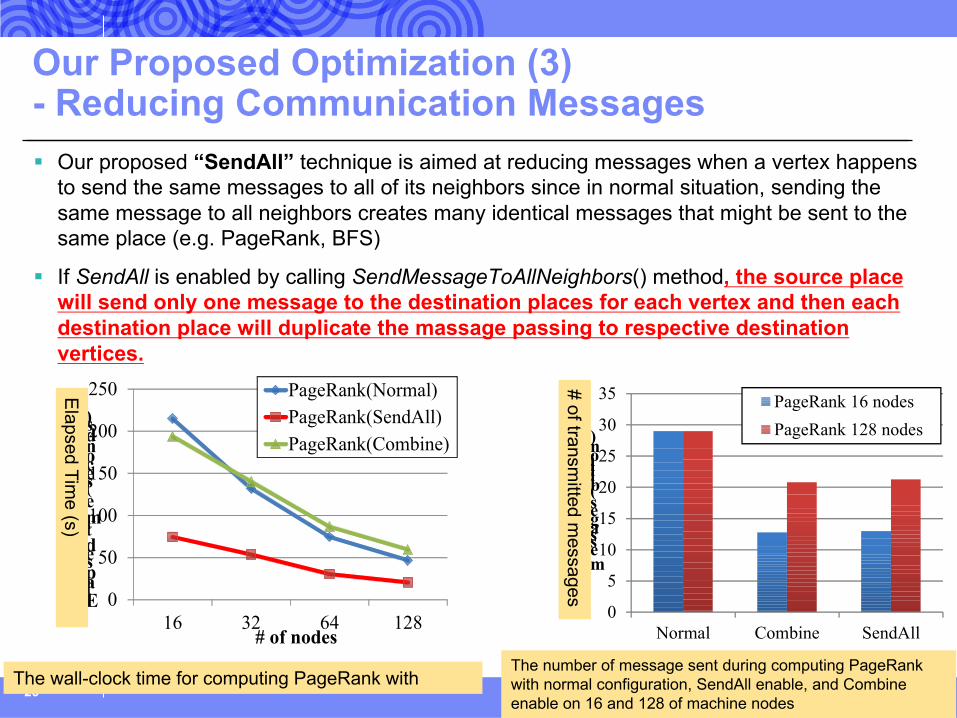
Our Proposed Optimization (3)- Reducing Communication Messages § Our proposed “SendAll” technique is aimed at reducing messages when a vertex happens
to send the same messages to all of its neighbors since in normal situation, sending the same message to all neighbors creates many identical messages that might be sent to the same place (e.g. PageRank, BFS)
§ If SendAll is enabled by calling SendMessageToAllNeighbors() method, the source place will send only one message to the destination places for each vertex and then each destination place will duplicate the massage passing to respective destination vertices.
26
0
50
100
150
200
250
16 32 64 128Elapsed time (seconds)
# of nodes
PageRank(Normal)PageRank(SendAll)PageRank(Combine)
0
5
10
15
20
25
30
35
Normal Combine SendAll
Number of transferred
messages (billion)
PageRank 16 nodesPageRank 128 nodes
The wall-clock time for computing PageRank with
Elapsed Time (s)
The number of message sent during computing PageRank with normal configuration, SendAll enable, and Combine enable on 16 and 128 of machine nodes
# of transmitted m
essages

Parallel Text File Reader/Writer for Graph§ Motivation
– Loading and writing data from IO storage are considered important equally to executing graph kernels.
– When loading a large graph, if the graph loader is not well designed, the time of loading graph will take longer significantly time than that of executing a graph kernel because of network communication overhead and the large latency of IO storage.
§ Solution– ScaleGraph provides parallel text file reader/writer.– At the beginning, an input file will be separated into even chunks, the number of
which is equal to the number of places available. – Each place will load only its respective chunk, and it then separates the chunk
into smaller, even chunks that the number of them is equal to the number of worker threads and assigns these smaller chunks to respective threads.
27
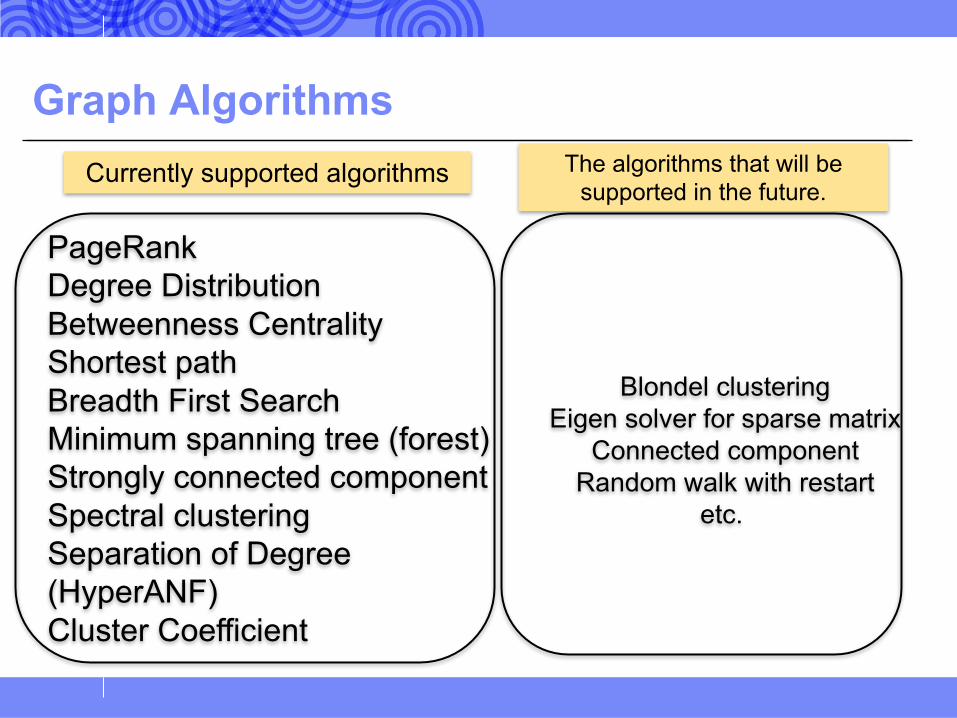
Graph Algorithms
PageRankDegree DistributionBetweenness CentralityShortest pathBreadth First SearchMinimum spanning tree (forest)Strongly connected componentSpectral clusteringSeparation of Degree(HyperANF)Cluster Coefficient
Blondel clusteringEigen solver for sparse matrix
Connected componentRandom walk with restart
etc.
Currently supported algorithms The algorithms that will be supported in the future.
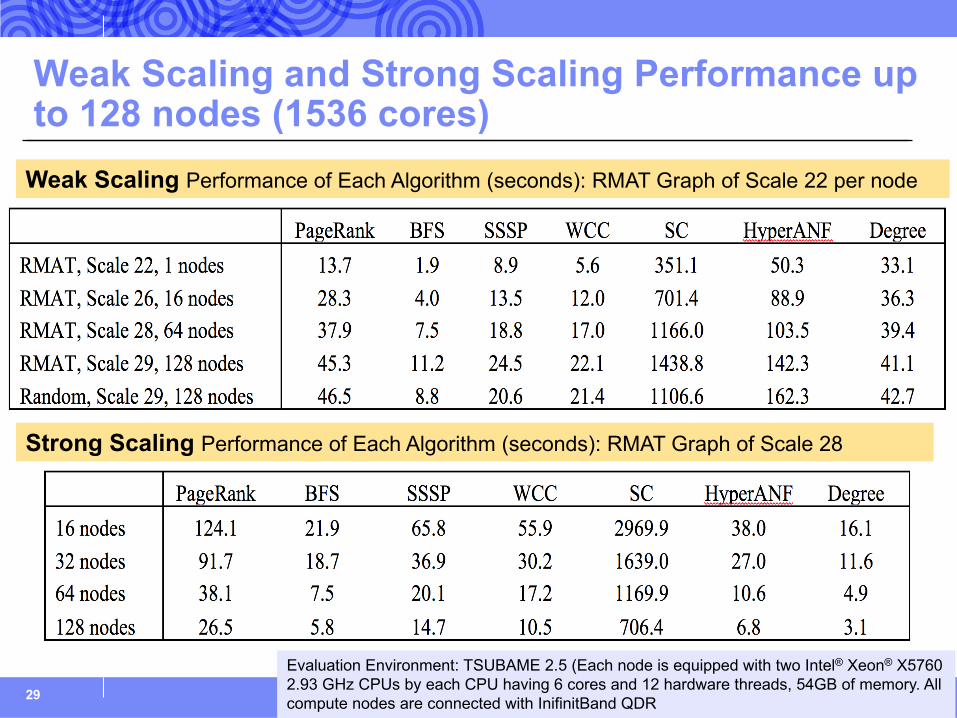
Weak Scaling and Strong Scaling Performance up to 128 nodes (1536 cores)
29
Evaluation Environment: TSUBAME 2.5 (Each node is equipped with two Intel® Xeon® X5760 2.93 GHz CPUs by each CPU having 6 cores and 12 hardware threads, 54GB of memory. All compute nodes are connected with InifinitBand QDR
Weak Scaling Performance of Each Algorithm (seconds): RMAT Graph of Scale 22 per node
Strong Scaling Performance of Each Algorithm (seconds): RMAT Graph of Scale 28
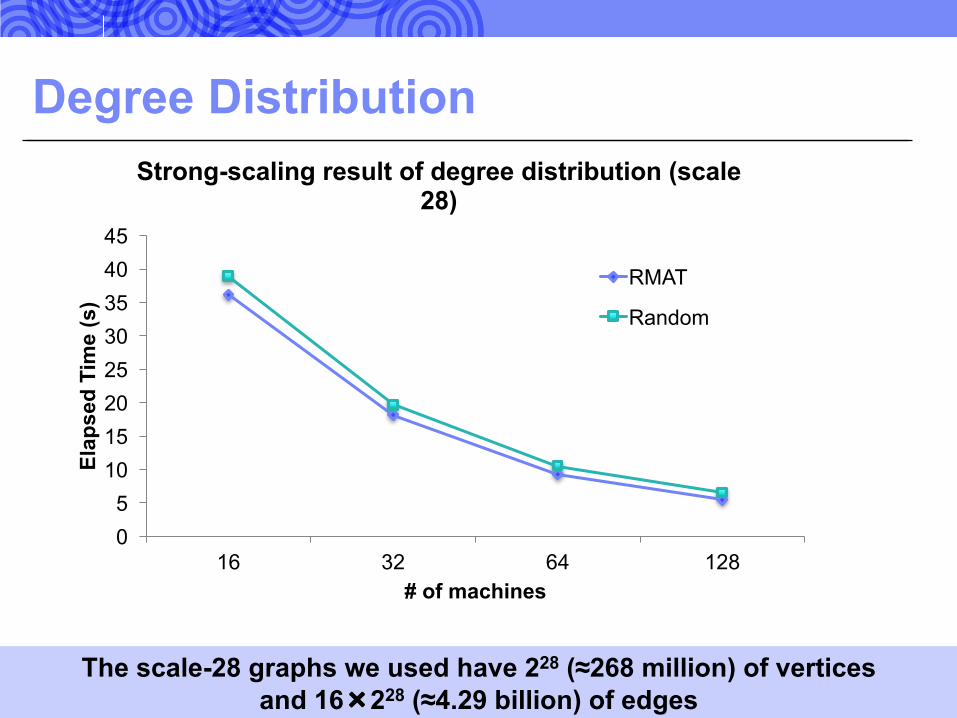
Degree Distribution
30
05
1015202530354045
16 32 64 128
Elap
sed
Tim
e (s
)
# of machines
Strong-scaling result of degree distribution (scale 28)
RMAT
Random
The scale-28 graphs we used have 228 (≈268 million) of vertices and 16×228 (≈4.29 billion) of edges
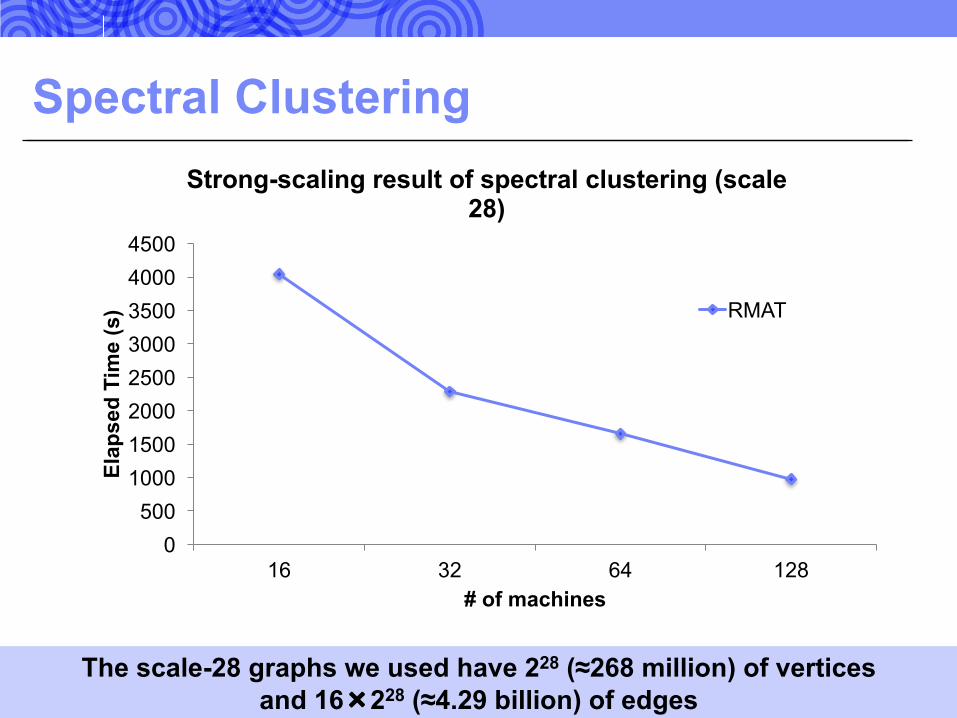
Spectral Clustering
31
0500
10001500200025003000350040004500
16 32 64 128
Elap
sed
Tim
e (s
)
# of machines
Strong-scaling result of spectral clustering (scale 28)
RMAT
The scale-28 graphs we used have 228 (≈268 million) of vertices and 16×228 (≈4.29 billion) of edges
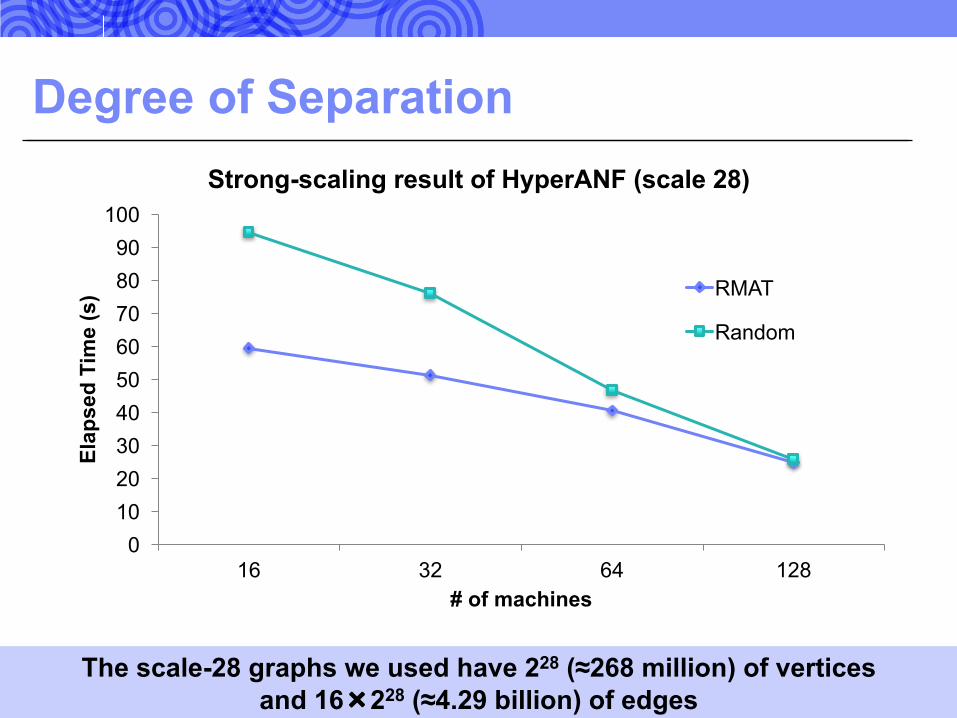
Degree of Separation
32The scale-28 graphs we used have 228 (≈268 million) of vertices and 16×228 (≈4.29 billion) of edges
0102030405060708090
100
16 32 64 128
Elap
sed
Tim
e (s
)
# of machines
Strong-scaling result of HyperANF (scale 28)
RMAT
Random
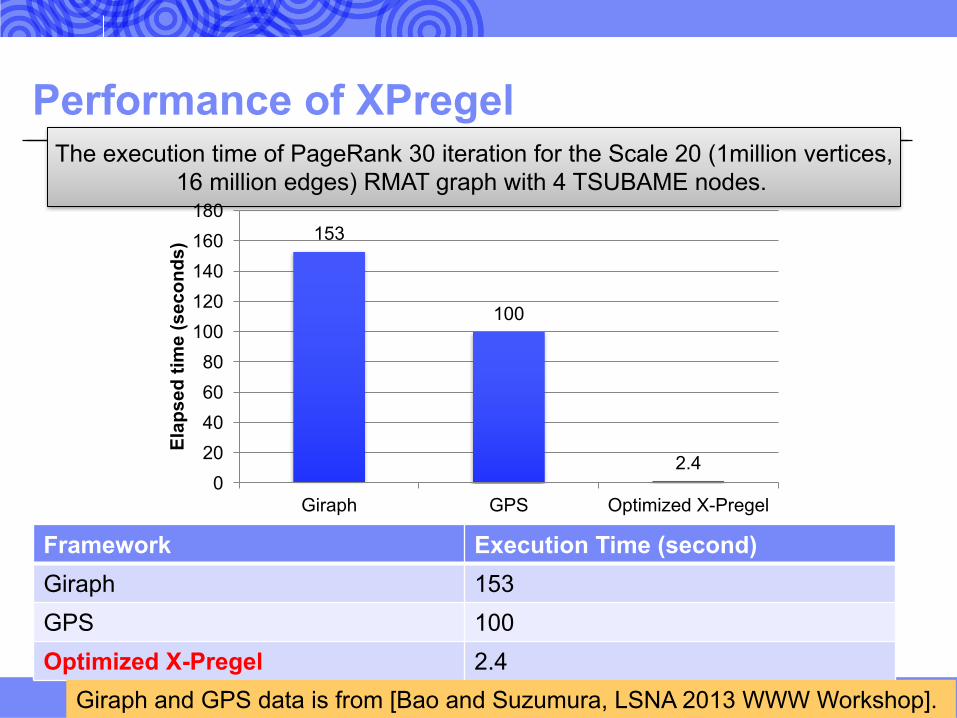
Performance of XPregel
Framework Execution Time (second)Giraph 153GPS 100Optimized X-Pregel 2.4
The execution time of PageRank 30 iteration for the Scale 20 (1million vertices, 16 million edges) RMAT graph with 4 TSUBAME nodes.
153
100
2.40
20406080
100120140160180
Giraph GPS Optimized X-Pregel
Elap
sed
time
(sec
onds
)
Giraph and GPS data is from [Bao and Suzumura, LSNA 2013 WWW Workshop].
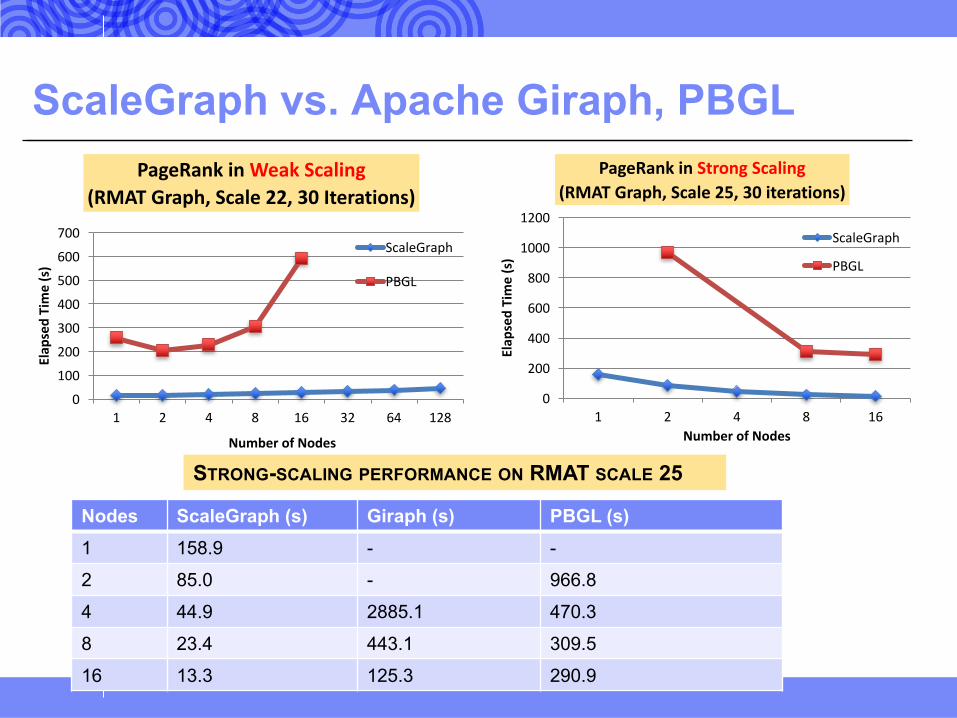
ScaleGraph vs. Apache Giraph, PBGL
0
200
400
600
800
1000
1200
1 2 4 8 16
Elap
sedTime(s)
NumberofNodes
PageRankinStrongScaling(RMATGraph,Scale25,30iterations)
ScaleGraph
PBGL
0
100
200
300
400
500
600
700
1 2 4 8 16 32 64 128
Elap
sedTime(s)
NumberofNodes
PageRankinWeakScaling(RMATGraph,Scale22,30Iterations)
ScaleGraph
PBGL
Nodes ScaleGraph (s) Giraph (s) PBGL (s)1 158.9 - -
2 85.0 - 966.8
4 44.9 2885.1 470.3
8 23.4 443.1 309.5
16 13.3 125.3 290.9
STRONG-SCALING PERFORMANCE ON RMAT SCALE 25
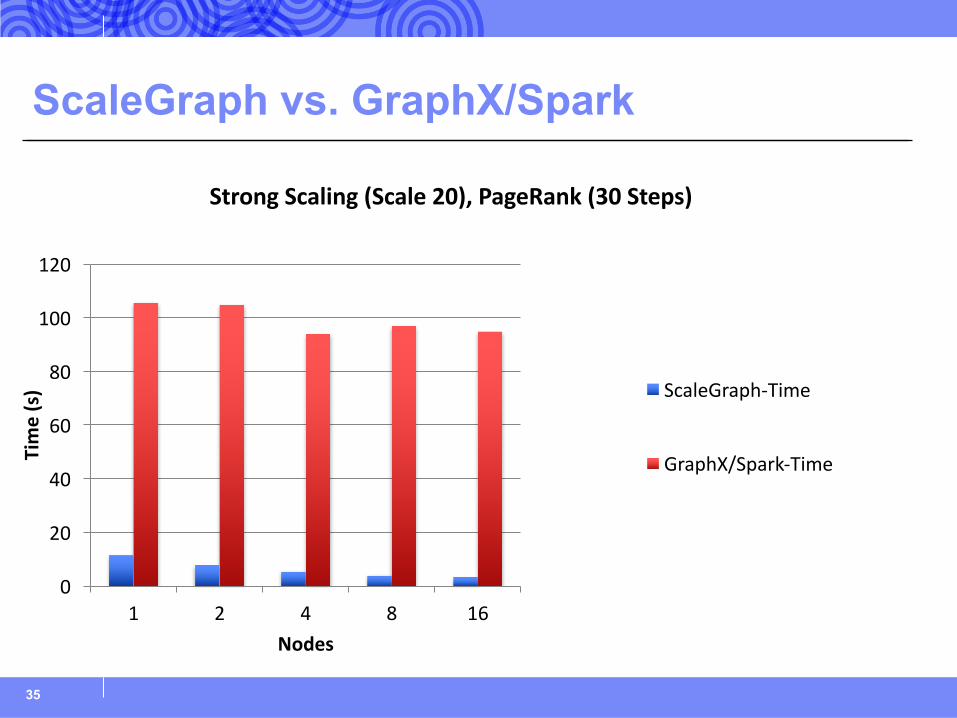
ScaleGraph vs. GraphX/Spark
35
0
20
40
60
80
100
120
1 2 4 8 16
Time(s)
Nodes
StrongScaling(Scale20),PageRank(30Steps)
ScaleGraph-Time
GraphX/Spark-Time
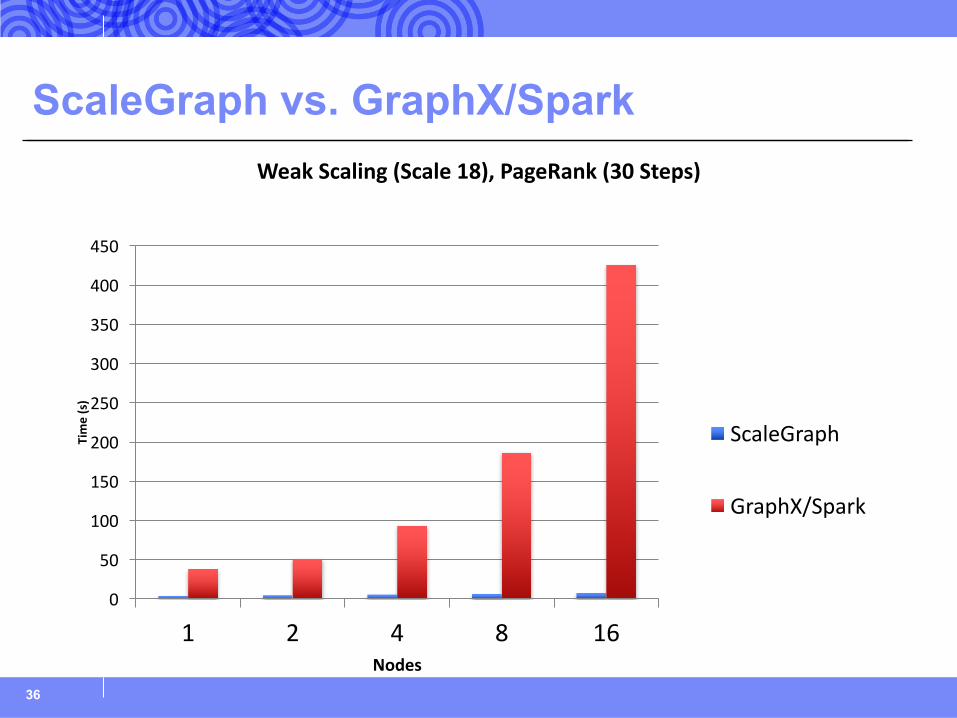
ScaleGraph vs. GraphX/Spark
36
0
50
100
150
200
250
300
350
400
450
1 2 4 8 16
Time(s)
Nodes
WeakScaling(Scale18),PageRank(30Steps)
ScaleGraph
GraphX/Spark
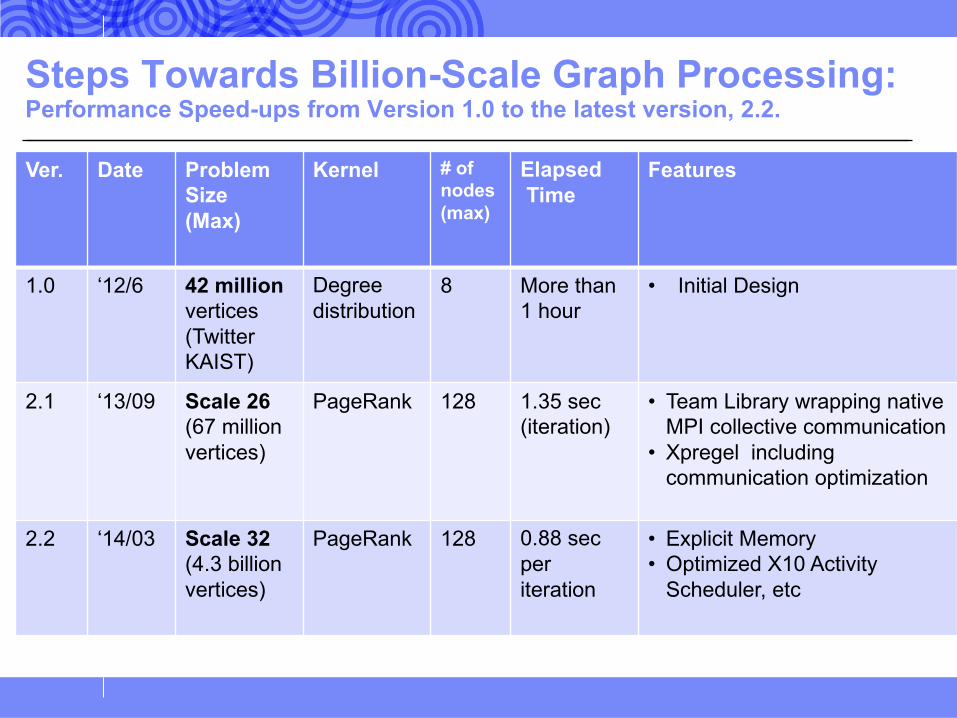
Steps Towards Billion-Scale Graph Processing: Performance Speed-ups from Version 1.0 to the latest version, 2.2.
Ver. Date Problem Size (Max)
Kernel # of nodes(max)
ElapsedTime
Features
1.0 ‘12/6 42 million vertices (Twitter KAIST)
Degree distribution
8 More than 1 hour
• Initial Design
2.1 ‘13/09 Scale 26 (67 million vertices)
PageRank 128 1.35 sec (iteration)
• Team Library wrapping native MPI collective communication
• Xpregel including communication optimization
2.2 ‘14/03 Scale 32 (4.3 billion vertices)
PageRank 128 0.88 secperiteration
• Explicit Memory • Optimized X10 Activity
Scheduler, etc

Performance Summary for ScaleGraph 2.2 § Artificial big graph that follows various features
of Social Network – Largest data : 4.3 billion vertices and 68.7 billion edges
(RMAT : Scale 32, 128 nodes)– PageRank : 16.7 seconds for 1 iteration– HyperANF (b=5) = 71 seconds
§ Twitter Graph (0.47 billion vertices and 7 billion edges – around Scale 28.8) – PageRank (128 nodes): 76 seconds – Spectral Clustering (128 nodes) : 1,839 seconds – Degree of Separation (128 nodes): 56 seconds– Degree Distribution (128 nodes): 128 seconds

Concluding Remarks§ ScaleGraph Official web site – http://www.scalegraph.org/
– License: Eclipse Public License v1.0– Project information and Documentation– Source code distribution / VM Image – Source Code Repository : http://github.com/scalegraph/
§ Ongoing/Future Work– Integration with Graph Databases such as IBM System G Native Store– Other domains: RDF Graph, Human Brain Project (EU) – More temporal web analytics on our whole Twitter follower-followee
network and all the user profile as of 2012/10
39
Special thanks for contributors in this talk including my current and past students, Koji Ueno, Charuwat Houngkaew, Hiroki Kanezashi, Hidefumi Ogata,
Masaru Watanabe and ScaleGraph Team

40
Questions
?? Thank You










![Graph Sweet? Suite?! - Analytics, Business Intelligence … [特集] ODS統計グラフのカスタマイズ FÙFôGnGaG GLFô 7 :Fõ GTG G](https://img.pdfslide.tips/doc/110x75/5acd59ea7f8b9a63398dfa51/graph-sweet-suite-analytics-business-intelligence-ods.jpg)