Embed Size (px)
Citation preview

Big Data’15Лекция VI: NoSQL и согласованность
Дмитрий Барашев[email protected]
Computer Science Center
24 марта 2015
1/62

Этот материал распространяется под лицензией
Creative Commons ”Attribution - Share Alike” 3.0http://creativecommons.org/licenses/by-sa/3.0/us/deed.ru
сверстано в онлайн LATEX редакторе
Pa
peeriapapeeria.com
2/62

Сегодня в программе
CAP, ACID, BASE, PACELC
Модели физической согласованности
Percolator
3/62

Сегодня в программе
CAP, ACID, BASE, PACELC
Модели физической согласованности
Percolator
4/62

CAP теорема
▶ В асинхронной системе1 из этих трех вещейможно выбрать только две:
▶ Atomic Consistency (атомарная согласованность)▶ Availability (доступность)▶ Partition tolerance (устойчивость к разделению)
Это теорема, но не догма
1система в которой нет единых часов и узлы принимаютрешения основываясь только на полученных сообщениях илокальных вычислениях
5/62

CAP теорема
▶ В асинхронной системе1 из этих трех вещейможно выбрать только две:
▶ Atomic Consistency (атомарная согласованность)▶ Availability (доступность)▶ Partition tolerance (устойчивость к разделению)
Это теорема, но не догма
1система в которой нет единых часов и узлы принимаютрешения основываясь только на полученных сообщениях илокальных вычислениях
5/62

Согласованность
▶ Сложное понятие▶ Логическая согласованность vs физическаясогласованность
▶ Бывают разные модели физическойсогласованности
6/62

Доступность
▶ Любой запрос, полученный работоспособнымузлом, должен получить ответ, содержащийзапрошенные данные
▶ Ответ «ой, у нас модем сломался, приходитезавтра» ответом не считается
▶ Считается ли система из 10 идентичныхread-only серверов в одном ЦОД доступнойпосле попадания в ЦОД ядерной бомбы?
▶ Может ли запрос выполняться неделю?
7/62

Доступность
▶ Любой запрос, полученный работоспособнымузлом, должен получить ответ, содержащийзапрошенные данные
▶ Ответ «ой, у нас модем сломался, приходитезавтра» ответом не считается
▶ Считается ли система из 10 идентичныхread-only серверов в одном ЦОД доступнойпосле попадания в ЦОД ядерной бомбы?
▶ Может ли запрос выполняться неделю?
7/62

Доступность
▶ Любой запрос, полученный работоспособнымузлом, должен получить ответ, содержащийзапрошенные данные
▶ Ответ «ой, у нас модем сломался, приходитезавтра» ответом не считается
▶ Считается ли система из 10 идентичныхread-only серверов в одном ЦОД доступнойпосле попадания в ЦОД ядерной бомбы?
▶ Может ли запрос выполняться неделю?
7/62

Устойчивость к разделению
▶ Потеря сообщений (частичная или полная)между компонентами системы не влияет наработоспособность системы.
▶ Речь в основном о сбоях в сети
8/62

Физическая согласованность
▶ Соглашения относительно того, в какомпорядке применяются обновления и в какоймомент они становятся видны всем клиентамсистемы
9/62

Сильная и слабая физическаясогласованность
▶ Атомарная согласованность: существуетглобальный порядок применения обновлений ивсе операции чтения возвращают данные,записанные последней из предыдущихопераций записи, вне зависимости от того, вкаком узле они сделаны
▶ Слабая согласованность (weak consistency)▶ операции чтения необязательно возвращаютпоследнее записанное значение
▶ восстановление согласованности требуетвыполнения каких-то условий
▶ окно несогласованности (inconsistency window) -интервал между обновлением игарантированной его видимостью всемчитателям
10/62

BASE свойства распределённойсистемы
▶ Практически всегда доступна (BasicallyAvailable)
▶ Не всегда согласована (Soft-state)▶ В конечном счете согласуется (Eventuallyconsistent)
11/62

Логическая согласованность
▶ В базе данных выполняются все заданныеадминистратором ограничения. Состояние,нарушающее какое-либо ограничение, не имеетправа стать подтверждённым.
12/62

ACID свойства транзакций
▶ Атомарность: транзакция неделима: еёдействия применяются либо отклоняютсяцеликом
▶ Согласованность: после завершениятранзакции база данных находится всогласованном состоянии
▶ Изолированность: События, происходящиевнутри транзакции, должны быть скрыты отдругих одновременно выполняемых транзакций
▶ Долговечность: результаты зафиксированнойтранзакции не могут исчезнуть в результатесбоя
▶ Atomicity, Consistency, Isolation, Durability
13/62

ACID vs BASE?
▶ Невозможно построить высокодоступноераспределённое хранилище с ACID семантикой,поэтому NoSQL СУБД это и не делает?
▶ Или может просто системы, неподдерживающие не только ACID-транзакции,но и физическую согласованность реплик,создаются проще и быстрее?
14/62

ACID vs BASE?
▶ Невозможно построить высокодоступноераспределённое хранилище с ACID семантикой,поэтому NoSQL СУБД это и не делает?
▶ Или может просто системы, неподдерживающие не только ACID-транзакции,но и физическую согласованность реплик,создаются проще и быстрее?
14/62

Физическая vs логическая
▶ Логическая согласованность гарантируетпользователю выполнение его бизнес правил
▶ Физическая согласованность определяет, чтомогут ожидать прикладные программы,выполняющие операции записи
▶ «C» из ACID не то же самое что «C» из CAP▶ Но часто для одновременного обеспечениявысокой доступности и ACID-согласованноститребуется CAP-согласованность
15/62

Выбор CP
▶ Выбираем устойчивость к распаду исогласованность, жертвуем доступностью
▶ Гарантируем некую сильную модельсогласованности и будем отказывать вобслуживании некоторых запросов в случаераспада
▶ Например будем обслуживать:▶ только запросы на чтение (системы ссинхронной репликацией)
▶ только доступ к данным, целиком находящимсявнутри одной сетевой компоненты(шардированные системы)
16/62

Выбор AP
▶ Выбираем устойчивость к распаду идоступность, жертвуем согласованностью
▶ Гарантируем что все запросы будут обслужены,но в случае распада произойдетрассогласованность:
▶ пользователи из одной компоненты связности неувидят изменения, сделанные в другойкомпоненте
▶ разные версии обновлений данных в разныхкомпонентах
▶ Тем не менее, хочется чтоб в конце концовсистема пришла в согласованное состояние
17/62

Выбор AP
▶ Выбираем устойчивость к распаду идоступность, жертвуем согласованностью
▶ Гарантируем что все запросы будут обслужены,но в случае распада произойдетрассогласованность:
▶ пользователи из одной компоненты связности неувидят изменения, сделанные в другойкомпоненте
▶ разные версии обновлений данных в разныхкомпонентах
▶ Тем не менее, хочется чтоб в конце концовсистема пришла в согласованное состояние
17/62

Выбор CA
▶ Гарантируем согласованность и доступность,при условии что нет распада сети
▶ Однозначно работает если системанераспределенная
▶ В распределенной кажется неразумнымповедением. По Закону Мерфи, сетьобязательно упадет и нельзя это игнорировать
▶ Система может просто прекратить работу принеустранимом распаде.
▶ И это, возможно, будет случаться не так часто
18/62

Выбор CA
▶ Гарантируем согласованность и доступность,при условии что нет распада сети
▶ Однозначно работает если системанераспределенная
▶ В распределенной кажется неразумнымповедением. По Закону Мерфи, сетьобязательно упадет и нельзя это игнорировать
▶ Система может просто прекратить работу принеустранимом распаде.
▶ И это, возможно, будет случаться не так часто
18/62

Что же выбрать?
▶ Утверждение CAP: если сеть распалась то вампридется выбрать между согласованностью идоступностью
▶ Распад сети – вещь редкая.▶ Поддержка логической согласованности – вещьнужная
19/62

То есть CA?
▶ В нормальной ситуации надо бытьсогласованными и доступными
▶ В редкие моменты распада что-то деградирует▶ Когда сеть восстановится, надо привестисистему в согласованное состояние и житьдальше
20/62

Но нет
▶ Вокруг полно систем, заранее жертвующихсогласованностью
Но почему?!
21/62

Но нет
▶ Вокруг полно систем, заранее жертвующихсогласованностью
Но почему?!
21/62

Время отклика
22/62

Время отклика
▶ Высокая доступность не обсуждается▶ Нужно дублировать данные и сервисы▶ Много реплик ⇒ расходы на поддержкусогласованности
▶ Строгая согласованность ⇒ повышенное времяотклика
23/62

Расширенное пространство планов
if has Partition thentrade off Availability and Consistency;
elsetrade off Latency and Consistency;
end
Пространство PACELC
24/62

Сегодня в программе
CAP, ACID, BASE, PACELC
Модели физической согласованности
Percolator
25/62

Согласованность в конечном счете
▶ Eventual consistency▶ Любое обновление через некоторое времяраспространится и станет доступным длячтения при отсутствии последующихобновлений
eventual consistency is so eventual
26/62

Согласованность в конечном счете
▶ Eventual consistency▶ Любое обновление через некоторое времяраспространится и станет доступным длячтения при отсутствии последующихобновлений
eventual consistency is so eventual
26/62

Некоторые полутона▶ «Что запишешь то прочтешь» (Read Your OwnWrites)
▶ клиент может читать свои собственныеобновления немедленно, вне зависимости оттого, на каком узле они сделаны
▶ Сессионная согласованность▶ что запишешь то прочтешь, но в рамках однойсессии
▶ Причинная согласованность▶ если процесс P1 прочитал объект X и записалобъект Y то процесс P2, увидевший новоезначение Y, увидит то же самое значение X, чтои P1
▶ Монотонное чтение▶ номер версии объекта, читаемого процессом, неуменьшается
27/62

В практическом применении
▶ Монотонное чтение + сессионнаясогласованность – хороший практическийвариант
28/62

Модель принятия обновлений отклиента
▶ Послать запись всем узлам сразу▶ узлы могут рассинхронизироваться
▶ Послать запись выделенному мастеру▶ запись нужно распространить на другие узлы
▶ Послать запись случайному узлу▶ Послать запись узлу, выбранному алгоритмомшардирования (хеш-функцией)
▶ Процесс записи становится непрозрачным,клиент слишком много знает
29/62

Модель распространения обновлений
▶ Синхронные и асинхронные▶ Асинхронное распространение
▶ обновление принимается узлом, записываетсялокально и подтверждается
▶ фоновый процесс рассылает обновления другимузлам
▶ разумеется не гарантирует строгуюсогласованность
▶ Синхронное распространение▶ запись подтверждается только если ее принялии подтвердили W узлов
▶ клиент может ждать▶ при некоторых условиях может обеспечитьстрогую согласованность
30/62

Немного синхронной математики
▶ Пусть N узлов хранят реплику объекта, записьидет на W узлов, чтение с R узлов
▶ Если W+ R > N то множества узлов записи ичтения пересекаются и можно обеспечитьстрогую согласованность
▶ если есть два MySQL сервера с синхроннойрепликацией то N = 2,W = 2,R = 1
▶ Если W+ R <= N то множества могут непересечься
▶ два MySQL сервера с асинхронной репликацией:N = 2,W = 1,R = 1
31/62

Вариации▶ Системы, ориентированные на согласованность,будут устанавливать W = N,R = 1
▶ и будут отказывать в записи если какой-то из Wузлов упадет
▶ Системы, ориентированные на доступность,будут устанавливать W = 1 и разные варианты R
▶ интересный вариант W = 1,R = N,W+ R > N:чтение всегда может выбрать последнююверсию, но узел с ней может упасть
▶ Системы, допускающие запись в разные узлы,скорее всего захотят W >= N+1
2▶ иначе могут получиться разные версии объекта
▶ Если W+ R <= N то нет особого смысла иметьR > 1
▶ согласованности нет все равно, зачем же читатьнесколько реплик
32/62

Привязка сессии к серверу
▶ Поддержка RYOW и сессионнойсогласованности
▶ Пока сессия жива, запросы прилетают к одномуи тому же серверу
▶ Сложнее делать балансировку нагрузки иустойчивость к сбоям
33/62

Версионирование данных
▶ Если допускается слабая согласованность топоявляются разные версии данных
▶ Нужна модель поведения, которая позволитобработать эти разные версии и сойтись кединой
34/62

Оптимистичные блокировки
▶ Каждый элемент данных имеет свою временнуюметку
▶ Метки читаются вместе с данными▶ При записи транзакция должна убедиться, чтометки имеющихся у нее данных совпадают сактуальными на момент записи
▶ Если это не так, транзакция не принимается▶ Если метки совпали то производится запись иметки записанных элементов обновляются
▶ сильно помогает атомарная операцияCompare-And-Swap (CAS)
▶ Много приложений: ETag и If-Match заголовки вHTTP, редактирование страниц в Wikipedia, etc.
35/62

Мультиверсионный протокол
▶ У каждого элемента есть временная метка икаждой метке соответствует ревизия элемента
▶ У каждой транзакции есть временная метка▶ Метки монотонно увеличиваются▶ Транзакция с меткой ti читает элементы сметкой tj < ti, ∄k : tj < tk < ti
▶ При записи обновленные данные получаютметку от транзакции
36/62

Сегодня в программе
CAP, ACID, BASE, PACELC
Модели физической согласованности
Percolator
37/62
Percolator
38/62

Проблема построения веб индекса
▶ Map-Reduce это прекрасно но он производитцелый индекс или никакого
▶ Хочешь обновить индекс – запускаешь цепьMap-Reduce’ов и ждешь
▶ Это плохо подходит для новостей и блогов▶ Хотелось бы обновлять индекс подокументно
39/62

Проблема подокументного обновления
▶ Map-Reduce неприменим: ему нужен весь входчтобы построить весь выход
▶ Наивное обновление индекса может нарушитьограничения целостности
▶ например если есть несколько дубликатовстраниц то в индексе должна быть страница ссамым высоким рангом и отдельный списокдубликатов
▶ Для высокогранулярного обновления нужнытранзакции
40/62

Проблемы с транзакциями
▶ DBMS либо разорвутся либо озолотятся▶ Bigtable as is поддерживает атомарность записиодной строки
▶ Нужно что-то что обеспечивает ACID свойствадля групп строк
41/62

Percolator
▶ Percolator – протокол и библиотекареализующая ACID транзакции поверх Bigtable
▶ Это клиентская библиотека, не встроенная вBigtable
42/62

Действующие лица
▶ Bigtable и GFS▶ Клиентские бинарники, использующиеPercolator
▶ Сервер временных меток▶ Легковесный сервис блокировок
43/62

Что обещается и что нет
▶ Обещается▶ ACID семантика▶ Snapshot isolation▶ использование императивного языка
▶ Не обещается▶ быстрый отклик
44/62

Snapshot isolation
▶ У каждого элемента данных есть версии свременно́й меткой
▶ У каждой транзакции есть временна́я метканачала и подтверждения
▶ Транзакция читает версии элементов с меткой,ближайшей снизу к своей метке начала
▶ Новая версия элемента равна меткеподтверждения записывающей транзакции
45/62

Схема работы
▶ При старте транзакция получает метку начала ts▶ Транзакция читает данные с временной меткойt < ts и записывает изменения локально
▶ Когда клиентский код решает подтвердитьтранзакцию
▶ выполняется стадия блокировок двухфазногопротокола с возможными исходами:
▶ успех▶ обрыв из-за наличия более позднейподтвержденной записи
▶ обрыв из-за наличия конкурирующих блокировок▶ транзакция получает метку коммита tc▶ выполняется стадия снятия блокировок иподтверждения записанных значений с новойметкой
46/62

Где держать блокировки?
▶ Сервис блокировок должен:▶ переживать сбои▶ обепечивать относительно низкое времяотклика
▶ обеспечивать относительно высокуюпропускную способность
▶ То есть наверное быть распределенным,реплицируемым, сбалансированным
▶ Погодите, так это ж Bigtable
47/62

Где держать блокировки?
▶ Сервис блокировок должен:▶ переживать сбои▶ обепечивать относительно низкое времяотклика
▶ обеспечивать относительно высокуюпропускную способность
▶ То есть наверное быть распределенным,реплицируемым, сбалансированным
▶ Погодите, так это ж Bigtable
47/62

Где держать блокировки?
▶ Сервис блокировок должен:▶ переживать сбои▶ обепечивать относительно низкое времяотклика
▶ обеспечивать относительно высокуюпропускную способность
▶ То есть наверное быть распределенным,реплицируемым, сбалансированным
▶ Погодите, так это ж Bigtable
47/62

Организация Percolator-строки вBigtable
▶ Для каждого столбца данных c создаются:c:data Собственно данные, как
подтвержденные, так инеподтвержденные
c:lock Блокировка. Наличие записиозначает что транзакция находится вкакой-то из стадий двухфазногопротокола
c:write Метка последнего подтвержденногозначения
48/62
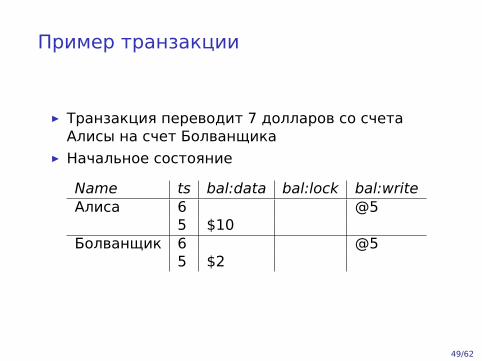
Пример транзакции
▶ Транзакция переводит 7 долларов со счетаАлисы на счет Болванщика
▶ Начальное состояние
Name ts bal:data bal:lock bal:writeАлиса 6 @5
5 $10Болванщик 6 @5
5 $2
49/62
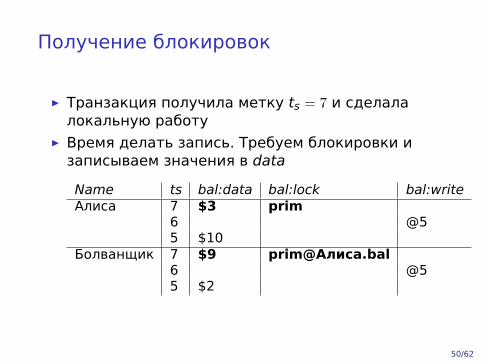
Получение блокировок
▶ Транзакция получила метку ts = 7 и сделалалокальную работу
▶ Время делать запись. Требуем блокировки изаписываем значения в data
Name ts bal:data bal:lock bal:writeАлиса 7 $3 prim
6 @55 $10
Болванщик 7 $9 prim@Алиса.bal6 @55 $2
50/62

Возможные неприятности
▶ Наличие записи в bal:write с меткой > 7 – поводупасть
▶ Наличие записи с какой-либо меткой в bal:lock– повод задуматься
▶ может кто-то с меньшей меткой тормозит и нечистит записи о блокировках
▶ а может кто-то делает конкурирующую запись
51/62

Подтверждение
▶ Все блокировки получены и неподтвержденныезначения записаны
▶ Время подтверждаться. Получаем меткукоммита tc, обновляем значения в столбце writeи чистим блокировки, начиная с главной
Name ts bal:data bal:lock bal:writeАлиса 8 @7
7 $36 @55 $10
Болванщик 7 $9 prim@Алиса.bal6 @55 $2
52/62

Главная блокировка
▶ Признак (не)подтвержденности транзакции▶ Главная блокировка висит → транзакция неподтверждена и возможно еще пишетизменения
▶ Главная блокировка снята → транзакциязаписала все изменения по крайней мере в data
▶ Все остальные взятые блокировки показываютна главную
53/62

Завершение подтверждения
▶ Продолжаем снимать блокировки иподтверждать значения
Name ts bal:data bal:lock bal:writeАлиса 8 @7
7 $36 @55 $10
Болванщик 8 @77 $96 @55 $2
54/62

Возможные неприятности▶ Транзакция в клиенте может упасть призавершении подтверждения
▶ тогда кто-то может доделать ее работу.Например, следующая транзакция, котораяобнаружит вторичную блокировку, но не найдетглавной
▶ Транзакция может упасть между взятиемблокировок и подтверждением. Тогда ужевзятые замки будут мешать последующимтранзакциям
▶ вводится политика сборки мусора другимитранзакциями
▶ используется наличие главной блокировки какпризнак неподтвержденности транзакции (ивозможного ее падения)
▶ используется сторонний сервис блокировок дляхранения абсолютного времени началатранзакции
55/62

Операция чтения
▶ Чтение просит значения с меткой меньше ts▶ Если чтение видит блокировку то оно ждет ееснятия (это означает что транзакцияначавшаяся, а может и закончившаяся раньшеts, записывает значения)
▶ Утверждение: чтение всегда будет получатьподтвержденные значения с меткой меньше ts
56/62

Корректность snapshot изоляции▶ пусть транзакция W с временем подтвержденияTW < TR пишет значения параллельно с R
▶ так как TW < TR то значит сервис часов выдалметку W в том же запросе что и метку R илираньше
▶ значит W попросила метку раньше чем R ееполучила
▶ W обязана все заблокировать, прежде чемполучить метку подтверждения
▶ R обязана попросить метку старта прежде чемначать читать
▶ значит W заблокировала < W запросила меткуподтверждения < R получила метку начала < Rчитает
57/62

Результат внедрения Percolator
▶ Медиана времени обновления документа сталаменьше в сотни раз
▶ Система стала проще в обслуживании▶ Потребление ресурсов стало гораздо болеегладким
▶ хотя в целом и выросло
58/62

Занавес
▶ CAP теорема считается верной при некоторыхусловиях и для некоторых систем
▶ Кроме экстремальных случаев есть полутона▶ Физическая согласованность в CAP – не то жесамое что логическая согласованность в ACID
▶ Бывают разные модели физическойсогласованности
▶ Логической согласованности можно достичьдаже внешними средствами
59/62

Литература I
Daniel J Abadi.Consistency tradeoffs in modern distributeddatabase system design: Cap is only part of thestory.Computer, (2):37–42, 2012.Seth Gilbert and Nancy Lynch.Brewer’s conjecture and the feasibility of consistent,available, partition-tolerant web services.ACM SIGACT News, 33(2):51–59, 2002.
60/62

Литература II
Daniel Peng and Frank Dabek.Large-scale incremental processing usingdistributed transactions and notifications.In Proceedings of the 9th USENIX conference onOperating systems design and implementation,pages 1–15. USENIX Association, 2010.Michael Stonebraker.In search of database consistency.Commun. ACM, 53(10):8–9, October 2010.Christof Strauch, Ultra-Large Scale Sites, and WalterKriha.Nosql databases.Lecture Notes, Stuttgart Media University, 2011.
61/62

Литература III
СД Кузнецов.Транзакционные параллельные СУБД: новаяволна.Труды Института системного программированияРАН, 20, 2011.
62/62



























