Embed Size (px)
Citation preview

深度学习 AMI开发人员指南

深度学习 AMI 开发人员指南
深度学习 AMI: 开发人员指南Copyright © 2019 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's,in any manner that is likely to cause confusion among customers, or in any manner that disparages or discreditsAmazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may notbe affiliated with, connected to, or sponsored by Amazon.

深度学习 AMI 开发人员指南
Table of ContentsAWS Deep Learning AMI是什么? ........................................................................................................ 1
关于本指南 ................................................................................................................................ 1先决条件 .................................................................................................................................... 1用例 .......................................................................................................................................... 1功能 .......................................................................................................................................... 1
预装框架 ............................................................................................................................ 1预装 GPU 软件 .................................................................................................................. 2模型处理和可视化 ............................................................................................................... 2
入门 .................................................................................................................................................. 3如何开始使用 DLAMI ................................................................................................................... 3DLAMI 选择 ............................................................................................................................... 3
Conda ............................................................................................................................... 3Base ................................................................................................................................. 4CUDA ............................................................................................................................... 5OS ................................................................................................................................... 6
实例选择 .................................................................................................................................... 6GPU ................................................................................................................................. 7CPU ................................................................................................................................. 7定价 .................................................................................................................................. 8
启动 DLAMI ....................................................................................................................................... 9步骤 1:启动 DLAMI ................................................................................................................... 9EC2 控制台 .............................................................................................................................. 10Marketplace 搜索 ...................................................................................................................... 10步骤 2:连接到 DLAMI .............................................................................................................. 11步骤 3:保护 DLAMI 实例 .......................................................................................................... 11步骤 4:测试您的 DLAMI ........................................................................................................... 11清除 ........................................................................................................................................ 11Jupyter 设置 ............................................................................................................................. 12
保护 Jupyter ..................................................................................................................... 12启动服务器 ....................................................................................................................... 13配置客户端 ....................................................................................................................... 13登录 Jupyter Notebook 服务器 ............................................................................................ 14
使用 DLAMI ..................................................................................................................................... 18Conda DLAMI .......................................................................................................................... 18
采用 Conda 的 Deep Learning AMI 简介 .............................................................................. 18步骤 1:登录您的 DLAMI ................................................................................................... 18步骤 2:启动 MXNet Python 3 环境 ..................................................................................... 19步骤 3:测试某些 MXNet 代码 ............................................................................................ 20步骤 4:切换到 TensorFlow 环境 ........................................................................................ 20删除环境 .......................................................................................................................... 21
基础 DLAMI ............................................................................................................................. 21使用 Deep Learning Base AMI ............................................................................................ 21配置 CUDA 版本 ............................................................................................................... 21
Jupyter 笔记本电脑 ................................................................................................................... 22导航已安装的教程 .............................................................................................................. 22通过 Jupyter 切换环境 ....................................................................................................... 23
教程 ........................................................................................................................................ 2310 分钟教程 ..................................................................................................................... 23激活框架 .......................................................................................................................... 23调试和可视化 .................................................................................................................... 34分布式训练 ....................................................................................................................... 37Elastic Fabric Adapter ....................................................................................................... 53GPU 监控和优化 ............................................................................................................... 60推理 ................................................................................................................................ 65
iii

深度学习 AMI 开发人员指南
将框架用于 ONNX ............................................................................................................. 69模型处理 .......................................................................................................................... 76
Deep Learning Containers .................................................................................................................. 81Amazon EC2 上的Deep Learning Containers ................................................................................ 81
设置 ................................................................................................................................ 81教程 ................................................................................................................................ 82
ECS 上的 Deep Learning Containers ........................................................................................... 87设置 ................................................................................................................................ 87教程 ................................................................................................................................ 89
Amazon EKS 上的 Deep Learning Containers ............................................................................. 106设置 .............................................................................................................................. 106教程 .............................................................................................................................. 111EKS 上的 AWS Deep Learning Containers故障排除 .............................................................. 144EKS 上的 AWS Deep Learning Containers词汇表 ................................................................. 146
Amazon SageMaker 上的 Deep Learning Containers .................................................................... 147附录 ...................................................................................................................................... 147
Deep Learning Containers映像 .......................................................................................... 147自定义映像 ..................................................................................................................... 151MKL 建议 ....................................................................................................................... 152
升级 DLAMI .................................................................................................................................... 156DLAMI 升级 ............................................................................................................................ 156软件更新 ................................................................................................................................ 156
资源 .............................................................................................................................................. 157论坛 ...................................................................................................................................... 157博客 ...................................................................................................................................... 157常见问题 ................................................................................................................................ 157
附录 .............................................................................................................................................. 160AMI 选项 ................................................................................................................................ 160
Conda ........................................................................................................................... 160Base ............................................................................................................................. 161CUDA 10.1 ..................................................................................................................... 162CUDA 10 ....................................................................................................................... 162CUDA 9 ......................................................................................................................... 163CUDA 8 ......................................................................................................................... 163Ubuntu 18.04 .................................................................................................................. 164Ubuntu 16.04 .................................................................................................................. 164Amazon Linux ................................................................................................................. 165Amazon Linux 2 .............................................................................................................. 166Windows ........................................................................................................................ 167
DLAMI:发行说明 .................................................................................................................... 168版本存档 ........................................................................................................................ 168
文档历史记录 .................................................................................................................................. 260AWS 词汇表 ................................................................................................................................... 263
iv

深度学习 AMI 开发人员指南关于本指南
AWS Deep Learning AMI是什么?欢迎阅读 AWS Deep Learning AMI 用户指南。
AWS Deep Learning AMI (DLAMI) 是在云中进行深度学习的一站式商店。此自定义计算机实例可用于大多数Amazon EC2 区域中的各种实例类型,从仅包含 CPU 的小型实例到最新的高性能多 GPU 实例。它预配置了NVIDIA CUDA 和 NVIDIA cuDNN 以及最常用的深度学习框架的最新版本。
关于本指南本指南将帮助您启动并使用 DLAMI。它介绍了用于培训和推导的深度学习的几种常见使用案例。本指南还介绍了如何针对您的用途选择合适的 AMI 和您喜欢的实例类型。DLAMI 针对每个框架提供多个教程。您将找到关于如何配置 Jupyter 以在浏览器中运行教程的说明。
先决条件您应该熟悉命令行工具和基本 Python 才能成功运行 DLAMI。框架自身提供有关如何使用每个框架的教程,但是本指南可以向您展示如何激活每个框架并找到适当的入门教程。
示例 DLAMI 用法了解深度学习:DLAMI 是学习或教授机器学习和深度学习框架的理想选择。它不需要对每个框架的安装进行故障排除,并在同一台计算机上运行框架。DLAMI 附带 Jupyter Notebook,可以轻松地向不熟悉机器学习和深度学习的人运行框架提供的教程。
应用程序开发:如果您是应用程序开发人员,并且有兴趣使用深度学习来使您的应用程序利用 AI 方面的最新进步,则 DLAMI 是理想的测试平台。每个框架都附带了关于如何开始使用深度学习的教程,其中许多教程都有模型动物园,可以让您轻松试用深度学习,您不需要自己创建神经网络或进行模型训练。一些示例向您展示如何在几分钟内构建映像检测应用程序,或如何为您自己的聊天自动程序构建语音识别应用程序。
机器学习和数据分析:如果您是数据科学家或有兴趣通过深度学习处理数据,您会发现许多框架都支持 R 和Spark。您将找到关于进行简单回归的教程,以及为个性化和预测系统构建可扩展的数据处理系统的教程。
研究:如果您是一名研究人员,并且希望试用新框架、测试新模型或培训新模型,DLAMI 和 AWS 扩展功能可以减少安装和管理多个培训节点的繁琐工作。您可以使用 EMR 和 AWS CloudFormation 模板轻松启动完整的实例集群,它们随时可以用于可扩展的培训。
Note
虽然您的最初选择可能是将实例类型升级到具有多个 GPU(最多 8 个)的更大实例,但您也可以通过创建 DLAMI 实例集群来进行水平扩展。要快速设置集群,您可以使用预定义的 AWSCloudFormation 模板。有关集群构建的更多信息,请参阅 资源和支持 (p. 157)。
DLAMI 的功能预装框架目前有三种主要的 DLAMI,均包含与操作系统 (OS) 和软件版本相关的其他变体:
1

深度学习 AMI 开发人员指南预装 GPU 软件
• 采用 Conda 的 Deep Learning AMI (p. 3) - 在单独的 Python 环境中使用 conda 程序包单独安装的框架
• Deep Learning Base AMI (p. 4) - 不安装任何框架;只有 NVIDIA CUDA 和其他依赖项
新的 采用 Conda 的 Deep Learning AMI 使用 Anaconda 环境来隔离每个框架,因此您可以随意切换框架,而不用担心其依赖项发生冲突。
有关选择最佳 DLAMI 的更多信息,请查看入门 (p. 3)。
这是 采用 Conda 的 Deep Learning AMI 支持的框架的完整列表:
• Apache MXNet• Caffe• Caffe2**• CNTK**• Keras• PyTorch• TensorFlow• Theano**
预装 GPU 软件即使您使用仅包含 CPU 的实例,DLAMI 也将具有 NVIDIA CUDA 和 NVIDIA cuDNN。无论实例类型是什么,安装的软件都是相同的。请记住,GPU 特定工具只适用于至少包含一个 GPU 的实例。选择 DLAMI 的实例类型 (p. 6)中包含有关此内容的更多信息。
• NVIDIA CUDA 9• NVIDIA cuDNN 7• 也可以使用 CUDA 8、9、10 和 10.1。有关更多信息,请参阅CUDA 安装和框架绑定 (p. 5)。
模型处理和可视化采用 Conda 的 Deep Learning AMI 预装有两种模型服务器,一种用于 MXNet,一种用于 TensorFlow,还预装有 TensorBoard,用于模型可视化。
• 适用于 Apache MXNet 的模型服务器 (MMS) (p. 77)• TensorFlow Serving (p. 78)• TensorBoard (p. 36)
2

深度学习 AMI 开发人员指南如何开始使用 DLAMI
入门如何开始使用 DLAMI
入门很简单。本指南包括了关于选择适合您的 DLAMI、选择适合您的使用案例和预算的实例类型的技巧,以及介绍您可能感兴趣的自定义设置的资源和支持 (p. 157)。
如果您刚开始使用 AWS 或 Amazon EC2,请先从 采用 Conda 的 Deep Learning AMI (p. 3) 开始。如果您熟悉 Amazon EC2 和其他 AWS 服务(如 Amazon EMR、Amazon EFS 或 Amazon S3),并且有兴趣集成这些服务以用于需要分布式培训或推导的项目,则在资源和支持 (p. 157)中查看是否有符合您的使用案例的服务。
我们建议您查看选择 DLAMI (p. 3),以了解最适合您的应用程序的实例类型。
另一个选项是此快速教程:启动 AWS Deep Learning AMI (在 10 分钟内)。
下一步
选择 DLAMI (p. 3)
选择 DLAMI您可能会发现 DLAMI 有很多选项,并且不清楚哪个选项最适合您的使用案例。本部分可以帮助您做出决定。当我们提及 DLAMI 时,通常这实际上是围绕某个常见类型或功能的一组 AMI。有三种变量定义了这些类型和/或功能:
• Conda 与 Base• CUDA 8、CUDA 9 与 CUDA 10• Amazon Linux、Ubuntu 与 Windows
本指南中的其他主题有助于进一步给您提供信息和进一步让您了解详情。
主题• 采用 Conda 的 Deep Learning AMI (p. 3)• Deep Learning Base AMI (p. 4)• CUDA 安装和框架绑定 (p. 5)• DLAMI 操作系统选项 (p. 6)
后续步骤
采用 Conda 的 Deep Learning AMI (p. 3)
采用 Conda 的 Deep Learning AMIConda DLAMI 使用 Anaconda 虚拟环境。这些环境配置为单独安装不同的框架。它还可以让您轻松切换框架。这对了解和体验 DLAMI 必须提供的所有框架很有好处。大多数用户会发现新的 采用 Conda 的 DeepLearning AMI 非常适合他们。
这些“Conda”AMI 将是主要的 DLAMI。它将经常使用框架中的最新版本进行更新,并拥有最新的 GPU 驱动程序和软件。在大多数文档中,它通常被称为 AWS Deep Learning AMI。
3

深度学习 AMI 开发人员指南Base
• Ubuntu 18.04 DLAMI 具有以下框架:Apache MXNet、Chainer、PyTorch 和 TensorFlow• Ubuntu 16.04 和 Amazon Linux DLAMI 具有以下框架:Apache
MXNet、Caffe、Caffe2、Chainer、CNTK、Keras、PyTorch、TensorFlow 和 Theano• Amazon Linux 2 DLAMI 具有以下框架:Apache MXNet、Chainer、PyTorch、TensorFlow 和 Keras
稳定版本与候选版本Conda AMI 使用每个框架中最新正式版本的优化二进制文件。不会有候选版本和实验性功能。优化取决于框架对 Intel 的 MKL DNN 等加速技术的支持,这些技术可加快在 C5、C4 和 C3 CPU 实例类型上的训练和推理速度。二进制文件也将被编译以支持高级 Intel 指令集,包括但不限于 AVX、AVX-2、SSE4.1 和SSE4.2。这些指令将加快 Intel CPU 架构上向量和浮点运算的速度。此外,对于 GPU 实例类型,将使用最新官方版本支持的任何版本更新 CUDA 和 cuDNN。
采用 Conda 的 Deep Learning AMI 会在框架首次激活时自动为您的 EC2 实例安装框架的最优化版本。有关更多信息,请参阅 使用 采用 Conda 的 Deep Learning AMI (p. 18)。
如果要使用自定义或优化的版本选项从源安装,Deep Learning Base AMI (p. 4) 可能是更好的选择。
CUDA 支持采用 Conda 的 Deep Learning AMI 的 CUDA 版本以及每个所支持的框架:
• 使用 cuDNN 7 的 CUDA 10.1:Apache MXNet• 使用 cuDNN 7 的 CUDA 10:PyTorch、TensorFlow、Apache MXNet、Caffe2、Chainer• 使用 cuDNN 7 的 CUDA 9:CNTK、Keras、Theano• 使用 cuDNN 6 的 CUDA 8:Caffe
可以在 DLAMI:发行说明 (p. 168)中找到特定的框架版本号
选择这个 DLAMI 类型,或通过“后续步骤”选项了解有关其他 DLAMI 的更多信息。
• 采用 Conda 的 Deep Learning AMI 选项 (p. 160)
后续步骤
Deep Learning Base AMI (p. 4)
相关主题• 有关使用采用 Conda 的 Deep Learning AMI 的教程,请参阅使用 采用 Conda 的 Deep Learning
AMI (p. 18)教程。
Deep Learning Base AMIDeep Learning Base AMI 就像是一个用于深度学习的空白画布。它包含您需要的一切,直到安装特定的框架。它将拥有您选择的 CUDA 版本。
为什么选择 Base DLAMI该 AMI 团队对于那些想要分享深度学习项目和建立最新版本的项目贡献者非常有用。适用于那些希望推出自己环境且有信心安装和使用最新 NVIDIA 软件的人员,从而他们可以专注于选择要安装的框架和版本。
4

深度学习 AMI 开发人员指南CUDA
选择这个 DLAMI 类型,或通过“后续步骤”选项了解有关其他 DLAMI 的更多信息。
• Deep Learning Base AMI 选项 (p. 161)
后续步骤
CUDA 安装和框架绑定 (p. 5)
相关主题• 使用 Deep Learning Base AMI (p. 21)
CUDA 安装和框架绑定深度学习都非常一流,但每个框架都提供“稳定”版本。这些稳定版本可能不适用于最新的 CUDA 或 cuDNN实施和功能。您决定怎么做? 这最终取决于您的使用案例和您需要的功能。如果您不确定,则使用最新的 采用 Conda 的 Deep Learning AMI.它具有所有框架的官方 PIP 二进制文件(包含 CUDA 8、CUDA 9、CUDA10 和 CUDA 10.1),使用每个框架都支持的任何最新版本。如果您需要最新版本,并要自定义深度学习环境,请使用 Deep Learning Base AMI。
如需进一步指导,请在 稳定版本与候选版本 (p. 4) 上查看我们的指南。
选择具有 CUDA 的 DLAMIDeep Learning Base AMI (p. 4) 具有 CUDA 8、9、10 和 10.1。
采用 Conda 的 Deep Learning AMI (p. 3) 具有 CUDA 8、9、10 和 10.1。
• 使用 cuDNN 7 的 CUDA 10.1:Apache MXNet• 使用 cuDNN 7 的 CUDA 10:PyTorch、TensorFlow、Apache MXNet、Caffe2、Chainer• 使用 cuDNN 7 的 CUDA 9:CNTK、Keras、Theano• 使用 cuDNN 6 的 CUDA 8:Caffe
有关 DLAMI 类型和操作系统的安装选项,请参阅每个 CUDA 版本和 选项页面:
• 采用 CUDA 10.1 的深度学习 AMI 选项 (p. 162)• 采用 CUDA 10 的 Deep Learning AMI 选项 (p. 162)• 采用 CUDA 9 的 Deep Learning AMI 选项 (p. 163)• 采用 CUDA 8 的 Deep Learning AMI 选项 (p. 163)• 采用 Conda 的 Deep Learning AMI 选项 (p. 160)• Deep Learning Base AMI 选项 (p. 161)
可以在 DLAMI:发行说明 (p. 168)中找到特定的框架版本号
选择这个 DLAMI 类型,或通过“后续步骤”选项了解有关其他 DLAMI 的更多信息。
选择一个 CUDA 版本并在附录中查看具有该版本的完整 DLAMI 列表,或者使用“后续步骤”选项了解不同DLAMI 的更多信息。
后续步骤
DLAMI 操作系统选项 (p. 6)
5

深度学习 AMI 开发人员指南OS
相关主题• 有关在 CUDA 版本之间切换的说明,请参阅使用 Deep Learning Base AMI (p. 21)教程。
DLAMI 操作系统选项DLAMI 针对以下列出的操作系统提供。如果您更熟悉 CentOS 或 RedHat,您将更能适应 AWS DeepLearning AMI Amazon Linux 选项 (p. 165) 或 AWS Deep Learning AMI Amazon Linux 2 选项 (p. 166)。否则,您可能更喜欢 AWS Deep Learning AMI,Ubuntu 18.04 选项 (p. 164) 或 AWS Deep LearningAMI,Ubuntu 16.04 选项 (p. 164)。
如果您需要 Windows 操作系统,可在此处找到几个选项:AWS Deep Learning AMI,Windows 选项 (p. 167)。
选择其中一个操作系统并在附录中查看完整列表,或继续后续步骤,选择您的 AMI 和实例类型。
• AWS Deep Learning AMI Amazon Linux 选项 (p. 165)• AWS Deep Learning AMI Amazon Linux 2 选项 (p. 166)• AWS Deep Learning AMI,Ubuntu 18.04 选项 (p. 164)• AWS Deep Learning AMI,Ubuntu 16.04 选项 (p. 164)• AWS Deep Learning AMI,Windows 选项 (p. 167)
如入门概述中所述,您有几个访问 DLAMI 的选项,但首先您应评估您所需的实例类型。您还应该确定您打算使用的 AWS 区域。
后续步骤
选择 DLAMI 的实例类型 (p. 6)
选择 DLAMI 的实例类型选择实例类型可能是另一个挑战,但是我们可以通过几个关于如何选择最佳实例的指针来让这个过程更容易。请记住,DLAMI 是免费的,但底层的计算资源并不是。
• 如果您不熟悉深度学习,那么您可能需要一个具有单一 GPU 的“入门级”实例。• 如果您注重预算,那么您将需要启动更小一点的实例,即看看只有 CPU 的实例。• 如果您有兴趣运行训练模型来进行推理和预测(而不是训练),则您可能需要运行 Amazon Elastic
Inference。这将使您能够访问一部分 GPU,因此,您可以经济地进行扩展。对于大量推理服务,您可能会发现具有大量内存的 CPU 实例(甚至是这些实例的集群)是更佳的解决方案。
• 如果您有兴趣训练包含大量数据的模型,那么您可能需要更大的实例,甚至是 GPU 实例集群。• 如果您有兴趣使用 NVIDIA 集体通信库 (NCCL) 运行机器学习应用程序,且需要大规模的节点间通信,那
么您可能需要使用 弹性结构适配器 (EFA)。
DLAMI 并非在每个区域都可用,但可以将 DLAMI 复制到您选择的区域。有关更多信息,请参阅 复制 AMI。每个区域支持不同范围的实例类型,而且不同区域的实例类型成本通常稍有不同。在每个 DLAMI 主页面上,您将看到一个实例成本列表。请注意区域选择列表,并确保您选择一个靠近您或您的客户的区域。如果您打算使用多个 DLAMI 且可能创建一个集群,请确保为集群中的所有节点使用相同的区域。
• 有关实例更多详细信息,请查看 EC2 实例类型。• 有关区域的更多信息,请访问 EC2 区域。
6

深度学习 AMI 开发人员指南GPU
因此,在考虑到所有这些要点后,请记下最适用于您的使用案例和预算的实例类型。本指南中的其他主题有助于进一步给您提供信息和进一步让您了解详情。
Important
Deep Learning AMI 包含由 NVIDIA Corporation 开发、拥有或提供的驱动程序、软件或工具包。您同意仅在包含 NVIDIA 硬件的 Amazon EC2 实例上使用这些 NVIDIA 驱动程序、软件或工具包。
主题• 推荐的 GPU 实例 (p. 7)• 推荐的 CPU 实例 (p. 7)• DLAMI 的定价 (p. 8)
后续步骤
推荐的 GPU 实例 (p. 7)
推荐的 GPU 实例GPU 实例被推荐用于最深度的学习目的。在 GPU 实例上训练新模型比 CPU 实例更快。您可以在有多个GPU 实例的情况下以线性方式进行缩放,也可以在具有 GPU 的多个实例上使用分布式训练。
• Amazon EC2 P3 实例 最多具有 8 个 NVIDIA Tesla V100 GPU。• Amazon EC2 P2 实例 最多具有 16 个 NVIDIA NVIDIA K80 GPU。• Amazon EC2 G3 实例 最多具有 4 个 NVIDIA Tesla M60 GPU。• 查看 EC2 实例类型 并选择“加速计算”来查看不同的 GPU 实例选项。
后续步骤
推荐的 CPU 实例 (p. 7)
推荐的 CPU 实例无论您是在关注预算,了解深度学习,还是只是想运行一项预测服务,您在 CPU 类别中都有许多经济实惠的选项。某些框架利用了 Intel 的 MKL DNN,这将加快 C5 (并非在所有区域中都可用)、C4 和 C3 CPU 实例类型上的训练和推理速度。它还将加快 GPU 实例类型上的推理。
• Amazon EC2 C5 实例最多具有 72 个 Intel vCPU。• Amazon EC2 C4 实例拥有多达 36 个 Intel vCPU。• 查看 EC2 实例类型并查找计算优化来查看其他 CPU 实例选项。
Note
C5 实例 (并未在所有区域提供) 在科学建模、批处理、分布式分析、高性能计算 (HPC) 和机器/深度学习推理方面表现出色。
Important
如果您计划使用 Caffe,则应改为选择一个 GPU 实例。在 DLAMI 上,Caffe 仅适用于 GPU 支持,无法在 CPU 模式下运行。
后续步骤
DLAMI 的定价 (p. 8)
7

深度学习 AMI 开发人员指南定价
DLAMI 的定价DLAMI 是免费的,但是,您仍然需要承担 Amazon EC2 或其他 AWS 服务成本。包含的深度学习框架是免费的,每个都有自己的开源许可证。NVIDIA 的 GPU 软件是免费的,也有自己的许可证。
为何说它既免费,也不免费呢? 什么是“Amazon EC2 或其他 AWS 服务成本”?
这是一个常见的问题。Amazon EC2 上的一些实例类型被标记为免费。这些实例通常较小,但仍可以在这些免费的实例上运行 DLAMI。这意味着当您只使用该实例的容量时,它是完全免费的。如果您需要一个功能更强大、具有更多 CPU 核心、更多磁盘空间、更多 RAM 和一个或多个 GPU 的实例,那么这些实例很可能不在免费套餐实例类中。这意味着,您将需要支付这些成本。一种想法是软件仍然是免费的,但是您必须为您使用的底层硬件付费。
看看选择 DLAMI 的实例类型 (p. 6)了解更多关于可选择的实例大小的相关信息,以及每种类型的实例可以预期完成的事情。
下一步
启动和配置 DLAMI (p. 9)
8

深度学习 AMI 开发人员指南步骤 1:启动 DLAMI
启动和配置 DLAMI如果您在这里,您应该已经有了想要启动哪个 AMI 的想法。如果没有,请使用从整个入门 (p. 3)中找到的AMI 选择指南选择一个 DLAMI,或使用附录部分 AMI 选项 (p. 160)中的完整 AMI 列表。
您还应该知道您要选择哪个实例类型和区域。否则,请浏览选择 DLAMI 的实例类型 (p. 6)。
Note
我们将在示例中使用 p2.xlarge 作为默认实例类型。只需将此替换为您心中的任何实例类型。
Important
如果您计划使用 Elastic Inference,您必须在启动 DLAMI 之前完成 Elastic Inference 设置。
主题• 步骤 1:启动 DLAMI (p. 9)• EC2 控制台 (p. 10)• Marketplace 搜索 (p. 10)• 步骤 2:连接到 DLAMI (p. 11)• 步骤 3:保护 DLAMI 实例 (p. 11)• 步骤 4:测试您的 DLAMI (p. 11)• 清除 (p. 11)• 设置 Jupyter Notebook 服务器 (p. 12)
步骤 1:启动 DLAMINote
对于本演练,我们可能会针对 Deep Learning AMI (Ubuntu 16.04) 进行引用。即使您选择其他DLAMI,您也应能按照本指南进行操作。
启动实例
1. 您可以通过几种方式启动 DLAMI。请选择一种:
• EC2 控制台 (p. 10)• Marketplace 搜索 (p. 10)
Tip
CLI 选项:如果您选择使用 AWS CLI 启动 DLAMI,您将需要 AMI 的 ID、区域和实例类型、以及您的安全令牌信息。请确保您已拥有 AMI 和实例 ID。如果您尚未设置 AWS CLI,请首先按照安装 AWS 命令行接口指南进行设置。
2. 如果您已经完成了上述某个选项的步骤,请等待实例准备好。这通常仅需要几分钟时间。您可以在 EC2控制台中验证实例的状态。
9

深度学习 AMI 开发人员指南EC2 控制台
EC2 控制台Note
要使用弹性结构适配器 (EFA) 启动实例,请参阅以下步骤。
1. 打开 EC2 控制台.2. 请注意最顶层的导航中的当前区域。如果这不是您所需的 AWS 区域,请更改此选项,然后再继续。有
关更多信息,请参阅 EC2 区域。3. 选择 Launch Instance。4. 根据名称搜索所需的实例:
1. 选择 AWS Marketplace,或...2. 选择 QuickStart。 此处只会列出一部分可用的 DLAMI。3. 搜索 Deep Learning AMI。只查找子类型,例如所需的操作系统,或基础、Conda、源等。4. 浏览这些选项,并在选择时单击 Select。
5. 检查详细信息,然后选择 Continue。6. 选择一个实例类型。
Note
如果您要使用 Elastic Inference (EI),请单击 Configure Instance Details (配置实例详细信息),选择 Add an Amazon EI accelerator (添加 Amazon EI 加速器),然后选择 Amazon EI 加速器的大小。
7. 选择 Review and Launch。8. 检查详细信息和定价。选择 Launch。
Tip
查看 开始使用 AWS Deep Learning AMI 进行深度学习,这里有包含屏幕截图的演练!
下一步
步骤 2:连接到 DLAMI (p. 11)
Marketplace 搜索1. 浏览 AWS Marketplace 并搜索 AWS Deep Learning AMI。2. 浏览这些选项,并在选择时单击 Select。3. 检查详细信息,然后选择 Continue。4. 浏览详细信息,并记录 Region。如果这不是您所需的 AWS 区域,请更改此选项,然后再继续。有关更
多信息,请参阅 EC2 区域。5. 选择一个实例类型。6. 选择一个密钥对,可以使用您的默认密钥对,也可以创建新密钥对。7. 检查详细信息和定价。8. 选择 Launch with 1-Click。
下一步
10

深度学习 AMI 开发人员指南步骤 2:连接到 DLAMI
步骤 2:连接到 DLAMI (p. 11)
步骤 2:连接到 DLAMI从客户端(Windows、MacOS 或 Linux)连接到您启动的 DLAMI。有关更多信息,请参阅 Amazon EC2 用户指南(适用于 Linux 实例) 中的连接到您的 Linux 实例。
如果在登录后您希望执行 Jupyter 设置,请在手边保留一份 SSH 登录命令。您将使用这个命令的各种变体连接到 Jupyter 网页。
下一步
步骤 3:保护 DLAMI 实例 (p. 11)
步骤 3:保护 DLAMI 实例一旦有修补程序和更新推出便立即应用,从而始终保持操作系统和其他已安装软件为最新。
如果您使用的是 Amazon Linux 或 Ubuntu,则当您登录到您 DLAMI 时,便会收到更新通知(如果有)并且会看到更新说明。有关 Amazon Linux 维护的更多信息,请参阅更新实例软件。对于 Ubuntu 实例,请参阅官方 Ubuntu 文档。
在 Windows 上,定期检查 Windows Update 有无软件和安全更新。如果您愿意,可以自动应用更新。
Important
有关 Meltdown 和 Spectre 漏洞以及如何修补操作系统解决以这些问题的信息,请参阅安全公告AWS-2018-013。
步骤 4:测试您的 DLAMI根据您的 DLAMI 版本不同,您的测试选项也会不同:
• 采用 Conda 的 Deep Learning AMI (p. 3) – 转到 使用 采用 Conda 的 Deep Learning AMI (p. 18)。• Deep Learning Base AMI (p. 4) – 引用所需框架的安装文档。
您还可以创建 Jupyter 笔记本电脑,试用教程,或开始使用 Python 编码。有关更多信息,请参阅设置Jupyter Notebook 服务器 (p. 12)。
清除当您不再需要 DLAMI 时,您可以将其停止或终止,以避免产生持续的费用。停止的实例会保留,以便您可以稍后再继续。您的配置、文件和其他非易失性信息都存储在 Amazon S3 上的卷中。在实例停止的情况下,将收取您小额 S3 费用来保留该卷,但在计算资源处于停止状态时将不再对其收取费用。当您重新启动实例时,它将挂载该卷,且您的数据会重新恢复。如果您终止实例,它将消失,且您将无法重新启动它。您的数据实际仍驻留在 S3 中,因此,为了防止任何进一步的费用,您还需要删除该卷。有关更多说明,请参阅Amazon EC2 用户指南(适用于 Linux 实例) 中的 终止您的实例。
11

深度学习 AMI 开发人员指南Jupyter 设置
设置 Jupyter Notebook 服务器Jupyter Notebook 是一个 Web 应用程序,可以让您使用 Web 浏览器管理笔记本文档。
要设置 Jupyter Notebook,您需要完成以下操作:
• 在您的 Amazon EC2 实例上配置 Jupyter Notebook 服务器。• 配置您的客户端,以便您可以连接到 Jupyter Notebook 服务器。我们提供适用于 Windows、macOS 和
Linux 客户端的配置说明。• 登录 Jupyter Notebook 服务器,测试设置。
有关 Jupyter Notebook 的更多信息,请参阅 Jupyter。
主题• 保护您的 Jupyter 服务器 (p. 12)• 启动 Jupyter Notebook 服务器 (p. 13)• 配置客户端以连接到 Jupyter 服务器 (p. 13)• 登录 Jupyter Notebook 服务器进行测试 (p. 14)
保护您的 Jupyter 服务器下面我们使用 SSL 和自定义密码来设置 Jupyter。
连接到 Amazon EC2 实例,然后完成以下步骤。
配置 Jupyter 服务器
1. Jupyter 提供了一个密码实用工具。运行以下命令,在命令提示符处输入您的首选密码。
$ jupyter notebook password
输出类似如下:
Enter password:Verify password:[NotebookPasswordApp] Wrote hashed password to /home/ubuntu/.jupyter/jupyter_notebook_config.json
2. 创建自签名 SSL 证书。按照提示填写您认为适当的区域。您的答案将不会影响证书的功能性。
$ cd ~$ mkdir ssl$ cd ssl$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout mykey.key -out mycert.pem
Note
您可能希望创建一个常规的 SSL 证书,该证书为第三方签名,且不会导致浏览器向您发出安全警告。此过程涉及内容较多。访问 Jupyter 的文档以了解更多信息。
下一步
12

深度学习 AMI 开发人员指南启动服务器
启动 Jupyter Notebook 服务器 (p. 13)
启动 Jupyter Notebook 服务器现在,您可以通过登录实例,然后运行以下命令来启动 Jupyter 服务器,该命令将使用您在上一步中创建的SSL 证书。
$ jupyter notebook --certfile=~/ssl/mycert.pem --keyfile ~/ssl/mykey.key
启动服务器后,即可通过 SSH 隧道从您的客户端计算机连接到服务器。当服务器运行时,您将看到来自Jupyter 的一些输出,这些输出证实服务器正在运行。此时,请忽略称您可以通过本地主机 URL 访问服务器的标注,因为这其实不可以,直到您创建了隧道为止。
Note
当您使用 Jupyter Web 界面切换框架时,Jupyter 将处理切换环境。更多有关信息见于通过 Jupyter切换环境 (p. 23)。
下一步
配置客户端以连接到 Jupyter 服务器 (p. 13)
配置客户端以连接到 Jupyter 服务器配置您的客户端连接到 Jupyter Notebook 服务器后,您可以在您的工作区中的服务器上创建和访问笔记本,并在服务器上运行深度学习代码。
有关配置信息,请选择以下链接之一。
主题• 配置 Windows 客户端 (p. 13)• 配置 Linux 或 macOS 客户端 (p. 14)
配置 Windows 客户端准备
请确保您拥有设置 SSH 隧道所需的以下信息:
• Amazon EC2 实例的公有 DNS 名称。您可以在 EC2 控制台中找到公有 DNS 名称。• 私有密钥文件的密钥对。有关访问密钥对的更多信息,请参阅 Amazon EC2 用户指南(适用于 Linux 实
例) 中的 Amazon EC2 密钥对。
从 Windows 客户端使用 Jupyter 笔记本
请参阅这些关于从 Windows 客户端连接到您的 Amazon EC2 实例的指南。
1. 排查实例的连接问题2. 使用 PuTTY 从 Windows 连接到 Linux 实例
要创建连接 Jupyter 服务器的隧道,建议先在您的 Windows 客户端上安装 Git Bash,然后按照 Linux/macOS 客户端说明操作。不过,您可以使用任何方法打开包含端口映射的 SSH 隧道。请参阅 Jupyter 的文档了解更多信息。
13

深度学习 AMI 开发人员指南登录 Jupyter Notebook 服务器
下一步
配置 Linux 或 macOS 客户端 (p. 14)
配置 Linux 或 macOS 客户端1. 打开终端。2. 运行以下命令,将本地端口 8888 上的所有请求转发到远程 Amazon EC2 实例上的端口 8888。通过替
换密钥位置来更新命令,以访问 Amazon EC2 实例和您的 Amazon EC2 实例的公有 DNS 名称。注意,对于 Amazon Linux AMI,用户名是 ec2-user 而非 ubuntu。
$ ssh -i ~/mykeypair.pem -N -f -L 8888:localhost:8888 ubuntu@ec2-###-##-##-###.compute-1.amazonaws.com
该命令在您的客户端与运行 Jupyter Notebook 服务器的远程 Amazon EC2 实例之间打开一个隧道。
下一步
登录 Jupyter Notebook 服务器进行测试 (p. 14)
登录 Jupyter Notebook 服务器进行测试现在,您已准备就绪,可登录到 Jupyter Notebook 服务器。
接下来,通过浏览器测试与服务器的连接。
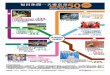
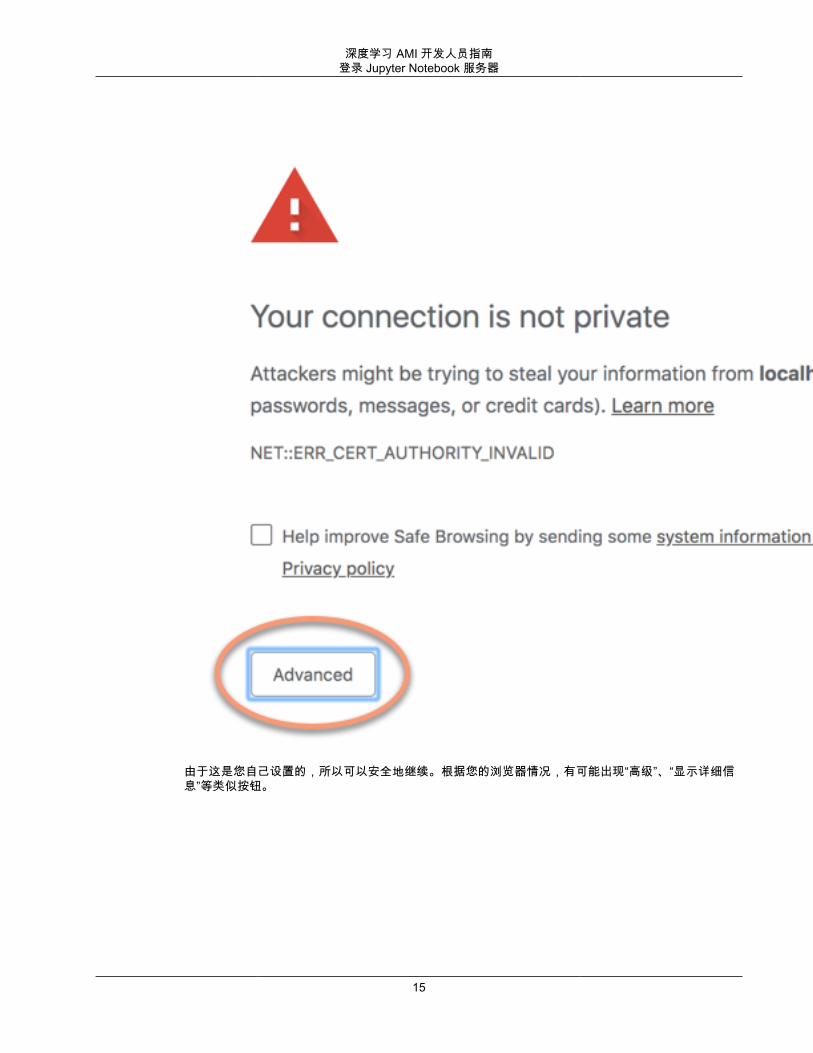
1. 在浏览器的地址栏中,键入以下 URL,或单击此链接:https://localhost:88882. 借助自签名 SSL 证书,您的浏览器会警告和提示您避免继续访问网站。
14
深度学习 AMI 开发人员指南登录 Jupyter Notebook 服务器
由于这是您自己设置的,所以可以安全地继续。根据您的浏览器情况,有可能出现“高级”、“显示详细信息”等类似按钮。
15
深度学习 AMI 开发人员指南登录 Jupyter Notebook 服务器
单击此消息,然后单击“proceed to localhost”(前进到本地主机)链接。如果连接成功,则会看到Jupyter Notebook 服务器网页。此时,系统将要求您提供先前设置的密码。
16

深度学习 AMI 开发人员指南登录 Jupyter Notebook 服务器
现在,您可以访问 DLAMI 上运行的 Jupyter Notebook 服务器了。您可以创建新的笔记本或运行提供的教程 (p. 23)。
17

深度学习 AMI 开发人员指南Conda DLAMI
使用 DLAMI主题
• 使用 采用 Conda 的 Deep Learning AMI (p. 18)• 使用 Deep Learning Base AMI (p. 21)• 运行 Jupyter 笔记本电脑教程 (p. 22)• 教程 (p. 23)
以下部分介绍如何使用 采用 Conda 的 Deep Learning AMI 切换环境、从每个框架运行示例代码以及运行Jupyter,以便您可以尝试不同的笔记本教程。
使用 采用 Conda 的 Deep Learning AMI主题
• 采用 Conda 的 Deep Learning AMI 简介 (p. 18)• 步骤 1:登录您的 DLAMI (p. 18)• 步骤 2:启动 MXNet Python 3 环境 (p. 19)• 步骤 3:测试某些 MXNet 代码 (p. 20)• 步骤 4:切换到 TensorFlow 环境 (p. 20)• 删除环境 (p. 21)
采用 Conda 的 Deep Learning AMI 简介Conda 是一个开源程序包管理系统和环境管理系统,在 Windows、macOS 和 Linux 上运行。Conda 快速安装、运行和更新程序包及其依赖项。Conda 可轻松创建、保存、加载和切换本地计算机上的环境。
采用 Conda 的 Deep Learning AMI 已完成配置,以便让您轻松切换深度学习环境。以下说明为您介绍与conda 相关的一些基本命令。它们还可以帮助您验证框架的基本导入正常运行,并且您可以使用框架运行一些简单操作。然后,您可以继续查看随 DLAMI 提供的更全面的教程,或者每个框架的项目站点上提供的框架示例。
步骤 1:登录您的 DLAMI登录服务器后,您会看到服务器的“每日消息”(MOTD),它介绍了可以用来切换不同深度学习框架的各种Conda 命令。以下是示例 MOTD。由于新版本 DLAMI 的发布,您的特定 MOTD 可能不同。
============================================================================= __| __|_ ) _| ( / Deep Learning AMI (Ubuntu) ___|\___|___|=============================================================================
Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.4.0-1062-aws x86_64v)
Please use one of the following commands to start the required environment with the framework of your choice:
18

深度学习 AMI 开发人员指南步骤 2:启动 MXNet Python 3 环境
for MXNet(+Keras2) with Python3 (CUDA 9.0 and Intel MKL-DNN) _______________________________ source activate mxnet_p36for MXNet(+Keras2) with Python2 (CUDA 9.0 and Intel MKL-DNN) _______________________________ source activate mxnet_p27for TensorFlow(+Keras2) with Python3 (CUDA 9.0 and Intel MKL-DNN) _____________________ source activate tensorflow_p36for TensorFlow(+Keras2) with Python2 (CUDA 9.0 and Intel MKL-DNN) _____________________ source activate tensorflow_p27for Theano(+Keras2) with Python3 (CUDA 9.0) _______________________________________________ source activate theano_p36for Theano(+Keras2) with Python2 (CUDA 9.0) _______________________________________________ source activate theano_p27for PyTorch with Python3 (CUDA 9.0 and Intel MKL) ________________________________________ source activate pytorch_p36for PyTorch with Python2 (CUDA 9.0 and Intel MKL) ________________________________________ source activate pytorch_p27for CNTK(+Keras2) with Python3 (CUDA 9.0 and Intel MKL-DNN) _________________________________ source activate cntk_p36for CNTK(+Keras2) with Python2 (CUDA 9.0 and Intel MKL-DNN) _________________________________ source activate cntk_p27for Caffe2 with Python2 (CUDA 9.0) ________________________________________________________ source activate caffe2_p27for Caffe with Python2 (CUDA 8.0) __________________________________________________________ source activate caffe_p27for Caffe with Python3 (CUDA 8.0) __________________________________________________________ source activate caffe_p35for Chainer with Python2 (CUDA 9.0 and Intel iDeep) ______________________________________ source activate chainer_p27for Chainer with Python3 (CUDA 9.0 and Intel iDeep) ______________________________________ source activate chainer_p36for base Python2 (CUDA 9.0) __________________________________________________________________ source activate python2for base Python3 (CUDA 9.0) __________________________________________________________________ source activate python3
每个 Conda 命令具有以下模式:
source activate framework_python-version
例如,您可能会看到 for MXNet(+Keras1) with Python3 (CUDA 9) _____________________source activate mxnet_p36,这意味着该环境具有 MXNet、Keras 1、Python 3 和 CUDA 9。要激活此环境,您可以使用以下命令:
$ source activate mxnet_p36
此命令的另一个变体是:
$ source activate mxnet_p27
这意味着该环境具有 MXNet 和 Python 2 (使用 Keras 1 和 CUDA 9)。
步骤 2:启动 MXNet Python 3 环境我们首先测试 MXNet,以便让您了解它有多么简单。
Note
在启动您的第一个 Conda 环境时,请在其加载期间耐心等待。采用 Conda 的 Deep Learning AMI会在框架首次激活时自动为您的 EC2 实例安装框架的最优化版本。您不应期望后续的延迟。
19

深度学习 AMI 开发人员指南步骤 3:测试某些 MXNet 代码
• 激活适用于 Python 3 的 MXNet 虚拟环境。
$ source activate mxnet_p36
这将激活使用 Python 3 的 MXNet 环境。或者,您也可以激活 mxnet_p27,以构建使用 Python 2 的环境。
步骤 3:测试某些 MXNet 代码要测试您的安装,请使用 Python 编写 MXNet 代码,以使用 NDArray API 创建并打印数组。有关更多信息,请参阅 NDArray API。
1. 启动 iPython 终端。
(mxnet_p36)$ ipython
2. 导入 MXNet。
import mxnet as mx
您可能会看到一条关于第三方软件包的警告消息。您可以忽略它。3. 创建一个 5x5 矩阵、一个 NDArray 实例,将元素初始化为 0。打印数组。
mx.ndarray.zeros((5,5)).asnumpy()
验证结果。
array([[ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.]], dtype=float32)
您可以在 MXNet 教程部分找到 MXNet 的更多示例。
步骤 4:切换到 TensorFlow 环境现在我们将切换到 TensorFlow! 如果您仍然处于 iPython 控制台中,则使用 quit(),然后准备切换环境。
1. 激活适用于 Python 3 的 TensorFlow 虚拟环境。
$ source activate tensorflow_p36
2. 启动 iPython 终端。
(tensorflow_36)$ ipython
3. 运行快速 TensorFlow 程序。
import tensorflow as tfhello = tf.constant('Hello, TensorFlow!')sess = tf.Session()
20

深度学习 AMI 开发人员指南删除环境
print(sess.run(hello))
您应该会看到“Hello, Tensorflow!” 现在,您已测试了两种不同的深度学习框架,您已了解如何切换框架。
Tip
有关已知问题的信息,请参阅发行说明:
• 已知问题 (p. 188)• Deep Learning AMI (Amazon Linux) 已知问题 (p. 184)
后续步骤
运行 Jupyter 笔记本电脑教程 (p. 22)
删除环境注意:如果您用尽了 DLAMI 上的空间,则可以选择卸载不用的 Conda 软件包:
conda env listconda env remove –name <env_name>
使用 Deep Learning Base AMI使用 Deep Learning Base AMIBase AMI 附带 GPU 驱动程序基础平台,以及可用来部署您自己的自定义深度学习环境的加速库。默认情况下,该 AMI 配置为采用 NVIDIA CUDA 10 环境。但是,您也可以切换到 CUDA 9 或 CUDA 8 环境。有关如何执行此操作,请参阅以下说明。
配置 CUDA 版本您可以使用以下 bash 命令选择并验证特定 CUDA 版本。
• CUDA 10:
$ sudo rm /usr/local/cudasudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
• CUDA 9.2:
$ sudo rm /usr/local/cudasudo ln -s /usr/local/cuda-9.2 /usr/local/cuda
• CUDA 9:
$ sudo rm /usr/local/cudasudo ln -s /usr/local/cuda-9.0 /usr/local/cuda
• CUDA 8:
21

深度学习 AMI 开发人员指南Jupyter 笔记本电脑
$ sudo rm /usr/local/cudasudo ln -s /usr/local/cuda-8.0 /usr/local/cuda
Tip
然后,您可以通过运行 NVIDIA 的 deviceQuery 程序验证 CUDA 版本。
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuerysudo make./deviceQuery
运行 Jupyter 笔记本电脑教程每个深度学习项目的源代码都附带了教程和示例,大多数情况下,它们可以在任何 DLAMI 上运行。如果您选择了 采用 Conda 的 Deep Learning AMI (p. 3),那么您将获得一些已经建立并准备好尝试的精选教程的额外好处。
Important
要运行安装在 DLAMI 上的 Jupyter 笔记本电脑教程,您需要设置 Jupyter Notebook 服务器 (p. 12)。
Jupyter 服务器运行后,您可以通过 Web 浏览器运行这些教程。如果您正在运行 采用 Conda 的 DeepLearning AMI 或者如果您已经建立了 Python 环境,则可以从 Jupyter 笔记本界面切换 Python 内核。在尝试运行特定于框架的教程之前,请选择合适的内核。我们为 采用 Conda 的 Deep Learning AMI 用户提供了更多这方面的示例。
Note
许多教程需要一些额外 Python 模块,它们在您的 DLAMI 上可能尚未设置。如果您收到类似 "xyzmodule not found" 的错误,请登录到 DLAMI,激活环境(如上所述),然后安装必要的模块。
Tip
深度学习教程和示例通常依赖于一个或多个 GPU。如果您的实例类型没有 GPU,您可能需要更改一些示例代码才能使其运行。
导航已安装的教程一旦您登录到 Jupyter 服务器且可以看到教程目录(仅限 采用 Conda 的 Deep Learning AMI 上)时,也会看到按每个框架名称排列的教程文件夹。如果您没有看到某个框架,则表明在您当前 DLAMI 上该框架的教程不可用。单击框架名称以查看列出的教程,然后单击一个教程,将其启动。
在 采用 Conda 的 Deep Learning AMI 上第一次运行笔记本电脑时,它会想知道您想使用哪个环境。它会提示您从列表中进行选择。每个环境都根据以下模式命名:
Environment (conda_framework_python-version)
例如,您可能会看到 Environment (conda_mxnet_p36),这意味着该环境具有 MXNet 和 Python 3。您也可能会看到 Environment (conda_mxnet_p27),这意味着该环境具有 MXNet 和 Python 2。
22

深度学习 AMI 开发人员指南通过 Jupyter 切换环境
Tip
如果您想知道哪个版本的 CUDA 处于活动状态,一种查看方法是在首次登录到 DLAMI 时在 MOTD中查看。
通过 Jupyter 切换环境如果您决定尝试一个不同框架的教程,一定要验证当前正在运行的内核。此信息可以在 Jupyter 界面的右上方看到,就在注销按钮的下方。您可以在任何打开的笔记本电脑上更改内核,方法是依次单击Kernel、Change Kernel 菜单项,然后单击正运行的笔记本电脑适合的环境。
此时您需要重新运行任何单元,因为内核中的更改将会擦除之前运行的任何内容的状态。
Tip
在框架之间进行切换可能很有趣而且很有教育意义,但是可能导致耗尽内存。如果您开始遇到错误,请查看运行 Jupyter 服务器的终端窗口。这里包含有用的消息和错误记录,您可能会看到内存不足的错误。要解决这一问题,您可以转到 Jupyter 服务器的主页中,单击 Running 选项卡,然后为每个教程单击 Shutdown,因为这些教程可能仍然在后台运行,导致耗尽了所有内存。
后续步骤
有关每个框架的更多示例和示例代码,请单击 Next 或继续 Apache MXNet (incubating) (p. 24)。
教程以下是有关如何使用 采用 Conda 的 Deep Learning AMI 的软件的教程。
主题• 10 分钟教程 (p. 23)• 激活框架 (p. 23)• 调试和可视化 (p. 34)• 分布式训练 (p. 37)• Elastic Fabric Adapter (p. 53)• GPU 监控和优化 (p. 60)• 推理 (p. 65)• 将框架用于 ONNX (p. 69)• 模型处理 (p. 76)
10 分钟教程• 启动 AWS Deep Learning AMI (在 10 分钟内)• 在 Amazon EC2 上使用 AWS Deep Learning Containers 训练深度学习模型(10 分钟)
激活框架以下是 采用 Conda 的 Deep Learning AMI 上安装的深度学习框架。单击某个框架即可了解如何将其激活。
主题
23

深度学习 AMI 开发人员指南激活框架
• Apache MXNet (incubating) (p. 24)• Caffe2 (p. 25)• Chainer (p. 26)• CNTK (p. 27)• Keras (p. 28)• PyTorch (p. 29)• TensorFlow (p. 31)• TensorFlow with Horovod (p. 32)• Theano (p. 33)
Apache MXNet (incubating)激活 MXNet
本教程介绍如何在运行 采用 Conda 的 Deep Learning AMI (DLAMI on Conda) 的实例上激活 MXNet 并运行MXNet 程序。
当框架的稳定的 Conda 程序包发布时,它会在 DLAMI 上进行测试并预安装。如果您希望运行最新的、未经测试的每日构建版本,您可以手动安装 MXNet 的每日构建版本(试验) (p. 24)。
在 DLAMI with Conda 上运行 MXNet
1. 要激活该框架,请打开 DLAMI with Conda 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。• 对于使用 CUDA 9.0 和 MKL-DNN 的 Python 3 上的 MXNet 和 Keras 2,运行以下命令:
$ source activate mxnet_p36
• 对于使用 CUDA 9.0 和 MKL-DNN 的 Python 2 上的 MXNet 和 Keras 2,运行以下命令:
$ source activate mxnet_p27
2. 启动 iPython 终端。
(mxnet_p36)$ ipython
3. 运行快速 MXNet 程序。创建一个 5x5 矩阵、一个 NDArray 实例,将元素初始化为 0。打印数组。
import mxnet as mxmx.ndarray.zeros((5,5)).asnumpy()
4. 验证结果。
array([[ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0.]], dtype=float32)
安装 MXNet 的每日构建版本(试验)
您可以将最新的 MXNet 工作版本安装到您的 采用 Conda 的 Deep Learning AMI 上的任一或两个 MXNetConda 环境。
24

深度学习 AMI 开发人员指南激活框架
从每日构建版本安装 MXNet
1. • 对于 Python 3 MXNet 环境,请运行以下命令:
$ source activate mxnet_p36
• 对于 Python 2 MXNet 环境,请运行以下命令:
$ source activate mxnet_p27
2. 删除当前安装的 MXNet。
Note
其余步骤假定您使用的是 mxnet_p36 环境。
(mxnet_p36)$ pip uninstall mxnet-cu90mkl
3. 安装 MXNet 的最新的每日构建版本。
(mxnet_p36)$ pip install --pre mxnet-cu90mkl
4. 要验证您是否已成功安装最新的每日构建版本,请启动 IPython 终端并检查 MXNet 版本。
(mxnet_p36)$ ipython
import mxnetprint (mxnet.__version__)
输出应打印 MXNet 的最新稳定版本。
更多教程
您可以在 DLAMI 主目录的 采用 Conda 的 Deep Learning AMI 教程文件夹中找到更多教程。
1. 将 Apache MXNet for Inference 与 ResNet 50 模型结合使用 (p. 67)2. 将适用于推理的 Apache MXNet 与 ONNX 模型结合使用 (p. 66)3. 适用于 Apache MXNet 的模型服务器 (MMS) (p. 77)
有关更多教程和示例,请参阅该框架的官方 Python 文档、适用于 MXNet 的 Python API 或 Apache MXNet网站。
Caffe2Caffe2 教程
要激活框架,请按照您的 采用 Conda 的 Deep Learning AMI 上的这些说明进行操作。
只有使用 CUDA 9 和 cuDNN 7 的 Python 2 选项:
$ source activate caffe2_p27
启动 iPython 终端。
25

深度学习 AMI 开发人员指南激活框架
(caffe2_p27)$ ipython
运行快速 Caffe2 程序。
from caffe2.python import workspace, model_helperimport numpy as np# Create random tensor of three dimensionsx = np.random.rand(4, 3, 2)print(x)print(x.shape)workspace.FeedBlob("my_x", x)x2 = workspace.FetchBlob("my_x")print(x2)
您应该会看到系统输出初始 numpy 随机数组,然后这些数组加载到了 Caffe2 blob 中。请注意,加载之后,它们是相同的。
更多教程
如需查看更多教程和示例,请参阅该框架的官方 Python 文档、Python API for Caffe2 和 Caffe2 网站。
ChainerChainer 是一种基于 Python 的灵活框架,用于轻松直观地编写复杂的神经网络架构。利用 Chainer,您可以轻松使用多 GPU 实例进行训练。Chainer 还会自动记录结果、图表损失和精度并生成用于使用计算图来可视化神经网络的输出。Chainer 包含在 采用 Conda 的 Deep Learning AMI (DLAMI with Conda) 中。
激活 Chainer
1. 连接到正在运行 采用 Conda 的 Deep Learning AMI 的实例。有关如何选择或连接到实例,请参阅thesection called “实例选择” (p. 6)或 Amazon EC2 文档。
2. • 激活 Python 3 Chainer 环境:
$ source activate chainer_p36
• 激活 Python 2 Chainer 环境:
$ source activate chainer_p27
3. 启动 iPython 终端:
(chainer_p36)$ ipython
4. 测试导入 Chainer 以验证其是否运行正常:
import chainer
您可能会看到几条警告消息,但没有错误。
更多信息
• 请尝试有关Chainer (p. 37) 的教程。
26

深度学习 AMI 开发人员指南激活框架
• 您之前下载的位于源内的 Chainer 示例文件夹包含更多示例。请试用这些示例以了解其性能。• 要了解有关 Chainer 的更多信息,请参阅 Chainer 文档网站。
CNTK激活 CNTK
本教程介绍如何在运行 采用 Conda 的 Deep Learning AMI (DLAMI on Conda) 的实例上激活 CNTK 并运行CNTK 程序。
当框架的稳定的 Conda 程序包发布时,它会在 DLAMI 上进行测试并预安装。如果您希望运行最新的、未经测试的每日构建版本,您可以手动安装 CNTK 的每日构建版本(试验) (p. 27)。
在 DLAMI with Conda 上运行 CNTK
1. 要激活 CNTK,请打开 DLAMI with Conda 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。• 对于使用 CUDA 9 和 cuDNN 7 的 Python 3:
$ source activate cntk_p36
• 对于使用 CUDA 9 和 cuDNN 7 的 Python 2:
$ source activate cntk_p27
2. 启动 iPython 终端。
(cntk_p36)$ ipython
3. • 如果您具有 CPU 实例,请运行此快速 CNTK 程序。
import cntk as CC.__version__c = C.constant(3, shape=(2,3))c.asarray()
您应该看到 CNTK 版本,然后输出一个 2x3 的 3 数组。• 如果您有 GPU 实例,可以使用以下代码示例对其进行测试。如果 CNTK 可以访问 GPU,则 True
的结果就是您所期望的。
from cntk.device import try_set_default_device, gputry_set_default_device(gpu(0))
安装 CNTK 的每日构建版本(试验)
您可以将最新的 CNTK 版本安装到 采用 Conda 的 Deep Learning AMI 上的任一或两个 CNTK Conda 环境。
从每日构建安装 CNTK
1. • 对于使用 CUDA 9.0 和 MKL-DNN 的 Python 3 上的 CNTK 和 Keras 2,运行以下命令:
$ source activate cntk_p36
27

深度学习 AMI 开发人员指南激活框架
• 对于使用 CUDA 9.0 和 MKL-DNN 的 Python 2 上的 CNTK 和 Keras 2,运行以下命令:
$ source activate cntk_p27
2. 其余步骤假定您使用的是 cntk_p36 环境。删除当前安装的 CNTK。
(cntk_p36)$ pip uninstall cntk
3. 要安装 CNTK 每日构建,您首先需要从 CNTK 每日构建网站查找您要安装的版本。4. • (适用于 GPU 实例的选项)- 要安装每日构建版本,您将使用以下内容,从而在所需的构建版本中
进行替换:
(cntk_p36)$ pip install https://cntk.ai/PythonWheel/GPU/latest-nightly-build
将上一条命令中的 URL 替换为您的当前 Python 环境的 GPU 版本。• (适用于 CPU 实例的选项)- 要安装每日构建版本,您将使用以下内容,从而在所需的构建版本中
进行替换:
(cntk_p36)$ pip install https://cntk.ai/PythonWheel/CPU-Only/latest-nightly-build
将上一条命令中的 URL 替换为您的当前 Python 环境的 CPU 版本。5. 要验证您已成功安装最新的每日构建版本,请启动 IPython 终端并检查 CNTK 的版本。
(cntk_p36)$ ipython
import cntkprint (cntk.__version__)
输出应类似于以下内容:2.6-rc0.dev20181015
更多教程
有关更多教程和示例,请参阅该框架的官方 Python 文档、Python API for CNTK 或 CNTK 网站。
KerasKeras 教程
1. 要激活此框架,请在您的the section called “Conda DLAMI” (p. 18) CLI 上使用这些命令。• 对于使用 CUDA 9 和 cuDNN 7 的 Python 3 上的具有 MXNet 后端的 Keras 2:
$ source activate mxnet_p36
• 对于使用 CUDA 9 和 cuDNN 7 的 Python 2 上的具有 MXNet 后端的 Keras 2:
$ source activate mxnet_p27
• 对于使用 CUDA 9 和 cuDNN 7 的 Python 3 上具有 TensorFlow 后端的 Keras 2:
$ source activate tensorflow_p36
• 对于在使用 CUDA 9 和 cuDNN 7 的 Python 2 上具有 TensorFlow 后端的 Keras 2:
28

深度学习 AMI 开发人员指南激活框架
$ source activate tensorflow_p27
2. 要测试导入 Keras 以验证激活哪些后端,请使用这些命令:
$ ipythonimport keras as k
以下内容应显示您的屏幕上:
Using MXNet backend
如果 Keras 使用的是 TensorFlow,则会显示以下内容:
Using TensorFlow backend
Note
如果您收到错误,或如果仍在使用错误的后端,则可以手动更新您的 Keras 配置。编辑~/.keras/keras.json 文件并将后端设置更改为 mxnet 或 tensorflow。
更多教程
• 有关使用具有 MXNet 后端的 Keras 的多 GPU 教程,请尝试Keras-MXNet Multi-GPU 训练教程 (p. 46)。
• 您可以在 采用 Conda 的 Deep Learning AMI ~/examples/keras-mxnet 目录中查找有关具有 MXNet后端的 Keras 的示例。
• 您可以在 采用 Conda 的 Deep Learning AMI ~/examples/keras 目录中查找有关具有 TensorFlow 后端的 Keras 的示例。
• 有关其他教程和示例,请参阅 Keras 网站。
PyTorch激活 PyTorch当框架的稳定的 Conda 程序包发布时,它会在 DLAMI 上进行测试并预安装。如果您希望运行最新的、未经测试的每日构建版本,您可以手动安装 PyTorch 的每日构建版本(试验) (p. 30)。
要激活当前安装的框架,请按照您的 采用 Conda 的 Deep Learning AMI 上的这些说明进行操作。
对于具有 CUDA 10 和 MKL-DNN 的 Python 3 上的 PyTorch,运行以下命令:
$ source activate pytorch_p36
对于具有 CUDA 10 和 MKL-DNN 的 Python 2 上的 PyTorch,运行以下命令:
$ source activate pytorch_p27
启动 iPython 终端。
(pytorch_p36)$ ipython
29

深度学习 AMI 开发人员指南激活框架
运行快速 PyTorch 程序。
import torchx = torch.rand(5, 3)print(x)print(x.size())y = torch.rand(5, 3)print(torch.add(x, y))
您应该会看到系统输出初始随机数组,然后输出大小,然后添加另一个随机数组。
安装 PyTorch 的每日构建版本(试验)
如何从每日构建安装 PyTorch
您可以将最新的 PyTorch 工作版本安装到您的 采用 Conda 的 Deep Learning AMI 上的任一或两个 PyTorchConda 环境。
1. • (适用于 Python 3 的选项)- 激活 Python 3 PyTorch 环境:
$ source activate pytorch_p36
• (适用于 Python 2 的选项)- 激活 Python 2 PyTorch 环境:
$ source activate pytorch_p27
2. 其余步骤假定您使用的是 pytorch_p36 环境。删除当前安装的 PyTorch:
(pytorch_p36)$ pip uninstall torch
3. • (适用于 GPU 实例的选项)- 使用 CUDA 10.0 安装最新的 PyTorch 每日构建版本:
(pytorch_p36)$ pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu100/torch_nightly.html
• (适用于 CPU 实例的选项)- 对于不使用 GPU 的实例,安装最新的 PyTorch 每日构建版本:
(pytorch_p36)$ pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
4. 要验证您已成功安装最新的每日构建版本,请启动 IPython 终端并检查 PyTorch 版本。
(pytorch_p36)$ ipython
import torchprint (torch.__version__)
输出应类似于以下内容:1.0.0.dev20180922
5. 要验证 PyTorch 每日构建版本是否适用于 MNIST 示例,您可以从 PyTorch 的示例存储库运行测试脚本:
(pytorch_p36)$ cd ~(pytorch_p36)$ git clone https://github.com/pytorch/examples.git pytorch_examples(pytorch_p36)$ cd pytorch_examples/mnist(pytorch_p36)$ python main.py || exit 1
30

深度学习 AMI 开发人员指南激活框架
更多教程您可以在 DLAMI 主目录的 采用 Conda 的 Deep Learning AMI 教程文件夹中找到更多教程。如需查看更多教程和示例,请参阅该框架的官方文档、PyTorch 文档和 PyTorch 网站。
• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)
TensorFlow激活 TensorFlow本教程介绍如何在运行 采用 Conda 的 Deep Learning AMI (DLAMI on Conda) 的实例上激活 TensorFlow 并运行 TensorFlow 程序。
当框架的稳定的 Conda 程序包发布时,它会在 DLAMI 上进行测试并预安装。如果您希望运行最新的、未经测试的每日构建版本,您可以手动安装 TensorFlow 的每日构建版本(试验) (p. 31)。
在 DLAMI with Conda 上运行 TensorFlow
1. 为了激活 TensorFlow,打开 DLAMI with Conda 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。• 对于具有 CUDA 9.0 和 MKL-DNN 的 Python 3 上的 TensorFlow 和 Keras 2,运行以下命令:
$ source activate tensorflow_p36
• 对于具有 CUDA 9.0 和 MKL-DNN 的 Python 2 上的 TensorFlow 和 Keras 2,运行以下命令:
$ source activate tensorflow_p27
2. 启动 iPython 终端:
(tensorflow_p36)$ ipython
3. 运行 TensorFlow 程序以验证其是否正常运行:
import tensorflow as tfhello = tf.constant('Hello, TensorFlow!')sess = tf.Session()print(sess.run(hello))
Hello, TensorFlow! 应显示在您的屏幕上。
安装 TensorFlow 的每日构建版本(试验)您可以将最新的 TensorFlow 版本安装到您的 采用 Conda 的 Deep Learning AMI 上的任一或两个TensorFlow Conda 环境。
从每日构建版本安装 TensorFlow
1. • 对于 Python 3 TensorFlow 环境,运行以下命令:
$ source activate tensorflow_p36
31

深度学习 AMI 开发人员指南激活框架
• 对于 Python 2 TensorFlow 环境,运行以下命令:
$ source activate tensorflow_p27
2. 删除当前安装的 TensorFlow。Note
其余步骤假定您使用的是 mxnet_p36 环境。
(tensorflow_p36)$ pip uninstall tensorflow
3. 安装 TensorFlow 的最新每日构建版本。
(tensorflow_p36)$ pip install tf-nightly
4. 要验证您是否已成功安装最新的每日构建版本,请启动 IPython 终端并检查 TensorFlow 版本。
(tensorflow_p36)$ ipython
import tensorflowprint (tensorflow.__version__)
输出应类似于以下内容:1.12.0-dev20181012
更多教程TensorFlow with Horovod (p. 47)
TensorBoard (p. 36)
TensorFlow Serving (p. 78)
有关教程,请参阅 DLAMI 的主目录中名为 ## Conda # Deep Learning AMI tutorials 的文件夹。
有关更多教程和示例,请参阅 TensorFlow Python API 的 TensorFlow 文档或访问 TensorFlow 网站。
TensorFlow with Horovod本教程介绍如何在 AWS Deep Learning AMI (DLAMI) with Conda 上激活 TensorFlow withHorovod。Horovod 已为 TensorFlow 预安装在 Conda 环境中。推荐使用 Python3 环境。
Note
仅支持 P3.*、P2.* 和 G3.* 实例类型。
在 DLAMI with Conda 上激活 TensorFlow 并测试 Horovod
1. 打开 DLAMI with Conda 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。有关 DLAMI 入门帮助,请参阅the section called “如何开始使用 DLAMI” (p. 3)。• (推荐)对于使用 CUDA 9 的 Python 3 上的 TensorFlow with Horovod,请运行此命令:
$ source activate tensorflow_p36
• 对于使用 CUDA 9 的 Python 2 上的 TensorFlow with Horovod,请运行此命令:
$ source activate tensorflow_p27
32

深度学习 AMI 开发人员指南激活框架
2. 启动 iPython 终端:
(tensorflow_p36)$ ipython
3. 测试导入 TensorFlow with Horovod 以验证其是否运行正常:
import horovod.tensorflow as hvdhvd.init()
以下内容可能显示在您的屏幕上(您可能会忽略任何警告消息)。
--------------------------------------------------------------------------[[55425,1],0]: A high-performance Open MPI point-to-point messaging modulewas unable to find any relevant network interfaces:
Module: OpenFabrics (openib) Host: ip-172-31-72-4
Another transport will be used instead, although this may result inlower performance.--------------------------------------------------------------------------
更多信息
• TensorFlow with Horovod (p. 47)• 有关教程,请参阅 DLAMI 的主目录中的 examples/horovod 文件夹。• 有关更多教程和示例,请参阅 Horovod GitHub 项目。
TheanoTheano 教程
要激活框架,请按照您的 采用 Conda 的 Deep Learning AMI 上的这些说明进行操作。
对于使用 CUDA 9 和 cuDNN 7 的 Python 3 中的 Theano + Keras:
$ source activate theano_p36
对于使用 CUDA 9 和 cuDNN 7 的 Python 2 中的 Theano + Keras:
$ source activate theano_p27
启动 iPython 终端。
(theano_p36)$ ipython
运行快速 Theano 程序。
33

深度学习 AMI 开发人员指南调试和可视化
import numpyimport theanoimport theano.tensor as Tfrom theano import ppx = T.dscalar('x')y = x ** 2gy = T.grad(y, x)pp(gy)
您应该会看到 Theano 计算符号梯度。
更多教程
如需查看更多教程和示例,请参阅该框架的官方文档、Theano Python API 和 Theano 网站。
调试和可视化了解适用于 DLAMI 的调试和可视化选项。单击其中一个选项可了解如何使用该选项。
主题• MXBoard (p. 34)• TensorBoard (p. 36)
MXBoardMXBoard 可让您使用 TensorBoard 软件目视检查和解释您的 MXNet 运行和图表。它运行了一个 Web 服务器,该服务器提供了一个用于查看 MXBoard 可视化并与之交互的网页。
MXNet、TensorBoard 和 MXBoard 随 采用 Conda 的 Deep Learning AMI (DLAMI with Conda) 一起预安装。在本教程中,您使用 MXBoard 功能生成与 TensorBoard 兼容的日志。
主题• 将 MXNet 与 MXBoard 结合使用 (p. 34)• 更多信息 (p. 36)
将 MXNet 与 MXBoard 结合使用
生成与 TensorBoard 兼容的 MXBoard 日志数据
1. 连接到 DLAMI with Conda 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。2. 激活 Python 3 MXNet 环境。
$ source activate mxnet_p36
3. 准备 Python 脚本以将一般运算符生成的数据写入事件文件中。数据生成 10 次,标准偏差减小,然后每次将写入到事件文件中。您将看到数据分布逐渐以平均值为中心。请注意,您将在日志文件夹中指定事件文件。您将此文件夹路径传递到 TensorBoard 二进制文件。
$ vi mxboard_normal.py
4. 将以下内容粘贴到文件中并保存它:
34

深度学习 AMI 开发人员指南调试和可视化
import mxnet as mxfrom mxboard import SummaryWriter
with SummaryWriter(logdir='./logs') as sw: for i in range(10): # create a normal distribution with fixed mean and decreasing std data = mx.nd.normal(loc=0, scale=10.0/(i+1), shape=(10, 3, 8, 8)) sw.add_histogram(tag='norml_dist', values=data, bins=200, global_step=i)
5. 运行脚本。这将在 logs 文件夹中生成可用于可视化的日志。
$ python mxboard_normal.py
6. 现在,您必须切换到 TensorFlow 环境以使用 TensorBoard 和 MXBoard 可视化日志。这是 MXBoard 和TensorBoard 所需的依赖项。
$ source activate tensorflow_p36
7. 将日志的位置传递到 tensorboard:
$ tensorboard --logdir=./logs --host=127.0.0.1 --port=8888
TensorBoard 在端口 8888 上启动了可视化 Web 服务器。8. 为了方便从您的本地浏览器进行访问,您可以将 Web 服务器端口更改为端口 80 或其他端口。无论您使
用哪个端口,都需要在 EC2 安全组中为您的 DLAMI 打开此端口。您还可以使用端口转发。有关更改安全组设置和端口转发的说明,请参阅设置 Jupyter Notebook 服务器 (p. 12)。默认设置如下一步中所述。
Note
如果您需要同时运行 Jupyter 服务器和 MXBoard 服务器,请对每个服务器使用不同的端口。9. 在您的 EC2 实例上打开端口 8888 (或您分配给可视化 Web 服务器的端口)。
a. 在 https://console.aws.amazon.com/ec2/ 上的 Amazon EC2 控制台中打开您的 EC2 实例。b. 在 Amazon EC2 控制台中,选择 Network & Security (网络与安全),然后选择 Security Groups (安
全组)。c. 对于 Security Group (安全组),选择最近创建的一个安全组 (请参阅描述中的时间戳)。d. 选择 Inbound (入站) 选项卡,然后选择 Edit (编辑)。e. 选择 Add Rule。f. 在新行中,键入以下内容:
类型:自定义 TCP Rule
协议:TCP
端口范围:8888(或您分配给可视化服务器的端口)
源:Anywhere (0.0.0.0/0,::/0)10. 如果您需要从本地浏览器可视化数据,请键入以下命令以将 EC2 实例上渲染的数据转发到本地计算机。
$ ssh -Y -L localhost:8888:localhost:8888 user_id@ec2_instance_ip
11. 使用运行 DLAMI with Conda 的 EC2 实例的公有 IP 或 DNS 地址以及您为 MXBoard 打开的端口打开用于 MXBoard 可视化的网页:
http://127.0.0.1:8888
35

深度学习 AMI 开发人员指南调试和可视化
更多信息
要了解有关 MXBoard 的更多信息,请参阅 MXBoard 网站。
TensorBoardTensorBoard 可让您以视觉方式检查和解释您的 TensorFlow 运行和图表。它运行了一个 Web 服务器,该服务器提供了一个用于查看 TensorBoard 可视化并与之交互的网页。
TensorFlow 和 TensorBoard 随 采用 Conda 的 Deep Learning AMI (DLAMI with Conda) 一起预安装。DLAMI with Conda 还包含一个示例脚本,该脚本使用 TensorFlow 通过启用额外的日志记录功能训练MNIST 模型。MNIST 是通常用于训练图像识别模型的手写编号的数据库。在本教程中,您将使用该脚本来训练 MNIST 模型、TensorBoard 和日志,以创建可视化。
主题• 训练 MNIST 模型并使用 TensorBoard 将训练可视化 (p. 36)• 更多信息 (p. 37)
训练 MNIST 模型并使用 TensorBoard 将训练可视化
使用 TensorBoard 将 MNIST 模型训练可视化
1. 连接到 DLAMI with Conda 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。2. 激活 Python 2.7 TensorFlow 环境并导航到包含带 TensorBoard 示例脚本的文件夹所在的目录:
$ source activate tensorflow_p27$ cd ~/examples/tensorboard/
3. 运行训练启用了延长日志记录的 MNIST 模型的脚本:
$ python mnist_with_summaries.py
该脚本将日志写入 /tmp/tensorflow/mnist。4. 将日志的位置传递到 tensorboard:
$ tensorboard --logdir=/tmp/tensorflow/mnist
TensorBoard 在端口 6006 上启动了可视化 Web 服务器。5. 为了方便从您的本地浏览器进行访问,您可以将 Web 服务器端口更改为端口 80 或其他端口。无论您使
用哪个端口,都需要在 EC2 安全组中为您的 DLAMI 打开此端口。您还可以使用端口转发。有关更改安全组设置和端口转发的说明,请参阅设置 Jupyter Notebook 服务器 (p. 12)。默认设置如下一步中所述。
Note
如果您需要同时运行 Jupyter 服务器和 TensorBoard 服务器,请对每个服务器使用不同的端口。
6. 在您的 EC2 实例上打开端口 6006 (或您分配给可视化 Web 服务器的端口)。
a. 在 https://console.aws.amazon.com/ec2/ 上的 Amazon EC2 控制台中打开您的 EC2 实例。b. 在 Amazon EC2 控制台中,选择 Network & Security (网络与安全),然后选择 Security Groups (安
全组)。c. 对于 Security Group (安全组),选择最近创建的一个安全组(请参阅描述中的时间戳)。d. 选择 Inbound (入站) 选项卡,然后选择 Edit (编辑)。
36

深度学习 AMI 开发人员指南分布式训练
e. 选择 Add Rule。f. 在新行中,键入以下内容:
类型:自定义 TCP Rule
协议:TCP
端口范围:6006(或您分配给可视化服务器的端口)
源:Anywhere (0.0.0.0/0,::/0)7. 使用运行 DLAMI with Conda 的 EC2 实例的公有 IP 或 DNS 地址以及您为 TensorBoard 打开的端口打
开用于 TensorBoard 可视化的网页:
http:// YourInstancePublicDNS:6006
更多信息
要了解有关 TensorBoard 的更多信息,请参阅 TensorBoard 网站。
分布式训练了解 DLAMI 中用于训练多个 GPU 的选项。要提高性能,请参阅Elastic Fabric Adapter (p. 53)单击其中一个选项可了解如何使用该选项。
主题• Chainer (p. 37)• 带 MXNet 的 Keras (p. 46)• TensorFlow with Horovod (p. 47)
ChainerChainer 是一种基于 Python 的灵活框架,用于轻松直观地编写复杂的神经网络架构。利用 Chainer,您可以轻松使用多 GPU 实例进行训练。Chainer 还会自动记录结果、图表损失和精度并生成用于使用计算图来可视化神经网络的输出。Chainer 包含在 采用 Conda 的 Deep Learning AMI (DLAMI with Conda) 中。
以下主题介绍如何在多个 GPU、单个 GPU 和一个 CPU 上进行训练,如何创建可视化以及如何测试您的Chainer 安装。
主题• 使用 Chainer 训练模型 (p. 37)• 使用 Chainer 在多个 GPU 上训练 (p. 38)• 使用 Chainer 在单个 GPU 上训练 (p. 40)• 使用 Chainer 在 CPU 上训练 (p. 41)• 绘制结果 (p. 42)• 测试 Chainer (p. 46)• 更多信息 (p. 46)
使用 Chainer 训练模型
本教程介绍如何使用示例 Chainer 脚本来通过 MNIST 数据集训练模型。MNIST 是通常用于训练图像识别模型的手写编号的数据库。本教程还将介绍在一个 CPU 上训练与在一个或多个 GPU 上训练之间的训练速度差异。
37

深度学习 AMI 开发人员指南分布式训练
使用 Chainer 在多个 GPU 上训练
在多个 GPU 上训练
1. 连接到正在运行 采用 Conda 的 Deep Learning AMI 的实例。有关如何选择或连接到实例,请参阅thesection called “实例选择” (p. 6)或 Amazon EC2 文档。要运行此教程,您将需要使用带至少两个 GPU的实例。
2. 激活 Python 3 Chainer 环境:
$ source activate chainer_p36
3. 要获取最新教程,请克隆 Chainer 存储库并导航到示例文件夹:
(chainer_p36) :~$ cd ~/src(chainer_p36) :~/src$ CHAINER_VERSION=v$(python -c "import chainer; print(chainer.__version__)")(chainer_p36) :~/src$ git clone -b $CHAINER_VERSION https://github.com/chainer/chainer.git(chainer_p36) :~/src$ cd chainer/examples/mnist
4. 在 train_mnist_data_parallel.py 脚本中运行示例。默认情况下,该脚本使用在 采用 Conda 的Deep Learning AMI 的实例上运行的 GPU。该脚本最多可在两个 GPU 上运行。它将忽略前两个 GPU之后的所有 GPU。它会自动检测其中一个 GPU 或检测到这两个 GPU。如果您运行的是不带 GPU 的实例,请跳到本教程后面的使用 Chainer 在 CPU 上训练 (p. 41)。
(chainer_p36) :~/src/chainer/examples/mnist$ python train_mnist_data_parallel.py
Note
由于包含未在 DLAMI 中包含 beta 功能,此示例将返回以下错误。chainerx ModuleNotFoundError: No module named 'chainerx'
当 Chainer 脚本使用 MNIST 数据库训练模型时,您会看到每个纪元的结果。
然后,您会在脚本运行时看到示例输出。以下示例输出是在 p3.8xlarge 实例上运行的。该脚本的输出显示“GPU: 0, 1”,这表示它正在使用 4 个可用 GPU 中的前两个。这些脚本通常使用的是以零开头而不是以总计数开头的 GPU 索引。
GPU: 0, 1
# unit: 1000# Minibatch-size: 400# epoch: 20
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time1 0.277561 0.114709 0.919933 0.9654 6.59261 2 0.0882352 0.0799204 0.973334 0.9752 8.25162 3 0.0520674 0.0697055 0.983967 0.9786 9.91661 4 0.0326329 0.0638036 0.989834 0.9805 11.5767 5 0.0272191 0.0671859 0.9917 0.9796 13.2341 6 0.0151008 0.0663898 0.9953 0.9813 14.9068 7 0.0137765 0.0664415 0.995434 0.982 16.5649
38
深度学习 AMI 开发人员指南分布式训练
8 0.0116909 0.0737597 0.996 0.9801 18.2176 9 0.00773858 0.0795216 0.997367 0.979 19.8797 10 0.00705076 0.0825639 0.997634 0.9785 21.5388 11 0.00773019 0.0858256 0.9978 0.9787 23.2003 12 0.0120371 0.0940225 0.996034 0.9776 24.8587 13 0.00906567 0.0753452 0.997033 0.9824 26.5167 14 0.00852253 0.082996 0.996967 0.9812 28.1777 15 0.00670928 0.102362 0.997867 0.9774 29.8308 16 0.00873565 0.0691577 0.996867 0.9832 31.498 17 0.00717177 0.094268 0.997767 0.9802 33.152 18 0.00585393 0.0778739 0.998267 0.9827 34.8268 19 0.00764773 0.107757 0.9975 0.9773 36.4819 20 0.00620508 0.0834309 0.998167 0.9834 38.1389
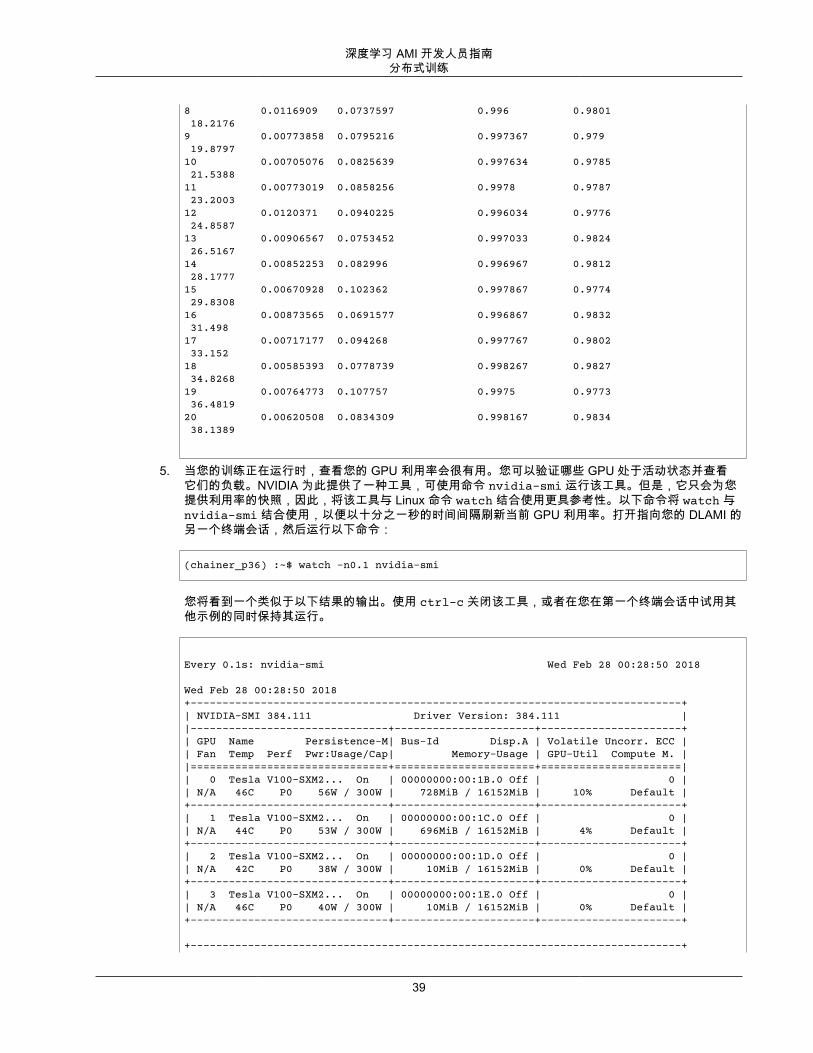
5. 当您的训练正在运行时,查看您的 GPU 利用率会很有用。您可以验证哪些 GPU 处于活动状态并查看它们的负载。NVIDIA 为此提供了一种工具,可使用命令 nvidia-smi 运行该工具。但是,它只会为您提供利用率的快照,因此,将该工具与 Linux 命令 watch 结合使用更具参考性。以下命令将 watch 与nvidia-smi 结合使用,以便以十分之一秒的时间间隔刷新当前 GPU 利用率。打开指向您的 DLAMI 的另一个终端会话,然后运行以下命令:
(chainer_p36) :~$ watch -n0.1 nvidia-smi
您将看到一个类似于以下结果的输出。使用 ctrl-c 关闭该工具,或者在您在第一个终端会话中试用其他示例的同时保持其运行。
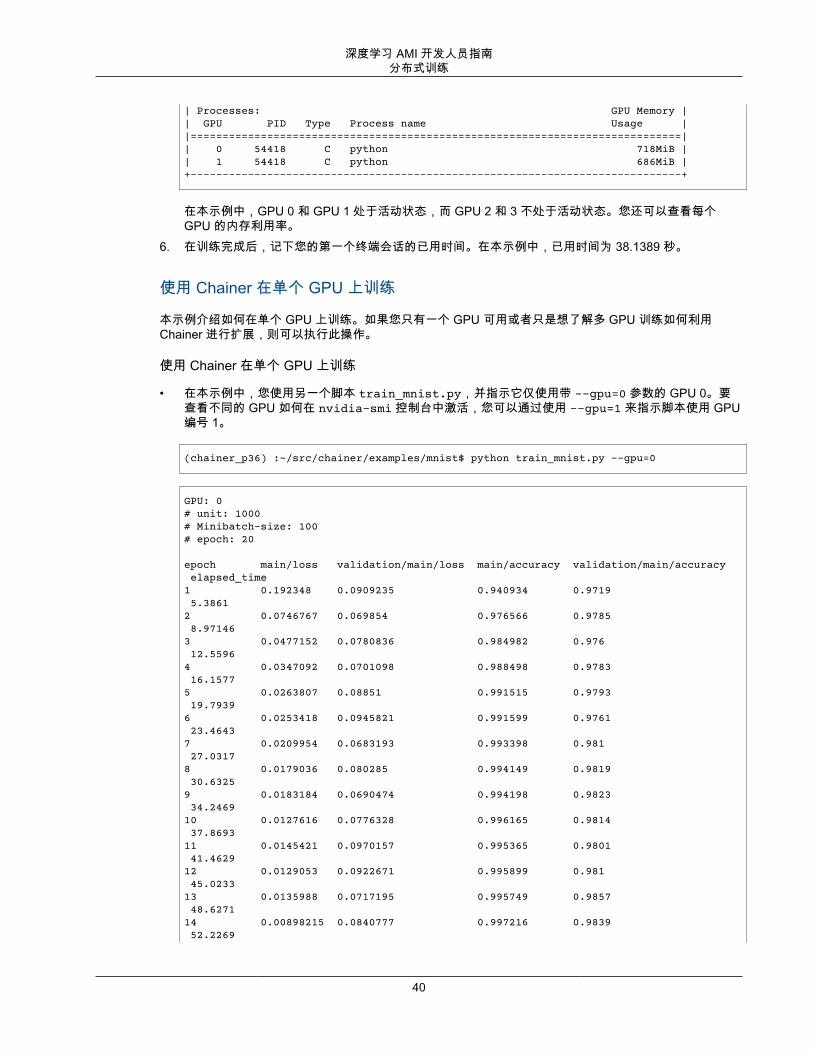
Every 0.1s: nvidia-smi Wed Feb 28 00:28:50 2018
Wed Feb 28 00:28:50 2018+-----------------------------------------------------------------------------+| NVIDIA-SMI 384.111 Driver Version: 384.111 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. ||===============================+======================+======================|| 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 || N/A 46C P0 56W / 300W | 728MiB / 16152MiB | 10% Default |+-------------------------------+----------------------+----------------------+| 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 || N/A 44C P0 53W / 300W | 696MiB / 16152MiB | 4% Default |+-------------------------------+----------------------+----------------------+| 2 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 || N/A 42C P0 38W / 300W | 10MiB / 16152MiB | 0% Default |+-------------------------------+----------------------+----------------------+| 3 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 || N/A 46C P0 40W / 300W | 10MiB / 16152MiB | 0% Default |+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
39
深度学习 AMI 开发人员指南分布式训练
| Processes: GPU Memory || GPU PID Type Process name Usage ||=============================================================================|| 0 54418 C python 718MiB || 1 54418 C python 686MiB |+-----------------------------------------------------------------------------+
在本示例中,GPU 0 和 GPU 1 处于活动状态,而 GPU 2 和 3 不处于活动状态。您还可以查看每个GPU 的内存利用率。
6. 在训练完成后,记下您的第一个终端会话的已用时间。在本示例中,已用时间为 38.1389 秒。
使用 Chainer 在单个 GPU 上训练
本示例介绍如何在单个 GPU 上训练。如果您只有一个 GPU 可用或者只是想了解多 GPU 训练如何利用Chainer 进行扩展,则可以执行此操作。
使用 Chainer 在单个 GPU 上训练
• 在本示例中,您使用另一个脚本 train_mnist.py,并指示它仅使用带 --gpu=0 参数的 GPU 0。要查看不同的 GPU 如何在 nvidia-smi 控制台中激活,您可以通过使用 --gpu=1 来指示脚本使用 GPU编号 1。
(chainer_p36) :~/src/chainer/examples/mnist$ python train_mnist.py --gpu=0
GPU: 0# unit: 1000# Minibatch-size: 100# epoch: 20
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time1 0.192348 0.0909235 0.940934 0.9719 5.3861 2 0.0746767 0.069854 0.976566 0.9785 8.97146 3 0.0477152 0.0780836 0.984982 0.976 12.5596 4 0.0347092 0.0701098 0.988498 0.9783 16.1577 5 0.0263807 0.08851 0.991515 0.9793 19.7939 6 0.0253418 0.0945821 0.991599 0.9761 23.4643 7 0.0209954 0.0683193 0.993398 0.981 27.0317 8 0.0179036 0.080285 0.994149 0.9819 30.6325 9 0.0183184 0.0690474 0.994198 0.9823 34.2469 10 0.0127616 0.0776328 0.996165 0.9814 37.8693 11 0.0145421 0.0970157 0.995365 0.9801 41.4629 12 0.0129053 0.0922671 0.995899 0.981 45.0233 13 0.0135988 0.0717195 0.995749 0.9857 48.6271 14 0.00898215 0.0840777 0.997216 0.9839 52.2269
40
深度学习 AMI 开发人员指南分布式训练
15 0.0103909 0.123506 0.996832 0.9771 55.8667 16 0.012099 0.0826434 0.996616 0.9847 59.5001 17 0.0066183 0.101969 0.997999 0.9826 63.1294 18 0.00989864 0.0877713 0.997116 0.9829 66.7449 19 0.0101816 0.0972672 0.996966 0.9822 70.3686 20 0.00833862 0.0899327 0.997649 0.9835 74.0063
在本示例中,在单个 GPU 上运行花费了将近两倍的时间! 训练较大的模型或较大的数据集将产生不同于本示例的结果,因此,请通过试验来进一步评估 GPU 性能。
使用 Chainer 在 CPU 上训练
现在尝试在仅 CPU 模式下训练。运行相同的脚本 python train_mnist.py (不带参数):
(chainer_p36) :~/src/chainer/examples/mnist$ python train_mnist.py
在输出中,GPU: -1 表示未使用任何 GPU:
GPU: -1# unit: 1000# Minibatch-size: 100# epoch: 20
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time1 0.192083 0.0918663 0.94195 0.9712 11.2661 2 0.0732366 0.0790055 0.977267 0.9747 23.9823 3 0.0485948 0.0723766 0.9844 0.9787 37.5275 4 0.0352731 0.0817955 0.987967 0.9772 51.6394 5 0.029566 0.0807774 0.990217 0.9764 65.2657 6 0.025517 0.0678703 0.9915 0.9814 79.1276 7 0.0194185 0.0716576 0.99355 0.9808 93.8085 8 0.0174553 0.0786768 0.994217 0.9809 108.648 9 0.0148924 0.0923396 0.994983 0.9791 123.737 10 0.018051 0.099924 0.99445 0.9791 139.483 11 0.014241 0.0860133 0.995783 0.9806 156.132 12 0.0124222 0.0829303 0.995967 0.9822 173.173 13 0.00846336 0.122346 0.997133 0.9769 190.365 14 0.011392 0.0982324 0.996383 0.9803 207.746 15 0.0113111 0.0985907 0.996533 0.9813 225.764
41

深度学习 AMI 开发人员指南分布式训练
16 0.0114328 0.0905778 0.996483 0.9811 244.258 17 0.00900945 0.0907504 0.9974 0.9825 263.379 18 0.0130028 0.0917099 0.996217 0.9831 282.887 19 0.00950412 0.0850664 0.997133 0.9839 303.113 20 0.00808573 0.112367 0.998067 0.9778 323.852
在本示例中,MNIST 在 323 秒内完成了训练,这比使用两个 GPU 时的训练的时间多 11 倍以上。如果您曾怀疑过 GPU 的能力,本示例将展示它们的效率高多少。
绘制结果
Chainer 还会自动记录结果、图表损失和精度并生成用于绘制计算图的输出。
生成计算图
1. 在任何训练运行完成之后,您可导航到 result 目录并查看运行的精度和损失(以两个自动生成的图像形式显示)。现在,导航到该处,然后列出内容:
(chainer_p36) :~/src/chainer/examples/mnist$ cd result(chainer_p36) :~/src/chainer/examples/mnist/result$ ls
result 目录包含两个 .png 格式的文件:accuracy.png 和 loss.png。2. 要查看这些图表,请使用 scp 命令将它们复制到您的本地计算机。
在 macOS 终端中,运行以下 scp 命令会将这三个文件全部下载到您的 Downloads 文件夹。将密钥文件的位置和服务器地址的占位符替换为您的信息。对于其他操作系统,请使用合适的 scp 命令格式。注意,对于 Amazon Linux AMI,用户名是 ec2-user。
(chainer_p36) :~/src/chainer/examples/mnist/result$ scp -i "your-key-file.pem" [email protected]:~/src/chainer/examples/mnist/result/*.png ~/Downloads
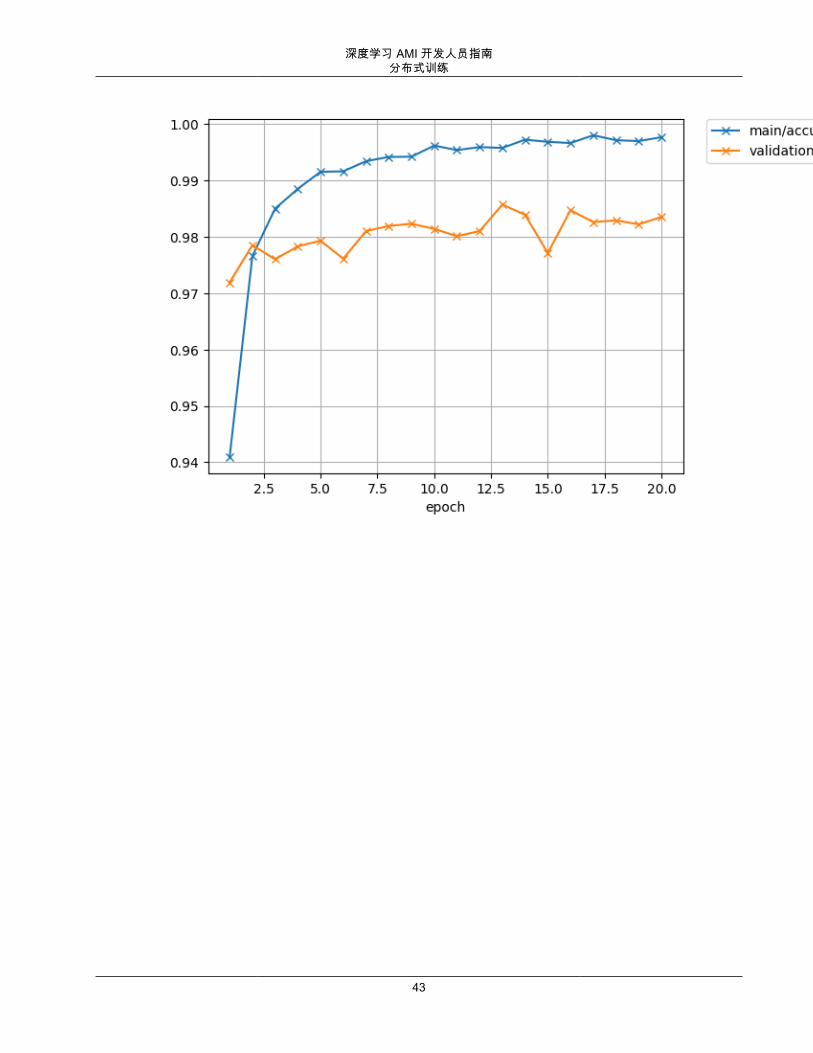
下图分别是精度图、损失图和计算图的示例。
42
深度学习 AMI 开发人员指南分布式训练
43
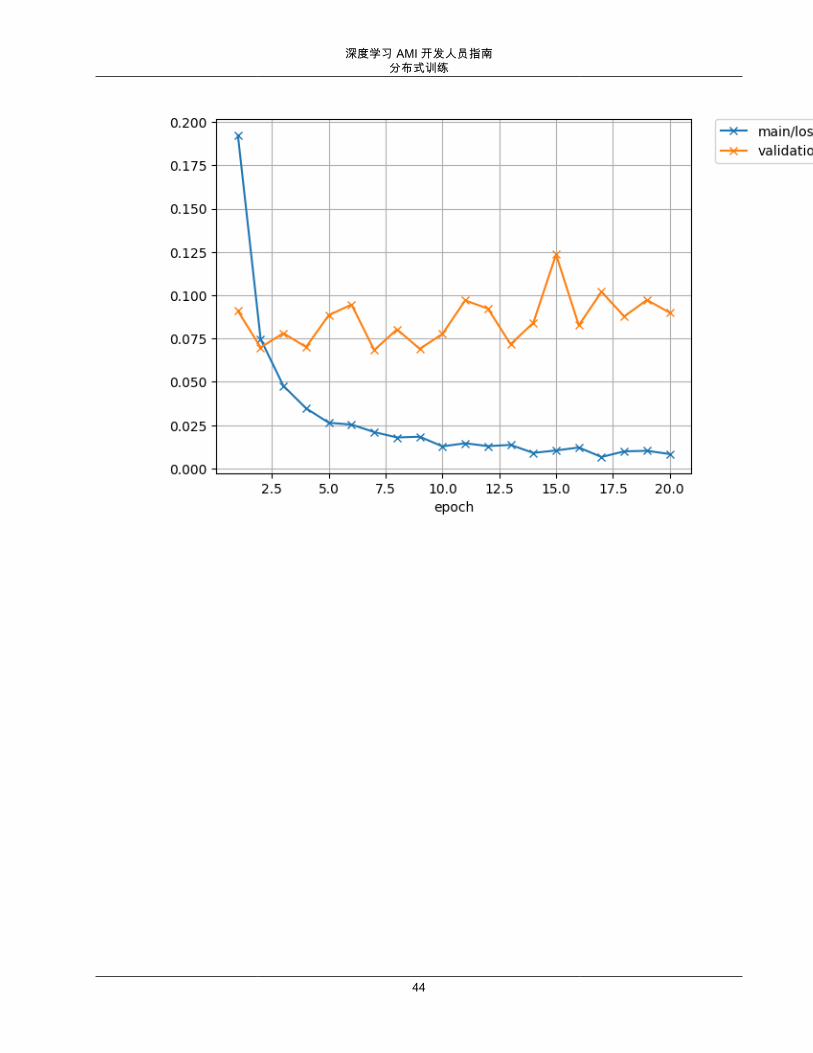
深度学习 AMI 开发人员指南分布式训练
44
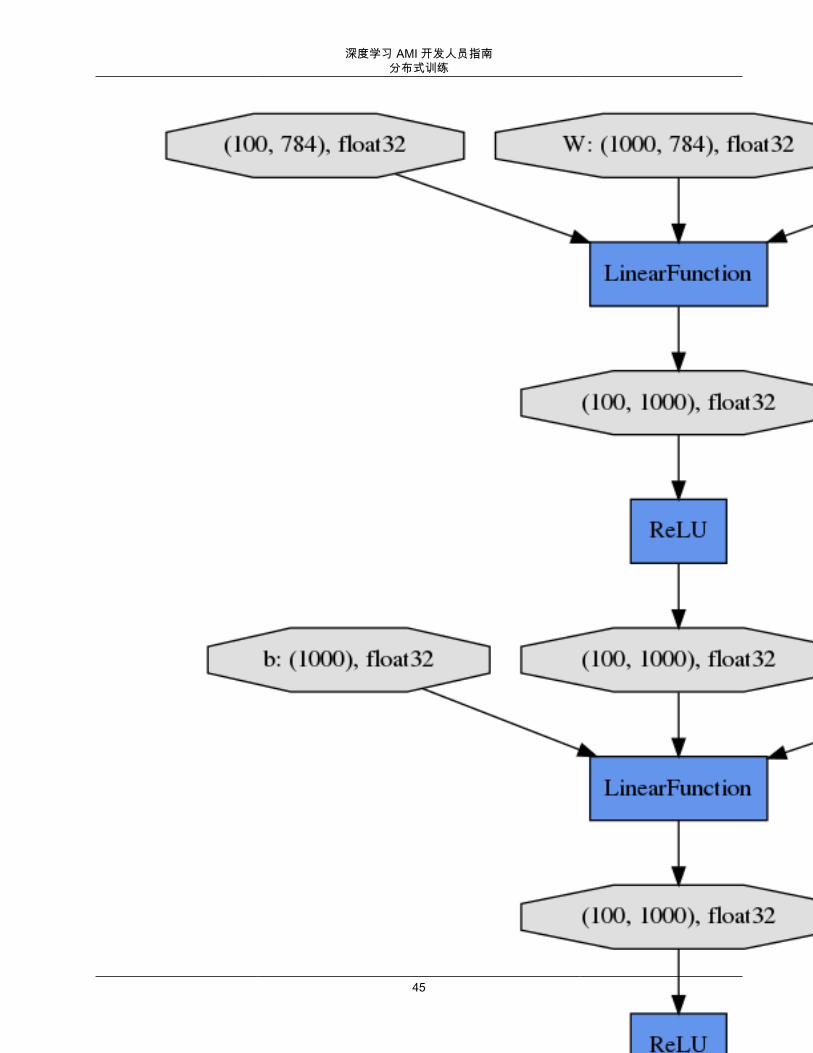
深度学习 AMI 开发人员指南分布式训练
45

深度学习 AMI 开发人员指南分布式训练
测试 Chainer要使用预安装的测试脚本测试 Chainer 和验证 GPU 支持,请运行以下命令:
(chainer_p36) :~/src/chainer/examples/mnist/result$ cd ~/src/bin(chainer_p36) :~/src/bin$ ./testChainer
这将下载 Chainer 源代码并运行 Chainer 多 GPU MNIST 示例。
更多信息要了解有关 Chainer 的更多信息,请参阅 Chainer 文档网站。Chainer 示例文件夹包含多个示例。请试用这些示例以了解其性能。
带 MXNet 的 Keras本教程介绍如何在 采用 Conda 的 Deep Learning AMI 上激活和使用带 MXNet 后端的 Keras 2。
激活带 MXNet 后端的 Keras,并在 DLAMI with Conda 上测试它
1. 要激活带 MXNet 后端的 Keras,请打开 DLAMI with Conda 的 Amazon Elastic Compute Cloud(Amazon EC2) 实例。• 对于 Python 3,运行以下命令:
$ source activate mxnet_p36
• 对于 Python 2,运行以下命令:
$ source activate mxnet_p27
2. 启动 iPython 终端:
(mxnet_p36)$ ipython
3. 测试导入带 MXNet 的 Keras 以验证其是否运行正常:
import keras as k
以下内容应显示在您的屏幕上(可能出现在一些警告消息之后)。
Using MXNet backend
Note
如果您收到错误,或如果仍在使用 TensorFlow 后端,则您需要手动更新您的 Keras 配置。编辑 ~/.keras/keras.json 文件并将后端设置更改为 mxnet。
Keras-MXNet Multi-GPU 训练教程训练卷积神经网络 (CNN)
1. 在 DLAMI 中打开终端和 SSH。2. 导航到 ~/examples/keras-mxnet/ 文件夹。
46

深度学习 AMI 开发人员指南分布式训练
3. 在终端窗口中运行 nvidia-smi 以确定 DLAMI 上的可用 GPU 数。在下一步骤中,您将按原样运行脚本(如果您有四个 GPU)。
4. (可选)运行以下命令可打开脚本以进行编辑。
(mxnet_p36)$ vi cifar10_resnet_multi_gpu.py
5. (可选)脚本具有定义 GPU 数的以下行。如果需要,请更新它。
model = multi_gpu_model(model, gpus=4)
6. 现在,运行训练。
(mxnet_p36)$ python cifar10_resnet_multi_gpu.py
Note
利用 channels_first image_data_format 设置,Keras-MXNet 的运行速度可以加快 2 倍。要更改为 channels_first,请编辑 Keras 配置文件 (~/.keras/keras.json) 并设置以下内容:"image_data_format": "channels_first"。有关更多的性能优化方法,请参阅 Keras-MXNet 性能优化指南。
更多信息
• 您可以在 采用 Conda 的 Deep Learning AMI ~/examples/keras-mxnet 目录中查找有关具有 MXNet后端的 Keras 的示例。
• 有关更多教程和示例,请参阅 Keras-MXNet GitHub 项目。
TensorFlow with Horovod本教程介绍如何在 采用 Conda 的 Deep Learning AMI 上使用 TensorFlow with Horovod。Horovod 已为TensorFlow 预安装在 Conda 环境中。推荐使用 Python 3 环境。此处的说明假定您具有一个正在运行的DLAMI 实例,此实例包含一个或多个 GPU。有关更多信息,请参阅如何开始使用 DLAMI (p. 3)。
Note
仅支持 P3.*、P2.* 和 G3.* 实例类型。
使用 Horovod 激活和测试 TensorFlow
1. 验证您的实例是否具有活动的 GPU。NVIDIA 为此提供了一个工具:
$ nvidia-smi
2. 激活 Python 3 TensorFlow 环境:
$ source activate tensorflow_p36
3. 启动 iPython 终端:
(tensorflow_p36)$ ipython
4. 测试导入 TensorFlow with Horovod 以验证其是否运行正常:
import horovod.tensorflow as hvdhvd.init()
47

深度学习 AMI 开发人员指南分布式训练
以下内容可能显示在您的屏幕上(可能出现在一些警告消息之后)。
--------------------------------------------------------------------------[[55425,1],0]: A high-performance Open MPI point-to-point messaging modulewas unable to find any relevant network interfaces:
Module: OpenFabrics (openib) Host: ip-172-31-72-4
Another transport will be used instead, although this may result inlower performance.--------------------------------------------------------------------------
配置您的 Horovod 主机文件
您可以将 Horovod 用于单节点多 GPU 训练或多节点多 GPU 训练。如果您计划使用多个节点进行分布式训练,则必须向主机文件添加每个 DLAMI 的私有 IP 地址。您当前登录的 DLAMI 称为领导。作为集群的一部分的其他 DLAMI 实例称为成员。
在开始本节之前,请启动一个或多个 DLAMI,然后等待它们进入“准备就绪”状态。示例脚本需要一个主机文件,即使您计划只使用一个 DLAMI,也请创建仅具有一个条目的主机文件。如果您在训练开始后编辑主机文件,则必须重新启动训练以使已添加或删除的主机生效。
针对训练配置 Horovod
1. 将目录更改为训练脚本所在的目录。
cd ~/examples/horovod/tensorflow
2. 使用 vim 编辑领导的主目录中的文件。
vim hosts
3. 在 Amazon Elastic Compute Cloud 控制台中选择其中一个成员,控制台的说明窗格将出现。查找Private IPs (私有 IP) 字段,并将 IP 复制并粘贴到一个文本文件中。在新行上复制每个成员的私有 IP。然后,在每个 IP 的旁边添加一个空格,然后添加文本 slots=8,如下所示。这表示每个实例具有的GPU 的数目。p3.16xlarge 实例具有 8 个 GPU,因此,如果您选择其他实例类型,请提供每个实例的实际 GPU 数。对于领导,您可使用 localhost。对于包含 4 个节点的集群,它应类似于以下内容:
172.100.1.200 slots=8172.200.8.99 slots=8172.48.3.124 slots=8localhost slots=8
保存文件并退回到领导的终端。4. 现在,您的领导知道如何联系每个成员。这一切都将在专用网络接口上发生。接下来,使用简短的 bash
函数来帮助将命令发送到每个成员。
function runclust(){ while read -u 10 host; do host=${host%% slots*}; ssh -o "StrictHostKeyChecking no" $host ""$2""; done 10<$1; };
5. 当天的第一个命令旨在告知其他成员不要进行“StrickHostKeyChecking”,因为这可能导致训练挂起。
runclust hosts "echo \"StrictHostKeyChecking no\" >> ~/.ssh/config"
48

深度学习 AMI 开发人员指南分布式训练
使用合成数据训练DLAMI 附带一个可用于使用合成数据训练模型的示例脚本。这将测试您的领导是否能与集群的成员通信。需要主机文件。有关说明,请参阅 配置您的 Horovod 主机文件 (p. 48)。
使用示例数据测试 Horovod 训练
1. ~/examples/horovod/tensorflow/train_synthetic.sh 默认为 8 个 GPU,但您可以为它提供要运行的 GPU 的数量。以下示例运行此脚本,并将 4 作为 4 个 GPU 的参数传递。
$ ./train_synthetic.sh 4
在显示一些警告消息后,您将看到以下输出,其验证 Horovod 正在使用 4 个 GPU。
PY3.6.5 |Anaconda custom (64-bit)| (default, Apr 29 2018, 16:14:56) [GCC 7.2.0]TF1.11.0Horovod size: 4
然后,在显示一些其他警告后,您将看到表的开头和一些数据点。如果您不想查看 1000 次批处理,请退出训练。
Step Epoch Speed Loss FinLoss LR 0 0.0 105.6 6.794 7.708 6.40000 1 0.0 311.7 0.000 4.315 6.38721 100 0.1 3010.2 0.000 34.446 5.18400 200 0.2 3013.6 0.000 13.077 4.09600 300 0.2 3012.8 0.000 6.196 3.13600 400 0.3 3012.5 0.000 3.551 2.30401
2. Horovod 先使用所有本地 GPU,然后再尝试使用集群成员的 GPU。因此,要确保跨集群的分布式训练正常运行,请试用您计划使用的全部 GPU。例如,如果您有 4 个属于 p3.16xlarge 实例类型的成员,则集群中可包含 32 个 GPU。这是您希望试用全部 32 个 GPU 的位置。
./train_synthetic.sh 32
您的输出与之前的测试类似。Horovod 大小为 32,速度约为四倍。随着此实验完成,您已测试您的领导及其与成员通信的能力。如果您遇到任何问题,请查看 问题排查 (p. 52) 部分。
准备 ImageNet 数据集在本部分中,您将下载 ImageNet 数据集,然后从原始数据集生成 TFRecord 格式的数据集。DLAMI 上提供了一组适用于 ImageNet 数据集的预处理脚本,您可用于 ImageNet 或用作其他数据集的模板。还提供了为ImageNet 配置的主训练脚本。以下部分假定您已启动一个 DLAMI 和一个包含 8 个 GPU 的 EC2 实例。建议使用 p3.16xlarge 实例类型。
在 DLAMI 上的 ~/examples/horovod/tensorflow/utils 目录中,您将找到以下脚本:
• utils/preprocess_imagenet.py - 使用此脚本将原始 ImageNet 数据集转换为 TFRecord 格式。• utils/tensorflow_image_resizer.py - 使用此脚本将 TFRecord 数据集的大小调整为 ImageNet
训练所建议的大小。
准备 ImageNet 数据集
1. 访问 image-net.org,创建账户,获取访问密钥,然后下载数据集。image-net.org 托管原始数据集。要下载此数据集,您需要有一个 ImageNet 账户和访问密钥。账户是免费的,要获取免费访问密钥,您必须同意 ImageNet 许可证。
49

深度学习 AMI 开发人员指南分布式训练
2. 使用图像预处理脚本来从原始 ImageNet 数据集生成 TFRecord 格式的数据集。从 ~/examples/horovod/tensorflow/utils/preprocess 目录中:
python preprocess_imagenet.py \ --local_scratch_dir=[YOUR DIRECTORY] \ --imagenet_username=[imagenet account] \ --imagenet_access_key=[imagenet access key]
3. 使用图像调整大小脚本。如果您调整图像大小,训练将更快地运行并更好地符合 ResNet 参考文件。从~/examples/horovod/utils/preprocess 目录中:
python tensorflow_image_resizer.py \ -d imagenet \ -i [PATH TO TFRECORD TRAINING DATASET] \ -o [PATH TO RESIZED TFRECORD TRAINING DATASET] \ --subset_name train \ --num_preprocess_threads 60 \ --num_intra_threads 2 \ --num_inter_threads 2
在单个 DLAMI 上训练 ResNet-50 ImageNet 模型Note
• 本教程中的脚本预计经过预处理的训练数据位于 ~/data/tf-imagenet/ 文件夹中。有关说明,请参阅 准备 ImageNet 数据集 (p. 49)。
• 需要主机文件。有关说明,请参阅 配置您的 Horovod 主机文件 (p. 48)。
在 ImageNet 数据集上使用 Horovod 训练 ResNet50 CNN
1. 导航到 ~/examples/horovod/tensorflow 文件夹。
cd ~/examples/horovod/tensorflow
2. 验证您的配置并设置要在训练中使用的 GPU 数量。首先,查看与脚本位于相同文件夹中的 hosts。如果您使用的是具有少于 8 个 GPU 的实例,则必须更新此文件。默认为 localhost slots=8。将数量8 更新为要使用的 GPU 的数量。
3. 提供了一个 Shell 脚本,此脚本采用您计划使用的 GPU 数作为其唯一参数。运行此脚本以开始训练。以下示例对 4 个 GPU 使用 4。
./train.sh 4
4. 完成此操作需要几个小时。它使用 mpirun 来跨您的 GPU 分布训练。
在 DLAMI 的集群上训练 ResNet-50 ImageNet 模型Note
• 本教程中的脚本预计经过预处理的训练数据位于 ~/data/tf-imagenet/ 文件夹中。有关说明,请参阅 准备 ImageNet 数据集 (p. 49)。
• 需要主机文件。有关说明,请参阅 配置您的 Horovod 主机文件 (p. 48)。
50

深度学习 AMI 开发人员指南分布式训练
此示例为您演练如何跨 DLAMI 的集群中的多个节点对已准备就绪的数据集训练 ResNet-50 模型。
• 要获得更快的性能,建议您将数据集本地置于集群的每个成员中。
使用此 copyclust 函数将数据复制到其他成员。
function copyclust(){ while read -u 10 host; do host=${host%% slots*}; rsync -azv "$2" $host:"$3"; done 10<$1; };
或者,如果您的文件位于 S3 存储桶中,请使用 runclust 函数直接将文件下载到每个成员。
runclust hosts "tmux new-session -d \"export AWS_ACCESS_KEY_ID=YOUR_ACCESS_KEY && export AWS_SECRET_ACCESS_KEY=YOUR_SECRET && aws s3 sync s3://your-imagenet-bucket ~/data/tf-imagenet/ && aws s3 sync s3://your-imagenet-validation-bucket ~/data/tf-imagenet/\""
使用允许您一次性管理多个节点的工具将节省大量时间。您可以等待每个步骤并单独管理每个实例,也可以使用 tmux 或 screen 等工具断开连接并恢复会话。
在复制操作完成后,您已准备好开始训练。运行脚本,并将 32 作为我们用于此次运行的 32 个 GPU 的参数传递。如果您担心断开连接并终止会话(这将结束训练运行),请使用 tmux 或类似工具。
./train.sh 32
以下输出是您在使用 32 个 GPU 的 ImageNet 上运行训练时将看到的内容。32 个 GPU 需要 90–110 分钟。
Step Epoch Speed Loss FinLoss LR 0 0.0 440.6 6.935 7.850 0.00100 1 0.0 2215.4 6.923 7.837 0.00305 50 0.3 19347.5 6.515 7.425 0.10353 100 0.6 18631.7 6.275 7.173 0.20606 150 1.0 19742.0 6.043 6.922 0.30860 200 1.3 19790.7 5.730 6.586 0.41113 250 1.6 20309.4 5.631 6.458 0.51366 300 1.9 19943.9 5.233 6.027 0.61619 350 2.2 19329.8 5.101 5.864 0.71872 400 2.6 19605.4 4.787 5.519 0.82126 ... 13750 87.9 19398.8 0.676 1.082 0.00217 13800 88.2 19827.5 0.662 1.067 0.00156 13850 88.6 19986.7 0.591 0.997 0.00104 13900 88.9 19595.1 0.598 1.003 0.00064 13950 89.2 19721.8 0.633 1.039 0.00033 14000 89.5 19567.8 0.567 0.973 0.00012 14050 89.8 20902.4 0.803 1.209 0.00002 Finished in 6004.354426383972
在训练运行完成后,脚本将跟进评估运行。它将在领导上运行,因为它运行得足够快,而不必将作业分配给其他成员。以下是评估运行的输出。
Horovod size: 32EvaluatingValidation dataset size: 50000[ip-172-31-36-75:54959] 7 more processes have sent help message help-btl-vader.txt / cma-permission-denied[ip-172-31-36-75:54959] Set MCA parameter "orte_base_help_aggregate" to 0 to see all help / error messages step epoch top1 top5 loss checkpoint_time(UTC)
51

深度学习 AMI 开发人员指南分布式训练
14075 90.0 75.716 92.91 0.97 2018-11-14 08:38:28
以下是使用 256 个 GPU 运行此脚本时的示例输出,其中运行时间为 14 到 15 分钟。
Step Epoch Speed Loss FinLoss LR 1400 71.6 143451.0 1.189 1.720 0.14850 1450 74.2 142679.2 0.897 1.402 0.10283 1500 76.7 143268.6 1.326 1.809 0.06719 1550 79.3 142660.9 1.002 1.470 0.04059 1600 81.8 143302.2 0.981 1.439 0.02190 1650 84.4 144808.2 0.740 1.192 0.00987 1700 87.0 144790.6 0.909 1.359 0.00313 1750 89.5 143499.8 0.844 1.293 0.00026Finished in 860.5105031204224
Finished evaluation1759 90.0 75.086 92.47 0.99 2018-11-20 07:18:18
问题排查以下命令可能有助于解决您在使用 Horovod 进行实验时出现的错误。
• 如果训练因某种原因发生崩溃,则 mpirun 可能无法清理每台计算机上的所有 python 进程。在此情况下,在您开始下一个作业之前,请终止所有计算机上的 python 进程,如下所示:
runclust hosts "pkill -9 python"
• 如果进程突然完成且没有错误,请尝试删除您的日志文件夹。
runclust hosts "rm -rf ~/imagenet_resnet/"
• 如果弹出其他无法解释的问题,请检查您的磁盘空间。如果您已退出,请尝试删除日志文件夹,因为其中包含所有检查点和数据。您也可以为每个成员增加卷的大小。
runclust hosts "df /"
• 作为最后的手段,您也可以尝试重新启动。
runclust hosts "sudo reboot"
如果您尝试在不受支持的实例类型上使用 TensorFlow with Horovod,则可能会收到以下错误代码:
---------------------------------------------------------------------------NotFoundError Traceback (most recent call last)<ipython-input-3-e90ed6cabab4> in <module>()----> 1 import horovod.tensorflow as hvd
~/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/horovod/tensorflow/__init__.py in <module>()** *34* check_extension('horovod.tensorflow', 'HOROVOD_WITH_TENSORFLOW', __file__, 'mpi_lib')** *35* ---> 36 from horovod.tensorflow.mpi_ops import allgather, broadcast, _allreduce** *37* from horovod.tensorflow.mpi_ops import init, shutdown** *38* from horovod.tensorflow.mpi_ops import size, local_size, rank, local_rank
~/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/horovod/tensorflow/mpi_ops.py in <module>()
52

深度学习 AMI 开发人员指南Elastic Fabric Adapter
** *56* ** *57* MPI_LIB = _load_library('mpi_lib' + get_ext_suffix(),---> 58 ['HorovodAllgather', 'HorovodAllreduce'])** *59* ** *60* _basics = _HorovodBasics(__file__, 'mpi_lib')
~/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/horovod/tensorflow/mpi_ops.py in _load_library(name, op_list)** *43* """** *44* filename = resource_loader.get_path_to_datafile(name)---> 45 library = load_library.load_op_library(filename)** *46* for expected_op in (op_list or []):** *47* for lib_op in library.OP_LIST.op:
~/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/tensorflow/python/framework/load_library.py in load_op_library(library_filename)** *59* RuntimeError: when unable to load the library or get the python wrappers.** *60* """---> 61 lib_handle = py_tf.TF_LoadLibrary(library_filename)** *62* ** *63* op_list_str = py_tf.TF_GetOpList(lib_handle)
NotFoundError: /home/ubuntu/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/horovod/tensorflow/mpi_lib.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN10tensorflow14kernel_factory17OpKernelRegistrar12InitInternalEPKNS_9KernelDefEN4absl11string_viewEPFPNS_8OpKernelEPNS_20OpKernelConstructionEE
更多信息
有关实用工具和示例,请参阅 DLAMI 的主目录中的 ~/examples/horovod 文件夹。
有关更多教程和示例,请参阅 Horovod GitHub 项目。
Elastic Fabric AdapterElastic Fabric Adapter (EFA) 是一种网络设备,可以将其附加到 DLAMI 实例以加速高性能计算 (HPC) 应用程序。通过使用 EFA,您可以实现本地 HPC 集群的应用程序性能,并具有 AWS 云提供的可扩展性、灵活性和弹性。
以下主题将向您展示如何开始将 EFA 与 DLAMI 结合使用。
主题• 使用 EFA 启动 AWS Deep Learning AMI 实例 (p. 53)• 在 DLAMI 上使用 EFA (p. 56)
使用 EFA 启动 AWS Deep Learning AMI 实例最新 DLAMI可随时与 EFA 结合使用,并随附所需的驱动程序、内核模块、libfabric、openmpi 和适用于GPU 实例的 NCCL OFI 插件。
支持的 CUDA 版本:只有使用 EFA 的 NCCL 应用程序才在 CUDA-10.0 和 CUDA-10.1 上受支持,因为NCCL OFI 插件要求 NCCL 版本 > 2.4.2。
注意:
• 在 EFA 上使用 mpirun 运行 NCCL 应用程序时,必须将 EFA 支持的安装的完整路径指定为:
/opt/amazon/openmpi/bin/mpirun <command>
53

深度学习 AMI 开发人员指南Elastic Fabric Adapter
• 要使您的应用程序能够使用 EFA,请将 FI_PROVIDER="efa" 添加到 mpirun 命令,如 在 DLAMI 上使用 EFA (p. 56) 中所示。
主题• 准备启用 EFA 的安全组 (p. 54)• 启动实例 (p. 54)• 验证 EFA 附件 (p. 55)
准备启用 EFA 的安全组
EFA 需要使用一个安全组,以允许进出安全组本身的所有入站和出站流量。 有关更多信息,请参阅 EFA 文档。
1. 通过以下网址打开 Amazon EC2 控制台:https://console.aws.amazon.com/ec2/。2. 在导航窗格中,选择 Security Groups (安全组),然后选择 Create Security Group (创建安全组)。3. 在 Create Security Group (创建安全组) 窗口中,执行以下操作:
• 对于 Security group name (安全组名称),请输入一个描述性的安全组名称,例如 EFA-enabledsecurity group。
• (可选)对于 Description (描述),请输入安全组的简要描述。• 对于 VPC,请选择要在其中启动启用了 EFA 的实例的 VPC。• 选择 Create (创建)。
4. 选择您创建的安全组,然后在 Description (描述) 选项卡上复制 Group ID (组 ID)。5. 在 Inbound (入站) 和 Outbound (出站) 选项卡上,执行以下操作:
• 选择 Edit (编辑)。• 对于 Type (类型),请选择 All traffic (所有流量)。• 对于 Source (源),选择 Custom (自定义)。• 将您复制的安全组 ID 粘贴到该字段中。• 选择 Save (保存)。
6. 启用入站流量,请参考授权您 Linux 实例的入站流量。如果您跳过此步骤,您将无法与您的 DLAMI 实例进行通信。
启动实例
有关更多信息,请参阅在集群置放群组中启动启用 EFA 的实例。
1. 通过以下网址打开 Amazon EC2 控制台:https://console.aws.amazon.com/ec2/。2. 选择 Launch Instance (启动实例)。3. 在 Choose an AMI (选择 AMI) 页面上,选择“深度学习 AMI (Ubuntu 18.04) 25.0版”4. 在 Choose an Instance Type (选择实例类型) 页面上,选择以下支持的实例类型之一,然后选择下
一步:配置实例详细信息。 有关支持的实例列表,请参阅此链接:https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/efa-start.html
5. 在 Configure Instance Details (配置实例详细信息) 页面中,执行以下操作:
• 对于 Number of instances (实例的数量),请输入要启动的启用了 EFA 的实例数量。• 对于 Network (网络) 和 Subnet (子网),请选择要在其中启动实例的 VPC 和子网。• 对于 Placement group (置放群组),请选择 Add instance to placement group (将实例添加到置放群
组)。为获得最佳性能,请在置放群组中启动实例。
54

深度学习 AMI 开发人员指南Elastic Fabric Adapter
• (可选)对于 Placement group name (置放群组名称),请选择 Add to a new placement group (添加到新的置放群组),输入一个描述性的置放群组名称,然后为 Placement group strategy (置放群组策略) 选择 cluster (集群)。
• 请确保在此页面上启用“Elastic Fabric Adapter”。如果禁用此选项,请将子网更改为支持所选实例类型的子网。
• 在 Network Interfaces (网络接口) 部分中,为设备 eth0 选择 New network interface (新网络接口)。您可以选择指定主 IPv4 地址以及一个或多个辅助 IPv4 地址。如果在具有关联的 IPv6 CIDR 块的子网中启动实例,您可以选择指定主 IPv6 地址以及一个或多个辅助 IPv6 地址。
• 选择 Next: Add Storage (下一步:添加存储)。6. 在 Add Storage (添加存储) 页面上,除了 AMI 指定的卷(如根设备卷)以外,还要指定要附加到实例的
卷,然后选择 Next: Add Tags (下一步:添加标签)。7. 在 Add Tags (添加标签) 页面上,为实例指定标签(例如,便于用户识别的名称),然后选择 Next:
Configure Security Group (下一步:配置安全组)。8. 在 Configure Security Group (配置安全组) 页面上,为 Assign a security group (分配安全组) 选择
Select an existing security group (选择一个现有的安全组),然后选择先前创建的安全组。9. 选择 Review and Launch (审核并启动)。10. 在 Review Instance Launch (核查实例启动) 页面上,检查这些设置,然后选择 Launch (启动) 以选择一
个密钥对并启动您的实例。
验证 EFA 附件
通过控制台
启动实例后,在 AWS 控制台中查看实例详细信息。为此,请在 EC2 控制台中选择实例,然后查看页面下部窗格中的 Description (描述) 选项卡。找到参数“Network Interfaces: eth0”,然后单击 eth0,这将弹出一个弹出窗口。确保“Elastic Fabric Adapter”已启用。
如果未启用 EFA,您可以通过以下任一方式解决此问题:
• 终止 EC2 实例并使用相同步骤启动新实例。确保已附加 EFA。• 将 EFA 附加到现有实例。
1. 在 EC2 控制台中,转到 Network Interfaces (网络接口)。2. 单击 Create a Network Interface (创建虚拟网络接口)。3. 选择您的实例所在的相同子网。4. 确保启用“Elastic Fabric Adapter”并点击 Create (创建)。5. 返回 EC2 Instances (EC2 实例) 选项卡并选择您的实例。6. 转到“操作:实例状态”并在附加 EFA 之前停止实例。7. 从 “操作”中,选择“网络连接:连接网络接口”。8. 选择您刚刚创建的界面,然后点击“附加”。9. 重新启动您的实例。
通过实例
以下测试脚本已存在于 DLAMI 中。运行它以确保内核模块正确加载。
$ fi_info -p efa
您的输出应类似于以下内容。
provider: efa
55

深度学习 AMI 开发人员指南Elastic Fabric Adapter
fabric: EFA-fe80::e5:56ff:fe34:56a8 domain: efa_0-rdm version: 2.0 type: FI_EP_RDM protocol: FI_PROTO_EFAprovider: efa fabric: EFA-fe80::e5:56ff:fe34:56a8 domain: efa_0-dgrm version: 2.0 type: FI_EP_DGRAM protocol: FI_PROTO_EFAprovider: efa;ofi_rxd fabric: EFA-fe80::e5:56ff:fe34:56a8 domain: efa_0-dgrm version: 1.0 type: FI_EP_RDM protocol: FI_PROTO_RXD
验证安全组配置
以下测试脚本已存在于 DLAMI 中。运行它以确保您创建的安全组配置正确。
$ cd ~/src/bin/efa-tests/$ ./efa_test.sh
您的输出应类似于以下内容。
Starting server...Starting client...bytes #sent #ack total time MB/sec usec/xfer Mxfers/sec64 10 =10 1.2k 0.02s 0.06 1123.55 0.00256 10 =10 5k 0.00s 17.66 14.50 0.071k 10 =10 20k 0.00s 67.81 15.10 0.074k 10 =10 80k 0.00s 237.45 17.25 0.0664k 10 =10 1.2m 0.00s 921.10 71.15 0.011m 10 =10 20m 0.01s 2122.41 494.05 0.00
如果它挂起或未完成,请确保您的安全组具有正确的入站/出站规则。
在 DLAMI 上使用 EFA以下部分描述如何使用 EFA 在 AWS Deep Learning AMI 上运行多节点应用程序。
主题• 使用 EFA 运行多节点应用程序 (p. 56)
使用 EFA 运行多节点应用程序
要跨节点集群运行应用程序,需要进行某些配置。
启用无密码 SSH
选择集群中的一个节点作为领导节点。其余节点称为成员节点。
1. 在领导节点上,生成 RSA 密钥对。
ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
56

深度学习 AMI 开发人员指南Elastic Fabric Adapter
2. 更改领导节点上私有密钥的权限。
chmod 600 ~/.ssh/id_rsa
3. 将公有密钥 ~/.ssh/id_rsa.pub 复制并附加到集群中成员节点的 ~/.ssh/authorized_keys 之后。
4. 现在,您应该能够使用私有 ip 从领导节点直接登录到成员节点。
ssh <member private ip>
5. 通过将以下内容添加到领导节点上的 ~/.ssh/config 文件中,禁用 strictHostKeyChecking 并在领导节点上启用代理转发:
Host * ForwardAgent yesHost * StrictHostKeyChecking no
6. 在 Amazon Linux 和 Amazon Linux 2 实例上,在主节点上运行以下命令,为配置文件提供正确的权限:
chmod 600 ~/.ssh/config
创建主机文件
在领导节点上,创建主机文件以标识集群中的节点。主机文件必须针对集群中的每个节点都有一个条目。创建文件 ~/hosts 并使用私有 IP 添加每个节点,如下所示:
localhost slots=8<private ip of node 1> slots=8<private ip of node 2> slots=8
P3dn.24xlarge 上的 2 节点 NCCL 插件检查
nccl_message_transfer 是一项简单的测试,可确保 NCCL OFI 插件按预期工作。该测试验证 NCCL 的连接建立和数据传输 API 的功能。当使用 EFA来运行 NCCL 应用程序时,请确保按照示例所示使用到 mpirun 的完整路径。根据集群中实例和 GPU 的数量更改参数 np 和 N。有关更多信息,请参阅 AWS OFI NCCL 文档。
/opt/amazon/openmpi/bin/mpirun -n 2 -N 1 --hostfile hosts ~/src/bin/efa-tests/efa-cuda-10.0/nccl_message_transfer
您的输出应与以下内容类似。您可以检查输出以查看 EFA 是否正在将其用作 OFI 提供程序。
INFO: Function: ofi_init Line: 702: NET/OFI Forcing AWS OFI ndev 4INFO: Function: ofi_init Line: 714: NET/OFI Selected Provider is efaINFO: Function: main Line: 49: NET/OFI Process rank 1 started. NCCLNet device used on ip-172-31-15-30 is AWS Libfabric.INFO: Function: main Line: 53: NET/OFI Received 4 network devicesINFO: Function: main Line: 57: NET/OFI Server: Listening on dev 0INFO: Function: ofi_init Line: 702: NET/OFI Forcing AWS OFI ndev 4INFO: Function: ofi_init Line: 714: NET/OFI Selected Provider is efaINFO: Function: main Line: 49: NET/OFI Process rank 0 started. NCCLNet device used on ip-172-31-15-30 is AWS Libfabric.INFO: Function: main Line: 53: NET/OFI Received 4 network devicesINFO: Function: main Line: 57: NET/OFI Server: Listening on dev 0
57

深度学习 AMI 开发人员指南Elastic Fabric Adapter
INFO: Function: main Line: 96: NET/OFI Send connection request to rank 0INFO: Function: main Line: 69: NET/OFI Send connection request to rank 1INFO: Function: main Line: 100: NET/OFI Server: Start accepting requestsINFO: Function: main Line: 73: NET/OFI Server: Start accepting requestsINFO: Function: main Line: 103: NET/OFI Successfully accepted connection from rank 0INFO: Function: main Line: 107: NET/OFI Rank 1 posting 255 receive buffersINFO: Function: main Line: 76: NET/OFI Successfully accepted connection from rank 1INFO: Function: main Line: 80: NET/OFI Sent 255 requests to rank 1INFO: Function: main Line: 131: NET/OFI Got completions for 255 requests for rank 0INFO: Function: main Line: 131: NET/OFI Got completions for 255 requests for rank 1
P3dn.24xlarge 上的多节点 NCCL 性能测试
要使用 EFA 检查 NCCL 性能,请运行官方 NCCL 测试存储库上提供的标准 NCCL 性能测试。DLAMI 测试随附了已针对 CUDA 10 和 CUDA 10.1 构建的这一测试。您也可以使用 EFA运行自己的脚本。
构建您自己的脚本时,请参阅以下指南:
• 提供 FI_PROVIDER="efa" 标志以启用 EFA。• 当使用 EFA来运行 NCCL 应用程序时,按照示例所示使用到 mpirun 的完整路径。• 根据集群中实例和 GPU 的数量更改参数 np 和 N。• 添加 NCCL_DEBUG=INFO 标志,并确保日志将 EFA 用法指示为“所选提供程序是 EFA”。• 在任何成员节点上使用 watch nvidia-smi 命令来监视 GPU 使用情况。
$ /opt/amazon/openmpi/bin/mpirun -x FI_PROVIDER="efa" -n 16 -N 8 -x NCCL_DEBUG=INFO -x FI_EFA_TX_MIN_CREDITS=64 -x NCCL_TREE_THRESHOLD=0 --hostfile hosts --mca btl tcp,self --mca btl_tcp_if_exclude lo,docker0 --bind-to none $HOME/src/bin/efa-tests/efa-cuda-10.0/all_reduce_perf -b 8 -e 1G -f 2 -g 1 -c 1 -n 100
您的输出应与以下内容类似。
# nThread 1 nGpus 1 minBytes 8 maxBytes 1073741824 step: 2(factor) warmup iters: 5 iters: 100 validation: 1## Using devices# Rank 0 Pid 3801 on ip-172-31-41-105 device 0 [0x00] Tesla V100-SXM2-32GB# Rank 1 Pid 3802 on ip-172-31-41-105 device 1 [0x00] Tesla V100-SXM2-32GB# Rank 2 Pid 3803 on ip-172-31-41-105 device 2 [0x00] Tesla V100-SXM2-32GB# Rank 3 Pid 3804 on ip-172-31-41-105 device 3 [0x00] Tesla V100-SXM2-32GB# Rank 4 Pid 3805 on ip-172-31-41-105 device 4 [0x00] Tesla V100-SXM2-32GB# Rank 5 Pid 3807 on ip-172-31-41-105 device 5 [0x00] Tesla V100-SXM2-32GB# Rank 6 Pid 3810 on ip-172-31-41-105 device 6 [0x00] Tesla V100-SXM2-32GB# Rank 7 Pid 3813 on ip-172-31-41-105 device 7 [0x00] Tesla V100-SXM2-32GB# Rank 8 Pid 4124 on ip-172-31-41-36 device 0 [0x00] Tesla V100-SXM2-32GB# Rank 9 Pid 4125 on ip-172-31-41-36 device 1 [0x00] Tesla V100-SXM2-32GB# Rank 10 Pid 4126 on ip-172-31-41-36 device 2 [0x00] Tesla V100-SXM2-32GB# Rank 11 Pid 4127 on ip-172-31-41-36 device 3 [0x00] Tesla V100-SXM2-32GB# Rank 12 Pid 4128 on ip-172-31-41-36 device 4 [0x00] Tesla V100-SXM2-32GB# Rank 13 Pid 4130 on ip-172-31-41-36 device 5 [0x00] Tesla V100-SXM2-32GB# Rank 14 Pid 4132 on ip-172-31-41-36 device 6 [0x00] Tesla V100-SXM2-32GB# Rank 15 Pid 4134 on ip-172-31-41-36 device 7 [0x00] Tesla V100-SXM2-32GBip-172-31-41-105:3801:3801 [0] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3801:3801 [0] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3801:3801 [0] NCCL INFO NET/OFI Selected Provider is efaNCCL version 2.4.8+cuda10.0ip-172-31-41-105:3810:3810 [6] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3810:3810 [6] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3810:3810 [6] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3805:3805 [4] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>
58
深度学习 AMI 开发人员指南Elastic Fabric Adapter
ip-172-31-41-105:3805:3805 [4] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3805:3805 [4] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3807:3807 [5] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3807:3807 [5] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3807:3807 [5] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3803:3803 [2] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3803:3803 [2] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3803:3803 [2] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3813:3813 [7] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3802:3802 [1] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3813:3813 [7] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3813:3813 [7] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3802:3802 [1] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3802:3802 [1] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3804:3804 [3] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.105<0>ip-172-31-41-105:3804:3804 [3] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-105:3804:3804 [3] NCCL INFO NET/OFI Selected Provider is efaip-172-31-41-105:3801:3862 [0] NCCL INFO Setting affinity for GPU 0 to ffffffff,ffffffff,ffffffffip-172-31-41-105:3801:3862 [0] NCCL INFO NCCL_TREE_THRESHOLD set by environment to 0.ip-172-31-41-36:4128:4128 [4] NCCL INFO Bootstrap : Using [0]ens5:172.31.41.36<0>ip-172-31-41-36:4128:4128 [4] NCCL INFO NET/OFI Forcing AWS OFI ndev 4ip-172-31-41-36:4128:4128 [4] NCCL INFO NET/OFI Selected Provider is efa
-----------------------------some output truncated-----------------------------------
ip-172-31-41-105:3804:3869 [3] NCCL INFO comm 0x7f8c5c0025b0 rank 3 nranks 16 cudaDev 3 nvmlDev 3 - Init COMPLETE## out-of-place in-place# size count type redop time algbw busbw error time algbw busbw error# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)ip-172-31-41-105:3801:3801 [0] NCCL INFO Launch mode Parallelip-172-31-41-36:4124:4191 [0] NCCL INFO comm 0x7f28400025b0 rank 8 nranks 16 cudaDev 0 nvmlDev 0 - Init COMPLETEip-172-31-41-36:4126:4192 [2] NCCL INFO comm 0x7f62240025b0 rank 10 nranks 16 cudaDev 2 nvmlDev 2 - Init COMPLETEip-172-31-41-105:3802:3867 [1] NCCL INFO comm 0x7f5ff00025b0 rank 1 nranks 16 cudaDev 1 nvmlDev 1 - Init COMPLETEip-172-31-41-36:4132:4193 [6] NCCL INFO comm 0x7ffa0c0025b0 rank 14 nranks 16 cudaDev 6 nvmlDev 6 - Init COMPLETEip-172-31-41-105:3803:3866 [2] NCCL INFO comm 0x7fe9600025b0 rank 2 nranks 16 cudaDev 2 nvmlDev 2 - Init COMPLETEip-172-31-41-36:4127:4188 [3] NCCL INFO comm 0x7f6ad00025b0 rank 11 nranks 16 cudaDev 3 nvmlDev 3 - Init COMPLETEip-172-31-41-105:3813:3868 [7] NCCL INFO comm 0x7f341c0025b0 rank 7 nranks 16 cudaDev 7 nvmlDev 7 - Init COMPLETEip-172-31-41-105:3810:3864 [6] NCCL INFO comm 0x7f5f980025b0 rank 6 nranks 16 cudaDev 6 nvmlDev 6 - Init COMPLETEip-172-31-41-36:4128:4187 [4] NCCL INFO comm 0x7f234c0025b0 rank 12 nranks 16 cudaDev 4 nvmlDev 4 - Init COMPLETEip-172-31-41-36:4125:4194 [1] NCCL INFO comm 0x7f2ca00025b0 rank 9 nranks 16 cudaDev 1 nvmlDev 1 - Init COMPLETEip-172-31-41-36:4134:4190 [7] NCCL INFO comm 0x7f0ca40025b0 rank 15 nranks 16 cudaDev 7 nvmlDev 7 - Init COMPLETEip-172-31-41-105:3807:3865 [5] NCCL INFO comm 0x7f3b280025b0 rank 5 nranks 16 cudaDev 5 nvmlDev 5 - Init COMPLETEip-172-31-41-36:4130:4189 [5] NCCL INFO comm 0x7f62080025b0 rank 13 nranks 16 cudaDev 5 nvmlDev 5 - Init COMPLETEip-172-31-41-105:3805:3863 [4] NCCL INFO comm 0x7fec100025b0 rank 4 nranks 16 cudaDev 4 nvmlDev 4 - Init COMPLETE 8 2 float sum 145.4 0.00 0.00 2e-07 152.8 0.00 0.00 1e-07
59
深度学习 AMI 开发人员指南GPU 监控和优化
16 4 float sum 137.3 0.00 0.00 1e-07 137.2 0.00 0.00 1e-07 32 8 float sum 137.0 0.00 0.00 1e-07 137.4 0.00 0.00 1e-07 64 16 float sum 137.7 0.00 0.00 1e-07 137.5 0.00 0.00 1e-07 128 32 float sum 136.2 0.00 0.00 1e-07 135.3 0.00 0.00 1e-07 256 64 float sum 136.4 0.00 0.00 1e-07 137.4 0.00 0.00 1e-07 512 128 float sum 135.5 0.00 0.01 1e-07 151.0 0.00 0.01 1e-07 1024 256 float sum 151.0 0.01 0.01 2e-07 137.7 0.01 0.01 2e-07 2048 512 float sum 138.1 0.01 0.03 5e-07 138.1 0.01 0.03 5e-07 4096 1024 float sum 140.5 0.03 0.05 5e-07 140.3 0.03 0.05 5e-07 8192 2048 float sum 144.6 0.06 0.11 5e-07 144.7 0.06 0.11 5e-07 16384 4096 float sum 149.4 0.11 0.21 5e-07 149.3 0.11 0.21 5e-07 32768 8192 float sum 156.7 0.21 0.39 5e-07 183.9 0.18 0.33 5e-07 65536 16384 float sum 167.7 0.39 0.73 5e-07 183.6 0.36 0.67 5e-07 131072 32768 float sum 193.8 0.68 1.27 5e-07 193.0 0.68 1.27 5e-07 262144 65536 float sum 243.9 1.07 2.02 5e-07 258.3 1.02 1.90 5e-07 524288 131072 float sum 309.0 1.70 3.18 5e-07 309.0 1.70 3.18 5e-07 1048576 262144 float sum 709.3 1.48 2.77 5e-07 693.2 1.51 2.84 5e-07 2097152 524288 float sum 1116.4 1.88 3.52 5e-07 1105.7 1.90 3.56 5e-07 4194304 1048576 float sum 2088.9 2.01 3.76 5e-07 2157.3 1.94 3.65 5e-07 8388608 2097152 float sum 2869.7 2.92 5.48 5e-07 2847.2 2.95 5.52 5e-07 16777216 4194304 float sum 4631.7 3.62 6.79 5e-07 4643.9 3.61 6.77 5e-07 33554432 8388608 float sum 8769.2 3.83 7.17 5e-07 8743.5 3.84 7.20 5e-07 67108864 16777216 float sum 16964 3.96 7.42 5e-07 16846 3.98 7.47 5e-07 134217728 33554432 float sum 33403 4.02 7.53 5e-07 33058 4.06 7.61 5e-07 268435456 67108864 float sum 59045 4.55 8.52 5e-07 58625 4.58 8.59 5e-07 536870912 134217728 float sum 115842 4.63 8.69 5e-07 115590 4.64 8.71 5e-07 1073741824 268435456 float sum 228178 4.71 8.82 5e-07 224997 4.77 8.95 5e-07# Out of bounds values : 0 OK# Avg bus bandwidth : 2.80613#
GPU 监控和优化以下部分将指导您完成 GPU 优化和监控选项。本部分的组织方式如同一个典型工作流程一样,其中包含监控监督预处理和训练。
• 监控 (p. 61)
60

深度学习 AMI 开发人员指南GPU 监控和优化
• 使用 CloudWatch 监控 GPU (p. 61)• 优化 (p. 63)
• 预处理 (p. 64)• 训练 (p. 65)
监控您的 DLAMI 已预安装多个 GPU 监控工具。本指南还将介绍可用于下载和安装的工具。
• 使用 CloudWatch 监控 GPU (p. 61) - 一个预安装的实用工具,可向 CloudWatch 报告 GPU 使用情况统计数据。
• nvidia-smi CLI - 一个监控总体 GPU 计算和内存利用率的实用工具。此项已预安装在您的 DLAMI 上。• NVML C 库 - 一个基于 C 的 API,可直接访问 GPU 监控和管理功能。此项已在后台由 nvidia-smi CLI 所
使用且已预安装在您的 DLAMI 上。它还具有 Python 和 Perl 绑定以方便采用这些请求进行开发。已预安装在您的 DLAMI 上的 gpumon.py 实用工具使用 nvidia-ml-py 中的 pynvml 程序包。
• NVIDIA DCGM - 一个集群管理工具。请访问开发人员页面,了解如何安装和配置此工具。
Tip
请查看 NVIDIA 的开发人员博客,了解有关使用已安装在您的 DLAMI 上的 CUDA 工具的最新信息。
• 使用 Nsight IDE 和 nvprof 监控 TensorCore 使用率。
使用 CloudWatch 监控 GPU
当您将 DLAMI 与 GPU 结合使用时,您可能会发现,您要寻找在训练或推理期间跟踪其使用率的方式。这对于优化您的数据管道以及调整深度学习网络非常有用。
一个名为 gpumon.py 的实用工具已预安装在您的 DLAMI 上。该工具与 CloudWatch 集成并支持监控每个GPU 使用率:GPU 内存、GPU 温度和 GPU 功率。脚本会将监控的数据定期发送到 CloudWatch。您可以通过更改脚本中的几个设置来配置要发送到 CloudWatch 的数据的粒度级别。但是,在启动脚本之前,您将需要设置 CloudWatch 以接收这些指标。
如果使用 CloudWatch 设置并运行 GPU 监控
1. 创建 IAM 用户或修改现有 IAM 用户,以具有用于将指标发布到 CloudWatch 的策略。如果创建新用户,请记下凭证,因为您将在下一步中需要这些凭证。
要搜索的 IAM 策略是“cloudwatch:PutMetricData”。要添加的策略如下所示:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "cloudwatch:PutMetricData", ], "Effect": "Allow", "Resource": "*" } ]}
61

深度学习 AMI 开发人员指南GPU 监控和优化
Tip
有关针对 CloudWatch 创建 IAM 用户和添加策略的更多信息,请参阅 CloudWatch 文档。2. 在您的 DLAMI 上,运行 AWS 配置并指定 IAM 用户凭证。
$ aws configure
3. 您可能需要先对 gpumon 实用工具进行一些修改,然后再运行该工具。您可以在以下位置中找到gpumon 实用工具和 README。
Folder: ~/tools/GPUCloudWatchMonitorFiles: ~/tools/GPUCloudWatchMonitor/gpumon.py ~/tools/GPUCloudWatchMonitor/README
选项:
• 如果您的实例不在 us-east-1 中,请在 gpumon.py 中更改区域。• 更改其他参数(如 CloudWatch namespace 或带 store_resolution 的报告期间)。
4. 目前,该脚本仅支持 Python 2.7。激活您的首选框架的 Python 2.7 环境或激活 DLAMI 的一般 Python2.7 环境。
$ source activate python2
5. 在后台中运行 gpumon 实用工具。
(python2)$ gpumon.py &
6. 打开您的浏览器前往 https://console.aws.amazon.com/cloudwatch/,然后选择指标。它将有一个命名空间“DeepLearningTrain”。
Tip
您可以修改 gpumon.py 来更改该命名空间。您也可以通过调整 store_resolution 来修改报告间隔。
下面是一个报告在 p2.8xlarge 实例上运行 gpumon.py 监控训练任务的示例 CloudWatch 图表。
62
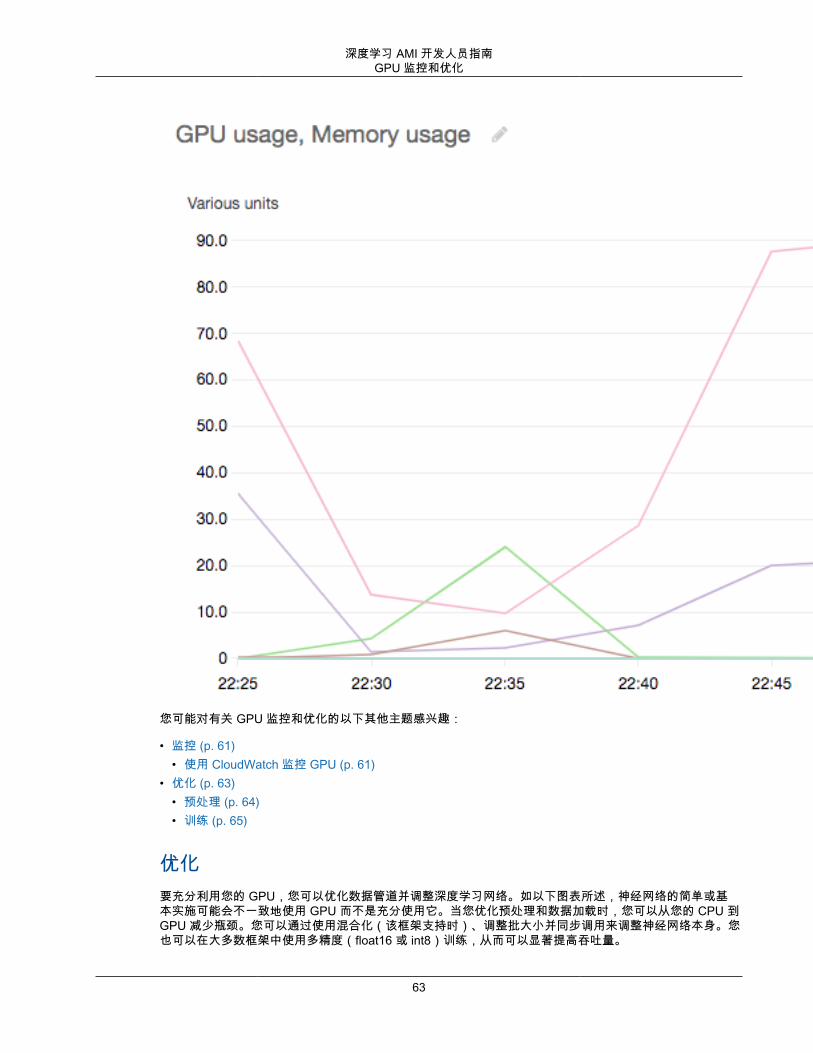
深度学习 AMI 开发人员指南GPU 监控和优化
您可能对有关 GPU 监控和优化的以下其他主题感兴趣:
• 监控 (p. 61)• 使用 CloudWatch 监控 GPU (p. 61)
• 优化 (p. 63)• 预处理 (p. 64)• 训练 (p. 65)
优化要充分利用您的 GPU,您可以优化数据管道并调整深度学习网络。如以下图表所述,神经网络的简单或基本实施可能会不一致地使用 GPU 而不是充分使用它。当您优化预处理和数据加载时,您可以从您的 CPU 到GPU 减少瓶颈。您可以通过使用混合化(该框架支持时)、调整批大小并同步调用来调整神经网络本身。您也可以在大多数框架中使用多精度(float16 或 int8)训练,从而可以显著提高吞吐量。
63
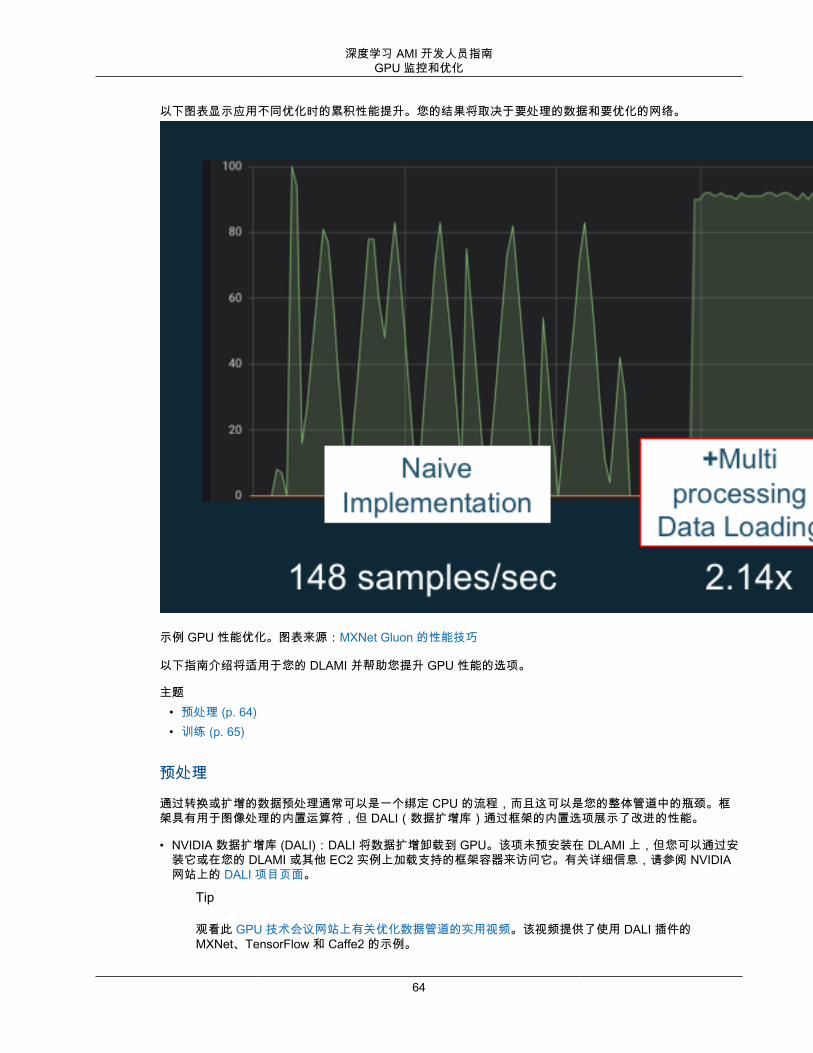
深度学习 AMI 开发人员指南GPU 监控和优化
以下图表显示应用不同优化时的累积性能提升。您的结果将取决于要处理的数据和要优化的网络。
示例 GPU 性能优化。图表来源:MXNet Gluon 的性能技巧
以下指南介绍将适用于您的 DLAMI 并帮助您提升 GPU 性能的选项。
主题• 预处理 (p. 64)• 训练 (p. 65)
预处理
通过转换或扩增的数据预处理通常可以是一个绑定 CPU 的流程,而且这可以是您的整体管道中的瓶颈。框架具有用于图像处理的内置运算符,但 DALI(数据扩增库)通过框架的内置选项展示了改进的性能。
• NVIDIA 数据扩增库 (DALI):DALI 将数据扩增卸载到 GPU。该项未预安装在 DLAMI 上,但您可以通过安装它或在您的 DLAMI 或其他 EC2 实例上加载支持的框架容器来访问它。有关详细信息,请参阅 NVIDIA网站上的 DALI 项目页面。
Tip
观看此 GPU 技术会议网站上有关优化数据管道的实用视频。该视频提供了使用 DALI 插件的MXNet、TensorFlow 和 Caffe2 的示例。
64

深度学习 AMI 开发人员指南推理
• nvJPEG:一个面向 C 编程人员的 GPU 加速型 JPEG 解码器库。它支持解码单个图像或批处理以及深度学习中常见的后续转换操作。nvJPEG 具有内置 DALI,或者您可以从 NVIDIA 网站的 nvjpeg 页面下载并单独使用它。
您可能对有关 GPU 监控和优化的以下其他主题感兴趣:
• 监控 (p. 61)• 使用 CloudWatch 监控 GPU (p. 61)
• 优化 (p. 63)• 预处理 (p. 64)• 训练 (p. 65)
训练
利用混合精度训练,您可以使用相同的内存量部署更大的网络,或者减少内存使用量(与您的单精度或双精度网络相比),并且您将看到计算性能增加。您还将受益于更小且更快的数据传输,这在多节点分布式训练中是一个重要因素。要利用混合精度训练,您需要调整数据转换和损失比例。以下是介绍如何针对支持混合精度的框架执行此操作的指南。
• NVIDIA 深度学习开发工具包 - 有关 NVIDIA 网站的文档,介绍了NVCaffe、Caffe2、CNTK、MXNet、PyTorch、TensorFlow 和 Theano 的混合精度实施。
Tip
请务必针对您选择的框架检查网站,并且搜索“混合精度”或“fp16”,了解最新的优化方法。下面是可能对您有帮助的一些混合精度指南:
• 使用 TensorFlow 进行混合精度训练(视频) - 在 NVIDIA 博客站点上。• 结合使用 float16 与 MXNet 进行混合精度训练 - MXNet 网站上的常见问题解答文章。• NVIDIA Apex:用于使用 PyTorch 轻松进行混合精度训练的工具 - NVIDIA 网站上的博客文章。
您可能对有关 GPU 监控和优化的以下其他主题感兴趣:
• 监控 (p. 61)• 使用 CloudWatch 监控 GPU (p. 61)
• 优化 (p. 63)• 预处理 (p. 64)• 训练 (p. 65)
推理此部分提供了有关如何使用 DLAMI 的框架和工具运行推理的教程。
有关使用 Elastic Inference 的教程,请参阅使用 Amazon Elastic Inference
带框架的推理• 将适用于推理的 Apache MXNet 与 ONNX 模型结合使用 (p. 66)• 将 Apache MXNet for Inference 与 ResNet 50 模型结合使用 (p. 67)• 在推理中将 CNTK 与 ONNX 模型配合使用 (p. 68)
65

深度学习 AMI 开发人员指南推理
推理工具• 适用于 Apache MXNet 的模型服务器 (MMS) (p. 77)• TensorFlow Serving (p. 78)
将适用于推理的 Apache MXNet 与 ONNX 模型结合使用如何将适用于映像推理的 ONNX 模型与 MXNet 结合使用
1. • (适用于 Python 3 的选项)- 激活 Python 3 MXNet 环境:
$ source activate mxnet_p36
• (适用于 Python 2 的选项)- 激活 Python 2 MXNet 环境:
$ source activate mxnet_p27
2. 其余步骤假定您使用的是 mxnet_p36 环境。3. 下载一张哈士奇的照片。
$ curl -O https://upload.wikimedia.org/wikipedia/commons/b/b5/Siberian_Husky_bi-eyed_Flickr.jpg
4. 下载将使用此模型的类的列表。
$ curl -O https://gist.githubusercontent.com/yrevar/6135f1bd8dcf2e0cc683/raw/d133d61a09d7e5a3b36b8c111a8dd5c4b5d560ee/imagenet1000_clsid_to_human.pkl
5. 使用您的首选文本编辑器来创建具有以下内容的脚本。此脚本将使用哈士奇的图片,从预训练模型中获得预测结果,然后在类文件中查找,并返回一个预测结果。
import mxnet as mximport numpy as npfrom collections import namedtuplefrom PIL import Imageimport pickle
# Preprocess the imageimg = Image.open("Siberian_Husky_bi-eyed_Flickr.jpg")img = img.resize((224,224))rgb_img = np.asarray(img, dtype=np.float32) - 128bgr_img = rgb_img[..., [2,1,0]]img_data = np.ascontiguousarray(np.rollaxis(bgr_img,2))img_data = img_data[np.newaxis, :, :, :].astype(np.float32)
# Define the model's inputdata_names = ['data']Batch = namedtuple('Batch', data_names)
# Set the context to cpu or gpuctx = mx.cpu()
# Load the modelsym, arg, aux = onnx_mxnet.import_model("vgg16.onnx")mod = mx.mod.Module(symbol=sym, data_names=data_names, context=ctx, label_names=None)mod.bind(for_training=False, data_shapes=[(data_names[0],img_data.shape)], label_shapes=None)mod.set_params(arg_params=arg, aux_params=aux, allow_missing=True, allow_extra=True)
66

深度学习 AMI 开发人员指南推理
# Run inference on the imagemod.forward(Batch([mx.nd.array(img_data)]))predictions = mod.get_outputs()[0].asnumpy()top_class = np.argmax(predictions)print(top_class)labels_dict = pickle.load(open("imagenet1000_clsid_to_human.pkl", "rb"))print(labels_dict[top_class])
6. 然后运行脚本,您应看到一个如下所示的结果:
248Eskimo dog, husky
将 Apache MXNet for Inference 与 ResNet 50 模型结合使用如何将预训练的 MXNet 模型与 Symbol API for Image Inference 和 MXNet 结合使用
1. • (适用于 Python 3 的选项)- 激活 Python 3 MXNet 环境:
$ source activate mxnet_p36
• (适用于 Python 2 的选项)- 激活 Python 2 MXNet 环境:
$ source activate mxnet_p27
2. 其余步骤假定您使用的是 mxnet_p36 环境。3. 使用您的首选文本编辑器来创建具有以下内容的脚本。此脚本将下载 ResNet-50 模型文件
(resnet-50-0000.params 和 resnet-50-symbol.json)和标签列表 (synset.txt),下载一张猫的图片以从预训练模型中获得预测结果,然后在标签列表中的结果中查找,并返回一个预测结果。
import mxnet as mximport numpy as np
path='http://data.mxnet.io/models/imagenet/'[mx.test_utils.download(path+'resnet/50-layers/resnet-50-0000.params'), mx.test_utils.download(path+'resnet/50-layers/resnet-50-symbol.json'), mx.test_utils.download(path+'synset.txt')]
ctx = mx.cpu()
with open('synset.txt', 'r') as f: labels = [l.rstrip() for l in f]
sym, args, aux = mx.model.load_checkpoint('resnet-50', 0)
fname = mx.test_utils.download('https://github.com/dmlc/web-data/blob/master/mxnet/doc/tutorials/python/predict_image/cat.jpg?raw=true')img = mx.image.imread(fname)# convert into format (batch, RGB, width, height)img = mx.image.imresize(img, 224, 224) # resizeimg = img.transpose((2, 0, 1)) # Channel firstimg = img.expand_dims(axis=0) # batchifyimg = img.astype(dtype='float32')args['data'] = img
softmax = mx.nd.random_normal(shape=(1,))args['softmax_label'] = softmax
exe = sym.bind(ctx=ctx, args=args, aux_states=aux, grad_req='null')
67

深度学习 AMI 开发人员指南推理
exe.forward()prob = exe.outputs[0].asnumpy()# print the top-5prob = np.squeeze(prob)a = np.argsort(prob)[::-1]for i in a[0:5]: print('probability=%f, class=%s' %(prob[i], labels[i]))
4. 然后运行脚本,您应看到一个如下所示的结果:
probability=0.418679, class=n02119789 kit fox, Vulpes macrotisprobability=0.293495, class=n02119022 red fox, Vulpes vulpesprobability=0.029321, class=n02120505 grey fox, gray fox, Urocyon cinereoargenteusprobability=0.026230, class=n02124075 Egyptian catprobability=0.022557, class=n02085620 Chihuahua
在推理中将 CNTK 与 ONNX 模型配合使用如何在推理中将 ONNX 模型与 CNTK 配合使用
1. • (适用于 Python 3 的选项)- 激活 Python 3 CNTK 环境:
$ source activate cntk_p36
• (适用于 Python 2 的选项)- 激活 Python 2 CNTK 环境:
$ source activate cntk_p27
2. 其余步骤假定您使用的是 cntk_p36 环境。3. 使用文本编辑器创建一个新文件,并在脚本中使用以下程序以在 CNTK 中打开 ONNX 格式文件。
import cntk as C# Import the Chainer model into CNTK via CNTK's import APIz = C.Function.load("vgg16.onnx", device=C.device.cpu(), format=C.ModelFormat.ONNX)print("Loaded vgg16.onnx!")
在运行此脚本后,CNTK 将加载模型。4. 您还可以尝试使用 CNTK 运行推理。首先,下载一张哈士奇的照片。
$ curl -O https://upload.wikimedia.org/wikipedia/commons/b/b5/Siberian_Husky_bi-eyed_Flickr.jpg
5. 接下来,下载将使用此模型的类的列表。
$ curl -O https://gist.githubusercontent.com/yrevar/6135f1bd8dcf2e0cc683/raw/d133d61a09d7e5a3b36b8c111a8dd5c4b5d560ee/imagenet1000_clsid_to_human.pkl
6. 编辑先前创建的脚本以包含以下内容。此新版本将使用哈士奇的图片,得到一个预测结果,然后在类文件中查找,返回一个预测结果。
import cntk as Cimport numpy as npfrom PIL import Imagefrom IPython.core.display import displayimport pickle
68

深度学习 AMI 开发人员指南将框架用于 ONNX
# Import the model into CNTK via CNTK's import APIz = C.Function.load("vgg16.onnx", device=C.device.cpu(), format=C.ModelFormat.ONNX)print("Loaded vgg16.onnx!")img = Image.open("Siberian_Husky_bi-eyed_Flickr.jpg")img = img.resize((224,224))rgb_img = np.asarray(img, dtype=np.float32) - 128bgr_img = rgb_img[..., [2,1,0]]img_data = np.ascontiguousarray(np.rollaxis(bgr_img,2))predictions = np.squeeze(z.eval({z.arguments[0]:[img_data]}))top_class = np.argmax(predictions)print(top_class)labels_dict = pickle.load(open("imagenet1000_clsid_to_human.pkl", "rb"))print(labels_dict[top_class])
7. 然后运行脚本,您应看到一个如下所示的结果:
248Eskimo dog, husky
将框架用于 ONNX采用 Conda 的 Deep Learning AMI 现在对于部分框架支持开放神经网络交换 (ONNX) 模型。选择下方列出的主题之一,以了解如何在 采用 Conda 的 Deep Learning AMI 上使用 ONNX。
关于 ONNX开放神经网络交换 (ONNX) 是一种用于表示深度学习模型的开放格式。ONNX 受到 Amazon WebServices、Microsoft、Facebook 和其他多个合作伙伴的支持。您可以使用任何选定的框架来设计、训练和部署深度学习模型。ONNX 模型的好处是,它们可以在框架之间轻松移动。
采用 Conda 的 Deep Learning AMI 当前的特色是支持以下教程集中的一些 ONNX 功能。• 有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程 (p. 69)• 有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程 (p. 71)• 有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程 (p. 72)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)
您可能还需要参考 ONNX 项目文档和教程:
• GitHub 上的 ONNX 项目• ONNX 教程
有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程ONNX 概述
开放神经网络交换 (ONNX) 是一种用于表示深度学习模型的开放格式。ONNX 受到 Amazon WebServices、Microsoft、Facebook 和其他多个合作伙伴的支持。您可以使用任何选定的框架来设计、训练和部署深度学习模型。ONNX 模型的好处是,它们可以在框架之间轻松移动。
本教程介绍如何将 采用 Conda 的 Deep Learning AMI 与 ONNX 结合使用。通过执行以下步骤,您可以训练模型或从一个框架中加载预先训练的模型,将此模型导出为 ONNX,然后将此模型导入到另一个框架中。
69

深度学习 AMI 开发人员指南将框架用于 ONNX
ONNX 先决条件要使用此 ONNX 教程,您必须有权访问 采用 Conda 的 Deep Learning AMI 版本 12 或更高版本。有关如何开始使用 采用 Conda 的 Deep Learning AMI 的更多信息,请参阅 采用 Conda 的 Deep LearningAMI (p. 3)。
Important
这些示例使用可能需要多达 8 GB 内存(或更多)的函数。请务必选择具有足量内存的实例类型。
使用 采用 Conda 的 Deep Learning AMI 启动终端会话以开始以下教程。
将 Apache MXNet(孵化)模型转换为 ONNX,然后将模型加载到 CNTK 中
如何从 Apache MXNet(孵化)中导出模型
您可以将最新的 MXNet 工作版本安装到您的 采用 Conda 的 Deep Learning AMI 上的任一或两个 MXNetConda 环境。
1. • (适用于 Python 3 的选项)- 激活 Python 3 MXNet 环境:
$ source activate mxnet_p36
• (适用于 Python 2 的选项)- 激活 Python 2 MXNet 环境:
$ source activate mxnet_p27
2. 其余步骤假定您使用的是 mxnet_p36 环境。3. 下载模型文件。
curl -O https://s3.amazonaws.com/onnx-mxnet/model-zoo/vgg16/vgg16-symbol.jsoncurl -O https://s3.amazonaws.com/onnx-mxnet/model-zoo/vgg16/vgg16-0000.params
4. 要将模型文件从 MXNet 导出为 ONNX 格式,使用文本编辑器创建一个新文件,并在脚本中使用以下程序。
import numpy as npimport mxnet as mxfrom mxnet.contrib import onnx as onnx_mxnetconverted_onnx_filename='vgg16.onnx'
# Export MXNet model to ONNX format via MXNet's export_model APIconverted_onnx_filename=onnx_mxnet.export_model('vgg16-symbol.json', 'vgg16-0000.params', [(1,3,224,224)], np.float32, converted_onnx_filename)
# Check that the newly created model is valid and meets ONNX specification.import onnxmodel_proto = onnx.load(converted_onnx_filename)onnx.checker.check_model(model_proto)
您可能会看到一些警告消息,不过您目前可以安全地忽略它们。在您运行此脚本后,您将在同一目录中看到新创建的 .onnx 文件。
5. 现在您有一个 ONNX 文件,可以将其与以下示例结合使用来尝试运行推理:
• 在推理中将 CNTK 与 ONNX 模型配合使用 (p. 68)
ONNX 教程
• 有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程 (p. 69)
70

深度学习 AMI 开发人员指南将框架用于 ONNX
• 有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程 (p. 71)• 有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程 (p. 72)• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)
有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程ONNX 概述
开放神经网络交换 (ONNX) 是一种用于表示深度学习模型的开放格式。ONNX 受到 Amazon WebServices、Microsoft、Facebook 和其他多个合作伙伴的支持。您可以使用任何选定的框架来设计、训练和部署深度学习模型。ONNX 模型的好处是,它们可以在框架之间轻松移动。
本教程介绍如何将 采用 Conda 的 Deep Learning AMI 与 ONNX 结合使用。通过执行以下步骤,您可以训练模型或从一个框架中加载预先训练的模型,将此模型导出为 ONNX,然后将此模型导入到另一个框架中。
ONNX 先决条件
要使用此 ONNX 教程,您必须有权访问 采用 Conda 的 Deep Learning AMI 版本 12 或更高版本。有关如何开始使用 采用 Conda 的 Deep Learning AMI 的更多信息,请参阅 采用 Conda 的 Deep LearningAMI (p. 3)。
Important
这些示例使用可能需要多达 8 GB 内存(或更多)的函数。请务必选择具有足量内存的实例类型。
使用 采用 Conda 的 Deep Learning AMI 启动终端会话以开始以下教程。
将 Chainer 模型转换为 ONNX,然后将模型加载到 CNTK 中
首先,激活 Chainer 环境:
$ source activate chainer_p36
使用文本编辑器创建一个新文件,并在脚本中使用以下程序来从 Chainer Model Zoo 中提取模型,然后将它导出为 ONNX 格式。
import numpy as npimport chainerimport chainercv.links as Limport onnx_chainer
# Fetch a vgg16 modelmodel = L.VGG16(pretrained_model='imagenet')
# Prepare an input tensorx = np.random.rand(1, 3, 224, 224).astype(np.float32) * 255
# Run the model on the datawith chainer.using_config('train', False): chainer_out = model(x).array
# Export the model to a .onnx fileout = onnx_chainer.export(model, x, filename='vgg16.onnx')
# Check that the newly created model is valid and meets ONNX specification.import onnx
71

深度学习 AMI 开发人员指南将框架用于 ONNX
model_proto = onnx.load("vgg16.onnx")onnx.checker.check_model(model_proto)
在您运行此脚本后,您将在同一目录中看到新创建的 .onnx 文件。
现在您有一个 ONNX 文件,可以将其与以下示例结合使用来尝试运行推理:
• 在推理中将 CNTK 与 ONNX 模型配合使用 (p. 68)
ONNX 教程
• 有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程 (p. 69)• 有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程 (p. 71)• 有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程 (p. 72)• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)
有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程ONNX 概述开放神经网络交换 (ONNX) 是一种用于表示深度学习模型的开放格式。ONNX 受到 Amazon WebServices、Microsoft、Facebook 和其他多个合作伙伴的支持。您可以使用任何选定的框架来设计、训练和部署深度学习模型。ONNX 模型的好处是,它们可以在框架之间轻松移动。
本教程介绍如何将 采用 Conda 的 Deep Learning AMI 与 ONNX 结合使用。通过执行以下步骤,您可以训练模型或从一个框架中加载预先训练的模型,将此模型导出为 ONNX,然后将此模型导入到另一个框架中。
ONNX 先决条件要使用此 ONNX 教程,您必须有权访问 采用 Conda 的 Deep Learning AMI 版本 12 或更高版本。有关如何开始使用 采用 Conda 的 Deep Learning AMI 的更多信息,请参阅 采用 Conda 的 Deep LearningAMI (p. 3)。
Important
这些示例使用可能需要多达 8 GB 内存(或更多)的函数。请务必选择具有足量内存的实例类型。
使用 采用 Conda 的 Deep Learning AMI 启动终端会话以开始以下教程。
将 Chainer 模型转换为 ONNX,然后将模型加载到 MXNet 中首先,激活 Chainer 环境:
$ source activate chainer_p36
使用文本编辑器创建一个新文件,并在脚本中使用以下程序来从 Chainer Model Zoo 中提取模型,然后将它导出为 ONNX 格式。
import numpy as npimport chainerimport chainercv.links as Limport onnx_chainer
# Fetch a vgg16 model
72

深度学习 AMI 开发人员指南将框架用于 ONNX
model = L.VGG16(pretrained_model='imagenet')
# Prepare an input tensorx = np.random.rand(1, 3, 224, 224).astype(np.float32) * 255
# Run the model on the datawith chainer.using_config('train', False): chainer_out = model(x).array
# Export the model to a .onnx fileout = onnx_chainer.export(model, x, filename='vgg16.onnx')
# Check that the newly created model is valid and meets ONNX specification.import onnxmodel_proto = onnx.load("vgg16.onnx")onnx.checker.check_model(model_proto)
在您运行此脚本后,您将在同一目录中看到新创建的 .onnx 文件。
现在您有一个 ONNX 文件,可以将其与以下示例结合使用来尝试运行推理:
• 将适用于推理的 Apache MXNet 与 ONNX 模型结合使用 (p. 66)
ONNX 教程
• 有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程 (p. 69)• 有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程 (p. 71)• 有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程 (p. 72)• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)
有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程ONNX 概述
开放神经网络交换 (ONNX) 是一种用于表示深度学习模型的开放格式。ONNX 受到 Amazon WebServices、Microsoft、Facebook 和其他多个合作伙伴的支持。您可以使用任何选定的框架来设计、训练和部署深度学习模型。ONNX 模型的好处是,它们可以在框架之间轻松移动。
本教程介绍如何将 采用 Conda 的 Deep Learning AMI 与 ONNX 结合使用。通过执行以下步骤,您可以训练模型或从一个框架中加载预先训练的模型,将此模型导出为 ONNX,然后将此模型导入到另一个框架中。
ONNX 先决条件
要使用此 ONNX 教程,您必须有权访问 采用 Conda 的 Deep Learning AMI 版本 12 或更高版本。有关如何开始使用 采用 Conda 的 Deep Learning AMI 的更多信息,请参阅 采用 Conda 的 Deep LearningAMI (p. 3)。
Important
这些示例使用可能需要多达 8 GB 内存(或更多)的函数。请务必选择具有足量内存的实例类型。
使用 采用 Conda 的 Deep Learning AMI 启动终端会话以开始以下教程。
将 PyTorch 模型转换为 ONNX,然后将模型加载到 CNTK 中
首先,激活 PyTorch 环境:
73

深度学习 AMI 开发人员指南将框架用于 ONNX
$ source activate pytorch_p36
使用文本编辑器创建一个新文件,并在脚本中使用以下程序来训练 PyTorch 中的模拟模型,然后将它导出为ONNX 格式。
# Build a Mock Model in Pytorch with a convolution and a reduceMean layer\import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.autograd import Variableimport torch.onnx as torch_onnx
class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=(3,3), stride=1, padding=0, bias=False)
def forward(self, inputs): x = self.conv(inputs) #x = x.view(x.size()[0], x.size()[1], -1) return torch.mean(x, dim=2)
# Use this an input trace to serialize the modelinput_shape = (3, 100, 100)model_onnx_path = "torch_model.onnx"model = Model()model.train(False)
# Export the model to an ONNX filedummy_input = Variable(torch.randn(1, *input_shape))output = torch_onnx.export(model, dummy_input, model_onnx_path, verbose=False)
在您运行此脚本后,您将在同一目录中看到新创建的 .onnx 文件。现在,切换到 CNTK Conda 环境以使用CNTK 加载模型。
接下来,激活 CNTK 环境:
$ source deactivate$ source activate cntk_p36
使用文本编辑器创建一个新文件,并在脚本中使用以下程序以在 CNTK 中打开 ONNX 格式文件。
import cntk as C# Import the PyTorch model into CNTK via CNTK's import APIz = C.Function.load("torch_model.onnx", device=C.device.cpu(), format=C.ModelFormat.ONNX)
在运行此脚本后,CNTK 将加载模型。
您也可以通过以下方式使用 CNTK 导出为 ONNX:将以下内容追加到上一脚本,然后运行它。
# Export the model to ONNX via CNTK's export APIz.save("cntk_model.onnx", format=C.ModelFormat.ONNX)
74

深度学习 AMI 开发人员指南将框架用于 ONNX
ONNX 教程
• 有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程 (p. 69)• 有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程 (p. 71)• 有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程 (p. 72)• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)
有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程ONNX 概述
开放神经网络交换 (ONNX) 是一种用于表示深度学习模型的开放格式。ONNX 受到 Amazon WebServices、Microsoft、Facebook 和其他多个合作伙伴的支持。您可以使用任何选定的框架来设计、训练和部署深度学习模型。ONNX 模型的好处是,它们可以在框架之间轻松移动。
本教程介绍如何将 采用 Conda 的 Deep Learning AMI 与 ONNX 结合使用。通过执行以下步骤,您可以训练模型或从一个框架中加载预先训练的模型,将此模型导出为 ONNX,然后将此模型导入到另一个框架中。
ONNX 先决条件
要使用此 ONNX 教程,您必须有权访问 采用 Conda 的 Deep Learning AMI 版本 12 或更高版本。有关如何开始使用 采用 Conda 的 Deep Learning AMI 的更多信息,请参阅 采用 Conda 的 Deep LearningAMI (p. 3)。
Important
这些示例使用可能需要多达 8 GB 内存(或更多)的函数。请务必选择具有足量内存的实例类型。
使用 采用 Conda 的 Deep Learning AMI 启动终端会话以开始以下教程。
将 PyTorch 模型转换为 ONNX,然后将模型加载到 MXNet 中
首先,激活 PyTorch 环境:
$ source activate pytorch_p36
使用文本编辑器创建一个新文件,并在脚本中使用以下程序来训练 PyTorch 中的模拟模型,然后将它导出为ONNX 格式。
# Build a Mock Model in PyTorch with a convolution and a reduceMean layerimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.autograd import Variableimport torch.onnx as torch_onnx
class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=(3,3), stride=1, padding=0, bias=False)
75

深度学习 AMI 开发人员指南模型处理
def forward(self, inputs): x = self.conv(inputs) #x = x.view(x.size()[0], x.size()[1], -1) return torch.mean(x, dim=2)
# Use this an input trace to serialize the modelinput_shape = (3, 100, 100)model_onnx_path = "torch_model.onnx"model = Model()model.train(False)
# Export the model to an ONNX filedummy_input = Variable(torch.randn(1, *input_shape))output = torch_onnx.export(model, dummy_input, model_onnx_path, verbose=False)print("Export of torch_model.onnx complete!")
在您运行此脚本后,您将在同一目录中看到新创建的 .onnx 文件。现在,切换到 MXNet Conda 环境以使用MXNet 加载模型。
接下来,激活 MXNet 环境:
$ source deactivate$ source activate mxnet_p36
使用文本编辑器创建一个新文件,并在脚本中使用以下程序以在 MXNet 中打开 ONNX 格式文件。
import mxnet as mxfrom mxnet.contrib import onnx as onnx_mxnetimport numpy as np
# Import the ONNX model into MXNet's symbolic interfacesym, arg, aux = onnx_mxnet.import_model("torch_model.onnx")print("Loaded torch_model.onnx!")print(sym.get_internals())
运行此脚本后,MXNet 将拥有加载的模型,并打印一些基本模型信息。
ONNX 教程
• 有关将 Apache MXNet 转换为 ONNX,然后加载到 CNTK 的教程 (p. 69)• 有关将 Chainer 转换为 ONNX,然后加载到 CNTK 的教程 (p. 71)• 有关将 Chainer 转换为 ONNX,然后加载到 MXNet 的教程 (p. 72)• 有关将 PyTorch 转换为 ONNX,然后加载到 MXNet 的教程 (p. 75)• 有关将 PyTorch 转换为 ONNX,然后加载到 CNTK 的教程 (p. 73)
模型处理以下是已在 采用 Conda 的 Deep Learning AMI 上安装的模型处理选项。单击其中一个选项可了解如何使用该选项。
主题• 适用于 Apache MXNet 的模型服务器 (MMS) (p. 77)• TensorFlow Serving (p. 78)
76

深度学习 AMI 开发人员指南模型处理
适用于 Apache MXNet 的模型服务器 (MMS)适用于 Apache MXNet 的模型服务器 (MMS) 是一个灵活的工具,用于处理从 Apache MXNet(孵化) 导出或导出为开放神经网络交换 (ONNX) 模型格式的深度学习模型。MMS 随 DLAMI with Conda 一起预安装。本MMS 教程将演示如何处理图像分类模型。
主题• 在 MMS 上处理图像分类模型 (p. 77)• 其他示例 (p. 78)• 更多信息 (p. 78)
在 MMS 上处理图像分类模型本教程介绍如何利用 MMS 处理图像分类模型。该模型通过 MMS Model Zoo 提供,在您启动 MMS 时自动进行下载。在服务器开始运行后,它会立即侦听预测请求。在这种情况下,如果您上传图像 (一个小猫的图像),服务器会返回在其上训练该模型的 1,000 类中匹配的前 5 个类的预测。有关模型、模型的训练方式以及模型的测试方式的更多信息可在 MMS Model Zoo 中找到。
在 MMS 上处理示例图像分类模型
1. 连接到 采用 Conda 的 Deep Learning AMI 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。2. 激活 MXNet 环境:
• 对于使用 CUDA 9.0 和 MKL-DNN 的 Python 3 上的 MXNet 和 Keras 2,运行以下命令:
$ source activate mxnet_p36
• 对于使用 CUDA 9.0 和 MKL-DNN 的 Python 2 上的 MXNet 和 Keras 2,运行以下命令:
$ source activate mxnet_p27
3. 使用以下命令运行 MMS。添加 > /dev/null 将在您运行其他测试时生成无提示日志输出。
$ mxnet-model-server --start > /dev/null
MMS 现在正在您的主机上运行并且正在侦听推理请求。4. 接下来,使用 curl 命令管理 MMS 的管理终端节点,并告知它您希望它处理的模型。
$ curl -X POST "http://localhost:8081/models?url=https%3A%2F%2Fs3.amazonaws.com%2Fmodel-server%2Fmodels%2Fsqueezenet_v1.1%2Fsqueezenet_v1.1.model"
5. MMS 需要知道您要使用的工作线程的数量。对于此测试,您可以尝试 3。
$ curl -v -X PUT "http://localhost:8081/models/squeezenet_v1.1?min_worker=3"
6. 下载一个小猫图像并将其发送到 MMS 预测终端节点:
$ curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg$ curl -X POST http://127.0.0.1:8080/predictions/squeezenet_v1.1 -T kitten.jpg
该预测终端节点将返回一个 JSON 格式的预测 (类似于下面的前 5 个预测),其中,图像具有 94% 的可能性为埃及猫,然后有 5.5% 的可能性为猞猁或山猫:
{
77

深度学习 AMI 开发人员指南模型处理
"prediction": [ [{ "class": "n02124075 Egyptian cat", "probability": 0.940 }, { "class": "n02127052 lynx, catamount", "probability": 0.055 }, { "class": "n02123045 tabby, tabby cat", "probability": 0.002 }, { "class": "n02123159 tiger cat", "probability": 0.0003 }, { "class": "n02123394 Persian cat", "probability": 0.0002 } ] ]}
7. 测试更多映像,或者如果您已完成测试,请停止服务器:
$ mxnet-model-server --stop
本教程重点介绍基本模型处理。MMS 还支持将 Elastic Inference 与模型服务一起使用。有关更多信息,请参阅模型服务与 Amazon Elastic Inference
当您准备好了解有关其他 MMS 功能的更多信息时,请参阅 GitHub 上的 MMS 文档。
其他示例MMS 具有可在 DLAMI 上运行的各种示例。您可以在 MMS 项目存储库上查看它们。
更多信息有关更多 MMS 文档,包括如何使用 Docker 设置 MMS — 或要利用最新的 MMS 功能,请在 GitHub 上启动MMS 项目页面。
TensorFlow ServingTensorFlow Serving 是一个用于机器学习模型的灵活、高性能的服务系统。
tensorflow-serving-api 会随 采用 Conda 的 Deep Learning AMI 一起预安装! 您将在 ~/examples/tensorflow-serving/ 中找到一个用于训练、导出和处理 MNIST 模型的示例脚本。
要运行这些示例中的任一示例,请先连接到您的 采用 Conda 的 Deep Learning AMI 并激活 Python 2.7TensorFlow 环境。该示例脚本不与 Python 3.x 兼容
$ source activate tensorflow_p27
现在,将目录更改至服务示例脚本文件夹。
$ cd ~/examples/tensorflow-serving/
78

深度学习 AMI 开发人员指南模型处理
处理预训练的 Inception 模型
以下是您可尝试为不同的模型(如 Inception)提供服务的示例。作为一般规则,您需要将可维护模型和客户端脚本下载到您的 DLAMI。
使用 Inception 模型处理和测试推理
1. 下载该模型。
$ curl -O https://s3-us-west-2.amazonaws.com/aws-tf-serving-ei-example/inception.zip
2. 解压缩模型。
$ unzip inception.zip
3. 下载一张哈士奇的照片。
$ curl -O https://upload.wikimedia.org/wikipedia/commons/b/b5/Siberian_Husky_bi-eyed_Flickr.jpg
4. 启动服务器。请注意,对于 Amazon Linux,您必须将用于 model_base_path 的目录从 /home/ubuntu 更改为 /home/ec2-user。
$ tensorflow_model_server --model_name=inception --model_base_path=/home/ubuntu/SERVING_INCEPTION/SERVING_INCEPTION --port=9000
5. 对于在前台运行的服务器,您将需要启动另一个终端会话才能继续。打开新的终端并使用 sourceactivate tensorflow_p27 激活 TensorFlow。然后,使用您的首选文本编辑器创建具有以下内容的脚本。将它命名为 inception_client.py。此脚本将映像文件名用作参数,并从预训练模型中获得预测结果。
from __future__ import print_function
import grpcimport tensorflow as tf
from tensorflow_serving.apis import predict_pb2from tensorflow_serving.apis import prediction_service_pb2_grpc
tf.app.flags.DEFINE_string('server', 'localhost:9000', 'PredictionService host:port')tf.app.flags.DEFINE_string('image', '', 'path to image in JPEG format')FLAGS = tf.app.flags.FLAGS
def main(_): channel = grpc.insecure_channel(FLAGS.server) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) # Send request with open(FLAGS.image, 'rb') as f: # See prediction_service.proto for gRPC request/response details. data = f.read() request = predict_pb2.PredictRequest() request.model_spec.name = 'inception' request.model_spec.signature_name = 'predict_images' request.inputs['images'].CopyFrom( tf.contrib.util.make_tensor_proto(data, shape=[1])) result = stub.Predict(request, 10.0) # 10 secs timeout print(result) print("Inception Client Passed")
79

深度学习 AMI 开发人员指南模型处理
if __name__ == '__main__': tf.app.run()
6. 现在,运行将服务器位置和端口以及哈士奇照片的文件名作为参数传递的脚本。
$ python inception_client.py --server=localhost:9000 --image Siberian_Husky_bi-eyed_Flickr.jpg
训练和处理 MNIST 模型
对于本教程,我们将导出模型并随后通过 tensorflow_model_server 应用程序处理它。最后,您可以使用示例客户端脚本测试模型服务器。
运行将训练和导出 MNIST 模型的脚本。作为脚本的唯一参数,您需要为其提供一个文件夹位置以保存该模型。现在,我们可以把它放入 mnist_model 中。该脚本将会为您创建此文件夹。
$ python mnist_saved_model.py /tmp/mnist_model
请耐心等待,因为此脚本可能需要一段时间才能提供输出。当训练完成并最终导出模型后,您应该看到以下内容:
Done training!Exporting trained model to mnist_model/1Done exporting!
下一步是运行 tensorflow_model_server 以处理导出的模型。
$ tensorflow_model_server --port=9000 --model_name=mnist --model_base_path=/tmp/mnist_model
为您提供了一个客户端脚本来测试服务器。
要对其进行测试,您将需要打开一个新的终端窗口。
$ python mnist_client.py --num_tests=1000 --server=localhost:9000
更多功能和示例
如果您有兴趣了解有关 TensorFlow Serving 的更多信息,请查看 TensorFlow 网站。
您也可以将 TensorFlow Serving 与 Amazon Elastic Inference 结合使用。了解有关如何将 Elastic Inference与 TensorFlow Serving 结合使用的指南。
80

深度学习 AMI 开发人员指南Amazon EC2 上的Deep Learning Containers
什么是 AWS Deep LearningContainers?
本指南将帮助您使用 AWS Deep Learning Containers设置深度学习环境。AWS 深度学习容器可包含各种用于深度学习的选项。例如,您可以选择深度学习框架,如 TensorFlow、PyTorch 或 MXNet、CUDA 版本和分布式训练增强器(如 Horovod)。Deep Learning Containers 可用于在 EC2、ECS和 EKS 上进行分布式训练。
本指南包含如何使用 EC2、ECS、EKS 和 SageMaker 上的 Deep Learning Containers 的设置和教程。
目录• Amazon EC2 上的 AWS Deep Learning Containers (p. 81)• Amazon ECS 上的 AWS Deep Learning Containers (p. 87)• Amazon EKS 上的 AWS Deep Learning Containers (p. 106)• Amazon SageMaker 上的 AWS Deep Learning Containers (p. 147)• 附录 (p. 147)
如需了解社区对于 AWS Deep Learning Containers的讨论,可访问 AWS 论坛。
Amazon EC2 上的 AWS Deep Learning ContainersAWS Deep Learning Containers是一组 Docker 映像,用于在 Amazon EC2 上的 TensorFlow、PyTorch 和MXNet 中训练和处理模型。Deep Learning Containers 为优化环境提供了 TensorFlow、MXNet、NvidiaCUDA(适用于 GPU 实例)以及 Intel MKL(适用于 CPU 实例)库且在 Elastic Container Registry(AmazonECR) 中可用。
本指南介绍如何将 AWS Deep Learning Containers与 Amazon EC2 结合使用。
内容• 设置 (p. 81)• 教程 (p. 82)
设置在开始之前,请满足以下先决条件:
• 创建 IAM 用户或修改具有下列策略的现有用户。您可以在 IAM 控制台的策略选项卡中按名称搜索策略。• AmazonECS_FullAccess 策略• AmazonEC2ContainerRegistryFullAccess
有关创建或编辑 IAM 用户的更多信息,请参阅 IAM 文档。• 启动 Amazon EC2 实例(CPU 或 GPU),最好是Deep Learning Base AMI (p. 4)。其他 AMI 虽然可运
行,但需要相关的 GPU 驱动程序。• 通过 SSH 连接到您的实例。有关更多详细信息,请参阅排查实例的连接问题。
81

深度学习 AMI 开发人员指南教程
• 在您的实例中,运行 aws configure 并提供已创建用户的凭证。• 在您的实例中,运行以下命令,登录到托管 AWS Deep Learning Containers映像的 Amazon ECR 存储
库。
$ $(aws ecr get-login --no-include-email --region us-east-1 --registry-ids 763104351884)
注:在上一个命令的开头处包含“'$”
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
教程本部分将指导您如何使用 MXNet、PyTorch 和 TensorFlow 在 EC2 的深度学习容器上运行训练和推理。
内容• 培训 (p. 82)• 推理 (p. 84)• 自定义入口点 (p. 87)
培训本部分将指导您如何使用 MXNet、PyTorch 和 TensorFlow 在 EC2 的深度学习容器上运行训练。
目录• TensorFlow 训练 (p. 82)• MXNet 训练 (p. 83)• PyTorch 训练 (p. 83)
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
TensorFlow 训练
我们可以使用以下命令运行容器。请注意,您必须对 GPU 映像使用“nvidia-docker”。
• 对于 CPU:
$ docker run -it <cpu training container>
• 对于 GPU:
$ nvidia-docker run -it <gpu training container>
82

深度学习 AMI 开发人员指南教程
上一命令以交互模式运行容器并在容器内提供一个 shell 提示符。然后,您可以运行以下命令以导入TensorFlow:
•$ python
•>> import tensorflow
按 CTRL+D 以返回到 bash 提示符。运行以下命令以开始训练:
•git clone https://github.com/fchollet/keras.git
•$ cd keras
•$ python examples/mnist_cnn.py
您将看到训练已开始。
MXNet 训练
要开始利用 MXNet 进行训练,请首先运行以下命令来运行容器:
• 对于 CPU:
$ docker run -it <cpu training container>
• 对于 GPU:
$ nvidia-docker run -it <gpu training container>
在容器的终端中,运行以下命令以开始训练:
• 对于 CPU:
$ git clone -b v1.4.1 https://github.com/apache/incubator-mxnet.gitpython incubator-mxnet/example/image-classification/train_mnist.py
• 对于 GPU:
$ git clone -b v1.4.1 https://github.com/apache/incubator-mxnet.gitpython incubator-mxnet/example/image-classification/train_mnist.py --gpus 0
PyTorch 训练
要开始利用 PyTorch 进行训练,请使用以下命令来运行容器。请注意,您必须对 GPU 映像使用“nvidia-docker”。
• 对于 CPU:
$ docker run -it <cpu training container>
• 对于 GPU:
83

深度学习 AMI 开发人员指南教程
$ nvidia-docker run -it <gpu training container>
• 如果您的 docker-ce 版本 >= 19.03,则可以在 docker 运行中使用 --gpus 标志:
$ docker run -it --gpus <gpu training container>
运行以下命令以开始训练:
• 对于 CPU:
$ git clone https://github.com/pytorch/examples.git$ python examples/mnist/main.py --no-cuda
• 对于 GPU:
$ git clone https://github.com/pytorch/examples.git$ python examples/mnist/main.py
您将看到训练已开始。
推理本部分将介绍如何使用 MXNet、PyTorch 和 TensorFlow 在 EC2 的深度学习容器上运行推理。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
目录• TensorFlow 推理 (p. 84)• MXNet 推理 (p. 85)• PyTorch 推理 (p. 86)
TensorFlow 推理为了演示如何将 Deep Learning Containers 用于推理,我们将以一个简单的“half plus two”模型为例来使用TensorFlow Serving。我们建议使用适用于 TensorFlow 的Deep Learning Base AMI (p. 4)。登录实例后,运行以下命令:
$ git clone -b r1.14 https://github.com/tensorflow/serving.git$ cd serving$ git checkout r1.14
现在,我们可以针对此模型使用Deep Learning Containers来启动 TensorFlow Serving。请注意,与用于训练的Deep Learning Containers不同,模型处理将在运行容器后立即开始,并且作为后台进程运行。
• 对于 CPU:
$ docker run -p 8500:8500 -p 8501:8501 --name tensorflow-inference --mount type=bind,source=$(pwd)/tensorflow_serving/servables/tensorflow/testdata/
84

深度学习 AMI 开发人员指南教程
saved_model_half_plus_two_cpu,target=/models/saved_model_half_plus_two -e MODEL_NAME=saved_model_half_plus_two -d <cpu inference container>
例如:
$ docker run -p 8500:8500 -p 8501:8501 --name tensorflow-inference --mount type=bind,source=$(pwd)/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu,target=/models/saved_model_half_plus_two -e MODEL_NAME=saved_model_half_plus_two -d 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.14.0-cpu-py36-ubuntu18.04
• 对于 GPU:
$ nvidia-docker run -p 8500:8500 -p 8501:8501 --name tensorflow-inference --mount type=bind,source=$(pwd)/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_gpu,target=/models/saved_model_half_plus_two -e MODEL_NAME=saved_model_half_plus_two -d <gpu inference container>
例如:
$ nvidia-docker run -p 8500:8500 -p 8501:8501 --name tensorflow-inference --mount type=bind,source=$(pwd)/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_gpu,target=/models/sad_model_half_plus_two -e MODEL_NAME=saved_model_half_plus_two -d 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.14.0-gpu-py36-cu100-ubuntu16.04
现在,我们可以通过 AWS Deep Learning Containers运行推理。
$ curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST http://127.0.0.1:8501/v1/models/saved_model_half_plus_two:predict
输出将类似如下:
{ "predictions": [2.5, 3.0, 4.5 ]}
Note
如果您想要调试容器的输出,可以使用名称来附加输出:
$ docker attach <your docker container name>
在此示例中,我们使用的是 tensorflow-inference。
MXNet 推理
为开始使用 MXNet 运行推理,我们将使用来自公有 S3 存储桶的一个预先训练好的模型。
对于 CPU 实例,运行:
$ docker run -itd --name mms -p 80:8080 -p 8081:8081 <your container image id> \mxnet-model-server --start --mms-config /home/model-server/config.properties \
85

深度学习 AMI 开发人员指南教程
--models squeezenet=https://s3.amazonaws.com/model-server/models/squeezenet_v1.1/squeezenet_v1.1.model
对于 GPU 实例,运行:
$ nvidia-docker run -itd --name mms -p 80:8080 -p 8081:8081 <your container image id> \mxnet-model-server --start --mms-config /home/model-server/config.properties \--models squeezenet=https://s3.amazonaws.com/model-server/models/squeezenet_v1.1/squeezenet_v1.1.model
注意:配置文件包含在容器中。
在启动您的服务器后,现在您可以使用以下命令从不同的窗口来运行推理:
$ curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpgcurl -X POST http://127.0.0.1/predictions/squeezenet -T kitten.jpg
一旦您使用完容器,即可使用以下命令将其删除:
$ docker rm -f mms
PyTorch 推理
要开始使用 PyTorch 进行推理,我们将使用来自公共 S3 存储桶的在 Imageet 上预先训练的模型。与 MXNet容器类似,使用 mxnet-model-server 提供推理,该服务器可以支持任何框架作为后端。有关更多信息,请参阅适用于 Apache MXNet 的模型服务器,以及这篇有关使用 MXNet Model Server 部署 PyTorch 推理的博客。
对于 CPU 实例,运行:
$ docker run -itd --name mms -p 80:8080 -p 8081:8081 <your container image id> \mxnet-model-server --start --mms-config /home/model-server/config.properties \--models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar
对于 GPU 实例,运行:
$ nvidia-docker run -itd --name mms -p 80:8080 -p 8081:8081 <your container image id> \mxnet-model-server --start --mms-config /home/model-server/config.properties \--models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar
如果您的 docker-ce 版本 >= 19.03,则可以在 docker 运行中使用 --gpus 标志。
注意:配置文件包含在容器中。
在启动您的服务器后,现在您可以使用以下命令从不同的窗口来运行推理:
$ curl -O https://s3.amazonaws.com/model-server/inputs/flower.jpgcurl -X POST http://127.0.0.1/predictions/densenet -T flower.jpg
一旦您使用完容器,即可使用以下命令将其删除:
$ docker rm -f mms
86

深度学习 AMI 开发人员指南ECS 上的 Deep Learning Containers
自定义入口点对于某些映像,AWS 容器使用自定义入口点脚本。如果您要使用自己的入口点,可以按如下方式覆盖入口点。
• 您可以指定要运行的自定义入口点脚本。
docker run --entrypoint=/path/to/custom_entrypoint_script -it <image> /bin/bash
• 或者,您可以将入口点设置为空。
docker run --entrypoint="" <image> /bin/bash
Amazon ECS 上的 AWS Deep Learning ContainersAWS Deep Learning Containers是一组 Docker 映像,用于在 Amazon Elastic Container Service (AmazonECS) 上的 TensorFlow、PyTorch 和 MXNet 中训练和处理模型。AWS Deep Learning Containers 为优化环境提供了 TensorFlow、MXNet、Nvidia CUDA(适用于 GPU 实例)以及 Intel MKL(适用于 CPU 实例)库且在 Amazon ECR 中可用。
本主题介绍如何将 AWS Deep Learning Containers与 Amazon ECS结合使用。
内容• 设置 (p. 87)• 教程 (p. 89)
设置本部分介绍如何使用 ECS 设置 AWS Deep Learning Containers。
目录• 先决条件 (p. 87)• 设置 Amazon ECS 以使用 AWS Deep Learning Containers (p. 88)
先决条件本教程假设您已完成以下先决条件:
• 安装并配置了最新版本的 AWS CLI。有关安装或升级 AWS CLI 的更多信息,请参阅安装 AWS CommandLine Interface。
• 您已完成使用 Amazon ECS 进行设置中的步骤。• 必须满足以下条件:
• 您的用户拥有管理员权限。有关更多信息,请参阅使用 Amazon ECS 进行设置。• 您的用户拥有创建服务角色的 IAM 权限。有关更多信息,请参阅创建角色以向 AWS 服务委派权限。• 一个拥有管理员权限的用户已手动创建这些 IAM 角色,使之对所用的账户可用。有关更多信息,请参
阅 Amazon Elastic Container Service Developer Guide 中的 Amazon ECS 服务计划程序 IAM 角色和Amazon ECS 容器实例 IAM 角色。
• Amazon CloudWatch Logs IAM 策略已经添加到 Amazon ECS 容器实例 IAM 角色,从而允许 AmazonECS 将日志发送到 Amazon CloudWatch。有关更多信息,请参阅 Amazon Elastic Container ServiceDeveloper Guide 中的 CloudWatch Logs IAM 策略。
87

深度学习 AMI 开发人员指南设置
• 您已生成密钥对。有关更多信息,请参阅 Amazon EC2 密钥对。• 您已经创建了一个新的安全组或更新了一个现有安全组,以便为所需的推理打开必要的端口。
• MXNet 推理:对于 TCP 流量打开端口 80 和 8081• TensorFlow 推理:对于 TCP 流量打开端口 8501 和 8500
有关更多信息,请参阅 Amazon EC2 安全组。
设置 Amazon ECS 以使用 AWS Deep Learning Containers本部分介绍如何设置 Amazon ECS 以便使用 AWS Deep Learning Containers。从您的主机运行以下操作。
1. 在包含您之前创建的密钥对和安全组的区域中创建 Amazon ECS 集群。
aws ecs create-cluster --cluster-name ecs-ec2-training-inference --region us-east-1
2. 在集群中启动一个或多个 Amazon EC2 实例。对于基于 GPU 的工作,请参阅在 Amazon ECS 上使用GPU 来指导实例类型选择。选择了实例类型后,再选择适合您的使用案例的 ECS 优化的 AMI。对于基于 CPU 的工作,可以使用 Amazon Linux 或 Amazon Linux 2 ECS 优化的 AMI。对于基于 GPU 的工作,必须使用 ECS GPU 优化的 AMI 和 p2/p3 实例类型。可在此处找到 Amazon ECS-优化的 AMI 的Amazon ECS-optimized AMI ID。在本示例中,我们将在 us-east-1 中启动一个具有基于 GPU 的 AMI和 100 GB 磁盘大小的实例。
a. 使用以下内容创建名为 my_script.txt 的文件。引用您在上一步中创建的同一集群名称。
#!/bin/bashecho ECS_CLUSTER=ecs-ec2-training-inference >> /etc/ecs/ecs.config
b. (可选)使用以下内容创建名为 my_mapping.txt 的文件,这将在创建实例后更改根卷的大小。
[ { "DeviceName": "/dev/xvda", "Ebs": { "VolumeSize": 100 } }]
c. 使用Amazon ECS-optimized AMI 启动 Amazon EC2 实例并将其附加到集群。使用您的安全组 ID和创建的密钥对名称并在以下命令中替换它们。要获取最新的 Amazon ECS-optimized AMI ID,请参阅 Amazon Elastic Container Service Developer Guide 中的 Amazon ECS 优化的 AMI。
aws ec2 run-instances --image-id ami-0dfdeb4b6d47a87a2 \ --count 1 \ --instance-type p2.8xlarge \ --key-name key-pair-1234 \ --security-group-ids sg-abcd1234 \ --iam-instance-profile Name="ecsInstanceRole" \ --user-data file://my_script.txt \ --block-device-mapping file://my_mapping.txt \ --region us-east-1
在 Amazon EC2 控制台中,您可以根据响应中的 instance-id 验证此步骤是否成功。
现在,您有一个正在运行容器实例的 Amazon ECS 集群。使用以下步骤验证 Amazon EC2 实例已注册到集群。
88

深度学习 AMI 开发人员指南教程
验证 Amazon EC2 实例是否已注册到集群
1. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。2. 选择您将 Amazon EC2 实例注册到的集群。3. 在 Cluster (集群) 页面上,选择 ECS Instances (ECS 实例)。4. 验证对于在上一步骤中创建的 instance-id,Agent Connected (代理已连接) 值是否为 True (真)。此
外,记下控制台上显示的可用 CPU 和内存值,因为在随后的教程中会用到这些值。上述值可能需要几分钟才能显示在控制台中。
教程本部分将指导您如何使用 MXNet、PyTorch 和 TensorFlow 在 ECS 的 AWS Deep Learning Containers上运行训练和推理。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
内容• 培训 (p. 89)• 推理 (p. 95)• 自定义入口点 (p. 106)
培训本部分介绍如何使用 MXNet、PyTorch 和 TensorFlow 在 ECS 的 AWS Deep Learning ContainersAWSDeep Learning Containers 上运行训练。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
目录• TensorFlow 训练 (p. 89)• MXNet 训练 (p. 91)• PyTorch 训练 (p. 93)
TensorFlow 训练您必须先注册任务定义才能在 ECS 集群上运行任务。任务定义是分组在一起的一系列容器。以下示例使用将训练脚本添加到 AWS Deep Learning Containers的示例 Docker 映像。
1. 使用以下内容创建名为 ecs-deep-learning-container-training-taskdef.json 的文件。
• 对于 CPU:
{ "requiresCompatibilities": [ "EC2"
89

深度学习 AMI 开发人员指南教程
], "containerDefinitions": [{ "command": [ "mkdir -p /test && cd /test && git clone https://github.com/fchollet/keras.git && chmod +x -R /test/ && python keras/examples/mnist_cnn.py" ], "entryPoint": [ "sh", "-c" ], "name": "tensorflow-training-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.14.0-cpu-py36-ubuntu16.04", "memory": 4000, "cpu": 256, "essential": true, "portMappings": [{ "containerPort": 80, "protocol": "tcp" }], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "awslogs-tf-ecs", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "tf", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "TensorFlow"}
• 对于 GPU
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [ { "command": [ "mkdir -p /test && cd /test && git clone https://github.com/fchollet/keras.git && chmod +x -R /test/ && python keras/examples/mnist_cnn.py" ], "entryPoint": [ "sh", "-c" ], "name": "tensorflow-training-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.14.0-gpu-py36-cu100-ubuntu16.04", "memory": 6111, "cpu": 256, "resourceRequirements" : [{ "type" : "GPU", "value" : "1" }], "essential": true, "portMappings": [ { "containerPort": 80,
90

深度学习 AMI 开发人员指南教程
"protocol": "tcp" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "awslogs-tf-ecs", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "tf", "awslogs-create-group": "true" } } } ], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "tensorflow-training" }
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-deep-learning-container-training-taskdef.json
3. 使用任务定义创建任务。您需要使用上一步中的修订 ID。
aws ecs run-task --cluster ecs-ec2-training-inference --task-definition tf:1
4. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。5. 选择 ecs-ec2-training-inference 集群。6. 在 Cluster (集群) 页面上,选择 Tasks (任务)。7. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。8. 在 Containers (容器) 下,展开容器详细信息。9. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日志 )。这
会将您转到 CloudWatch 控制台以查看训练进度日志。
MXNet 训练您必须先注册任务定义才能在 ECS 集群上运行任务。任务定义是分组在一起的一系列容器。以下示例使用将训练脚本添加到 AWS Deep Learning Containers的示例 Docker 映像。
1. 使用以下内容创建名为 ecs-deep-learning-container-training-taskdef.json 的文件。
• 对于 CPU:
{ "requiresCompatibilities":[ "EC2" ], "containerDefinitions":[ { "command":[ "git clone -b 1.4 https://github.com/apache/incubator-mxnet.git && python /incubator-mxnet/example/image-classification/train_mnist.py" ], "entryPoint":[ "sh", "-c" ],
91

深度学习 AMI 开发人员指南教程
"name":"mxnet-training", "image":"763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.1-cpu-py36-ubuntu16.04", "memory":4000, "cpu":256, "essential":true, "portMappings":[ { "containerPort":80, "protocol":"tcp" } ], "logConfiguration":{ "logDriver":"awslogs", "options":{ "awslogs-group":"/ecs/mxnet-training-cpu", "awslogs-region":"us-east-1", "awslogs-stream-prefix":"mnist", "awslogs-create-group":"true" } } } ], "volumes":[
], "networkMode":"bridge", "placementConstraints":[
], "family":"mxnet"}
• 对于 GPU:
{ "requiresCompatibilities":[ "EC2" ], "containerDefinitions":[ { "command":[ "git clone -b 1.4 https://github.com/apache/incubator-mxnet.git && python /incubator-mxnet/example/image-classification/train_mnist.py --gpus 0" ], "entryPoint":[ "sh", "-c" ], "name":"mxnet-training", "image":"763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04", "memory":4000, "cpu":256, "resourceRequirements":[ { "type":"GPU", "value":"1" } ], "essential":true, "portMappings":[ { "containerPort":80, "protocol":"tcp"
92

深度学习 AMI 开发人员指南教程
} ], "logConfiguration":{ "logDriver":"awslogs", "options":{ "awslogs-group":"/ecs/mxnet-training-gpu", "awslogs-region":"us-east-1", "awslogs-stream-prefix":"mnist", "awslogs-create-group":"true" } } } ], "volumes":[
], "networkMode":"bridge", "placementConstraints":[
], "family":"mxnet-training"}
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-deep-learning-container-training-taskdef.json
3. 使用任务定义创建任务。您需要使用上一步中的修订 ID。
aws ecs run-task --cluster ecs-ec2-training-inference --task-definition mx:1
4. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。5. 选择 ecs-ec2-training-inference 集群。6. 在 Cluster (集群) 页面上,选择 Tasks (任务)。7. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。8. 在 Containers (容器) 下,展开容器详细信息。9. 在 Log Configuration (日志配置) 中,选择 View logs in CloudWatch (查看 CloudWatch 中的日志)。这
会将您转到 CloudWatch 控制台以查看训练进度日志。
PyTorch 训练您必须先注册任务定义才能在 ECS 集群上运行任务。任务定义是分组在一起的一系列容器。以下示例使用将训练脚本添加到 AWS Deep Learning Containers的示例 Docker 映像。
1. 使用以下内容创建名为 ecs-deep-learning-container-training-taskdef.json 的文件。
• 对于 CPU:
{ "requiresCompatibilities":[ "EC2" ], "containerDefinitions":[ { "command":[ "git clone https://github.com/pytorch/examples.git && python examples/mnist/main.py --no-cuda" ], "entryPoint":[
93

深度学习 AMI 开发人员指南教程
"sh", "-c" ], "name":"pytorch-training-container", "image":"763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-cpu-py36-ubuntu16.04 ", "memory":4000, "cpu":256, "essential":true, "portMappings":[ { "containerPort":80, "protocol":"tcp" } ], "logConfiguration":{ "logDriver":"awslogs", "options":{ "awslogs-group":"/ecs/pytorch-training-cpu", "awslogs-region":"us-east-1", "awslogs-stream-prefix":"mnist", "awslogs-create-group":"true" } } } ], "volumes":[
], "networkMode":"bridge", "placementConstraints":[
], "family":"pytorch"}
• 对于 GPU:
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [ { "command": [ "git clone https://github.com/pytorch/examples.git && python examples/mnist/main.py" ], "entryPoint": [ "sh", "-c" ], "name": "pytorch-training-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-gpu-py36-cu100-ubuntu16.04 ", "memory": 6111, "cpu": 256, "resourceRequirements" : [{ "type" : "GPU", "value" : "1" }], "essential": true, "portMappings": [ { "containerPort": 80,
94

深度学习 AMI 开发人员指南教程
"protocol": "tcp" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/pytorch-training-gpu", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "mnist", "awslogs-create-group": "true" } } } ], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "pytorch-training" }
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-deep-learning-container-training-taskdef.json
3. 使用任务定义创建任务。您需要使用上一步中的修订 ID。
aws ecs run-task --cluster ecs-ec2-training-inference --task-definition pytorch:1
4. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。5. 选择 ecs-ec2-training-inference 集群。6. 在 Cluster (集群) 页面上,选择 Tasks (任务)。7. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。8. 在 Containers (容器) 下,展开容器详细信息。9. 在 Log Configuration (日志配置) 中,选择 View logs in CloudWatch (查看 CloudWatch 中的日志)。这
会将您转到 CloudWatch 控制台以查看训练进度日志。
推理本部分将指导您如何使用 MXNet、PyTorch 和 TensorFlow 在 ECS 的 AWS Deep Learning Containers上运行推理。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
目录• TensorFlow 推理 (p. 95)• MXNet 推理 (p. 99)• PyTorch 推理 (p. 103)
TensorFlow 推理
以下示例使用将 CPU 或 GPU 推理脚本添加到 AWS Deep Learning Containers的示例 Docker 映像。
95

深度学习 AMI 开发人员指南教程
基于 CPU 的推理
使用以下示例运行基于 CPU 的推理。
1. 使用以下内容创建名为 ecs-dlc-cpu-inference-taskdef.json 的文件。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mkdir -p /test && cd /test && git clone -b r1.14 https://github.com/tensorflow/serving.git && tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=saved_model_half_plus_two --model_base_path=/test/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu" ], "entryPoint": [ "sh", "-c" ], "name": "tensorflow-inference-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.14.0-cpu-py36-ubuntu18.04", "memory": 8111, "cpu": 256, "essential": true, "portMappings": [{ "hostPort": 8500, "protocol": "tcp", "containerPort": 8500 }, { "hostPort": 8501, "protocol": "tcp", "containerPort": 8501 }, { "containerPort": 80, "protocol": "tcp" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/tensorflow-inference-gpu", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "half-plus-two", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "tensorflow-inference"}
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-dlc-cpu-inference-taskdef.json
96

深度学习 AMI 开发人员指南教程
3. 创建 Amazon ECS 服务。当指定任务定义时,请将 revision_id 替换为上一步的输出中任务定义的修订号。
aws ecs create-service --cluster ecs-ec2-training-inference \ --service-name cli-ec2-inference-cpu \ --task-definition Ec2TFInference:revision_id \ --desired-count 1 \ --launch-type EC2 \ --scheduling-strategy="REPLICA" \ --region us-east-1
4. 通过完成以下步骤来验证服务并获取网络终端节点。
a. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。b. 选择 ecs-ec2-training-inference 集群。c. 在 Cluster (集群) 页面上,选择 Services (服务),然后选择 cli-ec2-inference-cpu。d. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。e. 在 Containers (容器) 下,展开容器详细信息。f. 在 Name (名称) 和 Network Bindings (网络绑定) 下,在 External Link (外部链接) 下,记下端口
8501 的 IP 地址。g. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日
志 )。这会将您转到 CloudWatch 控制台以查看训练进度日志。5. 要运行推理,请使用以下命令,并且将外部 IP 地址替换为上一步中的外部链接 IP 地址。
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST http://<External ip>:8501/v1/models/saved_model_half_plus_two:predict
下面是示例输出。
{ "predictions": [2.5, 3.0, 4.5 ]}
Important
If you are unable to connect to the external IP address, be sure that your corporate firewall isnot blocking non-standards ports, like 8501. You can try switching to a guest network to verify.
基于 GPU 的推理
使用以下示例运行基于 GPU 的推理。
1. 使用以下内容创建名为 ecs-dlc-gpu-inference-taskdef.json 的文件。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mkdir -p /test && cd /test && git clone -b r1.13 https://github.com/tensorflow/serving.git && tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=saved_model_half_plus_two --model_base_path=/test/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two" ],
97

深度学习 AMI 开发人员指南教程
"entryPoint": [ "sh", "-c" ], "name": "tensorflow-inference-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.14.0-gpu-py36-cu100-ubuntu16.04", "memory": 8111, "cpu": 256, "resourceRequirements": [{ "type": "GPU", "value": "1" }], "essential": true, "portMappings": [{ "hostPort": 8500, "protocol": "tcp", "containerPort": 8500 }, { "hostPort": 8501, "protocol": "tcp", "containerPort": 8501 }, { "containerPort": 80, "protocol": "tcp" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/TFInference", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "ecs", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "TensorFlowInference"}
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-dlc-gpu-inference-taskdef.json
3. 创建 Amazon ECS 服务。当指定任务定义时,请将 revision_id 替换为上一步的输出中任务定义的修订号。
aws ecs create-service --cluster ecs-ec2-training-inference \ --service-name cli-ec2-inference-gpu \ --task-definition Ec2TFInference:revision_id \ --desired-count 1 \ --launch-type EC2 \ --scheduling-strategy="REPLICA" \ --region us-east-1
4. 通过完成以下步骤来验证服务并获取网络终端节点。
a. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。
98

深度学习 AMI 开发人员指南教程
b. 选择 ecs-ec2-training-inference 集群。c. 在 Cluster (集群) 页面上,选择 Services (服务),然后选择 cli-ec2-inference-cpu。d. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。e. 在 Containers (容器) 下,展开容器详细信息。f. 在 Name (名称) 和 Network Bindings (网络绑定) 下,在 External Link (外部链接) 下,记下端口
8501 的 IP 地址。g. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日
志 )。这会将您转到 CloudWatch 控制台以查看训练进度日志。5. 要运行推理,请使用以下命令,并且将外部 IP 地址替换为上一步中的外部链接 IP 地址。
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST http://<External ip>:8501/v1/models/saved_model_half_plus_two_gpu:predict
下面是示例输出。
{ "predictions": [2.5, 3.0, 4.5 ]}
Important
If you are unable to connect to the external IP address, be sure that your corporate firewall isnot blocking non-standards ports, like 8501. You can try switching to a guest network to verify.
MXNet 推理
您必须先注册任务定义才能在 ECS 集群上运行任务。任务定义是分组在一起的一系列容器。以下示例使用将CPU 或 GPU 推理脚本添加到 AWS Deep Learning Containers的示例 Docker 映像。
基于 CPU 的推理
使用以下任务定义运行基于 CPU 的推理。
1. 使用以下内容创建名为 ecs-dlc-cpu-inference-taskdef.json 的文件。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mxnet-model-server --start --mms-config /home/model-server/config.properties --models squeezenet=https://s3.amazonaws.com/model-server/models/squeezenet_v1.1/squeezenet_v1.1.model" ], "name": "mxnet-inference-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.1-cpu-py36-ubuntu16.04", "memory": 8111, "cpu": 256, "essential": true, "portMappings": [{ "hostPort": 8081, "protocol": "tcp", "containerPort": 8081 },
99

深度学习 AMI 开发人员指南教程
{ "hostPort": 80, "protocol": "tcp", "containerPort": 8080 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/mxnet-inference-cpu", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "squeezenet", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "mxnet-inference"}
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-dlc-cpu-inference-taskdef.json
3. 创建 Amazon ECS 服务。当指定任务定义时,请将 revision_id 替换为上一步的输出中任务定义的修订号。
aws ecs create-service --cluster ecs-ec2-training-inference \ --service-name cli-ec2-inference-cpu \ --task-definition Ec2TFInference:revision_id \ --desired-count 1 \ --launch-type EC2 \ --scheduling-strategy REPLICA \ --region us-east-1
4. 验证服务并获取终端节点。
a. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。b. 选择 ecs-ec2-training-inference 集群。c. 在 Cluster (集群) 页面上,选择 Services (服务),然后选择 cli-ec2-inference-cpu。d. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。e. 在 Containers (容器) 下,展开容器详细信息。f. 在 Name (名称) 和 Network Bindings (网络绑定) 下,在 External Link (外部链接) 下,记下端口
8501 的 IP 地址。g. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日
志 )。这会将您转到 CloudWatch 控制台以查看训练进度日志。5. 要运行推理,请使用以下命令。
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpgcurl -X POST http://<External ip>/predictions/squeezenet -T kitten.jpg
下面是示例输出。
[ { "probability": 0.8582226634025574,
100

深度学习 AMI 开发人员指南教程
"class": "n02124075 Egyptian cat" }, { "probability": 0.09160050004720688, "class": "n02123045 tabby, tabby cat" }, { "probability": 0.037487514317035675, "class": "n02123159 tiger cat" }, { "probability": 0.0061649843119084835, "class": "n02128385 leopard, Panthera pardus" }, { "probability": 0.003171598305925727, "class": "n02127052 lynx, catamount" }]
Important
If you are unable to connect to the external IP address, be sure that your corporate firewall isnot blocking non-standards ports, like 8501. You can try switching to a guest network to verify.
基于 GPU 的推理
使用以下任务定义运行基于 GPU 的推理。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mxnet-model-server --start --mms-config /home/model-server/config.properties --models squeezenet=https://s3.amazonaws.com/model-server/models/squeezenet_v1.1/squeezenet_v1.1.model" ], "name": "mxnet-inference-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.1-gpu-py36-cu100-ubuntu16.04", "memory": 8111, "cpu": 256, "resourceRequirements": [{ "type": "GPU", "value": "1" }], "essential": true, "portMappings": [{ "hostPort": 8081, "protocol": "tcp", "containerPort": 8081 }, { "hostPort": 80, "protocol": "tcp", "containerPort": 8080 } ], "logConfiguration": { "logDriver": "awslogs", "options": {
101

深度学习 AMI 开发人员指南教程
"awslogs-group": "/ecs/mxnet-inference-gpu", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "squeezenet", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "mxnet-inference"}
1. 使用以下命令注册任务定义。记下修订号的输出。
aws ecs register-task-definition --cli-input-json file://<Task definition file>
2. 要创建服务,请在以下命令中将 revision_id 替换为上一步中的输出。
aws ecs create-service --cluster ecs-ec2-training-inference \ --service-name cli-ec2-inference-gpu \ --task-definition Ec2TFInference:<revision_id> \ --desired-count 1 \ --launch-type "EC2" \ --scheduling-strategy REPLICA \ --region us-east-1
3. 验证服务并获取终端节点。
a. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。b. 选择 ecs-ec2-training-inference 集群。c. 在 Cluster (集群) 页面上,选择 Services (服务),然后选择 cli-ec2-inference-cpu。d. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。e. 在 Containers (容器) 下,展开容器详细信息。f. 在 Name (名称) 和 Network Bindings (网络绑定) 下,在 External Link (外部链接) 下,记下端口
8501 的 IP 地址。g. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日
志 )。这会将您转到 CloudWatch 控制台以查看训练进度日志。4. 要运行推理,请使用以下命令。
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpgcurl -X POST http://<External ip>/predictions/squeezenet -T kitten.jpg
下面是示例输出。
[ { "probability": 0.8582226634025574, "class": "n02124075 Egyptian cat" }, { "probability": 0.09160050004720688, "class": "n02123045 tabby, tabby cat" }, { "probability": 0.037487514317035675, "class": "n02123159 tiger cat" },
102

深度学习 AMI 开发人员指南教程
{ "probability": 0.0061649843119084835, "class": "n02128385 leopard, Panthera pardus" }, { "probability": 0.003171598305925727, "class": "n02127052 lynx, catamount" }]
Important
If you are unable to connect to the external IP address, be sure that your corporate firewall isnot blocking non-standards ports, like 8501. You can try switching to a guest network to verify.
PyTorch 推理
您必须先注册任务定义才能在 ECS 集群上运行任务。任务定义是分组在一起的一系列容器。以下示例使用将CPU 或 GPU 推理脚本添加到 AWS Deep Learning Containers的示例 Docker 映像。
基于 CPU 的推理
使用以下任务定义运行基于 CPU 的推理。
1. 使用以下内容创建名为 ecs-dlc-cpu-inference-taskdef.json 的文件。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mxnet-model-server --start --mms-config /home/model-server/config.properties --models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar" ], "name": "pytorch-inference-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference:1.2.0-cpu-py36-ubuntu16.04", "memory": 8111, "cpu": 256, "essential": true, "portMappings": [{ "hostPort": 8081, "protocol": "tcp", "containerPort": 8081 }, { "hostPort": 80, "protocol": "tcp", "containerPort": 8080 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/densenet-inference-cpu", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "densenet", "awslogs-create-group": "true" } }
103

深度学习 AMI 开发人员指南教程
}], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "pytorch-inference"}
2. 注册任务定义。记下输出中的修订号。
aws ecs register-task-definition --cli-input-json file://ecs-dlc-cpu-inference-taskdef.json
3. 创建 Amazon ECS 服务。当指定任务定义时,请将 revision_id 替换为上一步的输出中任务定义的修订号。
aws ecs create-service --cluster ecs-ec2-training-inference \ --service-name cli-ec2-inference-cpu \ --task-definition Ec2PTInference:revision_id \ --desired-count 1 \ --launch-type EC2 \ --scheduling-strategy REPLICA \ --region us-east-1
4. 通过完成以下步骤来验证服务并获取网络终端节点。
a. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。b. 选择 ecs-ec2-training-inference 集群。c. 在 Cluster (集群) 页面上,选择 Services (服务),然后选择 cli-ec2-inference-cpu。d. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。e. 在 Containers (容器) 下,展开容器详细信息。f. 在 Name (名称) 和 Network Bindings (网络绑定) 下,在 External Link (外部链接) 下,记下端口
8501 的 IP 地址。g. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日
志 )。这会将您转到 CloudWatch 控制台以查看训练进度日志。5. 要运行推理,请使用以下命令。
curl -O https://s3.amazonaws.com/model-server/inputs/flower.jpgcurl -X POST http://<External ip>/predictions/densenet -T flower.jpg
Important
If you are unable to connect to the external IP address, be sure that your corporate firewall isnot blocking non-standards ports, like 8501. You can try switching to a guest network to verify.
基于 GPU 的推理
使用以下任务定义运行基于 GPU 的推理。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mxnet-model-server --start --mms-config /home/model-server/config.properties --models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar"
104

深度学习 AMI 开发人员指南教程
], "name": "pytorch-inference-container", "image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference:1.2.0-cpu-py36-ubuntu16.04", "memory": 8111, "cpu": 256, "essential": true, "portMappings": [{ "hostPort": 8081, "protocol": "tcp", "containerPort": 8081 }, { "hostPort": 80, "protocol": "tcp", "containerPort": 8080 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/densenet-inference-cpu", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "densenet", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "pytorch-inference"}
1. 使用以下命令注册任务定义。记下修订号的输出。
aws ecs register-task-definition --cli-input-json file://<Task definition file>
2. 要创建服务,请在以下命令中将 revision_id 替换为上一步中的输出。
aws ecs create-service --cluster ecs-ec2-training-inference \ --service-name cli-ec2-inference-gpu \ --task-definition Ec2PTInference:<revision_id> \ --desired-count 1 \ --launch-type "EC2" \ --scheduling-strategy REPLICA \ --region us-east-1
3. 通过完成以下步骤来验证服务并获取网络终端节点。
a. 在 https://console.aws.amazon.com/ecs/ 上打开 Amazon ECS 控制台。b. 选择 ecs-ec2-training-inference 集群。c. 在 Cluster (集群) 页面上,选择 Services (服务),然后选择 cli-ec2-inference-cpu。d. 一旦您的任务处于 RUNNING 状态,请选择任务 ID。e. 在 Containers (容器) 下,展开容器详细信息。f. 在 Name (名称) 和 Network Bindings (网络绑定) 下,在 External Link (外部链接) 下,记下端口
8501 的 IP 地址。g. 在 Log Configuration (日志配置) 下,选择 View logs in CloudWatch (查看 CloudWatch 中的日
志 )。这会将您转到 CloudWatch 控制台以查看训练进度日志。4. 要运行推理,请使用以下命令。
105

深度学习 AMI 开发人员指南Amazon EKS 上的 Deep Learning Containers
curl -O https://s3.amazonaws.com/model-server/inputs/flower.jpgcurl -X POST http://<External ip>/predictions/densenet -T flower.jpg
Important
If you are unable to connect to the external IP address, be sure that your corporate firewall isnot blocking non-standards ports, like 8501. You can try switching to a guest network to verify.
自定义入口点对于某些映像,AWS 容器使用自定义入口点脚本。如果您要使用自己的入口点,可以按如下方式覆盖入口点。
修改包含任务定义的 JSON 文件中的 entryPoint 参数,以将文件路径包含到自定义入口点脚本中。
"entryPoint":[ "sh", "-c", "/usr/local/bin/mxnet-model-server --start --foreground --mms-config /home/model-server/config.properties --models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar"],
Amazon EKS 上的 AWS Deep Learning ContainersAWS Deep Learning Containers是一组 Docker 映像,用于在 EKS 和 Elastic Container Service (AmazonECS) 上的 TensorFlow、PyTorch 和 MXNet 中训练和处理模型。Deep Learning Containers 为优化环境提供了 TensorFlow、PyTorch 和 MXNet、Nvidia CUDA(适用于 GPU 实例)以及 Intel MKL(适用于 CPU 实例)库且在 Elastic Container Registry(Amazon ECR) 中可用。
本指南介绍如何将 AWS Deep Learning Containers与 EKS 结合使用。
内容• 设置 (p. 106)• 教程 (p. 111)• EKS 上的 AWS Deep Learning Containers故障排除 (p. 144)• EKS 上的 AWS Deep Learning Containers词汇表 (p. 146)
设置本指南将帮助您使用 Amazon Elastic Container Service for Kubernetes (Amazon EKS) 和 AWS 深度学习容器来设置深度学习环境。使用 EKS,您可以借助 Kubernetes 容器扩展用于多节点训练和推理的生产就绪型环境。
如果您尚不熟悉 Kubernetes 或 EKS,也没关系。本指南及相关 EKS 文档将帮助您了解如何使用Kubernetes 系列工具,以便可以借助 Kubernetes 和 EKS 扩展深度学习训练或推理系统。本指南假定您已熟悉您的深度学习框架的多节点实施或推理以及如何在容器外部设置推理服务器。
EKS 上的深度学习容器设置包含一个或多个容器(形成集成)。您可以有专用集群类型,如用于训练的集群和用于推理的集群。您还可能希望对于您的训练或实例集群具有不同的实例类型,具体取决于您计划部署的深度学习神经网络和模型的需求。
目录
106

深度学习 AMI 开发人员指南设置
• 自定义映像 (p. 107)• 许可 (p. 107)• 安全配置 (p. 107)• 网关节点 (p. 107)• GPU 集群 (p. 108)• CPU 集群 (p. 110)• 测试您的集群 (p. 110)• 管理您的集群 (p. 110)• 清除 (p. 111)
自定义映像如果您要加载自己的代码或数据集并让其在您集群的每个节点均可用,则自定义映像将很有用。提供了使用自定义映像的示例,因此,您可以试用它们,而无需在开始时创建自己的自定义映像。
• AWS Deep Learning Containers 自定义映像 (p. 151)
许可要使用 GPU 硬件,您需要使用具有必需的 GPU 驱动程序的 AMI。我们建议结合使用经 EKS 优化 AMI 与GPU 支持,您将使用在本指南的后续步骤使用它们。由于此 AMI 包含需要最终用户许可协 (EULA) 的第三方软件,因此您必须在 AWS Marketplace 中订阅经 EKS 优化的 AMI 并选择接受 EULA,然后才能在工作线程节点组中使用该 AMI。
Important
要订阅该 AMI,请访问 AWS Marketplace。
安全配置要使用 EKS,您必须具有有权访问多个安全权限的用户账户。使用 IAM 工具设置这些内容。
1. 创建 IAM 用户或更新现有 IAM 用户。有关创建或编辑 IAM 用户的更多信息,请参阅 IAM 文档。2. 获取此用户的凭证。在“Users (用户)”下,选择您的用户,选择“Security Credentials (安全凭证)”,选
择“Create access key pair (创建访问密钥对)”,然后下载该密钥对或复制相关信息以供稍后使用。3. 将策略添加到此 IAM 用户。这些将为 EKS、IAM 和 EC2 提供所需的访问权限。首先,通过以下网址打
开 IAM 控制台:https://console.aws.amazon.com/iam/。4. 搜索 AmazonEKSAdminPolicy,单击复选框。5. 搜索 AmazonCloudFormationPolicy,单击复选框。6. 搜索 AmazonEC2FullAccess,单击复选框。7. 搜索 IAMFullAccess,单击复选框。8. 搜索 AmazonEC2ContainerRegistryReadOnly,单击复选框。9. 搜索 AmazonEKS_CNI_Policy,单击复选框。10. 搜索 AmazonS3FullAccess,单击复选框。11. 接受更改。
网关节点要设置 EKS 集群,建议使用开源工具 eksctl。还建议结合使用 EC2 实例与深度学习基础 AMI (Ubuntu) 来作为分配和控制您的集群的操作基础。可在您的 PC 或已运行的 EC2 实例上本地运行这些工具,但是为了简
107

深度学习 AMI 开发人员指南设置
化本指南,我们将假定您使用的是带 Ubuntu 16.04 的深度学习基础 AMI (DLAMI)。我们将此称为您的网关节点。
在开始之前,请考虑您的训练数据的位置或您要运行集群以响应推理请求的位置。通常情况下,您的用于训练或推理的数据和集群应位于同一区域。此外,您还可能要在此同一区域中启动您的网关节点。您可以按照此快速 10 分钟教程操作,该教程将指导您如何启动 DLAMI 以用作您的网关节点。
1. 登录到您的网关节点。2. 安装或升级 AWS CLI。要访问所需的新 kubernetes 功能,您必须具有最新版本。
$ sudo pip install --upgrade awscli
3. 通过运行以下命令安装 eksctl。有关 eksctl 的更多信息,请参阅:https://aws.amazon.com/blogs/opensource/eksctl-eks-cluster-one-command/
$ curl --silent \--location "https://github.com/weaveworks/eksctl/releases/download/latest_release/eksctl_$(uname -s)_amd64.tar.gz" \| tar xz -C /tmp$ sudo mv /tmp/eksctl /usr/local/bin
4. 通过运行以下命令安装 kubectl。有关 kubeclt 的更多信息,请参阅:https://docs.aws.amazon.com/eks/latest/userguide/install-kubectl.html
$ curl -o kubectl https://amazon-eks.s3-us-west-2.amazonaws.com/1.11.5/2018-12-06/bin/linux/amd64/kubectl$ chmod +x ./kubectl$ mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$HOME/bin:$PATH
5. 通过运行以下命令安装 aws-iam-authenticator。有关 aws-iam-authenticator 的更多信息,请参阅:https://docs.aws.amazon.com/eks/latest/userguide/getting-started.html#eks-prereqs
$ curl -o aws-iam-authenticator https://amazon-eks.s3-us-west-2.amazonaws.com/1.11.5/2018-12-06/bin/linux/amd64/aws-iam-authenticator$ chmod +x aws-iam-authenticator$ cp ./aws-iam-authenticator $HOME/bin/aws-iam-authenticator && export PATH=$HOME/bin:$PATH
6. 从“Security Configuration (安全配置)”部分中运行 IAM 用户的 aws configure。您要复制在 IAM 控制台中访问的 IAM 用户的 AWS 访问密钥和 AWS 秘密访问密钥并将这些密钥粘贴到 aws configure 中的提示符中。
7. 安装 ksonnet:
$ export KS_VER=0.13.1$ export KS_PKG=ks_${KS_VER}_linux_amd64$ wget -O /tmp/${KS_PKG}.tar.gz https://github.com/ksonnet/ksonnet/releases/download/v${KS_VER}/${KS_PKG}.tar.gz$ mkdir -p ${HOME}/bin$ tar -xvf /tmp/$KS_PKG.tar.gz -C ${HOME}/bin$ sudo mv ${HOME}/bin/$KS_PKG/ks /usr/local/bin
GPU 集群1. 检查以下使用 p3.8xlarge 实例类型创建集群的命令。您将需要修改它,然后再运行。
108

深度学习 AMI 开发人员指南设置
• 名称是您将用于管理集群的内容。您可以将 cluster-name 更改为希望的任何名称,只要其中没有空格或特殊字符。
• 节点是您希望集群中包含的实例的数量。在本示例中,我们将从三个节点开始。• 节点类型指的是实例类。如果您已知道最适合您的情况的实例类,则可以选择不同的实例类。• 超时和 *ssh-access *可以自行运行。• ssh-public-key 是您要用于登录工作线程节点的密钥的名称。使用已使用的安全密钥或创建新的安全
密钥,但请务必使用已为您使用的区域分配的密钥交换出 ssh-public-key。注意:您只需提供在 EC2控制台的“密钥对”部分中看到的密钥名称。
• 区域是将在其中启动集群的 EC2 区域。如果您计划使用驻留在某特定区域(非 <us-east-1>)中的训练数据,建议您使用同一区域。ssh-public-key 必须具有在此区域中启动实例的权限。
Note
本指南的其余部分假定 <us-east-1> 作为此区域。• auto-kubeconfig 可以自行运行。
2. 对该命令进行更改后,即可运行它,然后等待。这对于单节点集群可能需要几分钟时间,如果您选择创建大型集群,则甚至需要更长时间。
$ eksctl create cluster <cluster-name> \ --version 1.11 \ --nodes 3 \ --node-type=<p3.8xlarge> \ --timeout=40m \ --ssh-access \ --ssh-public-key <key_pair_name> \ --region <us-east-1> \ --auto-kubeconfig
您应该可以看到类似于如下输出的内容:
EKS cluster "training-1" in "us-east-1" region is ready
3. 理想情况下,auto-kubeconfig 应已配置您的集群。但是,如果您遇到问题,则可以运行以下命令来设置您的 kubeconfig。如果您要从其他位置更改网关节点和管理集群,也可使用此命令。
$ aws eks --region <region> update-kubeconfig --name <cluster-name>
您应该可以看到类似于如下输出的内容:
Added new context arn:aws:eks:us-east-1:999999999999:cluster/training-1 to /home/ubuntu/.kube/config
4. 如果您计划使用 GPU 实例类型,请确保运行以下步骤来安装适用于 Kubernetes 的 NVIDIA 设备插件:
$ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
5. 验证 GPU 在您集群的每个节点上是否可用
$ kubectl get nodes "-o=custom-columns=NAME:.metadata.name,GPU:.status.allocatable.nvidia\.com/gpu"
109

深度学习 AMI 开发人员指南设置
CPU 集群请参阅上一部分中有关使用 eksctl 命令启动 GPU 集群的讨论,并将 node-type 修改为使用 CPU 实例类型。
测试您的集群1. 您可以在集群上运行 kubectl 命令来检查其状态。试用该命令以确保其选择的是您要管理的当前集群。
$ kubectl get nodes -o wide
2. 简单了解 ~/.kube。此目录具有用于从您的网关节点配置的各个集群的 kubeconfig 文件。如果进一步浏览到该文件夹,您可以找到 ~/.kube/eksctl/clusters - 此文件夹包含用于使用 eksctl 创建的集群的kubeconfig 文件。此文件包含您在理想情况下不必修改的一些详细信息,因为将为您生成和更新配置的工具,但最好是在故障排除时引用。
3. 验证集群是否处于活动状态。
$ aws eks --region <region> describe-cluster --name <cluster-name> --query cluster.status
您应看到以下输出:
"ACTIVE"
4. 如果您在同一主机实例中具有多个集群设置,请验证 kubectl 上下文。有时,它有助于确保正确地设置kubectl 找到的默认上下文。使用以下命令检查此内容:
$ kubectl config get-contexts
5. 如果未按预期设置该上下文,请使用以下命令修复此问题:
$ aws eks --region <region> update-kubeconfig --name <cluster-name>
管理您的集群• 当您想要控制或查询集群时,可以使用 kubeconfig 参数通过配置文件对其进行寻址。这在您有多个集群时
很有用。例如,如果您有一个称为“training-gpu-1”的单独集群,则可以通过将配置文件作为参数传递来对该集群调用 get pods 命令,如下所示:
$ kubectl --kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-gpu-1 get pods
• 值得一提的是,可以不带 kubeconfig 参数运行这一命令,它将报告您的当前主动控制集群上的状态。
$ kubectl get pods
• 如果您设置了多个集群,而这些集群尚未安装 NVIDIA 插件,则可以采用以下方式安装该插件:
$ kubectl --kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-gpu-1 apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.10/nvidia-device-plugin.yml
• 您还可以通过更新 kubeconfig、传递要管理的集群的名称来更改活动集群。以下命令更新 kubeconfig 且无需使用 kubeconfig 参数。
110

深度学习 AMI 开发人员指南教程
$ aws eks —region us-east-1 update-kubeconfig —name training-gpu-1
• 如果因循本指南中的所有示例,您将频繁在活动集群之间切换,因此,您可以编排训练或推理,或者使用在不同集群上运行的不同框架。
清除当用完集群后,您可以将其删除以避免产生额外成本。
$ eksctl delete cluster --name=<cluster-name>
如果您只想删除 pod,请运行以下命令:
$ kubectl delete pods <name>
如果要重置密钥以便访问集群,请运行以下命令:
$ kubectl delete secret ${SECRET} -n ${NAMESPACE} || true
如果要删除已附加到集群的 nodegroup,请运行以下命令:
$ eksctl delete nodegroup --name <cluster_name>
要将 nodegroup 附加集群,请运行以下命令:
$ eksctl create nodegroup --cluster <cluster-name> \ --node-ami <ami_id> \ --nodes <num_nodes> \ --node-type=<instance_type> \ --timeout=40m \ --ssh-access \ --ssh-public-key <key_pair_name> \ --region <us-east-1> \ --auto-kubeconfig
教程本部分将指导您如何使用 MXNet、PyTorch 和 TensorFlow 在 EKS 的 AWS Deep Learning Containers上运行训练和推理。有些示例包含单节点或多节点训练。推理仅使用单节点配置。
内容• 训练 (p. 111)• 推理 (p. 127)• 自定义入口点 (p. 143)
训练一旦您已运行集群,即可尝试训练任务。本部分将指导您完成 MXNet、PyTorch 和 TensorFlow 训练示例。
目录
111

深度学习 AMI 开发人员指南教程
• CPU 训练 (p. 112)• GPU 训练 (p. 116)• 分布式 GPU 训练 (p. 120)
CPU 训练
本部分针对在 CPU 集群上的训练。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
目录• MXNet (p. 112)• TensorFlow (p. 113)• PyTorch (p. 114)
MXNet
本教程将指导您在单节点 CPU 集群上使用 MXNet 进行训练。
1. 为您的集群创建 pod 文件。pod 文件将提供有关集群应运行的内容的说明。此 pod 文件将下载 MXNet存储库并运行 MNIST 示例。打开 vi 或 vim 并复制和粘贴以下内容。将此文件另存为 mxnet.yaml。
apiVersion: v1kind: Podmetadata: name: mxnet-trainingspec: restartPolicy: OnFailure containers: - name: mxnet-training image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.1-cpu-py36-ubuntu16.04 command: ["/bin/sh","-c"] args: ["git clone -b v1.4.x https://github.com/apache/incubator-mxnet.git && python ./incubator-mxnet/example/image-classification/train_mnist.py"]
2. 使用 kubectl 将 pod 文件分配到集群。
$ kubectl create -f mxnet.yaml
3. 您应看到以下输出:
pod/mxnet-training created
4. 检查状态。任务“mxnet-training”的名称位于 mxnet.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
$ kubectl get pods
您应看到以下输出:
112

深度学习 AMI 开发人员指南教程
NAME READY STATUS RESTARTS AGEmxnet-training 0/1 Running 8 19m
5. 检查日志以查看训练输出。
$ kubectl logs mxnet-training
您应该可以看到类似于如下输出的内容:
Cloning into 'incubator-mxnet'...INFO:root:Epoch[0] Batch [0-100] Speed: 18437.78 samples/sec accuracy=0.777228INFO:root:Epoch[0] Batch [100-200] Speed: 16814.68 samples/sec accuracy=0.907188INFO:root:Epoch[0] Batch [200-300] Speed: 18855.48 samples/sec accuracy=0.926719INFO:root:Epoch[0] Batch [300-400] Speed: 20260.84 samples/sec accuracy=0.938438INFO:root:Epoch[0] Batch [400-500] Speed: 9062.62 samples/sec accuracy=0.938594INFO:root:Epoch[0] Batch [500-600] Speed: 10467.17 samples/sec accuracy=0.945000INFO:root:Epoch[0] Batch [600-700] Speed: 11082.03 samples/sec accuracy=0.954219INFO:root:Epoch[0] Batch [700-800] Speed: 11505.02 samples/sec accuracy=0.956875INFO:root:Epoch[0] Batch [800-900] Speed: 9072.26 samples/sec accuracy=0.955781INFO:root:Epoch[0] Train-accuracy=0.923424...
6. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
TensorFlow
本教程将指导您在单节点 CPU 集群上训练 TensorFlow 模型。
1. 为您的集群创建 pod 文件。pod 文件将提供有关集群应运行的内容的说明。此 pod 文件将下载 Keras 并运行 Keras 示例。此示例伤脑筋 TensorFlow 后端。打开 vi 或 vim 并复制和粘贴以下内容。将此文件另存为 tf.yaml。
apiVersion: v1kind: Podmetadata: name: tensorflow-trainingspec: restartPolicy: OnFailure containers: - name: tensorflow-training image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.14.0-cpu-py36-ubuntu18.04 command: ["/bin/sh","-c"] args: ["git clone https://github.com/fchollet/keras.git && python /keras/examples/mnist_cnn.py"]
2. 使用 kubectl 将 pod 文件分配到集群。
$ kubectl create -f tf.yaml
3. 您应看到以下输出:
pod/tensorflow-training created
4. 检查状态。任务“tensorflow-training”的名称位于 tf.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
113
深度学习 AMI 开发人员指南教程
$ kubectl get pods
您应看到以下输出:
NAME READY STATUS RESTARTS AGEtensorflow-training 0/1 Running 8 19m
5. 检查日志以查看训练输出。
$ kubectl logs tensorflow-training
您应该可以看到类似于如下输出的内容:
Cloning into 'keras'...Using TensorFlow backend.Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
8192/11490434 [..............................] - ETA: 0s 6479872/11490434 [===============>..............] - ETA: 0s 8740864/11490434 [=====================>........] - ETA: 0s11493376/11490434 [==============================] - 0s 0us/stepx_train shape: (60000, 28, 28, 1)60000 train samples10000 test samplesTrain on 60000 samples, validate on 10000 samplesEpoch 1/122019-03-19 01:52:33.863598: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX512F2019-03-19 01:52:33.867616: I tensorflow/core/common_runtime/process_util.cc:69] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.
128/60000 [..............................] - ETA: 10:43 - loss: 2.3076 - acc: 0.0625 256/60000 [..............................] - ETA: 5:59 - loss: 2.2528 - acc: 0.1445 384/60000 [..............................] - ETA: 4:24 - loss: 2.2183 - acc: 0.1875 512/60000 [..............................] - ETA: 3:35 - loss: 2.1652 - acc: 0.1953 640/60000 [..............................] - ETA: 3:05 - loss: 2.1078 - acc: 0.2422 ...
6. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
PyTorch
本教程将指导您在单节点 CPU 集群上使用 PyTorch 进行训练。
1. 为您的集群创建 pod 文件。pod 文件将提供有关集群应运行的内容的说明。此 Pod 文件将下载PyTorch 存储库并运行 MNIST 示例。打开 vi 或 vim,然后复制并粘贴以下内容。将此文件另存为pytorch.yaml。
apiVersion: v1kind: Podmetadata: name: pytorch-trainingspec: restartPolicy: OnFailure containers: - name: pytorch-training
114

深度学习 AMI 开发人员指南教程
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-cpu-py36-ubuntu16.04 command: - "/bin/sh" - "-c" args: - "git clone https://github.com/pytorch/examples.git && python examples/mnist/main.py --no-cuda" env: - name: OMP_NUM_THREADS value: "36" - name: KMP_AFFINITY value: "granularity=fine,verbose,compact,1,0" - name: KMP_BLOCKTIME value: "1"
2. 使用 kubectl 将 pod 文件分配到集群。
$ kubectl create -f pytorch.yaml
3. 您应看到以下输出:
pod/pytorch-training created
4. 检查状态。作业“pytorch-training”的名称位于 pytorch.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
$ kubectl get pods
您应看到以下输出:
NAME READY STATUS RESTARTS AGEpytorch-training 0/1 Running 8 19m
5. 检查日志以查看训练输出。
$ kubectl logs pytorch-training
您应该可以看到类似于如下输出的内容:
Cloning into 'examples'...Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../data/MNIST/raw/train-images-idx3-ubyte.gz9920512it [00:00, 40133996.38it/s] Extracting ../data/MNIST/raw/train-images-idx3-ubyte.gz to ../data/MNIST/rawDownloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../data/MNIST/raw/train-labels-idx1-ubyte.gzExtracting ../data/MNIST/raw/train-labels-idx1-ubyte.gz to ../data/MNIST/raw32768it [00:00, 831315.84it/s]Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw/t10k-images-idx3-ubyte.gz1654784it [00:00, 13019129.43it/s] Extracting ../data/MNIST/raw/t10k-images-idx3-ubyte.gz to ../data/MNIST/rawDownloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz8192it [00:00, 337197.38it/s]Extracting ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ../data/MNIST/rawProcessing...Done!
115

深度学习 AMI 开发人员指南教程
Train Epoch: 1 [0/60000 (0%)] Loss: 2.300039Train Epoch: 1 [640/60000 (1%)] Loss: 2.213470Train Epoch: 1 [1280/60000 (2%)] Loss: 2.170460Train Epoch: 1 [1920/60000 (3%)] Loss: 2.076699Train Epoch: 1 [2560/60000 (4%)] Loss: 1.868078Train Epoch: 1 [3200/60000 (5%)] Loss: 1.414199Train Epoch: 1 [3840/60000 (6%)] Loss: 1.000870
6. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
使用完集群后,请参阅 EKS 清除以获取有关清除集群的信息。
GPU 训练
本部分针对在 GPU 集群上的训练。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
目录• MXNet (p. 116)• TensorFlow (p. 117)• PyTorch (p. 118)
MXNet
本教程将指导您在单节点 GPU 集群上使用 MXNet 进行训练。
1. 为您的集群创建 pod 文件。pod 文件将提供有关集群应运行的内容的说明。此 pod 文件将下载 MXNet存储库并运行 MNIST 示例。打开 vi 或 vim 并复制和粘贴以下内容。将此文件另存为 mxnet.yaml。
apiVersion: v1kind: Podmetadata: name: mxnet-trainingspec: restartPolicy: OnFailure containers: - name: mxnet-training image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04 command: ["/bin/sh","-c"] args: ["git clone -b v1.4.x https://github.com/apache/incubator-mxnet.git && python ./incubator-mxnet/example/image-classification/train_mnist.py"]
2. 使用 kubectl 将 pod 文件分配到集群。
$ kubectl create -f mxnet.yaml
3. 您应看到以下输出:
pod/mxnet-training created
116

深度学习 AMI 开发人员指南教程
4. 检查状态。任务“tensorflow-training”的名称位于 tf.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
$ kubectl get pods
您应看到以下输出:
NAME READY STATUS RESTARTS AGEmxnet-training 0/1 Running 8 19m
5. 检查日志以查看训练输出。
$ kubectl logs mxnet-training
您应该可以看到类似于如下输出的内容:
Cloning into 'incubator-mxnet'...INFO:root:Epoch[0] Batch [0-100] Speed: 18437.78 samples/sec accuracy=0.777228INFO:root:Epoch[0] Batch [100-200] Speed: 16814.68 samples/sec accuracy=0.907188INFO:root:Epoch[0] Batch [200-300] Speed: 18855.48 samples/sec accuracy=0.926719INFO:root:Epoch[0] Batch [300-400] Speed: 20260.84 samples/sec accuracy=0.938438INFO:root:Epoch[0] Batch [400-500] Speed: 9062.62 samples/sec accuracy=0.938594INFO:root:Epoch[0] Batch [500-600] Speed: 10467.17 samples/sec accuracy=0.945000INFO:root:Epoch[0] Batch [600-700] Speed: 11082.03 samples/sec accuracy=0.954219INFO:root:Epoch[0] Batch [700-800] Speed: 11505.02 samples/sec accuracy=0.956875INFO:root:Epoch[0] Batch [800-900] Speed: 9072.26 samples/sec accuracy=0.955781INFO:root:Epoch[0] Train-accuracy=0.923424...
6. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
TensorFlow
本教程将指导您在单节点 GPU 集群上训练 TensorFlow 模型。
1. 为您的集群创建 pod 文件。pod 文件将提供有关集群应运行的内容的说明。此 pod 文件将下载 Keras 并运行 Keras 示例。此示例伤脑筋 TensorFlow 后端。打开 vi 或 vim 并复制和粘贴以下内容。将此文件另存为 tf.yaml。
apiVersion: v1kind: Podmetadata: name: tensorflow-trainingspec: restartPolicy: OnFailure containers: - name: tensorflow-training image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.14.0-gpu-py36-cu100-ubuntu16.04 command: ["/bin/sh","-c"] args: ["git clone https://github.com/fchollet/keras.git && python /keras/examples/mnist_cnn.py"] resources: limits: nvidia.com/gpu: 1
2. 使用 kubectl 将 pod 文件分配到集群。
117

深度学习 AMI 开发人员指南教程
$ kubectl create -f tf.yaml
3. 您应看到以下输出:
pod/tensorflow-training created
4. 检查状态。任务“tensorflow-training”的名称位于 tf.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
$ kubectl get pods
您应看到以下输出:
NAME READY STATUS RESTARTS AGEtensorflow-training 0/1 Running 8 19m
5. 检查日志以查看训练输出。
$ kubectl logs tensorflow-training
您应该可以看到类似于如下输出的内容:
Cloning into 'keras'...Using TensorFlow backend.Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
8192/11490434 [..............................] - ETA: 0s 6479872/11490434 [===============>..............] - ETA: 0s 8740864/11490434 [=====================>........] - ETA: 0s11493376/11490434 [==============================] - 0s 0us/stepx_train shape: (60000, 28, 28, 1)60000 train samples10000 test samplesTrain on 60000 samples, validate on 10000 samplesEpoch 1/122019-03-19 01:52:33.863598: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX512F2019-03-19 01:52:33.867616: I tensorflow/core/common_runtime/process_util.cc:69] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.
128/60000 [..............................] - ETA: 10:43 - loss: 2.3076 - acc: 0.0625 256/60000 [..............................] - ETA: 5:59 - loss: 2.2528 - acc: 0.1445 384/60000 [..............................] - ETA: 4:24 - loss: 2.2183 - acc: 0.1875 512/60000 [..............................] - ETA: 3:35 - loss: 2.1652 - acc: 0.1953 640/60000 [..............................] - ETA: 3:05 - loss: 2.1078 - acc: 0.2422 ...
6. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
PyTorch
本教程将指导您在单节点 GPU 集群上使用 PyTorch 进行训练。
118

深度学习 AMI 开发人员指南教程
1. 为您的集群创建 pod 文件。pod 文件将提供有关集群应运行的内容的说明。此 Pod 文件将下载PyTorch 存储库并运行 MNIST 示例。打开 vi 或 vim,然后复制并粘贴以下内容。将此文件另存为pytorch.yaml。
apiVersion: v1kind: Podmetadata: name: pytorch-trainingspec: restartPolicy: OnFailure containers: - name: pytorch-training image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-gpu-py36-cu100-ubuntu16.04 command: - "/bin/sh" - "-c" args: - "git clone https://github.com/pytorch/examples.git && python examples/mnist/main.py --no-cuda" env: - name: OMP_NUM_THREADS value: "36" - name: KMP_AFFINITY value: "granularity=fine,verbose,compact,1,0" - name: KMP_BLOCKTIME value: "1"
2. 使用 kubectl 将 pod 文件分配到集群。
$ kubectl create -f pytorch.yaml
3. 您应看到以下输出:
pod/pytorch-training created
4. 检查状态。作业“pytorch-training”的名称位于 pytorch.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
$ kubectl get pods
您应看到以下输出:
NAME READY STATUS RESTARTS AGEpytorch-training 0/1 Running 8 19m
5. 检查日志以查看训练输出。
$ kubectl logs pytorch-training
您应该可以看到类似于如下输出的内容:
Cloning into 'examples'...Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../data/MNIST/raw/train-images-idx3-ubyte.gz9920512it [00:00, 40133996.38it/s] Extracting ../data/MNIST/raw/train-images-idx3-ubyte.gz to ../data/MNIST/raw
119

深度学习 AMI 开发人员指南教程
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../data/MNIST/raw/train-labels-idx1-ubyte.gzExtracting ../data/MNIST/raw/train-labels-idx1-ubyte.gz to ../data/MNIST/raw32768it [00:00, 831315.84it/s]Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw/t10k-images-idx3-ubyte.gz1654784it [00:00, 13019129.43it/s] Extracting ../data/MNIST/raw/t10k-images-idx3-ubyte.gz to ../data/MNIST/rawDownloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz8192it [00:00, 337197.38it/s]Extracting ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ../data/MNIST/rawProcessing...Done!Train Epoch: 1 [0/60000 (0%)] Loss: 2.300039Train Epoch: 1 [640/60000 (1%)] Loss: 2.213470Train Epoch: 1 [1280/60000 (2%)] Loss: 2.170460Train Epoch: 1 [1920/60000 (3%)] Loss: 2.076699Train Epoch: 1 [2560/60000 (4%)] Loss: 1.868078Train Epoch: 1 [3200/60000 (5%)] Loss: 1.414199Train Epoch: 1 [3840/60000 (6%)] Loss: 1.000870
6. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
使用完集群后,请参阅 EKS 清除以获取有关清除集群的信息。
分布式 GPU 训练
本部分针对在多节点 GPU 集群上运行分布式训练。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
目录• MXNet (p. 121)• TensorFlow with Horovod (p. 124)• PyTorch (p. 126)
在 EKS 上运行分布式训练将使用 Kubeflow。Kubeflow 项目致力于简单、便携且可扩展地在 Kubernetes 上部署机器学习 (ML) 工作流。
通过安装 Kubeflow 设置您的集群进行分布式训练
1. 安装 Kubeflow。
$ export KUBEFLOW_VERSION=0.4.1$ curl https://raw.githubusercontent.com/kubeflow/kubeflow/v${KUBEFLOW_VERSION}/scripts/download.sh | bash
2. 使用 Kubeflow 程序包时,您将很快遇到 Github API 限制。您需要创建一个 Github 令牌并按以下方式导出它。您无需选择任何范围。
$ export GITHUB_TOKEN=<token>
120

深度学习 AMI 开发人员指南教程
MXNet
本教程将指导您在多节点 GPU 集群上使用 MXNet 进行分布式训练。它使用 Parameter Server。要在 EKS上运行 MXNet 分布式训练,我们将使用名为 MXJob 的 Kubernetes MXNet-operator。它将提供一种自定义资源,可让您轻松在 Kubernetes 上运行分布式或非分布式 MXNet 任务(训练和调整)。
1. 设置命名空间。
$ NAMESPACE=kubeflow-dist-train-mx; kubectl --kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-gpu-1 create namespace ${NAMESPACE}
2. 设置应用程序名称并将其初始化。
$ APP_NAME=kubeflow-mx-ps; ks init ${APP_NAME}; cd ${APP_NAME}
3. 将默认环境使用的命名空间更改为 ${NAMESPACE}。
$ ks env set default --namespace ${NAMESPACE}
4. 安装用于 kubeflow 的 MXNet-operator。这是使用参数服务器运行 MXNet 分布式训练所需的。
$ ks registry add kubeflow github.com/kubeflow/kubeflow/tree/${KUBEFLOW_VERSION}/kubeflow$ ks pkg install kubeflow/mxnet-job
5. 生成与 Kubernetes 兼容的 jsonnet 组件清单文件。
$ ks generate mxnet-operator mxnet-operator
6. 应用配置设置。
$ ks apply default -c mxnet-operator
7. 使用自定义资源定义 (CRD) 将使用户能够创建和管理 MX 任务,就像 builtin K8s 资源一样。验证是否已安装 MXNet 自定义资源。
$ kubectl get crd
该输出应包含 mxjobs.kubeflow.org。
使用参数服务器运行 MNIST 分布式训练示例
您的第一个任务是根据可用的集群配置和要运行的任务为您的任务创建一个 pod 文件 (mx_job_dist.yaml)。您需要指定 3 个任务模式:计划程序、服务器和工作线程。您可以指定要使用字段副本生成的 pod 的数量。计划程序、服务器和工作线程的实例类型将是在集群创建时指定的类型。
• 计划程序:只有一个计划程序。计划程序的作用是设置集群。这包括等待每个节点已启动以及节点正在侦听哪个端口的消息。然后,计划程序向所有进程通知集群中的每个其他节点,以便它们可以相互通信。
• 服务器:可能具有多个服务器,它们存储模型的参数并与工作线程进行通信。服务器可能与工作线程进程位于同一位置,也可能位于不同的位置。
• 工作线程:工作线程节点实际对一批训练样本进行训练。在处理每个批次之前,工作线程从服务器中提取权重。在每个批次后,工作线程还会将梯度发送到服务器。根据模型训练工作负载,在同一计算机上运行多个工作线程可能并不是一个好主意。
• 提供要用于字段映像的容器映像。• 您可以从“Always”、“OnFailure”和“Never”之一提供 restartPolicy。它确定 pod 是否在其退出时重新启
动。
121

深度学习 AMI 开发人员指南教程
• 提供要用于字段映像的容器映像。
1. 根据之前的讨论,您将根据您的要求修改以下代码块并将其保存在名为 mx_job_dist.yaml 的文件中。
apiVersion: "kubeflow.org/v1alpha1"kind: "MXJob"metadata: name: "gpu-dist-job"spec: jobMode: "dist" replicaSpecs: - replicas: 1 mxReplicaType: SCHEDULER PsRootPort: 9000 template: spec: containers: - image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04-example name: mxnet restartPolicy: OnFailure - replicas: 2 mxReplicaType: SERVER template: spec: containers: - image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04-example name: mxnet restartPolicy: OnFailure - replicas: 2 mxReplicaType: WORKER template: spec: containers: - image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04-example name: mxnet command: ["python"] args: ["/incubator-mxnet/example/image-classification/train_mnist.py","--num-epochs","1","--num-layers","2","--kv-store","dist_device_sync","--gpus","0,1"] resources: limits: nvidia.com/gpu: 2 restartPolicy: OnFailure
2. 使用您刚创建的 pod 文件运行分布式训练任务。
$ # Create a job by defining MXJobkubectl create -f mx_job_dist.yaml
3. 列出正在运行的任务。
$ kubectl get mxjobs
4. 要获取正在运行的任务的状态,请运行以下命令。将 JOB 变量替换为任务的任何名称。
$ JOB=gpu-dist-jobkubectl get -o yaml mxjobs $JOB
122

深度学习 AMI 开发人员指南教程
该输出值应该类似于以下内容:
apiVersion: kubeflow.org/v1alpha1kind: MXJobmetadata: creationTimestamp: 2019-03-21T22:00:38Z generation: 1 name: gpu-dist-job namespace: default resourceVersion: "2523104" selfLink: /apis/kubeflow.org/v1alpha1/namespaces/default/mxjobs/gpu-dist-job uid: c2e67f05-4c24-11e9-a6d4-125f5bb10adaspec: RuntimeId: j1ht jobMode: dist mxImage: jzp1025/mxnet:test replicaSpecs: - PsRootPort: 9000 mxReplicaType: SCHEDULER replicas: 1 template: metadata: creationTimestamp: null spec: containers: - image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04-example name: mxnet resources: {} restartPolicy: OnFailure - PsRootPort: 9091 mxReplicaType: SERVER replicas: 2 template: metadata: creationTimestamp: null spec: containers: - image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04-example name: mxnet resources: {} - PsRootPort: 9091 mxReplicaType: WORKER replicas: 2 template: metadata: creationTimestamp: null spec: containers: - args: - /incubator-mxnet/example/image-classification/train_mnist.py - --num-epochs - "15" - --num-layers - "2" - --kv-store - dist_device_sync - --gpus - "0" command: - python image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-mxnet-training:1.4.1-gpu-py36-cu100-ubuntu16.04-example
123

深度学习 AMI 开发人员指南教程
name: mxnet resources: limits: nvidia.com/gpu: 1 restartPolicy: OnFailure terminationPolicy: chief: replicaIndex: 0 replicaName: WORKERstatus: phase: Running reason: "" replicaStatuses: - ReplicasStates: Running: 1 mx_replica_type: SCHEDULER state: Running - ReplicasStates: Running: 2 mx_replica_type: SERVER state: Running - ReplicasStates: Running: 2 mx_replica_type: WORKER state: Running state: Running
Note
状态提供有关资源的状态的信息。阶段 - 表示任务的阶段且将为“Creating (正在创建)”、“Running (正在运行)”、“CleanUp (清除)”、“Failed (失败)”、“Done (完成)”之一。状态 - 提供任务的总体状态且将为“Running (正在运行)”、“Succeeded (成功)”、“Failed (失败)”之一。
5. 清除并重新运行任务:
$ eksctl delete cluster --name=<cluster-name>
如果要删除任务,请将目录更改为您启动任务的位置并运行以下命令:
$ ks delete default$ kubectl delete -f mx_job_dist.yaml
TensorFlow with Horovod
本教程将指导您如何在多节点 GPU 集群上设置 TensorFlow 模型的分布式训练。它还使用 Horovod。它使用已包含训练脚本的示例映像,并且将一个 3 节点集群与 node-type=p3.16xlarge 结合使用。
1. 设置应用程序名称并将其初始化。
$ APP_NAME=kubeflow-tf-hvd; ks init ${APP_NAME}; cd ${APP_NAME}
2. 在此应用程序的文件夹中的 kubeflow 安装 mpi-operator。
$ KUBEFLOW_VERSION=v0.5.1$ ks registry add kubeflow github.com/kubeflow/kubeflow/tree/${KUBEFLOW_VERSION}/kubeflow$ ks pkg install kubeflow/common@${KUBEFLOW_VERSION}$ ks pkg install kubeflow/mpi-job@${KUBEFLOW_VERSION}
124

深度学习 AMI 开发人员指南教程
$ ks generate mpi-operator mpi-operator$ ks param set mpi-operator image mpioperator/mpi-operator:0.2.0$ ks apply default -c mpi-operator
3. 创建 MPI 任务模板并定义节点数量(副本)以及每个节点具有的 GPU 数量 (gpusPerReplica),您还可以采用您的映像并自定义命令。
IMAGE="763104351884.dkr.ecr.us-east-1.amazonaws.com/aws-samples-tensorflow-training:1.14.0-gpu-py36-cu100-ubuntu16.04-example"GPUS_PER_WORKER=2NUMBER_OF_WORKERS=3JOB_NAME=tf-resnet50-horovod-jobks generate mpi-job-custom ${JOB_NAME}
ks param set ${JOB_NAME} replicas ${NUMBER_OF_WORKERS}ks param set ${JOB_NAME} gpusPerReplica ${GPUS_PER_WORKER}ks param set ${JOB_NAME} image ${IMAGE}
ks param set ${JOB_NAME} command "mpirun,-mca,btl_tcp_if_exclude,lo,-mca,pml,ob1,-mca,btl,^openib,--bind-to,none,-map-by,slot,-x,LD_LIBRARY_PATH,-x,PATH,-x,NCCL_SOCKET_IFNAME=eth0,-x,NCCL_DEBUG=INFO,python,/deep-learning-models/models/resnet/tensorflow/train_imagenet_resnet_hvd.py"ks param set ${JOB_NAME} args -- --num_epochs=10,--synthetic
4. 检查创建的任务清单以验证一切内容是否显示正常。
$ ks show default -c ${JOB_NAME}
5. 现在,将清单应用于默认环境。MPI 任务将创建启动 pod 并且日志将在此 pod 中聚合。
$ ks apply default -c ${JOB_NAME}
6. 检查状态。任务“tensorflow-training”的名称位于 tf.yaml 文件中。它现在将显示在状态中。如果您正在运行任何其他测试或之前已运行某些内容,它将显示在此列表中。多次运行此项,直到您看到状态更改为“Running (正在运行)”。
$ kubectl get pods -o wide
您应该可以看到类似于如下输出的内容:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODEmpi-operator-5fff9d76f5-wvf56 1/1 Running 0 23m 192.168.10.117 ip-192-168-22-21.ec2.internal <none>tf-resnet50-horovod-job-launcher-d7w6t 1/1 Running 0 21m 192.168.13.210 ip-192-168-4-253.ec2.internal <none>tf-resnet50-horovod-job-worker-0 1/1 Running 0 22m 192.168.17.216 ip-192-168-4-253.ec2.internal <none>tf-resnet50-horovod-job-worker-1 1/1 Running 0 22m 192.168.20.228 ip-192-168-27-148.ec2.internal <none>tf-resnet50-horovod-job-worker-2 1/1 Running 0 22m 192.168.11.70 ip-192-168-22-21.ec2.internal <none>
7. 根据上述启动程序 pod 的名称,检查日志以查看训练输出。
$ kubectl logs -f --tail 10 tf-resnet50-horovod-job-launcher-d7w6t
8. 您可以检查日志以观察训练进度。您还可以继续检查“get pods”以刷新状态。当状态变为“Completed (已完成)”时,您将知道该训练任务已完成。
9. 清除并重新运行任务:
125

深度学习 AMI 开发人员指南教程
# make sure ${JOB_NAME} and ${APP_NAME} are still set$ ks delete default -c ${JOB_NAME}$ ks delete default$ cd .. && rm -rf ${APP_NAME}
PyTorch
本教程将指导您在多节点 GPU 集群上使用 PyTorch 进行分布式训练。它使用 Gloo 作为后端。
1. 设置命名空间。
$ NAMESPACE=pytorch-multi-node-training; kubectl create namespace ${NAMESPACE}
2. 设置应用程序名称并将其初始化。
$ APP_NAME=eks-pytorch-mnist-app; ks init ${APP_NAME}; cd ${APP_NAME}
3. 将默认环境使用的命名空间更改为 ${NAMESPACE}。
$ ks env set default --namespace ${NAMESPACE}
4. 为 kubeflow 安装 pytorch 运算符。这是使用参数服务器运行 PyTorch 分布式训练所需的。
$ ks registry add kubeflow github.com/kubeflow/kubeflow/tree/master/kubeflow$ ks pkg install kubeflow/pytorch-job
5. 生成与 Kubernetes 兼容的 jsonnet 组件清单文件。
$ ks generate pytorch-operator pytorch-operator
6. 应用配置设置。
$ ks apply default -c pytorch-operator
7. 使用自定义资源定义 (CRD) 将使用户能够创建和管理 PyTorch 作业,就像内置的 K8s 资源一样。验证是否已安装 PyTorch 自定义资源。
$ kubectl get crd
8. 应用 nvidia 插件。
$ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.12/nvidia-device-plugin.yml
9. 使用以下文本创建基于 Gloo 的分布式数据并行作业。将其保存在名为 distributed.yaml 的文件中。
apiVersion: kubeflow.org/v1kind: PyTorchJobmetadata: name: "kubeflow-pytorch-gpu-dist-job"spec: pytorchReplicaSpecs: Master: replicas: 1 restartPolicy: OnFailure
126

深度学习 AMI 开发人员指南教程
template: spec: containers: - name: "pytorch" image: "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-gpu-py36-cu100-ubuntu16.04 " args: - "--backend" - "gloo" - "--epochs" - "5" Worker: replicas: 2 restartPolicy: OnFailure template: spec: containers: - name: "pytorch" image: "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-gpu-py36-cu100-ubuntu16.04 " args: - "--backend" - "gloo" - "--epochs" - "5" resources: limits: nvidia.com/gpu: 1
10. 使用您刚创建的 pod 文件运行分布式训练任务。
$ # kubectl create -f distributed.yaml
11. 您可以使用以下方法检查作业的状态:
$ kubectl logs kubeflow-pytorch-gpu-dist-job
要连续查看日志,请使用:
$kubectl logs -f <pod>
使用完集群后,请参阅 EKS 清除以获取有关清除集群的信息。
推理本部分将指导您如何使用 MXNet、PyTorch 和 TensorFlow 在 EKS 的 AWS Deep Learning Containers上运行推理。推理使用 CPU 或 GPU 集群,但仅限于单节点配置。
目录• CPU 推理 (p. 127)• GPU 推理 (p. 134)
CPU 推理本部分介绍如何使用 MXNet、PyTorch 和 TensorFlow 在 EKS CPU 集群的 AWS Deep Learning Containers上运行推理。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。
127

深度学习 AMI 开发人员指南教程
Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
Note
对于以下针对 MXNet 的基于 CPU 和 GPU 的推理示例,预训练 squeezenet 模型是公开的,因此,您无需修改提供的 yaml 文件。TensorFlow 示例将让您下载该模型,上传到您选择的 S3 存储桶,使用您的 AWS CLI 安全设置修改提供的 yaml 文件,然后使用修改过的 yaml 文件进行推理。
目录• MXNet (p. 128)• TensorFlow (p. 130)• PyTorch (p. 133)
MXNet
在此方法中,创建一个 Kubernetes 服务和部署。服务在其其他功能中公开了一个流程及其端口和部署,负责确保特定数量的 pod(在以下情况下,至少 1 个)始终启动并运行。
1. 创建命名空间。您可能需要更改 kubeconfig 以指向正确的集群。验证您已设置“training-cpu-1”或将其更改为您的 CPU 集群的配置:
$ NAMESPACE=mx-inference; kubectl —kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-cpu-1 create namespace ${NAMESPACE}
2. (使用公共模型时的可选步骤。) 在可装载的网络位置(如 S3)处设置您的模型。请参阅这些步骤以将训练后的模型上传到“利用 TensorFlow 进行推理”部分中提及的 S3。不要忘记将密钥应用于您的命名空间:
$ kubectl -n ${NAMESPACE} apply -f secret.yaml
3. 创建文件 mx_inference.yaml。使用下一个代码块的内容作为其内容。
---kind: ServiceapiVersion: v1metadata: name: squeezenet-service labels: app: squeezenet-servicespec: ports: - port: 8080 targetPort: mms selector: app: squeezenet-service---kind: DeploymentapiVersion: apps/v1metadata: name: squeezenet-service labels: app: squeezenet-servicespec: replicas: 1 selector:
128

深度学习 AMI 开发人员指南教程
matchLabels: app: squeezenet-service template: metadata: labels: app: squeezenet-service spec: containers: - name: squeezenet-service image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.1-cpu-py36-ubuntu16.04 args: - mxnet-model-server - --start - --mms-config /home/model-server/config.properties - --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.mar ports: - name: mms containerPort: 8080 - name: mms-management containerPort: 8081 imagePullPolicy: IfNotPresent
4. 将配置应用于之前定义的命名空间中的新 pod:
$ kubectl -n ${NAMESPACE} apply -f mx_inference.yaml
您的输出应类似于以下内容:
service/squeezenet-service createddeployment.apps/squeezenet-service created
5. 检查 pod 的状态并等待 pod 处于“RUNNING (正在运行)”状态:
$ kubectl get pods -n ${NAMESPACE}
6. 重复检查状态步骤,直到您看到以下“RUNNING (正在运行)”状态:
NAME READY STATUS RESTARTS AGEsqueezenet-service-xvw1 1/1 Running 0 3m
7. 要进一步描述 pod,您可以运行:
$ kubectl describe pod <pod_name> -n ${NAMESPACE}
8. 由于此处的 serviceType 为 ClusterIP,您可以将端口从您的容器转发至您的主机,(& 将在后台中运行此项):
$ kubectl port-forward -n ${NAMESPACE} `kubectl get pods -n ${NAMESPACE} --selector=app=squeezenet-service -o jsonpath='{.items[0].metadata.name}'` 8080:8080 &
9. 下载小猫的图像:
$ curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
10. 在该模型上运行推理:
$ curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpg
129

深度学习 AMI 开发人员指南教程
TensorFlow
在此方法中,创建一个 Kubernetes 服务和部署。服务在其其他功能中公开了一个流程及其端口和部署,负责确保特定数量的 pod(在以下情况下,至少 1 个)始终启动并运行。
1. 创建命名空间。您可能需要更改 kubeconfig 以指向正确的集群。验证您已设置“training-cpu-1”或将其更改为您的 CPU 集群的配置:
$ NAMESPACE=mx-inference; kubectl —kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-cpu-1 create namespace ${NAMESPACE}
2. 用于推理的模型可通过不同的方式进行检索,例如,使用共享卷、S3 等。由于该服务需要访问 S3 和ECR,您必须将您的 AWS 凭证存储为 Kubernetes 密钥。此项将设置为您之前安装的 tf-serving 程序包的参数。在本示例中,您将使用 S3 来存储和提取训练后的模型。
检查您的 AWS 凭证。这些凭证必须具有 S3 写入访问权限。
$ cat ~/.aws/credentials
3. 输出将类似于以下内容:
$ [default]aws_access_key_id = FAKEAWSACCESSKEYIDaws_secret_access_key = FAKEAWSSECRETACCESSKEY
4. 使用 base64 对这些凭证进行编码。首先编码访问密钥。
$ echo -n 'FAKEAWSACCESSKEYID' | base64
接下来编码秘密访问密钥。
$ echo -n 'FAKEAWSSECRETACCESSKEYID' | base64
您的输出应类似于以下内容:
$ echo -n 'FAKEAWSACCESSKEYID' | base64RkFLRUFXU0FDQ0VTU0tFWUlE$ echo -n 'FAKEAWSSECRETACCESSKEY' | base64RkFLRUFXU1NFQ1JFVEFDQ0VTU0tFWQ==
5. 创建 yaml 文件来存储密钥。在您的主目录中将该密钥另存为 secret.yaml。
apiVersion: v1kind: Secretmetadata: name: aws-s3-secrettype: Opaquedata: AWS_ACCESS_KEY_ID: BASE64OUTPUT== AWS_SECRET_ACCESS_KEY: BASE64OUTPUT==
6. 将密钥应用于您的命名空间:
$ kubectl -n ${NAMESPACE} apply -f secret.yaml
7. 在本示例中,您将克隆 tensorflow-serving 存储库并将预训练模型同步到 S3 存储桶。以下示例命名存储桶 tensorflow-serving-models。它还将已保存的模型同步到名为saved_model_half_plus_two 的 S3 存储桶。
130

深度学习 AMI 开发人员指南教程
$ git clone https://github.com/tensorflow/serving/$ cd serving/tensorflow_serving/servables/tensorflow/testdata/
8. 同步 CPU 模型。
$ aws s3 sync saved_model_half_plus_two_cpu s3://<your_s3_bucket>/saved_model_half_plus_two
9. 创建文件 tf_inference.yaml。使用下一个代码块的内容作为其内容,并将 --model_base_path更新为使用您的 S3 存储桶。
--- kind: Service apiVersion: v1 metadata: name: half-plus-two labels: app: half-plus-two spec: ports: - name: http-tf-serving port: 8500 targetPort: 8500 - name: grpc-tf-serving port: 9000 targetPort: 9000 selector: app: half-plus-two role: master type: ClusterIP --- kind: Deployment apiVersion: apps/v1 metadata: name: half-plus-two labels: app: half-plus-two role: master spec: replicas: 1 selector: matchLabels: app: half-plus-two role: master template: metadata: labels: app: half-plus-two role: master spec: containers: - name: half-plus-two image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.14.0-cpu-py36-ubuntu18.04 command: - /usr/bin/tensorflow_model_server args: - --port=9000 - --rest_api_port=8500 - --model_name=saved_model_half_plus_two - --model_base_path=s3://tensorflow-trained-models/saved_model_half_plus_two ports: - containerPort: 8500
131

深度学习 AMI 开发人员指南教程
- containerPort: 9000 imagePullPolicy: IfNotPresent env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: key: AWS_ACCESS_KEY_ID name: aws-s3-secret - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: key: AWS_SECRET_ACCESS_KEY name: aws-s3-secret - name: AWS_REGION value: us-east-1 - name: S3_USE_HTTPS value: "true" - name: S3_VERIFY_SSL value: "true" - name: S3_ENDPOINT value: s3.us-east-1.amazonaws.com
10. 将配置应用于之前定义的命名空间中的新 pod:
$ kubectl -n ${NAMESPACE} apply -f tf_inference.yaml
您的输出应类似于以下内容:
service/half-plus-two createddeployment.apps/half-plus-two created
11. 检查 pod 的状态并等待 pod 处于“RUNNING (正在运行)”状态:
$ kubectl get pods -n ${NAMESPACE}
12. 重复检查状态步骤,直到您看到以下“RUNNING (正在运行)”状态:
NAME READY STATUS RESTARTS AGEhalf-plus-two-vmwp9 1/1 Running 0 3m
13. 要进一步描述 pod,您可以运行:
$ kubectl describe pod <pod_name> -n ${NAMESPACE}
14. 由于此处的 serviceType 为 ClusterIP,您可以将端口从您的容器转发至您的主机,(& 将在后台中运行此项):
$ kubectl port-forward -n ${NAMESPACE} `kubectl get pods -n ${NAMESPACE} --selector=app=half-plus-two -o jsonpath='{.items[0].metadata.name}'` 8500:8500 &
15. 将以下 json 字符串置于名为 half_plus_two_input.json 的文件中
{"instances": [1.0, 2.0, 5.0]}
16. 在该模型上运行推理:
$ curl -d @half_plus_two_input.json -X POST http://localhost:8500/v1/models/saved_model_half_plus_two_cpu:predict
132
深度学习 AMI 开发人员指南教程
预期的输出如下所示:
{ "predictions": [2.5, 3.0, 4.5 ]}
PyTorch
在此方法中,创建一个 Kubernetes 服务和部署。服务在其其他功能中公开了一个流程及其端口和部署,负责确保特定数量的 pod(在以下情况下,至少 1 个)始终启动并运行。
1. 创建命名空间。您可能需要更改 kubeconfig 以指向正确的集群。验证您已设置“training-cpu-1”或将其更改为您的 CPU 集群的配置:
$ NAMESPACE=pt-inference; kubectl create namespace ${NAMESPACE}
2. (使用公共模型时的可选步骤。) 在可装载的网络位置(如 S3)处设置您的模型。请参阅这些步骤以将训练后的模型上传到“利用 TensorFlow 进行推理”部分中提及的 S3。不要忘记将密钥应用于您的命名空间:
$ kubectl -n ${NAMESPACE} apply -f secret.yaml
3. 创建文件 pt_inference.yaml。使用下一个代码块的内容作为其内容。
---kind: ServiceapiVersion: v1metadata: name: densenet-service labels: app: densenet-servicespec: ports: - port: 8080 targetPort: mms selector: app: densenet-service---kind: DeploymentapiVersion: apps/v1metadata: name: densenet-service labels: app: densenet-servicespec: replicas: 1 selector: matchLabels: app: densenet-service template: metadata: labels: app: densenet-service spec: containers: - name: densenet-service image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference:1.2.0-cpu-py36-ubuntu16.04 args:
133

深度学习 AMI 开发人员指南教程
- mxnet-model-server - --start - --mms-config /home/model-server/config.properties - --models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar ports: - name: mms containerPort: 8080 - name: mms-management containerPort: 8081 imagePullPolicy: IfNotPresent
4. 将配置应用于之前定义的命名空间中的新 pod:
$ kubectl -n ${NAMESPACE} apply -f pt_inference.yaml
您的输出应类似于以下内容:
service/densenet-service createddeployment.apps/densenet-service created
5. 检查 pod 的状态并等待 pod 处于“RUNNING (正在运行)”状态:
$ kubectl get pods -n ${NAMESPACE} -w
您的输出应类似于以下内容:
NAME READY STATUS RESTARTS AGEdensenet-service-xvw1 1/1 Running 0 3m
6. 要进一步描述 pod,您可以运行:
$ kubectl describe pod <pod_name> -n ${NAMESPACE}
7. 由于此处的 serviceType 为 ClusterIP,您可以将端口从您的容器转发至您的主机,(& 将在后台中运行此项):
$ kubectl port-forward -n ${NAMESPACE} `kubectl get pods -n ${NAMESPACE} --selector=app=densenet-service -o jsonpath='{.items[0].metadata.name}'` 8080:8080 &
8. 在启动您的服务器后,现在您可以使用以下命令从不同的窗口来运行推理:
$ curl -O https://s3.amazonaws.com/model-server/inputs/flower.jpgcurl -X POST http://127.0.0.1:8080/predictions/densenet -T flower.jpg
使用完集群后,请参阅 EKS 清除以获取有关清除集群的信息。
GPU 推理本部分介绍如何使用 MXNet、PyTorch 和 TensorFlow 在 EKS GPU 集群的 AWS Deep Learning Containers上运行推理。
有关 AWS Deep Learning Containers的完整列表,请参阅Deep Learning Containers映像 (p. 147)。Note
MKL 用户:读取 AWS Deep Learning Containers MKL 建议 (p. 152)以获得最佳训练或推理性能。
134

深度学习 AMI 开发人员指南教程
目录• MXNet (p. 135)• TensorFlow (p. 137)• PyTorch (p. 141)
MXNet
在此方法中,创建一个 Kubernetes 服务和部署。服务在其其他功能中公开了一个流程及其端口和部署,负责确保特定数量的 pod(在以下情况下,至少 1 个)始终启动并运行。
1. 对于基于 GPU 的推理,安装适用于 Kubernetes 的 NVIDIA 设备插件:
$ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
2. 验证 nvidia-device-plugin-daemonset 是否正在正确运行。
$ kubectl get daemonset -n kube-system
该输出值将类似于以下内容:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGEaws-node 3 3 3 3 3 <none> 6dkube-proxy 3 3 3 3 3 <none> 6dnvidia-device-plugin-daemonset 3 3 3 3 3 <none> 57s
3. 创建命名空间。您可能需要更改 kubeconfig 以指向正确的集群。验证您已设置“training-gpu-1”或将其更改为您的 GPU 集群的配置。
$ NAMESPACE=mx-inference; kubectl —kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-gpu-1 create namespace ${NAMESPACE}
4. (使用公共模型时的可选步骤。) 在可装载的网络位置(如 S3)处设置您的模型。请参阅这些步骤以将训练后的模型上传到“利用 TensorFlow 进行推理”部分中提及的 S3。不要忘记将密钥应用于您的命名空间:
$ kubectl -n ${NAMESPACE} apply -f secret.yaml
5. 创建文件 mx_inference.yaml。使用下一个代码块的内容作为其内容。
---kind: ServiceapiVersion: v1metadata: name: squeezenet-service labels: app: squeezenet-servicespec: ports: - port: 8080 targetPort: mms selector: app: squeezenet-service---
135

深度学习 AMI 开发人员指南教程
kind: DeploymentapiVersion: apps/v1metadata: name: squeezenet-service labels: app: squeezenet-servicespec: replicas: 1 selector: matchLabels: app: squeezenet-service template: metadata: labels: app: squeezenet-service spec: containers: - name: squeezenet-service image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.2-gpu-py36-cu100-ubuntu16.04 args: - mxnet-model-server - --start - --mms-config /home/model-server/config.properties - --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.mar ports: - name: mms containerPort: 8080 - name: mms-management containerPort: 8081 imagePullPolicy: IfNotPresent resources: limits: cpu: 4 memory: 4Gi nvidia.com/gpu: 1 requests: cpu: "1" memory: 1Gi
6. 将配置应用于之前定义的命名空间中的新 pod:
$ kubectl -n ${NAMESPACE} apply -f mx_inference.yaml
您的输出应类似于以下内容:
service/squeezenet-service createddeployment.apps/squeezenet-service created
7. 检查 pod 的状态并等待 pod 处于“RUNNING (正在运行)”状态:
$ kubectl get pods -n ${NAMESPACE}
8. 重复检查状态步骤,直到您看到以下“RUNNING (正在运行)”状态:
NAME READY STATUS RESTARTS AGEsqueezenet-service-xvw1 1/1 Running 0 3m
9. 要进一步描述 pod,您可以运行:
136

深度学习 AMI 开发人员指南教程
$ kubectl describe pod <pod_name> -n ${NAMESPACE}
10. 由于此处的 serviceType 为 ClusterIP,您可以将端口从您的容器转发至您的主机,(& 将在后台中运行此项):
$ kubectl port-forward -n ${NAMESPACE} `kubectl get pods -n ${NAMESPACE} --selector=app=squeezenet-service -o jsonpath='{.items[0].metadata.name}'` 8080:8080 &
11. 下载小猫的图像:
$ curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
12. 在该模型上运行推理:
$ curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpg
TensorFlow
在此方法中,创建一个 Kubernetes 服务和部署。服务在其其他功能中公开了一个流程及其端口和部署,负责确保特定数量的 pod(在以下情况下,至少 1 个)始终启动并运行。
1. 对于基于 GPU 的推理,安装适用于 Kubernetes 的 NVIDIA 设备插件:
$ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
2. 验证 nvidia-device-plugin-daemonset 是否正在正确运行。
$ kubectl get daemonset -n kube-system
该输出值将类似于以下内容:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGEaws-node 3 3 3 3 3 <none> 6dkube-proxy 3 3 3 3 3 <none> 6dnvidia-device-plugin-daemonset 3 3 3 3 3 <none> 57s
3. 创建命名空间。您可能需要更改 kubeconfig 以指向正确的集群。验证您已设置“training-gpu-1”或将其更改为您的 GPU 集群的配置:
$ NAMESPACE=mx-inference; kubectl —kubeconfig=/home/ubuntu/.kube/eksctl/clusters/training-gpu-1 create namespace ${NAMESPACE}
4. 用于推理的模型可通过不同的方式进行检索,例如,使用共享卷、S3 等。由于该服务需要访问 S3 和ECR,您必须将您的 AWS 凭证存储为 Kubernetes 密钥。此项将设置为您之前安装的 tf-serving 程序包的参数。在本示例中,您将使用 S3 来存储和提取训练后的模型。
检查您的 AWS 凭证。这些凭证必须具有 S3 写入访问权限。
$ cat ~/.aws/credentials
137

深度学习 AMI 开发人员指南教程
5. 输出将类似于以下内容:
$ [default]aws_access_key_id = FAKEAWSACCESSKEYIDaws_secret_access_key = FAKEAWSSECRETACCESSKEY
6. 使用 base64 对这些凭证进行编码。首先编码访问密钥。
$ echo -n 'FAKEAWSACCESSKEYID' | base64
接下来编码秘密访问密钥。
$ echo -n 'FAKEAWSSECRETACCESSKEYID' | base64
您的输出应类似于以下内容:
$ echo -n 'FAKEAWSACCESSKEYID' | base64RkFLRUFXU0FDQ0VTU0tFWUlE$ echo -n 'FAKEAWSSECRETACCESSKEY' | base64RkFLRUFXU1NFQ1JFVEFDQ0VTU0tFWQ==
7. 创建 yaml 文件来存储密钥。在您的主目录中将该密钥另存为 secret.yaml。
apiVersion: v1kind: Secretmetadata: name: aws-s3-secrettype: Opaquedata: AWS_ACCESS_KEY_ID: RkFLRUFXU0FDQ0VTU0tFWUlE AWS_SECRET_ACCESS_KEY: RkFLRUFXU1NFQ1JFVEFDQ0VTU0tFWQ==
8. 将密钥应用于您的命名空间:
$ kubectl -n ${NAMESPACE} apply -f secret.yaml
9. 在本示例中,您将克隆 tensorflow-serving 存储库并将预训练模型同步到 S3 存储桶。以下示例命名存储桶 tensorflow-serving-models。它还将已保存的模型同步到名saved_model_half_plus_two_gpu 的 S3 存储桶。
$ git clone https://github.com/tensorflow/serving/$ cd serving/tensorflow_serving/servables/tensorflow/testdata/
10. 同步 CPU 模型。
$ aws s3 sync saved_model_half_plus_two_gpu s3://<your_s3_bucket>/saved_model_half_plus_two_gpu
11. 创建文件 tf_inference.yaml。使用下一个代码块的内容作为其内容,并将 --model_base_path更新为使用您的 S3 存储桶。
--- kind: Service apiVersion: v1 metadata: name: half-plus-two labels: app: half-plus-two
138

深度学习 AMI 开发人员指南教程
spec: ports: - name: http-tf-serving port: 8500 targetPort: 8500 - name: grpc-tf-serving port: 9000 targetPort: 9000 selector: app: half-plus-two role: master type: ClusterIP --- kind: Deployment apiVersion: apps/v1 metadata: name: half-plus-two labels: app: half-plus-two role: master spec: replicas: 1 selector: matchLabels: app: half-plus-two role: master template: metadata: labels: app: half-plus-two role: master spec: containers: - name: half-plus-two image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.14.0-gpu-py36-cu100-ubuntu16.04 command: - /usr/bin/tensorflow_model_server args: - --port=9000 - --rest_api_port=8500 - --model_name=saved_model_half_plus_two_gpu - --model_base_path=s3://tensorflow-trained-models/saved_model_half_plus_two_gpu ports: - containerPort: 8500 - containerPort: 9000 imagePullPolicy: IfNotPresent env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: key: AWS_ACCESS_KEY_ID name: aws-s3-secret - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: key: AWS_SECRET_ACCESS_KEY name: aws-s3-secret - name: AWS_REGION value: us-east-1 - name: S3_USE_HTTPS value: "true" - name: S3_VERIFY_SSL value: "true" - name: S3_ENDPOINT
139

深度学习 AMI 开发人员指南教程
value: s3.us-east-1.amazonaws.com resources: limits: cpu: 4 memory: 4Gi nvidia.com/gpu: 1 requests: cpu: "1" memory: 1Gi
12. 将配置应用于之前定义的命名空间中的新 pod:
$ kubectl -n ${NAMESPACE} apply -f tf_inference.yaml
您的输出应类似于以下内容:
service/half-plus-two createddeployment.apps/half-plus-two created
13. 检查 pod 的状态并等待 pod 处于“RUNNING (正在运行)”状态:
$ kubectl get pods -n ${NAMESPACE}
14. 重复检查状态步骤,直到您看到以下“RUNNING (正在运行)”状态:
NAME READY STATUS RESTARTS AGEhalf-plus-two-vmwp9 1/1 Running 0 3m
15. 要进一步描述 pod,您可以运行:
$ kubectl describe pod <pod_name> -n ${NAMESPACE}
16. 由于此处的 serviceType 为 ClusterIP,您可以将端口从您的容器转发至您的主机,(& 将在后台中运行此项):
$ kubectl port-forward -n ${NAMESPACE} `kubectl get pods -n ${NAMESPACE} --selector=app=half-plus-two -o jsonpath='{.items[0].metadata.name}'` 8500:8500 &
17. 将以下 json 字符串置于名为 half_plus_two_input.json 的文件中
{"instances": [1.0, 2.0, 5.0]}
18. 在该模型上运行推理:
$ curl -d @half_plus_two_input.json -X POST http://localhost:8500/v1/models/saved_model_half_plus_two_cpu:predict
预期的输出如下所示:
{ "predictions": [2.5, 3.0, 4.5 ]}
140

深度学习 AMI 开发人员指南教程
PyTorch
在此方法中,创建一个 Kubernetes 服务和部署。服务在其其他功能中公开了一个流程及其端口和部署,负责确保特定数量的 pod(在以下情况下,至少 1 个)始终启动并运行。
1. 对于基于 GPU 的推理,安装适用于 Kubernetes 的 NVIDIA 设备插件。
$ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
2. 验证 nvidia-device-plugin-daemonset 是否正在正确运行。
$ kubectl get daemonset -n kube-system
该输出值将类似于以下内容。
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGEaws-node 3 3 3 3 3 <none> 6dkube-proxy 3 3 3 3 3 <none> 6dnvidia-device-plugin-daemonset 3 3 3 3 3 <none> 57s
3. 创建命名空间。
$ NAMESPACE=pt-inference; kubectl create namespace ${NAMESPACE}
4. (使用公共模型时的可选步骤。) 在可装载的网络位置(如 S3)处设置您的模型。请参阅这些步骤以将训练后的模型上传到“利用 TensorFlow 进行推理”部分中提及的 S3。不要忘记将密钥应用于您的命名空间。
$ kubectl -n ${NAMESPACE} apply -f secret.yaml
5. 创建文件 pt_inference.yaml。使用下一个代码块的内容作为其内容。
---kind: ServiceapiVersion: v1metadata: name: densenet-service labels: app: densenet-servicespec: ports: - port: 8080 targetPort: mms selector: app: densenet-service---kind: DeploymentapiVersion: apps/v1metadata: name: densenet-service labels: app: densenet-servicespec: replicas: 1 selector:
141

深度学习 AMI 开发人员指南教程
matchLabels: app: densenet-service template: metadata: labels: app: densenet-service spec: containers: - name: densenet-service image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference:1.2.0-gpu-py36-ubuntu16.04 args: - mxnet-model-server - --start - --mms-config /home/model-server/config.properties - --models densenet=https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar ports: - name: mms containerPort: 8080 - name: mms-management containerPort: 8081 imagePullPolicy: IfNotPresent resources: limits: cpu: 4 memory: 4Gi nvidia.com/gpu: 1 requests: cpu: "1" memory: 1Gi
6. 将配置应用于之前定义的命名空间中的新 pod。
$ kubectl -n ${NAMESPACE} apply -f pt_inference.yaml
您的输出应类似于以下内容:
service/densenet-service createddeployment.apps/densenet-service created
7. 检查 pod 的状态并等待 pod 处于“RUNNING (正在运行)”状态。
$ kubectl get pods -n ${NAMESPACE}
您的输出应类似于以下内容:
NAME READY STATUS RESTARTS AGEdensenet-service-xvw1 1/1 Running 0 3m
8. 要进一步描述 pod,您可以运行:
$ kubectl describe pod <pod_name> -n ${NAMESPACE}
9. 由于此处的 serviceType 为 ClusterIP,您可以将端口从您的容器转发至您的主机(& 将在后台中运行此项)。
$ kubectl port-forward -n ${NAMESPACE} `kubectl get pods -n ${NAMESPACE} --selector=app=densenet-service -o jsonpath='{.items[0].metadata.name}'` 8080:8080 &
142

深度学习 AMI 开发人员指南教程
10. 在启动您的服务器后,现在您可以从不同的窗口来运行推理。
$ curl -O https://s3.amazonaws.com/model-server/inputs/flower.jpgcurl -X POST http://127.0.0.1:8080/predictions/densenet -T flower.jpg
使用完集群后,请参阅 EKS 清除以获取有关清除集群的信息。
自定义入口点对于某些映像,AWS 容器使用自定义入口点脚本。如果您要使用自己的入口点,可以按如下方式覆盖入口点。
更新 Pod 文件中的 command 参数。将 args 参数替换为您的自定义入口点脚本。
---apiVersion: v1kind: Podmetadata: name: pytorch-multi-model-server-densenetspec: restartPolicy: OnFailure containers: - name: pytorch-multi-model-server-densenet image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference:1.2.0-cpu-py36-ubuntu16.04 command: - "/bin/sh" - "-c" args: - /usr/local/bin/mxnet-model-server - --start - --mms-config /home/model-server/config.properties - --models densenet="https://dlc-samples.s3.amazonaws.com/pytorch/multi-model-server/densenet/densenet.mar"
command 是 entrypoint 的 Kubernetes 字段名称。有关详细信息,请参阅此 Kubernetes 字段名称表。
如果 EKS 集群具有过期的 IAM 权限访问包含该映像的 ECR 存储库,或者您使用的 kubectl 来自与创建该集群的用户不同的用户,则您将收到以下错误消息。
error: unable to recognize "job.yaml": Unauthorized
要解决此问题,您需要刷新 IAM 令牌。请运行以下脚本。
set -ex
AWS_ACCOUNT=${AWS_ACCOUNT}AWS_REGION=us-east-1DOCKER_REGISTRY_SERVER=https://${AWS_ACCOUNT}.dkr.ecr.${AWS_REGION}.amazonaws.comDOCKER_USER=AWSDOCKER_PASSWORD=`aws ecr get-login --region ${AWS_REGION} --registry-ids ${AWS_ACCOUNT} | cut -d' ' -f6`kubectl delete secret aws-registry || truekubectl create secret docker-registry aws-registry \--docker-server=$DOCKER_REGISTRY_SERVER \--docker-username=$DOCKER_USER \--docker-password=$DOCKER_PASSWORDkubectl patch serviceaccount default -p '{"imagePullSecrets":[{"name":"aws-registry"}]}'
143

深度学习 AMI 开发人员指南EKS 上的 AWS Deep Learning Containers故障排除
将 spec 下的以下内容附加到您的 Pod 文件中。
imagePullSecrets: - name: aws-registry
EKS 上的 AWS Deep Learning Containers故障排除故障排除主题
• 设置错误 (p. 144)• 使用错误 (p. 145)• 清理错误 (p. 145)
设置错误
错误:错误。注册表 kubeflow 不存在
示例:
$ ks pkg install kubeflow/tf-servingERROR registry 'kubeflow' does not exist
解决方案:运行以下命令。
ks registry add kubeflow github.com/google/kubefl ow/tree/master/kubeflow
错误:上下文超出截止日期
示例:
$ eksctl create cluster <args>[#] waiting for CloudFormation stack "eksctl-training-cluster-1-nodegroup-ng-8c4c94bc" to reach "CREATE_COMPLETE" status: RequestCanceled: waiter context canceledcaused by: context deadline exceeded
解决方案:验证是否超出您的账户的容量。在其他区域中重试该命令。
$ kubectl get nodesThe connection to the server localhost:8080 was refused - did you specify the right host or port?
解决方案:尝试运行 cp ~/.kube/eksctl/clusters/<name-of-cluster> ~/.kube/config
$ ks apply defaultERROR handle object: patching object from cluster: merging object with existing state: Unauthorized
144

深度学习 AMI 开发人员指南EKS 上的 AWS Deep Learning Containers故障排除
解决方案:这是一个并发问题,当具有不同授权/凭证的多个用户试图在同一集群上启动作业时,便会发生此问题。
$ APP_NAME=kubeflow-tf-hvd; ks init ${APP_NAME}; cd ${APP_NAME}INFO Using context "arn:aws:eks:eu-west-1:999999999999:cluster/training-gpu-1" from kubeconfig file "/home/ubuntu/.kube/config"ERROR Could not create app; directory '/home/ubuntu/kubeflow-tf-hvd' already exists
解决方案:忽略此警告。但是,您可能需要对该文件夹执行额外的清理工作。您可能需要删除该文件夹以简化清理。
使用错误
ssh: Could not resolve hostname openmpi-worker-1.openmpi.kubeflow-dist-train-tf: Name or service not known
解决方案:在使用 EKS 集群时,只要看到此错误消息,则针对 Kubernetes 安装步骤再运行一遍 NVIDIA 设备插件。通过以下方式确保针对的是正确的集群:传入特定配置文件或切换活动集群到目标集群。
清理错误
$ kubectl delete namespace ${NAMESPACE}error: the server doesn't have a resource type "namspace"
解决方案:检查命名空间的拼写。可能拼写有错误。
$ ks delete defaultERROR the server has asked for the client to provide credentials
解决方案:确保 ~/.kube/config 指向正确的集群,并且已使用 aws configure 或通过导出 AWS 环境变量正确配置了 AWS 凭证。
$ ks delete defaultERROR finding app root from starting path: : unable to find ksonnet project$ kubectl logs -n ${NAMESPACE} -f ${COMPONENT}-master > results/benchmark_1.outError from server (NotFound): pods "openmpi-master" not found
解决方案:确保正确地更改目录到创建的 ksonnet 应用程序(执行 ks init 的文件夹),同时要注意,删除默认上下文将导致相应的资源被删除。
$ ks component rm openmpiERROR finding app root from starting path: : unable to find ksonnet project
解决方案:确保正确地更改目录到创建的 ksonnet 应用程序(执行 ks init 的文件夹)。
145

深度学习 AMI 开发人员指南EKS 上的 AWS Deep Learning Containers词汇表
EKS 上的 AWS Deep Learning Containers词汇表EKS 和深度学习容器术语词汇表
以下词汇表解释了本指南中提到的工具:
•AWS CLI:用于与许多 AWS 服务(如 aws eks --[args])交互的命令行工具
•aws-iam-authenticator:验证 EC2 实例是否具有适当的 AWS 凭证来访问 EKS。在这些凭证上可以应用授权或拒绝访问和功能性的策略。
•集群:在一个或多个 EC2 实例上运行的一个或多个容器
•容器:虚拟化的操作系统和/或服务
•EC2 实例或 Amazon 机器映像 (AMI):AMI 和实例常常互用。AMI 是在实例类型上运行的主机操作系统和捆绑软件,在速度、容量和算力上存在不同。GPU 是实例的可选计算硬件,被建议用于大多数深度学习应用程序中。EC2 实例随 AMI 一起加载,它们合在一起是您的“云计算机”。然后,使用来自 AMI 的操作系统运行容器。
•EKS:Amazon Elastic Container Service for Kubernetes (Amazon EKS)。EKS 具有用来管理、扩展和部署 Kubernetes 容器的工具和让容器运行的任务。
•eksctl:在 EKS 上创建 Kubernetes 集群的命令行工具。
•IAM:AWS 服务的身份管理工具
•ksonnet:Kubernetes 清单的配置管理工具。
•ksonnet 包:一个 ksonnet 应用程序可以分成一系列单独的组件。 组件可以很简单,如只是一个Kubernetes 资源(例如部署),也可以很复杂,如一个完整的日志记录堆栈。 原型是可以用作您的组件的基础的示例。 使用原型可以避免复制和粘贴样本代码,从而将精力专注在特定于您的应用程序的配置部分上。 软件包是一组相关的原型和帮助程序库,用来定义原型部分。 利用软件包可以在任何 ksonnet 应用程序中轻松分发和复用代码。 有关 ksonnet 软件包的更多信息,请参阅 ksonnet 项目 github 存储库中的ksonnet 概念文档。
•Kubeconfig:用于配置集群访问权的文件,有时称为 kubeconfig 文件。这是引用配置文件的通用方式。这并不意味着有一个名为 kubeconfig 的文件。该文件的默认位置在 ~/.kube。
•kubectl:针对 Kubernetes 集群运行命令的命令行界面。
•Kubeflow:使得在 Kubernetes 上部署机器学习 (ML) 工作流变得简单、可移植和可扩展的工具。使用Kubeflow 有助于独立于集群设置来部署 ML 工作负载,进而有助于支持 ML 工作流生命周期的复现性,以及跨不同工作流复用构建块。Kubeflow 还支持 ML 工作流中的可视化和协作。
•Kubernetes 或 k8s:用于扩展、部署和管理容器化应用程序的容器编排。
•清单:包含属于一个集合或整合单元的一组伴随文件的元数据的文件。在 Kubernetes 语法中,在资源清单文件中定义部署的资源集和资源的所需状态。
•命名空间:Kubernetes 支持同一个物理集群支持下的多个虚拟集群。这些虚拟集群称为命名空间。命名空间提供了一个名称范围。在同一个命名空间中,资源名称必须唯一,但在不同命名空间中则不需要。 命名空间是在多个用户之间划分集群资源的方式。命名空间适用于众多用户分散在多个团队或项目中的环境。
146

深度学习 AMI 开发人员指南Amazon SageMaker 上的 Deep Learning Containers
•pod:提供一项服务或功能的相关容器的集合。
•pod 文件:一个 yaml 格式的文件,其中包含有关 pod 的说明,包括集群应运行哪些操作或作业的引用。
Amazon SageMaker 上的 AWS Deep LearningContainers
AWS Deep Learning Containers 是 Amazon SageMaker 上 TensorFlow、PyTorch 和 MXNet 中训练和处理模型的一组 Docker 映像。AWS Deep Learning Containers 通过 TensorFlow 和 MXNet、Nvidia CUDA(适用于 GPU 实例)和 Intel MKL(适用于 CPU 实例)库提供优化环境,并在 Amazon ECR 中可用。有关更多信息,请参阅 SageMaker 文档
附录目录
• Deep Learning Containers映像 (p. 147)• AWS Deep Learning Containers 自定义映像 (p. 151)• AWS Deep Learning Containers MKL 建议 (p. 152)
Deep Learning Containers映像AWS Deep Learning Containers可用作 Amazon ECR 中的 Docker 映像。每个 Docker 映像专用于在带CPU 或 GPU 支持的特定深度学习框架版本、python 版本上运行训练或推理。下表列出了任务定义中的Amazon ECS 将使用的 Docker 映像 URL。
AWS Deep Learning Containers Docker 映像在以下区域中可用:us-east-1、us-east-2、us-west-1、us-west-2、ap-northeast-1、ap-northeast-2、ap-south-1、ap-southeast-1、ap-southeast-2、sa-east-1、ca-central-1、eu-central-1、eu-north-1、eu-west-1、eu-west-2、eu-west-3
注意:eu-north-1 从 2.0 发行版本开始可用。因此,MXNet-1.4.0 在此区域中不可用。
ECR 是一项区域性服务并且映像表包含 us-east-1 映像的 URL。要从之前提到的区域之一拉取映像,请将该区域插入此示例后面的存储库 URL 中:
763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:1.14.0-cpu-py27-ubuntu16.04
Important
要拉取映像,必须先登录并访问 映像存储库。在以下命令中指定您的区域:
$(aws ecr get-login --no-include-email --region us-east-1 --registry-ids 763104351884)
然后,运行以下命令,从 Amazon ECR 中拉取这些 Docker 映像:
docker pull <name of container image>
147
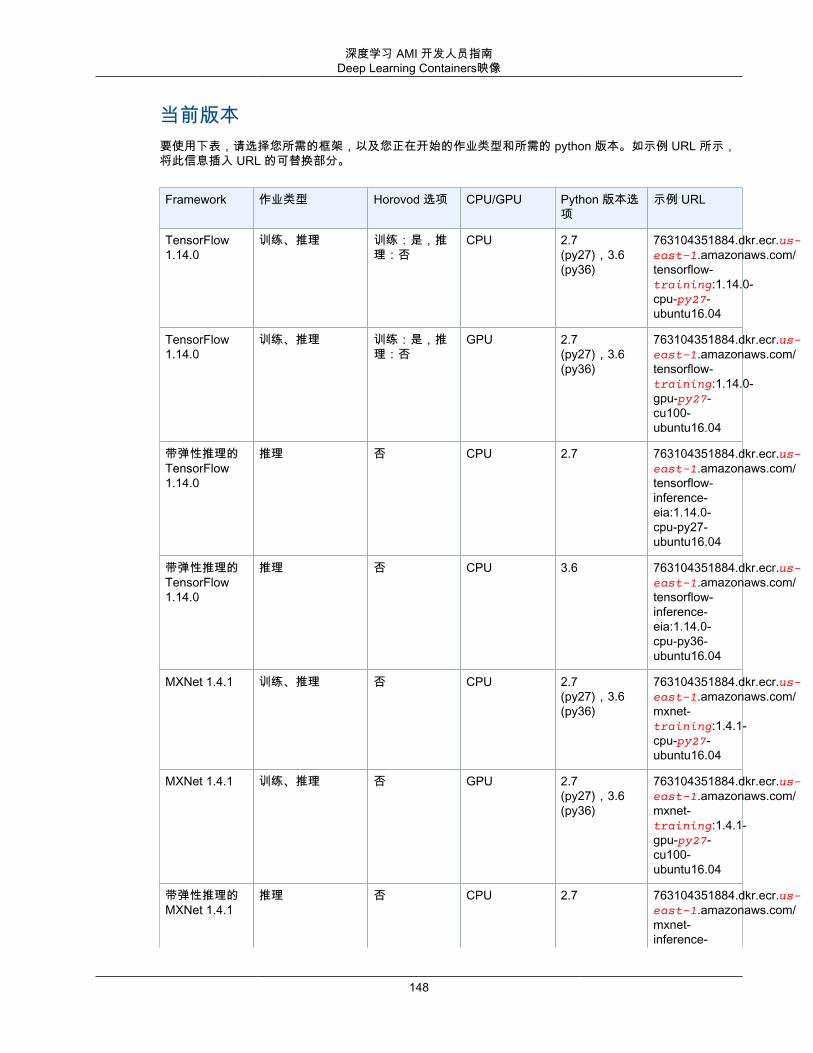
深度学习 AMI 开发人员指南Deep Learning Containers映像
当前版本要使用下表,请选择您所需的框架,以及您正在开始的作业类型和所需的 python 版本。如示例 URL 所示,将此信息插入 URL 的可替换部分。
Framework 作业类型 Horovod 选项 CPU/GPU Python 版本选项
示例 URL
TensorFlow1.14.0
训练、推理 训练:是,推理:否
CPU 2.7(py27),3.6(py36)
763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.14.0-cpu-py27-ubuntu16.04
TensorFlow1.14.0
训练、推理 训练:是,推理:否
GPU 2.7(py27),3.6(py36)
763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.14.0-gpu-py27-cu100-ubuntu16.04
带弹性推理的TensorFlow1.14.0
推理 否 CPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference-eia:1.14.0-cpu-py27-ubuntu16.04
带弹性推理的TensorFlow1.14.0
推理 否 CPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference-eia:1.14.0-cpu-py36-ubuntu16.04
MXNet 1.4.1 训练、推理 否 CPU 2.7(py27),3.6(py36)
763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.1-cpu-py27-ubuntu16.04
MXNet 1.4.1 训练、推理 否 GPU 2.7(py27),3.6(py36)
763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.1-gpu-py27-cu100-ubuntu16.04
带弹性推理的MXNet 1.4.1
推理 否 CPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference-
148
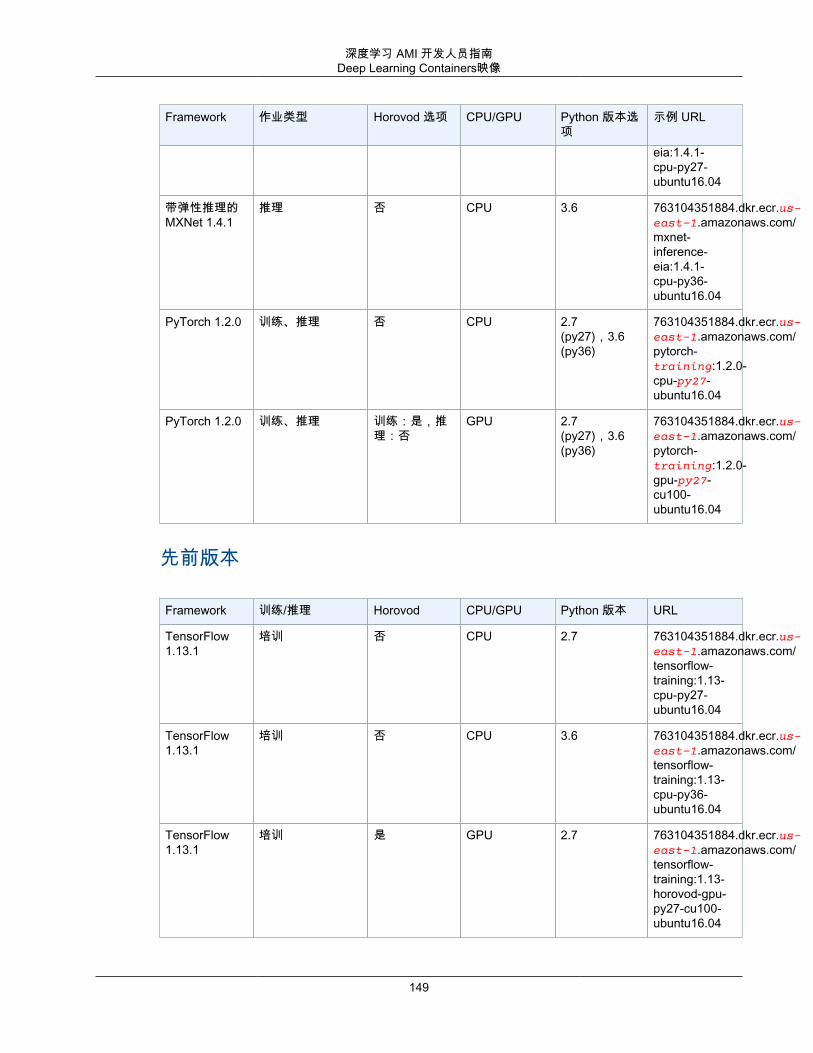
深度学习 AMI 开发人员指南Deep Learning Containers映像
Framework 作业类型 Horovod 选项 CPU/GPU Python 版本选项
示例 URL
eia:1.4.1-cpu-py27-ubuntu16.04
带弹性推理的MXNet 1.4.1
推理 否 CPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference-eia:1.4.1-cpu-py36-ubuntu16.04
PyTorch 1.2.0 训练、推理 否 CPU 2.7(py27),3.6(py36)
763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-cpu-py27-ubuntu16.04
PyTorch 1.2.0 训练、推理 训练:是,推理:否
GPU 2.7(py27),3.6(py36)
763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-gpu-py27-cu100-ubuntu16.04
先前版本
Framework 训练/推理 Horovod CPU/GPU Python 版本 URL
TensorFlow1.13.1
培训 否 CPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.13-cpu-py27-ubuntu16.04
TensorFlow1.13.1
培训 否 CPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.13-cpu-py36-ubuntu16.04
TensorFlow1.13.1
培训 是 GPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.13-horovod-gpu-py27-cu100-ubuntu16.04
149
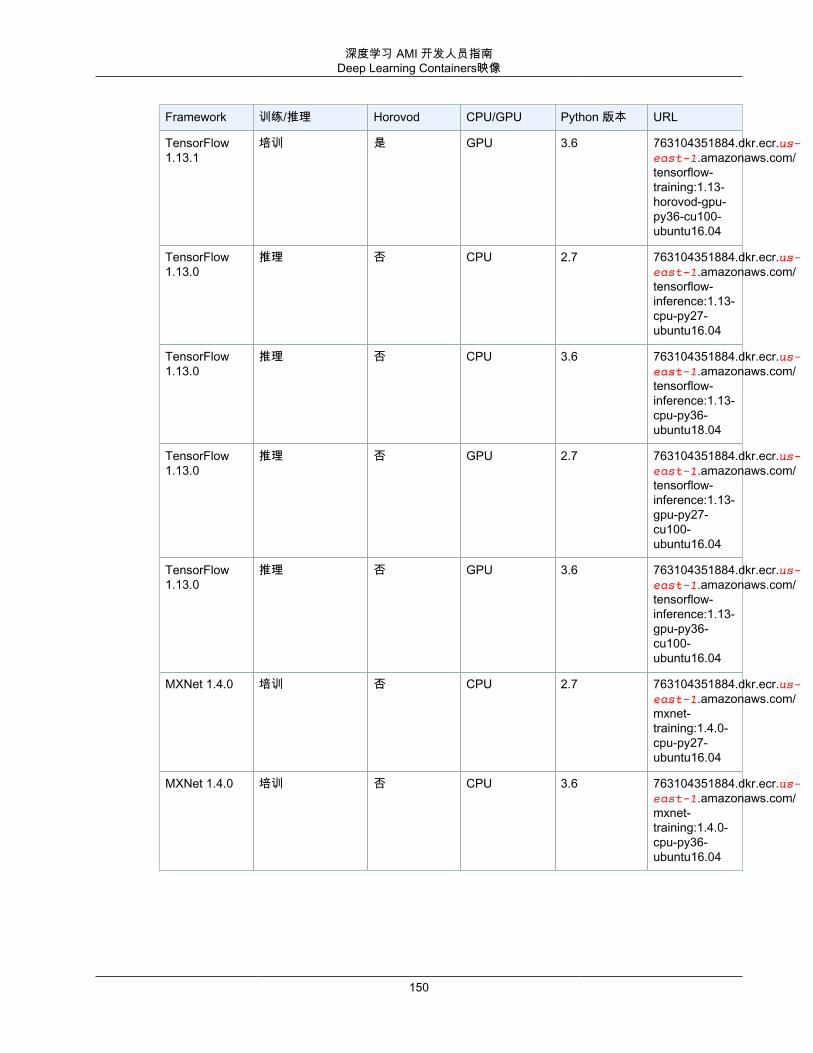
深度学习 AMI 开发人员指南Deep Learning Containers映像
Framework 训练/推理 Horovod CPU/GPU Python 版本 URL
TensorFlow1.13.1
培训 是 GPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.13-horovod-gpu-py36-cu100-ubuntu16.04
TensorFlow1.13.0
推理 否 CPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.13-cpu-py27-ubuntu16.04
TensorFlow1.13.0
推理 否 CPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.13-cpu-py36-ubuntu18.04
TensorFlow1.13.0
推理 否 GPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.13-gpu-py27-cu100-ubuntu16.04
TensorFlow1.13.0
推理 否 GPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:1.13-gpu-py36-cu100-ubuntu16.04
MXNet 1.4.0 培训 否 CPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.0-cpu-py27-ubuntu16.04
MXNet 1.4.0 培训 否 CPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.0-cpu-py36-ubuntu16.04
150
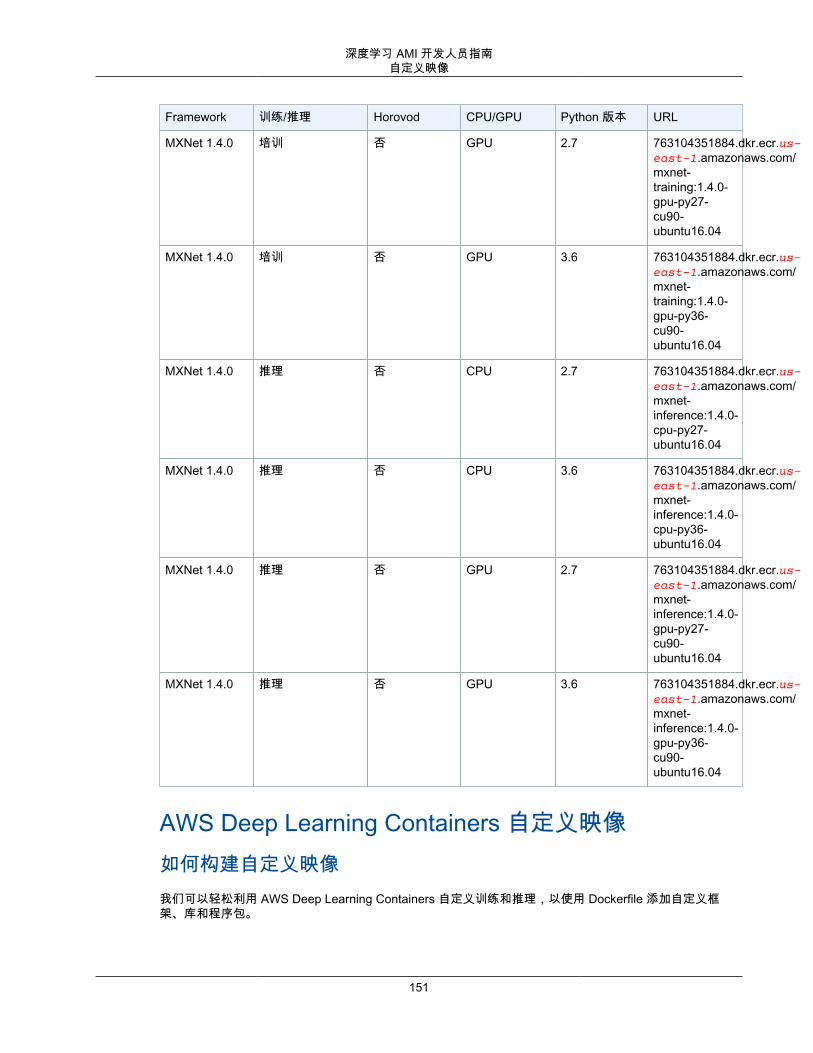
深度学习 AMI 开发人员指南自定义映像
Framework 训练/推理 Horovod CPU/GPU Python 版本 URL
MXNet 1.4.0 培训 否 GPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.0-gpu-py27-cu90-ubuntu16.04
MXNet 1.4.0 培训 否 GPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.0-gpu-py36-cu90-ubuntu16.04
MXNet 1.4.0 推理 否 CPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.0-cpu-py27-ubuntu16.04
MXNet 1.4.0 推理 否 CPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.0-cpu-py36-ubuntu16.04
MXNet 1.4.0 推理 否 GPU 2.7 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.0-gpu-py27-cu90-ubuntu16.04
MXNet 1.4.0 推理 否 GPU 3.6 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-inference:1.4.0-gpu-py36-cu90-ubuntu16.04
AWS Deep Learning Containers 自定义映像如何构建自定义映像我们可以轻松利用 AWS Deep Learning Containers 自定义训练和推理,以使用 Dockerfile 添加自定义框架、库和程序包。
151
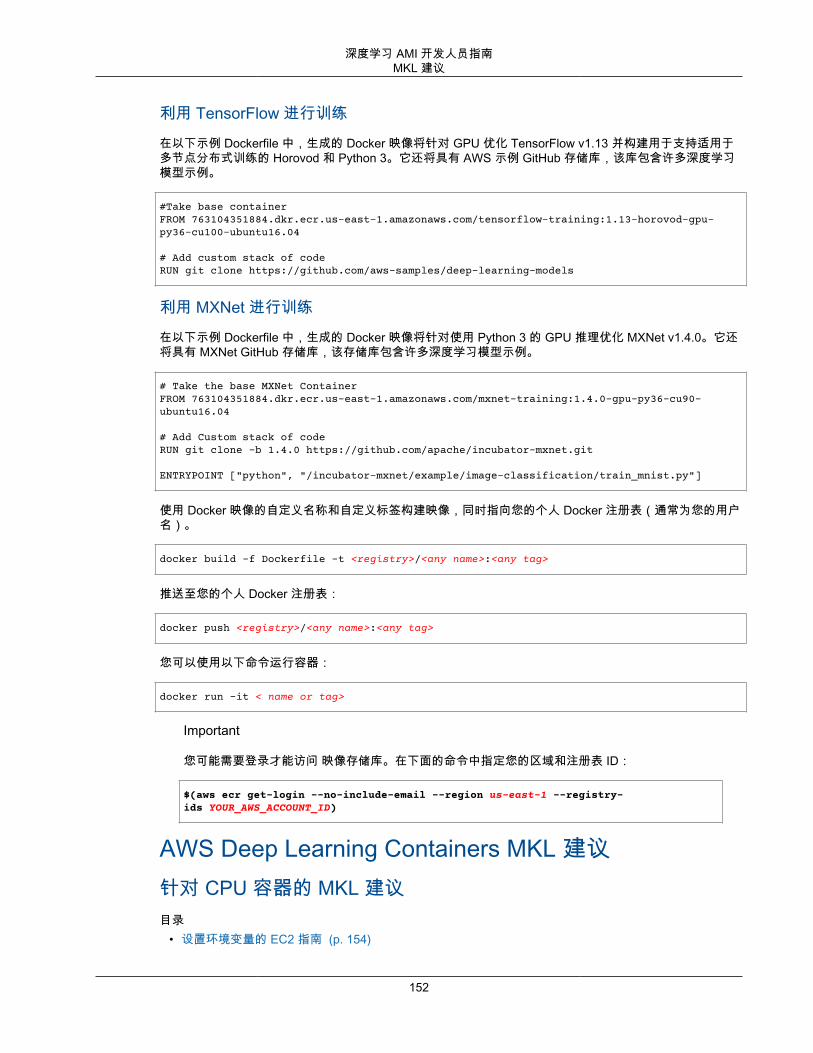
深度学习 AMI 开发人员指南MKL 建议
利用 TensorFlow 进行训练
在以下示例 Dockerfile 中,生成的 Docker 映像将针对 GPU 优化 TensorFlow v1.13 并构建用于支持适用于多节点分布式训练的 Horovod 和 Python 3。它还将具有 AWS 示例 GitHub 存储库,该库包含许多深度学习模型示例。
#Take base containerFROM 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.13-horovod-gpu-py36-cu100-ubuntu16.04
# Add custom stack of codeRUN git clone https://github.com/aws-samples/deep-learning-models
利用 MXNet 进行训练
在以下示例 Dockerfile 中,生成的 Docker 映像将针对使用 Python 3 的 GPU 推理优化 MXNet v1.4.0。它还将具有 MXNet GitHub 存储库,该存储库包含许多深度学习模型示例。
# Take the base MXNet ContainerFROM 763104351884.dkr.ecr.us-east-1.amazonaws.com/mxnet-training:1.4.0-gpu-py36-cu90-ubuntu16.04
# Add Custom stack of codeRUN git clone -b 1.4.0 https://github.com/apache/incubator-mxnet.git
ENTRYPOINT ["python", "/incubator-mxnet/example/image-classification/train_mnist.py"]
使用 Docker 映像的自定义名称和自定义标签构建映像,同时指向您的个人 Docker 注册表(通常为您的用户名)。
docker build -f Dockerfile -t <registry>/<any name>:<any tag>
推送至您的个人 Docker 注册表:
docker push <registry>/<any name>:<any tag>
您可以使用以下命令运行容器:
docker run -it < name or tag>
Important
您可能需要登录才能访问 映像存储库。在下面的命令中指定您的区域和注册表 ID:
$(aws ecr get-login --no-include-email --region us-east-1 --registry-ids YOUR_AWS_ACCOUNT_ID)
AWS Deep Learning Containers MKL 建议针对 CPU 容器的 MKL 建议目录
• 设置环境变量的 EC2 指南 (p. 154)
152

深度学习 AMI 开发人员指南MKL 建议
• 设置环境变量的 ECS 指南 (p. 154)• 设置环境变量的 EKS 指南 (p. 155)
CPU 实例上深度学习框架的训练和推理工作负载的性能情形不一,具体取决于各种配置设置。例如,在AWS EC2 c5.18xlarge 实例上,物理内核数为 36,而逻辑内核数为 72。MKL 的训练和推理的配置设置受这些因素影响。通过更新 MKL 的配置来匹配实例功能,则有可能实现性能改进。
请考虑以下使用 Intel-MKL 优化的 TensorFlow 二进制的示例:
•据对一个 ResNet50v2 模型(该模型使用 TensorFlow 来训练,训练好后使用TensorFlow Serving 来推理)的观察,当 MKL 设置调整到匹配实例的内核数量时,推理性能提高 2 倍。以下设置用于 c5.18xlarge实例。
export TENSORFLOW_INTER_OP_PARALLELISM=2# For an EC2 c5.18xlarge instance, number of logical cores = 72export TENSORFLOW_INTRA_OP_PARALLELISM=72# For an EC2 c5.18xlarge instance, number of physical cores = 36export OMP_NUM_THREADS=36export KMP_AFFINITY='granularity=fine,verbose,compact,1,0'# For an EC2 c5.18xlarge instance, number of physical cores / 4 = 36 /4 = 9export TENSORFLOW_SESSION_PARALLELISM=9export KMP_BLOCKTIME=1export KMP_SETTINGS=0
•据对一个 ResNet50_v1.5 模型(该模型使用 TensorFlow 在 ImageNet 数据集上训练,并且使用 NHWC图像形状)的观察,训练吞吐量性能加快了 9 倍左右。比较对象为未进行 MKL 优化的二级制,用“样本数/秒”指标来进行度量。使用以下环境变量:
export TENSORFLOW_INTER_OP_PARALLELISM=0# For an EC2 c5.18xlarge instance, number of logical cores = 72export TENSORFLOW_INTRA_OP_PARALLELISM=72# For an EC2 c5.18xlarge instance, number of physical cores = 36export OMP_NUM_THREADS=36export KMP_AFFINITY='granularity=fine,verbose,compact,1,0'# For an EC2 c5.18xlarge instance, number of physical cores / 4 = 36 /4 = 9export KMP_BLOCKTIME=1export KMP_SETTINGS=0
以下链接将帮助您了解如何调整 Intel MKL 和您的深度学习框架设置,以优化深度学习工作负载:
•Intel 优化的 TensorFlow Serving 的一般最佳实践
•TensorFlow 性能
•提高 Apache MXNet 性能的一些技巧
•包含 Intel MKL-DNN 的 MXNet 的性能基准测试
153

深度学习 AMI 开发人员指南MKL 建议
设置环境变量的 EC2 指南 请参阅 docker run 文档,了解在创建容器时如何设置环境变量:https://docs.docker.com/engine/reference/run/#env-environment-variables
下面是为 docker run 设置称为 OMP_NUM_THREADS 的环境变量的一个示例。
ubuntu@ip-172-31-95-248:~$ docker run -e OMP_NUM_THREADS=36 -it --entrypoint "" 999999999999.dkr.ecr.us-east-1.amazonaws.com/beta-tensorflow-inference:1.13-py2-cpu-build bashroot@d437faf9b684:/# echo $OMP_NUM_THREADS36
设置环境变量的 ECS 指南 要在 ECS 中为容器指定运行时环境变量,必须编辑 ECS 任务定义。在任务定义的containerDefinitions 部分,以“名称-值”密钥对的形式添加环境变量。下面为设置 OMP_NUM_THREADS和 KMP_BLOCKTIME 变量的示例。
{ "requiresCompatibilities": [ "EC2" ], "containerDefinitions": [{ "command": [ "mkdir -p /test && cd /test && git clone -b r1.13 https://github.com/tensorflow/serving.git && tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=saved_model_half_plus_two_cpu --model_base_path=/test/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu" ], "entryPoint": [ "sh", "-c" ], "name": "EC2TFInference", "image": "999999999999.dkr.ecr.us-east-1.amazonaws.com/tf-inference:1.12-cpu-py3-ubuntu16.04", "memory": 8111, "cpu": 256, "essential": true, "environment": [{ "name": "OMP_NUM_THREADS", "value": "36" }, { "name": "KMP_BLOCKTIME", "value": 1 } ], "portMappings": [{ "hostPort": 8500, "protocol": "tcp", "containerPort": 8500 }, { "hostPort": 8501, "protocol": "tcp", "containerPort": 8501 }, {
154

深度学习 AMI 开发人员指南MKL 建议
"containerPort": 80, "protocol": "tcp" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/TFInference", "awslogs-region": "us-west-2", "awslogs-stream-prefix": "ecs", "awslogs-create-group": "true" } } }], "volumes": [], "networkMode": "bridge", "placementConstraints": [], "family": "Ec2TFInference"}
设置环境变量的 EKS 指南
要为容器指定运行时环境变量,编辑 EKS 作业(.yaml、.json)的原始清单。以下清单的代码段显示名为 squeezenet-service 的容器的定义。除了其他属性如 args 和端口外,环境变量以“名称-值”密钥对的形式列出。
containers: - name: squeezenet-service image: 999999999999.dkr.ecr.us-east-1.amazonaws.com/beta-mxnet-inference:1.4.0-py3-gpu-build command: - mxnet-model-server args: - --start - --mms-config /home/model-server/config.properties - --models squeezenet=https://s3.amazonaws.com/model-server/models/squeezenet_v1.1/squeezenet_v1.1.model ports: - name: mms containerPort: 8080 - name: mms-management containerPort: 8081 imagePullPolicy: IfNotPresent env: - name: AWS_REGION`` value: us-east-1 - name: OMP_NUM_THREADS value: 36 - name: TENSORFLOW_INTER_OP_PARALLELISM value: 0 - name: KMP_AFFINITY value: 'granularity=fine,verbose,compact,1,0' - name: KMP_BLOCKTIME value: 1
155

深度学习 AMI 开发人员指南DLAMI 升级
升级 DLAMI在此处,您将找到有关升级 DLAMI 的信息以及有关在 DLAMI 上更新软件的提示。
主题• 升级到新版 DLAMI (p. 156)• 有关软件更新的提示 (p. 156)
升级到新版 DLAMIDLAMI 的系统映像定期更新,以利用新的深度学习框架版本、CUDA、其他软件更新和性能优化。如果您已使用 DLAMI 一段时间并想要利用更新,则需要启动新实例。您还必须手动传输任何数据集、检查点或其他宝贵的数据。或者,您可以使用 Amazon EBS 保留您的数据,并将其附加到新的 DLAMI。通过这种方法,您可以经常升级,同时最大限度地减少转换数据所需的时间。
Note
在 DLAMI 之间附加和移动 Amazon EBS 卷时,必须在同一个可用区同时具有 DLAMI 和新卷。
1. 使用 Amazon EC2 控制台创建新的 Amazon EBS 卷。有关详细指导,请参阅创建 Amazon EBS 卷。2. 将新创建的 Amazon EBS 卷附加到现有的 DLAMI。有关详细指导,请参阅附加 Amazon EBS 卷。3. 传输您的数据,如数据集、检查点和配置文件。4. 启动 DLAMI。有关详细指导,请参阅启动和配置 DLAMI (p. 9)。5. 从旧 DLAMI 中分离 Amazon EBS 卷。有关详细指导,请参阅分离 Amazon EBS 卷。6. 将 Amazon EBS 卷连接到新的 DLAMI。请按照步骤 2 中的相关说明附加卷。7. 在确认数据可用于新的 DLAMI 上时,停止并终止旧的 DLAMI。有关更详细的清理说明,请参阅清
除 (p. 11)。
有关软件更新的提示有时,您可能想要在 DLAMI 上手动更新软件。通常建议您使用 pip 来更新 Python 软件包。您还应在 采用Conda 的 Deep Learning AMI 上的 Conda 环境内使用 pip 以更新软件包。有关升级和安装说明,请参阅特定框架或软件的网站。
如果您有兴趣运行某个特定软件包的最新主分支,请激活相应的环境,然后将 --pre 添加到 pip install--upgrade 命令的结尾:例如:
source activate mxnet_p36pip install --upgrade mxnet --pre
156

深度学习 AMI 开发人员指南论坛
资源和支持主题
• 论坛 (p. 157)• 相关博客文章 (p. 157)• 常见问题 (p. 157)
论坛• 论坛:AWS Deep Learning AMI
相关博客文章• 与 Deep Learning AMI 相关的最新文章列表• 启动 AWS Deep Learning AMI (在 10 分钟内)• 在 Amazon EC2 C5 和 P3 实例上使用优化的 TensorFlow 1.6 加快训练• 面向机器学习从业人员的新 AWS Deep Learning AMI• 新的可用培训课程:AWS 机器学习和深度学习介绍• AWS 深度学习之旅
常见问题• 问: 如何跟踪与 DLAMI 相关的产品发布信息?
以下是两个建议:• 为此博客类别添加书签:“AWS Deep Learning AMIs”,网址为:与 Deep Learning AMI 相关的最新文章
列表。• 观看 论坛:AWS Deep Learning AMI
• 问: 是否安装了 NVIDIA 驱动程序和 CUDA?
是的。某些 DLAMI 具有不同的版本。采用 Conda 的 Deep Learning AMI (p. 3) 包含任何 DLAMI 的最新版本。CUDA 安装和框架绑定 (p. 5) 中进行了详细介绍。您也可以参阅市场上的特定 AMI 的详细信息页面,以确认安装的版本。
• 问: 是否安装了 cuDNN?
是的。• 问: 如何查看检测到的 GPU 及其当前状态?
运行 nvidia-smi.根据实例类型,将会显示一个或多个 GPU,及其当前的内存消耗。• 问: 是否为我设置了虚拟环境?
是的,但只在 采用 Conda 的 Deep Learning AMI (p. 3) 上。• 问: 安装了 Python 的哪个版本?
157
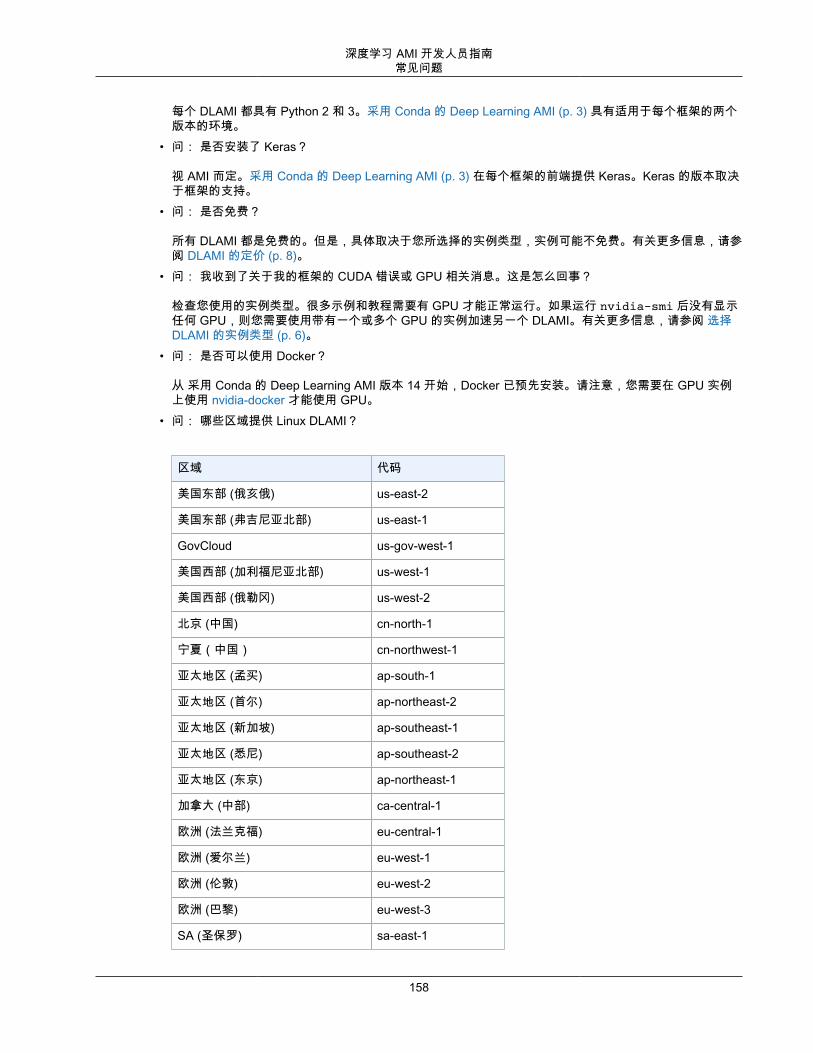
深度学习 AMI 开发人员指南常见问题
每个 DLAMI 都具有 Python 2 和 3。采用 Conda 的 Deep Learning AMI (p. 3) 具有适用于每个框架的两个版本的环境。
• 问: 是否安装了 Keras?
视 AMI 而定。采用 Conda 的 Deep Learning AMI (p. 3) 在每个框架的前端提供 Keras。Keras 的版本取决于框架的支持。
• 问: 是否免费?
所有 DLAMI 都是免费的。但是,具体取决于您所选择的实例类型,实例可能不免费。有关更多信息,请参阅 DLAMI 的定价 (p. 8)。
• 问: 我收到了关于我的框架的 CUDA 错误或 GPU 相关消息。这是怎么回事?
检查您使用的实例类型。很多示例和教程需要有 GPU 才能正常运行。如果运行 nvidia-smi 后没有显示任何 GPU,则您需要使用带有一个或多个 GPU 的实例加速另一个 DLAMI。有关更多信息,请参阅 选择DLAMI 的实例类型 (p. 6)。
• 问: 是否可以使用 Docker?
从 采用 Conda 的 Deep Learning AMI 版本 14 开始,Docker 已预先安装。请注意,您需要在 GPU 实例上使用 nvidia-docker 才能使用 GPU。
• 问: 哪些区域提供 Linux DLAMI?
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
158
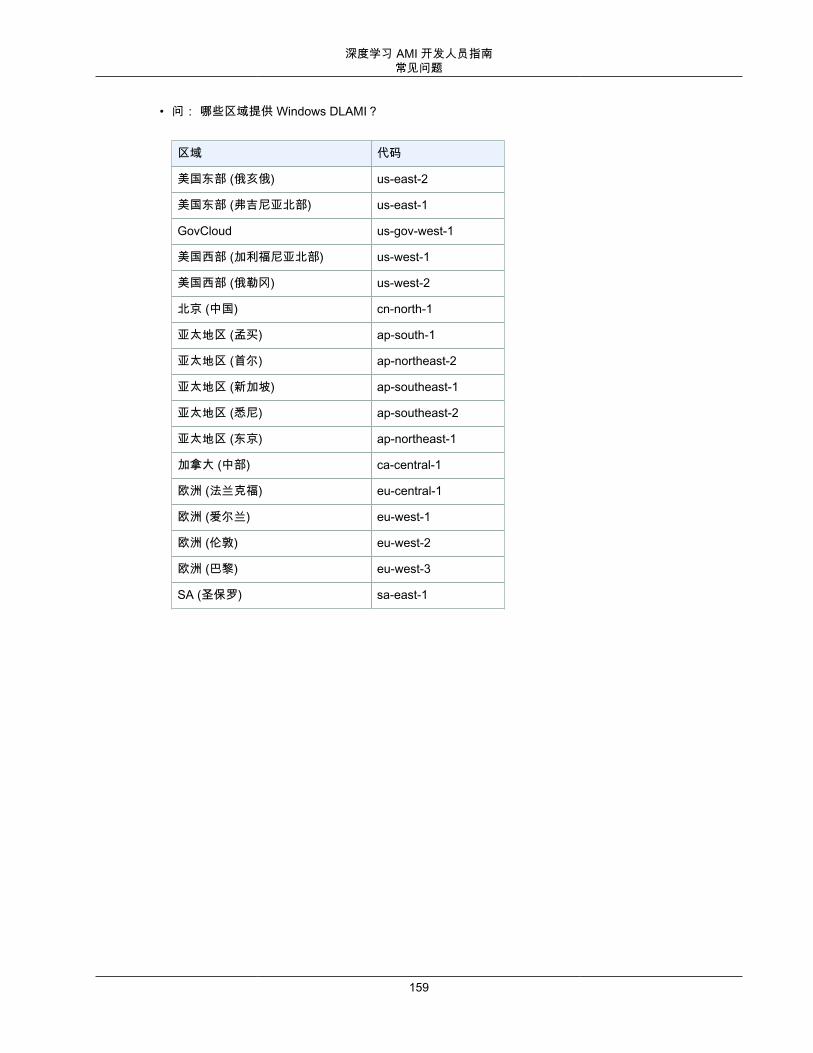
深度学习 AMI 开发人员指南常见问题
• 问: 哪些区域提供 Windows DLAMI?
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
159

深度学习 AMI 开发人员指南AMI 选项
附录主题
• AMI 选项 (p. 160)• DLAMI:发行说明 (p. 168)
AMI 选项以下主题介绍了 AWS Deep Learning AMI 的类别。
主题• 采用 Conda 的 Deep Learning AMI 选项 (p. 160)• Deep Learning Base AMI 选项 (p. 161)• 采用 CUDA 10.1 的深度学习 AMI 选项 (p. 162)• 采用 CUDA 10 的 Deep Learning AMI 选项 (p. 162)• 采用 CUDA 9 的 Deep Learning AMI 选项 (p. 163)• 采用 CUDA 8 的 Deep Learning AMI 选项 (p. 163)• AWS Deep Learning AMI,Ubuntu 18.04 选项 (p. 164)• AWS Deep Learning AMI,Ubuntu 16.04 选项 (p. 164)• AWS Deep Learning AMI Amazon Linux 选项 (p. 165)• AWS Deep Learning AMI Amazon Linux 2 选项 (p. 166)• AWS Deep Learning AMI,Windows 选项 (p. 167)
采用 Conda 的 Deep Learning AMI 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux 2)
在以下区域提供这些 DLAMI:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
160

深度学习 AMI 开发人员指南Base
区域 代码
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
Deep Learning Base AMI 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 16.04)• Deep Learning Base AMI (Amazon Linux) on the AWS Marketplace• AWS Marketplace 上的 Deep Learning Base AMI (Amazon Linux 2)
在以下区域提供这些 DLAMI:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
161
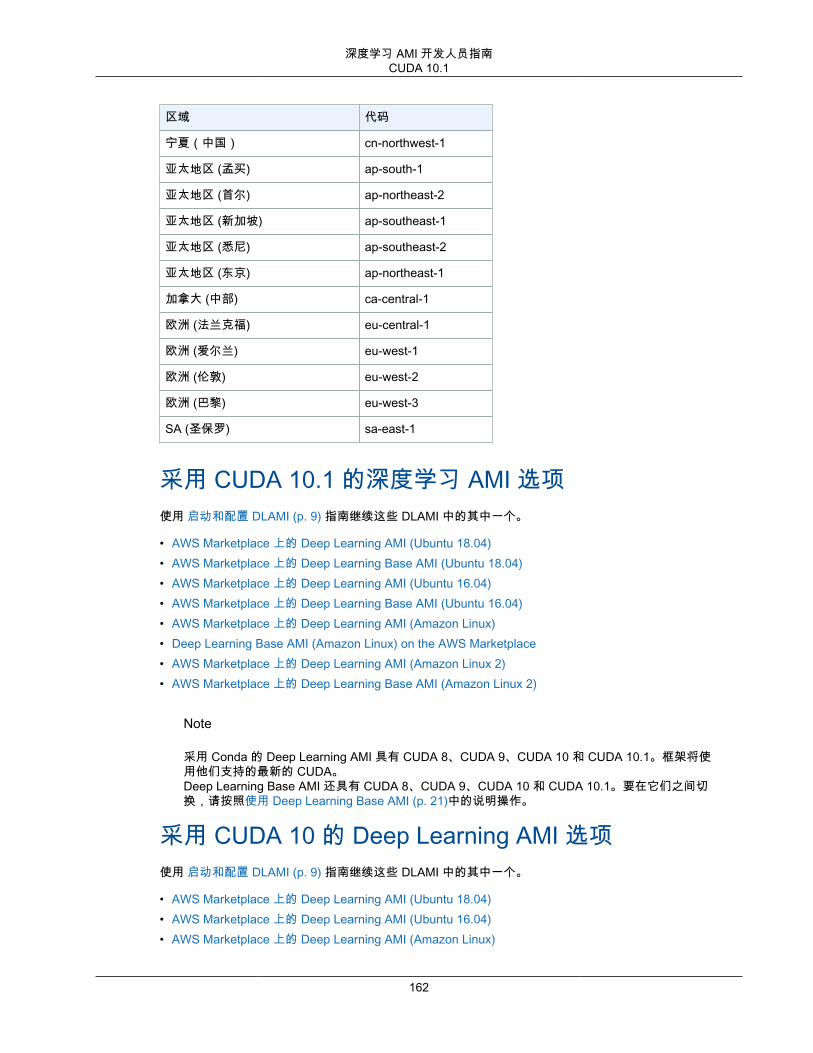
深度学习 AMI 开发人员指南CUDA 10.1
区域 代码
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
采用 CUDA 10.1 的深度学习 AMI 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux)• Deep Learning Base AMI (Amazon Linux) on the AWS Marketplace• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning Base AMI (Amazon Linux 2)
Note
采用 Conda 的 Deep Learning AMI 具有 CUDA 8、CUDA 9、CUDA 10 和 CUDA 10.1。框架将使用他们支持的最新的 CUDA。Deep Learning Base AMI 还具有 CUDA 8、CUDA 9、CUDA 10 和 CUDA 10.1。要在它们之间切换,请按照使用 Deep Learning Base AMI (p. 21)中的说明操作。
采用 CUDA 10 的 Deep Learning AMI 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux)
162

深度学习 AMI 开发人员指南CUDA 9
• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 16.04)• Deep Learning Base AMI (Amazon Linux) on the AWS Marketplace• AWS Marketplace 上的 Deep Learning Base AMI (Amazon Linux 2)
Note
采用 Conda 的 Deep Learning AMI 具有 CUDA 8、CUDA 9 和 CUDA 10。框架将使用他们支持的最新的 CUDA。Deep Learning Base AMI 还具有 CUDA 8、CUDA 9 和 CUDA 10。要在它们之间切换,请按照使用 Deep Learning Base AMI (p. 21)中的说明操作。
采用 CUDA 9 的 Deep Learning AMI 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 16.04)• Deep Learning Base AMI (Amazon Linux) on the AWS Marketplace• AWS Marketplace 上的 Deep Learning Base AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning AMI (Windows 2012 R2)• Deep Learning AMI (Windows 2016) on the AWS Marketplace
Note
采用 Conda 的 Deep Learning AMI 具有 CUDA 8、CUDA 9 和 CUDA 10。框架将使用他们支持的最新的 CUDA。Deep Learning Base AMI 还具有 CUDA 8、CUDA 9 和 CUDA 10。要在它们之间切换,请按照使用 Deep Learning Base AMI (p. 21)中的说明操作。
采用 CUDA 8 的 Deep Learning AMI 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux)• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 16.04)• Deep Learning Base AMI (Amazon Linux) on the AWS Marketplace• AWS Marketplace 上的 Deep Learning Base AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning AMI (Windows 2012 R2)• Deep Learning AMI (Windows 2016) on the AWS Marketplace
163
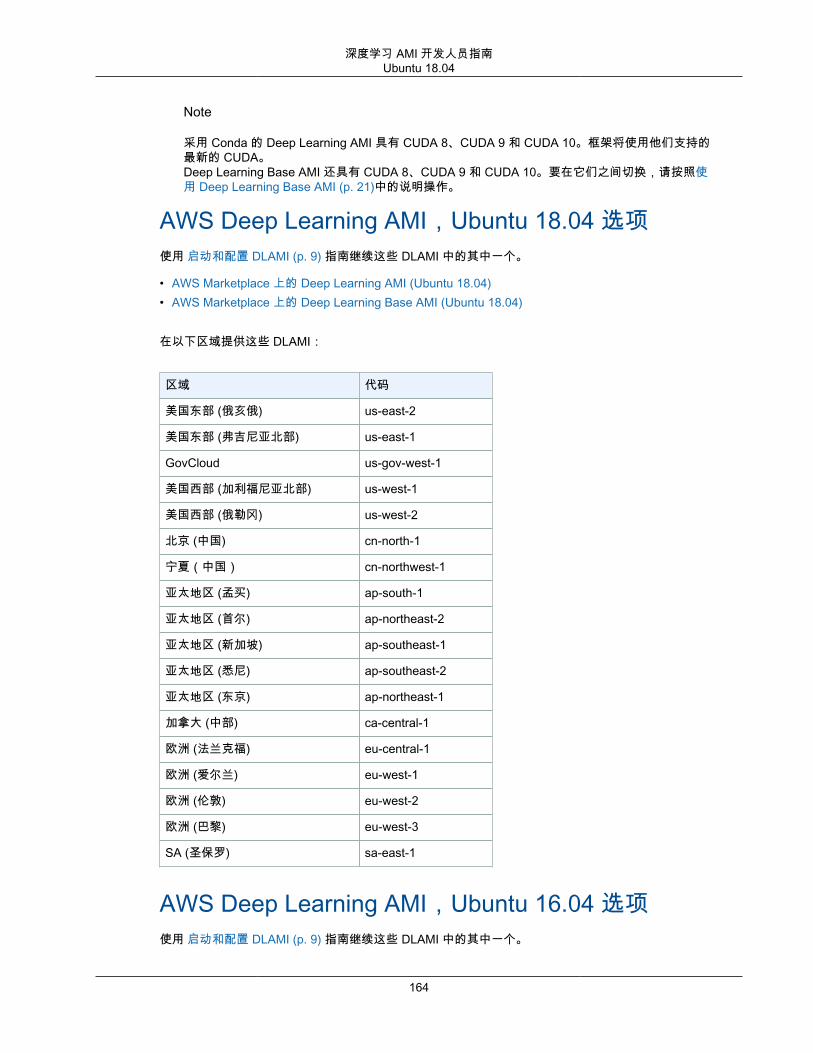
深度学习 AMI 开发人员指南Ubuntu 18.04
Note
采用 Conda 的 Deep Learning AMI 具有 CUDA 8、CUDA 9 和 CUDA 10。框架将使用他们支持的最新的 CUDA。Deep Learning Base AMI 还具有 CUDA 8、CUDA 9 和 CUDA 10。要在它们之间切换,请按照使用 Deep Learning Base AMI (p. 21)中的说明操作。
AWS Deep Learning AMI,Ubuntu 18.04 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 18.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 18.04)
在以下区域提供这些 DLAMI:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
AWS Deep Learning AMI,Ubuntu 16.04 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
164
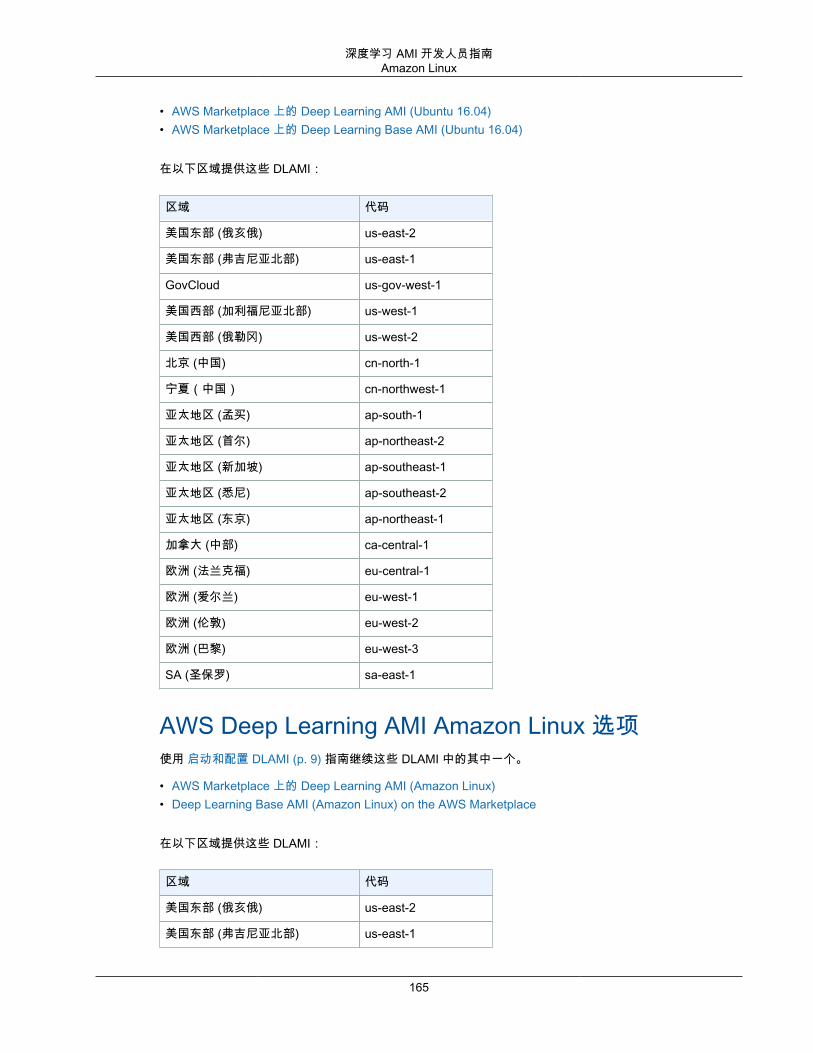
深度学习 AMI 开发人员指南Amazon Linux
• AWS Marketplace 上的 Deep Learning AMI (Ubuntu 16.04)• AWS Marketplace 上的 Deep Learning Base AMI (Ubuntu 16.04)
在以下区域提供这些 DLAMI:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
AWS Deep Learning AMI Amazon Linux 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux)• Deep Learning Base AMI (Amazon Linux) on the AWS Marketplace
在以下区域提供这些 DLAMI:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
165
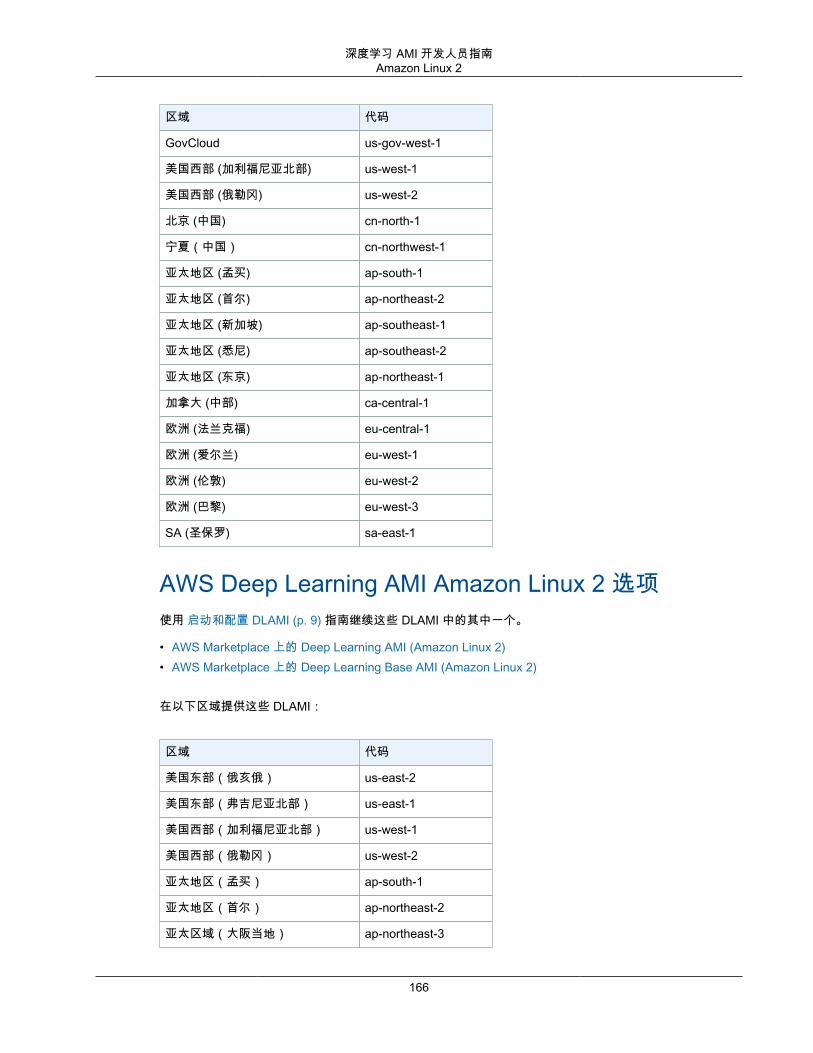
深度学习 AMI 开发人员指南Amazon Linux 2
区域 代码
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
AWS Deep Learning AMI Amazon Linux 2 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• AWS Marketplace 上的 Deep Learning AMI (Amazon Linux 2)• AWS Marketplace 上的 Deep Learning Base AMI (Amazon Linux 2)
在以下区域提供这些 DLAMI:
区域 代码
美国东部(俄亥俄) us-east-2
美国东部(弗吉尼亚北部) us-east-1
美国西部(加利福尼亚北部) us-west-1
美国西部(俄勒冈) us-west-2
亚太地区(孟买) ap-south-1
亚太地区(首尔) ap-northeast-2
亚太区域(大阪当地) ap-northeast-3
166

深度学习 AMI 开发人员指南Windows
区域 代码
亚太地区(新加坡) ap-southeast-1
亚太地区(悉尼) ap-southeast-2
亚太地区(东京) ap-northeast-1
加拿大(中部) ca-central-1
欧洲(法兰克福) eu-central-1
欧洲(爱尔兰) eu-west-1
欧洲(伦敦) eu-west-2
欧洲(巴黎) eu-west-3
SA(圣保罗) sa-east-1
Amazon Linux 2 发行说明
AWS Deep Learning AMI,Windows 选项使用 启动和配置 DLAMI (p. 9) 指南继续这些 DLAMI 中的其中一个。
• Deep Learning AMI (Windows 2016) on the AWS Marketplace• AWS Marketplace 上的 Deep Learning AMI (Windows 2012 R2)
在以下区域提供 Windows DLAMI:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
167

深度学习 AMI 开发人员指南DLAMI:发行说明
区域 代码
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
DLAMI:发行说明• 最新 AWS Deep Learning AMI 发行说明• AWS Deep Learning AMI 版本存档 (p. 168)
AWS Deep Learning AMI 版本存档主题
• AWS Deep Learning AMI 基础版本存档 (p. 168)• AWS Deep Learning AMI Conda 版本存档 (p. 174)• AWS Deep Learning AMI 源版本存档 (p. 188)• AWS Deep Learning AMI Windows 版本存档 (p. 255)
AWS Deep Learning AMI 基础版本存档主题
• Deep Learning Base AMI (Amazon Linux) 2.0 版的发行说明详细信息 (p. 168)• 2.0 版的发行说明详细信息 (p. 170)• Deep Learning Base AMI (Amazon Linux) 1.0 版的发行说明详细信息 (p. 171)• 1.0 版的发行说明详细信息 (p. 173)
Deep Learning Base AMI (Amazon Linux) 2.0 版的发行说明详细信息
AWS Deep Learning AMI
Deep Learning Base AMI 预置 CUDA 8 和 9,并准备好进行自定义深度学习设置。Deep Learning BaseAMI 与 Python2 和 Python3 一起共用 Anaconda 平台。
此发行版的亮点
1. 使用了 Amazon Linux 2017.09 (ami-8c1be5f6) 作为基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.15. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.0
168
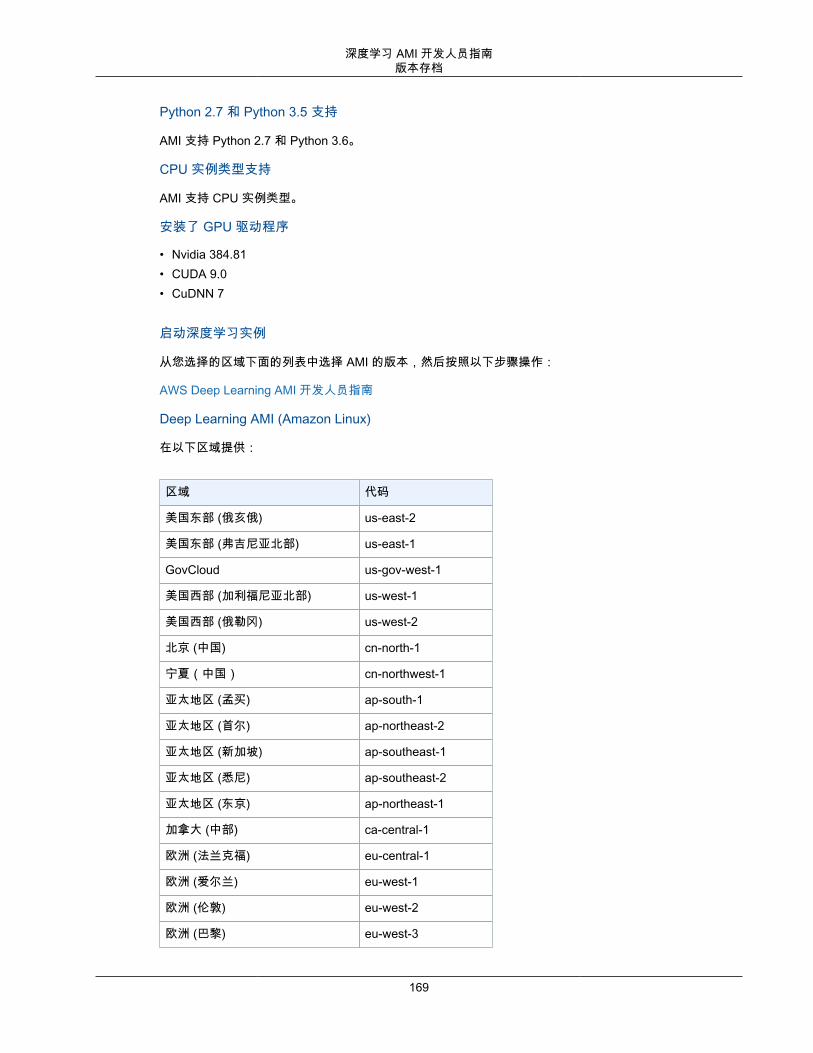
深度学习 AMI 开发人员指南版本存档
Python 2.7 和 Python 3.5 支持
AMI 支持 Python 2.7 和 Python 3.6。
CPU 实例类型支持
AMI 支持 CPU 实例类型。
安装了 GPU 驱动程序
• Nvidia 384.81• CUDA 9.0• CuDNN 7
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
Deep Learning AMI (Amazon Linux)
在以下区域提供:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
169

深度学习 AMI 开发人员指南版本存档
区域 代码
SA (圣保罗) sa-east-1
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 没有已知问题。
2.0 版的发行说明详细信息
AWS Deep Learning AMI
Deep Learning Base AMI 预置 CUDA 8 和 9,并准备好进行自定义深度学习设置。Deep Learning BaseAMI 与 Python2 和 Python3 一起共用 Anaconda 平台。
此发行版的亮点
1. 将 Ubuntu 2017.09 (ami-8c1be5f6) 用作基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.15. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.0
Python 2.7 和 Python 3.5 支持
AMI 支持 Python 2.7 和 Python 3.6。
CPU 实例类型支持
AMI 支持 CPU 实例类型。
安装了 GPU 驱动程序
• Nvidia 384.81• CUDA 9• CuDNN 7
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
在以下区域提供:
170
深度学习 AMI 开发人员指南版本存档
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 没有已知问题。
Deep Learning Base AMI (Amazon Linux) 1.0 版的发行说明详细信息
AWS Deep Learning AMI
Deep Learning Base AMI 预置 CUDA 8 和 9,并准备好进行自定义深度学习设置。Deep Learning BaseAMI 与 Python2 和 Python3 一起共用 Anaconda 平台。
此发行版的亮点
1. 使用了 Amazon Linux 2017.09 (ami-8c1be5f6) 作为基础 AMI2. CUDA 9
171

深度学习 AMI 开发人员指南版本存档
3. CuDNN 74. NCCL 2.0.55. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.0
Python 2.7 和 Python 3.5 支持
AMI 支持 Python 2.7 和 Python 3.6。
CPU 实例类型支持
AMI 支持 CPU 实例类型。
安装了 GPU 驱动程序
• Nvidia 384.81• CUDA 9.0• CuDNN 7
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
Deep Learning AMI (Amazon Linux)
此 AMI 在以下区域可用:
• 美国东部(俄亥俄):us-east-2• 美国东部(弗吉尼亚北部):us-east-1• 美国西部(加利福尼亚北部):us-west-1• 美国西部(俄勒冈):us-west-2• 亚太地区(首尔):ap-northeast-2• 亚太地区(新加坡):ap-southeast-1• 亚太地区(东京):ap-northeast-1• 欧洲(爱尔兰):eu-west-1
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
Deep Learning Base AMI (Amazon Linux) 已知问题
• 问题:对于 Amazon Linux 深度学习 AMI (DLAMI) (特别是 pip) 而言,pip 和 Python 版本不兼容,预计会安装 Python 2 绑定,但需要安装 Python 3 绑定。
这是在 pip 网站上记录的已知问题。未来的版本将解决这个问题。
解决办法:使用下面的相关命令为相应的 Python 版本安装程序包:
172

深度学习 AMI 开发人员指南版本存档
python2.7 -m pip install some-python-package
python3.4 -m pip install some-python-package
• 问题:MOTD 与这些发行说明的链接不正确。
解决办法:如果您在这里,那么您已经知道了。
未来的版本将解决这个问题。
1.0 版的发行说明详细信息
AWS Deep Learning AMI
Deep Learning Base AMI 预置 CUDA 8 和 9,并准备好进行自定义深度学习设置。Deep Learning BaseAMI 与 Python2 和 Python3 一起共用 Anaconda 平台。
此发行版的亮点
1. 将 Ubuntu 2017.09 (ami-8c1be5f6) 用作基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.0.55. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.0
Python 2.7 和 Python 3.5 支持
AMI 支持 Python 2.7 和 Python 3.6。
CPU 实例类型支持
AMI 支持 CPU 实例类型。
安装了 GPU 驱动程序
• Nvidia 384.81• CUDA 9• CuDNN 7
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
此 AMI 在以下区域可用:
• 美国东部(俄亥俄):us-east-2• 美国东部(弗吉尼亚北部):us-east-1• 美国西部(加利福尼亚北部):us-west-1• 美国西部(俄勒冈):us-west-2
173

深度学习 AMI 开发人员指南版本存档
• 亚太地区(首尔):ap-northeast-2• 亚太地区(新加坡):ap-southeast-1• 亚太地区(东京):ap-northeast-1• 欧洲(爱尔兰):eu-west-1
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:MOTD 与这些发行说明的链接不正确。
解决办法:如果您在这里,那么您已经知道了。
未来的版本将解决这个问题。
AWS Deep Learning AMI Conda 版本存档主题
• Deep Learning AMI (Amazon Linux) 2.0 版的发行说明详细信息 (p. 174)• 2.0 版的发行说明详细信息 (p. 178)• Deep Learning AMI (Amazon Linux) 1.0 版的发行说明详细信息 (p. 182)• 1.0 版的发行说明详细信息 (p. 185)
Deep Learning AMI (Amazon Linux) 2.0 版的发行说明详细信息
AWS Deep Learning AMI
AWS Deep Learning AMI 预置了 CUDA 8 和 9 以及若干深度学习框架。DLAMI 与 Python2 和 Python3 共用Anaconda 平台,可以轻松地在框架之间切换。
此发行版的亮点
1. 已将 Deep Learning Base AMI (Amazon Linux) 用作基础 AMI2. CUDA 93. CuDNN 7.0.34. NCCL 2.15. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.08. 改进了加载 Conda 环境的性能
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。
174

深度学习 AMI 开发人员指南版本存档
• 使用的分支/标签:v1.0• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.1• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate caffe2_p27• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.2• 理由:最新版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate cntk_p27• 适用于 Anaconda Python3+ - source activate cntk_p36
• Keras:Keras 是 Python 的深度学习库
v2.0.9 集成 Tensorflow• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
v1.2.2 集成 MXNet• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• PyTorch:PyTorch 是一个 python 程序包,它提供了两个高级功能:具有强大 GPU 加速功能的 Tensor计算 (如 numpy) 和基于磁带式 autograd 系统构建的练深度神经网络• 使用的分支/标签:v0.3.0• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate pytorch_p27• 适用于 Anaconda Python3+ - source activate pytorch_p36
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:v1.4• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:v0.9• 理由:稳定和全面的测试• 要进行激活:
175

深度学习 AMI 开发人员指南版本存档
• 适用于 Anaconda Python2.7+ - source activate theano_p27• 适用于 Anaconda Python3+ - source activate theano_p36
Python 2.7 和 Python 3.5 支持
所有安装的深度学习框架的 AMI 都支持 Python 2.7 和 Python 3.6,但 Caffe2 除外:
1. Apache MXNet2. Caffe2 (仅 Python 2.7)3. CNTK4. Keras5. PyTorch6. Tensorflow7. Theano
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。
安装了 GPU 驱动程序
• CuDNN 7• Nvidia 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ec2-user/src/bin 目录中找到。
Deep Learning AMI (Amazon Linux) 地区
在以下区域提供:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
176

深度学习 AMI 开发人员指南版本存档
区域 代码
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
参考
• Apache MXNet• Caffe2• CNTK• Keras• PyTorch• TensorFlow• Theano
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:PyTorch 测试失败。~/src/bin/testPyTorch - 安装与 pytorch 0.3.0 不兼容的测试环境
解决办法:尚无• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
177

深度学习 AMI 开发人员指南版本存档
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8057。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
2.0 版的发行说明详细信息
AWS Deep Learning AMI
AWS Deep Learning AMI 预置了 CUDA 8 和 9 以及若干深度学习框架。DLAMI 与 Python2 和 Python3 共用Anaconda 平台,可以轻松地在框架之间切换。
此发行版的亮点
1. 已将 用作基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.15. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.08. 改进了加载 Conda 环境的性能
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v1.0• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.1• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• 要进行激活:
178

深度学习 AMI 开发人员指南版本存档
• 适用于 Anaconda Python2.7+ - source activate caffe2_p27• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.2• 理由:最新版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate cntk_p27• 适用于 Anaconda Python3+ - source activate cntk_p36
• Keras:Keras 是 Python 的深度学习库
v2.0.9 集成 Tensorflow• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
v1.2.2 集成 MXNet• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• PyTorch:PyTorch 是一个 python 程序包,它提供了两个高级功能:具有强大 GPU 加速功能的 Tensor计算 (如 numpy) 和基于磁带式 autograd 系统构建的练深度神经网络• 使用的分支/标签:v0.3.0• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate pytorch_p27• 适用于 Anaconda Python3+ - source activate pytorch_p36
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:v1.4• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:v0.9• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate theano_p27• 适用于 Anaconda Python3+ - source activate theano_p36
Python 2.7 和 Python 3.5 支持
所有安装的深度学习框架的 AMI 都支持 Python 2.7 和 Python 3.6,但 Caffe2 除外:
1. Apache MXNet2. Caffe2 (仅 Python 2.7)3. CNTK4. Keras
179

深度学习 AMI 开发人员指南版本存档
5. PyTorch6. Tensorflow7. Theano
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。
安装了 GPU 驱动程序
• CuDNN 7• NVIDIA 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ubuntu/src/bin 目录中找到。
地区
在以下区域提供:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
180

深度学习 AMI 开发人员指南版本存档
区域 代码
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
参考
• Apache MXNet• Caffe2• CNTK• Keras• PyTorch• TensorFlow• Theano
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:PyTorch 测试失败。~/src/bin/testPyTorch - 安装与 pytorch 0.3.0 不兼容的测试环境
解决办法:尚无• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
181

深度学习 AMI 开发人员指南版本存档
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8057。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
Deep Learning AMI (Amazon Linux) 1.0 版的发行说明详细信息
AWS Deep Learning AMI
AWS Deep Learning AMI 预置了 CUDA 8 和 9 以及若干深度学习框架。DLAMI 与 Python2 和 Python3 共用Anaconda 平台,可以轻松地在框架之间切换。
此发行版的亮点
1. 使用了 Amazon Linux 2017.09 (ami-8c1be5f6) 作为基础 AMI2. CUDA 93. CuDNN 7.0.34. NCCL 2.0.55. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.0
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.12.0• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.1• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate caffe2_p27• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.2• 理由:最新版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate cntk_p27• 适用于 Anaconda Python3+ - source activate cntk_p36
• Keras:Keras 是 Python 的深度学习库
v2.0.9 集成 Tensorflow• 理由:稳定版本
182

深度学习 AMI 开发人员指南版本存档
• 要进行激活:• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
v1.2.2 集成 MXNet• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• PyTorch:PyTorch 是一个 python 程序包,它提供了两个高级功能:具有强大 GPU 加速功能的 Tensor计算 (如 numpy) 和基于磁带式 autograd 系统构建的练深度神经网络• 使用的分支/标签:v0.2• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate pytorch_p27• 适用于 Anaconda Python3+ - source activate pytorch_p36
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:v1.4• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:v0.9• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate theano_p27• 适用于 Anaconda Python3+ - source activate theano_p36
Python 2.7 和 Python 3.5 支持
所有安装的深度学习框架的 AMI 都支持 Python 2.7 和 Python 3.6,但 Caffe2 除外:
1. Apache MXNet2. Caffe2 (仅 Python 2.7)3. CNTK4. PyTorch5. Tensorflow6. Theano
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。
安装了 GPU 驱动程序
• CuDNN 7• Nvidia 384.81• CUDA 9.0
183

深度学习 AMI 开发人员指南版本存档
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ec2-user/src/bin 目录中找到。
Deep Learning AMI (Amazon Linux) 地区
Deep Learning AMI (Amazon Linux) 在以下区域提供:
• 美国东部(俄亥俄):us-east-2• 美国东部(弗吉尼亚北部):us-east-1• 美国西部(加利福尼亚北部):us-west-1• 美国西部(俄勒冈):us-west-2• 亚太地区(首尔):ap-northeast-2• 亚太地区(新加坡):ap-southeast-1• 亚太地区(东京):ap-northeast-1• 欧洲(爱尔兰):eu-west-1
参考
• Apache MXNet• Caffe2• CNTK• Keras• PyTorch• TensorFlow• Theano
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
Deep Learning AMI (Amazon Linux) 已知问题
• 问题:对于 Amazon Linux 深度学习 AMI (DLAMI) (特别是 pip) 而言,pip 和 Python 版本不兼容,预计会安装 Python 2 绑定,但需要安装 Python 3 绑定。
这是在 pip 网站上记录的已知问题。未来的版本将解决这个问题。
解决办法:使用下面的相关命令为相应的 Python 版本安装程序包:
python2.7 -m pip install some-python-package
python3.4 -m pip install some-python-package
• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
184

深度学习 AMI 开发人员指南版本存档
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8157。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
问题:MOTD 与这些发行说明的链接不正确。
解决办法:如果您在这里,那么您已经知道了。
未来的版本将解决这个问题。
1.0 版的发行说明详细信息AWS Deep Learning AMI
AWS Deep Learning AMI 预置了 CUDA 8 和 9 以及若干深度学习框架。DLAMI 与 Python2 和 Python3 共用Anaconda 平台,可以轻松地在框架之间切换。
此发行版的亮点
1. 将 Ubuntu 2017.09 (ami-8c1be5f6) 用作基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.0.55. CuBLAS 8 和 96. glibc 2.187. OpenCV 3.2.0
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。
185

深度学习 AMI 开发人员指南版本存档
• 使用的分支/标签:v0.12.0• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.1• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate caffe2_p27• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.2• 理由:最新版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate cntk_p27• 适用于 Anaconda Python3+ - source activate cntk_p36
• Keras:Keras 是 Python 的深度学习库
v2.0.9 集成 Tensorflow• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
v1.2.2 集成 MXNet• 理由:稳定版本• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate mxnet_p27• 适用于 Anaconda Python3+ - source activate mxnet_p36
• PyTorch:PyTorch 是一个 python 程序包,它提供了两个高级功能:具有强大 GPU 加速功能的 Tensor计算 (如 numpy) 和基于磁带式 autograd 系统构建的练深度神经网络• 使用的分支/标签:v0.2• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate pytorch_p27• 适用于 Anaconda Python3+ - source activate pytorch_p36
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:v1.4• 理由:稳定和全面的测试• 要进行激活:
• 适用于 Anaconda Python2.7+ - source activate tensorflow_p27• 适用于 Anaconda Python3+ - source activate tensorflow_p36
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:v0.9• 理由:稳定和全面的测试• 要进行激活:
186

深度学习 AMI 开发人员指南版本存档
• 适用于 Anaconda Python2.7+ - source activate theano_p27• 适用于 Anaconda Python3+ - source activate theano_p36
Python 2.7 和 Python 3.5 支持
所有安装的深度学习框架的 AMI 都支持 Python 2.7 和 Python 3.6,但 Caffe2 除外:
1. Apache MXNet2. Caffe2 (仅 Python 2.7)3. CNTK4. PyTorch5. Tensorflow6. Theano
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。
安装了 GPU 驱动程序
• CuDNN 7• NVIDIA 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
AWS Deep Learning AMI 开发人员指南
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ubuntu/src/bin 目录中找到。
地区
在以下区域提供:
• 美国东部(俄亥俄):us-east-2• 美国东部(弗吉尼亚北部):us-east-1• 美国西部(加利福尼亚北部):us-west-1• 美国西部(俄勒冈):us-west-2• 亚太地区(首尔):ap-northeast-2• 亚太地区(新加坡):ap-southeast-1• 亚太地区(东京):ap-northeast-1• 欧洲(爱尔兰):eu-west-1
参考
• Apache MXNet• Caffe2
187

深度学习 AMI 开发人员指南版本存档
• CNTK• Keras• PyTorch• TensorFlow• Theano
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8157。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
问题:MOTD 与这些发行说明的链接不正确。
解决办法:如果您在这里,那么您已经知道了。
未来的版本将解决这个问题。
AWS Deep Learning AMI 源版本存档主题
• 采用源代码 (CUDA 9,Ubuntu) 的 Deep Learning AMI 版本:2.0 (p. 189)• 深度学习 AMI Ubuntu 版本:2.4_Oct2017 (p. 192)• Ubuntu DLAMI 版本存档 (p. 196)
188

深度学习 AMI 开发人员指南版本存档
• Amazon Linux DLAMI 版本存档 (p. 225)
采用源代码 (CUDA 9,Ubuntu) 的 Deep Learning AMI 版本:2.0
深度学习 Amazon 系统映像
深度学习 AMI 预置了 CUDA9 和 MXNet,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. 已将 用作基础 AMI2. 经过更新的 TensorFlow master,支持 CUDA9/Volta3. MXNet 升级到 v1.04. PyTorch 升级到 v0.3.05. 增加了对 Keras 2.0.9 的支持,TensorFlow 作为默认后端
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v1.0• 理由:稳定和全面的测试• 源目录:
• /home/ubuntu/src/mxnet• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。
• 使用的分支/标签:v0.8.1 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• 源目录:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Keras:Keras 是 Python 的深度学习库
v2.0.9 集成 Tensorflow。Tensorflow 是默认的后端。• 理由:稳定版本• 源目录:
• /home/ec2-user/src/keras• PyTorch:PyTorch 是一个 python 程序包,它提供了两个高级功能:具有强大 GPU 加速功能的 Tensor
计算 (如 numpy) 和基于磁带式 autograd 系统构建的练深度神经网络.• 使用的分支/标签:v0.3.0• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/pytorch• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:主标签• 理由:稳定和全面的测试• 源目录:
189

深度学习 AMI 开发人员指南版本存档
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Apache MXNet2. Caffe23. Keras4. PyTorch5. Tensorflow
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。
安装了 GPU 驱动程序
• CuDNN 7• Nvidia 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ubuntu/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
AMI 区域可用性
在以下区域提供:
190
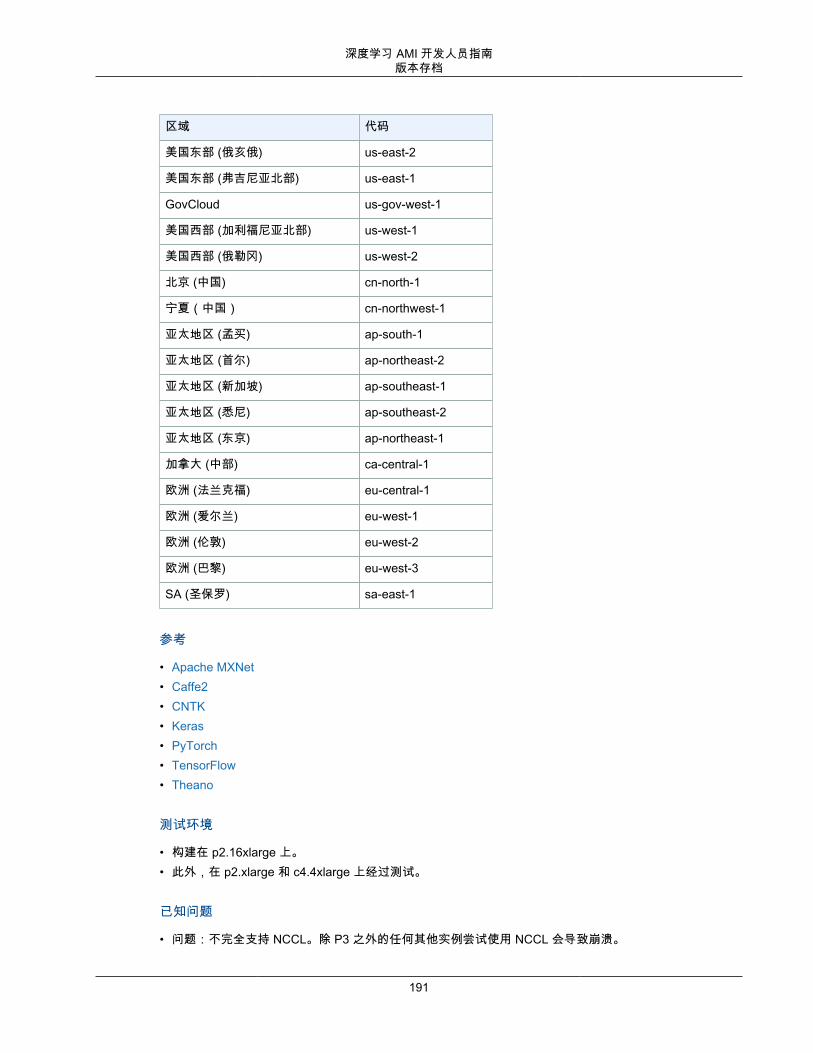
深度学习 AMI 开发人员指南版本存档
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
参考
• Apache MXNet• Caffe2• CNTK• Keras• PyTorch• TensorFlow• Theano
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:不完全支持 NCCL。除 P3 之外的任何其他实例尝试使用 NCCL 会导致崩溃。
191

深度学习 AMI 开发人员指南版本存档
解决办法:除 P3 之外的实例不要使用 NCCL。• 问题:PyTorch 测试失败。~/src/bin/testPyTorch - 安装与 pytorch 0.3.0 不兼容的测试环境
解决办法:尚无• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8057。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
深度学习 AMI Ubuntu 版本:2.4_Oct2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. 将 Ubuntu 16.04 (ami-d15a75c7) 用作基础 AMI2. CUDA 8 支持3. Tensorflow(v1.3.0)、Caffe2(v0.8.0)、Caffe(1.0)、CNTK(v2.0)、Theano(rel-0.9.0) 的框架升级
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.11.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet
192

深度学习 AMI 开发人员指南版本存档
• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:v1.0 标签• 理由:支持 cuda8.0 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.0 标签• 理由:稳定和全面的测试• 注意:这是一个试验版本,可能会有一些问题。只适用于 Python 2.7• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.3.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:v2.0.8• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/keras193

深度学习 AMI 开发人员指南版本存档
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/binsource activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 375.66• CUDA 8.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ubuntu/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
194
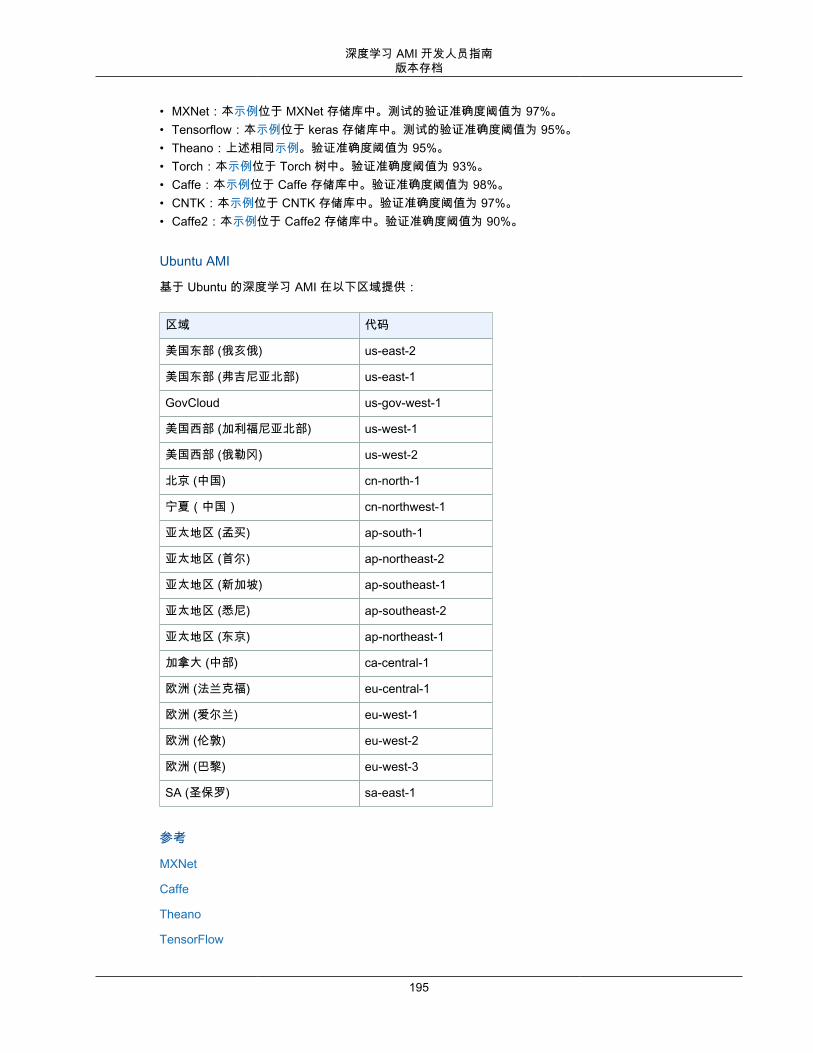
深度学习 AMI 开发人员指南版本存档
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
参考
MXNet
Caffe
Theano
TensorFlow
195

深度学习 AMI 开发人员指南版本存档
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK• conda 环境 keras1.2_p3 和 keras1.2_p2 随附仅限于 MXNet 版本的 CPU。
要使用带有 MXNet 后端的 Keras 在 GPU 上训练,可以通过运行以下内容来解决此问题:
pip install mxnet-cu80
从 conda 环境内。
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
Ubuntu DLAMI 版本存档
主题• 深度学习 CUDA 9 AMI Ubuntu 版本:1.0 (p. 196)• 深度学习 AMI Ubuntu 版本:2.3_Sep2017 (p. 199)• 深度学习 AMI Ubuntu 版本:2.2_August2017 (p. 203)• 深度学习 AMI Ubuntu 版本:1.5_June2017 (p. 206)• 深度学习 AMI Ubuntu 版本:1.4_June2017 (p. 210)• 深度学习 AMI Ubuntu 版本:1.3_Apr2017 (p. 213)• 深度学习 AMI Ubuntu 版本:1.2 (p. 216)• 深度学习 AMI Ubuntu 版本:1.1 (p. 219)• 深度学习 AMI Ubuntu 版本:1.0 (p. 222)
深度学习 CUDA 9 AMI Ubuntu 版本:1.0
深度学习 Amazon 系统映像
深度学习 AMI 预置了 CUDA9 和 MXNet,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
196

深度学习 AMI 开发人员指南版本存档
此发行版的亮点
1. 将 Ubuntu 16.04 (ami-d15a75c7) 用作基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.05. MXNet (带 CUDA9 支持)
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.12.0 候选版本标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。
• 使用的分支/标签:v0.8.1 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:主标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. MXNet2. Caffe23. Tensorflow
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。
安装了 GPU 驱动程序
• CuDNN 7
197

深度学习 AMI 开发人员指南版本存档
• Nvidia 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ubuntu/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
198

深度学习 AMI 开发人员指南版本存档
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8157。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
深度学习 AMI Ubuntu 版本:2.3_Sep2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. 将 Ubuntu 16.04 (ami-d15a75c7) 用作基础 AMI2. CUDA 8 支持3. Tensorflow(v1.3.0)、Caffe2(v0.8.0)、Caffe(1.0)、CNTK(v2.0)、Theano(rel-0.9.0) 的框架升级
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.11.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:v1.0 标签• 理由:支持 cuda8.0 和 cudnn 5.1• Source_Directories:
199

深度学习 AMI 开发人员指南版本存档
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.0 标签• 理由:稳定和全面的测试• 注意:这是一个试验版本,可能会有一些问题。只适用于 Python 2.7• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.3.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:master (带 MXNet 支持)• 理由:稳定版本 (1.2.2)• Source_Directories:
• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe
200

深度学习 AMI 开发人员指南版本存档
2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 375.66• CUDA 8.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ubuntu/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。
201

深度学习 AMI 开发人员指南版本存档
• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
202

深度学习 AMI 开发人员指南版本存档
相同的 Python 进程可能会导致问题。
深度学习 AMI Ubuntu 版本:2.2_August2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. 将 Ubuntu 16.04 (ami-d15a75c7) 用作基础 AMI2. CUDA 8 支持3. Tensorflow(v1.2.0)、Caffe2(v0.7.0)、Caffe(1.0)、CNTK(v2.0)、Theano(rel-0.9.0) 的框架升级
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.10.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:v1.0 标签• 理由:支持 cuda8.0 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.7.0 标签• 理由:预览版• 注意:这是一个试验版本,可能会有一些问题。只适用于 Python 2.7• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.2.0 标签
203

深度学习 AMI 开发人员指南版本存档
• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 375.66• CUDA 8.0
204

深度学习 AMI 开发人员指南版本存档
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
205

深度学习 AMI 开发人员指南版本存档
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 g2.2xlarge、g2.8xlarge、p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Ubuntu 版本:1.5_June2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. MXNet 使用 S3 支持编译 (USE_S3=1)。2. 使用了最新的基础 AMI for Ubuntu 14.04 (ami-b1143ba7)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.10.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1
206

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.7.0 标签• 理由:预览版• 注意:这是一个试验版本,可能会有一些问题。只适用于 Python 2.7• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.1.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0.rc1 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:207

深度学习 AMI 开发人员指南版本存档
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。
208

深度学习 AMI 开发人员指南版本存档
• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 g2.2xlarge、g2.8xlarge、p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK• 在 GPU 实例类型上运行时,Dropout 运算符存在已知问题。有关详细信息和解决方法,请参阅 Github 问
题。
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
209

深度学习 AMI 开发人员指南版本存档
深度学习 AMI Ubuntu 版本:1.4_June2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.10.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.7.0 标签• 理由:预览版• 注意:这是一个试验版本,可能会有一些问题。只适用于 Python 2.7• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.1.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支
210

深度学习 AMI 开发人员指南版本存档
• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0.rc1 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
211

深度学习 AMI 开发人员指南版本存档
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。
212

深度学习 AMI 开发人员指南版本存档
• 此外,还在 g2.2xlarge、g2.8xlarge、p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK• 在 GPU 实例类型上运行时,Dropout 运算符存在已知问题。有关详细信息和解决方法,请参阅 Github 问
题。
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Ubuntu 版本:1.3_Apr2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.9.3 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.6.0 标签• 理由:预览版• 注意:这是一个试验版本,可能会有一些问题。只适用于 Python 2.7
213

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• 适用于 Python2.7+ - /home/ubuntu/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.1 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0.rc1 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
214

深度学习 AMI 开发人员指南版本存档
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
/home/ubuntu/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)
215

深度学习 AMI 开发人员指南版本存档
• us-east-1(IAD)• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK• 在 GPU 实例类型上运行时,Dropout 运算符存在已知问题。有关详细信息和解决方法,请参阅 Github 问
题。
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Ubuntu 版本:1.2
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.9.3 标签• 理由:稳定和全面的测试
216

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• /home/ubuntu/src/mxnet
• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0beta12.0 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe
217

深度学习 AMI 开发人员指南版本存档
2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。
218
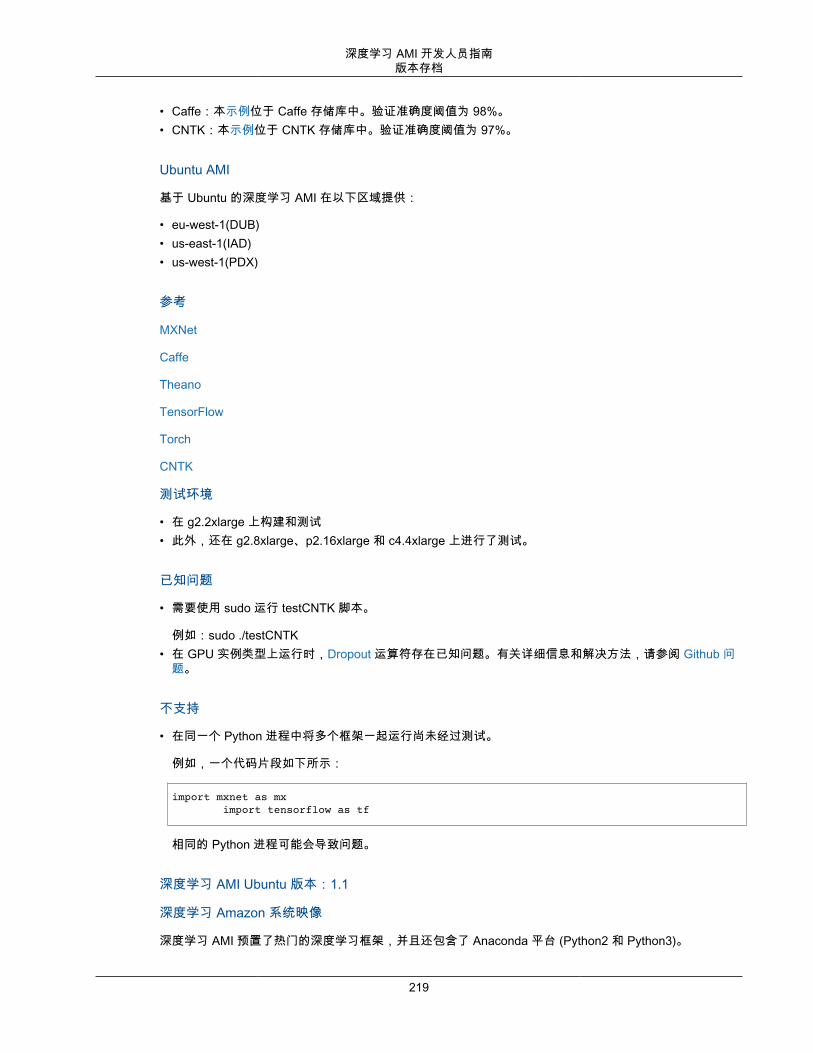
深度学习 AMI 开发人员指南版本存档
• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK• 在 GPU 实例类型上运行时,Dropout 运算符存在已知问题。有关详细信息和解决方法,请参阅 Github 问
题。
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Ubuntu 版本:1.1
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
219

深度学习 AMI 开发人员指南版本存档
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.9.3 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc4 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v0.12.1 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0beta7.0 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.1 标签• 理由:稳定版本
220

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• /home/ubuntu/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 352.99• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
221

深度学习 AMI 开发人员指南版本存档
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
深度学习 AMI Ubuntu 版本:1.0
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.9.3 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。
222

深度学习 AMI 开发人员指南版本存档
• 使用的分支/标签:主分支• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/caffe• 适用于 Python3+ - /home/ubuntu/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ubuntu/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ubuntu/src/caffe_cpu
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ubuntu/src/theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v0.12.1 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ubuntu/src/tensorflow• 适用于 Python3+ - /home/ubuntu/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ubuntu/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ubuntu/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ubuntu/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0beta7.0 标签• 理由:最新版本• Source_Directories:
• /home/ubuntu/src/cntk
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ubuntu/src/caffe_cpu/ 中的二进制文件
223

深度学习 AMI 开发人员指南版本存档
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ubuntu/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 352.99• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ubuntu/src/bin/testAll:测试所有框架
/home/ubuntu/src/bin/testMXNet:测试 MXNet
/home/ubuntu/src/bin/testTheano:测试 Theano
/home/ubuntu/src/bin/testTensorFlow:测试 TensorFlow
/home/ubuntu/src/bin/testTorch:测试 Torch
/home/ubuntu/src/bin/testCNTK:测试 CNTK
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。
Ubuntu AMI
基于 Ubuntu 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)
224

深度学习 AMI 开发人员指南版本存档
• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
Amazon Linux DLAMI 版本存档
主题• 采用源代码 (CUDA 9,Amazon Linux) 的 Deep Learning AMI 版本:2.0 (p. 225)• 深度学习 AMI Amazon Linux 版本:3.3_Oct2017 (p. 229)• 深度学习 CUDA 9 AMI Amazon Linux 版本:1.0 (p. 233)• 深度学习 AMI Amazon Linux 版本:3.1_Sep2017 (p. 236)• 深度学习 AMI Amazon Linux 版本:2.3_June2017 (p. 239)• 深度学习 AMI Amazon Linux 版本:2.2_June2017 (p. 243)• 深度学习 AMI Amazon Linux 版本:2.1_Apr2017 (p. 246)• 深度学习 AMI Amazon Linux 版本:2.0 (p. 250)• 深度学习 AMI Amazon Linux 版本:1.5 (p. 253)
采用源代码 (CUDA 9,Amazon Linux) 的 Deep Learning AMI 版本:2.0
深度学习 Amazon 系统映像
深度学习 AMI 预置了 CUDA9 和 MXNet,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. 已将 Deep Learning Base AMI (Amazon Linux) 用作基础 AMI2. 经过更新的 TensorFlow master,支持 CUDA9/Volta3. MXNet 升级到 v1.04. PyTorch 升级到 v0.3.05. 增加了对 Keras 2.0.9 的支持,TensorFlow 作为默认后端
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高
225

深度学习 AMI 开发人员指南版本存档
效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v1.0• 理由:稳定和全面的测试• 源目录:
• /home/ec2-user/src/mxnet• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。
• 使用的分支/标签:v0.8.1 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• 源目录:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Keras:Keras 是 Python 的深度学习库
v2.0.9 集成 Tensorflow。Tensorflow 是默认的后端。• 理由:稳定版本• 源目录:
• /home/ec2-user/src/keras• PyTorch:PyTorch 是一个 python 程序包,它提供了两个高级功能:具有强大 GPU 加速功能的 Tensor
计算 (如 numpy) 和基于磁带式 autograd 系统构建的练深度神经网络.• 使用的分支/标签:v0.3.0• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/pytorch• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:主标签• 理由:稳定和全面的测试• 源目录:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Apache MXNet2. Caffe23. Keras4. PyTorch5. Tensorflow
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。
226
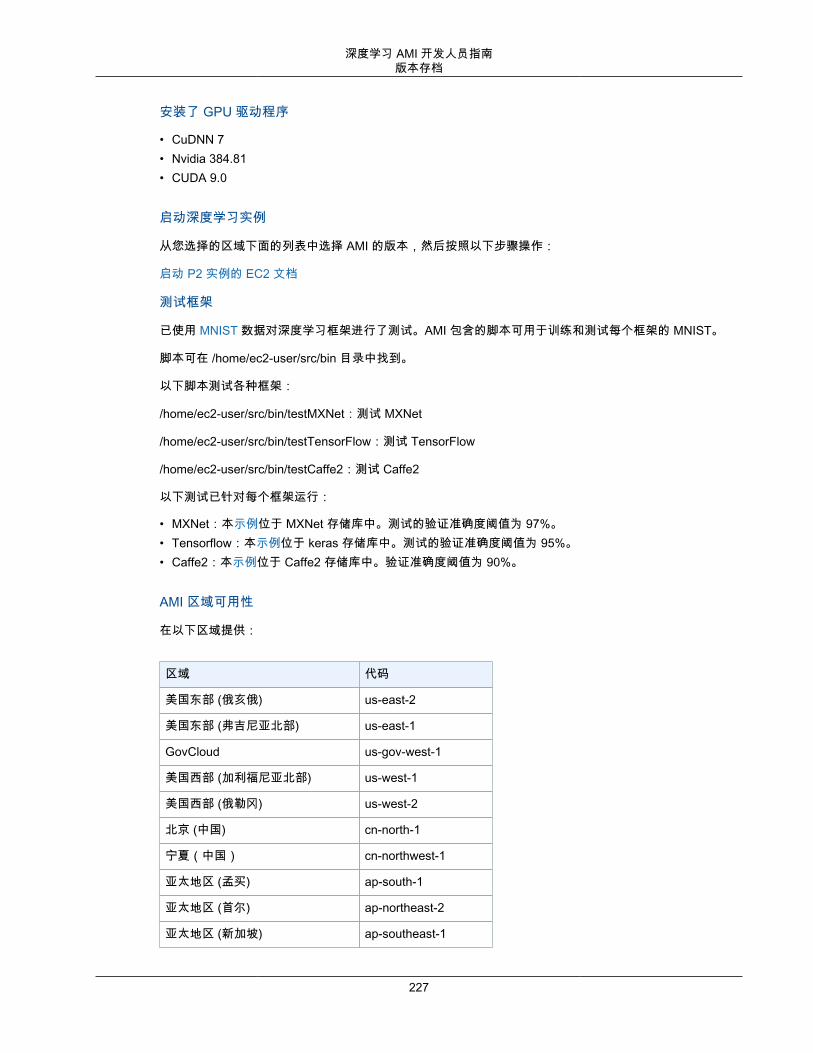
深度学习 AMI 开发人员指南版本存档
安装了 GPU 驱动程序
• CuDNN 7• Nvidia 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
AMI 区域可用性
在以下区域提供:
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
227

深度学习 AMI 开发人员指南版本存档
区域 代码
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
参考
• Apache MXNet• Caffe2• CNTK• Keras• PyTorch• TensorFlow• Theano
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:不完全支持 NCCL。除 P3 之外的任何其他实例尝试使用 NCCL 会导致崩溃。
解决办法:除 P3 之外的实例不要使用 NCCL。• 问题:PyTorch 测试失败。~/src/bin/testPyTorch - 安装与 pytorch 0.3.0 不兼容的测试环境
解决办法:尚无• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
228

深度学习 AMI 开发人员指南版本存档
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8057。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
深度学习 AMI Amazon Linux 版本:3.3_Oct2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. Linux AMI 现在使用 2017.09 基础 Amazon Linux AMI 构建2. CUDA 8 支持3. Tensorflow(v1.3.0)、Caffe2(v0.8.0)、Caffe(1.0)、CNTK(v2.0)、Theano(rel-0.9.0) 的框架升级
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.11.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:1.0 标签• 理由:支持 cuda8.0 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.0 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7
229

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.3.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0 标签• 理由:最新版本• Source_Directories:
• /home/ec2-user/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:v2.0.8• 理由:稳定版本• Source_Directories:
• /home/ec2-user/src/keras
Python 2.7 和 Python 3.4 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.4:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
230

深度学习 AMI 开发人员指南版本存档
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/binsource activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 375.66• CUDA 8.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
/home/ec2-user/src/bin/testCNTK:测试 CNTK
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
231
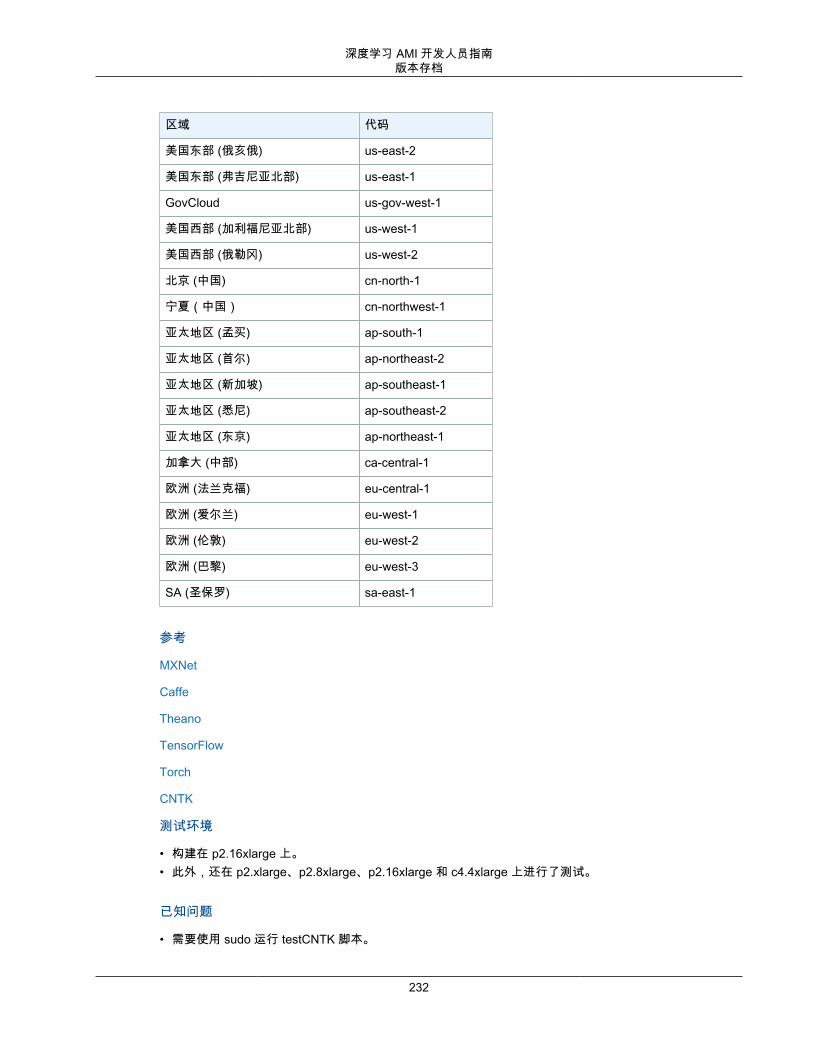
深度学习 AMI 开发人员指南版本存档
区域 代码
美国东部 (俄亥俄) us-east-2
美国东部 (弗吉尼亚北部) us-east-1
GovCloud us-gov-west-1
美国西部 (加利福尼亚北部) us-west-1
美国西部 (俄勒冈) us-west-2
北京 (中国) cn-north-1
宁夏(中国) cn-northwest-1
亚太地区 (孟买) ap-south-1
亚太地区 (首尔) ap-northeast-2
亚太地区 (新加坡) ap-southeast-1
亚太地区 (悉尼) ap-southeast-2
亚太地区 (东京) ap-northeast-1
加拿大 (中部) ca-central-1
欧洲 (法兰克福) eu-central-1
欧洲 (爱尔兰) eu-west-1
欧洲 (伦敦) eu-west-2
欧洲 (巴黎) eu-west-3
SA (圣保罗) sa-east-1
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
232

深度学习 AMI 开发人员指南版本存档
例如:sudo ./testCNTK• conda 环境 keras1.2_p3 和 keras1.2_p2 随附仅限于 MXNet 版本的 CPU。
要使用带有 MXNet 后端的 Keras 在 GPU 上训练,可以通过运行以下内容来解决此问题:
pip install mxnet-cu80
从 conda 环境内。
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mximport tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 CUDA 9 AMI Amazon Linux 版本:1.0
深度学习 Amazon 系统映像
深度学习 AMI 预置了 CUDA9 和 MXNet,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. 使用了 Amazon Linux 2017.09 (ami-8c1be5f6) 作为基础 AMI2. CUDA 93. CuDNN 74. NCCL 2.05. CUDA 9 支持6. MXNet (带 CUDA9 支持)
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.12.0 候选版本标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。
• 使用的分支/标签:v0.8.1 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• Source_Directories:
233

深度学习 AMI 开发人员指南版本存档
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:主标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. MXNet2. Caffe23. Tensorflow
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。
安装了 GPU 驱动程序
• CuDNN 7• Nvidia 384.81• CUDA 9.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。
234

深度学习 AMI 开发人员指南版本存档
• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
已知问题
• 问题:对于 Amazon Linux 深度学习 AMI (DLAMI) (特别是 pip) 而言,pip 和 Python 版本不兼容,预计会安装 Python 2 绑定,但需要安装 Python 3 绑定。
这是在 pip 网站上记录的已知问题。未来的版本将解决这个问题。
解决办法:使用下面的相关命令为相应的 Python 版本安装程序包:
python2.7 -m pip install some-python-package
python3.4 -m pip install some-python-package
• 问题:框架或第三方提供的教程可能没有在 DLAMI 上安装 Python 依赖项。
解决办法:您需要在激活环境中通过 conda 或 pip 安装这些依赖项。• 问题:模块没有找到运行 Caffe2 示例的错误。
解决办法:一些教程需要 Caffe2 可选依赖项• 问题:Caffe2 模型下载功能导致 404。自 v0.8.1 发布以来,这些模型已经改变了位置。更新 models/
download.py 以使用 update from master。• 问题:matplotlib 只能渲染 png。
解决办法:安装 Pillow,然后重新启动您的内核。• 问题:更改 Caffe2 源代码似乎不起作用。
解决办法:更改您的 PYTHONPATH 以使用安装位置 /usr/local/caffe2,而不是生成文件夹。• 问题:Caffe2 net_drawer 错误。
解决办法:使用在此次提交中找到的记录器补丁。• 问题:Caffe2 示例显示关于 LMDB 的错误 (无法打开数据库等)
235

深度学习 AMI 开发人员指南版本存档
解决办法:这需要在安装系统 LMDB 之后从源代码进行生成,例如:sudo apt-get installliblmdb-dev
• 问题:在使用 Jupyter 服务器连接本地端口时,SSH 断开连接。尝试创建一个到服务器的隧道时,您会看到 channel_setup_fwd_listener_tcpip: cannot listen to port: 8157。
解决方案:使用 lsof -ti:8057 | xargs kill -9,其中 8057 是您使用的本地端口。然后尝试再次创建到 Jupyter 服务器的隧道。
深度学习 AMI Amazon Linux 版本:3.1_Sep2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. CUDA 8 支持2. Tensorflow(v1.3.0)、Caffe2(v0.8.0)、Caffe(1.0)、CNTK(v2.0)、Theano(rel-0.9.0) 的框架升级
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.11.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:1.0 标签• 理由:支持 cuda8.0 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.8.0 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试
236

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• /home/ec2-user/src/Theano
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:v1.3.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0 标签• 理由:最新版本• Source_Directories:
• /home/ec2-user/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:主• 理由:稳定版本 (1.2.2 有 MXNet 支持)• Source_Directories:
• /home/ec2-user/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/bin source activate cntk-py34
237

深度学习 AMI 开发人员指南版本存档
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 375.66• CUDA 8.0
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 P2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
/home/ec2-user/src/bin/testCNTK:测试 CNTK
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)
238

深度学习 AMI 开发人员指南版本存档
• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Amazon Linux 版本:2.3_June2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
此发行版的亮点
1. MXNet 使用 S3 支持编译 (USE_S3=1)。2. 应用于 Stackclash 安全问题的安全修复。(https://alas.aws.amazon.com/ALAS-2017-845.html)
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。
239

深度学习 AMI 开发人员指南版本存档
• 使用的分支/标签:v0.10.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.7.0 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.1.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0.rc1 标签• 理由:最新版本• Source_Directories:
• /home/ec2-user/src/cntk• Keras:Keras 是 Python 的深度学习库
240

深度学习 AMI 开发人员指南版本存档
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ec2-user/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
241

深度学习 AMI 开发人员指南版本存档
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
/home/ec2-user/src/bin/testCNTK:测试 CNTK
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 构建在 p2.16xlarge 上。• 此外,还在 g2.2xlarge、g2.8xlarge、p2.xlarge、p2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
242

深度学习 AMI 开发人员指南版本存档
例如:sudo ./testCNTK
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Amazon Linux 版本:2.2_June2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.10.0 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.7.0 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.9.0 标签• 理由:稳定和全面的测试
243

深度学习 AMI 开发人员指南版本存档
• Source_Directories:• /home/ec2-user/src/Theano
• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。• 使用的分支/标签:v1.0.1.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0.rc1 标签• 理由:最新版本• Source_Directories:
• /home/ec2-user/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ec2-user/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/bin source activate cntk-py34
244

深度学习 AMI 开发人员指南版本存档
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
/home/ec2-user/src/bin/testCNTK:测试 CNTK
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)• us-east-2(CHM)• ap-southeast-2(SYD)
245

深度学习 AMI 开发人员指南版本存档
• ap-northeast-1(NRT)• ap-northeast-2(ICN)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Amazon Linux 版本:2.1_Apr2017
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.9.3 标签• 理由:稳定和全面的测试• Source_Directories:
246

深度学习 AMI 开发人员指南版本存档
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
• Caffe2:Caffe2 是一个以表达式、速度和模块性为基础的跨平台框架。• 使用的分支/标签:v0.7.0 标签• 理由:稳定和全面的测试• 注意:只适用于 Python2.7• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe2• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe2_anaconda2
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.1 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
• 使用的分支/标签:v2.0.rc1 标签• 理由:最新版本• Source_Directories:
• /home/ec2-user/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
247

深度学习 AMI 开发人员指南版本存档
• /home/ec2-user/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
248

深度学习 AMI 开发人员指南版本存档
/home/ec2-user/src/bin/testCNTK:测试 CNTK
/home/ec2-user/src/bin/testCaffe2:测试 Caffe2
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。• Caffe2:本示例位于 Caffe2 存储库中。验证准确度阈值为 90%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx
249

深度学习 AMI 开发人员指南版本存档
import tensorflow as tf
相同的 Python 进程可能会导致问题。
深度学习 AMI Amazon Linux 版本:2.0
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.9.3 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:rc5 标签• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/caffe_anaconda2• 适用于 Anaconda3 Python3+ - /home/ec2-user/src/caffe_anaconda3• 适用于 CPU_ONLY : /home/ec2-user/src/caffe_cpu
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.0.0 标签• 理由:稳定和全面的测试• Source_Directories:
• 适用于 Python2.7+ - /home/ec2-user/src/tensorflow• 适用于 Python3+ - /home/ec2-user/src/tensorflow3• 适用于 Anaconda Python2.7+ - /home/ec2-user/src/tensorflow_anaconda• 适用于 Anaconda Python3+ - /home/ec2-user/src/tensorflow_anaconda3
• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:主分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch
250
深度学习 AMI 开发人员指南版本存档
• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。• 使用的分支/标签:v2.0beta12.0 标签• 理由:最新版本• Source_Directories:
• /home/ec2-user/src/cntk• Keras:Keras 是 Python 的深度学习库
• 使用的分支/标签:1.2.2 标签• 理由:稳定版本• Source_Directories:
• /home/ec2-user/src/keras
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet5. CNTK
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 367.57• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
251

深度学习 AMI 开发人员指南版本存档
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
/home/ec2-user/src/bin/testCNTK:测试 CNTK
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
已知问题
• 需要使用 sudo 运行 testCNTK 脚本。
例如:sudo ./testCNTK
252

深度学习 AMI 开发人员指南版本存档
不支持
• 在同一个 Python 进程中将多个框架一起运行尚未经过测试。
例如,一个代码片段如下所示:
import mxnet as mx import tensorflow as tf
深度学习 AMI Amazon Linux 版本:1.5
深度学习 Amazon 系统映像
深度学习 AMI 预置了热门的深度学习框架,并且还包含了 Anaconda 平台 (Python2 和 Python3)。
预置了的深度学习框架
• MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:主分支• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/mxnet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的深度学习框架。它是由伯克利视觉与学习中心
(BVLC) 和社区贡献者开发出来的。• 使用的分支/标签:主分支• 理由:支持 cuda 7.5 和 cudnn 5.1• Source_Directories:
• 适用于 Python2.7+-/home/ec2-user/src/caffe• 适用于 Python3+ - /home/ec2-user/src/caffe3• 适用于 Python3+ - /home/ec2-user/src/caffe3
• Theano:Theano 是一个 Python 库,允许您高效地定义、优化和评估涉及多维数组的数学表达式。• 使用的分支/标签:rel-0.8.2 标签• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/Theano• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:r0.10 分支• 理由:稳定和全面的测试• Source_Directories:
• /home/ec2-user/src/tensorflow• Torch:Torch 是一个科学计算框架,广泛支持首先使用 GPU 的机器学习算法。由于使用了简单快捷的脚
本语言 LuaJIT 以及底层 C/CUDA 实现,因此使用起来非常简单,效率也很高。• 使用的分支/标签:rel-0.8.2 分支• 理由:没有其他稳定的分支或标签可用• Source_Directories:
• /home/ec2-user/src/torch• CNTK:CNTK (微软认知工具包) 是微软研究院提供的统一深度学习工具包。
253

深度学习 AMI 开发人员指南版本存档
• 使用的分支/标签:v2.0beta2.0• 理由:稳定版本• Source_Directories:
• /home/ec2-user/src/cntk
Python 2.7 和 Python 3.5 支持
以下深度学习框架的 AMI 中支持 Python 2.7 和 Python 3.5:
1. Caffe2. Tensorflow3. Theano4. MXNet
CPU 实例类型支持
AMI 支持所有框架的 CPU 实例类型。MXNet 内置有 Intel MKL2017 DNN 库支持。如果要为 CPU 实例使用caffe 二进制文件,则应使用 /home/ec2-user/src/caffe_cpu/ 中的二进制文件
CNTK Python 支持
您可以在 conda 环境中运行适用于 Python 的 CNTK。要实现此目的,应按照以下步骤进行:
cd /home/ec2-user/src/anaconda3/bin source activate cntk-py34
安装了 GPU 驱动程序
• CuDNN 5.1• NVIDIA 352.99• CUDA 7.5
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 G2 实例的 EC2 文档
测试框架
已使用 MNIST 数据对深度学习框架进行了测试。AMI 包含的脚本可用于训练和测试每个框架的 MNIST。该测试检查验证准确度是否高于特定阈值。为每个框架的阈值都不同。
脚本可在 /home/ec2-user/src/bin 目录中找到。
以下脚本测试各种框架:
/home/ec2-user/src/bin/testAll:测试所有框架
/home/ec2-user/src/bin/testMXNet:测试 MXNet
/home/ec2-user/src/bin/testTheano:测试 Theano
/home/ec2-user/src/bin/testTensorFlow:测试 TensorFlow
/home/ec2-user/src/bin/testTorch:测试 Torch
254

深度学习 AMI 开发人员指南版本存档
/home/ec2-user/src/bin/testCNTK:测试 CNTK
以下测试已针对每个框架运行:
• MXNet:本示例位于 MXNet 存储库中。测试的验证准确度阈值为 97%。• Tensorflow:本示例位于 keras 存储库中。测试的验证准确度阈值为 95%。• Theano:上述相同示例。验证准确度阈值为 95%。• Torch:本示例位于 Torch 树中。验证准确度阈值为 93%。• Caffe:本示例位于 Caffe 存储库中。验证准确度阈值为 98%。• CNTK:本示例位于 CNTK 存储库中。验证准确度阈值为 97%。
Amazon Linux AMI
基于 Amazon Linux 的深度学习 AMI 在以下区域提供:
• eu-west-1(DUB)• us-east-1(IAD)• us-west-1(PDX)
参考
MXNet
Caffe
Theano
TensorFlow
Torch
CNTK
测试环境
• 在 g2.2xlarge 上构建和测试• 此外,还在 g2.8xlarge、p2.16xlarge 和 c4.4xlarge 上进行了测试。
AWS Deep Learning AMI Windows 版本存档主题
• Deep Learning AMI (Windows 2016) 1.0 版的发行说明详细信息 (p. 255)• Deep Learning AMI (Windows 2012 R2) 1.0 版的发行说明详细信息 (p. 257)
Deep Learning AMI (Windows 2016) 1.0 版的发行说明详细信息
AWS Deep Learning AMI
AWS Deep Learning AMI 预置了 CUDA 8 和 9 以及若干深度学习框架。
此发行版的亮点
1. CUDA 8 和 9
255

深度学习 AMI 开发人员指南版本存档
2. CuDNN 6 和 73. NCCL 2.0.54. CuBLAS 8 和 95. OpenCV 3.2.06. SciPy 0.19.17. Conda 5.01
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.12.0• 预置了 CUDA 8 和 cuDNN 6.1• 理由:稳定和全面的测试• 源目录:
C:\MXNet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的框架。
• 使用的分支/标签:Windows 分支,提交 #5854• 预置了 CUDA 8 和 cuDNN 5• 理由:稳定和全面的测试• 源目录:
C:\Caffe• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.4• 预置了 CUDA 8 和 cuDNN 6.1• 理由:稳定和全面的测试• 源目录:
C:\ProgramData\Anaconda3\envs\tensorflow\Lib\site-packages
Python 2.7 和 Python 3.5 支持
所有安装的深度学习框架的 AMI 都支持 Python 2.7 和 Python 3.6,但 Caffe2 除外:
1. Apache MXNet2. Caffe3. Tensorflow
实例类型支持
尚不支持 P3 实例类型。
AMI 支持所有框架的所有其他 CPU 实例类型。
安装了 GPU 驱动程序
• CuDNN 6 和 7
256

深度学习 AMI 开发人员指南版本存档
• Nvidia 385.54• CUDA 8 和 9
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 Windows 实例
Deep Learning AMI (Windows 2016) 地区
Windows 2016 AMI 在以下区域可用:
• 美国东部(俄亥俄):us-east-2 - ami-6cc1ef09• 美国东部(弗吉尼亚北部):us-east-1 - ami-d50381af• GovCloud: us-gov-west-1 - ami-d5018db4• 美国西部(加利福尼亚北部):us-west-1 - ami-0abf876a• 美国西部(俄勒冈):us-west-2 - ami-d3be62ab• 北京(中国):cn-north-1 - ami-6f1e5000• 亚太地区(首尔):ap-northeast-2 - ami-9375d2fd• 亚太地区(新加坡):ap-southeast-1 - ami-5c64323f• 亚太地区(悉尼):ap-southeast-2 - ami-a0ca20c2• 亚太地区(东京):ap-northeast-1 - ami-c6fe42a0• 加拿大(中部):ca-central-1 - ami-4b82392f• 欧洲(法兰克福):eu-central-1 - ami-9e7efcf1• 欧洲(爱尔兰):eu-west-1 - ami-8aee58f3• 欧洲(伦敦):eu-west-2 - ami-09edf26d• SA(圣保罗):sa-east-1 - ami-10bffa7c
参考
• Apache MXNet• Caffe• TensorFlow
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
Deep Learning AMI (Windows 2012 R2) 1.0 版的发行说明详细信息
AWS Deep Learning AMI
AWS Deep Learning AMI 预置了 CUDA 8 和 9 以及若干深度学习框架。
此发行版的亮点
1. CUDA 8 和 92. CuDNN 6 和 7
257

深度学习 AMI 开发人员指南版本存档
3. NCCL 2.0.54. CuBLAS 8 和 95. OpenCV 3.2.06. SciPy 0.19.17. Conda 5.01
预置了的深度学习框架
• Apache MXNet:MXNet 是一个灵活、高效、可移植且可扩展的开源库,用于进行深度学习。它支持各种编程语言的声明式和命令式编程模型,使编写功能强大的深度学习应用程序变得很简单。MXNet 非常高效,本身支持可以在分布式环境中并行化的源代码部分的自动并行计划。MXNet 也很容易移植,内存优化技术的使用使它能在手机上运行完整的服务器。• 使用的分支/标签:v0.12.0• 预置了 CUDA 8 和 cuDNN 6.1• 理由:稳定和全面的测试• 源目录:
C:\MXNet• Caffe:Caffe 是一个以表达式、速度和模块性为基础的框架。
• 使用的分支/标签:Windows 分支,提交 #5854• 预置了 CUDA 8 和 cuDNN 5• 理由:稳定和全面的测试• 源目录:
C:\Caffe• TensorFlow:TensorFlow™ 是使用数据流图进行数值计算的开源软件库。
• 使用的分支/标签:v1.4• 预置了 CUDA 8 和 cuDNN 6.1• 理由:稳定和全面的测试• 源目录:
C:\ProgramData\Anaconda3\envs\tensorflow\Lib\site-packages
Python 2.7 和 Python 3.5 支持
所有安装的深度学习框架的 AMI 都支持 Python 2.7 和 Python 3.6,但 Caffe2 除外:
1. Apache MXNet2. Caffe3. Tensorflow
实例类型支持
尚不支持 P3 实例类型。
AMI 支持所有框架的所有其他 CPU 实例类型。
安装了 GPU 驱动程序
• CuDNN 6 和 7• Nvidia 385.54
258

深度学习 AMI 开发人员指南版本存档
• CUDA 8 和 9
启动深度学习实例
从您选择的区域下面的列表中选择 AMI 的版本,然后按照以下步骤操作:
启动 Windows 实例
Deep Learning AMI (Windows 2012 R2) 地区
Windows 2012 R2 AMI 在以下区域可用:
• 美国东部(俄亥俄):us-east-2 - ami-93c0eef6• 美国东部(弗吉尼亚北部):us-east-1 - ami-3375f749• GovCloud: us-gov-west-1 - ami-87018de6• 美国西部(加利福尼亚北部):us-west-1 - ami-04bf8764• 美国西部(俄勒冈):us-west-2 - ami-d2be62aa• 北京(中国):cn-north-1 - ami-221f514d• 亚太地区(首尔):ap-northeast-2 - ami-1975d277• 亚太地区(新加坡):ap-southeast-1 - ami-5d67313e• 亚太地区(悉尼):ap-southeast-2 - ami-a2f71dc0• 亚太地区(东京):ap-northeast-1 - ami-96fe42f0• 加拿大(中部):ca-central-1 - ami-1a863d7e• 欧洲(法兰克福):eu-central-1 - ami-cf78faa0• 欧洲(爱尔兰):eu-west-1 - ami-3eea5c47• 欧洲(伦敦):eu-west-2 - ami-caeef1ae• SA(圣保罗):sa-east-1 - ami-aabefbc6
参考
• Apache MXNet• Caffe• TensorFlow
测试环境
• 构建在 p2.16xlarge 上。• 此外,在 p2.xlarge 和 c4.4xlarge 上经过测试。
259

深度学习 AMI 开发人员指南
AWS Deep Learning AMI 开发人员指南 文档历史记录
update-history-change update-history-description update-history-date
Amazon EC2 上的 AWS DeepLearning Containers (p. 81)
Amazon EC2 上的 AWS DeepLearning Containers先决条件和相关信息已添加到设置指南中。
March 27, 2019
AWS 深度学习容器 (p. 81) 增加了有关使用深度学习容器的新指南。
March 27, 2019
具有 CUDA 10 的 PyTorch1.0 (p. 4)
采用 Conda 的 Deep LearningAMI 现在附带具有 CUDA 10 的PyTorch 1.0。
December 13, 2018
CUDA 10 在 Deep Learning BaseAMI 上可用 (p. 5)
CUDA 10 已作为 Deep LearningBase AMI 的选项添加。有关如何更改和测试 CUDA 版本的说明。
December 11, 2018
将 TensorFlow Serving 与Inception 模型一起使用 (p. 78)
为 TensorFlow Serving 添加了使用 Inception 模型进行推理的示例(对于有和没有 Elastic Inference的情况)。
November 28, 2018
使用具有 TensorFlow 和 Horovod的 256 GPU 进行培训 (p. 47)
TensorFlow with Horovod 教程已更新,以添加多节点培训的示例。
November 28, 2018
Elastic Inference (p. 9) 弹性推理先决条件和相关信息已添加到设置指南中。
November 28, 2018
在 DLAMI 上发布的 MMSv1.0。 (p. 77)
此 MMS 教程已更新为使用新的模型存档格式 (.mar) 并演示新的启动和停止功能。
November 15, 2018
从每日构建版本安装TensorFlow (p. 31)
增加了一个教程,其中讲述如何在您的 采用 Conda的 Deep Learning AMI 上卸载 TensorFlow,然后安装TensorFlow 的每日构建版本。
October 16, 2018
从每日构建安装 MXNet (p. 24) 增加了一个教程,其中讲述如何在您的 采用 Conda 的 DeepLearning AMI 上卸载 MXNet,然后安装 MXNet 的每日构建版本。
October 16, 2018
从每日构建安装 CNTK (p. 27) 增加了一个教程,其中讲述如何在您的 采用 Conda 的 DeepLearning AMI 上卸载 CNTK,然后安装 CNTK 的每日构建版本。
October 16, 2018
现在,Docker 预先安装在您的DLAMI 上 (p. 157)
从 采用 Conda 的 Deep LearningAMI 版本 14 开始,Docker 和Docker for GPU 的 NVIDIA 版本已预先安装。
September 25, 2018
260
深度学习 AMI 开发人员指南
从每日构建安装 PyTorch (p. 29) 增加了一个教程,其中讲述如何在您的 采用 Conda 的 DeepLearning AMI 上卸载 PyTorch,然后安装 PyTorch 的每日构建版本。
September 25, 2018
分布式训练教程 (p. 37) 增加了有关如何将 Keras-MXNet用于多 GPU 训练的教程。针对v4.2.0 更新了 Chainer 的教程。
July 23, 2018
TensorBoard 教程 (p. 36) 示例已移至 ~/examples/tensorboard。更新了教程路径。
July 23, 2018
MXBoard 教程 (p. 34) 增加了有关如何将 MXBoard 用于MXNet 模型的可视化的教程。
July 23, 2018
Conda 教程 (p. 18) 已更新示例 MOTD 以反映更新的版本。
July 23, 2018
Chainer 教程 (p. 38) 此教程已更新为使用来自 Chainer源的最新示例。
July 23, 2018
早期更新:
下表描述了 2018 年 7 月之前每个 AWS Deep Learning AMI 发行版中的重要更改。
变更 描述 日期
TensorFlow with Horovod 增加了有关利用 TensorFlow 和Horovod 训练 ImageNet 的教程。
2018 年 6 月 6 日
升级指南 添加了升级指南。 2018 年 5 月 15 日
新区域和新的 10 分钟教程 添加的新区域:美国西部 (加利福利亚北部)、南美洲、加拿大(中部)、欧洲 (伦敦) 和欧洲 (巴黎)。此外,第一版 10 分钟教程名为:“AWS Deep Learning AMI入门”。
2018 年 4 月 26 日
Chainer 教程 添加了有关在多 GPU、单个 GPU和 CPU 中使用 Chainer 的教程。CUDA 集成已针对多个框架从 CUDA 8 升级到 CUDA 9。
2018 年 2 月 28 日
Linux AMIs v3.0,以及 MXNetModel Server、TensorFlowServing 和 TensorBoard 的引入
添加了适用于 Conda AMI 的教程(使用新模型)以及可视化服务功能(使用 MXNet ModelServer v0.1.5、TensorFlowServing v1.4.0 和 TensorBoardv0.4.0.AMI)和框架 CUDA 功能(在 Conda 和 CUDA 概述中描述)。最新发行说明迁移到 https://aws.amazon.com/releasenotes/
2018 年 1 月 25 日
Linux AMI v2.0 基础、源和 Conda AMI 均已更新,涵盖了 NCCL 2.1。源
2017 年 12 月 11 日
261

深度学习 AMI 开发人员指南
变更 描述 日期和 Conda AMI 的更新还涵盖了MXNet v1.0、PyTorch 0.3.0 和Keras 2.0.9。
添加了两个 Windows AMI 选项 发布了 Windows 2012 R2 和2016 AMI:添加到 AMI 选择指南中并添加到发行说明中.
2017 年 11 月 30 日
初始文档版本 更改的详细说明,带有指向所更改主题/章节的链接。
2017 年 11 月 15 日
262

深度学习 AMI 开发人员指南
AWS 词汇表有关最新 AWS 术语,请参阅 AWS General Reference 中的 AWS 词汇表。
263