Embed Size (px)
DESCRIPTION
利用隨機森林演算法做車牌辨識 License plate recognition using the random forest algorithm. 作者:國立暨南國際大學資訊工程學系 研究所 簡嘉志 指導教授:石勝文 博士 報告人:碩研資工一甲 張任頡. OUTLINE. 一 、緒論 二 、隨機森林演算法 三 、 實驗與結果. 一、 緒論 (1/2). ( 一 ) 研究動機: 1 . 政府推廣 了新型車號,英文代碼由兩碼改為三碼,字 體也全面採用澳洲車牌字體,舊式的車牌辨識系統都須經過重新訓練字體才有 辦法繼續 使用 。 - PowerPoint PPT Presentation
Citation preview

利用隨機森林演算法做車牌辨識License plate recognition
using the random forest algorithm
作者:國立暨南國際大學資訊工程學系研究所 簡嘉志指導教授:石勝文博士
報告人:碩研資工一甲 張任頡

2
OUTLINE
一、緒論
二、隨機森林演算法
三、實驗與結果

3
一、 緒論 (1/2)
( 一 ) 研究動機:
1. 政府推廣了新型車號,英文代碼由兩碼改為三碼,字體也全面採用澳洲車牌字體,舊式的車牌辨識系統都須經過重新訓練字體才有辦法繼續使用。2. 採用隨機森林演算法辨識車牌字母,排除字母辨識的誤判。

4
一、 緒論 (2/2)
( 二 ) 車牌介紹:
車別舊型車牌 新型車牌
代碼、代號外框尺寸
字體尺寸
示意圖 代碼、代號外框尺
寸字體尺寸
示意圖
遊覽大客車
前二後三320
*150
45*
90前三後三
380*
160
45*
90
營業拖車
前二後二320
*150
47.5* 95
前二後三380
*160
47.5* 95
自用小客車
前二後四320
*150
45 * 90
前三後四380
*160
45 * 90
輕型機車
前三後三250
*140
32 * 65
前三後四300
*150
32 * 65
550cc大型重型機車
前二後二260
*150
45 * 90
前二後三310
*160
45 * 90

5
二、隨機森林演算法 (1/8)
( 一 ) 隨機森林演算法概述:
概念如範例。
世界狀態
有下過雨嗎 ?
yesno
yes
為何地面是濕的 ?
no
有灑水車經過嗎 ?
P(wet) = 0.95
P(wet) = 0.9P(wet) = 0.1
分類概念圖
圖 3.分類概念圖

6
二、隨機森林演算法 (2/8)
由此概念去建立二元樹:v 是特徵向量f(v) 為分裂函式tn 是閥值 Pn(c) 為類別 c 的機率值藍色節點為分裂節點而綠色節點為葉子節點

7
二、隨機森林演算法 (3/8)
訓練決策樹流程:
1. 先在根節點讀入所有類別的字母影像2. 計算最佳 Information Gain 值為它分裂的最佳結果3. 判斷此值是否滿足事先定義的 Max Gain 閥值 有或者到達最底層→將紀錄為葉節點並記錄影像類別數量 沒有→進入下個節點4. 最終將每個節點都依序執行完這些程序,並且都記錄 每個節點所分裂的參數5. 儲存整個樹的分類資訊,以利辨識字母時所使用

8
二、隨機森林演算法 (4/8)
在決策樹中訓練的方法:針對每個節點隨機產生兩個區塊和一個閥值,取得區塊範圍及位置,隨機產生兩塊區域作特徵擷取。特徵擷取方法是由藍色區域平均亮度值減去紅色區域平均亮度值
隨機產生區塊示意圖特徵分類說明示意圖

9
二、隨機森林演算法 (5/8)
Imformation gain 算法:)
Il = {i ∈ In | f(vi) < t}
Ir = In \ Il
In 表示總影像數量Il 表示走左邊的影像數量, Ir 則表示走右邊

10
二、隨機森林演算法 (6/8)
隨機森林樹的建構所調整的參數:
1. 隨機區域取得次數2. 平均亮度相減閥值設定範圍3.Information gain 最大值設定4. 決策樹的深度5. 訓練的資料影像數量6. 決策樹的數量

11
二、隨機森林演算法 (7/8)
Imformation gain 判斷:分裂好壞及是否為葉子節點表示類別分類的越有鑑別度

12
二、隨機森林演算法 (8/8) Threshold :

13
三、實驗成果 (1/7)( 一 ). 隨機森林最佳參數設定:
Threshold Total img True False accurate
100 5000 4466 534 0.89
200 5000 4549 451 0.91
300 5000 4669 331 0.93
400 5000 4735 265 0.95
500 5000 4743 275 0.95
上表:平均亮度相減範圍閥值比較

14
三、實驗成果 (2/7)
Max Gain Total img True False accurate
-0.5 5000 4466 534 0.89
-0.4 5000 4549 451 0.91
-0.3 5000 4669 331 0.93
-0.2 5000 4735 265 0.95
-0.1 5000 4743 275 0.95
-0.05 5000 4609 391 0.92
Threshold Total img True False accurate
5 5000 4561 439 0.91
6 5000 4566 434 0.91
7 5000 4685 315 0.94
8 5000 4613 387 0.93
9 5000 4638 362 0.93
10 5000 4571 429 0.92
上表: information gain 閥值比較;下表:樹的深度比較

15
三、實驗成果 (3/7)
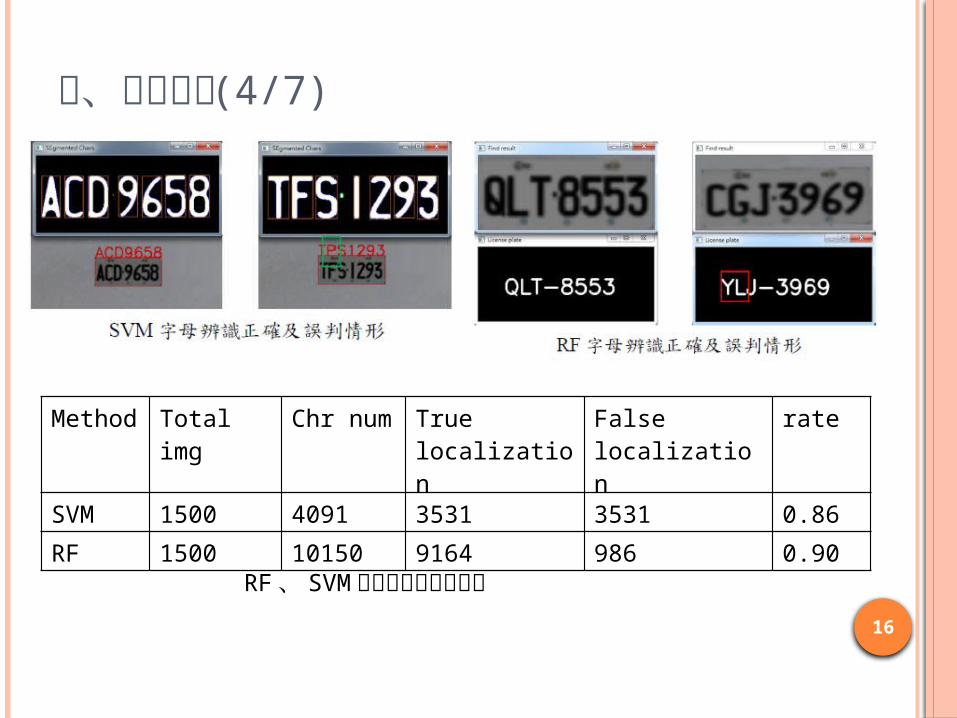
( 一 ).SVM(Support vector machine) 、 RF 字母辨識效果比較:
先隨機產生 1500 張車牌影像
圖 5. 模擬產生新型車牌過程圖
16
三、實驗成果 (4/7)
RF 、 SVM 字母辨識度比較實驗
Method
Total img Chr num True localization
False localization
rate
SVM 1500 4091 3531 3531 0.86
RF 1500 10150 9164 986 0.90

17
三、實驗成果 (5/7)
準確度上 SVM 稍微劣於 RF但在兩者所消耗的時間比較上, SVM 的速度卻優於RF
Method Total img Total chr Total time Mean time
SVM 1500 4251 6022ms 1.42ms
RF 1500 10150 104402ms 10.29ms
RF 、 SVM 字母辨識耗時比較

18
三、實驗成果 (6/7)
( 二 )SVM 、 RF 整體辨識率比較
Method
Total img
Localization
Total chr
True false L rate Chr rate
Overall rate
SVM 3000 1405 8558 7424 1134 0.47 0.87 0.35
EDM+RF
3000 2911 20377
18542 1835 0.97 0.91 0.88
表 .RF 、 EDM+ SVM 整體辨識率比較實驗

19
三、實驗成果 (6/7)
( 三 )SVM 、 RF 在自然環境下整體辨識率比較1.模擬新車牌

20
三、實驗成果 (7/7)
Method
Total img
Localization
Total chr
True false L rate Chr rate
Overall rate
SVM 3000 2562 15308
13033 2275 0.85 0.85 0.62
EDM+RF
3000 2911 18487
17196 1291 0.88 0.93 0.82
表 .RF 、 EDM+ SVM 在結合真實場景整體辨識率比較實驗

21
三、實驗成果 (7/7)
表: EDM+RF 、 SVM 在真實環境 + 定位成功辨識比較實驗
Method Total img Total chr True rate
SVM 96 372 322 0.84
EDM+RF(level 5) 96 644 596 0.93
2.真實新車牌:

22
四、結論與建議 (1/2)
( 一 ) 結論:1.成功實現了利用隨機森林演算法做車牌辨識,根據實驗結果其效能相當優良。2.本文透過隨機森林辨識字母能達到高速率的辨識,,成功的避免掉了在分割字母中常出現的誤判,提高辨識字母準確度。3. 實驗的部分,測試了幾組不同的實驗,在字母辨識準確度結果上 RF 演算法確實更優於 SVM 演算法。

23
四、結論與建議 (2/2)
( 二 ) 建議:1. 在辨識車牌字母耗時部分比其他方法來的差,這部分未來將考慮採用 CUDA 平行計算,並且也能除去耗時過長的這個缺點。•2.考慮加入舊式車牌影像來訓練隨機森林,並且重新訓練及設定參數,達到能夠辨識新車牌與舊車牌的車牌辨識系統。

24
Q&A
25
報告到此結束感謝您的聆聽 ~~





























