Embed Size (px)
Citation preview

Проект NumGRID и его текущее состояние
Максим Александрович Городничев
Расширенный семинар "Архитектура, системное и
прикладное программное обеспечение
кластерных суперЭВМ«
ИВМиМГ СО РАН, Новосибирск, 24.10.2013 г
Институт вычислительной математики и математической геофизики СО РАН www.sscc.ru
Отдел математического обеспечения высокопроизводительных вычислительных систем ssd.sscc.ru

План доклада
1. Обзор NumGRID
2. Проблема разработки программ для NumGRID
3. Проблема управления задачами в NumGRID
4. Разработка программного комплекса для повышения уровня взаимодействия пользователей с объединенными HPC-системами

Что такое NumGRID?
- это комплекс программ для построения единой вычислительной системы из отдельных вычислительных кластеров
Кластеры объединяются на основе общей коммуникационной среды, которая частично реализует стандарты MPI. Процессы одного приложения распределяются по узлам объединяемых кластеров
Кластер 2
Кластер 1
WAN

Цели объединения
• решение задач, которые из-за своего размера не могут быть решены на отдельных кластерах,
• продление срока службы старых вычислительных комплексов за счет объединения с новыми,
• использование специализации кластеров в многокомпонентных задачах,
• повышение гибкости при планировании распределения задач в грид,
• планирование постепенного наращивания мощностей вычислительных систем.

Почему стало возможным объединение?
• Развитие вычислительных алгоритмов, допускающих неоднородность и ненадежность сети связи,
• Развитие методов организации вычислений (+средств разработки программ): асинхронность коммуникаций, динамическая балансировка,
• Улучшение характеристик сетей связи между вычислительными системами.

Потребности в развитии сетей связи: ориентиры
• GridMPI (Япония): 1-10 Гб/с на расстоянии до 500 миль позволяют объединять суперкомьютеры для совместного решения задач
• Abilene Network (США):10 Гб/с между 230 центрами в 2004 г.
• TeraGrid (США) (проект 2004-2011): 10 Гб/с между вычислительными центрами
• National LambdaRail (США): 10 Гб/с -> 40 Гб/с -> 100, 280 центров

Цель проекта NumGRID-MPI
простой инструмент пользовательского уровня для распределения процессов параллельной программы между кластерами, к которым пользователь имеет непосредственный доступ посредством личных учетных записей.
Globus-Toolkit

Основные требования к ПО NumGRID
• Поддержка MPI
• Учет неоднородности межкластерной сети, оборудования и системного ПО кластеров
• NumGRID -- инструмент пользовательского уровня, минимум административных усилий
• Рабочие узлы кластеров находятся в закрытом от внешних сетей адресном пространстве, соединены между собой высокоскоростной сетью, и кроме того сетью TCP/IP, к которой также подключен головной узел кластера.
+ удобство + безопасность + эффективность
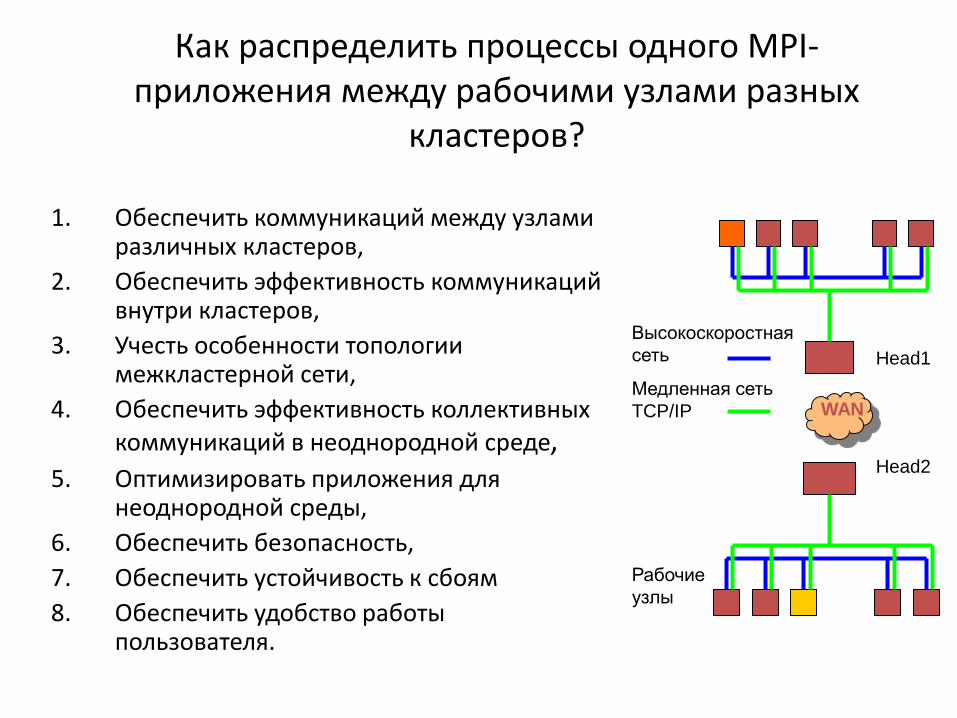
Как распределить процессы одного MPI-приложения между рабочими узлами разных
кластеров?
1. Обеспечить коммуникаций между узлами различных кластеров,
2. Обеспечить эффективность коммуникаций внутри кластеров,
3. Учесть особенности топологии межкластерной сети,
4. Обеспечить эффективность коллективных коммуникаций в неоднородной среде,
5. Оптимизировать приложения для неоднородной среды,
6. Обеспечить безопасность,
7. Обеспечить устойчивость к сбоям
8. Обеспечить удобство работы пользователя.
Head2
Рабочие
узлы
Head1
Высокоскоростная
сеть
Медленная сеть
TCP/IP WAN
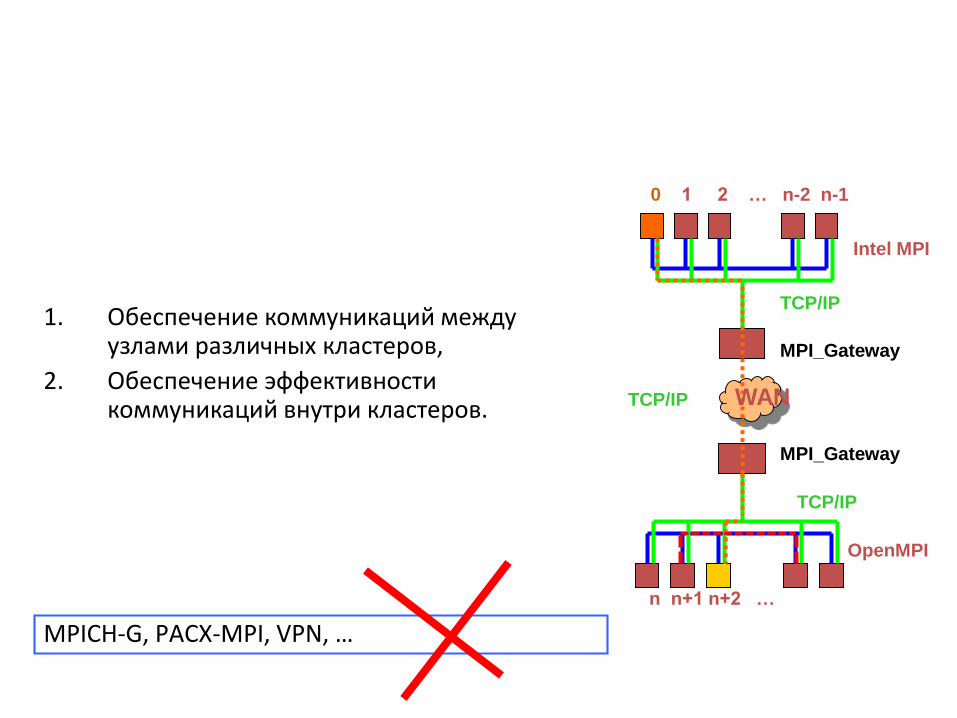
OpenMPI
TCP/IP
0 1 2 … n-2 n-1
TCP/IP
TCP/IP
Intel MPI
n n+1 n+2 …
MPI_Gateway
MPI_Gateway
WAN
1. Обеспечение коммуникаций между узлами различных кластеров,
2. Обеспечение эффективности коммуникаций внутри кластеров.
MPICH-G, PACX-MPI, VPN, …

Программные уровни NumGRID-MPI
Другие выч.узлы
Вычислительный узел
User Application Layer
GMPI Library
Local MPI Interface
High performance
Interconnect
GMPI Gateway Interface
TCP/IP
MPI Gateway
GMPI Gateway Interface
TCP/IP
Головной узел
Головные узлыдругих кластеровПользовательское приложение не
модифицируется

Неблокирующие коллективные коммуникационные операции
• Cтандарт MPI-3.0: раздел 5.12 Nonblocking Collective Operations
• MPI_Ireduce, MPI_Ibcast, MPI_Igather, MPI_Iscatter, MPI_Ibarrier, …
• int MPI_Ireduce(const void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm,
MPI_Request *request)
Реализации:
• LibNBC
http://www.unixer.de/research/nbcoll/libnbc/
• MPICH-3.0.4
http://www.mpich.org/
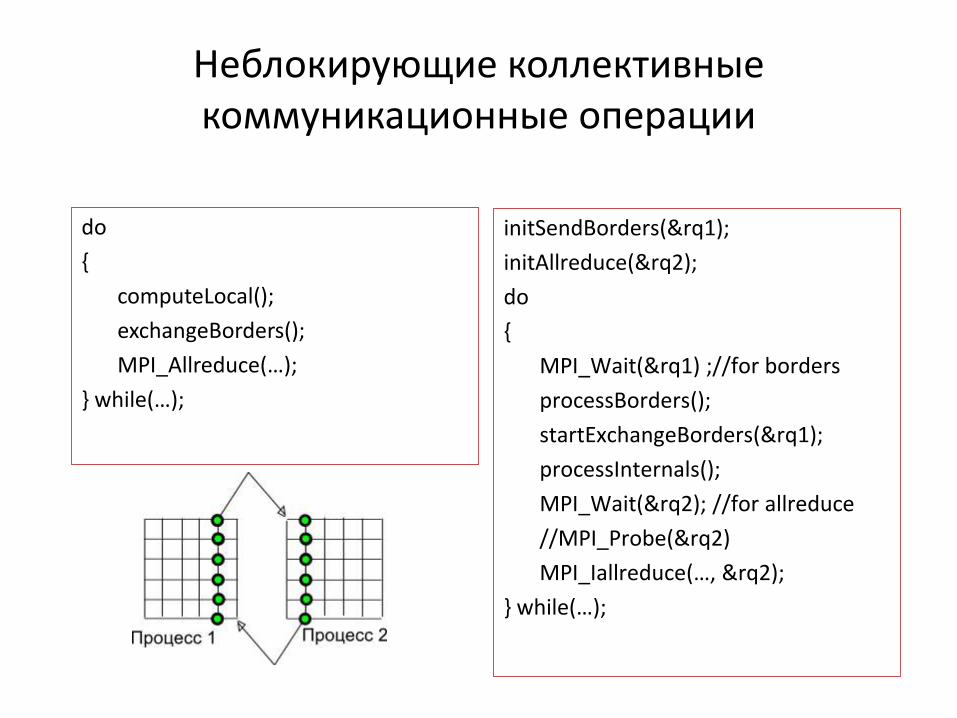
Неблокирующие коллективные коммуникационные операции
do
{
computeLocal();
exchangeBorders();
MPI_Allreduce(…);
} while(…);
initSendBorders(&rq1);
initAllreduce(&rq2);
do
{
MPI_Wait(&rq1) ;//for borders
processBorders();
startExchangeBorders(&rq1);
processInternals();
MPI_Wait(&rq2); //for allreduce
//MPI_Probe(&rq2)
MPI_Iallreduce(…, &rq2);
} while(…);
Неблокирующие коллективные коммуникационные операции

Препятствия для использования NumGrid
• Сложность использования комплекса NumGrid
• Сложность разработки эффективных программ для неоднородных вычислителей

Сложность разработки эффективных программ для неоднородных вычислителей
• Равномерное распределение вычислительной нагрузки в соответствии с производительностью вычислительных узлов, в т.ч. в динамике
• Необходимо учитывать различия в пропускной способности линий связи
Технология фрагментированного программирования, язык LuNA

Сложность работы с NumGRID
./numgrid_net --internalport 11234 --externalport 12345 -
-localquorum 1 --globalquorum 2 --name gw2 --connect
192.168.12.6
mpirun -np 1 ./test --gateway -address 192.168.12.6 --
gateway-port 11234 --rank-base 1 --subjob-id 1 --mtu
1500

8. Обеспечение удобства работы пользователя.

Развитие инструментов взаимодействия пользователей с HPC-системами

Разработка программного комплекса для повышения уровня взаимодействия пользователей
с объединенными HPC-системами
Цель работы:
повышение производительности труда прикладных исследователей в области численного моделирования и повышение эффективности использования вычислительных ресурсов

Направления исследований по повышению производительности труда пользователей HPC-центров в рамках проекта NumGRID
• Повышение уровня средств разработки параллельных программ,
• Общее повышение уровня интерфейсов и, в частности, автоматизация формирования заданий на исполнение в вычислительных системах, в т.ч. распределенных,
• Разработка интерактивных образовательные материалов, позволяющих в кратчайшие сроки осваивать принципы работы с вычислительными системами, прикладными пакетами.
• Организация доступа к различным вычислительным системам через единый интерфейс,
• Автоматизация разрешения проблем пользователей,
• Автоматизация и оптимизация пересылки больших объемов данных между пользователем и вычислительной системой, между различными сетевыми хранилищами
• ->

Направления исследований по повышению производительности труда пользователей HPC-центров в рамках проекта NumGRID
• Автоматизация проведения численных экспериментов с применением прикладных пакетов численного моделирования, современный уровень интерфейсов
• Автоматизация решения задач по управлению учетными записями пользователей,
• Мониторинг на уровне пользователя и системы,
• Объединение вычислительных ресурсов и автоматизация распределения вычислительной загрузки с целью минимизации простоев оборудования,
• Предоставление пользователям виртуальных сред в соответствии с требованиями задач и существующих программ к вычислительным ресурсам.
• …

HPC Community Cloud
• Система управления объединенными вычислительными ресурсами:– централизованная система управления прохождением задач
– коммуникационная библиотек на основе проекта NumGRID для обеспечения возможности запуска параллельных приложений c распределением процессов между узлами объединенных вычислительных систем
• Высокоуровневые инструменты разработки параллельных программ:– фреймворки
– технология фрагментированного программирования
• Система эффективных пользовательских интерфейсов и интерфейсов администрирования
• Программная платформа для разработки и развертывания интерактивных учебных материалов в области супекомпьютерных технологий.
• API для использования сервисов HPC Community Cloud сторонними приложениями
• Инструментарий для управления/перемещения массивов данных, интеграция с внешними сервисами хранения данных
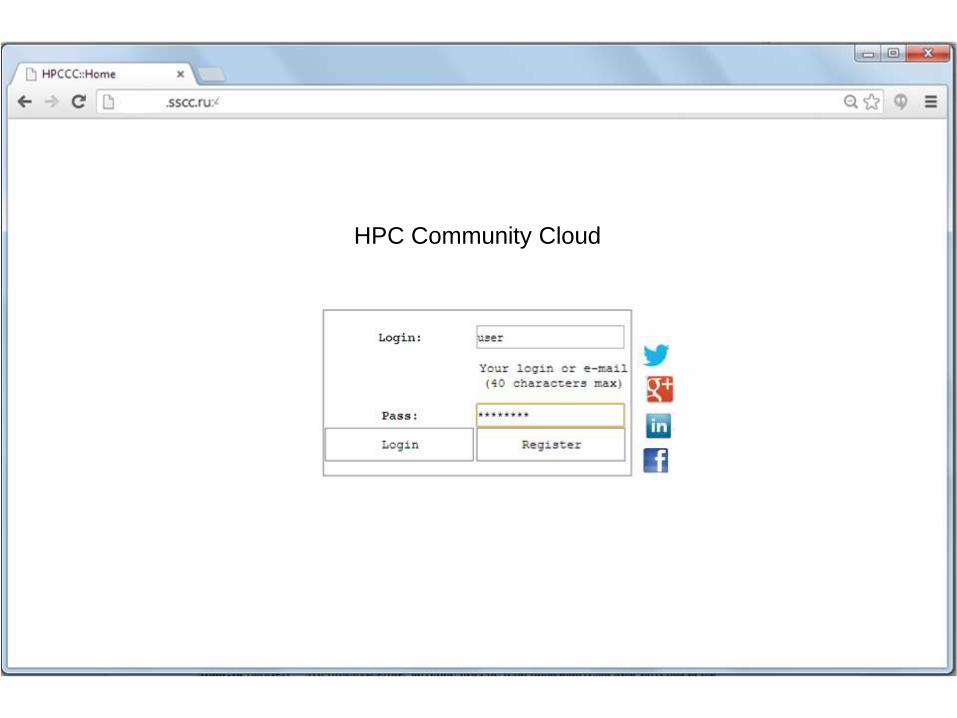
HPC Community Cloud

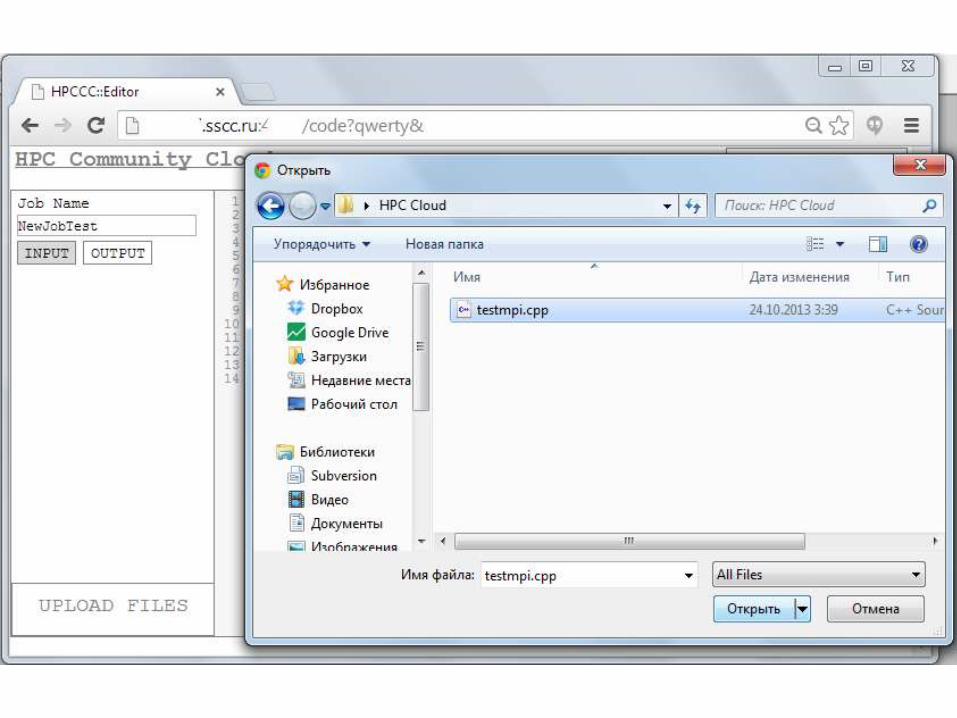

Пользовательский интерфейс: термины
• Приложение
• Фреймворк
• Модель
• Задача
• Личный кабинет

Настройки Выход
Приложения
Фреймворки
Модели
ЛК
JobID Job Name Cores Status
0 Heating3D S.10 D
1 HeartSim S.80+N.30 R
2 FluiTube N.10 E
3 Lab1extr S.200 Q
Running

Единый интерфейс для HPC-систем
HPC Cloud
ССКЦ: НКС-30Т
Кластер НГУ
Кластер МГУ
…
Amazon EC2

Настройки Выход
Приложения
Фреймворки
Модели
ЛК
JobID Job Name Cores Status
0 Heating3D S.10 D
1 HeartSim S.80+N.30 R
2 FluiTube N.10 E
3 Lab1extr S.200 Q
Running





Система управления прохождением заданий

Настройки Выход
Приложения
Фреймворки
Модели
ЛК
JobID Job Name Cores Status
0 Heating3D S.10 D
1 HeartSim S.80+N.30 R
2 FluiTube N.10 E
3 Lab1extr S.200 Q
Running
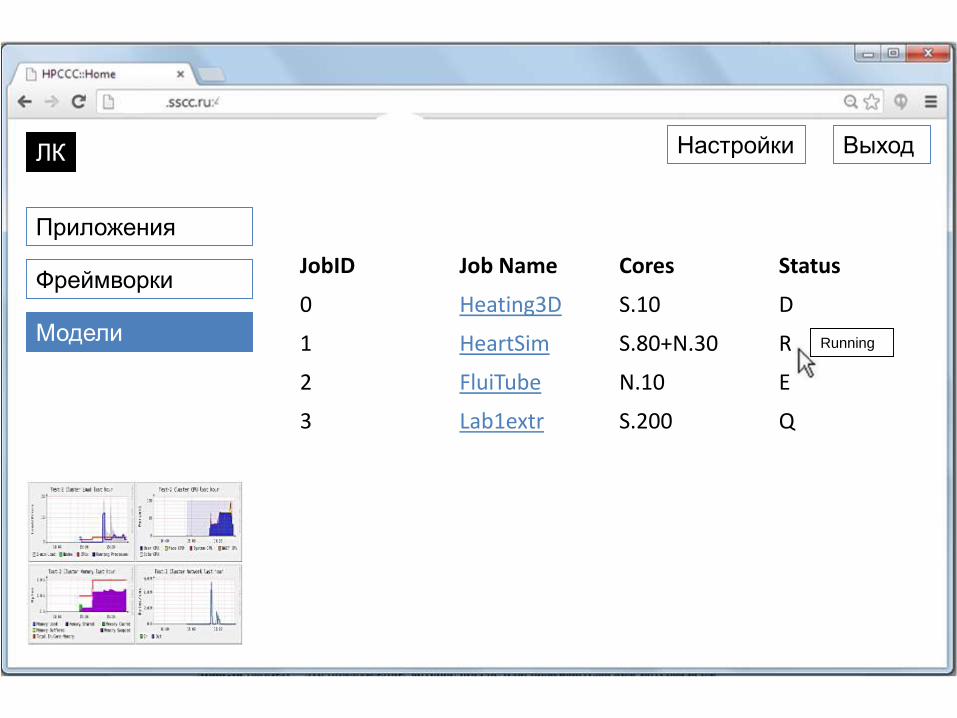
Настройки Выход
Приложения
Фреймворки
Модели
ЛК
JobID Job Name Cores Status
0 Heating3D S.10 D
1 HeartSim S.80+N.30 R
2 FluiTube N.10 E
3 Lab1extr S.200 Q
Running

Пример модели: программный комплекс клеточно-автоматного моделирвания (Ю. Г. Медведев)
Граничные и начальные
условия
Параметры
моделирования
Параметры
визуализации
Медведев Ю.Г. Программный комплекс клеточно-автоматного моделирования газопорошковых
потоков // Параллельные вычислительные технологии (ПаВТ’2012): труды международной
научной конференции (Новосибирск, 26 – 30 марта 2012 г.). Челябинск: Издательский центр
ЮУрГУ, 2012, с. 732.

Интерфейс конструктора
39
Тут должен быть принтскрин примера

Интерфейс симулятора
40
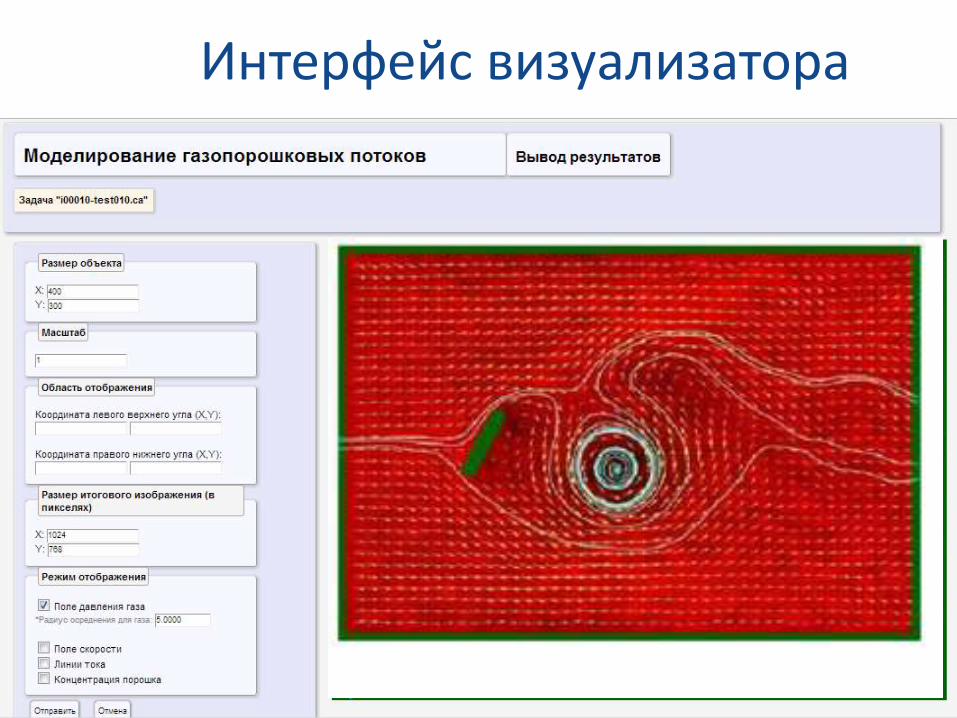
Интерфейс визуализатора
41

Настройки Выход
Приложения
Фреймворки
Модели
ЛК
JobID Job Name Cores Status
0 Heating3D S.10 D
1 HeartSim S.80+N.30 R
2 FluiTube N.10 E
3 Lab1extr S.200 Q
Running

Настройки Выход
Приложения
Фреймворки
Модели
ЛК
JobID Job Name Cores Status
0 Heating3D S.10 D
1 HeartSim S.80+N.30 R
2 FluiTube N.10 E
3 Lab1extr S.200 Q
Running

Фреймворк для метода частиц-в-ячейках
● Соединение подпрограмм, написанных пользователем для конкретной задачи и заранее реализованных подпрограмм для класса задач
● Повышение уровня программирования
● Ускорение и упрощение работы пользователя

Метод частиц-в-ячейках

Схема программы

Взаимодействие с пользователем
● Конфигурационный файл для статических параметров задачи (физические константы, параметры для сеток и т. д.)
● Набор объектов, чьи методы позволяют производить вычисления и действия с частицами
● Несколько готовых программ на основе этого фреймворка

Схема программы на основе фреймворка
Обработка пользовательских
параметров
Цикл по времени
Параметры задачи
Вычислительные действия
Межпроцессные коммуникации
Балансировка загрузки
Инициализация
- Реализовано во фреймворке
- Реализуется пользователем

Текущие результаты в разработке фреймворка
● Инициализация и считывание параметров
● Безопасные контейнеры для сеток и частиц
● Перемещение фрагментов сеток с частицами между процессами
● Ведение логов
● Заложены возможности балансировки загрузки и визуализации
● Некоторые пользовательские подпрограммы для задачи решения уравнений Максвелла как
пример использования

Планы развития фреймворка
● Многопоточный модуль коммуникаций для обмена служебными сообщениями и фрагментами сеток с частицами
● Балансировка загрузки
● Эффективная интерпретация результатов
● Интерфейс для встраивания в HPC Community Cloud

Программная платформа для разработки и развертывания интерактивных учебных
материалов в области супекомпьютерных технологий.
• Лекционные материалы
• «Тьюториалы», лабораторные работы
• Контролирующие материалы
• Автоматические генераторы отчетов по программам
• Контроль плагиата
• ….
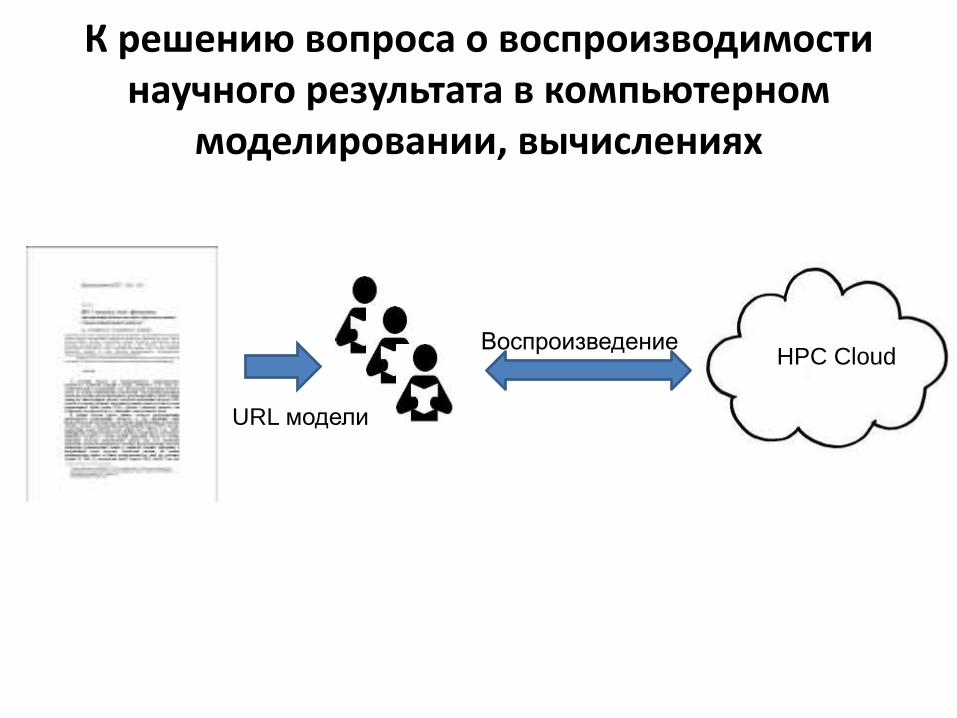
К решению вопроса о воспроизводимости научного результата в компьютерном
моделировании, вычислениях
URL модели
ВоспроизведениеHPC Cloud

Использования API внешними программными системами
Сервис локального
прогноза погоды
????
Global
weather
forecast
APIHPC Cloud
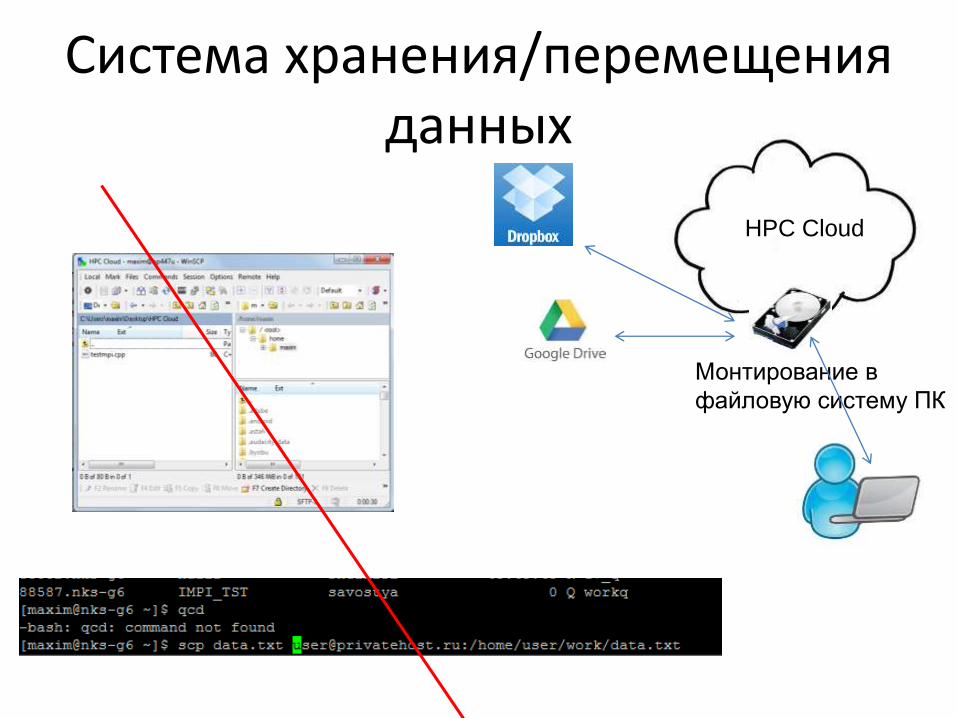
Система хранения/перемещения данных
HPC Cloud
Монтирование в
файловую систему ПК

Заключение
• Существующий инструментарий NumGRID-MPIобеспечивает устойчивую работу распределенных MPI-программ.
• Чтобы NumGRID-MPI мог продуктивно использоваться для целей численного моделирования требуется развитие прикладных аспектов.
• Спроектирована высокоуровневая система взаимодействия пользователей с HPC-системами
• Разработаны прототипы компонентов системы.

Проекты с родственными идеями
• Hubzero, Purdue University
http://hubzero.org,
• Метакластер, ННГУ
http://cluster.software.unn.ru
• Sabalcore
http://www.sabalcore.com/
• ProActive, INRIA, Activeeon
http://proactive.activeeon.com
• UGENE, Unipro
http://ugene.unipro.ru/
• …

Спасибо за внимание!





























