Embed Size (px)
Citation preview

통계학원론 Chapter 2. 데이터
2-1. 데이터 종류 및 요약
1) 데이터 정의
•관측 대상 개체(사람, 사물, 기업, 국가 등 조사 대상이 되는 집단)가 행과 개체에 대한 관심 특성(이를 변수)을 열로 하여 이루어진 행렬을 데이터라 한다.
•행렬 각 셀의 값을 관측치(observation)이라 한다.
•소프트웨어 사용울 위하여 데이터를 통계 패키지에 (엑셀 포함) 입력할 때 반드시 행렬의 형태를 유지해야 한다. 예를 들어 50명 남녀 수능성적 데이터를 입력할 때 행은 50개, 열은 2개(셩별, 수능성적)
(예) H대학 경상대학 학생 500명의 사회인구학적 특성 (성별, 가계소득(연), 주거형태, 가족 수)을 조사하였다면
2) 데이터 종류
(1) 측정형 continuous 정량, 양적 quantitative : 셀 수 있거나 측정할 수 있는 특성 (변수)
•비율 ratio : 절대개념의 0을 가지고 있어 값의 크기 배수 times 의미가 있음 (예) 몸무게, 용돈, 교통사고 건수
•구간 interval : 상대 개념으로 배수의 의미가 없음 (예) 온도
(2) 범주형 categorical 정성, 질적 qualitative : 개체를 분류하는데 사용되는 특성 (변수)
•순서형 ordinal : 개체 분류에 순서가 있음 - A,B 학점, 5점 척도, 소득 상중하
•명목형 nominal : 분류의 목적만 있음 - 흡연여부, 출신지역
3) 데이터 표현
표본 데이터 크기가 n인 경우 : 첨자 i는 개체 번호이고 변수 기호는 인 경우
관측값 : ,
양적 변수 : 일주일 공부시간 (3, 3.5, 7, 0, …)
질적 변수 : 기독교인 여부 (Y, N, N, N, Y, …)
x
(x1, x2,..., xn ) xi , for i = 1,2,...,n
x1 = 3, x2 = 3.5, x3 = 7, x4 = 0,...
x1 = 1, x2 = 0, x3 = 0, x4 = 0, x 5= 0,...
한남대학교 비즈니스 통계학과 Page16

통계학원론 Chapter 2. 데이터
1) 확률실험(측정) random experiment: 결과 값을 예측할 수 없는 실험 (예) 주사위 눈금, 학생 키, 흡연여부
2) 표본공간 sample space : 확률실험 결과 나타날 수 있는 결과 값의 모임 , ,
3) 원소 element : 표본공간을 구성하는 결과 값
4) (확률) 변수 (random) variable : 표본공간의 원소가 정의역, 그에 대응하는 실수 값을 치역으로 하는 함수 , 양적변수의 경우에는 정의역과 치역이 동일, 질적변수는 정
의역이 범주, 치역이 실수
5) 관측치 개수가 n이고, i는 관측치 순서를 나타내는 첨자라 하면 혹은
을 표본크기 n인 관측값들을 나타내는 기호임
6) 모수 parameter : 모집단에서 확률변수가 가지는 값들의 요약 값 (예) 모집단 평균, 모집단 분산, 모집단 비율
7) 확률표본 random sample : 모집단으로부터 확률적(각 관측치는 동일한 분포로부터 서로 독립적으로 관측됨)으로 추출된 개채 모임
8) 통계량 statistic : 확률표본으로부터 계산된 요약값 (예) 표본평균, 표본분산, 표본비율
S = {1,2,3,4,5,6} S = {x;100 < x < 250} S = {S,NS}
x = X(s)
(x1, x2,..., xn )xi , i = 1,2,...,n
한남대학교 비즈니스 통계학과 Page17

통계학원론 Chapter 2. 데이터
4) 데이터 요약
(1) 개별 변수
1) 숫자 요약 : n개의 관측치 정보를 하나의 값으로 요약하는 방법
•양적 변수 : 데이터 중앙 위치 요약 - 평균, 중앙값, 흩어짐 요약 - 범위, 분산, 중앙범위
•질적 변수 : 비율
2) 그래프 요약 : n개 관측치에 정보를 시각적 그래프로 표현하는 방법
•양적 변수 : 히스트그램, 상자-수염 그림
•질적 변수 : 막대 그래프, 파이 차트
2-2. 숫자 요약 (질적 변수)
10개 IT 기업을 대상으로 기업형태 (1=기업, 2=파트너, 3=개인)를 조사하였다.
,
IT 기업 중 개인 소유 기업형테 비율은 40%이다. 질적변수의 요약은 각 범주의 빈도(4), 혹은 상대빈도=비율(40%)이다.
(미국도시_사회지표2.XLS) 질적변수 “지역” 1=동부, 2=북부, 3=남부, 4=서부
4개 지역의 도시 빈도와 상대빈도를 구하시오.
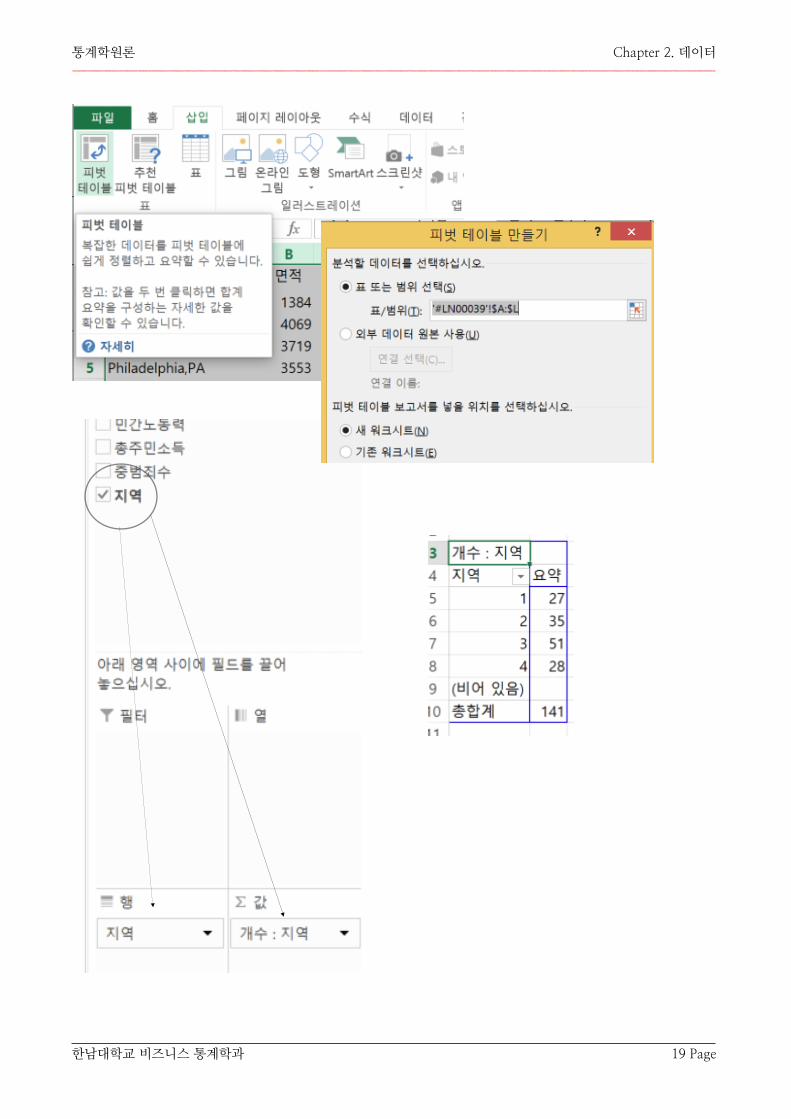
[IN 엑셀]
① 데이터 영역을 선택한다.
② 삽입 메뉴 -> 피벗 테이블을 선택한다. -> 피벗 테이블 만들기 창이 나타나면 범위는 이미 선택되어 있으므로 자동 나타난다. 테이블 위치를 지정한다.
③ 테이블 필드 창에서 지역을 선택하고 “행”과 “Σ 값”에 옮겨 넣으면 테이블에 빈도가 나타난다.
{xi;2,1,1,3,3,3,2,1,2,3} {x1 = 2, x2 = 1, x3 = 1,..., x10 = 3}
한남대학교 비즈니스 통계학과 Page18
통계학원론 Chapter 2. 데이터
한남대학교 비즈니스 통계학과 Page19

통계학원론 Chapter 2. 데이터
[지역별 인구수 합과 평균을 구하자]
“Σ 값”에 “인구” 변수를 끌어다 놓고 ▼ 버튼을 눌러 하위 메뉴가 나타나면 “값 필드 설정”이 나타나면 원하는 요약 통계량을 선택하면 된다.
한남대학교 비즈니스 통계학과 Page20

통계학원론 Chapter 2. 데이터
2-3. 그래프 요약 (질적 변수)
1) 바 그래프
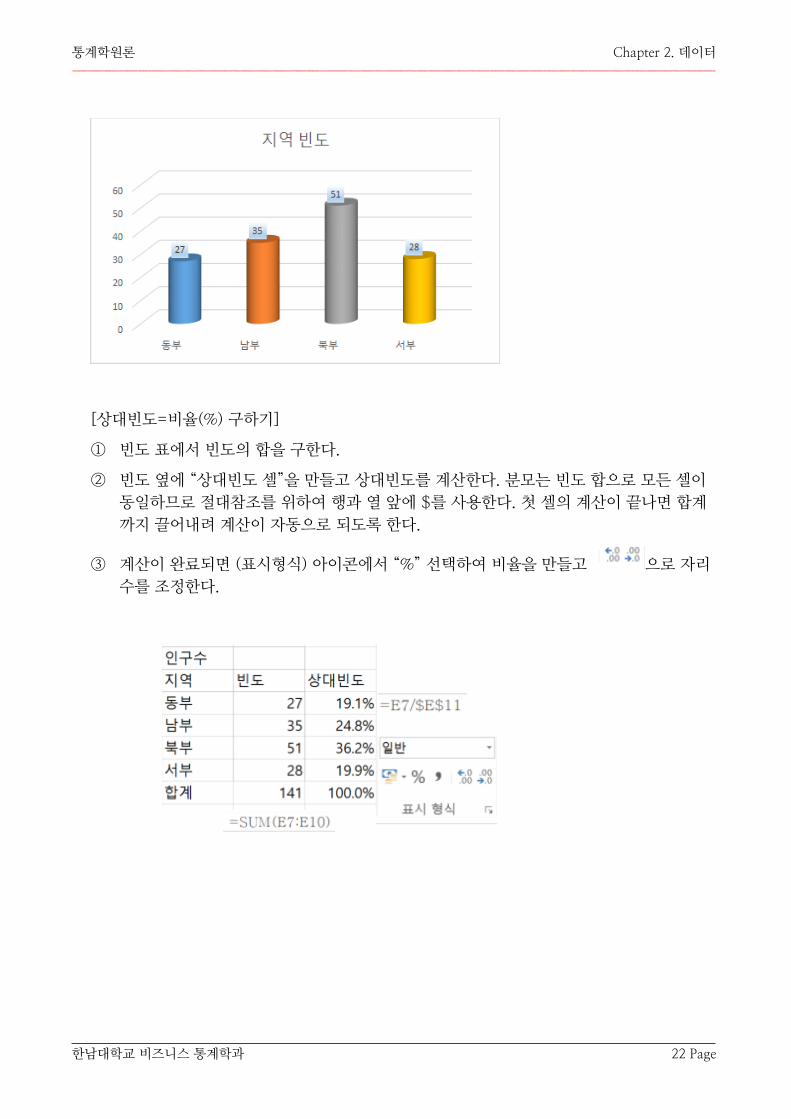
질적변수의 범주를 x-축, 대응하는 빈도(frequency) 혹은 상대빈도(relative frequency) 값을 y-축으로 하여 그린 막대 그래프
1. 관측값이 가지는 값(범주)과 대응하는 빈도로 빈도표를 만든다 (피벗 테이블 활용)
2. 기둥의 높이는 그 범주에 속한 관측도수의 크기에 비례(그 값으로)하여야 한다. 예를 들면 10%가 관측된 범주의 기둥 크기는 20%가 관측된 범주의 기둥크기의 ½이어야 한다.
3. 기둥의 폭은 모든 범주에서 동일하여야 한다. 만약에 어떤 범주는 폭을 크게 하고 다른 범주에서는 폭을 작게 하면 두 범주에 대한 객관적인 비교를 하는 데 장애가 된다.
4. 기둥의 모양은 자료를 의미할 수 있는 것으로 하는 것이 좋다. 예를 들면 자동차에 대한 조사를 할 때 자동차를 쌓아 놓은 모양으로 기둥을 하면 이해에 도움이 된다.
[In 엑셀] 빈도표를 선택하고 삽입메뉴-> 차트 하위 메뉴에서 적절한 차트를 선택하면 자동으로 그래프가 그려진다. 그려진 그래프를 선택한 후 우측 마우스 버튼을 누른 후 나타나는 팝업 창에서 적절한 작업을 수행하여 그래프를 수정한다.
한남대학교 비즈니스 통계학과 Page21
통계학원론 Chapter 2. 데이터
[상대빈도=비율(%) 구하기]
① 빈도 표에서 빈도의 합을 구한다.
② 빈도 옆에 “상대빈도 셀”을 만들고 상대빈도를 계산한다. 분모는 빈도 합으로 모든 셀이 동일하므로 절대참조를 위하여 행과 열 앞에 $를 사용한다. 첫 셀의 계산이 끝나면 합계까지 끌어내려 계산이 자동으로 되도록 한다.
③ 계산이 완료되면 (표시형식) 아이콘에서 “%” 선택하여 비율을 만들고 으로 자리 수를 조정한다.
한남대학교 비즈니스 통계학과 Page22
통계학원론 Chapter 2. 데이터
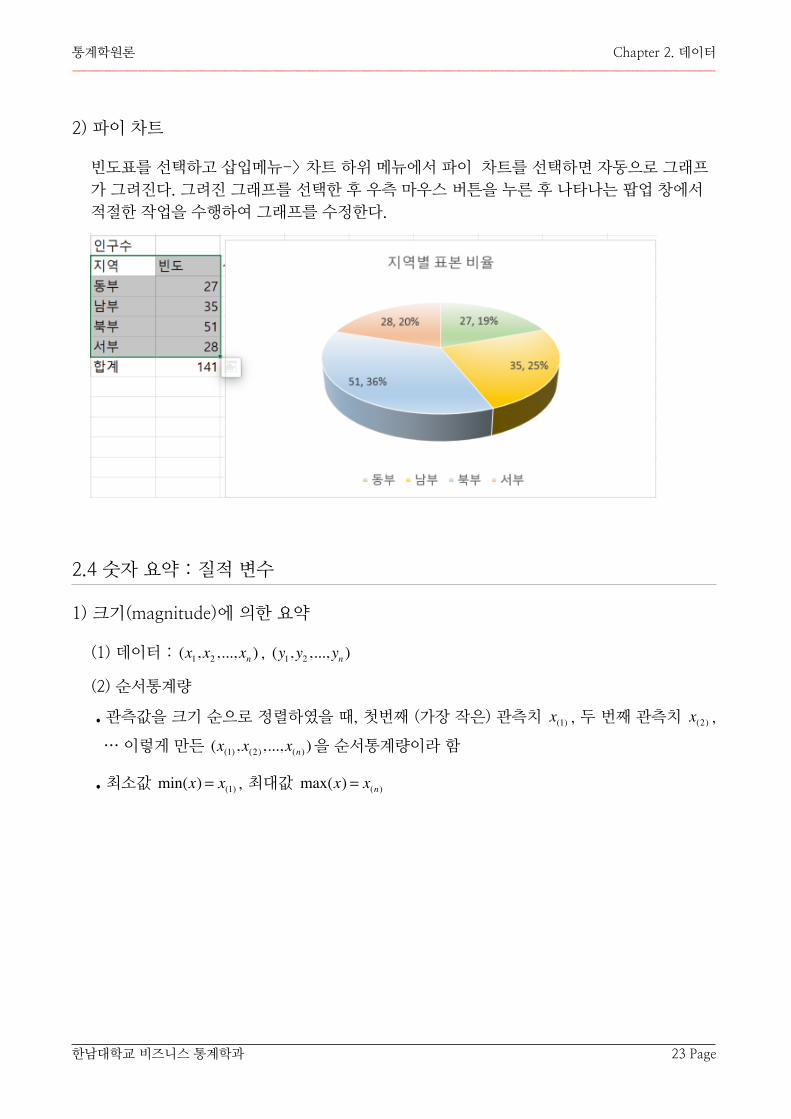
2) 파이 차트
빈도표를 선택하고 삽입메뉴-> 차트 하위 메뉴에서 파이 차트를 선택하면 자동으로 그래프가 그려진다. 그려진 그래프를 선택한 후 우측 마우스 버튼을 누른 후 나타나는 팝업 창에서 적절한 작업을 수행하여 그래프를 수정한다.
2.4 숫자 요약 : 질적 변수
1) 크기(magnitude)에 의한 요약
(1) 데이터 : ,
(2) 순서통계량
•관측값을 크기 순으로 정렬하였을 때, 첫번째 (가장 작은) 관측치 , 두 번째 관측치 ,
… 이렇게 만든 을 순서통계량이라 함
•최소값 , 최대값
(x1, x2,..., xn ) (y1, y2,..., yn )
x(1) x(2)(x(1), x(2),..., x(n) )
min(x) = x(1) max(x) = x(n)
한남대학교 비즈니스 통계학과 Page23
통계학원론 Chapter 2. 데이터
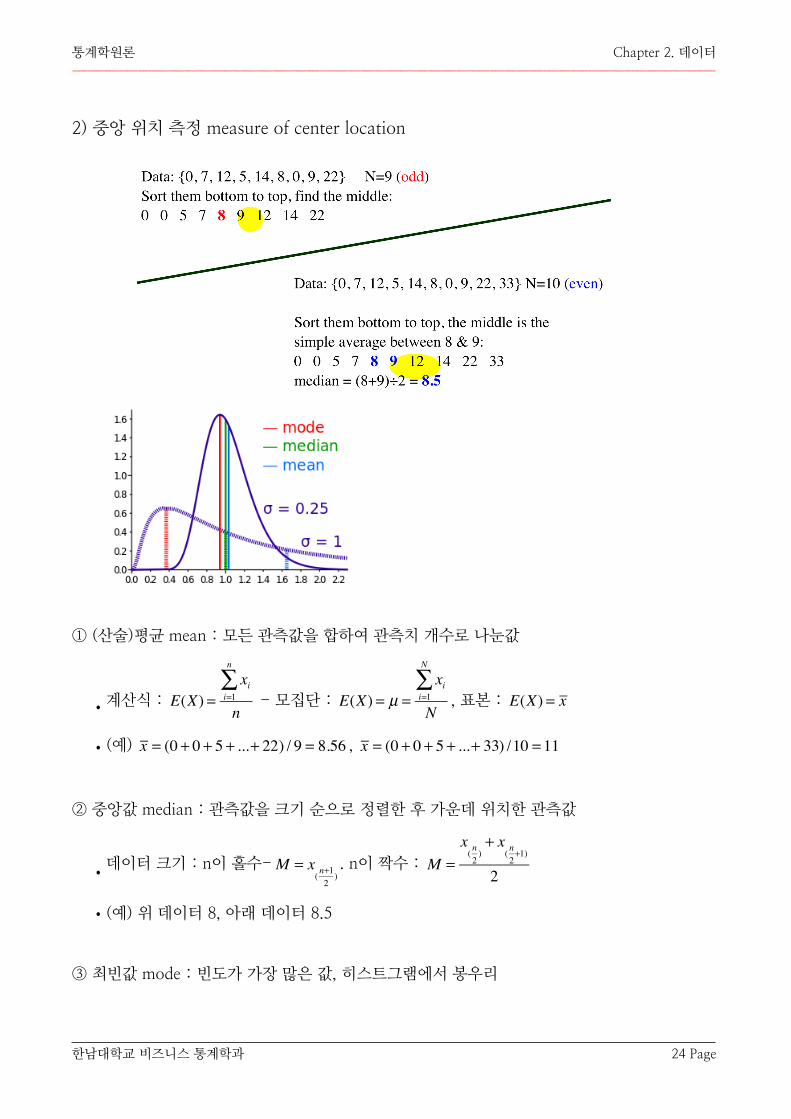
2) 중앙 위치 측정 measure of center location
① (산술)평균 mean : 모든 관측값을 합하여 관측치 개수로 나눈값
•계산식 : - 모집단 : , 표본 :
•(예) ,
② 중앙값 median : 관측값을 크기 순으로 정렬한 후 가운데 위치한 관측값
•데이터 크기 : n이 홀수- . n이 짝수 :
•(예) 위 데이터 8, 아래 데이터 8.5
③ 최빈값 mode : 빈도가 가장 많은 값, 히스트그램에서 봉우리
E(X) =xi
i=1
n
∑n
E(X) = µ =xi
i=1
N
∑N
E(X) = x
x = (0 + 0 + 5 + ...+ 22) / 9 = 8.56 x = (0 + 0 + 5 + ...+ 33) /10 = 11
M = x(n+12)
M =x(n2)+ x
(n2+1)
2
한남대학교 비즈니스 통계학과 Page24

통계학원론 Chapter 2. 데이터
•질적변수에서는 활용도가 높으나 양적변수에서는 활용도가 낮음 (예) 최빈값=0
④ 기하평균 geometric mean : 증감 비율에 대한 평균 개념.
•계산식 : ,
•산술 조화 평균 arithmetic harmonic mean 이라고도 불리움
•첫 해 10% 중가, 다음 해 20% 감소, 그 다음 해 15% 감소 했다고 하자. 3년 평균 증감율을
계산하시오. (산술평균) , (기하평균) - 산술
평균은 5% 상승, 기하평균은 3.91% 상승 (기하평균이 적합)
(치우침과 평균, 중앙값, 최빈값 관계)
GM = x1x2...xnn = ( xii=1
n
∏ )1/2 xi = 1+ ri
10 + 20 −153
= 5(%) (1.1*1.2*0.85)1/3 = 1.0391
한남대학교 비즈니스 통계학과 Page25
데이터의 중앙의 요약값으로 가장 적절한 값은 중앙값이다. 평균은 분포의 치우침이나 이상치가 존재할 때 영향을 받아 중앙 요약값으로 적절하지 않음 (예) 소득, 수능성적 그러나 통계는 평균을 사용 - why? 중심극한정리, 평균의 샘플링 분포 알고 있어 모집단에 대한 추론이 가능하다.
왼쪽 그래프를 히스토그램이라 하며 다음 절에서 다루기로 한다.
통계학원론 Chapter 2. 데이터
3) 흩어짐 (산포도) 측정 measure of spread
① 분산 variance : 데이터의 흩어짐을 측정함
•모집단 : , 표본 :
• ,
② 표준편차 standard deviation : 분산의 양의 제곱근 값
•모집단 : , 표본 :
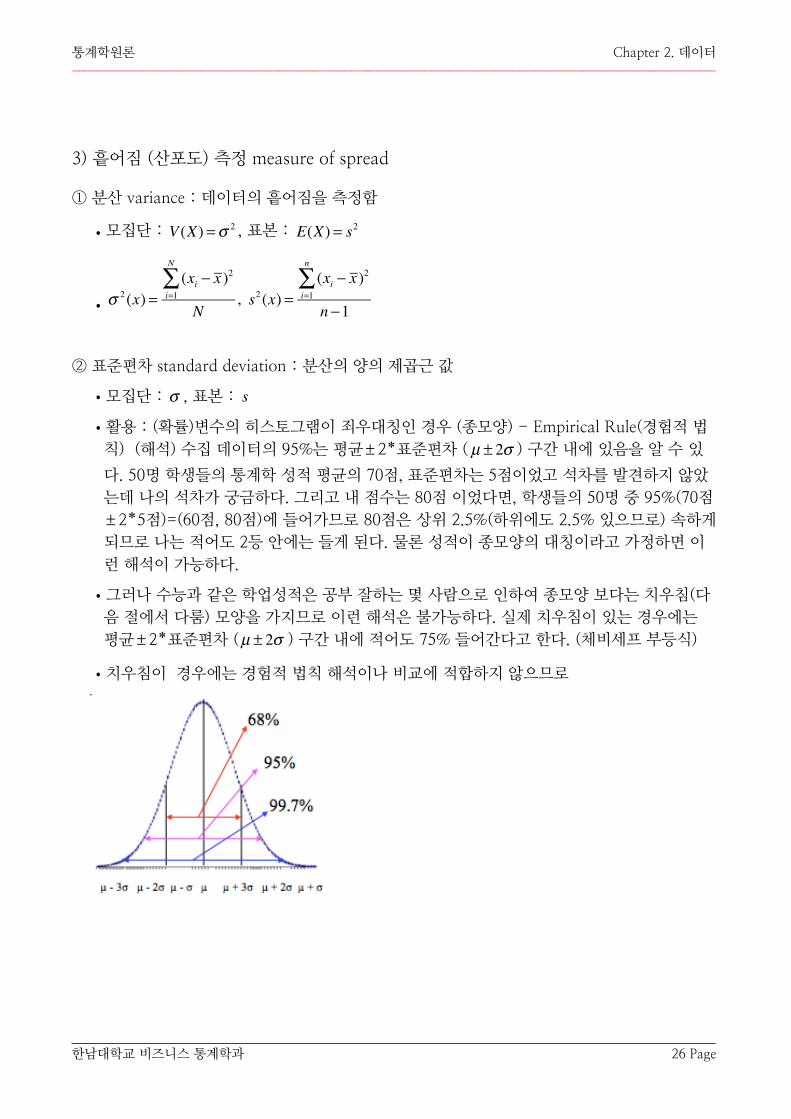
•활용 : (확률)변수의 히스토그램이 죄우대칭인 경우 (종모양) - Empirical Rule(경험적 법칙) (해석) 수집 데이터의 95%는 평균 2*표준편차 ( ) 구간 내에 있음을 알 수 있
다. 50명 학생들의 통계학 성적 평균의 70점, 표준편차는 5점이었고 석차를 발견하지 않았는데 나의 석차가 궁금하다. 그리고 내 점수는 80점 이었다면, 학생들의 50명 중 95%(70점 2*5점)=(60점, 80점)에 들어가므로 80점은 상위 2.5%(하위에도 2.5% 있으므로) 속하게 되므로 나는 적어도 2등 안에는 들게 된다. 물론 성적이 종모양의 대칭이라고 가정하면 이런 해석이 가능하다.
•그러나 수능과 같은 학업성적은 공부 잘하는 몇 사람으로 인하여 종모양 보다는 치우침(다음 절에서 다룸) 모양을 가지므로 이런 해석은 불가능하다. 실제 치우침이 있는 경우에는 평균 2*표준편차 ( ) 구간 내에 적어도 75% 들어간다고 한다. (체비세프 부등식)
•치우침이 경우에는 경험적 법칙 해석이나 비교에 적합하지 않으므로
V (X) =σ 2 E(X) = s2
σ 2 (x) =(xi − x )
2
i=1
N
∑N
s2 (x) =(xi − x )
2
i=1
n
∑n −1
σ s
± µ ± 2σ
±
± µ ± 2σ
한남대학교 비즈니스 통계학과 Page26

통계학원론 Chapter 2. 데이터
③ 변동계수 coefficient of variation
•계산식 :
•활용 : 두 집단의 흩어짐에 대한 비교
•(예) 지난 한달 간 조사 결과 A학생은 하루 공부시간 평균=2시간, 표준편차=3시간 공부하였고, B 학생은 평균=3시간, 표준편차=4시간 공부하였다. 누가 더 꾸준히 공부한다고 할 수 있나? 꾸준하다는 것은 변동계수가 적다는 것이다.
[In 엑셀] (미국도시_사회지표2.XLS) “중범죄수” 평균, 분산, 표준편차, 변동계수를 구하시오.
•S의 의미는 표본(sample), P는 모집단(population)을 의미함
•열에 있는 모든 데이터 값을 이용할 때는 행을 나타내는 숫자 사용할 필요 없음
•(K2:K142)의 의미는 K열 2행부터 K열 142행 데이터를 활용한다는 의미
CV = s(x)x
×100(%)
한남대학교 비즈니스 통계학과 Page27
통계학원론 Chapter 2. 데이터
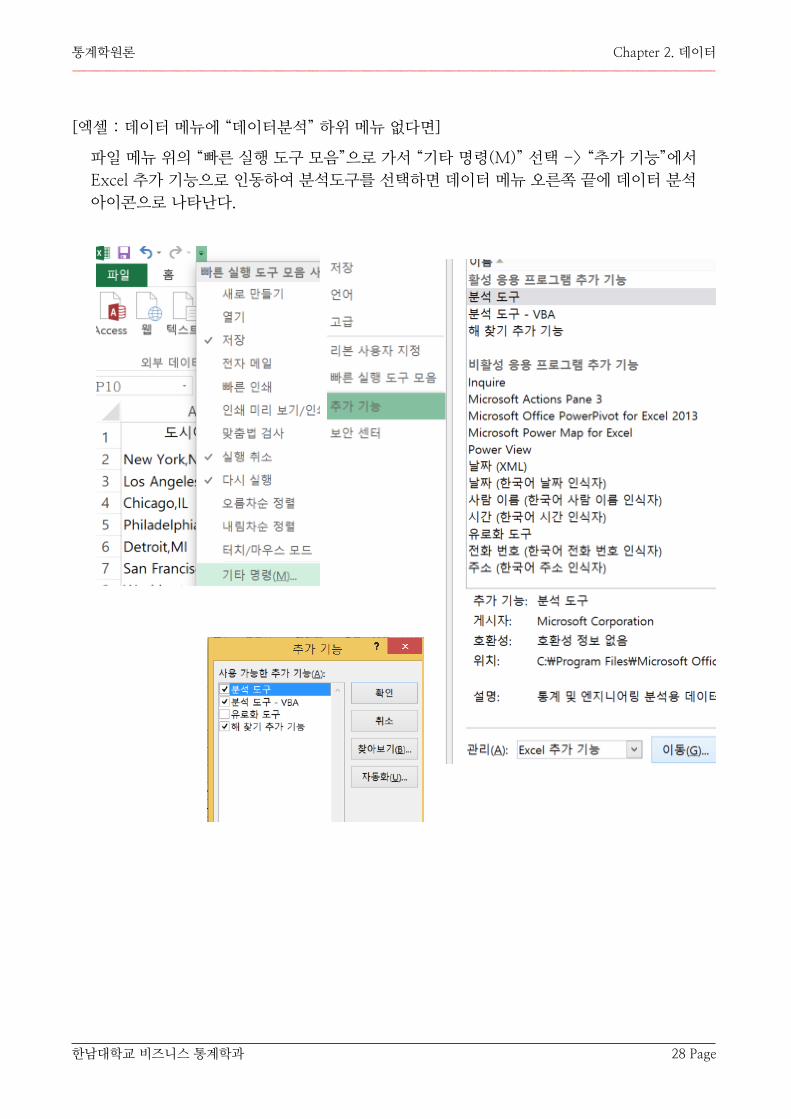
[엑셀 : 데이터 메뉴에 “데이터분석” 하위 메뉴 없다면]
파일 메뉴 위의 “빠른 실행 도구 모음”으로 가서 “기타 명령(M)” 선택 -> “추가 기능”에서 Excel 추가 기능으로 인동하여 분석도구를 선택하면 데이터 메뉴 오른쪽 끝에 데이터 분석 아이콘으로 나타난다.
한남대학교 비즈니스 통계학과 Page28

통계학원론 Chapter 2. 데이터
4) 순서 통계량 활용
(예제 데이터) 1 1 3 5 7 9 12 15 22 27 29 30 (n=12)
① 백분위 percentile : p-percentile (p-백분위)
•데이터 중 100(p)%가 그 값보다 작고 100(1-p)%가 그 값보다 큰 값을 p-백분위라 함
•(예) 70th 백분위 : 데이터의 70%가 그 값보다 작은 값
•계산식 : 근사값 위치
•(예제 데이터) 80th 백분위? 위치 - 10번=27, 11번째 29 - 그러므
로 27+0.4*(29-27)=27.8
② 분위 decile : 10th percentile = lower decile, 90th percentile = upper decile
•하위분위 lower decile : - 1+0.3*(1-1)=1
•상위분위 upper decile : - 29+0.7*(30-29)=29.7
③ 사분위 quartile :
first quartile 제일사분위 - 25th 백분위
second quartile 제이사분위/중위수 ,
third quartile 제삼사분위 - 75th 백분위
•중앙 위치 median depth : (예) - 6번째 관측치와 7번째 관
측치 평균 (7+8)/2=7.5
•분위 위치 Quartile depth : (예) , 앞에서 3번째 관측치가
제일사분위=3, 끝에서 3번째 관측치 27이 제삼사분위 값
Lp = (n +1)p100
L80 = (12 +1)80100
= 10.4
L10 = (12 +1)10100
= 1.3
L9 = (12 +1)90100
= 11.7
Q1
Q2 /M
Q3
MD = n +12
MD = 12 +12
= 6.5
QD =MD⎢⎣ ⎥⎦ +12
QD =5.5⎢⎣ ⎥⎦ +12
= 3
한남대학교 비즈니스 통계학과 Page29

통계학원론 Chapter 2. 데이터
④ 범위 range : - 순서의 흩어짐으로 사용, 극단치에 영향을 받음
•실증적법칙에 의해 평균 3*표준편차에 대부분의 관측치가 다 들어감
•그러므로 데이터 범위는 (6*표준편차)와 동일 - 그러므로 범위=6*표준편차이면 데이터가 좌우대칭임
•그리고 표준편차 값이 계산 되지 않으면 (범위/4)를 표준편차로 사용 (왜 6으로 나누지 않는가? 표준편차 추정 시 6으로 나누면 너무 작아져 문제가 발생)
⑤ 중앙범위 midrange
- 순서의 흩어짐으로 주로 사용 (예) 미국 대학 SAT 점수를 발표하는 경우 중앙범위
를 발표함
⑥ 사분위 범위 Inter-Quartile Range
[In 엑셀] (미국도시_사회지표2.XLS) “중범죄수” 범위, 사분위 값, 90%분위 값을 구하시오.
R = x(n) − x(1)
±
(Q1, Q3)
IQR =Q3 −Q1
한남대학교 비즈니스 통계학과 Page30

통계학원론 Chapter 2. 데이터
2.5 그래프 요약 : 질적 변수
1) (상대) 빈도 (relative) frequency 표
숫자로 관측된 양적 자료(연속형 자료)를 일정한 구간으로 나눈 후에 각 구간에 속한 개채들의 수를 빈도(도수)로 나타낸 표, 도수분포표라고 함
(작성법)
1. 관측값 중에서 가장 작은 값(최소값)과 가장 큰 값(최대값)을 찾는다.
2. 두 값 사이의 구간(범위 range)을 8~10개의 작은 구간(interval)으로 나눈다. 단 작은 구간들은 다음 조건을 만족하여야 한다.
a. 각 관측값들은 하나의 구간에만 속하여야 한다.
3. 각 구간은 겹치지 않아야 하며 구간을 합하면 데이터 법위를 포함해야 한다.
4. 각 구간에 속한 관측값의 수에 대한 빈도를 계산한다. 상대빈도는 각 소구간의 관측 빈도를 전체 관측값의 수로 나눈 비율이다.
[In 엑셀] (미국도시_사회지표2.XLS) “중범죄수” 빈도 표를 구하시오.
구간의 개수를 10개로 하면 구간 폭은 70,520이다. 이를 적절히 조정하여 주관적으로 80,000을 선택하였다. 빈 최대값은 0~80,000 첫 구간으로 하여 80,000~160,000 (두번 째 구간),... 이렇게 하여 구간 끝 값을 한 열에 입력한다. 테 이터 분석 창에서 히스토그램을 선택하여 그리면 된다.
한남대학교 비즈니스 통계학과 Page31
통계학원론 Chapter 2. 데이터
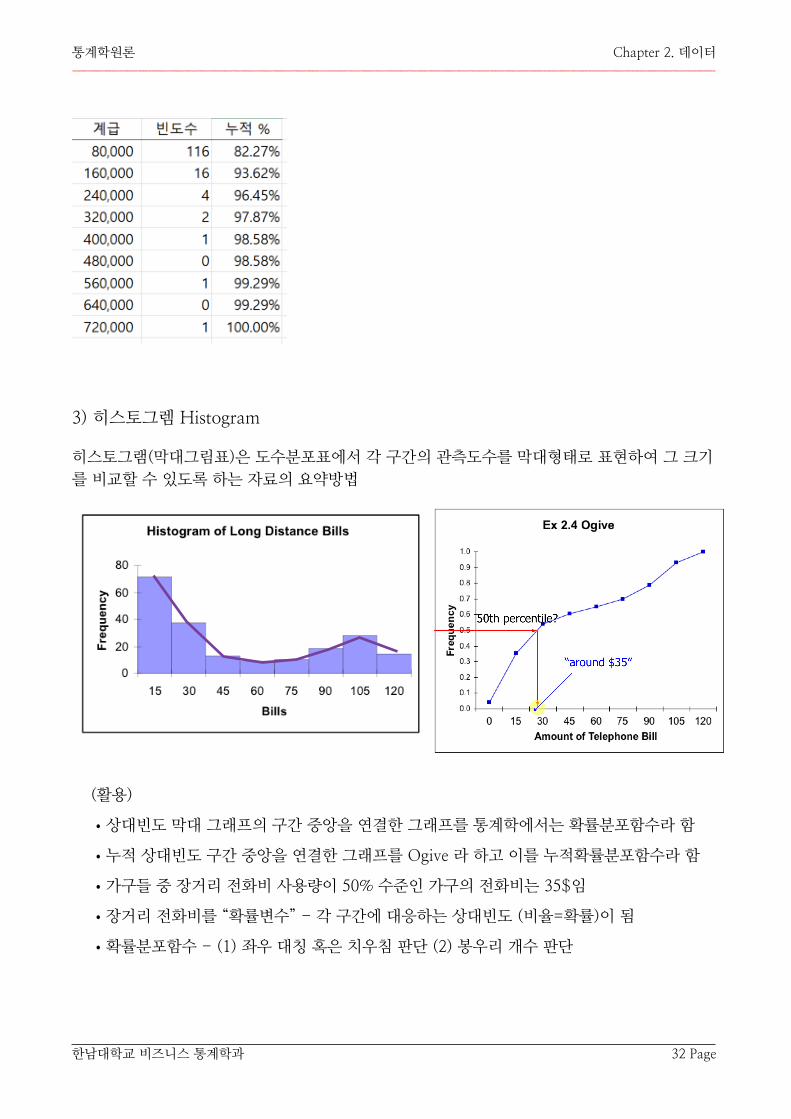
3) 히스토그렘 Histogram
히스토그램(막대그림표)은 도수분포표에서 각 구간의 관측도수를 막대형태로 표현하여 그 크기를 비교할 수 있도록 하는 자료의 요약방법
(활용)
•상대빈도 막대 그래프의 구간 중앙을 연결한 그래프를 통계학에서는 확률분포함수라 함
•누적 상대빈도 구간 중앙을 연결한 그래프를 Ogive 라 하고 이를 누적확률분포함수라 함
•가구들 중 장거리 전화비 사용량이 50% 수준인 가구의 전화비는 35$임
•장거리 전화비를 “확률변수” - 각 구간에 대응하는 상대빈도 (비율=확률)이 됨
•확률분포함수 - (1) 좌우 대칭 혹은 치우침 판단 (2) 봉우리 개수 판단
한남대학교 비즈니스 통계학과 Page32
통계학원론 Chapter 2. 데이터
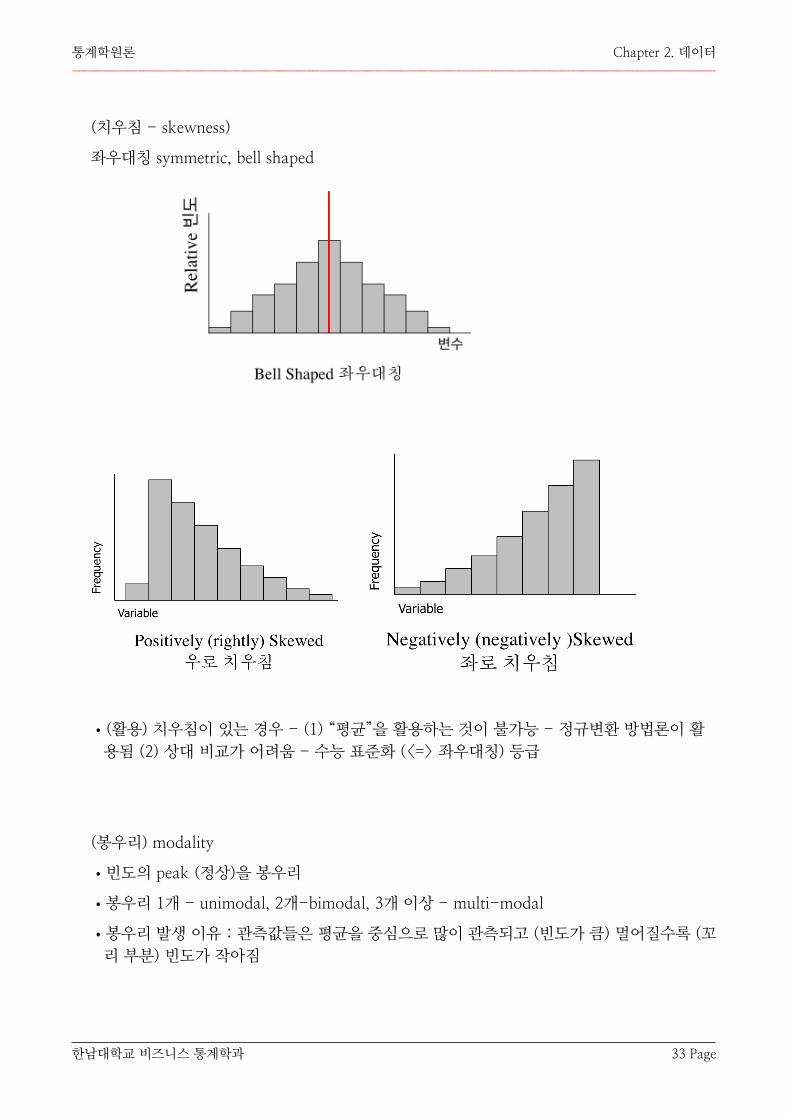
(치우침 - skewness)
좌우대칭 symmetric, bell shaped
•(활용) 치우침이 있는 경우 - (1) “평균”을 활용하는 것이 불가능 - 정규변환 방법론이 활용됨 (2) 상대 비교가 어려움 - 수능 표준화 (<=> 좌우대칭) 등급
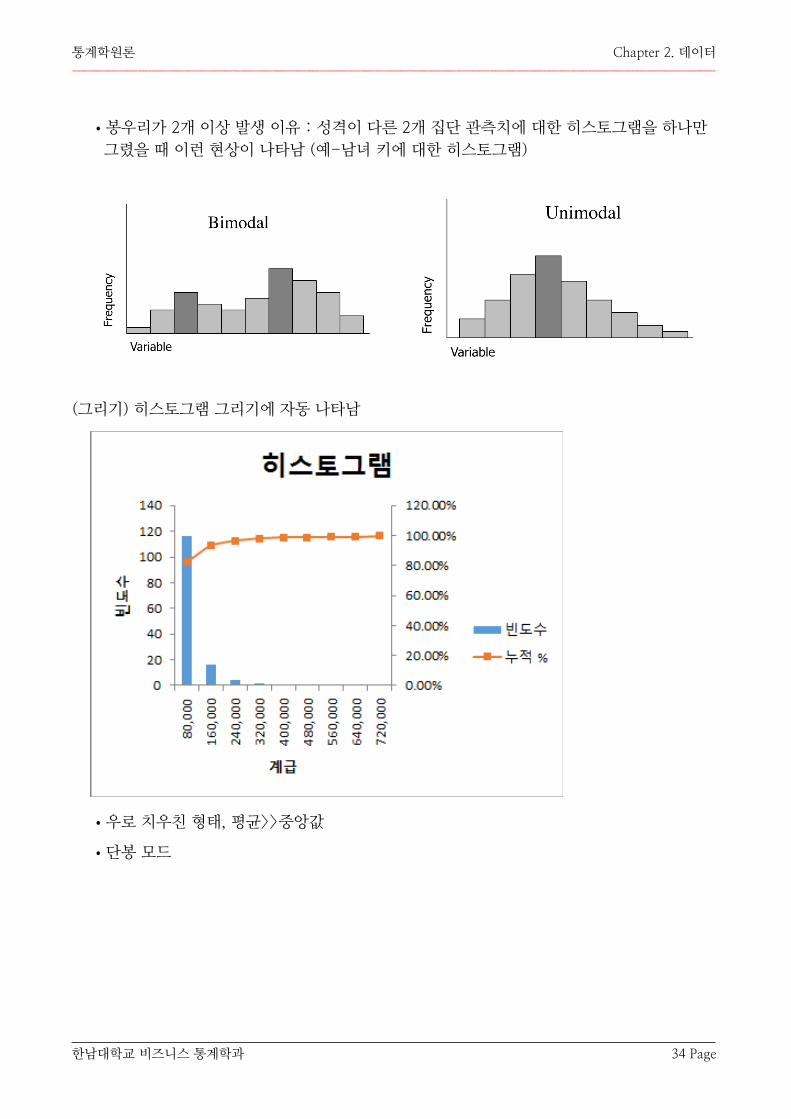
(봉우리) modality
•빈도의 peak (정상)을 봉우리
•봉우리 1개 - unimodal, 2개-bimodal, 3개 이상 - multi-modal
•봉우리 발생 이유 : 관측값들은 평균을 중심으로 많이 관측되고 (빈도가 큼) 멀어질수록 (꼬리 부분) 빈도가 작아짐
한남대학교 비즈니스 통계학과 Page33
통계학원론 Chapter 2. 데이터
•봉우리가 2개 이상 발생 이유 : 성격이 다른 2개 집단 관측치에 대한 히스토그램을 하나만 그렸을 때 이런 현상이 나타남 (예-남녀 키에 대한 히스토그램)
(그리기) 히스토그램 그리기에 자동 나타남
•우로 치우친 형태, 평균>>중앙값
•단봉 모드
한남대학교 비즈니스 통계학과 Page34

통계학원론 Chapter 2. 데이터
3) 줄기-잎 그림 Stem and Leaf
•줄기와 잎 그림(Stem-and-Leaf Plot)은 숫자로 관측된 양적 자료를 정리하는 방법으로 막대그림표와 유사하나 막대그림표에서는 얻을 수 없는 정보인 자료의 최소값, 최대값 그리고 각 구간 내부에 있어서의 자료의 분포에 대한 정확한 정보를 제공해 준다.
•막대그림표로 그렸을 때의 분포를 나타내는데 막대그림표가 각 구간 내 자료의 형태에 대한 정보를 제공하지 못하는 데 비하여 줄기와 잎 그림은 자료의 요약에 따른 정보의 손실이 전혀 없다.
(그리기)
•관측값을 크기 순으로 정렬하고 값을 두 부분(첫 자리와 나머지 자리)으로 나뉜다.
•관측값의 첫 자리 작은 수부터 한 열에 숫자를 나열한다. 이를 줄기(stem)라 한다.
•관측값의 두번째 자리 숫자를 속한 줄기 옆 잎 자리에(leaf) 순차적으로 적는다.
(활용) 세로 형태의 히스토그램과 동일하다
(장점) - Histogram 대비
•막대 안에 숫자가 표현되어 있어 구간 내 값들을 알 수 있음.
(단점)
•줄기의 개수는 관측값의 범위에 의존하므로 적정 줄기 수 (히스토그램과 동일한 8~10개)를 정할 수 없는 문제가 발생
Stem Leaf 0 0000000000111112222223333345555556666666778888999999 1 000001111233333334455555667889999 2 0000111112344666778999 3 001335589 4 1244455895 33566 6 3458 7 022224556789 8 334457889999 9 00112222233344555999 10 001344446699 11 124557889
한남대학교 비즈니스 통계학과 Page35
통계학원론 Chapter 2. 데이터
•줄기 수가 적은 경우 : (1) double stems - 1* (10~14), 1. (15~19)
•(2) five line stems - 1*(10, 11), 1t(12,13), 1f(14,15), 1s(16,17), 1.(18,19)
•줄기 수가 많은 경우 : squeeze stem - 1x+2x, 3x+4x, …
(그리기-엑셀)
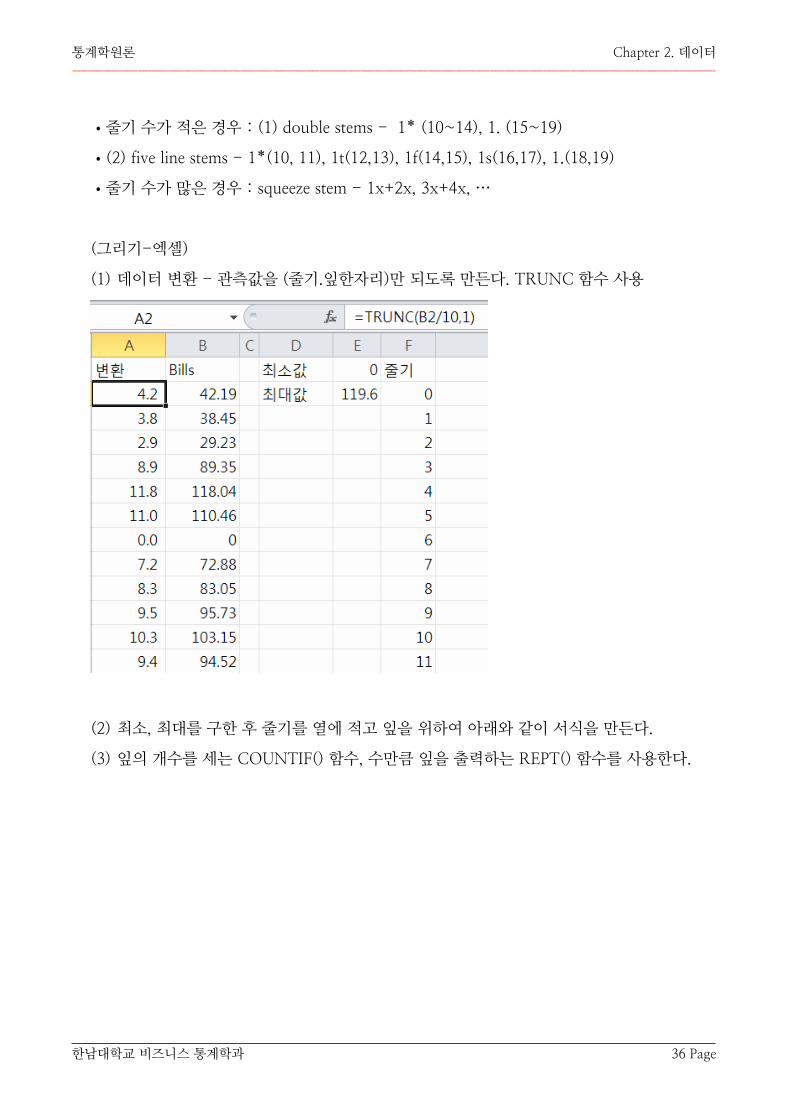
(1) 데이터 변환 - 관측값을 (줄기.잎한자리)만 되도록 만든다. TRUNC 함수 사용
(2) 최소, 최대를 구한 후 줄기를 열에 적고 잎을 위하여 아래와 같이 서식을 만든다.
(3) 잎의 개수를 세는 COUNTIF() 함수, 수만큼 잎을 출력하는 REPT() 함수를 사용한다.
한남대학교 비즈니스 통계학과 Page36

통계학원론 Chapter 2. 데이터
(4) 잎을 한셀에 합친다.
한남대학교 비즈니스 통계학과 Page37

통계학원론 Chapter 2. 데이터
4) 상자-수염 그림 box-whisker plot
(개념)
•5개 기초 순서 통계량 표시 - 최소값, , 중앙값, , 최대값
•왼쪽 수염 끝 단(이상치가 없다면 최소값)부터 박스 왼쪽 시작 선(Q1)까지 데이터의 하위 25%가 속함
•박스에는 데이터의 중앙 범위 50%가 속함
•동일하게 박스 오른쪽 시작 선(Q3)부터 수염 끝 단(이상치가 없다면 최대값)까지 상위 25% 데이터가 속함
이상치 outlier 진단에 사용
• 벗어나면 약한 mild 이상치로 진단
• 벗어나면 강한 severe 이상치로 진단
(활용)
•이상치 진단 가능
•분포의 치우침 판단 - 수염 꼬리와 박스의 길이에 의해 치우침 판단 (위의 예제 그림) 오른쪽 수염 길이가 왼쪽보다 길고 박스도 중앙값을 중심으로 오른쪽 꼬리가 길므로 우로 치우친 형태를 가짐 - 붉은 히스토그램 참고
Q1 Q3
(Q1 −1.5 × IQR, Q3 +1.5 × IQR)
(Q1 − 3× IQR, Q3 + 3× IQR)
한남대학교 비즈니스 통계학과 Page38

통계학원론 Chapter 2. 데이터
[In 엑셀] 상자수염 그리기 add on 도구 없음
① 표의 기초 통계량 표를 이용하여 아래 값 들을 계산하다. Min. Fence는 이상치 진단 하한 펜스이고 Max. 는 상한 펜스이다. 이 펜스를 넘어가면 이상치이다
② COUNTIF 함수를 이용하여 이상치 개수를 계산하면 큰 값 이상치 11개, 작은 값 이상치 없다.
③ 를 선택한 후(CTRL 키 누른 상태) 이차원 세로 막대형 그래프를 선택하여 기본 그래프를 그린다.
④ 총 4개의 박스 스텍이 그려진다. 가장 위의 박스는 위 수염으로, 가장 아래 박스는 아래 수염으로 바꾼다. 가장 위 박스를 선택한 다음 “차트도구”->”디자인”-> “차트요소추가” 아이콘에서 “오차막대”->”기타 오차막대” 옵션을 선택한다.
⑤ “양의 값”, 사용자 지정에서 최종 Max 셀 값을 선택한다.
한남대학교 비즈니스 통계학과 Page39























![CHAPTER 10 - wolfpack.hnu.ac.krwolfpack.hnu.ac.kr/Book/SURVEY/reg_surevy_wolfpack.pdf · Ñ )½ a)º ± & %)º ] í *b ± y CHAPTER 10 회귀 분석 10.1. 회귀 분석 개념 변수간의](https://img.pdfslide.tips/doc/110x75/5e02f277d9e2ea2f204108f8/chapter-10-a-b-y-chapter-10-oee-e-101.jpg)




