Embed Size (px)
Citation preview

UNIVERSITETI I TIRANËS
FAKULTETI I SHKENCAVE TË NATYRËS
DEPARTAMENTI I MATEMATIKËS SË APLIKUAR
PROGRAMI I STUDIMIT: KËRKIME OPERACIONALE
DISERTACION
Për marrjen e gradës Doktor i Shkencave
Tema:
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË
CALL CENTER
PARAQITUR NGA: UDHËHEQËS SHKENCOR:
Ditila Ekmekçiu Prof. Dr. Omer Stringa
Tiranë, 2019

UNIVERSITETI I TIRANËS
FAKULTETI I SHKENCAVE TË NATYRËS
DEPARTAMENTI I MATEMATIKËS SË APLIKUAR
PROGRAMI I STUDIMIT: KËRKIME OPERACIONALE
DISERTACION
Për marrjen e gradës Doktor i Shkencave
Tema:
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË
CALL CENTER
PARAQITUR NGA: UDHËHEQËS SHKENCOR:
Ditila Ekmekçiu Prof. Dr. Omer Stringa
Mbrohet më datë _____/_____/2019 para jurisë
1. _______________________________________ Kryetar
2. _______________________________________ Anëtar (Oponent)
3. _______________________________________ Anëtar (Oponent)
4. _______________________________________ Anëtar
5. _______________________________________ Anëtar

i
ABSTRAKTI ........................................................................................................................... iii
LISTA E FIGURAVE .............................................................................................................. v
LISTA E TABELAVE ............................................................................................................ vi
LISTA E SHKURTIMEVE ................................................................................................... vii
FALËNDERIME ..................................................................................................................... ix
HYRJE ...................................................................................................................................... x
ORGANIZIMI I PUNIMIT .................................................................................................. xiv
KAPITULLI 1: NJË ANALIZË EMPIRIKE E OPERACIONEVE NË CALL CENTER
................................................................................................................................................... 1
1.1. Subjekti i konsideruar ........................................................................................... 1
1.2. Karakteristikat Stokastike ................................................................................... 1
1.3. Braktisja e telefonatave ...................................................................................... 13
1.4. Projektet e konsideruara ne model ................................................................... 15
1.5. Përmbledhje .......................................................................................................... 20
KAPITULLI 2: NJË VËSHTRIM I DISA MODELEVE BASHKËKOHORE
STOKASTIKE TË OPERACIONEVE NË CALL CENTER ........................................... 22
2.1. Planifikimi i fuqisë punëtore .................................................................................. 22
2.2. Operacionet e Call Center-ave ............................................................................... 28
2.3. Optimizimi Stokastik ............................................................................................... 34
2.4. Dizenjimi i Eksperimenteve Statistikore .............................................................. 46
KAPITULLI 3: MODELET NË CALL CENTER-IN E KONSIDERUAR DHE
PËRDORIMI I TYRE NË PARASHIKIM ......................................................................... 53
3.1. Modeli i Skedulimit Afatshkurtër .......................................................................... 53
3.1.1. Formulimi i problemit dhe përqasja ndaj zgjidhjes .................................... 53
3.1.2. Përafrimi TSF dhe SIPP ..................................................................................... 61
3.1.3. Kompromiset ndërmjet Niveleve të Kostos dhe të Shërbimit .................... 68
3.1.4. Ndikimi i Variacionit dhe Vlera e Zgjidhjes Stokastike (VSS) ................. 71
3.1.5. Fleksibiliteti i Organizimit të Stafit ............................................................... 79
3.1.6. Krahasimi me Praktikën e Zakonshme ......................................................... 89
3.1.7. Sistemimet nëpërmjet Simulimit..................................................................... 94
3.2. Modeli i Trajnimit Miks .......................................................................................... 97
3.2.1. Grupimi i pjesshëm në Gjendje të Qëndrueshme ........................................ 98
3.2.2. Trajnimi miks Optimal në Gjendje të Qëndrueshme................................ 108
3.2.3. Trajnimi miks Optimal kur kemi Mbërritje me Kohë Variabël ............. 113
PËRFUNDIME DHE REKOMANDIME ......................................................................... 125

ii
REFERENCAT ................................................................................................................... 132

iii
ABSTRAKTI
Call Center-at janë një realitet shumë i rëndësishëm në ditët e sotme. Kjo, pasi bizneset janë të orientuara
gjithmonë e më shumë drejt shërbimit. Ky sektor ka patur një rritje shumë të madhe dhe me ritme të
shpejta edhe në tregun shqiptar. Sektori i call center-ave renditet i dyti në Shqipëri për numrin e të
punësuarve. Për këtë arsye, nevojitet një studim për të garantuar përmbushjen e kërkesave të klientëve
në lidhje me shërbimin, në mënyrën më efiçente dhe efikase të mundshme. Ky studim trajton temën e
dimensionimit të call center-it në rastin e një shërbimi klienti, në veçanti të operacioneve të një call
center-i me marrëveshje kontraktuale të nivelit të shërbimit (SLAs). E gjitha kjo e parë nga këndvështrimi
i radhëve, mekanizmave të Optimizimit dhe përdorimit të Simulimit. Fokusi i këtij studimi është në
planifikimin e skedulimit pavarësisht nga pasiguria përsa i përket normave të mbërritjeve. Do të shqyrtoj
ndikimin e kësaj pasigurie në zgjedhjen e dimensionimit dhe do të zhvilloj modelet që e përfshijnë qartë
në procesin e parashikimit dhe planifikimit të burimeve njerëzore. Modeli i parë i trajtuar është ai i
planifikimit afatshkurtër, i cili zhvillon plane të detajuara të organizimit të stafit (përcaktmit të numrit të
operatorëve për te operuar në një projekt të caktuar), duke pasur parasysh karakteristikat variabël dhe të
pasigurta të kërkesës. Modeli i dytë i trajtuar është ai i trajnimit miks, i cili kërkon të përcaktojë numrin
më të mirë të operatorëve për t’u trajnuar njëkohësisht në disa projekte. Gjatë studimit përdoren
programimi stokastik, simulimi i ngjarjeve diskrete dhe një heuristikë optimizimi e bazuar në simulim.
Kërkimi nuk përqendrohet në gjetjen e teorive apo metodologjive të reja, por në zbatimin e përqasjeve
ekzistuese për një problem real. Gjatë zhvillimit do të krijohen disa modele të reja dhe unike që
mbështesin literaturën. Teza është e motivuar nga puna e bërë nga autori pranë një kompanie call center-
i që ofron shërbim klienti dhe asistencë teknike. Puna pranë kësaj kompanie më,ka mundësuar të kem
përqasje në një sasi të madhe të të dhënave mbi të cilat kam bazuar analizën time. Është gjetur që
përfshirja e pasigurisë në procesin e parashikimit dhe planifikimit gjeneron zgjidhje me rezultate më të
mira dhe gjithashtu ofron një vizion më të mirë të kompromiseve kryesore të menaxhimit. Modeli
afatshkurtër i planifikimit tregon se mbrojtja kundrejt paqëndrueshmërisë së normës së mbërritjes ul
koston totale të operacioneve duke përmirësuar probabilitetin e arritjes së objetkivit të Niveleve të
Shërbimit. Ajo gjithashtu tregon se rritja e fleksibilitetit të modelit të organizimit të stafit, duke caktuar
edhe disa operatorë me kohë të pjesshme, mund të ulë kostot në mënyrë të konsiderueshme. Gjithashtu
do të zbulohet se rritja e probabilitetit të arritjes së objektivit të nivelit të shërbimit bëhet gjithnjë e më e
shtrenjtë. Modeli i trajnimit miks tregon se shtimi i fleksibilitetit me një sasie të arsyeshme në fuqinë
punëtore mund të ulë shpenzimet në mënyrë të kosniderueshme.
Fjalët kyçe: call center, dimensionim, skedulim, radhë, optimizim, simulim
ABSTRACT
Call Centers are a very important reality nowadays. This is because businesses are increasingly oriented
towards service. This sector has been growing very big and rapidly also in the Albanian market. The call
center sector is ranked second in Albania for the number of employees. For this reason, a study is required
to ensure that customer service requirements are met in the most efficient and effective way possible.
This study addresses the topic of the call center dimensioning and scheduling in the case of a customer
service’s company. All this is from the point of view of the Queuing Theory, the mechanisms of
Optimization and the application of Simulation. The focus of this study is on planning the optimal number
of the workforce, regardless of uncertainty faced in the arrival rates. I examine the impact of this aspect
in the choice of dimensioning/scheduling and develop models that clearly include uncertainty in the
forecasting process. The first model examined is the one of short-term scheduling/ planning, which
develops detailed staffing patterns (number of operators to work in a specific project), given the variable
and unreliable demand characteristics. The second model examined is that of the mixed training, which
objective is to find the best number of operators to train on two or more projects at the same time. During
the study are used simulation-based optimization heuristics, stochastic programming and simulation of
discrete events. The research does not focus on finding new theories or methodologies, but in
implementing existing approaches to a real problem by combining one or more models, which will create
some new and unique models that support the existing literature. The thesis is motivated by the work
done by me near a call center company that provides customer service and technical assistance. As I am
part of this company, I have had the opportunity to approach a large amount of data on which I have

iv
based my analysis. I have found that including uncertainty in the forecasting and planning process
generates solutions with better results. The short-term planning model shows that considering the arrival
rate instability reduces the total cost of operations because it improves the probability of reaching service
level objective. Another aspect analyzed is that increasing the flexibility of the staffing model and
considering not only full-time but also some part-time operators, can significantly reduce costs. The
mixed-training model demonstrates that increasing flexibility in the workforce and training operators to
work simultaneously in more than one project can significantly reduce costs, too.
Keywords: call center, dimensioning, sscheduling, queuing models, optimization, simulation

v
LISTA E FIGURAVE
FIGURA 1 PAMJE E NJË SALLE OPERATIVE NË CALL CENTER....................................................x
FIGURA 2 ARKITEKTURA E TEKNOLOGJISË SË NJË CALL CENTER-I......................................xii FIGURA 3 ARKITEKTURA E RADHËVE TË NJË CALL CENTER-I...............................................xiii
FIGURA 1-1 SHEMBULL I VOLUMEVE DITORE TË TELEFONATAVE..........................................4
FIGURA 1-2 SHEMBULL I DIAGRAMËS SË MBËRRITJEVE MESATARE DITORE.......................5
FIGURA 1-3 RANGU I VOLUMEVE TË TELEFONATAVE.................................................................6
FIGURA 1-4 GRAFIKËT E AUTOKORRELACIONIT DHE KORRELACIONIT TË PJESSHËM.......9
FIGURA 1-5 MBETJET SIPAS DITËVE TË JAVËS…………………………………………………...9
FIGURA 1-6 VARIACIONI/PERIUDHË I VOLUMEVE TË TELEFONATAVE................................11
FIGURA 1-7 GRAFIKU NORMAL I RAPORTIT TË MBËRRITJEVE................................................12
FIGURA 1-8 ALGORITMI I SIMULIMIT TË GJENERIMIT TË TELEFONATAVE..........................13
FIGURA 1-9 NORMA E BRAKTISJEVE – PROJEKT STABËL..........................................................14
FIGURA 1- 10 NORMA E BRAKTISJEVE – PROJEKT JO STABËL.................................................15
FIGURA 1-11 MBËRRITJET DITORE TË PROJEKTIT A...................................................................16
FIGURA 1-12 MBËRRITJET BRENDA DITËS PËR PROJEKTIN A..................................................17
FIGURA 1-13 MBËRRITJET DITORE TË PROJEKTIT B...................................................................17
FIGURA 1-14 MBËRRITJET MES. BRENDA DITËS PËR PROJEKTIN B.........................................18
FIGURA 1-15 MBËRRITJET DITORE TË PROJEKTIT C....................................................................19
FIGURA 1-16 MBËRRITJET MES. BRENDA DITËS PËR PROJEKTIN C.........................................19
FIGURA 2-1 KËRKESAT E KAMPIONIMIT TË OPERATORËVE....................................................24
FIGURA 2-2 PËRQASJA INTERAKTIVE E SKEDULIMIT................................................................26 FIGURA 2-3 ZGJIDHJET RELATIVE TË NJË PROBLEMI NË KUSHTE PASIGURIE.....................40
FIGURA 2.4 PROÇEDURA E LIDHJES STOKASTIKE.......................................................................43
FIGURA 2-5 PROÇEDURA E PËRAFRIMIT MESATAR TË KAMPIONIMIT (SAA).......................43
FIGURA 2-6 SHEMBULL I DIZAJNEVE UNIFORME 2 DIMENSIONALE......................................51
FIGURA 3-1 ALGORITMI I GJENERIMIT TË SIMULUAR TË TELEFONATAVE..........................56
FIGURA 3-2 KOHËT E ZGJIDHJES MESATARE................................................................................58
FIGURA 3-3 KOHËT E ZGJIDHJES INDIVIDUALE..........................................................................59
FIGURA 3-4 KONVERGJENCA E ALGORITMIT TË FORMËS L....................................................60
FIGURA 3-5 KURBA TSF PËR NJË NORMË FIKSE TË MBËRRITJEVE..........................................62
FIGURA 3-6 PËRAFRIMI LINEAR ME PJESË I TSF-SË.....................................................................63
FIGURA 3-7 NORMAT E MBËRRITJES PËR PËRAFRIMIN SIPP.....................................................64
FIGURA 3-8 PËRQSSJA E PËRAFRIMIT TSF E BAZUAR NË SKENARË........................................65
FIGURA 3-9 GJENERIMI I KUFIZIMEVE TË ORGANIZIMIT MINIMAL TË STAFIT...................65
FIGURA 3-10 PËRQASJA E VALIDIMIT TË TSF-SË..........................................................................66 FIGURA 3-11 BESIMI DHE NIVELET E SHËRBIMIT SI FUNKSION I NORMËS SË GJOBËS.......70
FIGURA 3-12 BESIMI DHE NIVELI I PRITUR I SHËRBIMIT............................................................71
FIGURA 3-13 KOSTOJA RELATIVE E ZGJIDHJEVE OPTIMALE....................................................72
FIGURA 3-14 VLERËSIMI I PIKAVE TË KUFIJVE............................................................................73
FIGURA 3-15 HENDEKU I OPTIMUMIT.............................................................................................74
FIGURA 3-16 KRAHASIMI NDËRMJET 2 SKEDULIMEVE..............................................................75
FIGURA 3-17 INTERVALI I BESIMIT PËR TELEFONATAT PËR PERIUDHË................................75
FIGURA 3-18 VLERA MESATARE VS ORGANIZIMI STOKASTIK I STAFIT...............................76
FIGURA 3-19 KOSTOT RELATIVE TË FLEKSIBILITETI TË ORGANIZIMIT TË STAFIT...........82
FIGURA 3-20 IMPKTI I OPERATORËVE ME KOHË TË PJESSHME NË SKEDULIMIN DITOR –
PROJEKTI A...........................................................................................................................................84
FIGURA 3-21 IMPKTI I OPERATORËVE ME KOHË TË PJESSHME NË SKEDULIMIN JAVOR –
PROJEKTI A............................................................................................................................................85
FIGURA 3-22 IMPKTI I OPERATORËVE ME KOHË TË PJESSHME NË SKEDULIMIN DITOR –
PROJEKTI B..................................................................................................................... .......................87
FIGURA 3-23 IMPKTI I OPERATORËVE ME KOHË TË PJESSHME NË SKEDULIMIN JAVOR –
PROJEKTI B................................................................................................................. ...........................87
FIGURA 3-24 VLERA E SHTUAR E STAFIT ME KOHË TË PJESSHME..........................................89

vi
FIGURA 3-25 TEPRICA E STAFIT NË PROBLEMIN E MBULIMIT TË GRUPIMIT - PROJEKTI A
– BS A......................................................................................................................................................91
FIGURA 3-26 TEPRICA E STAFIT NË PROBLEMIN E MBULIMIT TË GRUPIMIT - PROJEKTI A
– BS C.......................................................................................................................................................92
FIGURA 3-27 ALGORITMI I PËRGJITHSHËM I KËRKIMIT VNS....................................................95
FIGURA 3-28 MODELI I GRUPIMIT....................................................................................................98
FIGURA 3-29 SIPËRFAQJA E TSF-SË NË MODELIN E GRUPIMIT...............................................100
FIGURA 3-30 DIAGRAMA E KONTURIT TË TSF-SË SË GRUPUAR.............................................101
FIGURA 3-31 KONTURI I TFS-SË 80%..............................................................................................101
FIGURA 3-32 IMPAKTI MARGJINAL NË NIVELET E SHËRBIMIT..............................................102
FIGURA 3-33 IMPAKTI I GRUPIMIT ME NIVELE FIKSE TË ORGANIZIMIT TË STAFIT..........102
FIGURA 3-34 NDIKIMI I GRUPIMIT ME MBËRRITJE TË QËNDRUESHME POR TË
PASIGURTA.........................................................................................................................................107
FIGURA 3-35 DEVIJIMI STANDART I TSF-SË ME GRUPIM VARIABËL...................................108
FIGURA 3-36 ALGORITMI I PËRGJITHSHËEM I KËRKIMIT VNS...............................................110
FIGURA 3-37: STRUKTURA E FQINJËSISË E BAZUAR NË PROJEKT........................................115
FIGURA 3-38: HEURISTIKA E KËRKIMIT FQINJ............................................................................116
FIGURA 3-39 ORGANIZIMI OPTIMAL I STAFIT PERIUDHË PAS PERIUDHE...........................118
FIGURA 3-40 KËRKESAT PËR TRAJNIM MIKS PERIUDHË PAS PERIUDHE.............................119
FIGURA 3-41 PLANI I ORGANIZIMITT TË GRUPUAR TË STAFIT..............................................121
FIGURA 3-42 PLANI I ORGANIZIMIT TË OPERATORËVE TË TRAJNUAR MIKS....................122
FIGURA 4 LLOGARITJET E PUSHIMEVE TË NËNKUPTUARA...................................................123
FIGURA 5 PËRQASJA E GRUPIMIT TË TRE PROJEKTEVE..........................................................130
LISTA E TABELAVE
TABELA 1-1 VARIACIONI I VOLUMEVE JAVORE TË TELEFONATAVE.....................................3
TABELA 1-2 VOLUMI I TELEFONATAVE PARASHIKIMI VS REALJA.........................................5
TABELA 1-3 REZULTATET E MODELIT TË REGRESIONIT.............................................................8
TABELA 1 - 4: PËRMBLEDHJA E PROJEKTEVE MODEL...............................................................20
TABELA 2-1 DIZAJNI EKSPERIMENTAL FAKTORIAL I PLOTË ME 3 FAKTORË.......................47
TABELA 2-2 PËRKUFIZIMET PËR ZGJIDHJE FAKTORIALE ME PJESË.......................................48
TABELA 2-3 DIZAJNI EKSPERIMENTAL FAKTORIAL I PJESSHËM ME 3 FAKTORË................48
TABELA 2-4 PËRCAKTIMI I MARRËDHËNIEVE PËR DIZAJNET E ZAKONSHME ME PJESË..49
TABELA 3-1 VALIDIMI I TSF-SË – PROJEKTI A..............................................................................67
TABELA 3-2 VALIDIMI I TSF-SË – PROJEKTI C DHE PROJEKTI B................................................67
TABELA 3-3 KOMPOMISET E KOSTOT DHE NIVELIT TË SHËRBIMIT – PROJEKTI A..............68
TABELA 3-4 KOMPOMISET E KOSTOT DHE NIVELIT TË SHËRBIMIT – PROJEKTI B..............69
TABELA 3-5 KOMPOMISET E KOSTOT DHE NIVELIT TË SHËRBIMIT – PROJEKTI C.............69
TABELA 3-6 GABIMI I ZGJIDHJES DHE VSS...................................................................................72
TABELA 3-7 IMPAKTI I NDRYSHUESHMËRISË TË DIZAJNIT TE EKSPERIMENTIT................77
TABELA 3-8 IMPAKTI I VARIACIONIT I REZULTATEVE EKSPERIMENTALE.........................78
TABELA 3-9 IMPAKTI I VARIACIONIT NË REZULTATIN E PRITUR – EFEKTET KRYESORE.79
TABELA 3-10 MODELET E SKEDULIMIT..........................................................................................81
TABELA 3-11 IMPAKTI I SKEDULIMIT FLEKSIBËL – PROJEKTI A..............................................83
TABELA 3-12 IMPAKTI I SKEDULIMIT FLEKSIBËL – PROJEKTI B..............................................86
TABELA 3-13 IMPAKTI I SKEDULIMIT FLEKSIBËL – PROJEKTI C..............................................88
TABELA 3-14 KRAHASIMI I SKEDULIMEVE STOKASTIKE DHE ERLANG C LOKALE...........92
TABELA 3-15 KRAHASIMI I SKEDULIMEVE STOKASTIKE DHE ERLANG C GLOBALE.........94
TABELA 3-16 SISTEMIMI I BAZUAR NË SIMULIM – PROJEKTI A................................................96
TABELA 3-17 SISTEMIMI I BAZUAR NË SIMULIM – PROJEKTI B................................................96
TABELA 3-18 SISTEMIMI I BAZUAR NË SIMULIM – PROJEKTI C................................................96
TABELA 3-19 NDIKIMI I GRUPIMIT ME NIVELE FIKSE TË ORGANIZIMIT TË STAFIT NË TSF-
NË E PËRGJITHSHME........................................................................................................................103

vii
TABELA 3-20 NDIKIMI I GRUPIMIT ME NIVELE FIKSE TË ORGANIZIMIT TË STAFIT NË TSF-
NË E PROJEKTIT ME VOLUME TË ULËTA....................................................................................104
TABELA 3-21 NDIKIMI I GRUPIMIT ME NIVELE FIKSE TË ORGANIZIMIT TË STAFIT NË TSF-
NË E PROJEKTIT ME VOLUME TË LARTA....................................................................................104
TABELA 3-22 NDIKIMI I GRUPIMIT ME NIVELE FIKSE TË ORGANIZIMIT TË STAFIT NË
BRAKTISJEN E PROJEKTIT ME VOLUME TË ULËTA..................................................................105
TABELA 3-23 NDIKIMI I GRUPIMIT ME NIVELE FIKSE TË ORGANIZIMIT TË STAFIT NË
BRAKTISJEN E PROJEKTIT ME VOLUME TË LARTA.................................................................105
TABELA 3-24 TRAJNIMI MIKS ME MBËRRITJE TË NJOHURA NË GJENDJE TË
QËNDRUESHME – DIZAJN EKSPERIMENTAL..............................................................................111
TABELA 3-25 TRAJNIMI MIKS ME MBËRRITJE TË NJOHURA NË GJENDJE TË
QËNDRUESHME – REZULTATET EKSPERIMENTALE................................................................111
TABELA 3-26 TRAJNIMI MIKS ME MBËRRITJE TË PASIGURTA NË GJENDJE TË
QËNDRUESHME – REZULTATET EKSPERIMENTALE................................................................112
TABELA 3-27 KRAHASIMI I EKSPERIMENTEVE ME MBËRRITJE TË NJOHURA DHE TË
PASIGURTA.........................................................................................................................................113
TABELA 3-28 REZULTATET SIMOPT PROJEKTET A DHE B......................................................119
TABELA 3-29 REZULTATET OPTSIM PROJEKTET A DHE B......................................................120
TABELA 3-30 OPTIMIZIMI I GRUPIMIT – PROJEKTET A DHE B.................................................121
TABELA 3-31 OPTIMIZIMI I GRUPIMIT – PORJEKTET A DHE C.................................................122
TABELA 3-32 OPTIMIZIMI I GRUPIMIT – PROJEKTET B DHE C.................................................123
TABELA 3-33 REZULTATET E IMPAKTIT TË DIFERENCIMIT TË PAGAVE NË RASTIN E
TRAJNIMIT MIKS................................................................................................................................123
LISTA E SHKURTIMEVE
CC Call Center
IVR Interactive Voice Response
FIFO First In First Out
SLA Service Level Agreement
TSF Telephone Service Factor
AHT Average Handle Time
AR Abandonment Rate
ASA Average Speed of Answer
FCR (First Call Resolution)
WFM Workforce Management
ACD Automatic Call Distributor
DTMC Discrete Time Markov Chains
QED Quality Efficiency Driven
PASTA Poisson Arrivals See Time Averages

viii
SAA Simple Stationary Approximation
PSA Pointwise Stationary Approximation
SIPP Stationary Independent Period by Period
MAX Maximum
MIN Minimum
SD Stochastic Decomposition
LP Linear Programming
EVPI Expected Value of Perfect Information
VSS Value of the Stochastic Solution
SBO Simulation Based Optimization
DES Discrete Event Simulation
VNS Variable Neighborhood Search
DOE Design Of Experiments
UD Uniform Design
LH Latin Hypercube
MIP Mixed-Integer Programming
SIM Simulation
OPT Optimization

ix
FALËNDERIME
Ky punim disertacioni u realizua pas një pune të gjatë dhe të mundimshme që do të kishte qënë
e pamundur pa ndihmën e disa figurave kyçe, të cilave u jam shumë mirënjohëse dhe dua
t’i falenderoj me zemër.
Së pari, falenderoj Prof. Dr. Omer Stringën, i cili më udhëhoqi në çdo hap të këtij punimi me
shumë durim, profesionalizëm dhe me këshilla te vyera e të pakursyera. Pa këtë mbështjetje
nuk do të kisha arritur t’i jepja formën përfundimtare punimit dhe të mbyllja këtë cikël.
Së dyti, falenderoj të gjithë departamentin e Matematikës së Aplikuar, me në krye Prof. Dr.
Fatmir Hoxhën, i cili për çdo nevojë ka qënë disponibël dhe i mirëkuptueshëm dhe më ka
dhënë gjithmonë sugjerimet e duhura. Një falenderim i veçantë edhe për Dr. Markela
Muçën, që më ka ndihmuar shumë në këtë rrugëtim.
Mirënjohje pa fund për familjen time që më ka duruar dhe mbështur në këto vite të lodhshme,
faleminderit bashkëshortit dhe dy fëmijëve të mi të vegjël që kanë sakrifikuar bashkë me
mua dhe më janë gjendur pranë. Faleminderit Marino, Daniele dhe Luna për mbështetjen
pa kushte, për kohën që më keni kushtuar dhe mirëkuptimin që keni treguar.
Dhe në fund, por jo më pak e rëndësishme, falenderimet nga zemra shkojnë për prindërit e mi,
te cilët kanë qëne të parët që kanë besuar tek mua dhe më kanë shtyrë gjithmonë të jap më
të mirën e vetes. Ky disertacion është për ju!
Faleminderit të gjithëve!

x
HYRJE
Në kontekstin ekonomik dhe organizativ global aktual bizneset duhet të përforcojnë dhe
diversifikojnë kanalet e tyre të kontaktit me klientët për të rritur nivelin e besueshmerisë dhe
prezencës në treg duke krijuar në këtë mënyre një avantazh kompetitiv. Rritja e këtyre kanaleve
perceptohet nga klienti si një mundësi për të përfituar një shërbim të personalizuar dhe nga
kompania si nje instrument për të mbledhur informacione për të levizur me të njëjtin hap me
trendin e tregut dhe nevojat e klientit. Që në fillim të viteve ’80 kompanitë e mëdha ia besuan
shërbimin e klientit kompanive të specializuara për këtë, kompanive Call Center. Sektori i
Contact Center, i cili përfshin atë të Customer Relationship Management (shëbim klienti) dhe
Accounts Receivable Management (mbledhja e kredive) vazhdon të ketë një pozicion të
rëndësishëm në treg pasi mbetet akoma nje fushë që nuk arrin te zëvëndësohet nga automatizimi
informatik/teknologjik.
Në mesin e viteve 2000 filloi shfaqja e Call Center-ave te parë në Shqipëri dhe që atehere ato
vazhdojnë të jenë një realitet shumë i rëndësishëm në ekonominë tonë. Gjatë viteve të fundit në
Shqipëri numri i call center-ave ka shkuar në mbi 300, duke numëruar më shumë se 20.000 të
punësuar (Mapo Online, 2015). Në klasifikimin e 10 punëdhënësve më të mëdhenj për vitin
2016 janë tre call center-a, përkatësisht në vendin e tretë, të gjashtë dhe të tetë (Monitor 2018).
Një Call Center përbëhet nga një sërë burimesh (në përgjithësi operatorët, kompjuterat dhe
pajisje të tjera telekomunikimi), të cilat bëjnë të mundur ofrimin e shërbimeve përmes telefonit.
Mjedisi i punës i një call center-i tipik (Figura 1) mund të imagjinohet si një hapësirë shumë e
madhe me shumë vende pune të hapura, ku njerëzit me kufje (operatorët) ulen përpara
terminaleve kompjuterike, duke u ofruar shërbime / produkte klientëve "të padukshëm".
Figura 1 Pamje e një salle operative në call center
Shumica e call center-ave gjithashtu kanë njësi Zëri të Përgjigjeve Interaktive (IVR), të cilat
janë makineri përgjigjesh automatike që përfshijnë mundësinë e ndërveprimit (pra klienti mund
të marrë përgjigjen e kërkuar automatikishit nga IVR ose të adresohet në mënyrë të saktë për
të patur një përgjigje ndaj kërkesës që ka). Një tendencë e ditëve të sotme është zgjerimi i call

xi
center-ave në contact center-a, të cilat janë call center-a ku shërbimi tradicional telefonik është
përforcuar nga disa kanale shtesë të kontaktit me klientët, zakonisht IVR, e-mail, faks, internet
dhe / ose chat e së fundmi edhe nga mediat sociale. Kjo sepse në shekullin XXI dixhitalizimi
është një realitet që ka marrë përmasa madhore dhe klientët janë të prirur gjithnjë e më shumë
ndaj metodave alternative të komunikimit dhe telefonia sa vjen e zvogëlohet duke u
zëvendësuar nga këto kanale. Dixhitalizimi ka sjellë një ndryshim në mënyrën se si markat
lidhen dhe nderveprojnë me klientët e tyre. Sipas një grafiku të krijuar nga Shërbimet Analitike
të Shqyrtimit të Biznesit të Harvardit në bashkëpunim me Teleperformance, mediat sociale
vazhdojnë të dominojnë ndërveprimet: nga 86% e tregtarëve të lidhur me klientët që e përdorin
atë, 72% arritën audiencën e tyre nëpërmjet email-marketingut, 65% u lidhën me klientët
përmes videove online, 58% përdorën webinar-ët ose eventet online, ndërsa 44% përdorën chat.
Teknologjia ka krijuar me të vërtetë një rrugëtim të ri në përvojën e konsumatorit që është
shtruar me lehtësi me anë të një klikimi të vetëm; Gjithsesi, e gjithë kjo vjen me një sfidë - rreth
60% e tregtarëve të anketuar gjithashtu vunë në dukje se është e vështirë të riprodhosh përvojën
“person me person” me konsumatorët duke përdorur teknologjitë dixhitale.
Automatizimi me të vërtetë mund të sjellë shumë përfitime - efiçencë, saktësi dhe konsistencë,
por njerëzit, nga ana tjetër, janë të vetmit që janë në gjendje të sjellin lidhje të mirëfillta me
konsumatorin. Ndërveprimet e mëdha mund të fillojnë dhe të krijojnë marrëdhënie me klientët
e rinj, ndërkohë që një lidhje personale mund të shpërblejë me një lidhje afatgjatë. Vlera e
lidhjes njerëzore, emocioneve, ndjeshmërisë dhe personalizimit tani janë më të vlefshme se
kurrë, veçanërisht në një botë ku dixhitalizimi vazhdon të paraqesë avantazhet e veta
(Teleperformance 2018). Kjo do të thotë që, në formen e call center-it apo contact center-it,
shërbimet e klientëve do të jenë të pranishme për shumë kohë dhe nevojitet gjithnjë e më shumë
garantimi i përmbushjes së kërkesave të klientëve në lidhje me shërbimin, në mënyrën më
efiçente dhe efikase të mundshme
Kompanitë më të rëndësishme e kanë riorganizuar komunikimin e tyre me klientët përmes një
ose më shumë call center-ave, të cilat mund të menaxhohen brenda ose jashtë kompanisë nga
një i tretë. Tendenca ndaj contact center-ave është rritur edhe nga potenciali i njohur për
përfitime efiçente (kërkesat për shërbimet e e-mail dhe faks mund të "ruhen" për përgjigje të
mëvonshme dhe kur trafiku i shërbimeve telefonike është më i ulët se parashikimi, operatorët
mund të kalojnë në kanalet e tjera).
Call Center-at mund të kategorizohen në shumë dimensione të ndryshme: sipas funksionalitetit
(asistencë teknike, urgjencat, telemarketing, teleselling, sondazh i tregut, ofrues
informacionesh etj.), sipas madhësisë (nga disa në disa mijëra operatorë), gjeografikisht (një
ose disa vendndodhje, që mund të jenë brenda shtetit ku ndodhet kompania për të cilën ofrohet
shërbimi, i quajtur ndryshe domestic, në shtetitn fqinj, ndryshe nearshore, ose në një shtet
gjeografikisht larg nga kompania për të cilën shërbehet, ndryshe offshore), sipas kualifikimit të
operatorëve (me aftësi të vogla ose të mirëtrajnuar, me një kualifikim ose me disa etj.), sipas
industrisë ku operojnë (telekomunikacioni, financimi, blerje online, ofruesit e TV dhe internetit,
agjensi udhëtimi, marketingu, etj.), sipas linjës së biznesit (inbound, telefonata hyrëse, pra ështe
klienti ai që kontakton për te patur një shërbim, outbound, telefonata dalëse, pra janë operatorët
ata që kontaktojnë klientët për t’u ofruar një shërbim backoffice, që përfshin punën me email-
e, chat, etj), dhe kështu me radhë (Ekmekçiu 2015).
Çdo call center është i pajisur me kompjutera dhe pajisje të tjera telekomunikimi të avancuara.
Një telefonatë tipike inbound lidhet nga rrjeti telefonik publik i shërbimit (PSTN) me “switch-
in” e call center-it, shkëmbimi privat i sektorit (PBX), mbi një numër të caktuar linjash të
huazuara ose të blera. Telefonuesit mund të lidhen fillimisht me një IVR me anë të të cilit

xii
telefonuesi mund të përdorë tastierën për të zgjedhur opsionin e interesuar ose për t’i mundësuar
disa inpute sistemit të call center-it. Kur telefonuesi kërkon të flasë me një operator, telefonata
menaxhohet nga një Shpërndarës Automatik i Telefonatave (ACD). ACD-ja drejton telefonatat
në brendësi të call center-it dhe është përgjegjës i monitorimit të statusit të operatorit, për
mbledhjen e të dhënave, për menaxhimin e telefonatave në radhë për përgjigje, dhe për të marrë
vendime potencialisht komplekse të “routing” (drejtimi i telefonatave). Për shembull, në call
center-at ku zbatohet “routing” i bazuar në kompetencat e operatorëve, një proces kompleks
vendimmarrjeje përdoret për të përputhur telefonuesit me operatorët duke u bazuar në kritere të
shumëfishta që kanë lidhje si me telefonuesin ashtu edhe me operatorin. Në call center-at që
kanë të bëjnë me telefonata outbound përdoret një formues numri parashikues për të paraprirë
formimin e numrit. Përveç sistemit të telefonisë një call center është i pajisur edhe me terminalë
kompjuterikë të lidhura me një ose më shumë aplikacione ndërmarrjeje: këto të fundit janë
zakonisht të klasifikuara nën kategorinë e përgjithshme të Menaxhimit të Marrëdhënieve me
Klientët (CRM).
Një arkitekturë e përgjithshme tregohet në Figurën 2:
Figura 2 Arkitektura e Teknologjisë së një call center-i
Duke parë karakeristikat e lart përmendura të Call Center-ave, në kushte normale pune, kur
asnjë operator nuk është i dispunueshëm per t’ju përgjigjur telefonatës hyrëse, themi që krijohen
Radhë. Nga këndvështrimi i radhëve, një model i përgjithshëm i një call center-i është modeli
Erlang A, që tregohet në Figurën 3:

xiii
Figura 3 Arkitektura e Radhëve të një Call center-i
Në modelin Erlang A telefonatat mbërrijnë me një normë λ, me kohë mbërritjeje të pavarura
dhe me shpërndarje eksponenciale. Në qoftë se asnjë operator nuk është i lirë telefonatat
vendosen në një radhë të pafundme për të pritur shërbimin sipas rregullit FIFO. Telefonatat
kanë një kohë shërbimi eksponenciale me mesatare 1/µ. Çdo telefonatë ka të lidhur me të edhe
një kohë durimi: në qoftë se telefonuesit detyrohen të presin më shumë se koha e tyre e durimit,
ata e braktisin radhën (mbyllin telefonatën). Koha e durimit është e shpërndarë në mënyrë
eksponenciale me një kohë mesatare të braktisjes 1/Ɵ dhe norma individuale korrisponduese e
braktisjes është Ɵ (Mndelbaum and Zeltyn 2004).
Erlang A është më i komplikuar dhe më pak i aplikuar se modeli Erlang C (modeli Erlang C
është identik me radhën M/M/n. Modeli Erlang C përdoret gjërësisht në aplikimet e call center-
ave). Megjithatë, siç do të tregohet, braktisja është një kompnent shumë i rëndësishëm në këtë
ambjent dhe përdorimi i modelit Erlang A është më i sigurtë.
Synimi i këtij punimi është të tregojë se si metoda analitike, siç është Teoria e Radhëve, sikurse
edhe metoda eksperimentale, siç është Simulimi, mund të përdoren për dimensionimin,
skedulimin, planifikimin e personelit në këto struktura. Këto metoda mundësojnë ruajtjen e
cilësisë së shërbimit (efektivitet) duke minimizuar kostot direkte (efiçencë), pra optimizimi i
numrin të nevojshëm të personelit duke mbajtur nivelet e kërkuara të shërbimit.
Punimi do të përqëndrohet tek klientët që ofrojnë shërbim klienti (fushata inbound, pra me
telefonata hyrëse) dhe jo tek klientët ku bëhen shtije me anë të telefonatave (fushata Outbound,
pra me telefonata dalëse).
Në fillim të punimit do të jepet një përshkrim i Operacioneve të call center-ave nga pikëpamja
empirike. Më pas kjo tezë do te përqëndrohet në analizën e modeleve bashkëkohore stokastike.
Në kapitullin e fundit do të studiohen dy modelet e zgjedhura dhe do të shohim si përdoren ato
në procesin e parashikimit, duke u përqendruar në planifikimin afatshkurtër:
• Modeli afatshkurtër i skedulimit: Modeli afatshkurtër trajton çështjen e skedulimit
afatshkurtër (javor) të operatorëve. Ky problem shtrohet në kontekstin e operacioneve
të call center-it, duke ndërtuar një model që gjeneron një programim turnesh, që në
mënyrë eksplicite merr në konsideratë kohën e mbërritjes si një madhësi të rastit. Kjo
analizë tregon që njohja në mënyrë eksplicite e pasigurësisë çon në zgjidhje më të mira
të verifikueshme; që janë zgjidhje me një kosto më të ulët të operacioneve.

xiv
• Modeli i trajnimit miks: Ky model analizon impaktin e trajnimit miks (trajnimi i një
ose më shumë operatorëve për të pnunuar njëkohësisht në dy ose më shumë projekte)
në operacionet e call center-ave me mbërritje rastësore dhe tenton te gjejë nivelin
optimal të trajnimit miks të projektit. Analiza tregon që në përgjithesi një nivel i ulët i
kësaj forme të trajnimit jep një perfitim të konsiderueshëm. Në këtë model do të
zhvillohet nje algoritëm heuristik për të gjetur nivele thuajse optimale të trajnimeve të
ndërthurur duke na u dhënë kërkesa jo stacionare dhe e pasigurtë.
ORGANIZIMI I PUNIMIT
Kapitulli 1: Një Analizë Empirike e Operacioneve në Call Center
Në këtë kapitull do të diskutohet më shumë në lidhje me kontekstin e industrisë së call center-
ave. Çfarë janë ato dhe çfarë ofrojnë.Gjithashtu motivimi i cili më ka shtyrë drejt këtii punimi
Do të prezantohet një analizë empirike e të dhënave. Qëllimi i këtij rishikimi është për të
theksuar disa nga sfidat kryesore operacionale të lidhura me këtë lloj industrie, për të siguruar
të dhëna përfaqësuese për analiza të mëtejshme dhe për të motivuar një bashkësi me probleme
optimizimi. Gjithashtu bëhet një prezantim i projekteve që janë marrë në konsideratë për
punimin duke parë cilësitë e secilit prejt tyre.
Kapitulli 2: Një Vështrim i Disa Modeleve Bashkëkohore Stokastike të Operacioneve në
Call Center
Në këtë kapitull do të rishikohen dhe përmblidhen disa nga modelet bashkëkohore Stokastike
të Operacioneve në Call Center-a, të cilët do të jenë baza për strukturimin e modeleve të
trajtuara për rastin tonë. Do të shikohen modelet e lidhura me planifikimin e fuqisë punëtore,
optimizimit stokastik, eksperimenteve statistikore dhe si adresohen ato në operacionet e call
center-ave. Gjithashtu, bashkë me modelet do të rishikohet edhe literatura përkatëse ku ato janë
bazuar.
Kapitulli 3: Modelet në Call Center-in e Konsideruar dhe Përdorimi i Tyre në Parashikim
Në këtë kapitull do të shikohen dy modelet bazë të këtij punimi:
• Modeli i Skedulimit Afatshkurtër, ku shqyrtohet çështja e skedulimit afatshkurtër të
turneve për call center-at, për të cilët është e rëndësishme të përmbushin një
marrëveshje për nivelet e shërbimit gjatë një periudhe të caktuar. Analiza përqendrohet
ekskluzivisht në një SLA të bazuar në TSF (Telephone Service Factor, përqindja e
telefonatave të cilat marrin përgjigje Brenda 20 sekondave), por modeli mund të
përshtatet lehtësisht për të mbështetur forma të tjera të SLA-ve; të tilla si shkalla e
braktisjes ose shpejtësia mesatare për t'u përgjigjur. Modeli hartohet duke konsideruar
normat e mbëritjes si madhësi të rastit dhe formulohet si një programim stokastik miks
me numra të plotë me dy faza.
• Modeli i Trajnimit Miks, ku shqyrtohen më tej operacionet e një call center-i. Në këtë
model do të shqyrtohet mundësia e trajnimit të një nëngrupimi operatorësh në mënyrë
që ata të mund të operojnë njëkohësisht për dy projekte të ndara. Ky model kërkon të
përcaktojë përfitimin nga grupimi i pjesshëm dhe të karakterizojë kushtet nën të cilat
grupimi është më fitimprurës. Më pas do të përcaktohet numri optimal i operaorëve për
t’u trajnuar në mënyrë mikse duke pasur të dhënë investimin e trajnimit dhe shtesën në
pagë të paguar për operatorët në këtë rast.

xv
Përfundime dhe Rekomandime
Në këtë seksion do të trajtohen përfundimet teorike dhe praktike të arritura në këtë punim.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
1
KAPITULLI 1: NJË ANALIZË EMPIRIKE E OPERACIONEVE
NË CALL CENTER
1.1. Subjekti i konsideruar
Call Center-i i marrë në konsideratë është Teleperformance Albana, pjesë e korporatës
Teleperformance, një lider në këtë sektor në botë. Ajo është e pranishme në 62 vende, me 270
call center-a, të krijuara 36 vjet më parë, që faturoi në vitin 2014 2.7 miliardë dollarë.
Teleperformance Albania ka lindur në vitin 2008 si pjesë e Grupit Teleperformance Italy,
operon në Tiranë dhe Durrës dhe ka mbi 2000 të punësuar. U vlerësua kompania e gjashtë me
numrin më të madh të të punësuarve në vend. Duke qenë pjesë e kompanisë italiane, ajo operon
në tregun italian me klientë shumë të rëndësishëm (Ekmekçiu, 2015).
Teleperformance në Shqipëri u themelua në vitin 2008 për të ofruar një zgjidhje jashtë tregut
të CRM (Customer Relationship Management) për tregun italian. Fillimi ishte me një kapacitet
prej 100 operatorësh dhe u rrit në mënyrë eksponenciale duke e dyfishuar atë numër çdo gjashtë
muaj.
Misioni i kompanisë është të ofrojë një shërbim të shkëlqyeshëm nga jashtë Italisë përmes një
procesi të vështirë të përzgjedhjes së gjuhës dhe aftësive, nga një ekip shumë i motivuar dhe
nga miratimi sistematik i standardeve dhe mjeteve të klasit botëror të Teleperformance Group.
Entuziazmi dhe profesionalizmi i punonjësve, së bashku me një infrastrukturë solide të
sistemeve të informacionit, sigurojnë një zgjidhje fleksibile, të besueshme dhe të shkallëzuar
për nevojat e CRM-së së klientëve .(FIAA2018).
Kompania numëron mbi 20 klientë ndërkombëtare, të të gjithë sektorëve (IT, financë,
telekomunikim, udhëtim, blerje online, telefoni etj), që i besojnë shërbimin e klientit.
Strukturimi i kompanisë është në bazë të standarteve të vendosura nga Grupi. Puna ime pranë
TP ka filluar që në vitin 2008, duke mbuluar pozicione të ndryshme me kalimin e viteve. Për
këtë arsye kam pasur fatin ta njoh shumë mirë si biznes dhe mundësinë për te aksesuar të gjithë
databazën e kompanisë për përpunimin dhe analizën e të dhënave.
Strukturat kryesore organizative në këtë kompani janë “account”-ët e projekteve të ndryshme.
Në shumicën e rasteve çdo projekt menaxhohet si një operacion më vete me menaxherët e vet
dhe strukturën përkatëse dhe me pasqyrën e vet të të ardhurave dhe humbjeve. Duke u bazuar
tek ky sistem i decentralizuar secila skuadër e çdo projekti ka një gjërësi shpërndarjeje në lidhje
me mënyrën se si performon funksionet e organizimit të stafit.
1.2. Karakteristikat Stokastike
Çdo kompani shërbimi e mat produktivitetin e saj me anë të disa parametrave të performancës1.
Disa nga matësit kryesorë të performancës së një call center-i janë:
• AHT (Average Handle Time): është koha mesatare e zgjatjes së një telefonate. Sa më
i ulët të jetë ky parametër, aq më mire është pasi lidhet në mënyrë direkte me
kënaqësinë e telefonuesit.
• AR (Abandonment Rate): norma e braktisjes së telefonatave, pra përqindja e
telefonuesve që e mbyllin telefonatën përpara se dikush t’i përgjigjet. Edhe ky matës
1 KPI= Key performance Index

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
2
lidhet në mënyrë të drejtpërdrejtë me kënaqësinë e telefonuesit. Sa më e ulët të jete kjo
përqindje, aq më produktivë jemi.
• SL (Service Level): niveli i shërbimit, është përqindja e telefonatave të pergjigjura
brenda një numri të caktuar sekondash (pra klienti në radhë nuk ka pritur më shumë se
një numër i caktuar sekondash përpara se një operator t’i përgjigjej). Ky matës lidhet
në mënyrë të drejtpërdrejtë me orgainizimin e stafit të call center-it. Kjo sepse sa më
shumë operatorë të jenë prezent në një turn, aq më pak qëndron klienti në radhë. Nga
ana tjetër në qoftë se numri i operatorëve ështe shumë më i lartë se norma e mbërritjes
së telefonatave, aq më shumë kosto ka call center-i, pa një kthim. Në përgjithesi për të
gjitha projektet ka një normë SL objektiv (zakonisht për një periudhë 1 mujore), të
vendosur kontraktualisht me klientin. Kjo do të thotë që mosarritja e objektivit
përkthehet në një gjobë për call center-in. Ky objektiv quhet ndryshe SLA (Service
Level Agreement).
• Faktori i shërbimit telefonik (TSF): TSF është pjesa e telefonatave të paraqitura të
cilat janë shërbyer dhe për të cilat vonesa është nën një nivel të specifikuar. Për
shembull, një call center mund të raportojë TSF-në si përqindje e telefonuesve të lënë
në pritje në më pak se 30 sekonda.
• Shpejtësia mesatare e përgjigjes (ASA): kjo është koha mesatare e telefonatave në
pritje, duke pritur që një operator të përgjigjet.
• FCR (First Call Resolution) është përqindja e telefonatave që kanë marrë një zgjidhje
që herën e parë, pra klientit nuk i është dashur të telefonojë përsëri etj.
Sfida kryesore për procesin e organizimit të stafit të call center-it është sigurimi i një SLA fikse
me një kohë mbërritjeje të rastit. Volumi i telefonatave inbound (telefonata hyrëse) është
variabël me burime të shumëfishta të pasigurisë. Në analizën e mëposhtme do të konsiderohet
variacioni në nivele të shumëfishta grupimi: javore, ditore dhe çdo gjysëm ore. Në (Ekmekçiu,
Muça, Nano 2016) është bërë një analizë e disa prej këtyre indikatorëve të performances së call
center-it me anë te Simulimit dhe është treguar sesi ndikojnë ato ne dimensionimin e stafit të
një call center-i. Gjithashtu në (Ekmekçiu 2015) janë bërë disa analiza Optimizimi të
parametrave të perfomrancës në Call Center, duke përdorur Teorinë e Radhëve.
Praktikat e Menaxhimit të Dimensionimit të Call Center-it
Ndërkohë që kompania ka një sistem të sofistikuar të Workforce Management (WFM,
departamenti që merret me skedulimin dhe menaxhimin e kapacitetit) që mund të performojë
detyra të vështira skedulimi, sistemi përdoret nga shumë pak projekte. Shumica e stafit të
skedulimit i kryejnë detyrat e skedulimit në një mënyrë gjysëm të automatizuar duke përdorur
Excelin. Menaxherët mbledhin të dhënat historike të volumeve nga Distributori Automatik i
Telefonatave (ACD) dhe përdorin ato të dhëna për të zhvilluar një parashikim të volumeve të
telefonatave; zakonisht për periudha 30 minutëshe gjatë një jave. Shumë menaxherë përdorin
mesataren për periudhë mbi një periudhë gjashtë deri në tetë javore, dhe më pas manualisht
përshtasin atë skedulim dukë u bazuar në ditët e pushimit ose për ndryshime të tjera qe mund
të ndikojnë. Parashikimi përdoret për të drejtuar kërkesat e organizimit të stafit. Disa menaxherë
përdorin llogaritës të gatshëm të Erlang C, pra aplikime të thjeshta që llogarisin nivelin e stafit
të kërkuar për të arritur një nivel shërbimi të caktuar në çdo periudhë kohe. Megjithatë, për
shkak të një piku të lartë në volume gjatë periudhës 8-12 paradite, siç do të shohim më mbrapa,
shumica e menaxherëve nuk stafojnë në këtë nivel. Organizimi më shumë dhe më pak i stafit
bëhet në mënyrë heuristike, duke u bazuar tek eksperienca dhe attrition-i (numri mesatar i
operatorëve që largohen gjatë muajit me ose pa paralajmërim). Organizimi i stafit merr në
konsideratë për limite të tjera, siç është kërkesa e përgjithshme e të paturit gjithmonë të paktën
dy operatorë gjatë çdo periudhë.
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
3
Ndërkoë që shumica e menaxherëve përdorin Excelin për të kryer këto detyra, një numër i vogël
përdor aplikimin automatik të WFM. Procesi i përgjithshëm në këtë rast është i njejtë por
sistemi na jep suport automatik. Sistemi mbledh statistikat e ACD-së të cilat menaxheri mund
t’i sistemojë manualisht. Një menu me skedulimet e mundshme dhe me limitet mund të
përcaktohet dhe një gjenerues i automatizuar i skedulimit. Sistemimi manual i skedulimit mund
të bëhet pas optimizimit. Dokumentaconi i sistemit është shumë i pa qartë në lidhje me natyrën
e algoritmit të skedulimit. Algoritmi i skedulimit na jep një kontroll me zgjdhje ku planifikuesi
mund të zgjedhë ndërmjet 1 – Minimizimi i vlerave të pikut në nivelet e shërbimit dhe 2 –
Maksimizimi i përgjithshëm (javor) i Nivelit të Shërbimit. Sistemi mund të marrë parasysh
gjithashtu normën e braktisjes duke lejuar përdoruesin të fusë një parashikim të normës së
braktisjes ose një faktor durimi.
Sistemi i WFM përdoret gjërësisht në lançimet e projekteve të reja. Parashikimi i mbërritjeve
ditore mblidhet nga çdo burim i disponueshëm dhe alokohen në periudha kohore prej 30
minutash duke aplikuar një model standart sezonaliteti, i bazuar në projekte të tjera. Modeli i
organizimit të stafit të WFM ekzekutohet nga kjo pikë e parashikimit për mbërritjet sipas
periudhave për të llogaritur numrin e operatorëve të nevojshëm për arritjen e objektivit të
niveleve të shërbimit. Numri i parashikuar i operatorëve më pas reklutohet pa pagesë për
periudhën e trajnimit. Të gjithë operatorët punësohen për kërkesat e një projekti të caktuar.
Mbërritjet javore
Në periudhën afatshkurtër deri në atë afatmesme modeli kryesor sezonal ndodh në nivel javor.
Për qëllimin e kësaj analize do të injorohen periudha të pazakonta të ngadalta, siç janë periudha
ndërmjet Krishtlindjeve dhe Vitit të Ri, dhe do të shqyrtohet variacioni i volumeve të
telefonatave në nivel javor. Në skemën e mëposhtme mund të shohim grafikun që përmbledh
katër muaj të të dhënave të volumeve të Projekteve të konsideruara. Më poshtë listojmë
mesataren e volumeve javore inbound, devijimin standart të volumeve të telefonatave dhe
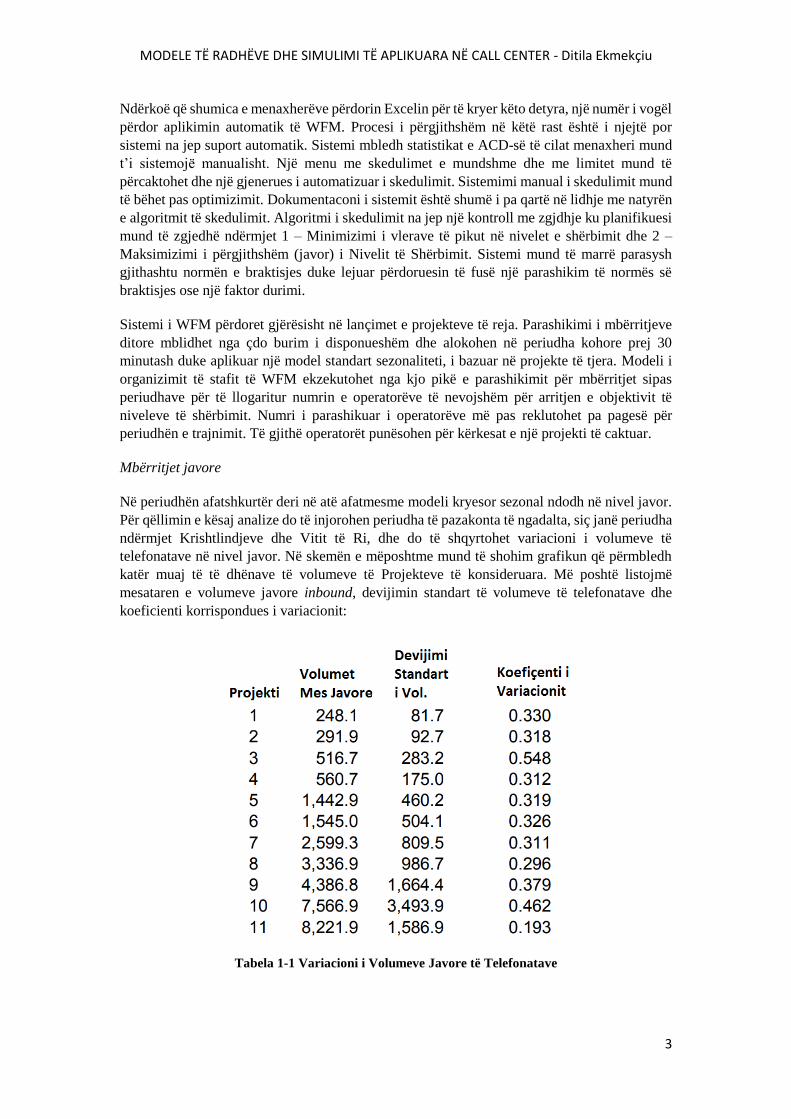
koeficienti korrispondues i variacionit:
Tabela 1-1 Variacioni i Volumeve Javore të Telefonatave
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
4
Tabela tregon që volumi varion në mënyrë të konsiderueshme nga një javë në tjetrën. Gjithashtu
tregon që grada e variacionit varet në mënyrë të kosniderueshme nga një projekt në tjetrin, me
koeficientë variacioni nga më i ulëti 0.193 në më të lartin 0.548.
Mbërritjet ditore
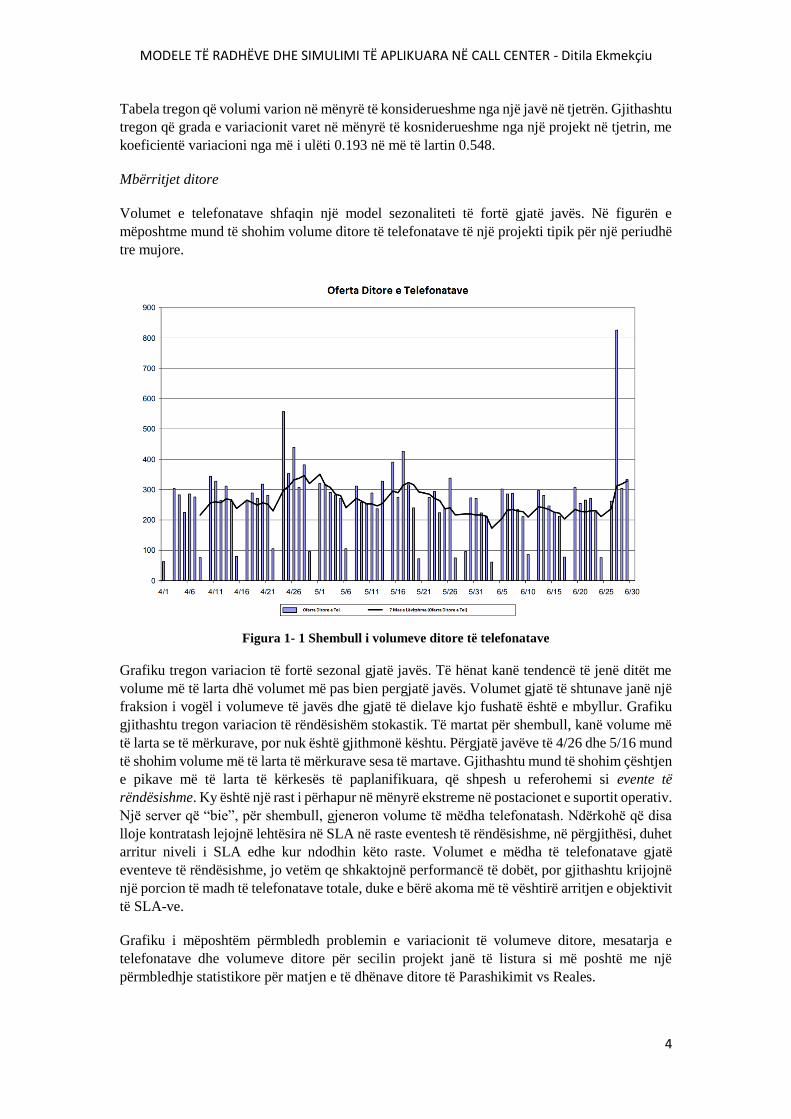
Volumet e telefonatave shfaqin një model sezonaliteti të fortë gjatë javës. Në figurën e
mëposhtme mund të shohim volume ditore të telefonatave të një projekti tipik për një periudhë
tre mujore.
Figura 1- 1 Shembull i volumeve ditore të telefonatave
Grafiku tregon variacion të fortë sezonal gjatë javës. Të hënat kanë tendencë të jenë ditët me
volume më të larta dhë volumet më pas bien pergjatë javës. Volumet gjatë të shtunave janë një
fraksion i vogël i volumeve të javës dhe gjatë të dielave kjo fushatë është e mbyllur. Grafiku
gjithashtu tregon variacion të rëndësishëm stokastik. Të martat për shembull, kanë volume më
të larta se të mërkurave, por nuk është gjithmonë kështu. Përgjatë javëve të 4/26 dhe 5/16 mund
të shohim volume më të larta të mërkurave sesa të martave. Gjithashtu mund të shohim çështjen
e pikave më të larta të kërkesës të paplanifikuara, që shpesh u referohemi si evente të
rëndësishme. Ky është një rast i përhapur në mënyrë ekstreme në postacionet e suportit operativ.
Një server që “bie”, për shembull, gjeneron volume të mëdha telefonatash. Ndërkohë që disa
lloje kontratash lejojnë lehtësira në SLA në raste eventesh të rëndësishme, në përgjithësi, duhet
arritur niveli i SLA edhe kur ndodhin këto raste. Volumet e mëdha të telefonatave gjatë
eventeve të rëndësishme, jo vetëm qe shkaktojnë performancë të dobët, por gjithashtu krijojnë
një porcion të madh të telefonatave totale, duke e bërë akoma më të vështirë arritjen e objektivit
të SLA-ve.
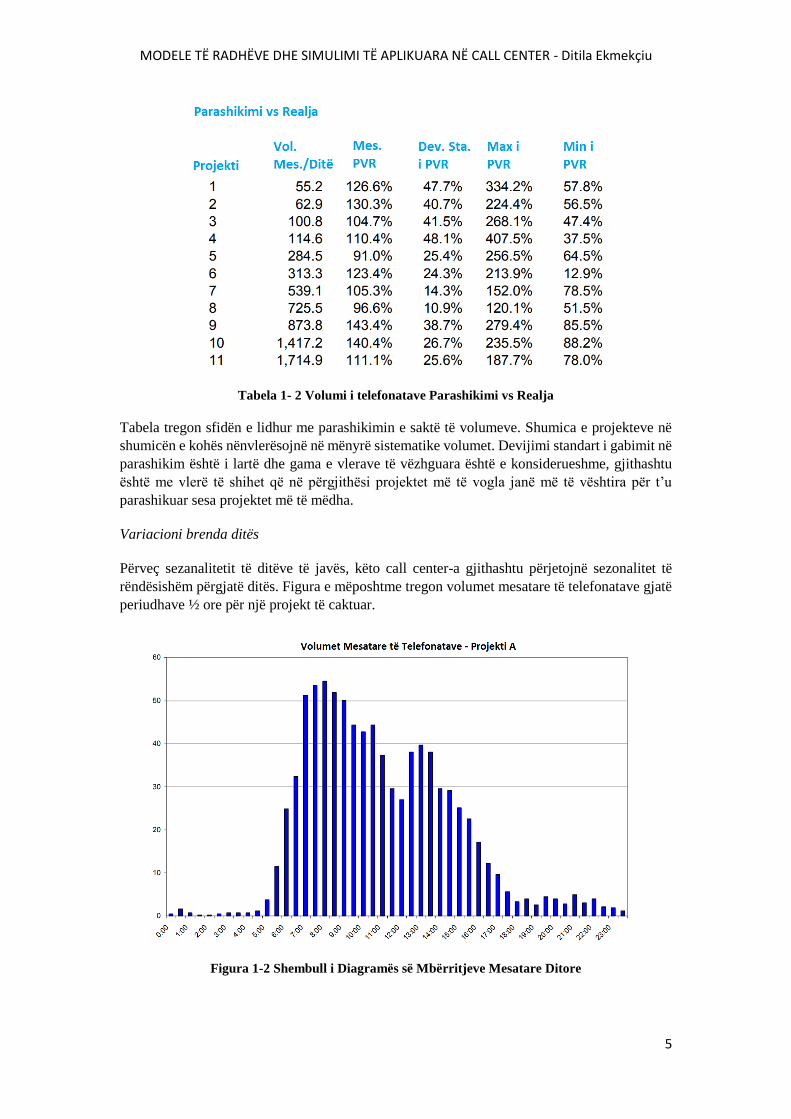
Grafiku i mëposhtëm përmbledh problemin e variacionit të volumeve ditore, mesatarja e
telefonatave dhe volumeve ditore për secilin projekt janë të listura si më poshtë me një
përmbledhje statistikore për matjen e të dhënave ditore të Parashikimit vs Reales.
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
5
Tabela 1- 2 Volumi i telefonatave Parashikimi vs Realja
Tabela tregon sfidën e lidhur me parashikimin e saktë të volumeve. Shumica e projekteve në
shumicën e kohës nënvlerësojnë në mënyrë sistematike volumet. Devijimi standart i gabimit në
parashikim është i lartë dhe gama e vlerave të vëzhguara është e konsiderueshme, gjithashtu
është me vlerë të shihet që në përgjithësi projektet më të vogla janë më të vështira për t’u
parashikuar sesa projektet më të mëdha.
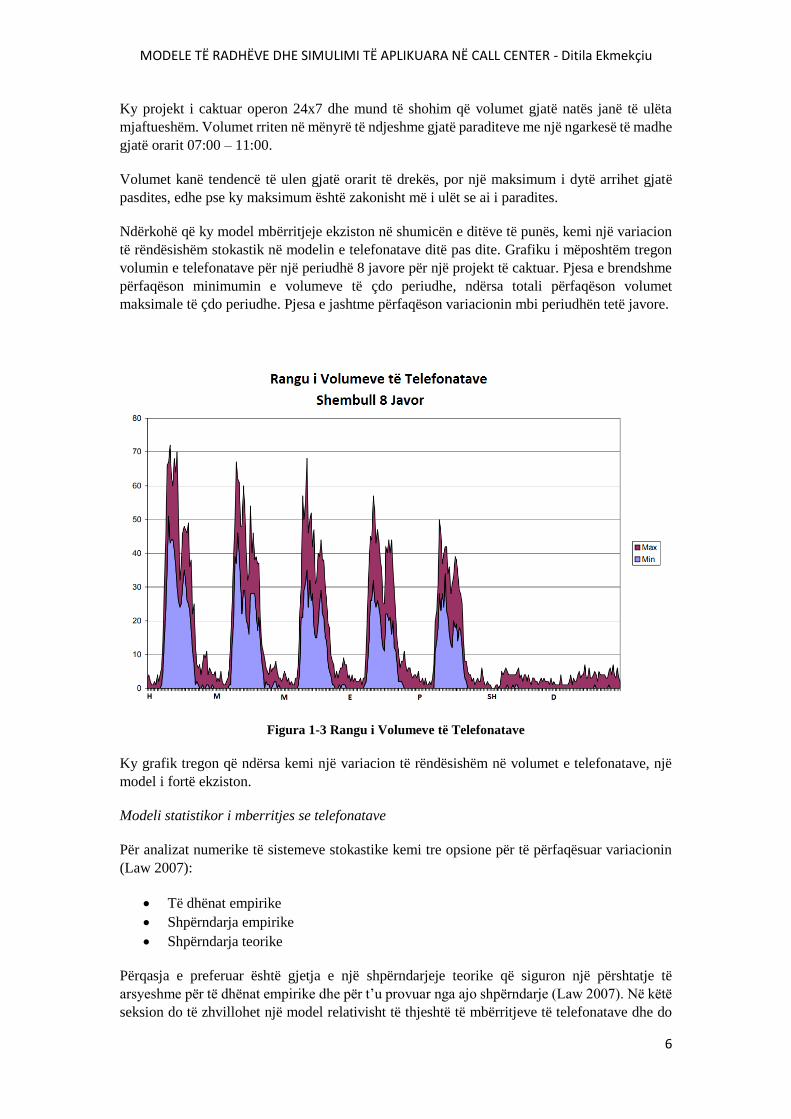
Variacioni brenda ditës
Përveç sezanalitetit të ditëve të javës, këto call center-a gjithashtu përjetojnë sezonalitet të
rëndësishëm përgjatë ditës. Figura e mëposhtme tregon volumet mesatare të telefonatave gjatë
periudhave ½ ore për një projekt të caktuar.
Figura 1-2 Shembull i Diagramës së Mbërritjeve Mesatare Ditore
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
6
Ky projekt i caktuar operon 24x7 dhe mund të shohim që volumet gjatë natës janë të ulëta
mjaftueshëm. Volumet rriten në mënyrë të ndjeshme gjatë paraditeve me një ngarkesë të madhe
gjatë orarit 07:00 – 11:00.
Volumet kanë tendencë të ulen gjatë orarit të drekës, por një maksimum i dytë arrihet gjatë
pasdites, edhe pse ky maksimum është zakonisht më i ulët se ai i paradites.
Ndërkohë që ky model mbërritjeje ekziston në shumicën e ditëve të punës, kemi një variacion
të rëndësishëm stokastik në modelin e telefonatave ditë pas dite. Grafiku i mëposhtëm tregon
volumin e telefonatave për një periudhë 8 javore për një projekt të caktuar. Pjesa e brendshme
përfaqëson minimumin e volumeve të çdo periudhe, ndërsa totali përfaqëson volumet
maksimale të çdo periudhe. Pjesa e jashtme përfaqëson variacionin mbi periudhën tetë javore.
Figura 1-3 Rangu i Volumeve të Telefonatave
Ky grafik tregon që ndërsa kemi një variacion të rëndësishëm në volumet e telefonatave, një
model i fortë ekziston.
Modeli statistikor i mberritjes se telefonatave
Për analizat numerike të sistemeve stokastike kemi tre opsione për të përfaqësuar variacionin
(Law 2007):
• Të dhënat empirike
• Shpërndarja empirike
• Shpërndarja teorike
Përqasja e preferuar është gjetja e një shpërndarjeje teorike që siguron një përshtatje të
arsyeshme për të dhënat empirike dhe për t’u provuar nga ajo shpërndarje (Law 2007). Në këtë
seksion do të zhvillohet një model relativisht të thjeshtë të mbërritjeve të telefonatave dhe do

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
7
të tregohet që ky model siguron një përshtatje të arsyeshme me të dhënat e vëzhguara. Modeli
i zgjedhur është një model hierarkik i mbërritjeve me dy faza. Modelet e këtij lloji janë të
përdorur gjërësisht në operacionet e call center-ave (Gans, Koole et al. 2003). Në nivelin e parë
do të modelojmë volume ditore të telefonatave. Në nivelin e dytë do të modelojmë shpërndarjen
e telefonatave ditore në periudha 30 minutëshe.
Volumet ditore të telefonatave
Qëllimi i modelit të nivelit të parë është zhvillimi i një shpërndarjeje statistikore për volume
ditore të telefonatave. Volumet ditore të telefonatave mund të variojnë për arsye të shumëfishta:
përfshirja e ndryshimeve me qëllim suportin, pushimet, sezonaliteti vjetor dhe variacioni
stokastik. Duke qënë se shqetësimi ynë është në lidhje me variacionin stokastik, do të injorojmë
çështjet e sezonalitetit të strukturuar dhe me gamë të gjërë dhe do të fokusohemi tek variacioni
stokastik ditë pas dite.
Supozimi është që telefonatat ditore gjenerohen nga një proces stacionar me efektet e ditëve të
javës dhe ditëve të pushimit. Matematikisht supozojmë një model të trajtës së mëposhtme:
�̂� = �̅� + 𝑏𝐻𝑑𝐻 + 𝑏𝑀𝑑𝑀 + 𝑏𝐸𝑑𝐸 + 𝑏𝑃𝑑𝑃 + 𝑏𝑆𝐻𝑑𝑆𝐻 + 𝑏𝐷𝑑𝐷 + 𝑏𝑃𝑈𝑑𝑃𝑈 + 𝜀 (1.1)
ŷ përfaqëson volumet e telefonatave të parashikuara në një ditë të dhënë. ȳ është mesatarja e
përgjithshme e volumeve të telefonatave. Kemi variablat “dummy” (dH – dD) për efektet e ditëve
të javës (në mënyrë arbitrare zgjedhim të Mërkurën si ditë referimi). Çdo “dummy” përfaqëson
ndryshimin mesatar në volume ditore që lidhen me të Mërkurën, për shembull dM përfaqëson
diferencën mesatare në telefonata ndërmjet një të Mërkure dhe një të Hëne. dH është një variabël
“dummy” i ngjashëm për efektet e pushimeve (fundjavës). Përshtasim një model duke përdorur
metodën e katrorëve më të vegjël për 6 muaj të dhëna afërsisht dhe marrim rezultatet e
mëposhtme:
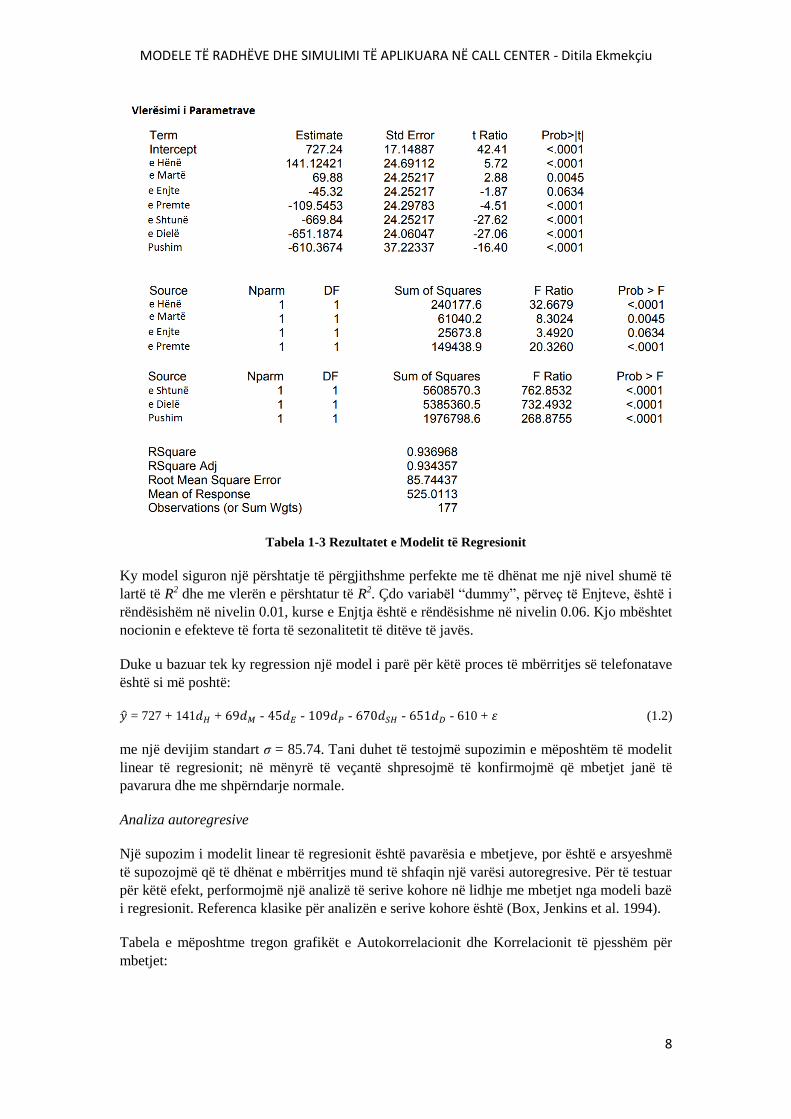
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
8
Tabela 1-3 Rezultatet e Modelit të Regresionit
Ky model siguron një përshtatje të përgjithshme perfekte me të dhënat me një nivel shumë të
lartë të R2 dhe me vlerën e përshtatur të R2. Çdo variabël “dummy”, përveç të Enjteve, është i
rëndësishëm në nivelin 0.01, kurse e Enjtja është e rëndësishme në nivelin 0.06. Kjo mbështet
nocionin e efekteve të forta të sezonalitetit të ditëve të javës.
Duke u bazuar tek ky regression një model i parë për këtë proces të mbërritjes së telefonatave
është si më poshtë:
�̂� = 727 + 141𝑑𝐻 + 69𝑑𝑀 - 45𝑑𝐸 - 109𝑑𝑃 - 670𝑑𝑆𝐻 - 651𝑑𝐷 - 610 + 𝜀 (1.2)
me një devijim standart σ = 85.74. Tani duhet të testojmë supozimin e mëposhtëm të modelit
linear të regresionit; në mënyrë të veçantë shpresojmë të konfirmojmë që mbetjet janë të
pavarura dhe me shpërndarje normale.
Analiza autoregresive
Një supozim i modelit linear të regresionit është pavarësia e mbetjeve, por është e arsyeshmë
të supozojmë që të dhënat e mbërritjes mund të shfaqin një varësi autoregresive. Për të testuar
për këtë efekt, performojmë një analizë të serive kohore në lidhje me mbetjet nga modeli bazë
i regresionit. Referenca klasike për analizën e serive kohore është (Box, Jenkins et al. 1994).
Tabela e mëposhtme tregon grafikët e Autokorrelacionit dhe Korrelacionit të pjesshëm për
mbetjet:
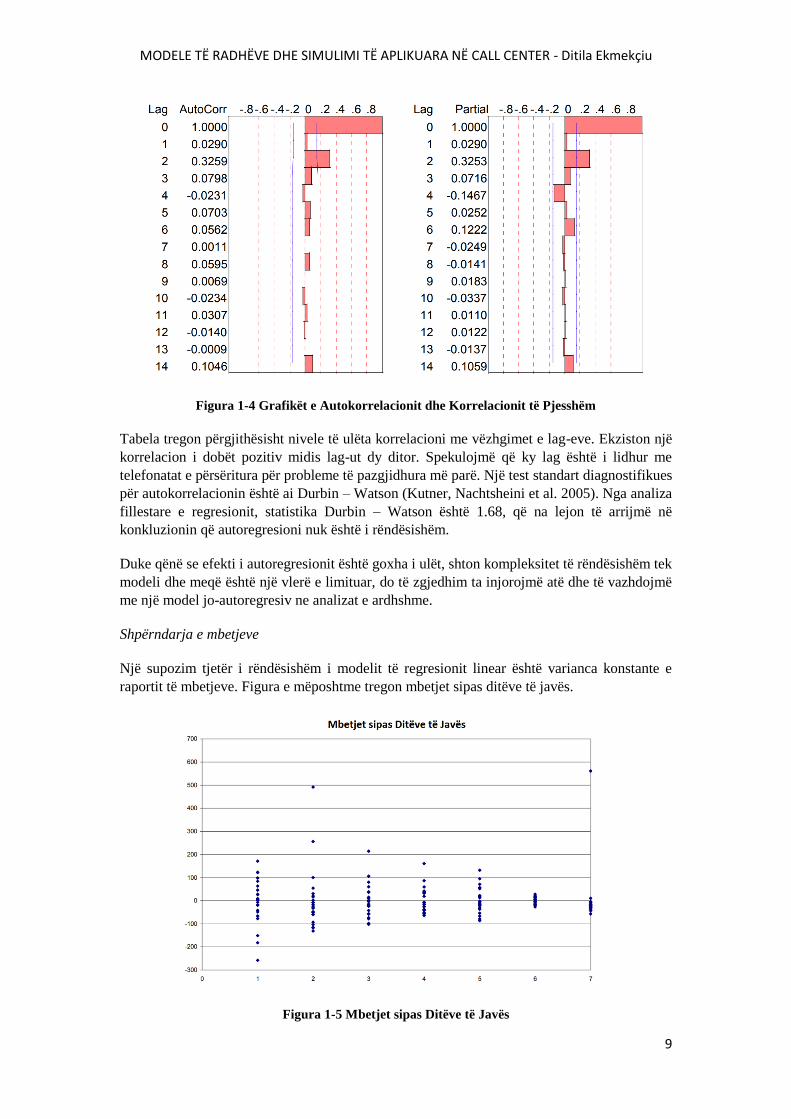
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
9
Figura 1-4 Grafikët e Autokorrelacionit dhe Korrelacionit të Pjesshëm
Tabela tregon përgjithësisht nivele të ulëta korrelacioni me vëzhgimet e lag-eve. Ekziston një
korrelacion i dobët pozitiv midis lag-ut dy ditor. Spekulojmë që ky lag është i lidhur me
telefonatat e përsëritura për probleme të pazgjidhura më parë. Një test standart diagnostifikues
për autokorrelacionin është ai Durbin – Watson (Kutner, Nachtsheini et al. 2005). Nga analiza
fillestare e regresionit, statistika Durbin – Watson është 1.68, që na lejon të arrijmë në
konkluzionin që autoregresioni nuk është i rëndësishëm.
Duke qënë se efekti i autoregresionit është goxha i ulët, shton kompleksitet të rëndësishëm tek
modeli dhe meqë është një vlerë e limituar, do të zgjedhim ta injorojmë atë dhe të vazhdojmë
me një model jo-autoregresiv ne analizat e ardhshme.
Shpërndarja e mbetjeve
Një supozim tjetër i rëndësishëm i modelit të regresionit linear është varianca konstante e
raportit të mbetjeve. Figura e mëposhtme tregon mbetjet sipas ditëve të javës.
Figura 1-5 Mbetjet sipas Ditëve të Javës

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
10
Figura tregon në mënyrë të qartë që varianca e mbetjeve nuk është e pavarur nga ditët e javës.
Të shtunat, për shembull, kanë volume mesatare shumë më të ulëta dhe variancë shumë më të
ulët se të Hënat. Kjo sjell që supozimet e modelit të regresionit linear standart nuk kënaqen.
Kjo duhet të jetë e dukshme nga output-i i regresionit ku devijimi standart i volumeve është më
i madh se sa volumet mesatare të Shtunave. Kjo sjell që mund të ndodhin telefonata negative
me probabilitet pozitiv, gjë që nuk ka kuptim për këtë rast.
Kjo analizë tregon që modeli i regresionit linear standart nuk është i vlefshëm, por kemi
përcaktuar çka më poshtë:
• Efektet e ditëve të javës janë statistikisht të rëndësishme për çdo ditë të javës.
• Efektet e ditëve të javës shpjegojnë një raport të rëndësishëm të variacionit në volumet
e telefonatave.
• Pasi konsiderohen efektet e ditëve të javës, efektet autoregresive janë minimale dhe
mund të injorohen.
• Varianca në volumet e telefonatave është e varur nga ditët e javës.
Ka disa masa korrektive që mund të përdoren për të adresuar çështjen e variancës siç është
transformimi i të dhënave ose katrorët më të vegjël të peshuar (Kutner, Nachtshein et al 2005).
Gjithsesi, të dhënat tona sugjerojnë një përqasje të qartë. Do të supozojmë që volumet në çdo
ditë janë një ekstrakt i rastësishëm i pavarur nga një shpërndarje normale me një mesatare dhe
devijim standart specifikë për atë ditë të javës. Duke qënë se kemi treguar që efektet
autoregresive janë minimale, supozimi i pavarësisë është i justifikuar. Duke qënë se volumet e
çdo dite gjenerohen nga një proces i pavarur, varianca e volumeve të çdo dite mund të jetë
unike.
Mbërritjet brenda ditës
Pasi zhvilluam një model të volumeve ditore të telefonatave, tani duhet të zhvillojmë një model
se si mbërrijnë këto telefonata gjatë ditës. Është e qartë nga Figura 1-3 që norma e mbërritjeve
varion në mënyrë të konsiderueshme gjatë ditës dhe ne nuk mund të supozojmë një normë
mbërritjeje konstante. Një përqasje e zakonshme në praktikë është të supozohet një formë fikse
e skemës së kërkesës që thjesht spostohet vertikalisht me volumet. Matematikisht kjo sjell që
volumet e telefomatave në secilën të jetë një porcion fiks i volumeve ditore. Gjithsesi grafiku
në Figurën 1-4 tregon që për një periudhë volumet janë më të ndryshueshme sesa do të na
tregonte ky supozim. Në figurën e mëposhtme tregohet raporti mesatar i volumeve ditore të
telefonatave në çdo periudhë 30 minutëshe, bashkë me koeficientin e variacionit të atij raporti.
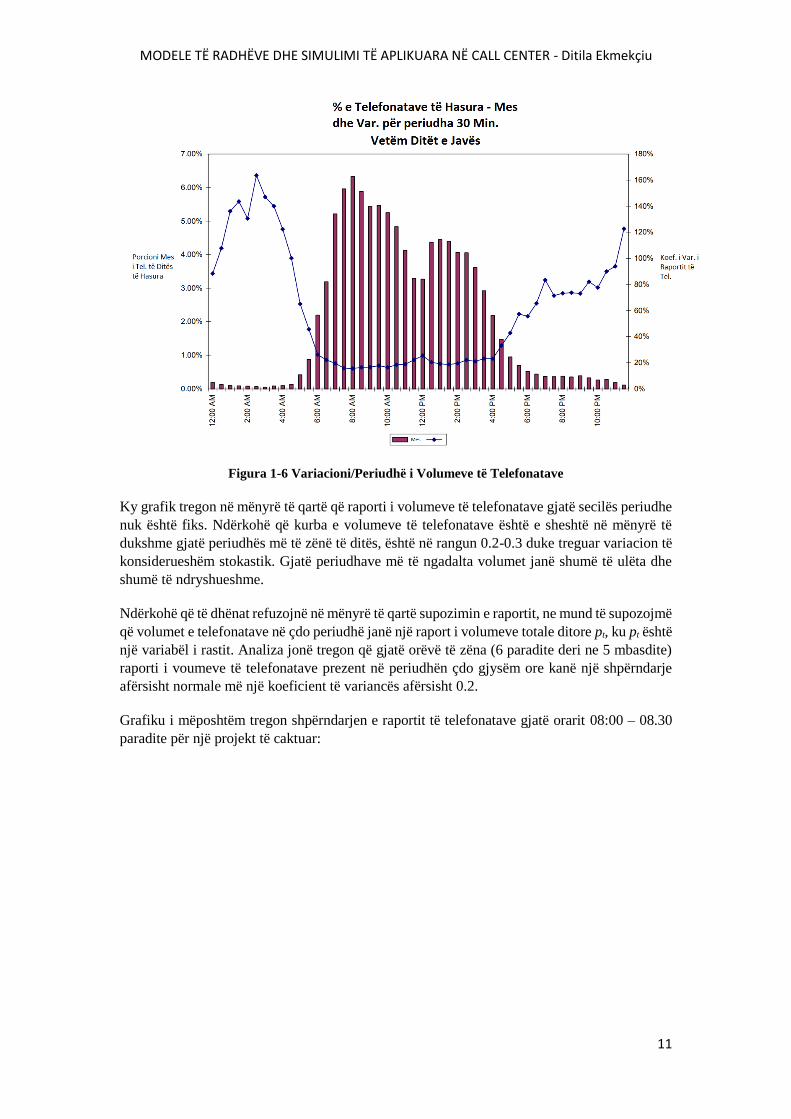
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
11
Figura 1-6 Variacioni/Periudhë i Volumeve të Telefonatave
Ky grafik tregon në mënyrë të qartë që raporti i volumeve të telefonatave gjatë secilës periudhe
nuk është fiks. Ndërkohë që kurba e volumeve të telefonatave është e sheshtë në mënyrë të
dukshme gjatë periudhës më të zënë të ditës, është në rangun 0.2-0.3 duke treguar variacion të
konsiderueshëm stokastik. Gjatë periudhave më të ngadalta volumet janë shumë të ulëta dhe
shumë të ndryshueshme.
Ndërkohë që të dhënat refuzojnë në mënyrë të qartë supozimin e raportit, ne mund të supozojmë
që volumet e telefonatave në çdo periudhë janë një raport i volumeve totale ditore pt, ku pt është
një variabël i rastit. Analiza jonë tregon që gjatë orëvë të zëna (6 paradite deri ne 5 mbasdite)
raporti i voumeve të telefonatave prezent në periudhën çdo gjysëm ore kanë një shpërndarje
afërsisht normale më një koeficient të variancës afërsisht 0.2.
Grafiku i mëposhtëm tregon shpërndarjen e raportit të telefonatave gjatë orarit 08:00 – 08.30
paradite për një projekt të caktuar:
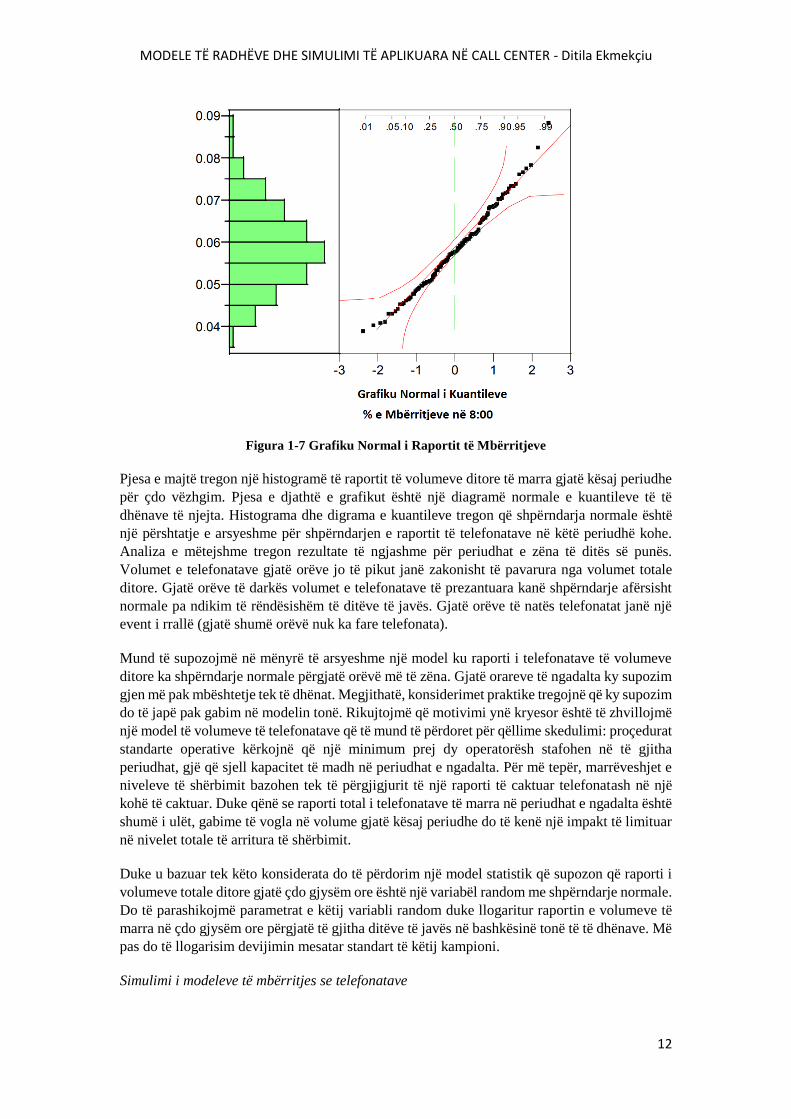
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
12
Figura 1-7 Grafiku Normal i Raportit të Mbërritjeve
Pjesa e majtë tregon një histogramë të raportit të volumeve ditore të marra gjatë kësaj periudhe
për çdo vëzhgim. Pjesa e djathtë e grafikut është një diagramë normale e kuantileve të të
dhënave të njejta. Histograma dhe digrama e kuantileve tregon që shpërndarja normale është
një përshtatje e arsyeshme për shpërndarjen e raportit të telefonatave në këtë periudhë kohe.
Analiza e mëtejshme tregon rezultate të ngjashme për periudhat e zëna të ditës së punës.
Volumet e telefonatave gjatë orëve jo të pikut janë zakonisht të pavarura nga volumet totale
ditore. Gjatë orëve të darkës volumet e telefonatave të prezantuara kanë shpërndarje afërsisht
normale pa ndikim të rëndësishëm të ditëve të javës. Gjatë orëve të natës telefonatat janë një
event i rrallë (gjatë shumë orëvë nuk ka fare telefonata).
Mund të supozojmë në mënyrë të arsyeshme një model ku raporti i telefonatave të volumeve
ditore ka shpërndarje normale përgjatë orëvë më të zëna. Gjatë orareve të ngadalta ky supozim
gjen më pak mbështetje tek të dhënat. Megjithatë, konsiderimet praktike tregojnë që ky supozim
do të japë pak gabim në modelin tonë. Rikujtojmë që motivimi ynë kryesor është të zhvillojmë
një model të volumeve të telefonatave që të mund të përdoret për qëllime skedulimi: proçedurat
standarte operative kërkojnë që një minimum prej dy operatorësh stafohen në të gjitha
periudhat, gjë që sjell kapacitet të madh në periudhat e ngadalta. Për më tepër, marrëveshjet e
niveleve të shërbimit bazohen tek të përgjigjurit të një raporti të caktuar telefonatash në një
kohë të caktuar. Duke qënë se raporti total i telefonatave të marra në periudhat e ngadalta është
shumë i ulët, gabime të vogla në volume gjatë kësaj periudhe do të kenë një impakt të limituar
në nivelet totale të arritura të shërbimit.
Duke u bazuar tek këto konsiderata do të përdorim një model statistik që supozon që raporti i
volumeve totale ditore gjatë çdo gjysëm ore është një variabël random me shpërndarje normale.
Do të parashikojmë parametrat e këtij variabli random duke llogaritur raportin e volumeve të
marra në çdo gjysëm ore përgjatë të gjitha ditëve të javës në bashkësinë tonë të të dhënave. Më
pas do të llogarisim devijimin mesatar standart të këtij kampioni.
Simulimi i modeleve të mbërritjes se telefonatave

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
13
Ky model i thjeshtuar i zhvilluar më lart tregon një përqasje të arsyeshme të një procesi
stokastik që gjeneron një skemë të mbërritjeve të telefonatave. Një algoritëm për të gjeneruar
një javë të teleofnatave të simuluara tregohet në figurën më poshtë:
Figura 1-8 Algoritmi i Simulimit të Gjenerimit të Telefonatave
Algoritmi ka tre cikle. Në ciklin e parë llogarisim volumet ditore të telefonatave duke gjeneruar
variabla random normalë me mesatare ditore dhe devijim standart. Në ciklin e dytë llogarisim
raportin fillestar të volumeve ditore të hasura në çdo periudhë prej 30 minutash. Cikli i tretë
normalizon raportin dhe llogarit mesataren e hasur të volumeve në çdo periudhë dhe normën
përkatëse të mbërritjes.
1.3. Braktisja e telefonatave
Një konsideratë e rëndësishme në operacionet e call center-it është braktisja e telefonatave,
sasia e telefonuesve që vendosin të mbyllin telefonatën përpara se t’u shërbehet. Norma e
braktisjes është një parametër kyç që haset në shumicën e call center-ave. Në këtë kontekst
firma bën një dallim ndërmjet braktisjeve pozitive dhe atyre negative. Braktisjet pozitive janë
sasia e telefonuesve që mbyllin telefonatën pa pritur për një periudhë të gjatë kohe. Logjika
është që kur një problem i njohur identifikohet një mesazh i regjistruar jepet zakonisht pëpara
çdo telefonate duke cituar problemin dhe zgjidhjen e mundshme. Telefonuesit që dëgjojnë këtë
mesazh dhe e mbyllin supozohet që janë shërbyer pasi mësuan që problemi i tyre është i njohur
dhe mësuan gjithashtu zgjidhjen e atij problemi. Për këtë arsye, braktisjet positive nuk
konsiderohen si një problem. Formalisht, braktisjet positive llogariten zakonisht si numri i
telefonuesve që braktisin me kohë pritjeje 30 sekonda ose më pak.
Braktisjet negative nga ana tjetër ndodhin kur një telefonues vendos të presë gjatë kësaj
periudhe fillestare, por së fundmi mbyll telefonatën përpara se të shërbehet. Normat e braktisjes
kanë tendencë të variojnë në mënyrë të gjërë dhe janë të lidhura me kohën e pritjes. Kur krijohen
radhë koha e pritjes rritet dhe telefonuesit ka më shumë gjasa të braktisin radhën. Norma e
braktisjes si pasojë ka tendencë të jetë në vlerat më të larta kur volumet janë të larta dhe
kapaciteti i vogël.
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
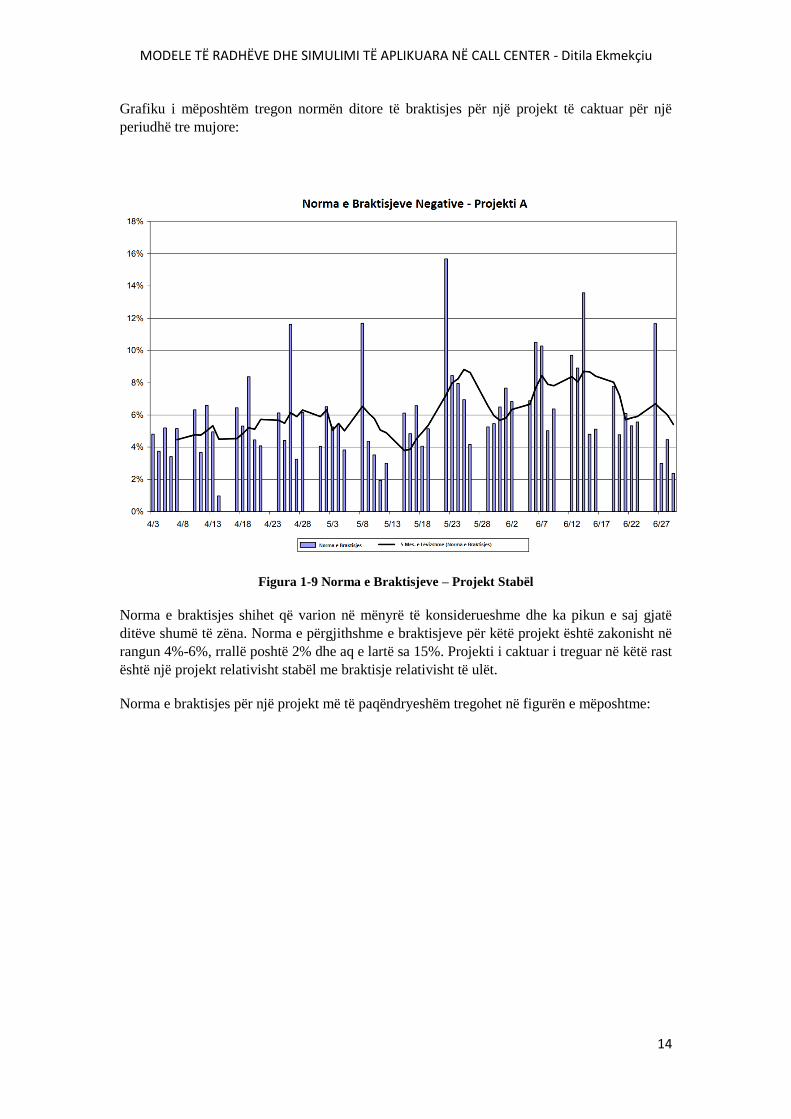
14
Grafiku i mëposhtëm tregon normën ditore të braktisjes për një projekt të caktuar për një
periudhë tre mujore:
Figura 1-9 Norma e Braktisjeve – Projekt Stabël
Norma e braktisjes shihet që varion në mënyrë të konsiderueshme dhe ka pikun e saj gjatë
ditëve shumë të zëna. Norma e përgjithshme e braktisjeve për këtë projekt është zakonisht në
rangun 4%-6%, rrallë poshtë 2% dhe aq e lartë sa 15%. Projekti i caktuar i treguar në këtë rast
është një projekt relativisht stabël me braktisje relativisht të ulët.
Norma e braktisjes për një projekt më të paqëndryeshëm tregohet në figurën e mëposhtme:
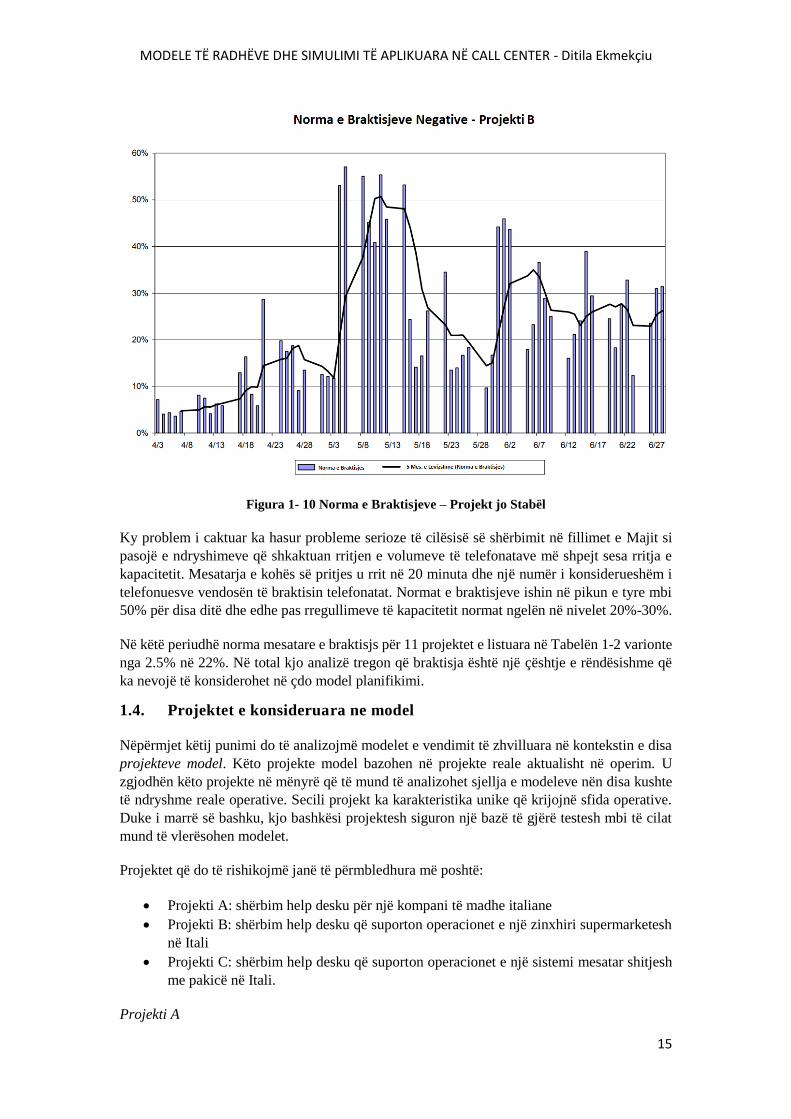
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
15
Figura 1- 10 Norma e Braktisjeve – Projekt jo Stabël
Ky problem i caktuar ka hasur probleme serioze të cilësisë së shërbimit në fillimet e Majit si
pasojë e ndryshimeve që shkaktuan rritjen e volumeve të telefonatave më shpejt sesa rritja e
kapacitetit. Mesatarja e kohës së pritjes u rrit në 20 minuta dhe një numër i konsiderueshëm i
telefonuesve vendosën të braktisin telefonatat. Normat e braktisjeve ishin në pikun e tyre mbi
50% për disa ditë dhe edhe pas rregullimeve të kapacitetit normat ngelën në nivelet 20%-30%.
Në këtë periudhë norma mesatare e braktisjs për 11 projektet e listuara në Tabelën 1-2 varionte
nga 2.5% në 22%. Në total kjo analizë tregon që braktisja është një çështje e rëndësishme që
ka nevojë të konsiderohet në çdo model planifikimi.
1.4. Projektet e konsideruara ne model
Nëpërmjet këtij punimi do të analizojmë modelet e vendimit të zhvilluara në kontekstin e disa
projekteve model. Këto projekte model bazohen në projekte reale aktualisht në operim. U
zgjodhën këto projekte në mënyrë që të mund të analizohet sjellja e modeleve nën disa kushte
të ndryshme reale operative. Secili projekt ka karakteristika unike që krijojnë sfida operative.
Duke i marrë së bashku, kjo bashkësi projektesh siguron një bazë të gjërë testesh mbi të cilat
mund të vlerësohen modelet.
Projektet që do të rishikojmë janë të përmbledhura më poshtë:
• Projekti A: shërbim help desku për një kompani të madhe italiane
• Projekti B: shërbim help desku që suporton operacionet e një zinxhiri supermarketesh
në Itali
• Projekti C: shërbim help desku që suporton operacionet e një sistemi mesatar shitjesh
me pakicë në Itali.
Projekti A
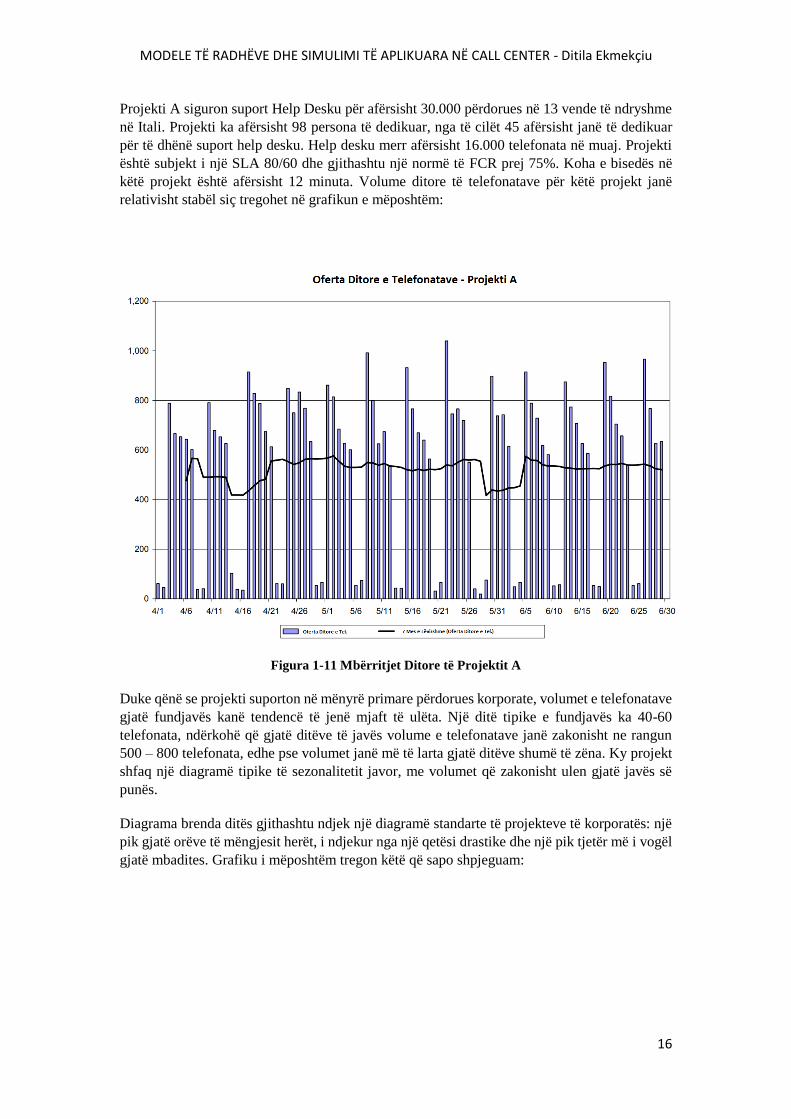
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
16
Projekti A siguron suport Help Desku për afërsisht 30.000 përdorues në 13 vende të ndryshme
në Itali. Projekti ka afërsisht 98 persona të dedikuar, nga të cilët 45 afërsisht janë të dedikuar
për të dhënë suport help desku. Help desku merr afërsisht 16.000 telefonata në muaj. Projekti
është subjekt i një SLA 80/60 dhe gjithashtu një normë të FCR prej 75%. Koha e bisedës në
këtë projekt është afërsisht 12 minuta. Volume ditore të telefonatave për këtë projekt janë
relativisht stabël siç tregohet në grafikun e mëposhtëm:
Figura 1-11 Mbërritjet Ditore të Projektit A
Duke qënë se projekti suporton në mënyrë primare përdorues korporate, volumet e telefonatave
gjatë fundjavës kanë tendencë të jenë mjaft të ulëta. Një ditë tipike e fundjavës ka 40-60
telefonata, ndërkohë që gjatë ditëve të javës volume e telefonatave janë zakonisht ne rangun
500 – 800 telefonata, edhe pse volumet janë më të larta gjatë ditëve shumë të zëna. Ky projekt
shfaq një diagramë tipike të sezonalitetit javor, me volumet që zakonisht ulen gjatë javës së
punës.
Diagrama brenda ditës gjithashtu ndjek një diagramë standarte të projekteve të korporatës: një
pik gjatë orëve të mëngjesit herët, i ndjekur nga një qetësi drastike dhe një pik tjetër më i vogël
gjatë mbadites. Grafiku i mëposhtëm tregon këtë që sapo shpjeguam:
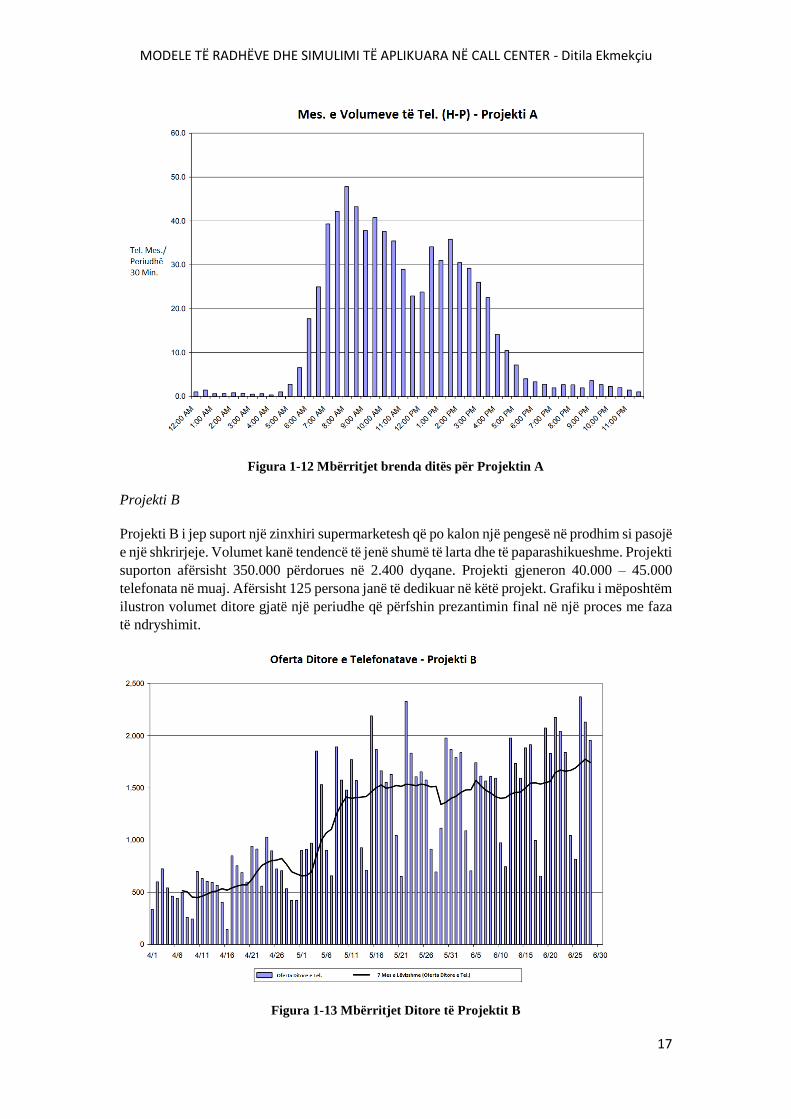
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
17
Figura 1-12 Mbërritjet brenda ditës për Projektin A
Projekti B
Projekti B i jep suport një zinxhiri supermarketesh që po kalon një pengesë në prodhim si pasojë
e një shkrirjeje. Volumet kanë tendencë të jenë shumë të larta dhe të paparashikueshme. Projekti
suporton afërsisht 350.000 përdorues në 2.400 dyqane. Projekti gjeneron 40.000 – 45.000
telefonata në muaj. Afërsisht 125 persona janë të dedikuar në këtë projekt. Grafiku i mëposhtëm
ilustron volumet ditore gjatë një periudhe që përfshin prezantimin final në një proces me faza
të ndryshimit.
Figura 1-13 Mbërritjet Ditore të Projektit B
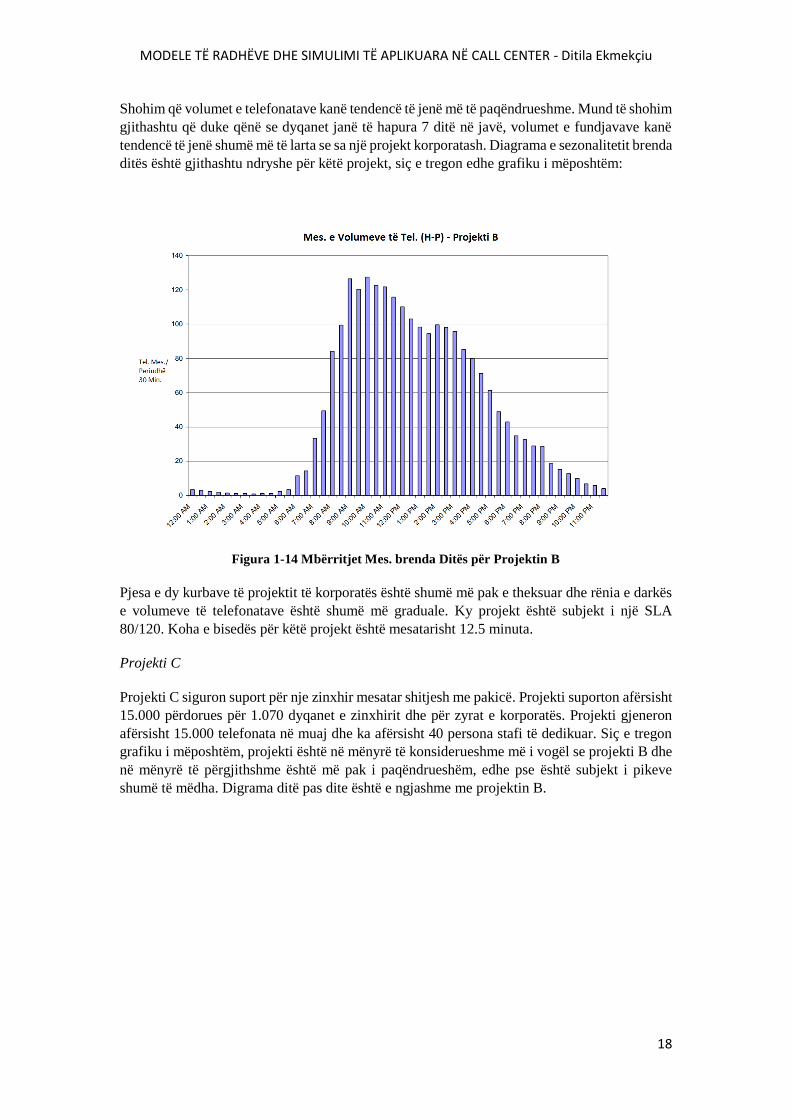
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
18
Shohim që volumet e telefonatave kanë tendencë të jenë më të paqëndrueshme. Mund të shohim
gjithashtu që duke qënë se dyqanet janë të hapura 7 ditë në javë, volumet e fundjavave kanë
tendencë të jenë shumë më të larta se sa një projekt korporatash. Diagrama e sezonalitetit brenda
ditës është gjithashtu ndryshe për këtë projekt, siç e tregon edhe grafiku i mëposhtëm:
Figura 1-14 Mbërritjet Mes. brenda Ditës për Projektin B
Pjesa e dy kurbave të projektit të korporatës është shumë më pak e theksuar dhe rënia e darkës
e volumeve të telefonatave është shumë më graduale. Ky projekt është subjekt i një SLA
80/120. Koha e bisedës për këtë projekt është mesatarisht 12.5 minuta.
Projekti C
Projekti C siguron suport për nje zinxhir mesatar shitjesh me pakicë. Projekti suporton afërsisht
15.000 përdorues për 1.070 dyqanet e zinxhirit dhe për zyrat e korporatës. Projekti gjeneron
afërsisht 15.000 telefonata në muaj dhe ka afërsisht 40 persona stafi të dedikuar. Siç e tregon
grafiku i mëposhtëm, projekti është në mënyrë të konsiderueshme më i vogël se projekti B dhe
në mënyrë të përgjithshme është më pak i paqëndrueshëm, edhe pse është subjekt i pikeve
shumë të mëdha. Digrama ditë pas dite është e ngjashme me projektin B.
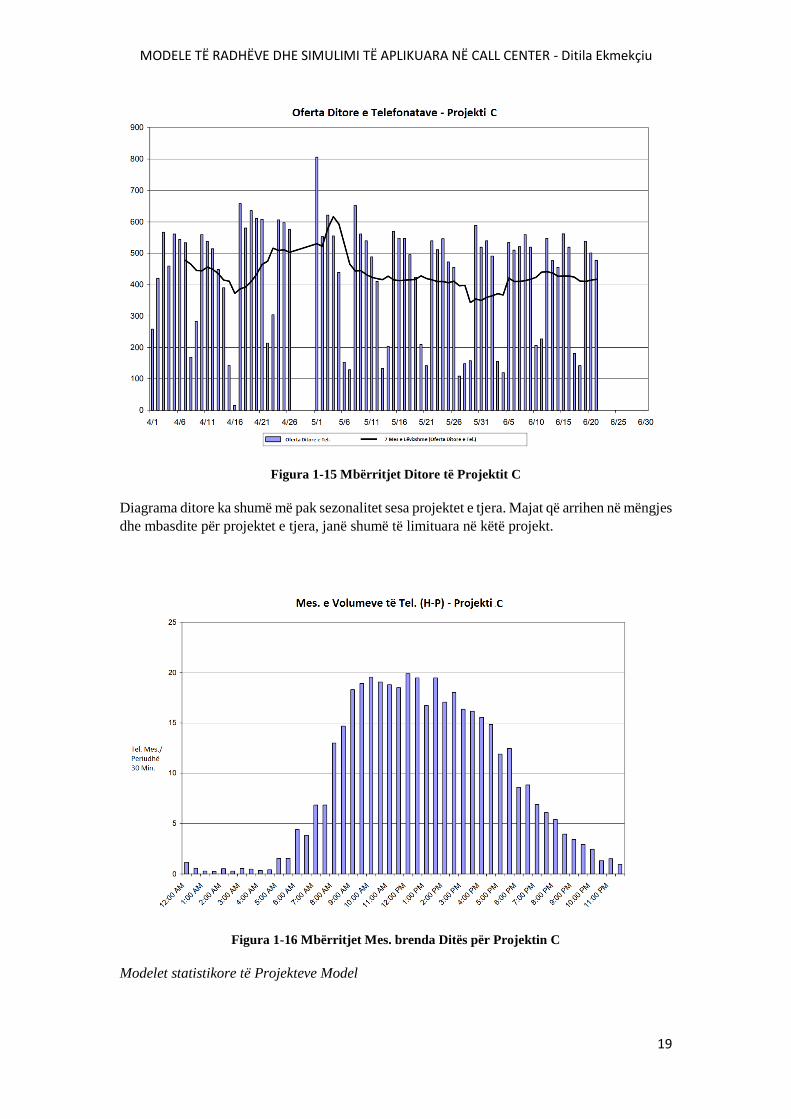
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
19
Figura 1-15 Mbërritjet Ditore të Projektit C
Diagrama ditore ka shumë më pak sezonalitet sesa projektet e tjera. Majat që arrihen në mëngjes
dhe mbasdite për projektet e tjera, janë shumë të limituara në këtë projekt.
Figura 1-16 Mbërritjet Mes. brenda Ditës për Projektin C
Modelet statistikore të Projekteve Model
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
20
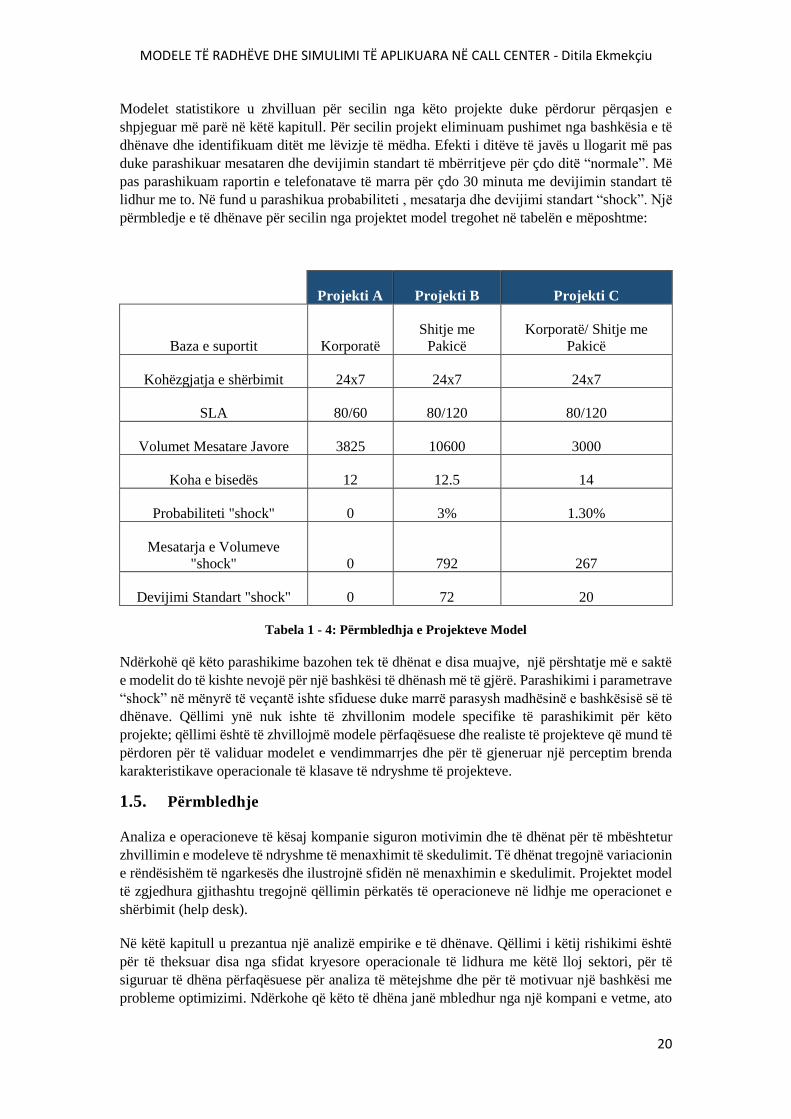
Modelet statistikore u zhvilluan për secilin nga këto projekte duke përdorur përqasjen e
shpjeguar më parë në këtë kapitull. Për secilin projekt eliminuam pushimet nga bashkësia e të
dhënave dhe identifikuam ditët me lëvizje të mëdha. Efekti i ditëve të javës u llogarit më pas
duke parashikuar mesataren dhe devijimin standart të mbërritjeve për çdo ditë “normale”. Më
pas parashikuam raportin e telefonatave të marra për çdo 30 minuta me devijimin standart të
lidhur me to. Në fund u parashikua probabiliteti , mesatarja dhe devijimi standart “shock”. Një
përmbledje e të dhënave për secilin nga projektet model tregohet në tabelën e mëposhtme:
Projekti A Projekti B Projekti C
Baza e suportit Korporatë
Shitje me
Pakicë
Korporatë/ Shitje me
Pakicë
Kohëzgjatja e shërbimit 24x7 24x7 24x7
SLA 80/60 80/120 80/120
Volumet Mesatare Javore 3825 10600 3000
Koha e bisedës 12 12.5 14
Probabiliteti "shock" 0 3% 1.30%
Mesatarja e Volumeve
"shock" 0 792 267
Devijimi Standart "shock" 0 72 20
Tabela 1 - 4: Përmbledhja e Projekteve Model
Ndërkohë që këto parashikime bazohen tek të dhënat e disa muajve, një përshtatje më e saktë
e modelit do të kishte nevojë për një bashkësi të dhënash më të gjërë. Parashikimi i parametrave
“shock” në mënyrë të veçantë ishte sfiduese duke marrë parasysh madhësinë e bashkësisë së të
dhënave. Qëllimi ynë nuk ishte të zhvillonim modele specifike të parashikimit për këto
projekte; qëllimi është të zhvillojmë modele përfaqësuese dhe realiste të projekteve që mund të
përdoren për të validuar modelet e vendimmarrjes dhe për të gjeneruar një perceptim brenda
karakteristikave operacionale të klasave të ndryshme të projekteve.
1.5. Përmbledhje
Analiza e operacioneve të kësaj kompanie siguron motivimin dhe të dhënat për të mbështetur
zhvillimin e modeleve të ndryshme të menaxhimit të skedulimit. Të dhënat tregojnë variacionin
e rëndësishëm të ngarkesës dhe ilustrojnë sfidën në menaxhimin e skedulimit. Projektet model
të zgjedhura gjithashtu tregojnë qëllimin përkatës të operacioneve në lidhje me operacionet e
shërbimit (help desk).
Në këtë kapitull u prezantua një analizë empirike e të dhënave. Qëllimi i këtij rishikimi është
për të theksuar disa nga sfidat kryesore operacionale të lidhura me këtë lloj sektori, për të
siguruar të dhëna përfaqësuese për analiza të mëtejshme dhe për të motivuar një bashkësi me
probleme optimizimi. Ndërkohe që këto të dhëna janë mbledhur nga një kompani e vetme, ato

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
21
përfaqësojnë kompani të tjera me të njejtat lloje të dhënash dhe për këtë arsye janë shumë të
përgjithshme. Vëzhgime të rëndësishme që mund të bëhen nga kjo analizë përfshijnë:
• Mbërritjet janë shumë variabël.
• Mbërritjet tregojnë sezonalitetin e ditëve të javës dhe orëve të ditës
• Parashikimi i mbërritjeve është shumë i vështirë dhe i prirur drejt gabimeve të
konsiderueshme.
Nga këto të dhëna ne identifikojmë disa pyetje kërkimore të vlerës teorike dhe praktike. Këto
pyetje përfshijnë të mëposhtmet:
• Çfarë duhet të masim në kushte pasigurie kur skedulojmë operatorët e call center-it?
• Çfarë ndikimi kanë pasiguria dhe variacioni në nivelet optimale të stafit?
• Si mund të krijojmë sisteme operative më rezistente ndaj madhësive rastësore dhe
variacionit?
Përgjigja e këtyre pyetjeve vjen duke zhvilluar dy modelet e përmendura më parë të menaxhimit
të skedulimit të call center-it.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
22
KAPITULLI 2: NJË VËSHTRIM I DISA MODELEVE
BASHKËKOHORE STOKASTIKE TË OPERACIONEVE NË
CALL CENTER
Në këtë kapitull do të rishikohen dhe përmblidhen disa nga modelet bashkëkohore Stokastike
të Operacioneve në CC, të cilët do të jenë baza për strukturimin e modeleve të trajtuara për
rastin tonë. Do të shikohen modelet e lidhura me fushat e mëposhtme:
• Planifikimi i fuqisë punëtore: Do të shikohen modelet taktike dhe strategjike të
lidhur me planifikimin e kapacitetit të fuqisë punëtore, analiza e shpërdorimeve
dhe modelet e sistemeve të planifikimit të fuqisë punëtore në praktikë.
• Call Center-at: modelet që adresojnë në mënyrë specifike operacionet e call
center-ave.
• Optimizimi stokastik: modelet që adresojnë çështjet metodologjike të lidhura me
optimizimin në kushtet e mbërritjeve të rastit.
• Dizenjimi i Eksperimenteve Statistikore: Modelet që adresojnë çështjet
metodologjike të lidhura me dizenjimin, ekzekutimin dhe analizën e
eksperimenteve statistikore
2.1. Planifikimi i fuqisë punëtore
Planifikimi i fuqisë punëtore u kthye në një çështje shumë të famshme në vitet e fillimit të
Kërkimeve Operacionale. Shumë artikuj kërkimorë dhe tekste të ndryshme (Holt, Modigliani
et al. 1960; Charnes, Cooper et al.1978; Bartholomeë and Forbes 1979) adresuan aspekte të
problemit të planifikimit të fuqisë punëtore duke u bazuar në gjatësinë e horizontit të
planifikimit.
Në planifikimin taktik, kapaciteti i fuqisë punëtore konsiderohet fiks dhe objektivi është të
zhvillohen skedulime efiçente që të balancojnë objektivat dhe kufizimet e qëndrueshme dhe
individuale. Planifikimi afatshkurtër përfshin përcaktimin në kohë graduale kërkesat për fuqi
punëtore. Kurse turnet përfshijnë caktimin e individëve në orare specifike. Në planifikimin
strategjik, kapaciteti i fuqisë punëtore është një variabël i zgjedhjes. Në planifikimin afatmesëm
kërkojmë të bëjmë sistemime të kapacitetit afër afatit nëpërmjet punësimeve të reja dhe
përfundimeve të kontratave. Planifikimi afatgjatë përfshin formimin e fuqisë punëtore në një
periudhë të zgjeruar kohe dhe konsideron çështje si progresi në karrierë dhe ndryshimin e
kompetencave. Gjithashtu do të rishikohet literatura e bazuar në praktikë, artikuj që
konsiderojnë se si modelet e planifikimit të fuqisë punëtore janë aplikuar në kompani reale.
Problemi i planifikimit taktik merret me caktimin e një numri specifik personash në skedulime
të detajuara. Ky problem është analizuar në literaturë gjerësisht, që daton nga problemi i
bashkësisë së mbulimit fillimisht i modeluar nga Dantzig në vitin 1954 (Dantzig 1954). Modeli
i Dantzig formuloi skedulimin taktik si një programim linear. Modeli i tij supozon se dita e
punës mund të ndahet në një numër periudhash diskrete, të themi bashkësi prej 15 ose 30
minutash, dhe se numri i kërkuar i punonjësve për secilën periudhë kohore mund të
specifikohet. Modeli i Dantzig gjithashtu supozonte se një numër i turneve të punës standarde
mund të përcaktohet, duke specifikuar periudhën e fillimit dhe mbarimit të punës, së bashku
me çdo ndërprerje.
Matematikisht modeli Dantzig mund të shprehet si:
Të minimizohet

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
23
∑ 𝑥𝑗𝑛𝑗=0 (2.1)
Me kushtin:
∑ 𝑎𝑡𝑗𝑥𝑗 ≥ 𝑏𝑡 , 𝑥𝑗 ≥ 0𝑛𝑡=0 (2.2)
Ku bt përfaqëson numrin e punonjësve të kërkuar në periudhën t dhe variabli i vendimit xt
nënkupton numrin e punonjësve të caktuar në turnin j. Koeficienti atj është i barabartë me një
nëse turni j punon në periudhën t dhe është zero në të kundërt. Në këtë formë të thjeshtë të
gjitha turnet janë njësoj të kushtueshme dhe objektivi është që të minimizohet numri total i
turneve të planifikuara. Një shtrirje e thjeshtë shton një koeficient kostoje cj në turn gjë që
lehtëson turnet e gjatësive të ndryshme, ose turne me diferenca në normat e pagave. Modeli i
Dantzig-ut kërkon një variabël vendimi për çdo turn që korrespondon me numrin e punonjësve
të caktuar dhe një kufizim për secilën periudhë kohore.
Ky model duket mjaft linear në sipërfaqe, por është në fakt mjaft i fuqishëm, dhe për fat të keq
mund të bëhet mjaft i ndërlikuar në llogaritje. Janë tre karakteristika që mund ta bëjnë atë të
vështirë në llogaritje.
Së pari, është kërkesa praktike që të gjithë variablet e vendimeve të jenë të vlerësuara si numra
të plotë2. E dyta është çështja e skedulimit të vazhdueshëm; që është 24 orë operacione pa
vonesa. Së fundi dhe ndoshta në mënyrë më të rëndësishme, është çështja e qartë e pushimeve
të skeduluara. Konsideroni një problem më të rëndësishëm që trajtohet në Henderson dhe Berry
(1976). Ata vlerësojnë një problem skedulimi të një operatori telefonik. Operatorët janë
skeduluar për turne 8 orarëshe, me një ndërprerje për pushim dreke me gjatësi variabël dhe
pushime prej 15 minutash të skeduluara në mënyrë eksplicite. Modeli adreson vetëm orët e
pikut të kërkesës nga ora 6:00 deri në 12 në mesnatë. Për shkak të kërkesës për të skeduluar një
pushim prej 15 minutash horizonti i planifikimit është i ndarë në 72 periudha prej
pesëmbëdhjetë minutash.
Kërkesat për organizimin e stafit janë përcaktuar në mënyrë të jashtme dhe ndryshojnë me
kalimin e kohës si në shembullin e mëposhtëm:
2 Modeli origjinal i Dantzig është zgjidhur me dorë si një Programim Linear. Ai sugjeroi rrumbullakimin
e zgjidhjeve si numra jo të plotë, ndërsa rrumbullakosja është një përqasje e zbatueshme për skedulimin
e një pike pagese në autostrada; nuk është praktike për një cell center me qindra, ose mijëra modele
potenciale turnesh

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
24
Figura 2-1 Kërkesat e Kampionimit të Operatorëve
Duke pasur parasysh mundësitë e ndryshme për kohën e fillimit dhe kombinimet e mundshme
të kohës së pushimit, modeli përfshin 7,120 variabla të ndryshëm vendimi. Modeli gjithashtu
përfshin 72 kufizime për të llogaritur kërkesën në secilën periudhë.
Kërkesa për të modeluar shprehimisht pushimet është e kushtueshme. Pa pushime ka më së
shumti 72 turne të ndryshme me kohë të plotë, një për çdo periudhë kohore diskrete. Pra,
plotësisht 98% e variablave të vendimit janë një rezultat i drejtpërdrejtë i problemit të
skedulimit të qartë të pushimeve. Vlen të përmendet se modeli Henderson dhe Berry thjeshton
problemin për të shmangur problemin e vazhdueshëm të organizimin të stafit (24 orë). Modeli
i tyre skedulon vetëm orët e pikut nga ora 6:00 deri në mesnatë, gjë që u lejon atyre të trajtojnë
çdo ditë si një problem skedulimi më vete. Pa këtë thjeshtim, numri i periudhave të skedulimit
do të rritej me një faktor shumëfishues të barabartë me numrin e ditëve në horizontin e
planifikimit.
Problemi i skedulmit të stafit është një rast i veçantë i problemit të bashkësisë së mbulimit në
të cilin objektivi është që të minimizohet shuma e ponderuar e bashkësisë së mbulimeve, me
peshat që janë kostoja e çdo turni. Problemi i Skedulimit të Stafit është i njohur të jetë “NP
Complete” (Problem polinomial jo determinist pa zgjidhje të njohur në kohë realiste), përveç
nëse ka karakteristikën ciklike 1 (Garey dhe Johnson 1979); që do të thotë nëse asnjë turn nuk
është i vazhdueshëm pa ndërprerje.
Të qënurit “NP Complete” nënkupton mungesën e një algoritmi të zgjidhjes për kohë
polinomiale.
Praktikisht kjo do të thotë se problemet e skedulimit të stafit që përfshijnë pushimet eksplicite
janë në thelb të pakapërcyeshme. Shumica e kërkimeve në lidhje me skedulimin e stafit është e
lidhur direkt ose indirekt me këtë problem kapërcimi.
Turne të vazhdueshme
Një numër artikujsh analizojnë problemet e skedulimit të stafit që nuk skedulojnë në mënyrë
eksplicite pushimet. Pa këtë kërkesë problemi nuk është më “NP Complete” dhe një numër
përqasjesh me kohë polinomiale janë në dispozicion. Segal tregon se pa pushime problemi
mund të modelohet si një problem i rrjedhës së rrjetit (Segal 1974). Baker shqyrton problemin
e skedulimit të infermierëve me orar të plotë për të përmbushur një kërkesë deterministike të
stafit në një seri artikujsh. Modeli i parë (Baker 1974a) konsideron vetëm punonjësit me orar
të plotë dhe përpjekjet për të gjetur një shpërndarje optimale të ditëve të pushimit gjatë një

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
25
skedulimi javor (7 ditor) ku çdo punonjës është skeduluar për dy ditë pushimi rresht. Një tjetër
artikull e shtrin këtë model për të lejuar fleksibilitetin e shtuar të skedulimit të punonjësve me
kohë të pjesshme së bashku me punonjësit me kohë të plotë (Baker 1974b). Një model i tretë
(Baker dhe Magazine 1977) përsëri konsideron vetëm punonjës me kohë të plotë, por vlerëson
një numër të ndryshëm politikash të ditëve pushim. Kjo seri artikujsh tregon se algoritme
efiçente mund të zhvillohen për raste specifike, duke shmangur nevojën për të zgjidhur
programimet me numra të plotë. Problemi i skedulimit të infermjereve është analizuar më tej
në një tjetër grup artikujsh nga Warner et al. Modeli në (Warner dhe Prawda 1972) gjithashtu
shmang problemin e pushimit eksplicit, por paraqet ndërlikime të tjera që gjithashtu e bëjnë
problemin e llogartijes të vështirë. Një tipar i rëndësishëm i këtij modeli është aftësia për të
zëvendësuar një klasë të infermierëve me një tjetër me një efiçencë proporcionale. Për
shembull, një person AB mund të skedulohet në vend të nje CD, por siguron vetëm 70% të
produktivitetit te CD-së. (Warner 1976) ndërton problemin e skedulimit të infermierëve dhe
trajton çështjen e planifikimit, caktimin e individëve specifikë në turne. Një rishikim i detajuar
dhe aktual i problemit të plnifikimit të infermierëve është dhënë në (Burke, De Causmaecker et
al. 2004),
Skedulimi i Pushimeve Fikse
Prezantimi i kohës eksplicite të pushimit në problemin e skedulimit shton kompleksitet
kompjuterik të konsiderueshëm, duke e bërë problemin të vështirë për probleme të madhësisë
mesatare.
Kërkuesit e kanë adresuar këtë problem në disa mënyra; përmes thjeshtimit të problemit, me
metoda heuriste dhe algoritme alternative. Modeli Henderson dhe Berry (Henderson dhe Berry
1976) zbaton dy lloj heuristikash. Heuristika e parë zvogëlon numrin e llojeve të turneve, duke
skeduluar vetëm kundrejt një grupi të reduktuar skedulimesh të referuara si nëngrupi i punës.
Përafrimi i dytë është algoritmi i skedulimit; autorët përdorin 3 heuristika të ndryshme
skedulimi.
Një rrymë alternative e kërkimit sulmon problemin duke përdorur një përqasje skedulimi
implicite. Modelet implicite të skedulimit zakonisht përdorin një përqasje me dy faza, duke
gjeneruar një skedulim të përgjithshëm në fazën e parë, dhe pastaj vendosja e pushimeve në
fazën e dytë. Përqasje implicite skedulimi janë adresuar në (Bechtold dhe Jacobs 1990),
(Thompson 1995) dhe (Aykin 1996). (Thompson 1995) përfshin një përmbledhje të artikujve
të lidhur dhe më pas zhvillon një Model Skedulimi të Turneve Dyfish Implicite (DISSM).
(Aykin 1996) Disa artikuj të tjerë adresojnë probleme të ngjashme (Brusco dhe Johns 1996,
Brusco dhe Jacobs 1998, Brusco dhe Jacobs 2000).
Një përmbledhje e shkurtër e një përqasjeje me dy faza për skedulimin në një mjedis call center-
i është parashikuar në seksionin 12.7 të (Pinedo 2005). Ky model është i motivuar nga një
aplikim i call center-it ku kërkesat e punonjësve janë të përcaktuara në mënyrë të jashtme dhe
pushimet duhet të skedulohen.
Pinedo e përmbledh përqasjen e tij në figurën e mëposhtme:

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
26
Figura 2-2 Përqasja interaktive e Skedulimit
Hapi “Zgjidh Rrugë të Sigurta” përdor një përqasje të programimit matematikor për të
përshtatur skedulimet pa konsiderata pushimi drejt Kërkesës Objektiv. Kërkesa Objektiv është
kërkesa e përgjithshme e fryrë për të qënë disi më e lartë se kërkesa aktuale për të llogaritur
humbjet për shkak të pushimeve. Vendosja e hapit të pushimeve përdor heuristikën për të
skeduluar pushimet në rrugët e sigurta. Hapi i krahasimit të vlerësimit llogarit një funksion të
formës së mëposhtme:
ℑ = 𝛹− ∑ 𝑒−(𝑡) + 𝐻𝑡=1 𝛹+ ∑ 𝑒+(𝑡) 𝐻
𝑡=1 (2.3)
Në këtë llogartije diferenca ndërmjet nivelit të kërkuar të organizimit të stafit dhe nivelit të
skeduluar të organizimit të stafit është shënuar me e(t); e+(t) është niveli i mbi organizimit të
stafit dhe ψ+ është gjoba e mbi organizimit të stafit. Algoritmi kërkon të minimizojë masën
totale të kostos:
C = ℑ + ∑ 𝑐𝑗𝑥𝑗𝑗 (2.4)
Një masë e pershtatshme e përgjithshme përcaktohet si zbutja:
L = ∑ 𝑒(𝑡)2𝐻𝑡=1 (2.5)
E cila llogaritet si shuma e devijimeve në katror nga kërkesat. (Cezik dhe L'Ecuyer 2007)
zgjidhin një problem të nivelit global të shërbimit duke përdorur simulimin dhe programimin
me numra të plotë. Ata përdorin simulimin për të vlerësuar arritjet në nivel të shërbimit dhe
programimin me numra të plotë për të gjeneruar skedulimin. Modeli i programimit me numra
të plotë gjeneron prerje nëpërmjet vlerësimit të nën gradientit të llogaritur nëpërmjet simulimit.
Modeli zgjidh problemin mesatar të mostrës dhe prandaj injoron pasigurinë në normën e
mbërritjes, por lejon aftësi të shumfishta. Ky model është një shtrirje e modelit të paraqitur në
(Atlason, Epelman et al 2004). Në një artikull të lidhur (Avramidis, Chan et al. 2007) përdoret
një algoritëm lokal kërkimi për të zgjidhur të njëjtin problem. Një model i lidhur paraqitet në
(Avramidis, Gendreau et al. 2007).
Literatura e planifikimit strategjik të kapaciteteve përgjithësisht ndahet në dy përqasje
plotësuese. Në një përqasje evolucioni i fuqisë punëtore modelohet si një proces stokastik që
evolon me kalimin e kohës (Bartolomeu dhe Forbes 1979; Bartolomeu 1982). Kjo përqasje
modelon në mënyrë eksplicite natyrën stokastike të punësimit, qarkullimit, përthithjes së
aftësive dhe kërkesës. Një përqasje alternative bazohet në një shembull optimizimi në të cilin

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
27
objektivi është të krijohet një grup kontrolli vendimesh përgjatë kohës që optimizohen disa
masa të performancës së sistemit, të tilla si kostoja totale, devijimi nga plani i organizimit të
stafit, ose fitimi i pritur (Holt, Modigliani et al. 1960). Punimet më të fundit kanë tentuar të
integrojnë pasigurinë dhe optimizimin, që është dhe fokusi i këtij kërkimi.
Kapaciteti i Fuqisë Punëtore si një Proces Stokastik
Modelet stokastike të sistemeve të fuqisë punëtore përqëndrohen në pasigurinë e qenësishme
në sistem. Bartholomew ofron një rishikim të përgjithshëm të aplikimit të modelimit stokastik
në sistemet sociale në (Bartholomew 1982), dhe një aplikim më specifik të këtyre principeve
në problemin i planifikimit të fuqisë punëtore në (Bartholomew dhe Forbes 1979). Një model
bazë përfshin një numër gradash diskrete të fuqisë punëtore. Gjendja e sistemit pastaj
përcaktohet si numri i punonjësve aktualisht në secilën gradë. Nëse bëjmë supozimet standarde
të Markovit atëherë sistemi mund të modelohet si një Zinxhir Markovian me Kohë Diskrete
(DTMC).
Shumë artikuj kanë ndërtuar mbi këtë model të thjeshtë Markovi për të analizuar sistemet e
fuqisë punëtore, duke futur objektiva të ndryshme të kontrollit në proces. Grinold zhvillon një
model stokastik të motivuar nga kërkesa për avionë detarë (Grinold 1976). Mjedisi evoluon si
një proces Markovian dhe kërkesa për aviatorë për pasojë ka një shpërndarje probabiliteti të
përcaktuar. Objektivi i kontrollit është pastaj për të gjetur politikën optimale të pranimit që
qeveris hyrjet e reja në sistem, dhe politikën e vazhdimit që rregullon lëvizjen përmes sistemit.
Një tipar i dobishëm i modelit është aftësia për të bërë dallimin ndërmjet numrit të punonjësve
bruto dhe personelit të kualifikuar dhe një implikim i rëndësishëm i këtij modeli është që
ndryshimet në kapacitet nuk janë të çastit por udhëhiqen nga vonesat që duhen për te trjanuar
rekrutimet e reja.
Kjo çështje trajtohet më tej në (Anderson 2001). Në këtë model kërkesa është nxitur nga një
proces sezonal i vazhdueshëm jostacionar i menduar për të përafruar një cikël biznesi. Modeli
në mënyrë eksplicite supozon që punonjësit përparojnë me norma diferenciale, ndryshe nga
normat deterministike në Grinold. Objektivi shkëmben koston e skontuar të plotësimit të
rekuiziteve të kërkesës me një normë gjobe për ndryshime të papritura në stokun e punonjësve.
Bazuar në këtë objektiv, Anderson përdor një përqasje dinamike të programimit për të
përcaktuar politikat optimale të kontrollit.
Një numër artikujsh të tjerë shqyrtojnë problemin strategjik të organizimit të stafit duke
përdorur një ambjentim stokastik. (Gans dhe Zhou 2002) zhvillojnë një model me kurbë të
mësimit dhe çështje stokastike të qarkullimit të personelit. (Gaimon 1997) shqyrton
planifikimin e fuqisë punëtore në kontekstin e punonjësve të IT-së me njohuri intensive.
(Bordoloi dhe Matsuo 2001) gjithashtu shqyrtojnë një mjedis pune me njohuri intensive me
qarkullim stokastik të punonjësve.
Planifikimi Strategjik i Fuqisë Punëtore si një Problem Optimizimi
Një përqasje alternative ndaj planifikimit të fuqisë punëtore bazohet në teorinë e optimizimit.
Themelet teorike të përqasjes optimizuese të fuqisë punëtore u zhvilluan në Holt et al. (Holt,
Modigliani et al. 1960). Holt vlerëson fuqinë punëtore si një komponent i kapacitetit produktiv
të një ndërmarrje prodhuese, duke vlerësuar vendimet e organizimit të stafit në një kontekst të
planifikimit të agreguar. Holt zhvillon një model katror të kostos që përfshin si shpenzimet e
mbajtjes së një fuqie punëtore dhe koston e ndryshimit të fuqisë punëtore. Modeli i kostos
katrore të Holt konvertohet në një model kostoje lineare në (Hanssmann dhe Hess 1960) dhe
zgjidhet nëpërmjet programimit linear. Modeli Holt është po ashtu i zgjeruar në (Ebert 1976)
me përfshirjen e produktivitetit të ndryshueshëm në kohë. Ebert përdor modelin e kostos katrore
direkt nga Holt, por lejon që produktiviteti të ndryshojë me kalimin e kohës ndërkohë që mësimi
zhvillohet. Ebert e zgjidh këtë programim jolinear duke përdorur një kërkim heuristik. Një

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
28
formulim alternativ që përfshin edhe efektet e kurbës së të nxënit është paraqitur në (Harrison
dhe Ketz, 1989). Ky model është jolinear por zgjidhet nëpërmjet programimit linear të
njëpasnjëshëm.
Të dyja përqasjet në planifikimin e fuqisë punëtore të përshkruara më sipër theksojnë aspekte
të ndryshme të sistemit dhe si të tilla kanë aplikime të ndryshme. Modelet stokastike në
përgjithësi janë abstraksione të nivelit të lartë të dobishme për identifikimin e fenomenit të
sistemit ose zhvillimin e politikave të përgjithshme. Modelet e optimizimit në anën tjetër janë
hartuar shpesh për të identifikuar veprimet e veçanta të menaxhimit por kanë tendencë të
injorojnë ndryshueshmërinë në sistem. Parametrat variabël zakonisht modelohen me vlerat e
pritshme të tyre dhe japin atë që njihet si problemi i vlerës mesatare që mund të rezultojë në
zgjidhje që janë larg nga optimalja (Birge dhe Louveaux 1997). Ndryshueshmëria e modelimit
në problemet e optimizimit ka të ngjarë të japë zgjidhje që janë superiore ndaj homologëve
deterministë, por zgjidhjet për këto programime stokastike janë të vështira për t'u gjetur.
Planifikimi i Fuqisë Punëtore në Praktikë
Ekztiston një numër artikujsh në literaturë që përshkruajnë implementimin e sistemeve të
planifikimit të fuqisë punëtore në praktikë. Shumë nga këto artikuj janë të përqendruar në
problemin e skedulimit taktik (Schindler dhe Semmel 1993) përshkruan një aplikacion që
përdoret për të skeduluar operatorët e stacionit ajror. (Mason, Ryan et al. 1998) trajton një
problem të ngjashëm, skedulimin e zyrtarëve të doganave në Aeroportin e Zelandës së Re.
(Gaballa dhe Pearce 1979) studiojnë skedulimin e operatorëve telefonikë në Quantas. (Andrews
dhe Parsons 1993) zhvillojnë një model që përcakton numrin e kërkuar të operatorëve për të
skeduluar në një call center bazuar në një optimizim të organizimit të stafit dhe shpenzimet e
shërbimit të klientit. (Saltzman dhe Mehrotra 2001) po ashtu shqyrtojnë çështjen e organizimit
të stafit të call center-ave. (Yu, Pachon et al. 2004) përshkruan një sistem të zhvilluar për
Continental Airlines që përfshin një përzierje interesante të vendime afatshkurtra dhe afatgjata.
Ka disa artikuj të tjerë në literaturë që adresojnë planifikimin strategjik të fuqisë punëtore në
praktikë, kryesisht në kontekstin e ushtrisë së Shteteve të Bashkuara. Një sistem i planifikimit
afatgjatë për Ushtrinë e SHBA-ve përshkruhet në 2 artikuj, (Holz dhe Wroth 1980) dhe (Gass,
Collins et al, 1988). (Bres, Burns et al. 1980) përshkruajnë një model të zhvilluar për Ushtrinë
e SHBA-ve në vitet 1970. (Shrimpton dhe Newman 2005) përshkruajnë një model të përdorur
për të përcaktuar fushat e karrierës për oficerët në Ushtrinë Amerikane. (Krass, Pinar et al.
1994) zhvillojnë një model për ndarjen e personelit për njësitë luftarake të marinës amerikane.
(Morey dhe McCann 1980) analizon çështjen e shpërndarjes së burimeve drejt rekrutimit.
2.2. Operacionet e Call Center-ave
Në këtë seksion do të diskuojmë modelet që adresojnë operacionet në Call Center-a. Ekzitojnë
tre kategori themelore që përshkruajnë objektivat e organizimit të stafit e të shërbimit të klientit
të call center-ave (Gans, Koole et al. 2003).
• Regjimi i drejtuar nga cilësia: kostot e pritjes së konsumatorëve supozohet të
dominojnë koston e kapacitetit dhe objektivi është që të shërbehet shumica e
konsumatorëve pa vonesë. Nivelet e organizimit të stafit rriten linearisht me ngarkesën
e ofruar. Shfrytëzimi mesatar në këtë regjim është zakonisht i ulët, në rendin e 65-75%
dhe koha mesatare e pritjes së klientit është gjithashtu e ulët.
• Regjimi i drejtuar nga efiçenca: kostot e organizimit të stafit supozohet të dominojnë
koston e vonesave të konsumatorit dhe objektivi operacional në këtë regjim është që të
maksimizohet efiçenca e operacioneve.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
29
• Regjimi i drejtuar nga Efiçenca e Cilësisë (QED): një mjedis operacional që përpiqet
të gjejë një balancë midis efiçencës dhe shërbimit të klientit është regjimi QED.
Ndryshe nga regjimi i cilësisë ku përqindja e klientëve të vonuar është afër zeros, ose
nga regjimi i efiçencës ku përqindja e vonuar është afër njëshit, regjimi QED balancon
kostot dhe përpjekjet për të arritur një përqindje të qëndrueshme të vonesës ndërmjet 0
dhe 1. Operacionet QED janë të lehtësuara nga ekonomitë e shkallës, sepse organizimi
i stafit të call center-it është subjekt i organizimit të stafit me rrënjë katrore dhe është e
mundur që të arrihen nivele të larta të shfrytëzimit dhe probabilitet të ulët të pritjes nëse
shkalla e call center-it është e madhe.
Kjo kornizë shfrytëzohet për të kategorizuar kërkimet në shumë punime në literaturë.
Një sasi e konsiderueshme e kërkimeve adreson modelet bazë të radhëve të call center-ave. Tre
modelet bazë të radhëve të përdorura më shumë në literature janë modelet Erlang C, Erlang B
dhe Erlang A. I rishikojmë shkurtimisht këto modele dhe literaturën përkatëse.
Erlang C
Modeli Erlang C është identik me radhën M / M / N dhe përdoret gjerësisht në sistemet e
menaxhimit të fuqisë punëtore (WFM) (Gans, Koole et al 2003, Mandelbaum dhe Zeltyn 2004).
Modeli Erlang C konsideron një proces të mbërritjeve të Puasonit me normë konstante λ, të
pavarur dhe kohë shërbimi të shpërndarë në mënyrë eksponenciale me mesataren 1/μ, dhe një
grupim operatorësh homogjenë (statistikisht identikë). Supozohet se sistemi ka një numër të
pafundëm linjash dhe një radhë të pafundme, kështu që asnjë telefonues nuk bllokohet
asnjëherë. Për më tepër, modeli supozon që të gjithë telefonuesit të cilët hyjnë në radhë
përfundimisht janë shërbyer kështu që modeli nuk lejon braktisjen. Ky model jep formula
relativisht të drejtpërdrejta për matësit kyç të performancës.
Duke ndjekur terminologjinë në (Gans, Koole et al. 2003) do të përcaktohet si ngarkesë te
ofruar:
Ri ≡ 𝜆𝑖/𝜇𝑖 = 𝜆𝑖𝐸[𝑆𝑖] (2.6)
Dhe si intensitet trafiku (e thënë ndryshe si shfrytëzimi):
ρi ≡ 𝜆𝑖/(𝑁𝜇𝑖) = 𝑅𝑖/𝑁 (2.7)
Duke patur parasysh mungesën e braktisjes dhe supozimet e gjendjes së qëndrueshme të
modelit Erlang C, intensiteti i trafikur duhet të jetë në menyrë strike më pak se një për
stabilitetin e sistemit.
Probabiliteti i gjëndjes së qëndrueshme që të gjithë N operatorët të jenë të zënë jepet më pas si:
𝐶(𝑁, 𝑅𝑖) ≜ 1 − (∑𝑅𝑖
𝑚
𝑚!
𝑁−1𝑚=0 ) / (∑
𝑅𝑖𝑚
𝑚!+ (
𝑅𝑖𝑚
𝑁!) (
1
1−𝑅𝑖/𝑁)𝑁−1
𝑚=0 ) (2.8)
Kjo është identike me përqindjen e konsumatorëve që duhet të presin për t’u shërbyer nga
dikush:
P{W>0} = C(N,Ri) (2.9)
Parimi "Mbërritjet e Puasonit Shohin Mesataret e Kohës" (PASTA) i zhvilluar në (Wolff 1982;
Wolff 1989) nënkupton që vonesa e kushtëzuar në radhë ka një shpërndarje eksponenciale me
mesatare ( Nµi – λi )-1. Matësi i nivelit të shërbimit pastaj mund të shprehet si:

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
30
𝑇𝑆𝐹 ≜ 𝑃{𝑊 ≤ 𝑇} = 1 − 𝑃{𝑊 > 0} ∙ 𝑃{𝑊 > 𝑇|𝑊 > 0} = 1 − 𝐶(𝑁, 𝑅𝑖) ∙ 𝑒−𝑁𝜇𝑖(1−𝜌𝑖)𝑇 (2.10)
Matësi i shpejtësisë në përgjigje përcaktohet në mënyrë të thjeshtë si:
𝐴𝑆𝐴 ≜ 𝐸[𝑊] = 𝑃{𝑊 > 0} ∙ 𝐸[𝑊 > 𝑇 |𝑊 > 0] = 𝐶(𝑁, 𝑅𝑖) ∙ (1
𝑁) ∙ (
1
𝜇𝑖) ∙ (
1
1−𝜌𝑖) (2.11)
Një artikull i rëndësishëm që analizon modelin Erlang C në kontekstin e regjimit QED është
(Halfin dhe Whitt 1981). Ky artikull zhvillon parimin e mirënjohur të organizimit të stafit me
rrënjë katrore që përcakton që numri i operatorëve të jetë:
𝑁 = 𝑅 + 𝛽√𝑅 (2.12)
ku β është një sasi jo-negative që përcakton gradën e shërbimit. Rëndësia e përafrimit Halfin-
Whitt është nocioni që për një cilësi fikse të shërbimit, kërkesat e organizimit të stafit rritet me
rrënjën katrore të ngarkesës së ofruar. Ky parim i thjeshtë thekson natyrshëm ekonomitë e
shkallës në organizimit e stafit e call center-ave.
Në artikullin (Ekmekçiu 2017) aplikohet pikërisht modeli Erlang C për të analizuar
performancën e call center-it. Analiza tregon që modeli Erlang C është subjekt i gabimeve të
rëndësishme në performancën e sistemit të parashikimit pasi nuk merr parasysh normën e
braktisjes dhe punon më mire në rastet e call center-ave me numër te lartë operatorësh.
Erlang B
Erlang B është një model i humbjes, një model që supozon se numri i linjave në dispozicion
është saktësisht i barabartë me numrin e operatorëve. Në këtë model, telefonuesit ose shërbehen
menjëherë ose bllokohen nga radha (ata përballen me një sinjal të zënë). Erlang B, i njohur
gjithashtu si Formula e Humbjes së Erlang-ut, është shpesh i përdorur për të llogaritur numrin
e linjave që kërkohen për të arritur një probabilitet të dëshiruar bllokimi. Formula e Humbjes
së Erlang-ut është paraqitur në (Hall 1991) si:
𝑃(𝑖 ℎ𝑢𝑚𝑏𝑗𝑒𝑠 𝑠ë 𝑘𝑜𝑛𝑠𝑢𝑚𝑎𝑡𝑜𝑟𝑖𝑡) =𝑟𝑚 𝑚!⁄
∑ 𝑟𝑖 𝑖!⁄𝑚𝑖=1
(2.13)
Edhe pse fillimisht rrjedh nga Erlangu nën supozimin e kohës eksponenciale të shërbimit,
ekuacioni (2.13) është treguar më vonë se aplikohet për çdo shpërndarje të kohës së bisedës.
Duke qenë se kostot e telekomunikacionit janë relativisht të ulëta, shumica e modeleve të
organizimit të stafit të call center-ave do të supozojnë kapacitet të mjaftueshëm të linjave në
mënyrë që asnjë thirrje të mos bllokohet dhe funksioni i humbjes të mos përdoret. Funksioni i
Humbjes së Erlang-ut nganjëherë përdoret në lloje të tjera të modeleve të radhës ku bllokimi
është i rëndësishëm, për shembull qendrat e traumave. Shihni (Cachon dhe Terwiesch 2006)
për disa shembuj.
Erlang A
Thjeshtësia relative e Erlang C është një rezultat i drejtpërdrejtë i supozimit relativisht të fortë
të mungesës së braktisjes. Siç kemi treguar në kapitullin e parë, normat e braktisjes në call
center-at e orientuara në dhënie shërbimi nuk janë të parëndësishme dhe injorimi i braktisjes
mund të sjellë gabim të rëndësishëm në model. Modelet e organizimit të stafit që injorojnë
braktisjen do të tentojnë të mbistafojnë call center-in për një nivel të synuar performance të
sistemit.
Modeli Erlang A i lejon telefonuesve që hyjnë në radhë për ta braktisur atë nëse pritja tejkalon
durimin e tyre. Në mënyrë të veçantë, modeli supozon se çdo telefonues ka një durim të

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
31
shpërndarë në mënyrë eksponenciale me një mesatare prej 1 / θ. Një telefonues që paraqitet me
një kohë të pritjes që tejkalon durimi e tij preferon ta mbyllë telefonatën se sa të presë në radhë.
Disa artikuj adresojnë modelin Erlang A. (Gans, Koole et al. 2003) diskutojnë shkurtimisht
modelin, ndërsa një pasqyrë më e plotë e modelit është dhënë në (Mandelbaum dhe Zeltyn
2004). Çështja e vlerësimit të parametrave dhe e ndjeshmërisë adresohet në (Whitt 2006a). Një
krahasim i plotë i modeleve Erlang A dhe Erlang C ofrohet në (Garnett, Mandelbaum et al.
2002). Ky artikull zhvillon heuristikë të organizimit të stafit në gjëndje të qëndrueshme për
secilin regjim të organizimit të stafit që janë analoge me heuristikën e organizimit të stafit me
rrënjë katrore Halfin-Whitt për modelin Erlang C. Ky punim gjithashtu paraqet përafrimet e
difuzionit për matësit kryesorë të performancës në modelin Erlang A.
Formulat e Erlang A janë dukshëm më të ndërlikuara se ato të modelit Erlang C. Probabilitetet
e gjëndjes së qëndrueshme për shpërndarjen e numrit të telefonuesve në sistem sigurohen në
artikullin e Palm dhe janë riprodhuar në një shtojcë të (Mandelbaum dhe Zeltyn 2004).
Shpërndarja në gjendje të qëndrueshme për modelin Erlang A jepet nga:
𝜋𝑗 = {
𝜋𝑛 ∙𝑁!
𝑗!𝑅𝑖𝑁−𝑗 , 0 ≤ 𝑗 ≤ 𝑁
𝜋𝑛 ∙(𝜆𝑖 𝜃𝑖⁄ )𝑗−𝑛
∏𝑁𝜇
𝜃
𝑗−𝑛𝑘=1 +𝑘
, 𝑗 ≥ 𝑁 + 1 (2.14)
Ku
𝜋𝑛 =𝐸1,𝑛
1+[𝐴(𝑁𝜇
𝜃,𝜆
𝜃)−1]𝐸1,𝑛
(2.15)
𝐴(𝑥, 𝑦) ≜𝑥𝑒𝑦
𝑦𝑥 𝛾(𝑥, 𝑦) (2.16)
Dhe
𝛾(𝑥, 𝑦) ≜ ∫ 𝑡𝑥−1𝑒−𝑡𝑑𝑡, 𝑥 > 0, 𝑦 ≥ 0𝑦
0 (2.17)
Është funksioni jo i plotë Gamma. Shprehja E1,n jep probabilitetit e bllokimit nga modeli Erlang
B:
𝐸1,𝑛 =𝑅𝑖
𝑚 𝑁!⁄
∑ 𝑅𝑖𝑗
𝑗!⁄𝑚𝑗=0
(2.18)
Probabiliteti që një telefonues duhet të presë jepet nga:
𝑃{𝑊 > 0} =𝐴(
𝑁𝜇
𝜃,𝜆
𝜃)𝐸1,𝑛
1+[𝐴(𝑁𝜇
𝜃,𝜆
𝜃)−1]𝐸1,𝑛
(2.19)
Koha e pritjes për një konsumator të futur në radhë është:
𝐸[𝑊|𝑊 > 0] =1
𝜃[
1
𝜌𝐴(𝑁𝜇
𝜃,𝜆
𝜃)
+ 1 −1
𝜌] (2.20)

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
32
Vlerësimi numerik i këtyre shprehjeve është i vështirë. Përafrime të dobishme të bazuara në
limitet e shpërndarjes janë zhvilluar në (Garnett, Mandelbaum et al. 2002). i përmbledh këto
llogaritje më poshtë.
Le të jetë φ(x) përfaqësuesi i funksionit i densitetit standard normal dhe Φ(x) shpërndarja
kumulative.
𝜙(𝑥) =1
√2𝜋𝑒−𝑥2 2⁄ (2.21)
Ф(𝑥) = ∫ 𝜙(𝑦)𝑑𝑦𝑥
−∞ (2.22)
Funksioni i normës së riskut më pas përcaktohet si:
ℎ(𝑥) =𝜙(𝑥)
1−Ф(𝑥)=
𝜙(𝑥)
Ф(−𝑥) (2.23)
Tani përcaktohen dy shprehjet e mëposhtme:
𝑤(𝑥, 𝑦) = [1 +ℎ(−𝑥𝑦)
𝑦ℎ(𝑥)]
−1
(2.24)
Gjithashtu përcaktohet grada e shërbimit β si:
𝛽 =𝑁−𝑅𝑖
√𝑅𝑖 (2.25)
Artikulli (Garnett, Mandelbaum et al. 2002) vazhdon të tregojë se si përafrimet për matësit
kryesorë të performancës mund të rrjedhin nga këto funksione. Në veçanti kemi këto shprehjet
e mëposhtme.
Probabiliteti që një telefonuesi i duhet të presë është:
𝑃{𝑊 > 0} ≈ 𝑤(−𝛽, √𝜇 𝜃⁄ ) (2.26)
Probabiliteti që pritja të jetë më e madhe se T është:
𝑃{𝑊 > 𝑇} ≈ 𝑤 (−𝛽, √𝜇
𝜃) ∙
ℎ(𝛽√𝜇 𝜃⁄ )
𝛹(𝛽√𝜇 𝜃⁄ , √𝑁𝜇𝜃𝑡)∙ 𝑒−𝜃𝑡 (2.27)
Probabiliteti i braktisjes është:
𝑃{𝐴𝑏} ≈ [1 −ℎ(𝛽√𝜇 𝜃⁄ )
(𝛽√𝜇 𝜃⁄ )+√𝜃 (𝑁𝜇)⁄] ∙ 𝑤 (−𝛽, √
𝜇
𝜃) (2.28)
Nga këto shprehje ne mund të shkruajmë një formulë për matësin tonë kryesor të Faktorit të
Shërbimit Telefonik (TSF). TSF është përcaktuar në praktikë si përqindja e të gjitha thirrjeve
hyrëse që janë shërbyer brenda T sekondave:
𝑇𝑆𝐹 ≜ 𝑃{𝑊 ≤ 𝑇⌊𝑆𝑟} = (1 − 𝑝{𝐴𝑏}) ∙ 𝐸{𝑊 > 𝑇} (2.29)
Ndërsa këto shprehje janë mjaft të komplikuara, ato janë relativisht të drejtpërdrejta për t'u
koduar dhe përdoren në llogaritjet numerike të zhvilluara në këtë tezë.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
33
Modelet jostacionare
Modelet bazë të radhëve janë ndërtuar mbi supozimin e sjelljes afatgjatë të gjëndjes së
qëndrueshme me procese stacionare të mbërritjeve dhe të shërbimit. Siç tregohet në kapitullin
e parë, shpesh kjo nuk ndodh në praktikë. Në (Robbins, Medeiros et al. 2006) përdoret simulimi
për të treguar se norma e mbërritjes si madhësi e rastit mund të shkaktojë devijim të
rëndësishëm nga objektivat e matësve të performancës së call center-it. Problemi me modelimin
e normave të mbërritjes me variacion në kohë është se sistemi nuk do të arrijë kurrë një gjendje
të qëndrueshme. Ne kërkojmë kushte dhe modele që janë përafrime të arsyeshme dhe sistemi
mund të thuhet në ate pikë që është në gjendje pothuajse të qëndrueshme (Salla 1991). Ka disa
përafrime relativisht të thjeshta që mund të merren në konsideratë me norma mbërritjeje të
ndryshime në kohë (Jennings, Mandelbaum et al. 1996).
• Përafrimi i Thjeshtë Stacionar (SSA) - përdor modelin stacionar me normën mesatare
të mbërritjes afatgjatë.
• Përafrimi Stacionar me Pikë (PSA) - përdor modelin stacionar me normë të
menjëhershme të mbërritjes t.
• Përafrimi Stacionar i Pavarur Periudhë pas Periudhe (SIPP) - aplikon modelin stacionar
për periudha diskrete të planifikimit, shpesh segmente të ditës prej 15 ose 30 minutash.
Modeli SSA është një përafrim shumë i thjeshtë që është i dobishëm kur normat e mbërritjes
ndryshojnë shumë shpejt në krahasim me kohën e shërbimit, por është pothuajse konstante gjatë
periudhës afatgjatë (domethënë variacioni stokastik rreth një niveli të qëndrueshëm).
Modeli PSA është i dobishëm në modelet me norma mbërritjesh që ndryshojnë ngadalë në
krahasim me nivelet e shërbimit, por mund të shprehen (ose të përafrohen) si një funksion i
kohës, për shembull një normë mbërritjeje me ndyshime sinusoidale. Modeli PSA llogarit një
përafrim stacionar në çdo pikë në kohë dhe integrohet për të llogaritur mesataren. Një shembull
i një serveri të vetëm është paraqitur në seksionin 6.3 të (Hall 1991), një analizë më e detajuar
është paraqitur në (Green dhe Kolesar 1991). Në këtë artikull autorët supozojnë se normat e
mbërritjes ndryshojnë në mënyrë periodike dhe prandaj sistemi do të zhvillojë një sjellje të
qëndrueshme periodike. Konsiderojmë gjatësinë mesatare të radhës Lq të dhënë nga:
𝐿𝑞 =1
𝑇∫ (∑ (𝑛 − 𝑠)𝑝𝑛
∞𝑛=𝑠 (𝑡)𝑑𝑡)
𝑇
0 (2.30)
Ku x është numri i server-ave.
Tani përcaktojmë përafrimin stacionar me pjesë si:
𝐿𝑞∞ =
1
𝑇∫ 𝐿𝑞(𝜆(𝑡))𝑑𝑡
𝑇
0 (2.31)
Ku Lq (λ(t)) është gjatësia e radhës në një radhë stacionare M/M/s me normë mbërritjeje λ(t).
Autorët supozojnë një normë mbërritjeje që mund të shprehet si:
𝜆(𝑡) = 𝜆 + 𝐴𝑐𝑜𝑠(2𝜋𝑡/24) (2.32)
Ata i zgjidhin këto ekuacione në mënyrë numerike dhe më tej kufizojnë veten në rastin kur
intensiteti i trafikut është më i vogël se 1 dhe tregojnë se në këto kushte PSA është një kufi i
sipërm në performancën aktuale.
(Green dhe Kolesar 1997) gjithashtu ekzaminojnë një variant të modelit PSA që autorët e
quajnë si modeli PSA i vonuar. PSA i vonuar është i motivuar nga fakti që bllokimi real i pikut
do të ndodhë në një pikë të mëvonshme, nga ç’ishte parashikuar nga PSA. Duke marrë parasysh
vetëm trafikun aktual kur llogaritet bllokimi, modeli injoron faktin se një vonesë në kohë

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
34
ekziston midis pikës së pikut të trafikut dhe bllokimit të pikut. Në këtë artikull autorët zhvillojnë
një metodë për vlerësimin e vonesës së pikut dhe rillogaritjen e bllokimit në pikun e sistemuar.
Metodat PSA dhe PSA me lag-e krijojnë vlerësime të sakta të performancës së sistemit
jostacionar, duke pasur parasysh supozimet e mungesës së braktisjes, shfrytëzimit të më pak se
një, dhe të normat të mbërritjes sinusoidale. Vizioni i përgjithshëm i grumbulluar nga këto
modele mund të përdoret më pas për të nxitur intuitën dhe për të gjeneruar heuristika për qëllime
të planifikimit. Megjithatë, në praktikë një përqasje më e zbatuar zakonisht është Përqasja
Stacionare e Pavarur Periudhë pas Periudhe (SIPP). Në këtë përqasje dita ndahet në grupe;
shpesh periudha prej 15 ose 30 minuta, dhe një normë mbërritjeje mesatare llogaritet për secilën
periudhë. Planet e organizimit të stafit pastaj bazohen në supozimin se gjendja e qëndrueshme
arrihet në secilën prej këtyre periudhave, zakonisht duke përdorur një model Erlangu3.
Saktësia e kësaj metode është analizuar në (Green, Kolesar et al., 2001). Në këtë punim autorët
përsëri supozojnë një model me norma mbërritjeje të ndryshueshme në mënyrë sinusoidale pa
braktisje. Autorët kryejnë analiza numerike të detajuara dhe tregojnë se SIPP mund të çojë në
përafrime të dobëta në rastet kur shtrirja relative e valës sinusoidale është e gjërë, periudhat e
planifikimit janë të gjata, nivelet e shërbimit janë të ulëta ose sistemi është i madh.
Autorët propozojnë disa variante të metodës SIPP për të zvogëluar gabimet.
• SIPP Max: zbaton SIPP-në duke përdorur normën maksimale të mbërritjes për
periudhën, dhe jo mesataren. SIPP Max është më konservatore nga SIPP dhe në mënyrë
të qartë çon në nivele më të larta të propozuara të organizimit të stafit.
• SIPP Mix: zbaton normën mesatare të mbërritjes për periudhat ku norma e mbërritjes
ështe në rritje dhe Max për periudhat ku ajo është në rënie.
Punimi gjithashtu analizon secilën prej këtyre përqasjeve me një opsion Lag-u, duke aplikuar
një vlerësim Lag-u të ngjashëm me atë të zhvilluar në artikullin e tyre të mëparshëm, duke
krijuar metodat Lag Mesatare, Max dhe Mix. Asnjë qasje nuk duket të jetë superiore në të gjitha
rrethanat dhe zhvillohen disa heuristika të përgjithshme.
Përasja SIPP e Lag-uar analizohet më tej në (Green, Kolesar et al 2003). Ky material mban
supozimin e normave të mbërritjes me ndryshuemshëri sinusoidale si në (2.32), por tani
supozon se call center-i vepron në më pak se 24 orë; prandaj fillon dhe mbaron bosh. Artikulli
tregon se modifikimet në përqasjen SIPP vazhdimisht arrijnë objektivin e nivelit të shërbimit
me vetëm rritje modeste të stafit.
2.3. Optimizimi Stokastik
Programimet e matematikës të cilat në mënyrë eksplicite përfshijnë ndryshueshmërinë në vlerat
e parametrave njihen si programime stokastike. Nocioni i programimit stokastik u prezantua
për herë të parë në vitet 1950 (Beale 1955; Dantzig 1955). Megjithëse koncepti i programimit
stokastik ka qenë në literaturë për më shumë se 60 vjet, aplikimi i programimit stokastik ka
qenë relativisht i rrallë. Kjo është kryesisht për shkak të sfidave kompjuterike që lidhen me
programimin stokastik.
Në nivelet bazë programimet stokastike vijnë në dy varietete, programimet e kufizuara të rastit
dhe programimet rekursive. Programimet e kufizuara të rastit zbatojnë një kufizim të llojit të
nivelit të besimit; për shembull duke specifikuar pozicionin inventar pozitiv me 95% besim.
Programimet rekursive në anën tjetër njohin dy lloje vendimesh; vendimet që ndodhin para se
3 Modelet e Erlang C shpesh përdoren në praktikë, pavarësisht nga supozimi i mungesës së braktisjes së
atij modeli.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
35
të zbulohet madhësia e rastit - vendimet e fazës së parë dhe vendimet që ndodhin pas zbulimit
të madhësisë së rastit - vendimet rekursive. Në këtë rishikim e kufizojmë analizën tonë në
problemet rekursive. Një rishikim gjithëpërfshirës i programimeve të kufizuara të rastit është
dhënë në (Prekopa 1995).
Problemet rekursive janë analizuar gjerësisht në literaturë. Një hyrje e shkurtër e tipit tutorial
është dhënë në (Higle 2005). Ekzistojnë gjithashtu disa tekste të shkëlqyera që përshkruajnë
strukturën dhe përqasjet e zgjidhjes për programimin stokastik. (Kall dhe Wallace 1994) është
një hyrje e shkëlqyer që përfshin një studim të teknikave dhe algoritmave të ndryshme të
zgjidhjes. (Birge dhe Louveaux 1997) është një rishikim i plotë i programimit stokastik linear
dhe jo-linear, ndërsa (Kall dhe Mayer 2005) fokusohet në mënyrë rigoroze në programimet
lineare stokastike.
Duke adoptuar notacionin nga (Birge dhe Louveaux 1997), problemi i përgjithshëm i
programimit linear stokastik mund të shprehet si:
Të minimizohet
𝒄𝑇𝒙 + 𝐸𝜉[𝑚𝑖𝑛𝒒(𝜔)𝑇𝒚(𝜔)] (2.33)
Me kushtet:
`𝐴𝒙 = 𝒃 (2.34)
𝑇(𝜔)𝒙 + 𝑊𝒚(𝜔) = 𝒉(𝜔) (2.35)
𝒙 ≥ 0, 𝒚(𝜔) ≥ 0 (2.36)
Objektivi i programimit linear stokastik (2.33) është minimizimi i kostos së vendimit të fazës
së parë, plus koston e pritshme të vendimeve të fazës së dytë. Optimizimi është i kufizuar nga
një grup kufizimesh (2.34) që varen vetëm nga variablat deterministë të fazës së parë, dhe një
grup kufizimesh (2.35) që varen nga vendimet e rekursit (y (ω)) dhe mund të jenë komponentë
të rastësishëm. Programimi stokastik zgjidhet në mënyrë tipike në krahasim me një grup të
caktuar skenarësh, skica kampionësh të vektorit të rastit ξ. Nëse numri i rezultateve të
kampionëve shënohet si K, atëherë mund të shkruajmë programimin stokastik në formë të
zgjeruar si:
Të minimizohet
𝒄𝑇𝒙 + ∑ 𝑝𝑘𝑞𝑘𝑇𝑦𝑘
𝐾𝑘=1 (2.37)
Me kushtet:
`𝐴𝒙 = 𝒃 (2.38)
𝑇𝑘𝒙 + 𝑊𝒚𝑘 = 𝒉𝒌, 𝑘 = 1, … . . , 𝐾 (2.39)
𝒙 ≥ 0, 𝒚𝒌 ≥ 0, 𝑘 = 1, … … . , 𝐾 (2.40)
Programimi i formës së zgjeruar (2.37) - (2.40) është ekuivalenti deterministik i (2.33) - (2.36)
me një numër të fundëm rezultatesh dhe si i tillë mund të shkruhet si një programim linear i
gjërë. Programimi pastaj mund të zgjidhet duke përdorur algoritmin standard të thjeshtë për
programimet lineare. Megjithatë, meqë numri i realizimeve rrit madhësinë e programimit mund
të jetë mjaft i madh dhe i vështirë për t'u zgjidhur.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
36
Algoritmi i dekompozimit i formës L është një metodë e përdorur zakonisht për zgjidhjen e
programimeve stokastike me shkallë të gjerë. Algoritmi diskutohet në hollësi në (Birge dhe
Louveaux 1997) si dhe (Kall 1976; Kall dhe Wallace 1994; Kall dhe Mayer 2005). Metoda e
formës L është një variacion i metodave të dekompozimit të Dantzig-Wolfe ose Bender. (Për
detaje rreth këtyre përqasjeve mund të shihet (Lasdon 2002)). Në metodën e formës L zgjidhet
një nën-problem për secilin skenar, ku një skenar është një realizim i kampionëve të vektorit të
rastit të problemit. Duke përdorur variabla dualë nga zgjidhja e nënproblemave, mund të
gjenerohet një përafrim linear me pjesë i funksionit të rekursit. Algoritmi në formë L-je
proçedon në mënyrë të përsëritur, duke shtuar prerje në secilin iteracion të madh. Metoda
standarde në formë L-je shton një prerje për çdo përsëritje, ndërsa metoda me shumë prerje në
formë L-je shton një prerje për skenar në çdo përsëritje (Birge dhe Louveaux 1997).
Një përqasje alternative është metoda e Dekompozimit Stokastik (SD). Ndërsa përqasja në
formë L-je fillon me një grup të caktuar skenarësh, SD përdor një numër të ndryshueshëm
skenaresh. Algoritmi SD shton skenarë të rinj; duke krijuar prerje të reja dhe përditësimin e
prerjeve ekzistuese derisa të arrihen disa kritere ndalimi. Përqasja SD është përshkruar në
hollësi në (Higle dhe Sen 1996).
Përfitimet e Programimit Stokastik
Edhe pse janë të vështira për t'u zgjidhur, programimet stokastike krijojnë modele që janë
përfaqësuese më realiste të fenomenit në studim. (Rrallë e dimë vlerën e saktë të parametrave
të rëndësishëm si kërkesa.) Përveç kësaj, zgjidhja e programimit stokastik është në përgjithësi
në mënyrë sasiore më superiore se zgjidhja alternative me vlerë mesatare; zgjidhja e LP kur
parametrat e ndryshueshëm përfaqësohen nga mesataret e tyre.
Nocioni i programimit stokastik u zhvillua së pari në mesin e viteve 1950 (Beale 1955; Dantzig
1955). Këto artikuj zhvillojnë disa tipare të rëndësishme të programimeve stokastike që janë të
dobishme për të vërtetuar rezultatet në lidhje me vlerën e informacionit. Do të ricitoj disa tipare
më poshtë. Për të thjeshtuar përkufizimet përcaktoj:
𝑧(𝑥, 𝜉) = 𝑐𝑇𝑥 + min [𝑞(𝜔)𝑦(𝜔)|𝑇(𝜔) + 𝑊𝑦(𝜔) = ℎ(𝜔), 𝑦(𝜔) ≥ 0] (2.41)
Më pas rishikoj programin stokastik si më poshtë:
Të minimizohet
𝑧(𝑥, 𝜉) (2.42)
Me kushtet:
`𝐴𝒙 = 𝒃 (2.43)
𝒙 ≥ 0 (2.44)
Rezultati i parë është që E[z(x, ω)] është një funksion konveks i x. Rezultati i dytë thotë se për
një x të dhënë, z është një funksion konveks i ω.
Një përmbledhje e kërkimit mbi vlerën e informacionit është programimi stokastik i dhënë në
(Birge dhe Louveaux 1997). Puna e hershme mbi këtë temë është zhvilluar në (Madansky
1960). Mandansky e përshkruan problemin rekursiv stokastik si problemin “këtu dhe tani”,
duke treguar problemin që duhet të zgjidhet para se të mund të zgjidhet pasiguria. Ai e
kundërshton atë me problemin “prit dhe shiko”, problemin që do të rezultojë nëse ishim disi të
aftë të prisnim për pasigurinë të zgjidhet para se të marrim një vendim të fazës sonë. Problemi
rekursiv “këtu dhe tani” (RP) mund të citohet matematikisht si më poshtë:

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
37
𝑅𝑃 = 𝑚𝑖𝑛𝑥𝐸𝜉𝑧(𝑥, 𝝃) (2.45)
Problemi është të gjejmë grupin e vendimeve që minimizojnë pritjen e funksionit objektiv
(2.41). në mënyrë alternative problemi “prit dhe shko” mund të shprehet si:
𝑊𝑆 = 𝐸𝜉[𝑚𝑖𝑛𝑥𝑧(𝑥, 𝝃)] (2.46)
Zgjidhja “prit dhe shiko” është pritja, e marrë mbi të gjitha realizimet e ξ, të vendimit optimal
x për çdo realizim të ξ. Me fjalë të tjera, rezultati mesatar nëse do të ishim në gjendje të
vëzhgonim ω përpara se të mernim vendimin e fazes së parë.
Siç kemi diskutuar më parë, problemi rekursiv (2.45) është shpesh i vështirë për t'u zgjidhur
kështu që një përafrim natyral është gjetur duke zëvendësuar vektorin e rastit ξ nga pritshmëria
e tij ξ̆.
𝐸𝑉 = 𝑚𝑖𝑛𝑥𝑧(𝑥, �̅�) (2.47)
E quajmë zgjidhjen e këtij problem si zgjidhja e vlerës mesatare, dhe e shënojmë atë si �̆�( ξ̆.).
Kam argumentuar se ky përafrim jo gjithmonë mund të japë një përgjigje të mirë të problemit
stokastik në fjalë. Për të kuantifikuar këtë argument, prezantoj një sasi që mat rezultatet e
përdorimit të zgjidhjes së vlerës mesatare. Shënojmë rezultatin e pritshëm të përdorimit të
zgjidhjes EV si:
𝐸𝐸𝑉 = 𝐸[𝑧(�̅�, (�̅�), 𝝃)] (2.48)
EEV përfaqëson rezultatin e pritur të zbatimit të zgjidhjes së vlerës mesatare në fazën e parë,
duke lejuar më pas vendimmarrësin që të marrë vendime optimale rekursive pasi të jetë zbuluar
pasiguria. Si i tillë ai përfaqëson fitimin mesatar që do të ndodhte nëse vendimet bazohen në
zgjidhjen e (2.47).
Mandansky tregon se meqenëse z është një funksion i vazhdueshëm, konveks, një aplikim i
drejtpërdrejtë i pabarazisë së Jensen jep pabarazinë e mëposhtme:
𝐸𝐸𝑉 ≥ 𝑅𝑃 ≥ 𝑊𝑆 ≥ 𝐸𝑉 (2.49)
Ekuacioni (2.49) siguron themelin për pjesën më të madhe të asaj që vijon kështu që ia vlen të
bëhet një shqyrtim i imët. Supozojmë se një vendimmarrës është përballur me një problem të
optimizimit stokastik, të cilin ai e zgjidh duke përdorur përqasjen (standarde) të zëvendësimit
të variablave të rastit me pritshmerinë e tyre. Ai zgjidh problemin dhe vlerëson një objektiv me
kosto minimale të EV. Themi se zgjidhja e vlerës mesatare është e njëanshme, në atë që është
më pak se (ose e barabartë) me rezultatin e pritur që do të ndodhte nga zbatimi i atij vendimi.
Njëanshmëria e Vlerave Mesatare është përcaktuar si
𝑀𝑉𝐵 = 𝐸𝐸𝑉 − 𝐸𝑉 (2.50)
Me fjalë të tjera rezultati i pritur i zbatimit të kësaj zgjidhjeje është të paktën po aq i madh sa
parashikohet nga problemi i vlerës mesatare, por mund të jetë më i madh. Shohim se zgjidhja e
problemit rekursiv nuk është më shumë i njëanshëm sesa problemi i vlerës mesatare. Me fjalë
të tjera, zgjidhja e gjetur nga zgjidhja e problemit mund të jetë në rastin më të keq po aq i
njëanshëm sa problemi i vlerës mesatare, por jo më shumë. Nga ana tjetër mund të jetë më pak
i njëanshëm.
Zgjidhja WS paraqet një pikë referimi të rëndësishme pasi na tregon vlerën objektive që do të
presim nëse mund ta zgjidhim pasigurinë para se të marrim vendimin tonë. Ekuacioni (2.49) na

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
38
tregon se kjo vlerë është e kufizuar midis zgjidhjeve të problemit rekursiv dhe atij të vlerës
mesatare RP ≥WS ≥ EV. Problemi i zgjidhjes së pritur na jep një vlerësim të paktën po aq të
ulët, dhe ndoshta më të ulët, se ajo ka mund të arrijmë edhe nëse mund të parashikojmë në
mënyrë të përkryer rezultatin e rastësishëm.
Problemi rekursiv nga ana tjetër nuk është më mirë se ajo që mund të arrijmë me njohjen e
rezultatit të rastësishëm. Në këtë kuptim, problemi rekursiv është një vlerësim më konservativ
dhe me gjasë një vlerësim më realist.
Tani konsiderojmë konceptin e Vlerës së Pritshme të informacionit Perfekt (EVPI). Nocioni i
EVPI në programimet stokastike është zhvilluar në (Avriel dhe Williams 1970). EVPI na tregon
se sa më mirë do të ishte marrja e vendimeve tona nëse do të kishim një pamje të përsosur të
rezultatit të pasigurisë në problemin tonë të vendimmarrjes, ose në terminologjinë e Madanskit,
përmirësimi që mund të merrnim, nëse në njëfarë mënyre mund të merrnim vendimin “prit dhe
shiko” në vend të vendimit “këtu dhe tani”. Për këtë arsye mund të përkufizojmë EVPI-në,
përsëri duke përdorur shënimin nga (Birge dhe Louveaux 1997) si:
𝐸𝑉𝑃𝐼 = 𝑅𝑃 − 𝑊𝑆 (2.51)
Avrieli dhe Williams zhvillojnë kufijtë në EVPI në programimet stokastike. Teorema e tyre 1
siguron një kufi të poshtëm:
𝐸𝑉𝑃𝐼 ≥ 0 (2.52)
dhe ndjek direkt nga përkufizimi dhe nga (2.49). Rezultati është mjaft intuitiv, veprojmë edhe
më keq (në terma pritshmërie) nëse kemi njohuri të përsosur se si do të zgjidhet pasiguria. Një
kufi i sipërm gjithashtu llogaritet lehtësisht si:
𝐸𝑉𝑃𝐼 ≤ 𝐸𝑉 − 𝑅𝑃 (2.53)
Kufiri i sipërm na tregon se dallimi ndërmjet problemit të vlerës së pritshme dhe problemit
rekursiv është një kufi i sipërm mbi vlerën që mund të arrijmë nga informacioni perfekt rreth
pasigurisë së problemit. Avrieli dhe Williams zhvillojnë një formë më të përgjithshme të (3,53)
që mund të llogaritet për çdo realizim të ξ, por provojnë se zgjedhja e 𝜉 siguron kufirin më të
ngushtë. Ato gjithashtu i zbatojnë këto kufij në një klasë më të përgjithshme të programimeve
stokastike që përfshijnë funksionet recursive kuadratike. Një sërë kufijsh më të forte janë
zhvilluar në (Huang, Vertinsky et al., 1977).
Nocioni i informacionit EVPI ka të bëjë me atë vlerë që i takon një vendimmarrësi nëse
pasiguria mund të zgjidhet para vendimmarrjes. Një koncept i lidhur është vlera që i takon
vendimmarrësit duke pranuar në mënyrë eksplicite pasigurinë e parametrave kur merr një
vendim. Në kontekstin tonë kjo lidhet me vlerën e përdorimit të programimit stokastik më të
komplikuar.
Vlera e Zgjidhjes Stokastike
Koncepti i kuantifikimit të vlerës së përdorimit të një formulimi programimi stokastik, në
krahasim me formulimin e vlerës mesatare, u zhvillua së pari (Birge 1982) dhe më vonë u
trajtua në (Birge dhe Louveaux 1997).
Birge (1982) prezanton konceptin kryesor që përdoret për të matur përfitimin e përdorimit të
programimit stokastik, Vlera e Zgjidhjes Stokastike (VSS) të cilën ai e përcaktonte si
𝑉𝑆𝑆 = 𝐸𝐸𝑉 − 𝑅𝑃 (2.54)

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
39
VSS është një matëse e thjeshtë e përmirësimit në objektivin e pritshëm që del nga përdorimi i
një formulimi rekursiv. Kujtojnë se termi EEV është rezultati i pritshëm i përdorimit të zgjidhjes
së vlerës mesatare ndërsa RP është rezultati i pritshëm i përdorimit të një formulimi stokastik.
Një kufi i poshtëm i thjeshtë në VSS rrjedh lehtë nga (2.49)
𝑉𝑆𝑆 ≥ 0 (2.55)
Ky rezultat i thjeshtë është mjaft i rëndësishëm; na tregon se nuk mund të bëjmë më keq duke
e konsideruar në mënyrë eksplicite ndryshueshmërinë kur zhvillojmë zgjidhjen tonë.
Megjithatë, meqë e dimë se kostoja e llogaritjes së zgjidhjes stokastike është e lartë, duam të
dimë se kur mund të bëjmë më mirë, dhe sa më mirë.
Birge paraqet një kufi të drejtpërdrejtë të sipërm që vlen për të dy VSS dhe EVPI për
programimet stokastike me rekursiv fiks dhe koefientët objektivë fikse
𝐸𝑉𝑃𝐼 ≤ 𝐸𝐸𝑉 − 𝐸𝑉 (2.56)
𝑉𝑆𝑆 ≤ 𝐸𝐸𝑉 − 𝐸𝑉 (2.57)
Ana e djathtë e këtyre ekuacioneve përfaqëson njëanshmërinë e zgjidhjes së vlerës mesatare;
kjo është shkalla në të cilën zgjidhja e vlerës mesatare ekzagjeron pritshmërinë aktuale të
rezultatit. Ekuacioni (2.56) na tregon se kjo njëanshmëri është një kufi i sipërm për sa shumë
më mirë mund të bëjmë duke patur informacion perfekt, ndërsa ekuacioni (2.57) na tregon se
kjo njëanshmëri është gjithashtu një limit në lidhje me sa më mirë mund të bëjmë duke përdorur
një formulim stokastik. Nëse zgjidhja e vlerës mesatare është e paanshme (EEV= EV), atëherë
nuk marrim ndonjë dobi nga informacioni perfekt ose nga programimi stokastik. Kjo do të
ndodhë për shembull, nëse zgjidhja optimale e problemit është e pavarur nga pasiguria e
modelit. Për shembull, nëse shpërndarja e sasisë së korrur në problemin e fermerit është e tillë
që shpërndarja e njëjtë është optimale për të gjitha realizimet e korrjeve, atëherë fermeri nuk
merr asnjë vlerë nga informacioni perfekt dhe në mënyrë të ngjashme nuk merr asnjë vlerë nga
programimi stokastik. implikimi i qartë është se duke pasur parasysh programimin stokastik,
mund të kufizohemi në konsiderimin e ndryshueshmërisë së parametrave, realizimi i të cilave
ka një efekt material në vektorin e vendimit.
Ndërsa EVPI dhe VSS kanë të njëjtat kufij të sipërm dhe të poshtëm, është e rëndësishme të
theksohet se ato nuk janë ekuivalente. Në përgjithësi do të presim që EVPI do të jetë më i madh
se VSS, ky nuk është gjithmonë rasti. Birge (1982) paraqet një ilustrim të një problemi ku
informacioni perfekt ka vlerë jo-zero, por vlera e zgjidhjes stokastike është zero4.
Ky rezultat nuk është për t'u habitur, na tregon se ka probleme kur njohja e rezultatit të vërtetë
të pasigurisë është i vlefshëm, por modelimi i qartë i ndryshueshmërisë nuk na ndihmon.
Rezultati më i habitshëm është një shembull i ngjashëm që tregon se EVPI = 0 ndërsa VSS> 0.
Shembulli i veçantë është një rast ku problemi ka zgjidhje të shumta optimale. Argumenti është
se zgjidhësi i programimit linear mund të kthejë një zgjidhje që është optimale për problemin e
vlerës mesatare, por nën-optimale për problemin rekursiv. Zgjidhja alternative është optimale
si për vlerën mesatare ashtu edhe për problemin rekursiv. Meqë gjejmë optimumin e duhur në
problemin rekursiv, por jo në problemin e vlerës mesatare,
VSS është pozitive. Megjithatë, njohja me siguri e rezultatit çon të njëjtën përgjigje si në
programimin rekursiv kështu që vlera e informacionit perfekt është zero. Birge bën atë
4 I njejti shembull është present në Birge (1982), Shtojca A dhe Birge dhe Louveaux (1997) faqet 142-
144

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
40
pretendimin se "Për shkak se programimet lineare shpesh përfshijnë zgjidhje të shumëfishta
optimale, kjo lloj zgjidhjeje është larg nga e jashtëzakonshmja5".
Diagrama e mëposhtme përmbledh marredhënien midis sasive të ndryshme të diskutuara.
Figura 2-3 Zgjidhjet Relative të një Problemi në Kushte Pasigurie
Zgjidhja e vlerës së pritur (EV) jep rezultatin më të mirë të parashikuar, ndërsa vlera aktuale e
pritur e zbatimit të zgjidhjes së vlerës së pritur (EEV) është rezultati më i keq. Dallimi midis
këtyre dy sasive është njëanshmëria e zgjidhjes së vlerës mesatare. Problemi rekursiv (RP)
siguron rezultatin më të mirë të pritur që mund të zbatohet në të vërtetë. Përmirësimi nga
përdorimi i formulimit rekursiv në krahasim me rezultatin e pritur të zgjidhjes së vlerës së pritur
është Vlera e Zgjidhjes Stokastike (VSS). Përfitimi shtesë që mund të arrihet duke zgjidhur
pasigurinë përpara vendimmarrjes është Vlera e Pritshme e informacionit Perfekt (EVPI),
dallimi midis RP dhe zgjidhjes “prit dhe shiko” (WSS).
Ky grafik ilustron atë që do ta quajmë paradoksin e problemit të vlerës mesatare; problemi i
vlerës mesatare jep vlerën objektiv më të mirë, por jep rezultatin e pritshëm më të keq. Jemi
ballafaquar me bërjen e një rekomandimi për të implementuarr një model vendimi që jep një
vlerë objektiv më të keqe, por një rezultat të pritshëm më të mirë. Kjo ndodh sepse objektivi i
problemit rekursiv është një rezultat i pritur; objektivi i problemit të vlerës mesatare nuk është.
Metodat Monte Carlo
Për shumicën e problemeve nuk është praktike të zgjidhësh problemin e optimizimit stokastik
kundrejt bashkësisë se plotë të të gjitha realizimeve të mundshme të vektorit të rastit dhe
problemi zgjidhet në mënyrë tipike për disa kampionë të rezultateve të mundshme. Meqë po
zgjidhim kundrejt një kampioni të rezultateve të mundshme, zgjidhje optimale e llogaritur është
një vlerësim statistikor i zgjidhjes së vërtetë, subjekt i gabimit statistikor të kampionimit
Një pjesë e literaturës në rritje trajton vetitë statistikore të programimeve stokastike të
kampionimeve nën kategorinë e përgjithshme të Metodave Monte Carlo. Një përshkrim i
metodave Monte Carlo ofrohet në (Birge dhe Louveaux 1997) Kapitulli 10. Metodat Monte
Carlo për programimi stokastik huazojnë shumë koncepte nga literatura e simulimit dhe
ndërfaqja midis këtyre dy metodologjive diskutohet në (Pflug 1996).
5 Birge dhe Louveaux (1997) faqe 145

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
41
Një konsideratë e rëndësishme në metodat Monte Carlo është dallimi ndërmjet problemit të
vërtetë dhe problemit të kampionimit. Problem i vërtetë mund të shkruhet si:
𝑧∗ = 𝑚𝑖𝑛𝑥∈𝑋𝐸[𝑓(𝑥, �̅�)] (2.58)
𝑥∗ ∈ 𝑎𝑟𝑔𝑚𝑖𝑛𝑥∈𝑋𝐸[𝑓(𝑥, �̅�)] (2.59)
Kërkojmë të gjejmë vektorin e vendimit x*, dhe vlerën objektiv përkatëse z* që minimizon
vlerën e pritshme të funksionit objektiv f(x, ξ̆) ku pritshmëria është marrë nën mbështetjen e
vektorit të rastit ξ̆. Problemi real që zgjidhim është problemi i përafrimit të shtegut të
kampionimit, një optimizim mbi një numër të fundëm kampionësh ξ̆. Problemi i përafrimit të
shtegut të kampionimit pastaj mund të shkruhet si:
𝑧𝑛∗ = 𝑚𝑖𝑛𝑥∈𝑋
1
𝑛∑ 𝑓(𝑥, 𝜉𝑖)𝑛
𝑖=1 (2.60)
𝑥𝑛∗ ∈ 𝑎𝑟𝑔𝑚𝑖𝑛𝑥∈𝑋
1
𝑛∑ 𝑓(𝑥, 𝜉𝑖)𝑛
𝑖=1 (2.61)
Një çështje e rëndësishme në programimin stokastik është konvergjenca statistikore e zgjidhjes
së shtegut të kampionimit zn* në zgjidhjen e vërtetë z*. Jemi të interesuar të dimë sa afër
zgjidhjes reale është zgjidhja jonë e përafruar. Anasjelltas, mund të jemi të interesuar të
përcaktojmë sa kampionë (skenarë) nevojiten për të arritur një nivel të dëshiruar besimi.
Një artikull i rëndësishëm për këtë temë është (Dupacova dhe Wets 1988). Ky artikull përcakton
vetitë themelore të konvergjencës të programimit stohastik të kampionimeve që provojnë se
zgjidhja e shtegut të kampionimit konvergon në zgjidhjen e vërtetë pasi madhësia e
kampionimit shkon në infinit. Artikuj të tjerë për këtë temë përfshijnë (Shapiro 1991, King dhe
Rockafeller 1993).
Ndërsa problemi i kampionimit konvergjon drejt zgjidhjes së vërtetë, ai gjeneron një vlerësim
të njëanshëm të zgjidhjes së vërtetë për kampionimet e fundme. (Mak, Morton et al. 1999)
tregojnë se rezultati i pritur i problemit të kampionimit është i njëanshëm në mënyrë optimiste
dhe që njëanshmëria është zvogëluar në numrin e kampionimeve. Vetitë e konvergjencës të
vektorit të zgjidhjes x janë diskutuar me hollësi më poshtë në (Shapiro dhe Homem-de-Mello
2000). Artikulli tregon se në rastin e një programimi stokastik linear me dy faza me një
shpërndarje diskrete, zgjidhja optimale e problemit të përafrimit do të jetë ekzaktësisht e
barabartë me zgjidhjen e problemit të vërtetë për një numër mjaftueshëm të madh N. Ata
gjithashtu tregojnë se shkalla e konvergjenca është eksponenciale në numrin e kampionimeve.
Një vlerësim empirik i njëanshmërise së kampionimit është dhënë në (Freimer, Thomas et al.
2006; Linderoth, Shapiro et al. 2006).
Një metodë për zhvillimin e intervalit të besimit në problemin e kampionimit është zhvilluar në
(Mak, Morton et al., 1999). Zgjidhja për çdo problem të kampionimit siguron një pikë vlerësimi
në kufirin e poshtëm të një problemi të minimizimit stokastik. Supozojmë se zgjedhim për të
zgjidhur përafrimin disa herë për të përmirësuar vlerësimin tonë. Le të jetë ξ̆i1, ….,ξ̆in, i = 1, ….,n
një bashkësi e n grupesh skenarësh të ndryshëm, ku secili prej tyre ka n vëzhgime.
Përcaktojmë:
𝑧𝑛∗ = 𝑚𝑖𝑛𝑥∈𝑋 [
1
𝑛∑ 𝑓(𝑥, 𝜉𝑖𝑗)𝑛
𝑖=1 ] (2.62)

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
42
Si vlera objektiv e gjetur nga zgjidhja e problemit të përafrimit të shtegut të kampionimit
kundrejt grupit të i-të të skenarëve të kampionimit.
Më pas mund të përcaktojmë kufirin e poshtëm të vlerësimit tonë si:
�̅�(𝑛𝑙) =1
𝑛𝑙∑ 𝑧𝑛
∗𝑖𝑛𝑙𝑖=1 (2.63)
Kufiri i poshtëm është vendosur si mesatare mbi grumbujt e ndryshëm të skenarëve të zgjidhur
nl.
Për të llogaritur një kufi të sipërm, supozojmë që kemi një zgjidhje kandidate 𝑥. Kjo zgjidhje
mund të jetë rezultati i zgjidhjes së problemit të vlerës mesatare, ose mund të jetë kufiri më i
ulët i gjetur duke zgjidhur problemin e përafrimit të kampionimit. Prandaj mund të llogaritim
një kufi të sipërm duke gjetur koston e pritur të zbatimit të zgjidhjes 𝑥.
𝑈(𝑛) =1
𝑛∑ 𝑓(�̂�, 𝜉𝑖)𝑛
𝑖=1 (2.64)
Zgjidhja e problemit të referencës siguron një vlerësim të paanshëm të kostos së pritur të
zbatimit të vendimit 𝑥 të fazës së parë.
Më pas mund të përcaktojmë një interval besimi të përafërt (1 - 2α) në hendekun e optimizimit
si:
[0, [𝑈(𝑛𝑢) − �̅�(𝑛𝑙)]+ + 𝜀�̃� + 𝜀�̃�] (2.65)
Ku (𝜀̃u, 𝜀̃l) janë gabimet standarte të vlerësimit për kufijtë e sipërm dhe të poshtëm.
Këto rezultate sugjerojnë një proçedurë të përgjithshme për vlerësimin e një sërë kufijsh në
zgjidhjen optimale për një problem optimizimi stokastik.
1) Përcaktimi i numrit te grupimeve (nl) që duhen zgjidhur dhe i numri të skenarëve (n) që do të
përdoren në çdo grupim.
2) Zgjidhja e secilit prej problemeve (nl) në optimalitet për të përdorur në mënyrë optimale çdo
algoritëm.
3) Llogaritja e një pikë vlerësimi për kufirin e poshtëm duke përdorur (2.63) (vlera mesatare
objektiv)
4) Llogaritja e variancës së kampionit të kufirit të poshtëm. Përdoret kjo statistikë për të vlerësuar
gabimin standard në kufirin e poshtëm εl .
5) Llogaritet një zgjidhje kandidate �̂� = 𝑛𝑙−1 ∑ 𝑥𝑛
∗𝑖𝑛𝑙𝑖=𝐼 ku 𝑥𝑛
∗𝑖 janë zgjidhjet për problemet
individuale të grumpimit.
6) Gjenerohet një grup prej nu skenarësh që do të përdoren për vlerësimin e kufirit të sipërm. Vini
re se shpesh ndodh që numri i skenarëve të përdorur për kufirin e sipërm është shumë më i madh
se numri i skenarëve të përdorur në llogaritjen e kufirit të poshtëm.
7) Llogaritet një vlerësim në kufirin e sipërm duke zgjidhur problemin e referencës me vendimin
e fazës 1 të fiksuar në �̂�. Vini re se kjo zgjidhje gjen rekursin optimal për çdo skenar të dhënë �̂�
dhe merr mesataren. Duke qënë se problemi master nuk është i optimizuar, duhet vetëm të
zgjidhim nën-programimin nu herë gjë që mund të bëhet relativisht shpejt.
8) Zgjidhja optimale e problemit e problemit të referencës është kostoja e pritur e zbatimit të �̂� dhe
është pika jonë e vlerësimit për kufirin e sipërm.
9) Llogaritet varianca e kampionimit të kufirit të sipërm dhe përdoret kjo për të llogaritur gabimin
standard.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
43
10) Llogaritet një pikë vlerësimi të hendekut optimal [𝑈(𝑛𝑢) − �̅�(𝑛𝑙)]+.
11) Llogaritet një interval besimi në hendekun e optimizimit duke përdorur (2.65).
Figura 2.4 Proçedura e lidhjes Stokastike
Kjo teknikë kufizuese përbën bazën për një përqasje zgjidhjeje të njohur si Përafrimi Mesatar i
Kampionimit (SAA) i cili është zhvilluar në (Kleywegt, Shapiro et al. 2001). ideja themelore e
SAA-së është që në vend të zgjidhjes së problemit me një bashkësi të madhe kampionësh,
zgjidhim problemin shumë herë me kampionë më të vegjël dhe shqyrtojmë vetitë statistikore të
zgjidhjeve që rezultojnë. Kjo procedurë është analoge me konceptin e xhirove të shumëfishta
në simulimin diskret.
Përqasja është një kornizë e lirshme që nuk specifikon algoritme specifike të zgjidhjes, por më
tepër një përqasje përsëritëse të përgjithëshme. Do të paraqes një version pak të thjeshtuar të
algoritmit të paraqitur në seksionin 2.5 të Kleywegt:
1) Zgjidh një madhësi fillestare të kampionit N dhe N ', një nivel tolerance ε, dhe një numër të
grupimeve M
2) Për çdo grupim m = 1, ...M kryej sa vijon:
a. Gjenero një kampion të madhësisë N dhe zgjidh problemin SSA me vlerë objektiv �̂�𝑁𝑀
dhe me zgjidhje optimale ε �̂�𝑁𝑀.
b. Vlerëso hendekun e optimumit dhe variancën e vlerësuesit të hendekut.
c. Nëse hendeku i optimumit dhe varianca e vlerësuesit të hendekut janë mjaftueshëm të
vogla shko në hapin 4.
3) Nëse hendeku i optimumit ose varianca e vlerësimit është shumë e lartë rrit madhësinë e
kampionit dhe shko në hapin 1.
4) Zgjidh zgjidhjen më të mirë �̂� midis të gjitha zgjidhjeve kandidate duke përdorur një proces
selektimi dhe seleksionimi. Stop.
Figura 2-5 Proçedura e Përafrimit Mesatar të Kampionimit (SAA)
Programimet Stokastike me shumë faza
Ndryshe nga modelet me dy faza, modelet me shumë faza lejojnë një sërë vendimesh që
zhvillohen gjatë një horizonti arbitrar (zakonisht të kufizuar) kohor. Një formulim i
përgjithshëm i modelit me shumë faza është si më poshtë:
Të minimizohet
𝑧 = 𝑐1𝑥1 + 𝐸𝜉2[𝑚𝑖𝑛𝑐2(𝜔)𝑥2(𝜔2) + ⋯ + 𝐸𝜉𝐻[𝑚𝑖𝑛𝑐𝐻(ω)𝑥𝐻(𝜔𝐻)]] (2.66)
Me kushtet:
`𝑊1𝑥1 = ℎ1 (2.67)
𝑇1(𝜔)𝑥1 + 𝑊2𝑥2(𝜔2) = ℎ2(𝜔) (2.68)
⋮
𝑇𝐻−1(𝜔)𝑥𝐻−1 + 𝑊2𝑥2(𝜔2) = ℎ2(𝜔) (2.69)
𝑥1 ≥ 0, 𝑥𝑡(𝜔𝑡 ≥ 0, 𝑡 = 2, … … . , 𝐻 (2.70)

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
44
Një problem i rëndësishëm në programimin stokastik me shumë faza është rritja e shpejtë në
madhësinë e pemës së skenarëve. Për një problem me T faza, me Rt realizime në çdo nyje në
fazë, numri total i skenarëve është:
𝑁 = ∏ 𝑅𝑡𝑇𝑡=1 (2.71)
Në një pemë të ekiulibruar me R realizime për fazë, numri i skenarëve është:
𝑁 = 𝑅𝑇 (2.72)
Numri i skenarëve në një problem me shumë faza lehtë mund të rritet lehtësisht e të bëht mjaft
i madh në qoftë se numri i fazat ose numri i realizimeve bëhet i madh. Duke qënë se madhësia
e një programimi stokastik lineari rritet në mënyrë jo-lineare me numrin e skenarëve, shumë
vëmendje i është kushtuar modelimit efiçent të skenarëve.
Teknikat për gjenerimin efiçent të skenarëve janë dhënë në (Dupačová, Savjet et al 2000,
Hoyland dhe Wallace 2001, Pflug 2001). Një përqasje për përzgjedhjen e një nënbashkësie të
skenarëve paraqitet në (Dupačová, Gröwe-Kuska et al 2003). Një metodë e bazuar në Rëndësinë
e Kampionimit paraqitet në (Dantzig dhe infanger 1993). Rëndësia e Kampionimit bazohet në
idenë se disa vlera të caktuara të vektorit të rastit kanë më shumë ndikim në parametrin që
vlerësphet se disa të tjerë.
Nëse përqasja e kampionimit modifikohet në mënyrë që këto vlera "të rëndësishme" të
kampionohen më shpesh, atëherë varianca e vlerësuesit mund të reduktohet.
Një përqasje post optimizimi, në të cilën problemi është zgjidhur për një grup fillestar
skenarësh, dhe më pas testohet për ndjeshmërinë ndaj skenarëve të kampionimit paraqitet në
(Dupačová 1995). Kjo metodë mbështet zhvillimin e kufijve në zgjidhjen optimale të problemit.
Zgjidhja e problemeve me shumë faza është shumë më e vështirë sesa problemet me dy faza.
(Higle 2005) jep një përmbledhje të shkurtër dhe disa algoritme janë shqyrtuar në (Birge dhe
Louveaux 1997). Shumica e metodave bazohen në ndonjë formë të dekompozimit.
Dekompozimi i Ndërthurur (Birge 1985) dhe MSLip (Gassman 1990) dekompozojnë
problemin me fazën e vendimit. Një strategji alternative e dekompozon problemin me skenarë.
Algoritmi Progresiv Mbulues (Rockafellar dhe Wets 1991) relakson kufizimet e
jpaparashikueshmërisë dhe zbaton një algoritëm të bazuar në relaksim Lagrazhi. (Higle dhe Sen
2006) shqyrtojnë vetitë e dualitetit të problemeve me shumë faza dhe (Higle, Rayco et al. 2004)
zbaton metodën e dekompozimit stokastik në problemin dual të problemit me shumë faza ku
variablat korrespondojnë me shumëzuesit të lidhur me kufizimet e paparashikueshmërisë së
problemit primar.
Optimizimi i Bazuar në Simulim
Një përqasje alternative ndaj optimizimit stokastik përfshin përdorimin e simulimit të ngjarjeve
diskrete. Përmbledhjet e optimizimit të bazuar në simulime janë paraqitur në Kapitullin 12 të
(Law 2007) dhe në (Fu 2002). Optimizimi i bazuar në Simulim (SBO) ka të njëjtin qëllim si
programimi stokastik, gjetja e vektorit të vendimit që optimizon disa matje të performancës së
një sistemi stokastik. Megjithatë SBO përdor një përqasje shumë të ndryshme.
Në nivelin më të përgjithshëm, një algoritëm optimizimi ka dy komponentë bazë; gjenerimin e
zgjidhjeve kandidate dhe vlerësimin e zgjidhjeve kandidate. Në programimin stokastik kemi
supozuar se zgjidhja candidate mund të vlerësohej nëpërmjet një funksioni objektiv të formës

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
45
së mbyllur, zakonisht lineare. Në një algoritëm dekompozimi ai funksioni linear vlerësohet
shumë herë, një herë për secilin skenar dhe rezultati i pritur është një kombinim i ponderuar i
këtyre rezultateve.
Për të gjetur zgjidhjen e ardhshme kandidate në një programim stokastik kryejmë një pivot të
thjeshtë nëse zgjidhim formën e gjerë, ose duke zgjidhur programimin master në një përqasje
të dekompozimit.
Në SBO hapi i vlerësimit të zgjidhjes kryhet duke ekzekutuar një model simulimi diskret të
ngjarjes (DES). Përdorimi i DES na lejon të vlerësojmë një model shumë të përgjithshëm të
sistemit tonë stokastik. Mundet, për shembull, të lëshojmë supozimet thjeshtuese në një model
radhësh që na lejoi të gjeneronim shprehje analitike për sjelljen e sistemit. Literatura për DES
është e gjerë; tekstet popullore përfshijnë (Law dhe Kelton 2000, Bankat 2005, Law 2007). Në
një SBO pjesa më e madhe e përpjekjes kompjuterike është shpenzuar në hapin e vlerësimit,
por nga një perspektiva e dizajnit të algoritmit, sfida është të zhvillohet një metodë për të gjetur
zgjidhjen e ardhshme kandidate. Për shkak se nuk kemi një model analitik të funksionit
objektiv, mekanizmat që e përdorin atë funksion në një mjedis deterministik (kërkimi gradient)
janë të vështira për t'u zbatuar në një mjedis stokastik. Disa metoda të tilla si Metodologjia e
Sipërfaqes së Përgjigjes përpiqen të vlerësojnë një model të funksionit objektiv dhe ta përdorin
atë në procesin e kërkimit.
Më të zakonshme janë mekanizmat që e trajtojnë funksionin objektiv (model simulimi) si një
kuti e zezë dhe thjesht kërkojnë hapësirën e mundshme për zgjidhje më të mira. Këto metoda
kërkimi shpesh përdorin rastësinë në procesin e kërkimit (kërkimi random). Ekziston një gamë
e gjerë metodash kërkimi në dispozicion, të cilat përgjithësisht klasifikohen në kategorinë e
përgjithshme të metauristikës (Fu 2002, Law 2007). Meta heuristikat janë "metoda të zgjidhjes
që orkestrojnë një ndërveprim midis proçedurave të përmirësimit lokal dhe strategjive të nivelit
më të lartë për të krijuar një proces të aftë për të ikur nga optimizimi lokal dhe për kryerjen e
një kërkimi të fuqishëm të një hapësire zgjidhje" (Glover dhe Kochenberger 2003). Shqyrtimet
gjithëpërfshirëse të metaheuristikave të ndryshme jepen në (Glover dhe Kochenberger 2003;
Burke dhe Kendall 2005). Metaheuristika është aplikuar gjerësisht në problemet optimizuese
deterministe kombinatoriale (Nemhauser dhe Wolsey 1988; Papadimitriou dhe Steiglitz 1998;
Wolsey 1998). Një rishikim hyrës i aplikimit të tyre për SBO është dhënë në (Fu 2002).
Metodologjitë e kërkimit përfshijnë algoritmet gjenetike (Reeves 2003, Sastry, Goldberg et al
2005), kërkimet Tabu (Gendreau dhe Potvin 2005) dhe simulimi i procesit të pjekjes së
metaleve (Henderson, Jacobson et al 2003, Aarts, Korst et al.2005).
Shumica e metaheuristikave implementojnë një formë të një kërkimi të bazuar në fqinjësi. Duke
pasur parasysh një zgjidhje kandidate x, fqinjësia N(x) është një grup pikash të mundshme që
janë afër në njëfarë kuptimi me x.
Formalisht, për një problem të optimizimit me bashkësi të mundshme X, një fqinjësi është një
lidhje N:X → 2X (Papadimitriou dhe Steiglitz 1998). Në një problem të vazhdueshëm ku X = Rn
një fqinjësi natyrale është bashkësia e të gjitha pikave brenda disa distancave fikse Euklidiane
të x.
Në problemet kombinatore, zgjedhja e fqinjësisë zakonisht është në varësi të problemit. Një
shembull standard është problemi i Udhëtimit të Shitësit për të cilin mund të përcaktojmë
fqinjësinë me 2 ndryshime duke qënë se çdo rrugë mund të formohet nga rruga aktuala duke
zëvendësuar 2 skajet. Zgjedhja e fqinjësisë është një konsideratë e rëndësishme gjatë hartimit

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
46
të një algoritmi të kërkimit lokal. Një fqinjësi më e vogël mund të kontrollohet më mirë, por e
bën më të vështirë të largohet nga optimumi lokal.
Një metaheuristikë që përpiqet të adresojë këtë është Kërkimi Variabël i Fqinjësisë (Hansen
dhe Mladenovic 2001; Hansen dhe Mladenovic 2005). Në një Kërkim Variabël të Fqinjësisë
(VNS) nuk përcaktojmë një, por disa fqinjësi të shumëfishta. Në shumë zbatime të VNS,
fqinjësitë janë të mbivendosura, të tilla që:
𝑁1(𝑥) ⊂ 𝑁2(𝑥) ⊂ ⋯ ⊂ 𝑁𝑘𝑀𝑎𝑥(𝑥) ∀𝑥 ∈ 𝑋 (2.73)
Algoritmi i kërkimit fillon duke kërkuar fqinjësinë më të afërt, duke përsëritur x çdo herë që
gjendet një zgjidhje e përmirësuar. Kur një kërkim në fqinjësi nuk arrin të gjejë një zgjidhje të
përmirësuar, kërkimi zgjerohet në fqinjesinne tjetër më të madhe dhe kërkimi vazhdon. Çdo
herë që gjendet një zgjidhje e përmirësuar, kërkimi kthehet në fqinjësinë më të vogël. VNS ka
avantazhin që fqinjësia mbahet e vogël për sa kohë që përmirësimet janë në dispozicion, por
bëhet e madhe kur përcaktohet një optimum lokal, duke ofruar mundësinë për të kërkuar jashtë
“luginës” së tanishme.
VNS është një kuadër shumë i përgjithshëm në të cilin virtualisht çdo perrqasje kërkimi mund
të inkorporohet.
2.4. Dizenjimi i Eksperimenteve Statistikore
Përgjatë këtij punimi do të kryej një numër eksperimentesh kompjuterike dhe përpiqem të
përdor dizajne formale efikase eksperimentale gjatë gjithë analizës. Një përmbledhje e
dizajneve eksperimentale gjendet në shumë tekste statistikore të përgjithshme si (Kutner,
Nachtsheim et al. 2005). Një analizë më e plotë e çështjeve të dizajnit eksperimental është
paraqitur në Box, Hunter dhe Hunter, shpesh të referuar si BH2. (Box, Hunter et al. 1978). BH2
siguron një analizë të plotë të dizajneve të plota dhe faktoriale dhe një hyrje në metodat e
sipërfaqes së përgjigjes. Një diskutim më i detajuar i Metodave të Sipërfaqjes së Përgjigjes
(RSM) është dhënë në (Box dhe Draper 1987). Aplikimi i Dizajnit Eksperimentale për
eksperimentet kompjuterike krijon një numër sfidash interesante. Një analizë e detajuar është
dhënë në (Santner, Williams et al. 2003). Zbatimi i dizajneve faktoriale të plota dhe të pjesshme
në modelet simuluese të ngjarjeve diskrete është dhënë në (Law 2007).
Dizajnet Faktoriale të Plota dhe të Pjesshme
Në një eksperiment statistikor kontrollojmë një bashkësi faktorësh dhe matim ndikimin në një
ose më shumë përgjigje. Dizajni eksperimental specifikon një numër parametrash të dallueshme
faktorialë të referuara si pikat e dizajnit. Në një eksperiment që është subjekt i gabimit
statistikor shpesh kryejmë përsëritje të shumëfishta të eksperimentit në secilën pikë të dizajnit.
Një përqasje e zakonshme për dizenjimin e eksperimenteve numerike është dizajni faktorial
(Box, Hunter et al. 2005, Law 2007). Në një aplikim standard të dizajnit faktorial, çdo faktor
është vendosur në një nga dy nivelet; një vlerë të lartë (+) dhe një vlerë të ulët (-). Në literaturën
DOE (dizajni i eksperimenteve) faktorët zakonisht kodohen në një formë të standardizuar. Për
shembull, supozoni që jemi të interesuar për një variabël ξ në intervalin [ξL, ξH]. Mund të
përcaktojmë variablën e koduar xi si:
𝑥𝑖 =𝜉𝑖−𝜉𝑙
(𝜉𝐻−𝜉𝐿)/2 (2.74)
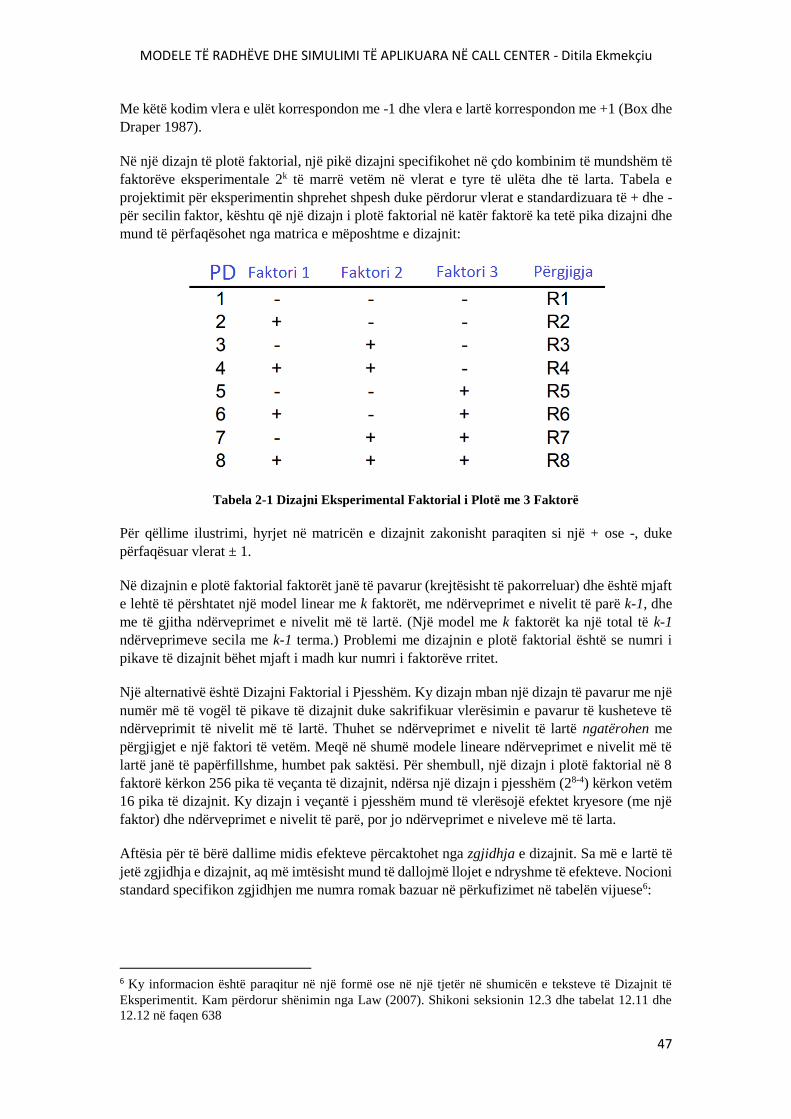
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
47
Me këtë kodim vlera e ulët korrespondon me -1 dhe vlera e lartë korrespondon me +1 (Box dhe
Draper 1987).
Në një dizajn të plotë faktorial, një pikë dizajni specifikohet në çdo kombinim të mundshëm të
faktorëve eksperimentale 2k të marrë vetëm në vlerat e tyre të ulëta dhe të larta. Tabela e
projektimit për eksperimentin shprehet shpesh duke përdorur vlerat e standardizuara të + dhe -
për secilin faktor, kështu që një dizajn i plotë faktorial në katër faktorë ka tetë pika dizajni dhe
mund të përfaqësohet nga matrica e mëposhtme e dizajnit:
Tabela 2-1 Dizajni Eksperimental Faktorial i Plotë me 3 Faktorë
Për qëllime ilustrimi, hyrjet në matricën e dizajnit zakonisht paraqiten si një + ose -, duke
përfaqësuar vlerat ± 1.
Në dizajnin e plotë faktorial faktorët janë të pavarur (krejtësisht të pakorreluar) dhe është mjaft
e lehtë të përshtatet një model linear me k faktorët, me ndërveprimet e nivelit të parë k-1, dhe
me të gjitha ndërveprimet e nivelit më të lartë. (Një model me k faktorët ka një total të k-1
ndërveprimeve secila me k-1 terma.) Problemi me dizajnin e plotë faktorial është se numri i
pikave të dizajnit bëhet mjaft i madh kur numri i faktorëve rritet.
Një alternativë është Dizajni Faktorial i Pjesshëm. Ky dizajn mban një dizajn të pavarur me një
numër më të vogël të pikave të dizajnit duke sakrifikuar vlerësimin e pavarur të kusheteve të
ndërveprimit të nivelit më të lartë. Thuhet se ndërveprimet e nivelit të lartë ngatërohen me
përgjigjet e një faktori të vetëm. Meqë në shumë modele lineare ndërveprimet e nivelit më të
lartë janë të papërfillshme, humbet pak saktësi. Për shembull, një dizajn i plotë faktorial në 8
faktorë kërkon 256 pika të veçanta të dizajnit, ndërsa një dizajn i pjesshëm (28-4) kërkon vetëm
16 pika të dizajnit. Ky dizajn i veçantë i pjesshëm mund të vlerësojë efektet kryesore (me një
faktor) dhe ndërveprimet e nivelit të parë, por jo ndërveprimet e niveleve më të larta.
Aftësia për të bërë dallime midis efekteve përcaktohet nga zgjidhja e dizajnit. Sa më e lartë të
jetë zgjidhja e dizajnit, aq më imtësisht mund të dallojmë llojet e ndryshme të efekteve. Nocioni
standard specifikon zgjidhjen me numra romak bazuar në përkufizimet në tabelën vijuese6:
6 Ky informacion është paraqitur në një formë ose në një tjetër në shumicën e teksteve të Dizajnit të
Eksperimentit. Kam përdorur shënimin nga Law (2007). Shikoni seksionin 12.3 dhe tabelat 12.11 dhe
12.12 në faqen 638
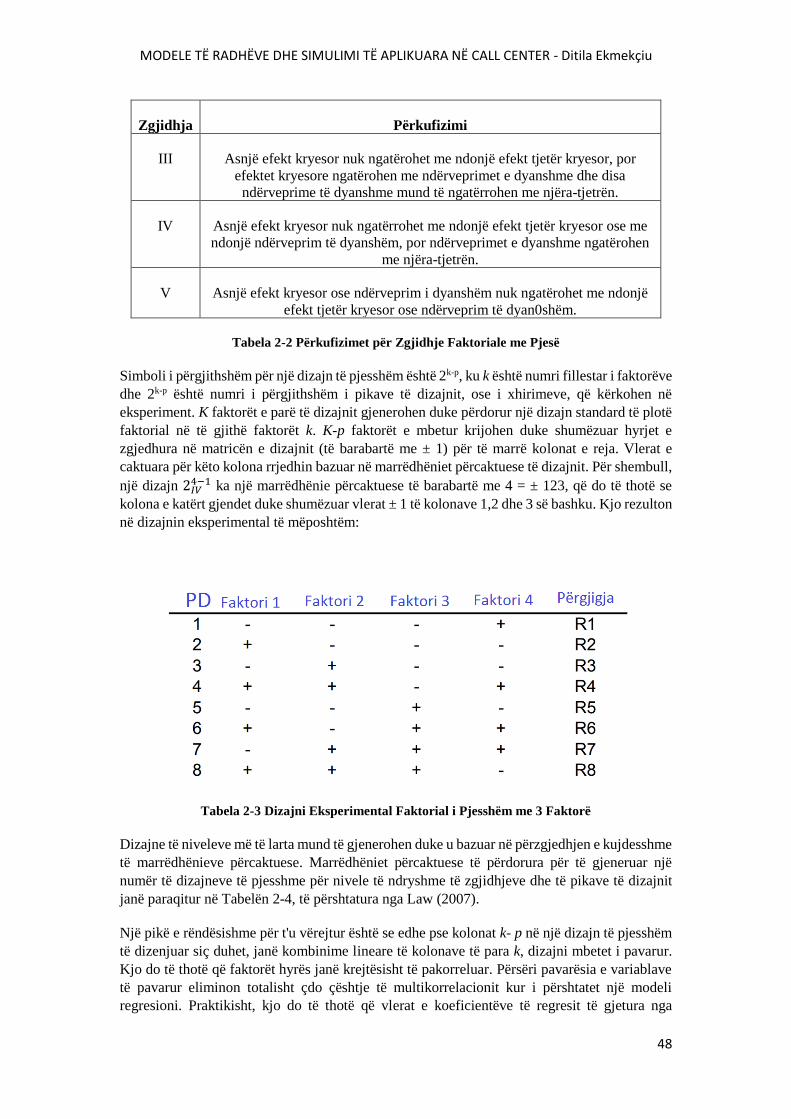
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
48
Zgjidhja Përkufizimi
III Asnjë efekt kryesor nuk ngatërohet me ndonjë efekt tjetër kryesor, por
efektet kryesore ngatërohen me ndërveprimet e dyanshme dhe disa
ndërveprime të dyanshme mund të ngatërrohen me njëra-tjetrën.
IV Asnjë efekt kryesor nuk ngatërrohet me ndonjë efekt tjetër kryesor ose me
ndonjë ndërveprim të dyanshëm, por ndërveprimet e dyanshme ngatërohen
me njëra-tjetrën.
V Asnjë efekt kryesor ose ndërveprim i dyanshëm nuk ngatërohet me ndonjë
efekt tjetër kryesor ose ndërveprim të dyan0shëm.
Tabela 2-2 Përkufizimet për Zgjidhje Faktoriale me Pjesë
Simboli i përgjithshëm për një dizajn të pjesshëm është 2k-p, ku k është numri fillestar i faktorëve
dhe 2k-p është numri i përgjithshëm i pikave të dizajnit, ose i xhirimeve, që kërkohen në
eksperiment. K faktorët e parë të dizajnit gjenerohen duke përdorur një dizajn standard të plotë
faktorial në të gjithë faktorët k. K-p faktorët e mbetur krijohen duke shumëzuar hyrjet e
zgjedhura në matricën e dizajnit (të barabartë me ± 1) për të marrë kolonat e reja. Vlerat e
caktuara për këto kolona rrjedhin bazuar në marrëdhëniet përcaktuese të dizajnit. Për shembull,
një dizajn 2𝐼𝑉4−1 ka një marrëdhënie përcaktuese të barabartë me 4 = ± 123, që do të thotë se
kolona e katërt gjendet duke shumëzuar vlerat ± 1 të kolonave 1,2 dhe 3 së bashku. Kjo rezulton
në dizajnin eksperimental të mëposhtëm:
Tabela 2-3 Dizajni Eksperimental Faktorial i Pjesshëm me 3 Faktorë
Dizajne të niveleve më të larta mund të gjenerohen duke u bazuar në përzgjedhjen e kujdesshme
të marrëdhënieve përcaktuese. Marrëdhëniet përcaktuese të përdorura për të gjeneruar një
numër të dizajneve të pjesshme për nivele të ndryshme të zgjidhjeve dhe të pikave të dizajnit
janë paraqitur në Tabelën 2-4, të përshtatura nga Law (2007).
Një pikë e rëndësishme për t'u vërejtur është se edhe pse kolonat k- p në një dizajn të pjesshëm
të dizenjuar siç duhet, janë kombinime lineare të kolonave të para k, dizajni mbetet i pavarur.
Kjo do të thotë që faktorët hyrës janë krejtësisht të pakorreluar. Përsëri pavarësia e variablave
të pavarur eliminon totalisht çdo çështje të multikorrelacionit kur i përshtatet një modeli
regresioni. Praktikisht, kjo do të thotë që vlerat e koeficientëve të regresit të gjetura nga
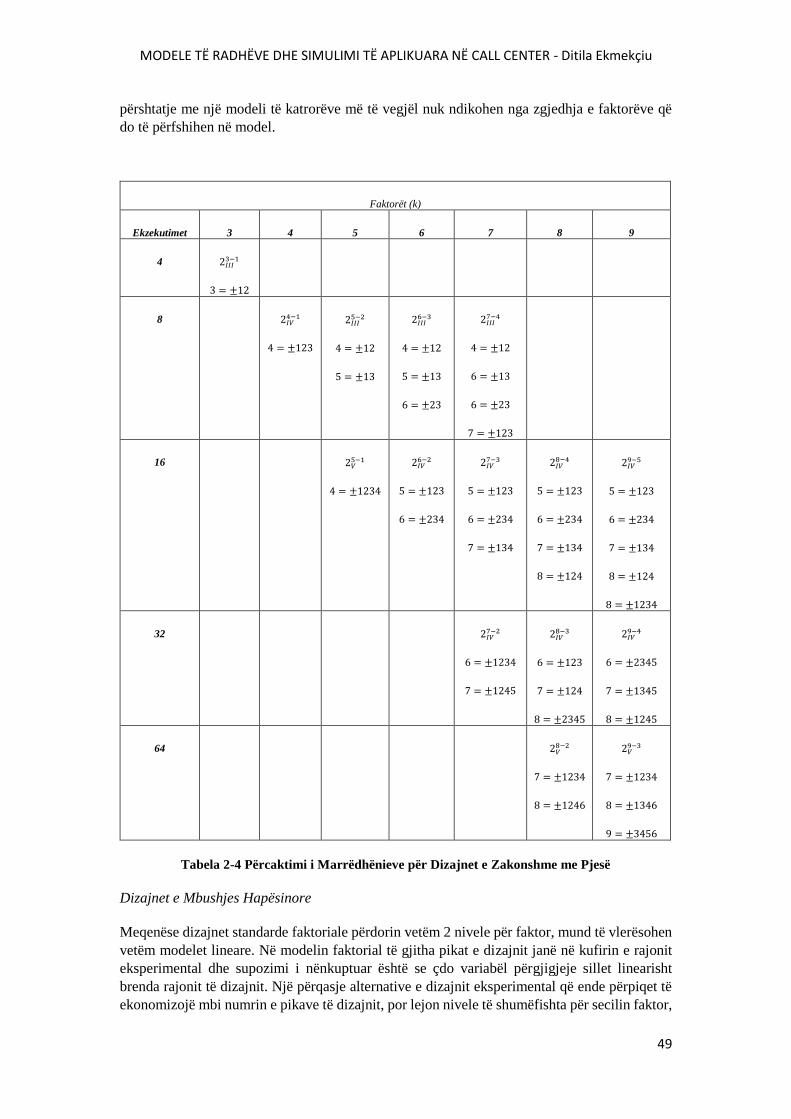
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
49
përshtatje me një modeli të katrorëve më të vegjël nuk ndikohen nga zgjedhja e faktorëve që
do të përfshihen në model.
Faktorët (k)
Ekzekutimet 3 4 5 6 7 8 9
4 2𝐼𝐼𝐼3−1
3 = ±12
8 2𝐼𝑉4−1
4 = ±123
2𝐼𝐼𝐼5−2
4 = ±12
5 = ±13
2𝐼𝐼𝐼6−3
4 = ±12
5 = ±13
6 = ±23
2𝐼𝐼𝐼7−4
4 = ±12
6 = ±13
6 = ±23
7 = ±123
16 2𝑉5−1
4 = ±1234
2𝐼𝑉6−2
5 = ±123
6 = ±234
2𝐼𝑉7−3
5 = ±123
6 = ±234
7 = ±134
2𝐼𝑉8−4
5 = ±123
6 = ±234
7 = ±134
8 = ±124
2𝐼𝑉9−5
5 = ±123
6 = ±234
7 = ±134
8 = ±124
8 = ±1234
32 2𝐼𝑉7−2
6 = ±1234
7 = ±1245
2𝐼𝑉8−3
6 = ±123
7 = ±124
8 = ±2345
2𝐼𝑉9−4
6 = ±2345
7 = ±1345
8 = ±1245
64 2𝑉8−2
7 = ±1234
8 = ±1246
2𝑉9−3
7 = ±1234
8 = ±1346
9 = ±3456
Tabela 2-4 Përcaktimi i Marrëdhënieve për Dizajnet e Zakonshme me Pjesë
Dizajnet e Mbushjes Hapësinore
Meqenëse dizajnet standarde faktoriale përdorin vetëm 2 nivele për faktor, mund të vlerësohen
vetëm modelet lineare. Në modelin faktorial të gjitha pikat e dizajnit janë në kufirin e rajonit
eksperimental dhe supozimi i nënkuptuar është se çdo variabël përgjigjeje sillet linearisht
brenda rajonit të dizajnit. Një përqasje alternative e dizajnit eksperimental që ende përpiqet të
ekonomizojë mbi numrin e pikave të dizajnit, por lejon nivele të shumëfishta për secilin faktor,

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
50
quhen dizajnet e mbushjes hapësinore (Santner, Williams dhe të tjerët, 2003). Ndërsa dizajni
faktorial vlerësoi nje pikë në kufirin e hapësirës së dizajnit, dizajnet e mbushjes hapësinore
vlerësojnë pikat në brendësi të hapësirës së projektimit duke lejuar që modelet jo lineare të
mund të përshtaten. Në përgjithësi dizajnet e mbushjes hapësinore kërkojnë në njëfarë kuptimi
të vendosin pikat e dizajnit në mënyrë të barabartë në të gjithë hapësirën e dizajnit.
Një dizajn i njohur i mbushjes hapësinore është dizajni i Latin Hypercube (Santner, Williams
et al. 2003). Në përgjithësi përqasja Latin Hypercube ndan rajonin eksperimental në një numër
fiks të hypercube-s dhe pastaj zgjedh pikat e dizajnit në mënyrë rastësore nga çdo hypercube.
Një tjetër përqasje e mbushjes hapësinore njihet si Dizajni Uniform (Fang, Lin et al. 2000; Fang
dhe Lin 2003; Santner, Williams et al. 2003). Ndërsa përqasja Latin Hypercube (LH) ka
komponentë deterministë dhe rastësorë, përqasja e dizajnit uniform (UD) është e gjitha
deterministe7.
Një UD vendos pikat e dizajnit në një mënyrë që minimizon mospërputhjen midis shpërndarjes
empirike të pikave të kampionit dhe të një funksioni me densitet uniform, ku mospërputhja
është një matës i caktuar i nisjes nga hapësira e përkryer uniforme.
Problemi i zgjedhjes së dizajnit uniform mund të shprehet si më poshtë. Për një grup të dhënë
s të parametrave, dhe hapësirën korresponduese s-dimensionale, gjejmë bashkësinë e n pikave
𝑃𝑛∗ = {x1, …, xn} ⊂ Rs, e tillë që matja e mospërputhjes D(Pn) të minimizohet. Për të përcaktuar
masën e mospërputhjes së pari përcaktojmë shpërndarjen empirike të Pn si:
𝐹𝑛(𝑥) =1
𝑛∑ 𝐼{𝑥𝑖 ≤ 𝑥}𝑛
𝑖=1 (2.75)
Ku i {⋅} është funksioni tregues dhe pabarazia është duke respektuare rendin sipas
komponentëve të Rs -së. Nga ky funksion përcaktojmë një grup të matjeve të mospërputhjeve,
matjet e mospërputhjeve Lp:
𝐷𝑝(𝑃𝑛) = [∫ |𝐹𝑛(𝑥) − 𝐹(𝑥)|𝑝𝑑𝑥
ℝ𝑆 ]1
𝑝⁄ (2.76)
Vlera të ndryshme të p-së krijojnë matje të ndryshme mospërputhjesh. Një zgjedhje e
zakonshme është që të zgjedhim p të barabartë me ∞, mospërputhja që rezulton L∞ (gjithashtu
e referuar si mospërputhja protagoniste ose thjeshtë mospërputhja) është atëherë:
𝐷(𝑃𝑛) = 𝑠𝑢𝑝𝑥∈ℝ𝑛|𝐹𝑛(𝑥) − 𝐹(𝑥)| (2.77)
Problemi me Dizajnin Uniform është se zgjedhja e 𝑃𝑛∗ është në vetvete një problem i vështirë.
(Fang dhe Lin 2003) jep një pasqyrë të teknikave të gjenerimit të dizajnit. Për problemet me
dimension të ulët - replikim të ulët, tabelat janë disponibël, shih për shembull (Wang, Lin dhe
të tjerët, 1995). Për dizajne relativisht të mëdha, tabelat mund të gjenerohen në mënyrë
interaktive nga faqja e internetit e dizajnit uniform8. Dizajne më të mëdha mund të gjenerohen
duke përdorur aplikacionin softuerik të Dizajnit Uniform (Fang and Du 1998).
Figura 2-6 tregon shembuj të UD-ve të gjeneruara në R2 për madhësitë e kampionëve prej 100
dhe 200 duke përdorur softuerin e Dizajnit Uniform.
7 Megjithëse përzgjedhja e pikave të dizajnit uniform është deterministe, UD në përgjithësi nuk është
unik në atë që dizajne të shumta mund të ekzistojnë me të njëjtën masë të mospërputhjes 8 Faqja e internetit të Dizajnit Uniform ( http://www.math.hkbu.edu.hk/UniformDesign/ ) është e lidhur
me Universitetin Baptist të Hong Kongut.
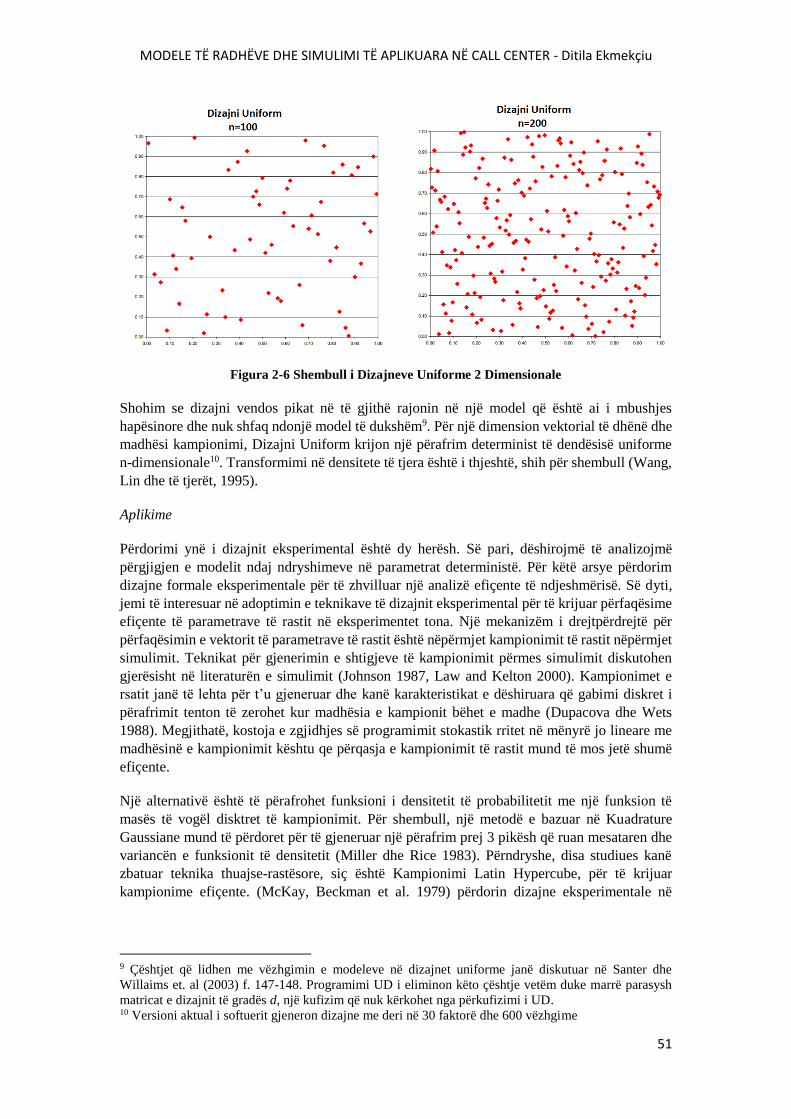
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
51
Figura 2-6 Shembull i Dizajneve Uniforme 2 Dimensionale
Shohim se dizajni vendos pikat në të gjithë rajonin në një model që është ai i mbushjes
hapësinore dhe nuk shfaq ndonjë model të dukshëm9. Për një dimension vektorial të dhënë dhe
madhësi kampionimi, Dizajni Uniform krijon një përafrim determinist të dendësisë uniforme
n-dimensionale10. Transformimi në densitete të tjera është i thjeshtë, shih për shembull (Wang,
Lin dhe të tjerët, 1995).
Aplikime
Përdorimi ynë i dizajnit eksperimental është dy herësh. Së pari, dëshirojmë të analizojmë
përgjigjen e modelit ndaj ndryshimeve në parametrat deterministë. Për këtë arsye përdorim
dizajne formale eksperimentale për të zhvilluar një analizë efiçente të ndjeshmërisë. Së dyti,
jemi të interesuar në adoptimin e teknikave të dizajnit eksperimental për të krijuar përfaqësime
efiçente të parametrave të rastit në eksperimentet tona. Një mekanizëm i drejtpërdrejtë për
përfaqësimin e vektorit të parametrave të rastit është nëpërmjet kampionimit të rastit nëpërmjet
simulimit. Teknikat për gjenerimin e shtigjeve të kampionimit përmes simulimit diskutohen
gjerësisht në literaturën e simulimit (Johnson 1987, Law and Kelton 2000). Kampionimet e
rsatit janë të lehta për t’u gjeneruar dhe kanë karakteristikat e dëshiruara që gabimi diskret i
përafrimit tenton të zerohet kur madhësia e kampionit bëhet e madhe (Dupacova dhe Wets
1988). Megjithatë, kostoja e zgjidhjes së programimit stokastik rritet në mënyrë jo lineare me
madhësinë e kampionimit kështu qe përqasja e kampionimit të rastit mund të mos jetë shumë
efiçente.
Një alternativë është të përafrohet funksioni i densitetit të probabilitetit me një funksion të
masës të vogël disktret të kampionimit. Për shembull, një metodë e bazuar në Kuadrature
Gaussiane mund të përdoret për të gjeneruar një përafrim prej 3 pikësh që ruan mesataren dhe
variancën e funksionit të densitetit (Miller dhe Rice 1983). Përndryshe, disa studiues kanë
zbatuar teknika thuajse-rastësore, siç është Kampionimi Latin Hypercube, për të krijuar
kampionime efiçente. (McKay, Beckman et al. 1979) përdorin dizajne eksperimentale në
9 Çështjet që lidhen me vëzhgimin e modeleve në dizajnet uniforme janë diskutuar në Santer dhe
Willaims et. al (2003) f. 147-148. Programimi UD i eliminon këto çështje vetëm duke marrë parasysh
matricat e dizajnit të gradës d, një kufizim që nuk kërkohet nga përkufizimi i UD. 10 Versioni aktual i softuerit gjeneron dizajne me deri në 30 faktorë dhe 600 vëzhgime

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
52
vlerësimin e një eksperimenti të simulimit të vazhdueshëm. (Simpson, Lin et al. 2001) heton
dizajnet LH dhe UD në vlerësimin e dy simulimeve inxhinierike.
Autorë të ndryshëm e kanë shtrirë këtë koncept për të përdorur dizajnet eksperimentale të
mbushjes hapësinore për të krijuar bashkësi skenarësh efiçentë për programimet stokastike.
Linderoth et al. kryejnë një test empirik të detajuar të disa programimeve stokastike duke
përdorur kampionime të rastit dhe LH (Linderoth, Shapiro et al. 2006). (Freimer, Thomas et al.
2006) krahasojnë kampionimet e rastit me kampionimet LH, dhe variantet e kundërta në
kontekstin e programimeve stokastike. (Mo, Harrison et al. 2006) përdorin UD në një model
stokastik lokacioni logjistike.
Në rishikimin e mësipërm përmbledh literaturën në fushat kryesore të lidhura me këtë tezë.
Disertacioni në vazhdim do të përmbledhë së bashku këto fusha dhe do t'i zbatojë ato në
problemin e menaxhimit të kapacitetit të call center-ave.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
53
KAPITULLI 3: MODELET NË CALL CENTER-IN E
KONSIDERUAR DHE PËRDORIMI I TYRE NË PARASHIKIM
3.1. Modeli i Skedulimit Afatshkurtër
Objektivi i modelit të skedulimit afatshkurtër është për të përcaktuar turne optimale duke
konsideruar kohën e mbërritjejes si madhësi e rastit. Modeli zhvillon një skedulim javor të
dizenjuar për të arritur një Nivel Shërbimi të caktuar, në bazë të marrëveshjes, duke caktuar një
“gjobë” financiare që bazohet në probabilitetin e mos arritjes së objetktivit të Nivelit të
Shërbimit. Formulohet dhe zgjidhet si një programim stokastik dhe optimizohet në bazë të një
serie të një modeli javor të stimuluar të mbërritjeve. Ndërkohë që objektivi ekplicit është të
modelojmë një model specifik të skedulimit në bazë të një situate të dhënë, një objektiv
sekondar është studimi i impaktit që ka madhësia e rastit në procesin e skedulimit. Duke qënë
se pjesa më e madhe e modeleve të skedulimit e injorojnë pasigurinë në Kohën e mbërritjeve,
do mundohemi të kuptojmë se si ndikon kjo e fundit në skedulimin optimal dhe me koston që i
shoqërohet.
Më pas do të formulojmë një model bashkë me algoritmin e zgjidhjes. Gjithashtu do të shohim
supozime të ndryshme të përdorura në formulimin e modelit dhe do të vlerësohet se sa i kuruar
është modeli për të parashikuar Nivelet e Shërbimit. Më pas do të diskutohet çështja e
kompromisit ndërmjet kostove dhe nivelit të shërbimit dhe impaktin e variacionit në skedulimin
optimal. Më tej do të krahasohet modeli stokastik me modelin me vlerë mesatare të përcaktuar,
do të analizohet impakti në fleksibilitetin e organizimit të stafit dhe do të vlerësohet impakti që
personat part-time kanë në koston totale të dhënies së shërbimit.
3.1.1. Formulimi i problemit dhe përqasja ndaj zgjidhjes
Në këtë model do të përpiqem të gjej një plan të organizimit të stafit me kosto minimale që
plotëson një përmbushje të nivelit global të shërbimit. Modeli vlerëson numrin e thirrjeve që
plotësojnë kërkesat e nivelit të shërbimit në çdo periudhë duke bërë një përafrim linear të kurbës
së TSF-së; një kurbë që i referohet numrit të ajgentëve me një nivel të caktuar shërbimi me një
norme të caktuar të mbërritjes. Gjenerojmë përafrimin linear të kurbës së TSF-së duke u bazuar
në një model të Erlang A që vlerëson nivelet e braktisjeve bazuar në një shpërndarje
eksponenciale të durimit. Duke qënë se modeli lejon braktisjen, mbetet e vlefshme nëse norma
e mbërritjes e kalon normën e shërbimit. Modeli Erlang C në anën tjetër bëhet i papërcaktuar
në këtë kusht dhe madhësia e radhës bëhet e pafundme. Për shkak të nivelit të lartë të
ndryshueshmërisë në mjedisin e asistencës teknike, norma e mbërritjeve do të tejkalojë shpesh
nivelet e shërbimit, të paktën përkohësisht. Kjo ndodh në qoftë se përjetojmë maksimume të
paplanifikuara në mbërritje. Mund të ndodhë edhe me planifikim për periudha të shkurtra të
kërkesës (të njohur) të lartë.
Do ta formulojmë modelin si një programim stokastik të integruar me dy faza. Në fazën e parë
janë marrë vendimet e organizimit të stafit dhe në fazën e dytë janë realizuar volumet e
telefonatave dhe llogarisim arritjen e niveleve të shërbimit (Ekmekçiu 2016).
Formulimi
Do të formuloj një model me përkufizimet e mëposhtme:
Bashkësitë Variablat e vendimmarrjes

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
54
I: periudha kohore xj: numri i personave të caktuar për skedulimin j
J: skedulimet e mundshme
K: skenarët
H: pikët në një përafrim linear
Parametrat deterministe Variablat
e gjëndjes
cj: kostoja e skedulimit j yik: numri i telefonatave në
periudhën i të skenarit k të përgjigjura
brenda niveleve të shërbimit
aij: tregon në qoftë se skedulimi j është stafuar në kohën i Sk: Mungesa e TSF-së në
skenarin k
g: objektivi i niveleveve globale të shërbimit
mikh: përkulja e përafrimit të pjesshëm të TSF-së h në peridhën i i skenarit k
bikh: intercepti i përafrimit të pjesshëm të TSF-së h në peridhën i i skenarit k
pk: probabiliteti i skenarit k Parametrat
Stokastike
µi: numri minimal i agjentëve në periudhën i nik: numri i telefonatave
në periudhën i të skenarit k
ηj: numri maksimal i agjentëve që mund t’i caktohen skedulimit j
r: kosto e gjobës për çdo pikë të mugesës së TSF-së
Ky model mund të shprehet si më poshtë:
Të minimizohet:
∑ 𝑐𝑗𝑥𝑗𝑗∊𝐽 + ∑ 𝑝𝑘𝑟𝑆𝑘𝑘∊𝐾 (3.1)
Me kushtet:
𝑦𝑖𝑘 ≤ 𝑚𝑖𝑘ℎ ∑ 𝑎𝑖𝑗𝑥𝑗 + 𝑏𝑖𝑘ℎ 𝑗∈𝐽 ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾, ℎ ∈ 𝐻 (3.2)
∑ 𝑛𝑖𝑘𝑆𝑘 ≥ ∑ (𝑔𝑛𝑖𝑘 − 𝑦𝑖𝑘)𝑖∈𝐼 𝑖∈𝐼 ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾 (3.3)
𝑦𝑖𝑘 ≤ 𝑛𝑖𝑘 ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾 (3.4)
∑ 𝑎𝑖𝑗𝑥𝑗 ≥ 𝜇𝑖𝑗∈𝐽 ∀𝑖 ∈ 𝐼 (3.5)
𝑥𝑗 ≤ 𝔶𝑗 ∀𝑗 ∈ 𝐽 (3.6)
𝑥𝑗 ∈ 𝑍+, 𝑦𝑖𝑘 ∈ ℝ+, 𝑆𝑘 ∈ ℝ+ ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾 (3.7)

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
55
Qëllimi i këtij modeli është të minimizojë koston totale të organizimit të stafit plus koston e
pritur të gjobës që lidhet me dështimin për të arritur nivelin e dëshiruar të shërbimit. Optimizimi
ndodh gjatë një realizimi të një bashkësie K të realizimit të mostrave të mbërritjeve të thirrjeve.
Këto mostra quhen skenarë. Kufizimi (3.2) përcakton variablin yik si numri i thirrjeve të
përgjigjura brenda niveleve të shërbimit në periudhën i të skenarit k bazuar në një përafrim
konveks linear të kurbës TSF. Kufizimi (3.3) llogarit mungesën proporcionale të TSF-së;
maksimumi i diferencës në pikë përqindjeje midis TSF--së objektiv dhe TSF-së së arritur dhe
zeros. Kufizimi (3.4) limiton thirrjet e përgjigjura brenda objektivit të nivelit të shërbimit nga
thirrjet totale të marra gjatë periudhës. Kufizimi (3.5) përcakton numrin minimal të agjentëve
në çdo periudhë. Kufizimi (3.6) përcakton një kufi të sipërm të numrit të agjentëve të caktuar
për secilin orar. Kufizimi (3.7) përcakton kushtet e jo-negativitetit dhe numrave të plotë për
variablat e programimit.
Ky model rrjedh nga formulimi bazë i mbulimit të bashkësive në modele të tilla si (Dantzig
1954), por me zgjerimet e mëposhtme:
• Madhësia e serverit dhe hapat e caktimit të skedulimit të stafit janë të kombinuara në
një programim optimizimi.
• Modeli është përcaktuar në mënyrë eksplicite për një proces radhësh me një normë
mbërritjesh jo homogjene.
• Modeli në mënyrë eksplicite pranon se norma e mbërritjes është një ndryshore e rastit.
• Ky model specifikon si kufizimin e performancës periudhë pas periudhe dhe gjithashtu
një kufizim global të saj.
• Modeli përdor një përafrim linear për kurbën e TSF-së që rrjedh nga një model Erlang
A.
Madhësia e modelit, dhe rrjedhimisht përpjekja kompjuterike e kërkuar për ta zgjidhur atë,
drejtohet më së shumti nga dy faktorë; numri i skedulimeve të mundshme (J) dhe numri i
skenarëve (K). Numri i variablave të numrave të plotë është i barabartë me numrin e
skedulimeve, ndërsa numri i variablave të vazhdueshëm është i barabartë me prodhimin e
numrit të skenarëve dhe numrit të periudhave kohore, plus numrin e skenarëve.
Në këtë analizë po krijojmë skedulimet për një javë (me ndërprerje të qartë midis turneve, por
jo brenda turneve). Në raste të thjeshta kur lejoj vetëm pesë ditë në javë me turn tetë-orarsh,
numri i skedulimeve të mundshme është 576. Në raste më komplekse ku kemi një gamë më të
gjerë të mundësive të skelulimit part-time ose full-time, kemi 3,696 skedulime. Do të hetoj
numrin e skenarëve të kërkuar në seksionin tjetër, por 50 skenarë nuk janë të paarsyeshme. Kjo
nënkupton kërkesën për të zgjidhur modele me 3,696 variabla si numra të plotë dhe mbi 16,000
variabla të vazhdueshëm.
Gjenerimi i skenarëve
Ky programim (3.1)-(3.7) është zgjidhur mbi disa bashkësi të rezultateve të mostrave nga
modeli statistikor i modeleve të mbërritjes së thirrjeve. Një algoritëm për gjenerimin e thirrjeve
të simuluara është paraqitur në figurën 1-8 dhe po e përsëris këtu për lehtësi.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
56
Figura 3-1 Algoritmi i Gjenerimit të Simuluar të Telefonatave
Ky algoritëm është koduar në Visual Basic.Net dhe përdoret për të gjeneruar skenarë për
algoritmin e optimizimit. Programimi është projektuar për të krijuar skenarë në grupe me
madhësi të ndryshueshme. Çdo grup është plotësisht i pavarur nga grupet e tjera; pra skenari i
parë në një seri prej 50 skenarësh është i ndryshëm nga skenari i parë në një seri prej 100
skenarësh. Algoritmi shkruan volumet e telefonatave në një file që mund të lexohet direkt nga
sistemi GAMS11.
Algoritmi i Zgjidhjes
Ky model është formuluar si një MIP (Programim i Përzierë i Numrave të Plotë) dhe si i tillë
mund të zgjidhet nga një algoritëm i numërimit të nënkuptuar (degë dhe nyje). Dega dhe nyjet
punojnë mirë për probleme më të vogla, por tenton të ngecë me rritjen e numrit të skenarëve.
Për të lehtësuar zgjidhjen e problemeve të shkallës së lartë implementova një version të
algoritmit të dekompozimit të formës L (Birge and Louveaux 1997).
Metoda ime e dekompozimit është një zbatim i drejtpërdrejtë i kësaj metode, i përshtatur për
një fazë të parë diskrete. E dekompozoj problemin në, një problem kryesor ku merret vendimi
i organizimit të stafit, dhe një seri nën-problemesh ku mungesa e TSF-së llogaritet për secilin
skenar.
Duke shënuar me v vlerësimin e përsëritjeve të mëdha të algoritmit, θv koston e përafërt të
rekursionit, dhe Eikv dhe eik
v koeficientët e prerjeve të funksionit të rekursionit, problemi master
mund të përcaktohet si:
Të minimizohet
∑ 𝑐𝑗𝑥𝑗𝑗∈𝐽 + 𝜃𝑣 (3.8)
Me kushtet:
11 GAMS është sistemi për përdoruesin e fundit i përdorur për të përcaktuar modelin dhe kodin e
algoritmit të zgjidhjes. GAMS bazohet tek CPLEX, i cili në të vërtetë zgjidh programimet lineare dhe
me numra të plotë.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
57
𝜃𝑣 ≥ ∑ 𝑝𝑘𝐸𝑖𝑘𝑣 ∑ 𝑎𝑖𝑗𝑥𝑗 + 𝑒𝑖𝑘
𝑣𝑗∈𝐽𝑘∈𝐾 ∀𝑖 ∈ 𝐼, 𝑣 (3.9)
∑ 𝑎𝑖𝑗𝑥𝑗 ≥ 𝜇𝑖𝑗∈𝐽 ∀𝑖 ∈ 𝐼 (3.10)
𝑥𝑗 ≤ 𝔶𝑗 ∀𝑗 ∈ 𝐽 (3.11)
𝑥𝑗 ∈ 𝑍+, 𝜃𝑣 ∈ ℝ+ ∀𝑗 ∈ 𝐽 (3.12)
Në këtë problem θv përfaqëson një parashikim të afatit të “gjobës” si pasojë e mungesës së TSF-
së. Le të jenë (xv, Ɵv) një zgjidhje optimale.
Për çdo realizim të vektorit të rastit k = 1, ..., K më pas zgjidhim nën-problemin e mëposhtëm
Të minimizohet
𝑟𝑆𝑘 (3.13)
Me kushtet:
𝑦𝑖𝑘 ≤ 𝑚𝑖𝑘ℎ ∑ 𝑎𝑖𝑗𝑥𝑗𝑣 + 𝑏𝑖𝑘ℎ 𝑗∈𝐽 ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾, ℎ ∈ 𝐻 (3.14)
∑ 𝑛𝑖𝑘𝑆𝑘 ≥ ∑ (𝑔𝑛𝑖𝑘 − 𝑦𝑖𝑘)𝑖∈𝐼 𝑖∈𝐼 ∀𝑘 ∈ 𝐾 (3.15)
𝑦𝑖𝑘 ≤ 𝑛𝑑𝑖𝑘 ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾 (3.16)
𝑥𝑗𝑣 ∈ 𝑍+, 𝑦𝑖𝑗 ∈ ℝ+, 𝑆𝑘 ∈ ℝ+ ∀𝑖 ∈ 𝐼, 𝑘 ∈ 𝐾, ℎ ∈ 𝐻 (3.17)
Do të përdor variablat dualë nga zgjidhja e grupit të nënproblemave për të përmirësuar
përafrimin e afatit të gjobës. Le të jetë π1ikhv variabli dual i lidhur me (3.14), π2k
v variabli dual
i lidhur me (3.15) dhe π3ikv variabli dual i lidhur me (3.16). Më pas do të llogaris parametrat e
mëposhtëm të përdorur për prodhimin e prerjes:
𝐸𝑖𝑘𝑣+1 = ∑ ∑ 𝜋1𝑖𝑘ℎ
𝑣 𝑚𝑖𝑘ℎ ∑ 𝑎𝑖𝑗𝑥𝑗𝑣
𝑗∈𝐽ℎ∈𝐻𝑖∈𝐼 (3.18)
𝑒𝑘𝑣+1 = ∑ [𝜋3𝑖𝑘
𝑣 𝑛𝑖𝑘 + ∑ 𝜋1𝑖𝑘ℎ𝑣 𝑏𝑖𝑘ℎ𝑛𝑖𝑘ℎ∈𝐻 ] − 𝜋2𝑘
𝑣𝑔 ∑ 𝑛𝑖𝑘𝑖∈𝐼𝑖∈𝐼 (3.19)
Do të përdor këto vlera për të gjeneruar një kufizim të formës (3.9). Përcaktoj v = v + 1, shtoj
kufizimin në problemin master dhe përsëris. Algoritmi zgjidh programimin master pastaj zgjidh
çdo nën-programim për nivelin e organizimit të stafit fiks të përcaktuar në zgjidhjen master.
Bazuar në zgjidhjen e nënproblemave, çdo përsëritje shton një prerje të vetme në problemin
master. Këto shkurtime krijojnë një linearizim të jashtëm të funksionit të “gjobës” (Geoffrion
1970).
Zgjidhja e problemit master siguron një kufizim më të ulët në zgjidhjen optimale, ndërsa
mesatarja e zgjidhjeve të nënproblemave siguron një kufizim të sipërm. Në implementimin tonë
do të zgjidh relaksimin me programim linear të masterit derisa të arrihet një nivel i parë i
tolerancës në hendekun e optimizimit dhe pastaj riaplikoj kufizimet e integralitetit. Do të
vazhdoj përsëritjen midis programimit master dhe nënprogramimit derisa të arrihet një
tolerancë finale e hendekut.
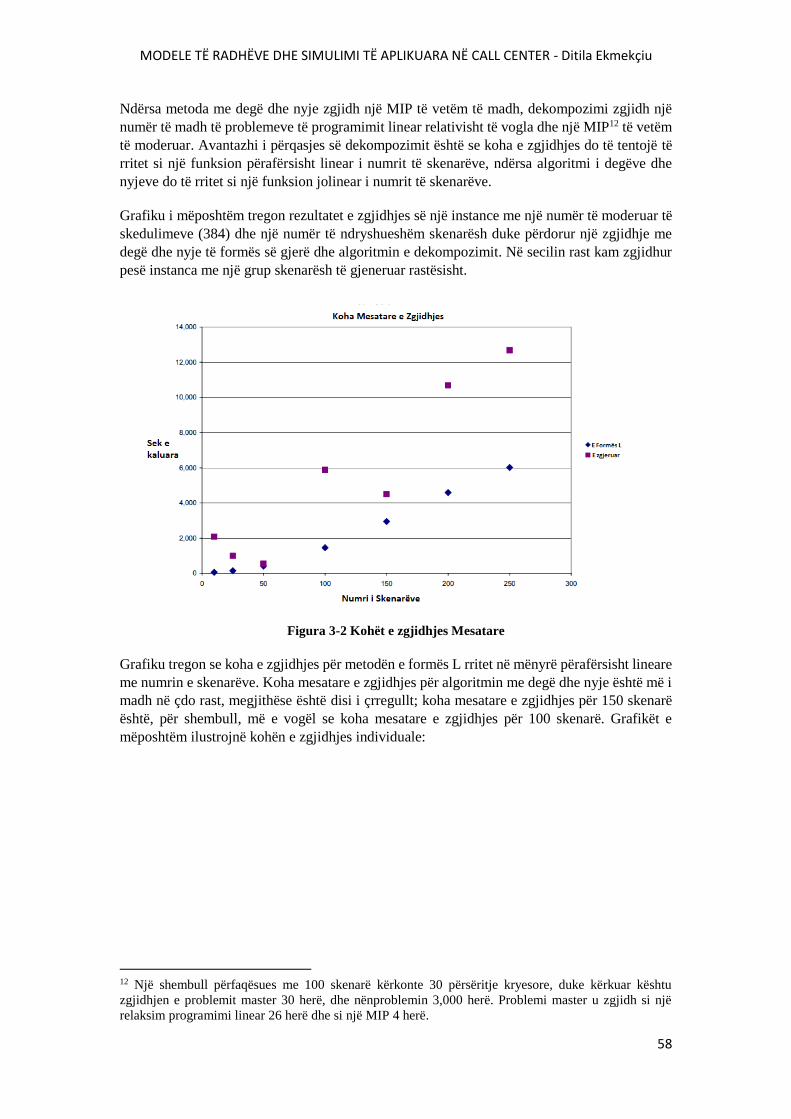
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
58
Ndërsa metoda me degë dhe nyje zgjidh një MIP të vetëm të madh, dekompozimi zgjidh një
numër të madh të problemeve të programimit linear relativisht të vogla dhe një MIP12 të vetëm
të moderuar. Avantazhi i përqasjes së dekompozimit është se koha e zgjidhjes do të tentojë të
rritet si një funksion përafërsisht linear i numrit të skenarëve, ndërsa algoritmi i degëve dhe
nyjeve do të rritet si një funksion jolinear i numrit të skenarëve.
Grafiku i mëposhtëm tregon rezultatet e zgjidhjes së një instance me një numër të moderuar të
skedulimeve (384) dhe një numër të ndryshueshëm skenarësh duke përdorur një zgjidhje me
degë dhe nyje të formës së gjerë dhe algoritmin e dekompozimit. Në secilin rast kam zgjidhur
pesë instanca me një grup skenarësh të gjeneruar rastësisht.
Figura 3-2 Kohët e zgjidhjes Mesatare
Grafiku tregon se koha e zgjidhjes për metodën e formës L rritet në mënyrë përafërsisht lineare
me numrin e skenarëve. Koha mesatare e zgjidhjes për algoritmin me degë dhe nyje është më i
madh në çdo rast, megjithëse është disi i çrregullt; koha mesatare e zgjidhjes për 150 skenarë
është, për shembull, më e vogël se koha mesatare e zgjidhjes për 100 skenarë. Grafikët e
mëposhtëm ilustrojnë kohën e zgjidhjes individuale:
12 Një shembull përfaqësues me 100 skenarë kërkonte 30 përsëritje kryesore, duke kërkuar kështu
zgjidhjen e problemit master 30 herë, dhe nënproblemin 3,000 herë. Problemi master u zgjidh si një
relaksim programimi linear 26 herë dhe si një MIP 4 herë.
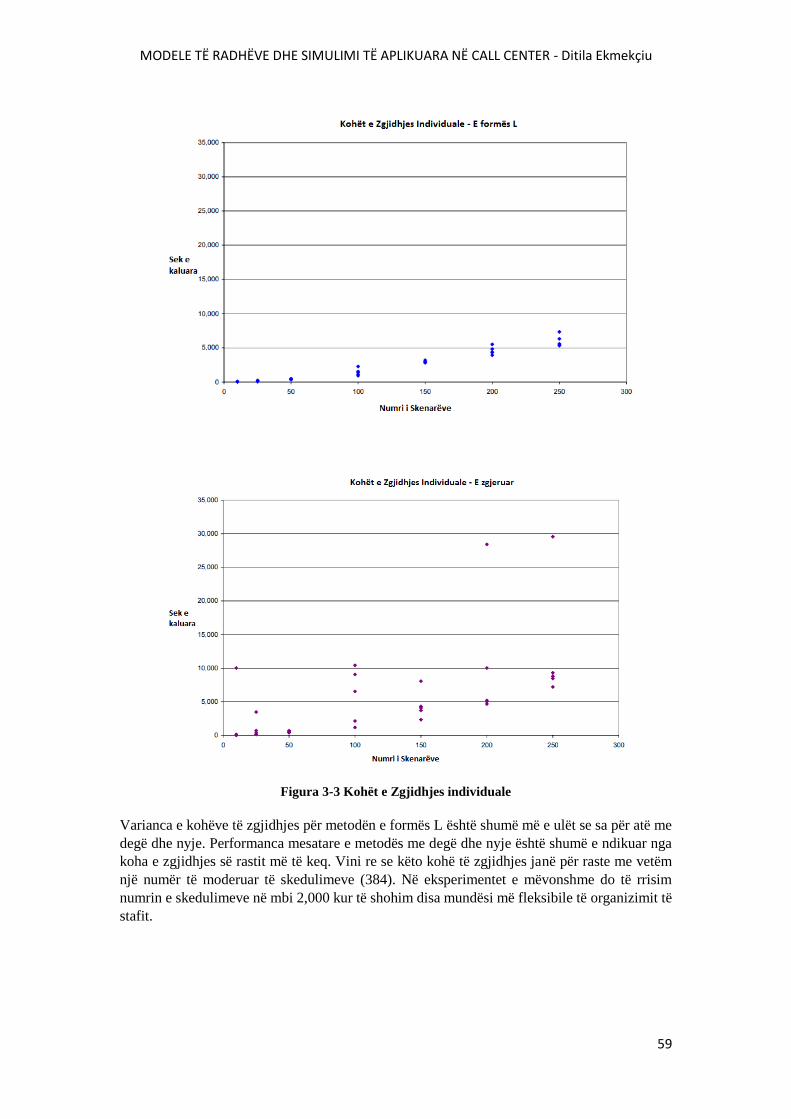
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
59
Figura 3-3 Kohët e Zgjidhjes individuale
Varianca e kohëve të zgjidhjes për metodën e formës L është shumë më e ulët se sa për atë me
degë dhe nyje. Performanca mesatare e metodës me degë dhe nyje është shumë e ndikuar nga
koha e zgjidhjes së rastit më të keq. Vini re se këto kohë të zgjidhjes janë për raste me vetëm
një numër të moderuar të skedulimeve (384). Në eksperimentet e mëvonshme do të rrisim
numrin e skedulimeve në mbi 2,000 kur të shohim disa mundësi më fleksibile të organizimit të
stafit.
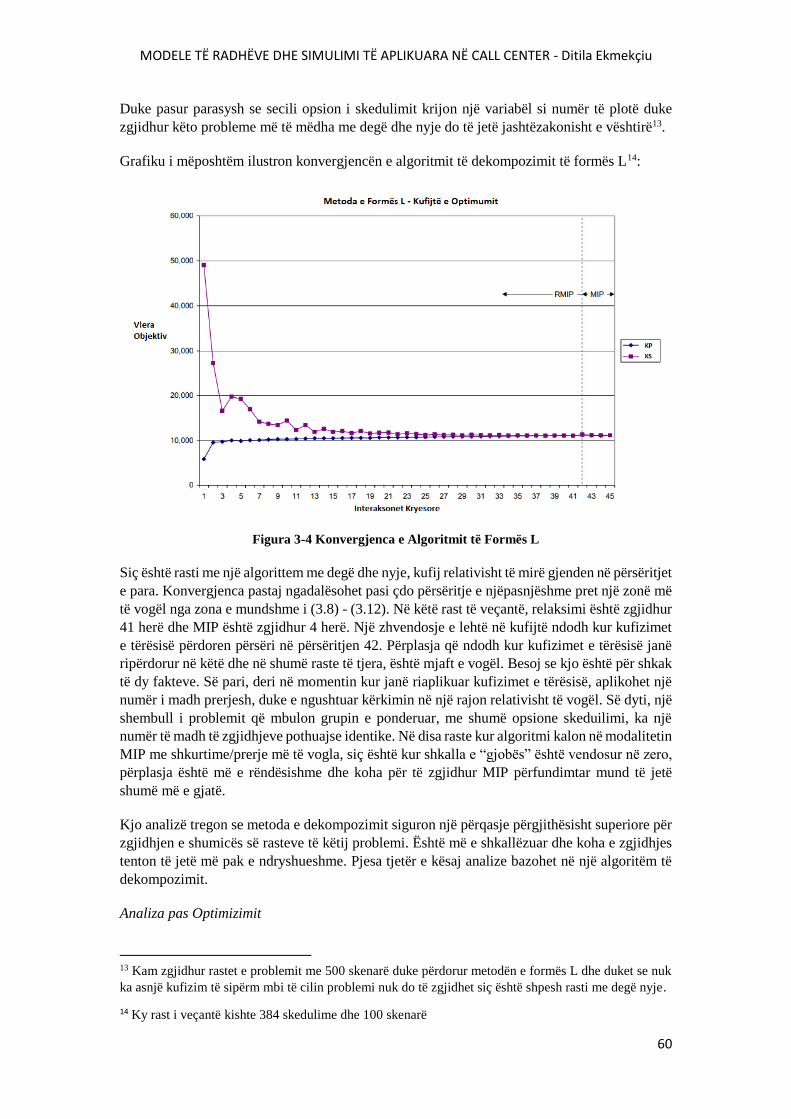
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
60
Duke pasur parasysh se secili opsion i skedulimit krijon një variabël si numër të plotë duke
zgjidhur këto probleme më të mëdha me degë dhe nyje do të jetë jashtëzakonisht e vështirë13.
Grafiku i mëposhtëm ilustron konvergjencën e algoritmit të dekompozimit të formës L14:
Figura 3-4 Konvergjenca e Algoritmit të Formës L
Siç është rasti me një algorittem me degë dhe nyje, kufij relativisht të mirë gjenden në përsëritjet
e para. Konvergjenca pastaj ngadalësohet pasi çdo përsëritje e njëpasnjëshme pret një zonë më
të vogël nga zona e mundshme i (3.8) - (3.12). Në këtë rast të veçantë, relaksimi është zgjidhur
41 herë dhe MIP është zgjidhur 4 herë. Një zhvendosje e lehtë në kufijtë ndodh kur kufizimet
e tërësisë përdoren përsëri në përsëritjen 42. Përplasja që ndodh kur kufizimet e tërësisë janë
ripërdorur në këtë dhe në shumë raste të tjera, është mjaft e vogël. Besoj se kjo është për shkak
të dy fakteve. Së pari, deri në momentin kur janë riaplikuar kufizimet e tërësisë, aplikohet një
numër i madh prerjesh, duke e ngushtuar kërkimin në një rajon relativisht të vogël. Së dyti, një
shembull i problemit që mbulon grupin e ponderuar, me shumë opsione skeduilimi, ka një
numër të madh të zgjidhjeve pothuajse identike. Në disa raste kur algoritmi kalon në modalitetin
MIP me shkurtime/prerje më të vogla, siç është kur shkalla e “gjobës” është vendosur në zero,
përplasja është më e rëndësishme dhe koha për të zgjidhur MIP përfundimtar mund të jetë
shumë më e gjatë.
Kjo analizë tregon se metoda e dekompozimit siguron një përqasje përgjithësisht superiore për
zgjidhjen e shumicës së rasteve të këtij problemi. Është më e shkallëzuar dhe koha e zgjidhjes
tenton të jetë më pak e ndryshueshme. Pjesa tjetër e kësaj analize bazohet në një algoritëm të
dekompozimit.
Analiza pas Optimizimit
13 Kam zgjidhur rastet e problemit me 500 skenarë duke përdorur metodën e formës L dhe duket se nuk
ka asnjë kufizim të sipërm mbi të cilin problemi nuk do të zgjidhet siç është shpesh rasti me degë nyje.
14 Ky rast i veçantë kishte 384 skedulime dhe 100 skenarë

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
61
Zgjidhja e (3.1) - (3.7) është zgjidhja optimale e problemit të trajektores kampion. E shënojmë
këtë zgjidhje si zn*, ku n është numri i skenarëve të përdorur për të llogaritur zgjidhjen. Ky
është një parashikim i njëanshëm i zgjidhjes së problemit të vërtetë; që është problemi i
vlerësuar kundër shpërndarjes së vazhdueshme të normave të mbërritjes. Do ta shënoj me z*
zgjidhjen e vërtetë. (Mak, Morton et al. 1999) tregojnë se gabimi i pritur në zgjidhje është në
rënie me madhësinë e kampionit.
𝐸[𝑧𝑛∗ ] ≤ 𝐸[𝑧𝑛+1
∗ ] ≤ 𝑧∗ (3.20)
Nga një perspektivë praktike, një vendim kyç është përcaktimi i numrit të skenarëve që duhet
përdorur në optimizimin tonë. Ndërsa rris numrin e skenarëve, zgjidhja bëhet një përafrim më
i mirë i zgjidhjes së vërtetë, por kostoja kompjuterike e gjetjes së kësaj zgjidhjeje rritet.
Për të ndihmuar në këtë proces, do të bëj një vlerësim të post-optimizimit të zgjidhjes kandidate
duke përdorur një proces kufizimi Monte-Carlo të përshkruar në (Mak, Morton et al., 1999).
Do të shënoj me x^ zgjidhjen e problemit kampion. Më pas do të zgjidh nënprogramimin (3.13)
- (3.17) duke përdorur x^ si zgjidhjen kandidat, për të marrë koston e pritshme të implementimit
të kësaj zgjidhjeje. Në këtë analizë do të zgjidh nënprogramimin me nu të barabartë me 500
skenarë të gjeneruar në mënyrë të pavarur nga skenarët e përdorur në optimizim. Zgjidhja e
nënprogramimit na jep një kufi të sipërm në zgjidhjen e vërtetë, ndërsa zgjidhja e problemit
origjinal zn* është një kufizim i poshtëm.
Për të marrë kufij më të mirë për zgjidhjen e vërtetë optimale mund të zgjedhim për të zgjidhur
problemin origjinal disa herë, secilën herë me skenarë të gjeneruar në mënyrë të pavarur.
Shënojmë numrin e grupeve (grupet e skenarëve) që përdoren për të zgjidhur problemin
origjinal me nl dhe variancën e kampionit të objektivit si sl (nl). Në mënyrë të ngjashme kam
llogaritur variancën e kampionit të rezultatit të pritshëm të zgjidhjes kandidate kundrejt nu
skenarëve të vlerësimit. Më pas mund të përcaktojmë gabimet e mëposhtme standarde:
𝜀�̃� =𝑡𝑛𝑢−1,𝛼𝑠𝑢(𝑛𝑢)
√𝑛𝑢 (3.21)
𝜀�̃� =𝑡𝑛𝑙−1,𝛼𝑠𝑙(𝑛𝑙)
√𝑛𝑙 (3.22)
Ku 𝑡𝑛𝑢−1,𝛼 është një statistikë t standarde, p.sh. P{𝑇𝑛 ≤ 𝑡𝑛𝑢−1,𝛼}= 1 - α. Tani mund të
përcaktojmë një interval të përafërt konfidence (1 - 2α) në hendekun e optimizimit si:
[0, [𝑈(𝑛𝑢) − �̅�(𝑛𝑙)]+ + 𝜀�̃� + 𝜀�̃�] (3.23)
Për t’u vënë re që marrim pjesën pozitive të diferencës ndërmjet kufijve të sipërm dhe të
poshtëm sepse është e mundur, për shkak të gabimit të kampionimit, që kjo diferencë të jetë
negative. Kjo proçedurë na lejon të gjenerojmë një kufi statistikor mbi cilësinë e zgjidhjes sonë,
domethënë distancën e mundshme nga optimumi i vërtetë.
3.1.2. Përafrimi TSF dhe SIPP
Ky model përpiqet të gjenerojë një plan skedulimi që plotëson një Marrëveshje të Nivelit të
Shërbimit (SLA) me një kosto minimale. Për hir të kësaj analize, supozoj që SLA është
përcaktuar bazuar vetëm në TSF. Për ta bërë këtë në mënyrë efektive, programimi i optimizimit
duhet të vlerësojë nivelin e shërbimit që do të arrihet për çdo plan skedulimi të stafit për çdo
realizim të telefonatave. Në këtë seksion do të përshkruaj përqasjen e përdorur për të vlerësuar
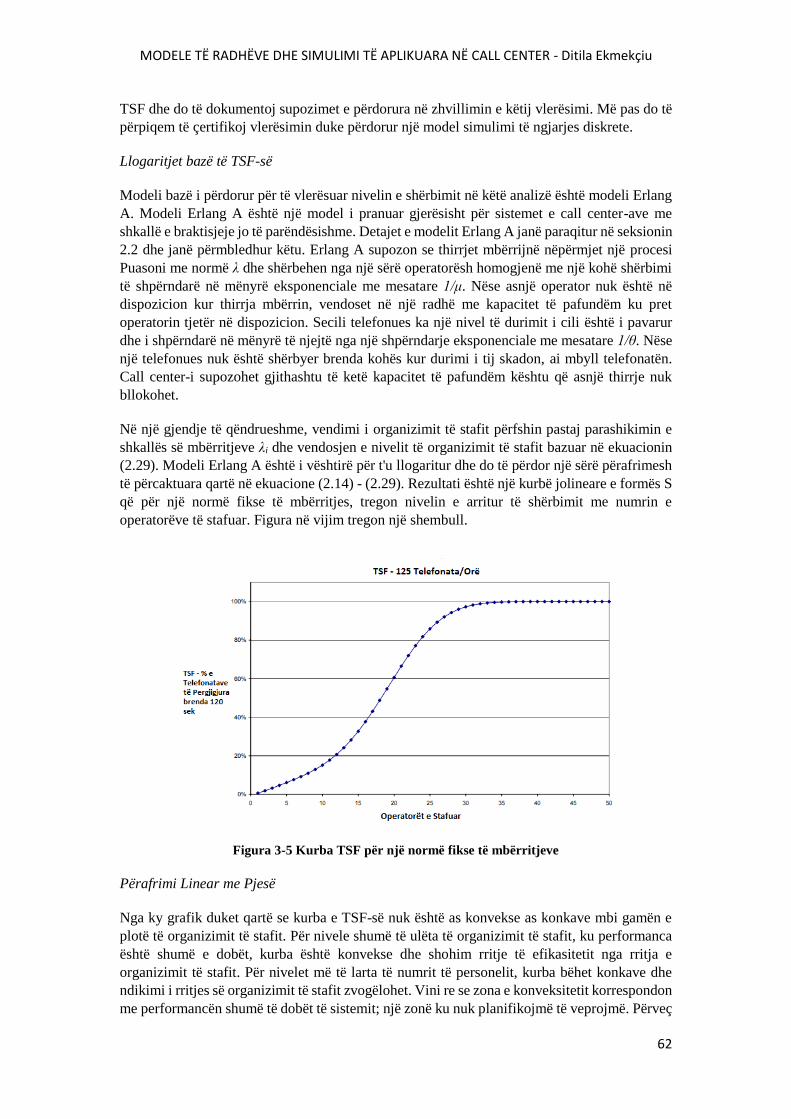
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
62
TSF dhe do të dokumentoj supozimet e përdorura në zhvillimin e këtij vlerësimi. Më pas do të
përpiqem të çertifikoj vlerësimin duke përdorur një model simulimi të ngjarjes diskrete.
Llogaritjet bazë të TSF-së
Modeli bazë i përdorur për të vlerësuar nivelin e shërbimit në këtë analizë është modeli Erlang
A. Modeli Erlang A është një model i pranuar gjerësisht për sistemet e call center-ave me
shkallë e braktisjeje jo të parëndësishme. Detajet e modelit Erlang A janë paraqitur në seksionin
2.2 dhe janë përmbledhur këtu. Erlang A supozon se thirrjet mbërrijnë nëpërmjet një procesi
Puasoni me normë λ dhe shërbehen nga një sërë operatorësh homogjenë me një kohë shërbimi
të shpërndarë në mënyrë eksponenciale me mesatare 1/μ. Nëse asnjë operator nuk është në
dispozicion kur thirrja mbërrin, vendoset në një radhë me kapacitet të pafundëm ku pret
operatorin tjetër në dispozicion. Secili telefonues ka një nivel të durimit i cili është i pavarur
dhe i shpërndarë në mënyrë të njejtë nga një shpërndarje eksponenciale me mesatare 1/θ. Nëse
një telefonues nuk është shërbyer brenda kohës kur durimi i tij skadon, ai mbyll telefonatën.
Call center-i supozohet gjithashtu të ketë kapacitet të pafundëm kështu që asnjë thirrje nuk
bllokohet.
Në një gjendje të qëndrueshme, vendimi i organizimit të stafit përfshin pastaj parashikimin e
shkallës së mbërritjeve λi dhe vendosjen e nivelit të organizimit të stafit bazuar në ekuacionin
(2.29). Modeli Erlang A është i vështirë për t'u llogaritur dhe do të përdor një sërë përafrimesh
të përcaktuara qartë në ekuacione (2.14) - (2.29). Rezultati është një kurbë jolineare e formës S
që për një normë fikse të mbërritjes, tregon nivelin e arritur të shërbimit me numrin e
operatorëve të stafuar. Figura në vijim tregon një shembull.
Figura 3-5 Kurba TSF për një normë fikse të mbërritjeve
Përafrimi Linear me Pjesë
Nga ky grafik duket qartë se kurba e TSF-së nuk është as konvekse as konkave mbi gamën e
plotë të organizimit të stafit. Për nivele shumë të ulëta të organizimit të stafit, ku performanca
është shumë e dobët, kurba është konvekse dhe shohim rritje të efikasitetit nga rritja e
organizimit të stafit. Për nivelet më të larta të numrit të personelit, kurba bëhet konkave dhe
ndikimi i rritjes së organizimit të stafit zvogëlohet. Vini re se zona e konveksitetit korrespondon
me performancën shumë të dobët të sistemit; një zonë ku nuk planifikojmë të veprojmë. Përveç
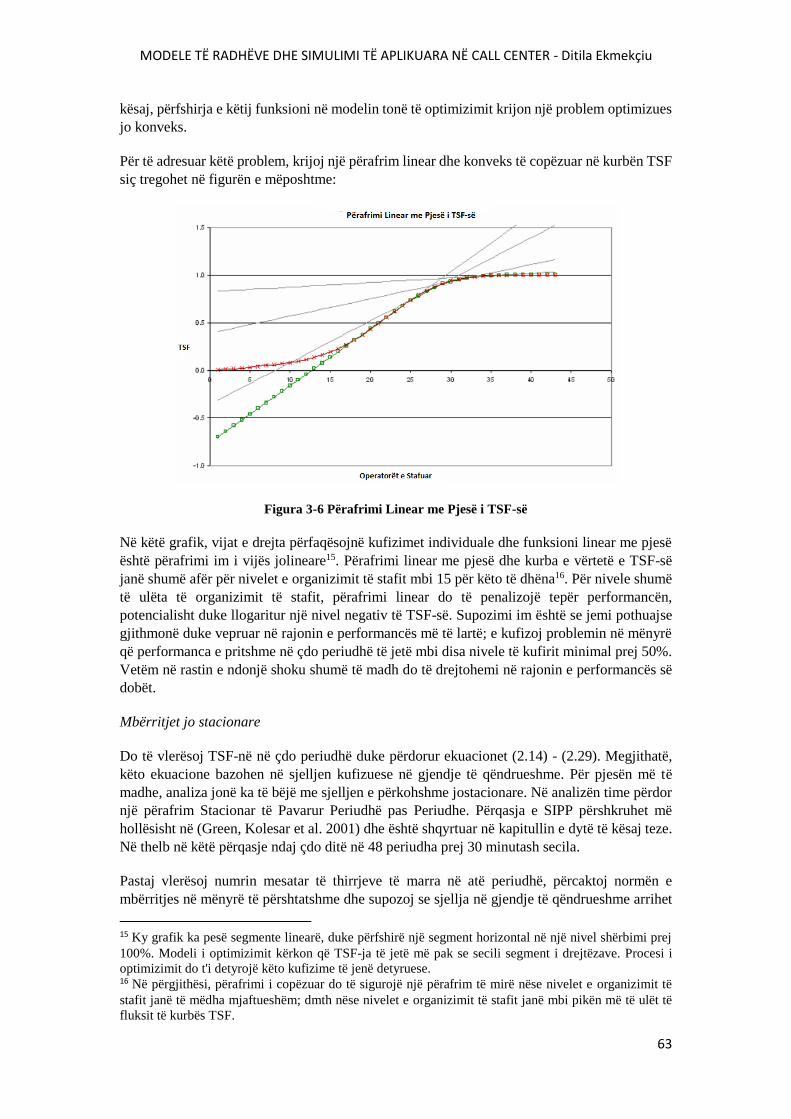
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
63
kësaj, përfshirja e këtij funksioni në modelin tonë të optimizimit krijon një problem optimizues
jo konveks.
Për të adresuar këtë problem, krijoj një përafrim linear dhe konveks të copëzuar në kurbën TSF
siç tregohet në figurën e mëposhtme:
Figura 3-6 Përafrimi Linear me Pjesë i TSF-së
Në këtë grafik, vijat e drejta përfaqësojnë kufizimet individuale dhe funksioni linear me pjesë
është përafrimi im i vijës jolineare15. Përafrimi linear me pjesë dhe kurba e vërtetë e TSF-së
janë shumë afër për nivelet e organizimit të stafit mbi 15 për këto të dhëna16. Për nivele shumë
të ulëta të organizimit të stafit, përafrimi linear do të penalizojë tepër performancën,
potencialisht duke llogaritur një nivel negativ të TSF-së. Supozimi im është se jemi pothuajse
gjithmonë duke vepruar në rajonin e performancës më të lartë; e kufizoj problemin në mënyrë
që performanca e pritshme në çdo periudhë të jetë mbi disa nivele të kufirit minimal prej 50%.
Vetëm në rastin e ndonjë shoku shumë të madh do të drejtohemi në rajonin e performancës së
dobët.
Mbërritjet jo stacionare
Do të vlerësoj TSF-në në çdo periudhë duke përdorur ekuacionet (2.14) - (2.29). Megjithatë,
këto ekuacione bazohen në sjelljen kufizuese në gjendje të qëndrueshme. Për pjesën më të
madhe, analiza jonë ka të bëjë me sjelljen e përkohshme jostacionare. Në analizën time përdor
një përafrim Stacionar të Pavarur Periudhë pas Periudhe. Përqasja e SIPP përshkruhet më
hollësisht në (Green, Kolesar et al. 2001) dhe është shqyrtuar në kapitullin e dytë të kësaj teze.
Në thelb në këtë përqasje ndaj çdo ditë në 48 periudha prej 30 minutash secila.
Pastaj vlerësoj numrin mesatar të thirrjeve të marra në atë periudhë, përcaktoj normën e
mbërritjes në mënyrë të përshtatshme dhe supozoj se sjellja në gjendje të qëndrueshme arrihet
15 Ky grafik ka pesë segmente linearë, duke përfshirë një segment horizontal në një nivel shërbimi prej
100%. Modeli i optimizimit kërkon që TSF-ja të jetë më pak se secili segment i drejtëzave. Procesi i
optimizimit do t'i detyrojë këto kufizime të jenë detyruese. 16 Në përgjithësi, përafrimi i copëzuar do të sigurojë një përafrim të mirë nëse nivelet e organizimit të
stafit janë të mëdha mjaftueshëm; dmth nëse nivelet e organizimit të stafit janë mbi pikën më të ulët të
fluksit të kurbës TSF.
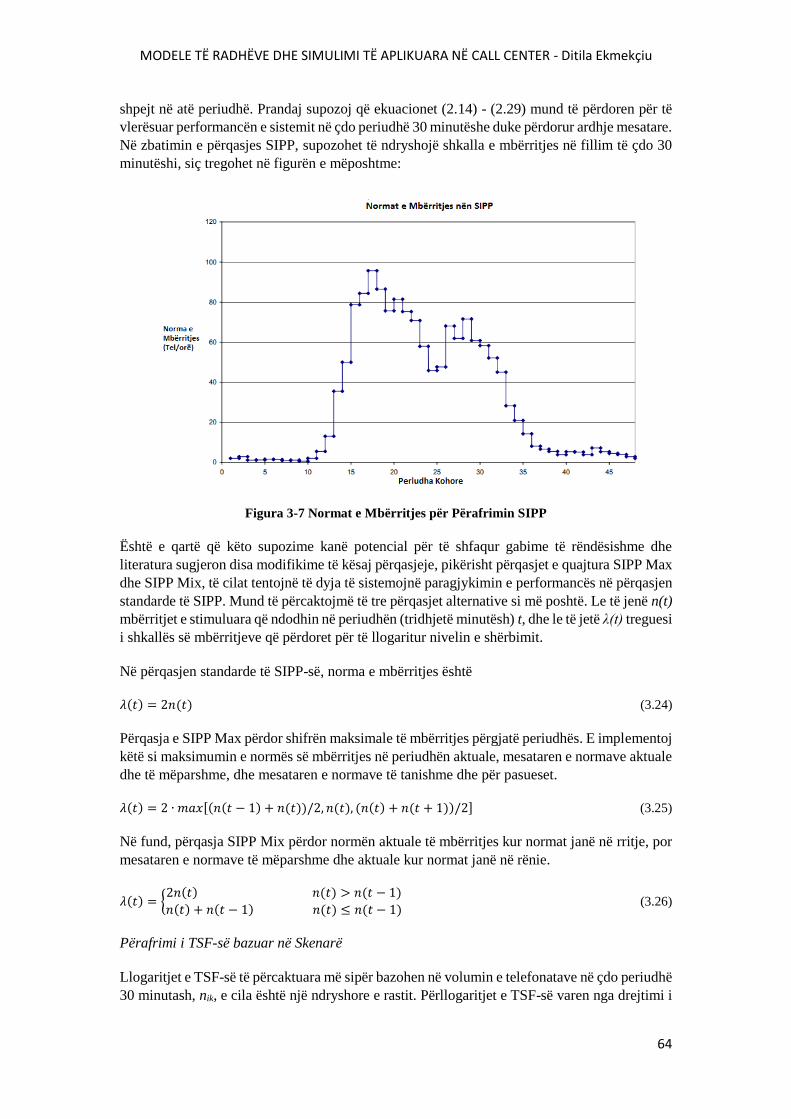
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
64
shpejt në atë periudhë. Prandaj supozoj që ekuacionet (2.14) - (2.29) mund të përdoren për të
vlerësuar performancën e sistemit në çdo periudhë 30 minutëshe duke përdorur ardhje mesatare.
Në zbatimin e përqasjes SIPP, supozohet të ndryshojë shkalla e mbërritjes në fillim të çdo 30
minutëshi, siç tregohet në figurën e mëposhtme:
Figura 3-7 Normat e Mbërritjes për Përafrimin SIPP
Është e qartë që këto supozime kanë potencial për të shfaqur gabime të rëndësishme dhe
literatura sugjeron disa modifikime të kësaj përqasjeje, pikërisht përqasjet e quajtura SIPP Max
dhe SIPP Mix, të cilat tentojnë të dyja të sistemojnë paragjykimin e performancës në përqasjen
standarde të SIPP. Mund të përcaktojmë të tre përqasjet alternative si më poshtë. Le të jenë n(t)
mbërritjet e stimuluara që ndodhin në periudhën (tridhjetë minutësh) t, dhe le të jetë λ(t) treguesi
i shkallës së mbërritjeve që përdoret për të llogaritur nivelin e shërbimit.
Në përqasjen standarde të SIPP-së, norma e mbërritjes është
𝜆(𝑡) = 2𝑛(𝑡) (3.24)
Përqasja e SIPP Max përdor shifrën maksimale të mbërritjes përgjatë periudhës. E implementoj
këtë si maksimumin e normës së mbërritjes në periudhën aktuale, mesataren e normave aktuale
dhe të mëparshme, dhe mesataren e normave të tanishme dhe për pasueset.
𝜆(𝑡) = 2 ∙ 𝑚𝑎𝑥[(𝑛(𝑡 − 1) + 𝑛(𝑡))/2, 𝑛(𝑡), (𝑛(𝑡) + 𝑛(𝑡 + 1))/2] (3.25)
Në fund, përqasja SIPP Mix përdor normën aktuale të mbërritjes kur normat janë në rritje, por
mesataren e normave të mëparshme dhe aktuale kur normat janë në rënie.
𝜆(𝑡) = {2𝑛(𝑡) 𝑛(𝑡) > 𝑛(𝑡 − 1)
𝑛(𝑡) + 𝑛(𝑡 − 1) 𝑛(𝑡) ≤ 𝑛(𝑡 − 1) (3.26)
Përafrimi i TSF-së bazuar në Skenarë
Llogaritjet e TSF-së të përcaktuara më sipër bazohen në volumin e telefonatave në çdo periudhë
30 minutash, nik, e cila është një ndryshore e rastit. Përllogaritjet e TSF-së varen nga drejtimi i

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
65
kampionit dhe duhet të përfshihen në algoritmin e gjenerimit të skenarit. Një algoritëm
gjithëpërfshirës për gjenerimin e skenarit sigurohet më pas nga algoritmi i mëposhtëm:
1) Gjenero një javë të volumit të telefonatave duke përdorur algoritmin e treguar në Figurën 3-1.
2) Bazuar në metodën SIPP llogarit normën e mbërritjes për periudhë duke përdorur ekuacionet
(3.24), (3.25) ose (3.26).
3) Për një volum të caktuar të telefonatave, zgjidh h +1 nivele probabiliteti për vlerësimin e pikave
në kurbën TSF17.
4) Llogarit nivelin e organizimit të stafit të kërkuar për të arritur probabilitetet objektiv të
përcaktuara në Hapin 3 duke përdorur ekuacionet (2.14) - (2.29).
5) Rillogarit TSF-në për nivelin integral të organizimit të stafit të llogaritur në Hapin 3. Tani kemi
h +1 çifte probabiliteti të niveleve të organizimit të stafit në kurbën TSF.
6) Llogarit përkuljen (mikh) dhe interceptin (bikh) për çdo çift pikash ngjitur të gjetura në Hapin 5.
7) Gjenero një skenar që përfshin volumet e telefonatave për periudhë (nik) dhe çiftet h të
parametrave të përkuljes dhe interceptit për secilën periudhë në horizontin e planifikimit.
Figura 3-8 Përqssja e Përafrimit TSF e bazuar në Skenarë
Përveç informacionit të skenarit individual, duhet të krijohen parametrat për kufirin minimal të
nivelit të operatorëve (3.5). Kjo është një procedurë e drejtpërdrejtë si më poshtë:
1) Përcakto w, rasti më i keq i pranueshëm i niveleve të pritura të shërbimit dhe nmin numri i
përgjithshëm i operatorëve që duhet të jenë të stafuar në çdo kohë18.
2) Përsërit hapat 2 - 6 për çdo periudhë i.
3) Përcakto nivelin e pritur të mbërritjeve të telefonatave.
4) Llogarit nivelin e organizimit të stafit nw të kërkuar për të arritur rastin më të keq të nivelit ë
shërbimit të pritur të përcaktuar në Hapin 1 duke përdorur ekuacionet (2.14) - (2.29).
5) Llogarit μi = [𝑚𝑖𝑛(𝑛𝑤 , 𝑛𝑚𝑖𝑛)], minimumi i operatorëve për t’u stafuar në periudhën i.
6) Shkruaj μi në një format kompatibël me GAMS.
Figura 3-9 Gjenerimi i kufizimeve të Organizimit Minimal të stafit
Algoritmi i gjenerimit të skenarit i përshkruar më sipër është shkruar në VB.Net. Gjeneron
skedarët e skenarit në një format që mund të lexohet nga GAMs dhe përdoren për të gjeneruar
modele CPLEX. Një skedar skenarësh 100 gjenerohet në pak sekonda në një kompjuter
desktop. Në përgjithësi, koha e krijimit të skenarit është e papërfillshme në krahasim me kohën
e zgjidhjes për programimin stokastik.
Testimi SIPP dhe vlefshmëria e modelit
Një numër i përafrimeve shkojnë në llogaritjen e nivelit të shërbimit në këtë model të
optimizimit stokastik. Meqenëse niveli i TSF-së është nxitësi kryesor i nivelit të organizimit të
stafit, është e arsyeshme që të vihet në dyshim saktësia e këtyre përafrimeve dhe të marrin në
konsideratë rregullimet e SIPP-së të diskutuara më sipër. Në këtë seksion do të kryej një
eksperiment numerik për të testuar saktësinë e çdo versioni të modelit SIPP. Do të testoj çdo
17 Në praktikë përdor vlerat .3, .72, .9, .98, .995 për të gjitha periudhat me volume telefonatash të paktën
5. Vlera të ndyrshme përdoren pë volumet më të ulëta telefonatash për të ruajtur përafrimin konveks. 18 Në këtë punim, përveç rasteve ku citohet ndryshe, do të përdor TSF të barabartë me 50% si rastin më
të keq dhe një minimum niveli të organizimit të stafit prej 2 personash.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
66
version SIPP kundrejt modeleve të bazuar në 3 prej projekteve të modeleve19 të përshkruar në
Kapitullin e Parë.
Përqasja eksperimentale
Siç është përshkruar më lart, procesi bazë i përfshirë në zgjidhjen e programimit stokastik është
të zgjidhet modeli (3.1) - (3.7) kundrejt një sërë skenarësh, realizime të simuluara të volumit të
telefonatave. Gjatë këtij procesi do të llogaris një nivel TSF-je dhe një vlerë objektive, të dyja
tkëto vlera janë vlerësime të pjesshme të vlerave të vërteta. Më pas do të kryej një analizë post-
optimizimi e cila teston zgjidhjen kandidate kundrejt një sërë skenarësh vlerësimi.
Në këtë proces llogaritet një rezultat i pritur (niveli i shërbimit dhe kostoja) që është një
vlerësim i paanshëm i zgjidhjes së vërtetë20. Qëllimi i kësaj vlefshmërie është të përcaktojë se
sa mirë është analiza e paanshme, pas optimizimit, në parashikimin e nivelit aktual të shërbimit
të realizuar. Vini re se që duke qëne se ardhjet janë të rastësishme, niveli i shërbimit të realizuar
do të jetë i rastësishëm. Për të bërë këtë vlerësim, i drejtohem Simulimit Diskret të Ngjarjeve
(DES). DES është një metodologji e përcaktuar mirë për shqyrtimin e sistemeve komplekse të
radhës siç është kjo. Me anë të përdorimit të DES-it mund të modelojmë më afër sjelljen
specifike të sistemit në modelet specifike të telefonatave të realizuara. Modeli DES i përdorur
në këtë analizë përdor të njëjtin algoritëm të treguar në Figurën 4-1 për të gjeneruar një model
telefonatash jostacionare. Modeli gjeneron më pas telefonatat individuale të simuluara të cilat
përpunohen duke përdorur të njëjtat shpërndarje teorike të përdorura në modelin Erlang A.
Përqasja e simulimit na lejon të lançojmë modelin për një numër të madh modelesh simulimi
të mbërritjeve dhe për të llogaritur kufijtë statistikorë të matësve kryesorë të performancës të
tilla si TSF. Shihni (Banks 2005) ose (Law 2007) për një përshkrim të hollësishëm të procesit
të simulimit. Duke supozuar se modeli DES është një përfaqësim i vlefshëm i modelit jo
stacionar të radhës Erlang-A, mund ta përdorim këtë model për të vlerësuar saktësinë e
llogaritjes së TSF-së në programimin e optimizimit.
Vlefshmëria e përpunuar është përshkruar më poshtë:
1) Gjenero një grup prej 100 skenarësh dhe përdor këto për të zgjidhur problemin e optimizimit
stokastik (3.1) - (3.7).
2) Duke përdorur zgjidhjen e gjetur në hapin 1 si zgjidhjen kandidate, kryej një vlerësim pas
optimizimit kundrejt 500 skenarëve të gjeneruara në mënyrë të pavarur për të gjetur nivelin e
pritur të shërbimit të lidhur me zgjidhjen kandidate.
3) Përdor organizimin periudhë pas periudhe të stafit të zhvilluar në hapin 1 për të krijuar profilin
e burimit në një model simulimi të ngjarjeve diskrete me një shpërndarje identike statistikore të
volumeve të telefonatave.
4) Kryej 50 replikime të modelit DES për të llogaritur një pikë vlerësimi të TSF-së së pritur nga
implementimi i zgjidhjes së gjetur në hapin 1 duke përdorur SIPP, SIPP Max dhe SIPP Mix.
5) Krahaso rezultatet e gjetura në hapin 2 me ato të gjetura në hapin 4 për të vlerësuar gabimin që
lidhet me secilën përqasje SIPP.
Figura 3-10 Përqasja e Validimit të TSF-së
19 Projekti i katërt i përshkruar në Kapitullin e Parë është tepër i vogël për t'u konsideruar në modelin e
skedulimit. Duke pasur parasysh vëllimet e tij shumë të ulëta, projekti pothuajse gjithmonë ka staf në
nivelin minimal të organizimit të stafit prej dy operatorëve. Do ta analizoj këtë projekt në modelin
përfundimtar të kësaj teze që trajton unifikimin e projektit.
20 Procesi i post-optimizimit diskutohet më me hollësi në sesionin e ardhshëm
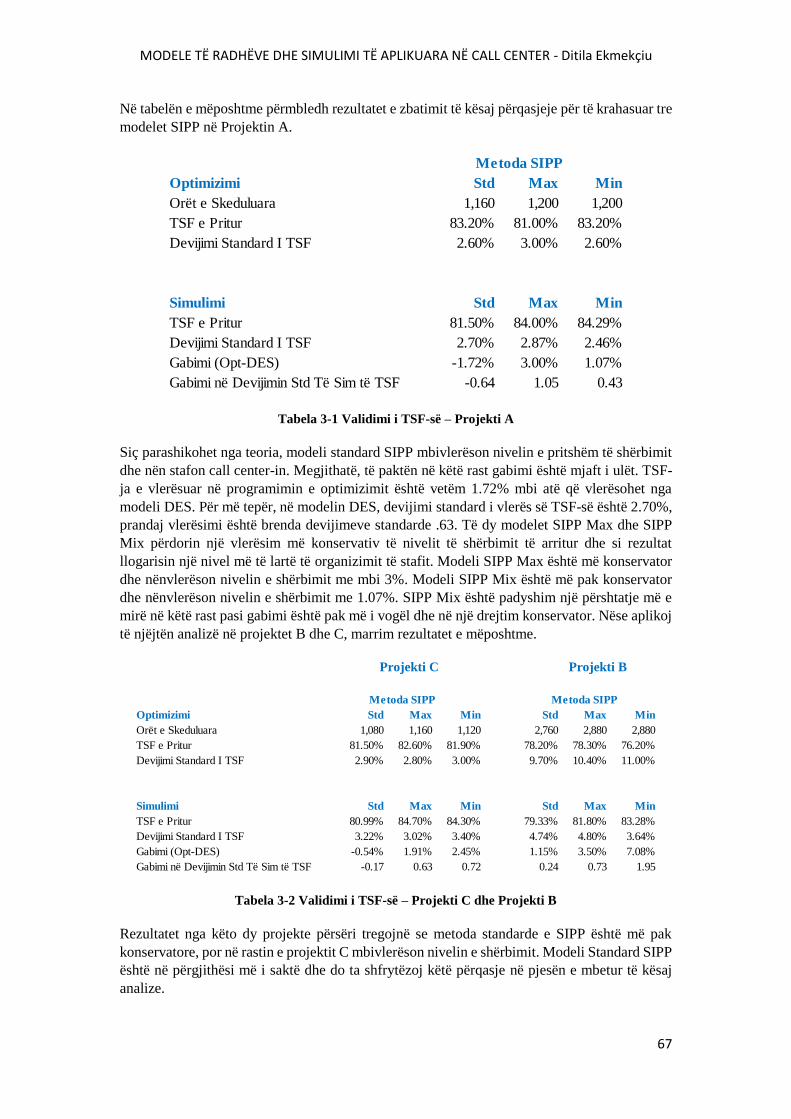
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
67
Në tabelën e mëposhtme përmbledh rezultatet e zbatimit të kësaj përqasjeje për të krahasuar tre
modelet SIPP në Projektin A.
Tabela 3-1 Validimi i TSF-së – Projekti A
Siç parashikohet nga teoria, modeli standard SIPP mbivlerëson nivelin e pritshëm të shërbimit
dhe nën stafon call center-in. Megjithatë, të paktën në këtë rast gabimi është mjaft i ulët. TSF-
ja e vlerësuar në programimin e optimizimit është vetëm 1.72% mbi atë që vlerësohet nga
modeli DES. Për më tepër, në modelin DES, devijimi standard i vlerës së TSF-së është 2.70%,
prandaj vlerësimi është brenda devijimeve standarde .63. Të dy modelet SIPP Max dhe SIPP
Mix përdorin një vlerësim më konservativ të nivelit të shërbimit të arritur dhe si rezultat
llogarisin një nivel më të lartë të organizimit të stafit. Modeli SIPP Max është më konservator
dhe nënvlerëson nivelin e shërbimit me mbi 3%. Modeli SIPP Mix është më pak konservator
dhe nënvlerëson nivelin e shërbimit me 1.07%. SIPP Mix është padyshim një përshtatje më e
mirë në këtë rast pasi gabimi është pak më i vogël dhe në një drejtim konservator. Nëse aplikoj
të njëjtën analizë në projektet B dhe C, marrim rezultatet e mëposhtme.
Projekti C Projekti B
Tabela 3-2 Validimi i TSF-së – Projekti C dhe Projekti B
Rezultatet nga këto dy projekte përsëri tregojnë se metoda standarde e SIPP është më pak
konservatore, por në rastin e projektit C mbivlerëson nivelin e shërbimit. Modeli Standard SIPP
është në përgjithësi më i saktë dhe do ta shfrytëzoj këtë përqasje në pjesën e mbetur të kësaj
analize.
Optimizimi Std Max Min
Orët e Skeduluara 1,160 1,200 1,200
TSF e Pritur 83.20% 81.00% 83.20%
Devijimi Standard I TSF 2.60% 3.00% 2.60%
Simulimi Std Max Min
TSF e Pritur 81.50% 84.00% 84.29%
Devijimi Standard I TSF 2.70% 2.87% 2.46%
Gabimi (Opt-DES) -1.72% 3.00% 1.07%
Gabimi në Devijimin Std Të Sim të TSF -0.64 1.05 0.43
Metoda SIPP
Optimizimi Std Max Min Std Max Min
Orët e Skeduluara 1,080 1,160 1,120 2,760 2,880 2,880
TSF e Pritur 81.50% 82.60% 81.90% 78.20% 78.30% 76.20%
Devijimi Standard I TSF 2.90% 2.80% 3.00% 9.70% 10.40% 11.00%
Simulimi Std Max Min Std Max Min
TSF e Pritur 80.99% 84.70% 84.30% 79.33% 81.80% 83.28%
Devijimi Standard I TSF 3.22% 3.02% 3.40% 4.74% 4.80% 3.64%
Gabimi (Opt-DES) -0.54% 1.91% 2.45% 1.15% 3.50% 7.08%
Gabimi në Devijimin Std Të Sim të TSF -0.17 0.63 0.72 0.24 0.73 1.95
Metoda SIPP Metoda SIPP
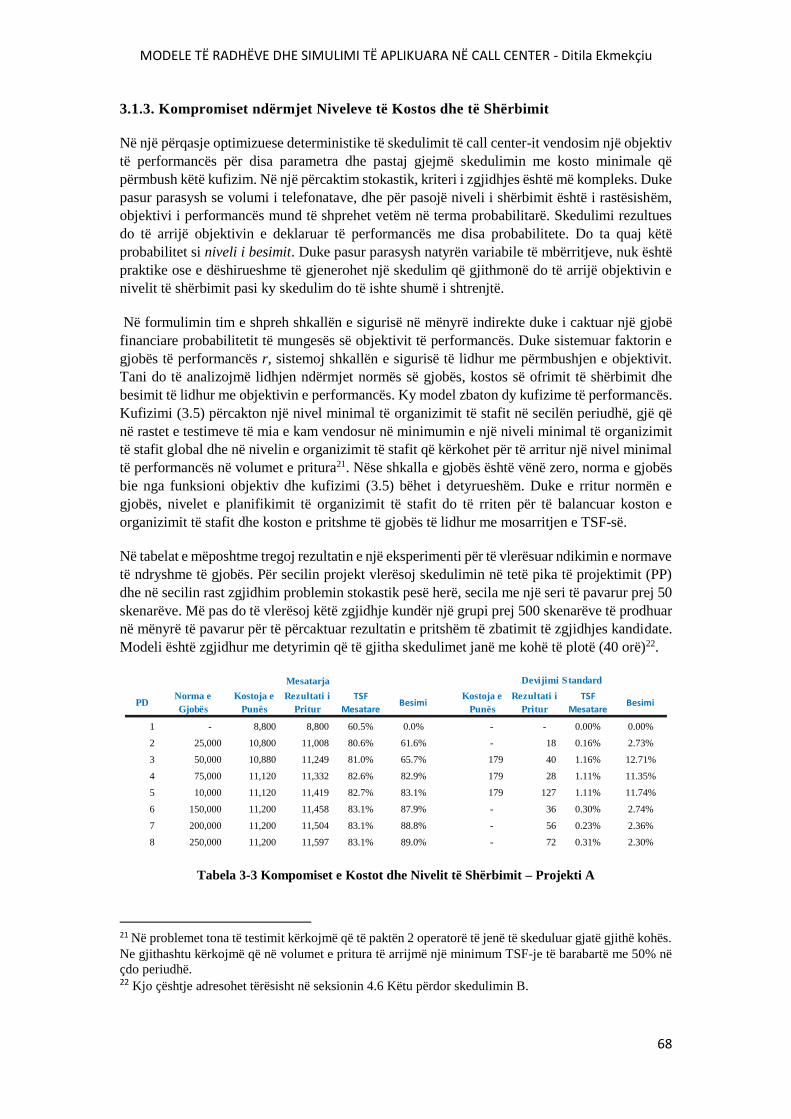
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
68
3.1.3. Kompromiset ndërmjet Niveleve të Kostos dhe të Shërbimit
Në një përqasje optimizuese deterministike të skedulimit të call center-it vendosim një objektiv
të performancës për disa parametra dhe pastaj gjejmë skedulimin me kosto minimale që
përmbush këtë kufizim. Në një përcaktim stokastik, kriteri i zgjidhjes është më kompleks. Duke
pasur parasysh se volumi i telefonatave, dhe për pasojë niveli i shërbimit është i rastësishëm,
objektivi i performancës mund të shprehet vetëm në terma probabilitarë. Skedulimi rezultues
do të arrijë objektivin e deklaruar të performancës me disa probabilitete. Do ta quaj këtë
probabilitet si niveli i besimit. Duke pasur parasysh natyrën variabile të mbërritjeve, nuk është
praktike ose e dëshirueshme të gjenerohet një skedulim që gjithmonë do të arrijë objektivin e
nivelit të shërbimit pasi ky skedulim do të ishte shumë i shtrenjtë.
Në formulimin tim e shpreh shkallën e sigurisë në mënyrë indirekte duke i caktuar një gjobë
financiare probabilitetit të mungesës së objektivit të performancës. Duke sistemuar faktorin e
gjobës të performancës r, sistemoj shkallën e sigurisë të lidhur me përmbushjen e objektivit.
Tani do të analizojmë lidhjen ndërmjet normës së gjobës, kostos së ofrimit të shërbimit dhe
besimit të lidhur me objektivin e performancës. Ky model zbaton dy kufizime të performancës.
Kufizimi (3.5) përcakton një nivel minimal të organizimit të stafit në secilën periudhë, gjë që
në rastet e testimeve të mia e kam vendosur në minimumin e një niveli minimal të organizimit
të stafit global dhe në nivelin e organizimit të stafit që kërkohet për të arritur një nivel minimal
të performancës në volumet e pritura21. Nëse shkalla e gjobës është vënë zero, norma e gjobës
bie nga funksioni objektiv dhe kufizimi (3.5) bëhet i detyrueshëm. Duke e rritur normën e
gjobës, nivelet e planifikimit të organizimit të stafit do të rriten për të balancuar koston e
organizimit të stafit dhe koston e pritshme të gjobës të lidhur me mosarritjen e TSF-së.
Në tabelat e mëposhtme tregoj rezultatin e një eksperimenti për të vlerësuar ndikimin e normave
të ndryshme të gjobës. Për secilin projekt vlerësoj skedulimin në tetë pika të projektimit (PP)
dhe në secilin rast zgjidhim problemin stokastik pesë herë, secila me një seri të pavarur prej 50
skenarëve. Më pas do të vlerësoj këtë zgjidhje kundër një grupi prej 500 skenarëve të prodhuar
në mënyrë të pavarur për të përcaktuar rezultatin e pritshëm të zbatimit të zgjidhjes kandidate.
Modeli është zgjidhur me detyrimin që të gjitha skedulimet janë me kohë të plotë (40 orë)22.
Tabela 3-3 Kompomiset e Kostot dhe Nivelit të Shërbimit – Projekti A
21 Në problemet tona të testimit kërkojmë që të paktën 2 operatorë të jenë të skeduluar gjatë gjithë kohës.
Ne gjithashtu kërkojmë që në volumet e pritura të arrijmë një minimum TSF-je të barabartë me 50% në
çdo periudhë. 22 Kjo çështje adresohet tërësisht në seksionin 4.6 Këtu përdor skedulimin B.
Mesatarja
PDNorma e
Gjobës
Kostoja e
Punës
Rezultati i
Pritur
TSF
MesatareBesimi
Kostoja e
Punës
Rezultati i
Pritur
TSF
MesatareBesimi
1 - 8,800 8,800 60.5% 0.0% - - 0.00% 0.00%
2 25,000 10,800 11,008 80.6% 61.6% - 18 0.16% 2.73%
3 50,000 10,880 11,249 81.0% 65.7% 179 40 1.16% 12.71%
4 75,000 11,120 11,332 82.6% 82.9% 179 28 1.11% 11.35%
5 10,000 11,120 11,419 82.7% 83.1% 179 127 1.11% 11.74%
6 150,000 11,200 11,458 83.1% 87.9% - 36 0.30% 2.74%
7 200,000 11,200 11,504 83.1% 88.8% - 56 0.23% 2.36%
8 250,000 11,200 11,597 83.1% 89.0% - 72 0.31% 2.30%
Devijimi Standard
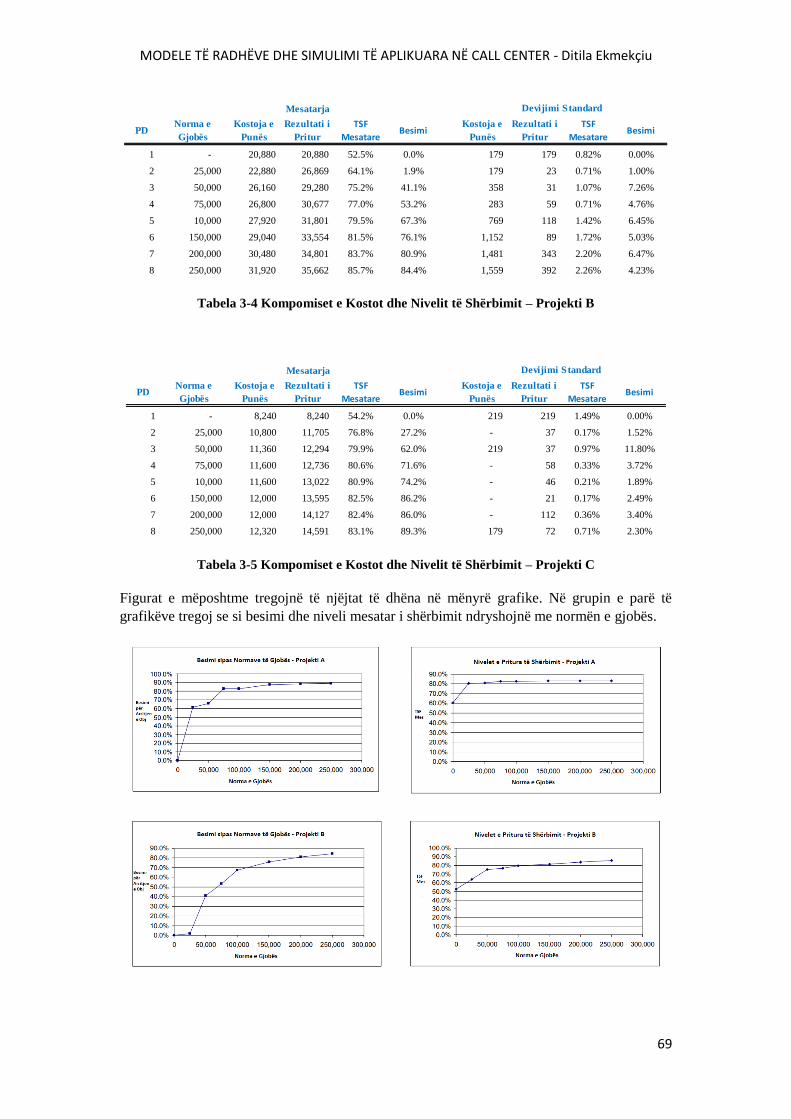
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
69
Tabela 3-4 Kompomiset e Kostot dhe Nivelit të Shërbimit – Projekti B
Tabela 3-5 Kompomiset e Kostot dhe Nivelit të Shërbimit – Projekti C
Figurat e mëposhtme tregojnë të njëjtat të dhëna në mënyrë grafike. Në grupin e parë të
grafikëve tregoj se si besimi dhe niveli mesatar i shërbimit ndryshojnë me normën e gjobës.
Mesatarja
PDNorma e
Gjobës
Kostoja e
Punës
Rezultati i
Pritur
TSF
MesatareBesimi
Kostoja e
Punës
Rezultati i
Pritur
TSF
MesatareBesimi
1 - 20,880 20,880 52.5% 0.0% 179 179 0.82% 0.00%
2 25,000 22,880 26,869 64.1% 1.9% 179 23 0.71% 1.00%
3 50,000 26,160 29,280 75.2% 41.1% 358 31 1.07% 7.26%
4 75,000 26,800 30,677 77.0% 53.2% 283 59 0.71% 4.76%
5 10,000 27,920 31,801 79.5% 67.3% 769 118 1.42% 6.45%
6 150,000 29,040 33,554 81.5% 76.1% 1,152 89 1.72% 5.03%
7 200,000 30,480 34,801 83.7% 80.9% 1,481 343 2.20% 6.47%
8 250,000 31,920 35,662 85.7% 84.4% 1,559 392 2.26% 4.23%
Devijimi Standard
Mesatarja
PDNorma e
Gjobës
Kostoja e
Punës
Rezultati i
Pritur
TSF
MesatareBesimi
Kostoja e
Punës
Rezultati i
Pritur
TSF
MesatareBesimi
1 - 8,240 8,240 54.2% 0.0% 219 219 1.49% 0.00%
2 25,000 10,800 11,705 76.8% 27.2% - 37 0.17% 1.52%
3 50,000 11,360 12,294 79.9% 62.0% 219 37 0.97% 11.80%
4 75,000 11,600 12,736 80.6% 71.6% - 58 0.33% 3.72%
5 10,000 11,600 13,022 80.9% 74.2% - 46 0.21% 1.89%
6 150,000 12,000 13,595 82.5% 86.2% - 21 0.17% 2.49%
7 200,000 12,000 14,127 82.4% 86.0% - 112 0.36% 3.40%
8 250,000 12,320 14,591 83.1% 89.3% 179 72 0.71% 2.30%
Devijimi Standard

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
70
Figura 3-11 Besimi dhe Nivelet e Shërbimit si funksion i Normës së Gjobës
Për secilin projekt paneli në të majtë tregon nivelin e besimit të zgjidhjes që rezulton,
përkatësisht përpjesëtimin e skenarëve të vlerësimit në të cilin është arritur objektivi i
performancës. Paneli në të djathtë tregon nivelin përkatës të shërbimit të pritur lidhur me
zgjidhjen kandidate. Këto sipërfaqe nënkuptojnë se ekziston një kufi efiçent, një rajon optimal
që balancon koston e punës dhe koston e gjobës për një vektor të caktuar të punës dhe normat
e gjobës.
Në të gjitha rastet gjobat e ulëta rezultojnë në një nivel besimi zero dhe në një TSF të pritur afër
60%23.
Me rritjen e shkallës së gjobës, TSF-ja e pritur fillon të rritet me rritjen e organizimit të stafit
për të kompensuar defiçitin e gjobës. Të dy faktorët rriten me shpejtësi dhe pastaj ulen pasi
bëhet gjithnjë e më e shtrenjtë për të përmbushur nivelet e shërbimit në fundin e shpërndarjes
së normës së ardhjes. Është interesante të theksohet se secili projekt kërkon një normë të
ndryshme të gjobës për të arritur nivelin e dëshiruar të besimit. Projekti B i cili ka nivelet më
të mëdha të organizimit të stafit dhe një shkallë të lartë ndryshueshmërie, kërkon norma gjoba
në rangun prej € 200,000 (2,000 për pikë përqindjeje) që të skedulohet me 80% plus besimi.
Projekti C, një projekt më i vogël me ndryshueshmëri të moderuar, rrotullohet tek normat e
gjobës rreth 100,000. Projekti A është një projekt relativisht i parashikueshëm dhe niveli i
besimit stabilizohet me normat e gjobës mbi 75,000.
Menaxheri i call center-it kërkon të minimizojë koston e organizimit të stafit, duke maksimizuar
probabilitetin e arritjes së nivelit të shërbimit të synuar. Këto dy qëllime janë qartësisht në
konflikt dhe menaxheri duhet të vendosë se si të balancojë koston dhe rrezikun; një vendim i
fshehur në një përqasje të optimizmit determinist.
Në grafikët e mëposhtëm i riformoj të dhënat nga Figura 3-10 për të ilustruar këtë pengesë. Në
anën e majtë shohim nivelin e besueshmërisë për arritjen e objektivit të performancës si një
funksion i kostos së organizimit të stafit, dhe në të djathtë shohim nivelin e pritur të shërbimit
në funksion të kostos së organizimit të stafit.
23 Ky model kërkon që niveli i shërbimit të jetë së paku 50% në çdo periudhë bazuar në volumet e pritura.
Për të arritur këtë nivel në periudhën më të ngarkuar të organizimit të stafit është i vendosur në mënyrë
të tillë që niveli i shërbimit të jetë mbi 50% në periudhat pasuese. Kjo është për shkak të kufizimit të
skedulimit të operatorëve në turne me kohë të plotë.
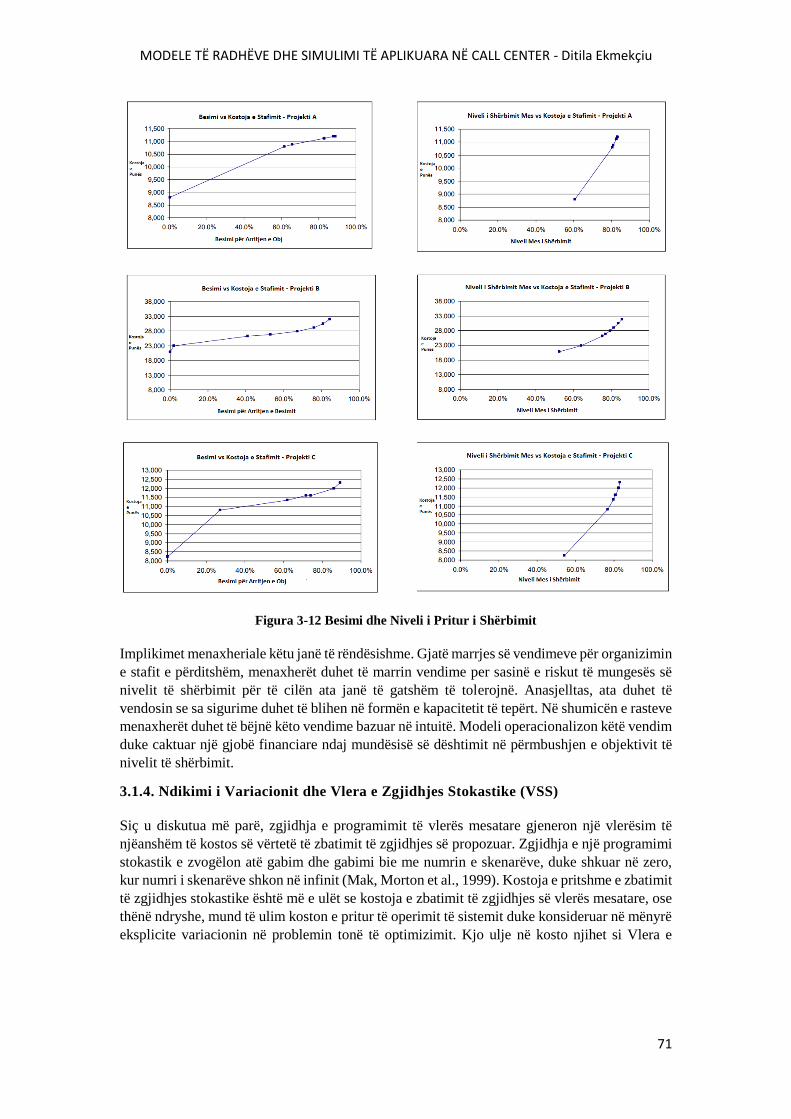
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
71
Figura 3-12 Besimi dhe Niveli i Pritur i Shërbimit
Implikimet menaxheriale këtu janë të rëndësishme. Gjatë marrjes së vendimeve për organizimin
e stafit e përditshëm, menaxherët duhet të marrin vendime per sasinë e riskut të mungesës së
nivelit të shërbimit për të cilën ata janë të gatshëm të tolerojnë. Anasjelltas, ata duhet të
vendosin se sa sigurime duhet të blihen në formën e kapacitetit të tepërt. Në shumicën e rasteve
menaxherët duhet të bëjnë këto vendime bazuar në intuitë. Modeli operacionalizon këtë vendim
duke caktuar një gjobë financiare ndaj mundësisë së dështimit në përmbushjen e objektivit të
nivelit të shërbimit.
3.1.4. Ndikimi i Variacionit dhe Vlera e Zgjidhjes Stokastike (VSS)
Siç u diskutua më parë, zgjidhja e programimit të vlerës mesatare gjeneron një vlerësim të
njëanshëm të kostos së vërtetë të zbatimit të zgjidhjes së propozuar. Zgjidhja e një programimi
stokastik e zvogëlon atë gabim dhe gabimi bie me numrin e skenarëve, duke shkuar në zero,
kur numri i skenarëve shkon në infinit (Mak, Morton et al., 1999). Kostoja e pritshme e zbatimit
të zgjidhjes stokastike është më e ulët se kostoja e zbatimit të zgjidhjes së vlerës mesatare, ose
thënë ndryshe, mund të ulim koston e pritur të operimit të sistemit duke konsideruar në mënyrë
eksplicite variacionin në problemin tonë të optimizimit. Kjo ulje në kosto njihet si Vlera e
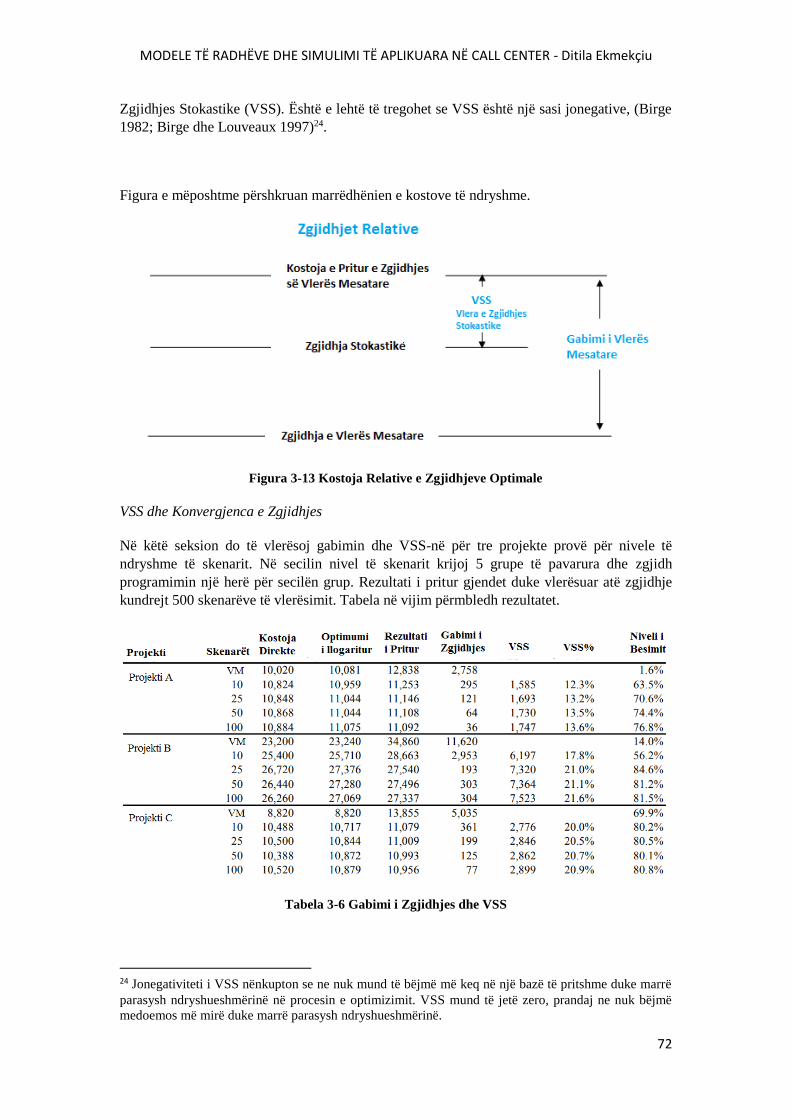
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
72
Zgjidhjes Stokastike (VSS). Është e lehtë të tregohet se VSS është një sasi jonegative, (Birge
1982; Birge dhe Louveaux 1997)24.
Figura e mëposhtme përshkruan marrëdhënien e kostove të ndryshme.
Figura 3-13 Kostoja Relative e Zgjidhjeve Optimale
VSS dhe Konvergjenca e Zgjidhjes
Në këtë seksion do të vlerësoj gabimin dhe VSS-në për tre projekte provë për nivele të
ndryshme të skenarit. Në secilin nivel të skenarit krijoj 5 grupe të pavarura dhe zgjidh
programimin një herë për secilën grup. Rezultati i pritur gjendet duke vlerësuar atë zgjidhje
kundrejt 500 skenarëve të vlerësimit. Tabela në vijim përmbledh rezultatet.
Tabela 3-6 Gabimi i Zgjidhjes dhe VSS
24 Jonegativiteti i VSS nënkupton se ne nuk mund të bëjmë më keq në një bazë të pritshme duke marrë
parasysh ndryshueshmërinë në procesin e optimizimit. VSS mund të jetë zero, prandaj ne nuk bëjmë
medoemos më mirë duke marrë parasysh ndryshueshmërinë.
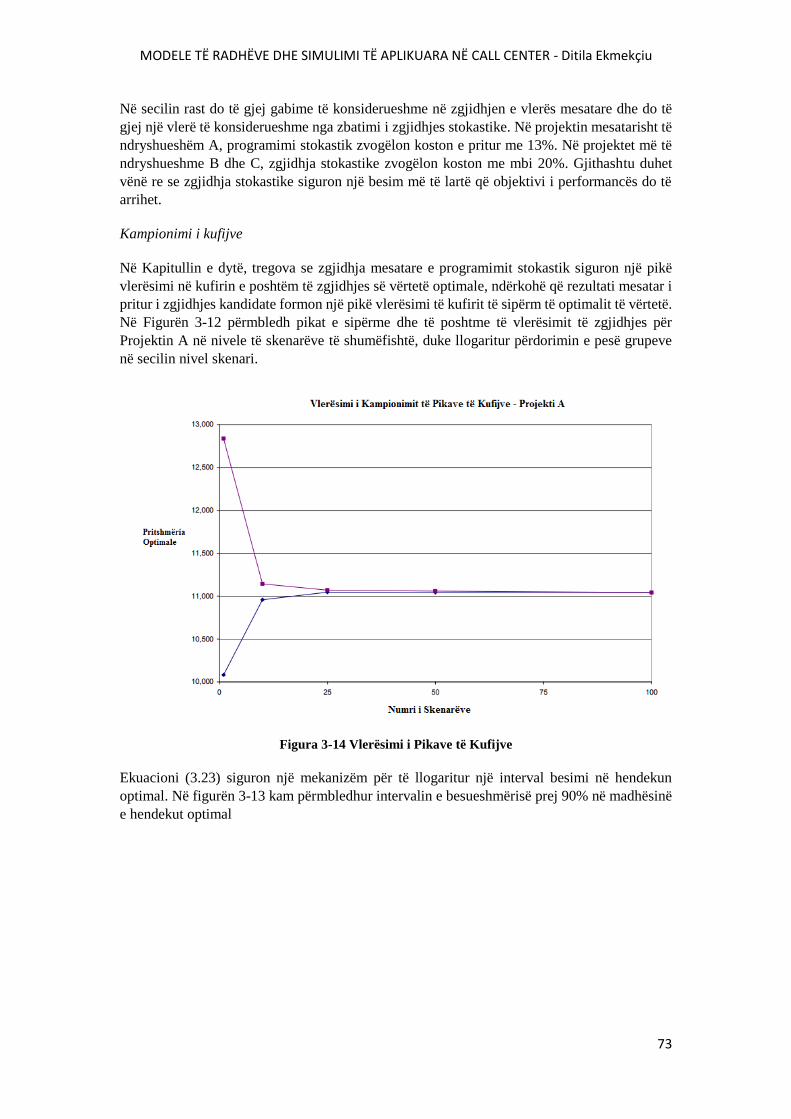
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
73
Në secilin rast do të gjej gabime të konsiderueshme në zgjidhjen e vlerës mesatare dhe do të
gjej një vlerë të konsiderueshme nga zbatimi i zgjidhjes stokastike. Në projektin mesatarisht të
ndryshueshëm A, programimi stokastik zvogëlon koston e pritur me 13%. Në projektet më të
ndryshueshme B dhe C, zgjidhja stokastike zvogëlon koston me mbi 20%. Gjithashtu duhet
vënë re se zgjidhja stokastike siguron një besim më të lartë që objektivi i performancës do të
arrihet.
Kampionimi i kufijve
Në Kapitullin e dytë, tregova se zgjidhja mesatare e programimit stokastik siguron një pikë
vlerësimi në kufirin e poshtëm të zgjidhjes së vërtetë optimale, ndërkohë që rezultati mesatar i
pritur i zgjidhjes kandidate formon një pikë vlerësimi të kufirit të sipërm të optimalit të vërtetë.
Në Figurën 3-12 përmbledh pikat e sipërme dhe të poshtme të vlerësimit të zgjidhjes për
Projektin A në nivele të skenarëve të shumëfishtë, duke llogaritur përdorimin e pesë grupeve
në secilin nivel skenari.
Figura 3-14 Vlerësimi i Pikave të Kufijve
Ekuacioni (3.23) siguron një mekanizëm për të llogaritur një interval besimi në hendekun
optimal. Në figurën 3-13 kam përmbledhur intervalin e besueshmërisë prej 90% në madhësinë
e hendekut optimal
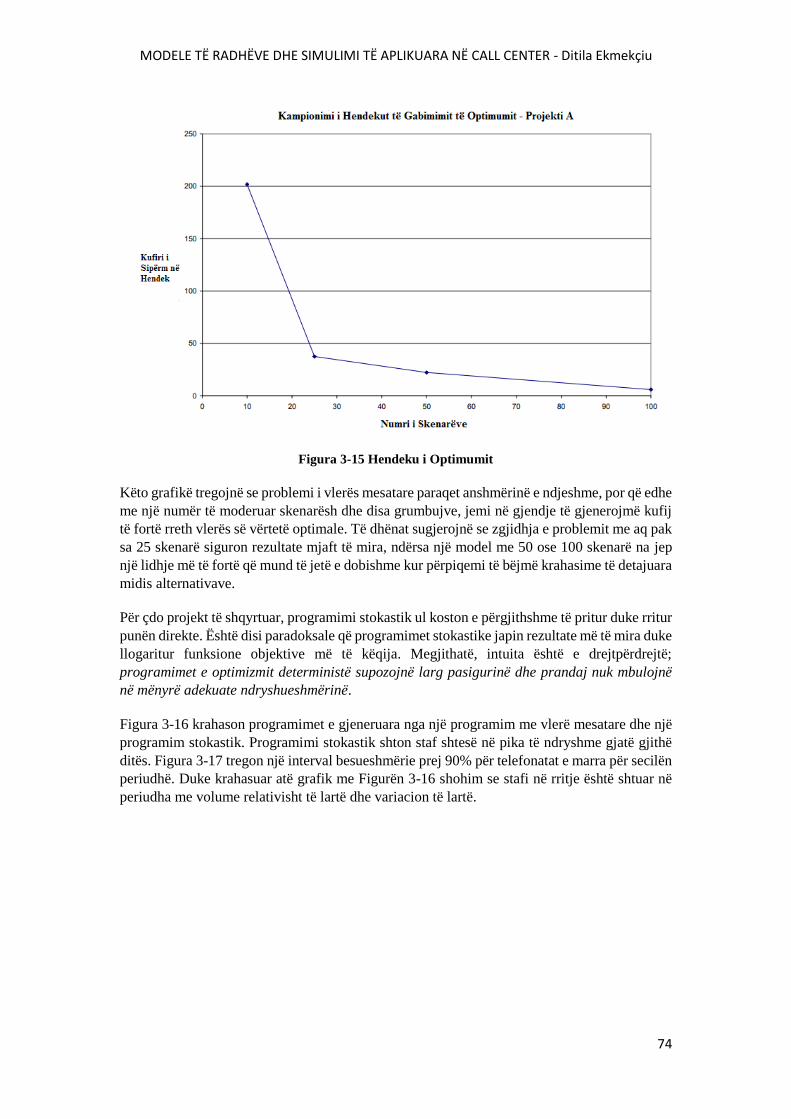
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
74
Figura 3-15 Hendeku i Optimumit
Këto grafikë tregojnë se problemi i vlerës mesatare paraqet anshmërinë e ndjeshme, por që edhe
me një numër të moderuar skenarësh dhe disa grumbujve, jemi në gjendje të gjenerojmë kufij
të fortë rreth vlerës së vërtetë optimale. Të dhënat sugjerojnë se zgjidhja e problemit me aq pak
sa 25 skenarë siguron rezultate mjaft të mira, ndërsa një model me 50 ose 100 skenarë na jep
një lidhje më të fortë që mund të jetë e dobishme kur përpiqemi të bëjmë krahasime të detajuara
midis alternativave.
Për çdo projekt të shqyrtuar, programimi stokastik ul koston e përgjithshme të pritur duke rritur
punën direkte. Është disi paradoksale që programimet stokastike japin rezultate më të mira duke
llogaritur funksione objektive më të këqija. Megjithatë, intuita është e drejtpërdrejtë;
programimet e optimizmit deterministë supozojnë larg pasigurinë dhe prandaj nuk mbulojnë
në mënyrë adekuate ndryshueshmërinë.
Figura 3-16 krahason programimet e gjeneruara nga një programim me vlerë mesatare dhe një
programim stokastik. Programimi stokastik shton staf shtesë në pika të ndryshme gjatë gjithë
ditës. Figura 3-17 tregon një interval besueshmërie prej 90% për telefonatat e marra për secilën
periudhë. Duke krahasuar atë grafik me Figurën 3-16 shohim se stafi në rritje është shtuar në
periudha me volume relativisht të lartë dhe variacion të lartë.
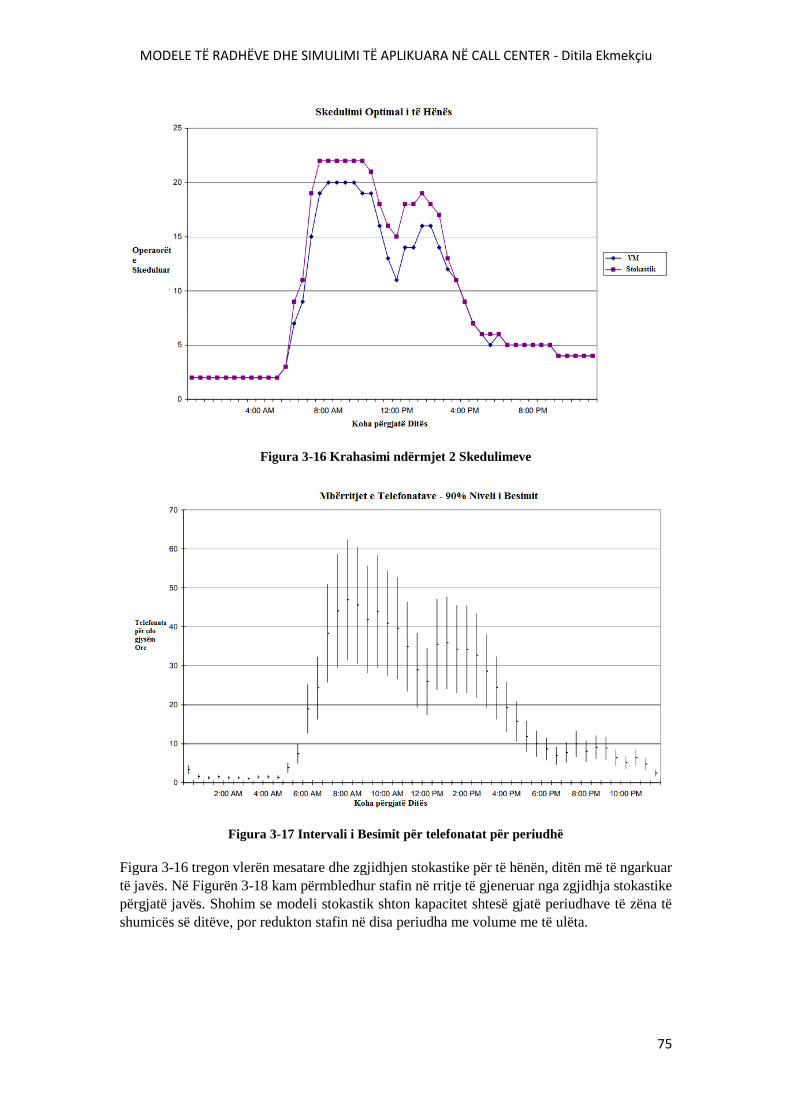
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
75
Figura 3-16 Krahasimi ndërmjet 2 Skedulimeve
Figura 3-17 Intervali i Besimit për telefonatat për periudhë
Figura 3-16 tregon vlerën mesatare dhe zgjidhjen stokastike për të hënën, ditën më të ngarkuar
të javës. Në Figurën 3-18 kam përmbledhur stafin në rritje të gjeneruar nga zgjidhja stokastike
përgjatë javës. Shohim se modeli stokastik shton kapacitet shtesë gjatë periudhave të zëna të
shumicës së ditëve, por redukton stafin në disa periudha me volume me të ulëta.
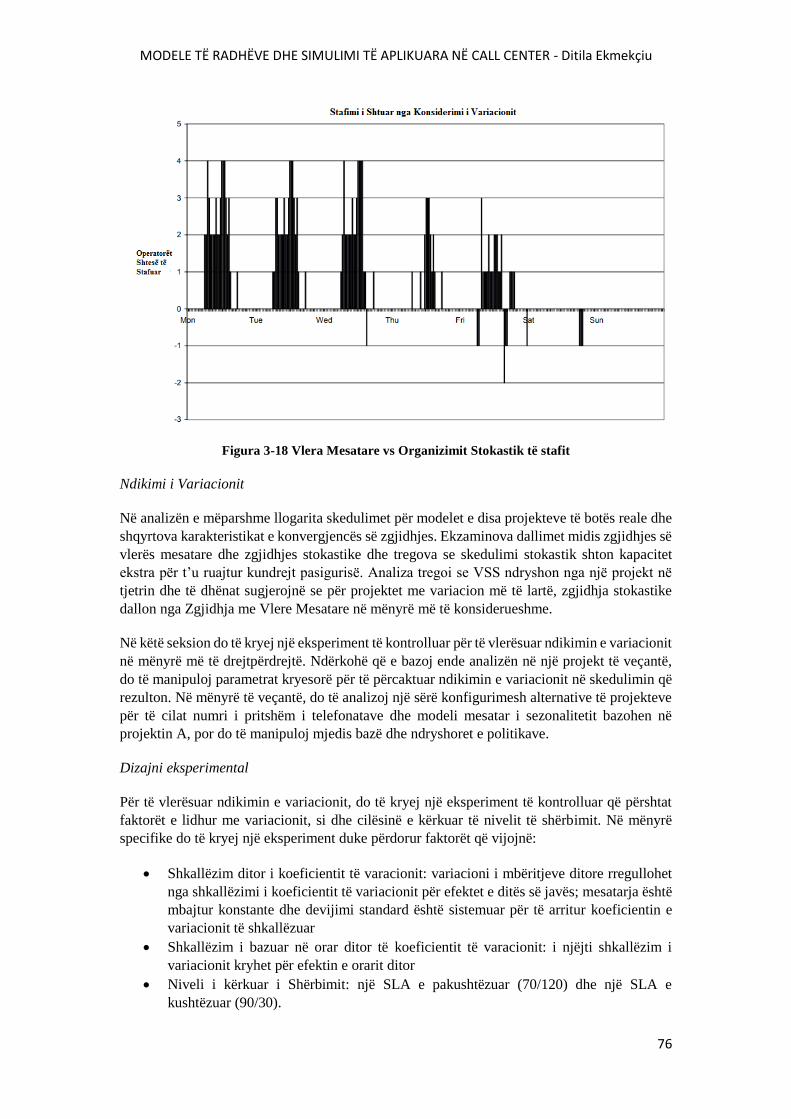
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
76
Figura 3-18 Vlera Mesatare vs Organizimit Stokastik të stafit
Ndikimi i Variacionit
Në analizën e mëparshme llogarita skedulimet për modelet e disa projekteve të botës reale dhe
shqyrtova karakteristikat e konvergjencës së zgjidhjes. Ekzaminova dallimet midis zgjidhjes së
vlerës mesatare dhe zgjidhjes stokastike dhe tregova se skedulimi stokastik shton kapacitet
ekstra për t’u ruajtur kundrejt pasigurisë. Analiza tregoi se VSS ndryshon nga një projekt në
tjetrin dhe të dhënat sugjerojnë se për projektet me variacion më të lartë, zgjidhja stokastike
dallon nga Zgjidhja me Vlere Mesatare në mënyrë më të konsiderueshme.
Në këtë seksion do të kryej një eksperiment të kontrolluar për të vlerësuar ndikimin e variacionit
në mënyrë më të drejtpërdrejtë. Ndërkohë që e bazoj ende analizën në një projekt të veçantë,
do të manipuloj parametrat kryesorë për të përcaktuar ndikimin e variacionit në skedulimin që
rezulton. Në mënyrë të veçantë, do të analizoj një sërë konfigurimesh alternative të projekteve
për të cilat numri i pritshëm i telefonatave dhe modeli mesatar i sezonalitetit bazohen në
projektin A, por do të manipuloj mjedis bazë dhe ndryshoret e politikave.
Dizajni eksperimental
Për të vlerësuar ndikimin e variacionit, do të kryej një eksperiment të kontrolluar që përshtat
faktorët e lidhur me variacionit, si dhe cilësinë e kërkuar të nivelit të shërbimit. Në mënyrë
specifike do të kryej një eksperiment duke përdorur faktorët që vijojnë:
• Shkallëzim ditor i koeficientit të varacionit: variacioni i mbëritjeve ditore rregullohet
nga shkallëzimi i koeficientit të variacionit për efektet e ditës së javës; mesatarja është
mbajtur konstante dhe devijimi standard është sistemuar për të arritur koeficientin e
variacionit të shkallëzuar
• Shkallëzim i bazuar në orar ditor të koeficientit të varacionit: i njëjti shkallëzim i
variacionit kryhet për efektin e orarit ditor
• Niveli i kërkuar i Shërbimit: një SLA e pakushtëzuar (70/120) dhe një SLA e
kushtëzuar (90/30).

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
77
• “Gjoba” e Nivelit të Shërbimit: kostot e ndryshme të gjobës për mos arritjen e objektivit
të specifikuar të nivelit të shërbimit.
• Probabiliteti Shock: Arritjet me dhe pa lëvizje të mëdha. Në rastin lëvizjesh të mëdha
do të zvogëloj volumiet pa-goditje në mënyrë që vëllimi i pritur i telefonatave të jetë
konstant në të gjitha pikat e dizenjimit.
Krijova një eksperiment me 16 pika modelimi si më poshtë:
Tabela 3-7 Impakti i Ndryshueshmërisë të Dizajnit te Eksperimentit
Ky është një model faktorial i pjesshëm 2𝑉5−1 dhe përmban 16 pika të modelimit. Ky model ka
një zgjidhje të V-të, e cila na lejon të parashikojmë të gjitha efektet kryesore dhe të gjitha efektet
e ndërveprimit në dy mënyra. Ndërveprimet e nivelit më të lartë janë të ç’orientuara dhe nuk
mund të vlerësohen në mënyrë të pavarur.
Rezultatet eksperimentale
Për të kryer këtë eksperiment, gjeneroj 5 grupe të 50 skenarëve dhe një grup të vetëm vlerësimi
prej 500 skenarësh në secilën nga 16 pikat e modelimit. Do të zgjidh problemet e optimizimit
për secilën grup, duke llogaritur një zgjidhje kandidat, e cila vlerësohet kundrejt grupit të
vlerësimit të 500 skenarëve për të llogaritur rezultatet e pritura. Bazuar në këto zgjidhje do të
llogaris variablet e përgjigjeve që vijojnë:
• Kostoja e punës: kostoja direkte e punës për zgjidhjen kandidate.
• Rezultati i Pritur: kostoja e gjetur e punës dhe e gjobës gjatë vlerësimit të zgjidhjes
kandidate
• Amortizimi i TSF--së: diferenca midis TSF-së të pritur që gjendet gjatë vlerësimit të
zgjidhjes kandidate dhe të objektivit të performancës së SLA-ve.
• Besimi: përqindja e skenarëve të vlerësimit për të cilat arrihet niveli objektiv i
shërbimit.
Kjo përqasje gjeneron 5 mostra për çdo përgjigje. Rezultatet e kësaj analize janë paraqitur në
tabelën e mëposhtme. Duhet kujtuar që të gjitha pikat e modelimit në këtë eksperiment kanë të
njëjtin vëllim të pritshëm të telefonatave.
A B C D E Përkufizimet e Faktorëve - +
1 - - - - + A Shkallëzimi ditor i koefiçentit të varacionit 0.75 1.25
2 + - - - - B Shkallëzimi i bazuar në orar ditor të koefiçentit të varacionit 0.75 1.25
3 - + - - - C Niveli i kërkuar i Shërbimit 70/120 90/30
4 + + - - + D Probabiliteti i Tronditjes 0% 5%
5 - - + - - E Gjoba e Nivelit të Shërbimit 50,000 150,000
6 + - + - +
7 - + + - +
8 + + + - -
9 - - - + -
10 + - - + +
11 - + - + +
12 + + - + -
13 - - + + +
14 + - + + -
15 - + + + -
16 + + + + +
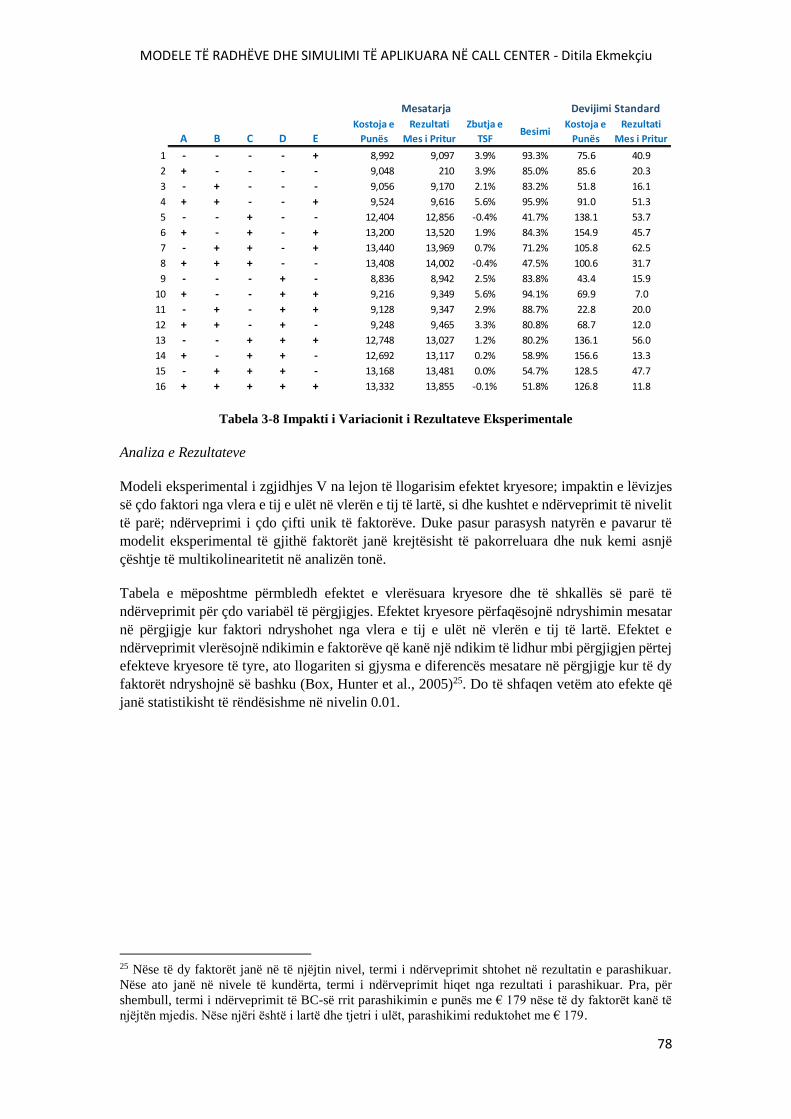
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
78
Tabela 3-8 Impakti i Variacionit i Rezultateve Eksperimentale
Analiza e Rezultateve
Modeli eksperimental i zgjidhjes V na lejon të llogarisim efektet kryesore; impaktin e lëvizjes
së çdo faktori nga vlera e tij e ulët në vlerën e tij të lartë, si dhe kushtet e ndërveprimit të nivelit
të parë; ndërveprimi i çdo çifti unik të faktorëve. Duke pasur parasysh natyrën e pavarur të
modelit eksperimental të gjithë faktorët janë krejtësisht të pakorreluara dhe nuk kemi asnjë
çështje të multikolinearitetit në analizën tonë.
Tabela e mëposhtme përmbledh efektet e vlerësuara kryesore dhe të shkallës së parë të
ndërveprimit për çdo variabël të përgjigjes. Efektet kryesore përfaqësojnë ndryshimin mesatar
në përgjigje kur faktori ndryshohet nga vlera e tij e ulët në vlerën e tij të lartë. Efektet e
ndërveprimit vlerësojnë ndikimin e faktorëve që kanë një ndikim të lidhur mbi përgjigjen përtej
efekteve kryesore të tyre, ato llogariten si gjysma e diferencës mesatare në përgjigje kur të dy
faktorët ndryshojnë së bashku (Box, Hunter et al., 2005)25. Do të shfaqen vetëm ato efekte që
janë statistikisht të rëndësishme në nivelin 0.01.
25 Nëse të dy faktorët janë në të njëjtin nivel, termi i ndërveprimit shtohet në rezultatin e parashikuar.
Nëse ato janë në nivele të kundërta, termi i ndërveprimit hiqet nga rezultati i parashikuar. Pra, për
shembull, termi i ndërveprimit të BC-së rrit parashikimin e punës me € 179 nëse të dy faktorët kanë të
njëjtën mjedis. Nëse njëri është i lartë dhe tjetri i ulët, parashikimi reduktohet me € 179.
Mesatarja
A B C D EKostoja e
Punës
Rezultati
Mes i Pritur
Zbutja e
TSFBesimi
Kostoja e
Punës
Rezultati
Mes i Pritur
1 - - - - + 8,992 9,097 3.9% 93.3% 75.6 40.9
2 + - - - - 9,048 210 3.9% 85.0% 85.6 20.3
3 - + - - - 9,056 9,170 2.1% 83.2% 51.8 16.1
4 + + - - + 9,524 9,616 5.6% 95.9% 91.0 51.3
5 - - + - - 12,404 12,856 -0.4% 41.7% 138.1 53.7
6 + - + - + 13,200 13,520 1.9% 84.3% 154.9 45.7
7 - + + - + 13,440 13,969 0.7% 71.2% 105.8 62.5
8 + + + - - 13,408 14,002 -0.4% 47.5% 100.6 31.7
9 - - - + - 8,836 8,942 2.5% 83.8% 43.4 15.9
10 + - - + + 9,216 9,349 5.6% 94.1% 69.9 7.0
11 - + - + + 9,128 9,347 2.9% 88.7% 22.8 20.0
12 + + - + - 9,248 9,465 3.3% 80.8% 68.7 12.0
13 - - + + + 12,748 13,027 1.2% 80.2% 136.1 56.0
14 + - + + - 12,692 13,117 0.2% 58.9% 156.6 13.3
15 - + + + - 13,168 13,481 0.0% 54.7% 128.5 47.7
16 + + + + + 13,332 13,855 -0.1% 51.8% 126.8 11.8
Devijimi Standard
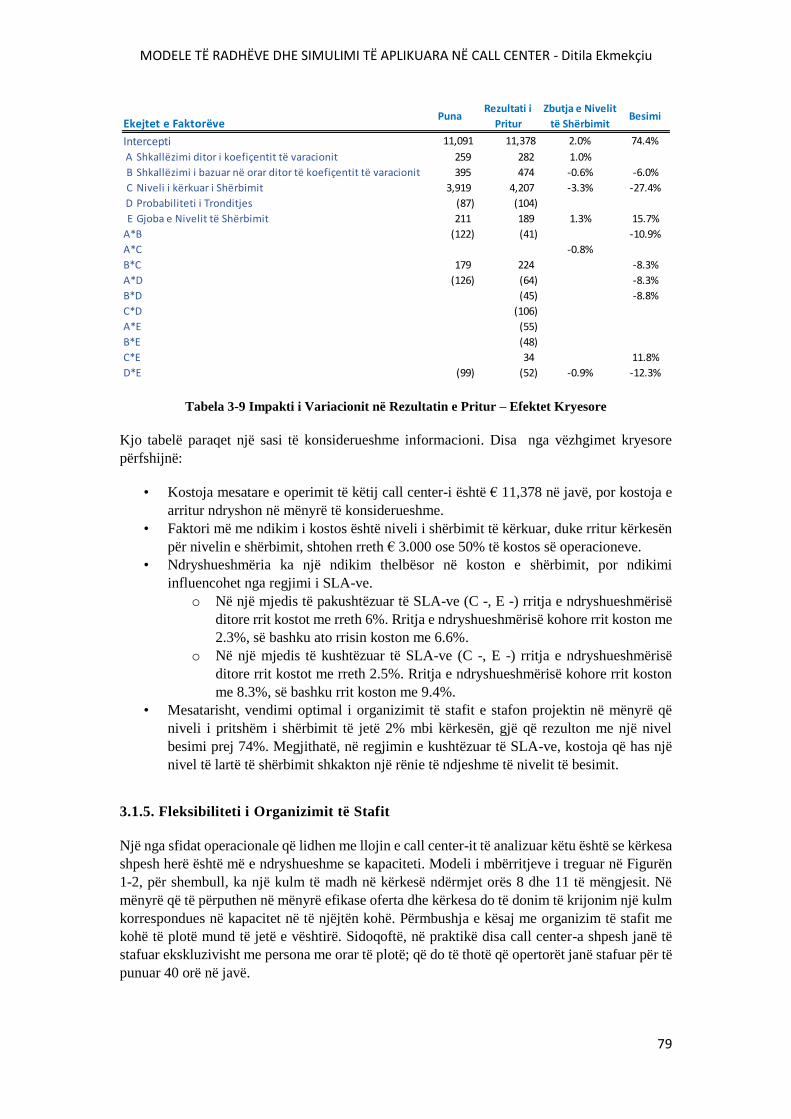
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
79
Tabela 3-9 Impakti i Variacionit në Rezultatin e Pritur – Efektet Kryesore
Kjo tabelë paraqet një sasi të konsiderueshme informacioni. Disa nga vëzhgimet kryesore
përfshijnë:
• Kostoja mesatare e operimit të këtij call center-i është € 11,378 në javë, por kostoja e
arritur ndryshon në mënyrë të konsiderueshme.
• Faktori më me ndikim i kostos është niveli i shërbimit të kërkuar, duke rritur kërkesën
për nivelin e shërbimit, shtohen rreth € 3.000 ose 50% të kostos së operacioneve.
• Ndryshueshmëria ka një ndikim thelbësor në koston e shërbimit, por ndikimi
influencohet nga regjimi i SLA-ve.
o Në një mjedis të pakushtëzuar të SLA-ve (C -, E -) rritja e ndryshueshmërisë
ditore rrit kostot me rreth 6%. Rritja e ndryshueshmërisë kohore rrit koston me
2.3%, së bashku ato rrisin koston me 6.6%.
o Në një mjedis të kushtëzuar të SLA-ve (C -, E -) rritja e ndryshueshmërisë
ditore rrit kostot me rreth 2.5%. Rritja e ndryshueshmërisë kohore rrit koston
me 8.3%, së bashku rrit koston me 9.4%.
• Mesatarisht, vendimi optimal i organizimit të stafit e stafon projektin në mënyrë që
niveli i pritshëm i shërbimit të jetë 2% mbi kërkesën, gjë që rezulton me një nivel
besimi prej 74%. Megjithatë, në regjimin e kushtëzuar të SLA-ve, kostoja që has një
nivel të lartë të shërbimit shkakton një rënie të ndjeshme të nivelit të besimit.
3.1.5. Fleksibiliteti i Organizimit të Stafit
Një nga sfidat operacionale që lidhen me llojin e call center-it të analizuar këtu është se kërkesa
shpesh herë është më e ndryshueshme se kapaciteti. Modeli i mbërritjeve i treguar në Figurën
1-2, për shembull, ka një kulm të madh në kërkesë ndërmjet orës 8 dhe 11 të mëngjesit. Në
mënyrë që të përputhen në mënyrë efikase oferta dhe kërkesa do të donim të krijonim një kulm
korrespondues në kapacitet në të njëjtën kohë. Përmbushja e kësaj me organizim të stafit me
kohë të plotë mund të jetë e vështirë. Sidoqoftë, në praktikë disa call center-a shpesh janë të
stafuar ekskluzivisht me persona me orar të plotë; që do të thotë që opertorët janë stafuar për të
punuar 40 orë në javë.
Ekejtet e FaktorëvePuna
Rezultati i
Pritur
Zbutja e Nivelit
të ShërbimitBesimi
11,091 11,378 2.0% 74.4%
A Shkallëzimi ditor i koefiçentit të varacionit 259 282 1.0%
B Shkallëzimi i bazuar në orar ditor të koefiçentit të varacionit 395 474 -0.6% -6.0%
C Niveli i kërkuar i Shërbimit 3,919 4,207 -3.3% -27.4%
D Probabiliteti i Tronditjes (87) (104)
E Gjoba e Nivelit të Shërbimit 211 189 1.3% 15.7%
A*B (122) (41) -10.9%
A*C -0.8%
B*C 179 224 -8.3%
A*D (126) (64) -8.3%
B*D (45) -8.8%
C*D (106)
A*E (55)
B*E (48)
C*E 34 11.8%
D*E (99) (52) -0.9% -12.3%
Intercepti

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
80
Menaxherët kanë arsye të shumta për punësimin vetëm të operatorëve me kohë të plotë.
Personat me kohë të plotë besohet të jenë më pak të shtrenjtë për t'u trajnuar, sepse kostoja e
tyre e punësimit dhe trajnimit amortizohet më shpejt. Shumë menaxherë gjithashtu besojnë se
operatorët me orar të plotë do të mësojnë më shpejt dhe në këtë mënyrë do të jenë më produktive
se një operator me kohë të pjesshme duke qenë të ekspozuar ndaj më shumë telefonatave. Disa
menaxherë besojnë gjithashtu se operatorët me kohë të pjesshme janë më të vështirë për t'u
rekrutuar dhe mbajtur26. Kursimet potenciale nga përdorimi i operatorëve me orar të pjesshëm
janë me interes, nga një perspektivë praktike dhe kërkimore. Do ta shqyrtoj këtë çështje në këtë
seksion.
Tipologjitë e Fleksibilitetit të Organizimit të Stafit
Në këtë seksion do të shqyrtoj çfarë nënkuptoj me fleksibilitet dhe të përcaktoj nivelet e
ndryshme të fleksibilitetit të organizimit të stafit. Fleksibiliteti konceptual i organizimit të stafit
nënkupton aftësinë për të skeduluar personat sipas nevojës për ta çuar sa me afër kapacitetin
me kërkesën; i palimituar nga kufizimet në skedulimet e mundshme. Kufizimet mund të
përfshijnë rregullat e bashkimit në skedulimet e mundshme, kufizimet në kohën e fillimit ose
ditët e pushimit.
Për qëllimet e kësaj analize përqendrohem në kufizimet e vendosura nga organizimi i stafit me
orar të plotë. Do të konsideroj një forcë pune që të jetë më fleksibile me rritjen e opsioneve që
kemi për të skeduluar operatorët për të punuar me turne me kohë të pjesshme nëse kjo është ajo
që dikton skema e kërkesës.
Do të konsideroj dy lloje të operatorëve me kohë të pjesshme:
- Turne të plota: turne me orar të plotë, me më pak se pesë ditë në javë
- Turne të pjesshme: turne me më pak se tetë orë në ditë, pesë ditë në javë
Duke u bazuar në këtë, do të përcaktoj modelet potenciale të turneve si në vijim:
- 5 x 8: 5 ditë në javë, 8 orë në ditë (40 orë javë)
- 4 x 10: 4 ditë në javë, 10 orë në ditë (40 orë javë)
- 4 x 8: 4 ditë në javë, 8 orë në ditë (32 orë javë)
- 5 x 6: 5 ditë në javë, 6 orë në ditë (30 orë javë)
- 5 x 4: 5 ditë në javë, 4 orë në ditë (20 orë javë)
Në secilin rast supozoj se një turn mund të fillojë gjatë çdo periudhe gjysëm ore, për një total
prej 48 kohësh fillestare në ditë. Gjithashtu do të supozoj një plotësim të plotë të modeleve të
përditshme të punës që kërkojnë një politikë të dy ditëve pushim të njëpasnjëshme. Për
skedulimet prej pesë ditësh në javë kjo nënkupton vetëm shtatë modele ditësh të realizueshme.
26 Kompania me të cilën kam punuar përdor operatorë me kohë të plotë pothuajse ekskluzivisht për të
gjitha arsyet e përmendura më lart. Përveç kësaj, politikat e tyre të burimeve njerëzore kufizojnë
përfitimet ndaj operatorëve me orar të plotë, duke e bërë të vështirë për ta që të mbajnë persona me kohë
të pjesshme nëse duhet t’i punësojnë ata.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
81
Për një skedulim prej katër ditësh në javë ka 28 modele ditësh që i plotësojnë kufizimet e dy
ditëve pushim të njëpasnjëshme.
Duke u bazuar në këtë do të përcaktoj grupin e mëposhtëm të modeleve të skedulimit:
Tabela 3-10 Modelet e Skedulimit
Për modelet A-E në mënyrë rritëse do të shtoj më shumë fleksibilitet në grupin e skedulimeve
në dispozicion. Tabela 3-9 ilustron problemin e kombinuar që lidhet me vlerësimin e modeleve
të skedulimit të shumëfishtë. Ndërsa lëvizim nga modeli A me pesë ditë në javë, 8 orë në ditë
A në opsionet e shumta të modelit E numri i skedulimeve të mundshme, dhe numri përkatës i
variablave të plotë, rritet pesë herë.
Vlera e Fleksibilitetit
Në seksionin e mëparshëm përmenda një numër opsionesh të ndryshme të skedulimit dhe
zhvillova një grup me mbi 2.700 skedulime prej të cilave mund të zgjidhej. Dimë nga teoria
themelore e optimizimit se duke shtuar më shumë opsione skedulimi nuk mund ta përkeqësojë
objektivin tonë dhe argumentuam në menyrë cilësore se shtimi i turneve me kohë të pjesshme
do të përmirësojë funksionin objektiv. Megjithatë, zgjedhjet e bëra në bërjen e kësaj liste janë
disi arbitrare. Kufizuam bashkësinë e orareve në ato që përfshinin të paktën 20 orë dhe 4 ditë
pune, por ndoshta duhet të marrim parasysh dy turne dhjetë orarëshe ose gjashtë turne tre
orarëshe. Numri i modeleve të mundshme të turneve është i pakufizuar. Në këtë seksion do të
përpiqem të përcaktoj një kufi të poshtëm për reduktimin e kostos që mund të arrihet nëpërmjet
organizimit fleksibël të stafit dhe në këtë proces do të zhvillohet një strukturë për kategorizimin
e kostove që lidhen me ofrimin e shërbimit.
Supozoni se telefonatat mbërrijnë përmes një procesi Puasoni jo-homogjen me një normë të
njohur të mbërritjeve në periudha 30 minutëshe. Gjithashtu supozojmë se kemi mundësinë të
planifikojmë çdo numër integral të serverave (operatorëve) në çdo periudhë prej 30 minutash,
pavarësisht nga çdo periudhë tjetër prej 30 minutash, sikur të mund të planifikonim punëtorët
me turne prej 30 minutash. Pastaj mund të marrim një vendim të pavarur të organizimit të stafit
në çdo periudhë, dhe për shkak të natyrës konkave të kurbës TSF çdo periudhë do të stafohej
për të arritur një nivel shërbimi pranë objektivit27. E quajmë këtë nivel të organizimit të stafit
si modeli ideal ose modeli i organizimit të stafit me fleksibilitetin maksimal. Kostoja e sigurimit
të këtij niveli të organizimit të stafit, në euro ose në orë pune, përfaqëson koston minimale të
nevojshme për të ofruar shërbimin e kërkuar.
Tani supozojmë se e relaksojmë supozimin e normës së njohur të mbërritjeve dhe lejojmë
volumin e telefonatave për të ndryshuar stokastikisht. Organizimi rritës i stafit do të kërkohet
27 Për shkak te kufizimit të intregralitetit numri i serverave TSF do të varionte përsëri në mënyrë të
moderuar nga një periudhë në tjetrën
Modeli Tipet e Skedulimeve të Përfshira Skedulimet e Mundhsme
A 5x8 vetëm 336
B 5x8, 4x10 1,680
C 5x8, 4x10, 4x8 3,024
D 5x8, 4x10, 4x8, 5x6 3,360
E 5x8, 4x10, 4x8, 5x6, 5x4 3,696

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
82
për t’u mbrojtur nga pasiguria dhe kostoja e ofrimit të shërbimit do të rritet. i referohem kësaj
kostoje shtesë si kosto e pasigurisë së ngarkesës.
Në realitet, nuk mund të marrim vendime të pavarura të organizimit të stafit në secilën periudhë.
Punëtorët janë skeduluar në turne, kështu që niveli i organizimit të stafit në çdo periudhë nuk
është i pavarur nga niveli i organizimit të stafit në periudhat fqinje. Nëse tani e relaksojmë
supozimin e fleksibilitetit maksimal dhe në vend të saj, marrim modelin e skedulimit nga tabela
3-5, atëherë do të kemi koston e organizimit të stafit me kufizim të turneve. Do ta quaj diferencën
ndërmjet këtyre dy kostove të organizimit të stafit, kostoja e organizimit të stafit jo fleksibël;
është kostoja shtesë e ofrimit të shërbimit për shkak të kufizimit të turneve. Figura e mëposhtme
ilustron këto kosto relative.
Figura 3-19 Kostot Relative të Fleksibiliteti të Organizimit të Stafit
Eksperiment numerik - Organizimi i stafit me orar të pjesshëm
Në këtë seksion do të kryej një eksperiment numerik për të vlerësuar koston e ofrimit të
shërbimit nën nivele të ndryshme të fleksibilitetit të organizimit të stafit. Dëshiroj të shqyrtoj
se si ndryshon skedulimi, në mënyrë cilësore dhe sasiore, kur rritim nivelin e fleksibilitetit të
fuqisë punëtore. Për secilin projekt llogaritet kostoja e organizimit të stafit dhe rezultati i pritur
për secilin opsion të skedulimit të renditur në Tabelën 3-9. Do të vlerësoj kursimet në koston e
ofrimit të shërbimit në secilin nivel nga baza, dhe gjithashtu do të shoh se si secili nivel
krahasohet me opsionin e maksimumit të fleksibilitetit. Në këtë analizë supozova se agjentët
paguhen 10 €/orë, pavarësisht nga orari në të cilin janë caktuar.
Për çdo kombinim të projekteve dhe orarit të skedulimit optimizuam kundrejt pesë grupeve prej
50 skenarëve secili dhe llogaritëm mesataren për të gjithë matësat e performancës. Secila
zgjidhje kandidate është vlerësuar kundrejt të njëjtit grup prej 500 skenarëve të vlerësimit për
të llogaritur rezultatin e pritshëm.
Projekti A
Në këtë eksperiment do të analizoj një model të bazuar në projektin A. Tabela e mëposhtme
përmbledh rezultatet e çdo mundësie skedulimi.
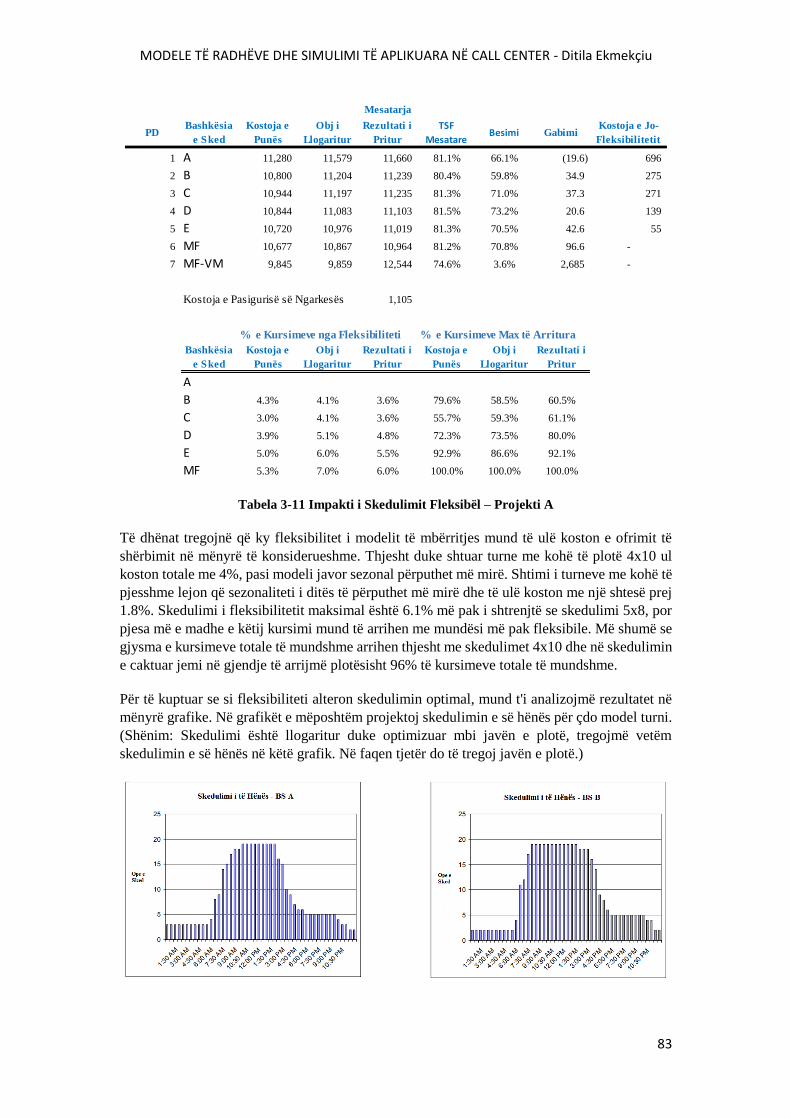
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
83
Tabela 3-11 Impakti i Skedulimit Fleksibël – Projekti A
Të dhënat tregojnë që ky fleksibilitet i modelit të mbërritjes mund të ulë koston e ofrimit të
shërbimit në mënyrë të konsiderueshme. Thjesht duke shtuar turne me kohë të plotë 4x10 ul
koston totale me 4%, pasi modeli javor sezonal përputhet më mirë. Shtimi i turneve me kohë të
pjesshme lejon që sezonaliteti i ditës të përputhet më mirë dhe të ulë koston me një shtesë prej
1.8%. Skedulimi i fleksibilitetit maksimal është 6.1% më pak i shtrenjtë se skedulimi 5x8, por
pjesa më e madhe e këtij kursimi mund të arrihen me mundësi më pak fleksibile. Më shumë se
gjysma e kursimeve totale të mundshme arrihen thjesht me skedulimet 4x10 dhe në skedulimin
e caktuar jemi në gjendje të arrijmë plotësisht 96% të kursimeve totale të mundshme.
Për të kuptuar se si fleksibiliteti alteron skedulimin optimal, mund t'i analizojmë rezultatet në
mënyrë grafike. Në grafikët e mëposhtëm projektoj skedulimin e së hënës për çdo model turni.
(Shënim: Skedulimi është llogaritur duke optimizuar mbi javën e plotë, tregojmë vetëm
skedulimin e së hënës në këtë grafik. Në faqen tjetër do të tregoj javën e plotë.)
Mesatarja
PDBashkësia
e Sked
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
TSF
MesatareBesimi Gabimi
Kostoja e Jo-
Fleksibilitetit
1 A 11,280 11,579 11,660 81.1% 66.1% (19.6) 696
2 B 10,800 11,204 11,239 80.4% 59.8% 34.9 275
3 C 10,944 11,197 11,235 81.3% 71.0% 37.3 271
4 D 10,844 11,083 11,103 81.5% 73.2% 20.6 139
5 E 10,720 10,976 11,019 81.3% 70.5% 42.6 55
6 MF 10,677 10,867 10,964 81.2% 70.8% 96.6 -
7 MF-VM 9,845 9,859 12,544 74.6% 3.6% 2,685 -
Kostoja e Pasigurisë së Ngarkesës 1,105
% e Kursimeve nga Fleksibiliteti % e Kursimeve Max të Arritura
Bashkësia
e Sked
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
A
B 4.3% 4.1% 3.6% 79.6% 58.5% 60.5%
C 3.0% 4.1% 3.6% 55.7% 59.3% 61.1%
D 3.9% 5.1% 4.8% 72.3% 73.5% 80.0%
E 5.0% 6.0% 5.5% 92.9% 86.6% 92.1%
MF 5.3% 7.0% 6.0% 100.0% 100.0% 100.0%
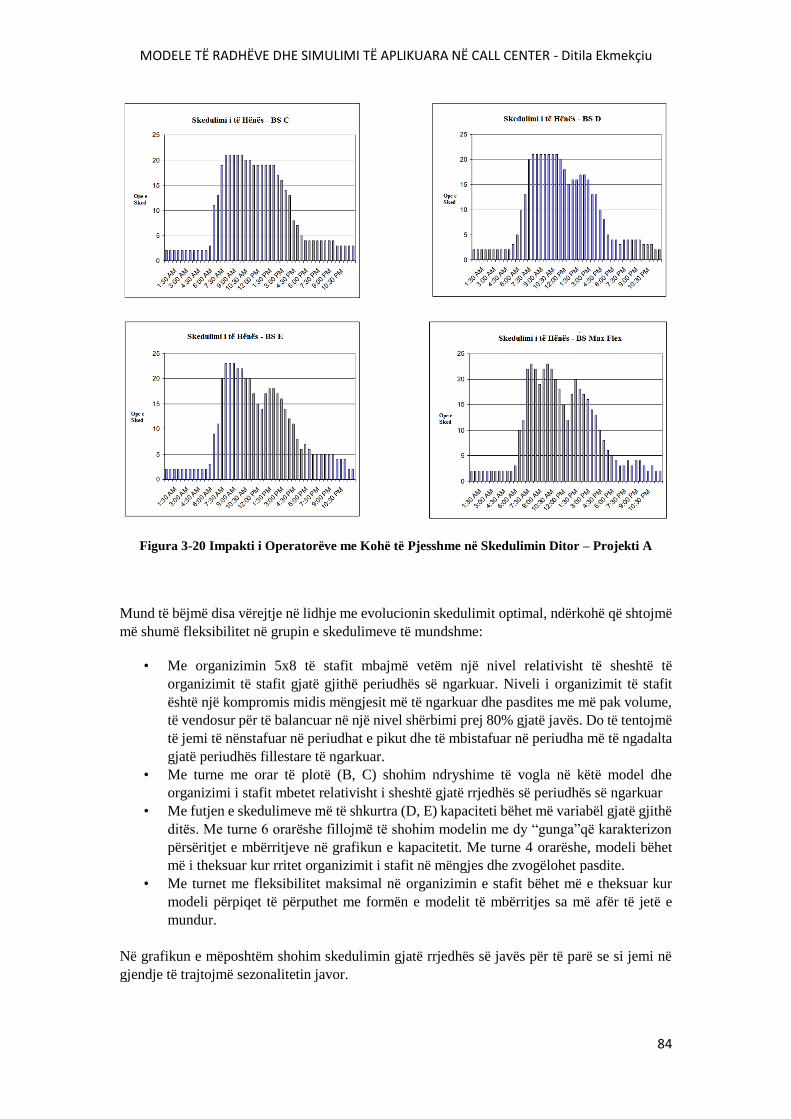
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
84
Figura 3-20 Impakti i Operatorëve me Kohë të Pjesshme në Skedulimin Ditor – Projekti A
Mund të bëjmë disa vërejtje në lidhje me evolucionin skedulimit optimal, ndërkohë që shtojmë
më shumë fleksibilitet në grupin e skedulimeve të mundshme:
• Me organizimin 5x8 të stafit mbajmë vetëm një nivel relativisht të sheshtë të
organizimit të stafit gjatë gjithë periudhës së ngarkuar. Niveli i organizimit të stafit
është një kompromis midis mëngjesit më të ngarkuar dhe pasdites me më pak volume,
të vendosur për të balancuar në një nivel shërbimi prej 80% gjatë javës. Do të tentojmë
të jemi të nënstafuar në periudhat e pikut dhe të mbistafuar në periudha më të ngadalta
gjatë periudhës fillestare të ngarkuar.
• Me turne me orar të plotë (B, C) shohim ndryshime të vogla në këtë model dhe
organizimi i stafit mbetet relativisht i sheshtë gjatë rrjedhës së periudhës së ngarkuar
• Me futjen e skedulimeve më të shkurtra (D, E) kapaciteti bëhet më variabël gjatë gjithë
ditës. Me turne 6 orarëshe fillojmë të shohim modelin me dy “gunga”që karakterizon
përsëritjet e mbërritjeve në grafikun e kapacitetit. Me turne 4 orarëshe, modeli bëhet
më i theksuar kur rritet organizimit i stafit në mëngjes dhe zvogëlohet pasdite.
• Me turnet me fleksibilitet maksimal në organizimin e stafit bëhet më e theksuar kur
modeli përpiqet të përputhet me formën e modelit të mbërritjes sa më afër të jetë e
mundur.
Në grafikun e mëposhtëm shohim skedulimin gjatë rrjedhës së javës për të parë se si jemi në
gjendje të trajtojmë sezonalitetin javor.
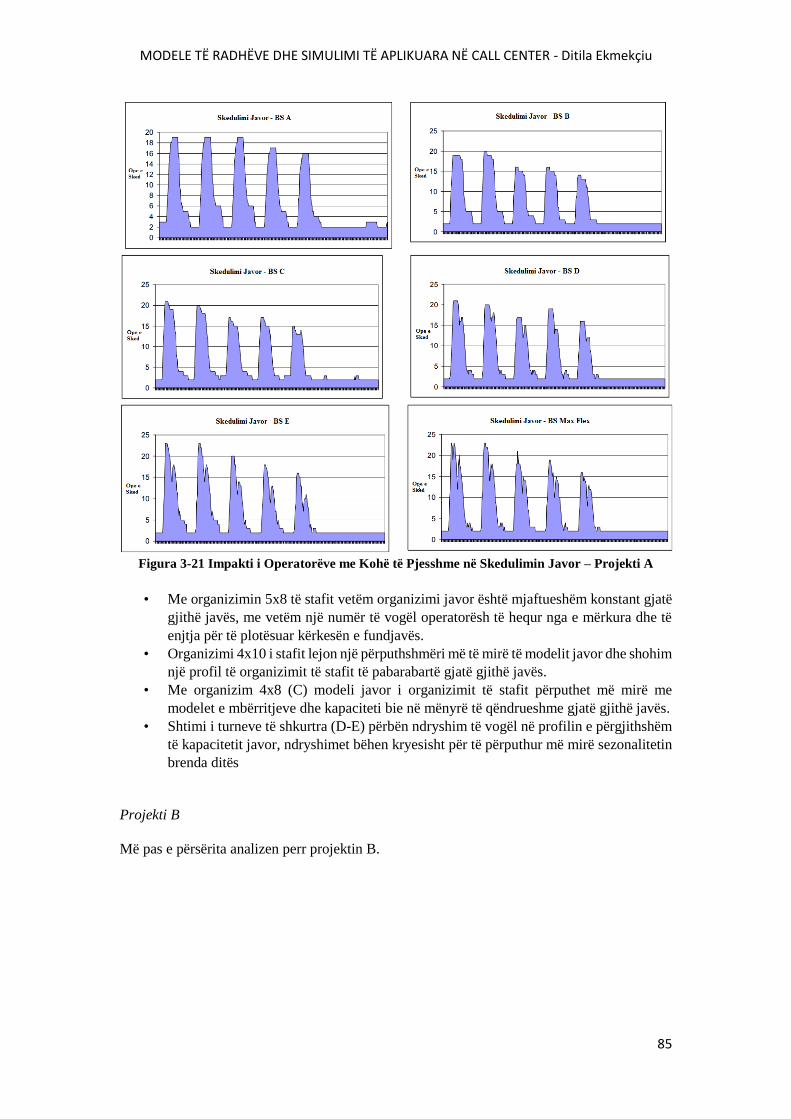
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
85
Figura 3-21 Impakti i Operatorëve me Kohë të Pjesshme në Skedulimin Javor – Projekti A
• Me organizimin 5x8 të stafit vetëm organizimi javor është mjaftueshëm konstant gjatë
gjithë javës, me vetëm një numër të vogël operatorësh të hequr nga e mërkura dhe të
enjtja për të plotësuar kërkesën e fundjavës.
• Organizimi 4x10 i stafit lejon një përputhshmëri më të mirë të modelit javor dhe shohim
një profil të organizimit të stafit të pabarabartë gjatë gjithë javës.
• Me organizim 4x8 (C) modeli javor i organizimit të stafit përputhet më mirë me
modelet e mbërritjeve dhe kapaciteti bie në mënyrë të qëndrueshme gjatë gjithë javës.
• Shtimi i turneve të shkurtra (D-E) përbën ndryshim të vogël në profilin e përgjithshëm
të kapacitetit javor, ndryshimet bëhen kryesisht për të përputhur më mirë sezonalitetin
brenda ditës
Projekti B
Më pas e përsërita analizen perr projektin B.
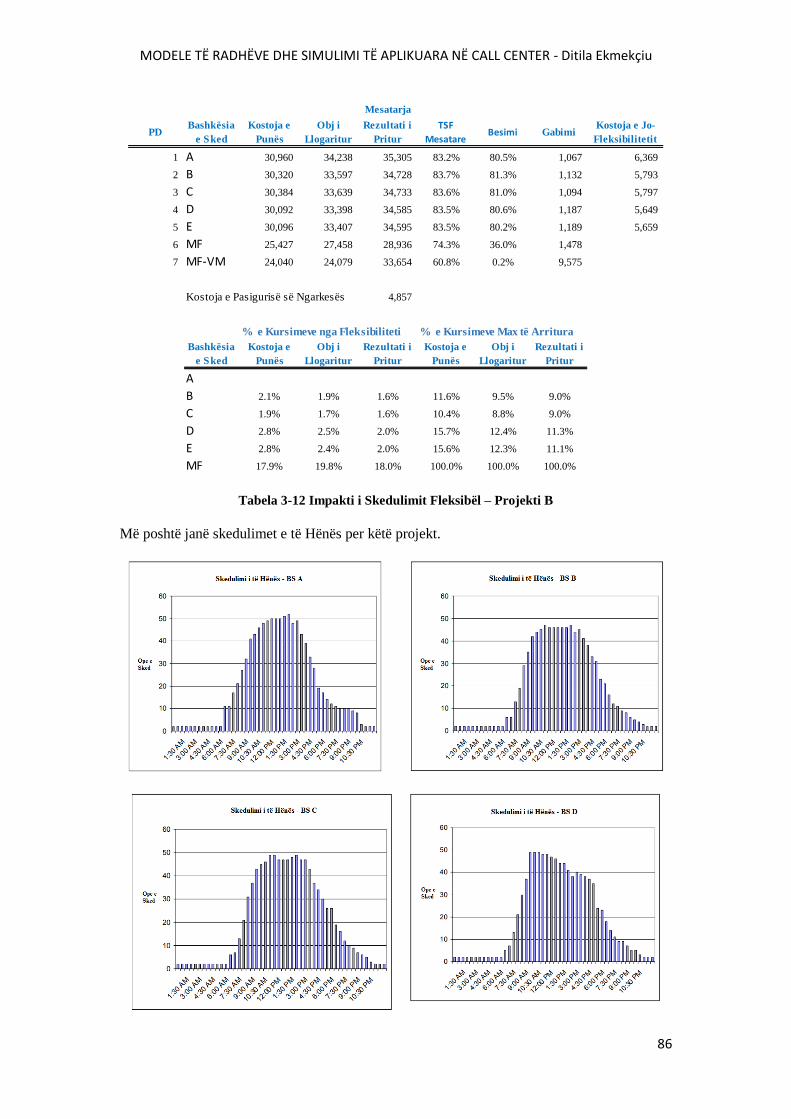
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
86
Tabela 3-12 Impakti i Skedulimit Fleksibël – Projekti B
Më poshtë janë skedulimet e të Hënës per këtë projekt.
Mesatarja
PDBashkësia
e Sked
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
TSF
MesatareBesimi Gabimi
Kostoja e Jo-
Fleksibilitetit
1 A 30,960 34,238 35,305 83.2% 80.5% 1,067 6,369
2 B 30,320 33,597 34,728 83.7% 81.3% 1,132 5,793
3 C 30,384 33,639 34,733 83.6% 81.0% 1,094 5,797
4 D 30,092 33,398 34,585 83.5% 80.6% 1,187 5,649
5 E 30,096 33,407 34,595 83.5% 80.2% 1,189 5,659
6 MF 25,427 27,458 28,936 74.3% 36.0% 1,478
7 MF-VM 24,040 24,079 33,654 60.8% 0.2% 9,575
Kostoja e Pasigurisë së Ngarkesës 4,857
% e Kursimeve nga Fleksibiliteti % e Kursimeve Max të Arritura
Bashkësia
e Sked
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
A
B 2.1% 1.9% 1.6% 11.6% 9.5% 9.0%
C 1.9% 1.7% 1.6% 10.4% 8.8% 9.0%
D 2.8% 2.5% 2.0% 15.7% 12.4% 11.3%
E 2.8% 2.4% 2.0% 15.6% 12.3% 11.1%
MF 17.9% 19.8% 18.0% 100.0% 100.0% 100.0%
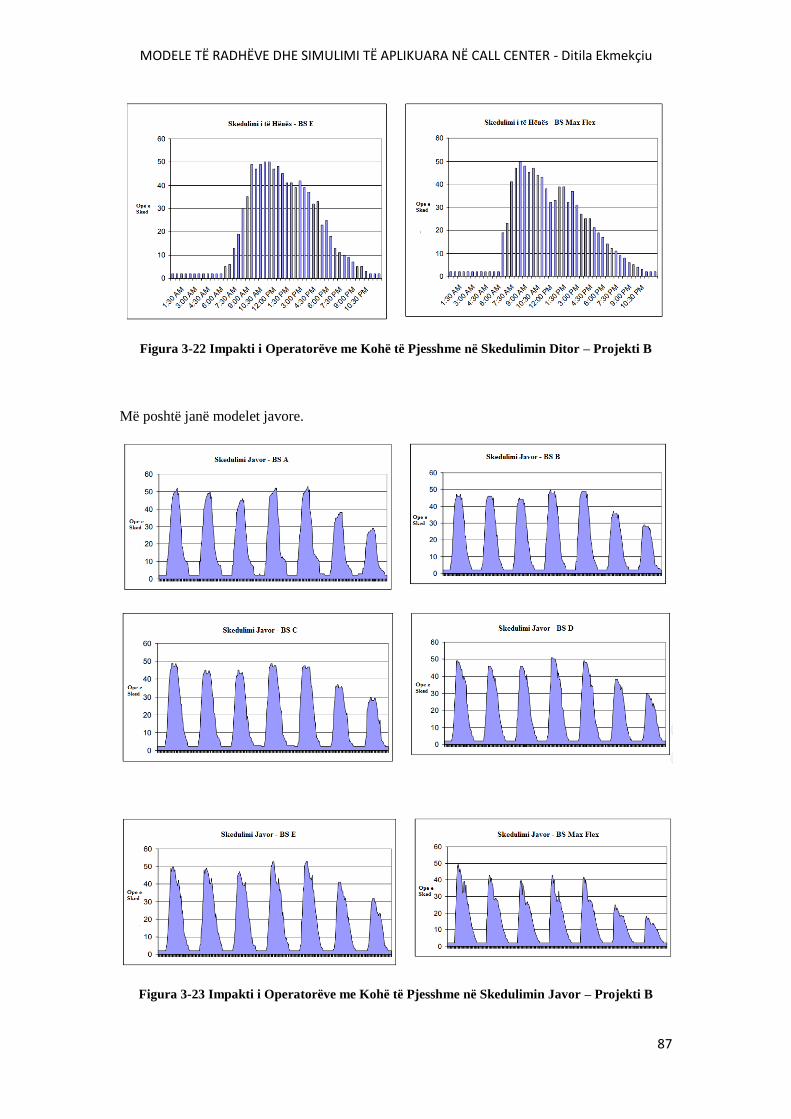
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
87
Figura 3-22 Impakti i Operatorëve me Kohë të Pjesshme në Skedulimin Ditor – Projekti B
Më poshtë janë modelet javore.
Figura 3-23 Impakti i Operatorëve me Kohë të Pjesshme në Skedulimin Javor – Projekti B
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
88
Të dyja të dhënat dhe grafikët dhe numrat tregojnë se organizimi i stafit me kohë të pjesshme
është më pak efektiv për këtë projekt. Disa arsye të mundshme janë përmbledhur më poshtë:
• Projekti ka një model sezonal më pak të përcaktuar.
• Volumi më i madh i telefonatave në fundjavë lejon përshtatjen më të mirë të profileve
të organizimit të stafit të mesjavës me operatorë me kohë të plotë.
• Natyra shumë e paqëndrueshme e projektit bën që formimi i kapacitetit të jetë më pak
efektiv.
Projekti C
Së fundi analizova projektin e tretë të modeluar nga Projekti C. rezultatet janë të ngjashme me
projektin B. Më poshtë janë rezultatet finale.
Tabela 3-13 Impakti i Skedulimit Fleksibël – Projekti C
Përsëri do të duket se mungesa e një modeli të fortë sezonal, si në nivel javor ashtu edhe në
nivel ditor; e bën strategjinë me kohë të pjesshme më pak efektive. Megjithatë, strategjia
siguron përfitime jo të parëndësishme, duke rritur përdorimin dhe uljen e kostove.
Vlera e Shtuar e punonjësve me kohë të pjesshme
Në këtë eksperiment të radhës do të shqyrtoj potencialin e përfitimit nga organizimi fleksibël i
stafit nëse numri i punonjësve me kohë të pjesshme është i kufizuar; qoftë nga politika ose
disponueshmëria. Do të vazhdoj të zgjidh programimin e optimizimit stokastik, por me një
kufizim shtesë që limiton numrin e operatorëve të caktuar për një turn prej më pak se 40 orësh
në disa parametra. Pastaj do të ndryshoj atë parametër nga 0 në 20, duke ekzekutuar 5 grupe në
çdo nivel dhe duke llogaritur kostot që rezultojnë. Në grafikun e mëposhtëm kam modeluar
Mesatarja
PDBashkësia
e Sked
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
TSF
MesatareBesimi Gabimi
Kostoja e Jo-
Fleksibilitetit
1 A 11,600 12,254 12,443 80.2% 66.3% 188.8 236
2 B 11,360 12,020 12,257 80.1% 64.5% 236.9 50
3 C 11,296 12,044 12,278 79.5% 58.4% 233.9 71
4 D 11,352 11,967 12,210 80.2% 66.9% 243.2 3
5 E 11,316 11,951 12,226 79.9% 62.8% 274.6 19
6 MF 11,287 11,856 12,207 79.8% 62.0% 351.2 -
7 MF-VM 9,275 9,275 15,662 67.2% -
Kostoja e Pasigurisë së Ngarkesës 2,932
% e Kursimeve nga Fleksibiliteti % e Kursimeve Max të Arritura
Bashkësia
e Sked
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
Kostoja e
Punës
Obj i
Llogaritur
Rezultati i
Pritur
A
B 2.1% 1.9% 1.5% 76.7% 58.6% 78.6%
C 2.6% 1.7% 1.3% 97.1% 52.7% 69.9%
D 2.1% 2.3% 1.9% 79.2% 72.0% 98.6%
E 2.4% 2.5% 1.7% 90.7% 76.1% 92.1%
MF 2.7% 3.2% 1.9% 100.0% 100.0% 100.0%
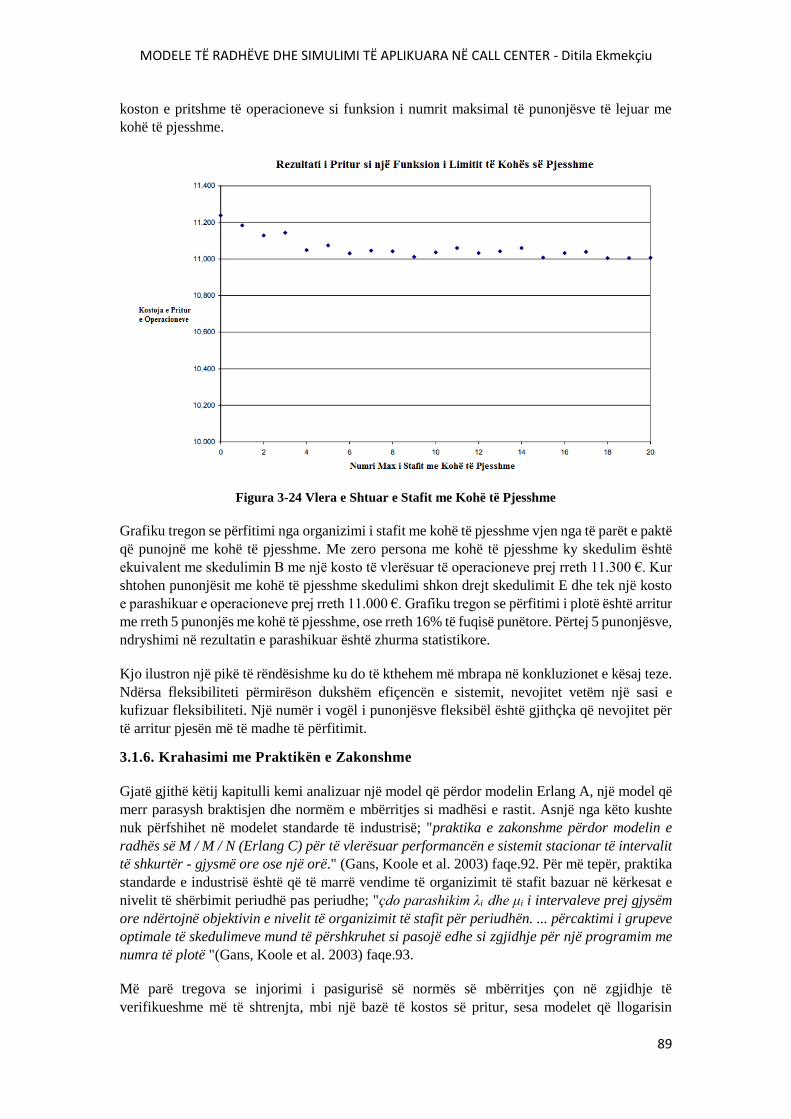
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
89
koston e pritshme të operacioneve si funksion i numrit maksimal të punonjësve të lejuar me
kohë të pjesshme.
Figura 3-24 Vlera e Shtuar e Stafit me Kohë të Pjesshme
Grafiku tregon se përfitimi nga organizimi i stafit me kohë të pjesshme vjen nga të parët e paktë
që punojnë me kohë të pjesshme. Me zero persona me kohë të pjesshme ky skedulim është
ekuivalent me skedulimin B me një kosto të vlerësuar të operacioneve prej rreth 11.300 €. Kur
shtohen punonjësit me kohë të pjesshme skedulimi shkon drejt skedulimit E dhe tek një kosto
e parashikuar e operacioneve prej rreth 11.000 €. Grafiku tregon se përfitimi i plotë është arritur
me rreth 5 punonjës me kohë të pjesshme, ose rreth 16% të fuqisë punëtore. Përtej 5 punonjësve,
ndryshimi në rezultatin e parashikuar është zhurma statistikore.
Kjo ilustron një pikë të rëndësishme ku do të kthehem më mbrapa në konkluzionet e kësaj teze.
Ndërsa fleksibiliteti përmirëson dukshëm efiçencën e sistemit, nevojitet vetëm një sasi e
kufizuar fleksibiliteti. Një numër i vogël i punonjësve fleksibël është gjithçka që nevojitet për
të arritur pjesën më të madhe të përfitimit.
3.1.6. Krahasimi me Praktikën e Zakonshme
Gjatë gjithë këtij kapitulli kemi analizuar një model që përdor modelin Erlang A, një model që
merr parasysh braktisjen dhe normëm e mbërritjes si madhësi e rastit. Asnjë nga këto kushte
nuk përfshihet në modelet standarde të industrisë; "praktika e zakonshme përdor modelin e
radhës së M / M / N (Erlang C) për të vlerësuar performancën e sistemit stacionar të intervalit
të shkurtër - gjysmë ore ose një orë." (Gans, Koole et al. 2003) faqe.92. Për më tepër, praktika
standarde e industrisë është që të marrë vendime të organizimit të stafit bazuar në kërkesat e
nivelit të shërbimit periudhë pas periudhe; "çdo parashikim λi dhe μi i intervaleve prej gjysëm
ore ndërtojnë objektivin e nivelit të organizimit të stafit për periudhën. ... përcaktimi i grupeve
optimale të skedulimeve mund të përshkruhet si pasojë edhe si zgjidhje për një programim me
numra të plotë "(Gans, Koole et al. 2003) faqe.93.
Më parë tregova se injorimi i pasigurisë së normës së mbërritjes çon në zgjidhje të
verifikueshme më të shtrenjta, mbi një bazë të kostos së pritur, sesa modelet që llogarisin

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
90
ndryshueshmërinë. Në këtë seksion do të krahasoj modelin stokastik Erlang-A me modelin e
aplikuar zakonisht Erlang C.
Modeli i Mbulimit të Ponderuar të Grupimit
Përqasja standarde e përshkruar më sipër gjeneron një sërë kërkesash të organizimit fiks të stafit
në çdo periudhë dhe pastaj përpiqet të gjejë skedulimin me koston më të ulët për të përmbushur
këto kërkesa. Programimi me numra të lotë që do të rezultojë është një problem standard i
mbulimit të ponderuar të grupimit i cili mund të shprehet si
Të minimizohet:
∑ 𝑐𝑗𝑥𝑗𝑗∈𝐽 (3.27)
Me kushtet:
∑ 𝑎𝑖𝑗𝑥𝑗 ≥ 𝑏𝑖 , ∀𝑖 ∈ 𝐼𝑗∈𝐽 (3.28)
𝑥𝑖𝑗 ∈ ℤ+ (3.29)
Ku cj është kostoja e skedulimit të j-të, xj është numri i personave që i caktohen skedulimit të
j-të, dhe aij është lidhja e skedulimit me periudhat kohore.
Modeli Erlang C i Kufizuar Lokalisht
Do t’i referohem përqasjes standarde të përshkruar në (Gans, Koole et al 2003) si modeli Erlang
C i kufizuar lokalisht sepse përdor Erlang C-në për të gjeneruar një kufizim lokal në çdo
periudhë28. Do të ndërtoj skedulimin Erlang C të kufizuar lokalisht duke përdorur procesin e
mëposhtëm:
1. Llogaris volumin mesatar në çdo periudhë 30 minutëshe të javës.
2. Duke përdorur volumet e llogaritura në hapin 1, do të përcaktojmë numrin e
operatorëve të kërkuar për të arritur nivelin e shërbimit të synuar në çdo periudhë prej
30 minutash duke kryer një kërkim me anë të përdorimit të ekuacionit (2.10).
3. Vendosim kërkesat e organizimit të stafit për periudhën në maksimumin e numrit të
llogaritur në hapin 2 dhe kërkesën minimale globale të organizimit të stafit.
4. Duke përdorur vektorin që rezulton të kërkesave të organizimit të stafit si parametri i
kërkesës bi në Programimin me Numra të Plotë (3.27) - (3.29).
Problemi i përgjithshëm me këtë përqasje është kufizimi i krijuar nga kërkesa e nivelit të
shërbimit për periudhë, së bashku me kërkesën për skedulimin e personave në turne.
Niveli i maksimal i organizimit të stafit është përcaktuar nga periudha e maksimumit të
mbërritjeve, dhe në varësi të gjatësisë së pikut të mbërritjeve dhe të gjatësisë së fleksibilitetit të
modelit të organizimit të stafit, mund të krijohet një sasi e konsiderueshme të kapacitetit të
28 Në këtë kontekst me lokale i referohemi një kufizimi periudhë pas periudhe, dhe me globale i
referohemi një kufizimi të aplikuar gjatë një periudhe më të gjatë le të thmië një javë ose një muaj. Kjo
është një terminologji përgjithësisht e pranuar, shohim për shembull Koole, van der Sluis (2003).
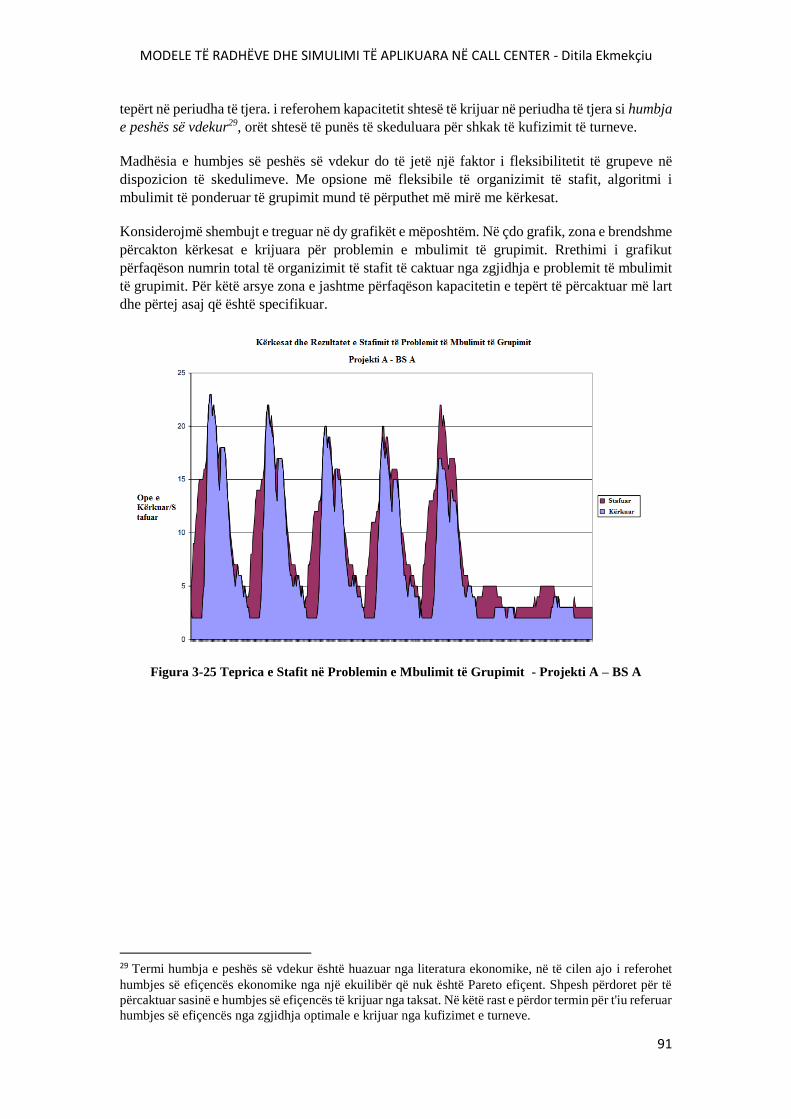
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
91
tepërt në periudha të tjera. i referohem kapacitetit shtesë të krijuar në periudha të tjera si humbja
e peshës së vdekur29, orët shtesë të punës të skeduluara për shkak të kufizimit të turneve.
Madhësia e humbjes së peshës së vdekur do të jetë një faktor i fleksibilitetit të grupeve në
dispozicion të skedulimeve. Me opsione më fleksibile të organizimit të stafit, algoritmi i
mbulimit të ponderuar të grupimit mund të përputhet më mirë me kërkesat.
Konsiderojmë shembujt e treguar në dy grafikët e mëposhtëm. Në çdo grafik, zona e brendshme
përcakton kërkesat e krijuara për problemin e mbulimit të grupimit. Rrethimi i grafikut
përfaqëson numrin total të organizimit të stafit të caktuar nga zgjidhja e problemit të mbulimit
të grupimit. Për këtë arsye zona e jashtme përfaqëson kapacitetin e tepërt të përcaktuar më lart
dhe përtej asaj që është specifikuar.
Figura 3-25 Teprica e Stafit në Problemin e Mbulimit të Grupimit - Projekti A – BS A
29 Termi humbja e peshës së vdekur është huazuar nga literatura ekonomike, në të cilen ajo i referohet
humbjes së efiçencës ekonomike nga një ekuilibër që nuk është Pareto efiçent. Shpesh përdoret për të
përcaktuar sasinë e humbjes së efiçencës të krijuar nga taksat. Në këtë rast e përdor termin për t'iu referuar
humbjes së efiçencës nga zgjidhja optimale e krijuar nga kufizimet e turneve.
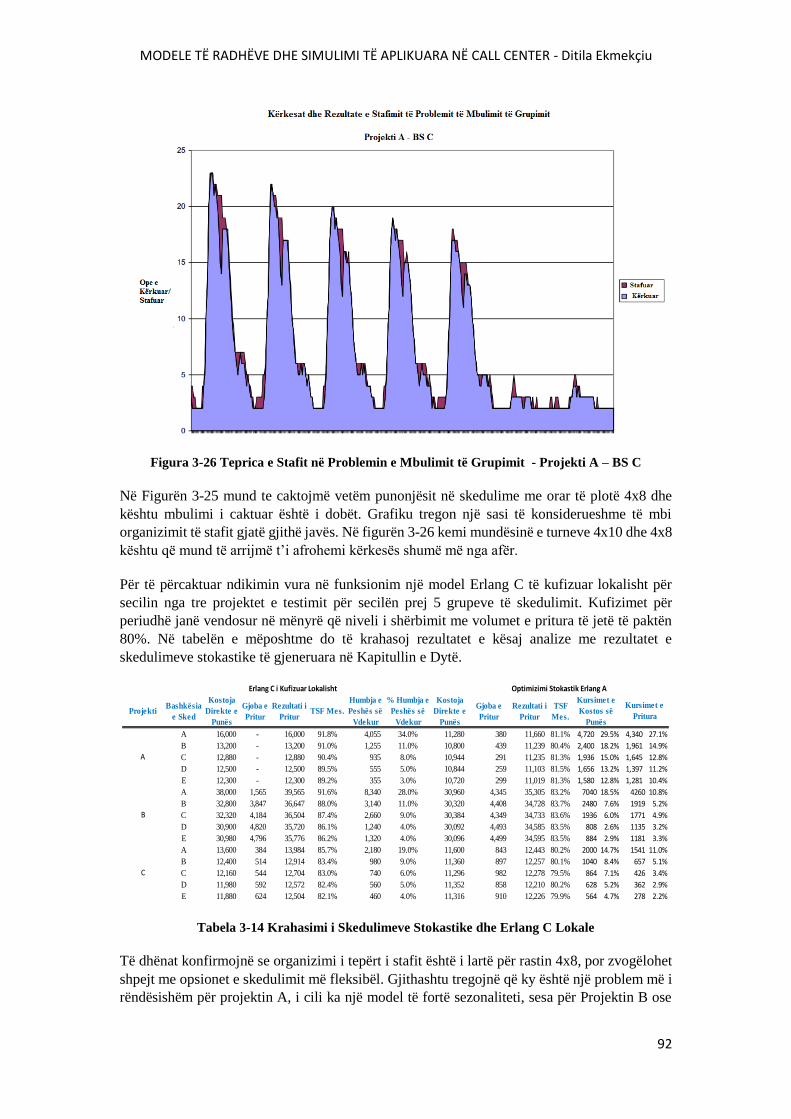
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
92
Figura 3-26 Teprica e Stafit në Problemin e Mbulimit të Grupimit - Projekti A – BS C
Në Figurën 3-25 mund te caktojmë vetëm punonjësit në skedulime me orar të plotë 4x8 dhe
kështu mbulimi i caktuar është i dobët. Grafiku tregon një sasi të konsiderueshme të mbi
organizimit të stafit gjatë gjithë javës. Në figurën 3-26 kemi mundësinë e turneve 4x10 dhe 4x8
kështu që mund të arrijmë t’i afrohemi kërkesës shumë më nga afër.
Për të përcaktuar ndikimin vura në funksionim një model Erlang C të kufizuar lokalisht për
secilin nga tre projektet e testimit për secilën prej 5 grupeve të skedulimit. Kufizimet për
periudhë janë vendosur në mënyrë që niveli i shërbimit me volumet e pritura të jetë të paktën
80%. Në tabelën e mëposhtme do të krahasoj rezultatet e kësaj analize me rezultatet e
skedulimeve stokastike të gjeneruara në Kapitullin e Dytë.
Tabela 3-14 Krahasimi i Skedulimeve Stokastike dhe Erlang C Lokale
Të dhënat konfirmojnë se organizimi i tepërt i stafit është i lartë për rastin 4x8, por zvogëlohet
shpejt me opsionet e skedulimit më fleksibël. Gjithashtu tregojnë që ky është një problem më i
rëndësishëm për projektin A, i cili ka një model të fortë sezonaliteti, sesa për Projektin B ose
ProjektiBashkësia
e Sked
Kostoja
Direkte e
Punës
Gjoba e
Pritur
Rezultati i
PriturTSF Mes.
Humbja e
Peshës së
Vdekur
% Humbja e
Peshës së
Vdekur
Kostoja
Direkte e
Punës
Gjoba e
Pritur
Rezultati i
Pritur
TSF
Mes.
A 16,000 - 16,000 91.8% 4,055 34.0% 11,280 380 11,660 81.1% 4,720 29.5% 4,340 27.1%
B 13,200 - 13,200 91.0% 1,255 11.0% 10,800 439 11,239 80.4% 2,400 18.2% 1,961 14.9%
C 12,880 - 12,880 90.4% 935 8.0% 10,944 291 11,235 81.3% 1,936 15.0% 1,645 12.8%
D 12,500 - 12,500 89.5% 555 5.0% 10,844 259 11,103 81.5% 1,656 13.2% 1,397 11.2%
E 12,300 - 12,300 89.2% 355 3.0% 10,720 299 11,019 81.3% 1,580 12.8% 1,281 10.4%
A 38,000 1,565 39,565 91.6% 8,340 28.0% 30,960 4,345 35,305 83.2% 7040 18.5% 4260 10.8%
B 32,800 3,847 36,647 88.0% 3,140 11.0% 30,320 4,408 34,728 83.7% 2480 7.6% 1919 5.2%
C 32,320 4,184 36,504 87.4% 2,660 9.0% 30,384 4,349 34,733 83.6% 1936 6.0% 1771 4.9%
D 30,900 4,820 35,720 86.1% 1,240 4.0% 30,092 4,493 34,585 83.5% 808 2.6% 1135 3.2%
E 30,980 4,796 35,776 86.2% 1,320 4.0% 30,096 4,499 34,595 83.5% 884 2.9% 1181 3.3%
A 13,600 384 13,984 85.7% 2,180 19.0% 11,600 843 12,443 80.2% 2000 14.7% 1541 11.0%
B 12,400 514 12,914 83.4% 980 9.0% 11,360 897 12,257 80.1% 1040 8.4% 657 5.1%
C 12,160 544 12,704 83.0% 740 6.0% 11,296 982 12,278 79.5% 864 7.1% 426 3.4%
D 11,980 592 12,572 82.4% 560 5.0% 11,352 858 12,210 80.2% 628 5.2% 362 2.9%
E 11,880 624 12,504 82.1% 460 4.0% 11,316 910 12,226 79.9% 564 4.7% 278 2.2%
B
C
Kursimet e
Kostos së
Punës
Kursimet e
Pritura
Erlang C i Kufizuar Lokalisht Optimizimi Stokastik Erlang A
A

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
93
C. Përqasja e përcaktimit të mbulimit tenton të mbistafojë projektin dhe të arrijë nivelet e
pritshme të shërbimit më të larta se ato të arritura në modelin stokastik. Megjithatë, për shkak
se modeli i caktimit të mbulimit konsideron vetëm vlerën e pritshme dhe jo variancën e
mbërritjeve, është më pak efektive në mbulim se sa modeli stokastik. Konsideroni rastin e
skedulimit D për projektin B. Modeli deterministik ka një nivel të pritshëm shërbimi prej
86.1%, kundrejt objektivit të 80%, por gjithashtu një kosto të pritshme të penalitetit prej 4.820
euro. Modeli stokastik nga ana tjetër ka një nivel të pritshëm shërbimi prej 83.5%, 2.6% më i
ulët, por një penalitet të pritur 4.493 euro.
Në të gjitha rastet modeli stokastik jep një kosto direkte më të ulët dhe një kosto më të ulët të
pritshme të operacioneve. Përfitimi i përdorimit të modelit stokastik është më i rëndësishëm
kur mbërritjet kanë një model të fortë sezonal, si në Projektin A, ose kur fleksibiliteti i fuqisë
punëtore është i ulët. Me stafmin vetëm 4x8 modeli stokastik siguron të paktën 10.8% më pak
kosto operative.
Modeli Erlang C i Kufizuar Globalisht
Në seksionin e mëparshëm tregova se modeli stokastik i bazuar në modelin Erlang A ofron
zgjidhje me kosto më të ulëta se sa modeli Erlang C i kufizuar lokalisht i diskutuar në literaturë.
Një përqasje alternative është përdorimi i një modeli deterministik të Erlang C, duke injoruar
braktisjen dhe pasigurinë si në modelin e mëparshëm, por duke optimizuar me një kufizim
global dhe jo lokal. Ndërsa kjo përqasje nuk është paraqitur në literaturën e realitetit shqiptar,
për aq sa jam në dijeni, është një thjeshtim i natyrshëm i modelit stokastik që kam analizuar
deri më tani. Duke qënë se modeli është determinist, ai supozon se normat e mbërritjes janë të
njohura, në përgjithësi do të jetë më e lehtë për të zgjidhur pastaj modelin stokastik. injorimi i
braktisjes do të tentojë të rrisë organizimin e rekomanduar të stafit, por injorimi i pasigurisë do
të tentojë të zvogëlojë organizimn e stafit. Mund të ndodhë që në disa rrethana këto gabime
mund të anullojnë njëra-tjetrën dhe mund të arrijmë zgjidhje të mira me një kosto llogaritjeje
më të ulët.
Metoda për formulimin dhe zgjidhjen e këtyre problemeve është një zbatim i drejtpërdrejtë i
modelit (3.1) - (3.7). Do të zgjidh një version të vlerës mesatare të problemit. Ndryshimi kryesor
është se koeficientët për kufizimet (3.3) dhe (3.5) llogariten bazuar në modelin e Erlang C.
Gjithsesi më duhet një minimum prej dy operatorësh të stafuar në të njejtën kohë dhe një nivel
shërbimi minimal në volumin e pritur në çdo periudhë prej së paku 50%.
Do të zgjidh një version të këtij problemi për secilin prej 3 projekteve për secilën mundësi
skedulimi. Meqenëse modeli është determinist nuk ka nevojë të zgjidhen grupet e shumëfishta.
Për të vlerësuar koston e pritur të zbatimit të zgjidhjes, do të vazhdoj të vlerësoj skedulimin që
rezulton kundrejt modelit stokastik Erlang A. Supozoj që modeli Erlang A me ambërritje të
pasigurta është modeli i saktë dhe objektivi i kësaj analize është të përcaktojë gabimin e
paraqitur duke përdorur një Model Erlang C të Kufizuar Globalisht.
Rezultatet e kësaj analize tregohen në tabelën e mëposhtme:

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
94
Tabela 3-15 Krahasimi i Skedulimeve Stokastike dhe Erlang C Globale
3.1.7. Sistemimet nëpërmjet Simulimit
Modelet e analizuara në këtë kapitull përdorin një përafrim analitik të modelit Erlang A për të
vlerësuar sjelljen e sistemit të radhës në përgjithësi për të vlerësuar nivelin e shërbimit në
veçanti. Modeli përdor një përafrim stacionar të pandërprerë për të vlerësuar sjelljen
jostacionare; përafrimi Stacionar indipendent Periudhë pas Periudhe (SIPP). Më parë kemi
shqyrtuar saktësinë e përqasjes SIPP dhe kemi gjetur se në përgjithësi ka dhënë një vlerësim të
saktë të saktë të nivelit total të shërbimit, por kemi gjetur gjithashtu se saktësia e përafrimit
ndryshonte nga projekti në projekt.
Në këtë seksion do të zhvilloj një zgjatje të procesit të skedulimit të përdorur gjatë gjithë këtij
kapitulli që do të quaj sistemime të bazuara në simulim. Ideja kyesore është që të marrim
skedulimet e gjeneruara nga zgjidhja e modelit stokastik të skedulimit dhe të shohim nëse mund
të gjendet një skedulim më i mirë nëpërmjet një kërkimi heuristik lokal të bazuar në simulim.
Përqasja e Optimizimit të Bazuar në Simulim
Në këtë përqasje do të përdor Simulimin Diskret te Ngjarjeve (DES) për të modeluar
operacionet e call center-it. Ndryshe nga modeli me bazë analitike i përdorur deri tani, përqasja
DES simulon përpunimin individual të ttelefonatave. Modeli i simulimit është projektuar për të
gjeneruar mbërritjet e telefonatave duke përdorur të njëjtin model statistikor të përshkruar në
figurën 1-8. Modeli i simulimit gjithashtu ndryshon numrin e operatorëve duke u bazuar në
modelin e organizimit të stafit në faza kohore të gjeneruara nga modeli i skedulimit.
DES-i bazik mund të vlerësojë rezultatin e pritshëm të skedulmmit kandidat, por për të gjetur
një skedulim më të mirë duhet të implementojmë një formë të algoritmit të optimizimit. Do të
implementoj një algoritëm lokal kërkimi që fillon me skedulimin e gjeneruar nga procesi i
optimizimit stokastik dhe kontrollon fqinjët e skedulimeve të lidhura ngushtë. Algoritmi lokal
i kërkimit udhëhiqet nga një kërkim fqinj variabël metaheuristik (VNS). VNS-ja është një
metaheuristik që bën ndryshime sistematike në zonat fqinje që po kontrollohet gjatë kërkimit
(Hansen dhe Mladenovic 2001; Hansen dhe Mladenovic 2005). Kur përdorim VNS një përqasje
e zakonshme është të përcaktojmë një sërë fqinjësh të mbivendosur, të tillë që
𝑁1(𝑥) ⊂ 𝑁2(𝑥) ⊂ ⋯ ⊂ 𝑁𝑘𝑀𝑎𝑥(𝑥) ∀𝑥 ∈ 𝑋 (3.30)
ProjektiBashkësia
e Sked
Kostoja
Direkte e
Punës
Gjoba e
Pritur
Rezultati i
PriturTSF Mes.
Kostoja
Direkte e
Punës
Gjoba e
Pritur
Rezultati i
Pritur
TSF
Mes.
A 14,000 20 14,020 88.6% 11,280 380 11,660 81.1% 2,720 19.4% 2,360 16.8%
B 12,000 2 12,002 87.1% 10,800 439 11,239 80.4% 1,200 10.0% 763 6.4%
C 11,760 5 11,765 86.3% 10,944 291 11,235 81.3% 816 6.9% 530 4.5%
D 11,600 7 11,607 86.3% 10,844 259 11,103 81.5% 756 6.5% 504 4.3%
E 11,580 26 11,606 85.8% 10,720 299 11,019 81.3% 860 7.4% 587 5.1%
A 35,200 953 36,153 87.3% 30,960 4,345 35,305 83.2% 4240 12.0% 848 2.3%
B 30,400 5,412 35,812 84.8% 30,320 4,408 34,728 83.7% 80 0.3% 1084 3.0%
C 30,160 5,426 35,586 84.7% 30,384 4,349 34,733 83.6% -224 -0.7% 853 2.4%
D 29,340 6,080 35,420 83.6% 30,092 4,493 34,585 83.5% -752 -2.6% 835 2.4%
E 29,320 6,050 35,370 83.7% 30,096 4,499 34,595 83.5% -776 -2.6% 775 2.2%
A 11,600 976 12,576 79.9% 11,600 843 12,443 80.2% 0 0.0% 133 1.1%
B 11,200 1,305 12,505 78.5% 11,360 897 12,257 80.1% -160 -1.4% 248 2.0%
C 11,120 1,394 12,514 78.3% 11,296 982 12,278 79.5% -176 -1.6% 236 1.9%
D 10,960 1,442 12,402 78.0% 11,352 858 12,210 80.2% -392 -3.6% 192 1.5%
E 11,080 1,421 12,501 78.1% 11,316 910 12,226 79.9% -236 -2.1% 275 2.2%
A
B
C
Erlang C i Kufizuar Globalisht Optimizimi Stokastik Erlang A
Kursimet e
Kostos së
Punës
Kursimet e
Pritura

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
95
Struktura e përgjithshme e VNS-së do të jetë më pas si më poshtë:
1) Fillimi
a. Zgjidh grupin e strukturave të fqinjësisë, Nk për k = 1, ...,kmax
b. Ndërto një zgjidhje fillestare në detyrë, xI, duke përdorur disa proçedura heuristike.
c. Zgjidh një nivel besimi α për zgjedhjen e një zgjidhjeje të re në detyrë
2) Kërko: përsërit sa vijon derisa Stop = True (E vërtetë)
a. Vendos k = 1
b. Gjej 𝑛𝑘𝑚𝑖𝑛 zgjidhje kandidate, xC që janë fqinjët e xI
c. Simulo sistemin me secilin kandidat dhe krahaso rezultatet me atë në detyrë duke
përdorur një Test T dy palësh.
d. Nëse ndonjë xC është superior ndaj xI në nivelin α atëherë vendos 𝑥𝐼 = 𝑥𝐶∗ ku 𝑥𝐶
∗ është
zgjidhja më e mirë kandidate
Përndryshe, vendos i = 𝑛𝑘𝑚𝑖𝑛, vendos gjetur = False (E Gabuar), dhe përsërit derisa (i
= 𝑛𝑘𝑚𝑎𝑥, ose gjetur = True (E Vërtetë)
i. Gjej një kandidat të ri i 𝑥𝑘𝑖
ii. Simulo sistemin me secilin kandidat dhe krahaso rezultatet duke përdorur një
Test T dy-palësh.
iii. Nëse 𝑥𝑘𝑖 është superior ndaj xI në nivelin α atëherë vendos xI = 𝑥𝑘𝑖
dhe gjetur
= True (E Vërtetë)
e. Në qoftë se nuk gjendet asnjë operator i ri në detyrë në fqinjësinë k atëherë
i. vendos k = k+1
ii. nëse max k > kmax atëherë Stop = True (E Vërtetë)
Figura 3-27 Algoritmi i përgjithshëm i Kërkimit VNS
Një perqasje e zakonshme e VNS-së është një seri strukturash fqinje të mbivendosura si më
poshtë:
𝑁1(𝑥) ⊂ 𝑁2(𝑥) ⊂ ⋯ ⊂ 𝑁𝑘𝑀𝑎𝑥(𝑥) ∀𝑥 ∈ 𝑋 (3.31)
Gjatë përcaktimit të strukturës fqinje, bëj dallimin mes grupit të skedulimeve aktive, atyre
skedulimeve me një caktim të ndryshëm nga zero në skedulimin kandidat dhe skedulimet e
mundshme që përfshijnë të gjitha skedulimet në bashkësinë e skedulimeve të mundshme. Duke
u bazuar në këtë dallim do të përcaktoj fqinjësitë e mëposhtme
• N1 (x): Ndryshimi Aktiv 1: grupi i të gjitha planifikimeve të organizimit të stafit ku një
skedulim aktiv është rritur ose zvogëluar me 1.
• N2 (x): Ndryshimi Aktiv 2: zgjedh dy skedulime aktive çfarëdo dhe në mënyrë të
pavarur rrit ose zvogëlon secilin
• N3 (x): Ndryshimi i Mundshëm 1: zgjedh çdo skedulim të mundshëm dhe shton një
caktim.
• N4 (x): Ndryshimi i Mundshëm 2: zgjedh çdo skedulim të mundshëm dhe shton një
caktim, zgjedh një skedulim aktiv dhe ul numrin e caktuar.
Procesi i Sistemimeve
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
96
Në këtë test do të vlerësoj skedulimin bazë të zhvilluar për secilin nga tri projektet e testimit
për secilin prej pesë opsioneve të skedulimit standard; duke rezultuar në një total prej 15
problemash të ndryshme optimizimi. Në secilin rast do të filloj me rezultatet e gjetura në
seksionin 3.1.5.
Rezultatet për projektin A janë si më poshtë:
Tabela 3-16 Sistemimi i bazuar në Simulim – Projekti A
Rezultatet tregojnë se një përmirësim i moderuar është i mundur në të gjitha rastet. Seksioni i
parë rendit rezultatet e gjetura duke simuluar rezultatet e skedulimit të gjeneruar nga modeli i
optimizimit stokastik. Krahasimi i rezultateve në këtë tabelë me ato të tabelës 3-11 tregon se
modeli i simulimit llogarit një nivel shërbimi më të ulët dhe gjobë më të lartë se ato të vlerësuara
në modelin e optimizimit. Kjo është në përputhje me gabimet optimiste të gjetura në seksionin
3.1.2 dhe të përmbledhura në tabelën 3-1. Kërkimi i simulimit është më pas në gjendje të gjejë
skedulimet me kosto më të ulëta duke shtuar operatorë. Kostoja në rritje e organizimit të stafit
është kompensuar nga kostoja e pritur e zvogëluar e gjobës për nivelet e shërbimit. Në këtë
projekt në veçanti përfitimet janë të moderuara në rangun prej 1.0% në 2.7%.
Rezultatet për projektet B dhe C janë të ngjashme dhe janë përmbledhur në tabelat e
mëposhtme:
Tabela 3-17 Sistemimi i bazuar në Simulim – Projekti B
Tabela 3-18 Sistemimi i bazuar në Simulim – Projekti C
Përmirësimi për Projektin C është më i rëndësishëm se sa ai i gjetur për Projektin A dhe në
përgjithësi rezulton nga zvogëlimi i fuqisë punëtore. Kjo është në përputhje me gjetjet e SIPP-
së për projektin B ku modeli i skedulimit tenton të nënvlerësojë nivelin e arritur të shërbimit.
Rezultatet për Projektin C janë të ngjashme me ato të projektit A me kursime në rangun nga
Zgjidhja Paraprake Rezultatet e Optimizimit Krahasimi
Bashkësia
e Sked.
Kostoja e
Punës
Rezultati i
Pritur
TSF
Mes
TSF
DS
Kostoja e
Punës
Rezultati
i Pritur
TSF
Mes
TSF
DS
Kursimi
i Punës
Kursimi
Total
% e
Kursimeve
Skedulimi A 11,200 12,362 79.3% 4.1% 11,600 12,105 81.0% 3.8% (400) 257 2.1%
Skedulimi B 10,800 11,933 78.1% 3.2% 11,200 11,611 80.6% 3.0% (400) 322 2.7%
Skedulimi C 10,960 11,867 78.9% 3.3% 11,360 11,697 81.5% 3.4% (400) 170 1.4%
Skedulimi D 10,840 11,609 79.4% 3.5% 11,060 11,380 81.2% 3.0% (220) 229 2.0%
Skedulimi E 10,720 11,521 78.9% 3.3% 10,920 11,402 80.3% 3.1% (200) 119 1.0%
Zgjidhja Paraprake Rezultatet e Optimizimit Krahasimi
Bashkësia
e Sked.
Kostoja e
Punës
Rezultati i
Pritur
TSF
Mes
TSF
DS
Kostoja e
Punës
Rezultati
i Pritur
TSF
Mes
TSF
DS
Kursimi
i Punës
Kursimi
Total
% e
Kursimeve
Skedulimi A 30,800 32,143 83.5% 4.5% 30,000 31,313 83.3% 4.9% 800 830 2.6%
Skedulimi B 30,400 31,167 84.7% 4.2% 29,200 29,866 84.0% 4.6% 1,200 1,301 4.2%
Skedulimi C 30,880 31,418 85.0% 4.0% 28,960 29,860 83.7% 4.7% 1,920 1,558 5.0%
Skedulimi D 29,860 30,759 84.4% 4.2% 29,060 29,960 84.1% 4.4% 800 799 2.6%
Skedulimi E 30,320 30,879 85.3% 4.1% 29,080 30,102 84.0% 4.6% 1,240 777 2.5%
Zgjidhja Paraprake Rezultatet e Optimizimit Krahasimi
Bashkësia
e Sked.
Kostoja e
Punës
Rezultati i
Pritur
TSF
Mes
TSF
DS
Kostoja e
Punës
Rezultati
i Pritur
TSF
Mes
TSF
DS
Kursimi
i Punës
Kursimi
Total
% e
Kursimeve
Skedulimi A 11,600 12,244 79.9% 3.7% 11,600 12,097 80.3% 3.6% - 147 1.2%
Skedulimi B 11,200 12,281 78.5% 3.6% 11,600 12,047 80.6% 3.5% (400) 234 1.9%
Skedulimi C 11,120 12,236 78.3% 3.5% 11,440 11,978 80.2% 3.6% (320) 258 2.1%
Skedulimi D 11,380 12,035 79.7% 3.4% 11,480 11,972 80.2% 3.3% (100) 63 0.5%
Skedulimi E 11,340 12,151 79.1% 3.3% 11,540 12,015 80.2% 3.1% (200) 136 1.1%

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
97
0.5% deri në 2.1% që rezultojnë nga rritja e organizimit të stafit dhe nga nivelet e përmirësuara
të shërbimit.
Ky eksperiment tregon dy gjëra. Së pari skedulimet e krijuara nga procesi i optimizimit
stokastik janë mjaft të mira, por jo optimale. Shtimi i një algoritmi sistemimi të bazuar në
simulim mund të përmirësojë lehtshëm skedulimin. Në këtë rast të veçantë, modeli i simulimit
aplikoi të njëjtin grup supozimesh si procesi i optimizimit; p.sh. koha e bisedës eksponenciale,
durimi eksponencial. Këto supozime ishin të nevojshme për të marrë shprehjet analitike të
modelit Erlang A dhe disa prej tyre janë shqetësuese, në veçanti supozimi i kohës së bisedës
eksponenciale30.
Megjithatë, këto supozime mund të relaksohen lehtësisht në përqasjen e bazuar në simulim. Një
proces alternativ skedulimi mund të përfshijë zgjidhjen e modelit të optimizimit stokastik nën
një supozim Erlang A, pastaj sistemimet nën një grup tjetër supozimesh, p.sh. koha e bisedës
lognormale.
Një çështje e hapur në secilin rast është saktësia e zbatuar në çdo hap të procesit të optimizimit.
Mund të përfytyrojmë një proces në të cilin programimi stokastik zgjidhet në më pak kohë me
më pak saktësi, ndoshta duke përdorur më pak skenarë ose një hendek më të madh optimizimi
në Programimin me numra të plotë përfundimtar dhe më pas një skedulim përfundimtar
gjenerohet nga optimizimi i bazuar në simulime.
Përmbledhje
Në këtë kapitull shqyrtova çështjen e skedulimit afatshkurtër të turneve për call center-at, për
të cilët është e rëndësishme të përmbushin një angazhim në nivel shërbimi gjatë një periudhe të
zgjatur31. Ndërsa analiza u përqendrua ekskluzivisht në një SLA të bazuar në TSF, modeli mund
të përshtatej lehtësisht për të mbështetur forma të tjera të SLA-ve; të tilla si shkalla e braktisjes
ose shpejtësia mesatare për t'u përgjigjur. Modeli u hartua për të njohur pasigurinë në normat e
mbëritjes dhe u formulua si një programim miks me numra të plotë stokastik me dy faza.
Megjithëse i vështirë për t’u zgjidhur, tregova se modeli është i manovrueshëm dhe mund të
zgjidhet në një kohë të arsyeshme. Në kapitujt e mëparshëm tregova se mbërritjet si madhësi e
rastit janë një shqetësim real për call center-at, dhe në këtë kapitull kam treguar se ka një ndikim
real në vendimet e skedulimit.
3.2. Modeli i Trajnimit Miks
Modeli i trajnimit miks shqyrton më tej operacionet e një call center-i. Do të shqyrtoj mundësinë
e trajnimit të një nëngrupimi operatorësh në mënyrë që ata të mund të operojnë njëkohësisht
për dy projekte të ndara, një proces të cilit do t’i referohem si grupim i pjesshëm. Meqenëse
sistemet e radhëve kanë ekonomi shkalle natyrale, trajnimi miks i operatorëve do të rrisë
performancën e përgjithshme të sistemit. Sidoqoftë, duke pasur parasysh investimin e kërkuar
për trajnim dhe kërkesën e mundshme për të paguar një pagë më të lartë për këto raste, mund
të mos jetë e dobishme të trajnohen në mënyrë miks të gjithë operatorët. Përndryshe, merret
30 Modele të tjera analitike janë të disponueshme për shpërndarjen e përgjithshme te kohës së bisedës pa
braktisje, por duke relaksuar supozimet eksponenciale dhe duke lejuar braktisjen krijon një situatë
analitike të vështirë. Shihet në punën empirike nga Brown et. al. që adreson supozimin e kohës
eksponenciale të bisedës.
31 Zakonisht SLA objektiv i një call center-i i referohet periudhave 1 mujore, bazuar në kontratën me
klientin.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
98
parasysh rasti i një call center-i shumëgjuhësh. Organizimit i stafit të call center-it me operatorë
shumëgjuhësh do të rrisë efikaçencën e tij. Por duke prezumuar që operatorët shumëgjuhësh
janë më të vështirë për t’u gjetur, mund të kërkojnë një pagë të lartë.
Ky model kërkon të përcaktojë përfitimin nga grupimi i pjesshëm dhe të karakterizojë kushtet
nën të cilat grupimi është më fitimprurës. Më pas përcaktojmë numrin optimal të operaorëve
për t’u trajnuar në mënyrë miks duke pasur të dhënë investimin e trajnimit dhe shtesën në pagë
të paguar për operatorët në këtë rast.
Sfida e organizimit të stafit në këtë model është gjetja e përzierjes optimale të operatorëve në
mënyrë që të arrihet objektivi global i SLA me një probabilitet të lartë dhe me koston më të ulët
të mundshme. Në grupimin e pjesshëm, një numër i vogël super operatorësh janë të trajnuar në
mënyrë miks për të marrë telefonata nga dy projekte. Call center-i më pas mund të shihet si një
model rutimi i bazuar në kompetenca (SBR) me dy kompetenca. Super operatorët i kanë të dyja
kompetencat, ndërsa agjentët bazë kanë vetëm një lloj kompetence. Është e qartë se trajnimi
miks i të gjithë operatorëve do të rrisë nivelin e shërbimit të call center-it për një nivel fiks të
organizimit të stafit. Hipoteza ime është që trajnimi miks i një numri të vogël operatorësh mund
të ofrojë një pjesë të konsiderueshme të përfitimit dhe objektivi im është gjetja e nivelit të
trajnimit miks që minimizon kostot e organizimit të stafit, duke përmbushur kufizimin e nivelit
të shërbimit me probabilitet të lartë.
Do të shqyrtoj rastin e trajnimit miks ndërmjet dy projekteve (ose dy grupeve gjuhësore) dhe
do të supozoj se sistemi i rutimit i bazuar në kompetenca është konfiguruar si më poshtë:
Figura 3-28 Modeli i Grupimit
Kemi dy tipologji telefonatash, një per secilin projekt, dhe tre grupime operatorësh. Grupimi
numër 1 ka kompetencën 1 dhe mund t’i shërbejë tipologjisë së telefonatës numër 1. Në menyre
të ngjashme grupimi numër 2 i shërben tipologjisë 2 të telefonatave. Grupimi numër 3 ka
trajnimin miks dhe mund t’i shërbejë telefonatave nga të dyja radhët (Ekmekçiu 2017).
3.2.1. Grupimi i pjesshëm në Gjendje të Qëndrueshme
Në këtë seksion do të analizojmë performancën e sistemit në gjendje të qëndrueshme duke
përdorur simulimin. Në këtë analizë supozoj një model të thjeshtë rutimi. Kur një telefonatë
mbërin ajo i dërgohet një operatori me kualifikim bazë nëse një është i lirë. Vetëm nëse të gjithë
operatorët bazë janë të zënë, thirrja do t'i dërgohet një super operatori. Nëse të gjithë super
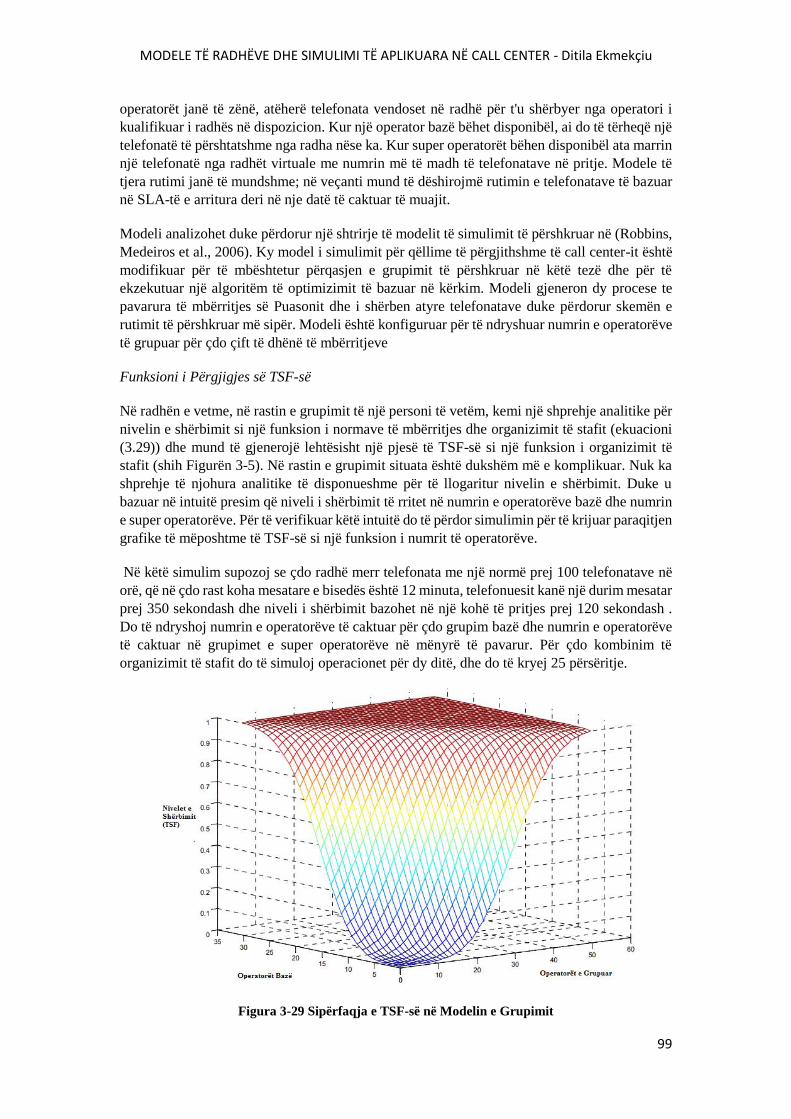
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
99
operatorët janë të zënë, atëherë telefonata vendoset në radhë për t'u shërbyer nga operatori i
kualifikuar i radhës në dispozicion. Kur një operator bazë bëhet disponibël, ai do të tërheqë një
telefonatë të përshtatshme nga radha nëse ka. Kur super operatorët bëhen disponibël ata marrin
një telefonatë nga radhët virtuale me numrin më të madh të telefonatave në pritje. Modele të
tjera rutimi janë të mundshme; në veçanti mund të dëshirojmë rutimin e telefonatave të bazuar
në SLA-të e arritura deri në nje datë të caktuar të muajit.
Modeli analizohet duke përdorur një shtrirje të modelit të simulimit të përshkruar në (Robbins,
Medeiros et al., 2006). Ky model i simulimit për qëllime të përgjithshme të call center-it është
modifikuar për të mbështetur përqasjen e grupimit të përshkruar në këtë tezë dhe për të
ekzekutuar një algoritëm të optimizimit të bazuar në kërkim. Modeli gjeneron dy procese te
pavarura të mbërritjes së Puasonit dhe i shërben atyre telefonatave duke përdorur skemën e
rutimit të përshkruar më sipër. Modeli është konfiguruar për të ndryshuar numrin e operatorëve
të grupuar për çdo çift të dhënë të mbërritjeve
Funksioni i Përgjigjes së TSF-së
Në radhën e vetme, në rastin e grupimit të një personi të vetëm, kemi një shprehje analitike për
nivelin e shërbimit si një funksion i normave të mbërritjes dhe organizimit të stafit (ekuacioni
(3.29)) dhe mund të gjenerojë lehtësisht një pjesë të TSF-së si një funksion i organizimit të
stafit (shih Figurën 3-5). Në rastin e grupimit situata është dukshëm më e komplikuar. Nuk ka
shprehje të njohura analitike të disponueshme për të llogaritur nivelin e shërbimit. Duke u
bazuar në intuitë presim që niveli i shërbimit të rritet në numrin e operatorëve bazë dhe numrin
e super operatorëve. Për të verifikuar këtë intuitë do të përdor simulimin për të krijuar paraqitjen
grafike të mëposhtme të TSF-së si një funksion i numrit të operatorëve.
Në këtë simulim supozoj se çdo radhë merr telefonata me një normë prej 100 telefonatave në
orë, që në çdo rast koha mesatare e bisedës është 12 minuta, telefonuesit kanë një durim mesatar
prej 350 sekondash dhe niveli i shërbimit bazohet në një kohë të pritjes prej 120 sekondash .
Do të ndryshoj numrin e operatorëve të caktuar për çdo grupim bazë dhe numrin e operatorëve
të caktuar në grupimet e super operatorëve në mënyrë të pavarur. Për çdo kombinim të
organizimit të stafit do të simuloj operacionet për dy ditë, dhe do të kryej 25 përsëritje.
Figura 3-29 Sipërfaqja e TSF-së në Modelin e Grupimit
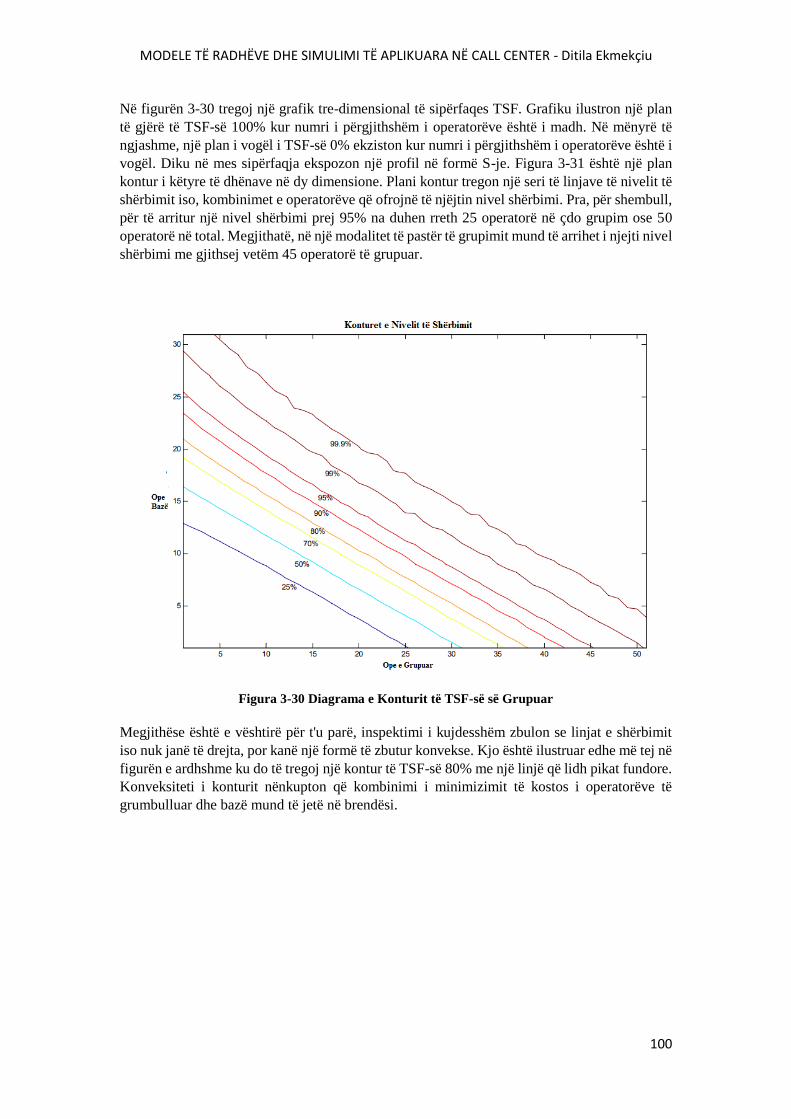
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
100
Në figurën 3-30 tregoj një grafik tre-dimensional të sipërfaqes TSF. Grafiku ilustron një plan
të gjërë të TSF-së 100% kur numri i përgjithshëm i operatorëve është i madh. Në mënyrë të
ngjashme, një plan i vogël i TSF-së 0% ekziston kur numri i përgjithshëm i operatorëve është i
vogël. Diku në mes sipërfaqja ekspozon një profil në formë S-je. Figura 3-31 është një plan
kontur i këtyre të dhënave në dy dimensione. Plani kontur tregon një seri të linjave të nivelit të
shërbimit iso, kombinimet e operatorëve që ofrojnë të njëjtin nivel shërbimi. Pra, për shembull,
për të arritur një nivel shërbimi prej 95% na duhen rreth 25 operatorë në çdo grupim ose 50
operatorë në total. Megjithatë, në një modalitet të pastër të grupimit mund të arrihet i njejti nivel
shërbimi me gjithsej vetëm 45 operatorë të grupuar.
Figura 3-30 Diagrama e Konturit të TSF-së së Grupuar
Megjithëse është e vështirë për t'u parë, inspektimi i kujdesshëm zbulon se linjat e shërbimit
iso nuk janë të drejta, por kanë një formë të zbutur konvekse. Kjo është ilustruar edhe më tej në
figurën e ardhshme ku do të tregoj një kontur të TSF-së 80% me një linjë që lidh pikat fundore.
Konveksiteti i konturit nënkupton që kombinimi i minimizimit të kostos i operatorëve të
grumbulluar dhe bazë mund të jetë në brendësi.
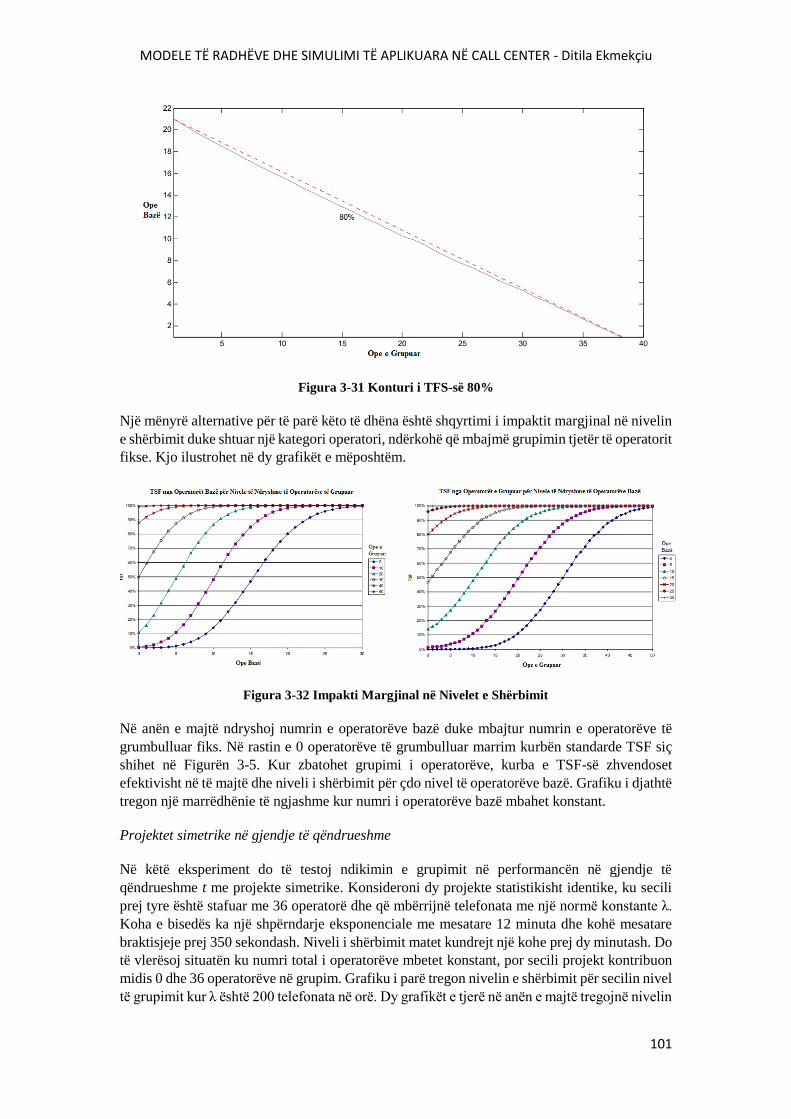
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
101
Figura 3-31 Konturi i TFS-së 80%
Një mënyrë alternative për të parë këto të dhëna është shqyrtimi i impaktit margjinal në nivelin
e shërbimit duke shtuar një kategori operatori, ndërkohë që mbajmë grupimin tjetër të operatorit
fikse. Kjo ilustrohet në dy grafikët e mëposhtëm.
Figura 3-32 Impakti Margjinal në Nivelet e Shërbimit
Në anën e majtë ndryshoj numrin e operatorëve bazë duke mbajtur numrin e operatorëve të
grumbulluar fiks. Në rastin e 0 operatorëve të grumbulluar marrim kurbën standarde TSF siç
shihet në Figurën 3-5. Kur zbatohet grupimi i operatorëve, kurba e TSF-së zhvendoset
efektivisht në të majtë dhe niveli i shërbimit për çdo nivel të operatorëve bazë. Grafiku i djathtë
tregon një marrëdhënie të ngjashme kur numri i operatorëve bazë mbahet konstant.
Projektet simetrike në gjendje të qëndrueshme
Në këtë eksperiment do të testoj ndikimin e grupimit në performancën në gjendje të
qëndrueshme t me projekte simetrike. Konsideroni dy projekte statistikisht identike, ku secili
prej tyre është stafuar me 36 operatorë dhe që mbërrijnë telefonata me një normë konstante λ.
Koha e bisedës ka një shpërndarje eksponenciale me mesatare 12 minuta dhe kohë mesatare
braktisjeje prej 350 sekondash. Niveli i shërbimit matet kundrejt një kohe prej dy minutash. Do
të vlerësoj situatën ku numri total i operatorëve mbetet konstant, por secili projekt kontribuon
midis 0 dhe 36 operatorëve në grupim. Grafiku i parë tregon nivelin e shërbimit për secilin nivel
të grupimit kur λ është 200 telefonata në orë. Dy grafikët e tjerë në anën e majtë tregojnë nivelin
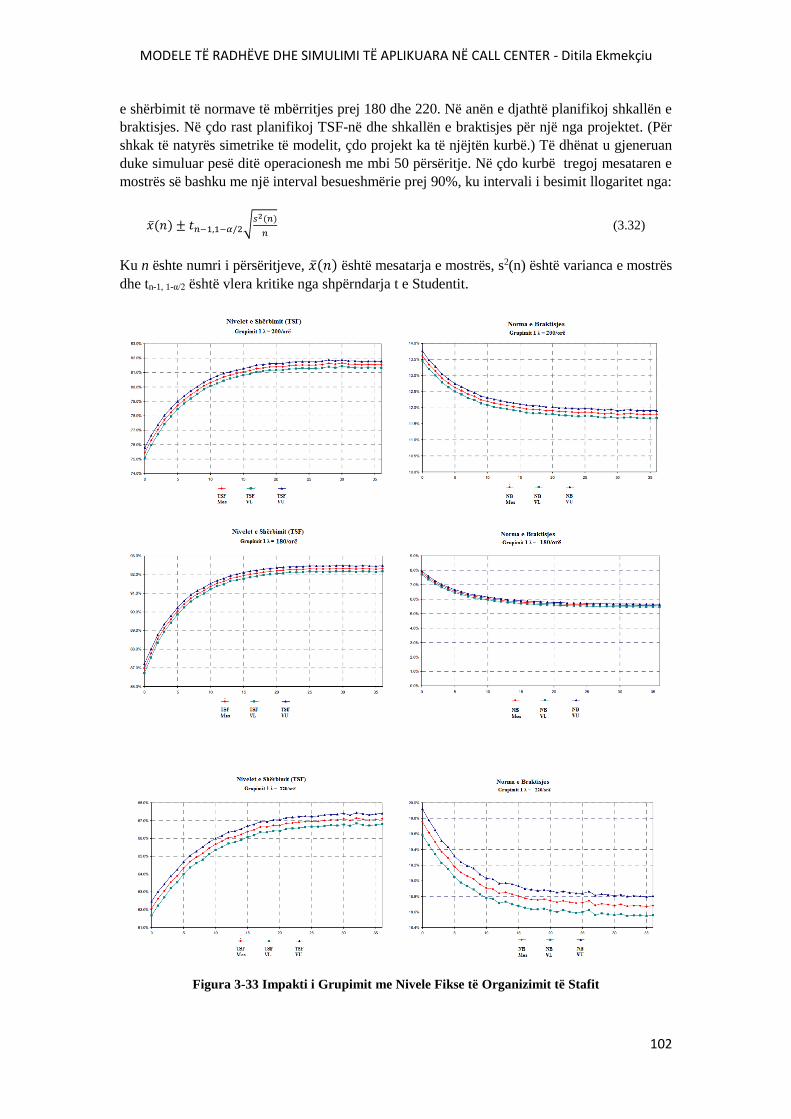
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
102
e shërbimit të normave të mbërritjes prej 180 dhe 220. Në anën e djathtë planifikoj shkallën e
braktisjes. Në çdo rast planifikoj TSF-në dhe shkallën e braktisjes për një nga projektet. (Për
shkak të natyrës simetrike të modelit, çdo projekt ka të njëjtën kurbë.) Të dhënat u gjeneruan
duke simuluar pesë ditë operacionesh me mbi 50 përsëritje. Në çdo kurbë tregoj mesataren e
mostrës së bashku me një interval besueshmërie prej 90%, ku intervali i besimit llogaritet nga:
�̅�(𝑛) ± 𝑡𝑛−1,1−𝛼/2√𝑠2(𝑛)
𝑛 (3.32)
Ku n ështe numri i përsëritjeve, �̅�(𝑛) është mesatarja e mostrës, s2(n) është varianca e mostrës
dhe tn-1, 1-α/2 është vlera kritike nga shpërndarja t e Studentit.
Figura 3-33 Impakti i Grupimit me Nivele Fikse të Organizimit të Stafit
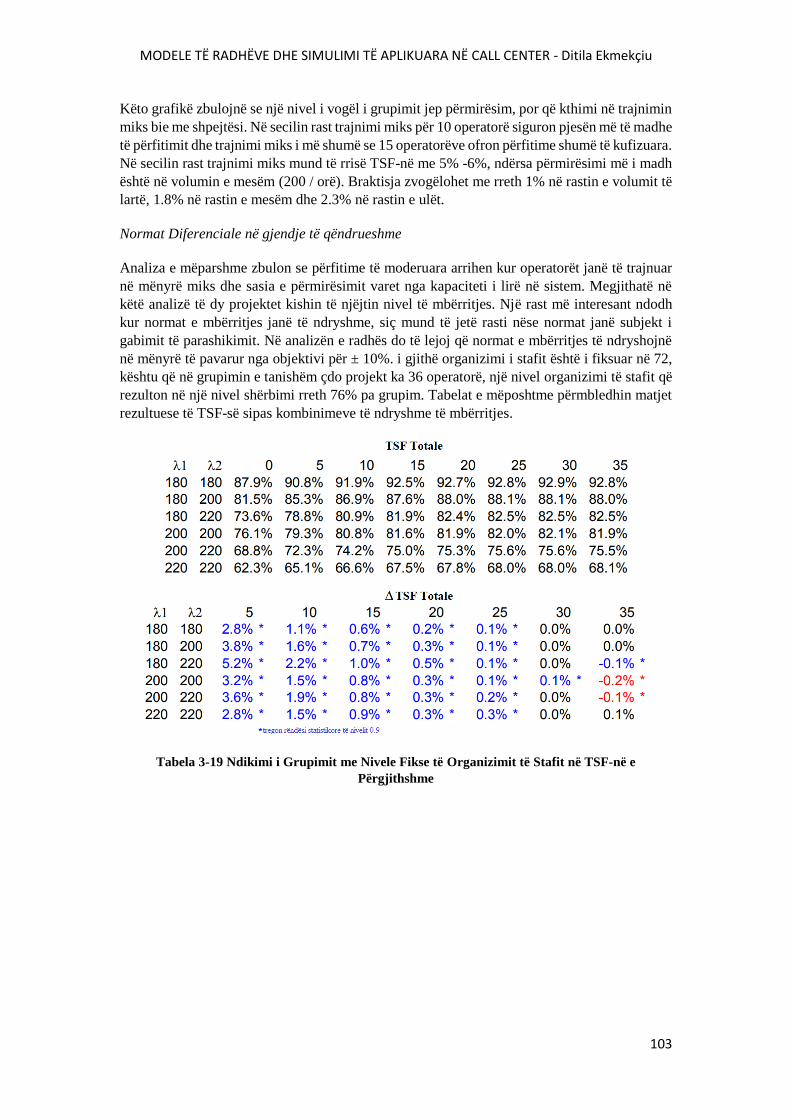
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
103
Këto grafikë zbulojnë se një nivel i vogël i grupimit jep përmirësim, por që kthimi në trajnimin
miks bie me shpejtësi. Në secilin rast trajnimi miks për 10 operatorë siguron pjesën më të madhe
të përfitimit dhe trajnimi miks i më shumë se 15 operatorëve ofron përfitime shumë të kufizuara.
Në secilin rast trajnimi miks mund të rrisë TSF-në me 5% -6%, ndërsa përmirësimi më i madh
është në volumin e mesëm (200 / orë). Braktisja zvogëlohet me rreth 1% në rastin e volumit të
lartë, 1.8% në rastin e mesëm dhe 2.3% në rastin e ulët.
Normat Diferenciale në gjendje të qëndrueshme
Analiza e mëparshme zbulon se përfitime të moderuara arrihen kur operatorët janë të trajnuar
në mënyrë miks dhe sasia e përmirësimit varet nga kapaciteti i lirë në sistem. Megjithatë në
këtë analizë të dy projektet kishin të njëjtin nivel të mbërritjes. Një rast më interesant ndodh
kur normat e mbërritjes janë të ndryshme, siç mund të jetë rasti nëse normat janë subjekt i
gabimit të parashikimit. Në analizën e radhës do të lejoj që normat e mbërritjes të ndryshojnë
në mënyrë të pavarur nga objektivi për ± 10%. i gjithë organizimi i stafit është i fiksuar në 72,
kështu që në grupimin e tanishëm çdo projekt ka 36 operatorë, një nivel organizimi të stafit që
rezulton në një nivel shërbimi rreth 76% pa grupim. Tabelat e mëposhtme përmbledhin matjet
rezultuese të TSF-së sipas kombinimeve të ndryshme të mbërritjes.
Tabela 3-19 Ndikimi i Grupimit me Nivele Fikse të Organizimit të Stafit në TSF-në e
Përgjithshme
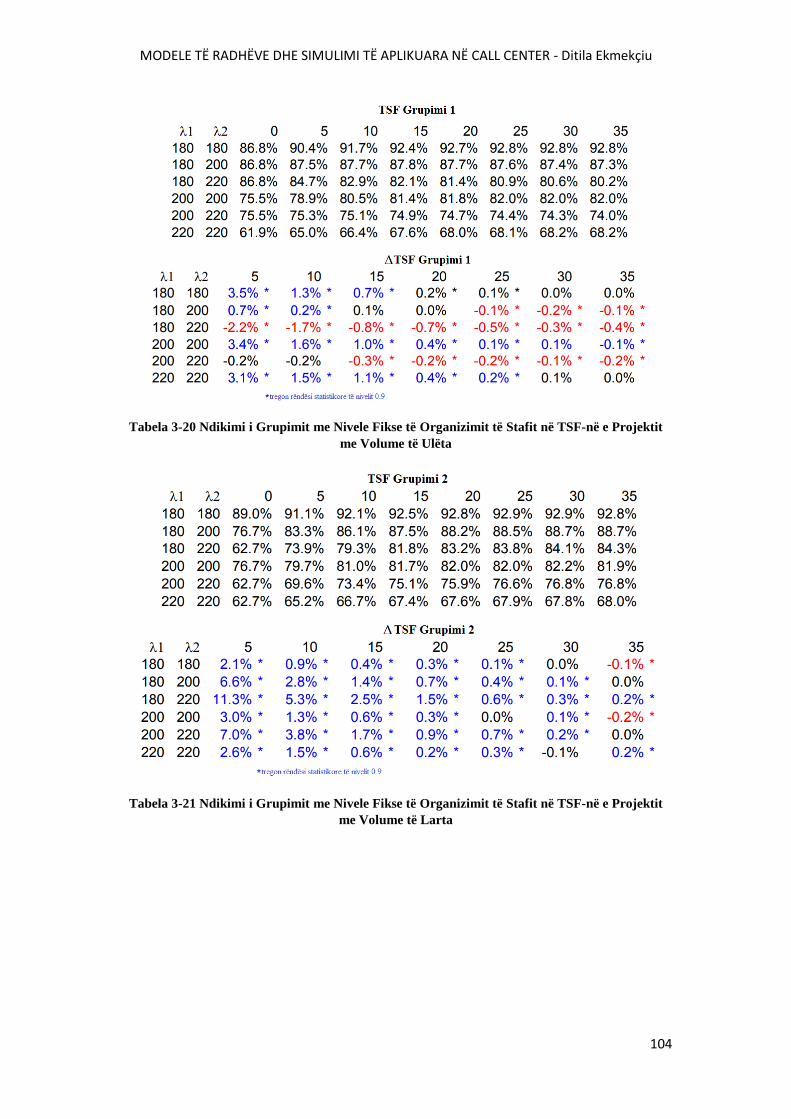
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
104
Tabela 3-20 Ndikimi i Grupimit me Nivele Fikse të Organizimit të Stafit në TSF-në e Projektit
me Volume të Ulëta
Tabela 3-21 Ndikimi i Grupimit me Nivele Fikse të Organizimit të Stafit në TSF-në e Projektit
me Volume të Larta
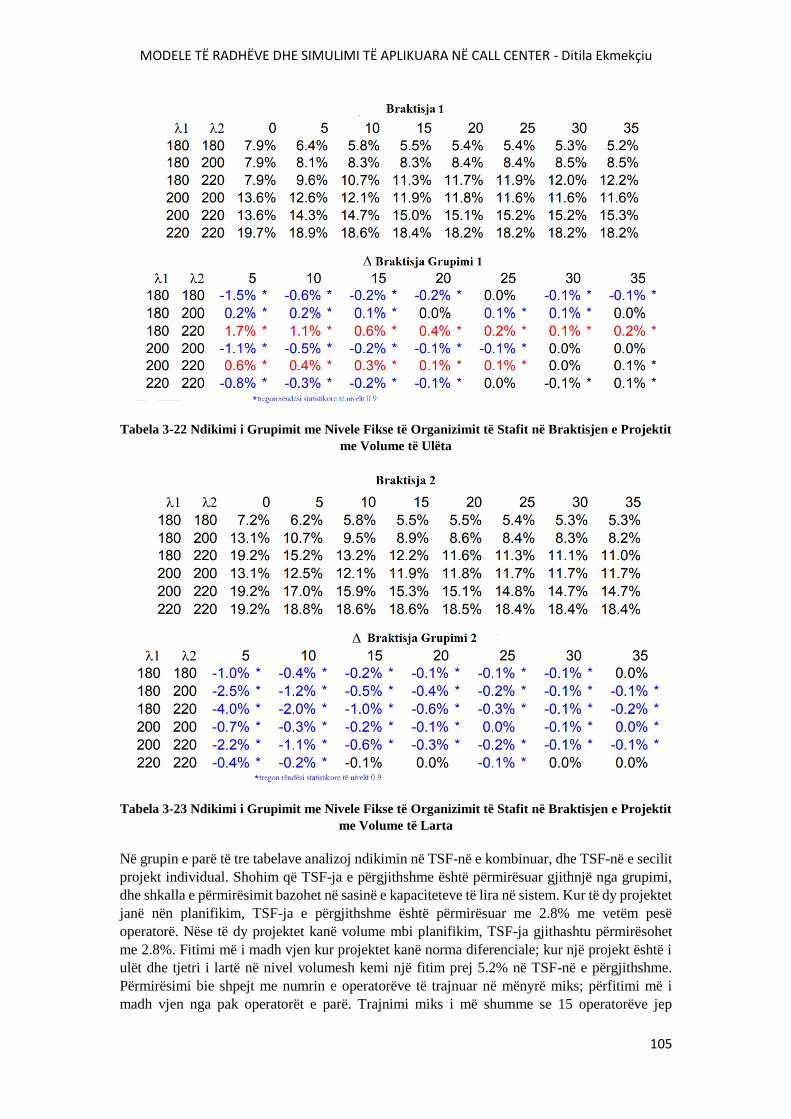
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
105
Tabela 3-22 Ndikimi i Grupimit me Nivele Fikse të Organizimit të Stafit në Braktisjen e Projektit
me Volume të Ulëta
Tabela 3-23 Ndikimi i Grupimit me Nivele Fikse të Organizimit të Stafit në Braktisjen e Projektit
me Volume të Larta
Në grupin e parë të tre tabelave analizoj ndikimin në TSF-në e kombinuar, dhe TSF-në e secilit
projekt individual. Shohim që TSF-ja e përgjithshme është përmirësuar gjithnjë nga grupimi,
dhe shkalla e përmirësimit bazohet në sasinë e kapaciteteve të lira në sistem. Kur të dy projektet
janë nën planifikim, TSF-ja e përgjithshme është përmirësuar me 2.8% me vetëm pesë
operatorë. Nëse të dy projektet kanë volume mbi planifikim, TSF-ja gjithashtu përmirësohet
me 2.8%. Fitimi më i madh vjen kur projektet kanë norma diferenciale; kur një projekt është i
ulët dhe tjetri i lartë në nivel volumesh kemi një fitim prej 5.2% në TSF-në e përgjithshme.
Përmirësimi bie shpejt me numrin e operatorëve të trajnuar në mënyrë miks; përfitimi më i
madh vjen nga pak operatorët e parë. Trajnimi miks i më shumme se 15 operatorëve jep

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
106
rezultate që nuk janë kuptimplote dhe në shumë raste nuk janë statistikisht të ndryshme nga
zero.
Rezultatet janë akoma më interesante kur analizojmë të dhënat në nivel individual të projektit.
Kur çdo projekt ka një normë të ngjashme të mbërritjes, përfitimet shpërndahen në mënyrë të
barabartë. Por fitimi maksimal ndodh kur normat e mbërritjes janë të ndryshme; dhe që fitimi
grumbullohet në mënyrë joproporcionale në projektin e nënstafuar. Kur volumet janë në
ekstreme të kundërta, projekti i nënstafuar merr një përfitim me një ngritje prej 11% në TSF
nga vetëm 5 operatorë të trajnuar në mënyre miks. Trajnimi miks i 10 aoperatorëve rrit TSF-në
me 10 pikë të tjera duke e çuar në gati 80%. Në rast të mospërputhjes së dukshme, projekti me
mbi organizimin e stafit mund të pësojë degradim në performancë, por kjo rënie është dukshëm
më e vogël se rritja në projektin tjetër dhe TSF-ja e agreguar rritet gjithmonë. Rasti më i
rëndësishëm është kur volumet kanë një mospërputhje maksimale dhe TSF-ja e projektit të
mbistafuar zvogëlohet me 2.2% me 5 operatorë të trajnuar në mënyrë tmiks. Duhet vënë re
megjithatë se ky projekt ka një TSF bazë prej 86%, që është shumë me lart se objektivi standard
prej 80%. Ky rezultat megjithatë ngre një kujdes për grupimin e projekteve me objektiva shumë
të larta (90%) të TSF-së. Në rastin e një mospërputhjeje më të vogël, degradimi ishte shumë i
moderuar, rreth 0.9% me 10 operatorë të trajnuar në mënyrë miks, ku projekti i zënë mund të
shohë një përmirësim në rendin e katër pikave nga vetëm 5 operatorë të trajnuar.
Tabelat 3-22 dhe 3-23 tregojnë një analizë të ngjashme për shkallën e braktisjes për secilin
projekt. Shohim rezultate të ngjashme; grupimi zvogëlon kohën maksimale të pritjes që has çdo
telefonues, dhe si rezultat zvogëlon përqindjen e telefonuesve që mbahen në pritje mbi nivelin
e durimit të tyre. Përmirësimi është më i rëndësishmi kur ndodh një mospërputhje në kapacitet.
Në përgjithësi kjo analizë tregon se grupimi i pjesshëm jep përfitime të konsiderueshme në
gjendje të qëndrueshme. Përmirësimi është më i madh kur ndodh një mospërputhje në kapacitet
dhe projekti nën kapacitet merr përfitim më të madh. Në seksionin e ardhshëm do të analizojmë
se si pasiguria e normës së mbërritjes ndikon në analizën e grupimit.
Gjendje e qëndrueshme por Norma e Mbërritjes e Pasigurtë
Në këtë analizë vazhdoj të analizoj ndikimin e grupimit kur projektet kanë një normë konstante,
por tani lejoj pasigurinë në normën e mbërritjes. Në mënyrë të veçantë supozoj se thirrjet në
çdo grupim do të mbërrijnë me një normë konstante, por norma e realizuar është një ndryshore
e rastit. Supozojmë se normat e mbërritjes janë variabla normalë të pavarura dhe me shpërndarje
identike të rastit me mesatare 200 dhe devijim standard 20. Do të analizoj se si grupimi i
pjesshëm ndikon në nivelin e pritur të TSF-së dhe shkallën e braktisjes.
Grafikët e mëposhtëm paraqesin rezultatet e një eksperimenti simulimi:
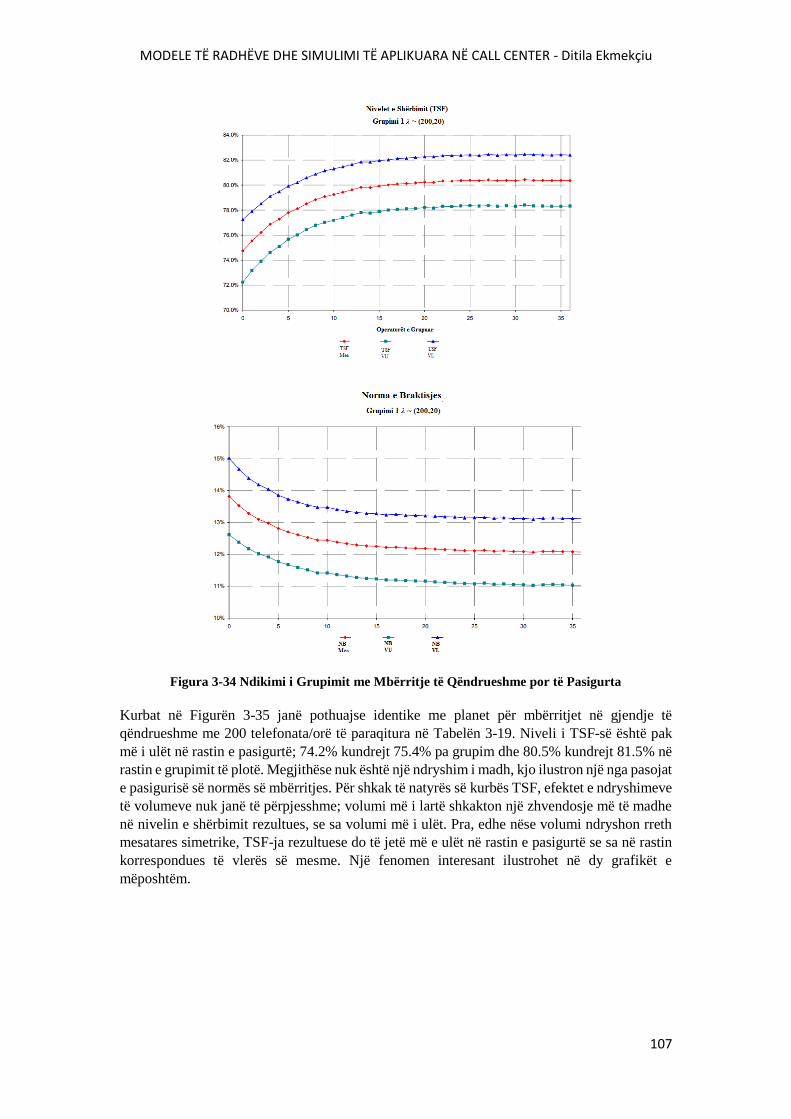
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
107
Figura 3-34 Ndikimi i Grupimit me Mbërritje të Qëndrueshme por të Pasigurta
Kurbat në Figurën 3-35 janë pothuajse identike me planet për mbërritjet në gjendje të
qëndrueshme me 200 telefonata/orë të paraqitura në Tabelën 3-19. Niveli i TSF-së është pak
më i ulët në rastin e pasigurtë; 74.2% kundrejt 75.4% pa grupim dhe 80.5% kundrejt 81.5% në
rastin e grupimit të plotë. Megjithëse nuk është një ndryshim i madh, kjo ilustron një nga pasojat
e pasigurisë së normës së mbërritjes. Për shkak të natyrës së kurbës TSF, efektet e ndryshimeve
të volumeve nuk janë të përpjesshme; volumi më i lartë shkakton një zhvendosje më të madhe
në nivelin e shërbimit rezultues, se sa volumi më i ulët. Pra, edhe nëse volumi ndryshon rreth
mesatares simetrike, TSF-ja rezultuese do të jetë më e ulët në rastin e pasigurtë se sa në rastin
korrespondues të vlerës së mesme. Një fenomen interesant ilustrohet në dy grafikët e
mëposhtëm.
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
108
Figura 3-35 Devijimi Standart i TSF-së me Grupim Variabël
Lart shohim se devijimi standard i nivelit të përgjithshëm (të kombinuar) të shërbimit është në
thelb i pandikuar nga grupimi, duke mbetur në një nivel afërsisht konstante pak më shumë se
8%. Grafiku i poshtëm sidoqoftë tregon që devijimi standard i nivelit të shërbimit për grupimin
zvogëlohet kur rritet niveli i grupimit, të paktën për operatorët e parë të grupuar. Në rast të mos
grupimit, niveli i shërbimit në çdo grupim është i pavarur nga niveli i shërbimit në grupimin
tjetër. Ndërsa grupimirritet, nivelii i shërbimit në çdo grupim bëhet variabël i varur i rastit.
3.2.2. Trajnimi miks Optimal në Gjendje të Qëndrueshme
Në seksionin e mëparshëm, analizova ndikimin e ndryshimit të numrit të operatorëve të trajnuar
në mënyrë miks për një grup të caktuar personash. Tregova se niveli i shërbimit rritet kur
operatorët trajnohen në mënyrë miks, por që përfitimi shtesë bie me shpejtësi. Kjo sugjeron,
duke supozuar që trajnimi miks është i kushtueshëm, që trajnimi miks i më shumë se një
proporcion i moderuar i operatorëve është nën-optimal. Në këtë seksion analizoj më shumë këtë
çështje dhe përpiqem të gjej nivelin optimal të trajnimit miks. Për ta bërë këtë relaksoj
supozimin e një grupimi fiks të personave Problemi i optimizimit si pasojë bëhet përzgjedhja e

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
109
vektorit të organizimit të stafit që përcakton numrin e operatorëve në secilin grupim në mënyrë
që të minimizohet kostoja e pritur e operacioneve.
Kostot Operacionale
Siç është diskutuar më parë, kostoja e trajnimit miks është relativisht e lartë. Në këtë model
supozoj se kostoja e rritur ka dy komponentë, një komponent trajnimi dhe një komponent
pagash. Komponenti i trajnimit përfaqëson investimin në një operator individual për t'i dhënë
atij aftësitë e nevojshme për të trajtuar llojin e dytë të projektit. Komponenti i pagës përfaqëson
pagën në rritje të paguar për një operator të trajnuar në mënyrë miks. Në mënyrë të veçantë
kostoja inkrementale e një operatori të trajnuar në mënyrë miks është përcaktuar si:
𝐾 =𝑇
𝛾+ 𝑤 (3.33)
Ku w është paga e rritur. T është kostoja e trajnimit dhe γ kohëzgjatja në kompani e një
operatori, kështu që T/γ përfaqëson koston mesatare të trajnimit të amortizuar gjatë jetës së
punësimit të operatorit.
Konsiderata e dytë është shkalla e besimit e kërkuar për te arritur nivelin objektiv të shërbimit.
Do ta kuantifikoj këtë duke caktuar një kosto gjobë në mënyrë të përpjesshme me mos arritjen
e nivelit të shërbimit. Nëse shënojmë me r normën e gjobës, objektivin me g dhe normën e
arritur të shërbimit me S, atëhere kostoja e gjobës P mund të shprehet si:
𝑃 = 𝑟(𝑔 − 𝑆)+ (3.34)
Modeli supozon një gjobë për mos arritjen e nivelit të shërbimit por nuk parashikon bonus në
rastin në rast se ajo tej kalohet, kështu që kostoja e gjobës ka nje vlerë jo negative. Sistemi ynë
ka tre nivele organizimit të stafit të shënuara me xi, ku i = 1,2,3 dhe kostoja totale për të operuar
sistemin është:
𝑇𝐶 = 𝐾1𝑥1 + 𝐾2𝑥2 + 𝑟2(𝑔2 − 𝑆2)+ + 𝑤(𝑥1 + 𝑥2 + 𝑥3) (3.35)
Objektivi ynë është të zgjedhim vektorin e organizimit të stafit që minimizon koston e operimit
të sistemit.
Metoda e Optimizimit e Bazuar në Simulim
Do të përdor një algoritëm lokal kërkimi të bazuar në simulim për të gjetur modelin optimal të
trajnimit miks për çdo konfigurim të caktuar të parametrave. Algoritmi lokal i kërkimit
udhëhiqet nga një metaheuristik i kërkimit fqinj (VNS). VNS-ja është një metaheuristik që bën
ndryshime sistematike në fqinjësinë që po kontrollohet gjatë përparimit të kërkimit (Hansen
dhe Mladenovic 2001; Hansen dhe Mladenovic 2005). Kur përdorni VNS-në një përqasje e
zakonshme është të përcaktojë një sërë fqinjesish të mbivendosur, të tillë që:
𝑁1(𝑥) ⊂ 𝑁2(𝑥) ⊂ ⋯ ⊂ 𝑁𝑘𝑀𝑎𝑥(𝑥) ∀𝑥 ∈ 𝑋 (3.36)
Struktura e përgjithsme më pas e VNS-së është si më poshtë:
1) Fillim
a. Zgjidhni bashkësinë e strukturave të fqinjësisë Nk për k = 1, ...,kmax
b. Ndërto një zgjidhje fillestare në detyrë, xI, duke përdorur disa proçedura heuristike.
c. Zgjidh një nivel besimi α për zgjedhjen e një zgjidhjeje të re në detyrë

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
110
2) Kërko: përsërit sa vijon derisa Stop = True (E Vërtetë)
a. Vendos k = 1
b. Gjej 𝑛𝑘𝑚𝑖𝑛 zgjidhjet kandidate, xC që janë fqinjët e xI
c. Simulo sistemin me secilin kandidat dhe krahaso rezultatet me atë në detyrë duke
përdorur një Test T dy-palësh.
d. Nëse ndonjë xC është superior ndaj xI në nivelin α atëherë vendos xI = 𝑥𝐶∗ , ku 𝑥𝐶
∗ është
zgjidhja më e mirë kandidate
Përndryshe, vendos 𝑖 = 𝑛𝑘𝑚𝑖𝑛, vendos gjetur = false (e gabuar), dhe përsërit derisa (𝑖 =
𝑛𝑘𝑚𝑎𝑥 = ose found = True (e vërtetë))
i. Gjej një kandidat të ri 𝑥𝑘𝑖
ii. Simulo sistemin me secilin kandidat dhe krahaso rezultatet duke përdorur një
Test T dy-palësh.
iii. Nëse 𝑥𝑘𝑖është superior ndaj xI në nivelin α atëherë vendos xI = 𝑥𝑘𝑖
dhe gjetur
= True (E Vërtetë)
e. Në qoftë se nuk gjendet asnjë operator i ri në detyrë në fqinjësinë k atëherë
i. vendos k = k +1
ii. Nëse k > kmax atëherë Stop = True (E Vërtetë)
Figura 3-36 Algoritmi i Përgjithshëem i Kërkimit VNS
Ky algoritëm kërkon fqinjën e atij që është në ngarkim aktualisht (gjendja aktuale) duke
vlerësuar të paktën nkmin pika. Nëse nuk gjendet një zgjidhje e përmirësuar statistikisht, ai
vazhdon të kërkojë derisa të gjendet një zgjidhje e përmirësuar ose derisa të vlerësohen të gjitha
pikat nkmax. Sa herë që gjendet një zgjidhje e përmirësuar, kërkimi fillon nga fillimi me gjendjen
aktuale të re. Nëse nuk gjendet ndonjë përmirësim i ri, kërkimi vazhdon në fqinjësinë tjetër më
të madhe. Procesi i kërkimit vazhdon derisa të mos gjendet zgjidhje tjetër e përmirësuar në
strukturën më të madhe të fqinjësive.
Dy parametra të rëndësishëm për këtë proces kërkimi janë nkmin dhe nkmax, kufijtë e poshtëm dhe
të sipërm të numrit të fqinjëve për t’u vlerësuar para se të kalojë në fqinjin e radhësr. Nëse fqinji
është përcaktuar në mënyrë të ngushtë, këto parametra janë vendosur të dy të barabartë me
numrin e përgjithshëm të fqinjëve dhe fqinjësia është kontrolluar në mënyrë të plotë. Në
fqinjësitë më të mëdha një kërkim i plotë nuk është praktik dhe zgjidhjet zgjidhen në mënyrë
të rastësishme. Në këtë rast nkmin është numri minimal i fqinjëve për t’u vlerësuar. Vendosja e
këtij parametri në “një” zbaton një kërkim të parë të përmirësimit lokal.
Trajnimi Optimal miks me Norma të Njohura të Mbërritjes
Në rastin e mbërritjeve në gjendje së qëndrueshme me norma të njohura, janë përcaktuar dy
fqinjësi të ndryshme. N1 është fqinjësiae të gjitha ndryshimeve-1; që është grupi i të gjitha
zgjidhjeve të mundshme xi të tilla që një element ndryshon nga xc me 1 ose -1. Për çdo gjendje
në ngarkim ekzistojnë deri në 6 zgjidhje në këtë fqinjësi. N2 është fqinjësia e të gjitha
ndryshimeve-2; që është grupi i të gjitha zgjidhjeve të mundshme xi të tilla që saktësisht dy
elemente ndryshojnë nga xc me 1 ose -1. Për çdo gjendje në ngarkim ekzistojnë deri në 12
zgjidhje në këtë fqinjësi.
Në këtë eksperiment kërkoj të përcaktoj vektorin optimal të organizimit të stafit për një proces
në gjendje të qëndrueshme me norma të njohura të mbërritjes. Jam e interesuar të përcaktoj se
si vektori i organizimit të stafit ndikohet nga normat relative të mbërritjes, si dhe vendimet e
menaxhimit që lidhen me cilësinë e dëshiruar të shërbimit. Në mënyrë të veçantë do të krijoj
një dizajn të plotë faktorial me dy nivele në katër faktorë siç tregohet më poshtë.
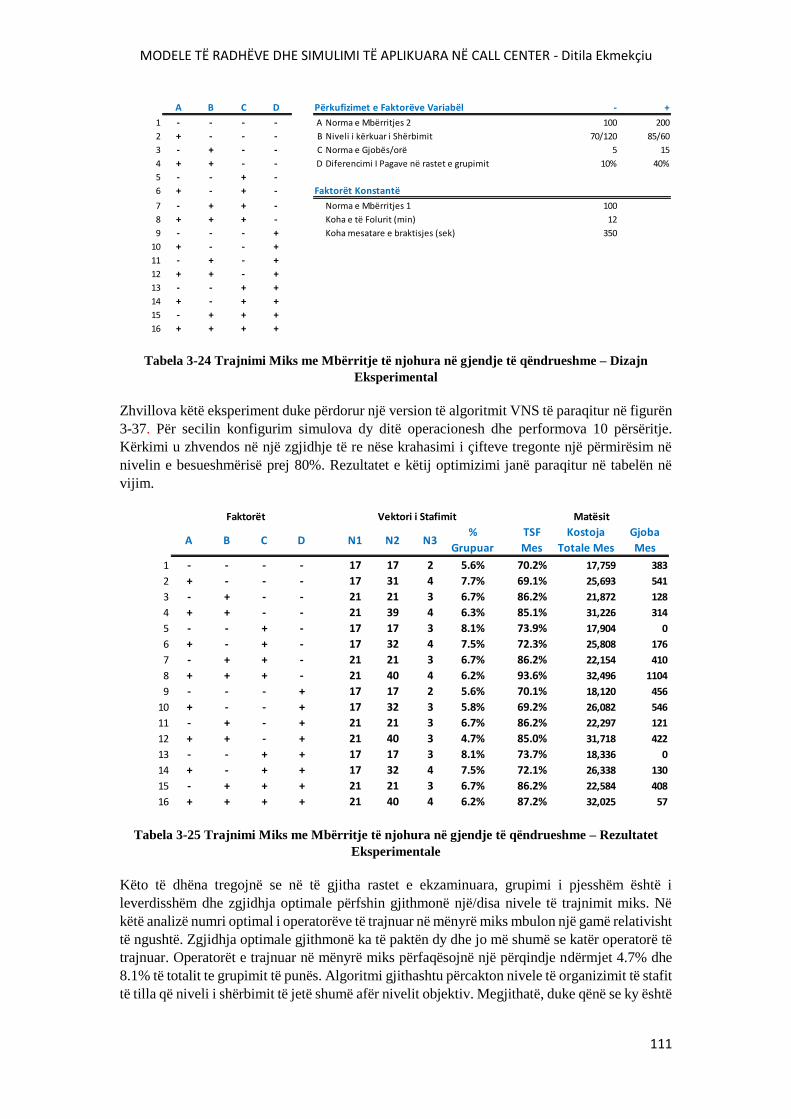
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
111
Tabela 3-24 Trajnimi Miks me Mbërritje të njohura në gjendje të qëndrueshme – Dizajn
Eksperimental
Zhvillova këtë eksperiment duke përdorur një version të algoritmit VNS të paraqitur në figurën
3-37. Për secilin konfigurim simulova dy ditë operacionesh dhe performova 10 përsëritje.
Kërkimi u zhvendos në një zgjidhje të re nëse krahasimi i çifteve tregonte një përmirësim në
nivelin e besueshmërisë prej 80%. Rezultatet e këtij optimizimi janë paraqitur në tabelën në
vijim.
Tabela 3-25 Trajnimi Miks me Mbërritje të njohura në gjendje të qëndrueshme – Rezultatet
Eksperimentale
Këto të dhëna tregojnë se në të gjitha rastet e ekzaminuara, grupimi i pjesshëm është i
leverdisshëm dhe zgjidhja optimale përfshin gjithmonë një/disa nivele të trajnimit miks. Në
këtë analizë numri optimal i operatorëve të trajnuar në mënyrë miks mbulon një gamë relativisht
të ngushtë. Zgjidhja optimale gjithmonë ka të paktën dy dhe jo më shumë se katër operatorë të
trajnuar. Operatorët e trajnuar në mënyrë miks përfaqësojnë një përqindje ndërmjet 4.7% dhe
8.1% të totalit te grupimit të punës. Algoritmi gjithashtu përcakton nivele të organizimit të stafit
të tilla që niveli i shërbimit të jetë shumë afër nivelit objektiv. Megjithatë, duke qënë se ky është
A B C D Përkufizimet e Faktorëve Variabël - +
1 - - - - A Norma e Mbërritjes 2 100 200
2 + - - - B Niveli i kërkuar i Shërbimit 70/120 85/60
3 - + - - C Norma e Gjobës/orë 5 15
4 + + - - D Diferencimi I Pagave në rastet e grupimit 10% 40%
5 - - + -
6 + - + - Faktorët Konstantë
7 - + + - Norma e Mbërritjes 1 100
8 + + + - Koha e të Folurit (min) 12
9 - - - + Koha mesatare e braktisjes (sek) 350
10 + - - +
11 - + - +
12 + + - +
13 - - + +
14 + - + +
15 - + + +
16 + + + +
A B C D N1 N2 N3%
Grupuar
TSF
Mes
Kostoja
Totale Mes
Gjoba
Mes
1 - - - - 17 17 2 5.6% 70.2% 17,759 383
2 + - - - 17 31 4 7.7% 69.1% 25,693 541
3 - + - - 21 21 3 6.7% 86.2% 21,872 128
4 + + - - 21 39 4 6.3% 85.1% 31,226 314
5 - - + - 17 17 3 8.1% 73.9% 17,904 0
6 + - + - 17 32 4 7.5% 72.3% 25,808 176
7 - + + - 21 21 3 6.7% 86.2% 22,154 410
8 + + + - 21 40 4 6.2% 93.6% 32,496 1104
9 - - - + 17 17 2 5.6% 70.1% 18,120 456
10 + - - + 17 32 3 5.8% 69.2% 26,082 546
11 - + - + 21 21 3 6.7% 86.2% 22,297 121
12 + + - + 21 40 3 4.7% 85.0% 31,718 422
13 - - + + 17 17 3 8.1% 73.7% 18,336 0
14 + - + + 17 32 4 7.5% 72.1% 26,338 130
15 - + + + 21 21 3 6.7% 86.2% 22,584 408
16 + + + + 21 40 4 6.2% 87.2% 32,025 57
Faktorët Vektori i Stafimit Matësit
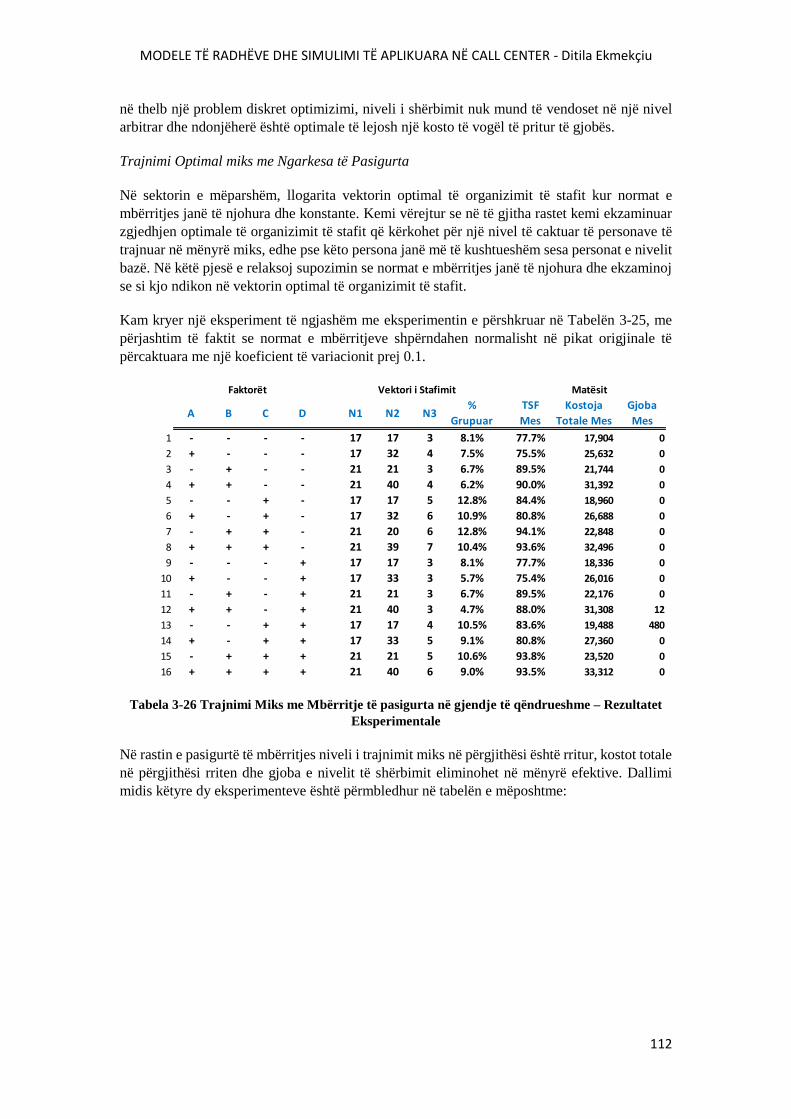
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
112
në thelb një problem diskret optimizimi, niveli i shërbimit nuk mund të vendoset në një nivel
arbitrar dhe ndonjëherë është optimale të lejosh një kosto të vogël të pritur të gjobës.
Trajnimi Optimal miks me Ngarkesa të Pasigurta
Në sektorin e mëparshëm, llogarita vektorin optimal të organizimit të stafit kur normat e
mbërritjes janë të njohura dhe konstante. Kemi vërejtur se në të gjitha rastet kemi ekzaminuar
zgjedhjen optimale të organizimit të stafit që kërkohet për një nivel të caktuar të personave të
trajnuar në mënyrë miks, edhe pse këto persona janë më të kushtueshëm sesa personat e nivelit
bazë. Në këtë pjesë e relaksoj supozimin se normat e mbërritjes janë të njohura dhe ekzaminoj
se si kjo ndikon në vektorin optimal të organizimit të stafit.
Kam kryer një eksperiment të ngjashëm me eksperimentin e përshkruar në Tabelën 3-25, me
përjashtim të faktit se normat e mbërritjeve shpërndahen normalisht në pikat origjinale të
përcaktuara me një koeficient të variacionit prej 0.1.
Tabela 3-26 Trajnimi Miks me Mbërritje të pasigurta në gjendje të qëndrueshme – Rezultatet
Eksperimentale
Në rastin e pasigurtë të mbërritjes niveli i trajnimit miks në përgjithësi është rritur, kostot totale
në përgjithësi rriten dhe gjoba e nivelit të shërbimit eliminohet në mënyrë efektive. Dallimi
midis këtyre dy eksperimenteve është përmbledhur në tabelën e mëposhtme:
A B C D N1 N2 N3%
Grupuar
TSF
Mes
Kostoja
Totale Mes
Gjoba
Mes
1 - - - - 17 17 3 8.1% 77.7% 17,904 0
2 + - - - 17 32 4 7.5% 75.5% 25,632 0
3 - + - - 21 21 3 6.7% 89.5% 21,744 0
4 + + - - 21 40 4 6.2% 90.0% 31,392 0
5 - - + - 17 17 5 12.8% 84.4% 18,960 0
6 + - + - 17 32 6 10.9% 80.8% 26,688 0
7 - + + - 21 20 6 12.8% 94.1% 22,848 0
8 + + + - 21 39 7 10.4% 93.6% 32,496 0
9 - - - + 17 17 3 8.1% 77.7% 18,336 0
10 + - - + 17 33 3 5.7% 75.4% 26,016 0
11 - + - + 21 21 3 6.7% 89.5% 22,176 0
12 + + - + 21 40 3 4.7% 88.0% 31,308 12
13 - - + + 17 17 4 10.5% 83.6% 19,488 480
14 + - + + 17 33 5 9.1% 80.8% 27,360 0
15 - + + + 21 21 5 10.6% 93.8% 23,520 0
16 + + + + 21 40 6 9.0% 93.5% 33,312 0
Faktorët Vektori i Stafimit Matësit
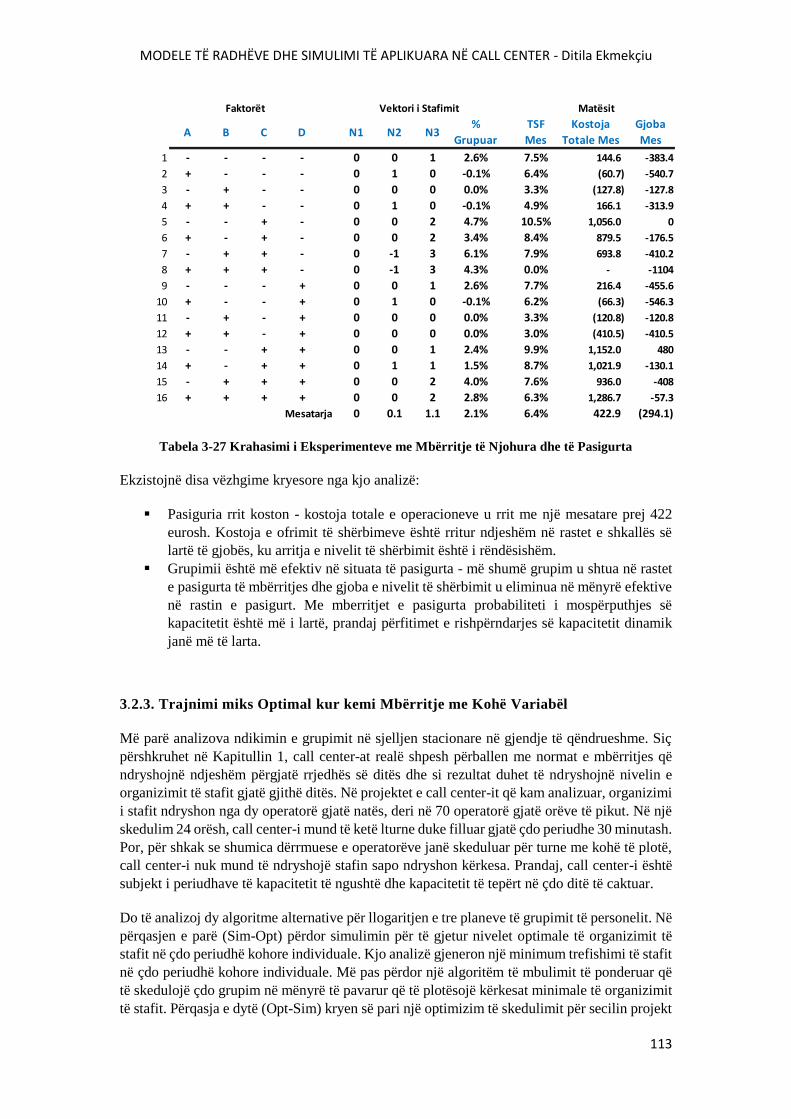
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
113
Tabela 3-27 Krahasimi i Eksperimenteve me Mbërritje të Njohura dhe të Pasigurta
Ekzistojnë disa vëzhgime kryesore nga kjo analizë:
▪ Pasiguria rrit koston - kostoja totale e operacioneve u rrit me një mesatare prej 422
eurosh. Kostoja e ofrimit të shërbimeve është rritur ndjeshëm në rastet e shkallës së
lartë të gjobës, ku arritja e nivelit të shërbimit është i rëndësishëm.
▪ Grupimii është më efektiv në situata të pasigurta - më shumë grupim u shtua në rastet
e pasigurta të mbërritjes dhe gjoba e nivelit të shërbimit u eliminua në mënyrë efektive
në rastin e pasigurt. Me mberritjet e pasigurta probabiliteti i mospërputhjes së
kapacitetit është më i lartë, prandaj përfitimet e rishpërndarjes së kapacitetit dinamik
janë më të larta.
3.2.3. Trajnimi miks Optimal kur kemi Mbërritje me Kohë Variabël
Më parë analizova ndikimin e grupimit në sjelljen stacionare në gjendje të qëndrueshme. Siç
përshkruhet në Kapitullin 1, call center-at realë shpesh përballen me normat e mbërritjes që
ndryshojnë ndjeshëm përgjatë rrjedhës së ditës dhe si rezultat duhet të ndryshojnë nivelin e
organizimit të stafit gjatë gjithë ditës. Në projektet e call center-it që kam analizuar, organizimi
i stafit ndryshon nga dy operatorë gjatë natës, deri në 70 operatorë gjatë orëve të pikut. Në një
skedulim 24 orësh, call center-i mund të ketë lturne duke filluar gjatë çdo periudhe 30 minutash.
Por, për shkak se shumica dërrmuese e operatorëve janë skeduluar për turne me kohë të plotë,
call center-i nuk mund të ndryshojë stafin sapo ndryshon kërkesa. Prandaj, call center-i është
subjekt i periudhave të kapacitetit të ngushtë dhe kapacitetit të tepërt në çdo ditë të caktuar.
Do të analizoj dy algoritme alternative për llogaritjen e tre planeve të grupimit të personelit. Në
përqasjen e parë (Sim-Opt) përdor simulimin për të gjetur nivelet optimale të organizimit të
stafit në çdo periudhë kohore individuale. Kjo analizë gjeneron një minimum trefishimi të stafit
në çdo periudhë kohore individuale. Më pas përdor një algoritëm të mbulimit të ponderuar që
të skedulojë çdo grupim në mënyrë të pavarur që të plotësojë kërkesat minimale të organizimit
të stafit. Përqasja e dytë (Opt-Sim) kryen së pari një optimizim të skedulimit për secilin projekt
A B C D N1 N2 N3%
Grupuar
TSF
Mes
Kostoja
Totale Mes
Gjoba
Mes
1 - - - - 0 0 1 2.6% 7.5% 144.6 -383.4
2 + - - - 0 1 0 -0.1% 6.4% (60.7) -540.7
3 - + - - 0 0 0 0.0% 3.3% (127.8) -127.8
4 + + - - 0 1 0 -0.1% 4.9% 166.1 -313.9
5 - - + - 0 0 2 4.7% 10.5% 1,056.0 0
6 + - + - 0 0 2 3.4% 8.4% 879.5 -176.5
7 - + + - 0 -1 3 6.1% 7.9% 693.8 -410.2
8 + + + - 0 -1 3 4.3% 0.0% - -1104
9 - - - + 0 0 1 2.6% 7.7% 216.4 -455.6
10 + - - + 0 1 0 -0.1% 6.2% (66.3) -546.3
11 - + - + 0 0 0 0.0% 3.3% (120.8) -120.8
12 + + - + 0 0 0 0.0% 3.0% (410.5) -410.5
13 - - + + 0 0 1 2.4% 9.9% 1,152.0 480
14 + - + + 0 1 1 1.5% 8.7% 1,021.9 -130.1
15 - + + + 0 0 2 4.0% 7.6% 936.0 -408
16 + + + + 0 0 2 2.8% 6.3% 1,286.7 -57.3
Mesatarja 0 0.1 1.1 2.1% 6.4% 422.9 (294.1)
Faktorët Vektori i Stafimit Matësit

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
114
në mënyrë individuale. Skedulimet e pavarura rezultuese bashkohen më pas në një përpjekje
optimizimi të bazuar në simulim. Të dyja metodat janë të përshkruara më në detaje më poshtë,
por së pari do të rishikoj se si llogaris vlerën e funksionit objektiv në një optimizim të bazuar
në një projekt.
Funksioni Objektiv
Konceptualisht, objektivi i këtij problemi optimizimi është gjetja e planit të organizimit të stafit
me kosto minimale që plotëson kërkesat e nivelit të shërbimit me nivelin e duhur të besimit.
Ashtu si në modelet e Skedulimit Afatshkurtër, do të zbatoj kërkesën e nivelit të shërbimit duke
shtuar një penallti për çdo mungesë të nivelit të shërbimit. Në formulimin matematikor të
programimit të Skedulimit Afatshkurtër gjithashtu shtuam disa kufizime anësore. Në veçanti
kërkova që organizimi i stafit të ishte të paktën në një nivel minimal në çdo kohë (zakonisht dy
operatorë) dhe se niveli i organizimit të stafit ishte i tillë që në volumet e pritura arrijmë një
nivel shërbimi minimal (zakonisht 50%). Përderisa është e mundur të modifikohet struktura e
fqinjësisë për të forcuar këto kufizime të vështira, një mekanizëm kërkimi më i drejtpërdrejtë
rezulton në qoftë se i zbusim këto kufizime dhe i shtojmë ato si terma gjobe në funksionin
objektiv
Përqasja Simulim – Optimizim (Sim-Opt
Në këtë përqasje do të krijoj një vektor stabël të organizimit të stafit për çdo grupim personash
nëpërmjet simulimit dhe më pas do të përdor një algoritëm determinist të skedulimit për të
caktuar turnet. Në hapin fillestar do të ekzekutoj analizën e simulimit në gjendje të qëndrueshme
për secilën periudhë kohore (336 periudha) për të krijuar një tripletë të vektorit të organizimit
të stafit(b1i, b2i, b3i) ku b1i përfaqëson kërkesën e organizimit të stafit në grupimin 1 në periudhën
i.
Duke pasur parasysh këto kërkesa për organizim të stafit më stabël, atëherë do të ekzekutoj një
algoritëm determinist të organizimit të stafit për të mbuluar këto kërkesa. Programimi me numra
të plotë që rezulton është një problem standard i ponderuar i mbulimit i cili mund të shprehet
si:
Të minimizohet:
∑ 𝑐𝑗𝑥𝑗𝑗∈𝐽 (3.37)
Me kushtet:
∑ 𝑎𝑖𝑗𝑥𝑗 ≥ 𝑏𝑖 , ∀𝑖 ∈ 𝐼𝑗∈𝐽 (3.38)
Ku cj është kostoja e skedulimit të j-të, xj është numri i personave të caktuar në skedulimin e j-
të dhe aij është planifikim i skedulimeve në periudha kohore.
Përqasja Optimizim – Simulim (Opt-Sim)
Në këtë përqasje do të gjeneroj një skeduilm paraprak për çdo projekt në mënyrë të pavarur
duke përdorur një programim optimizimi dhe më pas do të ekzekutoj një kërkim lokal nëpërmjet
simulimit për të optimizuar projektin në mënyrë të përgjithshme. Për të implementuar procesin

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
115
duhet të përcaktoj një përqasje për të gjeneruar një zgjidhje fillestare të mundshme dhe për
përzgjedhjen e zgjidhjeve të reja të mundshme kandidate.
Për të zhvilluar një zgjidhje fillestare të mundhsme, do të ekzekutoj programimin e optimizimit
(3.1) - (3.7) nga modeli afatshkurtër për secilin projekt individualisht. Në këtë rast modeli është
konfiguruar për të gjeneruar një skedulim me një TSF më të ulët dhe me një nivel minimal
organizimi stafi të një operatori në vend të dy. Kjo proçedurë krijon një plan të organizimit të
stafit që është pak i pamjaftueshëm. objektivi është të krijojë një plan fillestar ku trajnimi
selektiv miks mund të krijojë përmirësim të shpejtë.
Për të identifikuar zgjidhjet shtesë kandidate, do të zhvilloj një VNS siç përshkruhet në Figurën
3-37. Megjithatë, në këtë rast struktura e fqinjësisë është shumë më komplekse. Do të përcaktoj
një strukturë të fqinjësisë të mbivendosur me pesë lagje individuale.
Lë J të jetë grupi i skedulimeve në të cilat një operator mund të caktohet dhe të shënojmë si xj
numri i operatorëve të caktuar në skedulimin j. Një plan i organizimit të stafit është një vektor
i vlerave xj. Një plan i organizimit të stafit është i realizueshëm nëse çdo xj ka vlerë jo-negative
dhe të plotë. Supozojmë se çdo kufizim i ndërlikuar, siç janë nivelet minimale të organizimit të
stafit, janë zhvendosur në funksionin objektiv si një term gjobe. Shënojmë me X bashkësinë e
mundhsme të planeve të organizimit të stafit. Për më tepër, përcaktojmë bashkësinë Ai ⊆ J si
skedulimet aktive, për grupimin e personave i; që është skedulimi për të cilën të paktën një
person është caktuar në të dhe shënojmë me A = A1 ∪ A2 ∪ A3 bashkësinë e te gjitha skedulimeve
aktive nëpërmjet grupimit.
Tani, për disa x ∈ X arbitrare, përcaktojnë një seri të strukturave të fqinjësisë të mbivendosura
Kmax, të tilla që:
𝑁1(𝑥) ⊂ 𝑁2(𝑥) ⊂ ⋯ ⊂ 𝑁𝑘𝑀𝑎𝑥(𝑥) ∀𝑥 ∈ 𝑋 (3.39)
Përcatoj fqinjësitë e mëposhtme:
• N1 (x): Ndryshimi Aktiv 1: bashkësia e të gjithë planeve të organizimit të stafit ku një
caktim aktiv përditësohet dhe kompensohet nga një shtesë, δi ∈ {-1,1}.
• N2 (x): Ndryshimi Aktiv 2: zgjedh cilëndo dyshe skedulimi të mundshme në Ai dhe në
mënyrë të pavarur përditëson secilën me δi ∈ {-1,0,1}.
• N3 (x): Ndryshimi i Mundshëm 1: bashkësia e të gjitha planeve të organizimit të stafit
ku një caktim i mundshëm përditësohet me δi ∈ {-1,1}.
• N4 (x): Ndryshimi i Mundshëm 2: zgjedh cilëndo dyshe skedulimi të mundshme në J
dhe në mënyrë të pavarur përditëson secilin me δi ∈ {-1,0,1}.
• N5 (x): Ndryshimi i Mundshëm 3: zgjedh cilëndo treshe skedulimi të mundshme në J
dhe në mënyrë të pavarur përditëson secilin me δi ∈ {-1,0,1}.
Figura 3-37: Struktura e Fqinjësisë e Bazuar në Projekt
Për çdo fqinjësi një skedulim i ri është përzgjedhur rastësisht dhe një numër i madh i
skedulimeve alternative janë vlerësuar në çdo përsëritje të algoritmit. Ndërsa një kërkim i pastër
i rastësishëm ka të ngjarë të gjejë zgjidhje përmirësuese nëse tranformime të mjaftueshme
vlerësohen, kam gjetur se përdorimi i disa metodave heuriste të caktuara në çdo fqinjësi
përmirëson shkallën e konvergjencës. Në këtë përqasje të modifikuar çdo herë që kërkohet një
fqinj i ri, algoritmi zgjedh ose një transformim heuristik ose një të pastër të rastit.
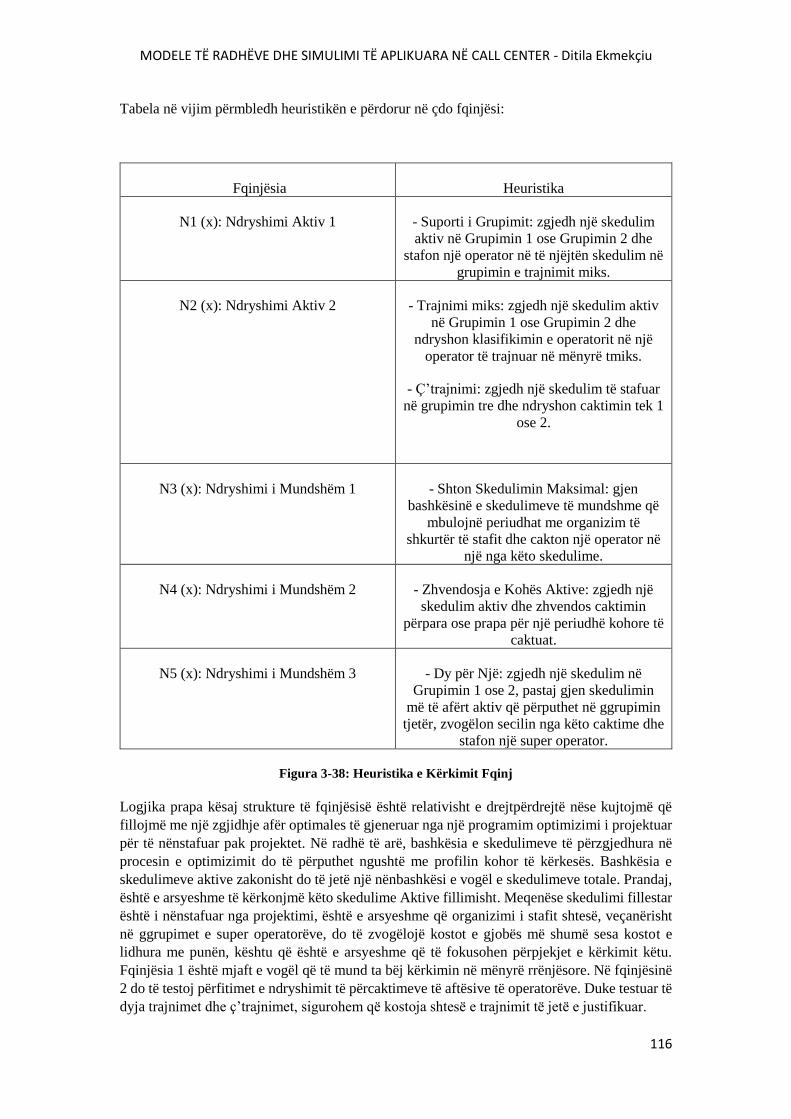
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
116
Tabela në vijim përmbledh heuristikën e përdorur në çdo fqinjësi:
Fqinjësia Heuristika
N1 (x): Ndryshimi Aktiv 1 - Suporti i Grupimit: zgjedh një skedulim
aktiv në Grupimin 1 ose Grupimin 2 dhe
stafon një operator në të njëjtën skedulim në
grupimin e trajnimit miks.
N2 (x): Ndryshimi Aktiv 2 - Trajnimi miks: zgjedh një skedulim aktiv
në Grupimin 1 ose Grupimin 2 dhe
ndryshon klasifikimin e operatorit në një
operator të trajnuar në mënyrë tmiks.
- Ç’trajnimi: zgjedh një skedulim të stafuar
në grupimin tre dhe ndryshon caktimin tek 1
ose 2.
N3 (x): Ndryshimi i Mundshëm 1 - Shton Skedulimin Maksimal: gjen
bashkësinë e skedulimeve të mundshme që
mbulojnë periudhat me organizim të
shkurtër të stafit dhe cakton një operator në
një nga këto skedulime.
N4 (x): Ndryshimi i Mundshëm 2 - Zhvendosja e Kohës Aktive: zgjedh një
skedulim aktiv dhe zhvendos caktimin
përpara ose prapa për një periudhë kohore të
caktuat.
N5 (x): Ndryshimi i Mundshëm 3 - Dy për Një: zgjedh një skedulim në
Grupimin 1 ose 2, pastaj gjen skedulimin
më të afërt aktiv që përputhet në ggrupimin
tjetër, zvogëlon secilin nga këto caktime dhe
stafon një super operator.
Figura 3-38: Heuristika e Kërkimit Fqinj
Logjika prapa kësaj strukture të fqinjësisë është relativisht e drejtpërdrejtë nëse kujtojmë që
fillojmë me një zgjidhje afër optimales të gjeneruar nga një programim optimizimi i projektuar
për të nënstafuar pak projektet. Në radhë të arë, bashkësia e skedulimeve të përzgjedhura në
procesin e optimizimit do të përputhet ngushtë me profilin kohor të kërkesës. Bashkësia e
skedulimeve aktive zakonisht do të jetë një nënbashkësi e vogël e skedulimeve totale. Prandaj,
është e arsyeshme të kërkonjmë këto skedulime Aktive fillimisht. Meqenëse skedulimi fillestar
është i nënstafuar nga projektimi, është e arsyeshme që organizimi i stafit shtesë, veçanërisht
në ggrupimet e super operatorëve, do të zvogëlojë kostot e gjobës më shumë sesa kostot e
lidhura me punën, kështu që është e arsyeshme që të fokusohen përpjekjet e kërkimit këtu.
Fqinjësia 1 është mjaft e vogël që të mund ta bëj kërkimin në mënyrë rrënjësore. Në fqinjësinë
2 do të testoj përfitimet e ndryshimit të përcaktimeve të aftësive të operatorëve. Duke testuar të
dyja trajnimet dhe ç’trajnimet, sigurohem që kostoja shtesë e trajnimit të jetë e justifikuar.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
117
Kur nuk mund të gjenden përmirësime në bashkësinë e skedulimeve aktive, kërkimi zgjerohet
në bashkësinë e plotë të skedulimeve të mundshme. Heuristika në fqinjësinë 3 është hartuar për
të adresuar gjobën e organizimit të stafit të shkurtër të gjetur duke mos pasur të paktën 2
operatorë në dispozicion për çdo projekt në çdo periudhë kohore. Ky heuristik është projektuar
për të testuar të gjitha skdulimet me mbulimin maksimal dhe shpesh do të zgjedhë një super
operator, pasi këta operatorë sigurojnë mbulim për të dy projektet. Në fqinjësinë 4 lejoj 2
ndryshime në skedulimin e mundshëm dhe në mënyrë specifike testoj për ndikimin e
zhvendosjes së një skedulimi përpara ose prapa me një periudhë kohore për të mbuluar
potencialisht më mirë një boshllëk të nivelit të shërbimit. Logjika e skedulimit të fqinjësisë 5
bazohet në nocionin se nëse kemi operatorë në secilin grupim në të njëjtin skedulim, mund të
jetë e dobishme që të zëvendësohen të dy me një operator të vetëm të trajnuar në mënyrë miks.
Kjo është e dobishme kur niveli i shërbimit po plotësohet me probabilitet të lartë dhe gjoba
është e ulët. Bërja e një shkëmbi dy për një zvogëlon koston e punës dhe nuk mund të ketë një
ndikim të madh në gjobat e nivelit të shërbimit.
Në praktikë numri më i madh i zgjidhjeve përmirësuese u gjet në fqinjësinë 1. Zgjidhje
përmirësuese u gjetën në çdo fqinjësi, megjithëse jo për çdo optimizim. Në një proces tipik
optimizimi, përmirësimet gjenden në tre deri në katër fqinjësi, edhe pse në disa raste të gjitha
fqinjësitë gjeneruan përmirësime. Numri i zgjidhjeve të testuara në çdo përsëritje ndryshon në
mënyrë të qartë bazuar në atë se ku është gjetur përmirësimi. Nga projektimi shumica e
përmirësimeve janë gjetur në fqinjësinë e parë. Në eksperimentin tim kërkova që të paktën 20
kandidatë të testoheshin përpara se të zgjidhej më i miri. Numri maksimal varion me numrin e
skedulimeve aktive, duke qenë se fqinjësia 1 kontrollohet në mënyrë të plotë. Në një skenarin
tipik, rreth 300 zgjidhje kandidate u testuan në përsëritjen përfundimtare të algoritmit, përsëritja
e cila nuk gjeti përmirësime.
Numri total i përsëritjeve deri në përfundim është gjithashtu i rastësishëm, dhe varet nga numri
i skedulimeve të mundshme. Numri i përgjithshëm i përsëritjeve prirej të ndryshonte ndërmjet
15 dhe 25. Gjithçka në tërësi nënkupton që një përpjekje e optimizimit do të vlerësojë në një
rang diku ndërmjet 500 deri në 1,500 kombinimeve të ndryshme të skedulimit. Bazuar në këtë
nevojë për të vlerësuar një numër të madh skedulimesh, kam marrë vendimin për të koduar një
model simulimi në VB, në vend që të përdor kodin e Automod-it të zhvilluar më parë.
Përsa i përket përzgjedhjes së metaheuristikës, ekziston një numër shumë i madh i algoritmeve
në dispozicion, duke përfshirë algoritme gjenetike, simulimi temperues, dhe kërkimi Tabu, si
dhe përqasje të tjera të tilla si metodat e kërkimit të bazuar në gradient dhe metodat e sipërfaqes
së përgjigjes. Duke qënë se problemi është diskret, vendosa të mos ndjek metodat e gradientit
ose të sipërfaqes së përgjigjes pasi këto algoritme janë më të përshtatshme për të zbutur
funksionet e përgjigjes. Zgjedhja ime e metauristikës u nxit nga natyra kombinuese e problemit.
Teknikisht bashkësia e mundshme për problemin është i pakufizuar. Supozojmë se vendosim
një kufi praktik të η-të si numri i përgjithshëm i operatorëve të caktuar për çdo skedulim, numri
i planeve të mundhsme të organizimit të stafit është 3Νƞ ku N është numri i skedulimeve të
mundshme për opsionin e skedulimit (shih Tabelën 3-10). Mundësia më pak fleksibël (A) ka
336 skedulime të mundshme. Nëse vendosim η të barabartë me 10 atëherë ka rreth 1030
skedulime të mundhsme. Për opsionin F numri zgjerohet në më shumë se 1040. Kam kërkuar
disa algoritme që lejojnë hulumtime të tjera heuristike (siç janë ato në Tabelën 3-10) që të
inkorporohen. Refuzova algoritme gjenerike, sepse nuk kishte asnjë mënyrë të dukshme për të
zbatuar një mekanizëm shkëmbimi që do të çonte në zgjidhje me cilësi të lartë. Përveç kësaj,
një përqasje e bazuar në popullatë rrit numrin e zgjidhjeve që duhet të testohen dhe procesi i
simulimit e bën vlerësimin relativisht të shtrenjtë. Procesi i përzgjedhjes është gjithashtu më i
vështirë kur përpiqet të zgjedhë zgjidhjen më të mirë për një popullatë kundrejt një krahasimi
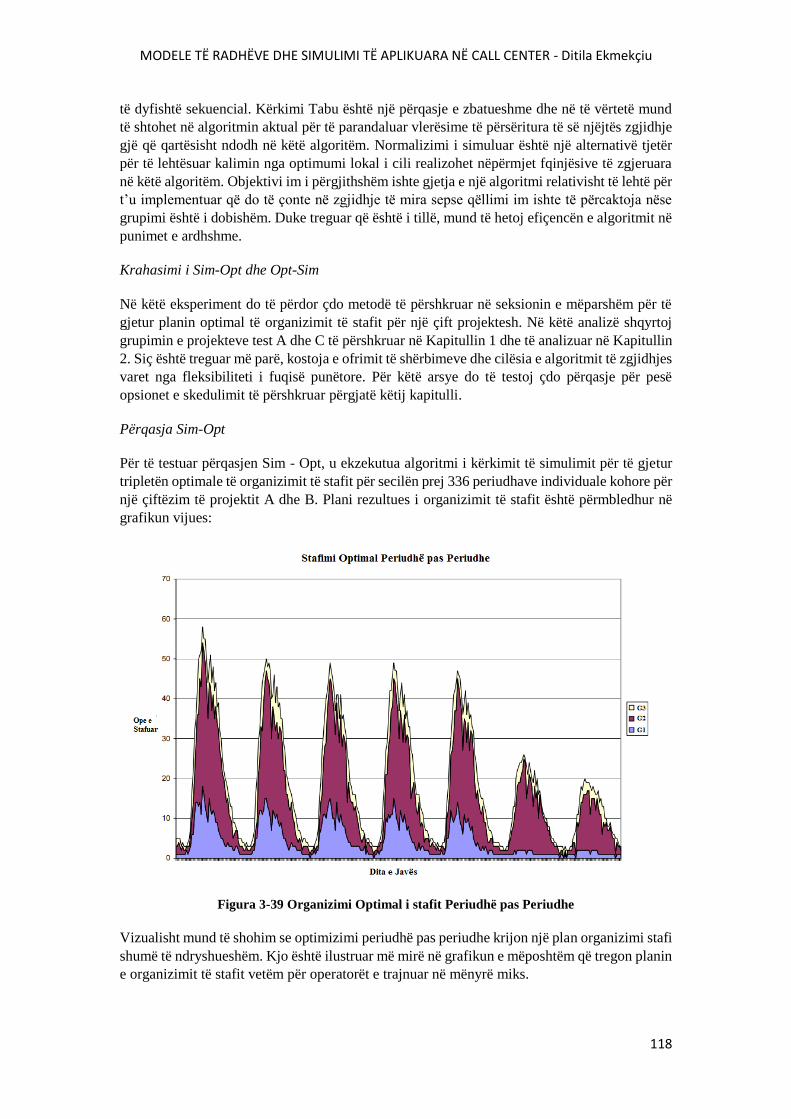
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
118
të dyfishtë sekuencial. Kërkimi Tabu është një përqasje e zbatueshme dhe në të vërtetë mund
të shtohet në algoritmin aktual për të parandaluar vlerësime të përsëritura të së njëjtës zgjidhje
gjë që qartësisht ndodh në këtë algoritëm. Normalizimi i simuluar është një alternativë tjetër
për të lehtësuar kalimin nga optimumi lokal i cili realizohet nëpërmjet fqinjësive të zgjeruara
në këtë algoritëm. Objektivi im i përgjithshëm ishte gjetja e një algoritmi relativisht të lehtë për
t’u implementuar që do të çonte në zgjidhje të mira sepse qëllimi im ishte të përcaktoja nëse
grupimi është i dobishëm. Duke treguar që është i tillë, mund të hetoj efiçencën e algoritmit në
punimet e ardhshme.
Krahasimi i Sim-Opt dhe Opt-Sim
Në këtë eksperiment do të përdor çdo metodë të përshkruar në seksionin e mëparshëm për të
gjetur planin optimal të organizimit të stafit për një çift projektesh. Në këtë analizë shqyrtoj
grupimin e projekteve test A dhe C të përshkruar në Kapitullin 1 dhe të analizuar në Kapitullin
2. Siç është treguar më parë, kostoja e ofrimit të shërbimeve dhe cilësia e algoritmit të zgjidhjes
varet nga fleksibiliteti i fuqisë punëtore. Për këtë arsye do të testoj çdo përqasje për pesë
opsionet e skedulimit të përshkruar përgjatë këtij kapitulli.
Përqasja Sim-Opt
Për të testuar përqasjen Sim - Opt, u ekzekutua algoritmi i kërkimit të simulimit për të gjetur
tripletën optimale të organizimit të stafit për secilën prej 336 periudhave individuale kohore për
një çiftëzim të projektit A dhe B. Plani rezultues i organizimit të stafit është përmbledhur në
grafikun vijues:
Figura 3-39 Organizimi Optimal i stafit Periudhë pas Periudhe
Vizualisht mund të shohim se optimizimi periudhë pas periudhe krijon një plan organizimi stafi
shumë të ndryshueshëm. Kjo është ilustruar më mirë në grafikun e mëposhtëm që tregon planin
e organizimit të stafit vetëm për operatorët e trajnuar në mënyrë miks.
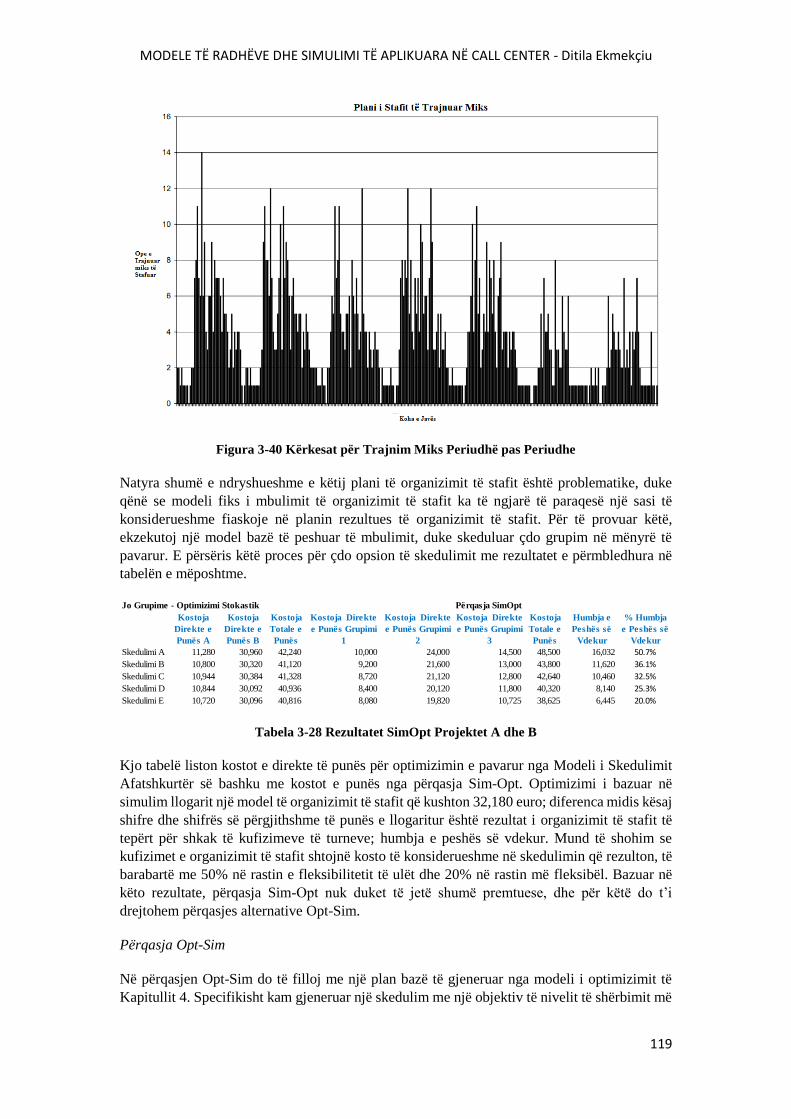
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
119
Figura 3-40 Kërkesat për Trajnim Miks Periudhë pas Periudhe
Natyra shumë e ndryshueshme e këtij plani të organizimit të stafit është problematike, duke
qënë se modeli fiks i mbulimit të organizimit të stafit ka të ngjarë të paraqesë një sasi të
konsiderueshme fiaskoje në planin rezultues të organizimit të stafit. Për të provuar këtë,
ekzekutoj një model bazë të peshuar të mbulimit, duke skeduluar çdo grupim në mënyrë të
pavarur. E përsëris këtë proces për çdo opsion të skedulimit me rezultatet e përmbledhura në
tabelën e mëposhtme.
Tabela 3-28 Rezultatet SimOpt Projektet A dhe B
Kjo tabelë liston kostot e direkte të punës për optimizimin e pavarur nga Modeli i Skedulimit
Afatshkurtër së bashku me kostot e punës nga përqasja Sim-Opt. Optimizimi i bazuar në
simulim llogarit një model të organizimit të stafit që kushton 32,180 euro; diferenca midis kësaj
shifre dhe shifrës së përgjithshme të punës e llogaritur është rezultat i organizimit të stafit të
tepërt për shkak të kufizimeve të turneve; humbja e peshës së vdekur. Mund të shohim se
kufizimet e organizimit të stafit shtojnë kosto të konsiderueshme në skedulimin që rezulton, të
barabartë me 50% në rastin e fleksibilitetit të ulët dhe 20% në rastin më fleksibël. Bazuar në
këto rezultate, përqasja Sim-Opt nuk duket të jetë shumë premtuese, dhe për këtë do t’i
drejtohem përqasjes alternative Opt-Sim.
Përqasja Opt-Sim
Në përqasjen Opt-Sim do të filloj me një plan bazë të gjeneruar nga modeli i optimizimit të
Kapitullit 4. Specifikisht kam gjeneruar një skedulim me një objektiv të nivelit të shërbimit më
Jo Grupime - Optimizimi Stokastik Përqasja SimOpt
Kostoja
Direkte e
Punës A
Kostoja
Direkte e
Punës B
Kostoja
Totale e
Punës
Kostoja Direkte
e Punës Grupimi
1
Kostoja Direkte
e Punës Grupimi
2
Kostoja Direkte
e Punës Grupimi
3
Kostoja
Totale e
Punës
Humbja e
Peshës së
Vdekur
% Humbja
e Peshës së
Vdekur
Skedulimi A 11,280 30,960 42,240 10,000 24,000 14,500 48,500 16,032 50.7%
Skedulimi B 10,800 30,320 41,120 9,200 21,600 13,000 43,800 11,620 36.1%
Skedulimi C 10,944 30,384 41,328 8,720 21,120 12,800 42,640 10,460 32.5%
Skedulimi D 10,844 30,092 40,936 8,400 20,120 11,800 40,320 8,140 25.3%
Skedulimi E 10,720 30,096 40,816 8,080 19,820 10,725 38,625 6,445 20.0%
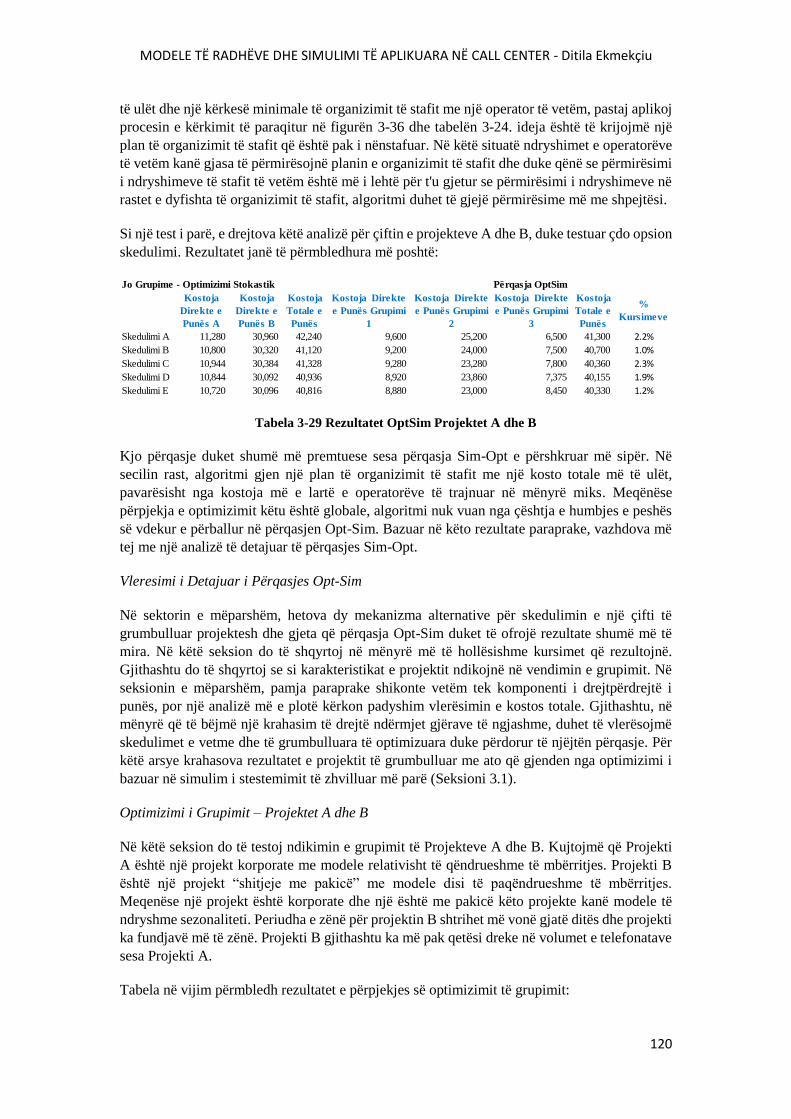
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
120
të ulët dhe një kërkesë minimale të organizimit të stafit me një operator të vetëm, pastaj aplikoj
procesin e kërkimit të paraqitur në figurën 3-36 dhe tabelën 3-24. ideja është të krijojmë një
plan të organizimit të stafit që është pak i nënstafuar. Në këtë situatë ndryshimet e operatorëve
të vetëm kanë gjasa të përmirësojnë planin e organizimit të stafit dhe duke qënë se përmirësimi
i ndryshimeve të stafit të vetëm është më i lehtë për t'u gjetur se përmirësimi i ndryshimeve në
rastet e dyfishta të organizimit të stafit, algoritmi duhet të gjejë përmirësime më me shpejtësi.
Si një test i parë, e drejtova këtë analizë për çiftin e projekteve A dhe B, duke testuar çdo opsion
skedulimi. Rezultatet janë të përmbledhura më poshtë:
Tabela 3-29 Rezultatet OptSim Projektet A dhe B
Kjo përqasje duket shumë më premtuese sesa përqasja Sim-Opt e përshkruar më sipër. Në
secilin rast, algoritmi gjen një plan të organizimit të stafit me një kosto totale më të ulët,
pavarësisht nga kostoja më e lartë e operatorëve të trajnuar në mënyrë miks. Meqënëse
përpjekja e optimizimit këtu është globale, algoritmi nuk vuan nga çështja e humbjes e peshës
së vdekur e përballur në përqasjen Opt-Sim. Bazuar në këto rezultate paraprake, vazhdova më
tej me një analizë të detajuar të përqasjes Sim-Opt.
Vleresimi i Detajuar i Përqasjes Opt-Sim
Në sektorin e mëparshëm, hetova dy mekanizma alternative për skedulimin e një çifti të
grumbulluar projektesh dhe gjeta që përqasja Opt-Sim duket të ofrojë rezultate shumë më të
mira. Në këtë seksion do të shqyrtoj në mënyrë më të hollësishme kursimet që rezultojnë.
Gjithashtu do të shqyrtoj se si karakteristikat e projektit ndikojnë në vendimin e grupimit. Në
seksionin e mëparshëm, pamja paraprake shikonte vetëm tek komponenti i drejtpërdrejtë i
punës, por një analizë më e plotë kërkon padyshim vlerësimin e kostos totale. Gjithashtu, në
mënyrë që të bëjmë një krahasim të drejtë ndërmjet gjërave të ngjashme, duhet të vlerësojmë
skedulimet e vetme dhe të grumbulluara të optimizuara duke përdorur të njëjtën përqasje. Për
këtë arsye krahasova rezultatet e projektit të grumbulluar me ato që gjenden nga optimizimi i
bazuar në simulim i stestemimit të zhvilluar më parë (Seksioni 3.1).
Optimizimi i Grupimit – Projektet A dhe B
Në këtë seksion do të testoj ndikimin e grupimit të Projekteve A dhe B. Kujtojmë që Projekti
A është një projekt korporate me modele relativisht të qëndrueshme të mbërritjes. Projekti B
është një projekt “shitjeje me pakicë” me modele disi të paqëndrueshme të mbërritjes.
Meqenëse një projekt është korporate dhe një është me pakicë këto projekte kanë modele të
ndryshme sezonaliteti. Periudha e zënë për projektin B shtrihet më vonë gjatë ditës dhe projekti
ka fundjavë më të zënë. Projekti B gjithashtu ka më pak qetësi dreke në volumet e telefonatave
sesa Projekti A.
Tabela në vijim përmbledh rezultatet e përpjekjes së optimizimit të grupimit:
Jo Grupime - Optimizimi Stokastik Përqasja OptSim
Kostoja
Direkte e
Punës A
Kostoja
Direkte e
Punës B
Kostoja
Totale e
Punës
Kostoja Direkte
e Punës Grupimi
1
Kostoja Direkte
e Punës Grupimi
2
Kostoja Direkte
e Punës Grupimi
3
Kostoja
Totale e
Punës
%
Kursimeve
Skedulimi A 11,280 30,960 42,240 9,600 25,200 6,500 41,300 2.2%
Skedulimi B 10,800 30,320 41,120 9,200 24,000 7,500 40,700 1.0%
Skedulimi C 10,944 30,384 41,328 9,280 23,280 7,800 40,360 2.3%
Skedulimi D 10,844 30,092 40,936 8,920 23,860 7,375 40,155 1.9%
Skedulimi E 10,720 30,096 40,816 8,880 23,000 8,450 40,330 1.2%
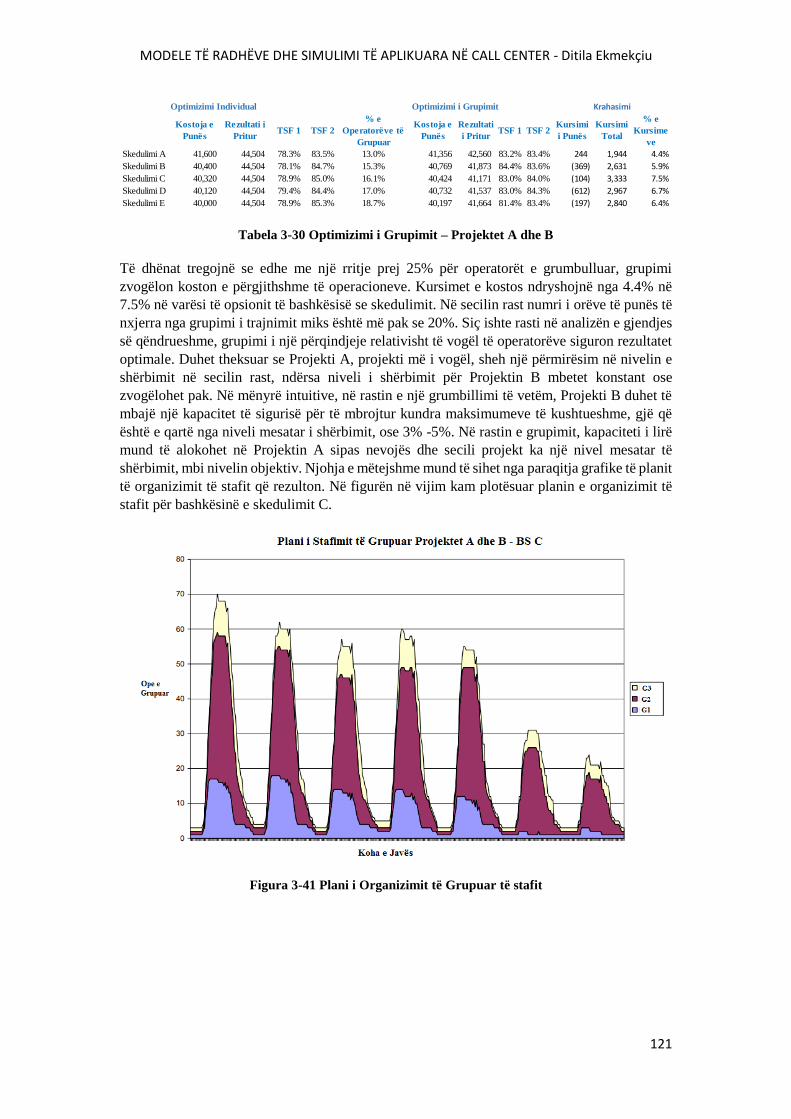
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
121
Tabela 3-30 Optimizimi i Grupimit – Projektet A dhe B
Të dhënat tregojnë se edhe me një rritje prej 25% për operatorët e grumbulluar, grupimi
zvogëlon koston e përgjithshme të operacioneve. Kursimet e kostos ndryshojnë nga 4.4% në
7.5% në varësi të opsionit të bashkësisë se skedulimit. Në secilin rast numri i orëve të punës të
nxjerra nga grupimi i trajnimit miks është më pak se 20%. Siç ishte rasti në analizën e gjendjes
së qëndrueshme, grupimi i një përqindjeje relativisht të vogël të operatorëve siguron rezultatet
optimale. Duhet theksuar se Projekti A, projekti më i vogël, sheh një përmirësim në nivelin e
shërbimit në secilin rast, ndërsa niveli i shërbimit për Projektin B mbetet konstant ose
zvogëlohet pak. Në mënyrë intuitive, në rastin e një grumbillimi të vetëm, Projekti B duhet të
mbajë një kapacitet të sigurisë për të mbrojtur kundra maksimumeve të kushtueshme, gjë që
është e qartë nga niveli mesatar i shërbimit, ose 3% -5%. Në rastin e grupimit, kapaciteti i lirë
mund të alokohet në Projektin A sipas nevojës dhe secili projekt ka një nivel mesatar të
shërbimit, mbi nivelin objektiv. Njohja e mëtejshme mund të sihet nga paraqitja grafike të planit
të organizimit të stafit që rezulton. Në figurën në vijim kam plotësuar planin e organizimit të
stafit për bashkësinë e skedulimit C.
Figura 3-41 Plani i Organizimit të Grupuar të stafit
Optimizimi Individual Optimizimi i Grupimit Krahasimi
Kostoja e
Punës
Rezultati i
PriturTSF 1 TSF 2
% e
Operatorëve të
Grupuar
Kostoja e
Punës
Rezultati
i PriturTSF 1 TSF 2
Kursimi
i Punës
Kursimi
Total
% e
Kursime
ve
Skedulimi A 41,600 44,504 78.3% 83.5% 13.0% 41,356 42,560 83.2% 83.4% 244 1,944 4.4%
Skedulimi B 40,400 44,504 78.1% 84.7% 15.3% 40,769 41,873 84.4% 83.6% (369) 2,631 5.9%
Skedulimi C 40,320 44,504 78.9% 85.0% 16.1% 40,424 41,171 83.0% 84.0% (104) 3,333 7.5%
Skedulimi D 40,120 44,504 79.4% 84.4% 17.0% 40,732 41,537 83.0% 84.3% (612) 2,967 6.7%
Skedulimi E 40,000 44,504 78.9% 85.3% 18.7% 40,197 41,664 81.4% 83.4% (197) 2,840 6.4%
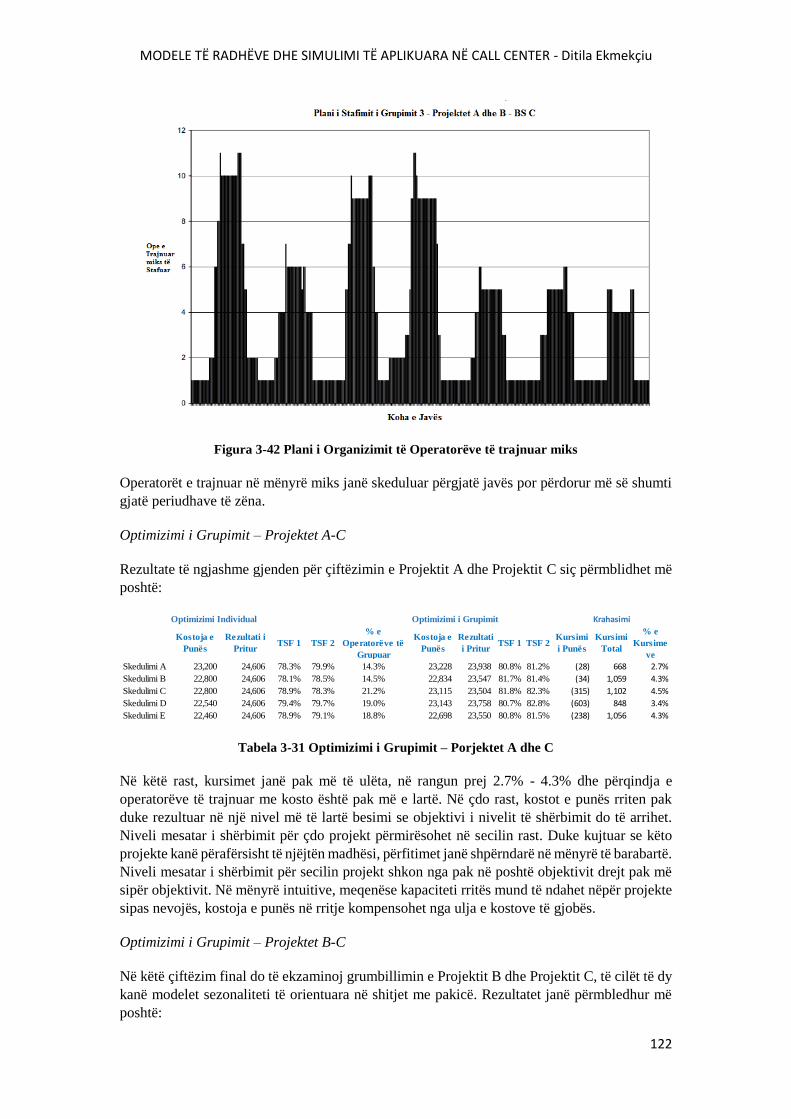
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
122
Figura 3-42 Plani i Organizimit të Operatorëve të trajnuar miks
Operatorët e trajnuar në mënyrë miks janë skeduluar përgjatë javës por përdorur më së shumti
gjatë periudhave të zëna.
Optimizimi i Grupimit – Projektet A-C
Rezultate të ngjashme gjenden për çiftëzimin e Projektit A dhe Projektit C siç përmblidhet më
poshtë:
Tabela 3-31 Optimizimi i Grupimit – Porjektet A dhe C
Në këtë rast, kursimet janë pak më të ulëta, në rangun prej 2.7% - 4.3% dhe përqindja e
operatorëve të trajnuar me kosto është pak më e lartë. Në çdo rast, kostot e punës rriten pak
duke rezultuar në një nivel më të lartë besimi se objektivi i nivelit të shërbimit do të arrihet.
Niveli mesatar i shërbimit për çdo projekt përmirësohet në secilin rast. Duke kujtuar se këto
projekte kanë përafërsisht të njëjtën madhësi, përfitimet janë shpërndarë në mënyrë të barabartë.
Niveli mesatar i shërbimit për secilin projekt shkon nga pak në poshtë objektivit drejt pak më
sipër objektivit. Në mënyrë intuitive, meqenëse kapaciteti rritës mund të ndahet nëpër projekte
sipas nevojës, kostoja e punës në rritje kompensohet nga ulja e kostove të gjobës.
Optimizimi i Grupimit – Projektet B-C
Në këtë çiftëzim final do të ekzaminoj grumbillimin e Projektit B dhe Projektit C, të cilët të dy
kanë modelet sezonaliteti të orientuara në shitjet me pakicë. Rezultatet janë përmbledhur më
poshtë:
Optimizimi Individual Optimizimi i Grupimit Krahasimi
Kostoja e
Punës
Rezultati i
PriturTSF 1 TSF 2
% e
Operatorëve të
Grupuar
Kostoja e
Punës
Rezultati
i PriturTSF 1 TSF 2
Kursimi
i Punës
Kursimi
Total
% e
Kursime
ve
Skedulimi A 23,200 24,606 78.3% 79.9% 14.3% 23,228 23,938 80.8% 81.2% (28) 668 2.7%
Skedulimi B 22,800 24,606 78.1% 78.5% 14.5% 22,834 23,547 81.7% 81.4% (34) 1,059 4.3%
Skedulimi C 22,800 24,606 78.9% 78.3% 21.2% 23,115 23,504 81.8% 82.3% (315) 1,102 4.5%
Skedulimi D 22,540 24,606 79.4% 79.7% 19.0% 23,143 23,758 80.7% 82.8% (603) 848 3.4%
Skedulimi E 22,460 24,606 78.9% 79.1% 18.8% 22,698 23,550 80.8% 81.5% (238) 1,056 4.3%
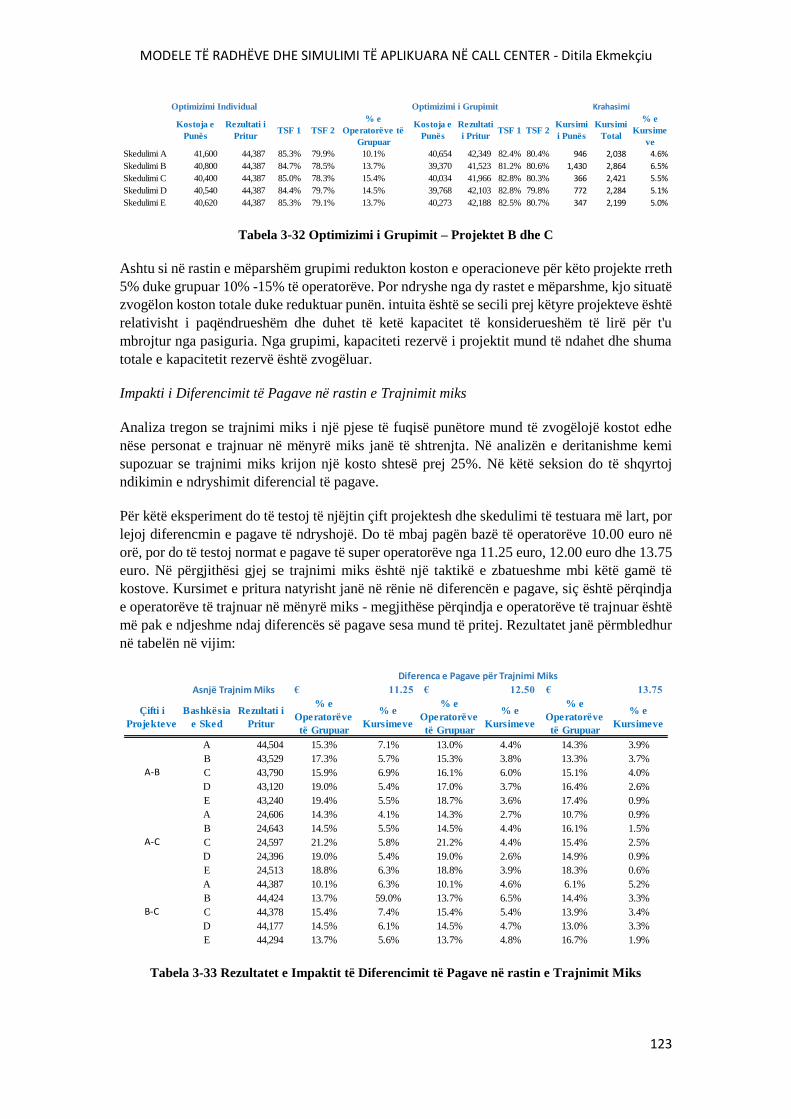
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
123
Tabela 3-32 Optimizimi i Grupimit – Projektet B dhe C
Ashtu si në rastin e mëparshëm grupimi redukton koston e operacioneve për këto projekte rreth
5% duke grupuar 10% -15% të operatorëve. Por ndryshe nga dy rastet e mëparshme, kjo situatë
zvogëlon koston totale duke reduktuar punën. intuita është se secili prej këtyre projekteve është
relativisht i paqëndrueshëm dhe duhet të ketë kapacitet të konsiderueshëm të lirë për t'u
mbrojtur nga pasiguria. Nga grupimi, kapaciteti rezervë i projektit mund të ndahet dhe shuma
totale e kapacitetit rezervë është zvogëluar.
Impakti i Diferencimit të Pagave në rastin e Trajnimit miks
Analiza tregon se trajnimi miks i një pjese të fuqisë punëtore mund të zvogëlojë kostot edhe
nëse personat e trajnuar në mënyrë miks janë të shtrenjta. Në analizën e deritanishme kemi
supozuar se trajnimi miks krijon një kosto shtesë prej 25%. Në këtë seksion do të shqyrtoj
ndikimin e ndryshimit diferencial të pagave.
Për këtë eksperiment do të testoj të njëjtin çift projektesh dhe skedulimi të testuara më lart, por
lejoj diferencmin e pagave të ndryshojë. Do të mbaj pagën bazë të operatorëve 10.00 euro në
orë, por do të testoj normat e pagave të super operatorëve nga 11.25 euro, 12.00 euro dhe 13.75
euro. Në përgjithësi gjej se trajnimi miks është një taktikë e zbatueshme mbi këtë gamë të
kostove. Kursimet e pritura natyrisht janë në rënie në diferencën e pagave, siç është përqindja
e operatorëve të trajnuar në mënyrë miks - megjithëse përqindja e operatorëve të trajnuar është
më pak e ndjeshme ndaj diferencës së pagave sesa mund të pritej. Rezultatet janë përmbledhur
në tabelën në vijim:
Tabela 3-33 Rezultatet e Impaktit të Diferencimit të Pagave në rastin e Trajnimit Miks
Optimizimi Individual Optimizimi i Grupimit Krahasimi
Kostoja e
Punës
Rezultati i
PriturTSF 1 TSF 2
% e
Operatorëve të
Grupuar
Kostoja e
Punës
Rezultati
i PriturTSF 1 TSF 2
Kursimi
i Punës
Kursimi
Total
% e
Kursime
ve
Skedulimi A 41,600 44,387 85.3% 79.9% 10.1% 40,654 42,349 82.4% 80.4% 946 2,038 4.6%
Skedulimi B 40,800 44,387 84.7% 78.5% 13.7% 39,370 41,523 81.2% 80.6% 1,430 2,864 6.5%
Skedulimi C 40,400 44,387 85.0% 78.3% 15.4% 40,034 41,966 82.8% 80.3% 366 2,421 5.5%
Skedulimi D 40,540 44,387 84.4% 79.7% 14.5% 39,768 42,103 82.8% 79.8% 772 2,284 5.1%
Skedulimi E 40,620 44,387 85.3% 79.1% 13.7% 40,273 42,188 82.5% 80.7% 347 2,199 5.0%
Çifti i
Projekteve
Bashkësia
e Sked
Rezultati i
Pritur
% e
Operatorëve
të Grupuar
% e
Kursimeve
% e
Operatorëve
të Grupuar
% e
Kursimeve
% e
Operatorëve
të Grupuar
% e
Kursimeve
A 44,504 15.3% 7.1% 13.0% 4.4% 14.3% 3.9%
B 43,529 17.3% 5.7% 15.3% 3.8% 13.3% 3.7%
C 43,790 15.9% 6.9% 16.1% 6.0% 15.1% 4.0%
D 43,120 19.0% 5.4% 17.0% 3.7% 16.4% 2.6%
E 43,240 19.4% 5.5% 18.7% 3.6% 17.4% 0.9%
A 24,606 14.3% 4.1% 14.3% 2.7% 10.7% 0.9%
B 24,643 14.5% 5.5% 14.5% 4.4% 16.1% 1.5%
C 24,597 21.2% 5.8% 21.2% 4.4% 15.4% 2.5%
D 24,396 19.0% 5.4% 19.0% 2.6% 14.9% 0.9%
E 24,513 18.8% 6.3% 18.8% 3.9% 18.3% 0.6%
A 44,387 10.1% 6.3% 10.1% 4.6% 6.1% 5.2%
B 44,424 13.7% 59.0% 13.7% 6.5% 14.4% 3.3%
C 44,378 15.4% 7.4% 15.4% 5.4% 13.9% 3.4%
D 44,177 14.5% 6.1% 14.5% 4.7% 13.0% 3.3%
E 44,294 13.7% 5.6% 13.7% 4.8% 16.7% 1.9%
€ 13.75
Diferenca e Pagave për Trajnimi Miks
A-B
A-C
B-C
Asnjë Trajnim Miks € 11.25 € 12.50

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
124
Vlerësimi i këtyre tre çiftimeve të projekteve tregon se aftësia për të zvogëluar kostot operative
nga grupimi i pjesshëm është i fuqishëm në kombinime të ndryshme të projekteve. Rezultatet
e përgjithshme në nivel kursimesh prej rreth 5% me një grupim prej rreth 15% të operatorëve
janë të qëndrueshme përgjatë çiftimeve. Mekanizmi në të cilin janë arrirë kursimet është
megjithatë i ndryshëm. Në disa raste niveli i agreguar i shërbimit rritet kur shtimi i më shumë
operatorëve (të grupuar) lejon përmirësim efiçent në arritjen e objektivit të nivelit të shërbimit.
Në raste të tjera grupimi lejon kapacitetin e tepërt të reduktohet përmes ndarjes efiçente të
kapacitetit rezervë.
Përmbledhje
Në këtë model ekzamiova konceptin e grupimit të pjesshëm të operatorëve në call center.
Premisa bazë është se në rastet kur trajnimi është i shtrenjtë, nuk është praktike të trajnohen të
gjithë operatorët për të menaxhuar llojet e shumta të telefonatave. Hetova mundësinë e trajnimit
të disa operatorëve për të trajtuar llojet e shumta të telefonatave dhe tregova se kjo përqasje
mund të sjellë përfitime të konsiderueshme.
Së pari, analizova performancën në gjëndje të qëndrueshme, pavarësisht nga kostot, dhe tregova
se grupimi jep përfitime të rëndësishme, por me shpejtësi në rënie. Më pas hetova nivelin
optimal të trajnimit miks në një mjedis të qëndrueshëm kur kostoja e trajnimit është e
kushtueshme. Zhvillova një metodë të optimizimit të drejtpërdrejtë dhe efiçent të simulimit për
gjetjen e nivelit optimal të trajnimit miks. Së fundi e zgjerova këtë metodë në një mjedis të
orientuar drejt projektit, ku ardhjet nuk janë stacionare me ditën e javës dhe me sezonalitetin e
kohës së ditës.
Modeli i simulimit i përdorur në këtë kapitull është një aplikim i personalizuar i zhvilluar nga
autori në Microsoft Visual Basic.NET. Kodi u zhvillua si një portë e një modeli të zhvilluar më
parë duke përdorur Automod. Është tranferuar kodi në VB në mënyrë që të ketë një aftësi në
rritje për të kryer një kërkim në fqinjësi për qëllime optimizimi. Transferunu i kodit në VB lejoi
gjithashtu një bazë të përbashkët kodesh për t'u përdorur për simulim dhe për gjenerim
skenarësh.
Për gjenerimin e numrave të rastit, kodi zbaton një gjenerator të kombinuar të shumëfishtë
rekursiv (CMRG) i bazuar në gjeneratorin e Mrg32k3a të përshkruar në (L'Ecuyer 1999).
Gjeneratori u përkthye nga kodi C i postuar në faqen e internetit të L'Ecuyer në VB nga autori.
Ky gjenerator numrash ka veti të shkëlqyera statistikore dhe konsiderohet si një nga
gjeneratorët më të mirë disponibël. Programimi u bë i mundur edhe falë bashkëpunimit me
Departamentin e Sistemeve të Informacionit, që dha një ndihmë të madhe në realizimin e
modeleve.
Programimet Lineare dhe me Numra të Plotë të përshkruara përgjatë kapitullit ishin të gjitha të
formuluara duke përdorur gjuhën e modelimit GAMS dhe zgjidhet duke përdorur CPLEX në
një host Unix. Modelet u ekzekutuan në servera të ndryshme brenda mjedisit e informatikës së
call center-it.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
125
PËRFUNDIME DHE REKOMANDIME
Fokusi i kesaj teze ka qenë krijimi i disa modeleve, duke shfrytëzuar Teorinë e Radhëve dhe
Simulimin për dimensionimin dhe skedulimin Optimal të Call Center-ave, duke marrë parasysh
ndikimin e parametrave të rastit (siç është koha e mbërritjes).
Puna bazohet në një call center që ofron shërbim klientësh. Nga perspektiva e biznesit,
problemet specifike të trajtuara në këtë tezë përfshijnë:
• Si mund ta përmirësojmë procesin e skedulimit të stafit për të ulur kostot e punës, duke
arritur përsëri nivelin e shërbimit mujor të kërkuar?
• Cilat inovacione janë të mundura në organizimin e stafit të projektit për të lejuar rritjen
e efiçencës pa sakrifikuar nivelet e shërbimit të klientit?
Gjatë punës sime me këtë kompani kemi analizuar modelet e mbërritjes së telefonatave në një
përpjekje për të karakterizuar procesin e mbërritjeve dhe për të kuptuar më mirë këtë parametër
të rastit. Kemi gjetur se menaxherët shpesh keqinterpretojnë ndryshueshmërinë dhe kanë
vështirësi për të ndarë ndryshueshmërinë stokastike, sezonalitetin dhe trendet. Në përgjithësi
kemi gjetur se pas kontrollimit të ndryshueshmërisë stokastike dhe trendeve javore, të dhënat
kanë tendencë të jenë shumë të qëndrueshme.
Gjithashtu kemi analizuar proceset dhe metodat e skedulimit dhe organizimit të stafit. Kemi
gjetur se edhe pse stafi përgjegjës per skedulimin (WFM) kishte akses në mjete relativisht të
sofistikuara skedulimi, ata shpesh mbështeteshin në proceset manuale me mbështetje minimale
automatike; për shembull, llogaritësit Erlang C për të identifikuar kërkesat themelore dhe
skedulimi manual përmes Excel-it.
Puna në këtë tezë kërkoi ndërtimin në këtë analizë dhe zhvillimin e modeleve mbështetëse të
marrjes së vendimeve për të adresuar vendimet e ndryshme të menaxhimit të kapaciteteve.
Objektivi ishte të zhvilloheshin modele specifike që mund të përdoren në të ardhmen për
menxahimin e operacioneve, në nivelet e dimensionit dhe skedulimit.
Të gjitha analizat statistikore në Kapitullin 1 janë në bashkëpunim me stafin e kompanisë, gjatë
gjithë procesit të analizës.
Pjesa më e madhe e punës së bërë për zhvillimin e kësaj teze ishte duke marrë analizën specifike
të projektit, të bërë gjatë studimit, duke e përgjithësuar atë dhe duke e studiuar atë në situata të
ndryshme. Shumica e njohurive të zhvilluara gjatë kësaj analize janë konsideruar për t’u
përdorur në kompani.
Duke u larguar nga çështjet specifike të kompanisë, disa vëzhgime të përgjithshme që dalin nga
kjo analizë përfshijnë pikat në vijim:
Ndryshueshmëria: Modelet e mbërritjeve të telefonatave janë shumë më të paqëndrueshme
sesa modelet e supozuara në literaturë. Konsiderimi në mënyrë eksplicite i kësaj
ndryshueshmërie ka një ndikim material.
Sezonaliteti: sezonaliteti i modeleve të telefonatave për shumë lloje të telefonatave është shumë
domethënës dhe ndikon dukshëm në koston e ofrimit të shërbimeve.
Pak fleksibilitet për rezultate afatgjata: gjithë kësaj analize kam gjetur se fleksibiliteti i
kufizuar mund të çojë në një përmirësim domethënës. Disa operatorë me kohë të pjesshme

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
126
arrijnë pjesën më të madhe të përfitimit të të gjithë personave me kohë të pjesshme universalë.
Në mënyrë të ngjashme, trajnimi në mënyrë mikse i disa operatorëve jep pjesën më të madhe
të përfitimit sesa trajnimi miks i të gjithëve.
Modeli i Skedulimit Afatshkurtër
Objektiv i modelit të skedulimit afatshkurtër ishte përcaktimi i turneve optimale duke
konsideruar kohën e mbërritjejes si madhësi e rastit. Modeli zhvilloi një skedulim javor të
dizenjuar për të arritur një Nivel Shërbimi të caktuar, në bazë të marrëveshjes, duke caktuar një
“gjobë” financiare që bazohet në probabilitetin e mos arritjes së objetktivit të Nivelit të
Shërbimit
Në fillim u tregua që Vlera e Zgjidhjes Stokastike për modelin e skedulimit afatshkurtër është
e konsiderueshme; duke filluar nga 12.3% në mbi 21%. Implikimi i qartë është se për këtë
formulim modeli, shpërfillja e ndryshueshmërisë është një vendim i kushtueshëm; megjithatë
shumica e modeleve në praktikë injorojnë si mbërritjet e rastit ashtu edhe braktisjen. Aludimi
është se nuk duhet të futet braktisja në model pa marrë parasysh edhe mbërritjet e rastit. Më
pas, u krahasua ky model me praktikën e zakonshme të skedulimit me një kufizim lokal të
Erlang C; që është skedulimi i bazuar në një model që injoron braktisjen dhe mbërritjet e rastit
por kërkon që objektivi i nivelit të shërbimit të arrihet në çdo periudhë. Duke krahasuar modelin
tim me këtë praktikë të zakonshme, përsëri u gjet që modeli im ka arritur rezultate më të ulëta
të kostos; duke filluar nga 2.4% në 27%. Implikimi themelor këtu është se modeli Erlang C
ndonjëhrë arrin rezultate të mira, pasi supozimet e braktisjes dhe mbërritjeve të rastit krijojnë
gabime që kundër balancohen. Megjithatë, modeli stokastik gjithmonë arrin një zgjidhje më të
mirë dhe në shumë raste praktike një rezultat shumë më të mirë. Kjo është veçanërisht e vërtetë
kur fleksibiliteti i fuqisë punëtore është i kufizuar në turne me kohë të plotë ose thuajse të plotë
dhe përqasja e grupit të mbulimit paraqet rënie të konsiderueshme në skedulim.
Së fundi u krahasua ky model me një Model Erlang C të Kufizuar Globalisht. Megjithëse nuk
është adresuar shumë në literaturë, sipas njohurive të mia, modeli global i Erlang C është një
zgjerim i thjeshtë i modelit Erlang C që e zbut kufizimin periudhë pas periudhe të nivelit të
shërbimit. Është shumë e qartë se duhet të presim një rezultat më të mirë nga një kufizim global.
Ky model jep rezultate më të mira në krahasim me Erlang C të kufizuar lokalisht, por përsëri
modeli im stokastik e tejkalon këtë model në çdo rast, minimalisht me 1%, por deri në 16%.
Konkluzioni i përgjithshëm është se krahasuar me metodat alternative të analizuara këtu,
Modeli Stokastik gjithmonë do të japë një kosto më të ulët të skedulimit të operacioneve, dhe
ndonjëherë kjo diferencë mund të jetë e konsiderueshme. Kjo është një karakteristikë themelore
e programimit stokastik në përgjithësi, por në këtë analizë është treguar se dallimi është i
rëndësishëm në rastet konkrete.
Për të ofruar një zgjidhje me kosto më të ulët, modeli i paraqitur në këtë seksion trajton
problemin e caktimit nga një perspektivë krejtësisht të ndryshme. Në përqasjen e grupit të
mbulimit standard, kufizimi i nivelit të shërbimit është një pengesë e vështirë, duhet të
plotësohet dhe çdo skedulim kandidat ose do të arrijë nivelin e shërbimit ose jo. Por në realitet
niveli i shërbimit është një ndryshore e rastit dhe do të arrijmë objektivin SLA me një
probabilitet të caktuar. Analiza shqyrton këtë në mënyrë eksplicite dhe adreson kompromisin
që menaxherët duhet të bëjnë në aspektin e kostos dhe besimin e arritjes së nivelit të shërbimit.
Analiza ime tregon se si kostoja e operacioneve rritet në mënyrë jo-lineare me nivelin e
dëshiruar të besimit. Ky kompromis fshihet në konfigurimin determinist.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
127
Në këtë seksion u shqyrtua gjithashtu se si kostoja e ofrimit të shërbimeve ndryshon me
fleksibilitetin e organizimit të stafit; që është disponueshmëria e punonjësve për skedulimet me
kohë të pjesshme. Natyrisht futja e më shumë opsioneve të organizimit të stafit (oraret e
mundshme) do të reduktojë kostot dhe analiza ime kuantifikon këtë reduktim. Do të tregoj në
mënyrë direkte se personeli me kohë të pjesshme mund të ulë ndjeshëm kostot kur menaxherët
përballen me tipet e modeleve të sezonalitetit të vlerësuara në këtë analizë. Po ashtu do të tregoj
se është e nevojshme që vetëm disa punëtorë të duan të punojnë me kohë të pjesshme për të
marrë shumicën e përfitimeve. Fleksibiliteti i fuqisë punëtore është gjithashtu një faktor kyç në
analizat pasuese. Modelet me grupet mbuluese në veçanti janë joefiçente nëse fuqia punëtore
është e kufizuar me turne me kohë të plotë.
Menaxherët duhet të marrin në konsideratë ndryshueshmërinë e mbërritjeve gjatë krijimit të
planeve të organizimit të stafit dhe/ose gjatë vlerësimit të kostos së ofrimit të shërbimeve.
Periudhat me ndryshueshmëri më të madhe kërkojnë kapacitet ekstra të stafit për t’u mbrojtur
siç duhet nga rreziku. Në mënyrë të ngjashme, nëse projektet kanë të njëjtin volum mesatar,
por një është më i ndryshueshëm se tjetri, projekti më i ndryshueshëm do të jetë më i shtrenjtë
për t'u shërbyer.
Modeli i trajnimit miks
Në këtë model u shqyrtuan më tej operacionet e një call center-i. U shqyrtua më tej mundësia e
trajnimit të një nëngrupimi operatorësh në mënyrë që ata të mund të operojnë njëkohësisht për
dy projekte të ndara, një proces të quajtur ndryshe si grupim i pjesshëm. Gjatë punimit u pa që
trajnimi miks i operatorëve rriti performancën e përgjithshme të sistemit. Duke pasur parasysh
investimin e kërkuar për trajnim dhe kërkesën e mundshme për të paguar një pagë më të lartë
për këto raste, u tregua që nuk është e dobishme të trajnohen në mënyrë mikse të gjithë
operatorët. Ky model përcaktoi përfitimin nga grupimi i pjesshëm dhe kushtet nën të cilat
grupimi është më fitimprurës. Më pas u përcaktua numri optimal i operaorëve për t’u trajnuar
në mënyrë mikse duke pasur të dhënë investimin e trajnimit dhe shtesën në pagë të paguar për
operatorët në këtë rast.
Kontributet
Ky disertacion jep disa kontribute të rëndësishme në literaturën e Kërkimeve Operacionale të
Aplikuar, duke përfshirë:
Integrimin e Dimensionimit të Call Center-it dhe Skedulimin e Stafit: modeli im i
skedulimit kombinon këto dy hapa në një model të vetëm optimizimi ndryshe nga literatura
ekzistuese që i trajton ato si procese të ndara. Është treguar se skedulimi që rezulton është me
kosto më të ulët.
Modeli Stokastik i Skedulimit të Call Center-it: modeli im i skedulimit është ndoshta
aplikimi i parë i programimit stokastik në problemin e skedulimit të stafit në vendin tonë.
Tregohet se marrja parasysh e ndryshueshmërisë ul kostot.
Modeli i Pjesshëm i Grupimit: modeli i trajnimit miks që kam prezantuar është shumë praktik
dhe i paeksploruar në literaturë në vendin tonë. Një model shumë i ngjashëm në koncept me
këtë është (Wallace dhe Whitt 2005). Në modelin W&W ka 6 lloje telefonatash dhe çdo
operator është trajnuar për të trajtuar një numër fiks të këtyre llojeve. Autorët përdorin një
model optimizimi i bazuar në simulim për të gjetur nivelin ideal të trajnimit miks. Vizioni i
përgjithshëm i artikullit është se një nivel i ulët i trajnimit miks siguron "shumicën" e përfitimit.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
128
Në mënyrë të veçantë, ata gjejnë se trajnimi i çdo operatori në menaxhimin e 2 lloje telefonatash
siguron pjesën më të madhe të përfitimit, ndërsa trajnimi shtesë ka një fitim relativisht të ulët.
Megjithëse gjetja e përgjithshme në modelin e këtij punimi është e ngjashme, p.sh. nivelet e
vogla të trajnimit miks japin shumicën e përfitimit, modelet janë shumë të ndryshme. Ndërsa
zgjidhja e tyre më e mirë është trajnimi në dy aftësi i çdo operatori, modeli ynë supozon se
vetëm një pjesë e vogël e operatorëve janë të trajnuar në mënyrë mikse. Në skenarin tonë
trajnimi miks është shumë i shtrenjtë dhe trajnimi 100% miks nuk është praktik. W&W tregojnë
se duke shtuar një aftësi të dytë jep pjesën më të madhe të vlerës, por ata nuk analizojnë koston
e ndërlidhur me trajnimin miks. Në modelin tonë përfshijmë koston e trajnimit miks dhe
kërkojmë një nivel optimal. Përveç kësaj, W&W ekzaminojnë trajnimin miks vetëm në gjendje
të qëndrueshme, ku nivelet e mbërritjes dhe nivelet e organizimit të stafit janë të fiksuara.
Analiza jonë përqendrohet në rastin kur të dy normat e mbërritjes dhe nivelet e organizimit të
stafit ndryshojnë në mënyrë dramatike gjatë rrjedhës së periudhës së SLA-ve. Jemi shumë të
interesuar në faktin se si përshtatshmëria variabël e kapacitetit të ngarkesës ndikon në dobi të
grupimit të pjesshëm. Në një nivel të detajuar modeli W&W injoron braktisjen - një konsideratë
e rëndësishme në situatën tonë. Modeli i paraqitur këtu shkon përtej modelit W & W për të
shqyrtuar rastin ku trajnimi miks është i kushtueshëm dhe nivelet e shërbimit janë të
rëndësishme. Ky model gjithashtu lejon braktisjen.
Trajnimii miks i një numri të kufizuar operatorësh është një opsion me kosto efektive nën një
gamë të gjerë supozimesh dhe kushtesh. Modeli i paraqitur këtu ofron një metodologji specifike
për gjetjen e nivelit të duhur të trajnimit miks, por gjithashtu ofron disa njohuri themelore.
Menaxherët duhet të kërkojnë të trajnojnë në mënyrë mikse një nivel të moderuar të operatorëve
bazë për të mbështetur rrjedhat e shumta të telefonatave. Në rastin e call center-ave
shumëgjuhëshe, menaxherët kanë nevojë për disa operatorë shumëgjuhësh, por nuk kanë nevojë
që të gjithë operatorët të jenë shumëgjuhësh
Problemi jo-Stacionar: analiza ime është një nga të paktat që e konsideron organizimit e stafit
të një call center-i me norma të mbërritjes jo stacionare dhe ndoshta është i pari në vend që
vlerëson një model realist të mbërritjeve.
Kërkimet e ardhshme
Kërkimi në këtë disertacion mund të zgjatet dhe të zgjerohet sigurisht. Disa nga fushat kyçe për
kërkime potenciale të ardhshme përfshijnë:
Heterogjeniteti i operatorëve: si shumica e modeleve në literaturë shumica e analizës në këtë
disertacion supozon se operatorët janë statistikisht identikë. Të dhënat tregojnë se produktiviteti
i operatorëve është shumë i ndryshueshëm, një sektor që ka marrë shumë pak vëmendje në
literaturën e Kërkimeve Operacionale.
Call Center-at shumëgjuhëshe: Kam aluduar për këtë disa herë në këtë disertacion, por
problemi i dimensionimit të një call center-i shumëgjuhësh është mjaft i vështirë, por mund të
jetë nje fushë ku mund të thellohemi në studimet e ardhshme.
Horizonti kohor variabël: në këtë analizë është trajtuar ekskluzivisht situata ku SLA-të
vlerësohen gjatë një periudhe njëmujore, pasi kjo është dhe praktika më e përhapur në Call
Cneter-a. Një zgjatje e kësaj pune do të analizojë ndikimin e ndryshimeve kohore në objektivin
e SLA-ve (2 ose 6 mujore për shembull) në koston e operacioneve.
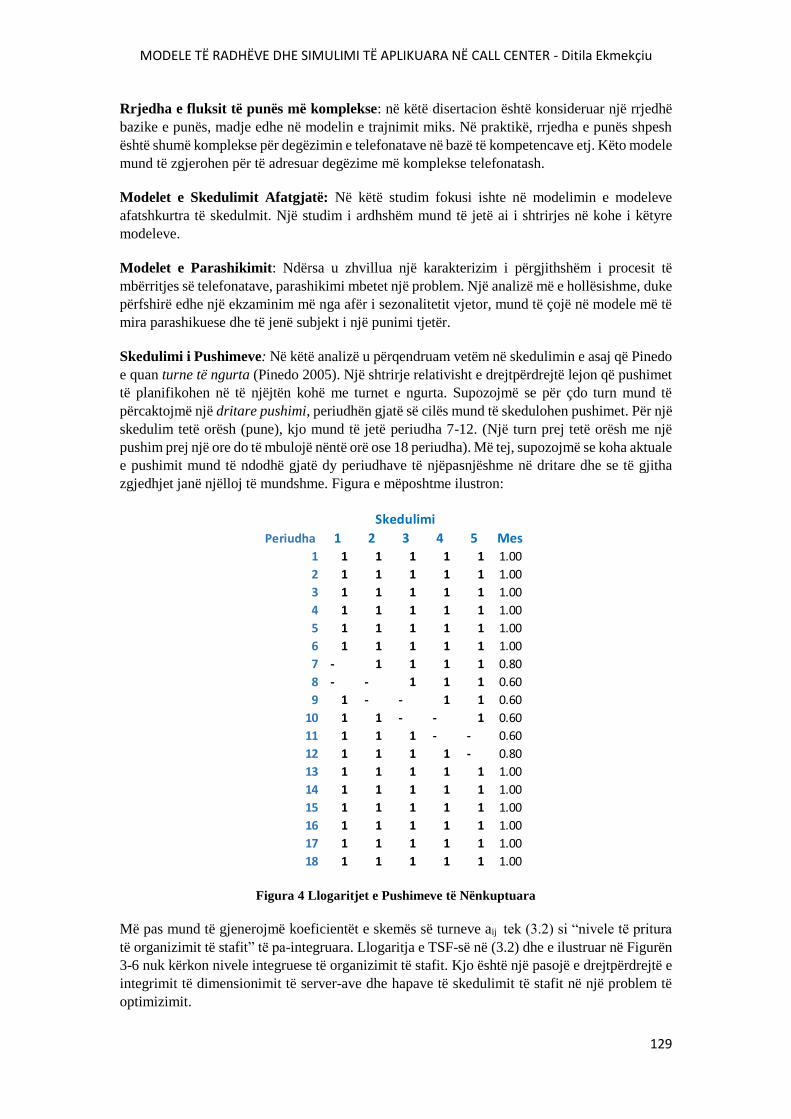
MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
129
Rrjedha e fluksit të punës më komplekse: në këtë disertacion është konsideruar një rrjedhë
bazike e punës, madje edhe në modelin e trajnimit miks. Në praktikë, rrjedha e punës shpesh
është shumë komplekse për degëzimin e telefonatave në bazë të kompetencave etj. Këto modele
mund të zgjerohen për të adresuar degëzime më komplekse telefonatash.
Modelet e Skedulimit Afatgjatë: Në këtë studim fokusi ishte në modelimin e modeleve
afatshkurtra të skedulmit. Një studim i ardhshëm mund të jetë ai i shtrirjes në kohe i këtyre
modeleve.
Modelet e Parashikimit: Ndërsa u zhvillua një karakterizim i përgjithshëm i procesit të
mbërritjes së telefonatave, parashikimi mbetet një problem. Një analizë më e hollësishme, duke
përfshirë edhe një ekzaminim më nga afër i sezonalitetit vjetor, mund të çojë në modele më të
mira parashikuese dhe të jenë subjekt i një punimi tjetër.
Skedulimi i Pushimeve: Në këtë analizë u përqendruam vetëm në skedulimin e asaj që Pinedo
e quan turne të ngurta (Pinedo 2005). Një shtrirje relativisht e drejtpërdrejtë lejon që pushimet
të planifikohen në të njëjtën kohë me turnet e ngurta. Supozojmë se për çdo turn mund të
përcaktojmë një dritare pushimi, periudhën gjatë së cilës mund të skedulohen pushimet. Për një
skedulim tetë orësh (pune), kjo mund të jetë periudha 7-12. (Një turn prej tetë orësh me një
pushim prej një ore do të mbulojë nëntë orë ose 18 periudha). Më tej, supozojmë se koha aktuale
e pushimit mund të ndodhë gjatë dy periudhave të njëpasnjëshme në dritare dhe se të gjitha
zgjedhjet janë njëlloj të mundshme. Figura e mëposhtme ilustron:
Figura 4 Llogaritjet e Pushimeve të Nënkuptuara
Më pas mund të gjenerojmë koeficientët e skemës së turneve aij tek (3.2) si “nivele të pritura
të organizimit të stafit” të pa-integruara. Llogaritja e TSF-së në (3.2) dhe e ilustruar në Figurën
3-6 nuk kërkon nivele integruese të organizimit të stafit. Kjo është një pasojë e drejtpërdrejtë e
integrimit të dimensionimit të server-ave dhe hapave të skedulimit të stafit në një problem të
optimizimit.
Periudha 1 2 3 4 5 Mes1 1 1 1 1 1 1.00
2 1 1 1 1 1 1.00
3 1 1 1 1 1 1.00
4 1 1 1 1 1 1.00
5 1 1 1 1 1 1.00
6 1 1 1 1 1 1.00
7 - 1 1 1 1 0.80
8 - - 1 1 1 0.60
9 1 - - 1 1 0.60
10 1 1 - - 1 0.60
11 1 1 1 - - 0.60
12 1 1 1 1 - 0.80
13 1 1 1 1 1 1.00
14 1 1 1 1 1 1.00
15 1 1 1 1 1 1.00
16 1 1 1 1 1 1.00
17 1 1 1 1 1 1.00
18 1 1 1 1 1 1.00
Skedulimi

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
130
Supozimet Alternative të Radhëve: Llogaritja e nivelit të shërbimit në këtë analizë u bazua
në një përafrim linear me pjesë të formulës së radhëve Erlang A. Ndërsa Erlang A është një
model mjaftueshëm i mirë, ai ka disa kufizime, sidomos supozimet e kohës së bisedës
eksponenciale. Këto supozime relaksohen lehtësisht. Një përqasje është përqasja e sistemimit
të bazuar në simulim, i diskutuar në këtë punim. Një alternativë është që të përdoret një model
tjetër i radhëve për të gjeneruar përafrimin e nivelit të shërbimit. Kjo nuk ka mundësi të
gjenerojë rezultate krejtësisht të ndryshme, por mund të krijojë një përshtatje më të mirë nëse
skedulon një projekt real.
Heuristika e Bazuar në Simulim: Modeli stokastik i paraqitur në këtë punim gjeneron një
skedulim më të mirë se modeli i vlerës së njeriut. Modeli stokastik megjithatë kërkon një sasi
jo të vogël të burimeve kompjuterike. Mund të jetë e mundur të krijohet një heuristikë më e
shpejtë që do të gjenerojë rezultate të mira. Një algoritëm që fillimisht aplikon një heuristikë
lakmitare për të mbuluar kufizimet lokale dhe më pas kryen një sistemim të bazuar në simulim
është një mundësi premtuese
Ndjeshmëria e Supozimit Erlang C: Analiza në Seksioni 3.1 tregon se modeli i skedulimit
stokastik performon në mënyrë të vazhdueshme më mirë se modeli i Erlang C. Çfarë është disi
e habitshme është se sa mirë performon modeli Erlang C, duke pasur parasysh supozimet e
diskutueshme. Mendoj se gabimi i krijuar nga braktisja dhe supozimet e pasigurisë tentojnë të
anulohen. Kërkimet e ardhshme mund të hetojnë kushtet nën të cilat modeli Erlang C ofron
rezultate të arsyeshme.
Sistemimi Algoritmik: Në këtë disertacion është zhvilluar një model për të gjetur një plan
optimal të organizimit të stafit kur mbërritjet janë të pasigurta. Është zbatuar një version i
algoritmit të Dekompozimit në Formë L-je që siguron një zgjidhje të arsyeshme të
përpunueshme. Megjithatë, nuk përqendrohemi në efiçencën algoritmike në këtë disertacion.
Nuk kam asnjë dyshim se analiza shtesë mund të përmirësojnë efiçencën e algoritmit
Kompleksiteti i Telefonatave: Në këtë analizë fillestare është shqyrtuar një rast relativisht i
thjeshtë i dy llojeve të telefonatave dhe tre llojeve të operatorëve. Një shtrirje e natyrshme është
të ekzaminohet një numër më i madh i llojit të telefonatave dhe llojeve shtesë të grupimit.
Konsiderojmë skenarin e paraqitur në grafikun e mëposhtëm:
Figura 5 Përqasja e Grupimit të tre Projekteve
Në këtë rast, tre projekte janë grupuar së bashku. Kapaciteti për projektin 2 tani është edhe më
fleksibël pasi agjentët mund të shtyhen ose të tërhiqen nga dy projekte të tjera. Ky konfigurim
mund të jetë veçanërisht i përshtatshëm nëse Projekti 2 është shumë i paqëndrueshëm. Ky
konfigurim mund të modifikohet më tej nëse një agjent i tipit te 6-të shtohet i trajnuar në mënyrë
miks në Projektin 1 dhe 2.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
131
Një përqasje alternative do të ishte krijimi i super operatorëve, të trajnuar në tre (ose më shumë)
projekte. Ky lloj konfigurimi tashmë ekziston në call center-at shumëgjuhësh. Të gjitha këto
mundësi paraqesin mundësi të rëndësishme për autorin që të vazhdojë këtë përpjekje kërkimore.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
132
REFERENCAT
[01] Aarts, E., J. Korst and W. Michiels (2005). Simulated Annealing. Search
Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques. E. K.
Burke and G. Kendall. New York, NY, Springer: 187-210.
[02] Anderson, E. G., Jr. 2001. The Nonstationary Staff-Planning Problem with Business
Cycle and Learning Effects. Management Science 47(6) 817-832.
[03] Andrews, B. and H. Parsons 1993. Establishing Telephone-Agent Staffing Levels
through Economic Optimization. Interfaces 23(2) 14.
[04] Andrews, B. H. and S. M. Cunningham 1995. L.L. Bean Improves Call-Center
Forecasting. Interfaces 25(6) 1.
[05] Andrews, B. H. and H. L. Parsons 1989. L.L. Bean Chooses a Telephone Agent
Scheduling System. Interfaces 19(6) 1.
[06] Atlason, J., M. A. Epelman and S. G. Henderson 2004. Call center staffing with
simulation and cutting plane methods. Annals of Operations Research 333-358.
[07] Avramidis, A. N., W. Chan and P. L'Ecuyer 2007. Staffing multi-skill call centers via
search methods and a performance approximation. Working Paper p.
[08] Avramidis, A. N., A. Deslauriers and P. L'Ecuyer 2004. Modeling Daily Arrivals to a
Telephone Call Center. Management Science 50(7) 896-908.
[09] Avramidis, A. N., M. Gendreau, P. L'Ecuyer and O. Pisacane 2007. Simulation-Based
Optimization of Agent Scheduling in Multiskill Call Centers. 2007 Industrial Simulation
Conference.
[10] Avriel, M. and A. C. Williams 1970. The Value of Information and Stochastic
Programming. Operations Research 18(5) 947-954.
[11] Aykin, T. 1996. Optimal Shift Scheduling with Multiple Break Windows.
Management Science 42(4) 591-602.
[12] Baker, K. R. 1974a. Scheduling a Full-Time Workforce to Meet Cyclic Staffing
Requirements. Management Science 20(12, Application Series) 1561-1568.
[13] Baker, K. R. 1974b. Scheduling Full-Time and Part-Time Staff to Meet Cyclic
Requirements. Operational Research Quarterly 25(1) 65-76.
[14] Baker, K. R. and M. J. Magazine 1977. Workforce Scheduling with Cyclic Demands
and Day-Off Constraints. Management Science 24(2) 161-167
[15] Banks, J. 2005. Discrete-event system simulation, Pearson Prentice Hall. Upper
Saddle River, N.J.
[16] Bartholomew, D. J. 1971. The Statistical Approach to Manpower Planning. The
Statistician 20(1, Statistics and Manpower Planning in the Firm) 3-26.
[17] Bartholomew, D. J. 1982. Stochastic models for social processes, Wiley. Chichester
[England]; New York.
[18] Bartholomew, D. J. and A. F. Forbes 1979. Statistical techniques for manpower
planning, Wiley Chichester [Eng.]; New York.
[19] Beale, E. M. L. 1955. On Minimizing A Convex Function Subject to Linear
Inequalities. Journal of the Royal Statistical Society. Series B (Methodological) 17(2) 173-184.
[20] Bechtold, S. E. and L. W. Jacobs 1990. Implicit Modeling of Flexible Break
Assignments in Optimal Shift Scheduling. Management Science 36(11) 1339-1351.
[21] Birge, J. R. 1982. The Value of the Stochastic Solution in Stochastic Linear Programs,
with Fixed Recourse. Mathematical Programming 24 314-325.
[22] Birge, J. R. 1985. Decomposition and Partitioning Methods for Multistage Stochastic
Linear Programs. Operations Research 33(5) 989-1007.
[23] Birge, J. R. and F. Louveaux 1997. Introduction to Stochastic Programming, Springer.
New York.
[24] Bordoloi, S. K. and H. Matsuo 2001. Human resource planning in knowledge-
intensive operations: A model for learning with stochastic turnover. European Journal of
Operational Research 130(1) 169.
[25] Box, G. E. P. and N. R. Draper 1987. Empirical model-building and response surfaces,
Wiley. New York.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
133
[26] Box, G. E. P., J. S. Hunter and W. G. Hunter 2005. Statistics for experimenters: design,
innovation, and discovery, Wiley-Interscience. Hoboken, N.J.
[27] Box, G. E. P., W. G. Hunter and J. S. Hunter 1978. Statistics for experimenters: an
introduction to design, data analysis, and model building, Wiley. New York.
[28] Box, G. E. P., G. N. Jenkins and G. C. Reinsel 1994. Time series analysis: forecasting
and control, Prentice Hall. Englewood Cliffs, N.J.
[29] Bres, E. S., D. Burns, A. Charnes and W. W. Cooper 1980. A Goal Programming
Model for Planning Officer Accessions. Management Science 26(8) 773-783.
[30] Brown, L., N. Gans, A. Mandelbaum, A. Sakov, S. Zeltyn, L. Zhao and S. Haipeng
2002. Statistical Analysis of a Telephone Call Center: A Queueing-Science Perspective.
Accepted to JASA. Working Paper p.
[31] Brusco, M. J. and L. W. Jacobs 1998. Personnel Tour Scheduling When Starting-Time
Restrictions Are Present. Management Science 44(4) 534-547.
[32] Brusco, M. J. and L. W. Jacobs 2000. Optimal Models for Meal-Break and Start-Time
Flexibility in Continuous Tour Scheduling. Management Science 46(12) 1630- 1641.
[33] Brusco, M. J. and T. R. Johns 1996. A sequential integer programming method for
discontinuous labor tour scheduling. European Journal of Operational Research 95(3) 537-548.
[34] Burke, E., K., P. De Causmaecker, G. Vanden Berghe and H. Van Landeghem 2004.
The State of the Art of Nurse Rostering. Journal of Scheduling 7(6) 441.
[35] Burke, E. K. and G. Kendall, Eds. (2005). Search Methodologies: Introductory
Tutorials in Optimization and Decision Support Techniques Springer. New York, NY. Cachon,
G. P. and C. Terwiesch 2006. Matching Supply With Demand, McGraw-Hill Irwin. New York,
NY.
[36] Cachon, G. P. and C. Terwiesch 2006. Matching Supply With Demand, McGraw-Hill
Irwin. New York, NY.
[37] Cezik, M. and P. L'Ecuyer 2007. Staffing Multiskill Call Centers via Linear
Programming and Simulation. Working Paper 34p.
[38] Charnes, A., W. W. Cooper and R. J. Niehaus 1978. Management science approaches
to manpower planning and organization design, North-Holland Publishing Co. Amsterdam;
New York.
[39] Dantzig, G. B. 1954. A Comment on Edie's "Traffic Delays at Toll Booths". Journal
of the Operations Research Society of America 2(3) 339-341.
[40] Dantzig, G. B. 1955. Linear Programming under Uncertainty. Management Science
1(3/4) 197-206.
[41] Dantzig, G. B. and G. Infanger 1993. Multi-stage stochastic linear programs for
portfolio optimization. Annals of Operations Research 45((1993)) 59-76.
[42] Dupačová, J. 1995. Postoptimality for Multistage stochastic linear programs. Annals
of Operations Research 56(1995) 65-78.
[43] Dupačová, J., G. Consigli and S. W. Wallace 2000. Scenarios for multistage stochastic
programs. Annals of Operations Research 100.
[44] Dupačová, J., N. Gröwe-Kuska and W. Römisch 2003. Scenario reduction in stochastic
programming. Mathematical Programming 95(3) 493-511.
[45] Dupacova, J. and R. Wets 1988. Asymptotic Behavior of Statistical Estimators and of
Optimal Solutions of Stochastic Optimization Problems. The Annals of Statistics 16(4) 1517-
1549.
[46] Ebert, R. J. 1976. Aggregate Planning with Learning Curve Productivity. Management
Science 23(2) 171-182.
[47] Ekmekçiu 2015: Optimizing a call center performance using queueing models - an
Albanian case. 5th INTERNATIONAL CONFERENCE Compliance of the standards in South-
Eastern European countries with the harmonized standards of European Union, 83-98
[48] Ekmekçiu, Muça, Naço 2016: Performance Indicators Analysis inside a Call Center
Using a Simulation Program. International Journal of Business and Technology: Vol. 4 : Iss. 2
, Article 7.
[49] Ekmekçiu, Muça 2015: QUEUE THEORY VS. SIMULATION IN CALL CENTERS.
SPNA 2015 30-42

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
134
[50] Ekmekçiu 2017: Queuing Models – A call Center Case. International Journal of
Science and Research (IJSR), ISSN (Online): 2319-7064, Index Copernicus Value (2015):
78.96 | Impact Factor (2015): 6.391 Volume 6 Issue 2, February 2017 727-733
[51] Ekmekçiu 2017: Limited Agents Mix-Training in Operations – A call Center Case.
International Journal of Science and Research (IJSR), ISSN (Online): 2319-7064, Index
Copernicus Value (2015): 78.96 | Impact Factor (2015): 6.391 Volume 6 Issue 10, October 2017
147-152
[52] Ekmekçiu 2016: Scheduling a Call Center utilizing a Stochastic Model. Journal of
Multidisciplinary Engineering Science and Technology (JMEST), ISSN: 2458-9403, Vol. 3
Issue 11, November – 2016 5921-5933
[53] Fang, K.-T. and M.-L. Du 1998. Uniform Design v 3.0, Hong Kong Baptist University.
[54] Fang, K.-T. and D. K. J. Lin (2003). Uniform Experiment Design and their Application
in Industry. Handbook of Statistics. R. Khattree and C. R. Rao, Elsevier. Vol 22.
[55] Fang, K.-T., D. K. J. Lin, P. Winker and Y. Zhang 2000. Uniform Design: Theory and
Application. Technometrics 42(3) 237-248.
[56] FIAA 2018 (http://fiaalbania.al/members-list/teleperformance-albania-a-m-s-sh-p-k/)
[57] Forbes, A. F. 1971. Non-Parametric Methods of Estimating the Survivor Function. The
Statistician 20(1, Statistics and Manpower Planning in the Firm) 27-52.
[58] Freimer, M. B., D. J. Thomas and J. T. Linderoth 2006. Reducing Bias in Stochastic
Linear Programs with Sampling Methods. Working Paper 37p.
[59] Fu, M. C. 2002. Optimization for Simulation: Theory vs. Practice. INFORMS Journal
on Computing 14(3) 192-215.
[60] Gaballa, A. and W. Pearce 1979. Telephone Sales Manpower Planning at Qantas.
Interfaces 9(3) 9p.
[61] Gaimon, C. 1997. Planning Information Technology-Knowledge Worker Systems.
Management Science 43(9) 1308-1328.
[62] Gaimon, C. and G. L. Thompson 1984. A Distributed Parameter Cohort Personnel
Planning Model that Uses Cross-Sectional Data. Management Science 30(6) 750-764.
[63] Gans, N., G. Koole and A. Mandelbaum 2003. Telephone call centers: Tutorial,
review, and research prospects. Manufacturing & Service Operations Management 5(2) 79-141.
[64] Gans, N. and Y.-P. Zhou 2002. Managing learning and turnover in employee staffing.
Operations Research 50(6) 991.
[65] Gans, N. and Y.-P. Zhou 2007. Call-Routing Schemes for Call-Center Outsourcing.
Manufacturing & Service Operations Management 9(1) 33-51.
[66] Garnett, O., A. Mandelbaum and M. I. Reiman 2002. Designing a Call Center with
impatient customers. Manufacturing & Service Operations Management 4(3) 208-227.
[67] Gass, S. I., R. W. Collins, C. W. Meinhardt, D. M. Lemon and M. D. Gillette 1988.
The Army Manpower Long-Range Planning System. Operations Research 36(1) 5- 17.
[68] Gassman, H. I. 1990. MSLip: A computer code for the multistage stochastic linear
programming problem. Mathematical Programming 47 407-423.
[69] Gendreau, M. and J.-Y. Potvin (2005). Tabu Search. Search Methodologies:
Introductory Tutorials in Optimization and Decision Support Techniques. E. K. Burke and G.
Kendall. New York, NY, Springer: 165-186.
[70] Geoffrion, A. M. 1970. Elements of Large-Scale Mathematical Programming: Part I:
Concepts. Management Science 16(11, Theory Series) 652-675.
[71] Glover, F. and G. A. Kochenberger 2003. Handbook of metaheuristics, Kluwer
Academic Publishers. Boston.
[72] Green, L. and P. Kolesar 1991. The Pointwise Stationary Approximation for Queues
with Nonstationary Arrivals. Management Science 37(1) 84-97.
[73] Green, L. V., P. Kolesar and J. Soares 2003. An Improved Heuristic for Staffing
Telephone Call Centers with Limited Operating Hours. Production and Operations Management
12(1) 46-61.
[74] Green, L. V. and P. J. Kolesar 1997. The Lagged PSA for Estimating Peak Congestion
in Multiserver Markovian Queues with Periodic Arrival Rates. Management Science 43(1) 80-
87.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
135
[75] Green, L. V., P. J. Kolesar and J. Soares 2001. Improving the SIPP Approach for
Staffing Service Systems That Have Cyclic Demands. Operations Research 49(4) 549-564.
[76] Green, L. V., P. J. Kolesar and W. Whitt 2005. Coping with Time-Varying Demand
when Setting Staffing Requirements for a Service System. Working Paper 58p. Grinold, R. C.
1976. Manpower Planning with Uncertain Requirements. Operations Research 24(3) 387-399.
[77] Halfin, S. and W. Whitt 1981. Heavy-Traffic Limits for Queues with Many
Exponential Servers. Operations Research 29(3) 567-588.
[78] Hall, R. W. 1991. Queueing methods: for services and manufacturing, Prentice Hall.
Englewood Cliffs, NJ.
[79] Hansen, P. and N. Mladenovic 2001. Variable neighborhood search: Principles and
applications. European Journal of Operational Research 130(3) 449-467.
[80] Hansen, P. and N. Mladenovic (2005). Variable Neighborhood Search. Search
Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques. E. K.
Burke and G. Kendall. New York, NY, Springer: 211-238.
[81] Hanssmann, F. and S. W. Hess 1960. A Linear Programming Approach to Production
and Employment Scheduling. Management Technology 1(1) 46-51.
[82] Harrison, T. P. and J. E. Ketz 1989. Modeling Learning Effects via Successive Linear
Programming. European Journal of Operational Research 40(1) 78-84.
[83] Henderson, D., S. H. Jacobson and A. W. Johnson (2003). The Theory and Practice of
Simulated Annealing. Handbook of metaheuristics. F. Glover and G. A. Kochenberger. Boston,
Kluwer Academic Publishers.
[84] Henderson, W. B. and W. L. Berry 1976. Heuristic Methods for Telephone Operator
Shift Scheduling: An Experimental Analysis. Management Science 22(12) 1372-1380.
[85] Higle, J. L. 2005. Stochastic Programming: Optimization When Uncertainty Matters.
Tutorials in Operations Research.
[86] Higle, J. L., B. Rayco and S. Sen 2004. Stochastic Scenario Decomposition for
MultiStage Stochastic Programs. Working Paper 41p.
[87] Higle, J. L. and S. Sen 1996. Stochastic decomposition: a statistical method for large
scale stochastic linear programming, Kluwer. Dordrecht; Boston.
[88] Higle, J. L. and S. Sen 2006. Multistage stochastic convex programs: Duality and its
implications. Annals of Operations Research 142 129-146.
[89] Holt, C. C., F. Modigliani, J. F. Muth and H. A. Simon 1960. Planning production,
inventories, and work force, Prentice-Hall. Englewood Cliffs, N.Y.
[90] Holz, B. W. and J. M. Wroth 1980. Improving Strength Forecasts: Support For Army
Manpower Management. Interfaces 10(6) 37.
[91] Hoyland, K. and S. W. Wallace 2001. Generating Scenario Trees for Multistage
Decision Problems. Management Science 47(2) 295-307.
[92] Huang, C. C., I. Vertinsky and W. T. Ziemba 1977. Sharp Bounds on the Value of
Perfect Information. Operations Research 25(1) 128-139.
[93] Jennings, O. B. and A. Mandelbaum 1996. Server staffing to meet time-varying
demand. Management Science 42(10) 1383.
[94] Jennings, O. B., A. Mandelbaum, W. A. Massey and W. Whitt 1996. Server Staffing
to Meet Time-Varying Demand. Management Science 42(10) 1383-1394.
[95] Johnson, M. E. 1987. Multivariate statistical simulation, Wiley. New York.
[96] Kall, P. 1976. Stochastic linear programming, Springer-Verlag. Berlin; New York.
[97] Kall, P. and J. Mayer 2005. Stochastic linear programming: models, theory, and
computation, Springer Science. New York.
[98] Kall, P. and S. W. Wallace 1994. Stochastic programming, Wiley. Chichester; New
York.
[99] King, A. J. and R. T. Rockafeller 1993. Asymptotic Theory for Solutions in Statistical
Estimation and Stochastic Programming. Mathematics of Operations Research 18(1) 148-162.
[100] Kleywegt, A. J., A. Shapiro and T. Homem-de-Mello 2001. The Sample Average
Approximation Method for Stochastic Discrete Optimization. SIAM Journal of Optimization
12(2) 479-502.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
136
[101] Koole, G. and A. Pot 2005. An Overview of Routing and Staffing in Multi-Skill
Contact Centers. Working Paper 1-32p.
[102] Koole, G. and E. van der Sluis 2003. Optimal shift scheduling with a global service
level constraint. IIE Transactions 35 1049-1055.
[103] Krass, I. A., M. C. Pinar, T. J. Thompson and S. A. Zenios 1994. A Network Model to
Maximize Navy Personnel Readiness and Its Solution. Management Science 40(5) 647-661.
[104] Kutner, M. H., C. Nachtsheim, J. Neter and W. Li 2005. Applied linear statistical
models, McGraw-Hill/Irwin. Boston; New York.
[105] L'Ecuyer, P. 1999. Good Parameters and Implementations for Combined Multiple
Recursive Random Number Generators. Operations Research 47(1) 159-164.
[106] Lasdon, L. S. 2002. Optimization theory for large systems, Macmillan. [New York].
[107] Law, A. M. 2007. Simulation modeling and analysis, McGraw-Hill. Boston.
[108] Law, A. M. and W. D. Kelton 2000. Simulation modeling and analysis, McGraw-Hill.
Boston.
[109] Linderoth, J. T., A. Shapiro and S. Wright 2006. The empirical behavior of sampling
methods for stochastic programming. Annals of Operations Research 142(1) 215-241.
[110] Madansky, A. 1960. Inequalities for Stochastic Linear Programming Problems.
Management Science 6(2) 197-204.
[111] Mak, W.-K., D. P. Morton and R. K. Wood 1999. Monte Carlo bounding techniques
for determining solution quality in stochastic programs. Operations Research Letters 24(1-2)
47-56.
[112] Mandelbaum, A. and S. Zeltyn 2004. Service Engineering in Action: The Palm/Erlang-
A Queue, with Applications to Call Centers Draft, December 2004. Working Paper p.
Mandelbaum A., Sakov A. and Z. S. 2001. Empirical Analysis of a Call Center. Working Paper
73p.
[113] Mapo Online 2015: https://gazetamapo.al/call-center-biznesi-qe-vijon-lulezimin/
[114] Mason, A. J., D. M. Ryan and D. M. Panton 1998. Integrated Simulation, Heuristic
and Optimisation Approaches to Staff Scheduling. Operations Research 46(2) 161- 175.
[115] McKay, M. D., R. J. Beckman and W. J. Conover 1979. A Comparison of Three
Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer
Code. Technometrics 21(2) 239-245.
[116] Miller, A. C., III and T. R. Rice 1983. Discrete Approximations of Probability
Distributions. Management Science 29(3) 352-362.
[117] Mo, Y., T. P. Harrison and R. R. Barton 2006. Solving Stochastic Programming
Models in Supply-Chain Design using Sampling Heuristics. Working Paper 21p.
[118] Morey, R. C. and J. M. McCann 1980. Evaluating and Improving Resource Allocation
for Navy Recruiting. Management Science 26(12, Application Series) 1198-1210.
[119] Nemhauser, G. L. and L. A. Wolsey 1988. Integer and combinatorial optimization,
Wiley. New York.
[120] Papadimitriou, C. H. and K. Steiglitz 1998. Combinatorial optimization: algorithms
and complexity, Dover Publications. Mineola, N.Y.
[121] Pflug, G. C. 1996. Optimization of stochastic models: the interface between simulation
and optimization, Kluwer Academic. Boston, Mass. Pflug, G. C. 2001. Scenario tree generation
for multiperiod financial optimization by optimal discretization. Mathematical Programming
89(2) 251-271.
[122] Pinedo, M. 2005. Planning and scheduling in manufacturing and services, Springer.
New York, NY.
[123] Prekopa, A. 1995. Stochastic programming, Kluwer Academic Publishers. Dordrecht;
Boston.
[124] Reeves, C. (2003). Genetic Algorithms. Handbook of metaheuristics. F. Glover and G.
A. Kochenberger. Boston, Kluwer Academic Publishers.
[125] Robbins, T. R. 2007. Addressing Arrival Rate Uncertainty in Call Center Workforce
Management. 2007 IEEE/INFORMS International Conference on Service Operations and
Logistics, and Informatics. Philadelphia, PA, Penn State University: 6.

MODELE TË RADHËVE DHE SIMULIMI TË APLIKUARA NË CALL CENTER - Ditila Ekmekçiu
137
[126] Robbins, T. R., D. J. Medeiros and P. Dum 2006. Evaluating Arrival Rate Uncertainty
in Call Centers. Proceedings of the 2006 Winter Simulation Conference, Monterey, CA.
[127] Rockafellar, R. T. and R. J.-B. Wets 1991. Sceanrios and policy aggregation
optimization under uncertainty. Mathematics of Operations Research 16(1) 119- 147.
[128] Santner, T. J., B. J. Williams and W. Notz 2003. The design and analysis of computer
experiments, Springer. New York.
[129] Sastry, K., D. Goldberg and G. Kendall (2005). Genetic Algorithms. Search
Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques. E. K.
Burke and G. Kendall. New York, NY: 97-126.
[130] Schindler, S. and T. Semmel 1993. Station Staffing at Pan American World Airways.
Interfaces 23(3) 91-98.
[131] Segal, M. 1974. The Operator-Scheduling Problem: A Network-Flow Approach.
Operations Research 22(4) 808-823.
[132] Shapiro, A. 1991. Asymptotic analysis of stochastic programs. Annals of Operations
Research 30 169-186.
[133] Shapiro, A. and T. Homem-de-Mello 2000. On the Rate of Convergence of Optimal
Solutions of Monte Carlo Approximations of Stochastic Programs. SIAM Journal of
Optimization 11(1) 70-86.
[134] Shrimpton, D. and A. M. Newman 2005. The US Army Uses a Network Optimization
Model to Designate Career Fields for Officers. Interfaces 35(3) 230-237.
[135] Simpson, T. W., D. K. J. Lin and W. Chen 2001. Sampling Strategies for Computer
Experiments: Design and Analysis. International Journal of Reliability and Application 2(3)
209-240.
[136] Teleperformance 2015. http://teleperformance.com/en-us/
[137] Thompson, G. M. 1995. Improved Implicit Optimal Modeling of the Labor Shift
Scheduling Problem. Management Science 41(4) 595-607.
[138] Wallace, R. B. and W. Whitt 2005. A Staffing Algorithm for Call Centers with Skill-
Based Routing. Manufacturing & Service Operations Management 7(4) 276-294.
[139] Wang, Y., D. K. J. Lin and K.-T. Fang 1995. Designing Outer Array Points. Journal of
Quality Technology 27(3) 226-241.
[140] Warner, D. M. 1976. Scheduling Nursing Personnel according to Nursing Preference:
A Mathematical Programming Approach. Operations Research 24(5, Special Issue on Health
Care) 842-856.
[141] Warner, D. M. and J. Prawda 1972. A Mathematical Programming Model for
Scheduling Nursing Personnel in a Hospital. Management Science 19(4, Application Series,
Part 1) 411-422.
[142] Whitt, W. 1989. An Interpolation Approximation for the Mean Workload in a GI/G/1
Queue. Operations Research 37(6) 936-952.
[143] Whitt, W. 2006a. Sensitivity of Performance in the Erlang A Model to Changes in the
Model Parameters. Operations Research 54(2) 247-260.
[144] Whitt, W. 2006b. Staffing a Call Center with Uncertain Arrival Rate and Absenteeism.
Production and Operations Management 15(1) 88-102.
[145] Wolff, R. W. 1982. Poisson Arrivals See Time Averages. Operations Research 30(2)
223-231.
[146] Wolff, R. W. 1989. Stochastic modeling and the theory of queues, Prentice Hall.
Englewood Cliffs, N.J.
[147] Wolsey, L. A. 1998. Integer programming, J. Wiley. New York. Yu, G., J. Pachon, B.
Thengvall, D. Chandler and A. Wilson 2004. Optimizing Pilot Planning and Training for
Continental Airlines. Interfaces 34(4) 253.





























