Embed Size (px)
Citation preview

腾 讯 大 讲 堂
第四十八期
研发管理部
大讲堂主页: http://km.oa.com/class与讲师互动: http://km.oa.com/group/class

数据库查询优化浅析数据库查询优化浅析
AlexyangAlexyang
无线产品部无线产品部
2008101320081013

提纲提纲
应用级查询优化应用级查询优化
SQLSQL 语句的解析方式语句的解析方式
索引的本质以及调优索引的本质以及调优
分析执行计划分析执行计划

提纲提纲
应用级查询优化应用级查询优化
SQLSQL 语句的解析方式语句的解析方式
索引的本质以及调优索引的本质以及调优
分析执行计划分析执行计划

一、需要性能一、需要性能 // 查询优化的原查询优化的原因 因 影响性能的因素:整个系统环境影响性能的因素:整个系统环境
软件:操作系统、中间件、应用程序、数软件:操作系统、中间件、应用程序、数
据库据库
硬件:硬件: CPUCPU 、内存、磁盘、网络、内存、磁盘、网络
上面任何一个都可能成为系统的性能瓶颈上面任何一个都可能成为系统的性能瓶颈

系统级性能优化的点系统级性能优化的点
操作系统:虚拟内存、文件系统格式、系统参数操作系统:虚拟内存、文件系统格式、系统参数(( LINUXLINUX ))
中间件:日志、部署时去掉打印信息(打印信息中间件:日志、部署时去掉打印信息(打印信息对性能影响较大对性能影响较大 )) 、工作线程数、连接池、、工作线程数、连接池、 JAVAJAVA垃圾回收模式、垃圾回收模式、 JAVAJAVA 内存设置内存设置
应用程序:使用连接池、合理的业务设计、尽可应用程序:使用连接池、合理的业务设计、尽可能不要对数据库操作进行同步、能不要对数据库操作进行同步、 JAVAJAVA 程序的性能程序的性能优化(参考网络资源)优化(参考网络资源)
数据库:工作线程、数据库:工作线程、 I/OI/O 线程、内存配置等、索线程、内存配置等、索引的利用、引的利用、 SQLSQL 改写、服务器代码改进改写、服务器代码改进

这里我们主要考虑以下两个点这里我们主要考虑以下两个点
应用层存在问题。应用层存在问题。
数据库层存在问题。数据库层存在问题。

合理的逻辑设计合理的逻辑设计
以某实际应用系统为例,原来任务管理模块并发用户数只有以某实际应用系统为例,原来任务管理模块并发用户数只有 1515 个,个,
该模块用来显示所有待处理的任务,以及每个任务的里程碑个数。该模块用来显示所有待处理的任务,以及每个任务的里程碑个数。
经过检查,发现其实现如下:经过检查,发现其实现如下:
执行语句执行语句 SELECT COUNT(*) FROM TASK;SELECT COUNT(*) FROM TASK;
select task_id from task order by task_id desc;select task_id from task order by task_id desc;
对结果集中的每条记录对结果集中的每条记录
{{
SELECT * FROM TASK_STEP WHERE TASK_STEP.TASK_ID=?SELECT * FROM TASK_STEP WHERE TASK_STEP.TASK_ID=?
}}
分析:如果分析:如果 TASKTASK 表有表有 1000010000 条记录,需要向数据库发送条记录,需要向数据库发送 1000010000 个查询。个查询。
假设通讯使用了假设通讯使用了 100ms100ms ,每个查询的执行时间是,每个查询的执行时间是 20ms20ms 。使用的时间为。使用的时间为::
(100ms+20ms)*10000=1200s=20min(100ms+20ms)*10000=1200s=20min

解决方案解决方案
select task_step.* select task_step.*
from task,task_stepfrom task,task_step
where task_step.task_id = task.task_idwhere task_step.task_id = task.task_id
order by task.task_id desc;order by task.task_id desc;
备注:备注:
11 )继续对)继续对 task_step.*task_step.* 处理,减少网络通讯量。处理,减少网络通讯量。
22 )默认看到自己的任务,提供连接查询其他任务)默认看到自己的任务,提供连接查询其他任务
。。

尽量使用数据库提供的功能尽量使用数据库提供的功能
在某实际应用系统中,对于每个任务、日记等对象都有一在某实际应用系统中,对于每个任务、日记等对象都有一个唯一的个唯一的 IDID ,该系统使用数据库的一个表的一条整型记,该系统使用数据库的一个表的一条整型记录来维持。录来维持。
当新建一个任务时,取用该表的当前记录值,操作完毕后当新建一个任务时,取用该表的当前记录值,操作完毕后加加 11 。为了防止不同对象使用相同。为了防止不同对象使用相同 IDID ,使用如下方法来,使用如下方法来保证:保证:
int temp = 0;int temp = 0;
synchronized{synchronized{
执行执行 SELECT * FROM OBJECTID;SELECT * FROM OBJECTID;
temp = temp = 结果集中的结果集中的 idid
update update 结果集中的结果集中的 idid (( id+1id+1 ))
}}
insert into task values(temp,...);insert into task values(temp,...);

解决方案解决方案
create sequence myseq increment by 1;create sequence myseq increment by 1;
insert into task insert into task
values(myseq.nextval,...);values(myseq.nextval,...);

二、二、 SQLSQL 语句的解析方式语句的解析方式
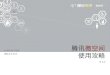
SQL 语句的处理过程

语法 / 词法分析
负责解析 SQL命令和过程性语句块
过滤注释 , 解析参数
使用成熟的工具(如 YACC/LEX )生成
灵活的语法规则定义
便于语法的扩展与修改
生成统一格式的语法树
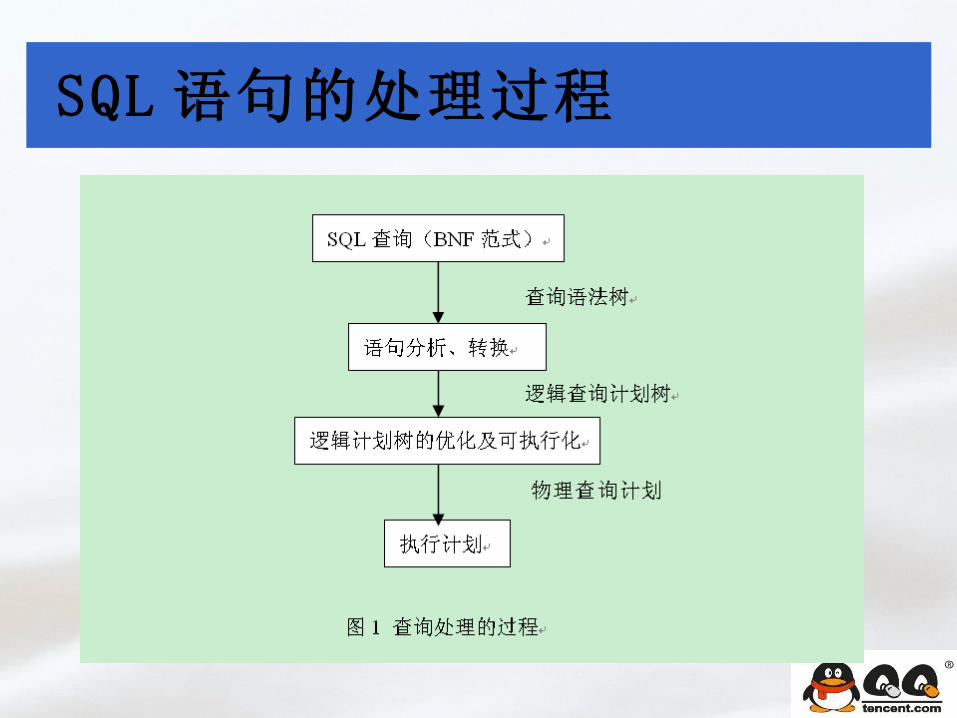
对应的语法结构
Select * from t1, t2, t3;
par_from_tv_list_struct 结构
par_from_tv_list_t* from_tv_list;
par_from_tv_t* from_tv
par_from_tv_list_struct 结构
par_from_tv_list_t* from_tv_list;
par_from_tv_t* from_tv
par_from_tv_list_struct 结构
par_from_tv_t* from_tv
par_from_tv_struct 结构
T1
par_from_tv_struct 结构
T2
par_from_tv_struct 结构
T3
规则2 规
则1

语义分析
数据库对象名字解析
合法性检查
内部 ID的转换
权限检查
语法树数据结构的简化与预处理
DDL 语句分解为对系统表的 DML
视图对象的替换等

代价优化器
接受语义分析的输入
统计信息的分析 数据分布
统计直方图
代价的计算 基于统计信息
操作符号的选择
基于成本的最优执行路径选择
生成优化的执行计划

基于操作符的执行计划
物理操作符功能简单专一 ,完成特定的数据库操作
如 :连接,过滤 ,排序等
执行计划操作符的组合 ,构成树型的执行计划
执行时 ,数据从叶子向根流动
在根汇集成结果集 ,或者得到结果状态
计划被自动缓存 ,以备重用
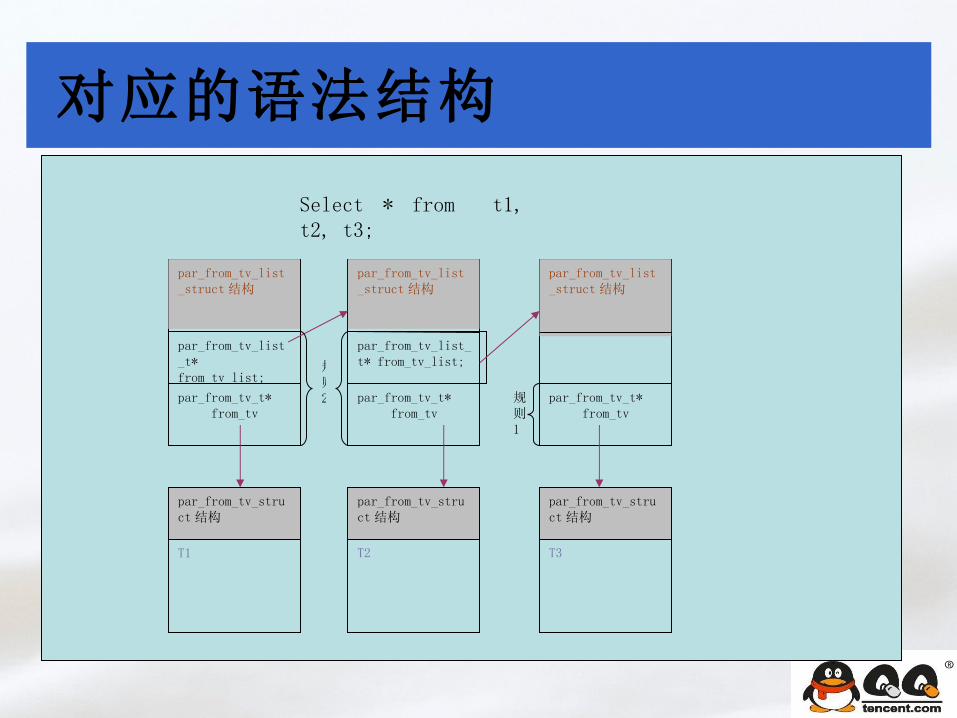
实例分析
select *
from A, B, C, D
where A.a = B.b
and B.b1 = C.c
and C.c1 = D.d
and A.a1 >123

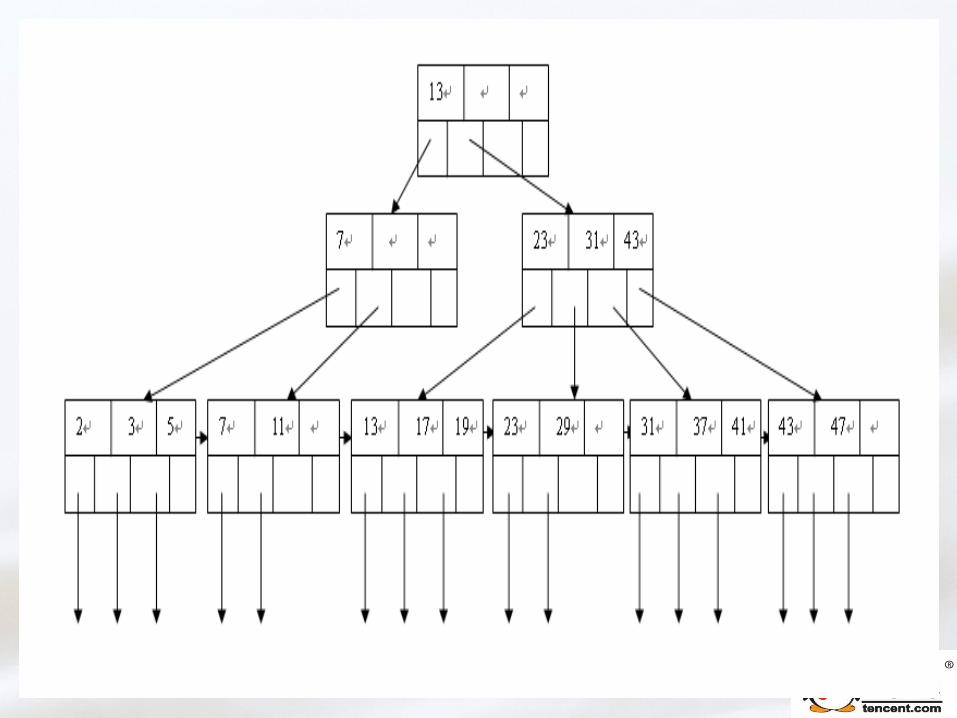
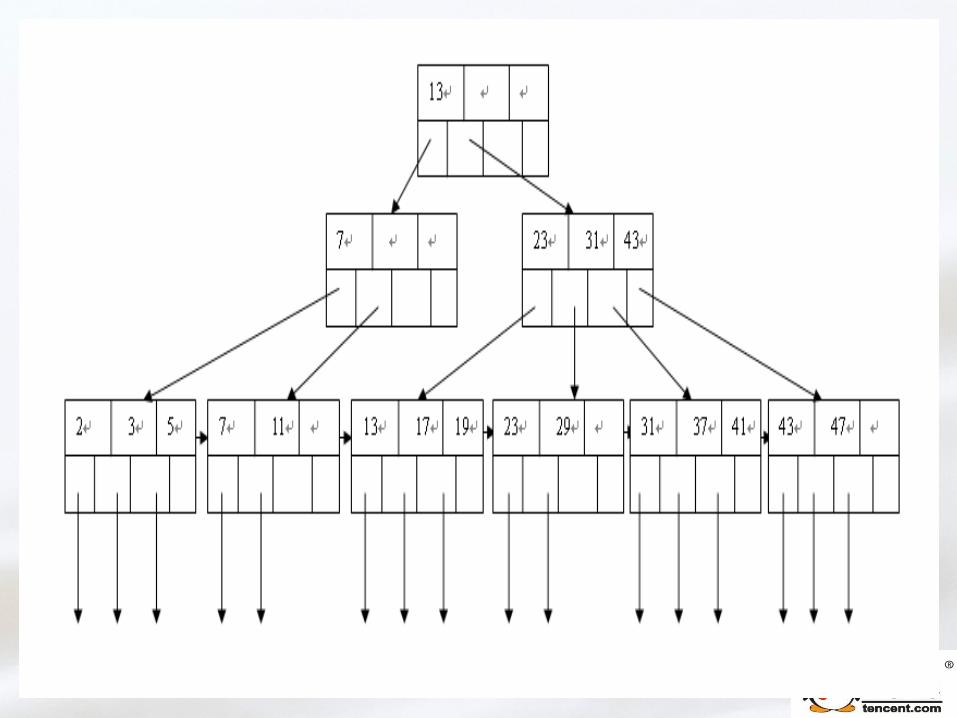
三、索引的本质以及调优三、索引的本质以及调优

需要了解的概念需要了解的概念
索引 索引
聚集索引、非聚集索引聚集索引、非聚集索引
唯一索引、非唯一索引唯一索引、非唯一索引
单列索引、组合索引单列索引、组合索引
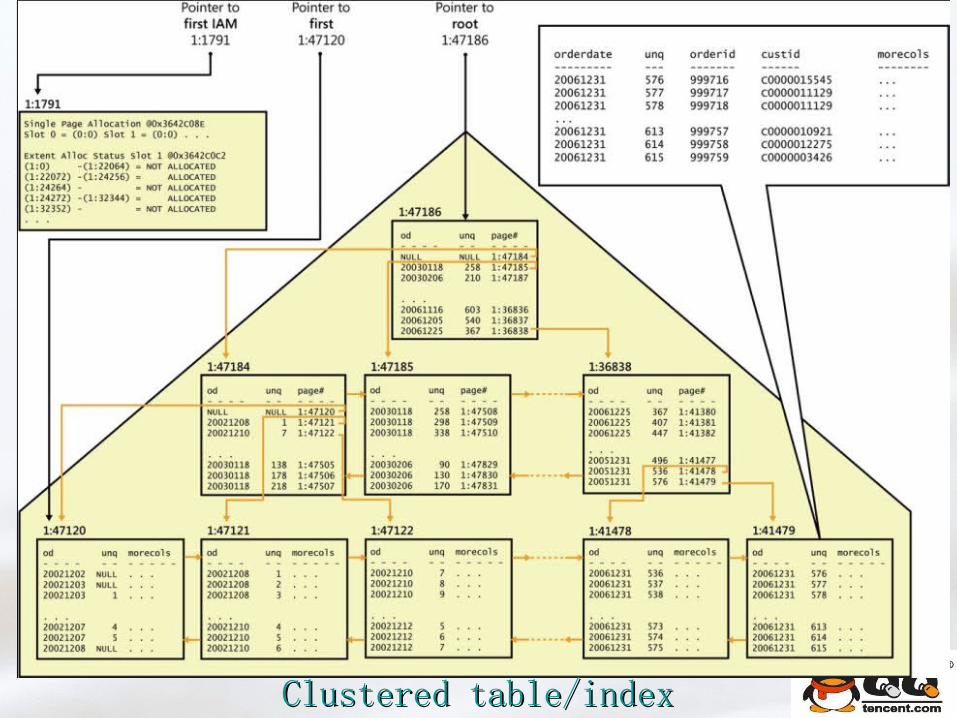
Clustered table/indexClustered table/index
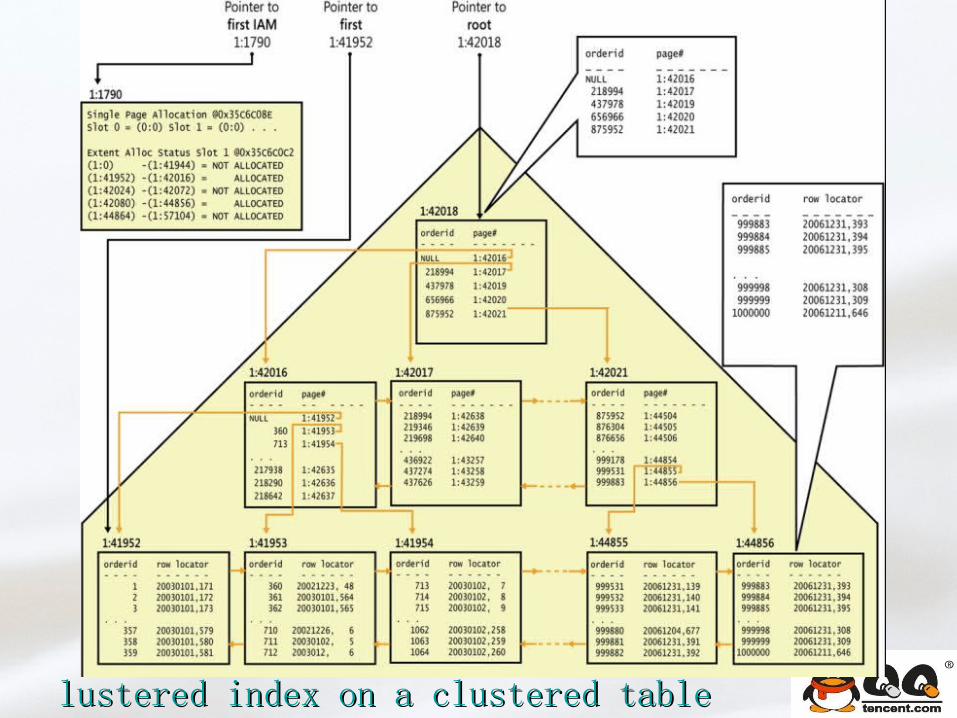
lustered index on a clustered tablelustered index on a clustered table
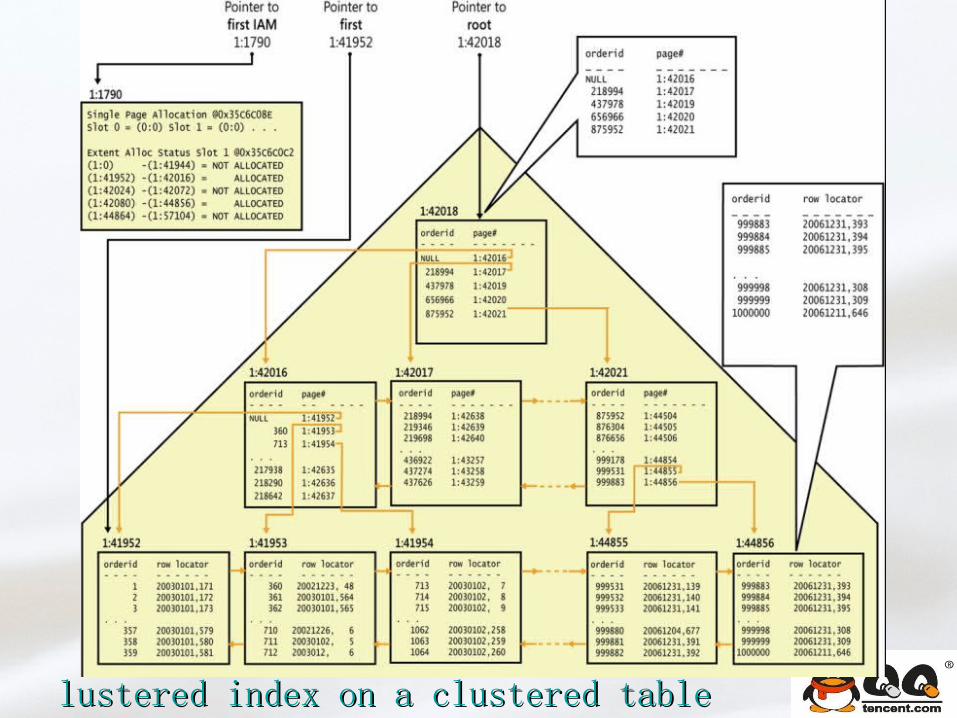
lustered index on a clustered tablelustered index on a clustered table
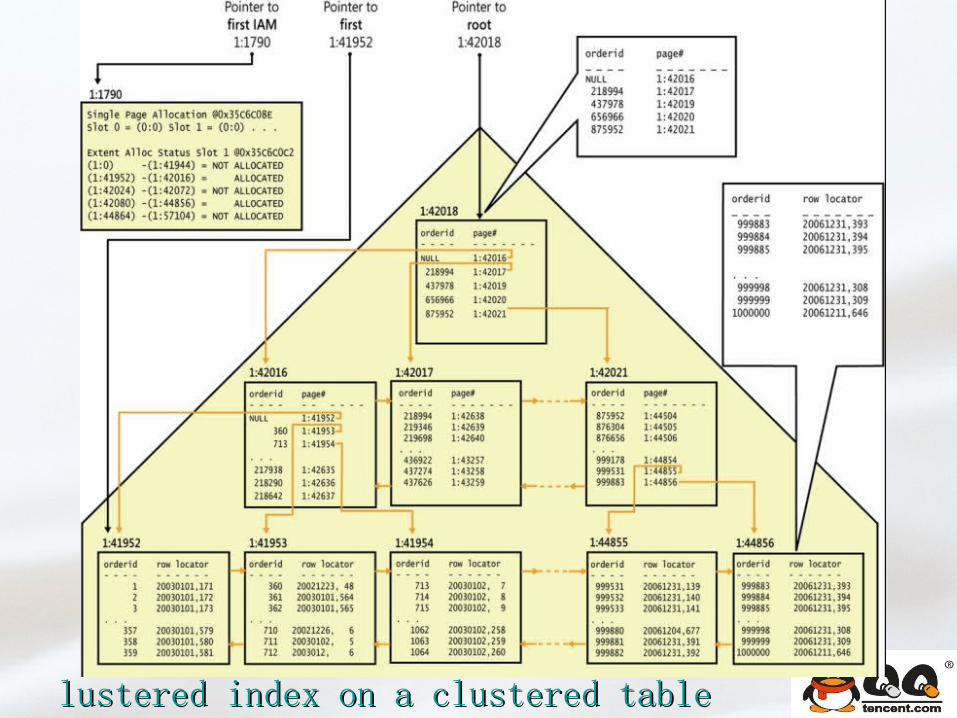
lustered index on a clustered tablelustered index on a clustered table
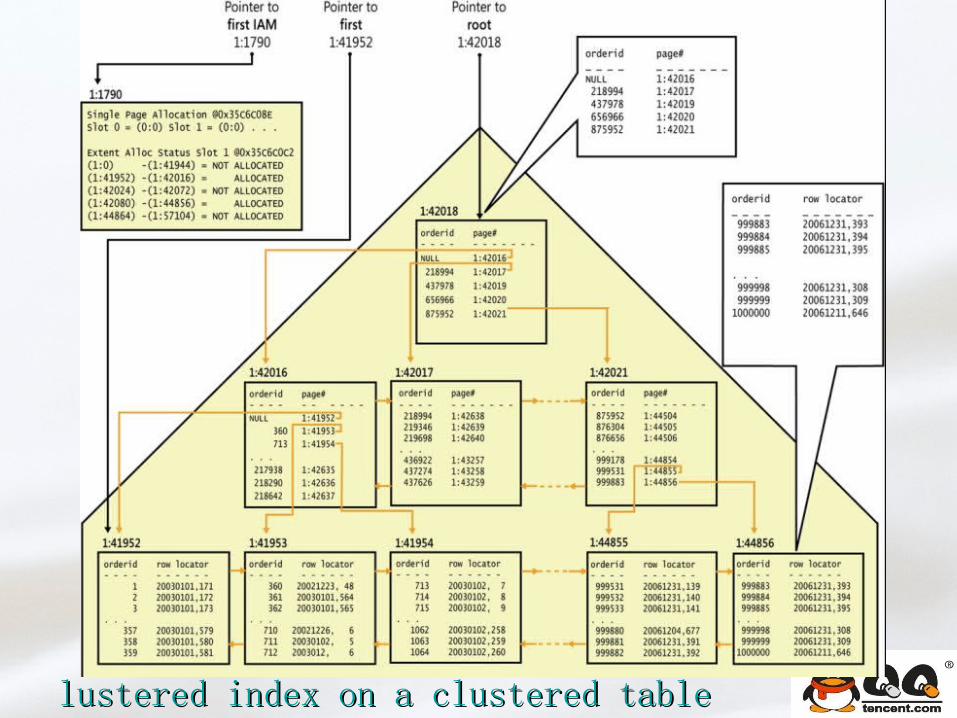
lustered index on a clustered tablelustered index on a clustered table

索引调优的索引调优的 66 个知识点个知识点
11 、将索引和数据存放到不同的文件组、将索引和数据存放到不同的文件组
22 、组合索引的使用、组合索引的使用
33 、唯一索引与非唯一索引的差异、唯一索引与非唯一索引的差异
44、非聚集索引的作用、非聚集索引的作用
55 、是不是使用非聚集索引的查询都需要进行、是不是使用非聚集索引的查询都需要进行
聚集的查询聚集的查询
66、创建索引的规则、创建索引的规则

执行计划执行计划
单表执行计划单表执行计划
多表执行计划多表执行计划

多表连接执行计划多表连接执行计划
11 、嵌套连接、嵌套连接
22 、、 HASHHASH 连接连接
33 、合并连接、合并连接
44、反合并连接、反合并连接
55 、半连接、半连接
66、反半连接、反半连接

谢谢谢谢 !!