Embed Size (px)
Citation preview

機械学習
第5回 分類(パーセプトロン)
白浜 公章

回帰(Regression) vs. 分類(Classification)
正確な予測ができるモデルを学習する
(前回まで)回帰問題事例:(特徴、 ラベル(連続値))
正確なクラス分けができるモデルを学習する
(今回から)分類問題事例:(特徴、 ラベル(離散値))
歳入
株価
特徴(横軸)
ラベル(縦軸)
鼻の大きさ
耳の形
特徴1
特徴2
ラベル(犬か猫かというクラス)

今日のポイント
正確なクラス分けができるモデルを学習する
分類問題事例:(特徴、 ラベル(離散値))
(トピック)• パーセプトロン• ソフトマックス・コスト関数
分類は、現在の機械学習(人工知能)の核をなす概念なので、必ず抑えておくこと!前回の回帰を少し変更すれば、分類を定式化できるので、安心していい。
鼻の大きさ
耳の形
特徴1
特徴2
ラベル(犬か猫かというクラス)
(顔検出:顔か非顔の分類)

パーセプトロンモデル(Perceptron Model)
2クラス分類:事例が、2つのうちのどちらのクラスに属するか判定する(基本!)(例:顔 vs. 非顔、ポジティブなレビュー vs. ネガティブなレビュー、特定の病気を持つ患者 vs. 持たない患者など)
線形近似
𝒙𝑝 = 𝑥1,𝑝 𝑥2,𝑝 ⋯ 𝑥𝑁,𝑝𝑇、𝑦𝑝 ∈ ℜ(連続値)
𝑁 + 1次元空間(𝒙𝑝 と𝑦𝑝)内でデータを
近似する超平面(直線)を求める
𝑏 + 𝒙𝑝𝑇𝒘 ≈ 𝑦𝑝 𝒘 = 𝑤1 𝑤2 ⋯𝑤𝑁
𝑇
線形2クラス分類
𝒙𝑝 = 𝑥1,𝑝 𝑥2,𝑝 ⋯ 𝑥𝑁,𝑝𝑇、𝑦𝑝 ∈ {−1,+1}(離散値)
𝑁次元空間(𝒙𝑝)の中で異なるラベルの事例を分割する
超平面(直線)を求める → パーセプトロンモデル
𝑏 + 𝒙𝑝𝑇𝒘 = 0 𝒘 = 𝑤1 𝑤2 ⋯𝑤𝑁
𝑇
• 𝑏 + 𝒙𝑝𝑇𝒘 > 0(𝒙𝑝が超平面の上にある)→ 𝑦𝑝 = +1
• 𝑏 + 𝒙𝑝𝑇𝒘 < 0(𝒙𝑝が超平面の下にある)→ 𝑦𝑝 = −1
扱いやすいため(後述)

パーセプトロンモデルのコスト関数
モデル(超平面)のパラメータは重み𝒘、バイアス𝑏で、各学習事例(𝒙𝑝, 𝑦𝑝)に対して、
• 𝑏 + 𝒙𝑝𝑇𝒘 > 0 if 𝑦𝑝 = +1
• 𝑏 + 𝒙𝑝𝑇𝒘 < 0 if 𝑦𝑝 = −1
下記を満たすパラメータを求めたい。1つの式にまとめると、
−𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘 < 0
うまく分類されていたら「コストゼロ」、そうでなければ「間違いの度合いに応じたコスト」とするために、
max 0,−𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
全P個の学習事例 𝒙𝑝, 𝑦𝑝 𝑝=1
𝑃に対するコストを足し合わせると、
𝑔1 𝑏,𝒘 =
𝑝=1
𝑃
max 0,−𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
よって、下記の最適化問題を解くことになる。
minimize𝑏,𝒘
𝑝=1
𝑃
max 0, −𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
学習事例が、うまく分類されていたら負(だから、ラベルを±1で定義)
回帰モデルと同じ
この表現は、色々な人工知能技術で使われる(hinge function, RectifiedLinear Unit (ReLU)と呼ばれることもある)

パーセプトロンモデルのコスト関数の問題点
minimize𝑏,𝒘
𝑝=1
𝑃
max 0, −𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
1. 𝑏 = 0,𝒘 = 0𝑁×1で最小になってしまう
2. 0と−𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘 の切り替わり時に微分できない
最急勾配法、ニュートン法が使えない
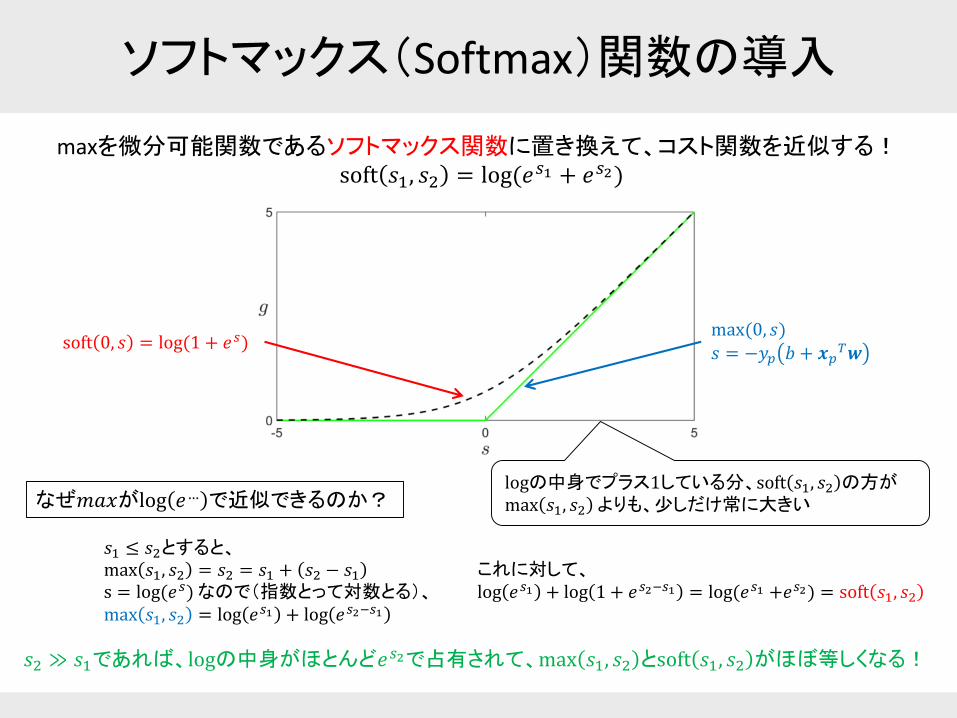
ソフトマックス(Softmax)関数の導入
max(0, 𝑠)
𝑠 = −𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
maxを微分可能関数であるソフトマックス関数に置き換えて、コスト関数を近似する!soft 𝑠1, 𝑠2 = log(𝑒𝑠1 + 𝑒𝑠2)
soft 0, 𝑠 = log(1 + 𝑒𝑠)
𝑠1 ≤ 𝑠2とすると、max 𝑠1, 𝑠2 = 𝑠2 = 𝑠1 + 𝑠2 − 𝑠1s = log(𝑒𝑠)なので(指数とって対数とる)、max 𝑠1, 𝑠2 = log 𝑒𝑠1 + log 𝑒𝑠2−𝑠1
これに対して、log 𝑒𝑠1 + log 1 + 𝑒𝑠2−𝑠1 = log(𝑒𝑠1 +𝑒𝑠2) = soft 𝑠1, 𝑠2
𝑠2 ≫ 𝑠1であれば、logの中身がほとんど𝑒𝑠2で占有されて、max 𝑠1, 𝑠2 とsoft 𝑠1, 𝑠2 がほぼ等しくなる!
なぜ𝑚𝑎𝑥がlog 𝑒… で近似できるのか?logの中身でプラス1している分、soft 𝑠1, 𝑠2 の方がmax 𝑠1, 𝑠2 よりも、少しだけ常に大きい

ソフトマックス・コスト関数
各事例に対するmaxによるコスト関数に対して、
𝑔1 𝑏,𝒘 =
𝑝=1
𝑃
max 0,−𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
maxをソフトマックス関数に置き換えると、
𝑔2 𝑏, 𝒘 =
𝑝=1
𝑃
log 1 + 𝑒−𝑦𝑝 𝑏+𝒙𝑝𝑇𝒘
というソフトマックス・コスト関数になる。
特に、maxによるコスト関数の問題は、以下の通り解決されている。1. 𝑏 = 0,𝒘 = 0𝑁×1では最小にならない(𝑒
0 = 1よりも小さくなれるから)
2. 全域で微分可能、かつ凸関数(後述) → 最急勾配法、ニュートン法で最適解が求まる
最終的に、線形2値分類のためのパーセプトロンモデルの最適化は、下記のようになる。
minimize𝑏,𝒘
𝑝=1
𝑃
log 1 + 𝑒−𝑦𝑝 𝑏+𝒙𝑝𝑇𝒘
max 0,−𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
≈ soft 0, −𝑦𝑝 𝑏 + 𝒙𝑝𝑇𝒘
= log 1 + 𝑒−𝑦𝑝 𝑏+𝒙𝑝𝑇𝒘
• (分類のための)ロジステック回帰(Logistic regression for classification)• ソフトマックス分類器(Softmax classifier)とも呼ばれる。

ソフトマックス・コスト関数の最適化
ここで、𝒙𝑝 = 1 𝑥1,𝑝 𝑥2,𝑝 ⋯ 𝑥𝑁,𝑝𝑇
𝒘 = 𝑏 𝑤1 𝑤2 ⋯𝑤𝑁𝑇
𝑔2 𝒘 =
𝑝=1
𝑃
log 1 + 𝑒−𝑦𝑝𝒙𝑝𝑇𝒘
コンパクト版
ロジステックシグモイド関数 𝜎 −𝑡 =1
1+𝑒𝑡
𝛻𝑔2 𝒘 = 𝟎 𝑁+1 ×1を直接解くのは無理
→ 最急勾配法、ニュートン法を使う
𝜕
𝜕𝑤𝑛𝑓 𝑟 𝑠 𝒘 =
𝑑𝑓
𝑑𝑟
𝑑𝑟
𝑑𝑠
𝜕
𝜕𝑤𝑛𝑠 𝒘 =
1
𝑟−𝑒−𝑠 𝑦𝑝 𝑥𝑛,𝑝 =
1
1 + 𝑒−𝑦𝑝 𝑥𝑝𝑇𝒘
−𝑒−𝑦𝑝 𝑥𝑝𝑇𝒘 𝑦𝑝 𝑥𝑛,𝑝
𝑛番目のパラメータ𝑤𝑛に関する微分:合成関数の微分で、𝑓 𝑟 = log 𝑟 , 𝑟 𝑠 = 1 + 𝑒−𝑠, 𝑠 𝒘 = 𝑦𝑝𝒙𝑝𝑇 𝒘
さらに、1
1+𝑒−𝑡−𝑒−𝑡 =
1
1+𝑒−𝑡−1
𝑒𝑡=
−1
1+𝑒𝑡= −𝜎(−𝑡)を使う。
1階微分
𝛻𝑔2 𝒘 = −
𝑝=1
𝑃
𝜎 −𝑦𝑝𝒙𝑝𝑇 𝒘 𝑦𝑝 𝒙𝑝
2階微分
𝛻2𝑔2 𝒘 =
𝑝=1
𝑃
𝜎 −𝑦𝑝𝒙𝑝𝑇 𝒘 1 − 𝜎 −𝑦𝑝𝒙𝑝
𝑇 𝒘 𝒙𝑝𝒙𝑝𝑇
1階微分の式に、合成関数の微分、• 𝜎′ 𝑡 = 𝜎 𝑡 (1 − 𝜎 𝑡 )• 𝑦𝑝
2 = 1
を適用
この2階微分をレイリー商の形に変形すれば、固有値が少なくともゼロ以上であるが証明できる→ ソフトマックス・コスト関数は凸
コード 5_perceptron.ipynb参照




















![イーストウエスト日本語学校 A1クラスの授業展開 (クラス担当 … · イーストウエスト日本語学校 A1クラスの授業展開 (クラス担当教師:磯部[担任]、伊瀬知、岡松)](https://img.pdfslide.tips/doc/110x75/5e3c25bdb32e7a10af1f3672/fffoee-a1fe-if.jpg)








