Embed Size (px)
DESCRIPTION
9 章:データの品質. 9 章のポイント. 誤差とは何か 質のよいデータとは? 標本抽出 無作為抽出(ランダムサンプリング) 標本のサイズ→大数の法則 実験(調査)のときの注意. 誤差とは何か?. 観測値(データ ) は真の値と誤差からなる 観測値=真の値+誤差 誤差には「偏り」と「偶然誤差(ばらつき)」 の 2 種類がある。. 誤差とは何か?(2). 偏り: 調査の際の不適切な質問のしかたや測定機器の狂いなどでシステマティックに真の値からずれた観測値を生み出す。 偶然誤差 観測の際に偶然に生じる誤差によるばらつき→標本が大きければだんだん小さくなる. - PowerPoint PPT Presentation
Citation preview

9 章:データの品質

9 章のポイント 誤差とは何か 質のよいデータとは? 標本抽出 無作為抽出(ランダムサンプリング) 標本のサイズ→大数の法則 実験(調査)のときの注意

誤差とは何か? 観測値(データ ) は真の値と誤差から
なる観測値=真の値+誤差
誤差には「偏り」と「偶然誤差(ばらつき)」
の 2 種類がある。

誤差とは何か?(2) 偏り:
調査の際の不適切な質問のしかたや測定機器の狂いなどでシステマティックに真の値からずれた観測値を生み出す。
偶然誤差 観測の際に偶然に生じる誤差によるばら
つき→標本が大きければだんだん小さくなる

質のよいデータとは? データに偏りがない(正確なデータ) 偶然誤差が少ない(精密なデータ)

標本とは 対象とする集団の性質を調べる際に、
集団全体をすべて実験(調査)することは不可能なので、ランダムに標本(サンプル)を抽出する。

標本抽出で重要なこと 無作為抽出
母集団の特定の下位集団のみに偏らないように名簿から無作為に抽出する
標本集団の代表性

標本のサイズ 標本が大きくなればなるほど偶然誤差
による影響が少なくなる→大数の法則 ただし、実施上の制約から無駄に大き
いサンプルにすることは好ましくない。

調査・実験の際の注意 インフォームド・コンセント 質問の仕方、実験の教示で被験者を特
定の回答へ誘導しない→偏りをなくす

10 章:クロス集計票と仮説検定

推定 標本から得られた結果に基づいて母
集団の性質はこうであるというように推論する。 現在の大学生の数学の学力は平均的に
どれくらいであろうか? 有権者の中で現在の総理大臣を支持し
ている人の割合はどれくらいであろうか?

統計的推論 データ分析を行う目的
データのもつ情報から一定の統計的推論(判断)を導くことである。
統計的推論には二つのタイプがある。 推定 仮説検定←今日の話の中心はこちら

仮説検定 母集団の性質について仮定したある事
柄(命題)が正しいかどうかを標本について調べた結果から判定すること。⇒ 偶然誤差を除外しても命題が正しいかどうかを判定する。 現在の高校生の学力は、5年前の高校生の
学力に比較して低いといえるだろうか? 男性と女性で平均初任給が異なるだろうか?

仮説検定
母集団
標本
標本抽出
データ計測
情報
統計処理
命題
仮説検定
考察
「たぶんこういう性質があるといえるだろう」
「命題が集団全体にとって正しいだろうか?」

仮説検定による判断ー事例① あるデパートでは、販売キャンペーン
のために 1 年間に何万通もの DM を出している。
従来の方法では、 DM に対する顧客の反応率は 10 %(受注の割合)であった。
このデパートの経営者は、ダイレクト・メールの方法を新しい方法に変えて効果(反応率)を高めることはできないかと考えている。

事例①つづき そこで、試験的に 1000 人(標本)に新し
い方法で D M を発送してみることにした(例えば、インターネットを利用する方法など)。
その結果によって新しい方法が効果的であると判断されたならば新しい方法に切りかえることにする。

事例①つづき では、新しい方法を用いて 1000 人に送
った結果がどれくらいあったら、新しい方法は効果的であったと言えるだろうか?
ちょっと考えてみよう。 ヒント:従来の方法の反応率は 10 %

事例①つづき 仮に反応率が 10 %以下、つまり受注数が 1000
人のうち 100 人以下であるならば、新しい方法が従来の方法よりも効果的であると思わないだろう。
それでは、受注が 102 人ならば?反応率は10.2 %であるから 10 %よりは高いがこの程度ではまだ新しい方法が効果的であると断言はできない。
では、 150 人ならば? 250 人ならばどうだろうか?

事例① つづき 通常、受注が多くなればなるほど新しい
方法が効果的であると認める方向に判断が傾いていくだろう。
10 %という従来の方法では、反応率が25 % ( 1000 人のうち 250 人の受注)という数字を出すことは難しい(可能性は少ない)と思うからである。つまり新しい方法の効果があると判断するだろう。

統計的な仮説検定へ 先ほどの事例では、新しい方法に対する反応率が
従来の方法の 10 %よりも上に大きく離れるほど新しい方法が従来の方法より効果的であると考えた。
では、具体的にどこを境界にして、すなわち受注がいくら以上であったら新しい方法が効果的であるとし、従来の方法から新しい方法へ切りかえるのだろうか?
統計学では、経営者の“直感”ではなく、客観的な基準、ルールに基づき仮説検定を行う。

仮説設定のルール 仮説は二つ設定する!
棄却したい仮説を帰無仮説とする。先の例では、「新しい方法と従来の方法には違いがない」。
帰無仮説では、データの差は全て偶然誤差であって実質的な差はないと考える。
帰無仮説の反対の仮説(証明したいと思う仮説)を対立仮説とする。先の例では、「新しい方法は、従来の方法に比べて効果が高い」。
棄却したい仮説を正しいと仮定した上で、検定を行う。自分にとって不利な条件にすることがポイント。これは、背理法の考え方に由来する。

仮説検定の論理:背理法<背理法の考え方>背理法の考え方> 命題「りんごは赤い」 赤いりんごをたくさんもって来ても、命題を証明することはできない。
しかし、「りんごは赤くない」例を一つでも示せれば、例えば青い(赤以外の)りんごをもってくれば、命題を否定できる。
この場合、帰無仮説は「りんごは赤くない」、対立仮説は「りんごは赤い」

背理法の考え方 帰無仮説がただしいとき、このような
データの特性をもつ標本が現れる確率はどのくらいか?
母集団から 100 回標本抽出をしたとして、この標本のような結果がでる確率は非常に少ない
もともとの仮説が間違っていたと結論 帰無仮説を棄却

クロス集計表とモザイク図 アメリカの自動車製造業のマーケティ
ング戦略立案 教科書 166P 年齢、性別、未婚・既婚別と所有する自
動車のタイプについての情報を分析する。 Databook フォルダの中の“ Carpool.jmp”
というサンプルデータをロード
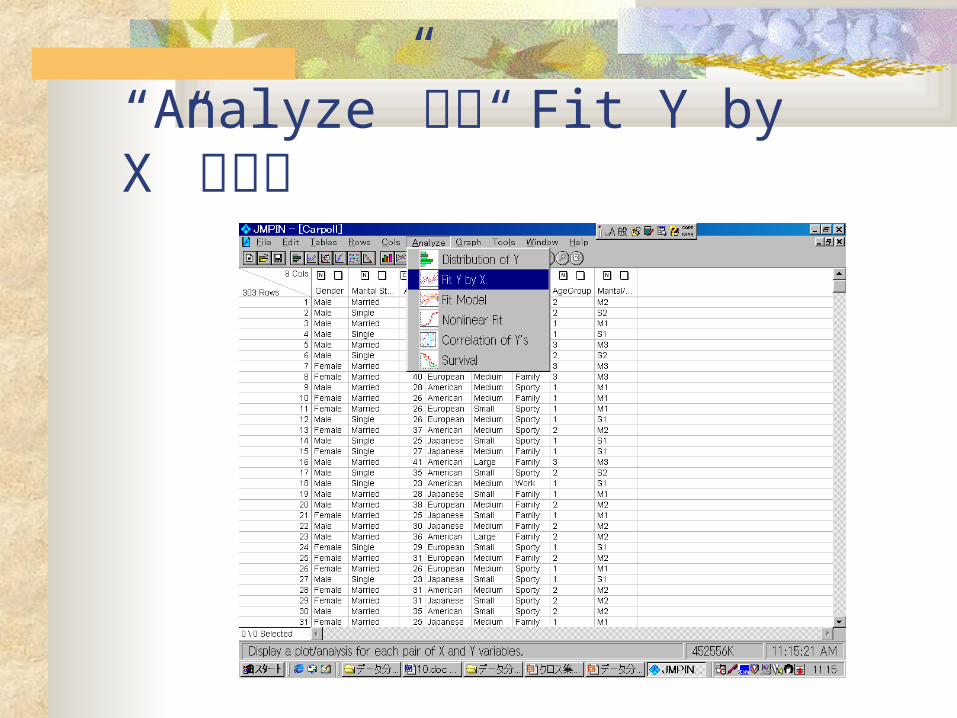
“Analyze” から“ Fit Y by X” を選択

変数の指定“Analyze” から“ Fit Y by X” で、 Y に「自動車の
タイプ( Type )」と X に「未既婚の別( Marital Status) 」を指定してみよう。
※X 、 Y がともに名義尺度又は、順序尺度の場合は、自動的にモザイク図とクロス集計表が表示される。

表示結果モザイク図Y 軸を自動車のタイプでを X 軸を未既婚の比率で分割し、色分けしている。
クロス集計表(分割表)二つの変数群の同時分布を表で表したもの。カテゴリー別のデータの数値的な情報が得られる。より詳しく見るために、%表示をしたい場合は、“ Crosstabs” 右側の三角形の印から“ Col%”( 縦方向)、“ Row%”( 横方向)、“ Total%”( 全体)を選択する。
Type By Marital Status
0
0.25
0.5
0.75
1
Married Single
Marital Status
Family
Sporty
Work
Crosstabs
Marital Status
Count
Family
Sporty
Work
Married Single
119 36
45 55
32 16
155
100
48
196 107 303
Tests
Source
Model
Error
C Total
Total Count
DF
2
299
301
303
-LogLikelihood
13.38280
289.81268
303.19548
RSquare (U)
0.0441
Test
Likelihood Ratio
Pearson
ChiSquare
26.766
26.963
Prob>ChiSq
<.0001
<.0001

表示結果の読み取り
既婚と未婚では選ぶタイプが違う。既婚の多くは、ファミリータイプの車を所有している!
クロス集計表で読むと数値的に理解できる

仮説検定( 1 ) モザイク図及びクロス集計表によって得られ
たデータを数値的、視覚的に要約して考察した。
その考察を、標本が偏りなく取られたとして、集団全体 ( 母集団)の状況の推測として利用してもよいだろうか?ある調査で得られた標本のモザイク図及びクロス集計表では、未既婚別で自動車のタイプが異なることが分かったが、それを全体に当てはめてもよいのだろうか?単なる標本誤差による偶然の結果の可能性は?

仮説検定( 2 )
母集団
標本
標本抽出
データ計測
情報
統計処理
命題
仮説検定
考察
「たぶんこういう性質があるといえるだろう」
「命題が集団全体にとって正しいだろうか?」

仮説検定の論理( 1 )■ 命題の正しさを証明するために、2つの仮説を用意する
帰無仮説( null hypothesis) : H0棄却したい仮説
命題がまったく正しくないという状態を考える。
例; 「未既婚と車のタイプは関連がまったくない」
対立仮説 (alternative hypothesis) : H 1帰無仮説と反対の仮説
命題の程度は分からないが、帰無仮説が誤りならば、 必ず対立仮説は正しいと考える。
例;「未既婚と車のタイプは関連がある」
⇒ 統計学は背理法の考え方を採用している。

仮説検定のステップ ステップ 1 :命題を立てる ステップ 2 :帰無仮説、対立仮説を立てる(ステップ 3 :仮説検定の手法の選択) ステップ 4 :有意水準を設定 ステップ 5 :検定を実行(統計統計量、P値を計算)
ステップ 6 :帰無仮説の棄却 / 棄却しない⇒結論 P 値 < 有意水準 : 帰無仮説を棄却⇒命題は正しい P 値 > 有意水準:帰無仮説を棄却できない(採択)⇒
標本数、分析方法などの見なおし⇒命題は正しくない、再調査の結論

有意水準( α ) 有意水準 α とは、仮説検定において帰無仮説を棄却
する基準となる確率であり、 危険率とも言う。 有意水準は任意に設定する。通常、5%、1%な
どを使う( α = 0.05 、 0.01 )。 結論をより厳密にしたい場合は 1 %の値を用いる
例えば、有意水準 5 %であれば、標本抽出による同じ調査を同じ母集団から異なる標本で 100 回繰り返したときに、誤って帰無仮説を棄却する回数が平均 5 回はおこるという水準←第一種の誤りの危険率と同じ

P 値(有意確率) P値は、帰無仮説 Ho が真として標本が、その
ような母集団から得られる上側(外側)確率 検定統計量( P 値に対応する)を計算して、有意
水準 α に対応する値と比較←伝統的な方法 あるいは、P値と α を直接比較←最近の主流
有意水準 α とp値から帰無仮説を棄却するかどうかを決める P 値≦ α : ( OR 統計検定量> α に対応する値) ⇒ 帰無仮説を棄却 P 値 > α : ( OR 統計検定量< α に対応する値) ⇒ 帰無仮説を棄却しない

検定統計量 検定統計量とは
仮説検定の種類により、検定統計量は異なる 母集団に関する統計的仮説を評価するための数値
で、母集団から抽出された標本データから計算される。 P 値は、検定統計量と対応関係にある。
クロス集計表の検定(カイ二乗検定)の場合は カイ二乗値( χ 2 )が検定統計量 カイ二乗値は、自由度 { (横のセル数 -1 ) × (縦
のセル数 -1 ) } によって決められる 分布( χ 2 分布)に従うことが分かっている。

カイ二乗分布例:自由度 3 のカイ二乗分布
P 値
α = 0.05
検定統計量カイ二乗値
α = 0.01
p値≦ α 帰無仮説を棄却なので、 α が1 %の時(青)は帰無仮説を棄却する。しかし、 5 %の時(緑)は棄却できない。※面積が確率。

クロス集計の検定① クロス集計の検定(カイ二乗検定)
質的データにおける二群間の関係性を調べるための仮説検定の手法
既婚 未婚 小計ファミリー車
119 36 155
スポーツ車 45 55 100
仕事車 32 16 48
小計 196 107 303 (総計)
自動車のタイプ
結婚ステイタス

クロス集計の検定② 帰無仮説、対立仮説の設定
帰無仮説:未既婚の別と自動車 のタイプは無関係(独立)である。
対立仮説:未既婚の別により自動車 のタイプに差がある。
検定手法の選択 質的データの関係性を見るのでクロス集計の検
定(独立性の検定)を行う 有意水準の設定
5 %とする。 a=0.05

クロス集計の検定③ 検定統計量の計算と検定の実行検定統計量の計算と検定の実行
χ 2 = Σ (観測値 - 期待値) 2
期待値• 未既婚別と車のタイプの例では、 χ 2 = 26.963
カイ二乗値は、自由度 { (横のセル数 -1 ) × (縦のセル数 -1 ) } のカイ二乗分布に 分布に従うことが分かっている。
∴ この例では、自由度 2 のカイ二乗分布に従う。
★ 最近は、統計ソフトが自動的に P 値を計算してくれるので数表を使う
必要はなくなりつつある。JMP- IN も計算してくれるので、手計算する必要はない
参考>自由度とカイ二乗値をいれると P 値を計算してくれるサイトもある。 http://aoki2.si.gunma-u.ac.jp/CGI-BIN/xxp.html

クロス集計の検定④ 帰無仮説の棄却帰無仮説の棄却 // 採択の判断採択の判断カイ二乗分布表で自由度 2 、有意水準 5 %( a=0.05 )に対応する値をみると、 5.9914 である。5.9914 < 26.963 なので帰無仮説は棄却できる。
JMP - IN の結果をみると、 P 値が< 0.0001 と記載されており、カイ二乗
分布の数表を見て検定統計量を比較する必要がないことが分かる。
つまり、 P 値は< 0.0001 なので、有意水準が 5 %( a=0.05) であっても、 1 %
( 0.001 )でもp値 <α になり帰無仮説を棄却できることが分かる。

クロス集計の検定⑤ Carpoll.jmp のデータの表示結果をチェック
Pearson の Prob>ChiSqを見る。統計量から計算されたP値
P値が .0001以下であることが分かる。つまり、 1万に1回も無関係であるような標本は得られない。
未既婚と車種は統計的に 関係がある有意水準が 5 %でも 1 %
でも帰無仮説は棄却される
Χ 二乗値

余裕のある人は①計算式 カイ二乗値の手計算をしてみよう
χ 2 = Σ (観測値 - 期待値) 2
期待値
期待値カイ二乗値
一般に、変数群間に関連がある場合(帰無仮説が棄却できる)は、カイ二乗値は大きな値になる。

余裕のある人は③表の見方B1 B2 ... Bj ... Bm 合計
A1 O1j n1・
A2 O2j n2・
: : :Ai Oi1 Oi2 ... Oij ... Oim ni・
: : :Ak Okj nk・
合計 n 1・ n 2・ ... n j・ ... n m・ n
× ÷期待値⇒観測値⇒

余裕のある人は②計算例 式はややこしそうだったが、実は簡単
例えば、男性と女性と免許の有無に差があるかどうかを見てみよう。
カイ二乗値= {4- ( 5*6/13 )} 2/ ( 5*6/13 ) +{ 2-( 8*6/13 )} 2 / ( 8*6/13 ) +{ 1- ( 5*7/13 )} 2 / ( 5*7/13 ) +{ 6- ( 8*7/13 )} 2 / ( 8*7/13 )=37.452
※自由度 1 のカイ二乗分布に従う。この場合、有意水準 5 %で棄却される。
あり
なし 合計
男子 4 2 6
女子 1 6 7
合計 5 8 13

検定結果からの結論の導き方 帰無仮説が棄却できる(p値≦ α )
積極的に命題(対立仮説)の正当性を主張できる 帰無仮説が棄却できない(p値> α )
対立仮説が誤っているとは必ずしも言えない 標本の大きさやデータの品質(誤差のばらつきや偏
り)に依存 標本を大きくしたり、調査、実験方法の改良の必要
がある。 つまり、今あるデータだけでは何も言えない
検定結果と命題が真であるかは別 知見にあった(一般常識に照らして)結論を導く

検定における 2 種類の誤り① 第 1 種の誤り
帰無仮説が正しいのに、棄却してしまう可能性 有意水準 α は第一種の誤りが起こる可能性と同じ。
第 2 種の誤り 帰無仮説が正しくないのに、棄却しない(採択)
する可能性。 β で表されるときもある。 母集団の平均や分散、標本数が分かっていないと第 2 種の誤りをおこす確率を計算することはなかなかできない。⇒深い統計知識が必要。
そのため、容易に決定できる第一種の誤りを基準に検定できる仮説を設定している。

検定における 2 種類の誤り②
帰無仮説を棄却する
帰無仮説を棄却しない
帰無仮説が真である
第 1 種の誤り( α )
正しい判断
帰無仮説が偽りである
正しい判断 第 2 種の誤り( β )