Embed Size (px)
Citation preview

Ácido nucleicoLos ácidos nucleicos son grandes polímeros formados por la repetición de monómeros
denominados nucleótidos, unidos mediante enlaces fosfodiéster . Se forman, así, largas cadenas;
algunas moléculas de ácidos nucleicos llegan a alcanzar tamaños gigantescos, con millones de
nucleótidos encadenados. Los ácidos nucleicos almacenan la información genética de
los organismos vivos y son los responsables de la transmisión hereditaria. Existen dos tipos
básicos, el ADN y el ARN.
Formula de los ácidos nucleicos
X+Y- xy X y + pn =
El descubrimiento de los ácidos nucleicos se debe a Friedrich Miescher, quien en el año1869 aisló
de los núcleos de las células una sustancia ácida a la que llamó nucleína,1nombre que
posteriormente se cambió a ácido nucleico. Posteriormente, en 1953, James Watson y Francis
Crick descubrieron la estructura del ADN, empleando la técnica de difracción de rayos X.
Existen dos tipos de ácidos nucleicos: ADN (ácido desoxirribonucleico) y ARN (ácido ribonucleico),
que se diferencian:
por el glúcido (la pentosa es diferente en cada uno; ribosa en el ARN y desoxirribosa en el
ADN);
por las bases nitrogenadas: adenina, guanina, citosina y timina, en el ADN; adenina, guanina,
citosina y uracilo, en el ARN;
en la inmensa mayoría de organismos, el ADN es bicatenario (dos cadenas unidas formando
una doble hélice), mientras que el ARN es monocatenario (una sola cadena), aunque puede
presentarse en forma extendida, como el ARNm, o en forma plegada, como el ARNt y el ARNr;
Las unidades que forman los ácidos nucleicos son los nucleótidos. Cada nucleótido es una
molécula compuesta por la unión de tres unidades: un monosacárido de
cinco carbonos (una pentosa, ribosa en el ARN y desoxirribosa en el ADN), una base
nitrogenadapurínica (adenina, guanina) o pirimidínica (citosina, timina o uracilo) y un grupo fosfato
(ácido fosfórico). Tanto la base nitrogenada como los grupos fosfato están unidos a la pentosa.
La unidad formada por el enlace de la pentosa y de la base nitrogenada se denomina nucleósido.
El conjunto formado por un nucleósido y uno o varios grupos fosfato unidos al carbono 5' de la
pentosa recibe el nombre de nucleótido. Se denomina nucleótido-monofosfato (como el AMP)
cuando hay un solo grupo fosfato, nucleótido-difosfato (como el ADP) si lleva dos y nucleótido-
trifosfato
Las bases nitrogenadas conocidas son:
Adenina, presente en ADN y ARN
Guanina, presente en ADN y ARN
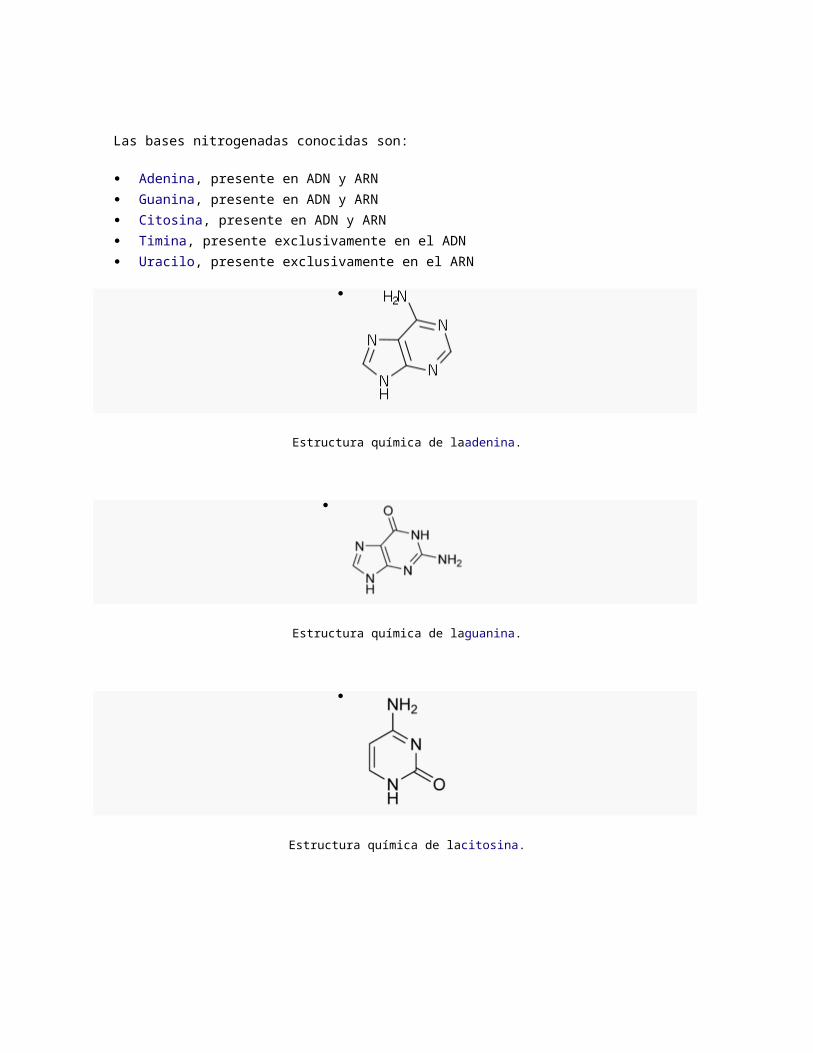
Citosina, presente en ADN y ARN
Timina, presente exclusivamente en el ADN
Uracilo, presente exclusivamente en el ARN
Estructura química de laadenina.
Estructura química de laguanina.
Estructura química de lacitosina.
Estructura química de latimina.

Estructura química deluracilo.
Estructura química de laribosa.
Estructura química del ácido fosfórico.
La historia cuenta ....
El descubrimiento de los ácidos nucleicos se debe a Meischer (1869), el cual trabajando con leucocitos y espermatozoides de salmón, obtuvo una sustancia rica en carbono, hidrógeno, oxígeno, nitrógeno y un porcentaje elevado de fósforo. A esta sustancia se le llamó en un principio nucleína, por encontrarse en el núcleo.
Años más tarde, se fragmentó esta nucleína, y se separó un componente proteico y un grupo prostético. A este último, por ser ácido, se lo llamó ácido nucleico. En los años ‘30, Kossel comprobó que tenían una estructura bastante compleja. En 1953, James Watson y Francis Crick descubrieron la estructura tridimensional de uno de estos ácidos, concretamente del ácido desoxirribonucleico (ADN).

Las proteínas o prótidos1 son moléculas formadas por cadenas lineales de aminoácidos. El
término proteína proviene de la palabra francesa protéine y ésta del griego πρωτεῖος(proteios), que
significa 'prominente, de primera calidad'.2
Por sus propiedades físico-químicas, las proteínas se pueden clasificar en proteínas simples
(holoproteidos), que por hidrólisis dan solo aminoácidos o sus derivados; proteínas conjugadas
(heteroproteidos), que por hidrólisis dan aminoácidos acompañados de sustancias diversas, y
proteínas derivadas, sustancias formadas por desnaturalización y desdoblamiento de las
anteriores. Las proteínas son necesarias para la vida, sobre todo por su función plástica
(constituyen el 80% del protoplasma deshidratado de toda célula), pero también por sus
funciones biorreguladoras (forman parte de las enzimas) y de defensa (losanticuerpos son
proteínas).3
Las proteínas desempeñan un papel fundamental para la vida y son las biomoléculas más
versátiles y diversas. Son imprescindibles para el crecimiento del organismo y realizan una enorme
cantidad de funciones diferentes, entre las que destacan:
Estructural. Esta es la función más importante de una proteína (Ej: colágeno)
Inmunológica (anticuerpos)
Enzimática (Ej: sacarasa y pepsina)
Contráctil (actina y miosina)
Homeostática: colaboran en el mantenimiento del pH (ya que actúan como un tampón químico)
Transducción de señales (Ej: rodopsina)
Protectora o defensiva (Ej: trombina y fibrinógeno)
Las proteínas están formadas por aminoácidos.
Las proteínas de todos los seres vivos están determinadas mayoritariamente por su genética (con
excepción de algunos péptidos antimicrobianos de síntesis no ribosomal), es decir, la información
genética determina en gran medida qué proteínas tiene una célula, un tejido y un organismo.
Las proteínas se sintetizan dependiendo de cómo se encuentren regulados los genes que las
codifican. Por lo tanto, son susceptibles a señales o factores externos. El conjunto de las proteínas
expresadas en una circunstancia determinada es denominado proteoma.
Funciones[editar · editar código]
Las proteínas ocupan un lugar de máxima importancia entre las moléculas constituyentes de los
seres vivos (biomoléculas). Prácticamente todos los procesos biológicos dependen de la presencia
o la actividad de este tipo de moléculas. Bastan algunos ejemplos para dar idea de la variedad y
trascendencia de las funciones que desempeñan. Son proteínas:
Casi todas las enzimas, catalizadores de reacciones químicas en organismos vivientes;
Muchas hormonas, reguladores de actividades celulares;
La hemoglobina y otras moléculas con funciones de transporte en la sangre;
Los anticuerpos, encargados de acciones de defensa natural contra infecciones o agentes
patógenos;

Los receptores de las células, a los cuales se fijan moléculas capaces de desencadenar una
respuesta determinada;
La actina y la miosina, responsables finales del acortamiento del músculo durante la
contracción;
El colágeno, integrante de fibras altamente resistentes en tejidos de sostén.
Funciones de reserva. Como la ovoalbúmina en el huevo, o la caseína de la leche.
Todas las proteínas realizan elementales funciones para la vida celular, pero además cada una de
éstas cuenta con una función más específica de cara a nuestro organismo.
Debido a sus funciones, se pueden clasificar en:
1. Catálisis: Está formado por enzimas proteicas que se encargan de realizar reacciones
químicas de una manera más rápida y eficiente. Procesos que resultan de suma
importancia para el organismo. Por ejemplo la pepsina, ésta enzima se encuentra en
elsistema digestivo y se encarga de degradar los alimentos.
2. Reguladoras: Las hormonas son un tipo de proteínas las cuales ayudan a que exista un
equilibrio entre las funciones que realiza el cuerpo. Tal es el caso de la insulina que se
encarga de regular la glucosa que se encuentra en la sangre.
3. Estructural: Este tipo de proteínas tienen la función de dar resistencia y elasticidad que
permite formar tejidos así como la de dar soporte a otras estructuras. Este es el caso de
la tubulina que se encuentra en el citoesqueleto.
4. Defensiva: Son las encargadas de defender al organismo. Glicoproteínas que se
encargan de producir inmunoglobulinas que defienden al organismo contra cuerpos
extraños, o la queratina que protege la piel, así como el fibrinógeno y protrombina que
forman coágulos.
5. Transporte: La función de estas proteínas es llevar sustancias a través del organismo a
donde sean requeridas. Proteínas como la hemoglobina que lleva el oxígeno por medio de
la sangre.
6. Receptoras: Este tipo de proteínas se encuentran en la membrana celular y llevan a
cabo la función de recibir señales para que la célula pueda realizar su función,
como acetilcolina que recibe señales para producir la contracción.
Estructura[editar · editar código]
Artículo principal: Estructura de las proteínas

Es la manera como se organiza una proteína para adquirir cierta forma,
presentan una disposición característica en condiciones fisiológicas, pero
si se cambian estas condiciones como temperatura o pH pierde la
conformación y su función, proceso denominado desnaturalización. La
función depende de la conformación y ésta viene determinada por
la secuencia de aminoácidos.
Para el estudio de la estructura es frecuente considerar una división en
cuatro niveles de organización, aunque el cuarto no siempre está
presente.
Conformaciones o niveles estructurales de la disposición
tridimensional:
Estructura primaria.
Estructura secundaria.
Nivel de dominio.
Estructura terciaria.
Estructura cuaternaria.
A partir del nivel de dominio sólo las hay globulares.
Propiedades de las proteínas[editar · editar código]

Solubilidad: Se mantiene siempre y cuando los enlaces fuertes y
débiles estén presentes. Si se aumenta la temperatura y el pH se
pierde la solubilidad.
Capacidad electrolítica: Se determina a través de la electroforesis,
técnica analítica en la cual si las proteínas se trasladan al polo
positivo es porque su molécula tiene carga negativa y viceversa.
Especificidad: Cada proteína tiene una función específica que está
determinada por su estructura primaria.
Amortiguador de pH (conocido como efecto tampón): Actúan como
amortiguadores de pH debido a su carácter anfótero, es decir,
pueden comportarse como ácidos (donando electrones) o como
bases (aceptando electrones).
Desnaturalización[editar · editar código]
Artículo principal: Desnaturalización de proteínas
Si en una disolución de proteínas se producen cambios de pH,
alteraciones en la concentración, agitación molecular o variaciones
bruscas de temperatura, la solubilidad de las proteínas puede verse
reducida hasta el punto de producirse su precipitación. Esto se debe a
que los enlaces que mantienen la conformación globular se rompen y la
proteína adopta la conformación filamentosa. De este modo, la capa de
moléculas de agua no recubre completamente a las moléculas proteicas,
las cuales tienden a unirse entre sí dando lugar a grandes partículas que
precipitan. Además, sus propiedades biocatalizadoras desaparecen al
alterarse el centro activo. Las proteínas que se hallan en ese estado no
pueden llevar a cabo la actividad para la que fueron diseñadas, en
resumen, no son funcionales.
Esta variación de la conformación se denomina desnaturalización. La
desnaturalización no afecta a los enlaces peptídicos: al volver a las
condiciones normales, puede darse el caso de que la proteína recupere
la conformación primitiva, lo que se denominarenaturalización.
Ejemplos de desnaturalización son la leche cortada como consecuencia
de la desnaturalización de la caseína, la precipitación de laclara de
huevo al desnaturalizarse la ovoalbúmina por efecto del calor o la fijación
de un peinado del cabello por efecto de calor sobre
las queratinas del pelo.9

Código genético
El código genético es el conjunto de reglas que definen la traducción de una secuencia de nucleótidos
en el ARN a una secuencia de aminoácidos en una proteína en todos los seres vivos. El código define la
relación entre secuencias de tres nucleótidos, llamadas codones, y aminoácidos. De ese modo, cada
codón se corresponde con un aminoácido específico.
La secuencia del material genético se compone de cuatro bases nitrogenadas distintas, que tienen una
función equivalente a letras en el código genético: adenina (A), timina (T),guanina (G) y citosina (C) en
el ADN y adenina (A), uracilo (U), guanina (G) y citosina (C) en el ARN.
Debido a esto, el número de codones posibles es 64, de los cuales 61 codifican aminoácidos (siendo
además uno de ellos el codón de inicio, AUG) y los tres restantes son sitios de parada (UAA, llamado
ocre; UAG, llamado ámbar; UGA, llamado ópalo). La secuencia de codones determina la secuencia de
aminoácidos en una proteína en concreto, que tendrá una estructura y una función específicas.
Cuando James Watson, Francis Crick, Maurice Wilkins y Rosalind Franklin crearon el modelo de la
estructura del ADN se comenzó a estudiar en profundidad el proceso de traducción en las
proteínas.
En 1955, Severo Ochoa y Marianne Grunberg-Manago aislaron la enzima polinucleótido
fosforilasa, capaz de sintetizar ARNm sin necesidad de modelo a partir de cualquier tipo de

nucleótidos que hubiera en el medio. Así, a partir de un medio en el cual tan sólo hubiera UDP
(urdín difosfato) se sintetizaba un ARNm en el cual únicamente se repetía el ácido uridílico, es
decir, un poli-U.
George Gamow postuló que un código de codones de tres bases debía ser el empleado por las
células para codificar la secuencia de aminoácidos, ya que tres es el mínimo número entero que
permite, con cuatro bases nitrogenadas distintas, al menos 20 combinaciones (64 para ser
exactos).
Los codones constan de tres nucleótidos fue demostrado por primera vez en el experimento de
Crick, Brenner y colaboradores. Marshall Nirenberg y Heinrich J. Matthaei en 1961 en los Institutos
Nacionales de Salud descubrieron la primera correspondencia codón-aminoácido. Empleando un
sistema libre de células, tradujeron una secuencia ARN de poli-uracilo (UUU...) y descubrieron que
el polipéptido que habían sintetizado sólo contenía fenilalanina. De esto se deduce que el codón
UUU especifica el aminoácido fenilalanina. Continuando con el trabajo anterior, Nirenberg y Philip
Leder fueron capaces de determinar la traducción de 54 codones, utilizando diversas
combinaciones de ARNm, pasadas a través de un filtro que contiene ribosomas. Los ARNt se
unían a tripletes específicos.
Posteriormente, Har Gobind Khorana completó el código, y poco después, Robert W. Holley
determinó la estructura del ARN de transferencia, la molécula adaptadora que facilita la traducción.
Este trabajo se basó en estudios anteriores de Severo Ochoa, quien recibió el premio Nobel en
1959 por su trabajo en la enzimología de la síntesis de ARN. En 1968, Khorana, Holley y Nirenberg
recibieron el Premio Nobel en Fisiología o Medicina por su trabajo.
Transferencia de información[editar · editar código]
El genoma de un organismo se encuentra en el ADN o, en el caso de algunos virus, en el ARN. La
porción de genoma que codifica varias proteínas o un ARN se conoce como gen. Esos genes que
codifican proteínas están compuestos por unidades de trinucleótidos llamadas codones, cada una
de los cuales codifica un aminoácido. Cada subunidad nucleotídica está formada por un fosfato,
una desoxirribosa y una de las cuatro posibles bases nitrogenadas. Las bases purínicas adenina
(A) y guanina (G) son más grandes y tienen dos anillos aromáticos. Las bases pirimidínicas citosina
(C) y timina (T) son más pequeñas y sólo tienen un anillo aromático. En la configuración en doble
hélice, dos cadenas de ADN están unidas entre sí por puentes de hidrógeno en una asociación
conocida como emparejamiento de bases. Además, estos puentes siempre se forman entre una
adenina de una cadena y una timina de la otra y entre una citosina de una cadena y una guanina
de la otra. Esto quiere decir que el número de residuos A y T será el mismo en una doble hélice y
lo mismo pasará con el número de residuos de G y C. En el ARN, la timina (T) se sustituye por
uracilo (U), y la desoxirribosa por una ribosa.
Cada gen que codifica una proteína se transcribe en una molécula plantilla, que se conoce como
ARN mensajero o ARNm. Éste, a su vez, se traduce en el ribosoma, en una cadena polipeptídica
(formada por aminoácidos). En el proceso de traducción se necesita un ARN de transferencia, o
ARNt, específico para cada aminoácido, con dicho aminoácido unido a él de forma covalente,
guanosina trifosfato como fuente de energía y ciertos factores de traducción. Los ARNt tienen
anticodones complementarios a los codones del ARNm y se pueden “cargar” covalentemente en su

extremo 3' terminal con aminoácidos. Los ARNt individuales se cargan con aminoácidos
específicos gracias a las enzimas llamadas aminoacil-ARNt sintetasas, que tienen alta
especificidad tanto por un aminoácido como por un ARNt. Esta alta especificidad es el motivo
fundamental del mantenimiento de la fidelidad en la traducción de proteínas.
Para un codón de tres nucleótidos (un triplete) son posibles 4³ = 64 combinaciones diferentes; los
64 codones están asignados a aminoácido o a señales de parada en la traducción. Si, por ejemplo,
tenemos una secuencia de ARN, UUUAAACCC, y la lectura del fragmento empieza en la primera U
(convenio 5' a 3'), habría tres codones que serían UUU, AAA y CCC, cada uno de los cuales
especifica un aminoácido. Esta secuencia de ARN se traducirá en una secuencia de tres
aminoácidos.
Características[editar · editar código]
Universalidad[editar · editar código]
El código genético es compartido por todos los organismos conocidos, incluyendo virus y
organelos, aunque pueden aparecer pequeñas diferencias. Así, por ejemplo, el codón UUU codifica
el aminoácido fenilalanina tanto en bacterias como en arqueas y en eucariontes. Este hecho indica
que el código genético ha tenido un origen único en todos los seres vivos conocidos.
Gracias a la genética molecular, se han distinguido 22 códigos genéticos,1 que se diferencian del
llamado código genético estándarpor el significado de uno o más codones. La mayor diversidad
se presenta en las mitocondrias, orgánulos de las células eucariotas que se originaron
evolutivamente a partir de miembros del dominio Bacteria a través de un proceso
de endosimbiosis. El genoma nuclear de los eucariotas sólo suele diferenciarse del código
estándar en los codones de iniciación y terminación.
Especificidad y continuidad[editar · editar código]
Ningún codón codifica más de un aminoácido; de no ser así, conllevaría problemas considerables
para la síntesis de proteínas específicas para cada gen. Tampoco presenta solapamiento: los
tripletes se hallan dispuesto de manera lineal y continua, de manera que entre ellos no existan
comas ni espacios y sin compartir ninguna base nitrogenada. Su lectura se hace en un solo sentido
(5' - 3'), desde el codón de iniciación hasta el codón de parada. Sin embargo, en un mismo ARNm
pueden existir varios codones de inicio, lo que conduce a la síntesis de varios polipéptidos
diferentes a partir del mismo transcrito.
Degeneración[editar · editar código]
El código genético tiene redundancia pero no ambigüedad (ver tablas de codones). Por ejemplo,
aunque los codones GAA y GAG especifican ambos el ácido glutámico (redundancia), ninguno
especifica otro aminoácido (no ambigüedad). Los codones que codifican un aminoácido pueden
difeiones puntuales en la tercera posición. Debido a que las mutaciones de transición (purina a
purina o pirimidina a pirimidina) son más probables que las de transversión (purina a pirimidina o
viceversa), la equivalencia de purinas o de pirimidinas en los lugares dobles degenerados añade
una tolerancia a los fallos complementaria.
Agrupamiento de codones por residuos aminoacídicos, volumen molar e hidropatía[editar · editar código]

Una consecuencia práctica de la redundancia es que algunos errores del código genético sólo
causen una mutación silenciosa o un error que no afectará a la proteína porque la hidrofilidad o
hidrofobidad se mantiene por una sustitución equivalente de aminoácidos; por ejemplo, un codón
de NUN (N =cualquier nucleótido) tiende a codificar un aminoácido hidrófobo. NCN codifica
residuos aminoacídicos que son pequeños en cuanto a tamaño y moderados en cuanto a
hidropatía; NAN codifica un tamaño promedio de residuos hidrofílicos; UNN codifica residuos que
no son hidrofílicos.2 3 Estas tendencias pueden ser resultado de una relación de las aminoacil ARNt
sintetasas con los codones heredada un ancestro común de los seres vivos conocidos.
Incluso así, las mutaciones puntuales pueden causar la aparición de proteínas disfuncionales. Por
ejemplo, un gen de hemoglobina mutado provoca la enfermedad de células falciformes. En la
hemoglobina mutante un glutamato hidrofílico (Glu) se sustituye por una valina hidrofóbica (Val), es
decir, GAA o GAG se convierte en GUA o GUG. La sustitución de glutamato por valina reduce la
solubilidad de β-globina que provoca que la hemoglobina forme polímeros lineales unidos por
interacciones hidrofóbicas entre los grupos de valina y causando la deformación falciforme de los
eritrocitos. La enfermedad de las células falciformes no está causada generalmente por una
mutación de novo. Más bien se selecciona en regiones de malaria (de forma parecida a la
talasemia), ya que los individuos heterocigotos presentan cierta resistencia ante el parásito
malárico Plasmodium (ventaja heterocigótica o heterosis).
La relación entre el ARNm y el ARNt a nivel de la tercera base se puede producir por bases
modificadas en la primera base del anticodón del ARNt, y los pares de bases formados se llaman
“pares de bases wobble” (tambaleantes). Las bases modificadas incluyen inosina y los pares de
bases que no son del tipo Watson-Crick U-G.
El código genético tiene redundancia pero no ambigüedad (ver tablas de codones). Por ejemplo,
aunque los codones GAA y GAG especifican ambos el ácido glutámico (redundancia), ninguno
especifica otro aminoácido (no ambigüedad). Los codones que codifican un aminoácido pueden
diferir en alguna de sus tres posiciones, por ejemplo, el ácido glutámico está codificado por GAA y
GAG (difieren en la tercera posición), el aminoácido leucina por los codones UUA, UUG, CUU,
CUC, CUA y CUG (difieren en la primera o en la tercera posición), mientras que la serina está
codificada por UCA, UCG, UCC, UCU, AGU, AGC (difieren en la primera, segunda o tercera
posición).
De una posición de un codón se dice que es cuatro veces degenerada si con cualquier nucleótido
en esta posición se especifica el mismo aminoácido. Por ejemplo, la tercera posición de los
codones de la glicina (GGA, GGG, GGC, GGU) es cuatro veces degenerada, porque todas las
sustituciones de nucleótidos en este lugar son sinónimos; es decir, no varían el aminoácido. Sólo la
tercera posición de algunos codones puede ser cuatro veces degenerada. Se dice que una
posición de un codón es dos veces degenerada si sólo dos de las cuatro posibles sustituciones de
nucleótidos especifican el mismo aminoácido. Por ejemplo, la tercera posición de los codones del
ácido glutámico (GAA, GAG) es doble degenerada. En los lugares dos veces degenerados, los
nucleótidos equivalentes son siempre dos purinas (A/G) o dos pirimidinas (C/U), así que sólo
sustituciones transversionales (purina a pirimidina o pirimidina a purina) en dobles degenerados
son antónimas. Se dice que una posición de un codón es no degenerada si una mutación en esta
posición tiene como resultado la sustitución de un aminoácido. Sólo hay un sitio triple degenerado
en el que cambiando tres de cuatro nucleótidos no hay efecto en el aminoácido, mientras que

cambiando los cuatro posibles nucleótidos aparece una sustitución del aminoácido. Esta es la
tercera posición de un codón de isoleucina: AUU, AUC y AUA, todos codifican isoleucina, pero
AUG codifica metionina. En biocomputación, este sitio se trata a menudo como doble degenerado.
Hay tres aminoácidos codificados por 6 codones diferentes: serina, leucina, arginina. Sólo dos
aminoácidos se especifican por un único codón; uno de ellos es la metionina, especificado por
AUG, que también indica el comienzo de la traducción; el otro es triptófano, especificado por UGG.
Que el código genético sea degenerado es lo que determina la posibilidad de mutaciones
silenciosas.
La degeneración aparece porque el código genético designa 20 aminoácidos y la señal parada.
Debido a que hay cuatro bases, los codones en triplete se necesitan para producir al menos 21
códigos diferentes. Por ejemplo, si hubiera dos bases por codón, entonces sólo podrían codificarse
16 aminoácidos (4²=16). Y dado que al menos se necesitan 21 códigos, 4³ da 64 codones posibles,
indicando que debe haber degeneración.
Esta propiedad del código genético lo hacen más tolerante a los fallos en mutaciones puntuales.
Por ejemplo, en teoría, los codones cuatro veces degenerados pueden tolerar cualquier mutación
puntual en la tercera posición, aunque el codón de uso sesgado restringe esto en la práctica en
muchos organismos; los dos veces degenerados pueden tolerar una de las tres posibles
mutaciones puntuales en la tercera posición. Debido a que las mutaciones de transición (purina a
purina o pirimidina a pirimidina) son más probables que las de transversión (purina a pirimidina o
viceversa), la equivalencia de purinas o de pirimidinas en los lugares dobles degenerados añade
una tolerancia a los fallos complementaria.
Usos incorrectos del término[editar · editar código]
La expresión "código genético" se utiliza con frecuencia en los medios de comunicación como
sinónimo de genoma, de genotipo, o deADN. Frases como «Se analizó el código genético de los
restos y coincidió con el de la desaparecida», o «se creará una base de datos con el código
genético de todos los ciudadanos» son científicamente incorrectas. Es insensato, por ejemplo,
aludir al «código genético de una determinada persona», porque el código genético es el mismo
para todos los individuos. Sin embargo, cada organismo tiene un genotipo propio, aunque es
posible que lo comparta con otros si se ha originado por algún mecanismo demultiplicación
asexual.
Tabla del código genético estándar[editar · editar código]
El código genético estándar se refleja en las siguientes tablas. La tabla 1 muestra qué aminoácido
está codificado por cada uno de los 64 codones. La tabla 2 muestra qué codones especifican cada
uno de los 20 aminoácidos que intervienen en la traducción. Estas tablas se llaman tablas de
avance y retroceso respectivamente. Por ejemplo, el codón AAU es el aminoácido asparagina, y
UGU y UGC representan cisteína (en la denominación estándar por 3 letras, Asn y Cys,
respectivamente).
Nótese que el codón AUG codifica la metionina pero además sirve de sitio de iniciación; el primer
AUG en un ARNm es la región que codifica el sitio donde la traducción de proteínas se inicia.

La siguiente tabla inversa indica qué codones codifican cada uno de los aminoácidos.
Ala (A) GCU, GCC, GCA, GCG Lys (K) AAA, AAG
Arg (R) CGU, CGC, CGA, CGG, AGA, AGG Met (M) AUG
Asn (N) AAU, AAC Phe (F) UUU, UUC
Asp (D) GAU, GAC Pro (P) CCU, CCC, CCA, CCG
Cys (C) UGU, UGC Sec (U) UGA
Gln (Q) CAA, CAG Ser (S) UCU, UCC, UCA, UCG, AGU, AGC
Glu (E) GAA, GAG Thr (T) ACU, ACC, ACA, ACG
Gly (G) GGU, GGC, GGA, GGG Trp (W) UGG
His (H) CAU, CAC Tyr (Y) UAU, UAC
Ile (I) AUU, AUC, AUA Val (V) GUU, GUC, GUA, GUG
Leu (L) UUA, UUG, CUU, CUC, CUA, CUG
Comienzo AUG Parada UAG, UGA, UA
origen
A pesar de las variaciones que existen, los códigos genéticos utilizados por todas las formas
conocidas de vida son muy similares. Esto sugiere que el código genético se estableció muy
temprano en la historia de la vida y que tiene un origen común en las formas de vida actuales. El

análisis filogenético sugiere que las moléculas ARNt evolucionaron antes que el conjunto actual de
aminoacil-ARNt sintetasas.7
El código genético no es una asignación aleatoria de los codones a aminoácidos.8 Por ejemplo, los
aminoácidos que comparten la misma vía biosintética tienden a tener la primera base igual en sus
codones9 y aminoácidos con propiedades físicas similares tienden a tener similares a codones.10 11
Experimentos recientes demuestran que algunos aminoácidos tienen afinidad química selectiva por
sus codones.12 Esto sugiere que el complejo mecanismo actual de traducción del ARNm que
implica la acción ARNt y enzimas asociadas, puede ser un desarrollo posterior y que, en un
principio, las proteínas se sintetizaran directamente sobre la secuencia de ARN, actuando éste
como ribozima y catalizando la formación de enlaces peptídicos (tal como ocurre con el ARNr 23S
del ribosoma).
Se ha planteado la hipótesis de que el código genético estándar actual surgiera por expansión
biosintética de un código simple anterior. La vida primordial pudo adicionar nuevos aminoácidos
(por ejemplo, subproductos del metabolismo), algunos de los cuales se incorporaron más tarde a la
maquinaria de codificación genética. Se tienen pruebas, aunque circunstanciales, de que formas de
vida primitivas empleaban un menor número de aminoácidos diferentes,13 aunque no se sabe con
exactitud que aminoácidos y en que orden entraron en el código genético.
Otro factor interesante a tener en cuenta es que la selección natural ha favorecido la degeneración
del código para minimizar los efectos de las mutaciones y es debido a la interacción de dos átomos
distintos en la reacción14 . Esto ha llevado a pensar que el código genético primitivo podría haber
constado de codones de dos nucleótidos, lo que resulta bastante coherente con la hipótesis del
balanceo del ARNt durante su acoplamiento (la tercera base no establece puentes de hidrógeno de
Watson y Crick).
Ácido desoxirribonucleico«ADN» redirige aquí. Para otras acepciones, véase ADN (desambiguación).
«DNA» redirige aquí. Para otras acepciones, véase DNA (desambiguación).

Situación del ADN dentro de una célula eucariota.
El ácido desoxirribonucleico, abreviado como ADN, es un ácido nucleico que contiene
instrucciones genéticas usadas en eldesarrollo y funcionamiento de todos los organismos vivos
conocidos y algunos virus, y es responsable de su transmisión hereditaria. El papel principal de la
molécula de ADN es el almacenamiento a largo plazo de información. Muchas veces, el ADN es
comparado con un plano o una receta, o un código, ya que contiene las instrucciones necesarias para
construir otros componentes de las células, como las proteínas y las moléculas de ARN. Los segmentos
de ADN que llevan esta información genética son llamados genes, pero las otras secuencias de ADN
tienen propósitos estructurales o toman parte en la regulación del uso de esta información genética.
Desde el punto de vista químico, el ADN es un polímero de nucleótidos, es decir, un polinucleótido. Un
polímero es un compuesto formado por muchas unidades simples conectadas entre sí, como si fuera un
largo tren formado por vagones. En el ADN, cadavagón es un nucleótido, y cada nucleótido, a su vez,
está formado por un azúcar (la desoxirribosa), una base nitrogenada (que puede
ser adenina→A, timina→T, citosina→C o guanina→G) y un grupofosfato que actúa como enganche de
cada vagón con el siguiente. Lo que distingue a un vagón (nucleótido) de otro es, entonces, la base
nitrogenada, y por ello la secuencia del ADN se especifica nombrando sólo la secuencia de sus bases.
La disposición secuencial de estas cuatro bases a lo largo de la cadena (el ordenamiento de los cuatro

tipos de vagones a lo largo de todo el tren) es la que codifica la información genética: por ejemplo, una
secuencia de ADN puede ser ATGCTAGATCGC... En los organismos vivos, el ADN se presenta como
una doble cadena de nucleótidos, en la que las dos hebras están unidas entre sí por unas conexiones
denominadas puentes de hidrógeno.1
Para que la información que contiene el ADN pueda ser utilizada por la maquinaria celular, debe
copiarse en primer lugar en unostrenes de nucleótidos, más cortos y con unas unidades diferentes,
llamados ARN. Las moléculas de ARN se copian exactamente del ADN mediante un proceso
denominado transcripción. Una vez procesadas en el núcleo celular, las moléculas de ARN pueden salir
alcitoplasma para su utilización posterior. La información contenida en el ARN se interpreta usando
el código genético, que especifica la secuencia de los aminoácidos de las proteínas, según una
correspondencia de un triplete de nucleótidos (codón) para cada aminoácido. Esto es, la información
genética (esencialmente: qué proteínas se van a producir en cada momento del ciclo de vida de una
célula) se halla codificada en las secuencias de nucleótidos del ADN y debe traducirse para poder
funcionar. Tal traducción se realiza usando el código genético a modo de diccionario. El diccionario
"secuencia de nucleótido-secuencia de aminoácidos" permite el ensamblado de largas cadenas de
aminoácidos (las proteínas) en el citoplasma de la célula. Por ejemplo, en el caso de la secuencia de
ADN indicada antes (ATGCTAGATCGC...), la ARN polimerasa utilizaría como molde la cadena
complementaria de dicha secuencia de ADN (que sería TAC-GAT-CTA-GCG-...) para transcribir una
molécula de ARNm que se leería AUG-CUA-GAU-CGC-... ; el ARNm resultante, utilizando el código
genético, se traduciría como la secuencia de aminoácidos metionina-leucina-ácido aspártico-arginina-...
Las secuencias de ADN que constituyen la unidad fundamental, física y funcional de la herencia se
denominan genes. Cada gen contiene una parte que se transcribe a ARN y otra que se encarga de
definir cuándo y dónde deben expresarse. La información contenida en los genes (genética) se emplea
para generar ARN y proteínas, que son los componentes básicos de las células, los "ladrillos" que se
utilizan para la construcción de los orgánulos u organelos celulares, entre otras funciones.
Dentro de las células, el ADN está organizado en estructuras llamadas cromosomas que, durante
el ciclo celular, se duplican antes de que la célula se divida. Los organismos eucariotas (por
ejemplo, animales, plantas, y hongos) almacenan la mayor parte de su ADN dentro del núcleo celular y
una mínima parte en elementos celulares llamados mitocondrias, y en los plastos y los centros
organizadores de microtúbulos o centríolos, en caso de tenerlos; los organismos
procariotas (bacterias y arqueas) lo almacenan en elcitoplasma de la célula, y, por último, los virus
ADN lo hacen en el interior de la cápsida de naturaleza proteica. Existen multitud de proteínas, como por
ejemplo las histonas y los factores de transcripción, que se unen al ADN dotándolo de una estructura
tridimensional determinada y regulando su expresión. Los factores de transcripción reconocen
secuencias reguladoras del ADN y especifican la pauta de transcripción de los genes. El material

genético completo de una dotación cromosómica se denomina genomay, con pequeñas variaciones, es
característico de cada especie.
El ADN lo aisló por primera vez, durante el invierno de 1869, el médico suizo Friedrich
Miescher mientras trabajaba en la Universidad de Tubinga. Miescher realizaba experimentos
acerca de la composición química del pus de vendas quirúrgicas desechadas cuando notó un
precipitado de una sustancia desconocida que caracterizó químicamente más tarde.2 3Lo
llamó nucleína, debido a que lo había extraído a partir de núcleos celulares.4 Se necesitaron casi
70 años de investigación para poder identificar los componentes y laestructura de los ácidos
nucleicos.
En 1919 Phoebus Levene identificó que un nucleótido está formado por una base nitrogenada,
un azúcar y un fosfato.5 Levene sugirió que el ADN generaba una estructura con forma
de solenoide (muelle) con unidades de nucleótidos unidos a través de los grupos fosfato. En 1930
Levene y su maestro Albrecht Kossel probaron que la nucleína de Miescher es un ácido
desoxirribonucleico (ADN) formado por cuatro bases nitrogenadas
(citosina (C), timina (T), adenina (A) y guanina (G)), el azúcar desoxirribosa y un grupo fosfato, y
que, en su estructura básica, el nucleótido está compuesto por un azúcar unido a la base y al
fosfato.6 Sin embargo, Levene pensaba que la cadena era corta y que las bases se repetían en un
orden fijo. En 1937 William Astbury produjo el primer patrón dedifracción de rayos X que mostraba
que el ADN tenía una estructura regular.7
Maclyn McCarty con Francis Crick y James D Watson.
La función biológica del ADN comenzó a dilucidarse en 1928, con una serie básica de
experimentos de la genética moderna realizados por Frederick Griffith, quien estaba trabajando con
cepas "lisas" (S) o "rugosas" (R) de la bacteria Pneumococcus (causante de la neumonía), según
la presencia (S) o no (R) de una cápsula azucarada, que es la que confiere virulencia (véase
también experimento de Griffith). La inyección de neumococos S vivos en ratones produce la
muerte de éstos, y Griffith observó que, si inyectaba ratones con neumococos R vivos o con
neumococos S muertos por calor, los ratones no morían. Sin embargo, si inyectaba a la vez
neumococos R vivos y neumococos S muertos, los ratones morían, y en su sangre se podían aislar
neumococos S vivos. Como las bacterias muertas no pudieron haberse multiplicado dentro del
ratón, Griffith razonó que debía producirse algún tipo de cambio o transformación de un tipo
bacteriano a otro por medio de una transferencia de alguna sustancia activa, que
denominó principio transformante. Esta sustancia proporcionaba la capacidad a los neumococos R

de producir una cápsula azucarada y transformarse así en virulentas. En los siguientes 15 años,
estos experimentos iniciales se replicaron mezclando distintos tipos de cepas bacterianas muertas
por el calor con otras vivas, tanto en ratones (in vivo) como en tubos de ensayo (in vitro).8 La
búsqueda del «factor transformante» que era capaz de hacer virulentas a cepas que inicialmente
no lo eran continuó hasta 1944, año en el cual Oswald Avery, Colin MacLeod y Maclyn
McCarty realizaron un experimento hoy clásico. Estos investigadores extrajeron la fracción activa
(el factor transformante) y, mediante análisis químicos, enzimáticos y serológicos, observaron que
no contenía proteínas, ni lípidos no ligados, ni polisacáridos activos, sino que estaba constituido
principalmente por "una forma viscosa de ácido desoxirribonucleico altamente polimerizado", es
decir, ADN. El ADN extraído de las cepas bacterianas S muertas por el calor lo mezclaron "in vitro"
con cepas R vivas: el resultado fue que se formaron colonias bacterianas S, por lo que se concluyó
inequívocamente que el factor o principio transformante era el ADN.9
A pesar de que la identificación del ADN como principio transformante aún tardó varios años en ser
universalmente aceptada, este descubrimiento fue decisivo en el conocimiento de la base
molecular de la herencia, y constituye el nacimiento de la genética molecular. Finalmente, el papel
exclusivo del ADN en la heredabilidad fue confirmado en 1952 mediante los experimentos de Alfred
Hershey y Martha Chase, en los cuales comprobaron que el fago T2 transmitía su información
genética en su ADN, pero no en su proteína10 (véase también experimento de Hershey y Chase).
En cuanto a la caracterización química de la molécula, en 1940 Chargaff realizó algunos
experimentos que le sirvieron para establecer las proporciones de las bases nitrogenadas en el
ADN. Descubrió que las proporciones de purinas eran idénticas a las de pirimidinas, la
"equimolecularidad" de las bases ([A]=[T], [G]=[C]) y el hecho de que la cantidad de G+C en una
determinada molécula de ADN no siempre es igual a la cantidad de A+T y puede variar desde el 36
hasta el 70 por ciento del contenido total.6 Con toda esta información y junto con los datos
de difracción de rayos X proporcionados por Rosalind Franklin, James Watson y Francis
Crick propusieron en1953 el modelo de la doble hélice de ADN para representar
la estructura tridimensional del polímero.11 En una serie de cinco artículos en el mismo número
de Nature se publicó la evidencia experimental que apoyaba el modelo de Watson y Crick.12 De
éstos, el artículo de Franklin y Raymond Gosling fue la primera publicación con datos de difracción
de rayos X que apoyaba el modelo de Watson y Crick,13 14 y en ese mismo número
de Nature también aparecía un artículo sobre la estructura del ADN de Maurice Wilkins y sus
colaboradores.15
Watson, Crick y Wilkins recibieron conjuntamente, en 1962, después de la muerte de Rosalind
Franklin, el Premio Nobel en Fisiología o Medicina.16 Sin embargo, el debate continúa sobre quién
debería recibir crédito por el descubrimiento.17
Propiedades físicas y químicas[editar · editar código]

Estructura química del ADN: dos cadenas de nucleótidos conectadas mediante puentes de hidrógeno, que aparecen
como líneas punteadas.
El ADN es un largo polímero formado por unidades repetitivas, losnucleótidos.18 19 Una doble
cadena de ADN mide de 22 a 26angstroms (2,2 a 2,6 nanómetros) de ancho, y una unidad (un
nucleótido) mide 3,3 Å (0,33 nm) de largo.20 Aunque cada unidad individual que se repite es muy
pequeña, los polímeros de ADN pueden ser moléculas enormes que contienen millones
denucleótidos. Por ejemplo, el cromosoma humano más largo, elcromosoma número 1, tiene
aproximadamente 220 millones de pares de bases.21
En los organismos vivos, el ADN no suele existir como una molécula individual, sino como una
pareja de moléculas estrechamente asociadas. Las dos cadenas de ADN se enroscan sobre sí
mismas formando una especie de escalera de caracol, denominada doble hélice. El modelo de
estructura en doble hélice fue propuesto en1953 por James Watson y Francis Crick (el
artículo Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acidfue publicado
el 25 de abril de 1953 en Nature), después de obtener una imagen de la estructura de doble hélice
gracias a la refracción por rayos X hecha por Rosalind Franklin.22 El éxito de este modelo radicaba
en su consistencia con las propiedades físicas y químicas del ADN. El estudio mostraba además
que la complementariedad de bases podía ser relevante en su replicación, y también la importancia
de la secuencia de bases como portadora de información genética.2324 25 Cada unidad que se
repite, el nucleótido, contiene un segmento de la estructura de soporte (azúcar + fosfato), que
mantiene la cadena unida, y una base, que interacciona con la otra cadena de ADN en la hélice. En

general, una base ligada a un azúcar se denomina nucleósido y una base ligada a un azúcar y a
uno o más grupos fosfatos recibe el nombre de nucleótido.
Cuando muchos nucleótidos se encuentran unidos, como ocurre en el ADN, el polímero resultante
se denomina polinucleótido.26
Componentes[editar · editar código]
Estructura de soporte: La estructura de soporte de una hebra de ADN está formada por unidades
alternas de grupos fosfato y azúcar(desoxirribosa).27 El azúcar en el ADN es una pentosa,
concretamente, la desoxirribosa.
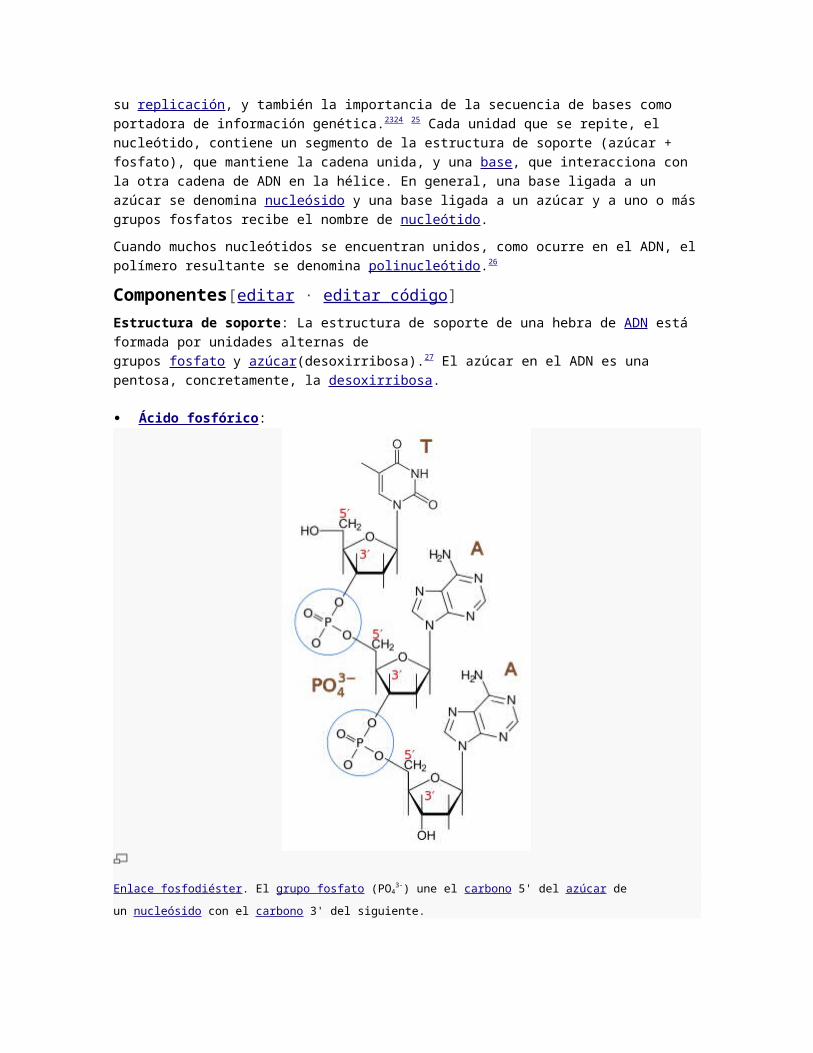
Ácido fosfórico :
Enlace fosfodiéster. El grupo fosfato (PO43-) une el carbono 5' del azúcar de un nucleósido con el carbono 3' del
siguiente.
Su fórmula química es H3PO4. Cada nucleótido puede contener uno (monofosfato:AMP),
dos (difosfato: ADP) o tres (trifosfato: ATP) grupos de ácido fosfórico, aunque como
monómeros constituyentes de los ácidos nucleicos sólo aparecen en forma de nucleósidos
monofosfato.
Desoxirribosa :

Es un monosacárido de 5 átomos de carbono (una pentosa) derivado de la ribosa, que
forma parte de la estructura de nucleótidos del ADN. Su fórmula es C5H10O4. Una de las
principales diferencias entre el ADN y el ARN es el azúcar, pues en el ARN la 2-
desoxirribosa del ADN es reemplazada por una pentosa alternativa, laribosa.25
Las moléculas de azúcar se unen entre sí a través de grupos fosfato, que formanenlaces
fosfodiéster entre los átomos de carbono tercero (3′, «tres prima») y quinto (5′, «cinco
prima») de dos anillos adyacentes de azúcar. La formación de enlacesasimétricos implica
que cada hebra de ADN tiene una dirección. En una doble hélice, la dirección de
los nucleótidos en una hebra (3′ → 5′) es opuesta a la dirección en la otra hebra (5′ → 3′).
Esta organización de las hebras de ADN se denomina antiparalela; son cadenas paralelas,
pero con direcciones opuestas. De la misma manera, los extremos asimétricos de las
hebras de ADN se denominanextremo 5′ («cinco prima») y extremo 3′ («tres prima»),
respectivamente.
Bases nitrogenadas :
Las cuatro bases nitrogenadas mayoritarias que se encuentran en el ADN son
laadenina (A), la citosina (C), la guanina (G) y la timina (T). Cada una de estas cuatro
bases está unida al armazón de azúcar-fosfato a través del azúcar para formar el
nucleótido completo (base-azúcar-fosfato). Las bases son compuestos
heterocíclicos y aromáticos con dos o más átomos de nitrógeno, y, dentro de las bases
mayoritarias, se clasifican en dos grupos: las bases púricas o purinas(adenina y guanina),
derivadas de la purina y formadas por dos anillos unidos entre sí, y las bases
pirimidínicas o bases pirimídicaso pirimidinas (citosina y timina), derivadas de la pirimidina
y con un solo anillo.25 En los ácidos nucleicos existe una quinta base pirimidínica,
denominada uracilo (U), que normalmente ocupa el lugar de la timina en el ARN y difiere
de ésta en que carece de un grupo metilo en su anillo. El uracilo no se encuentra
habitualmente en el ADN, sólo aparece raramente como un producto residual de la
degradación de la citosina por procesos de desaminación oxidativa.
Timina: 2, 4-dioxo, 5-metilpirimidina.

Timina :
En el código genético se representa con la letra T. Es un derivado pirimidínico con
un grupo oxoen las posiciones 2 y 4, y un grupo metil en la posición 5. Forma
el nucleósido timidina (siempre desoxitimidina, ya que sólo aparece en el ADN) y
el nucleótido timidilato o timidina monofosfato (dTMP). En el ADN, la timina siempre
se empareja con la adenina de la cadena complementaria mediante 2 puentes de
hidrógeno, T=A. Su fórmula química es C5H6N2O2 y su nomenclatura 2, 4-dioxo, 5-
metilpirimidina.
Citosina: 2-oxo, 4-aminopirimidina.
Citosina :
En el código genético se representa con la letra C. Es un derivado pirimidínico, con
un grupo amino en posición 4 y un grupo oxo en posición 2. Forma
el nucleósido citidina (desoxicitidina en el ADN) y elnucleótido citidilato o (desoxi)citidina
monofosfato (dCMP en el ADN, CMP en el ARN). La citosina siempre se empareja en el
ADN con la guanina de la cadena complementaria mediante un triple enlace,C≡G. Su
fórmula química es C4H5N3O y su nomenclatura 2-oxo, 4 aminopirimidina. Su masa
moleculares de 111,10 unidades de masa atómica. La citosina se descubrió en 1894, al
aislarla del tejido deltimo de carnero.
Adenina: 6-aminopurina.

Adenina :
En el código genético se representa con la letra A. Es un derivado de la purina con un
grupo amino en la posición 6. Forma el nucleósidoadenosina (desoxiadenosina en el ADN)
y el nucleótido adenilato o (desoxi)adenosina monofosfato (dAMP, AMP). En el ADN
siempre se empareja con la timina de la cadena complementaria mediante 2 puentes de
hidrógeno, A=T. Su fórmula química es C5H5N5 y su nomenclatura 6-aminopurina. La
adenina, junto con la timina, fue descubierta en 1885 por el médico alemán Albrecht
Kossel.
Guanina: 6-oxo, 2-aminopurina.
Guanina :
En el código genético se representa con la letra G. Es un derivado púrico con un grupo oxo
en la posición 6 y un grupo amino en la posición 2. Forma el nucleósido
(desoxi)guanosina y el nucleótido guanilato o (desoxi)guanosina monofosfato (dGMP,
GMP). La guanina siempre se empareja en el ADN con la citosina de la cadena
complementaria mediante tres enlaces de hidrógeno, G≡C. Su fórmula química es
C5H5N5O y su nomenclatura 6-oxo, 2-aminopurina.
También existen otras bases nitrogenadas (las llamadas bases
nitrogenadas minoritarias), derivadas de forma natural o
sintética de alguna otra base mayoritaria. Lo son por ejemplo
la hipoxantina, relativamente abundante en el tRNA, o
la cafeína, ambas derivadas de la adenina; otras, como
elaciclovir, derivadas de la guanina, son análogos sintéticos
usados en terapia antiviral; otras, como una de las derivadas del
uracilo, son antitumorales.
Las bases nitrogenadas tienen una serie de características que
les confieren unas propiedades determinadas. Una
característica importante es su carácter aromático,
consecuencia de la presencia en el anillo de dobles enlaces en
posición conjugada. Ello les confiere la capacidad de absorber
luz en la zona ultravioleta del espectro en torno a los 260 nm, lo
cual puede aprovecharse para determinar el coeficiente de
extinción del ADN y hallar la concentración existente de los
ácidos nucleicos. Otra de sus características es que
presentan tautomería o isomería de grupos funcionales, debido
a que un átomo de hidrógeno unido a otro átomo puede migrar a
una posición vecina; en las bases nitrogenadas se dan dos tipos
de tautomerías: tautomería lactama-lactima, donde el hidrógeno
migra del nitrógeno al oxígeno del grupo oxo (forma lactama) y
viceversa (forma lactima), y tautomería imina-amina primaria,
donde el hidrógeno puede estar formando el grupo amina (forma
amina primaria) o migrar al nitrógeno adyacente (forma imina).
La adenina sólo puede presentar tautomería amina-imina, la
timina y el uracilo muestran tautomería doble lactama-lactima, y
la guanina y citosina pueden presentar ambas. Por otro lado, y
aunque se trate de moléculas apolares, las bases nitrogenadas
presentan suficiente carácter polar como para
establecer puentes de hidrógeno, ya que tienen átomos
muy electronegativos (nitrógeno y oxígeno) que presentan carga
parcial negativa, y átomos de hidrógeno con carga parcial
positiva, de manera que se forman dipolos que permiten que se
formen estos enlaces débiles.
Se estima que el genoma humano haploide tiene alrededor de
3.000 millones de pares de bases. Para indicar el tamaño de las
moléculas de ADN se indica el número de pares de bases, y
como derivados hay dos unidades de medida muy utilizadas,
la kilobase(kb), que equivale a 1.000 pares de bases, y
la megabase (Mb), que equivale a un millón de pares de bases.
Apareamiento de bases[editar · editar código]
Véase también: Par de bases
Un par de bases C≡G con tres puentes de hidrógeno.

Un par A=T con dos puentes de hidrógeno. Los puentes de hidrógeno
se muestran como líneas discontinuas.
La dóble hélice de ADN se mantiene estable mediante la
formación de puentes de hidrógeno entre las bases asociadas a
cada una de las dos hebras. Para la formación de unenlace de
hidrógeno una de las bases debe presentar un "donador" de
hidrógenos con un átomo de hidrógeno con carga parcial
positiva (-NH2 o -NH) y la otra base debe presentar un grupo
"aceptor" de hidrógenos con un átomo
cargado electronegativamente (C=O o N). Los puentes de
hidrógeno son uniones más débiles que los típicos enlaces
químicoscovalentes, como los que conectan los átomos en cada
hebra de ADN, pero más fuertes que interacciones hidrófobas
individuales, enlaces de Van der Waals, etc. Como los puentes
de hidrógeno no son enlaces covalentes, pueden romperse y
formarse de nuevo de forma relativamente sencilla. Por esta
razón, las dos hebras de la doble hélice pueden separarse como
una cremallera, bien por fuerza mecánica o por
alta temperatura.28 La doble hélice se estabiliza además por el
efecto hidrofóbico y el apilamiento, que no se ven influidos por la
secuencia de bases del ADN.29
Cada tipo de base en una hebra forma un enlace únicamente
con un tipo de base en la otra hebra, lo que se
denomina complementariedad de las bases. Así, las purinas
forman enlaces con las pirimidinas, de forma que A se enlaza
sólo con T, y C sólo con G. La organización de dos nucleótidos
apareados a lo largo de la doble hélice se
denominaapareamiento de bases. Este emparejamiento
corresponde a la observación ya realizada por Erwin
Chargaff (1905-2002),30 que mostró que la cantidad de adenina
era muy similar a la cantidad de timina, y que la cantidad de
citosina era igual a la cantidad de guanina en el ADN. Como
resultado de esta complementariedad, toda la información
contenida en la secuencia de doble hebra de la hélice de ADN
está duplicada en cada hebra, lo cual es fundamental durante el
proceso de replicación del ADN. En efecto, esta interacción

reversible y específica entre pares de bases complementarias es
crítica para todas las funciones del ADN en los organismos
vivos.18
Como se ha indicado anteriormente, los dos tipos de pares de
bases forman un número diferente de enlaces de hidrógeno:
A=T forman dos puentes de hidrógeno, y C≡G forman tres
puentes de hidrógeno (ver imágenes). El par de bases GC es
por tanto más fuerte que el par de bases AT. Como
consecuencia, tanto el porcentaje de pares de bases GC como
la longitud total de la doble hélice de ADN determinan la fuerza
de la asociación entre las dos hebras de ADN. Las dobles
hélices largas de ADN con alto contenido en GC tienen hebras
que interaccionan más fuertemente que las dobles hélices cortas
con alto contenido en AT.31 Por esta razón, las zonas de la doble
hélice de ADN que necesitan separarse fácilmente tienden a
tener un alto contenido en AT, como por ejemplo la secuencia
TATAAT de la caja de Pribnow de algunos promotores.32 En el
laboratorio, la fuerza de esta interacción puede medirse
buscando la temperatura requerida para romper los puentes de
hidrógeno, la temperatura de fusión (también denominado
valor Tm, del inglésmelting temperature). Cuando todas las pares
de bases en una doble hélice se funden, las hebras se separan
en solución en dos hebras completamente independientes.
Estas moléculas de ADN de hebra simple no tienen una única
forma común, sino que algunas conformaciones son más
estables que otras.33





























