Embed Size (px)
Citation preview
機械学習
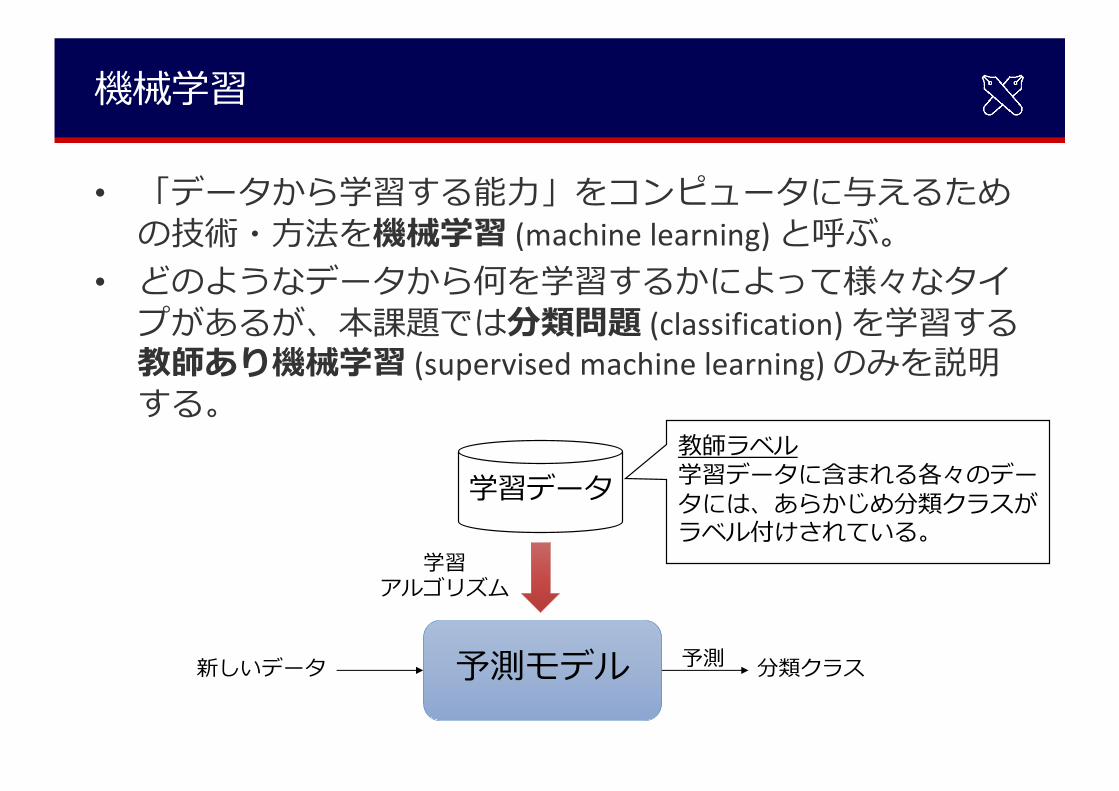
• 「データから学習する能⼒」をコンピュータに与えるための技術・⽅法を機械学習 (machine learning) と呼ぶ。
• どのようなデータから何を学習するかによって様々なタイプがあるが、本課題では分類問題 (classification) を学習する教師あり機械学習 (supervised machine learning) のみを説明する。
学習データ
学習アルゴリズム
教師ラベル学習データに含まれる各々のデータには、あらかじめ分類クラスがラベル付けされている。
予測モデル新しいデータ 分類クラス予測
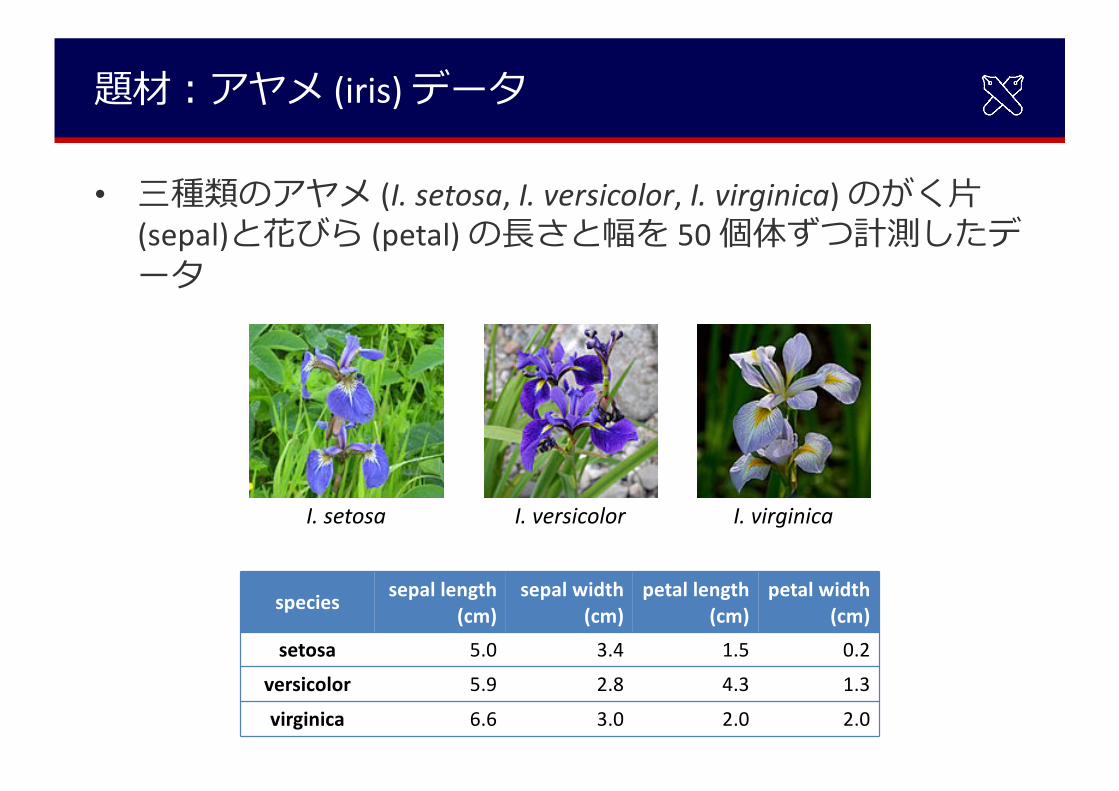
題材︓アヤメ (iris) データ
• 三種類のアヤメ (I. setosa, I. versicolor, I. virginica) のがく⽚(sepal)と花びら (petal) の⻑さと幅を 50 個体ずつ計測したデータ
species sepal length (cm)
sepal width (cm)
petal length(cm)
petal width(cm)
setosa 5.0 3.4 1.5 0.2
versicolor 5.9 2.8 4.3 1.3
virginica 6.6 3.0 2.0 2.0
I. setosa I. versicolor I. virginica
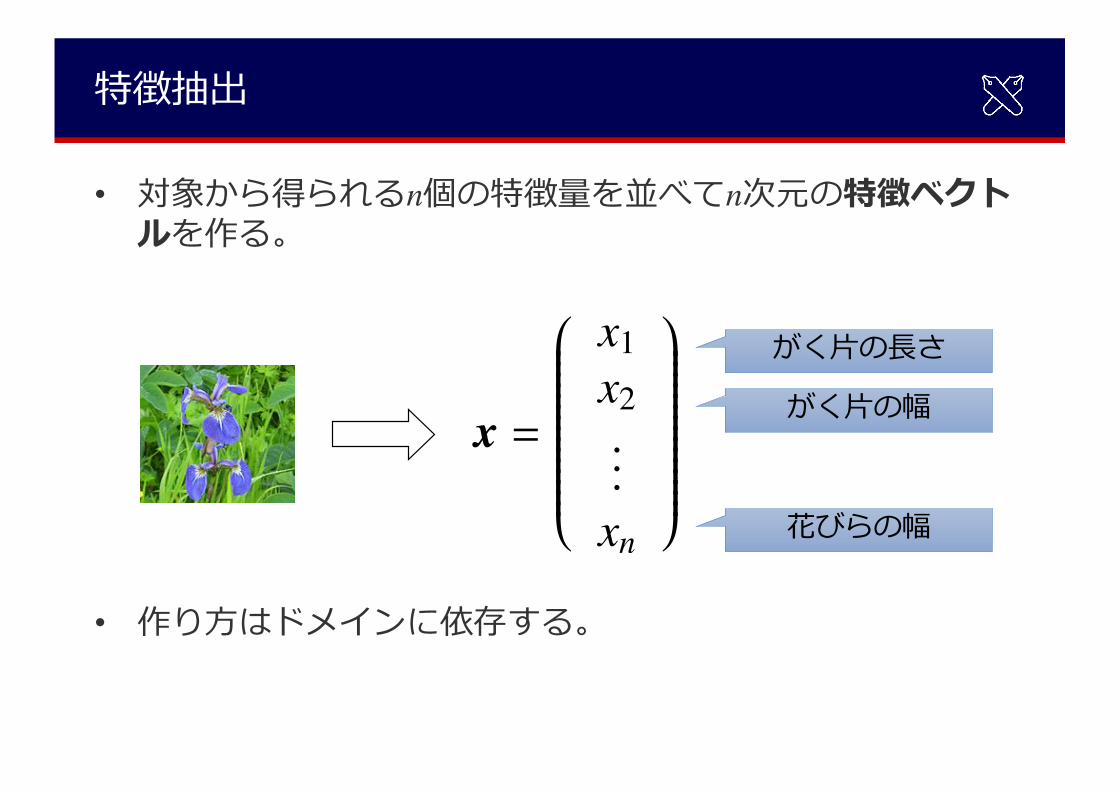
特徴抽出
• 対象から得られるn個の特徴量を並べてn次元の特徴ベクトルを作る。
• 作り⽅はドメインに依存する。
がく⽚の⻑さ
がく⽚の幅
花びらの幅
x =
0BBBBBBBBBBBBBBB@
x1x2...
xn
1CCCCCCCCCCCCCCCA
<latexit sha1_base64="RRVmJ4PLO4EE29tBwMPkIxuoPSk=">AAAC6HichVHNahRBEK6MP4njT1a9CF4Gl0i8LDUxkCAIwVw85m+TSDoMM7O9mzY9PUN377LrsC+QU24heDLgQXwFwYMXXyCHPIAHEfQQwYsHa2YHRIOmmp6q/vr7qrqmokwKYxFPxpwLFy9dHp+44l69dv3GZO3mrXWTdnXMm3EqU70ZhYZLoXjTCiv5ZqZ5mESSb0S7i8X9Ro9rI1K1ZgcZ307CjhJtEYeWoKD2jEWpbJlBQi7vD73HHpO8bac9l0W8I1Qeah0Ohnk8dPuB7zHm9YOZwrFeK7VmBCiXcdWqqC7TorNjHwS1OjawNO9s4FdBHSpbSmvvgEELUoihCwlwUGAplhCCobUFPiBkhG1DTpimSJT3HIbgkrZLLE6MkNBd+nbotFWhis5FTlOqY6oiaWtSejCFx/gGT/EjvsXP+POfufIyR/GWAflopOVZMLl3Z/XHuaqEvIWd36r/KCz0oU3vK/6AOac7S8z5sitB/KxEin7jUaXei4PT1UcrU/l9PMIv1OkrPMEP1KvqfY9fL/OVl+DSqPy/B3M2WJ9p+A8buDxbX3hSDW0C7sI9mKbJzMECPIUlaFLd9/AJvsI357mz7xw4hyOqM1ZpbsMf5hz9AvdztXk=</latexit>
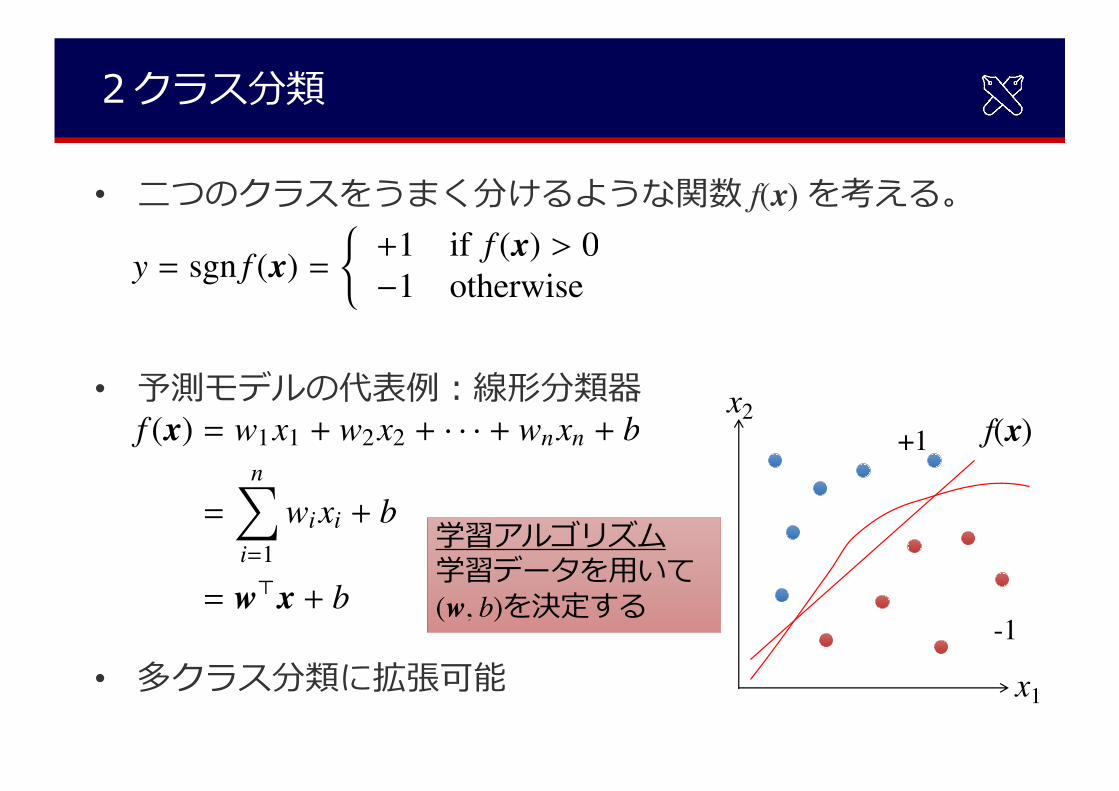
2クラス分類
• ⼆つのクラスをうまく分けるような関数 f(x) を考える。
• 予測モデルの代表例︓線形分類器
• 多クラス分類に拡張可能
f (x) = w1x1 + w2x2 + · · · + wnxn + b
=
nX
i=1
wixi + b
= w>x + b<latexit sha1_base64="kdOQtx0N+NGxCPVzzA43xF+Xma8=">AAADG3ichVFLa9VAFD6JrxofvW03BTdjLy0V4TK5Ci1CoejGZR/ettBpQ5I7tw5NZkJm7qshf0DcuxAXCi7Ev+CuGxG3XfQniDsruHHhSW5Aa9FOmMw33/m+OXPmBEkktKH02LIvXLx0+crYVefa9Rs3x2sTkxtaddOQt0IVqXQr8DWPhOQtI0zEt5KU+3EQ8c1g/1ER3+zxVAsln5hhwndif0+Kjgh9g5RXe96ZZ4GK2noY45IN8jtkbok4fc8lA5x3Sd9rImoiYmFbGV1SEimJKGCMOKhnuht7mVhy812JYYFhUYQJY2X4jwz9fDdjRiU5OZ23kHu1Om3QcpCzwK1AHaqxomofgEEbFITQhRg4SDCII/BB47cNLlBIkNuBDLkUkSjjHHJw0NtFFUeFj+w+/vdwt12xEvfFmbp0h5glwpmik8AsPaLv6An9SN/TL/TnP8/KyjOKuwxxDUZennjjz6bXf5zrinE18PS36z8OAwPo4P2KF9DnVGdQuVhWJVCflExRbzjK1Dt4cbL+YG02m6Nv6Fes9DU9podYq+x9D9+u8rWX4GCr3L8bcxZsNBvuvQZdvV9fflg1bQxuwQzMY2cWYBkewwq0MO83a9q6bc3Yr+xD+5P9eSS1rcozBaeGffQLAB7CiA==</latexit>
x1
x2+1
-1
f(x)
y = sgn f (x) =(+1 if f (x) > 0�1 otherwise
<latexit sha1_base64="gysc2JoxgAAtDQConjpsFJ08/Hk=">AAADJXichVFLaxRBEK4ZX3F8ZNWL4KXJJiGSuPSooAhK0IvHPNwkkA7LzGzPbJOeB929667D/AF/gB48KYiIf8GbFy/eVMjJs3iM4CUHa2YHfCyaanqq+uvvq+qa8jMptKF0z7KPHD12/MTUSefU6TNnpxvnzm/otK8C3g5Smaot39NcioS3jTCSb2WKe7Ev+aa/e6+83xxwpUWaPDCjjO/EXpSIUASeQajTeDIitwmLPdNTca6jpCDhAvNT2dWjGF0+LC6XBMlDw3KH+TwSSe4p5Y2KPJCFs+iSecIMHxrUi5DMTsrvEDpbEMacK79zU9Pj6qHQvHAYT7p1TocpEfVMq9No0hatjEwGbh00obaVtPEWGHQhhQD6EAOHBAzGEjzQuLbBBQoZYjuQI6YwEtU9hwIc1PaRxZHhIbqL3whP2zWa4LnMqSt1gFUkboVKAnP0E31N9+l7+oZ+pQf/zJVXOcq3jND7Yy3POtOPL67/OFQVozfQ+6X6j8LAEEJ8X/kH9CHdGWTerLoSyM8qpOw3GFcaPHq6v35rbS6fpy/oN+z0Od2j77DXZPA9eLnK156Bg6Ny/x7MZLBxteVea9HV683lu/XQpuASzMACTuYGLMN9WIE21j2wZqxFa8l+ZX+wP9qfx1TbqjUX4A+zv/wEZZDK1w==</latexit>
学習アルゴリズム学習データを⽤いて(w, b)を決定する
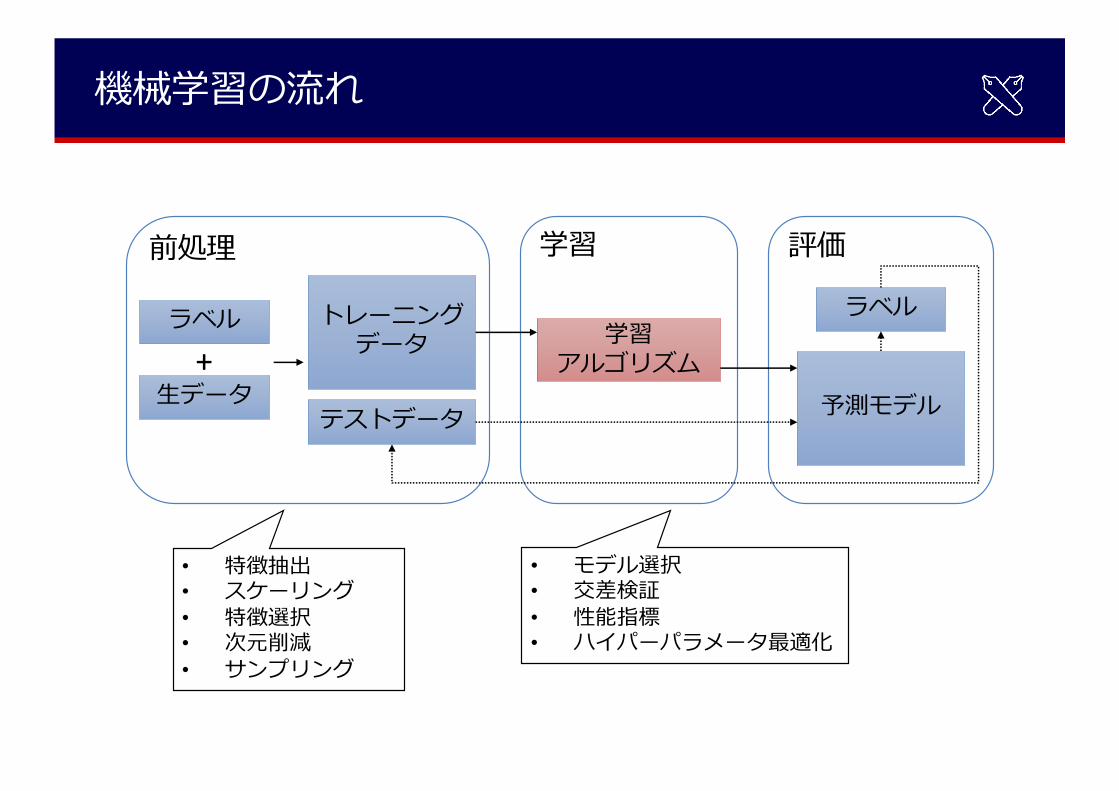
機械学習の流れ
学習
学習アルゴリズム
前処理
トレーニングデータ
テストデータ
ラベル
⽣データ+
評価
予測モデル
ラベル
• 特徴抽出• スケーリング• 特徴選択• 次元削減• サンプリング
• モデル選択• 交差検証• 性能指標• ハイパーパラメータ最適化
scikit-learn
• Pythonの代表的な機械学習ライブラリ– インストール
– Google Colaboratory や Anaconda ではインストール済みpip install scikit-learn
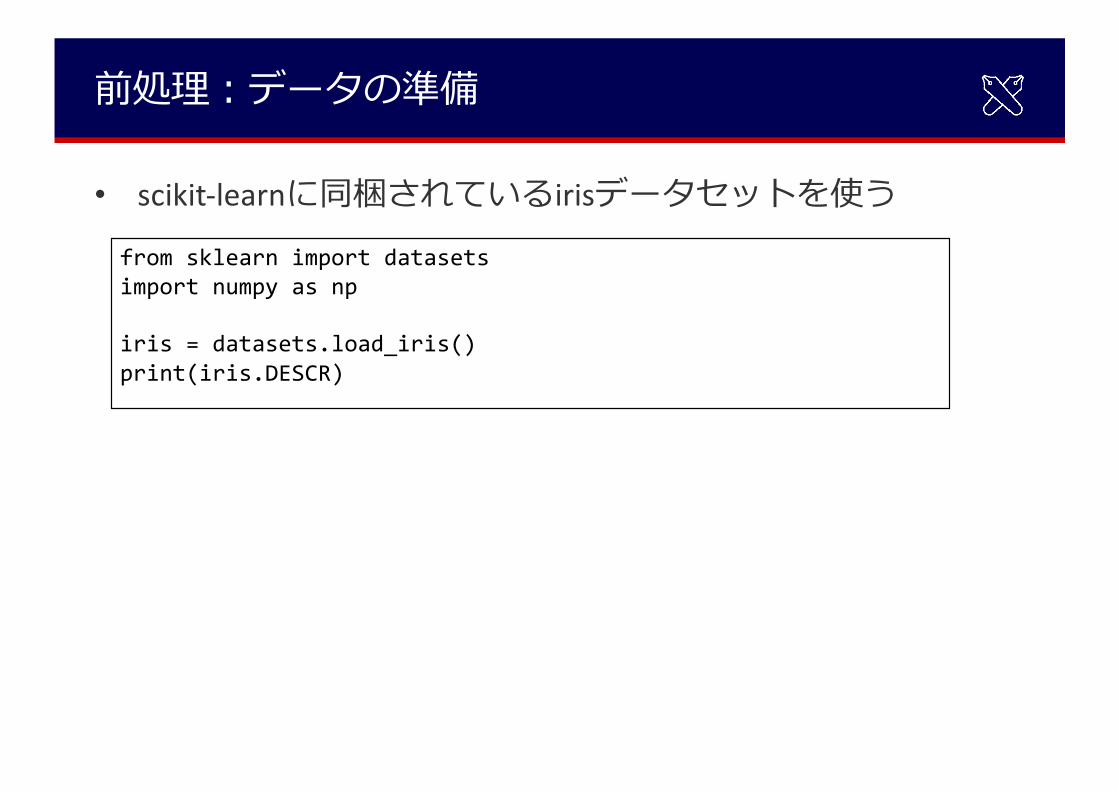
前処理︓データの準備
• scikit-learnに同梱されているirisデータセットを使うfrom sklearn import datasetsimport numpy as np
iris = datasets.load_iris()print(iris.DESCR)
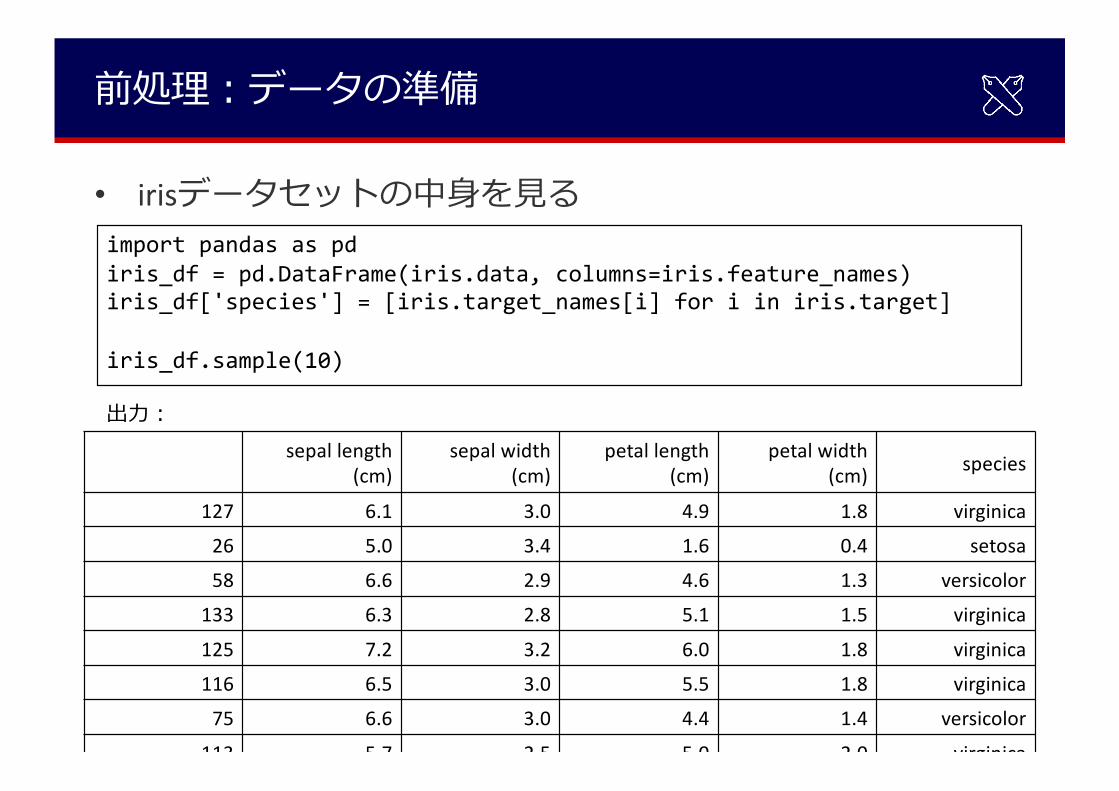
前処理︓データの準備
• irisデータセットの中⾝を⾒るimport pandas as pdiris_df = pd.DataFrame(iris.data, columns=iris.feature_names)iris_df['species'] = [iris.target_names[i] for i in iris.target]
iris_df.sample(10)
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm) species
127 6.1 3.0 4.9 1.8 virginica
26 5.0 3.4 1.6 0.4 setosa
58 6.6 2.9 4.6 1.3 versicolor
133 6.3 2.8 5.1 1.5 virginica
125 7.2 3.2 6.0 1.8 virginica
116 6.5 3.0 5.5 1.8 virginica
75 6.6 3.0 4.4 1.4 versicolor
113 5.7 2.5 5.0 2.0 virginica
出⼒︓

前処理︓データの準備
• irisデータセットの分布を眺めるimport seaborn as snssns.pairplot(iris_df, hue='species', markers=["o", "s", "+"])
Pairplotで特徴量の相関を眺めてみると、”petal length”と”petal width”はクラスとの相関が⾼く、これらで分類できそうなことがわかる。

前処理︓データの準備
• 特徴選択︓petal lengthとpetal width ([2, 3]) を特徴量として使うことにする。
X = iris.data[:, [2, 3]]y = iris.targetprint('Class labels:', np.unique(y))
Class labels: [0 1 2]
出⼒︓

前処理︓データの分割
• トレーニングデータとテストデータに分割する。from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
print('Labels counts in y:', np.bincount(y))print('Labels counts in y_train:', np.bincount(y_train))print('Labels counts in y_test:', np.bincount(y_test))
Labels counts in y: [50 50 50] Labels counts in y_train: [35 35 35] Labels counts in y_test: [15 15 15]
出⼒︓
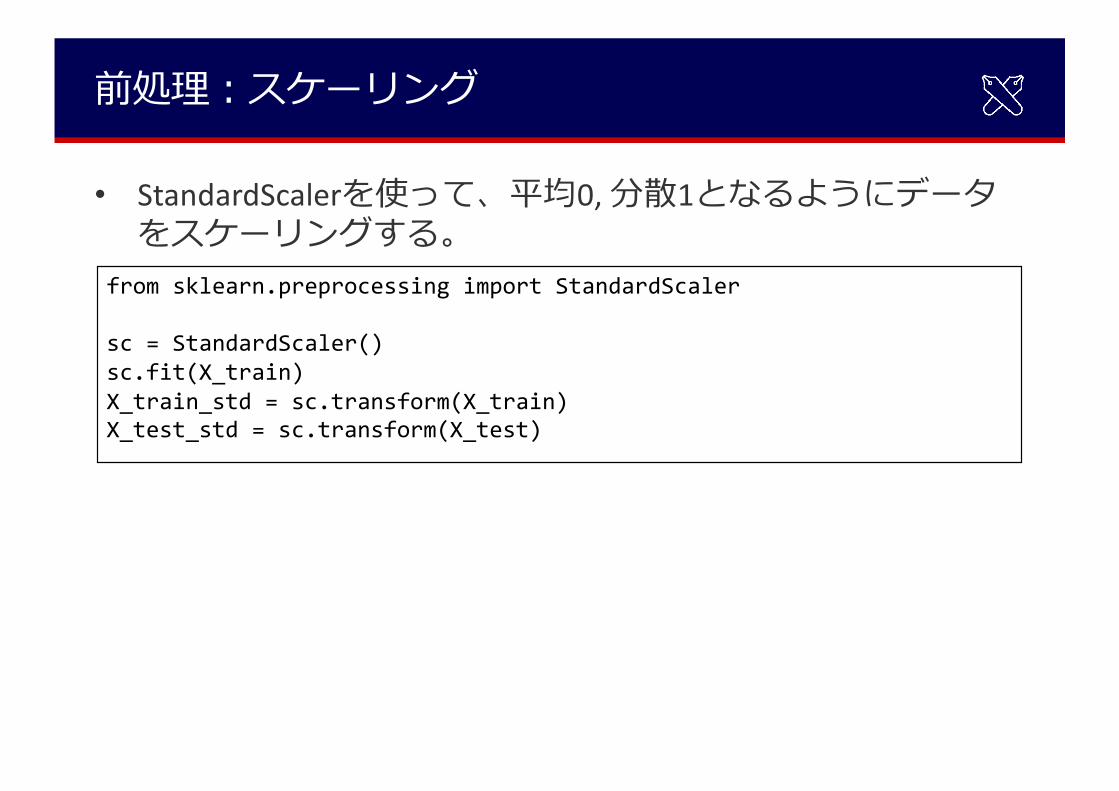
前処理︓スケーリング
• StandardScalerを使って、平均0, 分散1となるようにデータをスケーリングする。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()sc.fit(X_train)X_train_std = sc.transform(X_train)X_test_std = sc.transform(X_test)

学習︓トレーニングデータによる予測モデル学習
• パーセプトロンと呼ばれる学習アルゴリズムにより学習
• 他に使⽤可能なアルゴリズム(⼀部)– k最近傍法 (sklearn.neighbors.KNeighborsClassifier)– ロジスティック回帰 (sklearn.linear_model.LogisticRegression)– サポートベクタマシン (sklearn.svm.SVC)– ランダムフォレスト (sklearn.ensemble.RandomForestClassifier)
from sklearn.linear_model import Perceptron
ppn = Perceptron(max_iter=40, tol=1e-3, eta0=0.1, random_state=1234)ppn.fit(X_train_std, y_train)
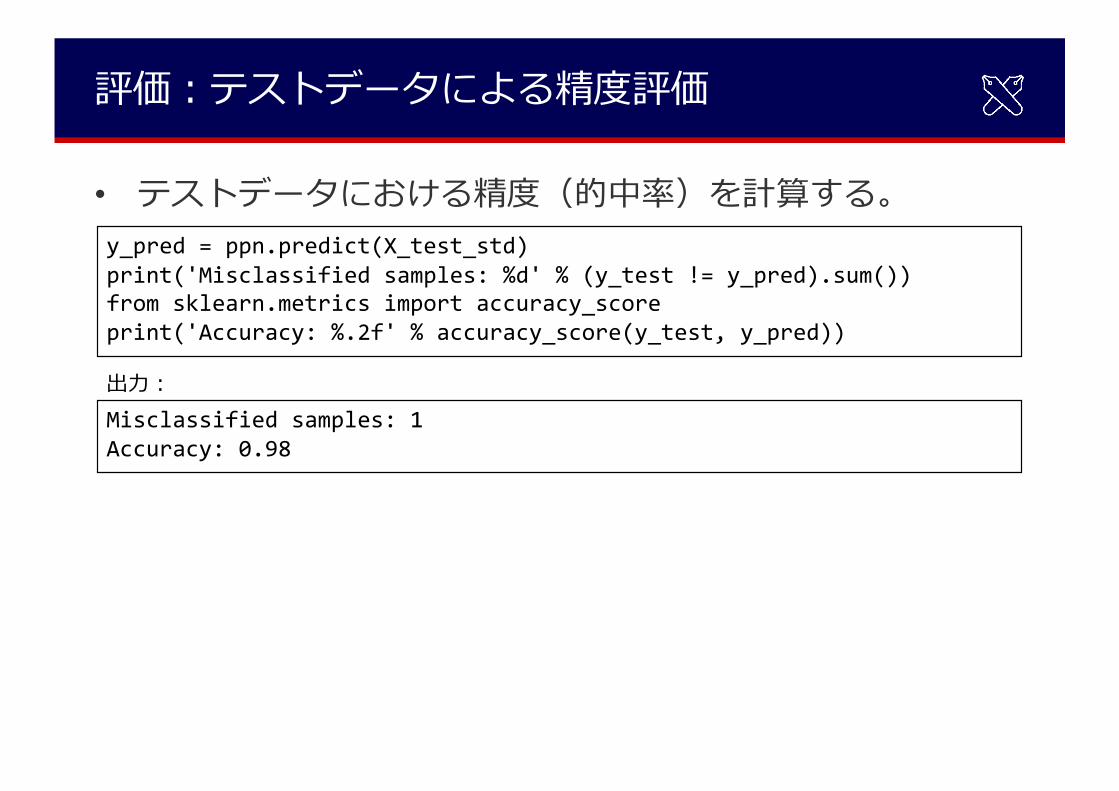
評価︓テストデータによる精度評価
• テストデータにおける精度(的中率)を計算する。y_pred = ppn.predict(X_test_std)print('Misclassified samples: %d' % (y_test != y_pred).sum())from sklearn.metrics import accuracy_scoreprint('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
Misclassified samples: 1Accuracy: 0.98
出⼒︓
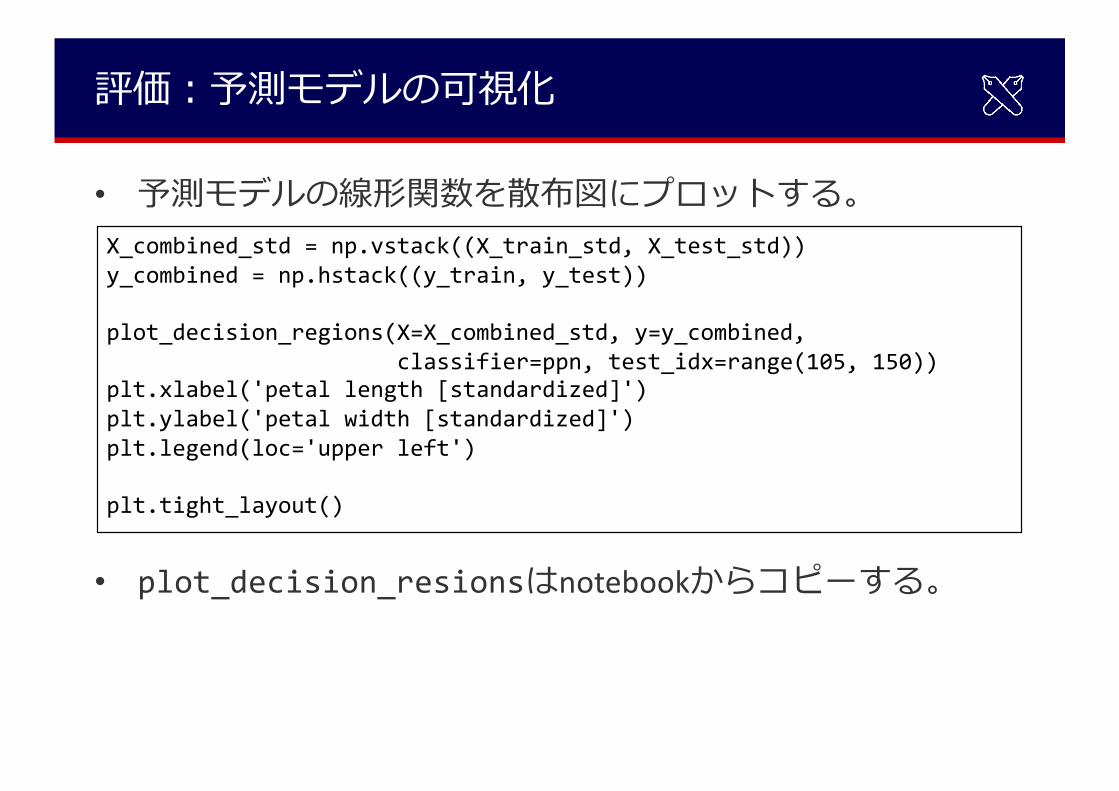
評価︓予測モデルの可視化
• 予測モデルの線形関数を散布図にプロットする。
• plot_decision_resionsはnotebookからコピーする。
X_combined_std = np.vstack((X_train_std, X_test_std))y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined,classifier=ppn, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')plt.ylabel('petal width [standardized]')plt.legend(loc='upper left')
plt.tight_layout()
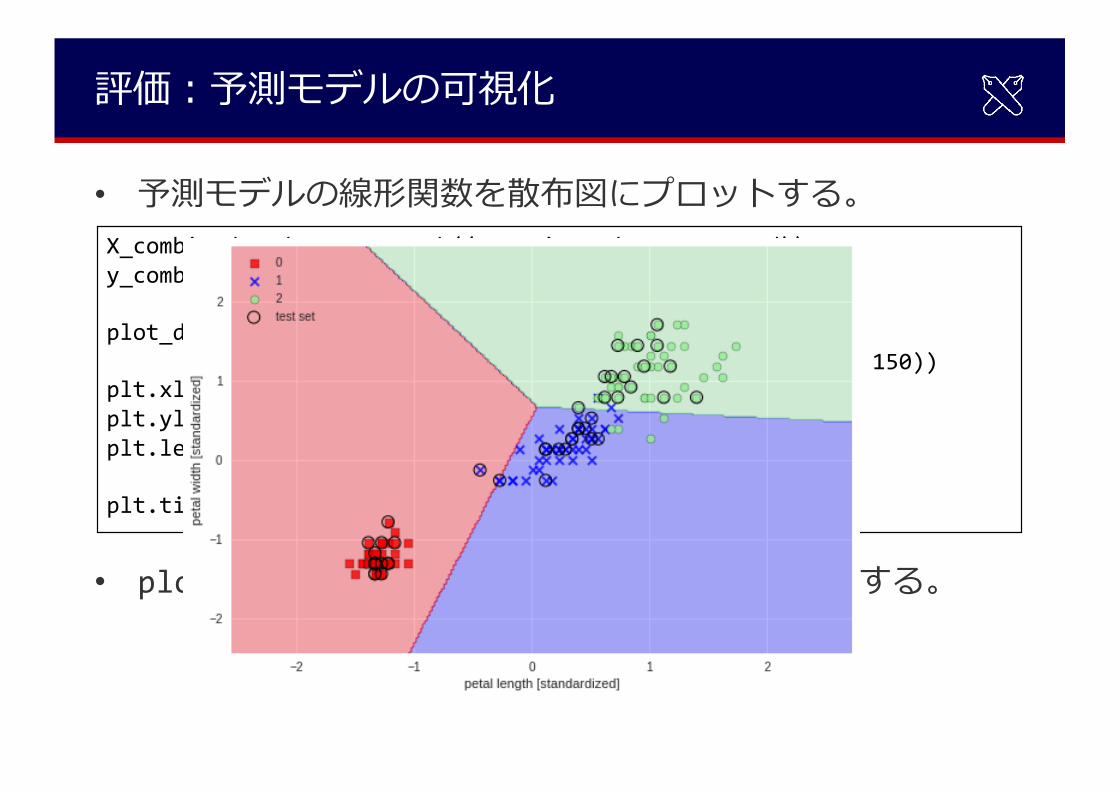
評価︓予測モデルの可視化
• 予測モデルの線形関数を散布図にプロットする。
• plot_decision_resionsはnotebookからコピーする。
X_combined_std = np.vstack((X_train_std, X_test_std))y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined,classifier=ppn, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')plt.ylabel('petal width [standardized]')plt.legend(loc='upper left')
plt.tight_layout()






























