Embed Size (px)
Citation preview

Planejamento (Regra)• Geral
– 9 Aulas (Trimestre)– 19h às 20h40 - 20h55 às 22h35 – Tolerância de 15 Minutos– ED
• Entrega: 31/05/2016 / Formato: Digital, PDF (50% da nota)• Grupo (no máximo 4 pessoas)• Tema (Pesquisa)
– Aplicações e exemplo de arquiteturas tolerantes a falhas– Projetando um sistemas de alta disponibilidade
• Estrutura: Introdução, Objetivo, Desenvolvimento e conclusão• Apresentação (50% Nota)
• U1 (24/05/2016) – Segunda parte da aula• U2 (28/06/2016) 19:45• Bons modos é fundamental• Respeito

Planejamento1. Conceitos e terminologia de segurança quanto a disponibilidade 2. Avaliação de Segurança3. Mecanismos de Controle de falhas4. Aplicações e exemplo de arquiteturas tolerantes a falhas5. Projetando um sistemas de alta disponibilidade6. Clusters de alta disponibilidade7. Grids computacionais8. Virtualização9. Tolerância a falhas em rede de computadores

Planejamento• 19:00 – 19:45 – Revisão sobre calculo de Confiabilidade
e Disponibilidade
• 19:45 – Exercicio de ficção
• 19:55 – 20:40 - Aplicações e exemplo de arquiteturas tolerantes a falhas
• 20:55 – 21:45 - Projetando um sistemas de alta disponibilidade
• 21:45 – 22:35 – Trabalho em sala de aula

Curva da Banheira

Confiabilidade• TEMPO MÉDIO PARA FALHAR (Mean Time to Failure – MTTF)
• TEMPO MÉDIO ENTRE FALHAS (Mean Time Between Failure – MTBF) = é obtido pela dos tempos de operação de todas as unidades, incluindo as que não falharam e dividindo pela somatória de falhas das unidades. O tempo de operação é a somatória de horas que as unidades estavam em uso, ou seja, não estavam desligadas.
• Quanto maior (MTTF e MTBF), menor a probabilidade da unidade falhar para uma dada missão de tempo e maior a confiabilidade. Um decréscimo na taxa de falha resulta em um aumento da MTTF e MTBF e consequentemente, um aumento da confiabilidade
ConfiabilidadeMTBF = (Tempo Total de operação / (Numero de Falhas + 1))

Confiabilidade
• MTTF = (Dt1 + Dt2 + Dt3)/nº defeitos• MTTF = 46,5/3 = 15,5 h• Taxa de defeitos () = 1/MTTF = 0,064 def/h

Confiabilidade• MTTR – Mean time to repair (Tempo médio de
reparação) = Tempo médio da parada do processo a até a recuperaçã como um todo
• MTBI – Mean time Between Interruption (Tempo médio de Interrupção) = Tempo médio entre interrupções
• OEE - Overall Equipament Effectiveness (Eficiência Geral de Equipamento)

Disponibilidade• Disponibilidade é a probabilidade que uma unidade estará pronta
para uso num instante de tempo determinado, ou sobre um período de tempo determinado, baseados em aspectos combinados de confiabilidade e mantenabilidade. Em outras palavras, a disponibilidade é uma função de sua taxa de falha (confiabilidade) e o tempo requerido para restaurar a unidade após uma falha (mantenabilidade).
( )MTTRMTBF
MTBFDisponibilidade =
+

Disponibilidade e Confiabilidade
Disponibilidade e Confiabilidade são os atributos mais conhecidos e usados, muitas vezes aparecem como sinônimos de
Dependabilidade (Dependability)

FormulaMTBF = (Tempo Total de operação / (Numero de Falhas + 1))
MTTR = Soma(Total de horas utilizado para reparo) / nr. de vezes
( )MTTRMTBF
MTBFDisponibilidade =
+

Calculo• Equipamento
– Trabalhou 8640 Horas Durante um ano– Falho 17 Vezes– Tempo médio de reparo foi de 2 Horas (MTTR)
Confiabilidade = 8640 / (17 + 1) = 480 (MTBF)
(MTBF + MTTR)
MTBFDisponibilidade = =(480 + 2)
480 =0,9958
ou
99,58%

Exercicio• Equipamento
– Trabalhou 14 Horas por dia Durante 360 dias– Falho 2 Vezes– Total de tempo para realizar o reparo das 2 falhas
foram de 3 horas

Exercicio• Equipamento
– Trabalhou 14 Horas por dia Durante 360 dias– Falho 2 Vezes– Tempo médio de reparo foi de 1,5 Horas (MTTR)
Confiabilidade = 5040/ (2 + 1) = 1680 (MTBF)
(MTBF + MTTR)
MTBFDisponibilidade = =(1680 + 1,5)
1680 =0,9991
ou
99,91%

Exercicio• Equipamento
– Trabalhou 6 Horas e 30 Minutos por dia Durante 360 dias– Falho 5 Vezes– Total de tempo para realizar o reparo das 5 falhas foram
de 4 horas

Exercicio• Equipamento
– Trabalhou 170 Horas Durante 360 dias– Falho 2 Vezes– Total de tempo para realizar o reparo das 2 falhas
foram de 12 horas

Exercicio• Equipamento– Trabalhou 24 Horas Durante 360 dias
– Falho 4 Vezes
–A média de reparo foi de 15 minutos
–Qual foi o tempo total de reparo

Exercicio• Equipamento
– Trabalhou 24 Horas Durante 360 dias– Falho 4 Vezes– A média de reparo foi de 15 minutos
– Qual foi o índice de confiabilidade / Tempo médio de funcionamento?
MTBF = (Tempo Total de operação / (Numero de Falhas + 1))
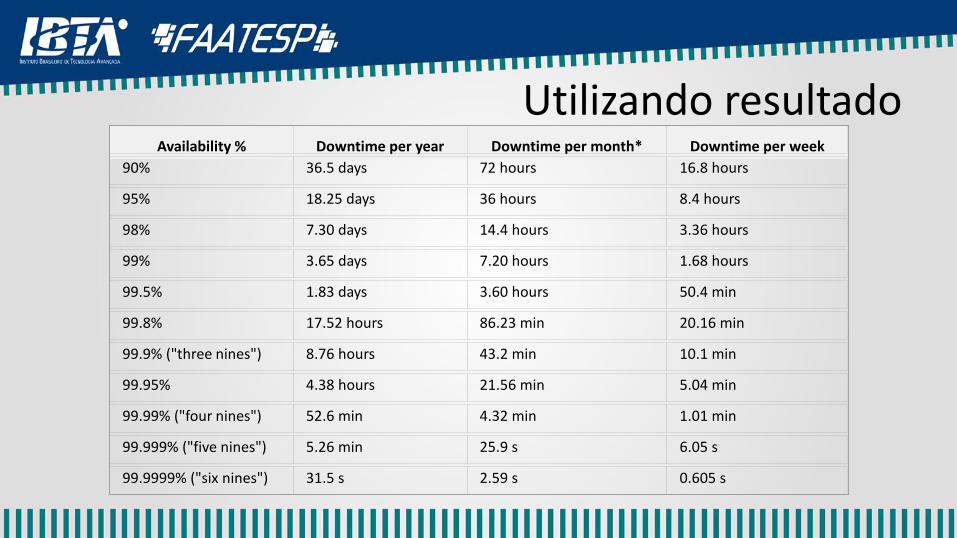
Utilizando resultadoAvailability % Downtime per year Downtime per month* Downtime per week
90% 36.5 days 72 hours 16.8 hours
95% 18.25 days 36 hours 8.4 hours
98% 7.30 days 14.4 hours 3.36 hours
99% 3.65 days 7.20 hours 1.68 hours
99.5% 1.83 days 3.60 hours 50.4 min
99.8% 17.52 hours 86.23 min 20.16 min
99.9% ("three nines") 8.76 hours 43.2 min 10.1 min
99.95% 4.38 hours 21.56 min 5.04 min
99.99% ("four nines") 52.6 min 4.32 min 1.01 min
99.999% ("five nines") 5.26 min 25.9 s 6.05 s
99.9999% ("six nines") 31.5 s 2.59 s 0.605 s

Aplicações e exemplos de arquiteturas tolerantes a falhas

Agenda
I) Computação de propósitos
gerais
II) Sistemas de alta
disponibilidade
III) Sistemas de vida longa
IV) Computação crítica

Sistema• Teoria Geral de Sistemas
– “Um conjunto de elementos inter-relacionados com um objetivo comum”
– Todo sistema é um sub-sistema de um sistema maior
– Homeostase – Capacidade do organismode apresentar uma situação físico-quimica característica e constante, dentro de determinados limites, mesmo diante de alterações impostas pelo meio ambiente.

Sistema• Atributos
– Interface– Ponto de vista– Nivel de abordagem (Detalhe)– Hierarquia (divisão)
• Caracteristicas– Elemento– Ambiente– Objetivo Comum– Relação entre elementos– Cumprir uma Função

Computação de propósitos Gerais

Computação de propósitos Gerais• GPOS – General Purpose Operating System
• Realização de atividades comum
• Não precisa de um algo especifico
• Generalista
• Sistemas Gerais - São aqueles em que falhas e interrupções curtas de serviço são toleráveis desde que o sistema volte a funcionar posteriormente.

Sistemas de alta disponibilidade• Sistemas que buscam-se manter ativos no maior tempo
possível• Utilização
– Redundância– Segurança– Contigência– Normas– Gestão– Cluster
• Preciso de sincronização (Processamento e dados)

Sistemas de alta disponibilidade• Rede
– Dados
• Banco de Dados• Serviço
– Banco– Cartão de Crédito– Segurança publica
• Energia• Telecomunicações

Sistemas de alta disponibilidade

Sistemas de vida longa• A confiabilidade é prioridade máxima e normalmente é impossível
realizar manutenção não-planejada. • Baixa utilização de energia, leves e finos• Resiliência = Capacidade de superar, de recuperar de adversidades.• Exemplos:
– Satélites– Controladores de Vôo (Espacial, doméstico e demais)– Sondas (espacial, maritima, terrestre)– Sistemas de Saude– Sistemas de monitoramento Geográfico (Mar, Vulcão e outros)

Computação Critica• Missão critica em ti = é quando um processo, equipamento
ou aplicação, ao falharem ou ficarem indisponíveis, afetam a operação de uma empresa ou causam grandes perdas e transtornos
• União entre investigação técnica, desenvolvimento e Teoria Critica
• Advanced Identity Representation (AIR) • Caracteristicas
– Alta Disponibilidade e Disponibilidade Continua– Redundância

Computação Critica• Possui grande contribuição para as areas:
– Social
– Humana
– Cultural
• Exemplo:– Criação de avatar dinamico
– Second Life
– Rede Social

Computação Critica• Exemplos
– Sistema de controle de coleta de dados de um projeto em Física Experimental para criação de estado de plasma
– Um núcleo de negociação para o mercado financeiro, tratando milhões de operações/dia, envolvendo mensageria em banco de dados, cache distribuído, gerenciamento de recursos em memória, etc., com requisitos rígidos de baixa latência, também é um exemplo de missão crítica
– Um sistema SaaS – Software as a Service – sobre algum provedor em nuvem, para uma solução multi-inquilino com interfaces Web, responsável pelo núcleo de faturamento da empresa
– Jogos – Complexidade e montagem de cenários dinamicamente– Sistema de uma aeronave– Sistemas militares
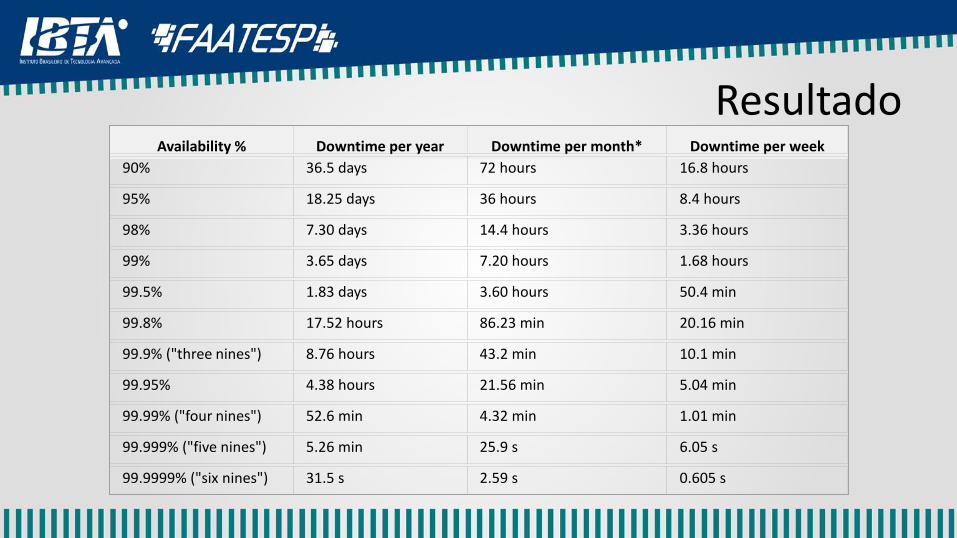
ResultadoAvailability % Downtime per year Downtime per month* Downtime per week
90% 36.5 days 72 hours 16.8 hours
95% 18.25 days 36 hours 8.4 hours
98% 7.30 days 14.4 hours 3.36 hours
99% 3.65 days 7.20 hours 1.68 hours
99.5% 1.83 days 3.60 hours 50.4 min
99.8% 17.52 hours 86.23 min 20.16 min
99.9% ("three nines") 8.76 hours 43.2 min 10.1 min
99.95% 4.38 hours 21.56 min 5.04 min
99.99% ("four nines") 52.6 min 4.32 min 1.01 min
99.999% ("five nines") 5.26 min 25.9 s 6.05 s
99.9999% ("six nines") 31.5 s 2.59 s 0.605 s

Revisão• Revisão
– Curva da Banheira– Confiabilidade– Disponibilidade– Métricas MTTR, MTBR, MTTF, MTBI
• Aplicações e Exemplos de arq. Tolerante a falhas– Sistema (Teoria Geral)– Atributos e Caracteristicas– Computação de propósitos Gerais– Sistemas de alta disponibilidade– Contingência X Redundância– Sistemas de vida longa– Computação Critica

Duvidas?

Projetando um sistema de alta disponibilidade

Agenda
I) Introdução
II) Implementando a
arquitetura
III) Pontos críticos de falha
IV) Eliminando SPOF

O que eu preciso?Availability of typical systems classes. Today’s best systems are in the
high-availability range. The best of the general-purpose systems are in the
fault-tolerant range as of 1990.
Unavailability Availability
System Type (min/year) Availability Class
unmanaged 50,000 90.% 1
managed 5,000 99.% 2
well-managed 500 99.9% 3
fault-tolerant 50 99.99% 4
high-availability 5 99.999% 5
very-high-availability .5 99.9999% 6
ultra-availability .05 99.99999% 7

O que eu preciso?
CustoPerformance
Segurança Disponbilidade

Introdução• Projetando
– Requisitos– Objetivo– Ambiente– Tempo– Custo– Quem?
• Metologia de apoio / suporte– PMBOK, SCRUM, PRINCE2 (Gestão do Projeto)– CMMI, RUP, XP, UML (Desenv Soft)– ISO 27000 e 20000 (Infra Estrutura)– SOA (Serviço)– Cobit (Gestão de TI)– ITIL (Gestão do Serviços)

Implementando a arquitetura• Planejamento Estratégico
– Visão compartilhada - Futuro– Objetivos de negócio - Melhorias– Processos de Negócio – Cronograma de alteração
• Criação de processo de negócios orientado a serviços• Mudança na concepção do usuario• Implementação de infra-estrutura
– Recursos de rede– Computadores pessoais de trabalhadores de conhecimento– Operações de servidor consolidadas– Serviços de autenticação– Proteção contra intrusos– Serviços de aplicações

Implementando a arquitetura• Gerenciamento de infra-estrutura
– Investimento– Unificação– Propriedade – Conhecimento interno e externo– Evolução– Controle de alterações
• Definição de Objetivos de integração de aplicações• Gerenciamento do desenvolvimento de aplicações• Definição de padrões• Gerenciamento de mudanças• Consolidação de gerenciamento de Sistemas de informação• Analise de fatores importantes para o sucesso

Ja sei o que preciso
CustoPerformance
Segurança Disponbilidade

Pontos criticos de falha (SPOF)• Single points of Failure (Pontos unicos de Falha)
– Compromete toda a disponibilidade
– Compromete todo o processo / Sistema
– Pode surgir por:
• Uma falha de projeto ou concepção
• Execução falha
• Monitoramento indevido

Pontos criticos de falha (SPOF)• Como reduzir riscos? Plano de resposta

Pontos criticos de falha (SPOF)• Fase de implementação
– Hardware• Estar atento a todo e qualquer componente• Saber da capacidade dos mesmos• Realizar testes de stress• Buscar referências
– Software• Buscar informações detalhadas• Alinhar requisitos e escopo• Simular, testar, ensaiar
– Processamento– Armazenamento

Eliminando SPOF• Rede
– Controle de disco– Controle de endereço IP por meio de aliases de IP– Controle de endereço IP por meio de substituição de IP (com ou sem
controle endereço de hardware)
• Aplicativo– Controlador de aplicativo– Controle de cluster– Monitores de aplicativo– Ferramenta de análise de disponibilidade de aplicativo
• Notificação de erro

Revisão• Projetando um Sistema HA
– Projeto
– Metodologia
– Implementação da arquitetura
– Pontos Criticos de Falha (SPOF)
– Eliminando SPOF

Duvidas?
































