Embed Size (px)
Citation preview

Arquitectura de ComputadoresProcessadores Multicore; GPUs; Clusters
Jose Monteiro
Licenciatura em Engenharia Informatica e de Computadores
Departamento de Engenharia Informatica (DEI)Instituto Superior Tecnico
20 de Maio, 2013
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 1 / 25

Sumario da Aula
multicores
UMA, Uniform Memory Access
NUMA, Non-Uniform Memory Access
GPUs, Graphics Processing Units
multicomputadores
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 2 / 25

Nıveis de Paralelismo
execucao simultanea de varias fases de instrucoes em sequencia
⇒ pipelining
execucao paralela de instrucoes de uma sequencia num unicoprocessador
⇒ processadores superescalares e VLIWs
execucao paralela em varios processadores num unico computador
⇒ multiprocessadores
execucao paralela em varios computadores
⇒ clusters, grids
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 3 / 25

Nıveis de Paralelismo
execucao simultanea de varias fases de instrucoes em sequencia
⇒ pipelining
execucao paralela de instrucoes de uma sequencia num unicoprocessador
⇒ processadores superescalares e VLIWs
execucao paralela em varios processadores num unico computador
⇒ multiprocessadores
execucao paralela em varios computadores
⇒ clusters, grids
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 3 / 25

Nıveis de Paralelismo
execucao simultanea de varias fases de instrucoes em sequencia
⇒ pipelining
execucao paralela de instrucoes de uma sequencia num unicoprocessador
⇒ processadores superescalares e VLIWs
execucao paralela em varios processadores num unico computador
⇒ multiprocessadores
execucao paralela em varios computadores
⇒ clusters, grids
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 3 / 25

Nıveis de Paralelismo
execucao simultanea de varias fases de instrucoes em sequencia
⇒ pipelining
execucao paralela de instrucoes de uma sequencia num unicoprocessador
⇒ processadores superescalares e VLIWs
execucao paralela em varios processadores num unico computador
⇒ multiprocessadores
execucao paralela em varios computadores
⇒ clusters, grids
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 3 / 25
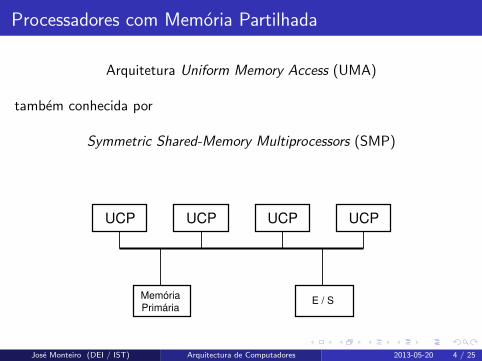
Processadores com Memoria Partilhada
Arquitetura Uniform Memory Access (UMA)
tambem conhecida por
Symmetric Shared-Memory Multiprocessors (SMP)
UCP UCP UCP UCP
Memória
PrimáriaE / S
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 4 / 25
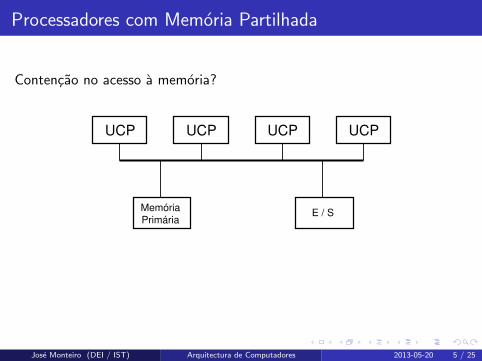
Processadores com Memoria Partilhada
Contencao no acesso a memoria?
UCP UCP UCP UCP
Memória
PrimáriaE / S
Caches write-back ou write-through?
Tipicamente write-back: reducao do numero de acessos a memoria central.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 5 / 25
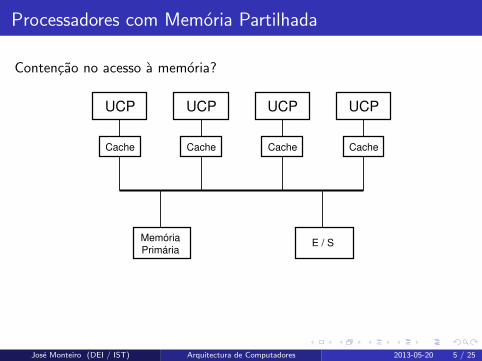
Processadores com Memoria Partilhada
Contencao no acesso a memoria?
UCP
Cache
UCP UCP UCP
Memória
PrimáriaE / S
Cache Cache Cache
Caches write-back ou write-through?
Tipicamente write-back: reducao do numero de acessos a memoria central.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 5 / 25
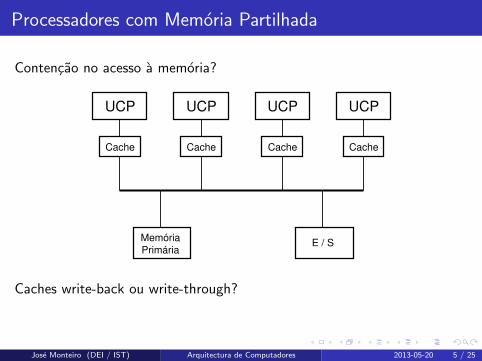
Processadores com Memoria Partilhada
Contencao no acesso a memoria?
UCP
Cache
UCP UCP UCP
Memória
PrimáriaE / S
Cache Cache Cache
Caches write-back ou write-through?
Tipicamente write-back: reducao do numero de acessos a memoria central.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 5 / 25
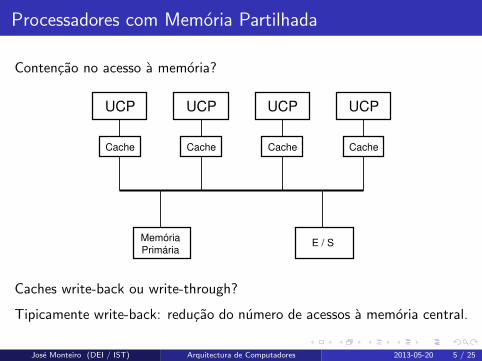
Processadores com Memoria Partilhada
Contencao no acesso a memoria?
UCP
Cache
UCP UCP UCP
Memória
PrimáriaE / S
Cache Cache Cache
Caches write-back ou write-through?
Tipicamente write-back: reducao do numero de acessos a memoria central.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 5 / 25

Coerencia de Memoria
Em sistemas paralelos, a migracao e replicacao de dados e normal, emesmo desejavel.
No entanto, uma vez que os dados podem estar em multiplas caches, enecessario lidar com o problema da coerencia de dados.
Tempo Evento Cache Cache MemoriaUCP A UCP B Primaria
0 0
1 UCP A le M[X] 0 0
2 UCP B le M[X] 0 0 0
3 UCP A 1→M[X] 1 0 1
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 6 / 25

Coerencia de Memoria
Em sistemas paralelos, a migracao e replicacao de dados e normal, emesmo desejavel.
No entanto, uma vez que os dados podem estar em multiplas caches, enecessario lidar com o problema da coerencia de dados.
Tempo Evento Cache Cache MemoriaUCP A UCP B Primaria
0 0
1 UCP A le M[X] 0 0
2 UCP B le M[X] 0 0 0
3 UCP A 1→M[X] 1 0 1
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 6 / 25

Coerencia de Memoria
Em sistemas paralelos, a migracao e replicacao de dados e normal, emesmo desejavel.
No entanto, uma vez que os dados podem estar em multiplas caches, enecessario lidar com o problema da coerencia de dados.
Tempo Evento Cache Cache MemoriaUCP A UCP B Primaria
0 0
1 UCP A le M[X] 0 0
2 UCP B le M[X] 0 0 0
3 UCP A 1→M[X] 1 0 1
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 6 / 25
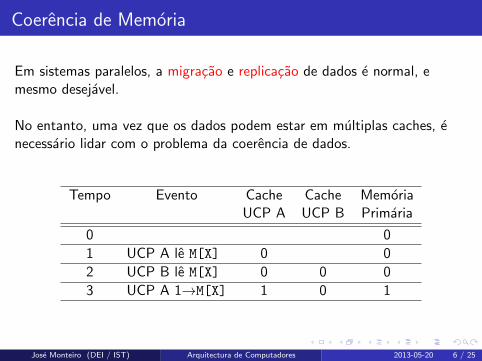
Coerencia de Memoria
Em sistemas paralelos, a migracao e replicacao de dados e normal, emesmo desejavel.
No entanto, uma vez que os dados podem estar em multiplas caches, enecessario lidar com o problema da coerencia de dados.
Tempo Evento Cache Cache MemoriaUCP A UCP B Primaria
0 0
1 UCP A le M[X] 0 0
2 UCP B le M[X] 0 0 0
3 UCP A 1→M[X] 1 0 1
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 6 / 25
Processadores com Memoria Partilhada
UCP
Cache
UCP UCP UCP
Memória
PrimáriaE / S
Cache Cache Cache
Limitacao principal desta arquitetura?
Escalabilidade limitada devido ao acesso a memoria primaria.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 7 / 25
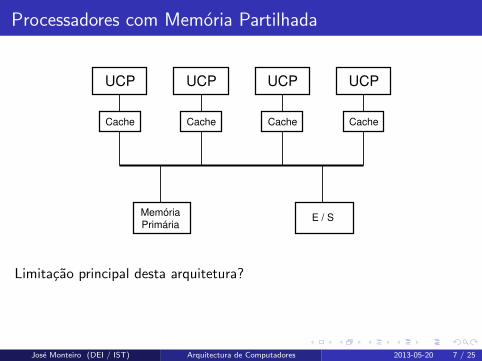
Processadores com Memoria Partilhada
UCP
Cache
UCP UCP UCP
Memória
PrimáriaE / S
Cache Cache Cache
Limitacao principal desta arquitetura?
Escalabilidade limitada devido ao acesso a memoria primaria.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 7 / 25
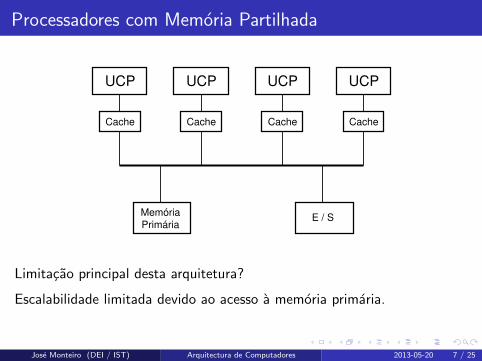
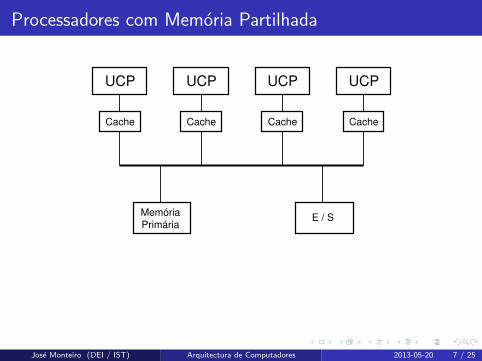
Processadores com Memoria Partilhada
UCP
Cache
UCP UCP UCP
Memória
PrimáriaE / S
Cache Cache Cache
Limitacao principal desta arquitetura?
Escalabilidade limitada devido ao acesso a memoria primaria.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 7 / 25
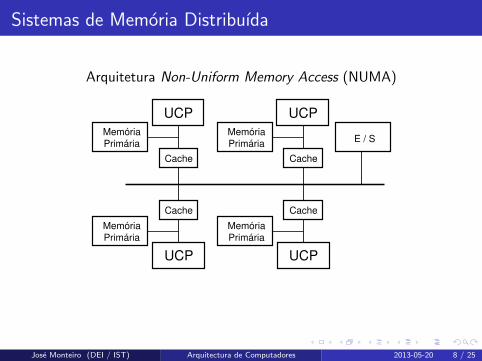
Sistemas de Memoria Distribuıda
Arquitetura Non-Uniform Memory Access (NUMA)
UCP
Cache
Cache
UCP
Memória
Primária
Memória
PrimáriaE / S
UCP
Cache
Cache
UCP
Memória
Primária
Memória
Primária
Principal problema desta arquitetura?
Acesso lento a dados remotos.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 8 / 25
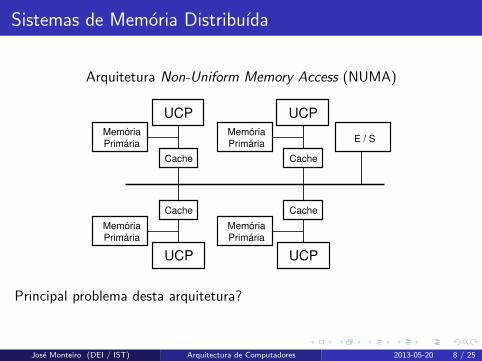
Sistemas de Memoria Distribuıda
Arquitetura Non-Uniform Memory Access (NUMA)
UCP
Cache
Cache
UCP
Memória
Primária
Memória
PrimáriaE / S
UCP
Cache
Cache
UCP
Memória
Primária
Memória
Primária
Principal problema desta arquitetura?
Acesso lento a dados remotos.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 8 / 25
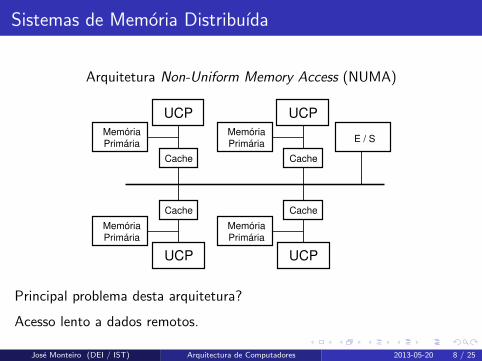
Sistemas de Memoria Distribuıda
Arquitetura Non-Uniform Memory Access (NUMA)
UCP
Cache
Cache
UCP
Memória
Primária
Memória
PrimáriaE / S
UCP
Cache
Cache
UCP
Memória
Primária
Memória
Primária
Principal problema desta arquitetura?
Acesso lento a dados remotos.
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 8 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Comparacao entre Sistemas UMA e NUMA
Em arquiteturas UMA:
partilha de dados muito mais facil
tempo de acesso a dados uniforme
mais faceis de programar
No entanto:
contencao no acesso a memoria e uma limitacao seria a suaescalabilidade
a memoria distribuıda permite uma maior largura de banda no acessoa memoria
partilha de dados e explıcita, portanto mais facil de perceber econtrolar
hardware mais simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 9 / 25

Multicores
Exemplos de processadores multicore atuais:
AMD
Opteron: dual, quad, hex, 8-, 12-coresPhenom: dual, quad, hex cores
Intel
Core i7: six hyperthreaded coresDunnington (Xeon): six cores
Sun
Niagara: 8 cores; 8-way fine-grain multithreading per core
IBM
Power 7: dual, quad, hex, 8-coreCell: 1 PPC core; 8 SPEs w/ SIMD parallelism
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 10 / 25

GPGPU
GPU - Graphics Processing Unit
processador dedicado para a geracao de imagens
GPGPU - General Purpose Graphics Processing Unit programming
desacoplar o GPU dos graficos
explorar o poder computacional do GPU
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 11 / 25
CUDA
A NVIDIA colocou muitos exemplos/aplicacoes interessantes na suapagina da internet para demonstrar o potencial da programacao GPGPU.
Alguns speedups sao difıceis de acreditar...
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 12 / 25

Fatores que Impulsionam o Desempenho dos GPUs
Porque tem os GPUs um desempenho tao elevado?
necessidade de geracao deimagens em tempo real
industria dos jogos e ummercado rico
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 13 / 25

Fatores que Impulsionam o Desempenho dos GPUs
Porque tem os GPUs um desempenho tao elevado?
necessidade de geracao deimagens em tempo real
industria dos jogos e ummercado rico
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 13 / 25
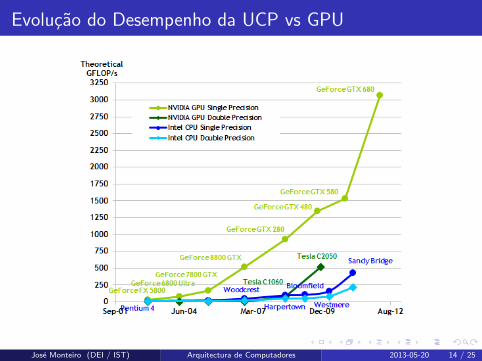
Evolucao do Desempenho da UCP vs GPU
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 14 / 25

Arquitetura dos GPUs
GPU desenhado para as funcoes que e usado:
processamento vetorial
vetores grandes de dados
stream processing
operacoes em vırgula flutuante rapidas
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 15 / 25
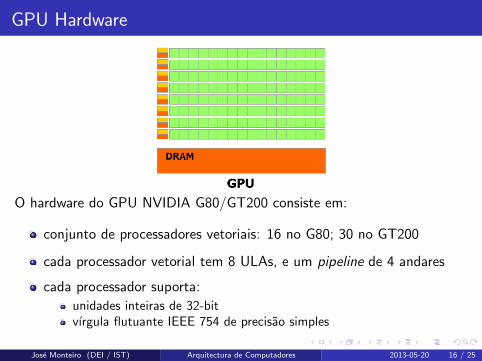
GPU Hardware
O hardware do GPU NVIDIA G80/GT200 consiste em:
conjunto de processadores vetoriais: 16 no G80; 30 no GT200
cada processador vetorial tem 8 ULAs, e um pipeline de 4 andares
cada processador suporta:
unidades inteiras de 32-bitvırgula flutuante IEEE 754 de precisao simples
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 16 / 25
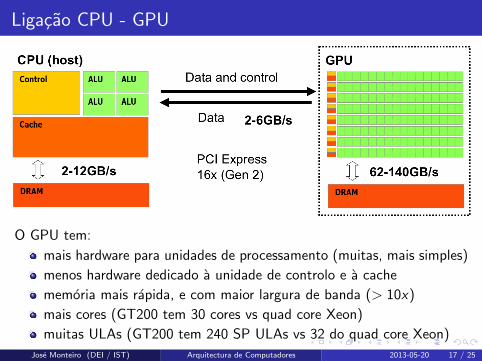
Ligacao CPU - GPU
O GPU tem:
mais hardware para unidades de processamento (muitas, mais simples)
menos hardware dedicado a unidade de controlo e a cache
memoria mais rapida, e com maior largura de banda (> 10x)
mais cores (GT200 tem 30 cores vs quad core Xeon)
muitas ULAs (GT200 tem 240 SP ULAs vs 32 do quad core Xeon)
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 17 / 25

Programacao GPGPU
Dificuldades da programacao GPGPU:
Aprendizagem complicada
Necessidade de mapear programa para calculo vetorial
Modelo de acesso a memoria limitado
Transferencia de dados CPU-GPU reduz desempenho
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 18 / 25

Programacao GPGPU
Dificuldades da programacao GPGPU:
Aprendizagem complicada
Necessidade de mapear programa para calculo vetorial
Modelo de acesso a memoria limitado
Transferencia de dados CPU-GPU reduz desempenho
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 18 / 25

Programacao GPGPU
Dificuldades da programacao GPGPU:
Aprendizagem complicada
Necessidade de mapear programa para calculo vetorial
Modelo de acesso a memoria limitado
Transferencia de dados CPU-GPU reduz desempenho
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 18 / 25

Programacao GPGPU
Dificuldades da programacao GPGPU:
Aprendizagem complicada
Necessidade de mapear programa para calculo vetorial
Modelo de acesso a memoria limitado
Transferencia de dados CPU-GPU reduz desempenho
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 18 / 25
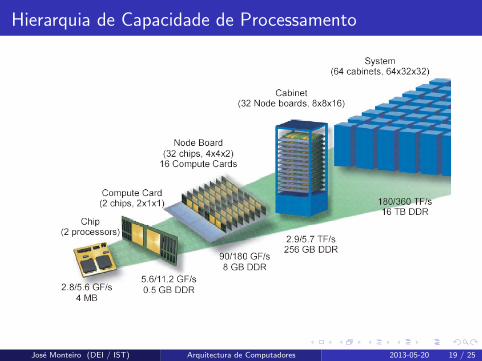
Hierarquia de Capacidade de Processamento
HPC: High Performance Computing
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 19 / 25
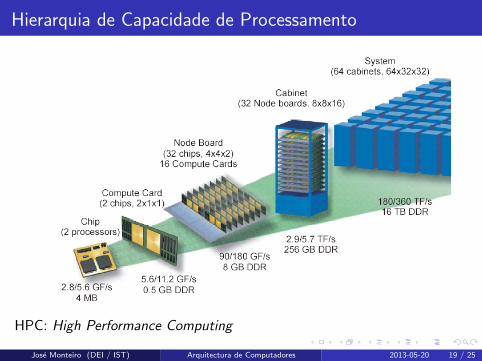
Hierarquia de Capacidade de Processamento
HPC: High Performance Computing
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 19 / 25

Computadores do Tamanho de Armazens
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 20 / 25

Computadores do Tamanho de Armazens
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 20 / 25
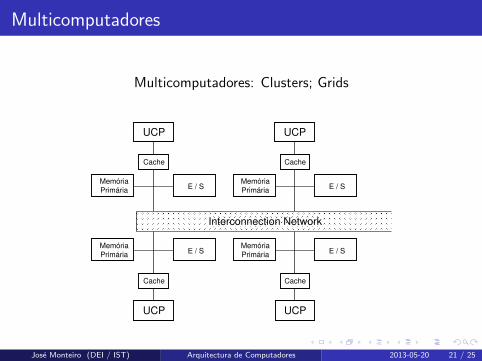
Multicomputadores
Multicomputadores: Clusters; Grids
Memória
PrimáriaE / S
UCP
Cache
Interconnection Network
Cache
Cache Cache
UCP
UCP UCP
Memória
Primária
Memória
Primária
Memória
Primária
E / S
E / S E / S
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 21 / 25
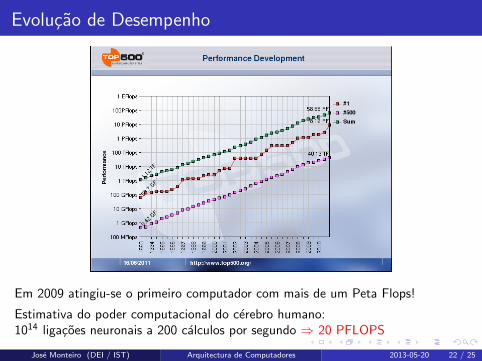
Evolucao de Desempenho
Em 2009 atingiu-se o primeiro computador com mais de um Peta Flops!
Estimativa do poder computacional do cerebro humano:1014 ligacoes neuronais a 200 calculos por segundo ⇒ 20 PFLOPS
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 22 / 25
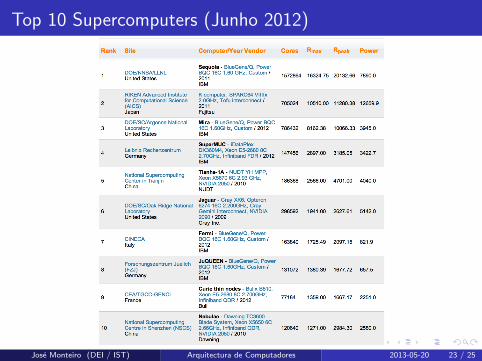
Top 10 Supercomputers (Junho 2012)
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 23 / 25

Revisao
multicores
UMA, Uniform Memory Access
NUMA, Non-Uniform Memory Access
GPUs, Graphics Processing Units
multicomputadores
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 24 / 25

Proximos Passos
esta semana, discussoes e definicao da nota de laboratorio
2o teste
teste dia 7 de Junho as 11h30
inscricoes abertas entre 28 de Maio e 4 de Junho
horario das aulas de duvidas para as proximas semanas vai ser alterado,novos perıodos vao ser colocados na pagina do Fenix
repescagem
teste dia 27 de Junho as 8h
inscricoes abertas entre 17 e 24 de Junho
⇒ escolher o teste certo!
⇒ a inscricao para a repescagem leva a perda do bonus!
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 25 / 25

Proximos Passos
esta semana, discussoes e definicao da nota de laboratorio
2o teste
teste dia 7 de Junho as 11h30
inscricoes abertas entre 28 de Maio e 4 de Junho
horario das aulas de duvidas para as proximas semanas vai ser alterado,novos perıodos vao ser colocados na pagina do Fenix
repescagem
teste dia 27 de Junho as 8h
inscricoes abertas entre 17 e 24 de Junho
⇒ escolher o teste certo!
⇒ a inscricao para a repescagem leva a perda do bonus!
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 25 / 25

Proximos Passos
esta semana, discussoes e definicao da nota de laboratorio
2o teste
teste dia 7 de Junho as 11h30
inscricoes abertas entre 28 de Maio e 4 de Junho
horario das aulas de duvidas para as proximas semanas vai ser alterado,novos perıodos vao ser colocados na pagina do Fenix
repescagem
teste dia 27 de Junho as 8h
inscricoes abertas entre 17 e 24 de Junho
⇒ escolher o teste certo!
⇒ a inscricao para a repescagem leva a perda do bonus!
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 25 / 25

Proximos Passos
esta semana, discussoes e definicao da nota de laboratorio
2o teste
teste dia 7 de Junho as 11h30
inscricoes abertas entre 28 de Maio e 4 de Junho
horario das aulas de duvidas para as proximas semanas vai ser alterado,novos perıodos vao ser colocados na pagina do Fenix
repescagem
teste dia 27 de Junho as 8h
inscricoes abertas entre 17 e 24 de Junho
⇒ escolher o teste certo!
⇒ a inscricao para a repescagem leva a perda do bonus!
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 25 / 25

Proximos Passos
esta semana, discussoes e definicao da nota de laboratorio
2o teste
teste dia 7 de Junho as 11h30
inscricoes abertas entre 28 de Maio e 4 de Junho
horario das aulas de duvidas para as proximas semanas vai ser alterado,novos perıodos vao ser colocados na pagina do Fenix
repescagem
teste dia 27 de Junho as 8h
inscricoes abertas entre 17 e 24 de Junho
⇒ escolher o teste certo!
⇒ a inscricao para a repescagem leva a perda do bonus!
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 25 / 25

Proximos Passos
esta semana, discussoes e definicao da nota de laboratorio
2o teste
teste dia 7 de Junho as 11h30
inscricoes abertas entre 28 de Maio e 4 de Junho
horario das aulas de duvidas para as proximas semanas vai ser alterado,novos perıodos vao ser colocados na pagina do Fenix
repescagem
teste dia 27 de Junho as 8h
inscricoes abertas entre 17 e 24 de Junho
⇒ escolher o teste certo!
⇒ a inscricao para a repescagem leva a perda do bonus!
Jose Monteiro (DEI / IST) Arquitectura de Computadores 2013-05-20 25 / 25

























![AODE ERWTHSEIS-09[TELIKO 1]](https://img.pdfslide.tips/doc/110x75/545efb63af795937758b4af1/aode-erwthseis-09teliko-1.jpg)



