Embed Size (px)
Citation preview

Chapter 6 :
Game Search게임 탐색(Adversarial Search)
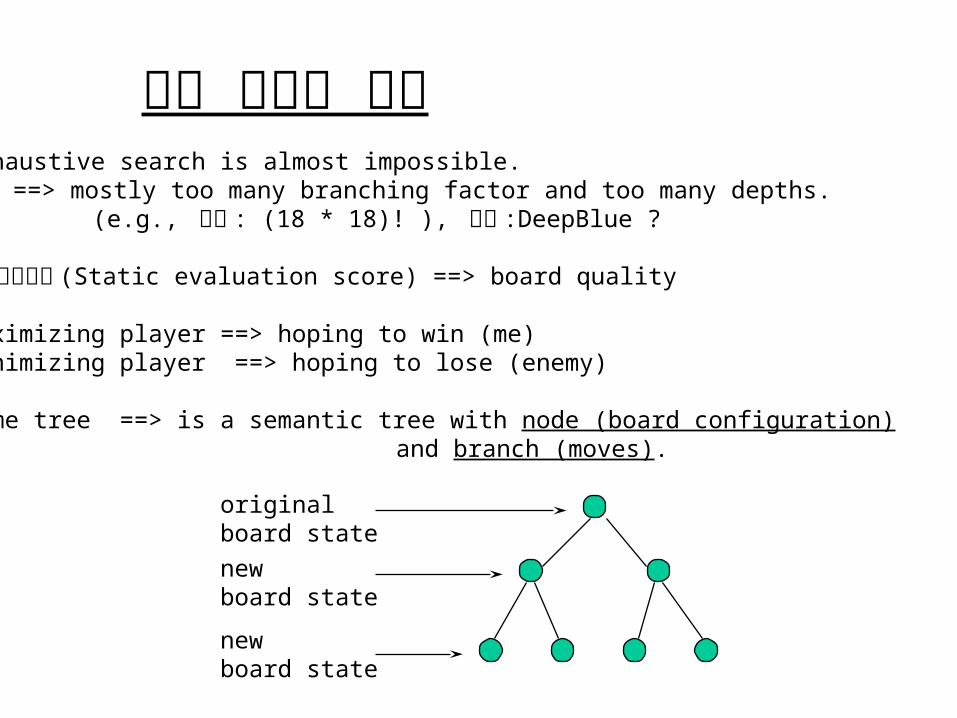
originalboard state
new board state
new board state
게임 탐색의 특성- Exhaustive search is almost impossible. ==> mostly too many branching factor and too many depths.
(e.g., 바둑 : (18 * 18)! ), 체스 :DeepBlue ?
- 정적평가점수 (Static evaluation score) ==> board quality
- maximizing player ==> hoping to win (me) minimizing player ==> hoping to lose (enemy)
- Game tree ==> is a semantic tree with node (board configuration) and branch (moves).
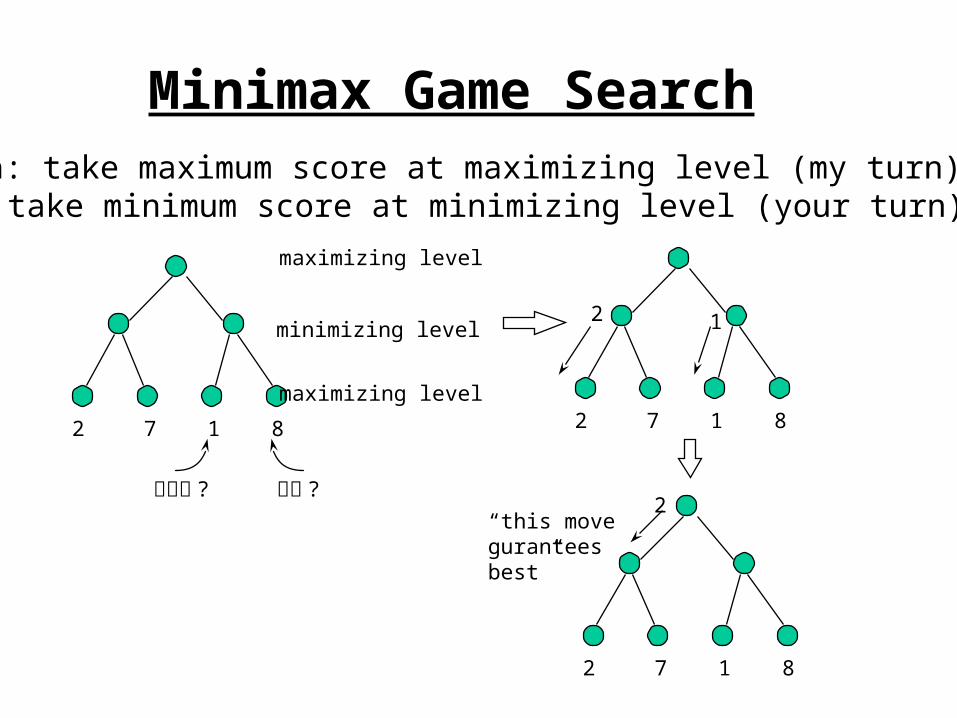
Minimax Game SearchIdea: take maximum score at maximizing level (my turn).
take minimum score at minimizing level (your turn).
2 7 1 8
maximizing level
minimizing level
maximizing level
나는 ?상대는 ?
2 7 1 8
2 7 1 8
2 1
2“this moveguranteesbest”
4
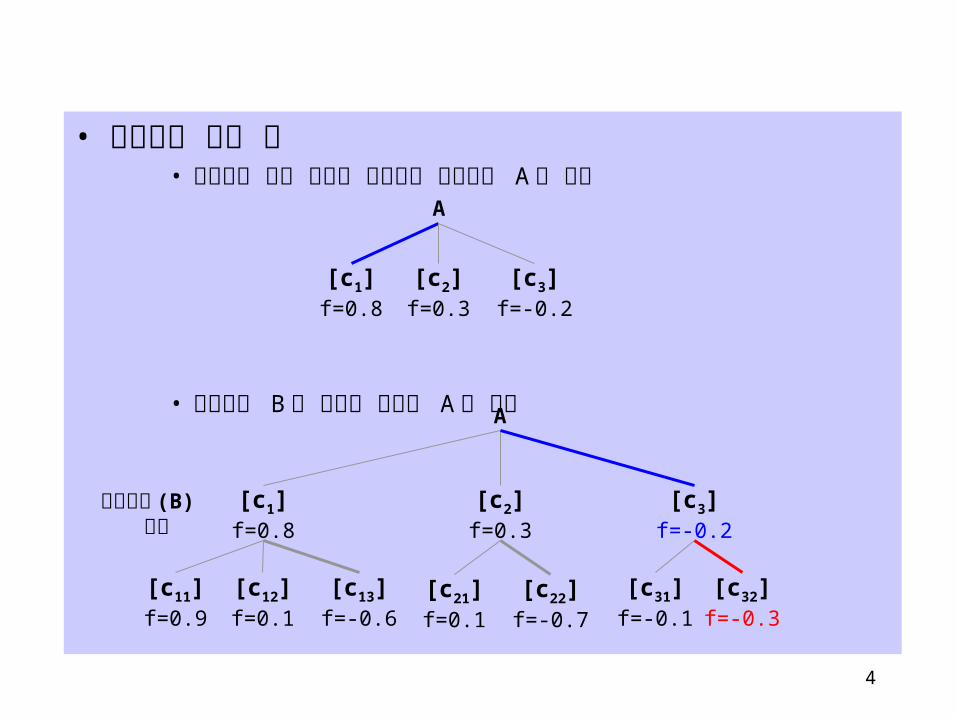
• 최소최대 탐색 예• 평가함수 값을 최대화 시키려는 최대화자 A 의 탐색
• 최소화자 B 의 의도를 고려한 A 의 선택
A
[c1]f=0.8
[c2]f=0.3
[c3]f=-0.2
A
[c1]f=0.8
[c2]f=0.3
[c3]f=-0.2
[c11]f=0.9
[c12]f=0.1
[c13]f=-0.6
[c21]f=0.1
[c22]f=-0.7
[c31]f=-0.1
[c32]f=-0.3
최소화자 (B) 단계

5
Minimax Algorithm
Function MINIMAX( state ) returns an action
inputs: state, current state in game
v = MAX-VALUE (state)
return the action corresponding with value v
Function MAX-VALUE( state ) returns a utility value
if TERMINAL-TEST( state ) then return UTILITY( state )
v = -for a, s in SUCCESSORS( state ) do
v = MAX( v, MIN-VALUE( s ) )
return v
Function MIN-VALUE( state ) returns a utility value
if TERMINAL-TEST( state ) then return UTILITY( state )
v = for a, s in SUCCESSORS( state ) do
v = MIN( v, MAX-VALUE( s ) )
return v

6
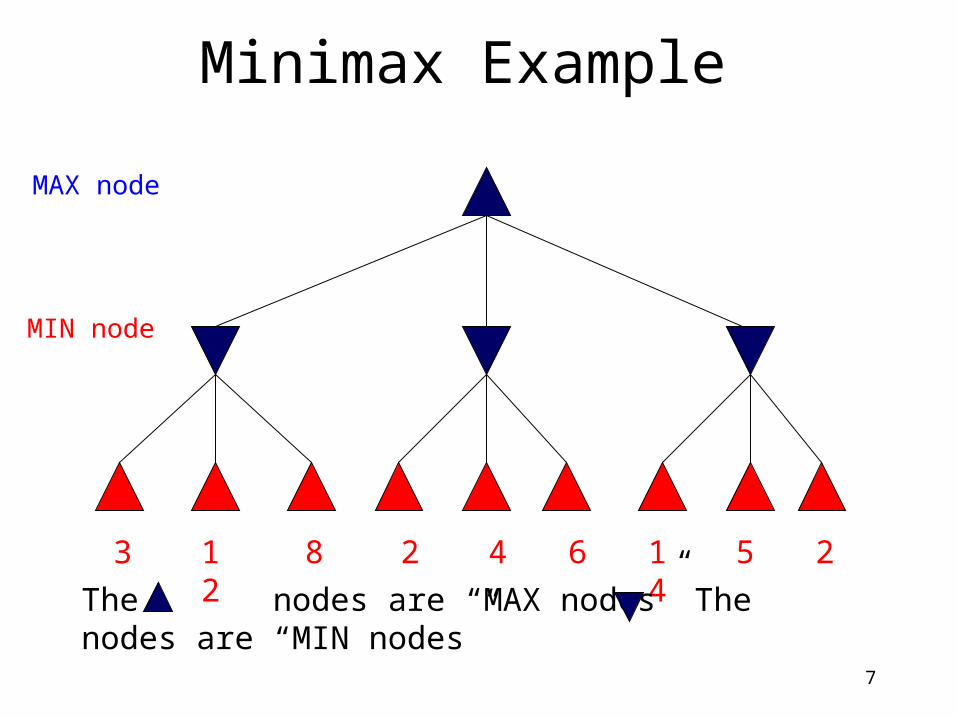
Minimax Example
3 12 8 2 4 6 14 5 2
The nodes are “MAX nodes” The nodes are “MIN nodes”
MIN node
MAX node
7
Minimax Example
3 12 8 2 4 6 14 5 2
The nodes are “MAX nodes” The nodes are “MIN nodes”
MIN node
MAX node
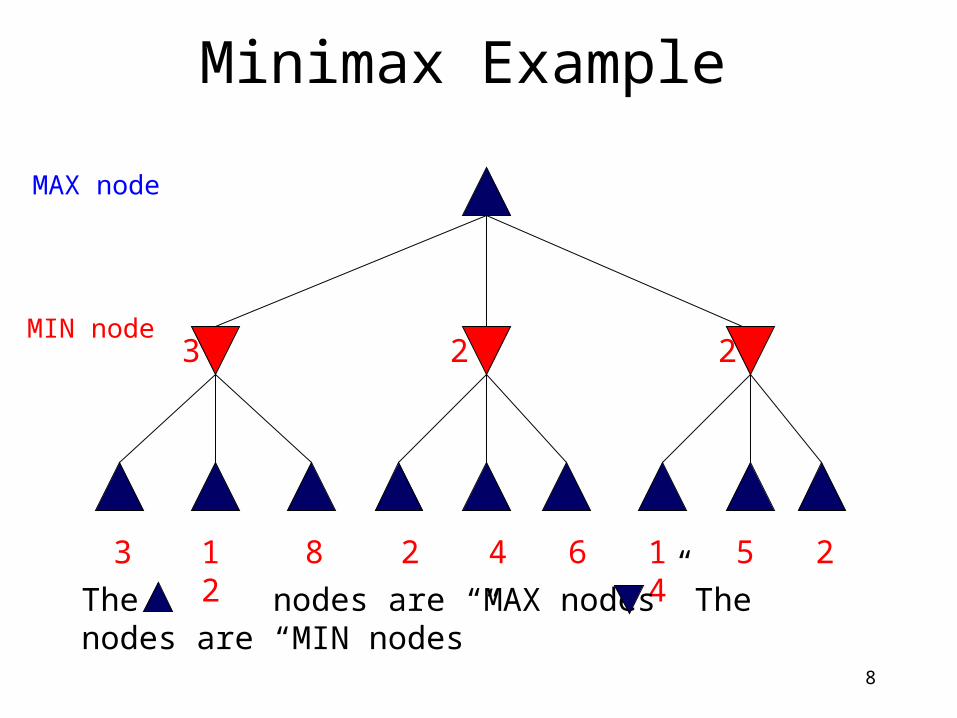
8
Minimax Example
3 12 8 2 4 6 14 5 2
3 2 2
The nodes are “MAX nodes” The nodes are “MIN nodes”
MIN node
MAX node

9
Minimax Example
3 12 8 2 4 6 14 5 2
3 2 2
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
MIN node
MAX node

Tic-Tac-Toe
• Tic-tac-toe, also called noughts and crosses (in the British Commonwealth countries) and X's and O's in the Republic of Ireland, is a pencil-and-paper game for two players, X and O, who take turns marking the spaces in a 3×3 grid. The X player usually goes first. The player who succeeds in placing three respective marks in a horizontal, vertical, or diagonal row wins the game.
• The following example game is won by the first player, X:

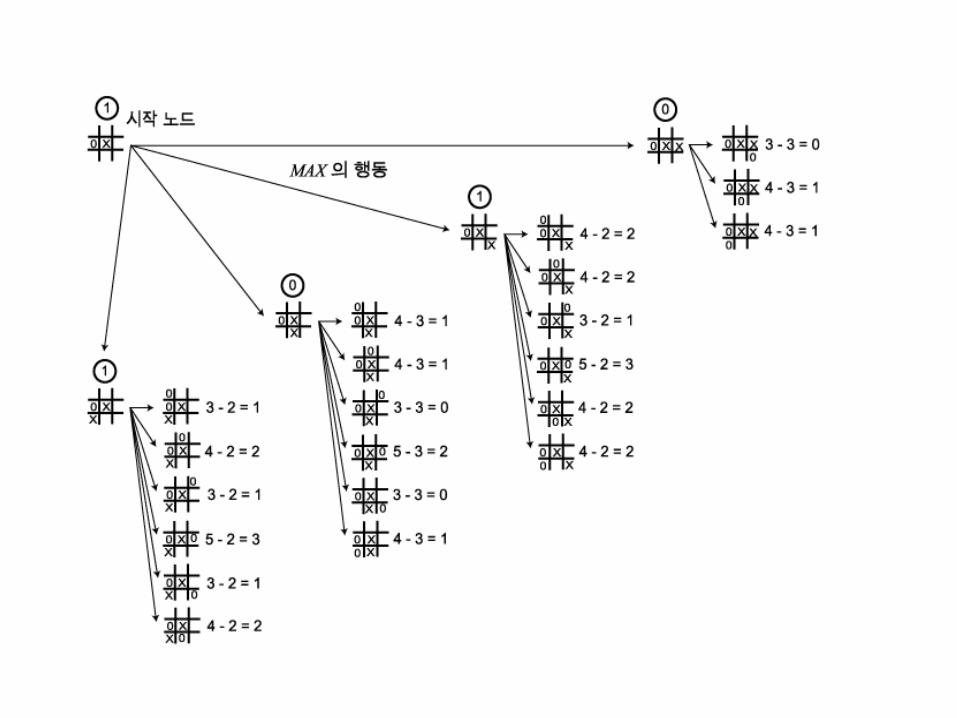

Savetime

Game tree (2-player)
How do we search this tree to find the optimal move?

Applying MiniMax to tic-tac-toe
• The static heuristic evaluation function

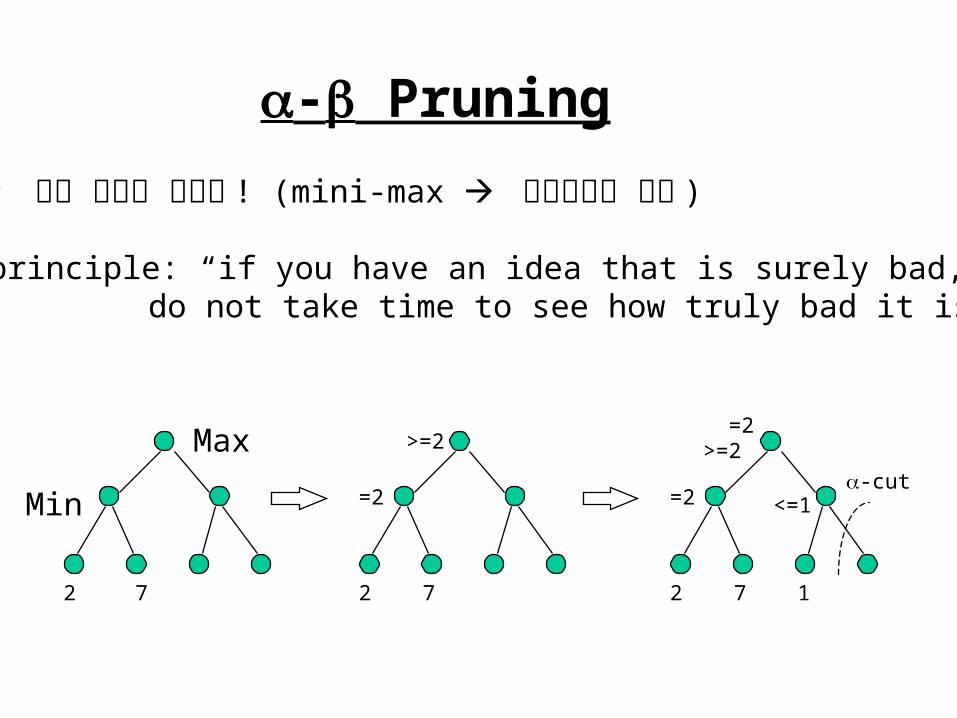
- Pruning
Idea: 탐색 공간을 줄인다 ! (mini-max 지수적으로 폭발 )
- principle: “if you have an idea that is surely bad, do not take time to see how truly bad it is.”
2 7
>=2
=2
2 7
=2>=2
=2
2 7 1
<=1-cut
Max
Min

• 알파베타 가지치기– 최대화 노드에서 가능한 최소의 값 ( 알파 ) 과
최소화의 노드에서 가능한 최대의 값 ( 베타 ) 를 사용한 게임 탐색법
– 기본적으로 DFS 로 탐색 진행[c0]=0.2
[c2]f= -0.1
[c1]f=0.2
[c21]f= -0.1
[c22] [c23][c11]f=0.2
[c12]f=0.7
C21 의 평가값 -0.1 이 C2 에 올려지면 나머지 노드들 (C22, C23) 을 더 이상 탐색할 필요가 없음
-cut

Tic-Tac-Toe Example with Alpha-Beta Pruning
Backup Values

- Procedure
never decrease (initially - infinite) -∞ never increase (initially infinite) +∞
- Search rule:
1. -cutoff ==> cut when below any minimizing node that have a <= (ancestor).
2, -cutoff ==> cut when below any maximizing nodethat have a >= (ancestor).
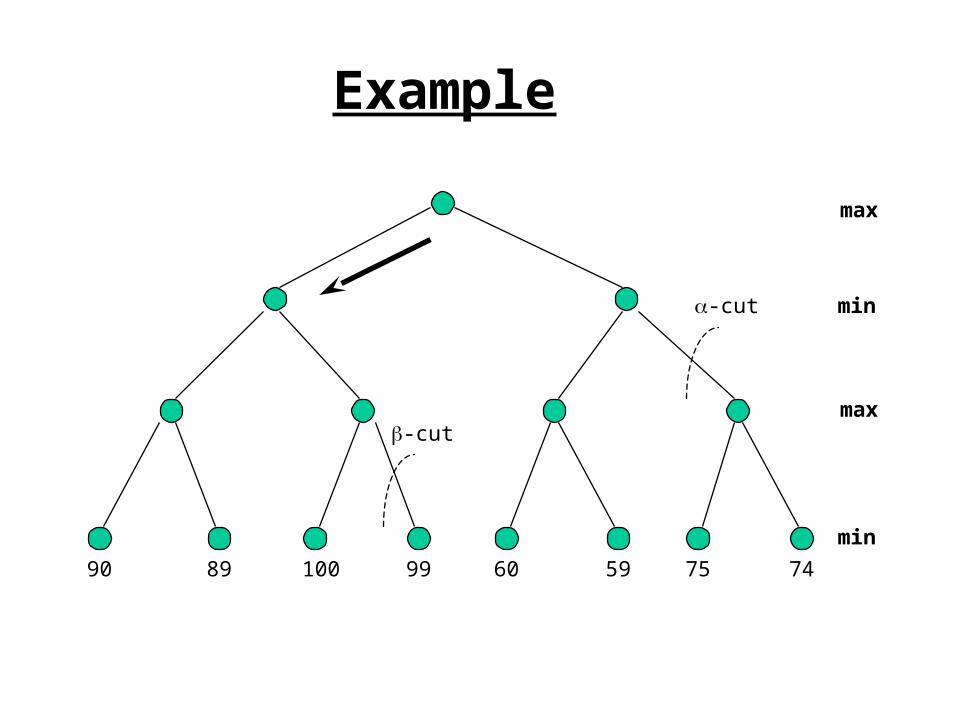
Example
90 89 100 99 60 59 75 74
-cut
-cut
max
min
max
min

22
Alpha-Beta Pruning Algorithm
Function ALPHA-BETA( state ) returns an action
inputs: state, current state in game
v = MAX-VALUE (state, -, +)
return the action corresponding with value v
Function MAX-VALUE( state, , ) returns a utility value
inputs: state, current state in game
, the value of the best alternative for MAX along the path to state
, the value of the best alternative for MIN along the path to state
if TERMINAL-TEST( state ) then return UTILITY( state )
v = -for a, s in SUCCESSORS( state ) do
v = MAX( v, MIN-VALUE( s, , ) )
if v >= then return v
= MAX(, v )
return v

23
Alpha-Beta Pruning Algorithm
Function MIN-VALUE( state, , ) returns a utility value
inputs: state, current state in game
, the value of the best alternative for MAX along the path to state
, the value of the best alternative for MIN along the path to state
if TERMINAL-TEST( state ) then return UTILITY( state )
v = +for a, s in SUCCESSORS( state ) do
v = MIN( v, MAX-VALUE( s, , ) )
if v <= then return v
= MIN( , v )
return v

24
Alpha-Beta Pruning Example
The nodes are “MAX nodes” The nodes are “MIN nodes”
=− =+
, , initial values
, , passed to kids
=− =+

25
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
=− =+
=− =3
MIN updates , based on kids

26
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[-, + ]

27
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[-, + ]
12
=− =3
MIN updates , based on kids.No change.
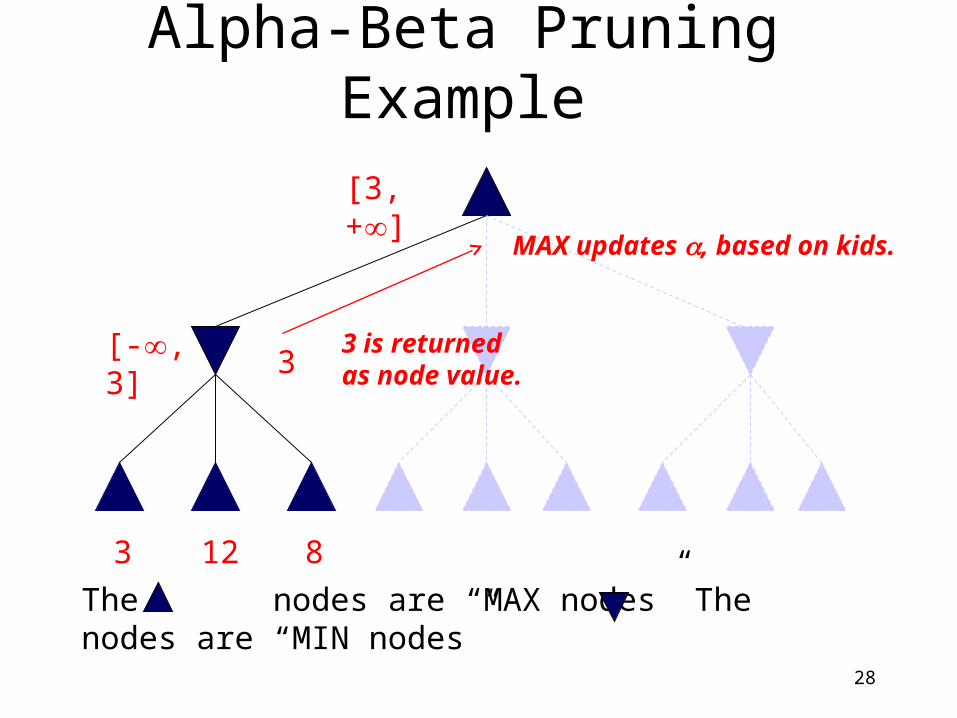
28
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8
33 is returnedas node value.
MAX updates , based on kids.

29
Alpha-Beta Pruning Example
3
[-, 3]
[3, +]
12 8
The nodes are “MAX nodes” The nodes are “MIN nodes”
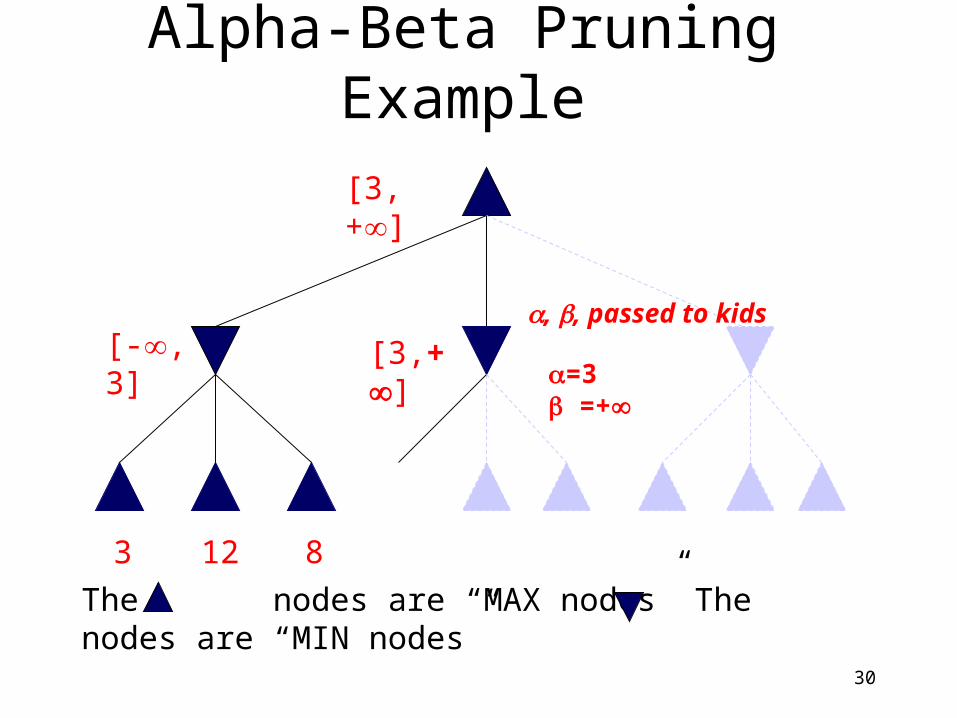
30
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8
[3,+], , passed to kids
=3 =+

31
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
MIN updates ,based on kids.
=3 =2
≥ ,so prune.
X X
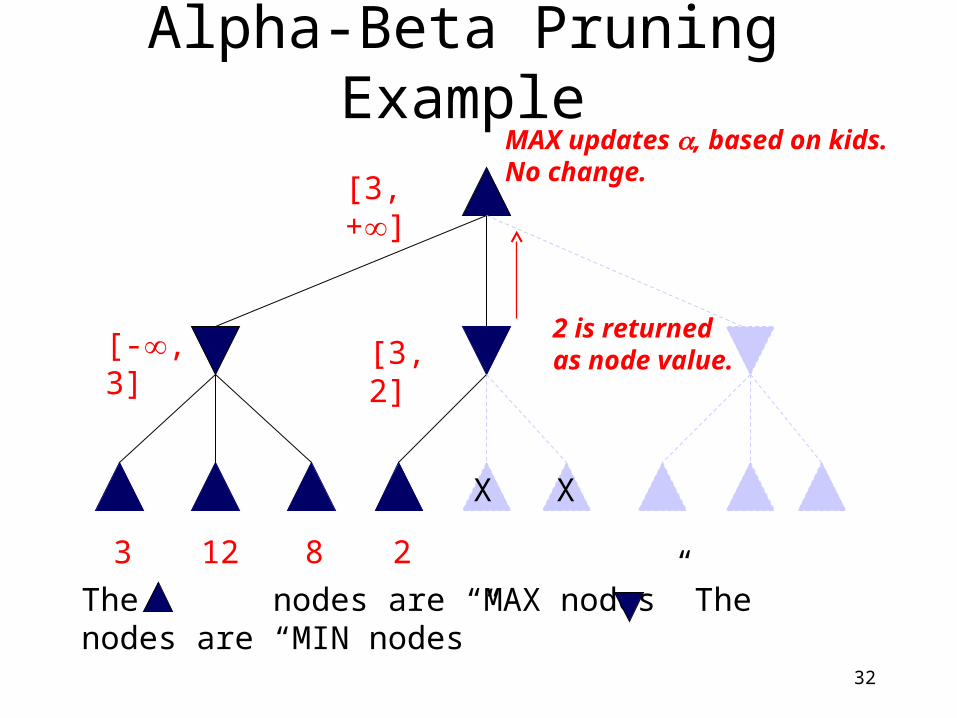
32
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
X X
2 is returnedas node value.
MAX updates , based on kids.No change.
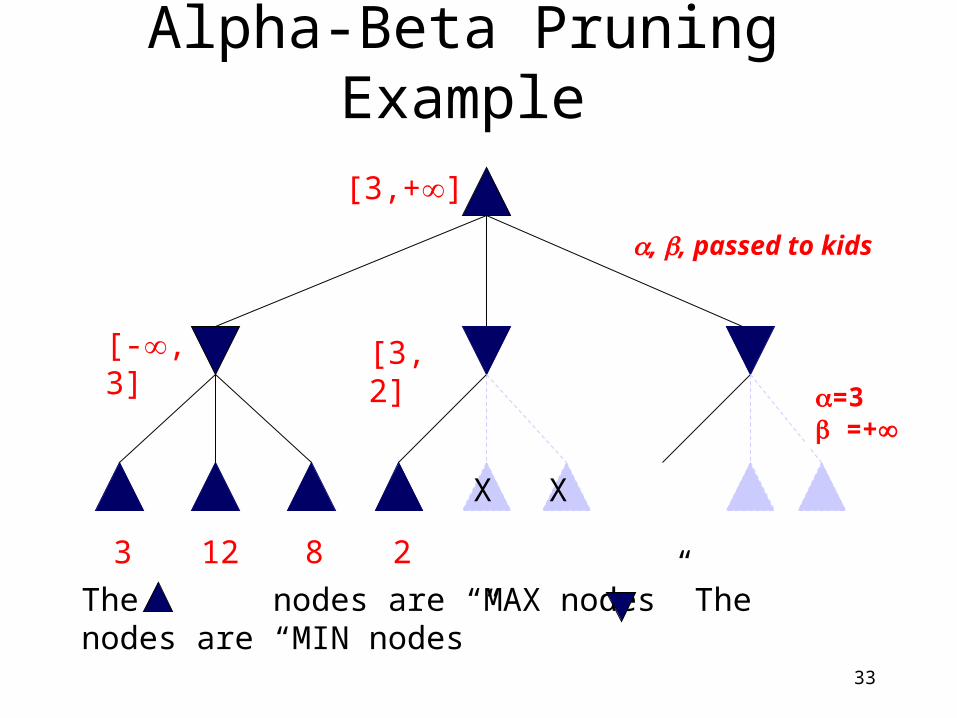
33
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3,+]
12 8 2
[3, 2]
, , passed to kids
=3 =+
X X

34
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
14
[3, 14]
MIN updates ,based on kids.
=3 =14
X X

35
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
14
[3, 5]
5
MIN updates ,
based on kids.
=3 =5
X X

36
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
14
[3, 2]
5 2
MIN updates ,
based on kids.
=3 =2
X X
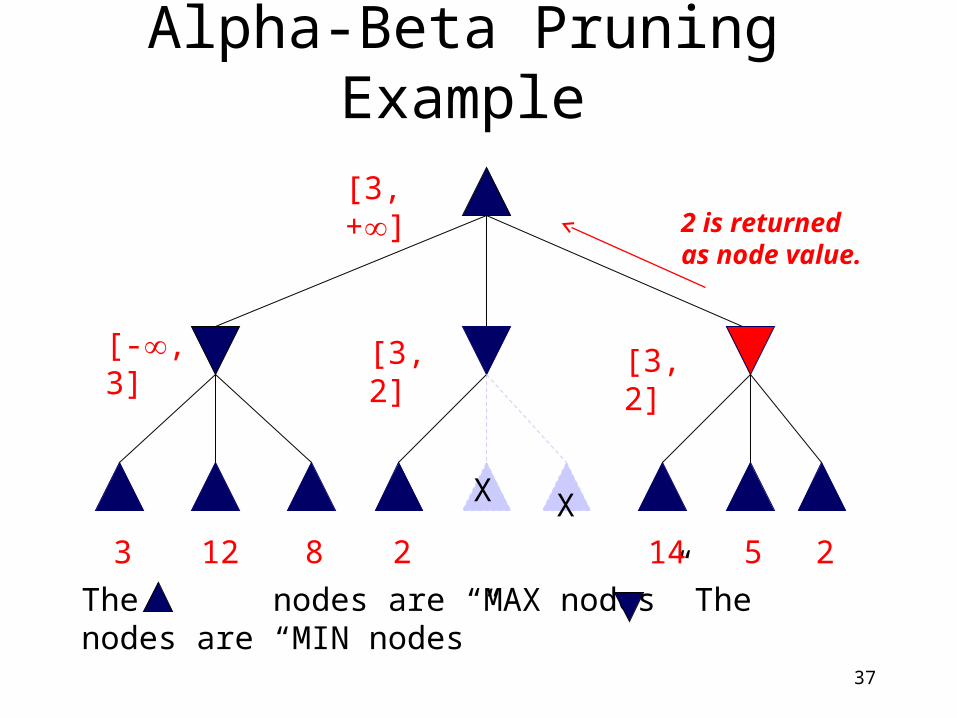
37
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
14
[3, 2]
5 2
2 is returnedas node value.
X X

38
Alpha-Beta Pruning Example
3
The nodes are “MAX nodes” The nodes are “MIN nodes”
[-, 3]
[3, +]
12 8 2
[3, 2]
14
[3, 2]
5 2
MAX updates , based on kids.No change.
X X

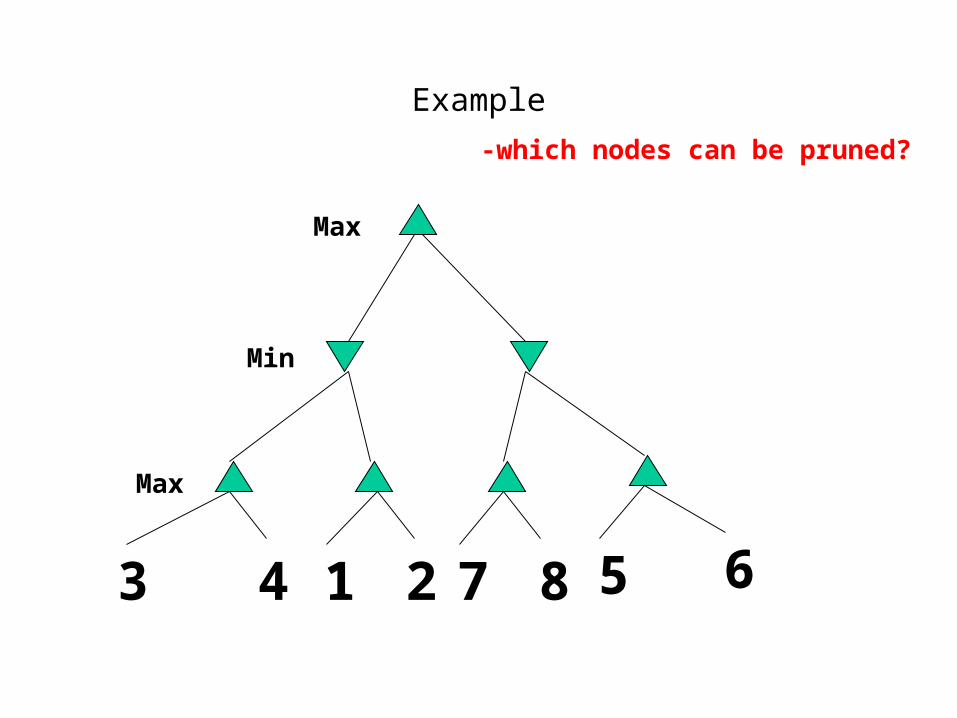
Example
-which nodes can be pruned?
3 4 1 2 7 8 5 6
Max
Min
Max

Answer to Example-which nodes can be pruned?
Answer: NONE! Because the most favorable nodes for both are explored last (i.e., in the diagram, are on the right-hand side).
3 4 1 2 7 8 5 6
Max
Min
Max
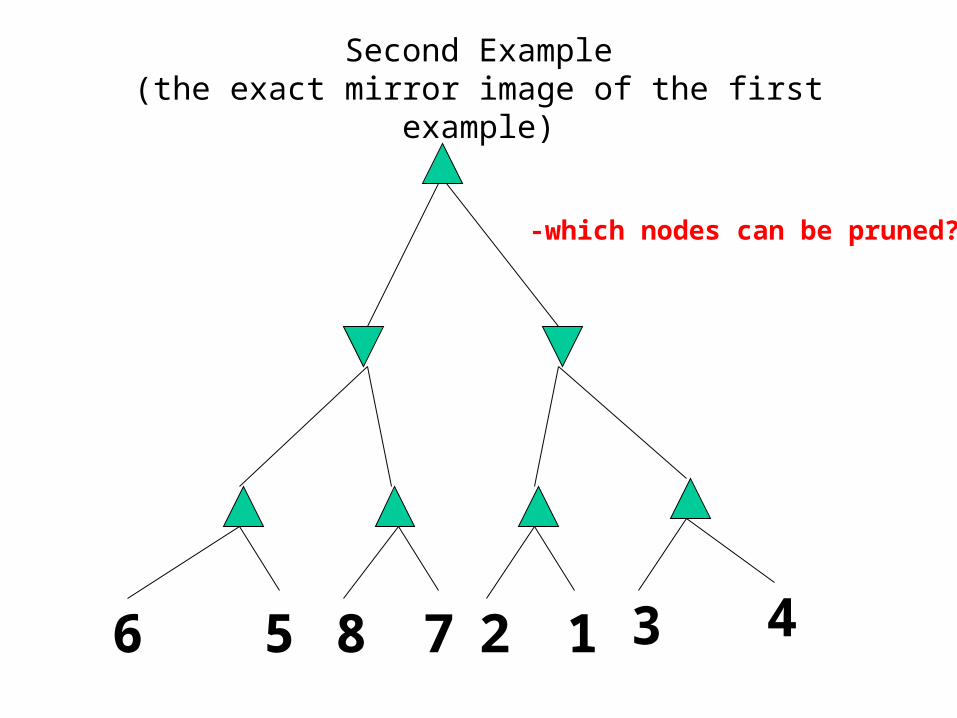
Second Example(the exact mirror image of the first example)
6 5 8 7 2 1 3 4
-which nodes can be pruned?

Answer to Second Example(the exact mirror image of the first example)
-which nodes can be pruned?
6 5 8 7 2 1 3 4
Min
Max
Max
Answer: LOTS! Because the most favorable nodes for both are explored first (i.e., in the diagram, are on the left-hand side).



점진적 심화방법
• Time limits unlikely to find goal, must approximate
•

Iterative (Progressive) Deepening: 점진적 심화방법
• In real games, there is usually a time limit T on making a move
• How do we take this into account? • using alpha-beta we cannot use “partial” results with any
confidence unless the full breadth of the tree has been searched– So, we could be conservative and set a conservative depth-
limit which guarantees that we will find a move in time < T• disadvantage is that we may finish early, could do more
search
• In practice, iterative deepening search (IDS) is used– IDS runs depth-first search with an increasing depth-limit– when the clock runs out we use the solution found at the
previous depth limit

점진적 심화방법

49
Iterative deepening search l =0
50
Iterative deepening search l =1

51
Iterative deepening search l =2

52
Iterative deepening search l =3


Heuristic Continuation: fight horizon effect






























