Embed Size (px)
DESCRIPTION
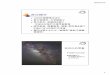
CMP におけるオンチップルータの 細粒度パワーゲーティングの評価. ( 東京大学 ) ( 国立情報学研究所 ) ( 慶應義塾大学 ) ( 芝浦工業大学 ) ( 東京大学 ) ( 慶應義塾大学 ). 松谷 宏紀 鯉渕 道紘 池淵 大輔 宇佐美 公良 中村 宏 天野 英晴. 最近のマルチコア・メニーコア. picoChip PC102. picoChip PC205. 256. ClearSpeed CSX700. 128. Intel 80-core. ClearSpeed CSX600. 64. TILERA TILE64. - PowerPoint PPT Presentation
Citation preview

CMP におけるオンチップルータの
細粒度パワーゲーティングの評価
松谷 宏紀鯉渕 道紘池淵 大輔宇佐美 公良中村 宏 天野 英晴
( 東京大学 )
( 国立情報学研究所 )
( 慶應義塾大学 )
( 芝浦工業大学 )
( 東京大学 )
( 慶應義塾大学 )

最近のマルチコア・メニーコア
4
8
16
32
64
128
256
2002 2004 2006 2008 2010
MIT RAW
STI Cell BE
Sun T1 Sun T2
TILERA TILE64
Intel Core, IBM Power7AMD Opteron
Intel 80-coreClearSpeed CSX600
ClearSpeed CSX700
picoChip PC102 picoChip PC205
UT TRIPS (OPN)
Nu
mb
er o
f P
Es
(cac
hes
are
no
t in
clu
ded
)
2
Fujitsu SPARC64
Intel SCC
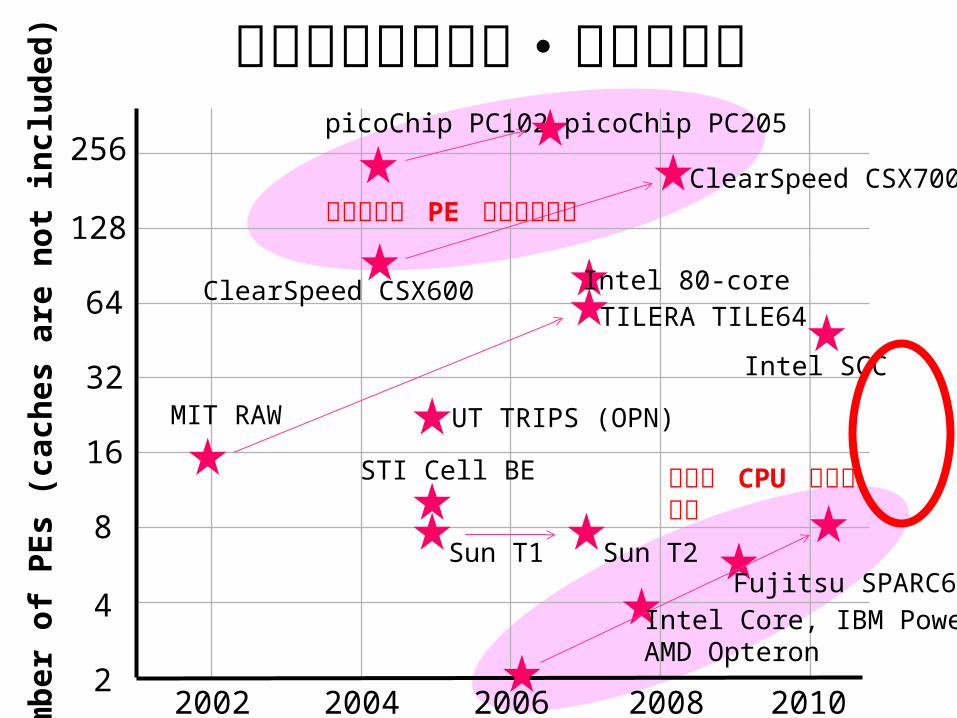
最近のマルチコア・メニーコア
4
8
16
32
64
128
256
2002 2004 2006 2008 2010
MIT RAW
STI Cell BE
Sun T1 Sun T2
TILERA TILE64
Intel Core, IBM Power7AMD Opteron
Intel 80-coreClearSpeed CSX600
ClearSpeed CSX700
picoChip PC102 picoChip PC205
UT TRIPS (OPN)
Nu
mb
er o
f P
Es
(cac
hes
are
no
t in
clu
ded
)
2
シンプルな PE を大量に接続
高性能 CPU を複数接続
Fujitsu SPARC64
Intel SCC
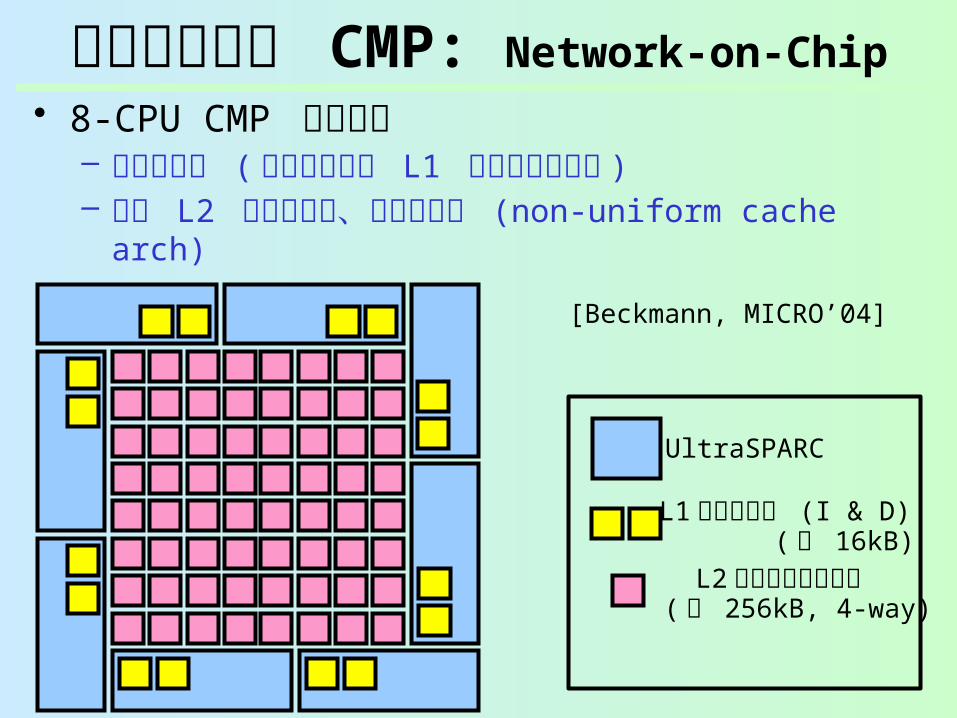
共有メモリ型 CMP: Network-on-Chip
• 8-CPU CMP の構成例– プロセッサ ( プライベート L1 キャッシュ内蔵 )– 共有 L2 キャッシュ、バンク分割 (non-uniform cache
arch)
UltraSPARC
L1 キャッシュ (I & D)
L2 キャッシュバンク ( 各 16kB)
( 各 256kB, 4-way)
[Beckmann, MICRO’04]

共有メモリ型 CMP: Network-on-Chip
• 8-CPU CMP の構成例– プロセッサ ( プライベート L1 キャッシュ内蔵 )– 共有 L2 キャッシュ、バンク分割 (non-uniform cache
arch)– プロセッサと L2 バンクの結合 Network-on-Chip
(NoC)
オンチップルータ
[Beckmann, MICRO’04]
UltraSPARC
L1 キャッシュ (I & D)
L2 キャッシュバンク ( 各 16kB)
( 各 256kB, 4-way)
NoC は CMP の通信インフラストラクチャーなので、
いつでもパケット転送できる状態でなければならない。
でも、それだと NoC が常にリーク電力を消費してしまう。。
そこで、 NoC にランタイム・パワーゲーティングを適用して、
リーク電力を最小限に抑えよう!

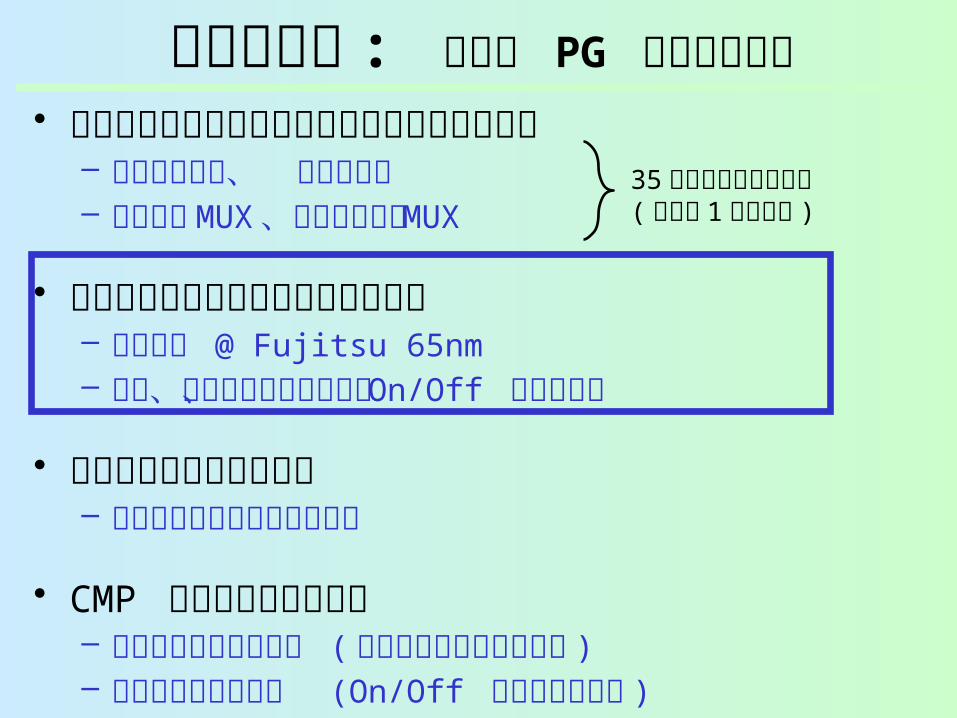
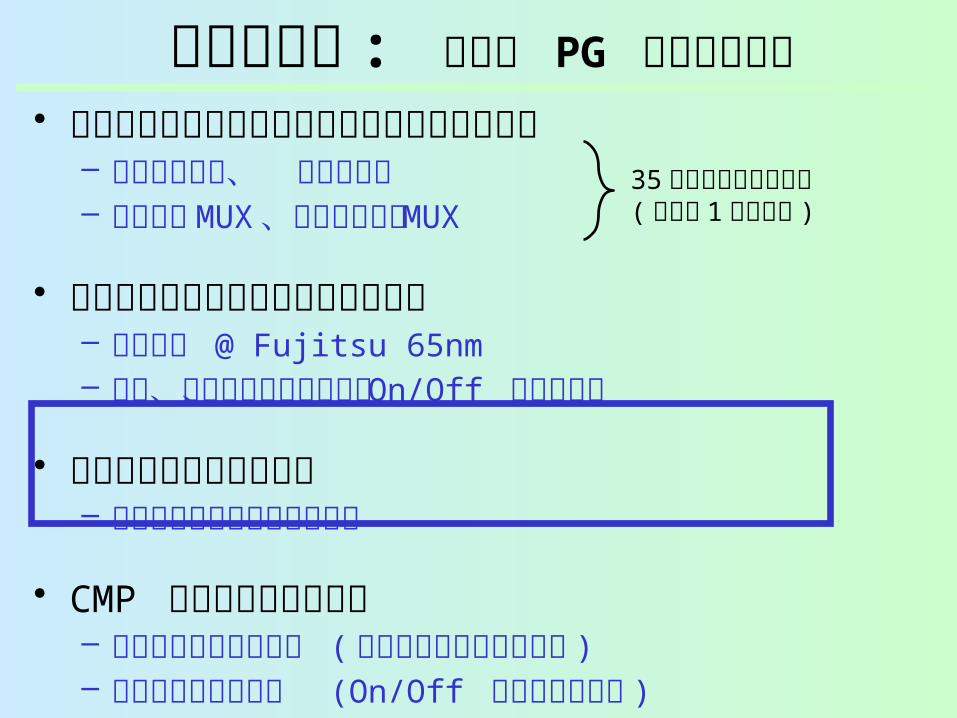
発表の流れ : 細粒度 PG ルータの評価• オンチップルータの細粒度パワーゲーティン
グ– 入力バッファ、 出力ラッチ– クロスバ MUX 、仮想チャネル MUX
• パワードメインのハードウェア評価– 回路設計 @ Fujitsu 65nm– 面積、ウェイクアップ遅延、 On/Off エネルギー
• 早期ウェイクアップ手法– ウェイクアップ遅延の隠ぺい
• CMP システムレベル評価– アプリケーション性能 ( 早期ウェイクアップ付き )– リーク電力の削減量 (On/Off エネルギー込み )
35 個のパワードメイン( ルータ 1 個あたり )
オーバヘッドをちゃんと評価します

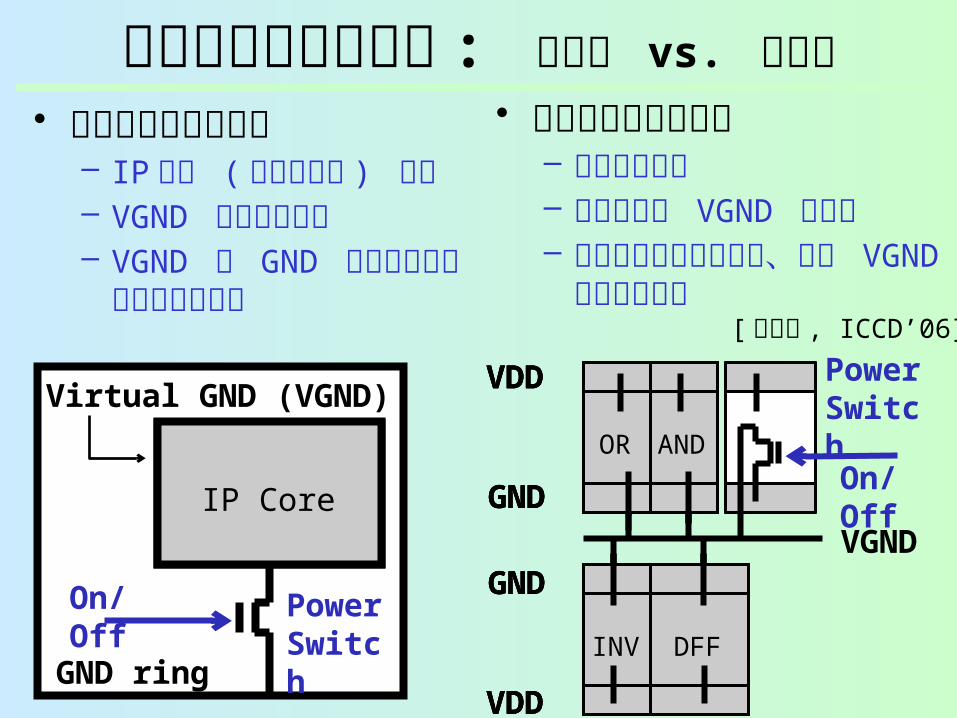
• 粗粒度なアプローチ– IP コア ( モジュール )
単位– VGND リングで囲む– VGND と GND の間に
パワースイッチを挿入
• 細粒度なアプローチ – スタセル単位– セルごとに VGND ポート– 同じドメインのセルは、
同じ VGND ラインを共有
パワーゲーティング : 粗粒度 vs. 細粒度
IP Core
GND ring
Virtual GND (VGND)
PowerSwitch
On/Off
IP Core IP CoreIP CoreIP CoreIP CoreIP CoreIP Core
[ 宇佐美 , ICCD’06]
IP Core
GND ring
Virtual GND (VGND)
PowerSwitch
On/Off
IP Core
OR AND
VDD
GND
INV DFF
GND
VDD
VGND
PowerSwitch
On/OffOR AND
VDD
GND
INV DFF
GND
VDD
OR AND
VDD
GND
INV DFF
GND
VDD
• 粗粒度なアプローチ– IP コア ( モジュール )
単位– VGND リングで囲む– VGND と GND の間に
パワースイッチを挿入
• 細粒度なアプローチ – スタセル単位– セルごとに VGND ポート– 同じドメインのセルは、
同じ VGND ラインを共有
パワーゲーティング : 粗粒度 vs. 細粒度
[ 宇佐美 , ICCD’06]

• ルータ内の細かい部品 ( 入力バッファ、マルチプレクサ ) は、互いに独立して動作する– 細粒度 PG のほうがスリープできるチャンスが多い
ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
Packet#2
Packet#1
パワーゲーティング : 粗粒度 vs. 細粒度

• 各ルータは、多数のマイクロパワードメインに分割– 入力 VC バッファ、 出力ラッチ– 仮想チャネル MUX 、クロスバ MUX
細粒度ランタイム PG ルータ
ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
35 個のパワードメイン( ルータ 1 個あたり )

ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
Packet
細粒度ランタイム PG ルータ• 各ルータは、多数のマイクロパワードメインに分
割– 入力 VC バッファ、 出力ラッチ– 仮想チャネル MUX 、クロスバ MUX
35 個のパワードメイン( ルータ 1 個あたり )

ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
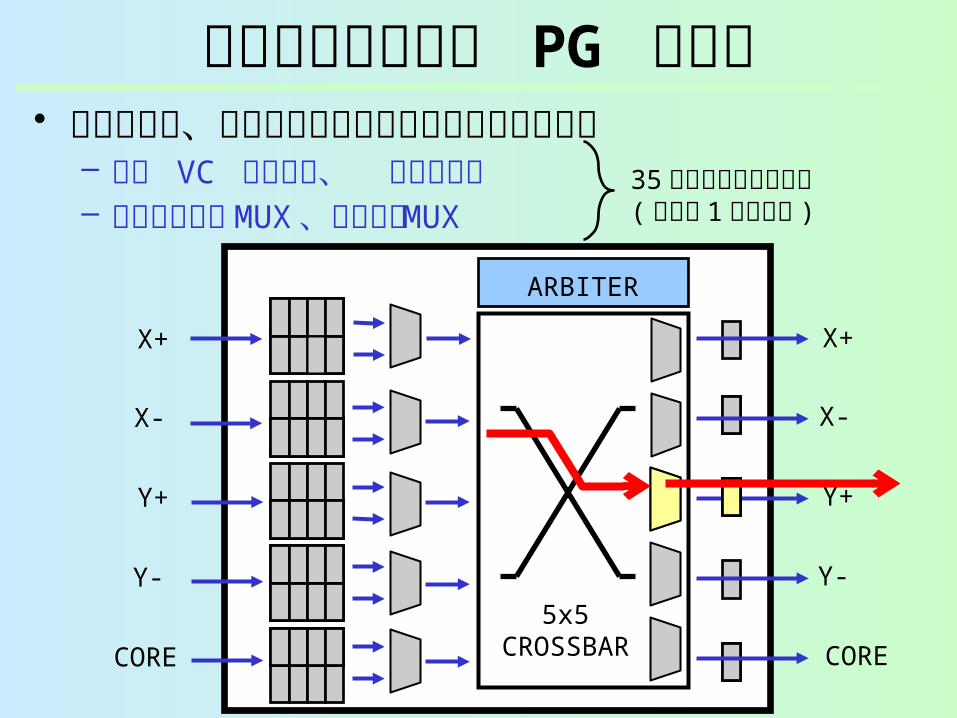
細粒度ランタイム PG ルータ• 各ルータは、多数のマイクロパワードメインに分
割– 入力 VC バッファ、 出力ラッチ– 仮想チャネル MUX 、クロスバ MUX
35 個のパワードメイン( ルータ 1 個あたり )
ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
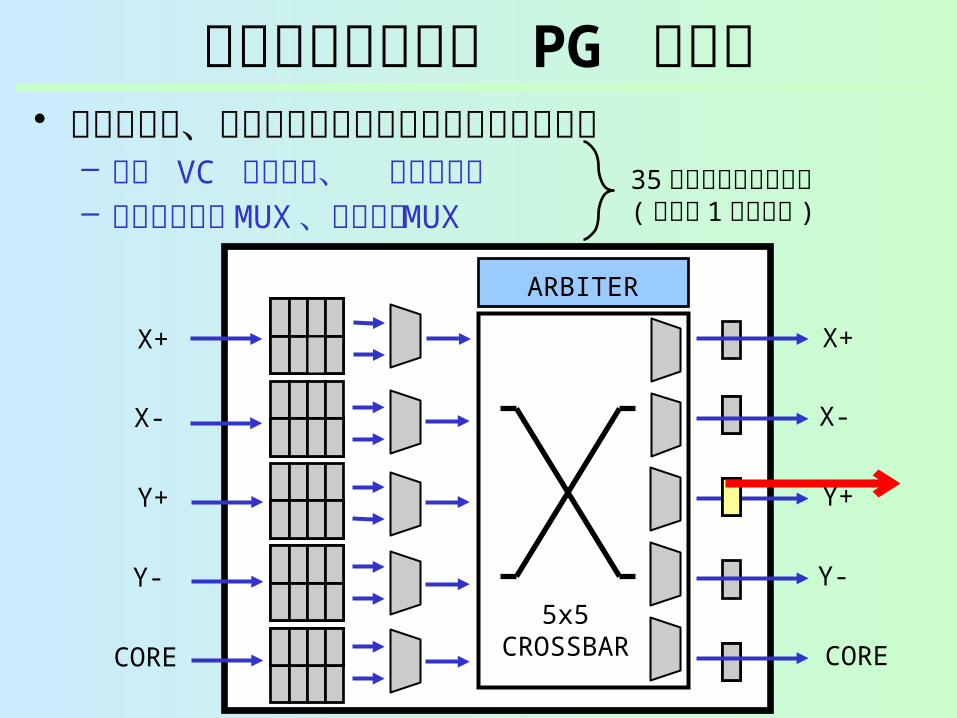
細粒度ランタイム PG ルータ• 各ルータは、多数のマイクロパワードメインに分
割– 入力 VC バッファ、 出力ラッチ– 仮想チャネル MUX 、クロスバ MUX
35 個のパワードメイン( ルータ 1 個あたり )
ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
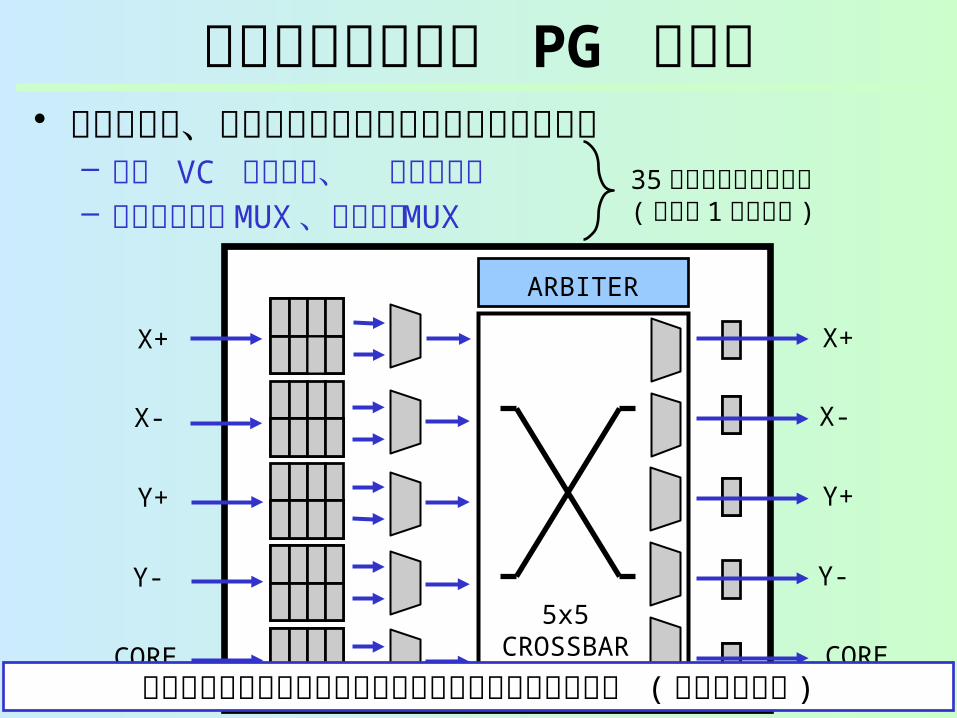
細粒度ランタイム PG ルータ• 各ルータは、多数のマイクロパワードメインに分
割– 入力 VC バッファ、 出力ラッチ– 仮想チャネル MUX 、クロスバ MUX
35 個のパワードメイン( ルータ 1 個あたり )
ARBITER
X+
X-
Y+
Y-
CORE
X+
X-
Y+
Y-
CORE
5x5 CROSSBAR
各パワードメインは本当に使われるときだけ起こされる ( リークを消費 )
細粒度ランタイム PG ルータ• 各ルータは、多数のマイクロパワードメインに分
割– 入力 VC バッファ、 出力ラッチ– 仮想チャネル MUX 、クロスバ MUX
35 個のパワードメイン( ルータ 1 個あたり )
発表の流れ : 細粒度 PG ルータの評価• オンチップルータの細粒度パワーゲーティン
グ– 入力バッファ、 出力ラッチ– クロスバ MUX 、仮想チャネル MUX
• パワードメインのハードウェア評価– 回路設計 @ Fujitsu 65nm– 面積、ウェイクアップ遅延、 On/Off エネルギー
• 早期ウェイクアップ手法– ウェイクアップ遅延の隠ぺい
• CMP システムレベル評価– アプリケーション性能 ( 早期ウェイクアップ付き )– リーク電力の削減量 (On/Off エネルギー込み )
35 個のパワードメイン( ルータ 1 個あたり )

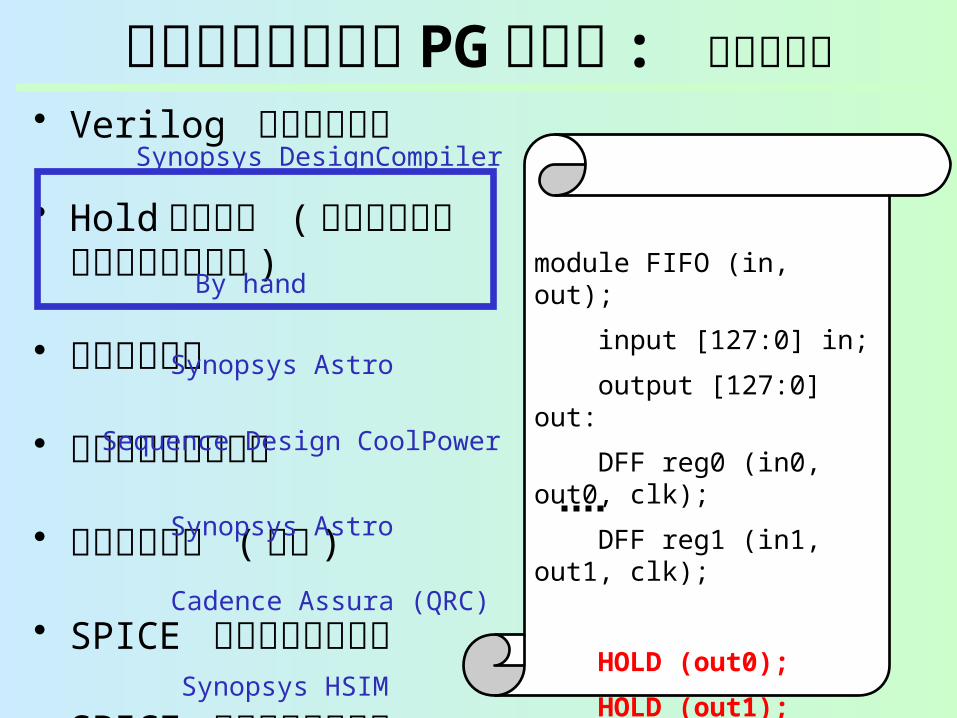
細粒度ランタイム PG ルータ : 設計フロー
• Verilog ネットリスト
• Hold セル挿入 ( スリープ時に不定値伝搬を防ぐ )
• 自動配置配線
• パワースイッチ挿入
• 自動配置配線 ( 再び )
• SPICE ネットリスト抽出
• SPICE シミュレーション
Synopsys DesignCompiler
Synopsys Astro
Sequence Design CoolPower
Synopsys Astro
Cadence Assura (QRC)
Synopsys HSIM
By handmodule FIFO (in, out);
input [127:0] in;
output [127:0] out:
DFF reg0 (in0, out0, clk);
DFF reg1 (in1, out1, clk);
endmodule
細粒度ランタイム PG ルータ : 設計フロー
• Verilog ネットリスト
• Hold セル挿入 ( スリープ時に不定値伝搬を防ぐ )
• 自動配置配線
• パワースイッチ挿入
• 自動配置配線 ( 再び )
• SPICE ネットリスト抽出
• SPICE シミュレーション
Synopsys DesignCompiler
Synopsys Astro
Sequence Design CoolPower
Synopsys Astro
Cadence Assura (QRC)
Synopsys HSIM
By handmodule FIFO (in, out);
input [127:0] in;
output [127:0] out:
DFF reg0 (in0, out0, clk);
DFF reg1 (in1, out1, clk);
HOLD (out0);
HOLD (out1);
endmodule

細粒度ランタイム PG ルータ : 設計フロー
• Verilog ネットリスト
• Hold セル挿入 ( スリープ時に不定値伝搬を防ぐ )
• 自動配置配線
• パワースイッチ挿入
• 自動配置配線 ( 再び )
• SPICE ネットリスト抽出
• SPICE シミュレーション
Synopsys DesignCompiler
Synopsys Astro
Sequence Design CoolPower
Synopsys Astro
Cadence Assura (QRC)
Synopsys HSIM
By hand OR AND
VDD
GND
INV DFF
GND
VDD
AND OR NOR
DFF
Domain#0 Domain#1

細粒度ランタイム PG ルータ : 設計フロー
• Verilog ネットリスト
• Hold セル挿入 ( スリープ時に不定値伝搬を防ぐ )
• 自動配置配線
• パワースイッチ挿入
• 自動配置配線 ( 再び )
• SPICE ネットリスト抽出
• SPICE シミュレーション
Synopsys DesignCompiler
Synopsys Astro
Sequence Design CoolPower
Synopsys Astro
Cadence Assura (QRC)
Synopsys HSIM
By hand OR AND
VDD
GND
INV DFF
GND
VDD
VGND
AND OR NOR
DFF
PowerSwitch
Domain#0 Domain#1

OR AND
VDD
GND
INV DFF
GND
VDD
VGND
AND OR NOR
DFF
PowerSwitch
Domain#0 Domain#1
• Hold セル– ゲート数 2.6% 増– ドメインの出力ポート
数に応じて増える• パワースイッチ
– ゲート数 1.7% 増– ウェイクアップ速度に
応じて増える• スタセルの改造
– 各セルに VGND ポートを取り付ける
– 全セルの高さを 10/9 倍
パワードメインの評価 : 面積オーバヘッド
Hold セル & パワースイッチで 4.3% 増、スタセル改造を含めると 15.9%

VDD
GND
FIFO
SwitchWakeup
VGND
FIFO
入力 VC バッファの例
Power ON
Wakeup
Clock
Correct output
Wakeup &Initialization
2.8nsec FIFOOUT[0]
FIFOOUT[1]
Fujitsu 65nm CMOS (1.20V, 75C)
• ウェイクアップ遅延– 電源オフの回路に電源を投入し、動作するまで
– パケット通信遅延が増える
パワードメインの評価 : ウェイクアップ遅延

パワードメインの評価 : ウェイクアップ遅延
Power ON
Wakeup
Clock
MUXOUT[0]
MUXOUT[1]
Fujitsu 65nm CMOS (1.20V, 75C)
• ウェイクアップ遅延– 電源オフの回路に電源を投入し、動作するまで
– パケット通信遅延が増える
VDD
GNDSwitchWakeup
VGND
MUX
クロスバ MUX の例
Correct output
Wakeup
1.3nsec
パワードメインの電源オンして動作するまで 3nsec (3-cycle@1GHz)

Fujitsu 65nm CMOS (1.20V, 75C)
• On/Off エネルギー– パワースイッチの駆動– ウェイクアップ信号の配
線– スリープ期間が短いと、
“元” が取れなくなる
VDD
GND
FIFO
SwitchWakeup
VGND
FIFO
入力 VC バッファの例
パワードメインの評価 : On/Off エネルギー
Current
Wakeup
FIFOOUT[1]
Clock is stopped to clearly show On/Off energy
On/Off energy
FIFOOUT[0]
Power Off
60~ 99nsec以上のスリープなら、 On/Off エネルギーを償却できる
発表の流れ : 細粒度 PG ルータの評価• オンチップルータの細粒度パワーゲーティン
グ– 入力バッファ、 出力ラッチ– クロスバ MUX 、仮想チャネル MUX
• パワードメインのハードウェア評価– 回路設計 @ Fujitsu 65nm– 面積、ウェイクアップ遅延、 On/Off エネルギー
• 早期ウェイクアップ手法– ウェイクアップ遅延の隠ぺい
• CMP システムレベル評価– アプリケーション性能 ( 早期ウェイクアップ付き )– リーク電力の削減量 (On/Off エネルギー込み )
35 個のパワードメイン( ルータ 1 個あたり )

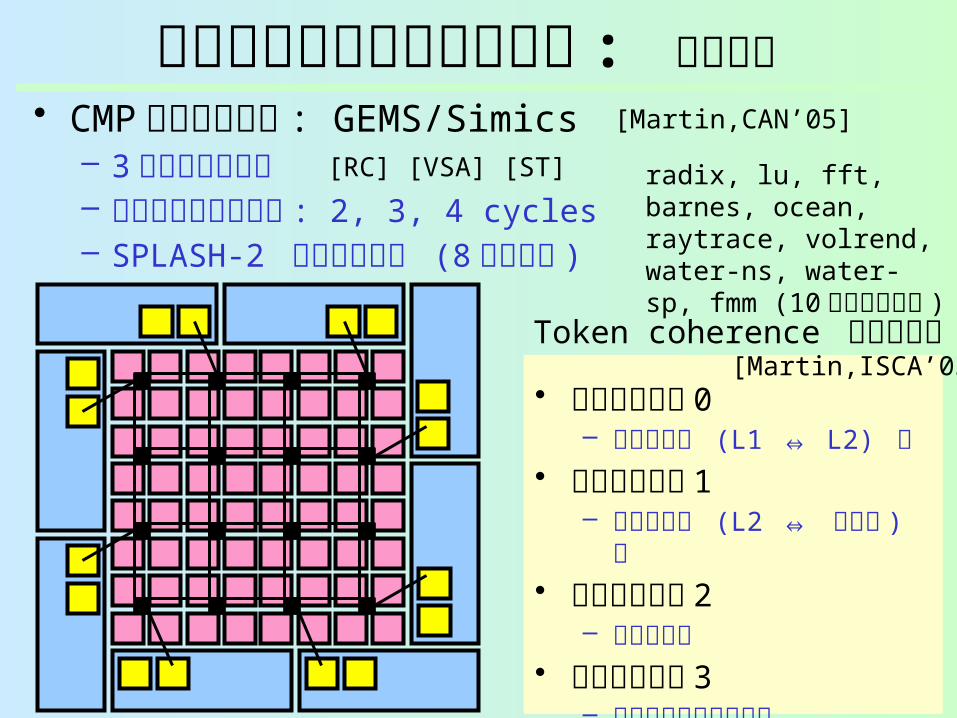
ウェイクアップ遅延の影響 : 評価環境
• CMP シミュレータ : GEMS/Simics– 3 サイクルルータ– ウェイクアップ遅延 : 2, 3, 4 cycles– SPLASH-2 ベンチマーク (8 スレッド )
オンチップルータ
UltraSPARC
L1 キャッシュ (I & D)
L2 キャッシュバンク ( 各 16kB)
( 各 256kB, 4-way)
radix, lu, fft, barnes, ocean, raytrace, volrend, water-ns, water-sp, fmm (10種類のアプリ )
[Martin,CAN’05]
[RC] [VSA] [ST]
ウェイクアップ遅延の影響 : 評価環境
• CMP シミュレータ : GEMS/Simics– 3 サイクルルータ– ウェイクアップ遅延 : 2, 3, 4 cycles– SPLASH-2 ベンチマーク (8 スレッド )
radix, lu, fft, barnes, ocean, raytrace, volrend, water-ns, water-sp, fmm (10種類のアプリ )
[Martin,CAN’05]
[RC] [VSA] [ST]
Token coherence プロトコル[Martin,ISCA’03]
• 仮想チャネル 0– リクエスト (L1 ⇔ L2) 用
• 仮想チャネル 1– リクエスト (L2 ⇔ 主記憶 ) 用
• 仮想チャネル 2– リプライ用
• 仮想チャネル 3– スタベイション回避用

ウェイクアップ遅延の影響 : 評価結果
SPLASH-2 ベンチ (10 個の並列アプリ ) の実行時間 3-cycle ウェイク2-cycle ウェイク 4-cycle ウェイク
(1000MHz)(667MHz) (1333MHz)
パワーゲーティングしないときの実行時間 = 1.00
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
アプリの実行時間が平均 23.2% ~ 46.3% 増加
実行時間の増加はエネルギ増 ウェイクアップ遅延の隠蔽が必須
アプ
リの実行
時間
(正規化
)

• 2ホップ先のルータモジュールを事前にウェイクアップ– Look-ahead ルーティングを使用
[ 松谷 ,ASPDAC’08]
早期ウェイクアップ : Look-ahead method
NRC VSA ST
ST
ST
ST
NRC VSA ST
ST
ST
ST
NRC VSA ST
ST
ST
ST
ルータ (1) ルータ (2) ルータ (3)
HEAD
DATA 1
DATA 2
DATA 3
SA
SA
SA
SA
SA
SA
SA
SA
SA
ルータ (1) が、ルータ (2) の出力ポートを決める ルータ (3) の入力ポートが判明
1ホップ目 2ホップ目 3ホップ目 4ホップ目 5ホップ目
Wakeup Wakeup Wakeup
ところで、、 1ホップ目はどうやって事前にウェイクアップさせるの ??
CPU L2 キャッシュ

• 2ホップ先のルータモジュールを事前にウェイクアップ– Look-ahead ルーティングを使用
• Ever-on ドメイン– 電源を落とさない– ウェイクアップ遅延無し
– CPU隣接ポートの VC0 、 VC2
のみ Ever-on に設定
[ 松谷 ,ASPDAC’08]
早期ウェイクアップ : LA + CPU ever-on
1ホップ目 2ホップ目 3ホップ目 4ホップ目 5ホップ目
Wakeup Wakeup WakeupCPU L2 キャッシュ
• 仮想チャネル 0– リクエスト (L1 ⇔ L2) 用
• 仮想チャネル 1– リクエスト (L2 ⇔ 主記憶 ) 用
• 仮想チャネル 2– リプライ用
• 仮想チャネル 3– スタベイション回避用
NoC のトラフィック量を解析
Ever-on
Ever-on チャネルは全体の 4.7% 最小コストで遅延を大幅に削減

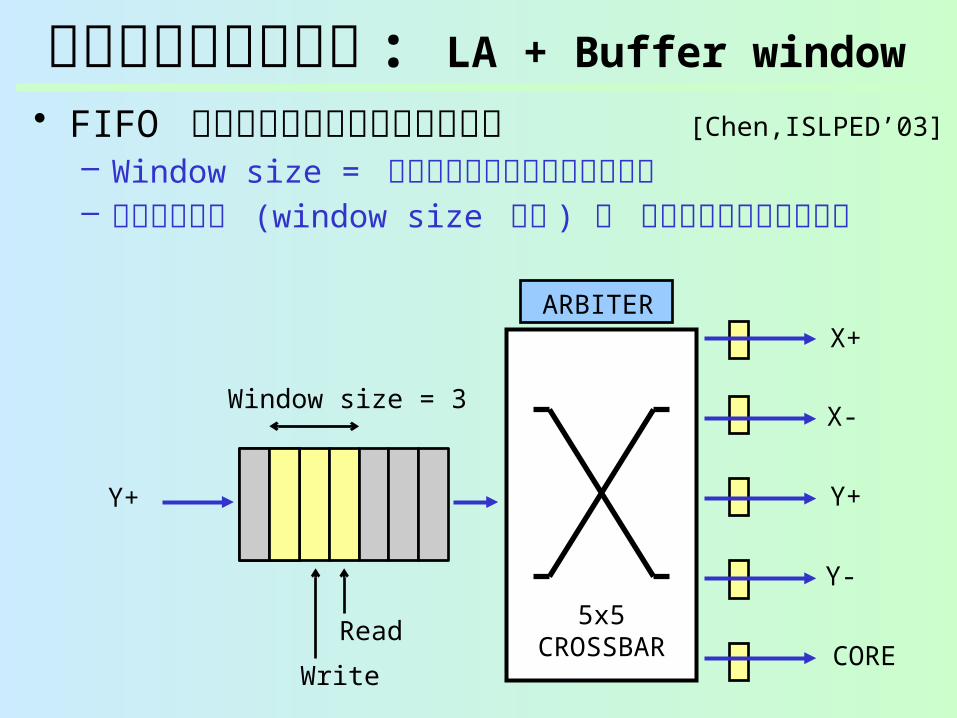
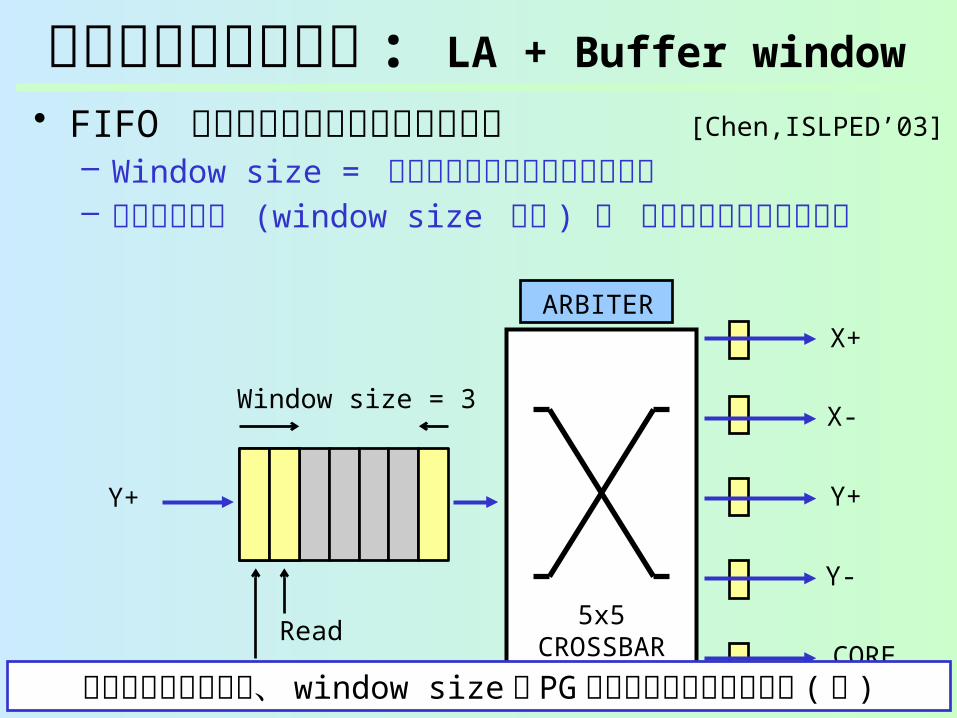
早期ウェイクアップ : LA + Buffer window
• FIFO バッファの先頭を予め電源オン– Window size = 常にオンにしておくバッファ量– 短いパケット (window size 以下 ) ウェイクアップ遅
延無し
5x5 CROSSBAR
ARBITER
Y+
X+
X-
Y+
Y-
CORERead
Write
Window size = 3
[Chen,ISLPED’03]

5x5 CROSSBAR
ARBITER
Y+
X+
X-
Y+
Y-
CORERead
Write
Window size = 3
早期ウェイクアップ : LA + Buffer window
• FIFO バッファの先頭を予め電源オン– Window size = 常にオンにしておくバッファ量– 短いパケット (window size 以下 ) ウェイクアップ遅
延無し
[Chen,ISLPED’03]

5x5 CROSSBAR
ARBITER
Y+
X+
X-
Y+
Y-
CORERead
Write
Window size = 3
早期ウェイクアップ : LA + Buffer window
• FIFO バッファの先頭を予め電源オン– Window size = 常にオンにしておくバッファ量– 短いパケット (window size 以下 ) ウェイクアップ遅
延無し
[Chen,ISLPED’03]
5x5 CROSSBAR
ARBITER
Y+
X+
X-
Y+
Y-
CORERead
Write
Window size = 3
早期ウェイクアップ : LA + Buffer window
• FIFO バッファの先頭を予め電源オン– Window size = 常にオンにしておくバッファ量– 短いパケット (window size 以下 ) ウェイクアップ遅
延無し
[Chen,ISLPED’03]

5x5 CROSSBAR
ARBITER
Y+
X+
X-
Y+
Y-
CORERead
Write
Window size = 3
早期ウェイクアップ : LA + Buffer window
• FIFO バッファの先頭を予め電源オン– Window size = 常にオンにしておくバッファ量– 短いパケット (window size 以下 ) ウェイクアップ遅
延無し
[Chen,ISLPED’03]
5x5 CROSSBAR
ARBITER
Y+
X+
X-
Y+
Y-
CORERead
Write
Window size = 3
遅延は隠蔽できるが、 window size 分 PG できないリーク削減量 (少 )
早期ウェイクアップ : LA + Buffer window
• FIFO バッファの先頭を予め電源オン– Window size = 常にオンにしておくバッファ量– 短いパケット (window size 以下 ) ウェイクアップ遅
延無し
[Chen,ISLPED’03]

発表の流れ : 細粒度 PG ルータの評価• オンチップルータの細粒度パワーゲーティン
グ– 入力バッファ、 出力ラッチ– クロスバ MUX 、仮想チャネル MUX
• パワードメインのハードウェア評価– 回路設計 @ Fujitsu 65nm– 面積、ウェイクアップ遅延、 On/Off エネルギー
• 早期ウェイクアップ手法– ウェイクアップ遅延の隠ぺい
• CMP システムレベル評価– アプリケーション性能 ( 早期ウェイクアップ付き )– リーク電力の削減量 (On/Off エネルギー込み )
35 個のパワードメイン( ルータ 1 個あたり )

CMP シミュレータ : GEMS/Simics • フルシステムシミュレーション
– CPU 8 個、 L2 バンク 64 個、 4x4 メッシュ– Sun Solaris 9 、 Sun Studio 12– SPLASH-2 ベンチマーク (8 スレッド )
オンチップルータ
UltraSPARC
L1 キャッシュ (I & D)
L2 キャッシュバンク ( 各 16kB)
( 各 256kB, 4-way)
radix, lu, fft, barnes, ocean, raytrace, volrend, water-ns, water-sp, fmm (10種類のアプリ )
[Martin,CAN’05]

CMP シミュレータ : GEMS/Simics • フルシステムシミュレーション
– CPU 8 個、 L2 バンク 64 個、 4x4 メッシュ– Sun Solaris 9 、 Sun Studio 12– SPLASH-2 ベンチマーク (8 スレッド )
radix, lu, fft, barnes, ocean, raytrace, volrend, water-ns, water-sp, fmm (10種類のアプリ )
[Martin,CAN’05]
Token coherence プロトコル[Martin,ISCA’03]
• 仮想チャネル 0– リクエスト (L1 ⇔ L2) 用
• 仮想チャネル 1– リクエスト (L2 ⇔ 主記憶 ) 用
• 仮想チャネル 2– リプライ用
• 仮想チャネル 3– スタベイション回避用

評価環境 : アプリケーション性能• フルシステムシミュレーション
– CPU 8 個、 L2 バンク 64 個、 4x4 メッシュ– Sun Solaris 9 、 Sun Studio 12– SPLASH-2 ベンチマーク (8 スレッド )
• 早期ウェイクアップ手法 (3種 ) で、アプリ性能を比較
• ウェイクアップ遅延 : 3nsec (3-cycle ウェイクアップ @ 1GHz)
radix, lu, fft, barnes, ocean, raytrace, volrend, water-ns, water-sp, fmm (10種類のアプリ )
SRC DST
Wakeup
SRC DST
Wakeup
Read
Write
Window size = 2
Ever-on
Look-ahead LA + CPU ever-on LA + Buffer window

早期ウェイクアップ手法がないときの実行時間 (+35.3%)
CPU ever-on のときの性能オーバヘッドは +4.0%
評価結果 : アプリケーション性能
SPLASH-2 ベンチの実行時間 (3-cycle ウェイクアップ @
1GHz)
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
(1.00 = パワーゲーティングしないときの実行時間 )
早期ウェイクアップ手法によって、性能オーバヘッドを大幅に緩和
Look-ahead +Look-aheadCPU ever-on
Look-ahead +Buffer window
アプ
リの実行
時間
(正規化
)
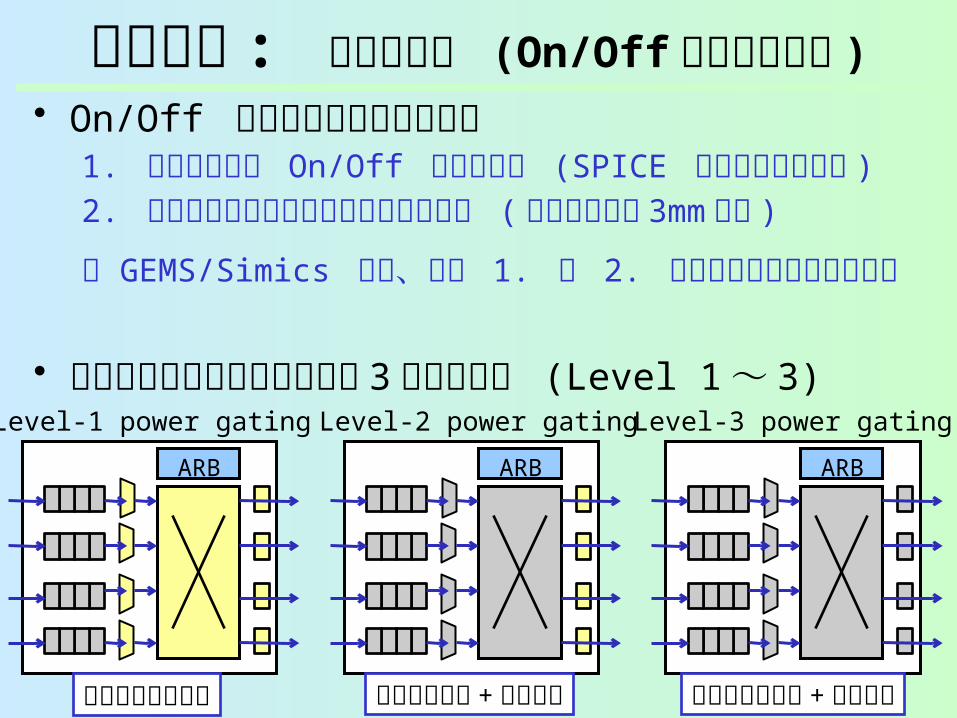
評価環境 : リーク電力 (On/Off エネルギー込 )
• On/Off エネルギーのモデリング1. 各ドメインの On/Off エネルギー (SPICE シミュレー
ション )
2. ウェイクアップ信号の配線エネルギー ( リピータ付き3mm 配線 )
GEMS/Simics には、上記 1. と 2. をパラメータとして与える
• 細粒度パワーゲーティングを 3段階で適用 (Level 1~ 3)
Level-1 power gating Level-2 power gating Level-3 power gating
ARB ARB ARB
入力バッファ + クロスバ 入出力バッファ + クロスバ入力バッファのみ

パワーゲーティングしないときのリーク電力
評価結果 : リーク電力 (On/Off エネルギー込 )
Level 1 PG: 入力バッファのみ (3-cycle ウェイクアップ@1GHz)
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
On/Off エネルギー
リー
ク電
力
(オ
ーバ
ヘッ
ド込
、正規化
) Look-ahead +Look-ahead
CPU ever-onLook-ahead +Buffer window
Level 1 PG によって、リーク電力を 51.8% 削減

パワーゲーティングしないときのリーク電力
評価結果 : リーク電力 (On/Off エネルギー込 )
Level 2 PG: 入力バッファ、クロスバ (3-cycle ウェイクアップ @1GHz)
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
On/Off エネルギー
リー
ク電
力
(オ
ーバ
ヘッ
ド込
、正規化
) Look-ahead +Look-ahead
CPU ever-onLook-ahead +Buffer window
Level 2 PG によって、リーク電力を 55.8% 削減
パワーゲーティングしないときのリーク電力
評価結果 : リーク電力 (On/Off エネルギー込 )
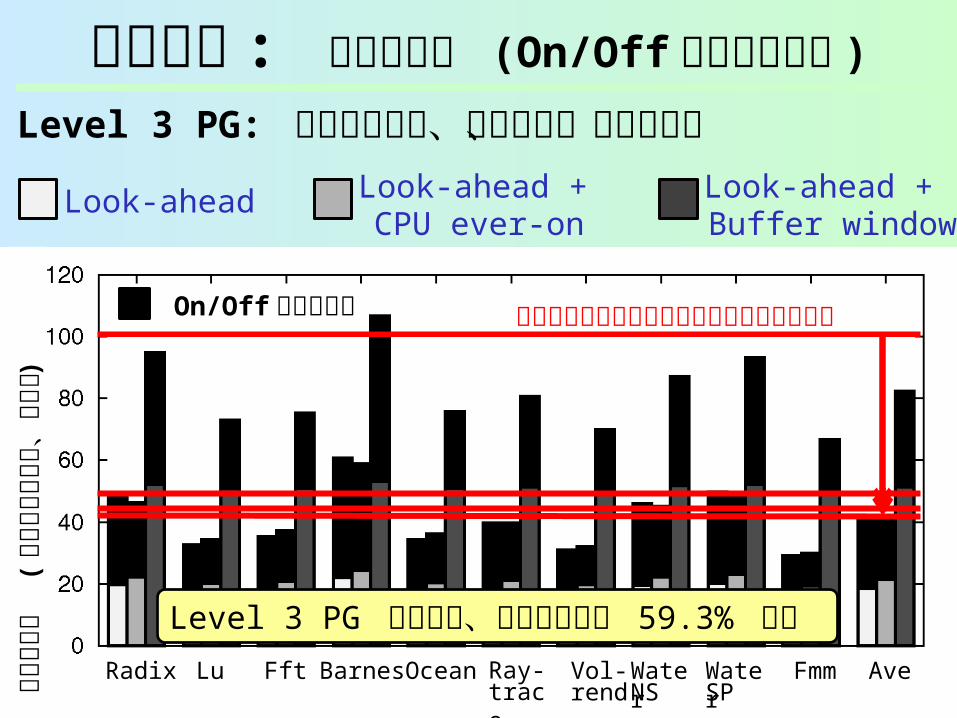
Level 3 PG: 入力バッファ、クロスバ、出力ラッチ
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
On/Off エネルギー
Look-ahead +Look-aheadCPU ever-on
Look-ahead +Buffer window
リー
ク電
力
(オ
ーバ
ヘッ
ド込
、正規化
)
Level 3 PG によって、リーク電力を 59.3% 削減

まとめ : CMP向け細粒度 PG ルータの評価
• パワードメインの実装 @ Fujitsu 65nm– 入力バッファ、 出力ラッチ– クロスバ MUX 、仮想チャネル MUX
• パワードメインのオーバヘッド (SPICE シミュレーション )
– 面積オーバヘッド : 4.3~ 15.9% 増– ウェイクアップ遅延 : 3nsec 以下– On/Off エネルギー : 60~ 99nsec のスリープで償却可
能
• CMP を想定した評価 ( フルシステム・シミュレーション )
– アプリの性能オーバヘッド : 35.3% ( 早期ウェイクアップ無し )
– アプリの性能オーバヘッド : 4.0% ( 早期ウェイクアップ有り )
– リーク電力の削減量は 59.3% (On/Off エネルギー込み )
35 個のパワードメイン( ルータ 1 個あたり )

今後の課題 : さらなるオーバヘッド削減
CPU L2 キャッシュ
Ever-on
• Return wakeup: 性能オーバヘッドのさらなる削減– リプライ (L2 CPU) の 1ホップ目遅延を隠ぺい– 宛先 (L2)到着時に、リプライで使われるポートをウェイ
クアップ
• パワードメイン統廃合 : 面積オーバヘッドのさらなる削減– クロスバ MUX と出力ラッチを統合
Return wakeup
ARBITER
X+
X-
X+
X-

ご清聴ありがとうございました

オンチップルータ : 消費電力の解析• 消費電力の分類
– スイッチング電力 : 回路がスイッチングする際に消費– リーク電力 : 電源が入っている限りちょっとずつ消
費• Fujitsu 65nm で配置配線し、 500MHz でシミュレー
ション
スタンバイ時の消費電力の 35.7% がリーク電力 ( 動作時 75℃のとき )

早期ウェイクアップ手法がないときの実行時間 (+23.2%)
CPU ever-on のときの性能オーバヘッドは +3.2%
評価結果 : アプリケーション性能
SPLASH-2 ベンチの実行時間 (2-cycle ウェイクアップ @
667MHz)
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
(1.00 = パワーゲーティングしないときの実行時間 )
Look-ahead +Look-aheadCPU ever-on
Look-ahead +Buffer window
アプ
リの実行
時間
(正規化
)

早期ウェイクアップ手法がないときの実行時間 (+46.3%)
CPU ever-on のときの性能オーバヘッドは +6.7%
評価結果 : アプリケーション性能
SPLASH-2 ベンチの実行時間 (4-cycle ウェイクアップ @
1333MHz)
Radix Lu Fft Barnes Ocean Ray-trace
Vol-rend
WaterNS
WaterSP
Fmm Ave
(1.00 = パワーゲーティングしないときの実行時間 )
Look-ahead +Look-aheadCPU ever-on
Look-ahead +Buffer window
アプ
リの実行
時間
(正規化
)