Embed Size (px)
Citation preview

소프트웨어학과 원성현 교수 1
자료구조 강의노트
교재 : C로 배우는 쉬운 자료구조(개정판) 출판사 : 한빛미디어(2011년 3월 발행) 저자 : 이지영

소프트웨어학과 원성현 교수 93
8장 트리

소프트웨어학과 원성현 교수 94
1. 트리
• 트리(tree)란? • 리스트, 스택, 큐 등은 선형 자료 구조(linear data structure)인 것에 반해서 트리는 계층(hierarchy)을 갖는 비선형 자료 구조(nonlinear data structure)임 • 트리란 한 개 이상의 노드로 이루어진 유한집합
• 트리 구조의 예 • 회사의 조직 구조 • 컴퓨터 내 폴더 혹은 디렉토리 구조 • 의사 결정 트리 구조
트리 개요
A
D B C

소프트웨어학과 원성현 교수 95
• 트리의 주요 용어 • 노드(node) : 트리를 구성하는 요소 하나하나(예 : A, B…) • 루트(root) : 트리의 시작이 되는 노드(예 : A) • 간선(edge) : 노드와 노드의 연결 • 부모(parent) : 자신과 직접 연결된 상위 노드 • 자식(children) : 자신과 직접 연결된 하위 노드 • 형제(sibling) : 동일한 부모를 갖는 노드들
A
D B C
G F E H J I

소프트웨어학과 원성현 교수 96
• 조상(ancestor) : 임의의 노드에서 루트까지 이르는 경로 상의 모든 노드 • 후손(descendent) : 임의의 노드 하위의 모든 노드 • 단말(terminal, leaf) : 자식을 갖지 않는 노드 • 비단말(non terminal) : 자식을 갖는 노드 • 서브트리(sub tree) : 특정 노드 아래 구성된 트리 • 차수(degree) : 임의의 노드가 갖는 자식 노드의 수 • 레벨(level) : 루트를 레벨 1로 하고 그 자식노드는 +1 • 높이(height) : 트리가 갖는 최대 레벨 • 숲(forest) : 루트를 제거했을 때 생기는 서브트리
• 트리의 표현 • 배열을 이용한 표현
• 표현하기 용이하나 크기가 고정되어 있어서 변화하는 트리를 적절하게 표현하기 어려움
• 연결 리스트를 이용한 표현 • 표현하기 어려우나 크기가 가변적이어서 변화하는 트리를 적절하게 표현하기 용이함

소프트웨어학과 원성현 교수 97
2. 이진 트리
이진 트리의 개요
• 일반 트리(general tree) • 각 노드가 가질 수 있는 자식의 개수가 제한되지 않은 트리 • 모든 노드의 차수가 다르기 때문에 배열로든 링키드 리스트든 구현하기 어려움
• 이진 트리(binary tree : BT) • 각 노드가 가질 수 있는 자식의 개수가 2개 이하로 제한된 트리 • 모든 노드의 최대 차수가 2로 동일하기 때문에 구현하기 매우 용이함
• 모든 노드는 링크 필드를 2개 갖는 링키드 리스트로 구현할 수 있음
LC data RC

소프트웨어학과 원성현 교수 98
추상자료형 이진 트리
• 이진 트리의 정의 • 공집합이거나 모든 노드의 차수가 2 이하이며 자식 노드는 왼쪽 자식과 오른쪽 자식으로 명확히 구분될 수 있어야 함 • 이진 트리의 서브 트리도 모두 이진트리여야 함
A
left subtree right subtree

소프트웨어학과 원성현 교수 99
• 이진 트리의 성질 • n개의 노드를 가진 이진 트리는 n-1개의 간선을 가짐 • 모든 노드는 오직 1개의 부모만 갖고 부모와 자식 간에는 정확히 1개의 간선만 존재하기 때문 • 높이가 h인 이진 트리는 최소 h개의 노드를 갖고 최대 2h-1개의 노드를 가짐 • n개의 노드를 갖는 이진 트리의 높이는 최대 n이거나 최소log2(n+1)이 됨
A
B
C
최소
A
B
D
C
E F G
최대

소프트웨어학과 원성현 교수 100
이진 트리의 분류
• 포화 이진 트리(full binary tree) • 각 레벨에 모든 노드가 꽉 차 있는 트리
• 완전 이진 트리(complete binary tree) • 마지막 레벨에서 왼쪽부터 노드가 꽉 차 있는 트리
• 편향 이진 트리(skewed binary tree) • 이진 트리를 구성하는 모든 노드가 한쪽 자식만 갖는 트리
A
B
D
C
E F G
포화 이진 트리
A
B
D
C
E F
완전 이진 트리
A
B
C
편향 이진 트리

소프트웨어학과 원성현 교수 101
3. 이진 트리의 구현
순차 자료구조를 이용한 이진 트리 구현
• 배열 표현법
A
B
D
C
E F
A B C D E F
1
2 3
4 5 6
[1] [0] [2] [3] [4] [5] [6] [7] [8]
A
B
C A B C D
1
2 3
4 5 6 [1] [0] [2] [3] [4] [5] [6] [7] [8]
D
7
8

소프트웨어학과 원성현 교수 102
연결 자료구조를 이용한 이진 트리 구현
• 링크 표현법
A
B
D
C
E F
A
B C
NULL D NULL NULL E NULL NULL E NULL
typedef struct treeNode { char data; struct treeNode *left struct treeNode *right; } treeNode;

소프트웨어학과 원성현 교수 103
4. 이진 트리의 순회
이진 트리의 순회
• 이진 트리의 순회(traversal)란? • 이진 트리를 구성하는 모든 노드를 오직 한번만 방문하는 연산
• 이진 트리의 순회법
A
L R
전위 순회(preorder traversal) : VLR 중위 순회(inorder traversal) : LVR 후위 순회(postorder traversal) : LRV
V
소프트웨어학과 원성현 교수 104
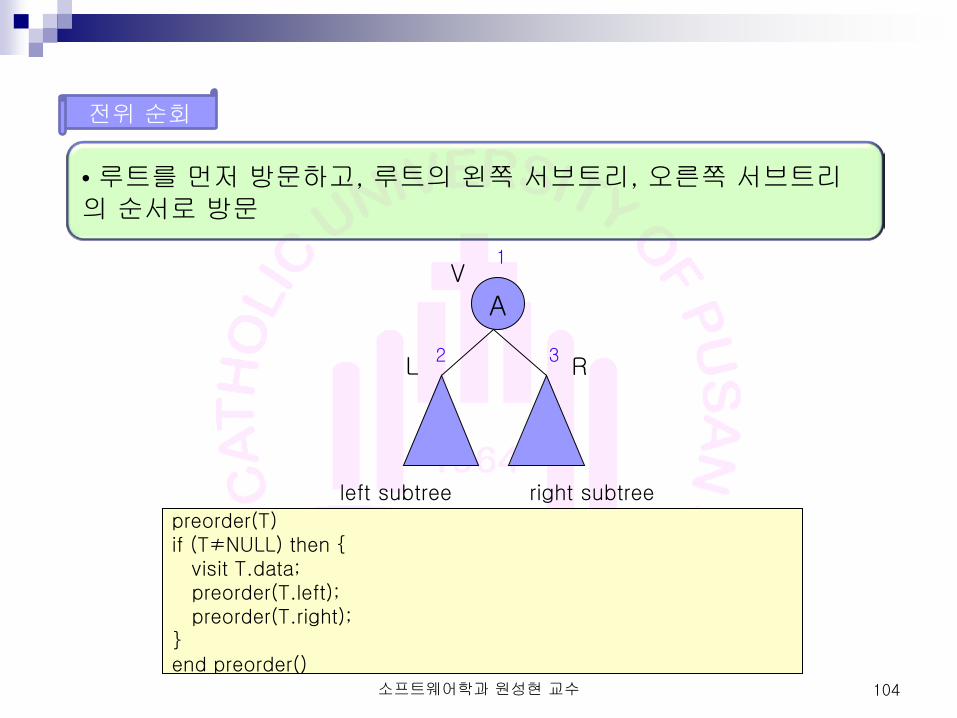
전위 순회
• 루트를 먼저 방문하고, 루트의 왼쪽 서브트리, 오른쪽 서브트리의 순서로 방문
A
left subtree right subtree
L R
preorder(T) if (T≠NULL) then { visit T.data; preorder(T.left); preorder(T.right); } end preorder()
V 1
2 3

소프트웨어학과 원성현 교수 105
중위 순회
• 루트의 왼쪽 서브트리를 먼저 방문하고, 루트, 오른쪽 서브트리의 순서로 방문
A
left subtree right subtree
L R
inorder(T) if (T≠NULL) then { inorder(T.left); visit T.data; inorder(T.right); } end inorder()
V
1
2
3

소프트웨어학과 원성현 교수 106
후위 순회
• 루트의 왼쪽 서브트리, 오른쪽 서브트리를 방문한 후 마지막으로 루트의 순서로 방문
A
left subtree right subtree
L R
postorder(T) if (T≠NULL) then { postorder(T.left); postorder(T.right); visit T.data; } end postorder()
V
1 2
3

소프트웨어학과 원성현 교수 107
이진 트리에서의 순회 방법을 응용한 프로그램
• 연산식에 대한 순회
+
*
*
/
A
D
C
B
E
<Inorder> A/B*C*D+E <Preorder> +**/ABCDE <Postorder> AB/C*D*E+

소프트웨어학과 원성현 교수 108
• 전위 순회와 중위 순회 결과를 아는 상태에서의 이진 트리 구성 • 전위 순회의 결과가 A B C D E F G H I이고, 중위 순회의 결과가 B C A E D G H F I인 이진 트리를 가정 • 이 두 순회 결과를 통해 유일한 본래의 이진 트리를 구성할 수 있을까?
A
B,C D,E,F,G,H,I
A
D,E,F,G,H,I B
C

소프트웨어학과 원성현 교수 109
A
B
C
D
E F,G,H,I
A
B
C
D
E F
I G,H A
B
C
D
E F
I G
H

소프트웨어학과 원성현 교수 110
• 스레드 이진 트리(threaded binary tree) • 이진 트리의 링크의 문제점
• n개의 노드로 구성된 이진 트리는 총 2n개의 링크를 갖고 있는데 그 중 n-1개만 실제 노드를 가리키고 나머지 n+1개의 링크는 NULL임
A
B C
D E 0 0 F 0 0 G 0 0
H 0 0 I 0 0

소프트웨어학과 원성현 교수 111
• 스레드 이진 트리란 모든 링크에게 임무를 부여 • 원래 가리킬 노드가 있는 링크와 원래는 가리킬 노드가 없었는데 새로이 임무를 부여받은 링크로 구분 • 새로운 임무란 자신의 이전 노드와 이후 노드를 가리키는 것
A
C B
D E F G
H I

소프트웨어학과 원성현 교수 112
• 스레드 이진 트리의 노드 구조
- f f
A f f
B f f C f f
D f f E t t
H t t I t t
F t t G t t
f : FALSE, t : TRUE root

소프트웨어학과 원성현 교수 113
5. 이진 탐색 트리
이진 트리의 순회
• 이진 탐색 트리(Binary Search Tree : BST)란? • 다음과 같은 조건을 만족하는 이진 트리
• 모든 원소의 키(key)는 유일하다. • 왼쪽 서브 트리의 키들은 루트의 키보다 작다. • 오른쪽 서브 트리의 키들은 루트의 키보다 크다. • 왼쪽과 오른쪽 서브 트리도 이진 탐색 트리이다.
A
< <
left subtree(루트보다 작은 값) right subtree(루트보다 큰 값)

소프트웨어학과 원성현 교수 114
18
7
3
26
12
27
31
3 7 12 18 26 27 31
• 이진 탐색 트리의 예
• 이진 탐색 트리의 중위 순회 예

소프트웨어학과 원성현 교수 115
이진 탐색 트리의 탐색 연산
• 이진 탐색 트리에서의 탐색 • 루트와 제일 먼저 비교
• 탐색값과 루트가 일치하면 탐색 종료 • 탐색값이 루트보다 작으면 왼쪽 서브 트리로 이동하여 왼쪽 서브 트리의 루트와 다시 비교 • 탐색값이 루트보다 크면 오른쪽 서브 트리로 이동하여 오른쪽 서브 트리의 루트와 다시 비교
• 교재 386쪽 알고리즘 8-4 참조

소프트웨어학과 원성현 교수 116
이진 탐색 트리의 삽입 연산
30
5 40
2
30
5 40
2
80 삽입
80
• 교재 387쪽 알고리즘 8-5 참조
소프트웨어학과 원성현 교수 117
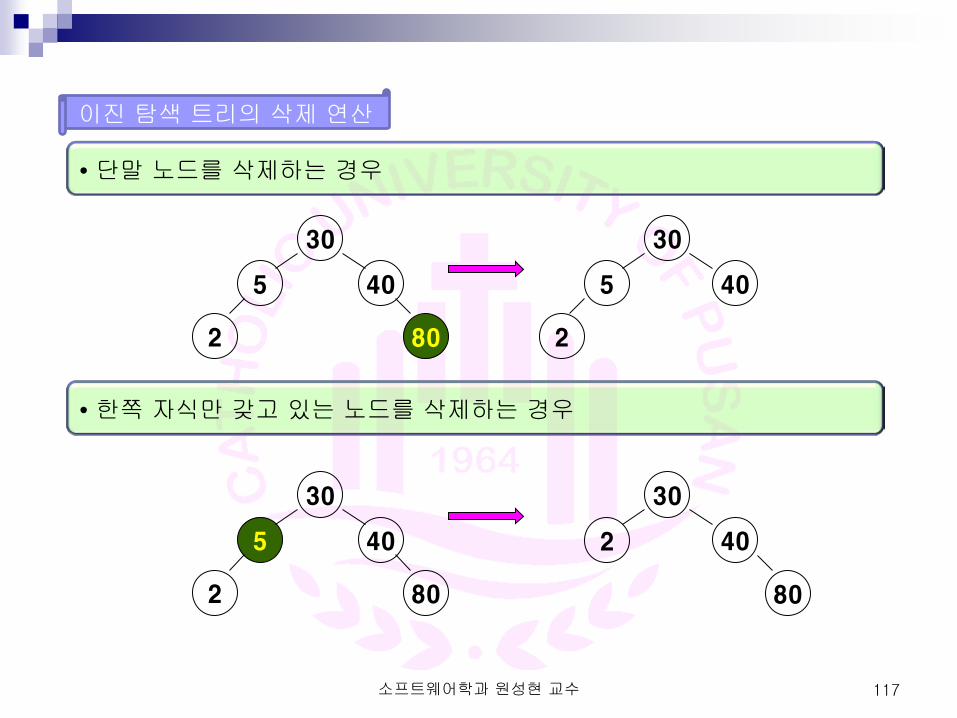
이진 탐색 트리의 삭제 연산
• 단말 노드를 삭제하는 경우
30
5 40
2 80
30
40 5
2
• 한쪽 자식만 갖고 있는 노드를 삭제하는 경우
30
5 40
2 80
30
40 2
80

소프트웨어학과 원성현 교수 118
• 양쪽 자식 모두를 갖고 있는 노드를 삭제하는 경우
30
5 40
2 80
35
40 5
80 35 2
or
5
40 2
80 35

소프트웨어학과 원성현 교수 119
6. 힙
힙의 개요
• 힙의 개념 •최대 힙(Max Heap)
•루트의 하위 노드들은 루트보다 값이 작거나 같은 이진 트리 •최소 힙(Min Heap)
•루트의 하위 노드들은 루트보다 값이 크거나 같은 이진 트리
9
7
5
6
4 3 2
2 1 3
1
4
7
2
5 3 3
7 8 9

소프트웨어학과 원성현 교수 120
힙의 구현
• 배열을 이용하는 경우, 루트부터 왼쪽 자식, 오른쪽 자식의 순서로 배열에 저장
9
7
5
6
4 3 2
2 1 3
1
2 3
4 5 6 7
8 9 10
9 7 6 5 4 3 2 2 1 3
[1] [0] [2] [3] [4] [5] [6] [7] [8] [9] [10]
왼쪽 자식 : 부모의 인덱스*2 오른쪽 자식 : 부모의 인덱스 * 2 + 1
부모의 인덱스 = 자식의 인덱스/2

소프트웨어학과 원성현 교수 121
힙에서의 삽입 연산
• 힙에서의 삽입 절차 • 가장 마지막에 새로운 노드(8)를 삽입 • 부모 노드(4)와 비교하여 삽입 노드(8)의 값이 더 크므로 교환
9
7
5
6
4 3 2
2 1 3
1
2 3
4 5 6 7
8 9 10
8
11
9
7
5
6
4
3 2
2 1 3
1
2 3
4 5 6 7
8 9 10
8
11

소프트웨어학과 원성현 교수 122
• 부모 노드(7)와 비교하여 삽입 노드(8)가 더 크므로 교환 • 부모 노드(9)와 비교하여 삽입 노드(8)가 더 이상 크지 않으므로 교환 종료
9
7 5
6
4
3 2
2 1 3
1
2 3
4 5 6 7
8 9 10
8
11
insertHeap(heap,item) if(n=heapSize) then heapFull(); n=n+1; for(i=n; ;) do { if(i=1) then exit; if(item <= heap[⌊i/2⌋]) then exit; heap[i]=heap[⌊i/2⌋]; i=⌊i/2⌋ } heap[i]=item; end insertHeap()
힙에서의 삽입 알고리즘

소프트웨어학과 원성현 교수 123
힙에서의 삭제 연산
• 힙에서의 삭제 절차 • 힙에서 삭제는 최대값을 가진 노드 즉 루트(9)부터 삭제 • 루트를 삭제하면 트리가 깨지므로 히프의 마지막 노드(3)를 루트의 위치로 이동하여 트리를 유지
9
7
5
6
4 3 2
2 1 3
1
2 3
4 5 6 7
8 9 10
7
5
6
4 3 2
2 1
3
1
2 3
4 5 6 7
8 9

소프트웨어학과 원성현 교수 124
• 그러나, 임시로 루트가 된 노드(3)는 자식 노드보다 값이 작으므로 자식 노드 중 값이 더 큰 노드(7)와 교환 • 그래도 자식 노드보다 값이 작으므로 자식 노드 중 값이 더 큰 노드(5)와 교환 • 더 이상은 자식 노드보다 값이 작지 않으므로 교환 종료
7
5
6
4 3 2
2 1
3
1
2 3
4 5 6 7
8 9
7
5 6
4 3 2
2 1
3
1
2 3
4 5 6 7
8 9

소프트웨어학과 원성현 교수 125
• 힙에서의 삭제 알고리즘
deleteHeap(heap) if(n=0) then return error; item=heap[1]; temp=heap[n]; n=n-1; i=1; j=2; while(j<=n) do { if(j<n) then if(heap[j]<heap[j+1]) then j=j+1; if(temp>=heap[j]) then exit; heap[i]=heap[j]; i=j; j=j*2; } heap[i]=temp; return item; end deleteHeap()

소프트웨어학과 원성현 교수 126
힙의 응용
• 힙 정렬
Input List : 26 5 77 1 61 11 59 15 48 19
26
5 77
1 61
15 48 19
11 59
[1]
[2] [3]
[4] [5] [6] [7]
[8] [9] [10]
Input Array
77
61 59
48 19
15 1 5
11 26
[1]
[2] [3]
[4] [5] [6] [7]
[9] [10]
Initial Heap

소프트웨어학과 원성현 교수 127
61
48 59
15 19
5 1
11 26
[1]
[2] [3]
[4] [5] [6] [7]
[8] [9]
Heap Size = 9 Sorted = [77]
59
48 26
15 19
5
11 1
[1]
[2] [3]
[4] [5] [6] [7]
[8]
Heap Size = 8 Sorted = [61,77]
48
19 26
15 5 11 1
[1]
[2] [3]
[4] [5] [6] [7]
Heap Size = 7 Sorted = [59,61,77]
26
19 11
15 5 1
[1]
[2] [3]
[4] [5] [6]
Heap Size = 6 Sorted = [48,59,61,77]

소프트웨어학과 원성현 교수 128
19
15 11
1 5
[1]
[2] [3]
[4] [5]
Heap Size = 5 Sorted = [26,48,59,61,77]
15
5 11
1
[1]
[2] [3]
[4]
Heap Size = 4
11
5 1
[1]
[2] [3]
Sorted = [19,26,48,59,61,77]
Heap Size = 3 Sorted = [15,19,26,48,59,61,77]
5
1
[1]
[2]
Heap Size = 2 Sorted = [5,11,15,19,26,48,59,61,77]
1 [1]
Heap Size = 1 Sorted = [1,5,11,15,19,26,48,59,61,77]

소프트웨어학과 원성현 교수 129
• 허프만 코딩(Huffman Coding) • 허프만 코딩이란?
• 데이터를 표현할 때 ASCII와 같이 고정된 길이의 비트 수를 문자에 할당하지 않고 가변 길이로 할당, 즉 자주 등장하는 문자에게는 짧은 비트 수만을 할당하고, 자주 등장하지 않는 문자에게는 긴 비트 수를 할당하여 식별
• 허프만 코딩의 예 • e : 15, t : 12, n : 8, i : 6, s : 4라는 빈도를 갖는다면 총 45글자이므로 이들 문자에게 각각 8비트를 할당한다면 360비트가 필요하지만 e : 2비트, t : 2비트, n : 2비트, i : 3비트, s : 3비트를 할당하면 88비트만으로도 충분히 표한 가능
• 각 문자에게 허프만 코드를 할당하는 방법 • 각 문자의 빈도수를 데이터르 갖는 이진 트리를 구성하고 이를 통해 힙을 구성. • 구성된 히프를 통해 코드를 할당

소프트웨어학과 원성현 교수 130
• 힙을 이용한 허프만 코딩 과정 • 가장 작은 값을 갖는 두 노드를 합한 값으로 부모를 생성
4 6 8 12 15
10
18
27
45
4 6 8 12 15
4 6 8 12 15
10

소프트웨어학과 원성현 교수 131
• 왼쪽 간선은 1로, 오른쪽 간선은 0으로 할당
4 6 8 12 15
10
18
27
45
1 0
1
1
0 0
0
1
빈도 4(s) : 111 3비트 할당 빈도 6(i) : 110 3비트 할당 빈도 8(n) : 10 2비트 할당 빈도 12(t) : 01 2비트 할당 빈도 15(e) : 00 2비트 할당
![1주차 강의노트 - baracademy.co.kr · 삼일한성학원() 인사노무관리(3/11) 강 사 : 박인수 노무사 - 1 - 1주차 강의노트 [성과주의 인적자원관리]](https://img.pdfslide.tips/doc/110x75/5b9753a609d3f2e10f8c7042/1-311-.jpg)

![CSE117 프로그래밍기 강의노트 - home [PLASSE] · PDF fileCSE117 프로그래밍기초 강의노트 1 1. 문자열, 수, 변수, 입출력 Strings, Numbers, Variables and Input/Output](https://img.pdfslide.tips/doc/110x75/5a79f3507f8b9ae5058b938d/cse117-home-plasse-.jpg)

![쉽게 배우는 알고리즘 강의노트 - jbnu.ac.krnlp.jbnu.ac.kr/AL/ch07.pdf · -22 한빛아카데미㈜ 수행시간 [정리5] Tree를이용해표현되는Exclusive set에서](https://img.pdfslide.tips/doc/110x75/5e518a2c1f0daa1c7210627b/eoe-ee-oeee-ee-jbnuackrnlpjbnuackralch07pdf.jpg)
























