Embed Size (px)
Citation preview

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
3
Experiencias en el uso del software Quimiometrix para el procesamiento multivariado de datos químicos y bioquímicos
Oneisys Núñez-Cuadra, Isneri Talavera-Bustamante,* Diana Porro-Muñoz, Noslen Hernández-Fernández y Lázaro Bustio-Martínez.
*Centro de Aplicaciones de Tecnologías de Avanzada Avenida 7ma No. 21812 entrre calles 218 y 222, Reparto Siboney, Playa, La Habana, Cuba. Email: [email protected]
Recibido: 13 de abril de 2010. Aceptado: 17 de febrero de 2011.
Palabras clave: quimiometría, análisis exploratorio de datos, clasificación, calibración multivariada.Key words: chemometrics, exploratory data analysis, classification, multivariate calibration.
RESUMEN. El creciente desarrollo de las técnicas de análisis químico instrumental y su vinculación con las tecnologías informáticas, ha posibilitado el procesamiento de gran cantidad de muestras en poco tiempo y en consecuencia, la ad-quisición de una gran cantidad de datos imposibles de ser analizados e interpretados de forma manual. La Quimiometría como nueva especialidad dentro de la Química, emerge en el escenario mundial para la solución de esta problemática, combinando de forma sistémica el empleo de técnicas químicas, matemáticas e informáticas que permiten la obtención y análisis de la información escondida, tras las inmensas matrices numéricas generadas en los procesos de investigación. El presente trabajo tiene como objetivo mostrar a través de ejemplos prácticos, resultados alcanzados en el quehacer investigativo nacional, con el empleo de estas valiosas herramientas de análisis multivariante, en especial, las potencia-lidades y facilidades que ofrece el software Quimiometrix, desarrollado para estos fines por investigadores del Centro de Aplicaciones de Tecnologías de Avanzada y actualmente a disposición de la comunidad científica nacional. Los casos de estudio que se presentan a modo de ejemplos, son representativos de diferentes áreas de trabajo y aplicación de la Qui-miometría, entre ellos: el procesamiento de datos de imágenes químicas para la lectura automática de perfiles de ADN en geles de poliacrilamida, la calibración multivariante en datos espectrales en el caso de la determinación cuantitativa de hidrocarburos en agua utilizando la espectroscopia FT-MIR y por último, un caso de reconocimiento de patrones de sustancias con el problema de la clasificación de combustibles derivados del petróleo con fines de identificación.
ABSTRACT. The increasing development of the techniques of chemical instrumental analysis and their linkage with computers has enabled the processing of a high amount of samples in a short time and as a result the access to a great deal of data otherwise impossible to analyze and interpret in a manual way. Chemometrics as a new specialty in Chemistry emerges at the worldwide scene for the solution of these problems, combining in a systemic form the use of chemical, mathematical and computational techniques that allows us to obtain and analyze the information hidden behind the immense numerical matrices generated in the research processes. The main objective of this work is to show through practical examples, results in chemical investigations obtained with the use of these valuables multivariate analysis tech-niques, specially the potentialities and usefulness offered by the “Quimiometrix” software developed for these purpose by researchers of the Advanced Technology Application Center, currently at the service of the scientific national community. The case studies that are presented as examples are representative of different working lines in Chemometrics applica-tions like: The data processing in chemical images for the automatic extraction of DNA profiles on polyacrialmide gels for identification purpose; the multivariate calibration of spectral data for the quantitative determination of petroleum hydrocarbons in water by FT-MIR spectroscopy, and finally, a case of pattern recognition in substance with the problem of classification of fuels.
INTRODUCCIÓN La automatización y computarización de los labo-
ratorios ha llevado consigo diversas consecuencias. Una de ellas es la rápida adquisición de gran canti-dad de datos. Ahora bien, se sabe que la posesión de dichos datos dista, muchas veces, de proporcionar respuestas adecuadas. Obtener datos no es sinóni-mo de poseer información; se debe interpretarlos y colocarlos en el contexto adecuado para convertirlos
en información útil para el usuario. La Quimiometría es la disciplina que tiene esta finalidad. Sus fun-dadores la definieron como: “la disciplina química que utiliza la Matemática, la Estadística y la lógica formal (a) para diseñar o seleccionar procedimientos experimentales óptimos; (b) proporcionar la máxima información química relevante a partir del análisis de datos químicos; (c) y obtener conocimiento de sistemas químicos.1

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
4
Por todo ello, la Quimiometría se sitúa en un campo interdisciplinario. Muchos autores,2 coinciden en consi-derarla como una rama aplicada de la Química Analítica y la Estadística aplicada, con una función análoga a la que desempeñan disciplinas como la Biometría, Socio-metría, Econometría o Psicometría en relación con la Biología, Sociología, Economía o Psicología, entre otras. Los fines de la Quimiometría están ligados a la Química y su éxito depende de los problemas químicos que sea capaz de resolver.
El desarrollo de la Quimiometría fue tardío como consecuencia de la lenta evolución de la instrumenta-ción científica, todavía en la década de los sesentas, la recopilación de los datos y su tratamiento manual con algoritmos matemáticos eran procesos lentos y tediosos. Por ello, los algoritmos con cierta complejidad de cálculo no tuvieron interés práctico hasta la introducción de las computadoras. Por otra parte, la idea de que los datos químicos generados por el nuevo instrumento podían transformarse en información significativa mediante la aplicación de técnicas estadísticas estaba poco ex-tendida.
El impulso definitivo de la Quimiometría como disciplina científica independiente ocurre al lograrse el acoplamiento de la instrumentación científica de alta tecnología con los microordenadores a mediados de la década 1980-1990 y con ello, el desarrollo vertiginoso del análisis químico instrumental. Actualmente, un labora-torio analítico automatizado es capaz de generar, tratar y almacenar en corto tiempo miles de datos, referentes a muestras que han sido secuencialmente analizadas mediante técnicas de enorme poder resolutivo como: cromatografía, electroforesis y espectroscopia IR, en-tre otras. Se abre ante la Quimiometría entonces, un campo inmenso de trabajo, no solo en el desarrollo de herramientas automatizadas para el procesamiento e interpretación de los datos, sino también, en su empleo por parte de los investigadores y especialistas en el campo de la Química, en la búsqueda de soluciones de los problemas que emergen de la investigaciones y aplicaciones en diferentes áreas de la industria.
En Cuba, el desarrollo de la Quimiometría es inci-piente, el análisis químico instrumental acoplado a la informática se enmarca en la segunda mitad de la década de los noventas y el desarrollo y aplicación de estas he-rramientas para el procesamiento de los datos químicos prácticamente no han sido empleadas y en la mayoría de las instituciones encargadas del procesamiento de este tipo de información, se desconoce su utilidad.
Motivados en 2004 por el fuerte auge en el desarrollo de la Quimiometría a nivel mundial; las potencialidades que se abrieron en el país para el desarrollo de sistemas computadorizados en instituciones como la Universidad de Ciencias Informáticas y el Centro de Aplicaciones de Tecnologías de Avanzada y las necesidades cada vez más crecientes de la incorporación de estas herramientas en el quehacer investigativo nacional, los autores del trabajo enfocaron sus esfuerzos en la profundización de toda la información actualizada concerniente a esta línea de trabajo. En un reporte técnico publicado3 como conclusión de esta fase de trabajo, se presenta la finali-dad de la Quimiometría, su posición entre las ciencias experimentales, sus principales áreas de trabajo, así como las investigaciones tanto teóricas como aplicadas más relevantes relacionadas con esta especialidad. Se brinda además, un resumen de los principales grupos de trabajo y personalidades en este campo a nivel mundial, así como las principales publicaciones (revistas, páginas
web, libros) relacionadas con el tema, que facilita a los lectores la continuación y profundización de los tópicos de interés.
También resulta de interés el epígrafe referido al aná-lisis de los softwares más utilizados en la especialidad, que tienen la característica de incorporar herramientas estadísticas específicas fruto de las investigaciones en Quimiometría, y poco extendidas entre las otras espe-cialidades de la Estadística aplicada. Por su relación con el presente trabajo se hace referencia a aquellos de mayor utilización entre la comunidad de especialistas químicos y bioquímicos:
Pirouette® for Windows. Infometrix, Inc.USA. Com-prehensive Chemometrics Modeling Software.4 Contiene módulos para la exploración de datos, clasificación, análisis de regresión y predicción, todo integrado en un solo programa. Es de fácil utilización y cuenta con una interfaz gráfica muy útil para la visualización de los resultados, la que constituye una de sus principales ventajas. No presenta un fuerte respaldo matemático. Se necesita el pago de licencia para su empleo. No vende a Cuba.
The Unscrambler®, CAMO Inc. Suecia. Multivariate & Experimental Design Software.5 Combina de forma eficiente las técnicas de análisis estadístico y el mapeo multivariante para la interpretación de datos quími-cos. Contiene módulos de estadística descriptiva, ex-ploración de datos, clasificación, análisis de regresión, y diseño de experimentos. Su interfaz gráfica para la visualización de los resultados es pobre. Tiene un fuerte respaldo matemático. Venta de las licencias, poco asequible para Cuba.
PLS_Toolbox, Eigenvector Research Inc. USA.6 Esta es una colección de rutinas quimiométricas avanza-das que trabajan en el ambiente computacional de MATLAB. Contiene herramientas que permiten la exploración de datos químicos, análisis de regresión, tareas de clasificación y la construcción de modelos de predicción. Buen respaldo matemático. Su desventaja principal radica en que se necesitan conocimientos avanzados por parte del especialista químico de MAT-LAB y que no vende a Cuba.Por todo lo antes expuesto, los autores consideran
que el desarrollo de software en esta línea de trabajo, cada vez más funcionales, integrales, y de alto nivel científico-tecnológico, así como su aplicación en pro-yectos aplicados que permitan lograr soluciones con rapidez en el procesamiento y mayor potencialidad para la interpretación de los datos de trabajo, es un reto a enfrentar de primer orden y de vital importancia para el desarrollo del país.
El sistema de herramientas quimiométricas, Quimio-metrix7,8 se desarrolló en respuesta a la inminente nece-sidad de investigadores y especialistas relacionados con las ramas de la química y bioquímica de Cuba, de contar con un producto autóctono, con posibilidades de una amplia generalización de su uso para el procesamiento y análisis de datos químicos. Entre las funcionalidades que ofrece se destacan: Conjunto de técnicas de pre-procesamiento y transformación para la preparación de los datos, técnicas para el análisis exploratorio de los datos, posibilidades de las construcciones de modelos, tanto para clasificación de muestras de interés, como de calibración multivariante para la predicción de pro-piedades químico físicas a partir de los datos de trabajo.
El sistema es un producto de fácil interacción con el usuario, seguro y eficiente, que incluye la mayoría de las funcionalidades que ofrecen sus homólogos a nivel

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
5
mundial. Posee una interfaz de visualización amigable e incorpora la utilización de las máquinas de soporte vecto-rial (SVM) tanto para clasificación como para calibración.
Desde su culminación, a finales de 2008 ha sido insta-lado en 18 instituciones del país, con más de 50 puestos de trabajos. Se han ofrecido cinco cursos de post grados y la realización de dos talleres “Aprendiendo en la Prác-tica” donde especialistas participantes en los diferentes cursos han demostrado el resultado de su aprendizaje a través de la presentación de resultados con el trabajo de sus propios datos.
El presente trabajo tuvo como objetivo mostrar a través de tres soluciones alcanzadas en el quehacer in-vestigativo nacional, la ayuda del análisis multivariante de datos y en especial, las potencialidades y facilidades que ofrece el software Quimiometrix, para estos fines. Los ejemplos fueron seleccionados sobre la base de que fueran representativos de varios campos de aplicación de las técnicas quimiométricas, como el procesamiento de imágenes químicas, la calibración y la clasificación multivariante.
MATERIALES Y MÉTODOSDescripción del software
Quimiometrix consiste en un paquete de herramien-tas quimiométricas, soportadas en técnicas estadísticas y de reconocimiento de patrones de avanzada, para el análisis de datos multivariados. El software está com-puesto por tres módulos básicos:
Módulo de gestión, pre-procesamiento, transforma-ción y exploración de datos
Gestión de datos. Como su nombre indica, el área de trabajo para la gestión de datos permite la entrada, ordenamiento, edición y salida de los datos a través de una amigable interfaz gráfica compuesta por un menú, un explorador de objetos y un área de trabajo. El menú ofrece el acceso a todas las funcionalidades que brinda el sistema, así como las funcionalidades referidas al trabajo con los ficheros tales como: Crear, abrir, guardar, importar y exportar datos desde y hacia las distintas configuraciones de archivos más utilizados. En el explo-rador de objeto garantiza el acceso de todos los datos y resultados obtenidos durante el trabajo con el software, guardando la relación entre los originales y todos los modelos creados sobre su base. En el área de trabajo se ejecutan las acciones de trabajo y se muestran a través de ventanas que permiten visualizar los resultados tanto de forma numérica como de forma gráfica.
Pre-tratamiento de los datos. Los datos experi-mentales deben ser mejorados y preparados conve-nientemente para el análisis. El objetivo es eliminar matemáticamente fuentes de variaciones indeseables, que pueden influiar en los resultados finales. Se divide en dos tipos de técnicas, las de pre-procesamiento y las de transformación.
Pre-procesamientos.9-12 Son un conjunto de opera-ciones estadísticas que se emplean principalmente para lograr que los datos estén dentro de un mismo rango de valores y siguiendo un comportamiento similar. La selección de la operación más adecuada es esencial para el éxito de cualquier análisis posterior. Se aplica a las columnas en una matriz de datos (variables). Entre ellas se tienen:
Centrado respecto a la media.13 Consiste en tratar el valor de cada variable restándole su media. Cambia de lugar el origen de los datos sin alterar las relaciones internas de las muestras, es apenas una traslación de ejes. Se recomienda centrar en la media para la
mayoría de los tipos de datos para lograr una buena exploración de los datos.
Autoescalamiento. Consiste en tratar el valor de cada variable restándole su media y dividiendo por su des-viación típica. El resultado obtenido es que los datos tengan media cero y varianza igual a la unidad. El autoescalado elimina cualquier peso indeseado debido a la diferencia en magnitud de las variables o de las muestras.
Escalamiento por amplitud. El escalado por la ampli-tud ajusta el intervalo de los valores para todas las variables entre 0 y 1, al dividir cada dato por el valor máximo que alcanza la variable en todo el conjunto de datos.
Escalamiento por la varianza. Consiste en tratar cada valor de las variable dividiendo por su desviación típica. Elimina la influencia de la variable dominante más grande con respecto a otras más pequeñas en los cálculos.Transformaciones.9-12 Conjunto de técnicas matemá-
ticas que se emplean fundamentalmente para disminuir o eliminar las variaciones aleatorias (ruido experimental) y variaciones sistemáticas de la señal medida. Se inclu-yen además, las conversiones de unidades de medida en busca de mejorar la interpretabilidad de los datos experimentales. Se aplican a las filas de la matriz de datos (muestras). Entre ellas se tiene:
Alisamientos. Las técnicas de alisamiento son utilizadas para eliminar el ruido experimental en las muestras. Aumentan la razón señal-ruido. Se incorporan en Qui-miometrix, el alisamiento por la media, por la media móvil y a través del algoritmo de Savinsky–Golay.13,14
Correcciones de la línea base. Se presentan de forma general dos alteraciones de la línea base en un espec-tro: el efecto de Offset cuando el espectro entero esta separado de la línea base en una cantidad constante y el efecto de Bias, cuando se aprecia una inclinación de la línea base con respecto a la horizontal. El efec-to Offset puede ser corregido aplicando la primera derivada a la función espectral y el Bias aplicando la segunda derivada. El algoritmo más utilizado para estos fines es el de Savitsky-Golay,13,14 ambas opciones para la derivada se encuentran implementadas en el software además de operaciones matemáticas simples para la sustracción de blancos.
Corrección multiplicativa de la dispersión15 (MSC). Usada para corregir efectos de dispersión de la luz en espectroscopia por reflectancia, causados por diferen-cias en el tamaño o forma de las partículas. Corrige el efecto de Offset en la línea base con la ventaja respecto al tratamiento con la primera derivada de que el es-pectro corregido se asemeja al original lo que ayuda a la interpretación.
Conversión logarítmica. Se aplica el logaritmo tanto base 10 como neperiano con el objetivo de linealizar los datos sin afectar la interpretación de los resulta-dos. También es útil para intensificar intensidades bajas, especialmente, en datos obtenidos mediante Fluorescencia de Rayos X.
Conversiones espectroscópicas. Permite conversiones de medidas de reflectancia en absorbancia y vice-versa, así como la utilización de la transformación de Kubelka Munk16 muy útil para la linealización de datos. La ecuación define una relación lineal entre la intensidad espectral relativa (en relación con un patrón) y la concentración. Es más sofisti-cada que la conversión logarítmica explicada en el inciso anterior.

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
6
Normalización. Es usada principalmente para elimi-nar variaciones sistemáticas asociadas al tamaño de la muestras. Se divide cada una de las variables de una muestra dada por un factor de normalización (Norma). El resultado es que las muestras estarán en una misma escala. Se incluye en el software las Normas superior, l1 y euclidiana o l2.Exploración de los datosLas técnicas de exploración de datos, se utilizan para
poner de manifiesto y resaltar la información contenida en una matriz de datos multidimensional. Son herra-mientas estadísticas de proyección y graficación, muy útiles para la identificación de tendencias y patrones, especialmente, en matrices de gran dimensión. Posibi-litan la visualización de los datos multivariados en un espacio bi o tridimensional. Estas herramientas tienen un carácter no supervisado, porque durante el análisis exploratorio no se tiene conocimiento de los agrupa-mientos o tendencias existentes, hay que descubrirlas a partir de la información que se obtenga del análisis. Entre las más utilizadas y que fueron incluidas en el software se encuentran: Análisis por componentes principales17-20 (conocida
por sus siglas en inglés como PCA, Principal Compo-nent Analysis). Es un método de proyección. Proyecta los datos multivariados en un espacio de dimensión menor, reduciendo la dimensionalidad del espacio del conjunto de los datos y por esto, se considera un método de compresión. Como resultado, las infor-maciones más importantes y relevantes se tornan más obvias. Se incorporan funcionalidades para la visualización de los resultados como: gráficos de autovectores loadings (pesos de las variables origi-nales en las componentes principales), de los scores (coordenadas de los objetos en el nuevo espacio de las componentes principales) presencia de datos anómalos (outliers), así como, gráficos del poder de modelación de las variables originales, matriz reconstruida, entre otros.
Análisis de agrupamiento jerárquico21,22 (conocido por sus siglas en inglés como HCA, Hierarchical Clus-ter Analysis): HCA es una técnica que tuvo su origen en la taxonomía numérica. El objetivo es formar gru-pos que contengan objetos semejantes. Los resulta-dos son presentados en forma de un árbol jerárquico conocido con el nombre de DENDROGRAMA, donde la compresión de dos ramas del árbol representa una gran similaridad entre los objetos. Se incluyen como opciones diferentes métodos de agrupamiento: sim-ple, completo, de la media, del Centroide y el Ward.Módulo de clasificaciónPermite la construcción de modelos de clasificación
capaces de determinar de forma automática a qué grupo de objetos (clases) pertenece uno nuevo, a partir de las características obtenidas por los diferentes análisis quí-micos realizados. Estos modelos se sustentan en técnicas de reconocimiento de patrones (clasificadores) que son usadas para establecer las semejanzas y diferencias entre diferentes tipos de muestras, comparándolas entre sí. Los modelos de clasificación supervisada se construyen a partir del conocimiento previo de los tipos de clases presentes a partir de información que se tiene de los datos o como resultado del análisis exploratorio donde se han obtenido agrupamientos representativos. Mues-tras con características representativas de cada clase conformaran el conjunto de aprendizaje o entrenamiento del clasificador. Su efectividad será comprobada con un conjunto de validación, conformado por muestras de
tipicidad conocida, pero no perteneciente al conjunto de entrenamiento.23 La utilización de uno u otro tipo de clasificador estará en dependencia de las caracte-rísticas de los datos y la complejidad del problema de clasificación. Se incluyeron dentro del software los clasificadores siguientes: K-Vecinos más cercanos (k-NN).24
Modelado blando independiente de analogías de clases (SIMCA).25
Análisis discriminante - regresión por mínimos cua-drados parciales (PLS-DA).12
Máquinas de soporte vectorial para clasificación (SVC).26,27
Módulo de calibraciónPermite la construcción de modelos de calibración
multivariada capaces de predecir de forma automática propiedades químico físicas de interés de muestras en es-tudio, a partir de los resultados obtenidos por los diferentes análisis químicos realizados. Estos modelos se sustentan en métodos de regresión con diferentes posibilidades de acuerdo con sus características. Al igual que para la clasificación, se parte de un conjunto de entrenamiento con muestras representativas del problema a resolver, en el que se conoce el valor de la propiedad químico física a predecir a través de los métodos tradicionales. Se construye el modelo de calibración con el método de regresión que más se ajuste a las características de los datos y el problema a resolver y se valida con mues-tras externas al conjunto de entrenamiento. De estas muestras, también se conoce el valor de la propiedad a predecir. Una vez validado el modelo, se está en condi-ciones de predecir el valor de una propiedad de interés en muestras dadas a partir de los resultados del análisis instrumental realizado.
Se incluyen en Quimiometrix los métodos de regre-sión lineal y no lineal siguientes: Regresión por componentes principales (PCR).28
Regresión por mínimos cuadrados parciales multiva-riante (PLS1).29-31
Regresión por mínimos cuadrados parciales multiva-riante (PLS2).32
Máquinas de soporte vectorial para regresión (SVR).27
RESULTADOS Y DISCUSIÓNCaso de estudio I. Lectura automática de perfiles de ADN en geles de poliacrilamida33,34
Los perfiles de ADN han atraído en los últimos años la atención de la comunidad científica internacional debido al impacto significativo que esta tecnología ha tenido so-bre las tareas de identificación de material molecular del hombre, los animales y las plantas. Entre los campos de aplicación más importantes de esta técnica se encuentra el de las Ciencias Forenses, lo que ha permitido nuevas tecnologías como el análisis de ADN en la investigación criminal a nivel mundial a partir de la segunda mitad de la década de los ochentas.35,36
Para la identificación de seres humanos, los cientí-ficos utilizan los llamados STR LOCI (Short Tandem Repeat).35 Cada STR LOCI exhibe una variación en la longitud de la molécula de ADN. Una persona hereda de sus padres dos longitudes específicas, las cuales tienden a ser diferentes del par de longitudes de otras personas. Cada STR LOCI de un individuo tiene dos “alelos”, por tanto, para generar el perfil de una persona es necesario analizar la información proveniente de los STR LOCI.
Para lograr el estudio comparativo de máculas u otros indicios de naturaleza biológica a través de su ADN es

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
7
necesario someter dichas muestras a un proceso confor-mado por los pasos siguientes:37
Extracción del ADN a partir de cualquier material biológico que permita su cuantificación.
Reacción en cadena de la polimerasa. Amplificación del extracto de ADN para incrementar la cantidad del mismo en la muestra.
Detección y lectura de la información del ADN. Los productos de la reacción en cadena son separados por tamaño, de forma que forman bandas o manchas en correspondencia con cada STR LOCI.
Los resultados se expresan a través de un par numé-rico, que son independientes para cada STR LOCI (marcador genético).
Para que dos perfiles se consideren provenientes del mismo individuo tiene que existir una corresponden-cia total entre los valores numéricos de cada marcador para ambos perfiles.Comúnmente para poder construir el perfil de ADN de
una persona se usan 10 STR (lo que equivale a 20 números), únicos para cada individuo. Esta unicidad hace que el ADN sea considerado actualmente como la Huella Dactilar Molecular, ya que permite establecer la individualidad genética o lo que es lo mismo, determinar de manera categórica la correspondencia entre un material biológico dado (sangre, semen, otros) y un individuo en particular.
El proceso de detección y lectura de los productos amplificados puede realizarse con la aplicación de dife-rentes técnicas de análisis químico. Entre las más cono-cidas se tienen la electroforesis en gel de poliacrilamida con tinción de plata y la electroforesis capilar. Esta última
es la más moderna y rápida, pero muy costosa, mientras que la primera es la más difundida y la que está más al alcance de la mayoría de los laboratorios.38
Como resultado del proceso de electroforesis sobre geles de poliacrilamida y su revelado, se obtiene un conjunto de manchas sobre la placa que contienen ADN las cuales son cotejadas visual y manualmente contra patrones de ADN de marcadores genéticos caracterís-ticos (STR LOCI) (Fig. 1) para lograr la extracción de la numeración de los alelos por LOCI (Tabla 1).
La detección de los productos amplificados se realiza actualmente en nuestro país para tareas forenses por electroforesis en gel de poliacrilamida y tinción con plata y la lectura de las bandas de ADN por marcador se ejecuta de forma visual y manual, proceso en extremo lento y muy engorroso, propenso inclusive a errores humanos. De igual manera, con este procedimiento el cotejo del perfil objeto de estudio contra una base de datos de sospechosos es prácticamente imposible.
Ante esta situación, se planteó el necesario desarrollo de un sistema automatizado para la captación, almacena-miento y procesamiento de imágenes de corridas de ADN sobre geles de poliacrilamida, su lectura automática para la obtención de los perfiles de ADN y desarrollo de base datos que permita su almacenamiento y comparación con fines identificativos con la mayor brevedad posible.
La captación de la imagen se realizó a través de una cámara marca Sony DSC717 colocada en la parte superior de un dispositivo de iluminación controlada, diseñado para tales efectos. La placa fue colocada en una gaveta móvil, si-tuada entre un filtro difusor de luz y la cámara. Las lámparas de iluminación se ubicaron en la base del dispositivo (Fig. 2).
Tabla 1. Perfil confeccionado para una muestra con el marcador y la numeración de los alelos correspon-dientes.
LOCI Valores
CSF1PO 7,8
TPOX 8,9
TH01 6,7
F13A01 11,12
FESFPS 9,10
vWA 13,14
D16S539 5,8
D7S820 6,7
D13S317 13,14
Fig. 1. Tres placas de poliacrilamida con sus respectivos mar-cadores genéticos patrones (LOCI) necesarias para la confor-mación de los perfiles de cuatro muestras en estudio.
Fig. 2. Módulo de adquisición. (a) Vista general. (b) Fuente de iluminación. (c) Gaveta móvil.
Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
8
Después de las corridas, las placas de forma general contienen un conjunto de defectos que se reflejan en la imagen digital obtenida, por lo que es necesario realizar-le un proceso de mejoramiento de su calidad que incluye los siguientes pasos: a) Conversión de la imagen color a tonos de grises, b) Reducción del ruido multiplicativo de baja frecuencia usando un filtro homomórfico39 c) Segmentación de las manchas aplicando un detector de borde Sobel y un umbral automático global.39
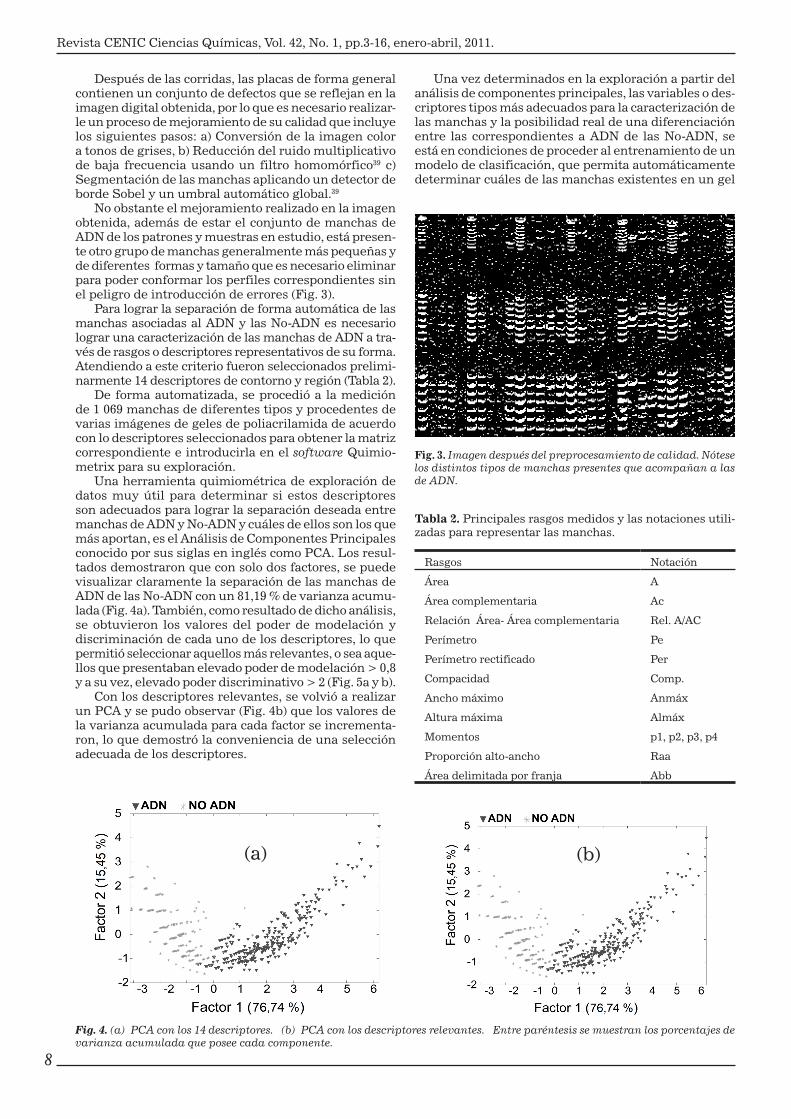
No obstante el mejoramiento realizado en la imagen obtenida, además de estar el conjunto de manchas de ADN de los patrones y muestras en estudio, está presen-te otro grupo de manchas generalmente más pequeñas y de diferentes formas y tamaño que es necesario eliminar para poder conformar los perfiles correspondientes sin el peligro de introducción de errores (Fig. 3).
Para lograr la separación de forma automática de las manchas asociadas al ADN y las No-ADN es necesario lograr una caracterización de las manchas de ADN a tra-vés de rasgos o descriptores representativos de su forma. Atendiendo a este criterio fueron seleccionados prelimi-narmente 14 descriptores de contorno y región (Tabla 2).
De forma automatizada, se procedió a la medición de 1 069 manchas de diferentes tipos y procedentes de varias imágenes de geles de poliacrilamida de acuerdo con lo descriptores seleccionados para obtener la matriz correspondiente e introducirla en el software Quimio-metrix para su exploración.
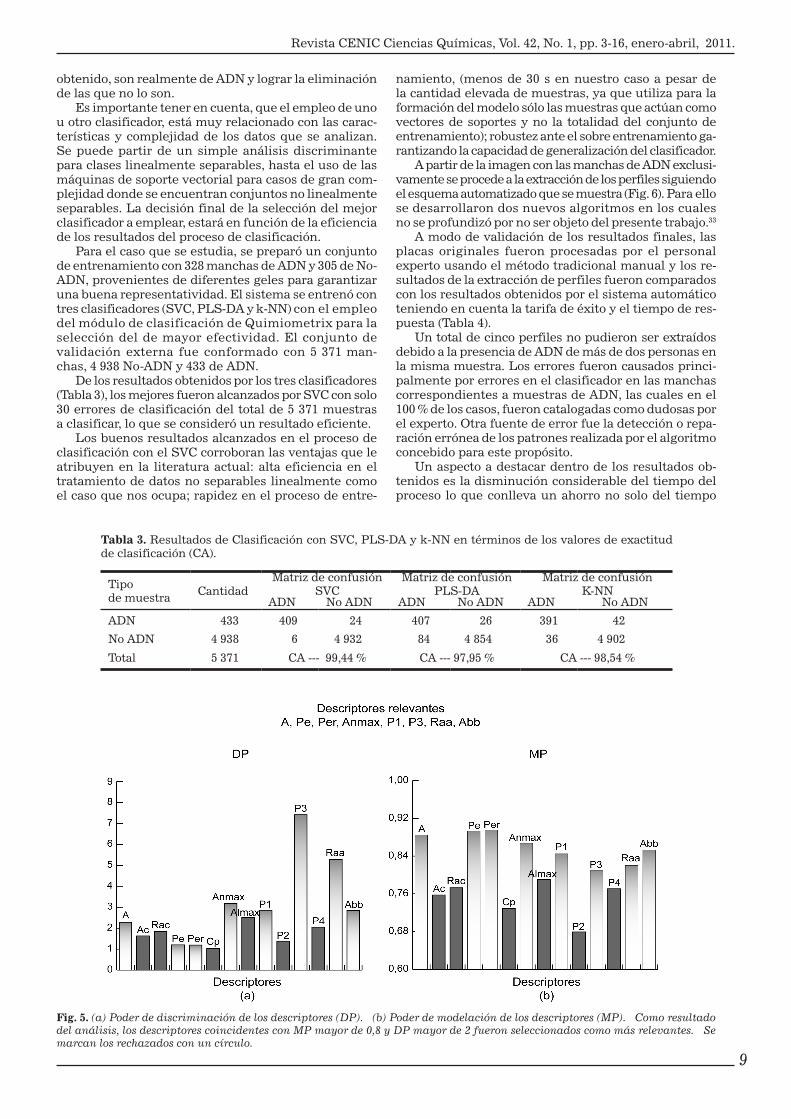
Una herramienta quimiométrica de exploración de datos muy útil para determinar si estos descriptores son adecuados para lograr la separación deseada entre manchas de ADN y No-ADN y cuáles de ellos son los que más aportan, es el Análisis de Componentes Principales conocido por sus siglas en inglés como PCA. Los resul-tados demostraron que con solo dos factores, se puede visualizar claramente la separación de las manchas de ADN de las No-ADN con un 81,19 % de varianza acumu-lada (Fig. 4a). También, como resultado de dicho análisis, se obtuvieron los valores del poder de modelación y discriminación de cada uno de los descriptores, lo que permitió seleccionar aquellos más relevantes, o sea aque-llos que presentaban elevado poder de modelación > 0,8 y a su vez, elevado poder discriminativo > 2 (Fig. 5a y b).
Con los descriptores relevantes, se volvió a realizar un PCA y se pudo observar (Fig. 4b) que los valores de la varianza acumulada para cada factor se incrementa-ron, lo que demostró la conveniencia de una selección adecuada de los descriptores.
Fig. 3. Imagen después del preprocesamiento de calidad. Nótese los distintos tipos de manchas presentes que acompañan a las de ADN.
Tabla 2. Principales rasgos medidos y las notaciones utili-zadas para representar las manchas.
Rasgos Notación
Área A
Área complementaria Ac
Relación Área- Área complementaria Rel. A/AC
Perímetro Pe
Perímetro rectificado Per
Compacidad Comp.
Ancho máximo Anmáx
Altura máxima Almáx
Momentos p1, p2, p3, p4
Proporción alto-ancho Raa
Área delimitada por franja Abb
Fig. 4. (a) PCA con los 14 descriptores. (b) PCA con los descriptores relevantes. Entre paréntesis se muestran los porcentajes de varianza acumulada que posee cada componente.
Una vez determinados en la exploración a partir del análisis de componentes principales, las variables o des-criptores tipos más adecuados para la caracterización de las manchas y la posibilidad real de una diferenciación entre las correspondientes a ADN de las No-ADN, se está en condiciones de proceder al entrenamiento de un modelo de clasificación, que permita automáticamente determinar cuáles de las manchas existentes en un gel
(a) (b)
Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
9
obtenido, son realmente de ADN y lograr la eliminación de las que no lo son.
Es importante tener en cuenta, que el empleo de uno u otro clasificador, está muy relacionado con las carac-terísticas y complejidad de los datos que se analizan. Se puede partir de un simple análisis discriminante para clases linealmente separables, hasta el uso de las máquinas de soporte vectorial para casos de gran com-plejidad donde se encuentran conjuntos no linealmente separables. La decisión final de la selección del mejor clasificador a emplear, estará en función de la eficiencia de los resultados del proceso de clasificación.
Para el caso que se estudia, se preparó un conjunto de entrenamiento con 328 manchas de ADN y 305 de No-ADN, provenientes de diferentes geles para garantizar una buena representatividad. El sistema se entrenó con tres clasificadores (SVC, PLS-DA y k-NN) con el empleo del módulo de clasificación de Quimiometrix para la selección del de mayor efectividad. El conjunto de validación externa fue conformado con 5 371 man-chas, 4 938 No-ADN y 433 de ADN.
De los resultados obtenidos por los tres clasificadores (Tabla 3), los mejores fueron alcanzados por SVC con solo 30 errores de clasificación del total de 5 371 muestras a clasificar, lo que se consideró un resultado eficiente.
Los buenos resultados alcanzados en el proceso de clasificación con el SVC corroboran las ventajas que le atribuyen en la literatura actual: alta eficiencia en el tratamiento de datos no separables linealmente como el caso que nos ocupa; rapidez en el proceso de entre-
Fig. 5. (a) Poder de discriminación de los descriptores (DP). (b) Poder de modelación de los descriptores (MP). Como resultado del análisis, los descriptores coincidentes con MP mayor de 0,8 y DP mayor de 2 fueron seleccionados como más relevantes. Se marcan los rechazados con un círculo.
namiento, (menos de 30 s en nuestro caso a pesar de la cantidad elevada de muestras, ya que utiliza para la formación del modelo sólo las muestras que actúan como vectores de soportes y no la totalidad del conjunto de entrenamiento); robustez ante el sobre entrenamiento ga-rantizando la capacidad de generalización del clasificador.
A partir de la imagen con las manchas de ADN exclusi-vamente se procede a la extracción de los perfiles siguiendo el esquema automatizado que se muestra (Fig. 6). Para ello se desarrollaron dos nuevos algoritmos en los cuales no se profundizó por no ser objeto del presente trabajo.33
A modo de validación de los resultados finales, las placas originales fueron procesadas por el personal experto usando el método tradicional manual y los re-sultados de la extracción de perfiles fueron comparados con los resultados obtenidos por el sistema automático teniendo en cuenta la tarifa de éxito y el tiempo de res-puesta (Tabla 4).
Un total de cinco perfiles no pudieron ser extraídos debido a la presencia de ADN de más de dos personas en la misma muestra. Los errores fueron causados princi-palmente por errores en el clasificador en las manchas correspondientes a muestras de ADN, las cuales en el 100 % de los casos, fueron catalogadas como dudosas por el experto. Otra fuente de error fue la detección o repa-ración errónea de los patrones realizada por el algoritmo concebido para este propósito.
Un aspecto a destacar dentro de los resultados ob-tenidos es la disminución considerable del tiempo del proceso lo que conlleva un ahorro no solo del tiempo
Tabla 3. Resultados de Clasificación con SVC, PLS-DA y k-NN en términos de los valores de exactitud de clasificación (CA).
Tipode muestra Cantidad
Matriz de confusiónSVC
Matriz de confusiónPLS-DA
Matriz de confusiónK-NN
ADN No ADN ADN No ADN ADN No ADN
ADN 433 409 24 407 26 391 42
No ADN 4 938 6 4 932 84 4 854 36 4 902
Total 5 371 CA --- 99,44 % CA --- 97,95 % CA --- 98,54 %

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
10
dedicado por el experto al análisis, sino también, a una reducción de los costos del análisis.
Caso de estudio II. Nuevo método de calibración mul-tivariante para la determinación de hidrocarburos en agua a través de la espectroscopia infrarroja.40
Una de las formas de contaminación más fre-cuente presente en el agua son los vertimientos de hidrocarburos en áreas urbanas e industriales, pro-venientes de su uso y desecho, o como consecuencia de accidentes. Para la detección y control de dicha contaminación, se necesita contar con métodos analí-ticos con apropiados límites de detección y exactitud y además que sean simples y rápidos.
Diferentes métodos analíticos se encuentran recogi-dos en la literatura para la determinación de hidrocarbu-ros del petróleo en agua. Los métodos gravimétricos41,42 han sido ampliamente utilizados no obstante se le atribuyen desventajas relacionadas con su complejidad, elevado consumo de tiempo para su ejecución, baja sen-sibilidad a concentraciones menores de 10 mg/L de hidro-carburo y pérdida de una fracción de los hidrocarburos volátiles, ocasionadas por las operaciones de remoción del disolvente asociadas al método. Una alternativa ha sido el método cromatográfico43 que muestra mejores niveles de sensibilidad y exactitud que los gravimétricos, pero subsiste la desventaja con relación al tiempo de su preparación y ejecución.
La espectroscopia infrarroja, ha sido una técnica muy utilizada para los análisis de rutina en el control de un conjunto de productos como parte de la protección me-dio ambiental. En este caso en particular, se encuentra
en uso un método de calibración univariada utilizando la espectroscopia infrarroja,44 registrado en la organización de normalización de materiales de Estados Unidos de América (American Society for Testing and Materials), al cual se le atribuyen ventajas relacionadas con su baja complejidad y gran rapidez en su ejecución, así como la eliminación de los pasos de evaporación inherentes a otros métodos que per-mite la detección de los hidrocarburos volátiles presentes.
No obstante, actualmente se le presta especial aten-ción a las ventajas que ofrece y el mejoramiento de los resultados que se obtiene cuando se aplica un trata-miento multivariante en contraposición con el clásico procedimiento de calibración univariada.45,46
Un análisis preliminar a espectros de mezclas de hidrocarburos del petróleo en agua muestra que existe en esos espectros mucha más información dispo-nible relacionadas con esas sustancias que la que puede ofrecer una sola longitud de onda (2 930 cm–1) de dichos espectros. La presencia de valores de intensidad signi-ficativos en el intervalo entre 2 975 y 2 840 cm–1 y entre los 3 080 y 3 010 cm–1 es una muestra de ello.
Tomando todos estos aspectos en consideración el objetivo de este caso de estudio fue el desarrollo de un método de calibración multivariante para la determina-ción cuantitativa de hidrocarburos del petróleo en agua y aguas de desecho utilizando espectroscopía infrarroja media (FT-MIR) y técnicas de calibración multivariante, para mejorar los resultados hasta ahora alcanzados con el método estándar univariado.
Breve resumen del método40
El método recoge la determinación de hidrocarburos de petróleo en agua y aguas de desecho en un intervalo
Fig. 6. (a) Delimitación de la regiones candidatas de presencia de ADN acorde con los histogramas a lo largo del eje X. (b) Determi-nación de las regiones de los patrones. (c) División en líneas. (d) Determinación de las subregiones de un LOCI. (e) Asignación del número de los alelos. (f) Construcción del perfil.
Tabla 4. Comparación de los resultados del sistema con respecto al proceso manual.
Perfiles extraídos Tiempo de respuesta
Muestras Por el experto Por el sistema Tarifa de éxito Manual Automatizada
200 2 004 1 999 97 % 20 d 15 min

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
11
entre 0,68 y 30 mg Hc/100 mL . Las muestras de agua son colectadas en conformidad con las regulaciones descritas en el documento de prácticas D337043, usando un envase de vidrio equipado con una tapa especial que contiene una cartulina de politetrafluoroetileno (PTFE) conocido comúnmente como teflón. Se requieren para el análisis 750 mL de muestra. Se debe preservar la muestra con (1 volumen de H2S04, densidad específica 1,68 + 1 volumen de agua) para garantizar un pH de 2 o menor. La muestra acidificada de agua es tratada de forma seriada tres veces con 30 mL de 1,1,2-trichloro-1, 2,2-trifluoroetano. El extracto es diluido a 100 mL y se le añaden 3 g de “Florisil” para remover las sustancias polares, con lo que se obtiene una disolución de hidro-carburo de petróleo después de un proceso de filtrado. Este extracto es entonces analizado a través de la espec-troscopia infrarroja.
Preparación del conjunto de calibraciónEl conjunto de muestras fue preparado utilizando
una mezcla estándar internacional (37,5 % isooctano, 37,5 % n-hexadecano y 25 % benceno). Las diluciones para la obtención de los distintos patrones de concen-tración se realizó con el disolvente: 1,1,2-tricloro-1,2,2 -trifluoroetano según la secuencia siguiente: Se colocan 20 mL del disolvente en un volumétrico de 100 mL, se tapa y pesa. A continuación, se añade 1 mL de la mezcla de calibración y se obtiene el peso exacto por diferencia. Se lleva el contenido hasta la marca del volumétrico con disolvente, se procede entonces a mezclar y agitar el frasco. Se calcula la concentración exacta del material de calibración en disolución en términos de mg/100 mL . Se preparan ocho patrones para construir el conjunto de calibración, todos dentro del rango de concentración entre 0,68 a 30 mg Hc/100 mL .
Preparación del conjunto de validaciónEl conjunto de validación fue confeccionado de forma
independiente para la evaluación del funcionamiento del método de calibración multivariante usando el sistema de muestras de aguas con un contenido de hidrocarburo conocido, por su nombre en inglés como spiked water samples. Una muestra de agua tipo reactivo (agua reactivo tipo II acorde con la norma ASTM D1193-00)47 es tratada con N1 199-09 diesel a diferentes niveles de concentración (mg/L): dos réplicas a (5;37; 10,44; 15,82; 25,03; 31,41) y cinco réplicas a (20,61). La extracción del hidrocarburo añadido fue realizada usando el mismo procedimiento utilizado para las muestras del conjunto de calibración.
Adquisición de los espectrosLos espectros infrarrojos fueron obtenidos en un
espectrofotómetro Jasco 4 100 A en el modo de absor-
bancia utilizando una celda de cuarzo con un paso de longitud de 1,0 cm. Los espectros fueron tomados en un intervalo entre los 3 200 – 2 700 cm–1 a una resolución de 4 cm–1 a un promedio de 100 corridas. Para el conjunto de calibración el disolvente fue incluido en la medida del background. En el caso del conjunto de validación, un blanco preparado con el agua reactivo incluyendo todos los demás reactivos y en el mismo envase que el utilizado para las muestras es el que se incluye en la medida del background. Los datos procedentes de las diferentes mediciones fueron importados hacia Quimio-metrix a través de su módulo de edición de datos para comenzar la aplicación de la técnicas quimiométricas para su procesamiento.
Técnicas quimiométricasPrevio al trabajo de calibración multivariada, a partir
de la visualización de los datos originales, se pudo advertir la necesidad de realizar una corrección de línea base por simple sustracción, ya que algunos espectros se veían desplazados por debajo de la línea base (Fig. 7). De igual manera, se ordenaron los espectros en forma descendente de su número de onda para una mejor comprensión.
Como preprocesamiento se realizó un centrado por la media tanto para las mediciones de las variables in-dependientes como de la variable dependiente. De tra-bajos anteriores realizados con el método de calibración univariado, se conocía que la relación de los datos era lineal, por lo que se seleccionó para el trabajo, el método de calibración multivariado lineal (MCML) basado en los mínimos cuadrados parciales (conocido por sus siglas en inglés como PLS). La selección del número óptimo de variables se realizó a través de una validación cruzada iterativa de extracción de una muestra (conocida en inglés como leave one out). Fue revisada la presencia además, de datos anómalos.
A modo de evaluación de la efectividad del modelo de calibración construido, fueron examinados cuatro indicadores obtenidos como respuesta del conjunto de validación: Raíz cuadrada del error medio en predicción (conocido
por su sigla en inglés RMSEP Root medium square error), definido como:
Fig. 7. Espectros infrarrojos del conjunto de calibración antes (a) y después (b) de la corrección de la línea base.
donde:n número de muestras del conjunto de validación. Promedio de recobrado (PR, expresada en %).
( )2. .
1
n
obs cali
Y YRMSEP
n=
−=∑
(a)(b)

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
12
Desviación estándar (DE). La desviación estándar relativa (DER, expresada en %).
Con el propósito de poder comparar los resultados, un modelo de calibración univariada fue desarrollado de forma paralela al modelo multivariado propuesto. Los resultados obtenidos durante el proceso de validación con los métodos univariado y multivariado (en este caso PLS) fueron resumidos en forma comparativa (Tabla 5).
Los resultados demuestran que el método multiva-riante mejora los resultados alcanzados por el univariado estándar; este comportamiento corrobora una vez más el análisis realizado en las fuentes bibliográficas acerca de las ventajas que se atribuyen a los métodos multivariados sobre los univariados.
De igual manera, en la (Fig. 8) se muestra la contribución de cada variable a través del valor de sus pesos con respecto a la primera variable latente, que contiene el 99,84 % de la infor-mación en el modelo multivariado PLS. Las variables en el intervalo entre 2 940 a 2 915 cm–1 con un máximo definido a 2 930 cm–1 exhiben los mayores pesos asociados, pero otras variables, como por ejemplo las que se encuentran en los intervalos entre 2 975 a 2 950 cm–1, 2 870 a 2 840 cm–1 y 3 080 a 3 010 cm–1 también exhiben valores importantes en sus pesos y como consecuencia ofrecen una impor-tante contribución al modelo. Estos resultados están en correspondencia también y explican la superioridad de la propuesta multivariante con respecto a lo que ofrece el método estándar univariado.
El cumplimiento de los indicadores de control de la calidad es, sin lugar a dudas, una medida demostrativa de la eficacia del método de calibración en cuestión; por eso una evaluación en términos de ellos es imprescin-dible. Tanto los resultados del método univariado como del método multivariado propuesto cumplen con las especificaciones de calidad establecidas por los están-dares internacionales (índices promedios de recobrado sobre el 83 % para niveles de concentración de 20 mg/L y valores de DER menores del 5 %), sin embargo, el mé-todo PLS propuesto exhibe índices por encima del 90 % y valores de DER del 1 %, además de disminuir casi el doble el error de predicción (RMSEP), lo cual constituye una demostración de la eficacia del método propuesto.
Caso de estudio III. Clasificación de combustibles derivados del petróleo por espectroscopia FT-MIR
La determinación del tipo de combustible, es una tarea a la que se enfrentan especialistas en diversos sectores del país, entre ellos, la industria del petróleo y
Tabla 5. Resumen comparativo de los resultados obtenidos por los dos métodos.
Método
HC añadido
(mg/L)
Réplicas HC
calculado
Valor Promedio
(mg/L)
DE
(mg/L)
DER (%)
Promedio de recobrado
(%)
RMSEP
Univariado
5,37 2 2,85 0,07 2,5 53,010,44 2 7,5 0,28 3,8 71,815,82 2 12,85 0,21 1,6 81,2320,61 5 17,96 0,25 1,39 87,14 2,9525,03 2 21,91 0,21 0,97 87,7031,41 2 27,2 1,13 4,16 86,60
PLS LV = 1
5,37 2 5,26 0,07 1,35 97,9510,44 2 9,82 0,31 3,13 94,0615,82 2 15,11 0,24 1,59 95,51 1,0520,61 5 19,83 0,20 1,00 96,2125,03 2 24,02 0,21 0,88 95,2631,41 2 29,15 1,13 3,86 92,80
Fig. 8. Coeficientes de los pesos en la primera variable latente en función del número de onda.
el frente forense-criminalista. El reto actual radica en cómo lograr una identificación rápida y certera de la mayor cantidad de combustibles posibles con métodos de análisis sencillos y la ayuda de técnicas quimiomé-tricas para el procesamiento de los datos multivariados.
Varios métodos abordan este tema. Los ensayos físico químicos oficialmente establecidos como proce-dimientos de referencia por diferentes organizaciones internacionales, como por ejemplo: la American Society for Testing Materials (ASTM), la Internacional Standard Organization (ISO) y el Institute of Petroleum (IP) son muy utilizados para estos fines. Se debe destacar que las propiedades físico químicas determinadas a través de los métodos de referencia emplean un tiempo de me-dición considerable y requieren de apreciable cantidad de muestra; además, cuando los productos presentan pequeñas diferencias o anomalías en su composición química, estas no son fácilmente detectables a través de ellas. De forma alternativa, la cromatografía de gases y la espectroscopia ultravioleta, también han sido utilizadas en los últimos años. A pesar de su reconocida sensibi-lidad y exactitud, la cromatografía gaseosa presenta desventajas relacionadas con el tiempo de preparación y ejecución de los análisis, por otra parte, la espectros-copia ultravioleta si bien es rápida y sencilla, no brinda toda la información espectral necesaria para poder lograr una diferenciación entre destilados medios del petróleo, así como entre las gasolinas especial y regular.48,49
Peso
s LV
1 (9
9,84
%)
Número de onda (cm–1)

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
13
El uso de la espectroscopia infrarroja tanto media como cercana combinadas con la utilización de técnicas quimiométricas, se ha impuesto en los últimos años por su sencillez, rapidez y poder discriminativo de una amplio espectro de tipos de derivados del petróleo.50-54 Entre los clasificadores más utilizados se encuentran los métodos SIMCA, PLS-DA y la novedosa incorporación de las máquinas de soporte vectorial para clasificación.55,27,25
Tomando en consideración lo antes expuesto, el objeti-vo de este caso de estudio estuvo dirigido a la obtención de un método de clasificación supervisada para la identifica-ción de seis tipos de combustibles derivados del petróleo a partir del empleo de la espectroscopia en el infrarrojo medio (FT-MIR) y el empleo de técnicas quimiométricas para el procesamiento multivariado de los datos.
Preparación de los conjuntos de calibración, y valida-ción. Técnicas quimiométricas empleadas
Para el caso de estudio, se cuenta con datos de entre-namiento de 64 muestras. Dichas muestras son repre-sentativas de seis tipos de combustibles destilados del petróleo provenientes de la Refinería de Petróleo “Ñico López” en Ciudad de La Habana: gasolina regular GR (1), gasolina especial GE (2), diesel regular DR (3), nafta N (4), turbo combustible TC (5) y keroseno HK (6), el nú-mero entre paréntesis notifica el número de asignación de la clase patrón.
El conjunto de validación está compuesto por un total de dieciséis muestras representativas de las mismas seis clases de patrones seleccionadas.
La adquisición de los espectros fue hecha con un espectrofotómetro infrarrojo medio con transformada de Fourier (FT-MIR); en transmitancia, en un intervalo de 4 000 a 600 cm-1 y una resolución de 4 cm-1. Se empleó el aditamento de reflectancia total atenuada (RTA), marca PIKE con cristal de diamante KRS5.
Todas las muestras fueron sometidas a las transfor-maciones: correcciones de ATR y de línea base, alisa-miento y eliminación del CO2 con el software propietario del equipo Spectra Manager Versión 2 (Fig. 9a). Ante la persistencia de la presencia de un efecto offset, se aplicó la corrección MSC (del inglés Multi Scatering Correction) con el software Quimiometrix (Fig. 9 b). Se aplicó como preprocesamiento el centrado por la media para lograr un adecuado análisis exploratorio por PCA.
El análisis exploratorio PCA reveló que toda la infor-mación correspondiente a las variables analizadas, puede
Fig. 9. Espectros de los datos de entrenamiento. (a) Antes de realizarle ninguna transformación, obsérvese el corrimiento del Offset. (b) Después de realizarle los preprocesamientos y transformaciones, obsérvese la corrección del offset.
ser agrupada en solo siete nuevas variables (factores) con un 95,55 % de varianza acumulativa. Con vistas a mejorar aún más la modelación a partir de la elimina-ción de información redundante, se procedió a estudiar la posibilidad de una reducción de variables mediante el análisis del poder de modelación y de discriminación de cada una de las variables originales, posibilidad que ofrece Quimiometrix en el análisis exploratorio PCA como se mostró en el caso de estudio I. Fueron elimina-das por su bajo poder de modelación y discriminación las variables entre los 4 000 y 3 200 cm–1 y desde los 2 700 hasta los 1 900 cm–1.
En la figura 10 se pueden observar las muestras repre-sentadas en las dos primeras componentes principales (scores), en las cuales se acumula el mayor porcentaje de varianza de las variables originales.
Se pudo comprobar con claridad que el factor 1 está íntimamente relacionado con el tipo de combustible (Fig. 10). Se observó una discriminación en función de su peso, hacia la derecha los más ligeros y hacia la izquierda los más pesados. Sin embargo, la marcada similaridad entre los kerosenos y turbocombustibles no permite su discriminación por parte de las dos primeras componentes, es precisamente el factor 3 el que ostenta la información discriminante.
El análisis exploratorio por PCA realizado indica la factibilidad de la utilización de la espectroscopia infra-rroja para extraer la información requerida con vistas a lograr una posible clasificación de este tipo de com-puesto y con ello la predicción automática de muestras desconocidas de combustibles del petróleo en función de su tipicidad. Terminado el análisis exploratorio de los datos, están las condiciones creadas para proceder a crear y entrenar diferentes modelos de clasificación, con el objetivo de encontrar aquel que mejor se comporte ante la tarea en cuestión. Se evaluaron tres clasificadores SIMCA, PLS-DA y SVC y se comparó su comportamiento en función de los errores de clasificación cometidos por cada uno de ellos durante el proceso de validación de los modelos (Fig. 11).
Los resultados muestran que los clasificadores SVC y SIMCA fueron los de mejores resultados al no presentar errores de clasificación, el PLS-DA no logra discriminar adecuadamente las muestras de kerosenos y turbocombustibles. Aunque ambos clasificadores dan buenos resultados, las ventajas que se atribuyen a las SVM relacionadas con: bajo costo computacional en la

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
14
Fig. 10. Análisis por PCA realizado al conjunto de entrenamiento. Gráfico de los “Scores” en función de las componentes princi-pales (Factores 1 y 2).
Fig. 11. Resultado del proceso de validación de los modelos de clasificación.
validación al estar sustentado el entrenamiento solo sobre parte de las muestras (vectores de soporte), su robustez ante el sobreentrenamiento, su capacidad de resolver casos no linealmente separables y su indepen-dencia de la dimensionalidad del sistema hacen que la selección del modelo SVC resulte la más indicada.
CONCLUSIONES
Se pone de manifiesto a través del los casos de estudio presentados en este artículo, cómo el empleo de las técnicas quimiométricas automatizadas para procesamiento multivariado de datos mejoran y am-plían la capacidad de respuesta de los investigadores en diversas formas entre ellas: capacidad de mayor procesamiento y extracción de información útil de los datos; posibilidad de fácil acople con rápidas y moder-nas técnicas de análisis instrumental generadoras de datos de interés; mayor rapidez en la obtención de los resultados sin disminuir su veracidad y exactitud y en muchos casos mejoran; capacidad de predicción para
la identificación de sustancias desconocidas a partir de modelos de reconocimiento de patrones obtenido del análisis químico de sustancias similares; capacidad de predicción cuantitativa de propiedades químico físicas de sustancias a partir de los datos provenientes de su análisis químico instrumental, entre otras.
Contar con un software autóctono que integre una gran parte de aquellas con funcionalidades de visua-lización y graficación es incuestionablemente una ventaja para investigadores, especialistas y técnicos cubanos relacionados con esta rama del saber, sin desestimar por supuesto otros de factura internacional a los cuales se pudiese acceder libremente. Algunas de las funcionalidades del software nacional Qui-miometrix se han presentado en este artículo como parte de su aplicación en la solución de problemas concretos y que han sido el fruto del trabajo conjunto entre desarrolladores e investigadores para lograr la introducción en la práctica social de un producto de beneficio nacional.
Gráfico de puntos para scores
SVC

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp. 3-16, enero-abril, 2011.
15
REFERENCIAS BIBLIOGRÁFICAS 1. Massart DL, Vandeginste BGM, Buydens LMC, Jong SD,
Lewi PJ, Smeyers-Verbeke J. Handbook of Chemometrics and Qualimetrics: Part A. Data Handling in Science and Technology (20B). Amsterdam: Elsevier Science: 1997.
2. Ramis Ramos G, Garcia Alvarez-Coque MC. Quimiometría. España: Ed Síntesis S.A.: 2001.
3. Talavera I, Rodríguez JL. Estado del Arte del Reconoci-miento de Patrones en la Quimiometría. RT_002, Serie Azul. Reconocimiento de Patrones. Versión digital. RNPS_ 2142 ISSN 2072-6287. CENATAV [Consultada: 1ro de agosto de 2010]. Disponible en: http://www.cenatav.co.cu/doc/RTecni-cos/RT%20SerieAzul_002web.pdf
4. Infometrix Inc. The Premier Chemometrics Company. [Consultada: 1ro de agosto de 2010]. Disponible en: http://www.infometrix.com
5. The Unscramber. All-in-one Multivariate Data Analisisand Designe of experiments package. [consultada: 1ro de agosto de 2010] Diponible en: http://www.camo.com
6. Eigenvector Research Incorporated. Powerful Resources for Intelligent data analysis. [Consultada: 1ro de agosto de 2010]. Disponible en: http://www.eigenvector.com
7. Talavera I, Hernández N, Núñez O, Porro D, Bustio L, Larín R, Bermúdez M. QUIMIOMETRIX. Sistema de herramien-tas quimiométricas para el preprocesamiento, clasificación y predicción de datas químicas espectrales. Conferencia Internacional FIE’08, [CD ROM] Santiago de Cuba. 14-16 de julio de 2008.
8. Núñez O, Porro D, Talavera I, Bustio L, Hernández N, Larín R. Nuevo sistema automatizado para el análisis de datos químicos y bioquímicos. Memorias de la Convencion de Salud e Informática 2009. [CD-ROM] Ciudad de La Habana 9-13 de febrero 2009.
9. Esbensen KH. Multivariate Data Analysis - In Practice. 5th edition. Alborg University, Esbjerg; August 2002.
10. Ferreira, M. Curso de Quimiometría. [consultada: 1ro de agosto de 2010] Diponible en: http://www.cenatav.co.cu.
11. Pirouette user Guide. Multivariate Data Analysis. Version 3.11 Infometrix Inc. [Consultada: 1ro de agosto de 2010] Diponible en: http://www.infometrix.com.
12. Manual de ayuda Quimiometrix. [consultada: 1ro de agosto de 2010] Diponible en: http://www.cenatav.co.cu.
13. Savitzky A, Golay E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36:1627-1639 .
14. Gorry A. General Least-Squares Smoothing and Differen-tiation by the Convolution (Savitzky-Golay) Method Anal Chem. 1990;62:570-573.
15. Isaksson T, Naes T. The effect of multiplicative scatter co-rrection (MSC) and linear improvement in NIR spectroscopy Applied Spectroscopy 1988, 42:1273.
16. Kortum G. Reflectance Spectroscopy, NY: Springer: 1969. 17. Hotteling, H. Analysis of a Complex Statistical Variables
into Principal Components, J Edu Psychol. 1933;24:417-424, 498-520.
18. Jackson JE. A User’s Guide to Principal Components. New York: J. Wiley & Sons: 1991.
19. Wold S, Sjöström M. Chemometrics: Theory and Appli-cation. B.R. Kowalski (Ed) ACS Symposium Series. 1977; 52:243-282 .
20. Mardia KV, Kent JT, Bibby JM. Multivariate Analysis. Aca-demic Press, London, 1980.
21. Hartigan JA. Clustering Algorithms. New York: J. Wiley & Sons: 1975.
22. Massart DL, Kaufman L. Interpretation of Analytical Che-mical Data By the Use of Cluster Analysis. New York: Wiley: 1983.
23. Derde MP, Massart DL. Supervised Pattern Recognition: The Ideal method. Anal Chim Acta. 1986;191:1-16.
24. Kowalski BR, Bender CF. The K-Nearest Neighbor Classifi-cation Rule (Pattern Recognition). Anal. Chim. Acta. 1972, 44:1405-1411.
25. Wold S, Sjöström M. SIMCA: A Method for Analying Che-mical Data in Terms of Similarity and Analogy. Research Group for Chemometrics, Institute of Chemistry, Umea University, 1977
26. Vapnik V. The nature of Statistical Learning Theory. Sprin-ger Verlag, New York, 1995.
27. Chen N, Wencong L, Jie Y, Gozheng L. Support Vector Ma-chines in Chemistry. World Scientific, 2004.
28. Martens H, Naes T. Multivariate Calibration. New York: Wiley: 1989.
29. Wold S, Sjöström M, Eriksson L. PLS-regression: a basic tool of chemometrics. Chemometrics Intell Lab Syst. 2001;58: 109-130.
30. Wold S, Trygg J, Berglum A, Antii H. Some recent deve-lopment in PLS modelling. Chemometrics Intell Lab Syst. 2001;58:131-150.
31. Haaland D, Thomas E. Partial Least-Squares methods for spectral analyses. Relation to other quantitative calibration methods and the extraction of qualitative information. Anal Chem. 1988;60(11):1193-1202.
32. Brereton R. Chemometrics: Data Analysis for the Laboratory and Chemical Plant. Wiley & Sons: 2003.
33. Silva F, Talavera I, González IR, Hernández N, Palau J, Santiesteban M. Automatic Extraction of DNA profiles in Polyacrilamide gel electrophoresis images. LNCS 3773, 2005:242-251.
34. Talavera I, Silva F, González R, Hernández N, Palau J, Castro MM. Application of Chemometrics tools for automatic clas-sification and profile extraction of DNA samples in forensic tasks. Anal Chim Acta. 2007;595:43-50.
35. Gill P, Urquhart A, Millican E, Oldroyd N, Watson S. Sparkers. Criminal Intelligence Databases and interpre-tation of STRs. Advances in Forensic Haemogenetics. 1996;6:235-42.
36. Lander ES. DNA fingerprinting: The NRC report. Science. 1993;259(5096):755-6.
37. Lewontin RC, Hartl DL. Population genetics in forensic DNA typing, Science. 1991;254:1745-1750.
38. Entrala C. Techniques for DNA analysis in forensic genetics. Disponible en: http//:www.ugr.es/~eianez,biotecnología/forensetec.htm#1. 2001.
39. Garea E, Silva FJ, Talavera I, Hernández N, González R. Improvement deoxyribo nucleic acid spots clasification in polyacrilamide gel images using photometric normalization algoritms. Anal Chim Acta. 2007;595:145-151.
40. Ruiz MD, Talavera I, Dago A, Hernández N, Núñez AC, Porro D. A multivariate calibration approach for determination of petroleum hydrocarbons in water by means of IR spectrocopy. In process of publication in Journal of Chemometrics. Published online in Wiley InterScience 2010. (www.interscience.wiley.com) DOI: 10.1002/cem.1284.
41. APHA Standard Methods for the Examination of Water and Waste Water 21st editions, Ed. APHA, 2005.
42. US Environmental Protection Agency Method 1664, Revi-sion A. n-hexane extractable material (HEM; oil and grease) and silica gel treated n-hexane extractable material by extraction and gravimetry. EPA-821-R-98-002; 40 CFR Part 136 (July 1, 2000), Federal Register 1998, 64(93): 26315. U.S. Environmental Protection Agency, Washington.
43. ISO93772/2000: Water Quality-Determination of Hydrocar-bon Oil Index, 2000.
44. ASTM D3921-03, Standard Test Method for Oil and Grease and Petroleum.
45. Bro R. Multivariate calibration: what is in chemometrics for the analytical chemist? Anal Chim Acta. 2003;500:185-194.
46. Hopke PK. The evolution of chemometrics. Anal Chim Acta. 2003;500:365-377.
47. ASTM D1193-00 Specification for Reagent Water. 48. Brudzewski K, Kesik A, Kolodziejczyk K, Zborowska U,
Ulaczyk J. Gasoline quality prediction using gas chroma-tography and FT-IR spectroscopy: An artificial intelligence approach. Fuel. 2006;85(4):553-558.
49. Flumignan DL, Tininis AG, Ferreira FO, de Oliveira JE. Screening brazilian C gasoline quality: Application of the SIMCA chemometric method to gas chromatographic data. Anal Chim Acta. 2007;595(1-2):128-135.
50. Hidajat K, Chong SM. Quality characterization of crude oils by partial least squares calibration of NIR spectral profile. J of Near Infrared Spect. 2000;8(1):53.

Revista CENIC Ciencias Químicas, Vol. 42, No. 1, pp.3-16, enero-abril, 2011.
16
51. Reboucas M V, Barros N. Near infrared spectroscopic pre-diction of physical properties of aromatic-rich hydrocarbon mixtures. J of Near Infrared Spect. 2001;9:263.
52. Caneca AR, Fernada PM, Kawakami HRG, Da Matta CE, Rodrigues de CF, et al. Assessment of infrared spectros-copy and multivariate techniques for monitoring the ser-vice condition of diesel-engine lubricanting oils. Talanta. 2006;70(2):344-52.
53. Pasadakis N, Kardamakis AA. Identifying constituents in commercial gasoline using Fourier transform-infrared
spectroscopy and independent component analysis. Anal Chim Acta 2006;578(2):250-255.
54. Balabin RM, Safieva RZ, Lomakina EI. Comparison of linear and nonlinear calibration models based on near infrared (NIR) spectroscopy data for gasoline properties prediction. Chem and Int Lab Syst. 2007;88:183-188.
55. Barker M, Rayens W. Partial squares for discrimination. J. Chemometrics 2003;17(3):166-173.





























