Embed Size (px)
Citation preview

データ解析
渡辺澄夫
第1回 モデルは真ではない

1 科目履修上の注意

この科目を履修するために必要な科目
「データ解析 MCS.T332」を履修するには
「確率論基礎 MCS.T212」「数理統計学 MCS.T223」
の両方の単位を取得していることが必要です。

この科目を履修するために必要な前提知識 1
必須 集合と位相 線形代数 微分積分 確率論 数理統計学
自己チェック
○ ある集合に位相を定めるとは何をすることですか。○ 行列の固有値を求めるアルゴリズムを述べてください。○ 積分の変数変換でヤコービ行列式がなぜ必要ですか。○ 確率変数の定義を述べ、その意味を説明してください。○ 尤度関数の定義を述べ、具体例をあげてください。
学部3年生以上の学力が必要になります。

この科目を履修するために必要な計算機技術 2
必須 計算機プログラムを使って確率系のシミュレーションを行えること。また、それが嫌いでないこと
言語例 C, java, R, Python, matlab, Julia, …
自己チェック
N(x|a,σ2) を平均が a で分散が σ2 の正規分布の確率密度関数を表すものとする。確率密度関数
p(x) = (1/3) N(x|0,12) + (2/3) N(x|1,22)
に従う確率変数を発生するプログラムを作れ。

履修しようかどうか 検討中のみなさまに
実社会には 次の意見がたくさんあります。
「データ解析は 数学なしで 簡単にできます」
しかしながら、この講義では 数学を学んで初めてできるデータ解析を学びます。
☆ この講義は必修科目ではありません。☆ 数理・計算科学系で開講されています。☆ 「〇〇のためのデータ解析」 については
他にたくさんの講義があります。
この講義があなたが求めているものかどうかご確認ください。

2 データと人間

データと人間
データ
データと人間がある。
コンピュータやネットワークの発展のおかげで膨大なデータが得られるようになった。
人間は、何を目標にして何を行なうのだろうか。
人間さん
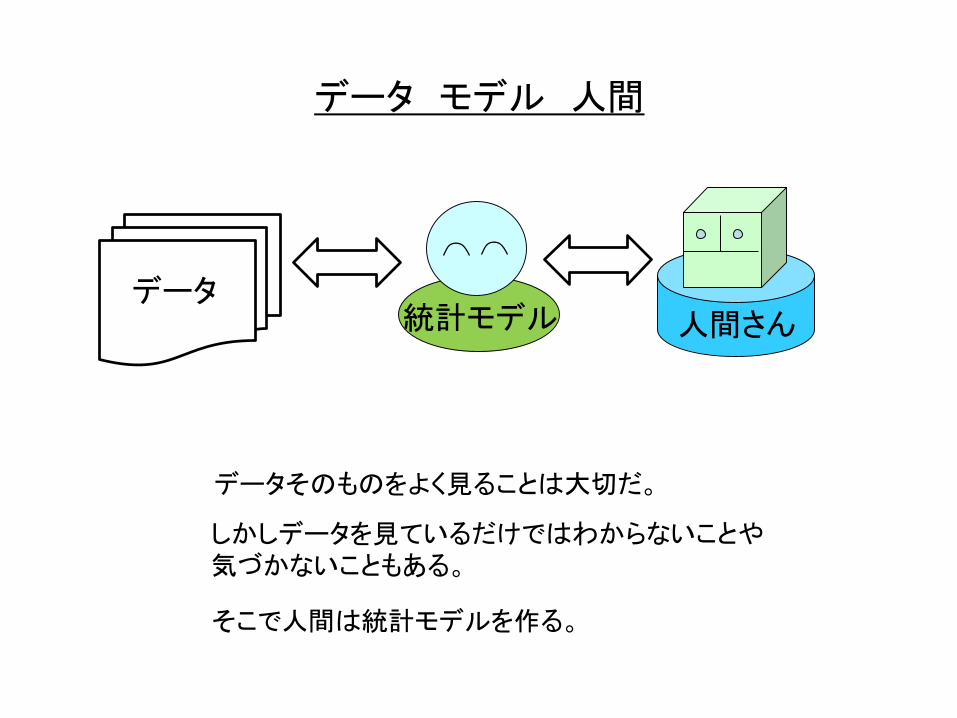
データ モデル 人間
データ
データそのものをよく見ることは大切だ。
統計モデル 人間さん
しかしデータを見ているだけではわからないことや気づかないこともある。
そこで人間は統計モデルを作る。

データ解析とは何ですか
実世界 データ
統計モデルは実世界を知るために作られる。人間は実世界を直接に知ることはできないので、データとモデルを通して実世界を推測する。
統計モデルは 実世界 ではない。
実世界とは異なる統計モデルを用いて実世界をどのくらい知ることができるかが問題だ。
統計モデル
推測

最後の敵は「実世界」
真の分布 q(x)
確率変数
実世界(=情報源)が未知の確率分布 q(x) である場合を考えよう。人間は統計モデルを設定しデータを経由して情報源を推測する。モデルは実世界ではない。モデルにより推測された結果 p(x) はどの程度に q(x) を正しく推定しているのだろうか。この問題は数学的な普遍性を持っており、数学の対象になる。
統計モデル
誤差
推測 p(x)
ラスボスです
モデルを作る=勇者
不明なものとの誤差が計算できるのか?
情報源

真の目標は何か
確率変数 X
データ解析 の真の目標は 未知の確率分布を推測すること である。
注意。たまたま得られたデータについて何かをすることに意味はない。○ プログラムをどのように作るかは真の目標ではない。○ 計算量を減らすことは真の目標ではない。○ 尤度を最大にすると返って真の目標から遠ざかる。
確率論では、確率空間を設定した上で確率変数の挙動を導出する。統計学では、確率変数の挙動から確率分布を推測する。完全には到達できない真の目標に どこまで迫れるかを問う。
最後まで
決して諦めない者
未知の確率分布
統計的推測

3 この講義で学ぶこと

この講義で学ぶこと
1.回帰・判別分析
2.因子・主成分・クラスタ分析
3.時系列予測
4.ベイズ法・階層ベイズ法
5.統計的検定
6.モデルの評価法
7.深層学習
8.実世界
か弱い人間が苛酷な実世界を生き抜くために考え出した方法です。最近はパワーアップして機械学習に進化し産業や社会のありかたを変えるとまで言われています。
六連銭は 勇気の印

15
人工知能と呼ばれてます
Y=f(X)+N…
X1, X2, …, Xn
Y1, Y2, …, Yn
回帰・判別分析 = 教師あり学習
確率変数 (X,Y) のデータが得られたとき、XからYへの条件つき確率を推測する方法が回帰分析・判別分析である。認識・予測など応用が広い。簡単な問題なら線形回帰で解けることも多い。近年、脚光を浴びている深層学習やサポートベクタマシンは、この道の先にある。

16
因子・主成分・クラスタ分析 = 教師なし学習
確率変数 X のデータが得られたとき、(Xに対するラベルYが与えられていなくても)、X の構造や潜在変数を取り出す方法が因子分析・主成分分析・クラスタ分析である。
構造や潜在変数を取り出す数理的な技法だけでなく、得られた構造や潜在変数が何を意味するかを考察する力量が必要になる。データサイエンティストへの第一歩。
データ 構造

月
値段
値段
学習データ赤:真青:学習結果
例:1970年1月から2013年12月までの白菜の値段「政府統計の総合窓口」のデータを使用しています。http://www.e-stat.go.jp/SG1/estat/eStatTopPortal.do
テストデータ赤:真青:予測
時系列予測
月
過去の時系列から未来を予測する。回帰分析とよく似ているが X が時間とともに変動する点が異なる。経済・金融などの実業は多すぎるほどある。人間トレーダーは機械学習に及ばなくなっている。
18
統計モデルp(x|w)事前分布
φ(w|a)
ベイズ法・階層ベイズ法
データ xパラメータ w
果物の特徴 x の確率分布を定めるパラメータ w は、果物が取れる地域により似ている点と異なる点がある。事前分布も含めてモデル化し推測しよう。現実のデータ解析で頻繁に現れる構造である。
長野県
青森県
台湾
フィリピン

19
統計的検定
これまでわが社の将棋ソフトは名人との対局で勝率が4割だった。このたび、わが精鋭チームが神経回路網を100億回自己対戦させ強化学習したところ、ついに名人との対戦で3勝2敗になった。わが社のソフトは本当に強くなったのだろうか。
真の確率分布がわかることのない実世界から得られたデータに対して、弱い人間はデータの解析を行なって何らかの推測を行なうがその推測はどの程度に正しいのだろうか。統計的検定では、実世界に対して仮説を作りデータの説明可能性を数量的に調べる。獲得した推論の正しさを数学的に吟味することは今日の機械学習でもっともおろそかにされているところであるが・・・。

統計モデルの評価法
データ(n=500) 多項式11次まで
真の確率分布がわかることのない実世界から得られたデータに対して、弱い人間は複数のモデルの候補を作り、複数の推測を行なうことができる。その中に実世界とぴったりと一致するモデルは存在しないが、最も適切なモデルはどれだろうか。そこで「適切さ」とは何に対する適切さだろうか。データ解析が「ただやってみただけ」とは違う客観性を持つにはどうしたらよいのか。数理科学によってもたらされた光である情報量規準を学ぼう。

現代から未来へ
今日ではデータの次元も個数も大きくなり、統計モデルも高度化しています。「機械学習」と呼ばれる分野では極めて大きな複雑さを持つモデルが使われます。この講義では、昔からあるデータ解析の方法が今日では機械学習による複雑なモデルに変化しつつある様子についても紹介します。
1960 1985 2015 2040

推定と検定
実世界
ベイズ法・階層ベイズ法
解析方法
時系列予測
回帰・判別分析評価法
因子・主成分・クラスタ分析
観測データ
統計的検定
旅の地図

4 確率論の準備

24
確率空間
2年生のとき確率論で 確率空間 を習いました。
確率空間 (Ω, B, Q) は次の三組からなる。
Ω:集合B: 「Ωの部分集合で確率が定義できるもの(※)」の集合族Q: B から区間 [0,1] への関数
具体的には次のものを考えることが多い。Ω: 可算集合、RN、C[0,1]、完備可分な距離空間B: Ωの開集合を含む最小の完全加法族
(※)公理「実数の任意の部分集合の確率を定めることができる」は選択公理と両立しないので、選択公理と矛盾せずに確率が定義できる部分集合の族をあらかじめ定めておく必要がある。

25
測度空間
測度論は数学基礎論として決して容易ではありません。
この講義では深刻に考えすぎないようにすること。
この講義では非可測集合などの話は出てきません。
統計学や機械学習の理論の論文は、確率論の概念を用いて記述されていることから、確率論とほぼ同じである測度論を学びたくなる人が多いと思います。関数解析、微分方程式、確率微分方程式、関数空間上の中心極限定理、作用素環論、など極めて広大な領域で測度論は必要になりますので、ぜひとも学生のときに学んでおくとよいでしょう。 しかしながら ・・・

26
確率変数
確率空間 (Ω, B, Q) から可測空間(たとえばRN) への可測関
数 X を確率変数という。X=X(ω)と書く。
確率空間 (Ω, B, Q) RN
Xω X(ω)
関数のことを確率変数と呼ぶ理由:Xの出力だけが観測できる人から見ると、ランダムに値を取るものと見分けがつかない。ランダムとは何かを定義せずにランダムでないとは言えないものが定義できた。

27
確率変数の確率分布
RN の部分集合 A に対して 「X∈A」 となる確率を P(A) とかきP を X の確率分布という。P(A)=Q(X-1(A)) が成り立つ。
確率空間 (Ω, B, Q) RN
AX
注意:これ以後、RNだけが舞台となるので基礎となる確率空間は証明で必要にならない限り忘れてよいが明記されなくても確率空間は常に存在が仮定されている。
X-1(A)

28
確率密度関数
表記の注意. 確率変数 X の確率密度関数を p(x) と書き、確率変数 Y の確率密度関数を p(y) と書くことがある。普通は p(x) と p(y) はまったく関係のない関数である。
確率変数 X の確率分布を P とする。RN の可測集合 A に対して
となるとき、 p(x) を X の確率密度関数という。
P(A)= ∫A p(x) dx
RN の中でランダムに値をとるように見える変数 X が集合 A に入る確率が p(x) の積分で書けるということ。
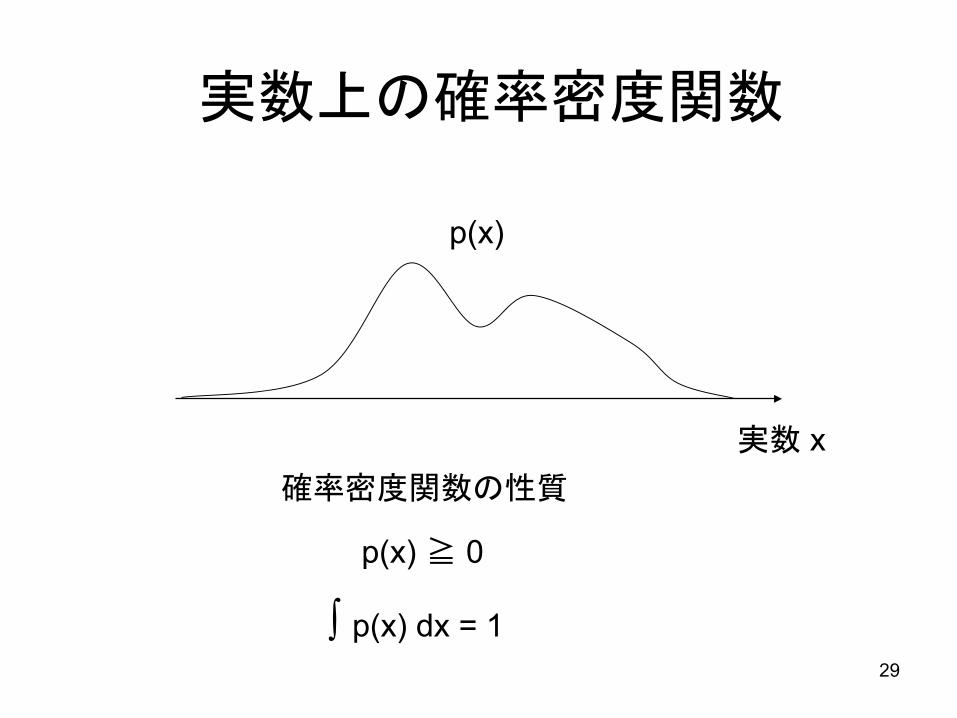
29
実数上の確率密度関数
実数 x
p(x)
確率密度関数の性質
p(x) ≧ 0
∫ p(x) dx = 1

確率密度関数の例
実数 x
p(x) = exp( - )1
2π
x2
2
p(x)
O
正規分布

31
準備 集合の確率
実数 x
p(x)
「A の確率」
集合Aの確率
A
A= ∫ p(x) dx

32
ユークリッド空間上の確率変数
x
y
p(x,y)
O
多変数になるだけで同じ
p(x,y)

33
超関数
R に値を取る確率変数 X が 常に X=0 となるとき、その確率密度関数に
相当するものを δ(x) と表記する。これは普通の関数ではないが、例えば
コンパクトサポートで無限回微分できる R 上の任意の複素数値関数 φ から C への線形写像 D で D(φ) = φ(0) を満たすものとして定義できる。この
とき
D(φ) = ∫ δ(x) φ(x) dx
のように表記する(右辺を左辺で定義した)。この積分の記号 ∫ dx は記号
にすぎずルベール積分ではない(従って、ルベーグの収束定理、フビニの
定理などの対象にならない)が、数学的に扱うための方法が確立されてい
る(超関数論:ものすごく強力)。この講義では、その結果を利用する。

5 統計学の準備

統計的推測とは
未知である真の分布から データが得られたとき
ある定められた手続き により データから真の分布を
推測することを 統計的推測 といいます。

統計的推測の方法は無限にある
ある定められた手続き の候補は無限にあります。
例. 最尤法,MAP法,ベイズ法,名もなき方法,
私だけの方法,あなただけの方法,・・・。
どの方法を使うこともできますが
どの方法を使っても 推測結果は 間違っています。
できるだけ推測が当たるためにはどうしたよいのでしょう。

統計学に「主義」はいらない
統計的推測を行うとき 「正しい主義」 はありません。
【主義】 が心配な人は下記のページをご覧ください。
http://watanabe-www.math.dis.titech.ac.jp/users/swatanab/bayes000.pdf
推測の正しさは 数学の法則で 知ることができます。

6 深層学習の準備

ニューロンの応答関数
ニューロン
u
σ(u) = 1/(1+e-u) : シグモイド関数
u
σ( u )1
0
1/2
(注意)この形の関数に数学的な意味があるかどうかはわかっていない。最近ではReLu関数なども。

神経素子
x1 x2 x3 xM
w1 w2 w3wM
∑ wi xiM
i=1
σ( ∑ wi xi + θ) : 出力M
i=1
神経素子(ニューロン)
シナプス結合荷重
バイアスθ
1個の Neuron のモデル
(x1,…,xM) : 外界からの入力(w1,…wM, θ):パラメータ

深層学習のネットワーク
パラメータ wij, wjk, wkm , θk , θj , θi を学習により最適化する
x1 xm xM
o1 oi oN
oj
ok
H2
H1
N
M
oj=σ(∑wjkok+θj)H1
k=1
oi =σ(∑wijoj+θi)H2
j=1
中間層2から出力へ
中間層1から中間層2へ
ok=σ(∑wkmxm+θk)M
m=1
入力から中間層1へ

42
教師あり学習
神経回路網の答えと正しい答えの誤差は
Σ (yi-oi(x,w))2
誤差が小さくなるようにw を変えていく
入力 x
結合荷重 w
神経回路の出力 o(x,w)
教師データ y
誤差
x1 xm xM
o1 oi oN
oj
ok
H2
H1
N
M
y1 yi yN

43
データ解析と神経回路網
神経回路網の研究は既に50年以上の歴史を持つが特にここ10年ほどでデータ解析のあらゆる領域に応用されるようになった。
この講義はデータ解析について基礎的なことを述べていくがほとんどのデータ解析に神経回路網を応用することができ、かつ、大規模で複雑なデータ(音声、画像、自然言語)などでは神経回路網のほうが高精度であることが多いため、この講義でも神経回路網を用いる方法について紹介していくことにする。







![沢山のアプローチがあるが,成果は少ない...Robert K. Merton( quoted in Zetterberg[ 1954] 1963:v) 序論 ロバート・マートンは,説明の性質,理論の性質,理論の経験的な証明の妥当性,今後](https://img.pdfslide.tips/doc/110x75/60cd71e230d7bc06462a16cb/ffffoeoeioeoe-robert-k-mertoni.jpg)



















![Title [論説] 方法としての「ユートピア」 --非理想理論の観点 ......はじめに 本稿の課題は、ユートピアについて、現代規範理論、なかでも非理想理論の観点から検討をく](https://img.pdfslide.tips/doc/110x75/60a378d22009001b3242cdc4/title-ee-oeffff-ecfceec.jpg)
