Embed Size (px)
Citation preview

Masarykova UniverzitaEkonomicko-správní fakulta
gretl – uživatelská příručka
Kolektiv autorů(Jaroslav Bil, Daniel Němec, Martin Pospiš)
podzim 2009

ii

Obsah
Předmluva ix
1 Úvod 11.1 Co je Gretl? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Instalace Gretlu . . . . . . . . . . . . . . . . . . . . . . . 11.1.2 Základy práce v Gretlu . . . . . . . . . . . . . . . . . . . 2
1.2 Import dat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Programovaní v Gretlu . . . . . . . . . . . . . . . . . . . . . . . . 51.4 Session koncept . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Jednoduchá lineární regrese 112.1 Načtení dat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2 Sestrojení grafu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.3 Odhad parametrů . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4 Elasticita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Model vícenásobné regrese 213.1 Vytvoření modelu . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2 Statistiky modelu . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.3 Testování parametrů modelu . . . . . . . . . . . . . . . . . . . . 25
3.3.1 Multikolinearita . . . . . . . . . . . . . . . . . . . . . . . 253.3.2 T–test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.3.3 F–test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4 Nelineární rozšíření modelu . . . . . . . . . . . . . . . . . . . . . 34
4 Testování klasických předpokladů 394.1 Normalita reziduí . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.2 Heteroskedasticita . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2.1 Testovaní homoskedasticity . . . . . . . . . . . . . . . . . 404.2.2 Řešení problémů s heteroskedasticitou . . . . . . . . . . . 44
4.3 Autokorelace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.3.1 Testování a řešení . . . . . . . . . . . . . . . . . . . . . . 47
Literatura 51

iv OBSAH

Seznam tabulek

vi SEZNAM TABULEK

Seznam obrázků
1.1 Hlavní okno programu Gretl. . . . . . . . . . . . . . . . . . . . . 21.2 Import dat prostřednictvím GUI Gretlu. . . . . . . . . . . . . . . 31.3 Záložky nainstalovaných datových zdrojů. . . . . . . . . . . . . . 41.4 Zobrazení hodnot proměnné y. . . . . . . . . . . . . . . . . . . . 41.5 Seznam dostupných příkazů. . . . . . . . . . . . . . . . . . . . . . 51.6 Seznam výpočetních funkcí. . . . . . . . . . . . . . . . . . . . . . 61.7 Editor skriptů programu Gretl. . . . . . . . . . . . . . . . . . . . 61.8 Nástrojová lišta Gretlu. . . . . . . . . . . . . . . . . . . . . . . . 71.9 Ikonický úložný prostor. . . . . . . . . . . . . . . . . . . . . . . . 81.10 Ukládání obsahu “session” do souboru. . . . . . . . . . . . . . . . 81.11 Modelová tabulka v okně Gretlu. . . . . . . . . . . . . . . . . . . 9
2.1 Otevření datového souboru. . . . . . . . . . . . . . . . . . . . . . 122.2 Úprava atributů proměnných. . . . . . . . . . . . . . . . . . . . . 122.3 Okno k editaci atributů proměnných. . . . . . . . . . . . . . . . . 132.4 Nastavení proměnných k grafu. . . . . . . . . . . . . . . . . . . . 132.5 Výsledný graf. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.6 Metoda nejmenších čtverců. . . . . . . . . . . . . . . . . . . . . . 152.7 Nastavení proměnných modelu. . . . . . . . . . . . . . . . . . . . 162.8 Okno s výsledkem regrese. . . . . . . . . . . . . . . . . . . . . . . 172.9 Kovarianční matice regresorů. . . . . . . . . . . . . . . . . . . . . 172.10 Popisná statistika dat. . . . . . . . . . . . . . . . . . . . . . . . . 182.11 Tabulka popisné statistiky dat. . . . . . . . . . . . . . . . . . . . 19
3.1 Řešení modelu vícenásobné regrese. . . . . . . . . . . . . . . . . . 223.2 Sestavení modelu. . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.3 Výsledky sestaveného modelu. . . . . . . . . . . . . . . . . . . . . 243.4 Sestavení ANOVA tabulky. . . . . . . . . . . . . . . . . . . . . . 243.5 Analýza rozptylu. . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.6 Zobrazení korelační matice. . . . . . . . . . . . . . . . . . . . . . 263.7 Sestavení korelační matice. . . . . . . . . . . . . . . . . . . . . . 273.8 Korelační matice. . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.9 Sestavení tabulky konfidenčních intervalů. . . . . . . . . . . . . . 293.10 Konfidenční intervaly koeficientů. . . . . . . . . . . . . . . . . . . 29

viii SEZNAM OBRÁZKŮ
3.11 Výsledky F–testu. . . . . . . . . . . . . . . . . . . . . . . . . . . 303.12 Vynechání proměnné. . . . . . . . . . . . . . . . . . . . . . . . . 313.13 Výběr proměnné k vynechání. . . . . . . . . . . . . . . . . . . . . 323.14 Výsledky redukovaného modelu. . . . . . . . . . . . . . . . . . . 333.15 Lineární omezení modelu. . . . . . . . . . . . . . . . . . . . . . . 343.16 Výsledky modelu s lineárním omezením. . . . . . . . . . . . . . . 353.17 Přidání druhých mocnin vybraných proměnných. . . . . . . . . . 36
4.1 Výsledky testů normality reziduí. . . . . . . . . . . . . . . . . . . 404.2 Graf reziduí. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.3 Graf reziduí v závislosti na WAGE. . . . . . . . . . . . . . . . . . 414.4 Graf reziduí v závislosti na EDUC. . . . . . . . . . . . . . . . . . 424.5 Graf reziduí v závislosti na EXPER. . . . . . . . . . . . . . . . . 424.6 Výběr příslušného testu heteroskedasticity. . . . . . . . . . . . . 434.7 Robustní směrodatné chyby. . . . . . . . . . . . . . . . . . . . . . 444.8 Výsledky odhadu metodou WLS s robustními sm. chybami. . . . 464.9 Nastavení časových řad. . . . . . . . . . . . . . . . . . . . . . . . 474.10 Výběr korelogramu reziduí. . . . . . . . . . . . . . . . . . . . . . 484.11 Nastavení maximálního zpoždění. . . . . . . . . . . . . . . . . . . 494.12 Graf ACF a PACF. . . . . . . . . . . . . . . . . . . . . . . . . . . 494.13 Tabulka korelogramu. . . . . . . . . . . . . . . . . . . . . . . . . 50

Předmluva
Tento text je založen primárně na anglickém, volně dostupném textu Adkinse[1], který doprovází učebnici základů ekonometrie trojice Hill, Griffiths a Lim[2]. Jedná se sice o velmi zkrácený (postupně doplňovaný) český překlad Adkin-sonovy příručky, nicméně pro základní orientaci v práci s gretlem je dostačující.

x Předmluva

Kapitola 1
Úvod
V první kapitole se seznámíme se základy programu Gretl, procesem jeho insta-lace a s popisem základního uživatelského rozhraní.
1.1 Co je Gretl?
Název programu Gretl je zkratkou vycházející z Gnu Regression, Econometricsand Time-series Library. Jedná sa o softvérový balíček, který obsahuje užitečnéa jednoduše aplikovatelné nástroje ekonometrické analýzy. Potěšující vlastnostíje jeho volná dostupnost, díky které si program můžete stáhnout zdarma z in-ternetové adresy gretl.sourceforge.net.
Gretl je možné rozšírit o množství vzorových datových zdrojů a databázímakroekonomických časových řad. Program využívá při výpočtech plejádu úče-lových odhadových techník, s kterými se postupně obeznámíme v následují-cích kapitolách. Samozřejmostí je schopnost vykreslovat data do přehlednýchgrafů, případně generovat textový výstup do standartních formátů (TXT, RTF),včetně populárního LATEX.
1.1.1 Instalace Gretlu
Práci s programem Gretl začneme jeho instalací. Po stáhnutí instalačního sou-boru z internetu nebo fakultního serveru a jeho následným spuštěním se apli-kace dotazuje na umístění programu a název složky v seznamu nainstalovanýchprogramů. Ideální je vše ponechat na přednastavených hodnotách, čím sa vy-hneme případným problémům při pozdějším instalování dodatečných modulů adatových zdrojů. Nahrávání těchto doplňků do Gretlu probíhá stejným triviál-ním způsobem jako jeho samotná instalace(tedy opakovaným stláčením tlačítka„Nextÿ).
Jelikož v této příručce využijeme příklady z publikace [2], je užitečné na-plnit Gretl daty. Spuštěním souboru “POEdata.exe”, nacházejícím se ve složce
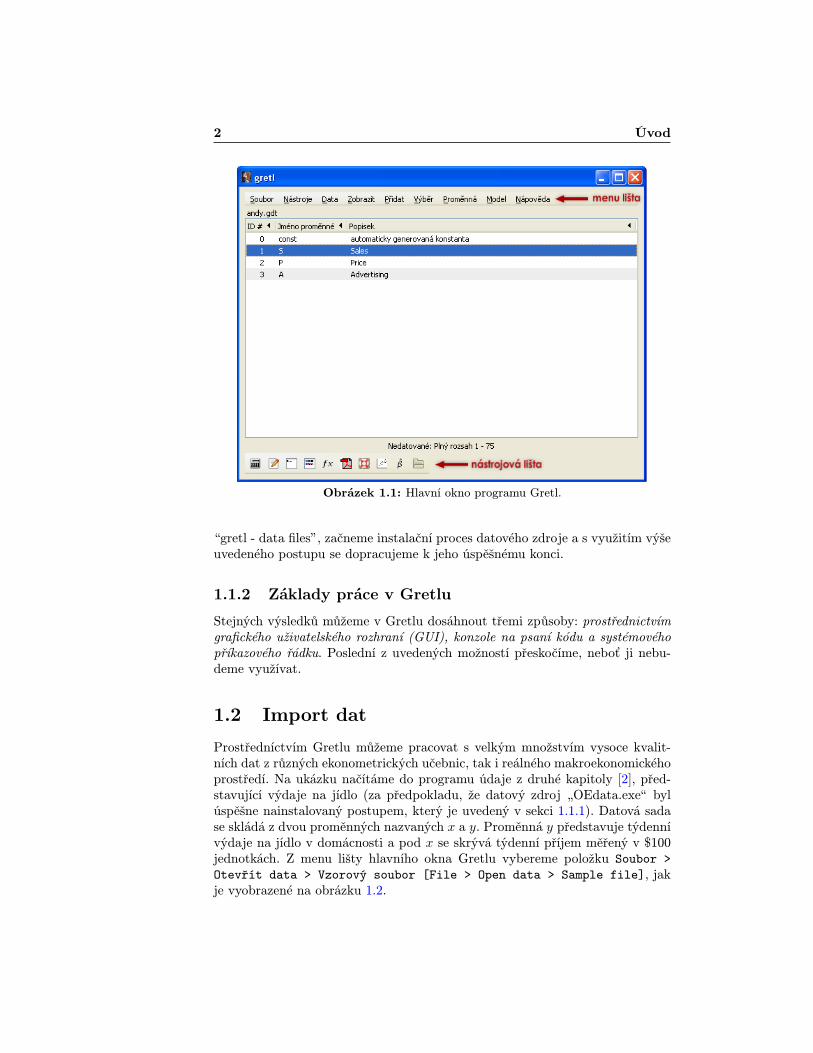
2 Úvod
Obrázek 1.1: Hlavní okno programu Gretl.
“gretl - data files”, začneme instalační proces datového zdroje a s využitím výšeuvedeného postupu se dopracujeme k jeho úspěšnému konci.
1.1.2 Základy práce v Gretlu
Stejných výsledků můžeme v Gretlu dosáhnout třemi způsoby: prostřednictvímgrafického uživatelského rozhraní (GUI), konzole na psaní kódu a systémovéhopříkazového řádku. Poslední z uvedených možností přeskočíme, neboť ji nebu-deme využívat.
1.2 Import dat
Prostředníctvím Gretlu můžeme pracovat s velkým množstvím vysoce kvalit-ních dat z různých ekonometrických učebnic, tak i reálného makroekonomickéhoprostředí. Na ukázku načítáme do programu údaje z druhé kapitoly [2], před-stavující výdaje na jídlo (za předpokladu, že datový zdroj „OEdata.exeÿ bylúspěšne nainstalovaný postupem, který je uvedený v sekci 1.1.1). Datová sadase skládá z dvou proměnných nazvaných x a y. Proměnná y představuje týdennívýdaje na jídlo v domácnosti a pod x se skrývá týdenní příjem měřený v $100jednotkách. Z menu lišty hlavního okna Gretlu vybereme položku Soubor >Otevřít data > Vzorový soubor [File > Open data > Sample file], jakje vyobrazené na obrázku 1.2.
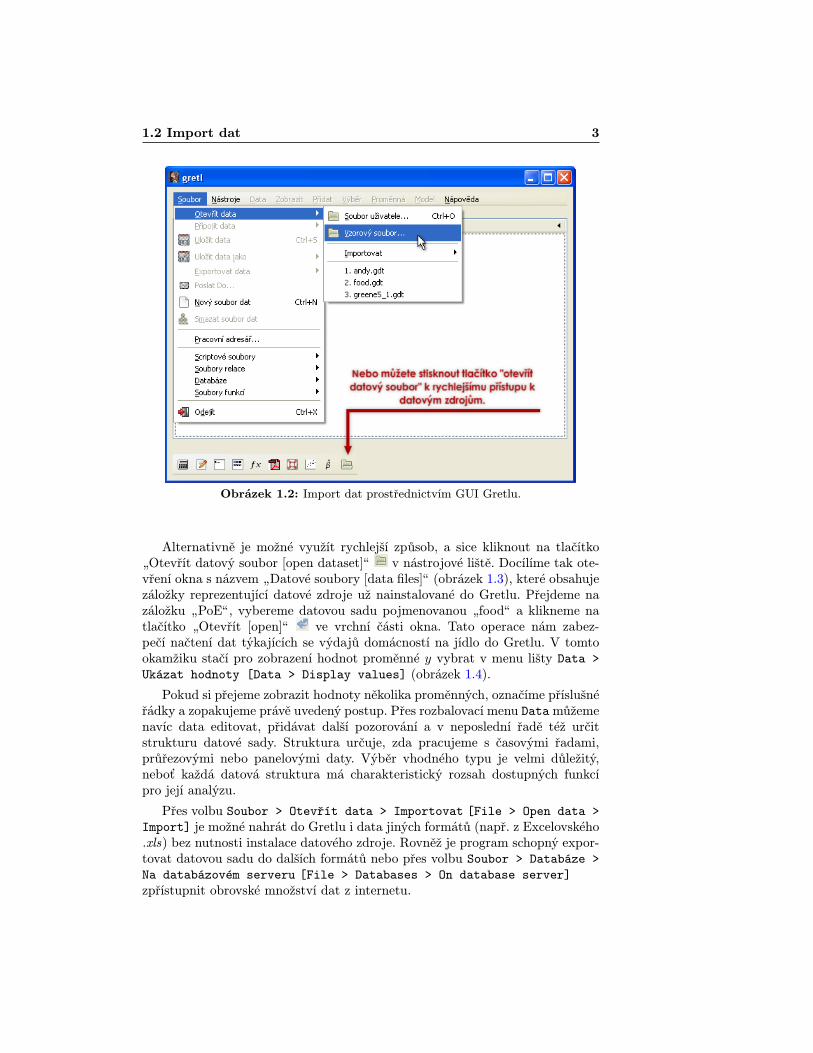
1.2 Import dat 3
Obrázek 1.2: Import dat prostřednictvím GUI Gretlu.
Alternativně je možné využít rychlejší způsob, a sice kliknout na tlačítko„Otevřít datový soubor [open dataset]ÿ v nástrojové liště. Docílíme tak ote-vření okna s názvem „Datové soubory [data files]ÿ (obrázek 1.3), které obsahujezáložky reprezentující datové zdroje už nainstalované do Gretlu. Přejdeme nazáložku „PoEÿ, vybereme datovou sadu pojmenovanou „foodÿ a klikneme natlačítko „Otevřít [open]ÿ ve vrchní části okna. Tato operace nám zabez-pečí načtení dat týkajících se výdajů domácností na jídlo do Gretlu. V tomtookamžiku stačí pro zobrazení hodnot proměnné y vybrat v menu lišty Data >Ukázat hodnoty [Data > Display values] (obrázek 1.4).
Pokud si přejeme zobrazit hodnoty několika proměnných, označíme příslušnéřádky a zopakujeme právě uvedený postup. Přes rozbalovací menu Datamůžemenavíc data editovat, přidávat další pozorování a v neposlední řadě též určitstrukturu datové sady. Struktura určuje, zda pracujeme s časovými řadami,průřezovými nebo panelovými daty. Výběr vhodného typu je velmi důležitý,neboť každá datová struktura má charakteristický rozsah dostupných funkcípro její analýzu.
Přes volbu Soubor > Otevřít data > Importovat [File > Open data >Import] je možné nahrát do Gretlu i data jiných formátů (např. z Excelovského.xls) bez nutnosti instalace datového zdroje. Rovněž je program schopný expor-tovat datovou sadu do dalších formátů nebo přes volbu Soubor > Databáze >Na databázovém serveru [File > Databases > On database server]zpřístupnit obrovské množství dat z internetu.
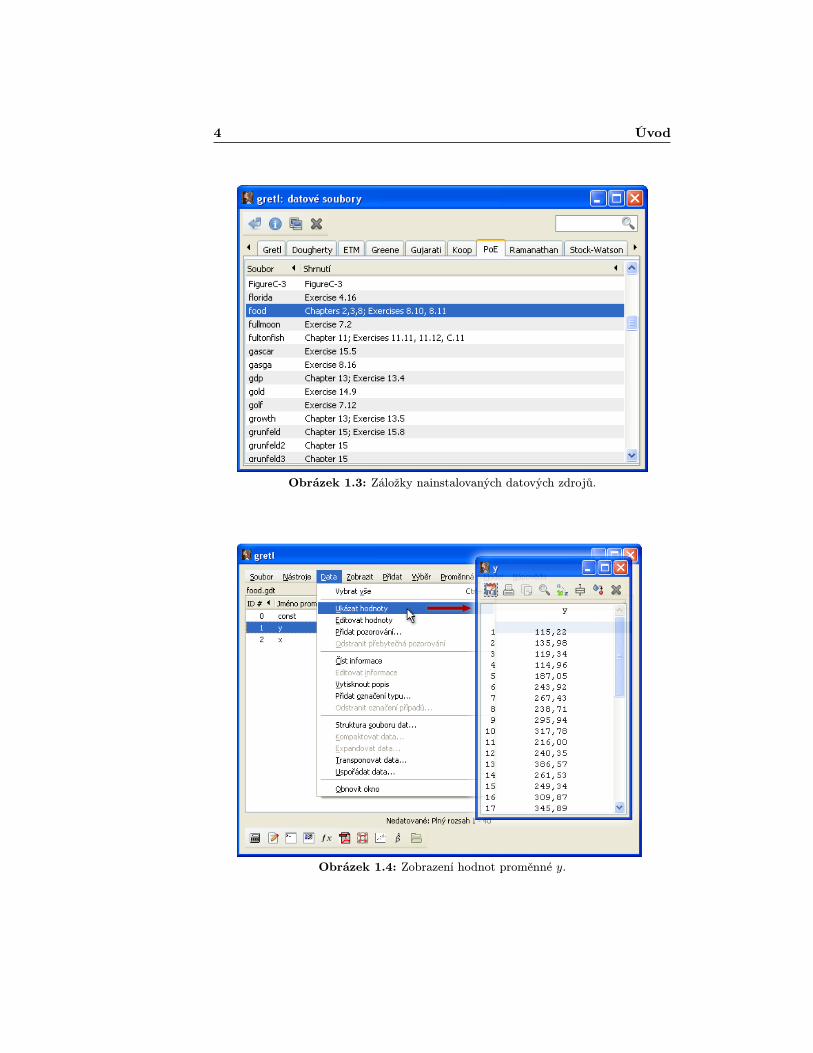
4 Úvod
Obrázek 1.3: Záložky nainstalovaných datových zdrojů.
Obrázek 1.4: Zobrazení hodnot proměnné y.

1.3 Programovaní v Gretlu 5
Obrázek 1.5: Seznam dostupných příkazů.
1.3 Programovaní v Gretlu
Gretlovské GUI se vyznačuje rychlostí a jednoduchostí použití, i když k nároč-nějším úlohám je výhodnější využít konzolu na psaní kódu v jazyce Gretl. Tu siotevřeme buď prostředníctvím tlačítka na nástrojové liště nebo přes Nástroje> Konzole gretlu [Tools > Gretl console] v menu. Je důležité mít na zře-teli, že jazyk Gretlu rozlišuje velká a malá písmena, takže názvy příkazů mu-síme psát tak, jak jsou uvedené v seznamu dostupných příkazů (obrázek 1.5).Ten získáme stlačením příslušného tlačítka na nástrojové liště, přes menuv Nápověda > Popis příkazu > Prostý text [Help > Command reference> Plain text], případně zadáním příkazu help do konzoly. Podobně nápověduk požadovanému příkazu vyvoláme napsáním “help název příkazu” (např. helparima).
K seznamu dostupných výpočtových funkcí (obrázek 1.6) se dostaneme přesNápověda > Popis funkce [Help > Function reference].
Nevýhodou konzole programu Gretl je skutečnost, že umožňuje jen postupnéa jednorázové zadávání příkazů. Toto omezení snadno překonáme v editoruna psani skriptů, přístupného buď přes menu Soubor > Scriptové soubory> Nový script [File > Script files > New script] nebo tlačítkem nanástrojové liště. Editor (obrázek 1.7) slouží na vytvoření série příkazů (v sou-hrnu označované jako skript), které jsou následně provedeny v jedné dávce stla-čením příslušného tlačítka . Skript může být uložen do samostatného souborua spuštěná později.
Pokud si nejsme jisti významem konkrétní funkce, stlačením „záchrannéhokruhuÿ v okně editoru skriptů se kurzor myši obohatí o otázník a následnýmkliknutím na text neznámeho příkazu vyskočí okno s nápovědou.
Dobrou zprávou je, že všechny příkazy vykonané přes GUI nebo konzoli
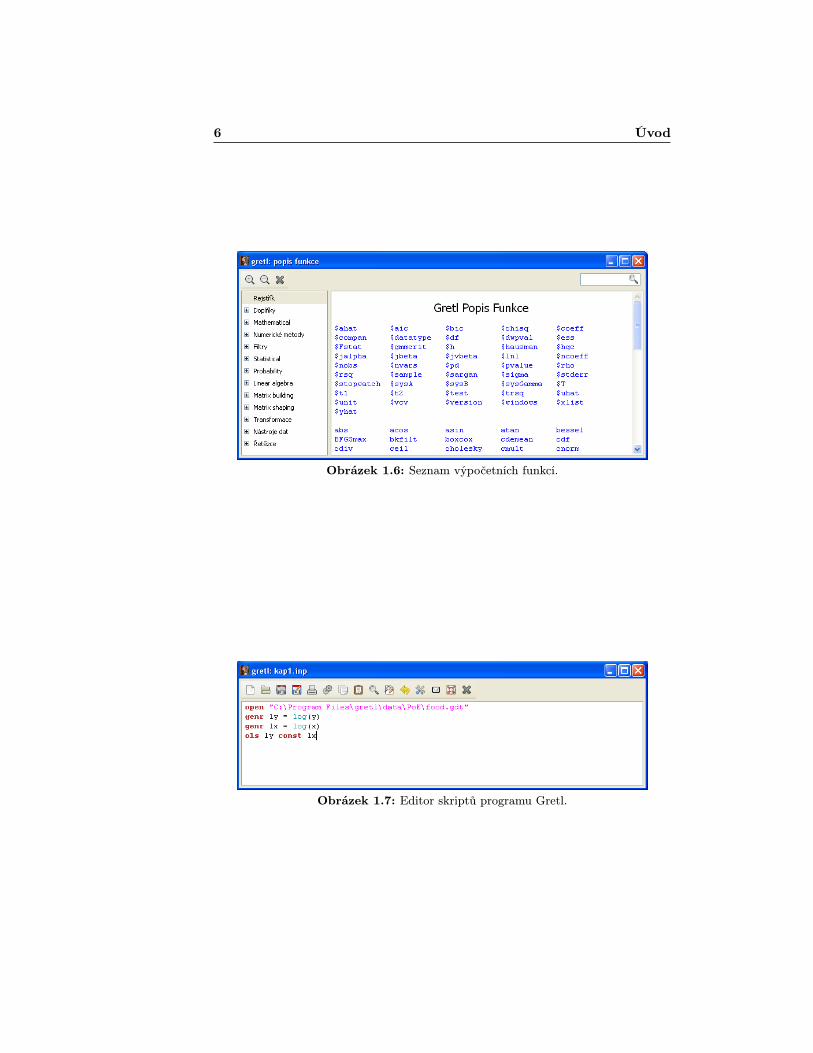
6 Úvod
Obrázek 1.6: Seznam výpočetních funkcí.
Obrázek 1.7: Editor skriptů programu Gretl.

1.4 Session koncept 7
Obrázek 1.8: Nástrojová lišta Gretlu.
Gretlu zůstanou zaznamenané v příkazovém protokole, který nájdeme v menuNástroje > Výpis příkazu [Tools > Command log].
Pro zopakovaní uvádíme obrázek 1.8 s popisem tlačítek na nástrojové lištěGretlu.
1.4 Session koncept
Gretl disponuje schopností ukládat modely, grafy a datové sady do společného,tzv. ikonického úložného prostoru s názvem „relace [session]ÿ. K tomuto prostoru(obrázek 1.9) sa dostaneme jako obvykle stlačením příslušného tlačítka na ná-strojové liště, a samozřejme též přes menu Zobrazit > Zobrazit ikony [View> Icon view]. Objekty (modely, grafy atd.) je možné do „relace [session]ÿ při-dávat výběrem Soubor > Uložit do relace jako ikonu [File > Save tosession as icon] v menu okna (případně vyvoláním kontextové nabídky stisk-nutím pravého tlačítka myši), které si přejeme uchovat na pozdější použití. Celýobsah „relace [session]ÿ následně uložíme přes Soubor > Soubory relace >Uložit relaci [File > Session files > Save session] z hlavního oknaprogramu Gretl, jak je vyobrazené na obrázku 1.10.
Vraťme se ještě k úložnému prostoru „icon viewÿ (obrázek 1.9). Z názvů jed-notlivých ikon vyplývá, že umožňují zobrazení výsledků modelů a grafů, infor-mace o datech a jejich editaci, náhled na souhrnou statistiku a korelace. Pokudposuneme kurzor myši na ikonu „Tabulka modelu [Model table]ÿ, sestavíme sipřehlednou tabulku dosažených výsledků (obrázek 1.11), kterou můžeme vyex-portovat do různých formátů včetně LATEXu. Podobný postup je možné aplikovatza účelem vytvoření tabulky grafů.
8 Úvod
Obrázek 1.9: Ikonický úložný prostor.
Obrázek 1.10: Ukládání obsahu “session” do souboru.

1.4 Session koncept 9
Obrázek 1.11: Modelová tabulka v okně Gretlu.

10 Úvod

Kapitola 2
Jednoduchá lineární regrese
Připomeňme, že jednoduchý lineární regresní model je tvaru:
yt = β1 + β2xt + εt,
kde yt je tzv. závisle proměnná, kterou odhadujeme pomocí parametrů β1 a β2na základě pozorované veličiny xt a εt je vektor reziduí, o němž předpokládáme,že jeho složky mají identické normální rozdělení s nulovou střední hodnotou ajsou nezávislé. Ještě doplňme, že odhad modelu je založen na metodě nejmenšíchčtverců.
2.1 Načtení dat
Po spuštení Gretlu klikněte na Soubor > Otevřít data > Soubor uživatele[File > Open data > User file] nebo Vzorový soubor [Sample file].Následně vyberte vámi zvolený datový soubor, s kterým budete chtít dále praco-vat. Dále pak klikněte pravým tlačítkem myši a vyberte “Otevřít [Open]” neboklikněte na ikonku nahoře vlevo viz obr. 2.1.
Pak by se vám mělo otevřít následující okno obr. 2.2 s uvedením všechproměnných, které jsou v datovém souboru uloženy popř. i s jejich popiskem.Budete-li chtít upravit atributy jednotlivé proměnné (např. jak se má danáproměnná zobrazovat v grafech), pak klikněte na zvolenou proměnnou pravýmtlačítkem myši a zvolte „Upravit atributy [Edit attributes]ÿ. Alternativní po-stup vede z hlavního panelu přes Proměnná > Upravit atributy [Variable> Edit attributes]. Mělo by se vám otevřít následující okno, kde můžete jed-notlivé atributy pozměnit či doplnit (obr. 2.3).
2.2 Sestrojení grafu
Pro vytvoření grafu nejdříve klikneme na ikonku dole „graf X-Y [X-Y graph]ÿ,(třetí zprava). Objeví se nám okno jako na obr. 2.4.
12 Jednoduchá lineární regrese
Obrázek 2.1: Otevření datového souboru.
Obrázek 2.2: Úprava atributů proměnných.
2.2 Sestrojení grafu 13
Obrázek 2.3: Okno k editaci atributů proměnných.
Obrázek 2.4: Nastavení proměnných k grafu.
14 Jednoduchá lineární regrese
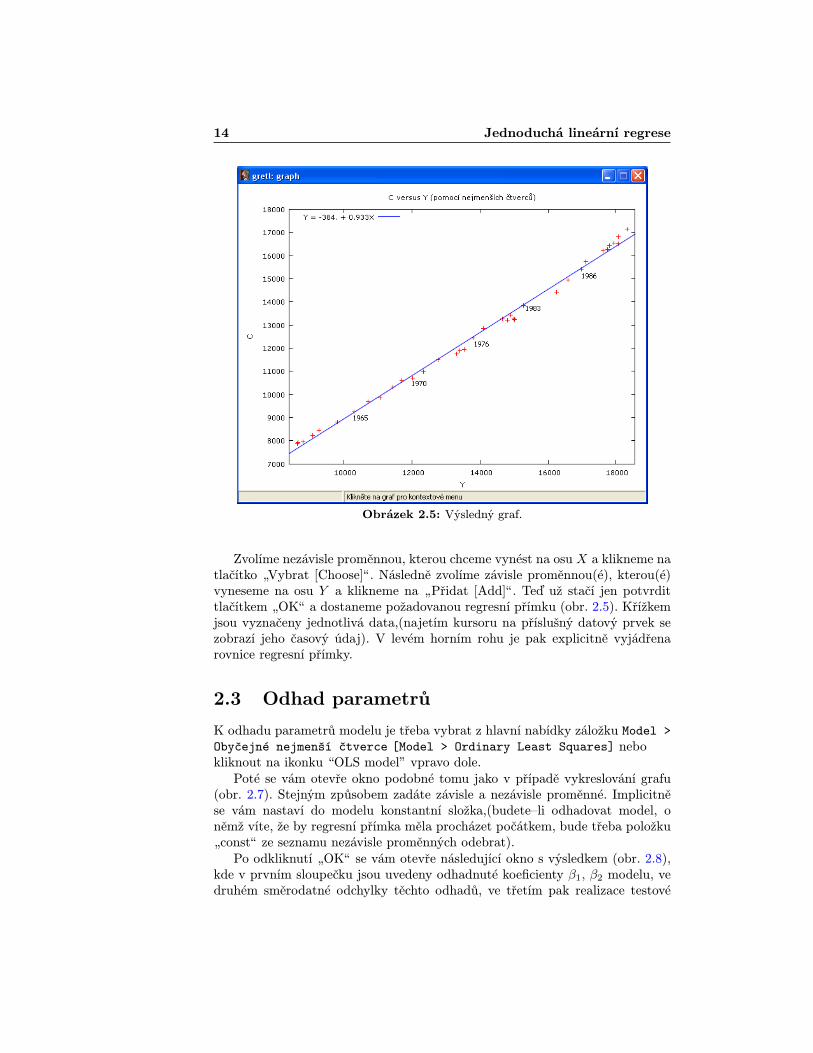
Obrázek 2.5: Výsledný graf.
Zvolíme nezávisle proměnnou, kterou chceme vynést na osu X a klikneme natlačítko „Vybrat [Choose]ÿ. Následně zvolíme závisle proměnnou(é), kterou(é)vyneseme na osu Y a klikneme na „Přidat [Add]ÿ. Teď už stačí jen potvrdittlačítkem „OKÿ a dostaneme požadovanou regresní přímku (obr. 2.5). Křížkemjsou vyznačeny jednotlivá data,(najetím kursoru na příslušný datový prvek sezobrazí jeho časový údaj). V levém horním rohu je pak explicitně vyjádřenarovnice regresní přímky.
2.3 Odhad parametrů
K odhadu parametrů modelu je třeba vybrat z hlavní nabídky záložku Model >Obyčejné nejmenší čtverce [Model > Ordinary Least Squares] nebokliknout na ikonku “OLS model” vpravo dole.
Poté se vám otevře okno podobné tomu jako v případě vykreslování grafu(obr. 2.7). Stejným způsobem zadáte závisle a nezávisle proměnné. Implicitněse vám nastaví do modelu konstantní složka,(budete–li odhadovat model, oněmž víte, že by regresní přímka měla procházet počátkem, bude třeba položku„constÿ ze seznamu nezávisle proměnných odebrat).
Po odkliknutí „OKÿ se vám otevře následující okno s výsledkem (obr. 2.8),kde v prvním sloupečku jsou uvedeny odhadnuté koeficienty β1, β2 modelu, vedruhém směrodatné odchylky těchto odhadů, ve třetím pak realizace testové
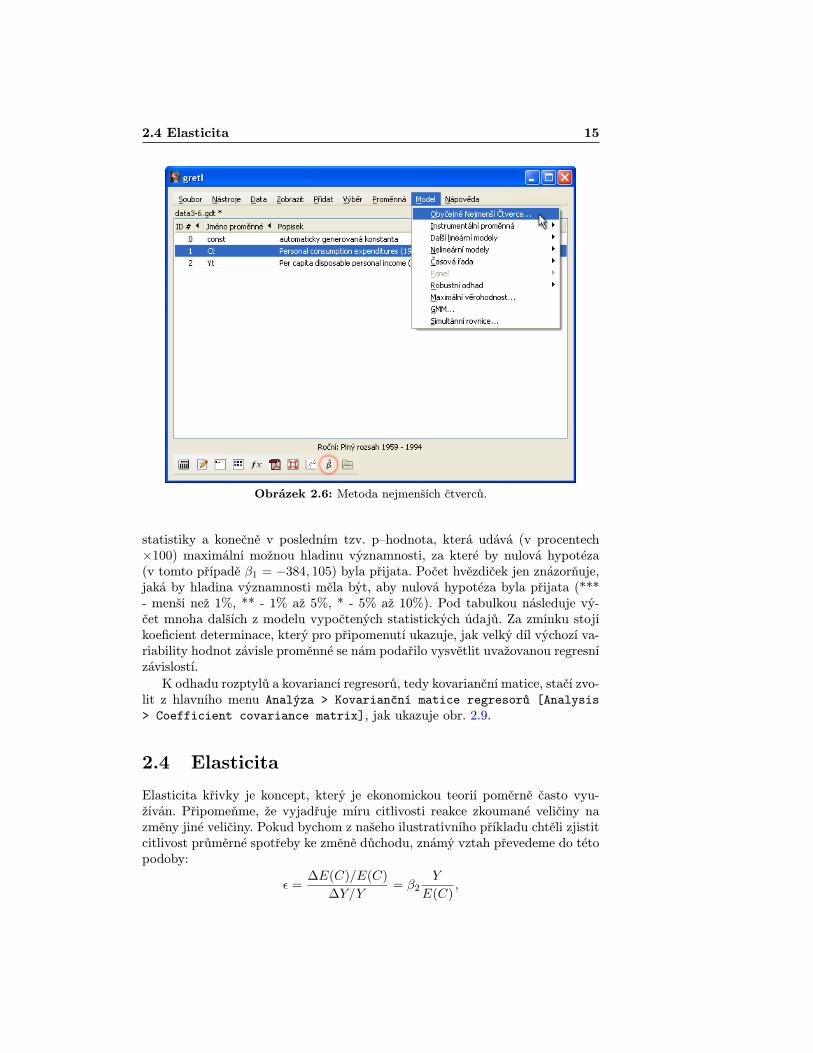
2.4 Elasticita 15
Obrázek 2.6: Metoda nejmenších čtverců.
statistiky a konečně v posledním tzv. p–hodnota, která udává (v procentech×100) maximální možnou hladinu významnosti, za které by nulová hypotéza(v tomto případě β1 = −384, 105) byla přijata. Počet hvězdiček jen znázorňuje,jaká by hladina významnosti měla být, aby nulová hypotéza byla přijata (***- menší než 1%, ** - 1% až 5%, * - 5% až 10%). Pod tabulkou následuje vý-čet mnoha dalších z modelu vypočtených statistických údajů. Za zmínku stojíkoeficient determinace, který pro připomenutí ukazuje, jak velký díl výchozí va-riability hodnot závisle proměnné se nám podařilo vysvětlit uvažovanou regresnízávislostí.
K odhadu rozptylů a kovariancí regresorů, tedy kovarianční matice, stačí zvo-lit z hlavního menu Analýza > Kovarianční matice regresorů [Analysis> Coefficient covariance matrix], jak ukazuje obr. 2.9.
2.4 Elasticita
Elasticita křivky je koncept, který je ekonomickou teorií poměrně často vyu-žíván. Připomeňme, že vyjadřuje míru citlivosti reakce zkoumané veličiny nazměny jiné veličiny. Pokud bychom z našeho ilustrativního příkladu chtěli zjistitcitlivost průměrné spotřeby ke změně důchodu, známý vztah převedeme do tétopodoby:
ε =∆E(C)/E(C)
∆Y/Y= β2
Y
E(C),
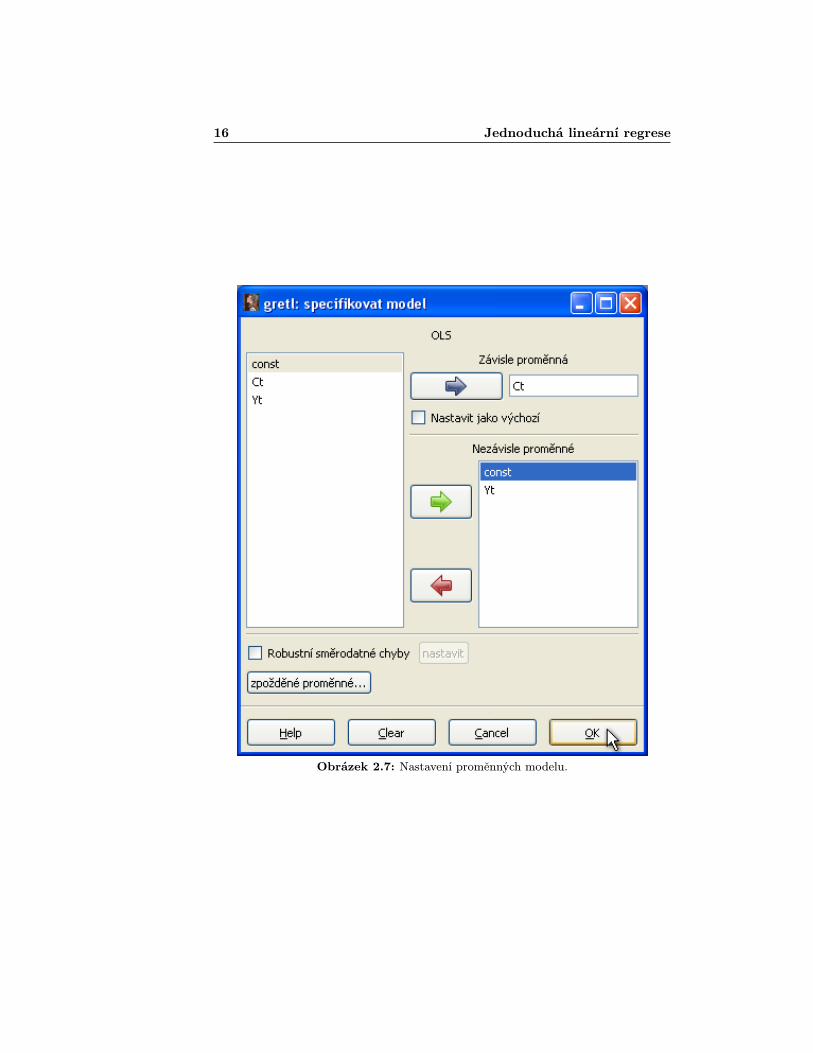
16 Jednoduchá lineární regrese
Obrázek 2.7: Nastavení proměnných modelu.
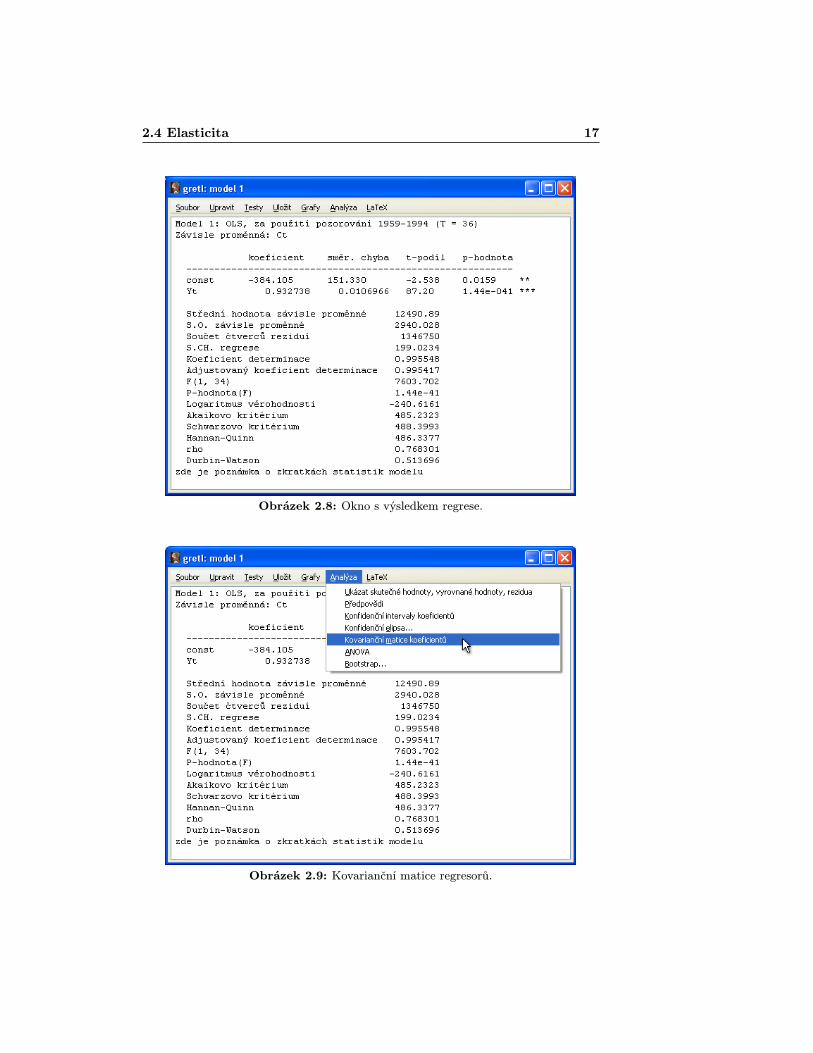
2.4 Elasticita 17
Obrázek 2.8: Okno s výsledkem regrese.
Obrázek 2.9: Kovarianční matice regresorů.
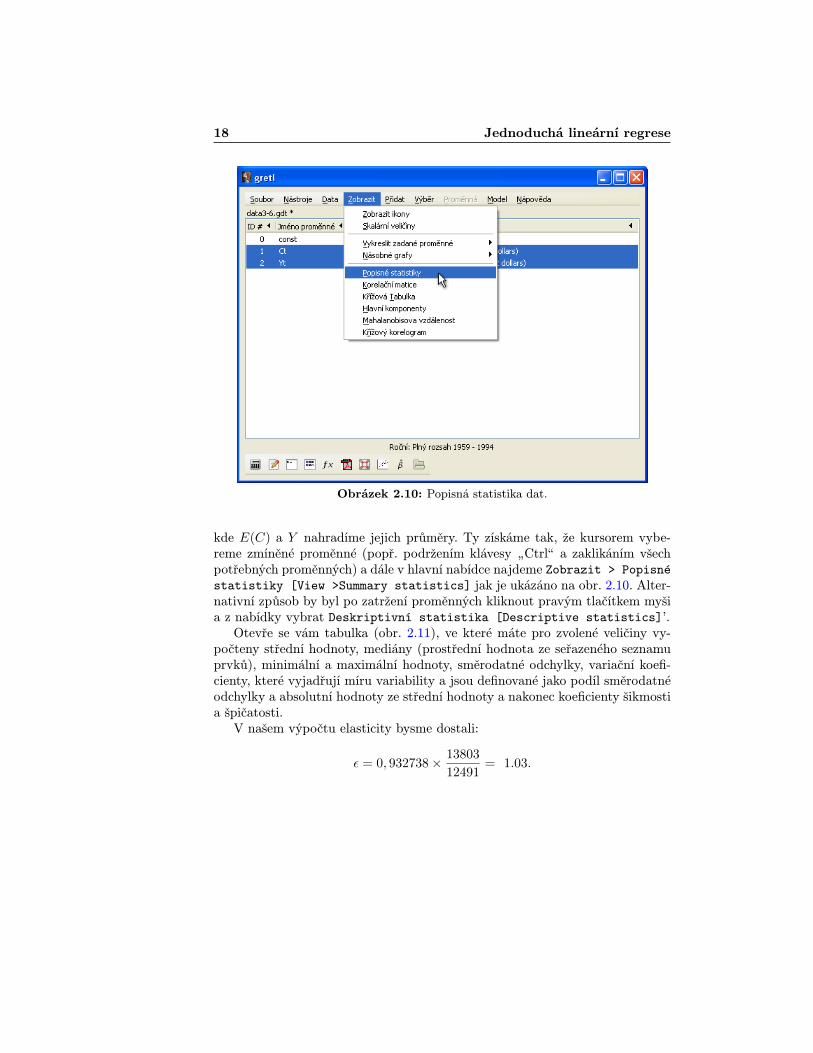
18 Jednoduchá lineární regrese
Obrázek 2.10: Popisná statistika dat.
kde E(C) a Y nahradíme jejich průměry. Ty získáme tak, že kursorem vybe-reme zmíněné proměnné (popř. podržením klávesy „Ctrlÿ a zaklikáním všechpotřebných proměnných) a dále v hlavní nabídce najdeme Zobrazit > Popisnéstatistiky [View >Summary statistics] jak je ukázáno na obr. 2.10. Alter-nativní způsob by byl po zatržení proměnných kliknout pravým tlačítkem myšia z nabídky vybrat Deskriptivní statistika [Descriptive statistics]’.
Otevře se vám tabulka (obr. 2.11), ve které máte pro zvolené veličiny vy-počteny střední hodnoty, mediány (prostřední hodnota ze seřazeného seznamuprvků), minimální a maximální hodnoty, směrodatné odchylky, variační koefi-cienty, které vyjadřují míru variability a jsou definované jako podíl směrodatnéodchylky a absolutní hodnoty ze střední hodnoty a nakonec koeficienty šikmostia špičatosti.
V našem výpočtu elasticity bysme dostali:
ε = 0, 932738× 13803
12491= 1.03.
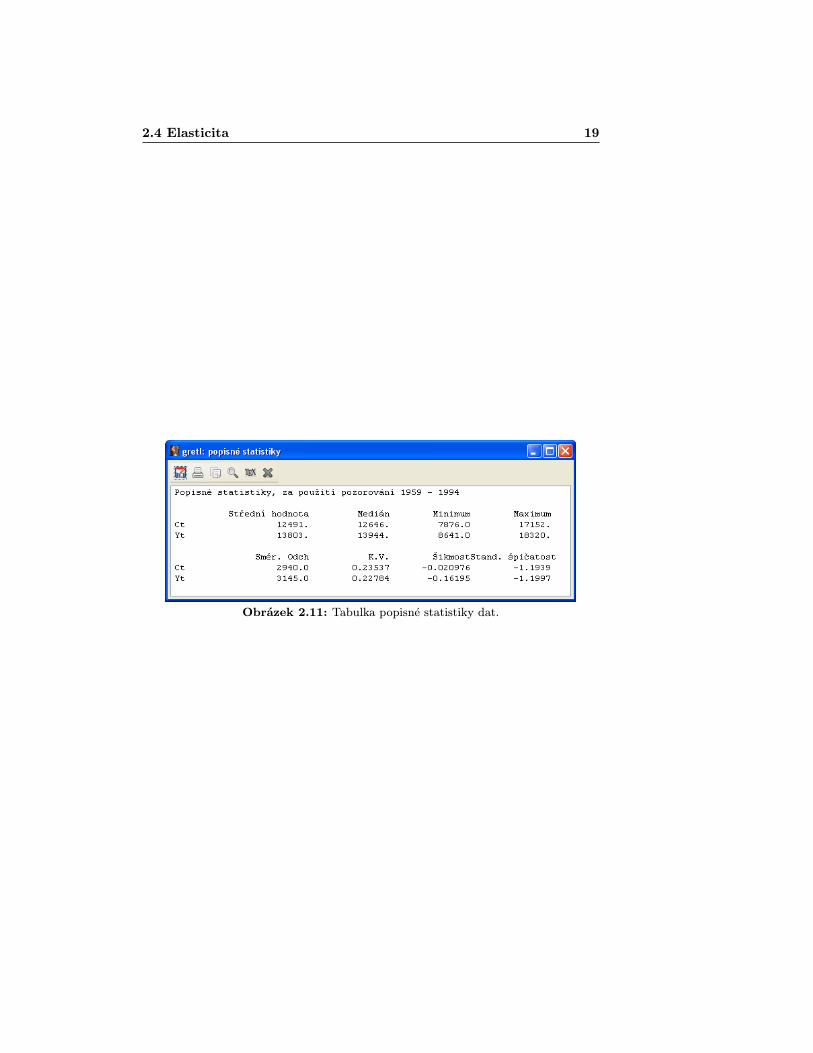
2.4 Elasticita 19
Obrázek 2.11: Tabulka popisné statistiky dat.

20 Jednoduchá lineární regrese

Kapitola 3
Model vícenásobné regrese
Tento model je určitým rozšířením předchozího modelu, které spocívá zejmé-na v tom, že nyní budeme pracovat s více než jednou vysvětlující proměnnou.Obecný tvar tohoto modelu můžeme zapsat následovně:
yi = β0 + β1xi1 + · · ·+ βKxiK i = 1, 2, . . . , N,
kde index i značí jednotlivá pozorování a index k = 1, 2, . . . ,K pak jednotlivévysvětlující proměnné, a tedy β0, β1, . . . .βK jsou parametry jež odhadujeme.Tento model oproti předchozímu musíme rovnež obohatit o jeden předpoklad,že libovolnou z vysvětlujících proměnných nejsme schopni vyjádřit jako nějakoulineární kombinaci ostatních vysvětlujících proměnných (pak by jsme totiž ne-mohli jednoznačně určit odhadované parametry, protože by existovala celá řadakombinací bet, která by stejně kvalitně vysvětlovala veličinu y). O tomto pro-blému se obecně mluví jako o problému multikolinearity,(v dusledku existencekorelací mezi vysvětlujícími proměnnými), a prakticky je jím do určité míryzatížen každý model.
Ještě dodejme poznámku ke správné interpretaci obdrženého modelu. Jed-notlivé odhadnuté parametry β1, . . . .βK udávájí, jak moc se v průměru změníodhadovaná veličina y, kdybysme o jednotku zvýšili příslušnou (k βk) vysvětlu-jící proměnnou xk o jednotku, za předpokladu, že ostatní vysvětlující proměnnése nezmění.
3.1 Vytvoření modelu
Nejprve opět musíme načíst nějaký datový soubor, s kterým budeme chtít praco-vat. Zde uvedený ilustrativní příklad najdete ve vzorových datových souborechGretlu v záložce Ramanathan pod názvem data6-4 (Salary and employmentcharacteristics). Kliknutím na ikonku s „íčkemÿ zjistíte, že tento datový sou-bor obsahuje informace o mzdách, úrovni vzdělání, věku a počtem roků jež jsouzaměstnanci u dané společnosti zaměstnáni.
22 Model vícenásobné regrese
Obrázek 3.1: Řešení modelu vícenásobné regrese.
Když už máme datový soubor načtený, můžeme se pustit do sestavení sa-motného modelu. Postup se prakticky shoduje s případem jednoduché regrese.Tedy klikneme buď na ikonu „OLS modelÿ v dolní liště nebo vybereme záložkuModel > Obyčejné nejmenší čtverce [Model > Ordinary Least Squares](obr. 3.1). Vyskočí nám již známé okno, kde postupně přidáme závisle proměn-nou mzdu (WAGE) a do nezávisle proměnných zbývající proměnné (není nutnéa zpravidla ne i optimální do modelu zahrnout všechny dostupné proměnné).My pro začátek do modelu zahrneme všechny dostupné proměnné: vliv vzdělání,věrnosti společnosti a věk, tedy k nezávisle proměnným přidáme veličiny EDUC,EXPER a AGE (obr. 3.2). Poté klikneme na tlačítko „OKÿ a můžeme se podívatna obdržené výsledky (obr. 3.3), kterým v této kapitolce věnujeme trošku vícepozornosti.
3.2 Statistiky modelu
K výpočtu jednotlivých statistik se často využívá hodnot, jež jsou obsaženy vtzv. ANOVA tabulce. Tu získame tak, že z okna s modelem klikneme na záložkuAnalýza > ANOVA [Analysis > ANOVA]. Otevře se nám pak následující okno sanalýzou rozptylu. Postup je zachycen na obrázcích 3.4 a 3.5.
V prvním sloupci najdeme postupně součet čtverců regrese, reziduií a nako-nec celkový součet čtverců, které jsou v literatuře obvykle značeny jako SSR,SSE a SST . Připomeňme, že SST vyjadřuje kvadratický součet odchylek od
3.2 Statistiky modelu 23
Obrázek 3.2: Sestavení modelu.
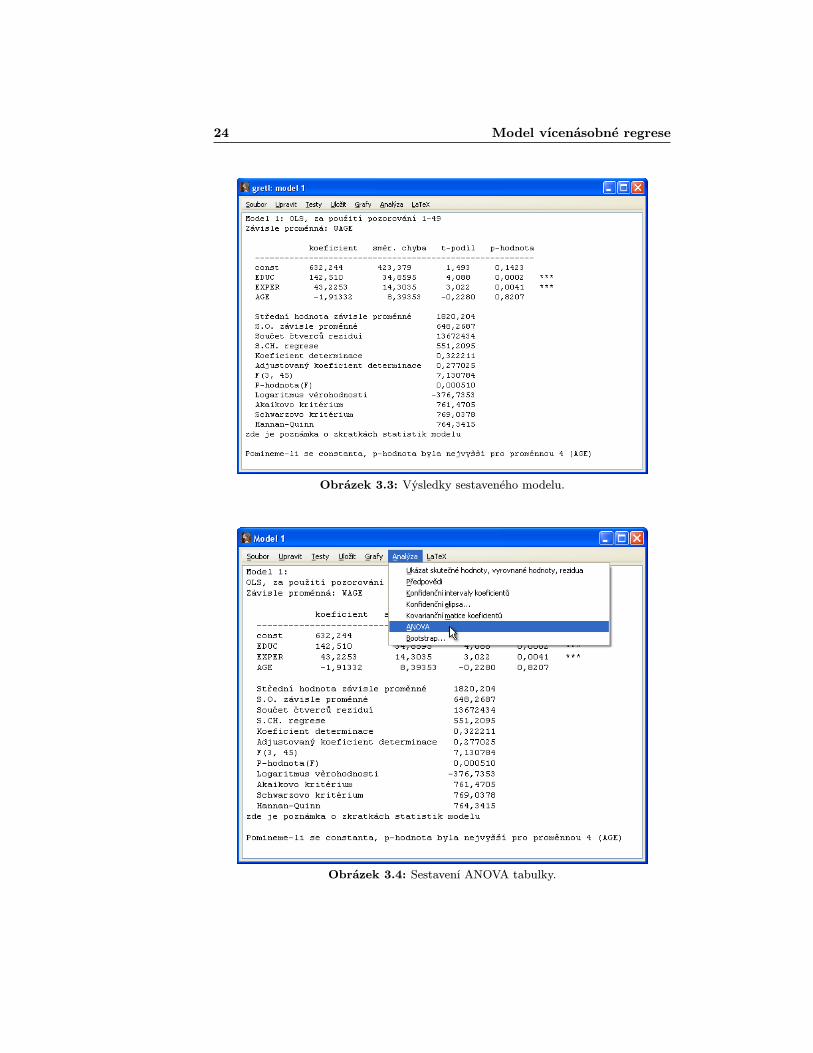
24 Model vícenásobné regrese
Obrázek 3.3: Výsledky sestaveného modelu.
Obrázek 3.4: Sestavení ANOVA tabulky.

3.3 Testování parametrů modelu 25
Obrázek 3.5: Analýza rozptylu.
střední hodnoty z pozorovaných dat, matematicky zapsáno SST =∑N
i=1(Yi −Y )2, kde Y značí střední hodnotu. SST se rozkládá na součet SSR a SSE, kdeSSR je kvadratický součet odchylek od střední hodnoty z odhadnutých dat,matematicky SSR =
∑Ni=1(Yi − Y )2, kde Y jsou odhadnuté hodnoty pomocí
modelu. Tedy můžeme říci, že SSR udává, vysvětlenou velikost variability způvodních dat. Ta nevysvětlená je pak zahrnuta v SSE, kterou vyjádříme jakoSSE =
∑Ni=1(Yi − Y )2. V druhém sloupci jsou pak uvedeny příslušné stupně
volnosti. Jejich vydělením pak obdržíme, zde uváděný „střední kvadrátÿ. Vý-znamná je zejména střední chyba reziduí, v literatuře značená jako MSE, jež jes využitím nestrannosti odhadu modelu pomocí metody nejmenších čtverců zá-roveň odhadem rozptylu reziduí. Poslední hodnota uvedená v ANOVA tabulcevyjadřuje odhad rozptylu závisle proměnné. Pod tabulkou pak máme vypočtenýkoeficient determinace, o nemž jsme se již zmínili dříve včetně postupu k jehourčení. Nakonec je tam i uvedena hodnota F-statistiky, ale o ní blíže pojednámev následující subkapitole.
Vraťme se ještě k výsledkům našeho modelu. Níže uvedené střední odchylkyjsou získány jednoduše jako odmocniny z rozptylu, získaných např. z ANOVAtabulky. Je zde však zapotřebí upozornit na nepříliš vhodně zvolený výraz prostřední chybu reziduí, která je v české verzi značena jako S.CH. regrese (v pů-vodní angl. verzi tento problém není). Spíše pro zajímavost ještě stručně vysvět-leme co je tzv. adjustovaný koeficient determinace. Jedná se o snahu klasickýkoeficient determinace očistit (snížit) od skutečnosti, že se koeficient zlepší jenv důsledku přidání další vysvětlující proměnné do modelu.
3.3 Testování parametrů modelu
3.3.1 Multikolinearita
V úvodu kapitoly jsme se zmínili o problému kolinearity, který vzniká v důsledkukorelace mezi nezávisle proměnnými. Nejjednodušším způsobem jak zjistit, zdaexistuje silná korelace mezi proměnnými je, se podívat na korelační matici. Tu
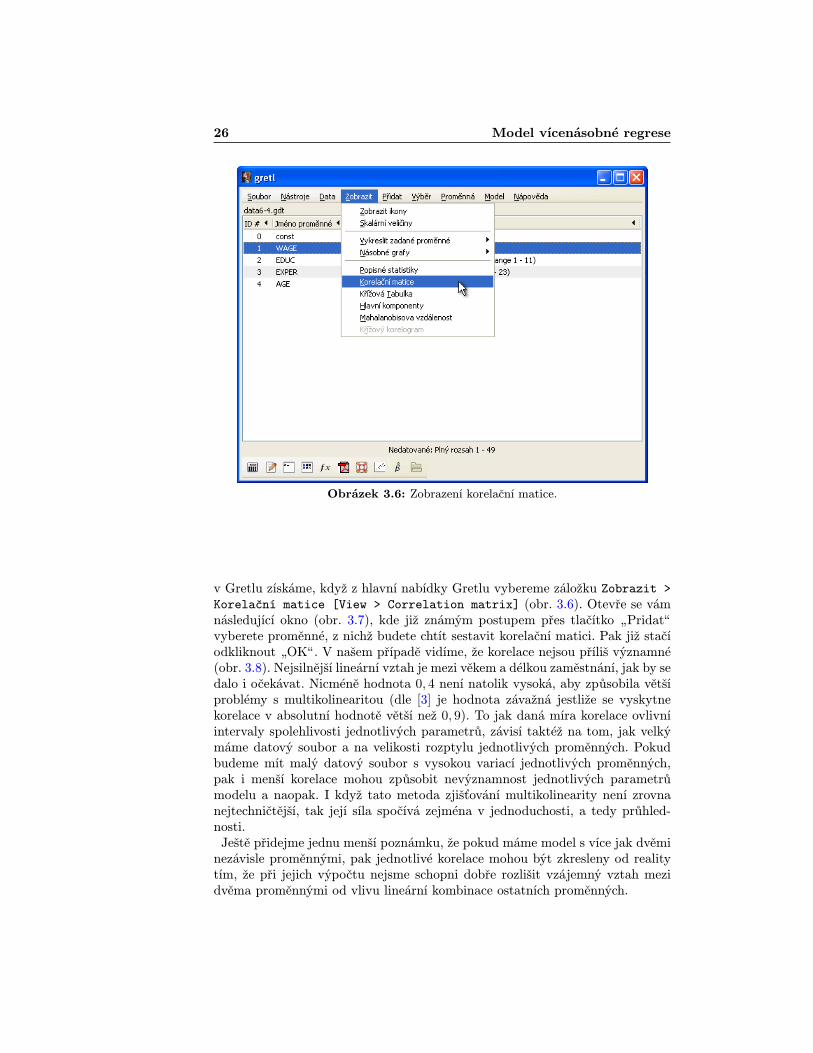
26 Model vícenásobné regrese
Obrázek 3.6: Zobrazení korelační matice.
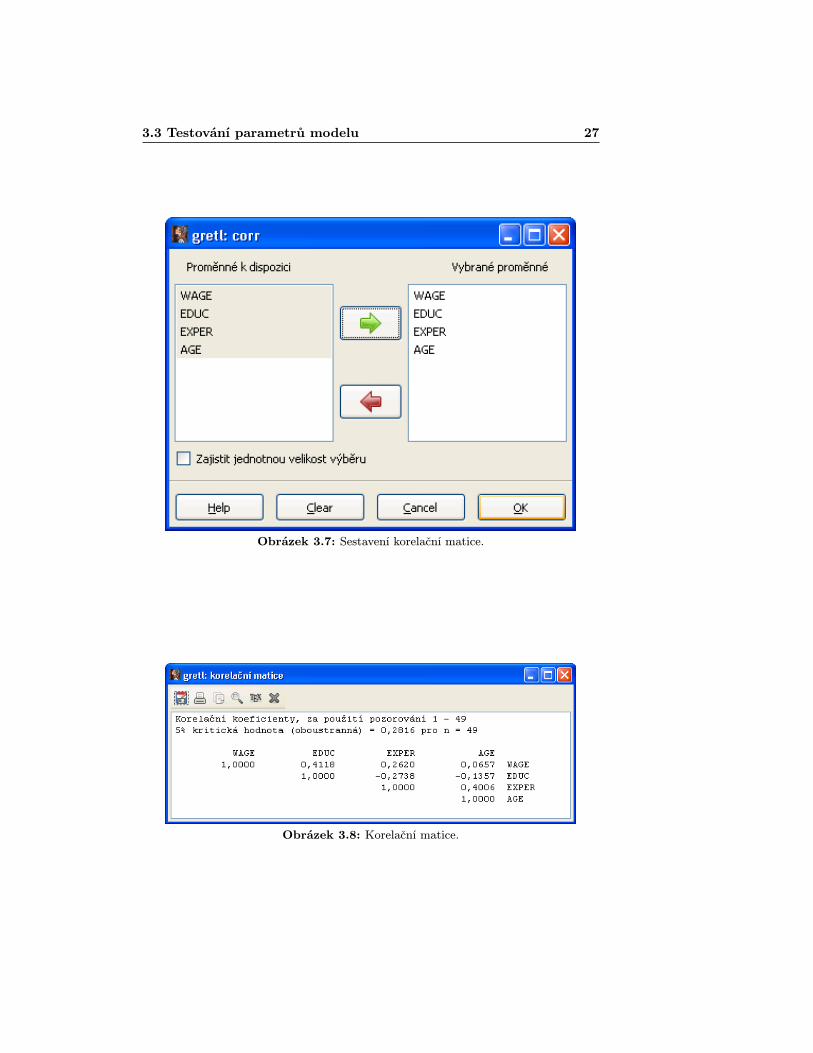
v Gretlu získáme, když z hlavní nabídky Gretlu vybereme záložku Zobrazit >Korelační matice [View > Correlation matrix] (obr. 3.6). Otevře se vámnásledující okno (obr. 3.7), kde již známým postupem přes tlačítko „Pridatÿvyberete proměnné, z nichž budete chtít sestavit korelační matici. Pak již stačíodkliknout „OKÿ. V našem případě vidíme, že korelace nejsou příliš významné(obr. 3.8). Nejsilnější lineární vztah je mezi věkem a délkou zaměstnání, jak by sedalo i očekávat. Nicméně hodnota 0, 4 není natolik vysoká, aby způsobila většíproblémy s multikolinearitou (dle [3] je hodnota závažná jestliže se vyskytnekorelace v absolutní hodnotě větší než 0, 9). To jak daná míra korelace ovlivníintervaly spolehlivosti jednotlivých parametrů, závisí taktéž na tom, jak velkýmáme datový soubor a na velikosti rozptylu jednotlivých proměnných. Pokudbudeme mít malý datový soubor s vysokou variací jednotlivých proměnných,pak i menší korelace mohou způsobit nevýznamnost jednotlivých parametrůmodelu a naopak. I když tato metoda zjišťování multikolinearity není zrovnanejtechničtější, tak její síla spočívá zejména v jednoduchosti, a tedy průhled-nosti.
Ještě přidejme jednu menší poznámku, že pokud máme model s více jak dvěminezávisle proměnnými, pak jednotlivé korelace mohou být zkresleny od realitytím, že při jejich výpočtu nejsme schopni dobře rozlišit vzájemný vztah mezidvěma proměnnými od vlivu lineární kombinace ostatních proměnných.
3.3 Testování parametrů modelu 27
Obrázek 3.7: Sestavení korelační matice.
Obrázek 3.8: Korelační matice.

28 Model vícenásobné regrese
3.3.2 T–test
T–testy slouží především ke zkoumání významnosti jednotlivých odhadnutýchkoeficientů. To zda nulovou hypotézu, že βi = 0 zamítneme (a tedy řekneme,že na zvolené hladině významnosti není daný koeficient statisticky nevýznam-ný) můžeme zjistit třemi způsoby:
• pomocí intervalů spolehlivosti,
• porovnáním testové statistiky s kritickou hodnotou,
• pomocí p–hodnoty.
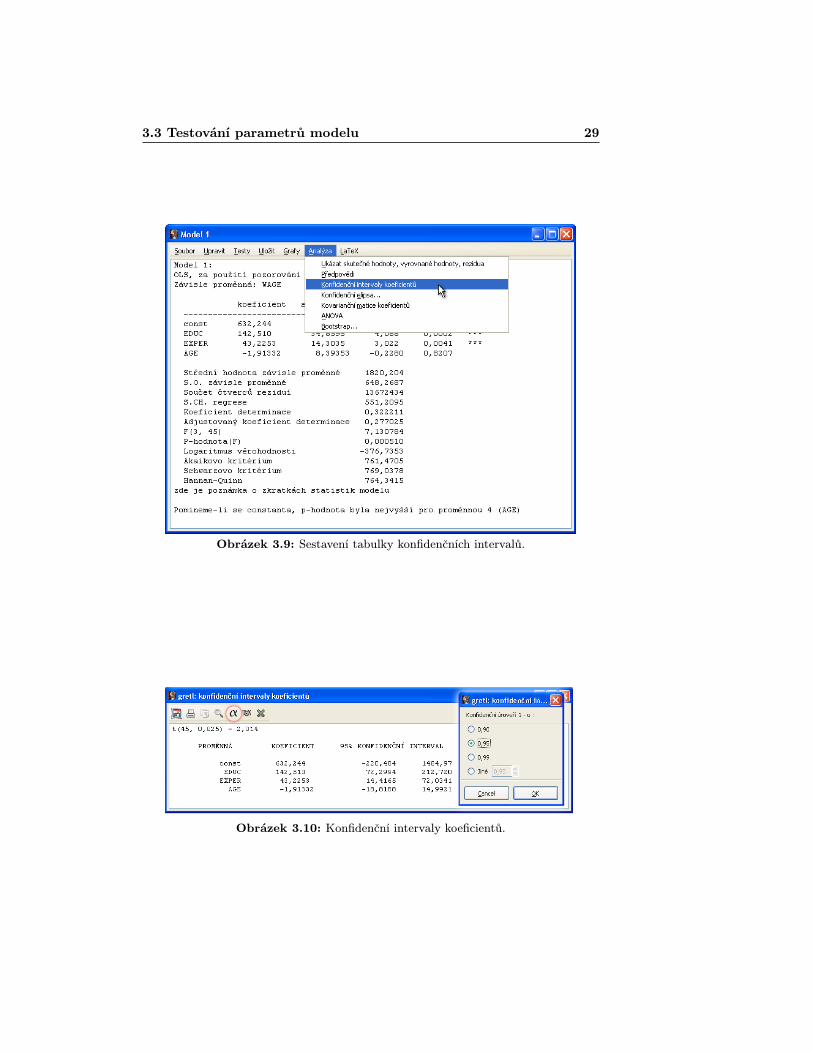
Intervaly spolehlivosti pro jednotlivé parametry modelu získáme jednodušetak, že v okně s výsledkem modelu vybereme Analýza > Konfidenční in-tervaly koeficientů [Analysis > Confidence intervals for coeffici-ents]. Pokud příslušný interval spolehlivosti obsahuje nulu, pak nulovou hypo-tézu nemůžeme zamítnout. V našem případe tedy nulové hypotézy, že const = 0a AGE = 0 nemůžeme na hladině významnosti 95% zamítnout. Ze šířky inter-valu také můžeme usuzovat o přesnosti odhadu. Čím je daný interval relativněvůči své střední hodnotě širší, tím je odhad parametru méně přesný (k tomutoúčelu však lépe poslouží směrodatné odchylky parametrů uvedené ve výsledcíchmodelu). Změnu hladiny významnosti provedete kliknutím na ikonku „alfyÿ.Proč se intervaly spolehlivosti při vyšší hladině významnosti rozšiřují a naopak,ponecháme na promyšlení čtenáři. Postup s výsledky najdete na obrázcích 3.9a 3.10.
K stejnému zjištění můžeme dojít porovnáme–li hodnoty realizací testovýchstatistik s kritickou hodnotou. Jestliže absolutní hodnota testové statistiky budevětší než kritická hodnota, tedy že se realizuje v kritickém oboru, pak nulovouhypotézu zamítame. Hodnoty testových statistik pro jednotlivé parametry mo-delu naleznete ve čtvrtém sloupečku v okně s výsledky modelu a kritickou hod-notu pak na prvním řádku okna konfidenčních intervalů spolehlivosti. Ještě udě-lejme poznámku, jak postupovat v případě alternetivní jednostranné,(pravo čilevostranné) hypotézy (H1 : βi > 0 βi < 0). Jednoduše kritickou hodnotu na-jdeme tak, že hladinu významnosti nastavíme na dvojnásobek než požadujeme.V případě levostranné hypotézy navíc využijeme vlastnosti symetrie studentovarozdělení (tedy si před kritickou hodnotu přimyslíme znaménko minus).
Na závěr jsme si nechali uživatelsky nejpohodlnější metodu založenou na tzv.p–hodnotě. O ní jsme již pojednali v předchozí kapitole, tak jen krátce shrneme,že nulovou hypotézu zamítneme, jestliže je p–hodnota nižší než požadovanáhladina významnosti.
3.3.3 F–test
F–testy lze formálně využít na testování jakékoli hypotézy, kterou lze zapsatlineární kombinací regresních koeficientů. My se zde hlavně zaměříme na tes-tování významnosti modelu jako celku a na testování podmodelů, které námumožní model co nejlépe specifikovat. Kdyby náš model obsahoval irelevantní
3.3 Testování parametrů modelu 29
Obrázek 3.9: Sestavení tabulky konfidenčních intervalů.
Obrázek 3.10: Konfidenční intervaly koeficientů.

30 Model vícenásobné regrese
Obrázek 3.11: Výsledky F–testu.
(z hlediska vysvětlovací síly) vysvětlující proměnné, pak by to vedlo k výššívariabilitě odhadnutých parametrů. Naopak kdybychom do modelu nezahrnulyrelevantní proměnné, pak by odhady našich parametrů byly vychýlené. Připo-meňme ještě matematickou konstrukci F–statistiky:
F =(SSEu − SSEr)/(Ru −Rr)
SSu/(N −Ru)∼ F(Ru−Rr,N−Ru) jestliže je H0 pravdivá,
kde N je počet pozorování, R = K+1 je počet regresorů modelu a indexy r a uznačí, zda se jedná o model omezený (restricted) nebo neomezený (unrestricted).Z této konstrukce je dobře vidět, že statistika nabyde nízkých hodnot, což nepo-vede k zamítnutí nulové hypotézy, jestliže se součty čtverců reziduí zkoumanýchmodelů nebudou výrazněji lišit.
Pokud nás zajímá, jestli náš model celkově dobře vysvěluje chování závisleproměnné, potom vlastně testujeme nulovou hypotézu H0 : β1, . . . , βk = 0.Výsledky tohoto testu včetně p–hodnoty jsou k nálezení v okně modelu popř.pod ANOVA tabulkou. V našem případě je p–hodnota velice nízká, což nás vedek jednoznačnému zamítnutí nulové hypotézy (obr. 3.11).
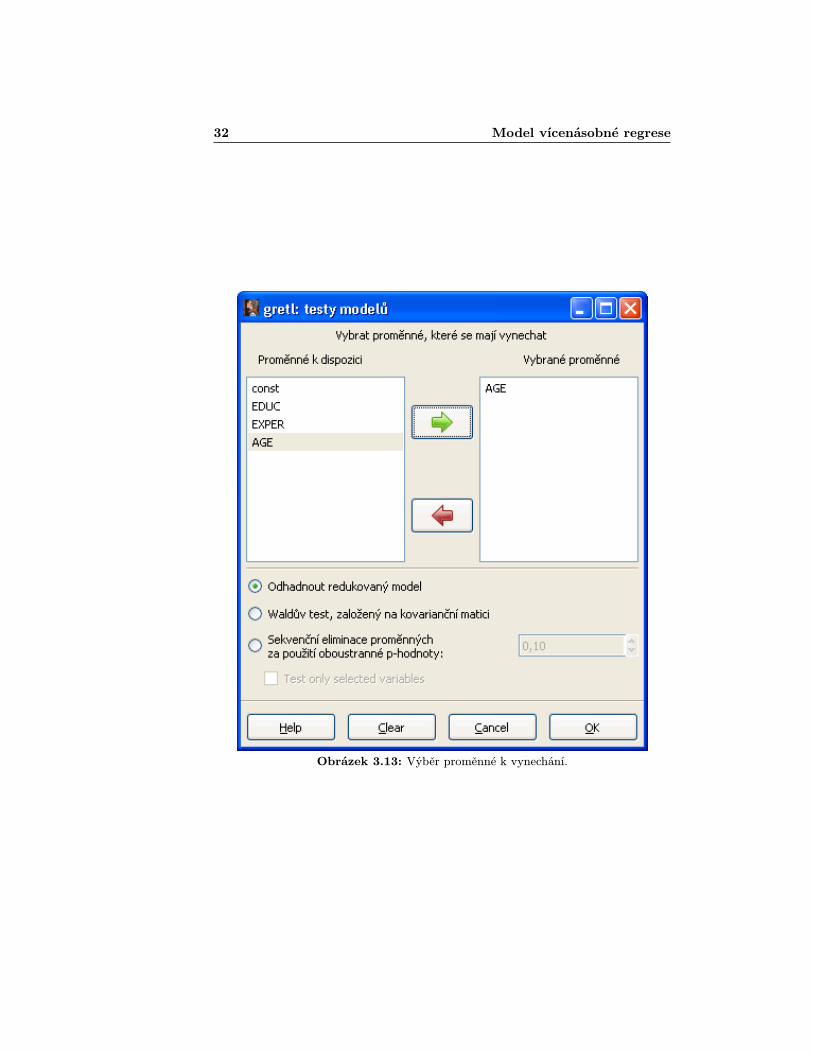
Pusťme se do zajímavějšího zkoumání toho, zda nějaké vysvětlující proměn-né nejsou v našem modelu nadbytečné. Z výsledků našeho modelu jako největšíkandidát na vyřazení se jeví parametr AGE. V Gretlu se s tím jednoduše vy-pořádáme tak, že v okně s modelem najedeme na Testy > Vynechat proměnné[Tests > Omit variables]. Otevře se nám následující okno, jak je zachycenona obr. 3.12 a 3.13.

3.3 Testování parametrů modelu 31
Obrázek 3.12: Vynechání proměnné.
Vybereme proměnnou AGE a přes tlačítko “Přidat” ji dáme do seznamuproměnných, které budou vynechány. Necháme zatržené políčko Odhadnout re-dukovaný model (Waldův test sice přinaší stejné výsledky, dokonce je operačněméně náročný, ale jeho výsledky jsou v Gretlu skromnějšího charakteru). Potéstačí odkliknout „OKÿ a dostane se nám podrobných informací o výsledcíchtestu (obr. 3.14). Tedy nejlepší lineární model, který z dostupných dat můžemenaestimovat je (můžete si sami vyzkoušet, že odbourání jakékoliv další proměnnék lepším výsledkům nepovede):
WAGEi = 561 + 143EDUCi + 42EXPERi + εi
Alternativní přístup, jak sestavit co nejlepší model je ten, že nejprve vy-tvoříme model s tou(těmi) vysvětlující(mi) proměnnou(-ými), u nichž jsme sijisti, že budou mít silnou vysvětlovací schopnost a pak postupně model zkou-šíme obohacovat o další proměnné, přičemž sledujeme, zda přidání určité novéproměnné zlepšilo statistiky modelu. K tomu slouží nástroj Přidat proměnné[Add variables], který najdete hned pod nástrojem Vynechat proměnné. Po-stup práce je analogický jako při odebírání proměnných, tedy není nutné ho zdeuvádět.
Závěrem se budeme zabývat případem testování složitějších hypotéz. Před-pokládejme, že se daná firma chválí tím, že každý dosažený vyšší stupeň vzdělání(pro jednoduchost budeme předpokládat, že každy další vyšší stupeň vzděláníje dosažen po třech letech) se u jejich zaměstnanců promítne v nárustu $500v měsíční mzdě, a že každým rokem jsou zaměstnacům platy navyšovány v
32 Model vícenásobné regrese
Obrázek 3.13: Výběr proměnné k vynechání.

3.3 Testování parametrů modelu 33
Obrázek 3.14: Výsledky redukovaného modelu.

34 Model vícenásobné regrese
Obrázek 3.15: Lineární omezení modelu.
průměru o $50. Naším úkolem bude na základě námi dostupných dat zjistit, zdachování firmy svědčí o tom, co prohlašuje. Tedy naší nulovou hypotézu, kteroubudeme chtít testovat můžeme zapsat následovně:
H0 : 3 ∗ EDUC = 500, EXPER = 70
K tomu bude zapotřebí kliknout na Testy > Lineární omezení [Tests > Li-near restrictions]. Otevře se vám následující okno (obr. 3.15), do kteréhobudeme muset ručně zadat požadovanou testovou hypotézu. Hypotéza se zadávájako systém rovnic, přičemž by mělo být respektováno to, že na levé straněrovnice bude nějaká lineární kombinace parametrů a na straně pravé pouzehodnota. Parametry modelu se zadávají ve formě b[pořadí parametru]. Zdeje nutno si dát pozor, neboť naše β0 odpovídá b[1] atd. . Tedy naší nulovouhypotézu zapíšeme jako:
3 ∗ b[2] = 500b[3] = 70
Pak stačí už jen odkliknout „OKÿ a otevře se nám následující okno (obr. 3.16)s výsledkem. Vidíme, že i toto na první pohled nadnesené tvrzení nemůžeme nahladině významnosti 95% (ani 90%) zamítnout.
3.4 Nelineární rozšíření modelu
Zatím jsme zkoumali jen lineární závislosti mezi vysvětlovanou a vysvětlující-mi proměnnými. V skutečnosti však může chování závisle proměnné lépe vy-jadřovat nějaký jiný funkcionální vztah. Na druhou stranu použitím nějakého

3.4 Nelineární rozšíření modelu 35
Obrázek 3.16: Výsledky modelu s lineárním omezením.
složitého modelu ztratíme jasnou vypovídací schopnost jednotlivých parametrů.Vyjímku tvoří datové soubory s exponenciálním trendem (v ekonomii je např.dobrým příkladem Cobb–Douglesova produkční funkce), které po jejich loga-ritmizaci nabydou lineární podoby, kdy pak při interpratice parametrů stačízaměnit slůvko o jednotku s o jeden procetní bod. Krom této log–lineární formyse v praxi můžeme setkat s tzv. polynomickými modely, kdy obecně jednotlivévysvětlující proměnné jsou vyjádřeny ve formě polynomu stupně n (ale většinouje dostačující použít kvadratickou závislost).
Nyní zkusme náš dosavadní model lépe odhadnout s využitím druhých moc-nin vysvětlujících proměnných EDUC a EXPER (u proměnné AGE nemá smysluvažovat existenci kvadratického vztahu vzhledem k nevýznamnosti lineárníhovztahu). Tedy náš nový model bude moci být zapsán v následujícím tvaru:
WAGEi = β0 + β1EDUCi + β2EXPERi + β3EDUC2i + β4EXPER
2i + εi
Abysme mohli náš nový model sestavit potřebujeme do datového souboru přidatproměnné EDUC2
i a EXPER2i . V Gretlu to provedeme nejdříve vybráním
požadovaných proměnných a následným najetím kurzoru myši na Přidat >Druhé mocniny vybraných proměnných [Add > Squares of selected va-riables], jak to ukazuje následující obrázek 3.17.
Přidání nových proměnných do dosavadního modelu se provede výše po-psaným způsobem. Je lepší do modelu proměnné přidávat postupně a přitomsledovat statistiky modelu (jestliže je model po přidání nové proměnné horší,tak tuto novou proměnnou do modelu nezahrneme, ale zkusíme přidat další, na-opak pokud se náš model vylepší, tak pouze náš model zkoušíme dále obohatit).Neexistuje však naprosto jednoznačné stanovisko, která by nám vždy řeklo, zdaje nový model lepší nebo horší než ten předchozí. Kromě výsledků, které námGretl při srovnání modelů vypíše je dobré sledovat, jak se mění t–statistiky či

36 Model vícenásobné regrese
Obrázek 3.17: Přidání druhých mocnin vybraných proměnných.
směrodatné odchylky parametrů a hodnotu koeficientu determinace. Může sestát, že nový model bude lepší vysvětlovací sílu na úkor zhoršení přesnosti od-hadů parametrů modelu. Pak závísí především na nás a na požadovaném cíli,s kterým model budujeme, pro který model se nakonec rozhodneme. Když sis naším modelem chvilku pohrajete, pak nejlepší forma, které pravděpodobnědosáhnete bude následující:
WAGEi = 937 + 44EXPERi + 11EDUC2i + εi
Z modelu vyplývá, že v daném podniku s délkou zaměstnání roste mzda lineárně,zatímco s dosaženým vyšším stupněm vzdělání kvadraticky.
Na závěr zkusme ještě obohatit náš uvedený příklad o vlivu vzdělání a věr-nosti podniku na průměrnou mzdu. Pro případné zájemce o práci v této firmě bybyla relevantnější informace o kolik procent jim ročně mzda poroste. Proto firmadodává, že průměrný roční růst mezd je 5%. Zkusme otestovat tuto hypotézu.Abysme přímo zjistili, jak se každý další rok strávený u této společnosti promítnev procentním zhodnocení mzdy, musíme náš model odhadnout ve tvaru:
logWAGEi = β0 + β1EDUCi + β2EXPERi + εi
Zlogaritmované hodnoty mezd dostaneme obdobným způsobem jako druhé moc-niny tak, že klikneme na Přidat > Logaritmy vybraných proměnných [Add> Logs of selected variables]. Pak odhadneme výše zmíněný model, na

3.4 Nelineární rozšíření modelu 37
kterém otestujeme hypotézu H0 : β2 = 0.05, kterou v Gretlu zapíšeme jakob[3] = 0, 051. V tomto případě již nulovou hypotézu zamítáme.
1V Gretlu se nepouživá klasická anglická tečková notace nýbrž česká s desetinnou čárkou.

38 Model vícenásobné regrese

Kapitola 4
Testování klasickýchpředpokladů
V této kapitole si ukážeme některé postupy, které nám poslouží k ověření předpo-kladů modelu. Pokud některé předpoklady nejsou dodrženy, dochází ke zkresleníobdržených výsledků. Zaměříme se na testování normality a homoskedasticityreziduí a v závěru také autokorelace, která bývá spíše spojováná jen s dynamic-kými modely. V následujících dvou podkapitolách budeme vycházet z lineárníhomodelu odhadnutého v předchozí kapitole, který měl následující podobu:
WAGEi = 561 + 143EDUCi + 42EXPERi + εi
4.1 Normalita reziduí
Dle předpokladů by náhodná složka εi, která je pro nás představována rezidui,měla mít normální rozdělení s nulovou střední hodnotou. Nulové střední hodnotybude v případě zahrnutí úrovňové konstaty do modelu vždy dosaženo. Pak pra-cujeme s dostatečně velkým souborem, tak i s normalitou se nemusíme moc trá-pit, neboť odhad vektoru parametrů β má asymptoticky normální rozdělení. Vnašem případě datový soubor je tvořen 49–ti pozorování, proto ověření normalitybude na místě. Abychom mohli s rezidui pohodlně pracovat, bude vhodné si jeuložit jako další proměnnou. K tomu stačí najet na záložku Uložit > Rezidua[Save > Residuals]. K otestovaní normality, kdy za nulovou hypotézu bereme,že rezidua mají normální rozdělení, stačí vybrat Proměnná > Test normality[Variable > Normality test]. Ukáže se nám okno (obr. 4.1) s výsledky čtyřrůzných testů včetně na přednášce uvedeného Jarque-Berova testu, využivají-cího koeficientu šikmosti a špičatosti. Vidíme, že nulová hypotéza je zamítnutajen v případě Lillieforsova testu. Tedy můžeme říct, že předpoklad normalityreziduí je pro náš model přípustný. Pokud bychom chtěli si Gretlovský výpočetověřit ručně, tak potřebné koeficienty získáme z tabulky popisných statistik,k níž se dostaneme přes Zobrazit > Popisné statistiky [View > Summary

40 Testování klasických předpokladů
Obrázek 4.1: Výsledky testů normality reziduí.
statistics] (mj. zde můžeme ověřit nulovost střední hodnoty reziduí).
Z okna s modelem najetím na Testy > Normalita reziduí [Tests >Normality of residuals] dostaneme výsledek Doornik-Hansenova testu-jehostavbou se zde však zabývat nebudeme.
4.2 Heteroskedasticita
4.2.1 Testovaní homoskedasticity
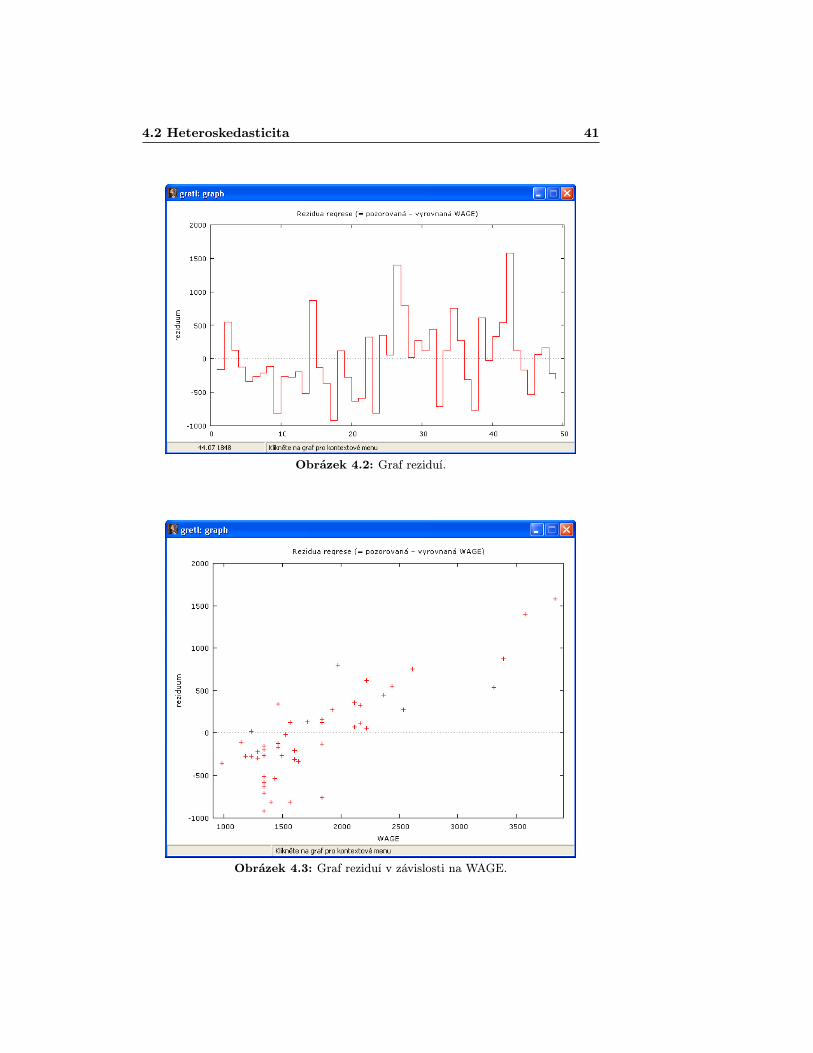
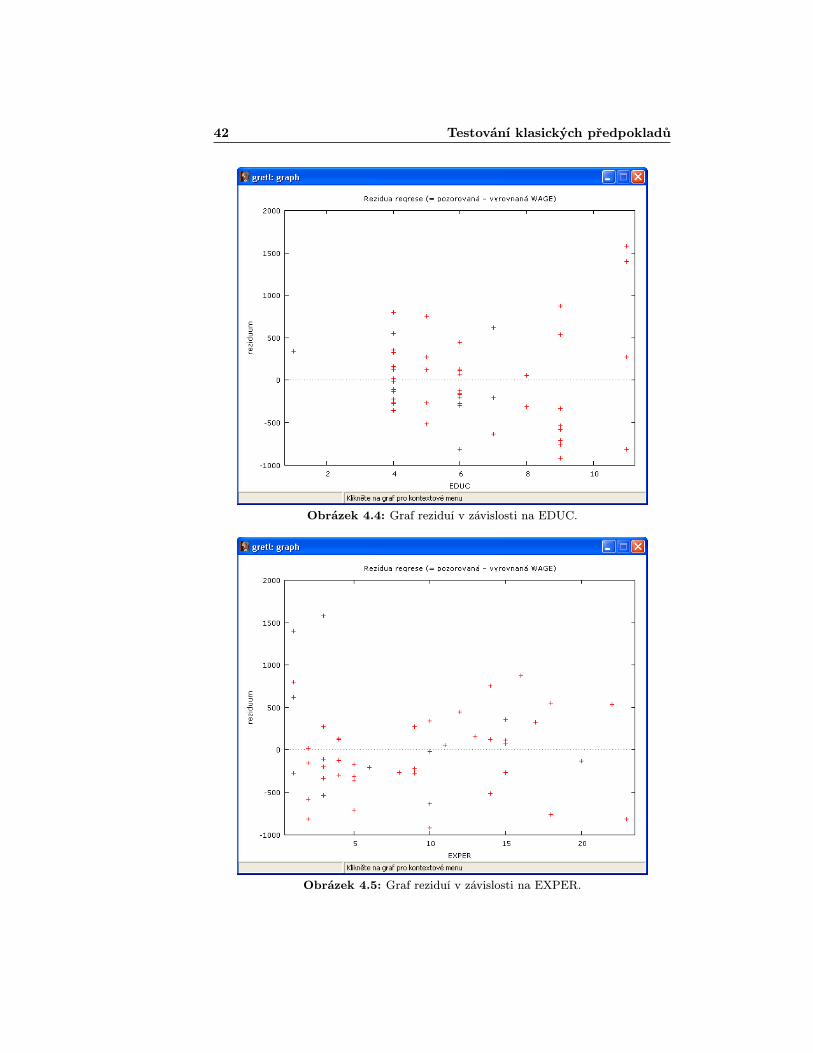
Jedním z nejjednoduších, i když technicky ne zrovna nejpřesnějších způsobů, jepodívat se čistě na graf reziduí a okem usoudit zda rozptyly můžeme považovatza homoskedastické. Graf jednoduše dostaneme, když v okně s modelem naje-deme na Grafy > Graf reziduí > Podle čísla pozorování [Graphs > Re-sidual graph > Against number of observations]. Pokud bychom chtělina grafu něco poupravit, nyní se např. může nabýzet úprava pro lepší znázor-nění na schodovity tvar. Té bysme docílili kliknutím na graf a z možností vybraliEditovat [Edit] a v nově otevřeném okně vybrali záložku Čáry [Lines], kdejako typ čáry zvolíme Kroky [Steps]. Z grafu vidíme (obr. 4.2), že několikavětších výkyvů složka reziduí dosahuje, i když to není až zas tak dramatické.Pokud by nás zajímala, zda rozptyl závisí na jednotlivých proměnných, pakstačí myší najet na Grafy > Graf reziduí > V závislosti na WAGE, EDUC,EXPER [Graphs > Residual graph > Against WAGE, EDUC, EXPER]. Zde vi-díme, že se určitá závislost projevuje (obr. 4.3, 4.4 a 4.5).
Nyní se podívejme na jednotlivé testy, které nám Gretl poskytuje. Ty jsoudostupné v záložce Testy > Heteroskedasticita [Tests > Heteroskedas-ticity] a kliknutím na příslušný test, který si přejeme provést (obr. 4.6). Whi-teův test patří k obecnější testům, kdy za alternativní hypotézu bereme obecně
4.2 Heteroskedasticita 41
Obrázek 4.2: Graf reziduí.
Obrázek 4.3: Graf reziduí v závislosti na WAGE.
42 Testování klasických předpokladů
Obrázek 4.4: Graf reziduí v závislosti na EDUC.
Obrázek 4.5: Graf reziduí v závislosti na EXPER.
4.2 Heteroskedasticita 43
Obrázek 4.6: Výběr příslušného testu heteroskedasticity.
H1 : σi 6= σ, kdy je pak v našem případě2 odhadován model:
ε2i = α1 + α2EDUCi + α3EXPERi + α4EDUCiEXPERi + α5EDUC2i +
+ α6EXPER2i + νi
Pak výsledná statistika N ∗ R2, kde N je počet pozorování by měla mít zaplatnosti nulové hypotézy chí–kvadrát rozdělení se tupni o jeden méně než jepočet parametrů. Whiteův test s dodatkem pouze mocniny provede stejný testjen s tím rozdílem, že v odhadovaném regresním modelu jsou vynechány smíšenéčleny.
Dalším v Gretlu uvedeným a zde posledně zmíněným je Breusch–Paganůvtest. V něm by byla obecně pro náš případ alternativní hypotéza brána ve forměH1 : σi = h(α1 + α2EDUCi + α3EXPERi), kdy za funkci h se obvykle berefunkce exponenciální nebo lineární, jak je tomu v případě Gretlu. Tedy přivýpočtu je odhadován model:
ε2i = α1 + α2EDUCi + α3EXPERi + νi
2Obecně jsou v regresi pro rozptyl jako nezávisle proměnné brány všechny nezávisle pro-měnné a jejich kvadráty z původního modelu plus smíšené součiny těchto regresorů.
44 Testování klasických předpokladů
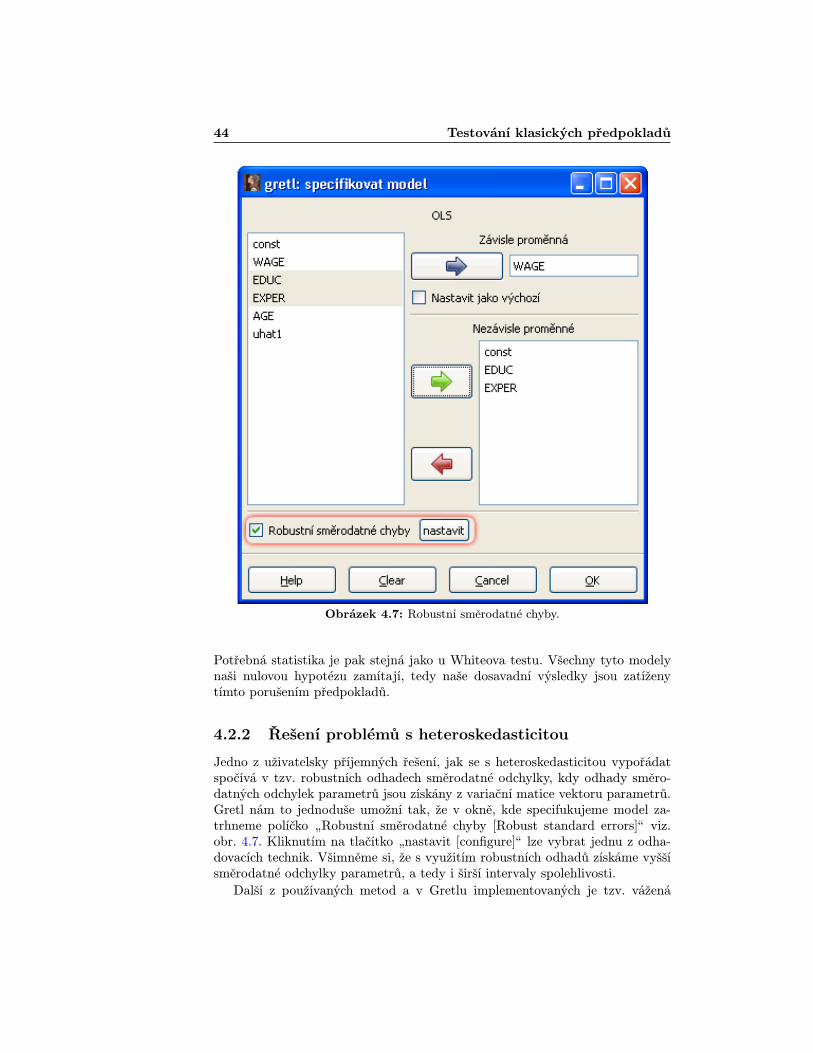
Obrázek 4.7: Robustní směrodatné chyby.
Potřebná statistika je pak stejná jako u Whiteova testu. Všechny tyto modelynaši nulovou hypotézu zamítají, tedy naše dosavadní výsledky jsou zatíženytímto porušením předpokladů.
4.2.2 Řešení problémů s heteroskedasticitou
Jedno z uživatelsky příjemných řešení, jak se s heteroskedasticitou vypořádatspočívá v tzv. robustních odhadech směrodatné odchylky, kdy odhady směro-datných odchylek parametrů jsou získány z variační matice vektoru parametrů.Gretl nám to jednoduše umožní tak, že v okně, kde specifukujeme model za-trhneme políčko „Robustní směrodatné chyby [Robust standard errors]ÿ viz.obr. 4.7. Kliknutím na tlačítko „nastavit [configure]ÿ lze vybrat jednu z odha-dovacích technik. Všimněme si, že s využitím robustních odhadů získáme vyššísměrodatné odchylky parametrů, a tedy i širší intervaly spolehlivosti.
Další z používaných metod a v Gretlu implementovaných je tzv. vážená

4.3 Autokorelace 45
metoda nejmenších čtverců. Tu je možné použít v případě, kdy jsme schopniodhadnout funkční závislost rozptylu na vysvětlujících proměných. Pro jedno-duchost se můžeme omezit pouze na možnou existenci lineárního, či v případěurčitého multiplikačního efektu exponenciálního tvaru. S využítím v předcho-zích kapitolách již zmíněných technik, dospějeme k tomuto nejlepšímu vyjádření(i když ne zrovna příliš přesvědčivému):
σ2i = −418784 + 112159EDUC + νi
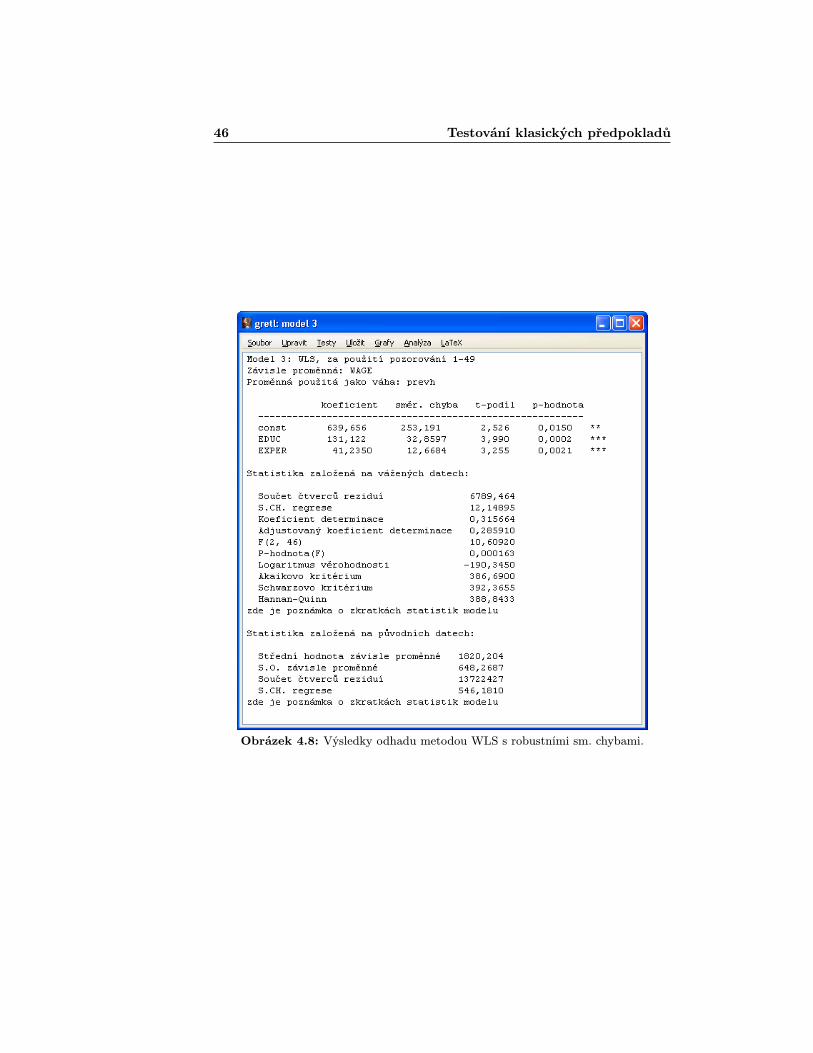
Kvadrát vektoru vah, který Gretl vyžaduje, je roven převrácené hodnotě výšeodhadnutého rozptylu. Nejdříve si tedy uložíme hodnoty odhadnutých rozptylůtak, že myší najedeme na Uložit > Vyrovnané hodnoty [Save > Predictedvalues]. Převrácené hodnoty pak docílíme najetím na Přidat > Definovatnovou proměnnou...[Add > Define new variable...]. Do otevřeného oknapak zapíšeme vzorec, kterým bude nová proměnná získána - v našem případětedy: prevh = 1/sighat.3 Nyní se již můžeme bez potíží pustit ke stanovenímodelu. Vybereme záložku Model > Další lineární modely > Vážené nej-menší čtverce... [Model > Other linear models > Weighted leastsquares...]. Otevře se nám podobné okno, jak je tomu u klasického modelu,jen s tím rozdílem, že zde je navíc políčko pro váhovou proměnou, do kterépřiáme zde značenou proměnnou prevh.4 Pak stačí kliknout na „OKÿ. Otevře sejiž známé okno s výsledky (obr. 4.8), které mj. nabízí i srovnání určitých hodnots klasickým modelem.
4.3 Autokorelace
V lineárním regresním modelu předpokládáme, že jednotlivá pozorování nejsoumezi sebou korelována. Tento předpoklad může být porušen zejména v případě,že pracujeme s časovými řadami. Dochází pak k tomu, že složky nevysvětlenéčásti modelu (jež je obsaženy ve vektoru reziduí) budou mezi sebou korelovány.Vliv autokorelace, podobně jako heteroskedasticity, způsobí, že odhady parame-trů nebudou nejlepší (tj. s minimálním rozptylem), a že odhady směrodatnýchodchylek parametrů nebudou konzistentní. Ke zkoumání autokorelace využi-jeme příklad z kapitoly o jednoduchém lineárním regresním modelu, kde jsmeodhadovali závislost spotřeby na produktu. Náš odhadnutý model dosáhl tétokonečné podoby:
Ct = −384 + 0, 93Yt + εt.
Aby Gretl mohl autokorelace testovat, je zapotřebí mít nastaveno, že pracu-jeme s časovými řadami. Toto nastavení můžeme zkontrolovat (bude-li třeba
3Pojmenování samozřejmě může být různé, zde jsme novou proměnnou nazvali prevh avyrovnané hodnoty rozptylu jsme uložili jako sighat.4V našem případě Gretl zahlásí chybu, že váhy obsahují záporné hodnoty. U 40–tého pozo-
rování došlo k tomu, že odhadnutá hodnota rozptylu je záporná. Jelikož až na tuto skutečnostmodel vykazoval poměrně dobré vlastnosti, tak tento problém byl zde vyřešen hrubou silou,a to přepsáním hodnoty 40–té proměnné na hodnotu 0. Provede se to pravým kliknutím naproměnnou prevh a následným kliknutím na Upravit hodnoty.
46 Testování klasických předpokladů
Obrázek 4.8: Výsledky odhadu metodou WLS s robustními sm. chybami.
4.3 Autokorelace 47
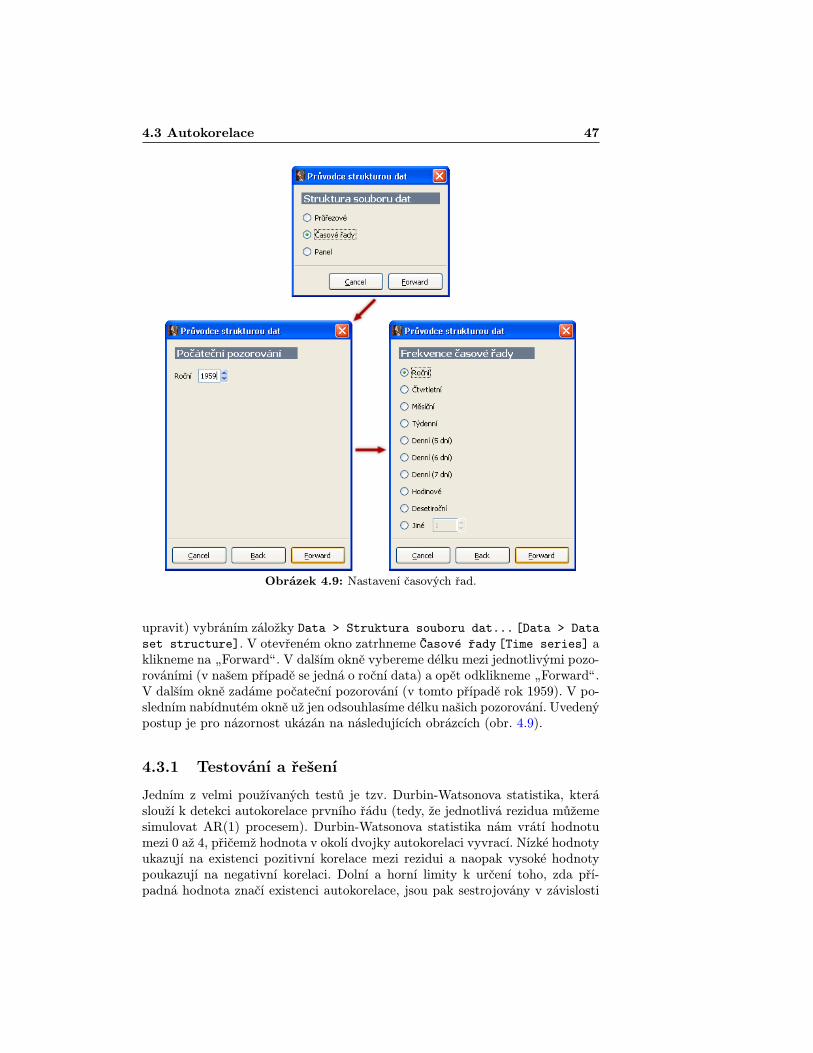
Obrázek 4.9: Nastavení časových řad.
upravit) vybráním záložky Data > Struktura souboru dat... [Data > Dataset structure]. V otevřeném okno zatrhneme Časové řady [Time series] aklikneme na „Forwardÿ. V dalším okně vybereme délku mezi jednotlivými pozo-rováními (v našem případě se jedná o roční data) a opět odklikneme „Forwardÿ.V dalším okně zadáme počateční pozorování (v tomto případě rok 1959). V po-sledním nabídnutém okně už jen odsouhlasíme délku našich pozorování. Uvedenýpostup je pro názornost ukázán na následujících obrázcích (obr. 4.9).
4.3.1 Testování a řešení
Jedním z velmi používaných testů je tzv. Durbin-Watsonova statistika, kteráslouží k detekci autokorelace prvního řádu (tedy, že jednotlivá rezidua můžemesimulovat AR(1) procesem). Durbin-Watsonova statistika nám vrátí hodnotumezi 0 až 4, přičemž hodnota v okolí dvojky autokorelaci vyvrací. Nízké hodnotyukazují na existenci pozitivní korelace mezi rezidui a naopak vysoké hodnotypoukazují na negativní korelaci. Dolní a horní limity k určení toho, zda pří-padná hodnota značí existenci autokorelace, jsou pak sestrojovány v závislosti

48 Testování klasických předpokladů
Obrázek 4.10: Výběr korelogramu reziduí.
na počtu pozorování. V Gretlu se pří výše uvedeném nastavení hodnota Durbin-Watsonova testu zobrazí přímo v okně s modelem. V našem případě hodnota0,514 jasně signalizuje existenci pozitivní autokorelace. Kdybychom chtěli znátpřipadně p-hodnotu testu (ve spornějších případech), pak je zapotřebí myší na-jet na Testy > Durbin-Watson p-value [Test > Durbin-Watson p-value].
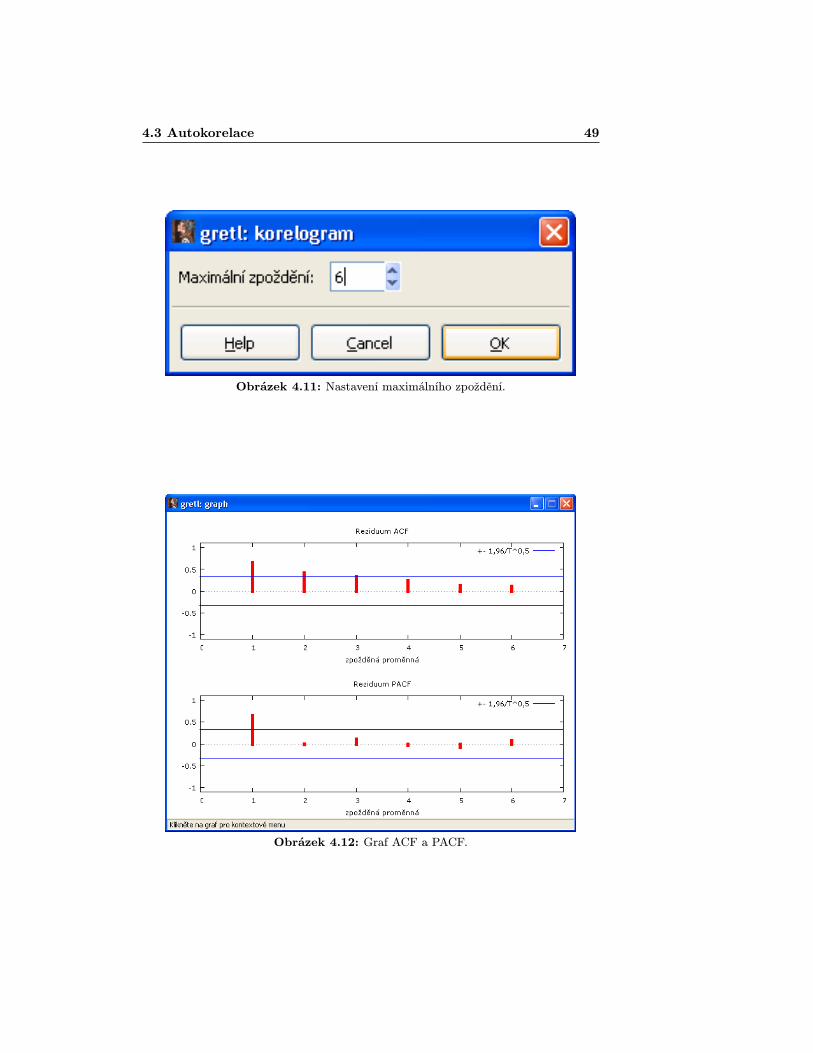
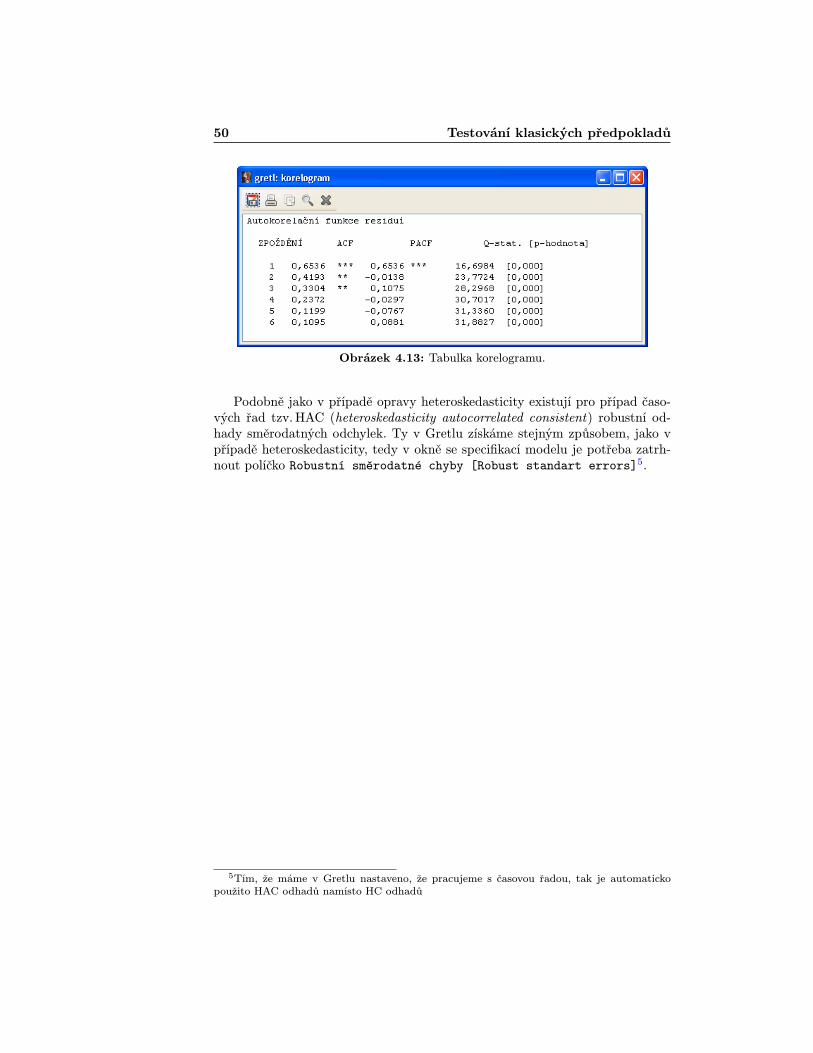
Dalším z užitečných nástrojů k prošetření autokorelace je tzv. korelogram,který vykreslí vzájemné korelace mezi rezidui až do zvoleného řádu. V Gretlu hozískáme vybráním položky Grafy > Korelogram reziduí [Graphs > Corre-logram]. Otevře se nám okno, kde je potřeba zadat délku zpoždení, do kteréchceme autokorelace zkoumat (zvolme např. 6). Poté se již zobrazí okno se spoč-tenými autokorelacemi (ACF), tak i parciálními autokorelacemi (PACF),jejichžhodnoty jsou v grafu vyznačeny červeně. Modrými linkami jsou pak vymezenyintervaly spolehlivosti, jejichž překročení signalizuje zamítnutí hypotézy o nu-lovosti příslušného koeficientu. V následujícím okně s tabulkou jsou již jen zná-zorněné hodnoty vyčísleny (navíc hodnoty Ljung-Box Q statistiky, o níž blížepojednávat nebudeme). Uvedený postup je pro ilustraci znázorněn na obráz-cích 4.10 – 4.13.
Hodnoty získané z korelogramu potvrzují výsledek Durbin-Watsonova testu,navíc signalizují i výskyt autokorelace druhého řádu. Kromě výše uvedených tes-tových možností Gretl nabízí i další, které naleznete vybráním Testy > Auto-korelace [Test > Autocorrelation].
4.3 Autokorelace 49
Obrázek 4.11: Nastavení maximálního zpoždění.
Obrázek 4.12: Graf ACF a PACF.
50 Testování klasických předpokladů
Obrázek 4.13: Tabulka korelogramu.
Podobně jako v případě opravy heteroskedasticity existují pro případ časo-vých řad tzv. HAC (heteroskedasticity autocorrelated consistent) robustní od-hady směrodatných odchylek. Ty v Gretlu získáme stejným způsobem, jako vpřípadě heteroskedasticity, tedy v okně se specifikací modelu je potřeba zatrh-nout políčko Robustní směrodatné chyby [Robust standart errors]5.
5Tím, že máme v Gretlu nastaveno, že pracujeme s časovou řadou, tak je automatickopoužito HAC odhadů namísto HC odhadů

Literatura
[1] Adkins, L. C. Using gretl for Principles of Econometrics, 3 ed. Version1.31, July 2009.
[2] Hill, R. C., Griffiths, W. E., and Lim, G. C. Principles of Econome-trics, 3 ed. John Wiley & Sons, 2008.
[3] Koop, G. Introduction to Econometrics, 1 ed. John Wiley & Sons, 2008.

![EKONOMICKO-FILOZOFICKÉ RUKOPISY · 2013-09-25 · Ekonomicko-Filozofické Page 4 [PRVNÍ RUKOPIS] MZDA [*11] //I/ Mzda č řý ěí . N íě í . K ůž ží ěí é ž ěí . Sč](https://img.pdfslide.tips/doc/110x75/5e5bb75bf18180459c101f45/ekonomicko-filozofick-2013-09-25-ekonomicko-filozofick-page-4-prvn-rukopis.jpg)






















![Tema 3 [3mm] Gestión de los datos en Gretl](https://img.pdfslide.tips/doc/110x75/62c2bd8afedbd304604356bf/tema-3-3mm-gestin-de-los-datos-en-gretl.jpg)




