Embed Size (px)
Citation preview

ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
27
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
最近になって、大量のデータの保存や処理を行うアプリ
ケーションを開発する需要が非常に高まっており、ビッグ・データを操作するためのプラットフォームとしてApache Hadoop が一般的な選択肢となっています。しかし、Hadoopでの開発の始め方はわかりづらいでしょう。そのため、本記事では Java 開発者の視点からHadoop について説明し、外部のソースによって生成された非定型のイベント・オブジェクトの保存や処理を行うアプリケーションを記述します。ご存じない読者のために説明すると、Hadoopとは、Hadoop分散ファイル・システム(HDFS)と呼ばれる分散ファイル・システムと、HDFS 内に保存された大規模データセットを処理するためのMapReduceと呼ばれるバッチ処理モデルを提供する、Apache 主導のプロジェクトです。もっとも、この定義は 2~ 3年前まではHadoopを適切に表現していたのですが、現在のHadoop は一般的に、HDFSとMapReduce による中心部を基礎として構築されたコンポーネントや、あるいはその
周辺に構築されたコンポーネントのスタックであると解釈されています。 このスタックは、Flume、Sqoop、Pig、Oozie(すべて独自の権利を有するApacheプロジェクト)などの一風変わった名前のコンポーネントで構成されています。Hadoop自体も、考案者の息子が持っていた黄色の象のぬいぐるみから名付けられました。表 1に、本記事に関連する一般的なHadoopコンポーネントの一部についてまとめます。 Hadoop の原型は確かにバッ
チ処理システムでした。しかし、最近のコンポーネントは、より応答性が高く待機時間の短い処理によって大規模データセットを分析するものであると理解することが重要です。たとえば、Impala などの対話型 SQLエンジンは、Hadoopプラットフォームに対して待機時間の短い SQL 問合せを実行でき、便利です。また、Apache Solr などのドキュメント検索システムは、現在ではHadoop 上でネイティブに稼働します。Spark(Apache Incubatorプロジェクト)のように、Java、
Python、Scala などのプログラミング言語で表された複雑なデータ処理パイプラインを実行するためのメモリ内処理エンジンもあります。これらすべてのコンポーネントの共通基盤となるのがHDFSという分散ファイル・システムです。各コンポーネントはHDFS に保存されているデータの読取りと書込みを行います。そのため、異なる複数のコンポーネント間で同じHDFS に保存されたデータセット
を使用できるという新たな可能性が開かれます。
Hadoopアプリケーションの構築とあるWeb上のサービスが、ユーザーの一連のクリック操作、アプリケーション・イベント、マシンのログ・イベントなどの複数のソースを基に大量のイベントを生成するというシナリオについて考えましょう。このサービスの目的は、利用パターンや行動の長期的変化をユーザーが調査できるよ
Hadoopの概要HadoopとKite SDKを利用してビッグ・データ対応アプリケーションを記述する
TOM WHITE
表 1
コンポーネント 説明
APACHE AVRO 複数言語に対応したデータ・シリアライズ用ライブラリ
APACHE HIVE データウェアハウス /SQL エンジン
APACHE PIG データフロー言語 /実行エンジン
APACHE FLUME ストリーミング・ログ取得 /配信システム
APACHE OOZIE ワークフロー・スケジューラ・システム
APACHE CRUNCH データ・パイプラインを記述するための JAVA API
CASCADING データ操作アプリケーションを記述するための API
PARQUET ネストされたデータに対応したカラム指向ストレージ・データ形式
CLOUDERA IMPALA HADOOPで実行される対話型SQLエンジン
HUE HADOOPを操作するためのWEB UIand JavaBig Data
Tom White:Apache Hadoopのコミッタ、『Hadoop: the Definitive Guide』(O'Reilly、2012年)の著者。Cloudera の創立時からソフトウェア・エンジニアとして、Apache および Cloudera の中心的なディストリビューションの開発に関与。イギリスのウェールズ地方で家族とともに暮らしている。

ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
28
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
うに、イベントの収集、保存、分析を行うことです。このサービスをHadoop により構築する手順は次のとおりです。まず、受信したイベント・データを、Flumeを利用してHDFS に書き込みます。また、Solrを利用して、イベント・データへのインデックス設定やHDFS 内の検索を行います。次に、定期的にデータセットの一部(例:過去 1日間、1週間、1か月間、1年間のデータ)をバッチ処理します。この処理にはMapReduce ベースのツール(Crunch、Cascading、Hive、Pig など)を利用します。元のデータセットと派生データセットの両方について、Impala のコマンドライン・インタフェース、Webダッシュボード、あるいはビジネス・インテリジェンス・パッケージを利用して対話的に問い合わせることができます。以上が概要レベルの説明です。では、
そのようなアプリケーションの構築に取り掛かるにはどうすればよいでしょうか。この段階こそ、Hadoopを初めて利用する人が行き詰まりやすいところです。Hadoopの各コンポーネントの詳細を調査しながら、次のような疑問に答えていく必要があるからです。
■ 使用すべきファイル形式は何か ■ HDFSで日付に基づいてパーティションを区切る場合、どのようにファイルをレイアウトすればよいか
■ Flume、Solr、Crunch、Impala などにおいて、エンティティのデータ・モデルをどのように表現するか 要するに、すべてのコンポーネントを各々の長所を出して連携させるためにはどうすればよいのか、という課題があり
ます。筆者が勤務するClouderaでは、ユーザーや顧客、パートナー企業からこれらの質問を受け付けてきました。その積み重ねが、Kite SDK(旧称 Cloudera Development Kit:CDK)の開発へとつながりました。Kite SDK は、Hadoopアプリケーション開発のベスト・プラクティスの一部を体系化したものであり、開発者が所属プロジェクトですぐに開発を始めるための API や各種サンプルを提供しています。これ以降は、Kite を使用してHadoop上にアプリケーションを構築する方法を確認していきます。注:本記事で紹介するすべてのソー
ス・コードはGitHub からダウンロードできます。こちらには、Cloudera のQuickStart VMでソース・コードを実行するための手順も含まれています。QuickStart VMとは、開発を始めるために必要となるHadoop サービス一式があらかじめインストールされた仮想マシンであり、無料でダウンロードできます。
データの表現システム内のエンティティを表す共通のデータ・モデルとしてAvroを利用していることが、Kite の土台の 1つとなっています。Avro は、単純かつ簡潔なデータ表現方法と、Avroデータのバイナリ・シリアライズ形式を定義しています。ただし、アプリケーション開発者が Avroの内部的な仕組みを深く知る必要はありません。エンティティをPlain Old Java Object(POJO)として定義するだけで、Avro へのマッピングが自動的に実行されるからです。
リスト1に示す単純な Eventクラスには、id、timestamp、sourceという3つのフィールドと、それぞれのフィールドに対応するgetter/setter があります。また、リスト2に、Summaryという別の POJO のクラスを示します。このクラスは、同じソースからEvent オブジェク
トを収集して、一定の期間ごとにまとめた単純なサマリー情報を生成します。Avro によって、これら2つの Javaクラスだけでデータ・モデルを完全に表現できます。
データセットの作成
すべてのリストのテキストをダウンロード
package com.tom_e_white.javamagazine;
import com.google.common.base.Objects;
public class Event { private long id; private long timestamp; private String source;
public long getId() { return id; } public void setId(long id) { this.id = id; }
public long getTimestamp() { return timestamp; } public void setTimestamp(long ts) { this.timestamp = ts; }
public String getSource() { return source; } public void setSource(String source) { this.source = source; }
@Override public String toString() { return Objects.toStringHelper(this) .add("id", id) .add("timestamp", timestamp) .add("source", source) .toString(); }}
リスト1 リスト2
ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
29
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
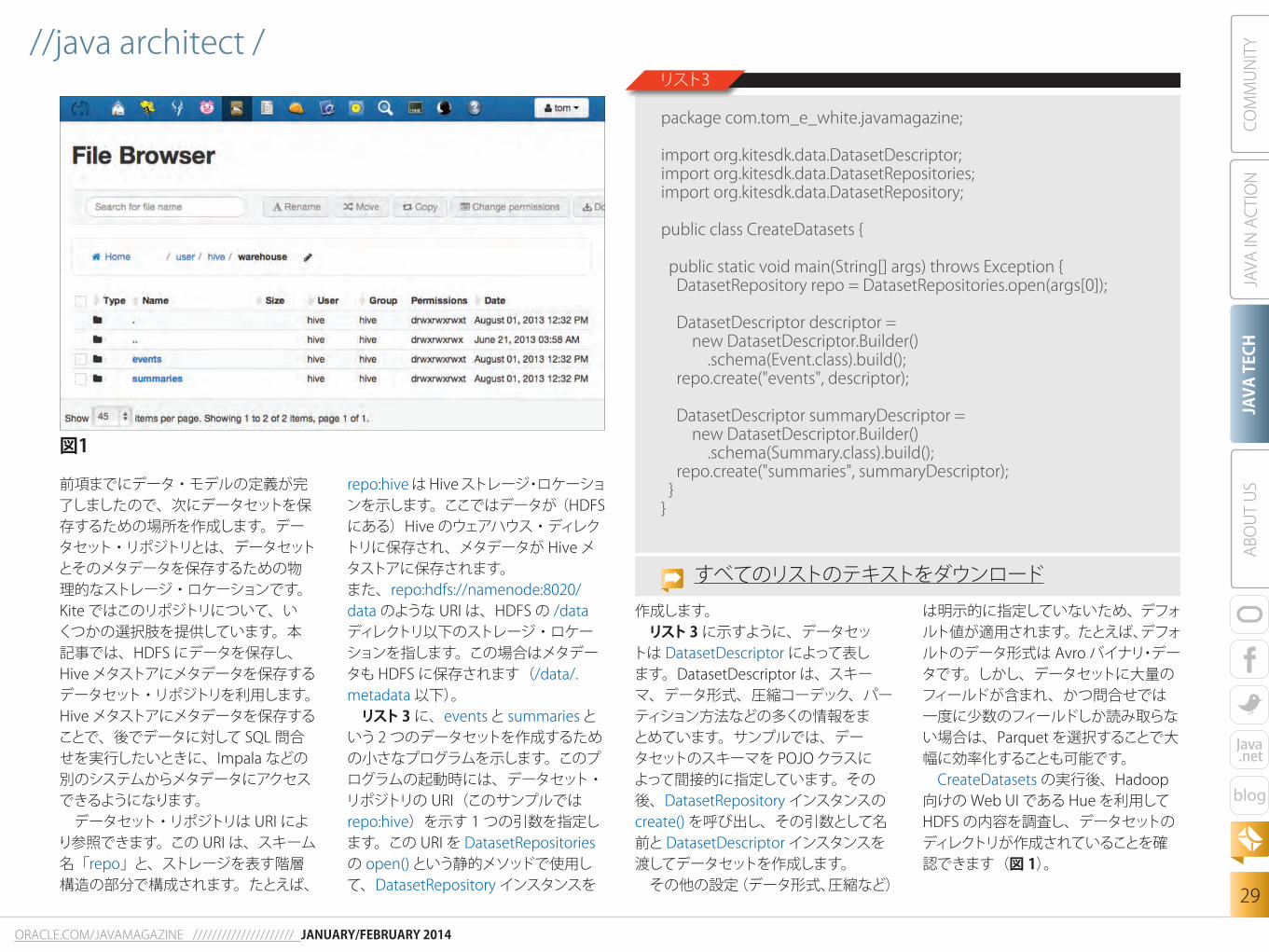
前項までにデータ・モデルの定義が完了しましたので、次にデータセットを保存するための場所を作成します。データセット・リポジトリとは、データセットとそのメタデータを保存するための物理的なストレージ・ロケーションです。Kiteではこのリポジトリについて、いくつかの選択肢を提供しています。本記事では、HDFS にデータを保存し、Hiveメタストアにメタデータを保存するデータセット・リポジトリを利用します。Hiveメタストアにメタデータを保存することで、後でデータに対してSQL 問合せを実行したいときに、Impala などの別のシステムからメタデータにアクセスできるようになります。データセット・リポジトリはURI によ
り参照できます。このURI は、スキーム名「repo」と、ストレージを表す階層構造の部分で構成されます。たとえば、
repo:hiveはHiveストレージ・ロケーションを示します。ここではデータが(HDFSにある)Hive のウェアハウス・ディレクトリに保存され、メタデータがHiveメタストアに保存されます。 また、repo:hdfs://namenode:8020/data のような URI は、HDFS の /dataディレクトリ以下のストレージ・ロケーションを指します。この場合はメタデータもHDFS に保存されます(/data/.metadata 以下)。リスト3に、eventsとsummariesという2つのデータセットを作成するための小さなプログラムを示します。このプログラムの起動時には、データセット・リポジトリのURI(このサンプルではrepo:hive)を示す 1つの引数を指定します。このURI を DatasetRepositoriesの open()という静的メソッドで使用して、DatasetRepository インスタンスを
作成します。リスト3に示すように、データセッ
トはDatasetDescriptor によって表します。DatasetDescriptor は、スキーマ、データ形式、圧縮コーデック、パーティション方法などの多くの情報をまとめています。サンプルでは、データセットのスキーマをPOJOクラスによって間接的に指定しています。その後、DatasetRepository インスタンスのcreate() を呼び出し、その引数として名前とDatasetDescriptor インスタンスを渡してデータセットを作成します。その他の設定(データ形式、圧縮など)
は明示的に指定していないため、デフォルト値が適用されます。たとえば、デフォルトのデータ形式はAvro バイナリ・データです。しかし、データセットに大量のフィールドが含まれ、かつ問合せでは一度に少数のフィールドしか読み取らない場合は、Parquet を選択することで大幅に効率化することも可能です。CreateDatasets の実行後、Hadoop向けのWeb UI であるHueを利用してHDFS の内容を調査し、データセットのディレクトリが作成されていることを確認できます(図 1)。
図1
すべてのリストのテキストをダウンロード
package com.tom_e_white.javamagazine;
import org.kitesdk.data.DatasetDescriptor;import org.kitesdk.data.DatasetRepositories;import org.kitesdk.data.DatasetRepository;
public class CreateDatasets {
public static void main(String[] args) throws Exception { DatasetRepository repo = DatasetRepositories.open(args[0]);
DatasetDescriptor descriptor = new DatasetDescriptor.Builder() .schema(Event.class).build(); repo.create("events", descriptor);
DatasetDescriptor summaryDescriptor = new DatasetDescriptor.Builder() .schema(Summary.class).build(); repo.create("summaries", summaryDescriptor); }}
リスト3

ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
30
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
Flumeを使用したデータセットへのデータ設定クライアントの視点からは、Event オブジェクトのロギングは簡単で、Apache log4j ロガーを適切に設定して使用するだけです。リスト4に、GenerateEventsというJavaアプリケーションを示します。このアプリケーションは新しい Event オブジェクトを100ミリ秒おきに作成し、org.apache.log4j.Logger インスタンスを使用して、作成したオブジェクトをロギングします。log4j 設定ファイルのlog4j.properties をリスト5に示します。 この設定ファイルでは、GenerateEventsの log4j アペンダを定義し、ポート41415で実行中のローカルの Flumeエージェントにログ・イベント・オブジェクトを送信するように設定しています。さらに、このアペンダはデータセットを認識できます。このサンプルの場合、repo:hiveリポジトリ内のeventsデータセット(先ほど作成したデータセット)にイベントを書き込む必要があることをアペンダが認識しています。
Crunchを使用した派生データセットの作成GenerateEvents をしばらく実行すると、HDFS 内の events ディレクトリにファイルが書き込まれていきます。次に、このイベント・データを処理して、
summariesという派生データセットを生成します。名前からわかるように、summaries はイベント・データの簡潔なサマリーです。リスト6は、このイベント・データ全体に対して実行され、ソースごとにその日の 1分おきのイベント数をカウントするCrunchプログラムです。数日間にわたってイベントを生成した場合は、このように 1日のデータを1分おきにまとめておくことで、1日におけるデータの変化のパターンを確認できます。
run() メソッド(リスト6)の最初の 3行は、先ほど作成した events、summaries の各データセットのロード方法を示します。以降のプログラムはCrunch API を使用して記述されています。この部分について見ていく前に、Crunch の基本を確認しましょう。Crunch はパイプラインに対して動作
します。パイプラインとは、1つ以上の入力ソースから1つ以上の出力ターゲットへのデータの流れを指定したものです。1 つのパイプラインの中では、任意に連結された複数の関数によってデータが変換されます。この関数は org.apache.crunch.DoFn<S, T> のインスタンスとして表されます。DoFn は、ソース型 Sからターゲット型 Tへのマッピング方法を定義します。DoFnクラスで定義されている関数群
は、Crunch の PCollection<T> 型に作用します。PCollection<T> 型は、T型の要素を持つ、分散型の順序なしコレクションです。PCollection<T> 型は多くの場合、java.util.Collection<T> の具現化されていない分散型バージョンと言えます。
PCollection には少数のプリミティブな変換メソッドがあります。たとえば、parallelDo()(PCollection 内のすべての要素に関数を適用するメソッド)や、by()(関数を使用して各要素からキーを抽出するメソッド)といったものです。by() メソッドは PCollection<T> のサブ
package com.tom_e_white.javamagazine;
import java.util.UUID;import org.apache.log4j.Logger;
public class GenerateEvents { public static void main(String[] args) throws Exception { Logger logger = Logger.getLogger(GenerateEvents.class); long i = 0; String source = UUID.randomUUID().toString(); while (true) { Event event = new Event(); event.setId(i++); event.setTimestamp(System.currentTimeMillis()); event.setSource(source); logger.info(event); Thread.sleep(100); } }}
リスト4 リスト5 リスト6
すべてのリストのテキストをダウンロード
HADOOPの現在Hadoopの原型は確かにバッチ処理システムでした。しかし、最近のコンポーネントは、より応答性が高く待機時間の短い処理によって大規模データセットを分析するものであると理解することが重要です。

ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
31
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
クラスであるPTable<K, V>を返します。PTable<K, V> は、キーと値のペアで構成されるテーブルであり、集約操作を実行するためのグループ化や連結を行うメソッドを提供しています。MapReduce に詳しい読者は、これらのプリミティブな操作がMapReduceと非常によく似ていることに気づくでしょう。主な違いは、Crunchではキーと値のペアに限定されず通常の Java オブジェクトを使用できること、および個別のMapReduceジョブを管理する必要がないことです。Crunch によってパイプラインが一連のMapReduceジョブへとコンパイルされ、自動的に実行されます。 典型的な Crunchプログラムではその後、ソースのデータセットをPCollection<S>インスタンスとして読み取り、連結された一連のメソッドを使用して変換したうえで、要素の型が異なる別の PCollection<T>を作成します。最後に、その作成したインスタンスをターゲットのデータセットに書き込みます。通常、ソースとターゲットの両方がHDFS に格納されます。以上の説明を実際の
コードで表すと、リスト6のようになります。リスト6では、まず eventsデータセットを読み取ってPCollection<Event>インスタンスを作成します(CrunchDatasets の
便利なメソッドを使用して、Dataset をCrunchソースに変換します)。次に、PCollection<Summary> に変換し、最後に、summaries データセットに書き込みます。なお、使用している Javaクラス(EventとSummary)は、先ほどデータセットに対して定義したものと同じです。最初の変換は、DoFn の実装であ
るGetTimeAndSourceBucket(リスト7)によって定義されたキー抽出操作です。このメソッドは、1日のある特定の 1分間を表すタイムスタンプ(minuteBucket)をそれぞれの Eventオブジェクトから抽出し、(minuteBucket, source) のペアをグループ化のためのキーとして返します。
2 つ目の変換はすべてのグループに対する並行処理であり、ここでは 1分おきに集計するために使用します。リスト8を見ると、MakeSummaryは、Pair<Long, String>, Iterable<Event>を入力とする関数です。つまりこの関数は、先ほどのグループ化操作によって得られたキーである(minuteBucket, source) のペアと、そのキーに関連するすべての Event オブジェクトに対する Iterableを受け取ります。この実装では単純にこの入力情報を利用して、関数の出力となるSummary オブジェクトを構成します。この関
数は、Summary オブジェクトをCrunch Emitter オブジェクトに書き込んで処理を終了します。注目すべき点は、Crunch の関数には、任意の Javaライブラリを利用して Javaコードを自由に記述できることです(サンプルでは、GetTimeAndSourceBucketにおいて Joda-Time API を利用しました)。そのため、記述できる分析手段の幅が広がります。
Java からのデータセットの読取りデータセット内のエンティティに対する繰返し処理は、Java API を利用することで容易に実行できます。リスト9に、先ほどCrunchジョブによって作成したsummaries データセットに対する繰返し処理の方法を示します。データセットをDataset<Summary> のインスタンスとしてロードし、そのインスタンスの newReader() メソッドを呼び出して
package com.tom_e_white.javamagazine;
import org.apache.crunch.MapFn;import org.apache.crunch.Pair;import org.joda.time.DateTime;import org.joda.time.DateTimeZone;
class GetTimeAndSourceBucket extends MapFn<Event, Pair<Long, String>> { @Override public Pair<Long, String> map(Event event) { long minuteBucket = new DateTime(event.getTimestamp()) .withZone(DateTimeZone.UTC) .minuteOfDay() .roundFloorCopy() .getMillis(); return Pair.of(minuteBucket, event.getSource()); }}
リスト7 リスト8 リスト9
すべてのリストのテキストをダウンロード
すぐに開始Kite SDKは、Hadoopアプリケーション開発のベスト・プラクティスの一部を体系化したものであり、開発者が所属プロジェクトですぐに開発を始めるためのAPIや各種サンプルを提供しています。

ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
32
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
DatasetReader<Summary>を取得します。DatasetReader は Java の Iterableであるため、拡張形式の for ループ内で入力に対して繰返し処理を実行し、各 Summary オブジェクトをコンソールに順次出力できます。その出力内容は次のとおりです。
JDBCを使用した Impala からのデータセットの読取りデータセットのメタデータはHiveメタストアに保存されるため、Hiveまたは Impala を利用して、SQL によりデータセットを問い合わせることができます。リスト10に、JDBC API を使用して summaries データセット内のレコードをコンソールにダンプ出力するプログラムを示します。Hive JDBCドライバはHive、Impala の両方をサポートしますが、このサンプルでは Impala に接続します(Impala はポート21050で JDBC接続をリスニングします)。コンソールへの出力は先ほどの出力によく似ています。
言うまでもありませんが、接続方法が
JDBCであるため、任意の JDBCフレームワークを利用してデータセットにアクセスできます。たとえばWebベースのダッシュボードにいくつかの重要な問合せを表示することが可能です。Kite により構築できる機能はほかにも多数あります。以降では、いくつかの高度な機能について見ていきます。
データセットの更新リスト6で紹介した Crunchジョブは、eventsデータセット全体に対して一度に実行されます。しかし、実際の環境では、events データセットは時刻によってパーティション化され、新しいデータセットのパーティションに対してジョブが定期的に実行されることになるでしょう。 このような場合には、アプリケーション(このサンプルでは Crunchジョブ)のパッケージ化、デプロイ、実行が可能なKite Mavenプラグインが便利です。アプリケーションはWARファイルに似た形式でパッケージ化され、依存先ライブラリと構成情報(利用するHadoopクラスタの情報など)がバンドルされます。また、Oozie の利用によって、アプリケーションは 1回限りのワークフローとして実行されるか、または規定のスケジュールに従って繰返しのコーディネータ・アプリケーションとして実行されます。Kite のサンプルには、繰返しジョブの実行例が含まれています。
検索機能の統合他の高度な機能として、Solr Flume Sinkをシステムに追加して、HDFS への送信前にイベントにインデックスを設定するという方法も考えられます。この設計で
Summary{source=973e9def..., bucket=1384965540000, count=212}Summary{source=973e9def..., bucket=1384965600000, count=37}
source=973e9def..., bucket=1384965540000, count=212source=973e9def..., bucket=1384965600000, count=37
package com.tom_e_white.javamagazine;
import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.Statement;
public class ReadSummariesJdbc {
public static void main(String[] args) throws Exception { Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection( "jdbc:hive2://localhost:21050/;auth=noSasl"); Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery( "SELECT * FROM summaries"); while (resultSet.next()) { String source = resultSet.getString("source"); String bucket = resultSet.getString("bucket"); String count = resultSet.getString("count"); System.out.printf("source=%s, bucket=%s, count=%s\n", source, bucket, count); }
resultSet.close(); statement.close(); connection.close(); }}
リスト10
すべてのリストのテキストをダウンロード

ORACLE.COM/JAVAMAGAZINE ///////////////////// JANUARY/FEBRUARY 2014
JAVA TECH
33
COMMUNITY
JAVA IN ACTION
ABOUT US
blog
//java architect /
は、LuceneインデックスをHDFS に保存して、SolrCloud サーバーをHadoopと同じクラスタ内で実行します。Solr APIを扱う任意のライブラリやフレームワークを利用して、データを「ほぼリアルタイム」で検索できます。つまり、通常はイベントの取得後、数秒以内にインデックス内にイベントが登録されます。
スキーマの進化の処理実世界ではデータ・モデルが変化していくため、コードがその変化に適応できることが不可欠です。Avro には、スキーマの変化に関する明確なルールがあり、そのルールはデータセットAPI に組み込まれています。そのため、互換性のある更新は許可され、互換性のない更新は拒否されます。例として、デフォルト値のない新しいフィールドの追加は許可されません。新しいフィールドのデフォルト値がなければ、古いデータを新しいスキーマによって読み取ることができないからです。Eventクラスに ipという新しいフィールドを追加してこのクラスを更新する例を次に示します。
Nullableアノテーションを使用して、フィールドのデフォルト値が null であることを示しています。古いイベント・オブジェクトがこの新しいオブジェクトに読
み込まれた場合には、ipフィールドがnull になります。
まとめ本記事では、ビッグ・データ向けプラットフォームのデファクト・スタンダードであるHadoop について、開発の始め方を Java 開発者の視点から説明しました。Kite の Java API を利用して、データセットを柔軟に保存し処理するリッチ・アプリケーションを構築しました。本記事で利用したテクニックは、今後実際のビッグ・データ関連プロジェクトでもお使いいただけます。</article>
本記事の草稿をお読みいただいたRyan Blue 氏に感謝いたします。
public class Event { private long id; private long timestamp; private String source; @Nullable private String ip; ... getters and setters elided}
LEARN MORE• Kite のドキュメント• Kite のサンプル• 『Hadoop: The Definitive Guide』
and JavaBig Data
MORE ON TOPIC:
Copyright © 2011, Oracle and/or its affiliates. All rights reserved. Oracle and Java are registered trademarks of Oracle and/or its affiliates.Other names may be trademarks of their respective owners.
oracle.com/goto/javaor call 1.800.ORACLE.1
3 BillionDevices Run Java
Computers, Printers, Routers, BlackBerry Smartphones,
Cell Phones, Kindle E-Readers, Parking Meters, Vehicle
Diagnostic Systems, On-Board Computer Systems,
Smart Grid Meters, Lottery Systems, Airplane Systems,
ATMs, Government IDs, Public Transportation Passes,
Credit Cards, VoIP Phones, Livescribe Smartpens, MRIs,
CT Scanners, Robots, Home Security Systems, TVs,
Cable Boxes, PlayStation Consoles, Blu-ray Disc Players…
#1 Development Platform





























![[C12]元気Hadoop! OracleをHadoopで分析しちゃうぜ by Daisuke Hirama](https://img.pdfslide.tips/doc/110x75/5597ed211a28abb1378b465c/c12hadoop-oraclehadoop-by-daisuke-hirama.jpg)